在RTX5060Ti上进行Qwen3-4B的GRPO强化微调
导语
最近赶上618活动,将家里的RTX 4060显卡升级为了RTX 5060Ti 16GB版本,显存翻了一番,可以进行一些LLM微调实验了,本篇博客记录使用unsloth框架在RTX 5060Ti 16GB显卡上进行Qwen3-4B-Base模型的GRPO强化微调实验。
简介
GPU性能对比
让ChatGPT帮我总结了一下整体性能规格参数的对比,简要整理如下:
| 关键指标 | RTX 5060 Ti 16 GB | RTX 4060 8 GB | AI-相关意义 |
|---|---|---|---|
| 架构 / GPU | Blackwell GB206 | Ada Lovelace AD107 | 50 系为全新第 5 代 Tensor Core & FP4 |
| 制程 | TSMC 4N 5 nm | TSMC 4N 5 nm | 相同能效基线,差距来自架构 |
| CUDA 核心 | 4 608 | 3 072 | +50% 原生算力 |
| Tensor Core 代际 | 第 5 代,FP4/FP8 | 第 4 代,FP8 | FP4 可把权重+激活再减半 |
| AI TOPS(INT8) | 759 TOPS | 242 TOPS | ~3.1× 推理吞吐提升 |
| VRAM 容量 / 类型 | 16 GB GDDR7 28 Gbps | 8 GB GDDR6 17 Gbps | 单卡能装下 fp16 7 B LLM / SD XL 全分辨率 |
| 内存总线 / 带宽 | 128-bit / 448 GB/s | 128-bit / 272 GB/s | 带宽 +65%,降低 KV-cache & 大卷积瓶颈 |
| L2 缓存 | 32 MB | 24 MB | 更高 KV-cache 命中率 |
| Base / Boost Clock | 2.41 / 2.57 GHz | 1.83 / 2.46 GHz | 核心频率略高 |
| FP16 (半精) 理论算力 | 23.7 TFLOPS | 15.1 TFLOPS | +57% 训练/推理混精吞吐 |
| PCIe 接口 | PCIe 5.0 ×8 | PCIe 4.0 ×8 | CPU↔GPU 传输带宽翻倍 |
| TBP / 供电 | 180 W,1×8-pin/Gen5 | 115 W,1×8-pin | 仍属“小电”级别,易于上机 |
unsloth框架
unsloth是一个专为 LLM 快速微调而生的开源 Python 框架,支持 LoRA/QLoRA 量化适配、4/8/16-bit 训练、完整微调与预训练等能力整合到统一 API 中,在单张消费级 GPU 上即可实现 2-5 倍的训练速度提升,同时节省约 60-70 % 的显存,却几乎不损失精度。
由于RTX 50系显卡是新一代GPU架构,所以环境安装暂时比较麻烦。折腾了好久后终于找到了一个解决方案,命令如下:
conda create --name unsloth_qwen3 python=3.12 -yconda activate unsloth_qwen3
pip install "unsloth @ git+https://github.com/unslothai/unsloth.git@main"
pip install unsloth_zoopip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128export MAX_JOBS=8
pip install "triton @ git+https://github.com/triton-lang/triton.git@main"
pip install bitsandbytes
conda install -c conda-forge libstdcxx-ng
pip install -v -U git+https://github.com/facebookresearch/xformers.git@main
pip install filecheck
GRPO训练
这里使用unsloth官方给出的notebook中代码来进行GRPO强化学习训练,使用的模型为最新的qwen3-4B-base
完整训练脚本如下:
# Part 0:导入相关库与配置模型、处理数据集
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Can increase for longer reasoning traces
lora_rank = 32 # Larger rank = smarter, but slowermodel, tokenizer = FastLanguageModel.from_pretrained(model_name = "/home/jxqi/project/model/Qwen3-4B-Base",max_seq_length = max_seq_length,load_in_4bit = True, # False for LoRA 16bitfast_inference = False, # Enable vLLM fast inferencemax_lora_rank = lora_rank,gpu_memory_utilization = 0.7, # Reduce if out of memory
)model = FastLanguageModel.get_peft_model(model,r = lora_rank, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128target_modules = ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj",],lora_alpha = lora_rank*2, # *2 speeds up traininguse_gradient_checkpointing = "unsloth", # Reduces memory usagerandom_state = 3407,
)reasoning_start = "<start_working_out>" # Acts as <think>
reasoning_end = "<end_working_out>" # Acts as </think>
solution_start = "<SOLUTION>"
solution_end = "</SOLUTION>"system_prompt = \
f"""You are given a problem.
Think about the problem and provide your working out.
Place it between {reasoning_start} and {reasoning_end}.
Then, provide your solution between {solution_start}{solution_end}"""chat_template = \"{% if messages[0]['role'] == 'system' %}"\"{{ messages[0]['content'] + eos_token }}"\"{% set loop_messages = messages[1:] %}"\"{% else %}"\"{{ '{system_prompt}' + eos_token }}"\"{% set loop_messages = messages %}"\"{% endif %}"\"{% for message in loop_messages %}"\"{% if message['role'] == 'user' %}"\"{{ message['content'] }}"\"{% elif message['role'] == 'assistant' %}"\"{{ message['content'] + eos_token }}"\"{% endif %}"\"{% endfor %}"\"{% if add_generation_prompt %}{{ '{reasoning_start}' }}"\"{% endif %}"# Replace with out specific template:
chat_template = chat_template\.replace("'{system_prompt}'", f"'{system_prompt}'")\.replace("'{reasoning_start}'", f"'{reasoning_start}'")
tokenizer.chat_template = chat_templatetokenizer.apply_chat_template([{"role" : "user", "content" : "What is 1+1?"},{"role" : "assistant", "content" : f"{reasoning_start}I think it's 2.{reasoning_end}{solution_start}2{solution_end}"},{"role" : "user", "content" : "What is 2+2?"},
], tokenize = False, add_generation_prompt = True)from datasets import load_dataset
import pandas as pd
import numpy as npdataset = load_dataset("unsloth/OpenMathReasoning-mini", split = "cot")
dataset = dataset.to_pandas()[["expected_answer", "problem", "generated_solution"]
]# Try converting to number - if not, replace with NaN
is_number = pd.to_numeric(pd.Series(dataset["expected_answer"]), errors = "coerce").notnull()
# Select only numbers
dataset = dataset.iloc[np.where(is_number)[0]]def format_dataset(x):expected_answer = x["expected_answer"]problem = x["problem"]# Remove generated <think> and </think>thoughts = x["generated_solution"]thoughts = thoughts.replace("<think>", "").replace("</think>", "")# Strip newlines on left and rightthoughts = thoughts.strip()# Add our custom formattingfinal_prompt = \reasoning_start + thoughts + reasoning_end + \solution_start + expected_answer + solution_endreturn [{"role" : "system", "content" : system_prompt},{"role" : "user", "content" : problem},{"role" : "assistant", "content" : final_prompt},]dataset["Messages"] = dataset.apply(format_dataset, axis = 1)
tokenizer.apply_chat_template(dataset["Messages"][0], tokenize = False)
dataset["N"] = dataset["Messages"].apply(lambda x: len(tokenizer.apply_chat_template(x)))
dataset = dataset.loc[dataset["N"] <= max_seq_length/3].copy()
print("dataset.shape: ", dataset.shape)from datasets import Dataset
dataset["text"] = tokenizer.apply_chat_template(dataset["Messages"].values.tolist(), tokenize = False)
dataset = Dataset.from_pandas(dataset)
print("dataset: ", dataset)# Part 1:有监督微淘冷启动实验
from trl import SFTTrainer, SFTConfig
trainer = SFTTrainer(model = model,tokenizer = tokenizer,train_dataset = dataset,args = SFTConfig(dataset_text_field = "text",per_device_train_batch_size = 1,gradient_accumulation_steps = 1, # Use GA to mimic batch size!warmup_steps = 5,num_train_epochs = 2, # Set this for 1 full training run.learning_rate = 2e-4, # Reduce to 2e-5 for long training runslogging_steps = 5,optim = "adamw_8bit",weight_decay = 0.01,lr_scheduler_type = "linear",seed = 3407,report_to = "none", # Use this for WandB etc),
)
trainer.train()
text = tokenizer.apply_chat_template(dataset[0]["Messages"][:2],tokenize = False,add_generation_prompt = True, # Must add for generation
)from transformers import TextStreamer
_ = model.generate(**tokenizer(text, return_tensors = "pt").to("cuda"),temperature = 0,max_new_tokens = 1024,streamer = TextStreamer(tokenizer, skip_prompt = False),
)del dataset
torch.cuda.empty_cache()
import gc
gc.collect()# Part 2:GRPO强化学习训练
from datasets import load_dataset
dataset = load_dataset("open-r1/DAPO-Math-17k-Processed", "en", split = "train")def extract_hash_answer(text):# if "####" not in text: return None# return text.split("####")[1].strip()return text
extract_hash_answer(dataset[0]["solution"])dataset = dataset.map(lambda x: {"prompt" : [{"role": "system", "content": system_prompt},{"role": "user", "content": x["prompt"]},],"answer": extract_hash_answer(x["solution"]),
})import re
# Add optional EOS token matching
solution_end_regex = r"</SOLUTION>[\s]{0,}" + \"(?:" + re.escape(tokenizer.eos_token) + ")?"match_format = re.compile(rf"{reasoning_end}.*?"\rf"{solution_start}(.+?){solution_end_regex}"\rf"[\s]{{0,}}$",flags = re.MULTILINE | re.DOTALL
)def match_format_exactly(completions, **kwargs):scores = []for completion in completions:score = 0response = completion[0]["content"]# Match if format is seen exactly!if match_format.search(response) is not None: score += 3.0scores.append(score)return scoresdef match_format_approximately(completions, **kwargs):scores = []for completion in completions:score = 0response = completion[0]["content"]# Count how many keywords are seen - we penalize if too many!# If we see 1, then plus some points!# No need to reward <start_working_out> since we always prepend it!# score += 0.5 if response.count(reasoning_start) == 1 else -1.0score += 0.5 if response.count(reasoning_end) == 1 else -1.0score += 0.5 if response.count(solution_start) == 1 else -1.0score += 0.5 if response.count(solution_end) == 1 else -1.0scores.append(score)return scoresdef check_answer(prompts, completions, answer, **kwargs):question = prompts[0][-1]["content"]responses = [completion[0]["content"] for completion in completions]extracted_responses = [guess.group(1)if (guess := match_format.search(r)) is not None else None \for r in responses]scores = []for guess, true_answer in zip(extracted_responses, answer):score = 0if guess is None:scores.append(-2.0)continue# Correct answer gets 5 points!if guess == true_answer:score += 5.0# Match if spaces are seen, but less rewardelif guess.strip() == true_answer.strip():score += 3.5else:# We also reward it if the answer is close via ratios!# Ie if the answer is within some range, reward it!try:ratio = float(guess) / float(true_answer)if ratio >= 0.9 and ratio <= 1.1: score += 2.0elif ratio >= 0.8 and ratio <= 1.2: score += 1.5else: score -= 2.5 # Penalize wrong answersexcept:score -= 4.5 # Penalizescores.append(score)return scoresglobal PRINTED_TIMES
PRINTED_TIMES = 0
global PRINT_EVERY_STEPS
PRINT_EVERY_STEPS = 5match_numbers = re.compile(solution_start + r".*?[\s]{0,}([-]?[\d\.\,]{1,})",flags = re.MULTILINE | re.DOTALL
)def check_numbers(prompts, completions, answer, **kwargs):question = prompts[0][-1]["content"]responses = [completion[0]["content"] for completion in completions]extracted_responses = [guess.group(1)if (guess := match_numbers.search(r)) is not None else None \for r in responses]scores = []# Print only every few stepsglobal PRINTED_TIMESglobal PRINT_EVERY_STEPSif PRINTED_TIMES % PRINT_EVERY_STEPS == 0:print('*'*20 + f"Question:\n{question}", f"\nAnswer:\n{answer[0]}", f"\nResponse:\n{responses[0]}", f"\nExtracted:\n{extracted_responses[0]}")PRINTED_TIMES += 1for guess, true_answer in zip(extracted_responses, answer):if guess is None:scores.append(-2.5)continue# Convert to numberstry:true_answer = float(true_answer.strip())# Remove commas like in 123,456guess = float(guess.strip().replace(",", ""))scores.append(3.5 if guess == true_answer else -1.5)except:scores.append(0)continuereturn scorestokenized = dataset.map(lambda x: {"tokens" : tokenizer.apply_chat_template(x["prompt"], add_generation_prompt = True, tokenize = True)},batched = True,
)
print(tokenizer.decode(tokenized[0]["tokens"]))
tokenized = tokenized.map(lambda x: {"L" : len(x["tokens"])})import numpy as np
maximum_length = int(np.quantile(tokenized["L"], 0.9))
print("Max Length = ", maximum_length)# Filter only samples smaller than 90% max length
dataset = dataset.select(np.where(np.array(tokenized["L"]) <= maximum_length)[0])
del tokenizedmax_prompt_length = maximum_length + 1 # + 1 just in case!
max_completion_length = max_seq_length - max_prompt_lengthfrom trl import GRPOConfig, GRPOTrainer
training_args = GRPOConfig(temperature = 1.0,learning_rate = 5e-6,weight_decay = 0.01,warmup_ratio = 0.1,lr_scheduler_type = "linear",optim = "adamw_8bit",logging_steps = 1,per_device_train_batch_size = 1,gradient_accumulation_steps = 4, # Increase to 4 for smoother trainingnum_generations = 8, # Decrease if out of memorymax_prompt_length = max_prompt_length,max_completion_length = max_completion_length,# num_train_epochs = 1, # Set to 1 for a full training runmax_steps = 100,save_steps = 100,report_to = "none", # Can use Weights & Biasesoutput_dir = "outputs",
)trainer = GRPOTrainer(model = model,processing_class = tokenizer,reward_funcs = [match_format_exactly,match_format_approximately,check_answer,check_numbers,],args = training_args,train_dataset = dataset,
)
trainer.train()
整体代码分为三个部分:
- 第0部分为导入相关库与配置模型、处理数据集
- 第1部分为SFT冷启动,主要帮助模型快速掌握回复的格式,使用OpenMathReasoning-mini数据集
- 第2部分为GRPO强化学习,使用GRPO算法对模型进行强化学习微调,使用open-r1/DAPO-Math-17k-Processed这个数据集
强化学习实验中,我们设置了每个Prompt采样8次,设置梯度累计gradient_accumulation_steps=4,这样一个group就是32个样本。
奖励函数包括4个:
- 精准格式匹配奖励:能否准确匹配。格式完全不符合时,不奖励,即0分;格式完全符合时,奖励 3.0 分。
- 模糊格式匹配奖励:这里共检查了 3 个关键标志:
- reasoning_end
- solution_start(即 )
- solution_end(即 )
如果每个标志恰好出现 1 次,给 +0.5;如果出现次数不是 1(包括 0 次或 >1 次),则给 -1.0。
- 答案正确性奖励:答案是否正确;
- 答案数字性奖励:输出里正确提取到与
true_answer完全相同的数值;最大值:+3.5,最小值:-2.5
训练过程的输出如下:
(torch28) (base) jxqi@DESKTOP-GD042P8:~/project/unsloth$ python grpo_unsloth_qwen3.py
🦥 Unsloth: Will patch your computer to enable 2x faster free finetuning.
🦥 Unsloth Zoo will now patch everything to make training faster!
==((====))== Unsloth 2025.5.10: Fast Qwen3 patching. Transformers: 4.52.4.\\ /| NVIDIA GeForce RTX 5060 Ti. Num GPUs = 1. Max memory: 15.928 GB. Platform: Linux.
O^O/ \_/ \ Torch: 2.8.0.dev20250529+cu128. CUDA: 12.0. CUDA Toolkit: 12.8. Triton: 3.3.0
\ / Bfloat16 = TRUE. FA [Xformers = 0.0.31+da84ce3.d20250530. FA2 = False]"-____-" Free license: http://github.com/unslothai/unsloth
Unsloth: Fast downloading is enabled - ignore downloading bars which are red colored!
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:11<00:00, 3.71s/it]
/home/jxqi/project/model/Qwen3-4B-Base does not have a padding token! Will use pad_token = <|vision_pad|>.
Unsloth 2025.5.10 patched 36 layers with 36 QKV layers, 36 O layers and 36 MLP layers.
dataset.shape: (1, 5)
dataset: Dataset({features: ['expected_answer', 'problem', 'generated_solution', 'Messages', 'N', 'text', '__index_level_0__'],num_rows: 1
})
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:- Avoid using `tokenizers` before the fork if possible- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
num_proc must be <= 1. Reducing num_proc to 1 for dataset of size 1.
Unsloth: Tokenizing ["text"]: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 134.70 examples/s]
==((====))== Unsloth - 2x faster free finetuning | Num GPUs used = 1\\ /| Num examples = 1 | Num Epochs = 2 | Total steps = 2
O^O/ \_/ \ Batch size per device = 1 | Gradient accumulation steps = 1
\ / Data Parallel GPUs = 1 | Total batch size (1 x 1 x 1) = 1"-____-" Trainable parameters = 66,060,288/4,000,000,000 (1.65% trained)0%| | 0/2 [00:00<?, ?it/s]huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
Unsloth: Will smartly offload gradients to save VRAM!
{'train_runtime': 2.5398, 'train_samples_per_second': 0.787, 'train_steps_per_second': 0.787, 'train_loss': 1.0110118389129639, 'epoch': 2.0}
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:02<00:00, 1.27s/it]
The following generation flags are not valid and may be ignored: ['temperature']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
You are given a problem.
Think about the problem and provide your working out.
Place it between <start_working_out> and <end_working_out>.
Then, provide your solution between <SOLUTION></SOLUTION><|endoftext|>Compute the value of the expression $(x-a)(x-b)\ldots (x-z)$.<start_working_out>Let's analyze the given expression: $(x-a)(x-b)\ldots (x-z)$. This expression is a product of terms, each of the form $(x - \text{letter})$, where the letters range from $a$ to $z$. There are 26 terms in total, corresponding to the 26 letters of the alphabet.Notice that the term $(x - x)$ is included in the product. This is because the sequence of letters goes from $a$ to $z$, and $x$ is the 24th letter in the alphabet. Therefore, the term $(x - x)$ is the 24th term in the product.Now, let's consider the value of the term $(x - x)$. Since $x - x = 0$, the entire product will be equal to 0, regardless of the values of the other terms. This is because any number multiplied by 0 is 0.Therefore, the value of the expression $(x-a)(x-b)\ldots (x-z)$ is 0.<end_working_out><SOLUTION>0</SOLUTION><|endoftext|>
You are given a problem.
Think about the problem and provide your working out.
Place it between <start_working_out> and <end_working_out>.
Then, provide your solution between <SOLUTION></SOLUTION><|endoftext|>In triangle $ABC$, $\sin \angle A = \frac{4}{5}$ and $\angle A < 90^\circ$. Let $D$ be a point outside triangle $ABC$ such that $\angle BAD = \angle DAC$ and $\angle BDC = 90^\circ$. Suppose that $AD = 1$ and that $\frac{BD}{CD} = \frac{3}{2}$. If $AB + AC$ can be expressed in the form $\frac{a\sqrt{b}}{c}$ where $a, b, c$ are pairwise relatively prime integers, find $a + b + c$.<start_working_out>
Max Length = 201
Unsloth: We now expect `per_device_train_batch_size` to be a multiple of `num_generations`.
We will change the batch size of 1 to the `num_generations` of 8
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:- Avoid using `tokenizers` before the fork if possible- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
==((====))== Unsloth - 2x faster free finetuning | Num GPUs used = 1\\ /| Num examples = 12,709 | Num Epochs = 1 | Total steps = 100
O^O/ \_/ \ Batch size per device = 8 | Gradient accumulation steps = 4
\ / Data Parallel GPUs = 1 | Total batch size (8 x 4 x 1) = 32"-____-" Trainable parameters = 66,060,288/4,000,000,000 (1.65% trained)0%| | 0/100 [00:00<?, ?it/s]/home/jxqi/miniconda3/envs/torch28/lib/python3.12/site-packages/unsloth/kernels/utils.py:443: UserWarning: An output with one or more elements was resized since it had shape [1, 32, 2560], which does not match the required output shape [32, 1, 2560]. This behavior is deprecated, and in a future PyTorch release outputs will not be resized unless they have zero elements. You can explicitly reuse an out tensor t by resizing it, inplace, to zero elements with t.resize_(0). (Triggered internally at /pytorch/aten/src/ATen/native/Resize.cpp:31.)out = torch_matmul(X, W, out = out)
********************Question:
Compute the number of positive integers that divide at least two of the integers in the set $\{1^1,2^2,3^3,4^4,5^5,6^6,7^7,8^8,9^9,10^{10}\}$.
Answer:
22
Response:Since $1^1 = 1$ and $10^{10} > 10^9 > 9^9>>8^8>10^8>>7^7>>6^7>>5^5>>4^4>>3^3>>2^2>>1$, the only integers that can divide at least $1$ element in the set are $1$, $2$ and $5$.
Computing the values, we find
$2^2 = 4$,
$5^5 = 3125$. …… # 太长省略
Extracted:
None
{'loss': 0.0002, 'grad_norm': 8.34195613861084, 'learning_rate': 0.0, 'num_tokens': 34381.0, 'completions/mean_length': 938.65625, 'completions/min_length': 1.0, 'completions/max_length': 1846.0, 'completions/clipped_ratio': 0.125, 'completions/mean_terminated_length': 809.0357666015625, 'completions/min_terminated_length': 1.0, 'completions/max_terminated_length': 1578.0, 'rewards/match_format_exactly/mean': 0.84375, 'rewards/match_format_exactly/std': 1.3704102039337158, 'rewards/match_format_approximately/mean': -0.609375, 'rewards/match_format_approximately/std': 1.517289400100708, 'rewards/check_answer/mean': -2.640625, 'rewards/check_answer/std': 1.0942250490188599, 'rewards/check_numbers/mean': -1.34375, 'rewards/check_numbers/std': 0.8838834762573242, 'reward': -3.75, 'reward_std': 2.124946117401123, 'frac_reward_zero_std': 0.0, 'completion_length': 938.65625, 'kl': 0.0039907393511384726, 'epoch': 0.0}1%|██▋ | 1/100 [06:46<11:10:56, 406.63s/it]/home/jxqi/miniconda3/envs/torch28/lib/python3.12/site-packages/unsloth/kernels/utils.py:443: UserWarning: An output with one or more elements was resized since it had shape [1, 32, 2560], which does not match the required output shape [32, 1, 2560]. This behavior is deprecated, and in a future PyTorch release outputs will not be resized unless they have zero elements. You can explicitly reuse an out tensor t by resizing it, inplace, to zero elements with t.resize_(0). (Triggered internally at /pytorch/aten/src/ATen/native/Resize.cpp:31.)out = torch_matmul(X, W, out = out)
{'loss': 0.0005, 'grad_norm': 0.2457444816827774, 'learning_rate': 5.000000000000001e-07, 'num_tokens': 97157.0, 'completions/mean_length': 1846.0, 'completions/min_length': 1846.0, 'completions/max_length': 1846.0, 'completions/clipped_ratio': 1.0, 'completions/mean_terminated_length': 0.0, 'completions/min_terminated_length': 0.0, 'completions/max_terminated_length': 0.0, 'rewards/match_format_exactly/mean': 0.0, 'rewards/match_format_exactly/std': 0.0, 'rewards/match_format_approximately/mean': -3.0, 'rewards/match_format_approximately/std': 0.0, 'rewards/check_answer/mean': -2.0, 'rewards/check_answer/std': 0.0, 'rewards/check_numbers/mean': -2.5, 'rewards/check_numbers/std': 0.0, 'reward': -7.5, 'reward_std': 0.0, 'frac_reward_zero_std': 1.0, 'completion_length': 1846.0, 'kl': 0.012083161040209234, 'epoch': 0.0}2%|█████▍ | 2/100 [11:40<9:16:16, 340.58s/it]
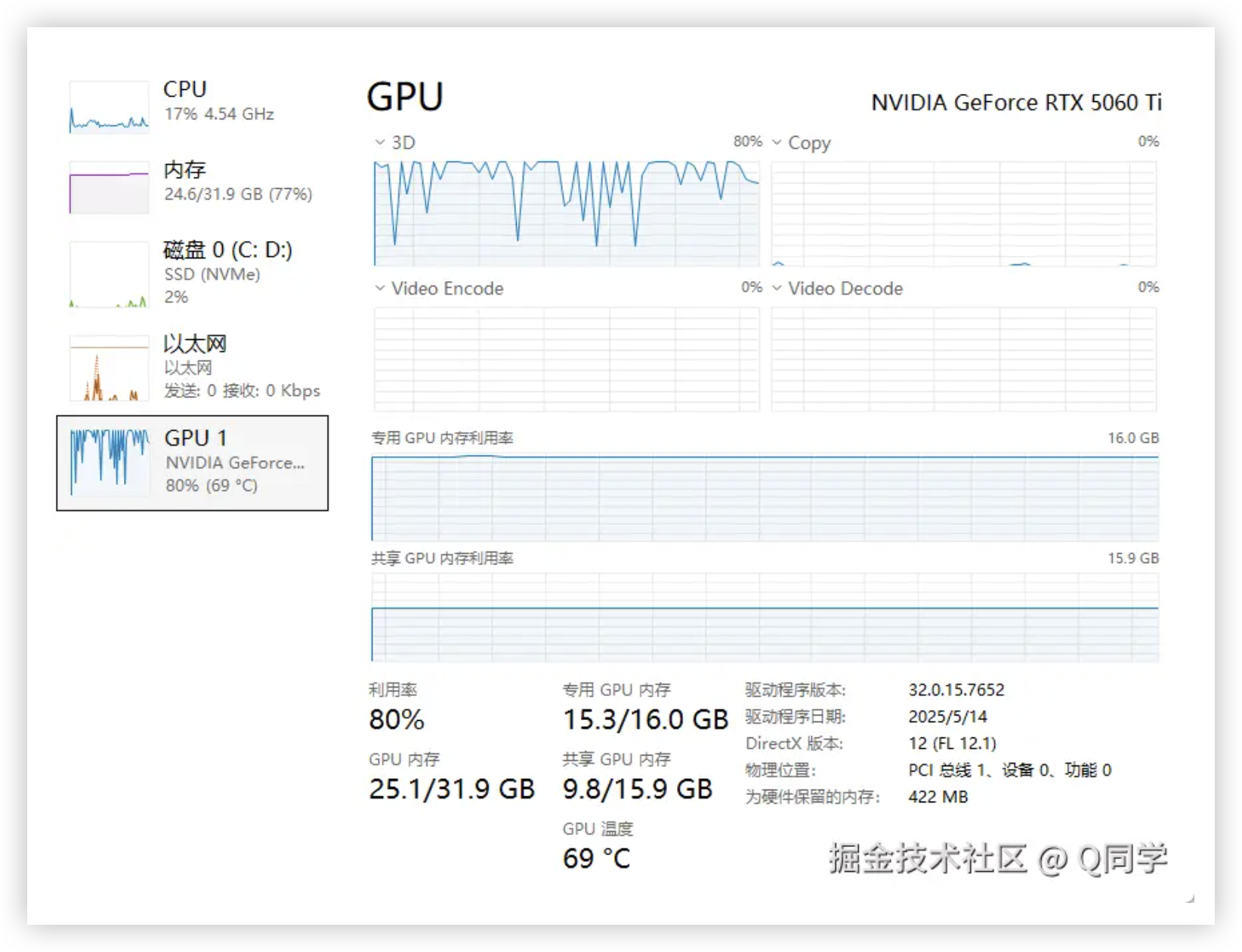
显存占用情况如下,基本可以吃满16GB的独立显存:
总结
这次使用RTX 5060Ti 16GB成功跑通了Qwen3-4B-Base模型的冷启动SFT和GRPO强化学习训练流程,由于架构较新,一些框架适配不是太好,后续随着各个框架的适配,整体实验环境配置应该会容易很多。
参考
- Please support RTX 50XX GPUs,https://github.com/unslothai/unsloth/issues/1856#issuecomment-2849009744
相关文章:
在RTX5060Ti上进行Qwen3-4B的GRPO强化微调
导语 最近赶上618活动,将家里的RTX 4060显卡升级为了RTX 5060Ti 16GB版本,显存翻了一番,可以进行一些LLM微调实验了,本篇博客记录使用unsloth框架在RTX 5060Ti 16GB显卡上进行Qwen3-4B-Base模型的GRPO强化微调实验。 简介 GPU性…...

SQL进阶之旅 Day 7:视图与存储过程入门
【SQL进阶之旅 Day 7】视图与存储过程入门 在SQL开发中,视图(View)和存储过程(Stored Procedure)是两个非常重要的数据库对象。它们不仅可以简化复杂查询逻辑,还能提高代码复用性和安全性。本文将深入探讨…...

武汉火影数字VR大空间制作
VR大空间是一种利用空旷的物理空间,结合先进的虚拟现实技术,让用户能够在其中自由移动并深度体验虚拟世界的创新项目方式。 在科技飞速发展的当下,VR大空间正以其独特的魅力,成为科技与娱乐领域的耀眼新星,掀起了一股沉…...

Docker部署项目无法访问,登录超时完整排查攻略
项目背景:迁移前后端应用,prod环境要求保留443端口,开发环境37800端口,后端容器端口为8000,前端为80,fastAPI对外端口为41000 生产环境部署在VM01,开发环境部署在VM03,在VM01配置nginx转发 [r…...
(增强)基于sqlite、mysql、redis的消息存储
原文链接:(增强)基于sqlite、mysql、redis的消息存储 教程说明 说明:本教程将采用2025年5月20日正式的GA版,给出如下内容 核心功能模块的快速上手教程核心功能模块的源码级解读Spring ai alibaba增强的快速上手教程…...

Windows上用FFmpeg推流及拉流的流程概览
1. 视频采集与推流(Windows FFmpeg) 采集设备:Windows上的摄像头,比如“Integrated Camera”。 采集方式:FFmpeg通过 dshow 设备接口读取摄像头。 推流协议:你可以选择推到 RTMP 或 RTSP 服务器。 推流…...
MFC坦克大战游戏制作
MFC坦克大战游戏制作 前言 现在的游戏制作一般是easyx,有没有直接只用mfc框架的,笔者研究了一番,做出了一个雏形,下面把遇到的问题总结出来 一、MFC框架制作游戏 初步设想,MFC可以选用 对话框 或者 单文档 结构&…...
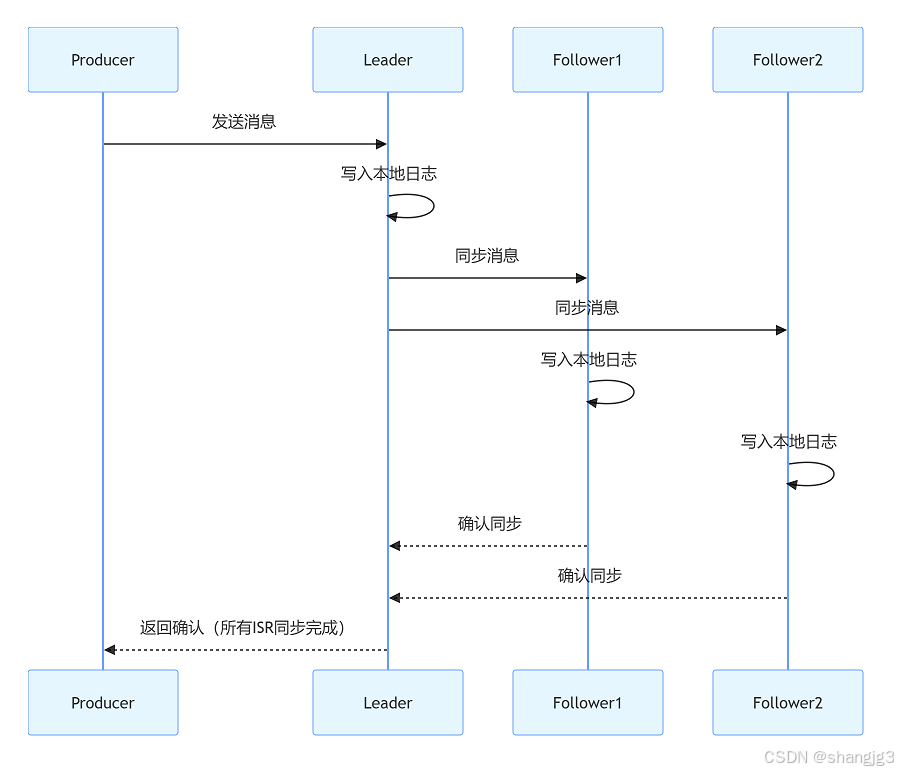
Kafka ACK机制详解:数据可靠性与性能的权衡之道
在分布式消息系统中,消息确认机制是保障数据可靠性的关键。Apache Kafka 通过 ACK(Acknowledgment)机制 实现了灵活的数据确认策略,允许用户在 数据可靠性 和 系统性能 之间进行权衡。本文将深入解析 Kafka ACK 机制的工作原理、配…...
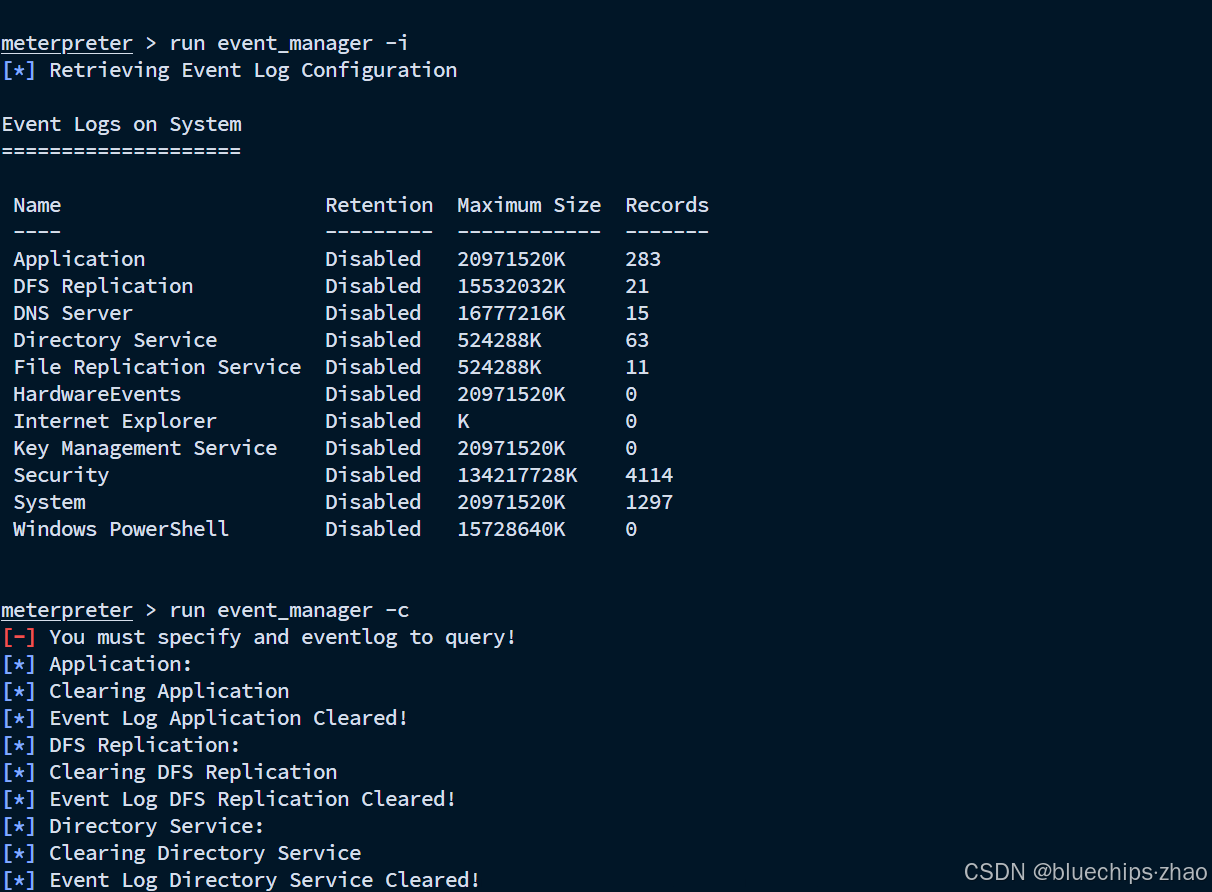
VulnStack|红日靶场——红队评估四
信息收集及漏洞利用 扫描跟kali处在同一网段的设备,找出目标IP arp-scan -l 扫描目标端口 nmap -p- -n -O -A -Pn -v -sV 192.168.126.154 3个端口上有web服务,分别对应三个漏洞环境 :2001——Struts2、2002——Tomcat、2003——phpMyAd…...
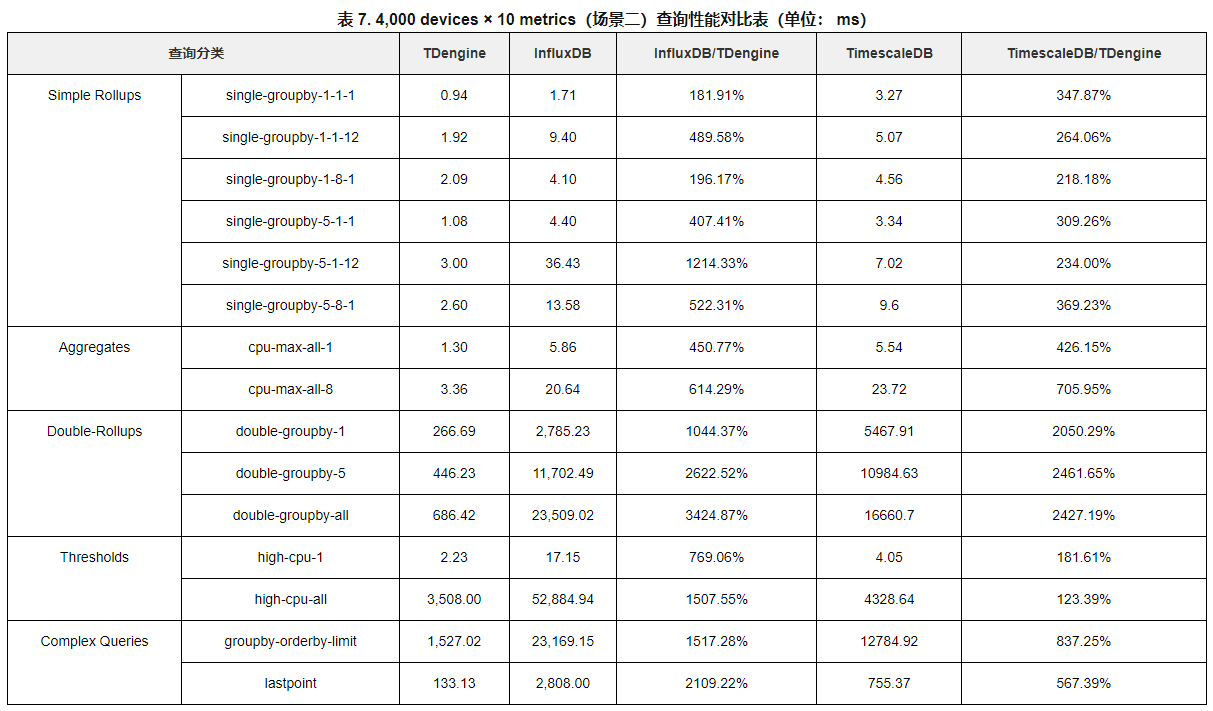
数据库 | 时序数据库选型
选型目标 高性能与低延迟:满足高频率数据写入与即时查询的需求。资源效率:优化存储空间使用,减少计算资源消耗。可扩展架构:支持数据量增长带来的扩展需求,易于维护。社区活跃度:有活跃的开发者社区&#…...
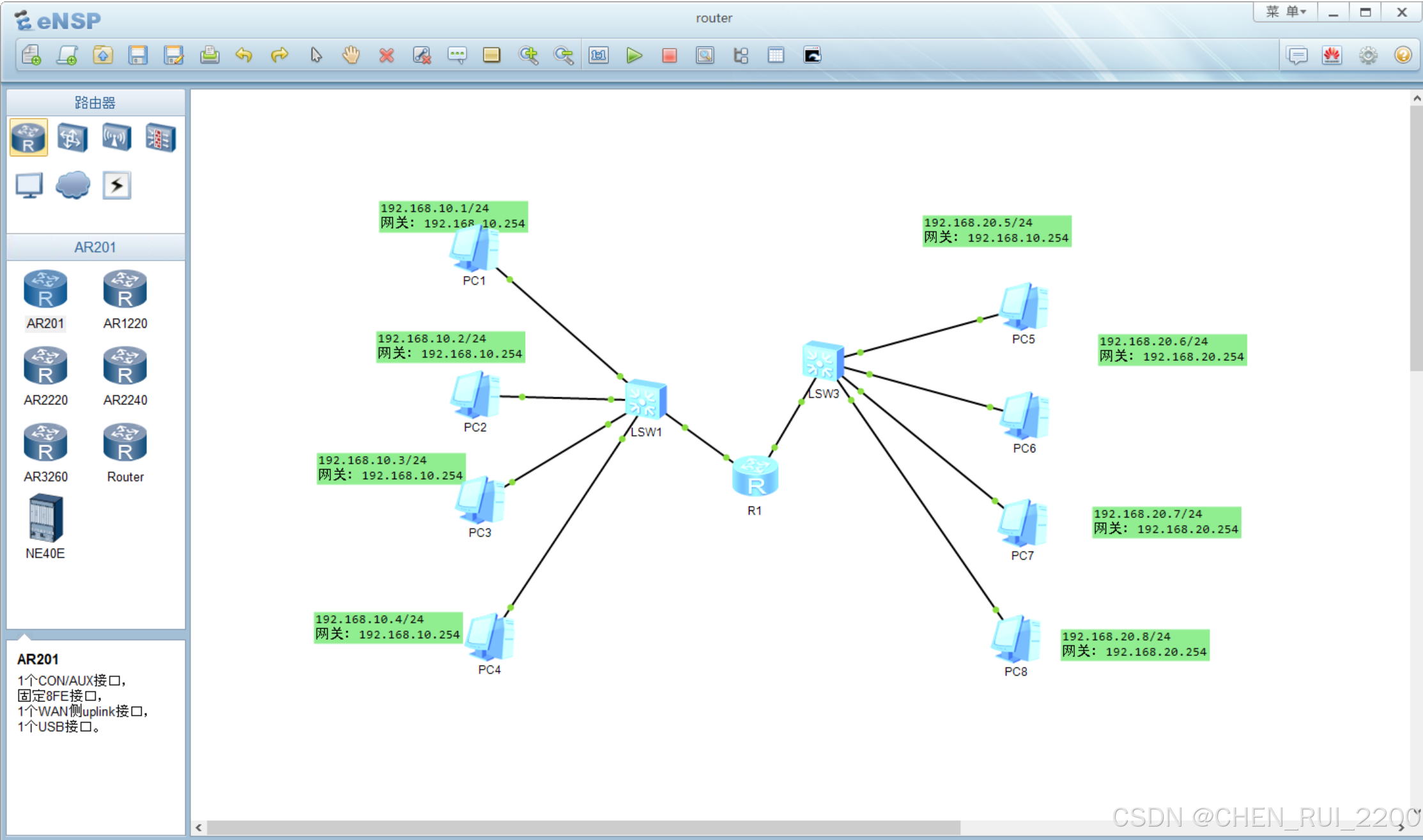
网络拓扑如何跨网段访问
最近领导让研究下跟甲方合同里的,跨网段访问怎么实现,之前不都是运维网工干的活么,看来裁员裁到动脉上了碰到用人的时候找不到人了, 只能赶鸭子上架让我来搞 IP 网络中,不同网段之间的通信需要通过路由器,…...

CppCon 2014 学习第1天:An SQL library worthy of modern C++
sqlpp11 — 现代 C 应用值得拥有的 SQL 库 template<typename T> struct _member_t {T feature; };你提到的是一个 C 中的“成员模板(Member Template)”,我们来一步步理解: 基本代码分析: template<typena…...

【LLM相关知识点】 LLM关键技术简单拆解,以及常用应用框架整理(二)
【LLM相关知识点】 LLM关键技术简单拆解,以及常用应用框架整理(二) 文章目录 【LLM相关知识点】 LLM关键技术简单拆解,以及常用应用框架整理(二)一、市场调研:业界智能问答助手的标杆案例1、技术…...
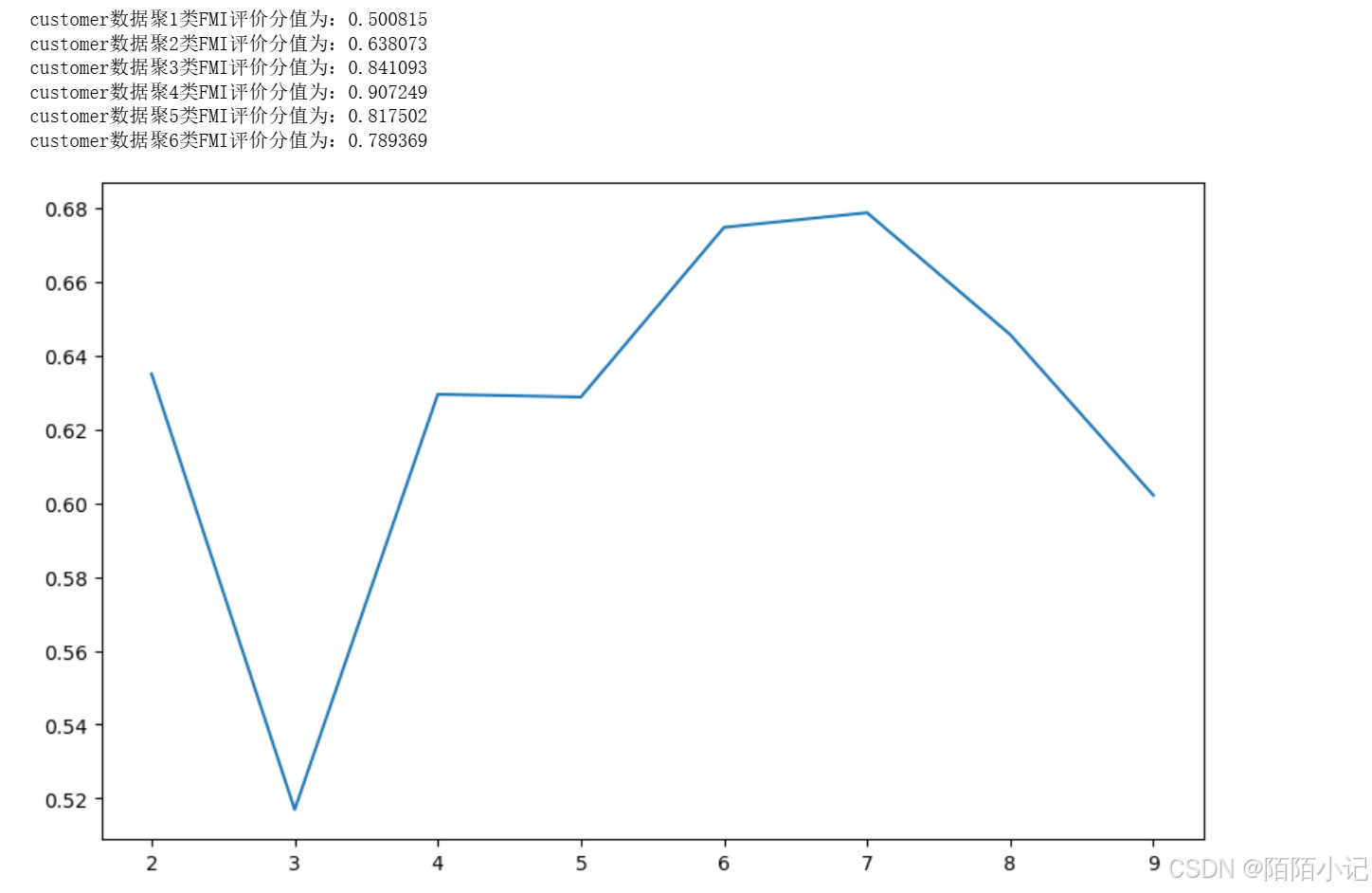
数据分析与应用-----使用scikit-learn构建模型
目录 一、使用sklearn转换器处理数据 (一)、加载datasets模块中的数据集 (二)、将数据集划分为训练集和测试集 编辑 train_test_spli (三)、使用sklearn转换器进行数据预处理与降维 PCA 二、 构…...
003 flutter初始文件讲解(2)
1.书接上回 首先,我们先来看看昨天最后的代码及展示效果: import "package:flutter/material.dart";void main(){runApp(MaterialApp(home:Scaffold(appBar:AppBar(title:Text("The World")), body:Center(child:Text("Hello…...

Windows系统下 NVM 安装 Node.js 及版本切换实战指南
以下是 Windows 11 系统下使用 NVM 安装 Node.js 并实现版本自由切换的详细步骤: 一、安装 NVM(Node Version Manager) 1. 卸载已有 Node.js 如果已安装 Node.js,请先卸载: 控制面板 ➔ 程序与功能 ➔ 找到 Node.js…...

基于热力学熵增原理的EM-GAM
简介 简介:提出基于热力学熵增原理的EM-GAN,通过生成器熵最大化约束增强输出多样性。引入熵敏感激活函数与特征空间熵计算模块,在MNIST/CelebA等数据集上实现FID分数提升23.6%,有效缓解模式崩溃问题。 论文题目:Entropy-Maximized Generative Adversarial Network (EM-G…...

2025.05.28-华为暑期实习第一题-100分
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 01. K小姐的网络信号优化方案 问题描述 K小姐在负责一个智慧城市项目,该项目需要在一条主干道上部署无线信号发射器。这条主干道有 n n...

鸿蒙OSUniApp滑动锁屏实战:打造流畅优雅的移动端解锁体验#三方框架 #Uniapp
UniApp滑动锁屏实战:打造流畅优雅的移动端解锁体验 引言 移动应用的安全性和用户体验是开发中不可忽视的重要环节。滑动锁屏作为一种直观、安全且用户友好的解锁方式,在移动应用中得到广泛应用。本文将深入探讨如何使用UniApp框架实现一个功能完备、动…...

数据库中 用一个值实现类似linux中的读 写执行以及理解安卓杂用的按位或运算
数据库定义了一个字段叫 allow, 4 读2 写 1 执行 如果是 7 就代表是可读可写 可执行 ,如果是5 就是可读 可执行 , 那具体代码咋写呢 [Flags] public enum Permission {None 0,Execute 1,Write 2,Read 4 }// 假设你从数据库取到的 allow 值是一个整数…...

什么是数据驱动?以及我们应如何理解数据驱动?
在谈到企业数字化转型时,很多人都会说起“数据驱动”,比如“数据驱动运营”、“数据驱动业务”等等。 在大家言必称“数据驱动”的时代背景下,我相信很多人并未深究和思考“数据驱动”的真正含义,只是过过嘴瘾罢了。那么ÿ…...

opencv(C++) 图像滤波
文章目录 介绍使用低通滤波器对图像进行滤波工作原理均值滤波器(Mean Filter / Box Filter)高斯滤波器(Gaussian Filter)案例实现通过滤波实现图像的下采样工作原理实现案例插值像素值(Interpolating pixel values)双线性插值(Bilinear interpolation)双三次插值(Bicu…...
)
【线上故障排查】缓存热点Key导致Redis性能下降的排查与优化(面试题 + 3 步追问应对 + 案例分析)
一、高频面试题 问题1:什么是缓存热点Key?它对Redis性能有什么影响? 参考答案: 缓存热点Key指的是短时间内被大量请求访问的缓存键。因为Redis是单线程处理请求的,一旦某个Key被高频访问,会导致线程长时间忙于处理它,其他请求只能排队等待,这会让Redis整体响应变慢、…...

cuda_fp8.h错误
现象: cuda_fp8.h错误 原因: CUDA Toolkit 小于11.8,会报fp8错误,因此是cuda工具版本太低。通过nvcc --version查看 CUDA Toolkit 是 NVIDIA 提供的一套 用于开发、优化和运行基于 CUDA 的 GPU 加速应用程序的工具集合。它的核心作用是让开发…...

Java设计模式从基础到实际运用
第一部分:设计模式基础 1. 设计模式概述 设计模式(Design Pattern)是一套被反复使用、多数人知晓的、经过分类编目的代码设计经验的总结,它描述了在软件设计过程中一些不断重复出现的问题以及该问题的解决方案。设计模式是在特定环境下解决软件设计问题…...

网络安全基础--第九天
动态路由: 所有路由器上运行同一种动态路由协议,之后通过路由器协商沟通,最终计算生成 路由条目。 静态路由的优点: 1.选路是由管理员选择,相对更好控制,更加合理 2.无需占用额外资源 3.更加安全 缺点…...

鸿蒙如何引入crypto-js
import CryptoJS from ohos/crypto-js 报错。 需要先安装ohom:打开DevEco,点击底部标签组(有Run, Build, Log等)中的Terminal,在Terminal下执行: ohpm install 提示 install completed in 0s 119ms&…...

通过HIVE SQL获取每个用户的最大连续登录时常
样本数据导入: drop table if exists user_login; create table user_login ( user_id bigint ,login_date string ) ;insert into table user_login values (1,2025-04-01) ,(1,2025-04-02) ,(1,2025-04-03) ,(1,2025-04-05) ,(1,2025-04-06) ,(2,2025-04-01) …...
如何轻松将 iPhone 备份到外部硬盘
当您的iPhone和电脑上的存储空间有限时,您可能希望将iPhone备份到外部硬盘上,这样可以快速释放iPhone上的存储空间,而不占用电脑上的空间,并为您的数据提供额外的安全性。此外,我们还提供 4 种有效的解决方案ÿ…...

Matlab数据类型
本篇介绍我在南农matlab课程上的所学,我对老师ppt上的内容重新进行了整理并且给出代码案例。主要内容在矩阵。如果真的想学matlab,我不认为有任何文档能够超过官方文档,请移步至官网,本篇说实话只是写出来给自己和学弟学妹作期末复…...