第三十七天打卡
- 过拟合的判断:测试集和训练集同步打印指标
- 模型的保存和加载
- 仅保存权重
- 保存权重和模型
- 保存全部信息checkpoint,还包含训练状态
- 早停策略
过拟合判断
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt
from tqdm import tqdm # 导入tqdm库用于进度条显示
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
model = MLP().to(device)# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每200个epoch的损失值和对应的epoch数
train_losses = [] # 存储训练集损失
test_losses = [] # 新增:存储测试集损失
epochs = []start_time = time.time() # 记录开始时间# 创建tqdm进度条
with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:# 训练模型for epoch in range(num_epochs):# 前向传播outputs = model(X_train) # 隐式调用forward函数train_loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()train_loss.backward()optimizer.step()# 记录损失值并更新进度条if (epoch + 1) % 200 == 0:# 计算测试集损失,新增代码model.eval()with torch.no_grad():test_outputs = model(X_test)test_loss = criterion(test_outputs, y_test)model.train()train_losses.append(train_loss.item())test_losses.append(test_loss.item())epochs.append(epoch + 1)# 更新进度条的描述信息pbar.set_postfix({'Train Loss': f'{train_loss.item():.4f}', 'Test Loss': f'{test_loss.item():.4f}'})# 每1000个epoch更新一次进度条if (epoch + 1) % 1000 == 0:pbar.update(1000) # 更新进度条# 确保进度条达到100%if pbar.n < num_epochs:pbar.update(num_epochs - pbar.n) # 计算剩余的进度并更新time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')# 可视化损失曲线
plt.figure(figsize=(10, 6))
plt.plot(epochs, train_losses, label='Train Loss') # 原始代码已有
plt.plot(epochs, test_losses, label='Test Loss') # 新增:测试集损失曲线
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss over Epochs')
plt.legend() # 新增:显示图例
plt.grid(True)
plt.show()# 在测试集上评估模型,此时model内部已经是训练好的参数了
# 评估模型
model.eval() # 设置模型为评估模式
with torch.no_grad(): # torch.no_grad()的作用是禁用梯度计算,可以提高模型推理速度outputs = model(X_test) # 对测试数据进行前向传播,获得预测结果_, predicted = torch.max(outputs, 1) # torch.max(outputs, 1)返回每行的最大值和对应的索引correct = (predicted == y_test).sum().item() # 计算预测正确的样本数accuracy = correct / y_test.size(0)print(f'测试集准确率: {accuracy * 100:.2f}%') 早停法
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt
from tqdm import tqdm # 导入tqdm库用于进度条显示
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
model = MLP().to(device)# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每200个epoch的损失值和对应的epoch数
train_losses = [] # 存储训练集损失
test_losses = [] # 存储测试集损失
epochs = []# ===== 新增早停相关参数 =====
best_test_loss = float('inf') # 记录最佳测试集损失
best_epoch = 0 # 记录最佳epoch
patience = 50 # 早停耐心值(连续多少轮测试集损失未改善时停止训练)
counter = 0 # 早停计数器
early_stopped = False # 是否早停标志
# ==========================start_time = time.time() # 记录开始时间# 创建tqdm进度条
with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:# 训练模型for epoch in range(num_epochs):# 前向传播outputs = model(X_train) # 隐式调用forward函数train_loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()train_loss.backward()optimizer.step()# 记录损失值并更新进度条if (epoch + 1) % 200 == 0:# 计算测试集损失model.eval()with torch.no_grad():test_outputs = model(X_test)test_loss = criterion(test_outputs, y_test)model.train()train_losses.append(train_loss.item())test_losses.append(test_loss.item())epochs.append(epoch + 1)# 更新进度条的描述信息pbar.set_postfix({'Train Loss': f'{train_loss.item():.4f}', 'Test Loss': f'{test_loss.item():.4f}'})# ===== 新增早停逻辑 =====if test_loss.item() < best_test_loss: # 如果当前测试集损失小于最佳损失best_test_loss = test_loss.item() # 更新最佳损失best_epoch = epoch + 1 # 更新最佳epochcounter = 0 # 重置计数器# 保存最佳模型torch.save(model.state_dict(), 'best_model.pth')else:counter += 1if counter >= patience:print(f"早停触发!在第{epoch+1}轮,测试集损失已有{patience}轮未改善。")print(f"最佳测试集损失出现在第{best_epoch}轮,损失值为{best_test_loss:.4f}")early_stopped = Truebreak # 终止训练循环# ======================# 每1000个epoch更新一次进度条if (epoch + 1) % 1000 == 0:pbar.update(1000) # 更新进度条# 确保进度条达到100%if pbar.n < num_epochs:pbar.update(num_epochs - pbar.n) # 计算剩余的进度并更新time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')# ===== 新增:加载最佳模型用于最终评估 =====
if early_stopped:print(f"加载第{best_epoch}轮的最佳模型进行最终评估...")model.load_state_dict(torch.load('best_model.pth'))
# ================================# 可视化损失曲线
plt.figure(figsize=(10, 6))
plt.plot(epochs, train_losses, label='Train Loss')
plt.plot(epochs, test_losses, label='Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss over Epochs')
plt.legend()
plt.grid(True)
plt.show()# 在测试集上评估模型
model.eval()
with torch.no_grad():outputs = model(X_test)_, predicted = torch.max(outputs, 1)correct = (predicted == y_test).sum().item()accuracy = correct / y_test.size(0)print(f'测试集准确率: {accuracy * 100:.2f}%') @浙大疏锦行
相关文章:

第三十七天打卡
过拟合的判断:测试集和训练集同步打印指标模型的保存和加载 仅保存权重保存权重和模型保存全部信息checkpoint,还包含训练状态 早停策略 过拟合判断 import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import load…...
详解:控制窗口样式与行为)
Qt 窗口标志(Window Flags)详解:控制窗口样式与行为
在 Qt 中,windowFlags 用于控制窗口的样式和行为,包括标题栏、边框、最大化/最小化按钮等。合理设置 windowFlags 可以自定义窗口的外观和交互方式。本文将详细介绍常用的窗口标志及其组合效果。 1. 基本概念 windowFlags 是一个 Qt::WindowFlags 类型的…...

ABP VNext + CRDT 打造实时协同编辑
🛠️ ABP VNext CRDT 打造实时协同编辑器 🎉 📚 目录 🛠️ ABP VNext CRDT 打造实时协同编辑器 🎉🧠 背景与挑战🔹 系统架构🛣️ 端到端流程 🚦🔒 安全与鉴…...

微信小程序真机调试时如何实现与本地开发环境服务器交互
最近在开发微信小程序项目,真机调试时需要在手机上运行小程序,为了实现本地开发服务器与手机小程序的交互,需要以下步骤 1.将手机连到和本地一样的局域网 2.Visual Studio中将IIS Express服务器的localhost端口地址修改为本机的IP自定义的端口: 1)找到web api项目…...

Linux: network: dpdk, VF, ip link set down 对VF不生效
文章目录 问题另一个测试的结果是从dpdk的文档看怎么设置VF给VM内核的调用需要使用的命令问题 最近遇到一个问题,也可以说是一种常识,至少是之前不知道的常识:如果一个VF分配给了VM用作dpdk的输入。在host做ip link set down 这个PF的接口,对这个VM里的VF的功能没有任何影…...
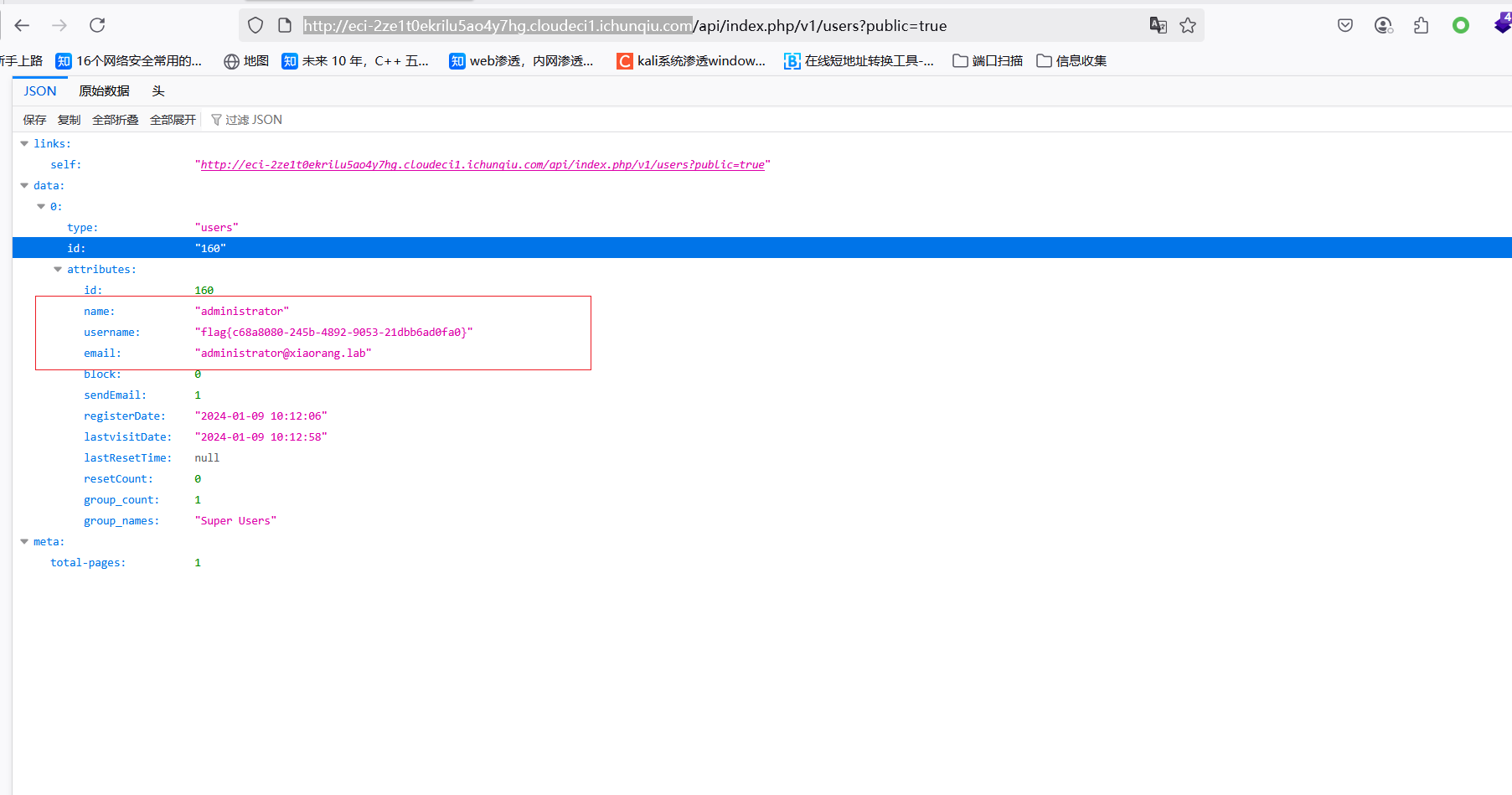
[春秋云镜] CVE-2023-23752 writeup
首先奉上大佬的wp表示尊敬:(很详细)[ 漏洞复现篇 ] Joomla未授权访问Rest API漏洞(CVE-2023-23752)_joomla未授权访问漏洞(cve-2023-23752)-CSDN博客 知识点 Joomla版本为4.0.0 到 4.2.7 存在未授权访问漏洞 Joomla是一套全球知名的内容管理…...

Java集合操作常见错误与最佳实践
错误69:搜索无关类型的对象 泛型方法的类型安全漏洞 在Java引入参数化类型前,集合元素只能声明为Object类型,导致可以随意将字符串添加到数值列表中。虽然泛型机制对添加元素的方法进行了类型约束,但搜索和删除相关方法仍保留了Object类型的参数设计。这包括以下关键方法…...

CSS专题之水平垂直居中
前言 石匠敲击石头的第 16 次 在日常开发中,经常会遇到水平垂直居中的布局,虽然现在基本上都用 Flex 可以轻松实现,但是在某些无法使用 Flex 的情况下,又应该如何让元素水平垂直居中呢?这也是一道面试的必考题…...

python打卡day41@浙大疏锦行
知识回顾 1. 数据增强 2. 卷积神经网络定义的写法 3. batch归一化:调整一个批次的分布,常用与图像数据 4. 特征图:只有卷积操作输出的才叫特征图 5. 调度器:直接修改基础学习率 卷积操作常见流程如下: 1. …...

vue3 基本语法 父子关系
在Vue 3中,父子组件的关系是通过组件的嵌套实现的。父组件可以传递数据(props)给子组件,同时子组件可以通过事件(emits)与父组件通信。下面是如何在Vue 3中建立和使用父子组件的基本语法: 1. 创…...

算法-js-子集
题:给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 方法一:迭代法 核心逻辑:动态扩展子集, 小规…...
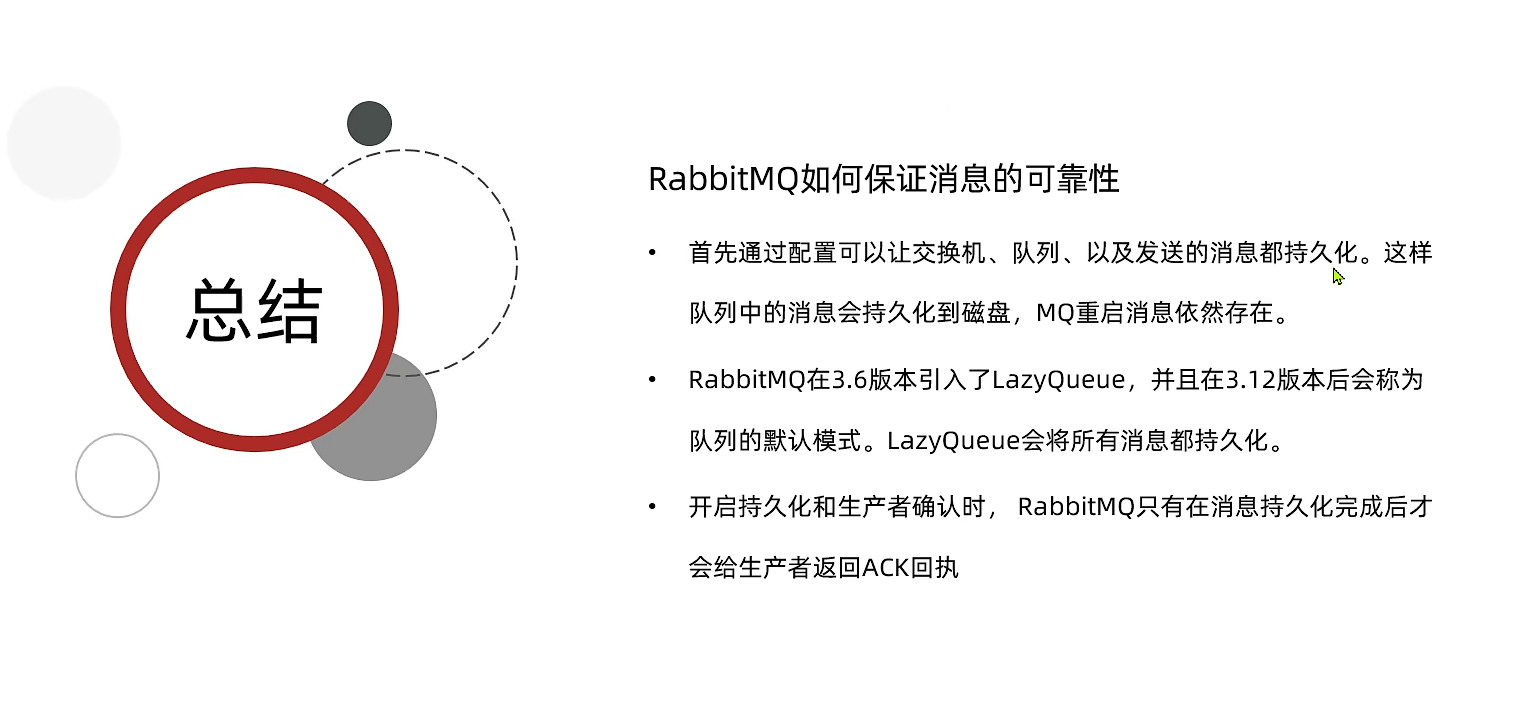
(新)MQ高级-MQ的可靠性
消息到达MQ以后,如果MQ不能及时保存,也会导致消息丢失,所以MQ的可靠性也非常重要。 一、数据持久化 为了提升性能,默认情况下MQ的数据都是在内存存储的临时数据,重启后就会消失。为了保证数据的可靠性,必须…...

Android设置界面层级为最上层实现
Android设置界面层级为最上层实现 文章目录 Android设置界面层级为最上层实现一、前言二、Android设置界面层级为最上层实现1、主要代码2、后遗症 三、其他1、Android设置界面层级为最上层小结2、悬浮框的主要代码悬浮框 注意事项(1)权限限制(…...

云原生微服务架构演进之路:理念、挑战与实践
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:架构的演进是业务进化的技术反射 在软件行业的发展过程中,架构变迁总是伴随着技术浪潮与业务复杂度的升…...

Go语言使用阿里云模版短信服务
在当今的互联网项目中,短信验证码、通知等功能已成为标配。本文将详细介绍如何使用Go语言集成阿里云短信服务(DYSMSAPI)实现短信发送功能。 一、准备工作 在开始之前,您需要完成以下准备工作: 注册阿里云账号并实名认证开通短信服务(SMS)申…...
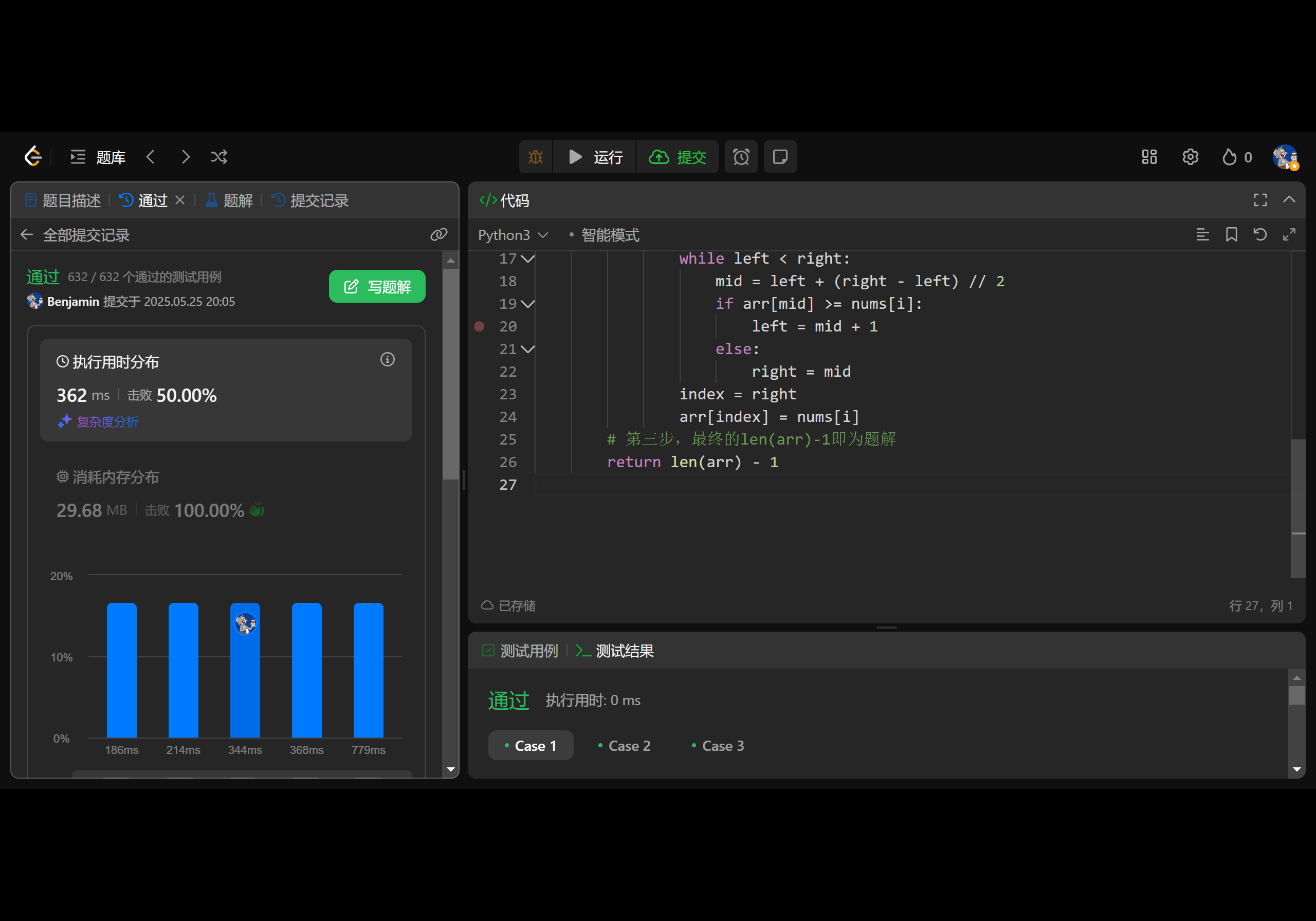
Leetcode 3231. 要删除的递增子序列的最小数量
1.题目基本信息 1.1.题目描述 给定一个整数数组 nums,你可以执行任意次下面的操作: 从数组删除一个 严格递增 的 子序列。 您的任务是找到使数组为 空 所需的 最小 操作数。 1.2.题目地址 https://leetcode.cn/problems/minimum-number-of-increas…...

4.2.5 Spark SQL 分区自动推断
在本节实战中,我们学习了Spark SQL的分区自动推断功能,这是一种提升查询性能的有效手段。通过创建具有不同分区的目录结构,并在这些目录中放置JSON文件,我们模拟了一个分区表的环境。使用Spark SQL读取这些数据时,Spar…...

基于昇腾MindSpeed训练加速库玩转智谱GLM-4-0414模型
智谱GLM-4-0414模型提供32B和9B两种参数规模,涵盖基础、推理和沉思等多种模型类型,均基于 MIT 许可协议开放。其中,推理模型 GLM-Z1-32B-0414 性能卓越,与 DeepSeek-R1 等领先模型相当,实测推理速度达每秒200个Tokens。…...

【图像处理入门】2. Python中OpenCV与Matplotlib的图像操作指南
一、环境准备 import cv2 import numpy as np import matplotlib.pyplot as plt# 配置中文字体显示(可选) plt.rcParams[font.sans-serif] [SimHei] plt.rcParams[axes.unicode_minus] False二、图像的基本操作 1. 图像读取、显示与保存 使用OpenCV…...
Spring Boot微服务架构(九):设计哲学是什么?
一、Spring Boot设计哲学是什么? Spring Boot 的设计哲学可以概括为 “约定优于配置” 和 “开箱即用”,其核心目标是极大地简化基于 Spring 框架的生产级应用的初始搭建和开发过程,让开发者能够快速启动并运行项目…...
)
GRCh38版本染色体位置转换GRCh37(hg19)
目录 方法 1:使用 Ensembl REST API(推荐,适用于少量位点查询)方法 2:使用 UCSC API方法 3:使用 NCBI API 并转换坐标(需要额外步骤)方法 4:使用本地数据库(最…...
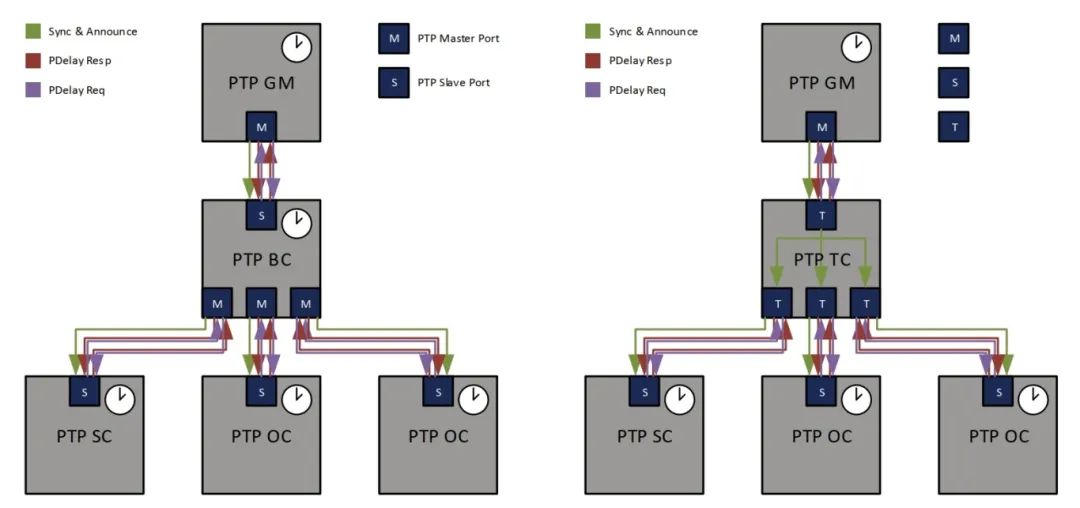
TC/BC/OC P2P/E2E有啥区别?-PTP协议基础概念介绍
前言 时间同步网络中的每个节点,都被称为时钟,PTP协议定义了三种基本时钟节点。本文将介绍这三种类型的时钟,以及gPTP在同步机制上与其他机制的区别 本系列文章将由浅入深的带你了解gPTP,欢迎关注 时钟类型 在PTP中我们将各节…...

解决微信小程序中 Flex 布局下 margin-right 不生效的问题
解决微信小程序中 Flex 布局下 margin-right 不生效的问题 在做微信小程序开发时,遇到了一个棘手的布局问题:在 flex 布局下,给元素设置的 margin-right 不生效,被“吞噬”了。这个问题导致了横向滚动列表的右边距失效࿰…...
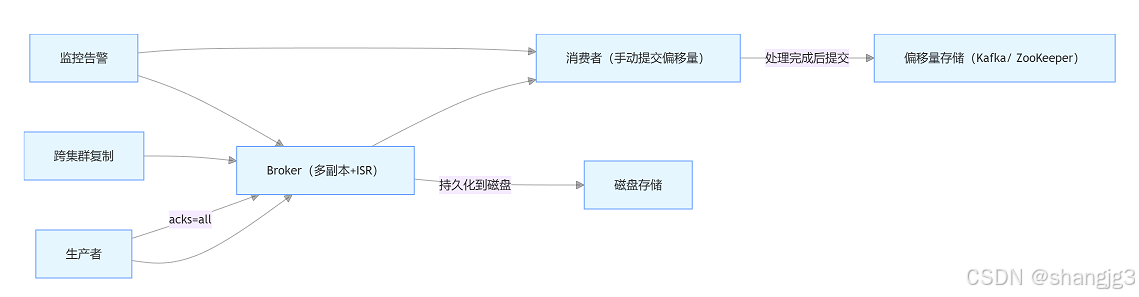
Kafka数据怎么保障不丢失
在分布式消息系统中,数据不丢失是核心可靠性需求之一。Apache Kafka 通过生产者配置、副本机制、持久化策略、消费者偏移量管理等多层机制保障数据可靠性。以下从不同维度解析 Kafka 数据不丢失的核心策略,并附示意图辅助理解。 一、生产者端:…...

使用HTTPS进行传输加密
说明 日期:2025年5月30日 与以纯文本形式发送和接收消息的标准 HTTP 不同,HTTPS 使用SSL/TLS等协议对服务器进行身份验证、加密通信内容和检测篡改。 这样可以防止欺骗、中间人攻击和窃听等攻击。 证书很重要,如果用户主动信任了伪造证书&…...
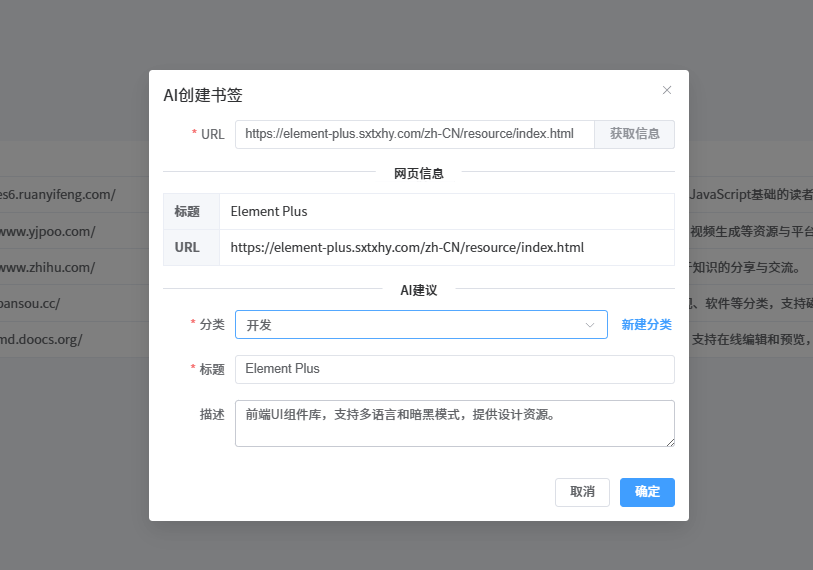
AI书签管理工具开发全记录(八):Ai创建书签功能实现
文章目录 AI书签管理工具开发全记录(八):AI智能创建书签功能深度解析前言 📝1. AI功能设计思路 🧠1.1 传统书签创建的痛点1.2 AI解决方案设计 2. 后端API实现 ⚙️2.1 新增url相关工具方法2.1 创建后端api2.2 创建crea…...
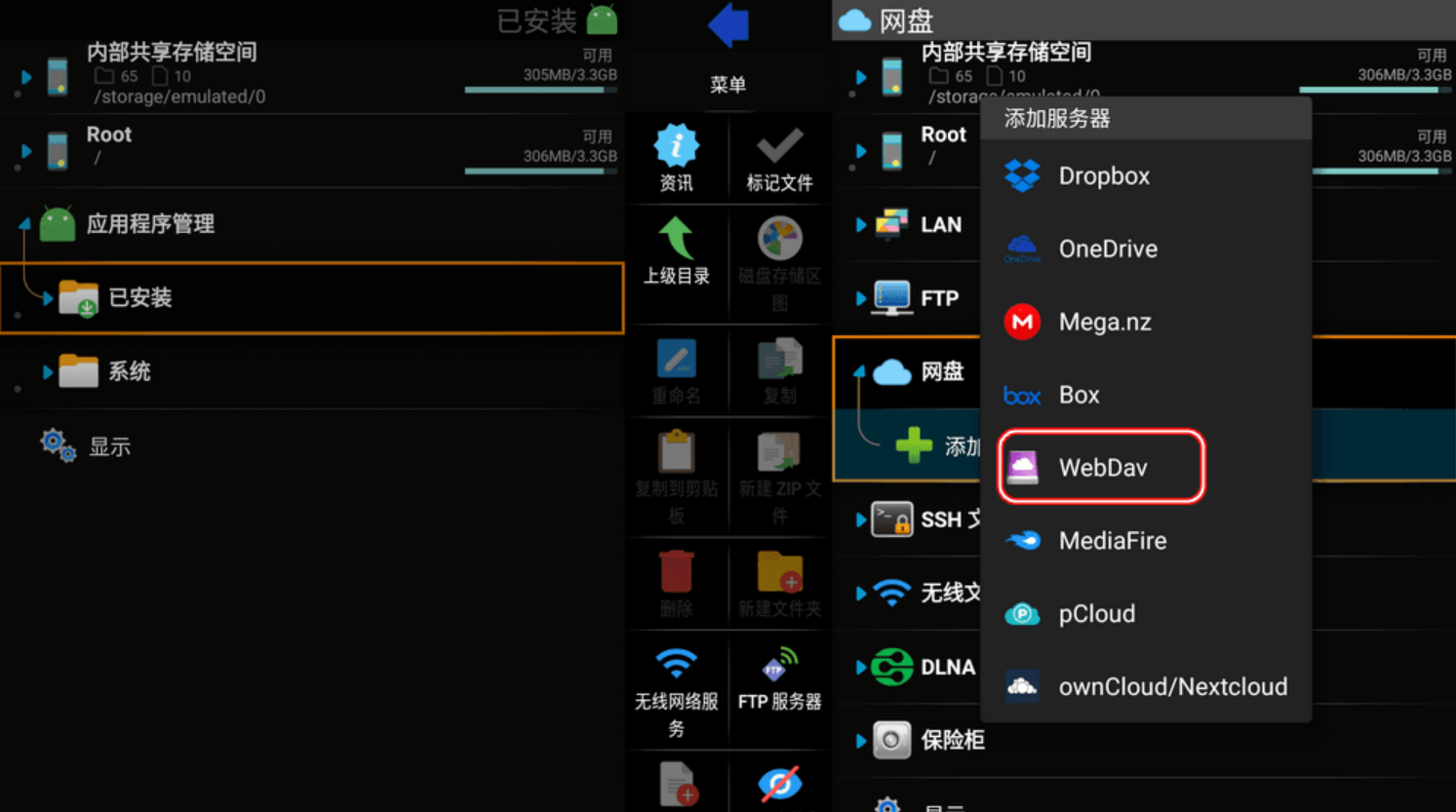
X-plore v4.43.05 强大的安卓文件管理器-MOD解锁高级版 手机平板/电视TV通用
X-plore v4.43.05 强大的安卓文件管理器-MOD解锁高级版 手机平板/电视TV通用 应用简介: X-plore 是一款强大的安卓端文件管理器,它可以在电视或者手机上管理大量媒体文件、应用程序。…...

使用多Agent进行海报生成的技术方案及评估套件-P2P、paper2poster
最近字节、滑铁卢大学相关团队同时放出了他们使用Agent进行海报生成的技术方案,P2P和Paper2Poster,传统方案如类似ppt生成等思路,基本上采用固定的模版,提取相关的关键元素进行模版填充,因此,海报生成的质量…...
Redis--缓存工具封装
经过前面的学习,发现缓存中的问题,无论是缓存穿透,缓存雪崩,还是缓存击穿,这些问题的解决方案业务代码逻辑都很复杂,我们也不应该每次都来重写这些逻辑,我们可以将其封装成工具。而在封装的时候…...

python:在 PyMOL 中如何查看和使用内置示例文件?
参阅:开源版PyMol安装保姆级教程 百度网盘下载 提取码:csub pip show pymol 简介: PyMOL是一个Python增强的分子图形工具。它擅长蛋白质、小分子、密度、表面和轨迹的3D可视化。它还包括分子编辑、射线追踪和动画。 可视化示例:打开 PyM…...