使用ray扩展python应用之流式处理应用
流式处理就是数据一来,咱们就得赶紧处理,不能攒批再算。这里的实时不是指瞬间完成,而是要在数据产生的那一刻,或者非常接近那个时间点,就做出响应。这种处理方式,我们称之为流式处理。
流式处理的应用场景
流式处理到底能干啥?它应用场景非常广泛。
-
日志分析。应用每天产生海量日志,边生产边分析,一旦发现异常,比如某个服务崩溃了,或者有安全事件发生,立刻就能报警,快速定位问题根源,大大缩短故障恢复时间。
-
金融交易,流式处理就能实时监控每一笔交易,结合用户行为模式、地理位置、交易金额等多维度信息,通过规则引擎或者机器学习模型,秒级识别出异常交易。
-
网络安全。实时监控网络流量、系统日志、用户登录行为等等。通过建立正常的安全基线,任何偏离这个基线的异常活动,比如大量未授权访问尝试、异常的数据包传输,都能被流式系统迅速捕捉到。
-
物流行业。GPS信号、传感器数据源源不断地传入系统,通过流式处理,可以实时计算最优路径,避开拥堵路段,动态调整配送计划。这不仅提高了效率,还能降低油耗和运营成本。
-
物联网IoT。无数的传感器设备,比如工厂里的机器、城市里的路灯、农田里的土壤湿度监测器,它们都在不停地产生数据。
-
推荐引擎。每一次点击、浏览、搜索,都被实时记录下来,形成你的行为数据流。推荐系统实时分析这些数据,结合协同过滤、深度学习等算法,不断更新你的兴趣画像,然后给你推送最相关的商品或内容。
Ray如何实现流式处理
了解了流式应用的重要性,我们来看看如何在 Ray 中实现它们。目前主要有两种方式:
-
利用 Ray 提供的强大底层组件,比如 Actors、Task 并行、共享内存等,自己动手构建一套定制化的流式处理框架。这种方式灵活性高,但开发量也相对较大。
-
将 Ray 与现有的成熟流式引擎集成,比如 Apache Flink,通常会借助 Kafka 这样的消息中间件来连接数据源和处理逻辑。
Ray 的定位不是要做一个独立的、功能全面的流式系统,而是提供一个强大的计算平台,让开发者可以更方便地构建自己的流式应用。既然提到了集成,那为什么 Kafka 成为了流式应用中最受欢迎的消息中间件之一呢?Kafka 能够以惊人的吞吐量处理海量数据流,同时保证数据的持久化存储,这意味着你可以随时回溯历史数据进行分析。而且,Kafka 的水平扩展性非常好,可以通过增加 Broker 节点轻松应对数据量的增长。更重要的是,围绕 Kafka 已经形成了一个非常成熟的生态系统,各种工具和库层出不穷。
kafka和ray集成
这里只关注那些kafka与 Ray 集成时最相关的特性。很多人把 Kafka 当作消息队列,比如 RabbitMQ,但其实它本质上是一个分布式日志系统。
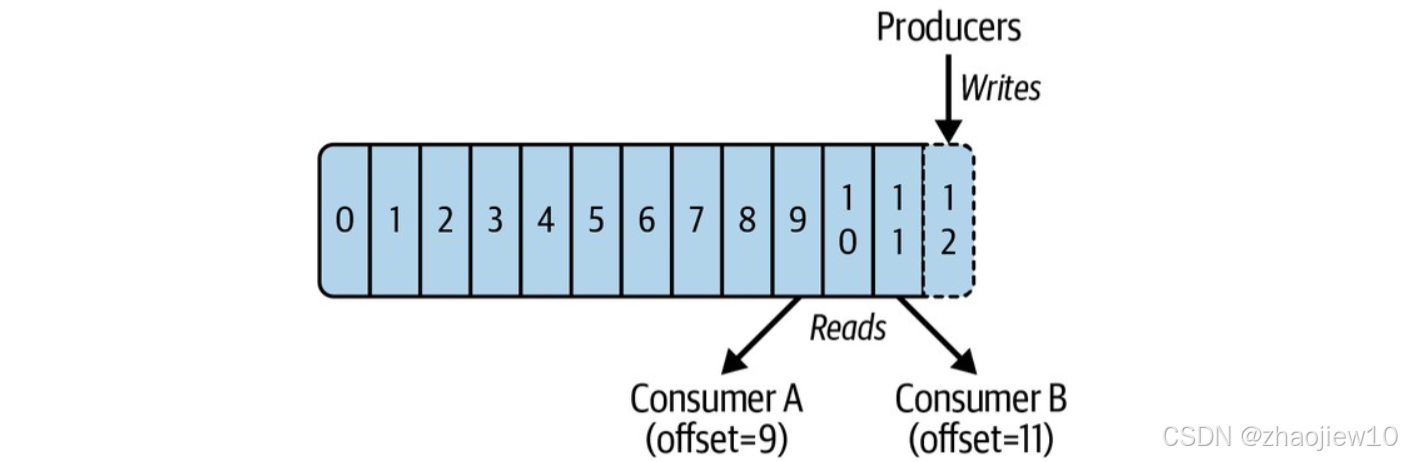
它不像传统的队列那样,消息发出去就没了,Kafka 把每一条消息都当作一个记录,按顺序追加写入到日志文件中。每条记录可以包含 Key 和 Value,当然两者都是可选的。生产者总是往日志的末尾写入新消息。而消费者呢,它可以选择从哪个位置开始读取,这个位置叫做 Offset。这意味着,消费者可以读取任意历史消息,也可以只读最新的消息。
这种基于日志的设计,带来了几个关键区别。
-
消息的生命周期。传统队列里的消息,一旦被消费者成功消费,通常就从队列里删除了,是临时的。而 Kafka 的消息是持久化的,会一直保存在磁盘上,直到达到配置的保留策略。这使得 Kafka 支持消息回溯。
-
消费者管理。在队列系统里,通常是 Broker 来管理消费者的 Offset,告诉消费者下次该从哪里读。但在 Kafka 里,Offset 是由消费者自己负责管理的。Kafka 可以支持大量的消费者同时读取同一个 Topic,因为每个消费者只需要记录自己的 Offset 即可,互不干扰。
Kafka 也像消息队列一样,用 Topic 来组织数据。但 Kafka 的 Topic 是一个纯粹的逻辑概念,它下面实际上是由多个 Partition 组成的。你可以把 Partition 理解为 Topic 的物理分片。为什么要这样做?主要是为了实现水平扩展和并行处理。每个 Partition 内部的数据是有序的,但不同 Partition 之间的数据是无序的。生产者写入数据时,会根据一定的策略选择写入哪个 Partition。那么,生产者是怎么决定把消息写到哪个 Partition 的呢?主要有两种情况。
- 如果你没有指定 Key,Kafka 默认会采用轮询的方式,均匀地把消息分配到不同的 Partition。这样可以保证负载均衡。
- 你给消息指定一个 Key,比如用户的 ID 或者订单号。Kafka 默认会使用 Key 的 Hash 值来决定写入哪个 Partition。这样做的好处是,同一个 Key 的所有消息,都会被写入同一个 Partition,保证了该 Key 下消息的顺序性。
- 如果有特殊需求,也可以实现自定义的 Partitioning 策略。
记住,Partition 内部消息是有序的,跨 Partition 的消息是无序的。有了 Partition,怎么让消费者高效地读取呢?这就引出了 Consumer Group 的概念。你可以把多个消费者组成一个组,让它们共同消费同一个 Topic 的消息。Kafka 会把这个 Topic 的所有 Partition 分配给这个 Consumer Group 里的消费者。
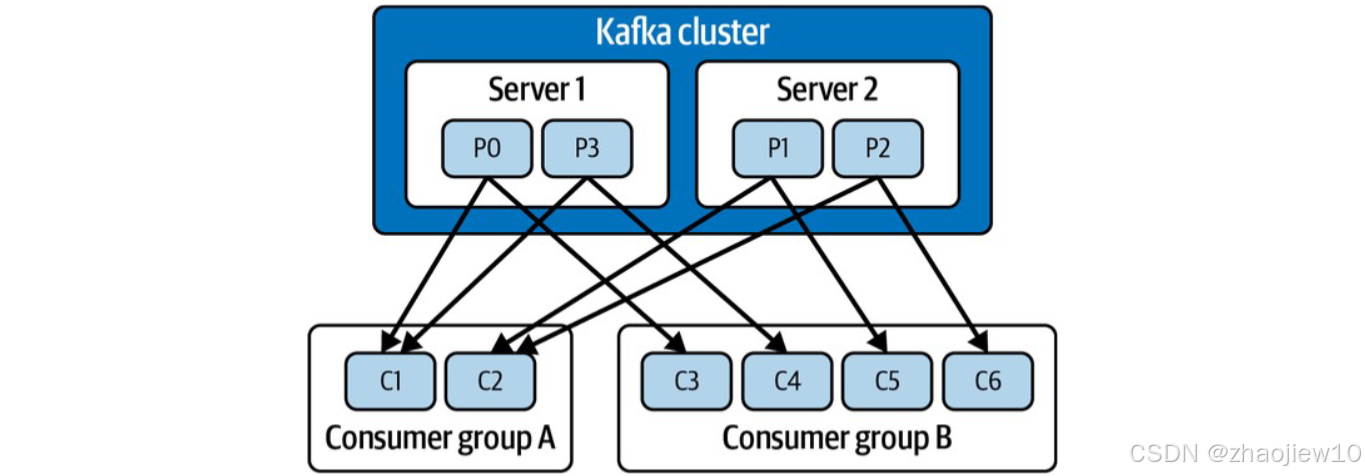
比如,一个 Topic 有 10 个 Partition,你在一个 Group 里放了 5 个消费者,那么 Kafka 会把每个消费者分配到 2 个 Partition。这样,每个消费者就可以并行地从自己的 Partition 里读取消息,大大提高了整体的消费速度。所以,想提升消费能力,要么增加消费者数量,要么增加 Partition 数量。Kafka 提供了丰富的 API 来支持各种操作。主要有五大类:
- Producer API 用来发送消息;
- Consumer API 用来读取消息;
- AdminClient API 用来管理 Topic、Broker 等元数据;
- Streams API 提供了更高级的流处理能力,可以直接在 Kafka 上做转换;
- Connect API 则是用来连接 Kafka 和外部系统的,比如数据库、搜索引擎等。
Kafka 本身只关心字节数组,所以我们需要把实际的数据结构序列化成字节数组才能发送,这个过程叫做 Marshaling。常用的格式有很多,比如 Avro、Protobuf、JSON、甚至是 Python 的 Pickle。选择哪种格式取决于你的具体需求,比如性能、消息大小、是否需要 Schema 定义、扩展性以及语言兼容性。另外要注意一点,Kafka 本身不保证消息的唯一性,也就是说,可能会出现重复消息。所以,确保消息只被处理一次的责任落在了消费者身上,通常需要消费者自己记录 Offset 并提交。
示例代码
现在我们把 Kafka 和 Ray 结合起来。为什么用 Ray Actors 来封装 Kafka 的 Consumer 和 Producer 呢?
- 对于 Kafka Consumer,它通常需要在一个无限循环里运行,不断拉取消息,并且需要记住自己已经读到哪里了,也就是维护 Offset。这正好符合 Ray Actor 的特点:一个 Actor 就是一个独立的状态服务。所以,把 Kafka Consumer 实现为一个 Ray Actor,非常自然。
- 对于 Producer,虽然它本身不需要维护状态,但把它放在一个 Actor 里,我们可以方便地异步调用 produce 方法,向任何 Kafka Topic 发送消息,而无需为每个 Topic 创建一个独立的 Producer 实例,简化了管理。
这是一个简单的 Kafka Producer Actor 的实现。
@ray.remote
class KafkaProducer:def __init__(self, server: str = 'localhost:9092'):from confluent_kafka import Producerconf = {'bootstrap.servers': server}self.producer = Producer(**conf)def produce(self, data: dict, key: str = None, topic: str = 'test'):def delivery_callback(err, msg):if err:print(f'Message failed delivery: {err}')else:print(f'Message delivered to topic {msg.topic()} partition 'f'{msg.partition()} offset {msg.offset()}')binary_key = Noneif key is not None:binary_key = key.encode('UTF8')self.producer.produce(topic=topic, value=json.dumps(data).encode('UTF8'),key=binary_key, callback=delivery_callback)self.producer.poll(0)def destroy(self):self.producer.flush(30)
它使用了 confluent_kafka 库,这是 Python 中常用的 Kafka 客户端。
- 在 init 方法里,我们根据 broker 地址初始化一个 Kafka Producer 对象。produce 方法就是我们用来发送消息的接口,它接收数据、可选的 key 和 topic 名称。内部,它会调用 Kafka Producer 的 produce 方法,这里我们用了 json.dumps 把 Python 字典序列化成 JSON 字符串,再 encode 成字节。
- delivery_callback 是一个回调函数,用来处理消息发送成功或失败的情况。
- destroy 方法在 Actor 销毁前调用,确保所有待发送的消息都被 flush 出去。
这是 Kafka Consumer Actor 的实现。
@ray.remote
class KafkaConsumer:def __init__(self, callback, group: str = 'ray', server: str = 'localhost:9092',topic: str = 'test', restart: str = 'latest'):from confluent_kafka import Consumerfrom uuid import uuid4# Configurationconsumer_conf = {'bootstrap.servers': server, # bootstrap server'group.id': group, # group ID'session.timeout.ms': 6000, # session tmout'auto.offset.reset': restart} # restart# Create Consumer instanceself.consumer = Consumer(consumer_conf)self.topic = topicself.callback = callbackself.id = str(uuid4())def start(self):self.run = Truedef print_assignment(consumer, partitions):print(f'Consumer: {self.id}')print(f'Assignment: {partitions}')# Subscribe to topicsself.consumer.subscribe([self.topic], on_assign = print_assignment)while self.run:msg = self.consumer.poll(timeout=1.0)if msg is None:continueif msg.error():print(f'Consumer error: {msg.error()}')continueelse:# Proper messageself.callback(self.id, msg)def stop(self):self.run = Falsedef destroy(self):self.consumer.close()
同样使用了 confluent_kafka 库。
-
init 方法里,除了 broker 地址,还需要配置 group.id、session.timeout.ms、auto.offset.reset 等参数。group.id 是 Consumer Group 的标识,auto.offset.reset 决定了消费者启动时没有 Offset 或者 Offset 不存在时的行为,比如 latest 表示从最新的消息开始读。
-
start 方法启动了一个无限循环,使用 consumer.poll 拉取消息。如果收到消息,就调用传入的 callback 函数进行处理。
-
stop 方法通过设置 run 为 False 来停止循环。
-
destroy 方法则关闭 Kafka Consumer 连接。
测试函数
def print_message(consumer_id: str, msg):print(f"Consumer {consumer_id} new message: topic={msg.topic()} "f"partition= {msg.partition()} offset={msg.offset()} "f"key={msg.key().decode('UTF8')}")print(json.loads(msg.value().decode('UTF8')))# Start Ray
ray.init()# Start consumers and producers
n_ = 5 # Number of consumers
consumers = [KafkaConsumer.remote(print_message) for _ in range(n_consumers)]
producer = KafkaProducer.remote()
refs = [c.start.remote() for c in consumers]# publish messages
user_name = 'john'
user_favorite_color = 'blue'try:while True:user = {'name': user_name,'favorite_color': user_favorite_color,'favorite_number': randint(0, 1000)}producer.produce.remote(user, str(randint(0, 100)))sleep(1)# end gracefully
except KeyboardInterrupt:for c in consumers:c.stop.remote()
finally:for c in consumers:c.destroy.remote()producer.destroy.remote()ray.kill(producer)
额外的阅读材料
- https://www.anyscale.com/blog/serverless-kafka-stream-processing-with-ray
相关文章:
使用ray扩展python应用之流式处理应用
流式处理就是数据一来,咱们就得赶紧处理,不能攒批再算。这里的实时不是指瞬间完成,而是要在数据产生的那一刻,或者非常接近那个时间点,就做出响应。这种处理方式,我们称之为流式处理。 流式处理的应用场景…...

IP证书的作用与申请全解析:从安全验证到部署实践
在网络安全领域,IP证书(IP SSL证书)作为传统域名SSL证书的补充方案,专为公网IP地址提供HTTPS加密与身份验证服务。本文将从技术原理、应用场景、申请流程及部署要点四个维度,系统解析IP证书的核心价值与操作指南。 一…...

第四十一天打卡
简单CNN 知识回顾 数据增强 卷积神经网络定义的写法 batch归一化:调整一个批次的分布,常用与图像数据 特征图:只有卷积操作输出的才叫特征图 调度器:直接修改基础学习率 卷积操作常见流程如下: 1. 输入 → 卷积层 →…...

C++中指针常量和常量指针的区别
C中指针常量和常量指针的区别 前言 在 C/C 编程中,指针是一个非常重要的概念,而指针常量和常量指针又是指针的两种特殊形式,它们在实际开发中有着不同的应用场景和语义,理解它们的区别对于编写高质量的代码至关重要。本文将详细…...

深入解析向量数据库:基本原理与主流实现
向量数据库(Vector Database)是专门用于存储和检索高维向量的数据库系统。近年来,随着机器学习和深度学习的发展,文本、图像、音频等非结构化数据常被转换为向量表示,用于语义搜索和推荐等场景。这篇博客将面向 Java/P…...

VectorNet:自动驾驶中的向量魔法
在自动驾驶的世界里,车辆需要像超级英雄一样,拥有“透视眼”和“预知未来”的能力,才能在复杂的交通环境中安全行驶。今天,我们要介绍一个神奇的工具——VectorNet,它就像是给自动驾驶车辆装上了一双智能的眼睛&#x…...

PostgreSQL性能监控双雄:深入解析pg_stat_statements与pg_statsinfo
在PostgreSQL的运维和优化工作中,性能监控工具的选择直接关系到问题定位的效率和数据库的稳定性。今天我们将深入探讨两款核心工具:pg_stat_statements(SQL执行统计)和pg_statsinfo(系统级监控),…...

【Linux系列】Linux/Unix 系统中的 CPU 使用率
博客目录 多核处理器时代的 CPU 使用率计算为什么要这样设计? 解读实际案例:268.76%的 CPU 使用率性能分析的意义 相关工具与监控实践1. top 命令2. htop 命令3. mpstat 命令4. sar 命令 实际应用场景容量规划性能调优故障诊断 深入理解:CPU …...

C++语法系列之模板进阶
前言 本次会介绍一下非类型模板参数、模板的特化(特例化)和模板的可变参数,不是最开始学的模板 一、非类型模板参数 字面意思,比如: template<size_t N 10> 或者 template<class T,size_t N 10>比如:静态栈就可以用到&#…...
基于图神经网络的自然语言处理:融合LangGraph与大型概念模型的情感分析实践
在企业数字化转型进程中,非结构化文本数据的处理与分析已成为核心技术挑战。传统自然语言处理方法在处理客户反馈、社交媒体内容和内部文档等复杂数据集时,往往难以有效捕获文本间的深层语义关联和结构化关系。大型概念模型(Large Concept Mo…...
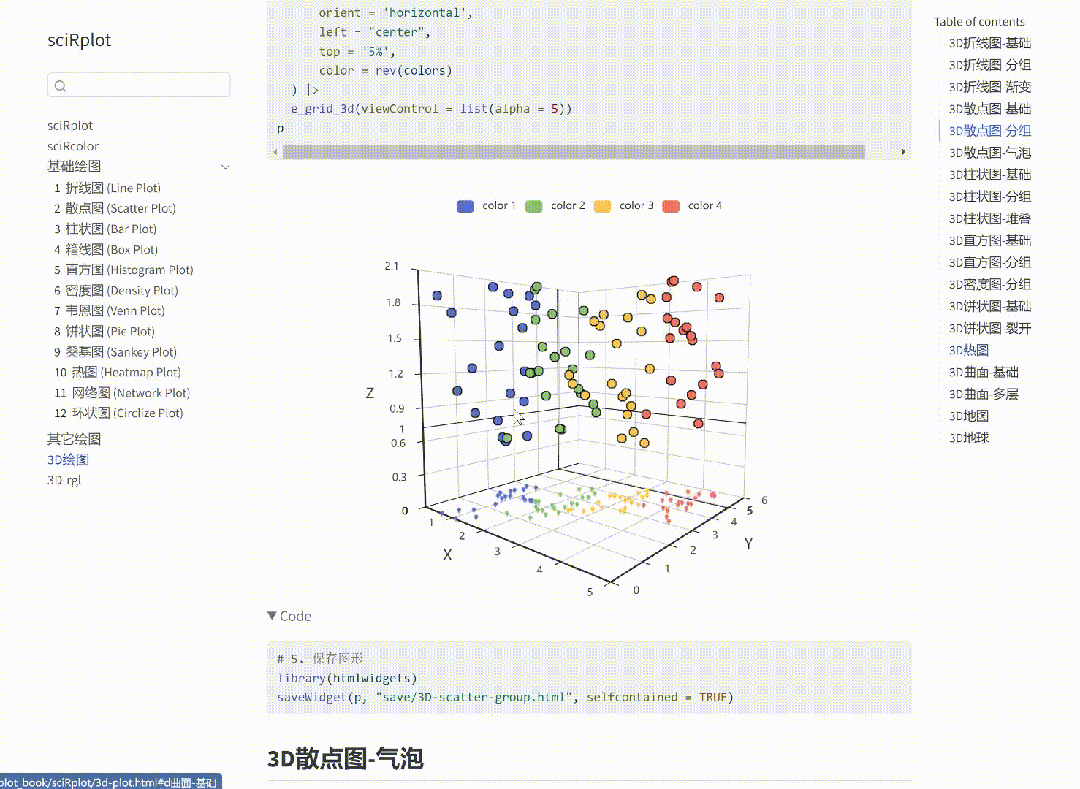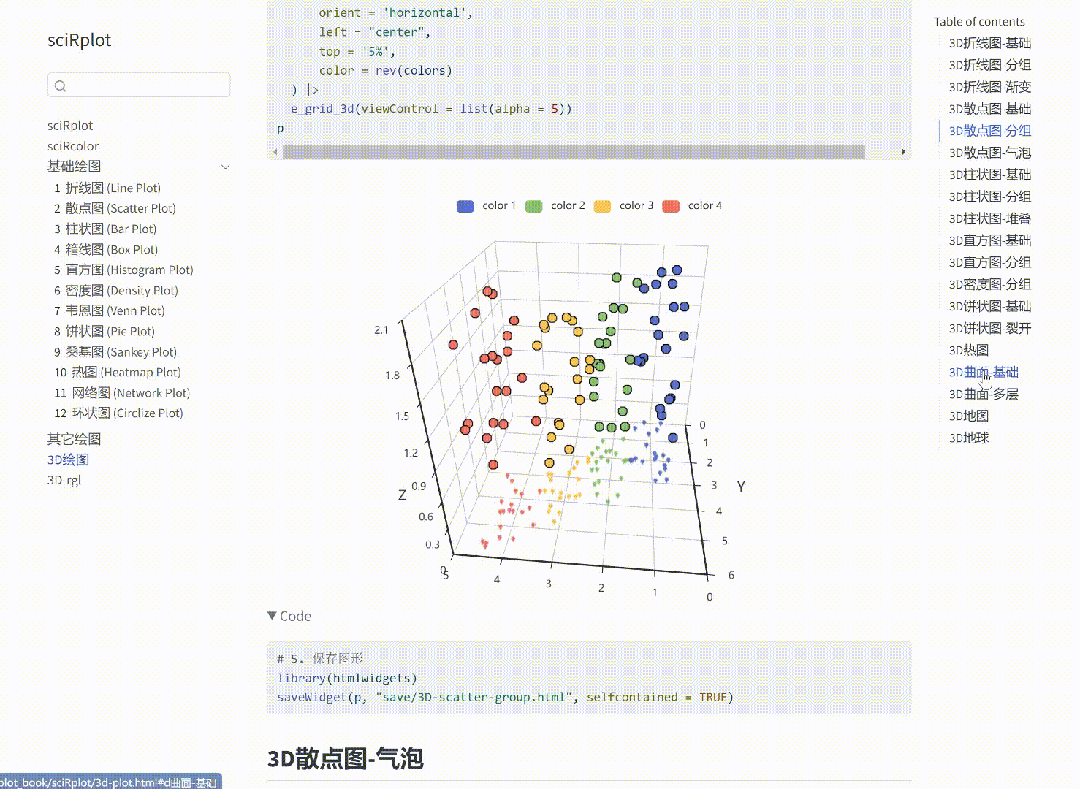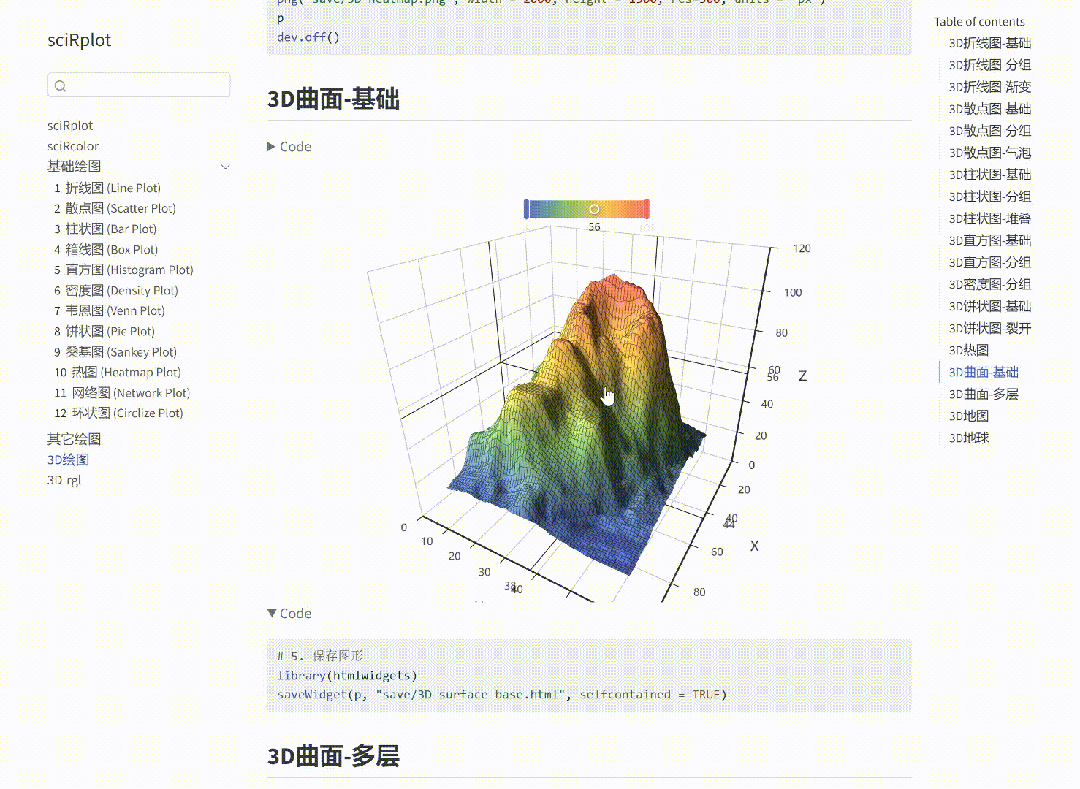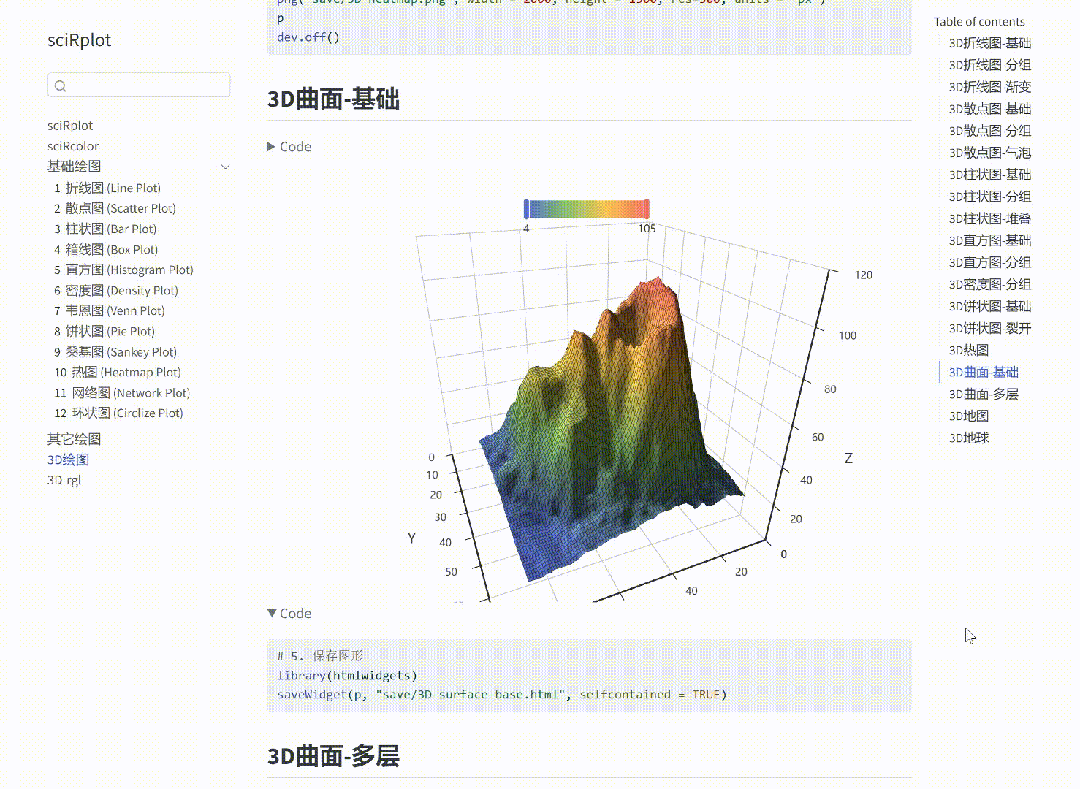
R 语言科研绘图 --- 热力图-汇总
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

基于DFT码本的波束方向图生成MATLAB实现
基于DFT码本的波束方向图生成MATLAB实现,包含参数配置、方向图生成和可视化模块: %% 基于DFT码本的波束方向图生成 clc; clear; close all;%% 参数配置 params struct(...N, 8, % 阵元数d, 0.5, % 阵元间距(λ/2)theta_sc…...
)
vBulletin未认证API方法调用漏洞(CVE-2025-48827)
免责声明 本文档所述漏洞详情及复现方法仅限用于合法授权的安全研究和学术教育用途。任何个人或组织不得利用本文内容从事未经许可的渗透测试、网络攻击或其他违法行为。使用者应确保其行为符合相关法律法规,并取得目标系统的明确授权。 对于因不当使用本文信息而造成的任何直…...
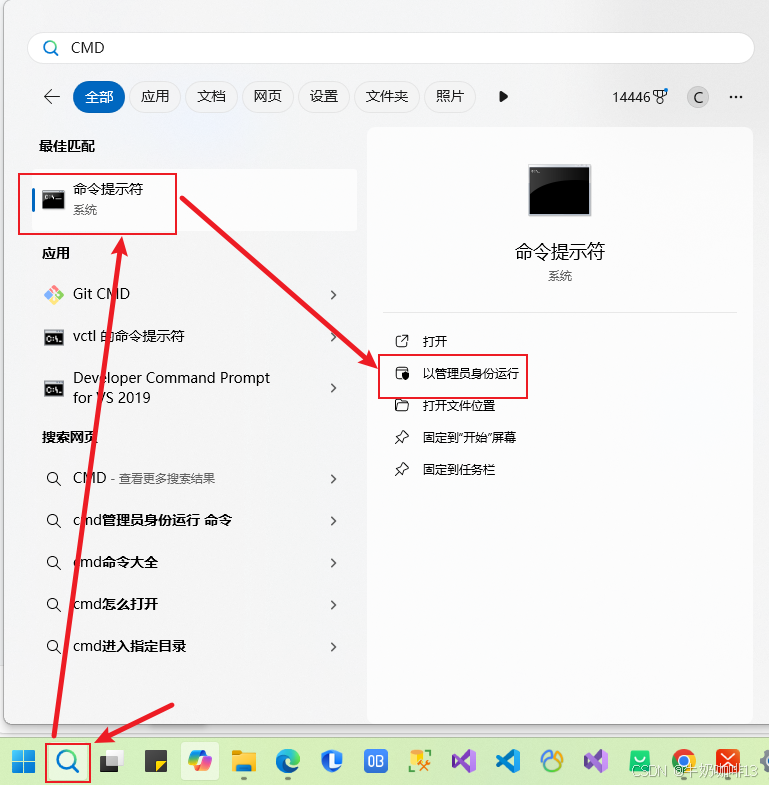
解决访问网站提示“405 很抱歉,由于您访问的URL有可能对网站造成安全威胁,您的访问被阻断”问题
一、问题描述 本来前几天都可以正常访问的网站,但是今天当我们访问网站的时候会显示“405 很抱歉,由于您访问的URL有可能对网站造成安全威胁,您的访问被阻断。您的请求ID是:XXXX”,而不能正常的访问网站,如…...

FeignClient发送https请求时的证书验证原理分析
背景 微服务之间存在调用关系,且部署为 SSL 协议时,Feignt 请求报异常: Caused by: javax.net.ssl.SSLHandshakeException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find vali…...

UDP组播套接字与URI/URL/URN技术详解
UDP组播套接字基础 Java通过MulticastSocket类提供对UDP组播通信的支持,该机制允许单个数据报同时发送给多个接收者。组播套接字的工作机制与标准DatagramSocket类似,但核心区别在于其基于组播组成员关系的通信模型。 组播组成员管理 创建并绑定组播套接字后,必须调用joi…...
机器学习中的关键术语及其含义
神经元及神经网络 机器学习中的神经网络是一种模仿生物神经网络的结构和功能的数学模型或计算模型。它是指按照一定的规则将多个神经元连接起来的网络。 神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。每个节点代表一…...

点云识别模型汇总整理
点云识别模型主要分类: 目前主流的点云识别模型主要分为 基于点直接处理的方法:PointNet、PointNet 、DGCNN、 PointCNN、 Point Transformer、 RandLA-Net、 PointMLP、 PointNeXt ;基于体素化的方法:VoxelNet、SECOND、PV-RCN…...

项目更改权限后都被git标记为改变,怎么去除
❗问题描述: 当你修改了项目中的文件权限(如使用 chmod 改了可执行权限),Git 会把这些文件标记为“已更改”,即使内容并没有发生任何改变。 ✅ 解决方法: ✅ 方法一:告诉 Git 忽略权限变化&am…...
网络编程1_网络编程引入
为什么需要网络编程? 用户再在浏览器中,打开在线视频资源等等,实质上说通过网络,获取到从网络上传输过来的一个资源。 与打开本地的文件类似,只是这个文件的来源是网络。相比本地资源来说,网络提供了更为…...

【Day38】
DAY 38 Dataset和Dataloader类 对应5. 27作业 知识点回顾: Dataset类的__getitem__和__len__方法(本质是python的特殊方法)Dataloader类minist手写数据集的了解 作业:了解下cifar数据集,尝试获取其中一张图片 import …...

HTML Day04
Day04 0.引言1. HTML字符实体2. HTML表单2.1 表单标签2.2 表单示例 3. HTML框架4. HTML颜色4.1 16进制表示法4.2 rgba表示法4.3 名称表达法 5. HTML脚本 0.引言 刚刚回顾了前面几篇博客,感觉写的内容倒是很详细,每个知识点都做了说明。但是感觉在知识组织…...

佳能 Canon G3030 Series 打印机信息
基本参数 连接方式:Hi-Speed USB 接口,支持 IEEE802.11n/802.11g/802.11b/802.11a/802.11ac 无线连接,可同时使用 USB 和网络连接。尺寸重量:外观尺寸约为 416337177mm,重量约为 6.0kg。电源规格:AC 100-2…...
云原生安全基石:Kubernetes 核心概念与安全实践指南
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. Kubernetes 架构全景 Kubernetes(简称 K8s)采用主从架构,由控制平面(Control Plane&…...

图像修复的可视化demo代码
做项目的时候需要用到一个windows窗口可视化来展示我们的工作,我们的工作是一个文本指导的人脸图像修复,所以窗口需要包括输入图像,文本指导输入和修复结果,并且提供在输入图像上画mask的功能,使用tkinter来实现&#…...

autodl 安装了多个conda虚拟环境 选择合适虚拟环境的语句
1.conda env list 列出所有虚拟环境 可以看到,我有两个虚拟环境,一个是joygen,一个是base conda activate base 或者 conda activate joygen 激活对应的环境。我选择激活 joygen 环境 然后就可以在joygen环境下进行操作了 base环境也是同理…...

【AI工具应用】使用 trae 实现 word 转成 html
假如我们要实现某个网站的《隐私协议》等静态页面,产品给了一个 word 文档,以前我都是手动从 word 文档复制一行的文字,然后粘贴到一个html文件中,还得自己加各种标签,很麻烦。 我们可以使用 trae 等 ai 工具实现 wor…...
ansible-playbook 进阶 接上一章内容
1.异常中断 做法1:强制正常 编写 nginx 的 playbook 文件 01-zuofa .yml - hosts : web remote_user : root tasks : - name : create new user user : name nginx-test system yes uid 82 shell / sbin / nologin - name : test new user shell : gete…...
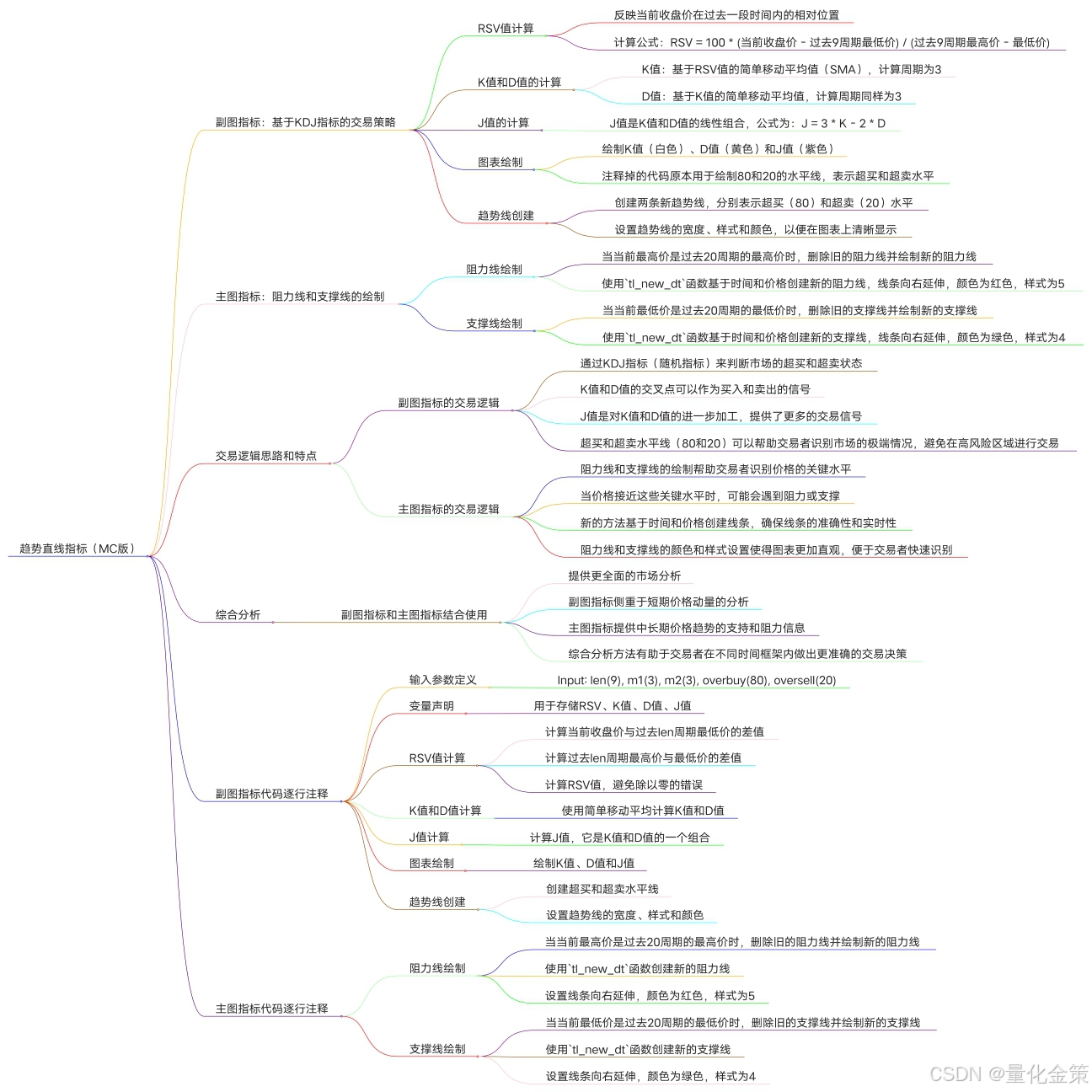
趋势直线指标
趋势直线副图和主图指标,旨在通过技术分析工具帮助交易者识别市场趋势和潜在的买卖点。 副图指标:基于KDJ指标的交易策略 1. RSV值计算: - RSV(未成熟随机值)反映了当前收盘价在过去一段时间内的相对位置。通过计算当前…...

基线配置管理:为什么它对网络稳定性至关重要
什么是基线配置(Baseline Configuration) 基线配置(Baseline Configuration)是经过批准的标准化主设置,代表所有设备应遵循的安全、合规且运行稳定的配置基准,可作为评估变更、偏差或未授权修改的参考基准…...