Spring Cache核心原理与快速入门指南
文章目录
- 前言
- 一、Spring Cache核心原理
- 1.1 架构设计思想
- 1.2 运行时执行流程
- 1.3 核心组件协作
- 1.4 关键机制详解
- 1.5 扩展点设计
- 1.6 与Spring事务的协同
- 二、快速入门实战
- 三、局限性
- 3.1 多级缓存一致性缺陷
- 3.2 分布式锁能力缺失
- 3.3 事务集成陷阱
- 总结
前言
在当今高并发、低延迟的应用生态中,缓存是提升系统性能的核心武器。但传统缓存实现往往让开发者陷入两难困境:
- 当你在方法中重复编写这样的代码时,是否感到窒息?
// 典型的手动缓存管理(每个方法都需要)
public Product getProduct(String id) {Product cached = cache.get("product_" + id);if (cached != null) return cached;Product dbData = productDao.findById(id); // 真实业务逻辑被淹没if (dbData != null) cache.set("product_" + id, dbData, 300);return dbData;
}
- 当系统需要支持多级缓存(本地缓存+Redis)时,代码复杂度是否呈指数级增长?
- 当缓存穿透、雪崩等问题袭来时,你的业务逻辑是否已变成防御性代码的牺牲品?
Spring Cache的设计思想:
- 关注点分离: 缓存逻辑与业务代码彻底解耦。
@Cacheable("products") // 业务逻辑纯净如初
public Product getProduct(String id) {return productDao.findById(id);
}
- 统一抽象层: 无缝切换缓存实现,无代码侵入。

- 智能缓存治理: 自动处理缓存一致性,规避脏数据风险。
@Caching(evict = @CacheEvict(key = "#product.id"),put = @CachePut(key = "#product.sku")
) // 原子化缓存操作
public void updateProduct(Product product) { ... }
- 生产级防御体系:
# 内置防护机制
spring.cache:caffeine.spec: maximumSize=1000, expireAfterWrite=5mredis.cache-null-values: false # 防穿透cache-prefix: "app_cache_" # 防冲突
本文将深入剖析Spring Cache的运行时架构,并提供快速入门实战。
一、Spring Cache核心原理
Spring Cache的核心原理是通过动态代理机制在方法调用前后植入缓存逻辑,基于抽象接口层(CacheManager统一管理Cache实例)实现对多种缓存实现的统一操作,其执行流程为:当调用@Cacheable方法时,缓存拦截器首先通过KeyGenerator生成缓存键,查询Cache实例是否存在缓存;若命中则直接返回,否则执行原始方法并将结果写入Cache,而@CachePut会强制更新缓存,@CacheEvict则负责清除缓存条目。整个过程通过CacheOperationSource解析注解配置,CacheResolver动态选择缓存实例,最终由CacheInterceptor协调完成缓存操作,实现了业务逻辑与缓存管理的彻底解耦。
1.1 架构设计思想

抽象分层设计:
- 应用层:@Cacheable等注解
- 抽象层:Cache/CacheManager接口
- 实现层:Caffeine/Redis/Ehcache等适配器
接口核心定义:
public interface Cache {String getName(); // 缓存名称Object get(Object key); // 读操作void put(Object key, Object value); // 写操作void evict(Object key); // 删除
}public interface CacheManager {Cache getCache(String name); // 获取缓存实例Collection<String> getCacheNames(); // 所有缓存名
}
1.2 运行时执行流程
以 @Cacheable 为例的完整调用链:

关键步骤详解:
- 代理拦截: 当客户端调用带有@Cacheable注解的方法时,Spring AOP创建的动态代理对象首先拦截该调用。代理对象将控制权交给CacheInterceptor。
- 注解解析:
CacheInterceptor委托CacheAspectSupport解析缓存操作:- 解析注解参数(value、key、condition等)
- 生成CacheOperationContext执行上下文
- 通过KeyGenerator计算缓存键(默认使用所有方法参数)
- 缓存查询:
通过CacheManager获取对应的Cache实例,使用生成的key执行cache.get()操作:- 命中:直接返回缓存结果(跳过业务方法执行)
- 未命中:继续执行原始方法
- 业务方法执行:
仅当缓存未命中时:- 通过MethodInvocation.proceed()执行实际业务逻辑
- 业务方法可能访问数据库或进行复杂计算
- 结果缓存:
业务方法执行完成后:- 检查unless条件(结果不为空等)
- 通过cache.put()将结果写入缓存
- 设置TTL(如果缓存实现支持)
- 结果返回
1.3 核心组件协作
- 缓存操作解析器 - CacheOperationSource
作为Spring Cache的注解解析引擎,CacheOperationSource通过反射分析方法的@Cacheable、@CacheEvict等注解,将其转换为可执行的CacheOperation对象(包含缓存名称、Key表达式、条件等元数据)。其核心作用是在运行时动态构建缓存操作上下文,使CacheInterceptor能基于统一的操作模型处理不同注解,实现"注解配置→缓存行为"的桥接,具体流程为:- 元数据提取: 解析方法/类上的缓存注解,生成CacheOperation集合。
- EL表达式处理: 解析SpEL表达式(如#id、#result),绑定到运行时上下文。
- 条件预判: 提前验证condition表达式,决定是否启用缓存逻辑。
- 多注解合并: 处理@Caching组合注解,合并多个缓存操作。
public interface CacheOperationSource {// 解析方法上的缓存注解Collection<CacheOperation> getCacheOperations(Method method, Class<?> targetClass);
}
- 缓存键生成器 - KeyGenerator
作为Spring Cache的缓存键生成器,KeyGenerator通过算法将方法调用信息(参数、目标对象等)转换为唯一的缓存键(Cache Key),其核心作用是确保相同业务逻辑输入对应固定缓存键,避免数据错乱。默认实现SimpleKeyGenerator按以下规则工作:- 无参数方法: 返回SimpleKey.EMPTY空键。
- 单参数方法: 直接使用参数对象作为键(需实现hashCode/equals)。
- 多参数方法: 组合所有参数生成SimpleKey。
// 默认实现逻辑(简化版)
public Object generate(Object target, Method method, Object... params) {if (params.length == 0) {return SimpleKey.EMPTY;}if (params.length == 1) {return params[0]; // 直接使用参数}return new SimpleKey(params); // 多参数组合
}
- 缓存解析器 - CacheResolver
CacheResolver是Spring Cache的动态缓存实例决策器,其核心作用是在运行时根据方法调用上下文(如参数、注解配置等)动态确定使用哪个或哪些Cache实例,实现多缓存灵活路由。其原理是通过解析@Cacheable等注解的value/cacheNames属性,结合当前缓存配置,返回最终参与操作的Cache对象集合,支持以下能力:- 基础路由: 将注解中的缓存名称(如@Cacheable(“users”))转换为具体的Cache实例。
- 动态选择: 基于方法参数或运行环境动态切换缓存(如多租户场景按tenantId选择不同Cache)
- 多缓存操作: 支持一个方法同时读写多个缓存(如主备缓存策略)。
// 典型实现:SimpleCacheResolver
public Collection<? extends Cache> resolveCaches(CacheOperationInvocationContext<?> context) {// 根据@Cacheable的value值从CacheManager获取对应Cache实例return context.getOperation().getCacheNames().stream().map(name -> cacheManager.getCache(name)).filter(Objects::nonNull).collect(Collectors.toList());
}
- 缓存拦截器 - CacheInterceptor
CacheInterceptor是Spring Cache的执行中枢,作为AOP拦截器(MethodInterceptor实现),它在目标方法调用前后植入缓存逻辑,协调CacheOperationSource、KeyGenerator、CacheResolver等组件完成完整的缓存操作流程。其核心原理是通过责任链模式,将@Cacheable/@CachePut/@CacheEvict等注解的语义转化为具体的缓存读写行为,实现以下核心功能:- 缓存决策: 根据CacheOperationSource解析的注解配置,判断是否启用缓存逻辑。
- 键值管理: 调用KeyGenerator生成缓存键,通过CacheResolver定位目标Cache实例。
- 缓存读写: 执行"查缓存→执行业务→写缓存"的标准流程(@Cacheable)或强制更新(@CachePut)。
- 异常处理: 通过CacheErrorHandler处理缓存访问异常,支持降级策略。
public class CacheInterceptor extends CacheAspectSupport implements MethodInterceptor {public Object invoke(MethodInvocation invocation) {// 核心拦截逻辑return execute(invocation, invocation.getThis(), invocation.getMethod(), invocation.getArguments());}
}
关键逻辑:
protected Object execute(CacheOperationInvoker invoker, Object target, Method method, Object[] args) {// 1. 获取缓存操作CacheOperationContext context = getOperationContext(operation, method, args);// 2. 处理@Cacheableif (isCacheableOperation(context)) {return processCacheable(context, invoker);}// 3. 处理@CachePutelse if (isPutOperation(context)) {return processPut(context, invoker);}// 4. 处理@CacheEvictelse if (isEvictOperation(context)) {processEvict(context);return invoker.invoke();}
}
1.4 关键机制详解
- 代理创建机制
- JDK动态代理:代理接口实现类
- CGLIB代理:代理无接口的类
- 代理触发条件:存在@Cacheable/@CachePut/@CacheEvict注解
- 缓存同步控制
@Cacheable(value="users", sync=true) // 启用同步锁
public User getUser(String id) {...}
- 多线程并发时,只有一个线程执行真实方法
- 基于ConcurrentMap的putIfAbsent实现
- 条件缓存实现原理
@Cacheable(condition = "#id.length() > 5")
执行流程:
- 解析SpEL表达式
- 创建ConditionEvaluator
- 在CacheAspectSupport中判断:
if (!context.canCacheBeApplied()) {return invoker.invoke(); // 跳过缓存
}
- 缓存异常处理
@Cacheable(unless = "#result == null") // 结果为空不缓存
@Cacheable(unless = "#exception != null") // 异常时不缓存
- unless在方法执行后评估
- condition在方法执行前评估
1.5 扩展点设计
Spring Cache提供丰富的扩展接口:
| 扩展点 | 作用 | 典型场景 |
|---|---|---|
| KeyGenerator | 自定义缓存键生成策略 | 复合键、业务键转换 |
| CacheResolver | 动态解析缓存实例 | 多租户缓存隔离 |
| CacheErrorHandler | 处理缓存读写异常 | 缓存降级策略 |
| CacheManagerCustomizer | 缓存管理器定制 | 初始化缓存配置 |
| CacheLoader | 缓存加载器 (JCache) | 自动刷新缓存 |
自定义KeyGenerator示例:
@Bean
public KeyGenerator businessKeyGenerator() {return (target, method, params) -> method.getName() + "_" + ((User)params[0]).getCompanyId() + "_" +((User)params[0]).getDepartmentId();
}
1.6 与Spring事务的协同

关键点:
- 缓存操作在事务提交后执行
- 避免事务回滚导致缓存不一致
二、快速入门实战
- 添加依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId>
</dependency>
- 启用缓存
@SpringBootApplication
@EnableCaching // 启用缓存
public class Application {public static void main(String[] args) {SpringApplication.run(Application.class, args);}
}
- 配置缓存(application.yml)
spring:cache:type: caffeinecaffeine:spec: maximumSize=500, expireAfterWrite=10m
- 实现缓存服务
@Service
public class BookService {// 查询时缓存结果@Cacheable(value = "books", key = "#isbn")public Book getBook(String isbn) {// 模拟数据库查询return fetchFromDatabase(isbn); }// 更新时刷新缓存@CachePut(value = "books", key = "#book.isbn")public Book updateBook(Book book) {return saveToDatabase(book);}// 删除时清除缓存@CacheEvict(value = "books", key = "#isbn")public void deleteBook(String isbn) {deleteFromDatabase(isbn);}
}
- 测试验证
@RestController
@RequestMapping("/books")
public class BookController {@Autowiredprivate BookService bookService;@GetMapping("/{isbn}")public Book getBook(@PathVariable String isbn) {// 首次调用访问数据库,后续请求直接读缓存return bookService.getBook(isbn);}
}
三、局限性
Spring Cache 虽然在简化缓存集成方面表现出色,但在复杂场景下存在明显的局限性:
3.1 多级缓存一致性缺陷
Spring Cache 的抽象层未原生支持本地缓存(如 Caffeine)与分布式缓存(如 Redis)的自动同步,导致:
- 节点间数据不一致:服务A更新数据后,服务B的本地缓存仍为旧值。
- 级联更新缺失:无法自动感知数据库变更(如通过Binlog)。
// 服务A更新数据
@CachePut("users")
public User updateUser(User user) {db.update(user); return user; // 仅更新当前节点的本地缓存和Redis
}
// 服务B仍读取到本地旧值
解决方案:
- 集成 JetCache 或 Ehcache+Terracotta 等支持多级同步的框架。
- 自定义 CacheManager 实现基于消息队列(如Kafka)的失效广播。
3.2 分布式锁能力缺失
@Cacheable(sync=true) 仅支持单机同步,无法解决分布式环境下的并发控制:
- 热点数据并发查询:多个节点同时缓存未命中,导致数据库被击穿。
- 复合操作竞争:如库存扣减需跨服务原子性。
@Cacheable(value = "inventory", sync = true) // 仅单机有效
public Integer getInventory(String sku) {return db.query("SELECT stock FROM inventory WHERE sku=?", sku);
}
解决方案:
- 集成 Redisson实现分布式锁。
- 改用 Redis Lua脚本 保证原子性。
3.3 事务集成陷阱
虽然支持事务绑定,但存在隐蔽问题:
- 脏读风险:@Cacheable 在事务提交前可能读取到未提交数据。
- 跨事务污染:事务回滚时缓存已更新。
@Transactional
@CacheEvict("orders")
public void updateOrder(Order order) {db.update(order); // 若事务回滚,缓存已被清除
}
解决方案:
- 使用 TransactionSynchronizationManager 注册事务回调。
- 采用 最终一致性 模式(如通过CDC同步)。
总结
Spring Cache 通过动态代理和统一抽象层简化了缓存集成,适合处理标准 CRUD 场景,但其在多级缓存同步、分布式锁等方面存在明显局限,复杂场景下需结合 Redisson/JetCache 等专业框架扩展,更适合作为基础缓存抽象层而非全功能解决方案。
相关文章:
Spring Cache核心原理与快速入门指南
文章目录 前言一、Spring Cache核心原理1.1 架构设计思想1.2 运行时执行流程1.3 核心组件协作1.4 关键机制详解1.5 扩展点设计1.6 与Spring事务的协同 二、快速入门实战三、局限性3.1 多级缓存一致性缺陷3.2 分布式锁能力缺失3.3 事务集成陷阱 总结 前言 在当今高并发、低延迟…...

Redisson学习专栏(四):实战应用(分布式会话管理,延迟队列)
文章目录 前言一、为什么需要分布式会话管理?1.1 使用 Redisson 实现 Session 共享 二、订单超时未支付?用延迟队列精准处理2.1 RDelayedQueue 核心机制2.2 订单超时处理实战 总结 前言 在现代分布式系统中,会话管理和延迟任务处理是两个核心…...
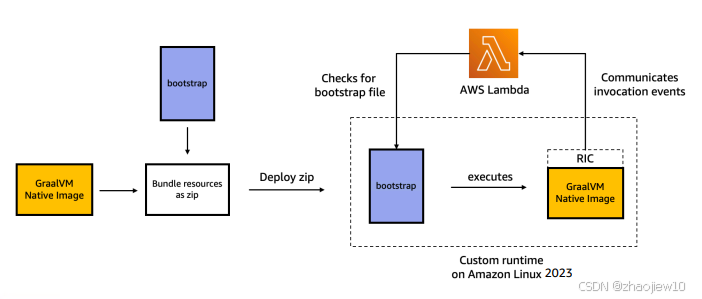
java程序从服务器端到Lambda函数的迁移与优化
source:https://www.jfokus.se/jfokus24-preso/From-Serverful-to-Serverless-Java.pdf 从传统的服务器端Java应用,到如今的无服务器架构。这不仅仅是技术名词的改变,更是开发模式和运维理念的一次深刻变革。先快速回顾一下我们熟悉的“服务…...

使用yocto搭建qemuarm64环境
环境 yocto下载 # 源码下载 git clone git://git.yoctoproject.org/poky git reset --hard b223b6d533a6d617134c1c5bec8ed31657dd1268 构建 # 编译镜像 export MACHINE"qemuarm64" . oe-init-build-env bitbake core-image-full-cmdline 运行 # 跑虚拟机 export …...

Vue 3前沿生态整合:WebAssembly与TypeScript深度实践
一、Vue 3 WebAssembly:突破性能天花板 01、WebAssembly:浏览器中的原生性能 WebAssembly(Wasm)是一种可在现代浏览器中运行的二进制指令格式,其性能接近原生代码。结合Vue 3的响应式架构,我们可以在前端…...
Linux系统下安装配置 Nginx
Windows Nginx https://nginx.org/en/download.htmlLinux Nginx https://nginx.org/download/nginx-1.24.0.tar.gz解压 tar -zxvf tar -zxvf nginx-1.18.0.tar.gz #解压安装依赖(如未安装) yum groupinstall "Development Tools" -y yum…...

Kotlin 中集合遍历有哪几种方式?
1 for-in 循环(最常用) val list listOf("A", "B", "C") for (item in list) {print("$item ") }// A B C 2 forEach 高阶函数 val list listOf("A", "B", "C") list.forEac…...

图像卷积OpenCV C/C++ 核心操作
图像卷积:OpenCV C 核心操作 图像卷积是图像处理和计算机视觉领域最基本且最重要的操作之一。它通过一个称为卷积核(或滤波器)的小矩阵,在输入图像上滑动,并对核覆盖的图像区域执行元素对应相乘后求和的运算ÿ…...

LiveGBS作为下级平台GB28181国标级联2016|2022对接海康大华宇视华为政务公安内网等GB28181国标平台查看级联状态及会话
LiveGBS作为下级平台GB28181国标级联2016|2022对接海康大华宇视华为政务公安内网等GB28181国标平台查看级联状态及会话 1、GB/T28181级联概述2、搭建GB28181国标流媒体平台3、获取上级平台接入信息3.1、向下级提供信息3.2、上级国标平台添加下级域3.3、接入LiveGBS示例 4、配置…...

leetcode17.电话号码的字母组合:字符串映射与回溯的巧妙联动
一、题目深度解析与字符映射逻辑 题目描述 给定一个仅包含数字 2-9 的字符串 digits,返回所有它能表示的字母组合。数字与字母的映射关系如下(与电话按键相同): 2: "abc", 3: "def", 4: "ghi", …...
Gartner《2025 年软件工程规划指南》报告学习心得
一、引言 软件工程领域正面临着前所未有的变革与挑战。随着生成式人工智能(GenAI)等新兴技术的涌现、市场环境的剧烈动荡以及企业对软件工程效能的更高追求,软件工程师们必须不断适应和拥抱变化,以提升自身竞争力并推动业务发展。Gartner 公司发布的《2025 年软件工程规划…...

数据库 | 使用timescaledb和大模型进行数据分析
时序数据库:timescaledb 大模型:通义千问2.5 对话开始前提示词: 我正在做数据分析,以下是已知信息: 数据库:timescaledb,表名:dm_tag_value,tag_name列是位号名,app_time列是时间,…...

快速阅读源码
Doxygen 轻松生成包含类图、调用关系图的 HTML 和 PDF 文档, Graphviz 可以用来生成类图、调用图 sudo apt-get install doxygen graphviz brew install doxygen graphviz#HTML 文档: open docs/html/index.html一、Doxyfile配置: Doxyfile 文件 doxygen Doxyfile P…...

linux创建虚拟网卡和配置多ip
1.展示当前网卡信息列表: linux上: ip a ifconfigwindows上: ipconfig 2.创建虚拟网卡对: sudo ip link add name veth0 type veth peer name veth1 在 ip link add 命令中,type 参数可以指定多种虚拟网络设备类型&…...

Java Class类文件结构
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,…...

AI问答-Vue3+TS:reactive创建一个响应式数组,用一个新的数组对象来替换它,同时保持响应性
在 Vue 3 中,当你使用 reactive 创建一个响应式数组后,如果你想用一个新的数组对象来替换它,同时保持响应性,有几种方法可以实现 方法一:直接替换整个数组(推荐) import { reactive } from vu…...
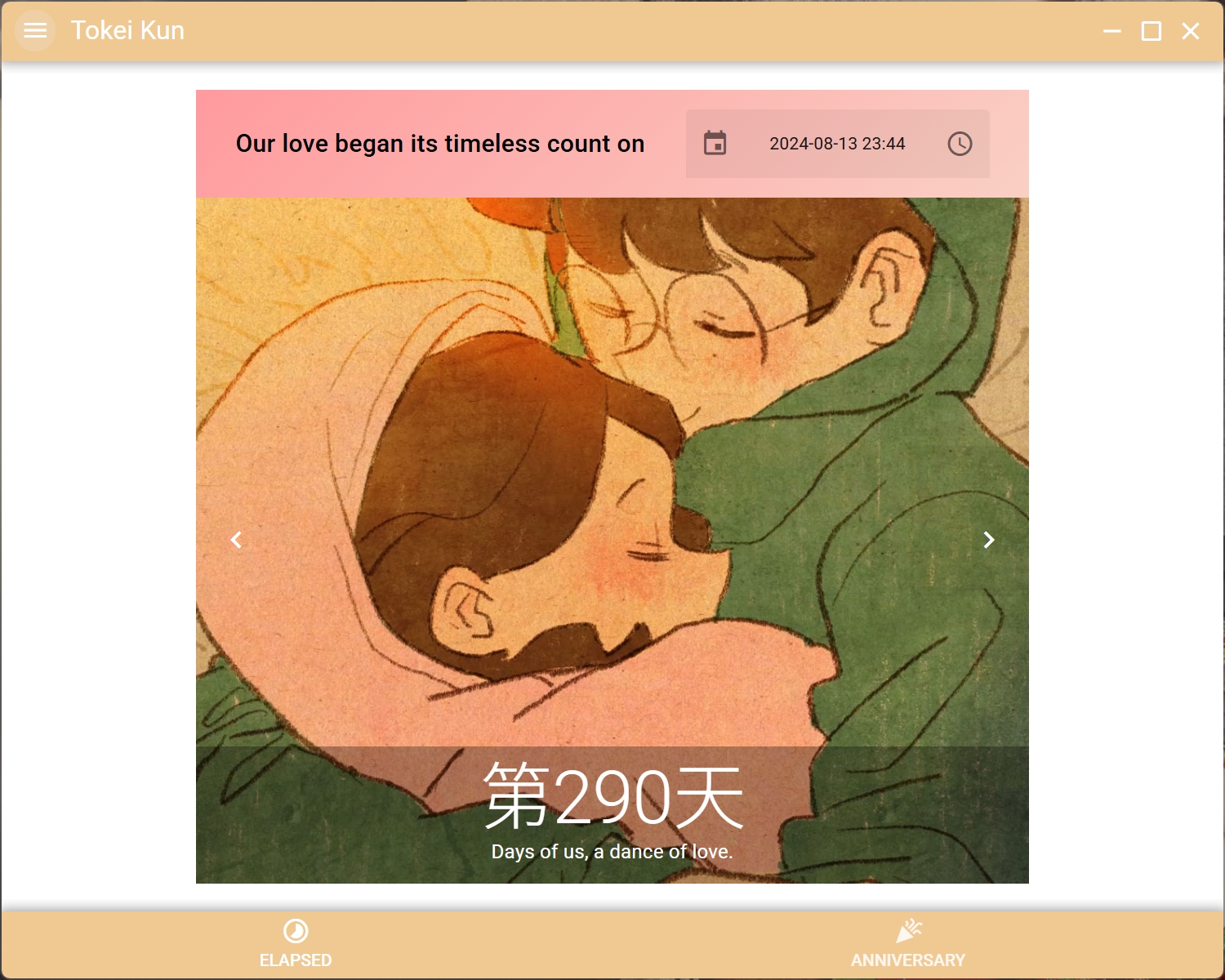
quasar electron mode如何打包无边框桌面应用程序
预览 开源项目Tokei Kun 一款简洁的周年纪念app,现已发布APK(安卓)和 EXE(Windows) 项目仓库地址:Github Repo 应用下载链接:Github Releases Preparation for Electron quasar dev -m elect…...
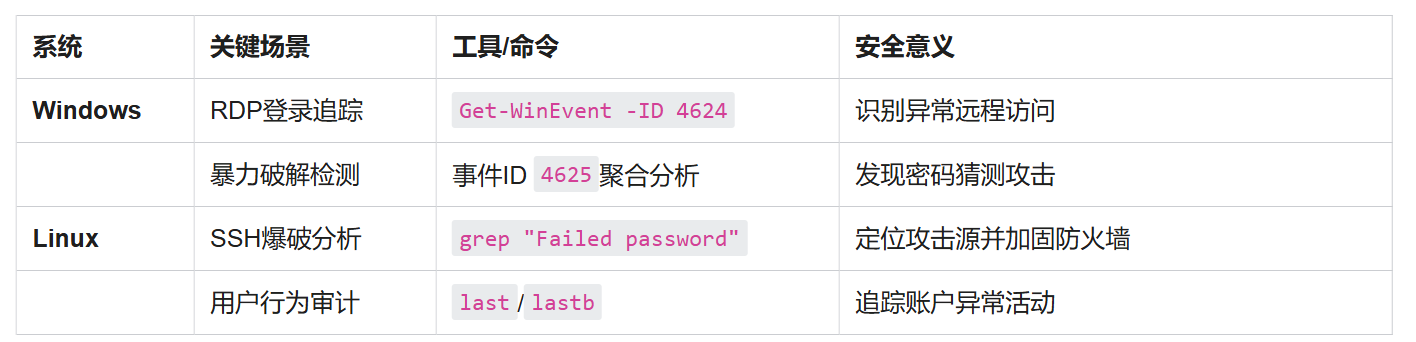
【HW系列】—Windows日志与Linux日志分析
文章目录 一、Windows日志1. Windows事件日志2. 核心日志类型3. 事件日志分析实战详细分析步骤 二、Linux日志1. 常见日志文件2. 关键日志解析3. 登录爆破检测方法日志分析核心要点 一、Windows日志 1. Windows事件日志 介绍:记录系统、应用程序及安全事件&#x…...
VIN码识别解析接口如何用C#进行调用?
一、什么是VIN码识别解析接口? VIN码不仅是车辆的“身份证”,更是连接制造、销售、维修、保险、金融等多个环节的数字纽带。而VIN码查询API,正是打通这一链条的关键工具。 无论是汽车电商平台、二手车商、维修厂,还是保险公司、金…...

动态规划之网格图模型(一)
文章目录 动态规划之网格图模型(一)LeetCode 64. 最小路径和思路Golang 代码 LeetCode 62. 不同路径思路Golang 代码 LeetCode 63. 不同路径 II思路Golang 代码 LeetCode 120. 三角形最小路径和思路Golang 代码 LeetCode 3393. 统计异或值为给定值的路径…...
PCB设计实践(三十)地平面完整性
在高速数字电路和混合信号系统设计中,地平面完整性是决定PCB性能的核心要素之一。本文将从电磁场理论、信号完整性、电源分配系统等多个维度深入剖析地平面设计的关键要点,并提出系统性解决方案。 一、地平面完整性的电磁理论基础 电流回流路径分析 在PC…...

x86_64-apple-ios-simulator 错误
Could not find module ImagePicker for target x86_64-apple-ios-simulator; found: arm64, arm64-apple-ios-simulator 解决方案一 添加 arm64。 搜索 Excluded Architectures ,添加arm64 解决方案二 在Podfild中,添加佐料。在文件的最下方添加如…...
使用ray扩展python应用之流式处理应用
流式处理就是数据一来,咱们就得赶紧处理,不能攒批再算。这里的实时不是指瞬间完成,而是要在数据产生的那一刻,或者非常接近那个时间点,就做出响应。这种处理方式,我们称之为流式处理。 流式处理的应用场景…...

IP证书的作用与申请全解析:从安全验证到部署实践
在网络安全领域,IP证书(IP SSL证书)作为传统域名SSL证书的补充方案,专为公网IP地址提供HTTPS加密与身份验证服务。本文将从技术原理、应用场景、申请流程及部署要点四个维度,系统解析IP证书的核心价值与操作指南。 一…...

第四十一天打卡
简单CNN 知识回顾 数据增强 卷积神经网络定义的写法 batch归一化:调整一个批次的分布,常用与图像数据 特征图:只有卷积操作输出的才叫特征图 调度器:直接修改基础学习率 卷积操作常见流程如下: 1. 输入 → 卷积层 →…...

C++中指针常量和常量指针的区别
C中指针常量和常量指针的区别 前言 在 C/C 编程中,指针是一个非常重要的概念,而指针常量和常量指针又是指针的两种特殊形式,它们在实际开发中有着不同的应用场景和语义,理解它们的区别对于编写高质量的代码至关重要。本文将详细…...

深入解析向量数据库:基本原理与主流实现
向量数据库(Vector Database)是专门用于存储和检索高维向量的数据库系统。近年来,随着机器学习和深度学习的发展,文本、图像、音频等非结构化数据常被转换为向量表示,用于语义搜索和推荐等场景。这篇博客将面向 Java/P…...

VectorNet:自动驾驶中的向量魔法
在自动驾驶的世界里,车辆需要像超级英雄一样,拥有“透视眼”和“预知未来”的能力,才能在复杂的交通环境中安全行驶。今天,我们要介绍一个神奇的工具——VectorNet,它就像是给自动驾驶车辆装上了一双智能的眼睛&#x…...

PostgreSQL性能监控双雄:深入解析pg_stat_statements与pg_statsinfo
在PostgreSQL的运维和优化工作中,性能监控工具的选择直接关系到问题定位的效率和数据库的稳定性。今天我们将深入探讨两款核心工具:pg_stat_statements(SQL执行统计)和pg_statsinfo(系统级监控),…...

【Linux系列】Linux/Unix 系统中的 CPU 使用率
博客目录 多核处理器时代的 CPU 使用率计算为什么要这样设计? 解读实际案例:268.76%的 CPU 使用率性能分析的意义 相关工具与监控实践1. top 命令2. htop 命令3. mpstat 命令4. sar 命令 实际应用场景容量规划性能调优故障诊断 深入理解:CPU …...