【办公类-18-07】20250527屈光检查PDF文件拆分成多个pdf(两页一份,用幼儿班级姓名命名文件)
背景需求:
今天春游,上海海昌公园。路上保健老师收到前几天幼儿的屈光视力检查单PDF。

她说:所有孩子的通知都做在一个PDF里,我没法单独发给班主任。你有什么办法拆开来?

我说:“没问题,问deep seek,它会写拆分代码。
过了一会儿保健老师与保健所联系,决定保健所打印这些胆子。
“那你就不用做了!”
讨论时,保健老师感叹:有145个孩子,这么多屈光有问题!信息化时代下,幼儿的远端视力越来越差了。
但是我没有作过PDF拆分,还是试了一下
设计过程:
PDF拆分成2页一个PDF
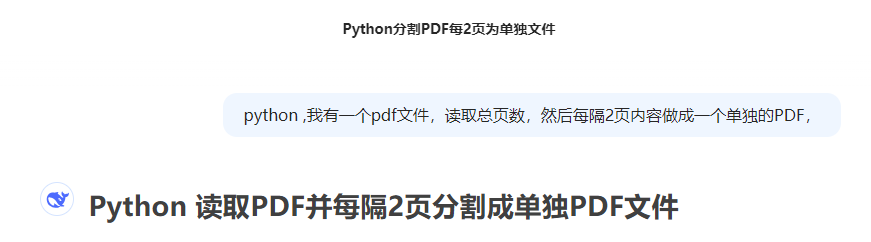 代码展示
代码展示
'''
屈光PDF按照2张一份,拆分成多个编号
deepseek 阿夏
20250527
'''
from PyPDF2 import PdfReader, PdfWriter
import osdef split_pdf_every_2_pages(input_pdf_path, output_folder):# 创建输出文件夹(如果不存在)if not os.path.exists(output_folder):os.makedirs(output_folder)# 读取PDF文件reader = PdfReader(input_pdf_path)total_pages = len(reader.pages)print(f"总页数: {total_pages}")# 计算需要分割的文件数量num_files = (total_pages + 1) // 2for i in range(num_files):writer = PdfWriter()# 计算当前文件的起始和结束页码start_page = i * 2end_page = min(start_page + 2, total_pages)# 添加页面到新PDFfor page_num in range(start_page, end_page):writer.add_page(reader.pages[page_num])# 生成输出文件名output_filename = os.path.join(output_folder, f"{i+1:003}_P{start_page+1}-P{end_page}.pdf")# 写入新PDF文件with open(output_filename, "wb") as out:writer.write(out)print(f"已创建: {output_filename}")# 使用示例
path=r'C:\Users\jg2yXRZ\OneDrive\桌面\20250527视力复诊屈光拆分'
input_pdf =path + r"\复诊通知XXXx.pdf" # 替换为你的PDF文件路径
output_dir = path + r"\拆分文件" # 输出文件夹
os.makedirs(output_dir,exist_ok=True)split_pdf_every_2_pages(input_pdf, output_dir)顺利实现两页一份PDF
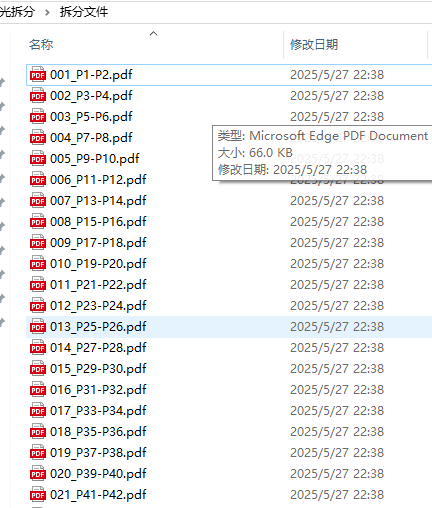
但是我还希望提取姓名、年级、班级号,作为文件名。
经过反复测试后,我发现姓名固定在第6行,年级固定在第7行,但是班级号的位置是不确定,可能在68,69和某些不确定的行上。
deepseek晚上总是容易断网,所以改用了星火讯飞写
 代码展示:
代码展示:
'''
屈光PDF按照2张一份,拆分成多个。提取单数页上的姓名(6)年级(7),班级(68、69或不确定的位置)
将大班七班改成大7班。做成文件名
deepseek 阿夏
20250527
'''import fitz # PyMuPDF
import os
import re
import pandas as pd # 确保已安装pandas库
from PyPDF2 import PdfReader, PdfWriterdef chinese_to_digit(chinese_num):"""将中文数字转换为阿拉伯数字。支持一到十的转换。"""chinese_dict = {'一': 1, '二': 2, '三': 3, '四': 4,'五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '十': 10}return chinese_dict.get(chinese_num, chinese_num)def extract_student_info(input_pdf_path, target_pages):"""动态提取学生姓名、年级和班级信息。:param input_pdf_path: PDF文件路径:param target_pages: 需要处理的页面列表(例如,单数页):return: 包含学生信息的字典列表"""doc = fitz.open(input_pdf_path)results = []# 定义匹配“X班”的正则表达式,X为阿拉伯数字或中文数字,可能带括号class_pattern = re.compile(r'[((]?(\d+|[一二三四五六七八九十]+)班[))]?') # 根据实际格式调整括号和数字类型for page_num in target_pages:page = doc.load_page(page_num - 1) # fitz的页码从0开始text = page.get_text("text")lines = [line.strip() for line in text.split('\n') if line.strip()]# 初始化变量name = Nonegrade = Noneclasses = []# 从第6行和第7行提取姓名和年级if len(lines) >= 6:name = lines[5].strip() # 第6行(索引5)if len(lines) >= 7:grade = lines[6].strip() # 第7行(索引6)# 遍历所有行查找班级信息for line in lines:matches = class_pattern.findall(line)for match in matches:# 将中文数字转换为阿拉伯数字converted_match = ''.join([str(chinese_to_digit(char)) if char in '一二三四五六七八九十' else char for char in match])class_name = converted_match # match 已经是字符串,无需调用 group()if class_name not in classes:classes.append(class_name)# 将提取的信息添加到结果中if name and grade:result = {"page_num": page_num,"name": name,"grade": grade[0],"class": classes}results.append(result)else:print(f"第{page_num}页缺少必要的信息。")return resultsdef convert_students_info(students):"""将学生信息转换为 "大7班_陈宇阳" 格式的字符串列表。:param students: 包含学生信息的字典列表:return: 格式化后的字符串列表"""formatted_list = []for student in students:grade = student.get('grade', '')class_list = student.get('class', [])name = student.get('name', '')class_str = ''.join(class_list)formatted_str = f"{grade}{class_str}班_{name}"formatted_list.append(formatted_str)return formatted_listdef split_pdf_every_2_pages(input_pdf_path, output_folder, formatted_names):"""将PDF每两页分割成一个新的PDF文件,并使用formatted_names列表中的名称命名文件。:param input_pdf_path: 输入PDF文件路径:param output_folder: 输出文件夹路径:param formatted_names: 用于命名的文件名列表:return: None"""# 创建输出文件夹(如果不存在)if not os.path.exists(output_folder):os.makedirs(output_folder)# 读取PDF文件reader = PdfReader(input_pdf_path)total_pages = len(reader.pages)print(f"总页数: {total_pages}")# 计算需要分割的文件数量num_files = (total_pages + 1) // 2print(f"需要创建的文件数量: {num_files}")# 确保formatted_names的长度足够if len(formatted_names) < num_files:print("警告: formatted_names列表长度小于需要创建的文件数量。多余的文件将使用默认命名。")for i in range(num_files):writer = PdfWriter()# 计算当前文件的起始和结束页码start_page = i * 2end_page = min(start_page + 2, total_pages)# 添加页面到新PDFfor page_num in range(start_page, end_page):writer.add_page(reader.pages[page_num])# 获取对应的文件名,如果不足则使用默认命名if i < len(formatted_names):filename = f"{formatted_names[i]}.pdf"else:filename = f"{i+1:003}_P{start_page+1}-P{end_page}.pdf"# 生成输出文件路径output_filename = os.path.join(output_folder, filename)# 写入新PDF文件with open(output_filename, "wb") as out:writer.write(out)print(f"已创建: {output_filename}")def main():# 设置PDF文件路径path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250527视力复诊屈光拆分'input_pdf = os.path.join(path, "复诊通知XXXX.pdf")output_dir = os.path.join(path, "拆分文件") # 输出文件夹os.makedirs(output_dir, exist_ok=True)# 获取所有单数页(假设页码从1开始)doc = fitz.open(input_pdf)all_pages = list(range(1, len(doc) + 1))odd_pages = [p for p in all_pages if p % 2 != 0]print(f"处理的单数页: {odd_pages}")# 提取内容students_info = extract_student_info(input_pdf, odd_pages)print(f"提取到的学生信息数量: {len(students_info)}")# 转换并打印格式化后的列表formatted_list = convert_students_info(students_info)print("格式化后的学生列表:")for item in formatted_list:print(item)# 分割PDF并使用formatted_list命名文件split_pdf_every_2_pages(input_pdf, output_dir, formatted_list)print("PDF分割完成。")if __name__ == "__main__":main()
结果展示
感觉必须添加序号(数据编码)
'''
屈光PDF按照2张一份,拆分成多个。提取单数页上的姓名(6)年级(7),班级(68、69或不确定的位置)
将大班七班改成大7班。做成文件名、有编号(先中班、再大班)
deepseek 阿夏
20250527
'''# 导入必要的依赖项
import os
from fpdf import FPDF
import re
import pandas as pd # 确保已安装pandas库
from PyPDF2 import PdfReader, PdfWriter
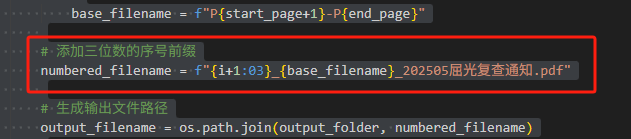
import fitz # PyMuPDFdef chinese_to_digit(chinese_num):"""将中文数字转换为阿拉伯数字。支持一到十的转换。"""chinese_dict = {'一': 1, '二': 2, '三': 3, '四': 4,'五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '十': 10}return chinese_dict.get(chinese_num, chinese_num)def extract_student_info(input_pdf_path, target_pages):"""动态提取学生姓名、年级和班级信息。:param input_pdf_path: PDF文件路径:param target_pages: 需要处理的页面列表(例如,单数页):return: 包含学生信息的字典列表"""doc = fitz.open(input_pdf_path)results = []# 定义匹配“X班”的正则表达式,X为阿拉伯数字或中文数字,可能带括号class_pattern = re.compile(r'[((]?(\d+|[一二三四五六七八九十]+)班[))]?') # 根据实际格式调整括号和数字类型for page_num in target_pages:page = doc.load_page(page_num - 1) # fitz的页码从0开始text = page.get_text("text")lines = [line.strip() for line in text.split('\n') if line.strip()]# 初始化变量name = Nonegrade = Noneclasses = []# 从第6行和第7行提取姓名和年级if len(lines) >= 6:name = lines[5].strip() # 第6行(索引5)if len(lines) >= 7:grade = lines[6].strip() # 第7行(索引6)# 遍历所有行查找班级信息for line in lines:matches = class_pattern.findall(line)for match in matches:# 将中文数字转换为阿拉伯数字converted_match = ''.join([str(chinese_to_digit(char)) if char in '一二三四五六七八九十' else char for char in match])class_name = converted_match # match 已经是字符串,无需调用 group()if class_name not in classes:classes.append(class_name)# 将提取的信息添加到结果中if name and grade:result = {"page_num": page_num,"name": name,"grade": grade[0],"class": classes}results.append(result)else:print(f"第{page_num}页缺少必要的信息。")return resultsdef convert_students_info(students):"""将学生信息转换为 "大7班_陈宇阳" 格式的字符串列表。:param students: 包含学生信息的字典列表:return: 格式化后的字符串列表"""formatted_list = []for student in students:grade = student.get('grade', '')class_list = student.get('class', [])name = student.get('name', '')class_str = ''.join(class_list)formatted_str = f"{grade}{class_str}班_{name}"formatted_list.append(formatted_str)return formatted_listdef split_pdf_every_2_pages(input_pdf_path, output_folder, formatted_names):"""将PDF每两页分割成一个新的PDF文件,并使用formatted_names列表中的名称命名文件。同时在文件名前添加三位数的序号前缀。:param input_pdf_path: 输入PDF文件路径:param output_folder: 输出文件夹路径:param formatted_names: 用于命名的文件名列表:return: None"""# 创建输出文件夹(如果不存在)if not os.path.exists(output_folder):os.makedirs(output_folder)# 读取PDF文件reader = PdfReader(input_pdf_path)total_pages = len(reader.pages)print(f"总页数: {total_pages}")# 计算需要分割的文件数量num_files = (total_pages + 1) // 2print(f"需要创建的文件数量: {num_files}")# 确保formatted_names的长度足够if len(formatted_names) < num_files:print("警告: formatted_names列表长度小于需要创建的文件数量。多余的文件将使用默认命名。")for i in range(num_files):writer = PdfWriter()# 计算当前文件的起始和结束页码start_page = i * 2end_page = min(start_page + 2, total_pages)# 添加页面到新PDFfor page_num in range(start_page, end_page):writer.add_page(reader.pages[page_num])# 获取对应的文件名,如果不足则使用默认命名if i < len(formatted_names):base_filename = formatted_names[i]else:base_filename = f"P{start_page+1}-P{end_page}"# 添加三位数的序号前缀numbered_filename = f"{i+1:03}_{base_filename}_202505屈光复查通知.pdf"# 生成输出文件路径output_filename = os.path.join(output_folder, numbered_filename)# 写入新PDF文件with open(output_filename, "wb") as out:writer.write(out)print(f"已创建: {output_filename}")def main():# 设置PDF文件路径path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250527视力复诊屈光拆分'input_pdf = os.path.join(path, "复诊通知XXXX.pdf")output_dir = os.path.join(path, "拆分文件") # 输出文件夹os.makedirs(output_dir, exist_ok=True)# 获取所有单数页(假设页码从1开始)doc = fitz.open(input_pdf)all_pages = list(range(1, len(doc) + 1))odd_pages = [p for p in all_pages if p % 2 != 0]print(f"处理的单数页: {odd_pages}")# 提取内容students_info = extract_student_info(input_pdf, odd_pages)print(f"提取到的学生信息数量: {len(students_info)}")# 转换并打印格式化后的列表formatted_list = convert_students_info(students_info)print("格式化后的学生列表:")for item in formatted_list:print(item)# 分割PDF并使用formatted_list命名文件,同时在文件名前添加序号前缀split_pdf_every_2_pages(input_pdf, output_dir, formatted_list)print("PDF分割完成。")if __name__ == "__main__":main()
按照先中班、后大班的顺序
为了明确文件内容,再添加了一个说明
最后是把所有PDF按班级合并文件夹,打包
'''
屈光PDF按照2张一份,拆分成多个。提取单数页上的姓名(6)年级(7),班级(68、69或不确定的位置)
将大班七班改成大7班。做成文件名、有编号(先中班、再大班)、
按班级分别保存,并打包,便于发送
deepseek 阿夏
20250527
'''
、import os
import re
import shutil
import zipfile
from PyPDF2 import PdfReader, PdfWriter
import fitz # PyMuPDFdef chinese_to_digit(chinese_num):"""将中文数字转换为阿拉伯数字。支持一到十的转换。"""chinese_dict = {'一': 1, '二': 2, '三': 3, '四': 4,'五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '十': 10}return chinese_dict.get(chinese_num, chinese_num)def extract_student_info(input_pdf_path, target_pages):"""从PDF中提取学生信息(姓名、年级、班级)"""doc = fitz.open(input_pdf_path)results = []class_pattern = re.compile(r'[((]?(\d+|[一二三四五六七八九十]+)班[))]?')for page_num in target_pages:page = doc.load_page(page_num - 1)text = page.get_text("text")lines = [line.strip() for line in text.split('\n') if line.strip()]name = lines[5].strip() if len(lines) >= 6 else Nonegrade = lines[6].strip() if len(lines) >= 7 else Noneclasses = []for line in lines:matches = class_pattern.findall(line)for match in matches:converted_match = ''.join([str(chinese_to_digit(char)) if char in '一二三四五六七八九十' else char for char in match])if converted_match not in classes:classes.append(converted_match)if name and grade:results.append({"page_num": page_num,"name": name,"grade": grade[0],"class": classes})else:print(f"第{page_num}页缺少必要的信息。")return resultsdef convert_students_info(students):"""格式化学生信息为'大7班_陈宇阳'格式"""return [f"{s['grade']}{''.join(s['class'])}班_{s['name']}" for s in students]def split_pdf_every_2_pages(input_pdf_path, output_folder, formatted_names):"""将PDF每两页分割成单独文件"""if not os.path.exists(output_folder):os.makedirs(output_folder)reader = PdfReader(input_pdf_path)total_pages = len(reader.pages)num_files = (total_pages + 1) // 2for i in range(num_files):writer = PdfWriter()start_page = i * 2end_page = min(start_page + 2, total_pages)for page_num in range(start_page, end_page):writer.add_page(reader.pages[page_num])base_filename = formatted_names[i] if i < len(formatted_names) else f"P{start_page+1}-P{end_page}"output_filename = os.path.join(output_folder, f"{i+1:03}_{base_filename}_屈光复查202505.pdf")with open(output_filename, "wb") as out:writer.write(out)print(f"已创建: {output_filename}")def classify_pdfs_by_class(source_folder):"""将PDF文件按班级分类到不同文件夹"""pdf_files = [f for f in os.listdir(source_folder) if f.lower().endswith('.pdf')]if not pdf_files:print(f"在文件夹 {source_folder} 中没有找到PDF文件")returnclass_stats = {}for pdf_file in pdf_files:match = re.search(r'(中\d+班|大\d+班)', pdf_file)if match:class_name = match.group(1)class_folder = os.path.join(source_folder, class_name)os.makedirs(class_folder, exist_ok=True)src_path = os.path.join(source_folder, pdf_file)dest_path = os.path.join(class_folder, pdf_file)shutil.move(src_path, dest_path)print(f"移动文件: {pdf_file} -> {class_folder}")class_stats[class_name] = class_stats.get(class_name, 0) + 1else:print(f"无法从文件名 {pdf_file} 中提取班级信息")print("\n分类完成,统计结果:")for class_name, count in class_stats.items():print(f"{class_name}: {count}个文件")return class_stats.keys()def zip_class_folders(source_folder, class_folders):"""将班级文件夹打包为ZIP压缩包"""print("\n=== 开始打包班级文件夹 ===")for folder_name in class_folders:folder_path = os.path.join(source_folder, folder_name)zip_path = os.path.join(source_folder, f"{folder_name}.zip")with zipfile.ZipFile(zip_path, 'w', zipfile.ZIP_DEFLATED) as zipf:for root, dirs, files in os.walk(folder_path):for file in files:file_path = os.path.join(root, file)arcname = os.path.relpath(file_path, folder_path)zipf.write(file_path, arcname)print(f"已创建压缩包: {zip_path}")def main():# 设置路径base_path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250527视力复诊屈光拆分'input_pdf = os.path.join(base_path, "复诊通知XXXX.pdf")output_dir = os.path.join(base_path, "拆分文件")# 第一步:拆分PDFprint("=== 开始拆分PDF ===")os.makedirs(output_dir, exist_ok=True)doc = fitz.open(input_pdf)odd_pages = [p for p in range(1, len(doc) + 1) if p % 2 != 0]students_info = extract_student_info(input_pdf, odd_pages)formatted_list = convert_students_info(students_info)split_pdf_every_2_pages(input_pdf, output_dir, formatted_list)print("PDF拆分完成!\n")# 第二步:分类PDFprint("=== 开始分类PDF ===")class_folders = classify_pdfs_by_class(output_dir)print("PDF分类完成!")# 第三步:打包文件夹zip_class_folders(output_dir, class_folders)if __name__ == "__main__":main()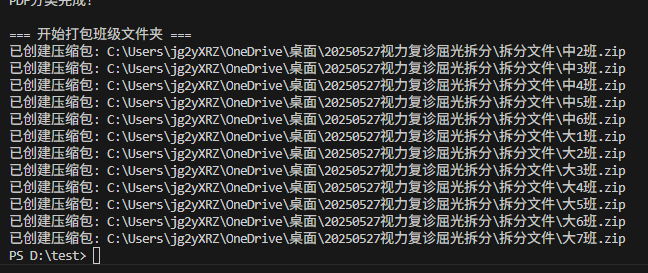

我看到终端显示了每个班级有几份,我还想标明文件内容是“屈光复查”
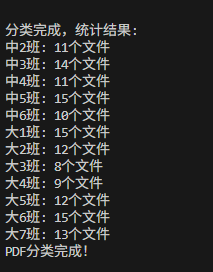
最终代码
'''
屈光PDF按照2张一份,拆分成多个。提取单数页上的姓名(6)年级(7),班级(68、69或不确定的位置)
将大班七班改成大7班。做成文件名、有编号(先中班、再大班)
按照班级转移PDF,班级文件名包括人数、屈光
deepseek 阿夏
20250527
'''import os
import re
import shutil
import zipfile
from PyPDF2 import PdfReader, PdfWriter
import fitz # PyMuPDFdef chinese_to_digit(chinese_num):"""将中文数字转换为阿拉伯数字。支持一到十的转换。"""chinese_dict = {'一': 1, '二': 2, '三': 3, '四': 4,'五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '十': 10}return chinese_dict.get(chinese_num, chinese_num)def extract_student_info(input_pdf_path, target_pages):"""从PDF中提取学生信息(姓名、年级、班级)"""doc = fitz.open(input_pdf_path)results = []class_pattern = re.compile(r'[((]?(\d+|[一二三四五六七八九十]+)班[))]?')for page_num in target_pages:page = doc.load_page(page_num - 1)text = page.get_text("text")lines = [line.strip() for line in text.split('\n') if line.strip()]name = lines[5].strip() if len(lines) >= 6 else Nonegrade = lines[6].strip() if len(lines) >= 7 else Noneclasses = []for line in lines:matches = class_pattern.findall(line)for match in matches:converted_match = ''.join([str(chinese_to_digit(char)) if char in '一二三四五六七八九十' else char for char in match])if converted_match not in classes:classes.append(converted_match)if name and grade:results.append({"page_num": page_num,"name": name,"grade": grade[0],"class": classes})else:print(f"第{page_num}页缺少必要的信息。")return resultsdef convert_students_info(students):"""格式化学生信息为'大7班_陈宇阳'格式"""return [f"{s['grade']}{''.join(s['class'])}班_{s['name']}" for s in students]def split_pdf_every_2_pages(input_pdf_path, output_folder, formatted_names):"""将PDF每两页分割成单独文件"""if not os.path.exists(output_folder):os.makedirs(output_folder)reader = PdfReader(input_pdf_path)total_pages = len(reader.pages)num_files = (total_pages + 1) // 2for i in range(num_files):writer = PdfWriter()start_page = i * 2end_page = min(start_page + 2, total_pages)for page_num in range(start_page, end_page):writer.add_page(reader.pages[page_num])base_filename = formatted_names[i] if i < len(formatted_names) else f"P{start_page+1}-P{end_page}"output_filename = os.path.join(output_folder, f"{i+1:03}_{base_filename}_屈光复查202505.pdf")with open(output_filename, "wb") as out:writer.write(out)print(f"已创建: {output_filename}")def classify_pdfs_by_class(source_folder):"""将PDF文件按班级分类到不同文件夹,并在文件夹名中加入人数统计"""pdf_files = [f for f in os.listdir(source_folder) if f.lower().endswith('.pdf')]if not pdf_files:print(f"在文件夹 {source_folder} 中没有找到PDF文件")returnclass_stats = {}# 第一次遍历:统计每个班级的人数for pdf_file in pdf_files:match = re.search(r'(中\d+班|大\d+班)', pdf_file)if match:class_name = match.group(1)class_stats[class_name] = class_stats.get(class_name, 0) + 1# 第二次遍历:移动文件到带人数的文件夹for pdf_file in pdf_files:match = re.search(r'(中\d+班|大\d+班)', pdf_file)if match:class_name = match.group(1)count = class_stats[class_name]new_folder_name = f"{class_name}_{count}人_屈光复查202505"class_folder = os.path.join(source_folder, new_folder_name)os.makedirs(class_folder, exist_ok=True)src_path = os.path.join(source_folder, pdf_file)dest_path = os.path.join(class_folder, pdf_file)shutil.move(src_path, dest_path)print(f"移动文件: {pdf_file} -> {new_folder_name}")print("\n分类完成,统计结果:")for class_name, count in class_stats.items():print(f"{class_name}: {count}个文件")# 返回带人数的文件夹名列表return [f"{k}({v}人)" for k, v in class_stats.items()]def zip_class_folders(source_folder, class_folders):"""将班级文件夹打包为ZIP压缩包"""print("\n=== 开始打包班级文件夹 ===")for folder_name in class_folders:folder_path = os.path.join(source_folder, folder_name)zip_path = os.path.join(source_folder, f"{folder_name}_屈光复查202505.zip")with zipfile.ZipFile(zip_path, 'w', zipfile.ZIP_DEFLATED) as zipf:for root, dirs, files in os.walk(folder_path):for file in files:file_path = os.path.join(root, file)arcname = os.path.relpath(file_path, folder_path)zipf.write(file_path, arcname)print(f"已创建压缩包: {zip_path}")def main():# 设置路径base_path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250527视力复诊屈光拆分'input_pdf = os.path.join(base_path, "复诊通知XXXX.pdf")output_dir = os.path.join(base_path, "拆分文件")# 第一步:拆分PDFprint("=== 开始拆分PDF ===")os.makedirs(output_dir, exist_ok=True)doc = fitz.open(input_pdf)odd_pages = [p for p in range(1, len(doc) + 1) if p % 2 != 0]students_info = extract_student_info(input_pdf, odd_pages)formatted_list = convert_students_info(students_info)split_pdf_every_2_pages(input_pdf, output_dir, formatted_list)print("PDF拆分完成!\n")# 第二步:分类PDFprint("=== 开始分类PDF ===")class_folders = classify_pdfs_by_class(output_dir)print("PDF分类完成!")# 第三步:打包文件夹zip_class_folders(output_dir, class_folders)if __name__ == "__main__":main()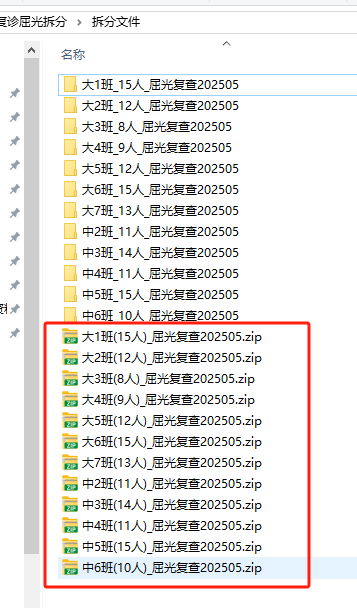
转发给保健老师:
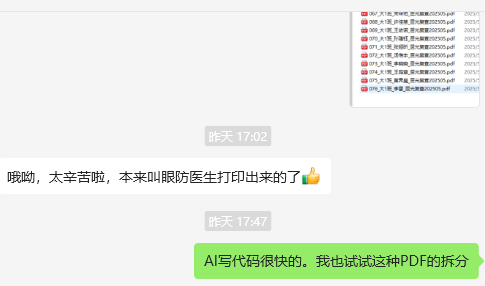
20250529
本来说是社区保健所打印通知,但是今天保健老师还是群发了各班PDF名单
很开心你,代码还是用上了。
但是转发时,我发现还要解压缩好麻烦啊,就准备上电脑再操作。
不一会儿,保健老师又发了单独的PDF
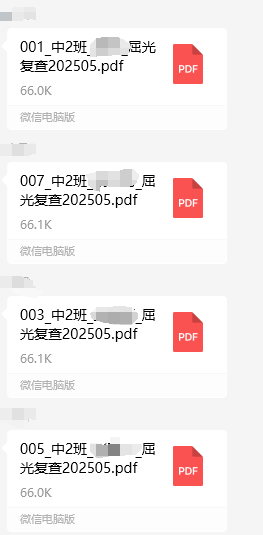
但是我发现发送编号不是按顺序的,而是跳着的,而且少了010、009,还以为是保健老师判定这两个孩子不同复查。
午餐时,保健老师打电话,说
1、班主任发现:原来的rar文件是空包。
我一看打包zip真的是空的
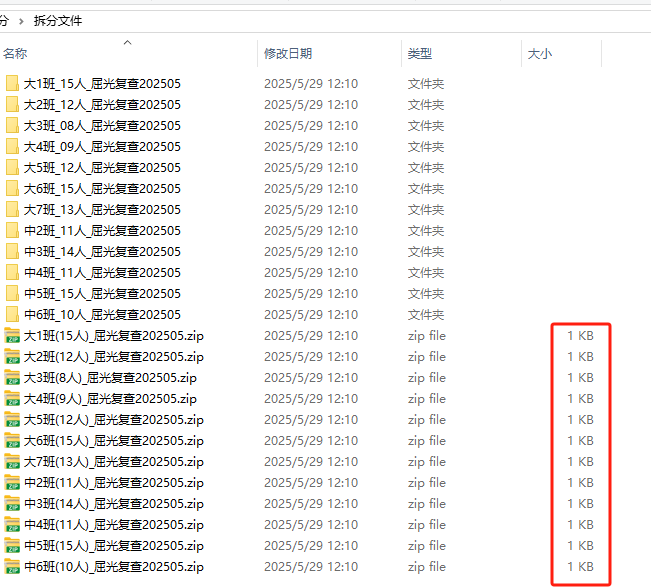
2、我只能发送单独PDF,结果一次只能9份,你们班缺了2个人是谁?
微信一次发送文件最多9个。以那一份先发全为准,所以不是按编号展示出来的。如果数量多,倒数第一个发(先显示),前8个发,所以就是倒数第2、3个不显示(1-11,就是9和10不显示)
问deep seek为什么是空白。
更新代码
'''
屈光PDF按照2张一份,拆分成多个。提取单数页上的姓名(6)年级(7),班级(68、69或不确定的位置)
将大班七班改成大7班。做成文件名、有编号(先中班、再大班)
按照班级转移PDF,班级文件名包括人数、屈光
deepseek 阿夏
20250527
'''import os
import re
import shutil
import zipfile
from PyPDF2 import PdfReader, PdfWriter
import fitz # PyMuPDFdef chinese_to_digit(chinese_num):"""将中文数字转换为阿拉伯数字。支持一到十的转换。"""chinese_dict = {'一': 1, '二': 2, '三': 3, '四': 4,'五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '十': 10}return chinese_dict.get(chinese_num, chinese_num)def extract_student_info(input_pdf_path, target_pages):"""从PDF中提取学生信息(姓名、年级、班级)"""doc = fitz.open(input_pdf_path)results = []class_pattern = re.compile(r'[((]?(\d+|[一二三四五六七八九十]+)班[))]?')for page_num in target_pages:page = doc.load_page(page_num - 1)text = page.get_text("text")lines = [line.strip() for line in text.split('\n') if line.strip()]name = lines[5].strip() if len(lines) >= 6 else Nonegrade = lines[6].strip() if len(lines) >= 7 else Noneclasses = []for line in lines:matches = class_pattern.findall(line)for match in matches:converted_match = ''.join([str(chinese_to_digit(char)) if char in '一二三四五六七八九十' else char for char in match])if converted_match not in classes:classes.append(converted_match)if name and grade:results.append({"page_num": page_num,"name": name,"grade": grade[0],"class": classes})else:print(f"第{page_num}页缺少必要的信息。")return resultsdef convert_students_info(students):"""格式化学生信息为'大7班_陈宇阳'格式"""return [f"{s['grade']}{''.join(s['class'])}班_{s['name']}" for s in students]def split_pdf_every_2_pages(input_pdf_path, output_folder, formatted_names):"""将PDF每两页分割成单独文件"""if not os.path.exists(output_folder):os.makedirs(output_folder)reader = PdfReader(input_pdf_path)total_pages = len(reader.pages)num_files = (total_pages + 1) // 2for i in range(num_files):writer = PdfWriter()start_page = i * 2end_page = min(start_page + 2, total_pages)for page_num in range(start_page, end_page):writer.add_page(reader.pages[page_num])base_filename = formatted_names[i] if i < len(formatted_names) else f"P{start_page+1}-P{end_page}"output_filename = os.path.join(output_folder, f"{i+1:03}_{base_filename}_屈光复查202505.pdf")with open(output_filename, "wb") as out:writer.write(out)print(f"已创建: {output_filename}")def classify_pdfs_by_class(source_folder):"""将PDF文件按班级分类到不同文件夹,并在文件夹名中加入人数统计"""pdf_files = [f for f in os.listdir(source_folder) if f.lower().endswith('.pdf')]if not pdf_files:print(f"在文件夹 {source_folder} 中没有找到PDF文件")return []class_stats = {}# 第一次遍历:统计每个班级的人数for pdf_file in pdf_files:match = re.search(r'(中\d+班|大\d+班)', pdf_file)if match:class_name = match.group(1)class_stats[class_name] = class_stats.get(class_name, 0) + 1# 第二次遍历:移动文件到带人数的文件夹created_folders = []for pdf_file in pdf_files:match = re.search(r'(中\d+班|大\d+班)', pdf_file)if match:class_name = match.group(1)count = class_stats[class_name]new_folder_name = f"{class_name}_{count:02}人_屈光复查202505"class_folder = os.path.join(source_folder, new_folder_name)if new_folder_name not in created_folders:os.makedirs(class_folder, exist_ok=True)created_folders.append(new_folder_name)src_path = os.path.join(source_folder, pdf_file)dest_path = os.path.join(class_folder, pdf_file)shutil.move(src_path, dest_path)print(f"移动文件: {pdf_file} -> {new_folder_name}")print("\n分类完成,统计结果:")for class_name, count in class_stats.items():print(f"{class_name}: {count}个文件")# 返回实际创建的文件夹路径列表return [os.path.join(source_folder, f"{k}_{v:02}人_屈光复查202505") for k, v in class_stats.items()]def zip_class_folders(source_folder, class_folders):"""将班级文件夹打包为ZIP压缩包"""print("\n=== 开始打包班级文件夹 ===")for folder_path in class_folders:folder_name = os.path.basename(folder_path)zip_path = os.path.join(source_folder, f"{folder_name}.zip")with zipfile.ZipFile(zip_path, 'w', zipfile.ZIP_DEFLATED) as zipf:for root, dirs, files in os.walk(folder_path):for file in files:file_path = os.path.join(root, file)arcname = os.path.relpath(file_path, folder_path)zipf.write(file_path, arcname)print(f"已创建压缩包: {zip_path}")def main():# 设置路径base_path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250527视力复诊屈光拆分'input_pdf = os.path.join(base_path, "复诊通知景谷二幼.pdf")output_dir = os.path.join(base_path, "03打包发给班主任")# 第一步:拆分PDFprint("=== 开始拆分PDF ===")os.makedirs(output_dir, exist_ok=True)doc = fitz.open(input_pdf)odd_pages = [p for p in range(1, len(doc) + 1) if p % 2 != 0]students_info = extract_student_info(input_pdf, odd_pages)formatted_list = convert_students_info(students_info)split_pdf_every_2_pages(input_pdf, output_dir, formatted_list)print("PDF拆分完成!\n")# 第二步:分类PDFprint("=== 开始分类PDF ===")class_folders = classify_pdfs_by_class(output_dir)print("PDF分类完成!")# 第三步:打包文件夹zip_class_folders(output_dir, class_folders)if __name__ == "__main__":main()结果:打包文件有大小了
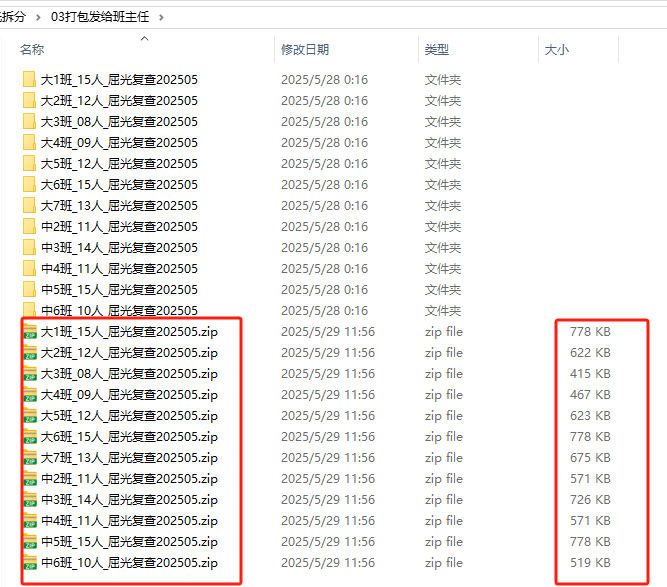
虽然打包发送每条PDF都有,更方便更完整
但是老师可能更喜欢单独PDF,便于转发。
可是保健老师转发又涉及一次只能9条。真是头疼。
相关文章:
【办公类-18-07】20250527屈光检查PDF文件拆分成多个pdf(两页一份,用幼儿班级姓名命名文件)
背景需求: 今天春游,上海海昌公园。路上保健老师收到前几天幼儿的屈光视力检查单PDF。 她说:所有孩子的通知都做在一个PDF里,我没法单独发给班主任。你有什么办法拆开来? 我说:“没问题,问deep…...

AI Agent的“搜索大脑“进化史:从Google API到智能搜索生态的技术变革
AI Agent搜索革命的时代背景 2025年agent速度发展之快似乎正在验证"2025年是agent元年"的说法,而作为agent最主要的应用工具之一(另外一个是coding),搜索工具也正在呈现快速的发展趋势。Google在2024年12月推出Gemini Deep Research࿰…...

Arduino学习-跑马灯
1、效果 2、代码 /**** 2025-5-30 跑马灯的小程序 */ //时间间隔 int intervaltime200; //初始化函数 void setup() {// put your setup code here, to run once://设置第3-第7个引脚为输出模式for(int i3;i<8;i){pinMode(i,OUTPUT);} }//循环执行 void loop() {// put you…...

python创建args命令行分析
这段代码是一个使用 Python 的 argparse 模块创建命令行界面的示例。它定义了一系列的命令行参数和子命令,通常用于构建和管理软件项目或版本控制系统中的操作。以下是对代码的逐行分析: 1初始化 ArgumentParser parser argparse.ArgumentParser(forma…...

2. 手写数字预测 gui版
2. 手写数字预测 gui版 背景1.界面绘制2.处理图片3. 加载模型4. 预测5.结果6.一点小问题 背景 做了手写数字预测的模型,但是老是跑模型太无聊了,就配合pyqt做了一个可视化界面出来玩一下 源代码可以去这里https://github.com/Leezed525/pytorch_toy拿 …...

js数据类型有哪些?它们有什么区别?
js数据类型共有8种,分别是undefined,null,boolean,number,string,Object,symbol,bigint symbol和bigint是es6中提出来的数据类型 symbol创建后独一无二不可变的数据类型,它主要是为了解决出现全局变量冲突的问题 bigint 是一种数字类型的数据,它可以表示任意精度格式的整数,…...
到未来自主Agent(L4))
大模型应用开发第五讲:成熟度模型:从ChatGPT(L2)到未来自主Agent(L4)
大模型应用开发第五讲:成熟度模型:从ChatGPT(L2)到未来自主Agent(L4) 资料取自《大模型应用开发:动手做AI Agent 》。 查看总目录:学习大纲 关于DeepSeek本地部署指南可以看下我之…...

特别篇-产品经理(三)
一、市场与竞品分析—竞品分析 1. 课后总结 案例框架:通过"小新吃蛋糕"案例展示行业分析方法,包含四个关键步骤: 明确目标行业调研确定竞品分析竞争策略输出结论 1)行业背景分析方法 PEST分析法:从四个…...

IP地址扫描 网络状态监测 企业网络管理 免安装,企业级 IP 监控防未授权接入
各位网络小卫士们!今天咱来聊聊一款超厉害的局域网IP地址扫描工具——IPScaner V1.22。这玩意儿就像网络世界的大侦探,能快速识别网络里设备的状态和资源分布。下面咱就好好唠唠它的那些事儿。 软件获取夸克网盘下载 先说说它的核心功能。第一个是IP…...

【unity游戏开发——编辑器扩展】AssetDatabase公共类在编辑器环境中管理和操作项目中的资源
注意:考虑到编辑器扩展的内容比较多,我将编辑器扩展的内容分开,并全部整合放在【unity游戏开发——编辑器扩展】专栏里,感兴趣的小伙伴可以前往逐一查看学习。 文章目录 前言一、AssetDatabase常用API1、创建资源1.1 API1.2 示例 …...

BLE协议全景图:从0开始理解低功耗蓝牙
BLE(Bluetooth Low Energy)作为一种针对低功耗场景优化的通信协议,已经广泛应用于智能穿戴、工业追踪、智能家居、医疗设备等领域。 本文是《BLE 协议实战详解》系列的第一篇,将从 BLE 的发展历史、协议栈结构、核心机制和应用领域出发,为后续工程实战打下全面认知基础。 …...
【机器学习基础】机器学习入门核心算法:GBDT(Gradient Boosting Decision Tree)
机器学习入门核心算法:GBDT(Gradient Boosting Decision Tree) 1. 算法逻辑2. 算法原理与数学推导2.1 目标函数2.2 负梯度计算2.3 决策树拟合2.4 叶子权重计算2.5 模型更新 3. 模型评估评估指标防止过拟合 4. 应用案例4.1 金融风控4.2 推荐系…...

基于开源AI大模型AI智能名片S2B2C商城小程序源码的销售环节数字化实现路径研究
摘要:在数字化浪潮下,企业销售环节的转型升级已成为提升竞争力的核心命题。本文基于清华大学全球产业研究院《中国企业数字化转型研究报告(2020)》提出的“提升销售率与利润率、打通客户数据、强化营销协同、构建全景用户画像、助…...

Spring Cache核心原理与快速入门指南
文章目录 前言一、Spring Cache核心原理1.1 架构设计思想1.2 运行时执行流程1.3 核心组件协作1.4 关键机制详解1.5 扩展点设计1.6 与Spring事务的协同 二、快速入门实战三、局限性3.1 多级缓存一致性缺陷3.2 分布式锁能力缺失3.3 事务集成陷阱 总结 前言 在当今高并发、低延迟…...

Redisson学习专栏(四):实战应用(分布式会话管理,延迟队列)
文章目录 前言一、为什么需要分布式会话管理?1.1 使用 Redisson 实现 Session 共享 二、订单超时未支付?用延迟队列精准处理2.1 RDelayedQueue 核心机制2.2 订单超时处理实战 总结 前言 在现代分布式系统中,会话管理和延迟任务处理是两个核心…...
java程序从服务器端到Lambda函数的迁移与优化
source:https://www.jfokus.se/jfokus24-preso/From-Serverful-to-Serverless-Java.pdf 从传统的服务器端Java应用,到如今的无服务器架构。这不仅仅是技术名词的改变,更是开发模式和运维理念的一次深刻变革。先快速回顾一下我们熟悉的“服务…...

使用yocto搭建qemuarm64环境
环境 yocto下载 # 源码下载 git clone git://git.yoctoproject.org/poky git reset --hard b223b6d533a6d617134c1c5bec8ed31657dd1268 构建 # 编译镜像 export MACHINE"qemuarm64" . oe-init-build-env bitbake core-image-full-cmdline 运行 # 跑虚拟机 export …...

Vue 3前沿生态整合:WebAssembly与TypeScript深度实践
一、Vue 3 WebAssembly:突破性能天花板 01、WebAssembly:浏览器中的原生性能 WebAssembly(Wasm)是一种可在现代浏览器中运行的二进制指令格式,其性能接近原生代码。结合Vue 3的响应式架构,我们可以在前端…...
Linux系统下安装配置 Nginx
Windows Nginx https://nginx.org/en/download.htmlLinux Nginx https://nginx.org/download/nginx-1.24.0.tar.gz解压 tar -zxvf tar -zxvf nginx-1.18.0.tar.gz #解压安装依赖(如未安装) yum groupinstall "Development Tools" -y yum…...

Kotlin 中集合遍历有哪几种方式?
1 for-in 循环(最常用) val list listOf("A", "B", "C") for (item in list) {print("$item ") }// A B C 2 forEach 高阶函数 val list listOf("A", "B", "C") list.forEac…...

图像卷积OpenCV C/C++ 核心操作
图像卷积:OpenCV C 核心操作 图像卷积是图像处理和计算机视觉领域最基本且最重要的操作之一。它通过一个称为卷积核(或滤波器)的小矩阵,在输入图像上滑动,并对核覆盖的图像区域执行元素对应相乘后求和的运算ÿ…...

LiveGBS作为下级平台GB28181国标级联2016|2022对接海康大华宇视华为政务公安内网等GB28181国标平台查看级联状态及会话
LiveGBS作为下级平台GB28181国标级联2016|2022对接海康大华宇视华为政务公安内网等GB28181国标平台查看级联状态及会话 1、GB/T28181级联概述2、搭建GB28181国标流媒体平台3、获取上级平台接入信息3.1、向下级提供信息3.2、上级国标平台添加下级域3.3、接入LiveGBS示例 4、配置…...

leetcode17.电话号码的字母组合:字符串映射与回溯的巧妙联动
一、题目深度解析与字符映射逻辑 题目描述 给定一个仅包含数字 2-9 的字符串 digits,返回所有它能表示的字母组合。数字与字母的映射关系如下(与电话按键相同): 2: "abc", 3: "def", 4: "ghi", …...
Gartner《2025 年软件工程规划指南》报告学习心得
一、引言 软件工程领域正面临着前所未有的变革与挑战。随着生成式人工智能(GenAI)等新兴技术的涌现、市场环境的剧烈动荡以及企业对软件工程效能的更高追求,软件工程师们必须不断适应和拥抱变化,以提升自身竞争力并推动业务发展。Gartner 公司发布的《2025 年软件工程规划…...

数据库 | 使用timescaledb和大模型进行数据分析
时序数据库:timescaledb 大模型:通义千问2.5 对话开始前提示词: 我正在做数据分析,以下是已知信息: 数据库:timescaledb,表名:dm_tag_value,tag_name列是位号名,app_time列是时间,…...

快速阅读源码
Doxygen 轻松生成包含类图、调用关系图的 HTML 和 PDF 文档, Graphviz 可以用来生成类图、调用图 sudo apt-get install doxygen graphviz brew install doxygen graphviz#HTML 文档: open docs/html/index.html一、Doxyfile配置: Doxyfile 文件 doxygen Doxyfile P…...

linux创建虚拟网卡和配置多ip
1.展示当前网卡信息列表: linux上: ip a ifconfigwindows上: ipconfig 2.创建虚拟网卡对: sudo ip link add name veth0 type veth peer name veth1 在 ip link add 命令中,type 参数可以指定多种虚拟网络设备类型&…...

Java Class类文件结构
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,…...

AI问答-Vue3+TS:reactive创建一个响应式数组,用一个新的数组对象来替换它,同时保持响应性
在 Vue 3 中,当你使用 reactive 创建一个响应式数组后,如果你想用一个新的数组对象来替换它,同时保持响应性,有几种方法可以实现 方法一:直接替换整个数组(推荐) import { reactive } from vu…...
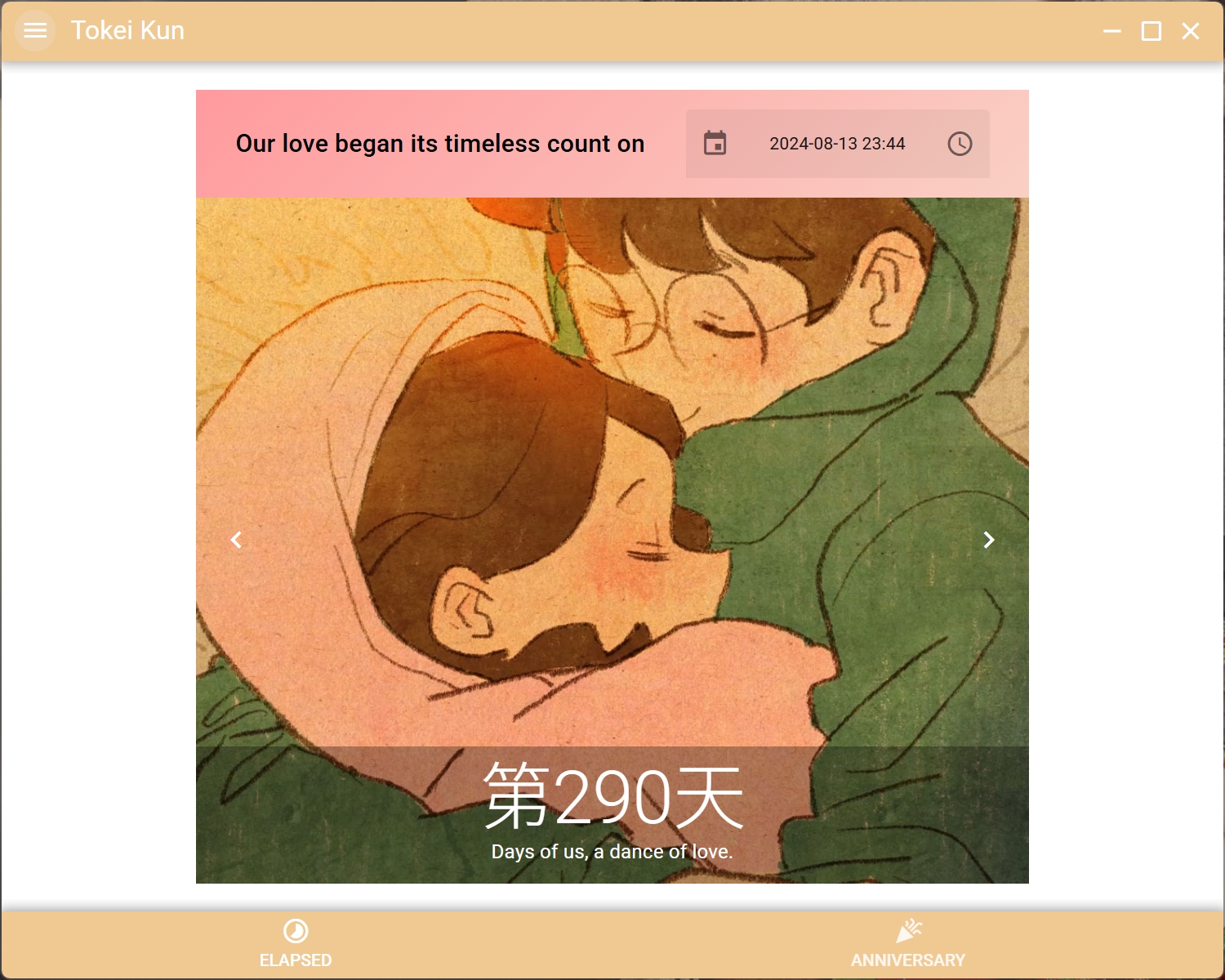
quasar electron mode如何打包无边框桌面应用程序
预览 开源项目Tokei Kun 一款简洁的周年纪念app,现已发布APK(安卓)和 EXE(Windows) 项目仓库地址:Github Repo 应用下载链接:Github Releases Preparation for Electron quasar dev -m elect…...