【数据分析】特征工程-特征选择
【数据分析】特征工程-特征选择
- (一)方差过滤法
- 1.1 消除方差为0的特征
- 1.2 保留一半的特征
- 1.3 特征是二分类时
- (二)相关性过滤法
- 2.1 卡方过滤
- 2.2 F检验
- 2.3 互信息法
- (三)其他
- 3.1 包装法
- 3.2 嵌入法
- 3.3 衍生特征法(寻找高级特征)
- (四)总结
相关数据集:数据集
数据预处理完成后,就进入特征工程
特征工程包括特征提取、特征创造、特征选择
- 特征提取(feature extraction)
从文字,图像,声音等其他非结构化数据中提取新信息作为特征。比如说,从淘宝宝贝的名称中提取出产品类别,产品颜色,是否是网红产品等等。 - 特征创造(feature creation)
把现有特征进行组合,或互相计算,得到新的特征。比如说,我们有一列特征是速度,一列特征是距离,我们就可以通过让两列相处,创造新的特征:通过距离所花的时间。 - 特征选择(feature selection)
从所有的特征中,选择出有意义,对模型有帮助的特征,以避免必须将所有特征都导入模型去训练的情况
特征工程的第一步是:理解业务
导入数据
import pandas as pddata = pd.read_csv('data/手写数字识别.csv')
x = data.iloc[:,1:]
y = data.iloc[:,0]
print(f'数据形状:{x.shape}') #(42000,784) 7百多列
数据集维度大,接下来使用多种方法对特征进行抽取。
(一)方差过滤法
方差选择法是一种进行特征选择的简单的baseline方法,它移除所有不满足给定阈值要求的特征。阈值默认为0,此方法默认移除方差为0的特征,即在所有样本上取值相同的特征。这是通过特征本身的方差来筛选特征的类。
- 特征的方差很小,表示样本在这个特征上基本没有差异,那这个特征对于样本区分没有什么作用。所以要优先消除方差为0的特征。
1.1 消除方差为0的特征
sklearn.feature_selection.VarianceThreshold(threshold=0.0)
VarianceThreshold有重要参数threshold,表示方差的阈值,表示舍弃所有方差小threshold的特征,不填默认为0,即删除所有的记录都相同的特征。
from sklearn.feature_selection import VarianceThresholdselector = VarianceThreshold() # 实例化,不填参数默认方差为0,即删除值都是一样的特征
x_fsvar = selector.fit_transform(x) # 获取删除后的新特征矩阵
print(f'消除方差为0的特征后的数据形状:{x_fsvar.shape}') # (42000,708) 确实减少了70多个特征
已经删除了方差为0的特征,但是依然剩下了708多个特征,还需要进一步的特征选择。如果我们知道我们需要多少个特征,方差也可以帮助我们将特征选择一步到位。
1.2 保留一半的特征
例子:我们希望留下一半的特征,那可以设定一个让特征总数减半的方差阈值,只要找到特征方差的中位数,再将这个中位数作为参数threshold的值输入
import numpy as np# np.median(x.var().values)# 即方差的中位数
selector = VarianceThreshold(np.median(x.var().values))
x_fsvar = selector.fit_transform(x)
print(f'特征减半后数据形状:{x_fsvar.shape}') # 输出(42000,392)减少到一半了
1.3 特征是二分类时
若特征是二分类时的处理,特征的取值就是伯努利变量,方差=p(1-p)
# 假设特征是伯努利变量,p=0.8,即二分类特征中某种分类占80%以上的时候删除特征
selector = VarianceThreshold(0.8 * (1 - 0.8))
X_fsvar = selector.fit_transform(x)
print(f'二分类特征处理后的数据形状:{X_fsvar.shape}') # 输出(42000,685)只剩下了685个特征
为什么随机森林运行如此之快?为什么方差过滤对随机森林没很大的有影响?
- 这是由于两种算法的原理中涉及到的计算量不同。最近邻算法KNN,单棵决策树,支持向量机SVM,神经网络,回归算法,都需要遍历特征或升维来进行运算,所以他们本身的运算量就很大,需要的时间就很长,因此方差过滤这样的特征选择对他们来说就尤为重要。但对于不需要遍历特征的算法,比如随机森林,它随机选取特征进行分枝,本身运算就非常快速,因此特征选择对它来说效果平平。
- 无论过滤法如何降低特征的数量,随机森林也只会选取固定数量的特征来建模;而最近邻算法就不同了,特征越少,距离计算的维度就越少,模型明显会随着特征的减少变得轻量。
- 因此,过滤法的主要对象是:需要遍历特征或升维的算法们,而过滤法的主要目的是:在维持算法表现的前提下,帮助算法们降低计算成本。
(二)相关性过滤法
希望选出与标签相关且有意义的特征,因为这样的特征能够提供大量信息。如果特征与标签无关,那只会白白浪费我们的计算内存,可能还会给模型带来噪音。
在sklearn当中,我们有三种常用的方法来评判特征与标签之间的相关性:卡方,F检验,互信息。
- 导入数据
# 1.导入依赖包
from sklearn.datasets import load_iris# 2.获取数据
iris = load_iris()
X, Y = iris.data, iris.target
print(f'X的形状:{X.shape}') # (150, 4)
2.1 卡方过滤
卡方过滤是专门针对离散型标签(即分类问题)的相关性过滤。卡方检验类feature_selection.chi2计算每个非负特征和标签之间的卡方统计量,并依照卡方统计量由高到低为特征排名。
再结合feature_selection.SelectKBest这个可以输入”评分标准“来选出前K个分数最高的特征的类,我们可以借此除去最可能独立于标签,与我们分类目的无关的特征。
SelectKBest:按照scores保留K个特征;SelectPercentile:按照scores保留指定百分比的特征;SelectFpr、SelectFdr和SelectFwe:对每个特征使用通用的单变量统计检验;GenericUnivariateSelect:允许使用可配置策略如超参数搜索估计器选择最佳的单变量选择策略。
# 卡方检验-鸢尾花案例
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
iris = load_iris()
X, Y = iris.data, iris.target
print(f'X的形状:{X.shape}') # (150, 4)selector = SelectKBest(chi2, k=2)
X_new = selector.fit_transform(X, Y)
print(f'X_new的形状:{X_new.shape}') # (150, 2)print(f'特征得分:{selector.scores_}')
print(f'特征索引:{selector.get_support(indices=True)}')
print(f'特征名称:{[iris.feature_names[i] for i in selector.get_support(indices=True)]}')
# 卡方过滤法-案例-手写数字识别
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2# 假设在这里需要300个特征
selector = SelectKBest(chi2, k=300)
X_fschi = selector.fit_transform(x, y)
print(f'卡方过滤后数据的形状:{X_fschi.shape}')
# 验证一下模型的效果
print(f'卡方过滤后的模型效果:{cross_val_score(RFC(n_estimators=10,random_state=0),X_fschi,y,cv=5).mean()}')print(f'特征得分:{selector.scores_}')
print(f'特征索引:{selector.get_support(indices=True)}')
print(f'特征名称:{x.columns[selector.get_support(indices=True)]}')
2.2 F检验
F检验,又称ANOVA,方差齐性检验,是用来捕捉每个特征与标签之间的线性关系的过滤方法。它即可以做回归也可以做分类,因此包含feature_selection.f_classif(F检验分类)和feature_selection.f_regression(F检验回归)两个类。其中F检验分类用于标签是离散型变量的数据,而F检验回归用于标签是连续型变量的数据。
F检验的本质是寻找两组数据之间的线性关系,其原假设是”数据不存在显著的线性关系“。它返回F值和p值两个统计量。和卡方过滤一样,我们希望选取p值小于0.05或0.01的特征,这些特征与标签时显著线性相关的,而p值大于0.05或0.01的特征则被我们认为是和标签没有显著线性关系的特征,应该被删除。
- f_classif
from sklearn.feature_selection import f_classiffrom sklearn.feature_selection import f_classiff_values, p_values = f_classif(X, Y) # f_values是每个特征的F值,p_values是对应的p值。
print(f'特征F值:{f_values}, 特征p值:{p_values}')
# 特征F值:[ 119.26450218 49.16004009 1180.16118225 960.0071468 ]
# 特征p值:[1.66966919e-31 4.49201713e-17 2.85677661e-91 4.16944584e-85]- f-regression
from sklearn.feature_selection import f_regression- 案例
import pandas as pd
import numpy as np
from sklearn.feature_selection import f_regression
from sklearn.impute import SimpleImputer# 读取数据
data = pd.read_csv('data/Titanic_train.csv')# 显式定义需要使用的特征列
feature_columns = ['Age', 'Fare'] # 示例,可根据实际情况扩展
target_column = 'Survived' # 确认目标列名称是否正确# 处理缺失值
imputer = SimpleImputer(missing_values=np.nan, strategy='most_frequent')
x_imputed = imputer.fit_transform(data[feature_columns])
# print(f'F验证法-f_regression-处理缺失值后的数据:{x_imputed}')# 获取目标变量
y = data[target_column].values# 特征选择
f_values, p_values = f_regression(x_imputed, y)# 输出结果
print(f'f_regression特征F值:{f_values}, f_regression特征p值:{p_values}')-
X是特征矩阵,y是目标变量,center表示是否对X和y进行中心化
-
第一步,计算每个特征与目标变量的相关系数

-
第二步,将相关系数转换为F score和p-value
2.3 互信息法
互信息法是用来捕捉每个特征与标签之间的任意关系(包括线性和非线性关系)的过滤方法。和F检验相似,它既可以做回归也可以做分类,并且包含两个类feature_selection.mutual_info_classif(互信息分类)和feature_selection.mutual_info_regression(互信息回归)。
这两个类的用法和参数都和F检验一模一样,不过互信息法比F检验更加强大,F检验只能够找出线性关系,而互信息法可以找出任意关系。
- feature_selection.mutual_info_regression(互信息回归)
sklearn.feature_selection.mutual_info_regression(X, y, discrete_features=’auto’, n_neighbors=3, copy=True, random_state=None)- X是特征矩阵,y是目标变量,discrete_features用于指定哪些是离散的特征,n_neighbors是[1][2]中用来估计随机变量互信息的近邻数,大的n_neighbors可以降低估计器的方差,但会造成偏差。
- 两个随机变量之间的互信息是一个非负值,度量变量之间的依赖关系。独立随机变量之间的互信息等于0,互信息越大表示依赖关系越强。
- feature_selection.mutual_info_classif(互信息分类)
from sklearn.feature_selection import mutual_info_classif as MIC
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_scoreresult = MIC(X,Y)k = result.shape[0] - sum(result <= 0)
X_fsmic = SelectKBest(MIC, k=2).fit_transform(X, Y)
print(f'互信息过滤后的模型效果:{cross_val_score(RFC(n_estimators=10, random_state=0), X_fsmic, Y, cv=5).mean()}')(三)其他
3.1 包装法
通过选择一个目标函数来一步步的筛选特征。通常是预测效果评分,每次选择部分特征,或者排除部分特征。
- feature_selection.RFE(estimator)
递归消除特征法(recursive feature elimination, RFE),使用一个机器学习模型来进行多轮训练,每轮训练后,消除若干权值系数对应的特征,再基于新的特征集进行下一轮训练。 - SVM-RFE算法:每轮使用特征集中特征来训练,得到分类超平面𝑤𝑥+𝑏=0后,选出𝑤中分量的平方值最小的那个序号i对应的特征,将其排除。
3.2 嵌入法
用机器学习的方法来选择特征,但是它和RFE的区别是它不是通过不停的筛掉特征来进行训练,而是使用的都是特征全集。
- feature_selection.SelectFromModel(estimator)
最常用的是使用L1正则化和L2正则化来选择特征。正则化惩罚项越大,那么模型的系数就会越小,当正则化惩罚项大到一定程度时,部分特征系数会更容易先变成0,这部分系数就是可以筛掉的。 - 常用逻辑回归作为基学习器。此外也可以使用决策树或GBDT。
3.3 衍生特征法(寻找高级特征)
- 若干项特征加和: 假设希望根据每日销售额得到一周销售额的特征。可以将最近7天的销售额相加得到。
- 若干项特征之差: 假设已经拥有每周销售额以及每月销售额两项特征,可以求一周前一月内的销售额。
- 若干项特征乘积: 假设有商品价格和商品销量的特征,就可以得到销售额的特征。
- 若干项特征除商: 假设有销售额和购买的商品件数,就可以得到平均每件商品的销售额。
注意:不是随便两两组合就可以形成高级特征,这样容易导致特征爆炸,反而没有办法得到较好的模型。
(四)总结
| 类 | 说明 | 超参数选择 |
|---|---|---|
| VarianceThreshold | 方差过滤,可输入方差阈值,返回方差大于阈值的新特征矩阵 | 看具体数据究竟是否包含有更多噪声还是更多的有效特征,一般就使用0或者1来筛选,也可以画学习曲线或取中位数跑模型来帮助确认 |
| SelectKBest | 用来选取K个统计量结果最佳的特征,生成符合统计量要求的新特征矩阵 | 看配合使用的统计量 |
| chi2 | 卡方检验,专用于分类算法,捕捉相关性 | 追求p小于显著性水平的特征 |
| f_classif | F检验分类,只能捕捉线性相关性;要求数据服从正态分布 | 追求p小于显著性水平的特征 |
| f_regression | F检验回归,只能捕捉线性相关性;要求数据服从正态分布 | 追求p小于显著性水平的特征 |
| mutual_info_classif | 互信息分类,可以捕捉任何相关性;不能用于稀疏矩阵 | 追求互信息估计大于0的特征 |
| mutual_info_regression | 互信息回归,可以捕捉任何相关性;不能用于稀疏矩阵 | 追求互信息估计大于0的特征 |
按照特征的发散性或者相关性指标对各个特征进行评分,设定评分阈值或者待选择阈值的个数,选择合适特征。
feature_selection.VarianceThreshold([threshold])
方差筛选。方差越大的特征,那么可以认为它是比较有用的。如果方差较小,比如小于1,那么这个特征可能对算法作用很小。可以指定一个方差的阈值,方差小于这个阈值的特征会被筛掉。feature_selection.SelectKBest([score_func, k])
相关系数。主要用于输出连续值的监督学习算法中。分别计算所有训练集中各个特征与输出值之间的相关系数,设定一个阈值,选择相关系数较大的部分特征。feature_selection.chi2(X, y)
假设检验如卡方检验。卡方检验可以检验某个特征分布和输出值分布之间的相关性。使用chi2这个类来做卡方检验得到所有特征的卡方值与显著性水平P临界值,可以给定卡方值阈值, 选择卡方值较大的部分特征。feature_selection.f_classif(X, y),feature_selection.f_regression(X, y)
假设检验除了卡方检验,还可以使用F检验和t检验。F检验的函数f_classif和f_regression,分别在分类和回归特征选择时使用。feature_selection.mutual_info_classif(X, y),`feature_selection.mutual_info_regression(X, y)``
互信息,即从信息熵的角度分析各个特征和输出值之间的关系评分。在决策树中出现过互信息(信息增益)。互信息值越大,说明该特征和输出值之间的相关性越大,越需要保留。
(可以优先使用卡方检验和互信息来做特征选择)
相关文章:
【数据分析】特征工程-特征选择
【数据分析】特征工程-特征选择 (一)方差过滤法1.1 消除方差为0的特征1.2 保留一半的特征1.3 特征是二分类时 (二)相关性过滤法2.1 卡方过滤2.2 F检验2.3 互信息法 (三)其他3.1 包装法3.2 嵌入法3.3 衍生特…...

第4节 Node.js NPM 使用介绍
本文介绍了 Node.js 中 NPM 的使用,我们先来了解什么是 NPM。 NPM是随同NodeJS一起安装的包管理工具,能解决NodeJS代码部署上的很多问题,常见的使用场景有以下几种: 允许用户从NPM服务器下载别人编写的第三方包到本地使用。允许…...

RK3399 Android7.1增加应用安装白名单机制
通过设置应用包名白名单的方式限制未授权的应用软件安装。 diff --git a/frameworks/base/services/core/java/com/android/server/pm/PackageManagerService.java b/frameworks/base/services/core/java/com/android/server/pm/PackageManagerService.java index af9a533..ca…...
uni-app 安卓消失的字符去哪里了?maxLength失效了!
前情提要 皮一下~这个标题我还蛮喜欢的嘿嘿嘿【附上一个自行思考的猥琐的笑容】 前段时间不是在开发uni-app的一个小应用嘛,然后今天测试发现,有一个地方在苹果是没有问题的,但是在安卓上出现了问题,附上安卓的截图 在这里我是有限制maxLength=50的,而且,赋值字符串到字…...

#AI短视频制作完整教程
目录 前期准备AI工具选择制作流程后期优化发布策略 前期准备 1. 确定视频主题和风格 内容定位:教育、娱乐、商业推广、个人分享目标受众:年龄、兴趣、平台偏好视频时长:15-60秒(根据平台调整)风格调性:…...
嵌入式STM32学习——串口USART 2.0(printf重定义及串口发送)
printf重定义: C语言里面的printf函数默认输出设备是显示器,如果要实现printf函数输出正在串口或者LCD显示屏上,必须要重定义标准库函数里调用的与输出设备相关的函数,比如printf输出到串口,需要将fputc里面的输出指向…...
【大模型】情绪对话模型项目研发
一、使用框架: Qwen大模型后端Open-webui前端实现使用LLamaFactory的STF微调数据集,vllm后端部署, 二、框架安装 下载千问大模型 安装魔塔社区库文件 pip install modelscope Download.py 内容 from modelscope import snapshot_downlo…...
)
Git 教程 | 如何将指定文件夹回滚到上一次或某次提交状态(命令详解)
在日常开发中,我们经常会遇到这样的情况: “我想把某个文件夹恢复到之前的状态,但又不想影响整个项目,怎么办?” 别担心!这篇文章就教你如何用 Git 把项目中某个特定文件夹(或文件)回…...
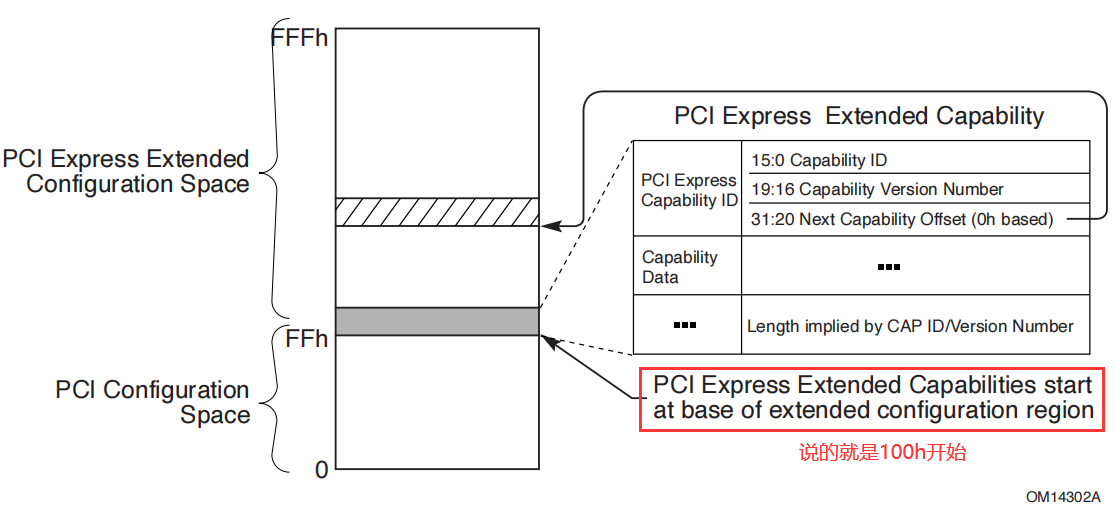
【PCI】PCI入门介绍(包含部分PCIe讲解)
先解释一下寻址空间: 机器是32bit的话,意味着4G(2的32次方)寻址空间,内存条作为它的实际物理存储设备。大部分在跑内存程序运行,少部分用来存放其他东西。这是一个常见的4G寻址空间分布(不一定是…...

Cloudera Manager 学习笔记
目录 1 基础概念与原理1.1 Cloudera Manager的主要作用是什么?1.2 与Ambari有何区别?1.3 Cloudera Manager 的核心功能和架构是什么?1.4 解释一下 Cloudera Manager 中的服务模型和角色?1.5 Cloudera Manager 是如何实现对 CDH 集群的集中管…...

Deepin 23.10安装Docker
个人博客地址:Deepin 23.10安装Docker | 一张假钞的真实世界 Deepin 是基于 Debian 的国产 Linux 发行版,安装 Docker Desktop 可能会遇到兼容性问题,因为 Docker Desktop 官方主要支持 Ubuntu/Debian/Red Hat/Fedora/Arch 等主流发行版&…...
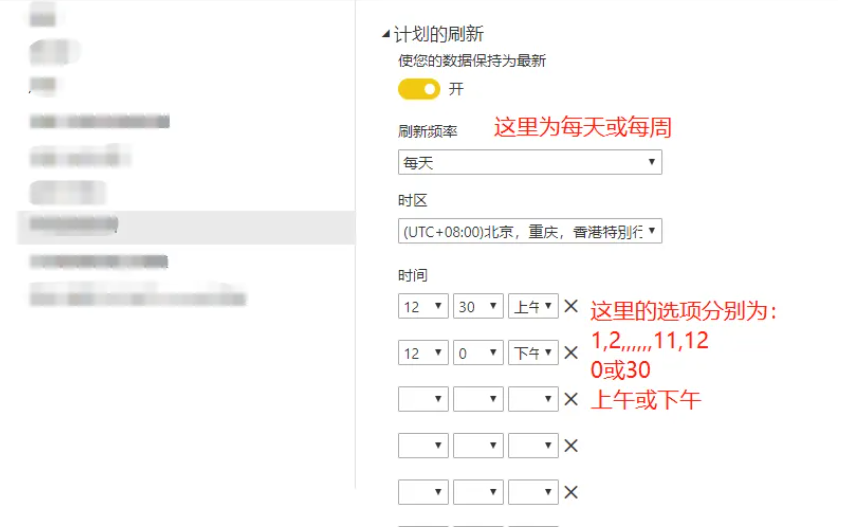
使用PowerBI个人网关定时刷新数据
使用PowerBI个人网关定时刷新数据 PowerBI desktop连接mysql,可以设置定时刷新数据或在PowerBI服务中手动刷新数据,步骤如下: 第一步: 下载网关。以个人网关为例,如图 第二步: 双击网关,点击下一步&…...

数字人引领政务新风尚:智能设备助力政务服务
在信息技术飞速发展的今天,政府机构不断探索提升服务效率和改善服务质量的新途径。实时交互数字人在政务服务中的应用正成为一大亮点,通过将“数字公务员”植入各种横屏智能设备中,为民众办理业务提供全程辅助。这种创新不仅优化了政务大厅的…...
深入剖析Java类加载机制:双亲委派模型的突破与实战应用
引言:一个诡异的NoClassDefFoundError 某金融系统在迁移到微服务架构后,突然出现了一个诡异问题:在调用核心交易模块时,频繁抛出NoClassDefFoundError,但类明明存在于classpath中。经过排查,发现是由于不同…...

Kotlin JVM 注解详解
前言 Kotlin 作为一门现代 JVM 语言,提供了出色的 Java 互操作性。为了更好地支持与 Java 代码的交互,Kotlin 提供了一系列 JVM 相关注解。这些注解不仅能帮助我们控制 Kotlin 代码编译成 Java 字节码的行为,还能让我们的 Kotlin 代码更好地…...

将 node.js 项目作为后台进程持续运行
将 node.js 项目作为后台进程持续运行 方法 1:使用 pm2(生产环境推荐) 安装 pm2(Node.js 进程管理器):npm install pm2 -g启动应用:pm2 start hd/src/app.js --name "my-app"常用命…...
)
【PhysUnits】15.5 引入P1后的标准化表示(standardization.rs)
一、源码 这段代码实现了一个类型级别的二进制数标准化系统,主要用于处理二进制数的前导零和特殊值的简化。 use super::basic::{Z0, P1, N1, B0, B1, NonNegOne, NonZero};/// 处理 B0<H> 类型的标准化 /// Standardization for B0<H> types /// ///…...

MySQL-5.7 修改密码和连接访问权限
一、MySQL-5.7 修改密码和连接权限设置 修改密码语法 注意:rootlocalhost 和 root192.168.56.% 是两个不同的用户。在修改密码时,两个用户的密码是各自分别保存,如果两个用户密码设置不一样则登陆时注意登陆密码 GRANT ALL PRIVILEGES ON …...
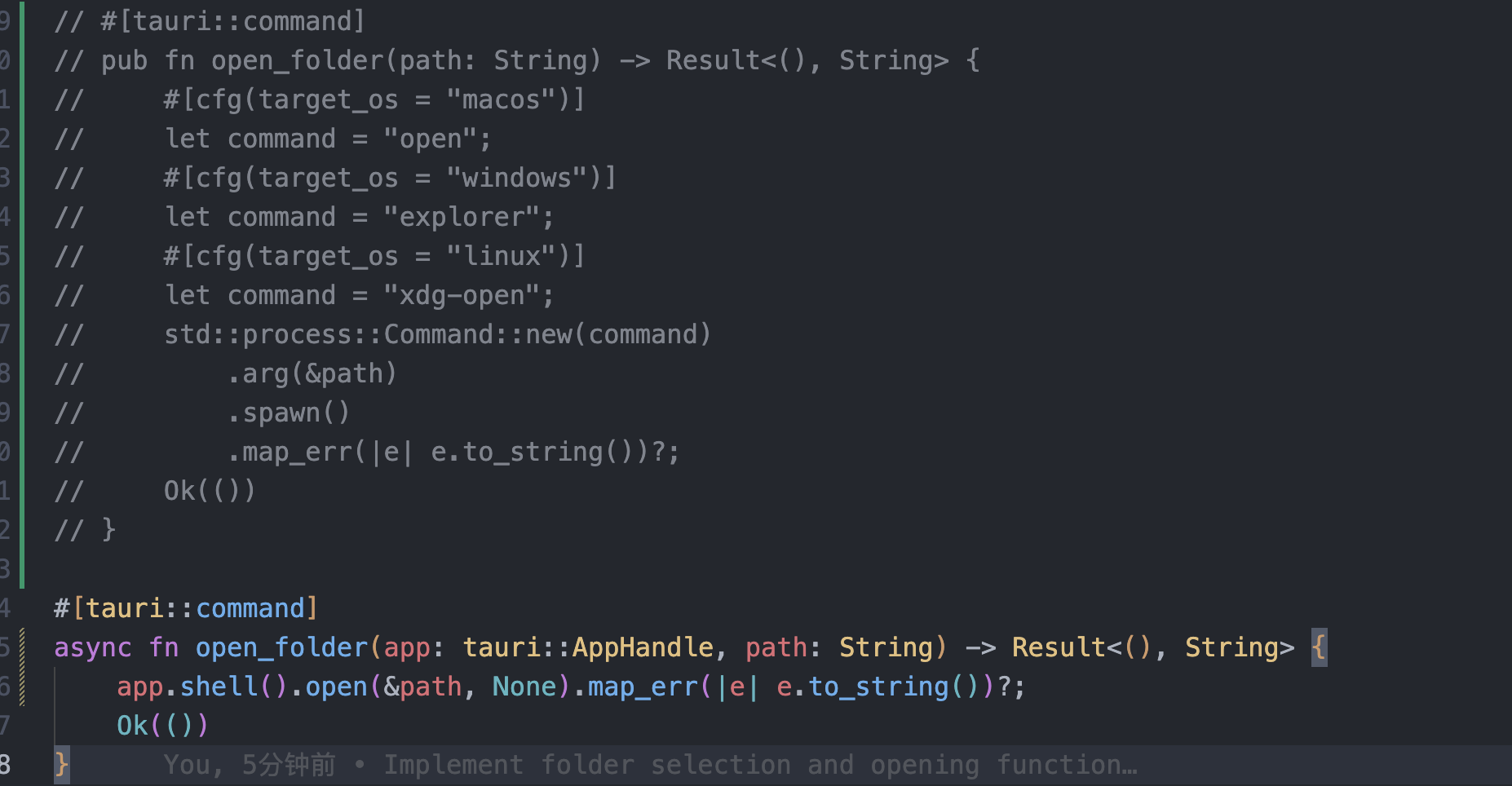
tauri2项目打开某个文件夹,类似于mac系统中的 open ./
在 Tauri 2 项目中打开文件夹 在 Tauri 2 项目中,你可以使用以下几种方法来打开文件夹,类似于 macOS 中的 open ./ 命令功能: 方法一:使用 shell 命令 use tauri::Manager;#[tauri::command] async fn open_folder(path: Strin…...

企业文件乱、传输慢?用群晖 NAS 构建安全高效的共享系统
在信息化办公不断加速的今天,企业对文件存储、共享与安全管理的需求愈发严苛。传统文件共享方式效率低下、权限混乱、远程访问困难,极大影响了协同办公效率。此时,一套可靠、高效、安全的文件共享解决方案便成为众多企业的“刚需”。 这正是…...

防爆手机VS普通手机,区别在哪里?
在加油站掏出手机接打电话、在化工厂车间随手拍照记录……这些看似寻常的行为,实则暗藏致命风险。普通手机在易燃易爆环境中可能成为“隐形炸弹”,而防爆手机却能安全护航。这两者看似相似,实则从底层基因到应用场景都存在着本质差异…...

C语言结构体的别名与创建结构体变量
这段代码是用C语言定义了一个链表节点的结构体,并通过typedef为相关类型创建了别名。下面分别解释Lnode和pNode: 1. Lnode Lnode是通过typedef为struct node定义的一个别名。struct node是一个结构体类型,表示一个链表节点。它的定义如下&a…...
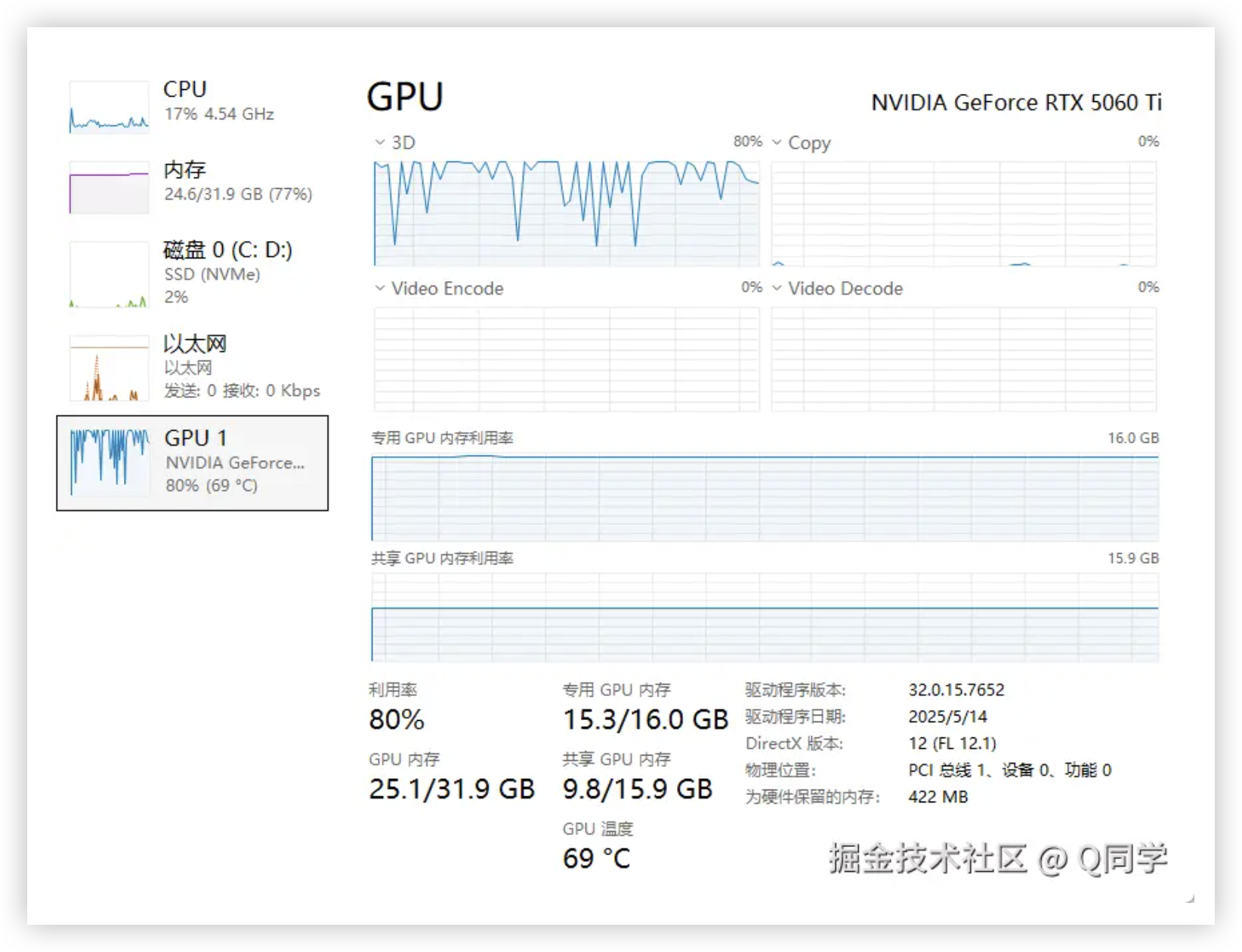
在RTX5060Ti上进行Qwen3-4B的GRPO强化微调
导语 最近赶上618活动,将家里的RTX 4060显卡升级为了RTX 5060Ti 16GB版本,显存翻了一番,可以进行一些LLM微调实验了,本篇博客记录使用unsloth框架在RTX 5060Ti 16GB显卡上进行Qwen3-4B-Base模型的GRPO强化微调实验。 简介 GPU性…...

SQL进阶之旅 Day 7:视图与存储过程入门
【SQL进阶之旅 Day 7】视图与存储过程入门 在SQL开发中,视图(View)和存储过程(Stored Procedure)是两个非常重要的数据库对象。它们不仅可以简化复杂查询逻辑,还能提高代码复用性和安全性。本文将深入探讨…...

武汉火影数字VR大空间制作
VR大空间是一种利用空旷的物理空间,结合先进的虚拟现实技术,让用户能够在其中自由移动并深度体验虚拟世界的创新项目方式。 在科技飞速发展的当下,VR大空间正以其独特的魅力,成为科技与娱乐领域的耀眼新星,掀起了一股沉…...

Docker部署项目无法访问,登录超时完整排查攻略
项目背景:迁移前后端应用,prod环境要求保留443端口,开发环境37800端口,后端容器端口为8000,前端为80,fastAPI对外端口为41000 生产环境部署在VM01,开发环境部署在VM03,在VM01配置nginx转发 [r…...
(增强)基于sqlite、mysql、redis的消息存储
原文链接:(增强)基于sqlite、mysql、redis的消息存储 教程说明 说明:本教程将采用2025年5月20日正式的GA版,给出如下内容 核心功能模块的快速上手教程核心功能模块的源码级解读Spring ai alibaba增强的快速上手教程…...

Windows上用FFmpeg推流及拉流的流程概览
1. 视频采集与推流(Windows FFmpeg) 采集设备:Windows上的摄像头,比如“Integrated Camera”。 采集方式:FFmpeg通过 dshow 设备接口读取摄像头。 推流协议:你可以选择推到 RTMP 或 RTSP 服务器。 推流…...
MFC坦克大战游戏制作
MFC坦克大战游戏制作 前言 现在的游戏制作一般是easyx,有没有直接只用mfc框架的,笔者研究了一番,做出了一个雏形,下面把遇到的问题总结出来 一、MFC框架制作游戏 初步设想,MFC可以选用 对话框 或者 单文档 结构&…...
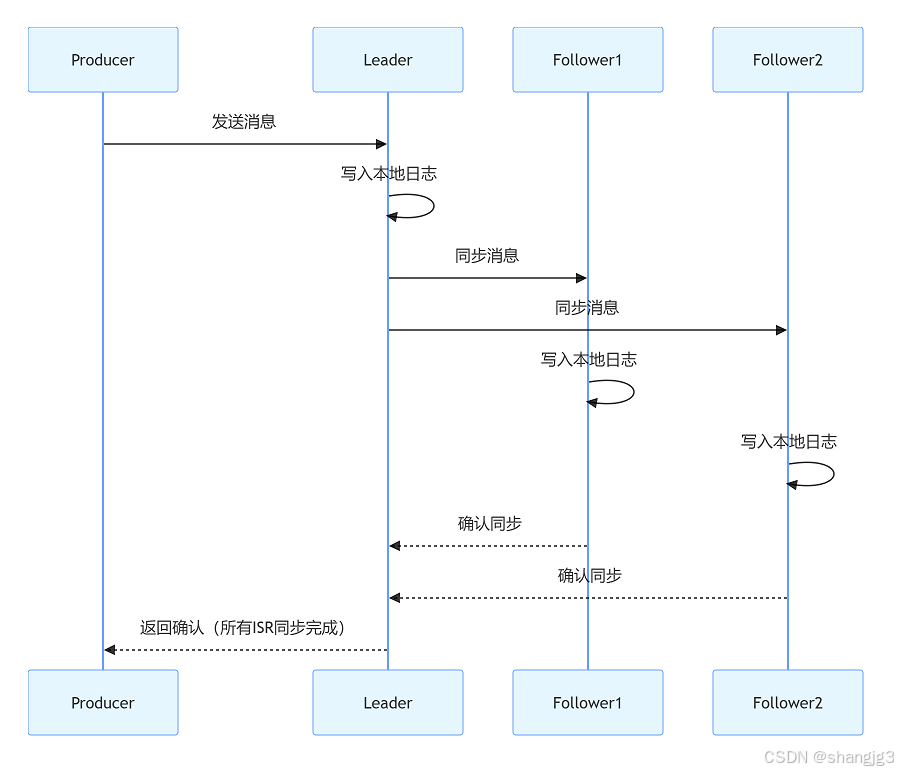
Kafka ACK机制详解:数据可靠性与性能的权衡之道
在分布式消息系统中,消息确认机制是保障数据可靠性的关键。Apache Kafka 通过 ACK(Acknowledgment)机制 实现了灵活的数据确认策略,允许用户在 数据可靠性 和 系统性能 之间进行权衡。本文将深入解析 Kafka ACK 机制的工作原理、配…...