TensorFlow深度学习实战(19)——受限玻尔兹曼机
TensorFlow深度学习实战(19)——受限玻尔兹曼机
- 0. 前言
- 1. 受限玻尔兹曼机
- 1.1 受限玻尔兹曼机架构
- 1.2 受限玻尔兹曼机的数学原理
- 2. 使用受限玻尔兹曼机重建图像
- 3. 深度信念网络
- 小结
- 系列链接
0. 前言
受限玻尔兹曼机 (Restricted Boltzmann Machine, RBM) 是一种无监督学习的概率图模型,用于学习数据的特征表示。它是由两层神经元组成的网络,其中一层是可见层 (visible layer),用于表示输入数据;另一层是隐层 (hidden layer),用于捕捉数据的潜在特征,而深度信念网络是堆叠的 RBM。本节中,将介绍 RBM 的基本原理,并使用 TensorFlow 实现 RBM 和深度信念网络用于重建图像。
1. 受限玻尔兹曼机
1.1 受限玻尔兹曼机架构
受限玻尔兹曼机 (Restricted Boltzmann Machine, RBM) 是一种双层神经网络,一层称为可见层 (visible layer),另一层称为隐层 (hidden layer)。因为只有两层,因此称为浅层神经网络。RBM 最早由 Paul Smolensky 于 1986 年提出,后来由 Geoffrey Hinton 在 2006 年提出使用对比散度 (Contrastive Divergence, CD) 作为训练方法。所有可见层的神经元(称为可见单元,visible unit )都与隐层的所有神经元(称为隐单元,hidden unit )连接,但有一个限制——同一层中的神经元之间不能连接。RBM 中的所有神经元本质上都是二进制的,要么激活,要么不激活。
RBM 可以用于降维、特征提取和协同过滤。RBM 的训练可以分为三个部分:前向传递 (forward pass)、反向传递 (backward pass) 以及比较 (comparison)。
1.2 受限玻尔兹曼机的数学原理
接下来,我们从数学原理方面介绍 RBM,将 RBM 的操作分为两个过程:
前向传递: 可见单元 V V V 的信息通过权重 W W W 和偏置 c c c 传递到隐单元 h 0 h_0 h0。隐单元可能会激活或不激活,这取决于随机概率 σ \sigma σ,通常使用 sigmoid 函数:
ρ ( v 0 ∣ h 0 ) = σ ( V T W + c ) \rho (v_0|h_0)=\sigma(V^TW+c) ρ(v0∣h0)=σ(VTW+c)
反向传递: 隐单元的表示 h 0 h_0 h0 通过相同的权重 W W W,但使用不同的偏置 c c c,传递回可见单元,从而模型重建输入。同样,取决于随机概率 σ \sigma σ:
ρ ( v i ∣ h 0 ) = σ ( V T h 0 + c ) \rho(v_i|h_0)=\sigma(V^Th_0+c) ρ(vi∣h0)=σ(VTh0+c)
重复执行以上两个过程 k k k 次,或者直到收敛。根据研究, k = 1 k=1 k=1 可以得到良好的结果,因此本节将 k k k 设置为 1 1 1。
可见向量 V V V 和隐向量 h h h 的联合能量表示如下:
E ( v , h ) = − b T V − c T h − V T W h E(v,h)=-b^TV-c^Th-V^TWh E(v,h)=−bTV−cTh−VTWh
每个可见向量 V V V 还关联有自由能量:
F ( v ) = − b T V − ∑ j ∈ h i d d e n l o g ( 1 + e x p ( c j + V T W ) ) F(v)=-b^TV-\sum_{j\in hidden}log(1+exp(c_j+V^TW)) F(v)=−bTV−j∈hidden∑log(1+exp(cj+VTW))
使用对比散度目标函数,即 M e a n ( F ( V o r i g i n a l ) ) − M e a n ( F ( V r e c o n s t r u c t e d ) ) Mean(F(V_{original})) - Mean(F(V_{reconstructed})) Mean(F(Voriginal))−Mean(F(Vreconstructed)),权重的变化由下式表示:
d W = η [ ( V T h ) i n p u t − ( V T h ) r e c o n s t r u c t e d ] dW=\eta[(V^Th)_{input}-(V^Th)_{reconstructed}] dW=η[(VTh)input−(VTh)reconstructed]
其中, η \eta η 是学习率,偏置 b b b 和 c c c 变化的表达式与此类似。
2. 使用受限玻尔兹曼机重建图像
接下来,使用 TensorFlow 构建一个受限玻尔兹曼机 (Restricted Boltzmann Machine, RBM) 模型,用于重建 MNIST 手写数字图像。
(1) 导入 TensorFlow、NumPy 和 Matplotlib 库:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
(2) 定义 RBM 类。RBM 类的 __init__() 函数初始化可见层的神经元数量 input_size 和隐层的神经元数量 output_size,初始化隐层和可见层的权重和偏置,本节中将它们初始化为零。也可以尝试随机初始化:
#Class that defines the behavior of the RBM
class RBM(object):def __init__(self, input_size, output_size, lr=1.0, batchsize=100):"""m: Number of neurons in visible layern: number of neurons in hidden layer"""#Defining the hyperparametersself._input_size = input_size #Size of Visibleself._output_size = output_size #Size of outpself.learning_rate = lr #The step used in gradient descentself.batchsize = batchsize #The size of how much data will be used for training per sub iteration#Initializing weights and biases as matrices full of zeroesself.w = tf.zeros([input_size, output_size], np.float32) #Creates and initializes the weights with 0self.hb = tf.zeros([output_size], np.float32) #Creates and initializes the hidden biases with 0self.vb = tf.zeros([input_size], np.float32) #Creates and initializes the visible biases with 0
定义前向和反向传递方法:
#Forward Passdef prob_h_given_v(self, visible, w, hb):#Sigmoid return tf.nn.sigmoid(tf.matmul(visible, w) + hb)#Backward Passdef prob_v_given_h(self, hidden, w, vb):return tf.nn.sigmoid(tf.matmul(hidden, tf.transpose(w)) + vb)
创建生成随机二进制值的函数。这是因为隐层和可见层的单元更新是使用随机概率的,这取决于每个单元的输入(对于隐层)以及从上到下的反向输入(对于可见层):
#Generate the sample probabilitydef sample_prob(self, probs):return tf.nn.relu(tf.sign(probs - tf.random.uniform(tf.shape(probs))))
定义函数重建输入数据:
def rbm_reconstruct(self,X):h = tf.nn.sigmoid(tf.matmul(X, self.w) + self.hb)reconstruct = tf.nn.sigmoid(tf.matmul(h, tf.transpose(self.w)) + self.vb)return reconstruct
定义 train() 函数用于训练 RBM。该函数计算对比散度的正梯度和负梯度,并使用权重更新公式来更新权重和偏置:
#Training method for the modeldef train(self, X, epochs=10): loss = []for epoch in range(epochs):#For each step/batchfor start, end in zip(range(0, len(X), self.batchsize),range(self.batchsize,len(X), self.batchsize)):batch = X[start:end]#Initialize with sample probabilitiesh0 = self.sample_prob(self.prob_h_given_v(batch, self.w, self.hb))v1 = self.sample_prob(self.prob_v_given_h(h0, self.w, self.vb))h1 = self.prob_h_given_v(v1, self.w, self.hb)#Create the Gradientspositive_grad = tf.matmul(tf.transpose(batch), h0)negative_grad = tf.matmul(tf.transpose(v1), h1)#Update learning rates self.w = self.w + self.learning_rate *(positive_grad - negative_grad) / tf.dtypes.cast(tf.shape(batch)[0],tf.float32)self.vb = self.vb + self.learning_rate * tf.reduce_mean(batch - v1, 0)self.hb = self.hb + self.learning_rate * tf.reduce_mean(h0 - h1, 0)#Find the error rateerr = tf.reduce_mean(tf.square(batch - v1))print ('Epoch: %d' % epoch,'reconstruction error: %f' % err)loss.append(err)return loss
(3) 实例化一个 RBM 对象并在 MNIST 数据集上进行训练:
(train_data, _), (test_data, _) = tf.keras.datasets.mnist.load_data()
train_data = train_data/np.float32(255)
train_data = np.reshape(train_data, (train_data.shape[0], 784))test_data = test_data/np.float32(255)
test_data = np.reshape(test_data, (test_data.shape[0], 784))#Size of inputs is the number of inputs in the training set
input_size = train_data.shape[1]
rbm = RBM(input_size, 200)err = rbm.train(train_data,50)
(4) 绘制学习曲线:
plt.plot(err)
plt.xlabel('epochs')
plt.ylabel('cost')
plt.show()

(5) 可视化重建图像:
out = rbm.rbm_reconstruct(test_data)# Plotting original and reconstructed images
row, col = 2, 8
idx = np.random.randint(0, 100, row * col // 2)
f, axarr = plt.subplots(row, col, sharex=True, sharey=True, figsize=(20,4))
for fig, row in zip([test_data,out], axarr):for i,ax in zip(idx,row):ax.imshow(tf.reshape(fig[i],[28, 28]), cmap='Greys_r')ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)
plt.show()
重建图像如下所示:

第一行是输入的手写图像,第二行是重建的图像,可以看到这些图像与人类手写的数字非常相似。
3. 深度信念网络
我们已经了解了受限玻尔兹曼机 (Restricted Boltzmann Machine, RBM),并知道如何使用对比散度进行训练,接下来,我们将介绍第一个成功的深度神经网络架构——深度信念网络 (Deep Belief Network, DBN)。DBN 架构在 2006 年由 Hinton 提出,在此模型之前,训练深度架构非常困难,不仅是由于计算资源有限,还因为梯度消失问题。在 DBN 中首次展示了如何通过贪婪的逐层训练来训练深度架构。
简单来说,DBN 只是堆叠的 RBM,每个 RBM 都使用对比散度单独训练。从训练第一个 RBM 层开始,训练完成后,训练第二个 RBM 层。第二个 RBM 的可见单元接收第一个 RBM 隐单元的输出作为输入数据。每次添加 RBM 层时重复以上过程。
(1) 堆叠 RBM 类。为了构建 DBN,需要在 RBM 类中定义一个额外的函数 rbm_output(),用于将前一 RBM 隐单元的输出传递到下一个 RBM 中:
class RBM(object):def __init__(self, input_size, output_size, lr=1.0, batchsize=100):"""m: Number of neurons in visible layern: number of neurons in hidden layer"""#Defining the hyperparametersself._input_size = input_size #Size of Visibleself._output_size = output_size #Size of outpself.learning_rate = lr #The step used in gradient descentself.batchsize = batchsize #The size of how much data will be used for training per sub iteration#Initializing weights and biases as matrices full of zeroesself.w = tf.zeros([input_size, output_size], np.float32) #Creates and initializes the weights with 0self.hb = tf.zeros([output_size], np.float32) #Creates and initializes the hidden biases with 0self.vb = tf.zeros([input_size], np.float32) #Creates and initializes the visible biases with 0#Forward Passdef prob_h_given_v(self, visible, w, hb):#Sigmoid return tf.nn.sigmoid(tf.matmul(visible, w) + hb)#Backward Passdef prob_v_given_h(self, hidden, w, vb):return tf.nn.sigmoid(tf.matmul(hidden, tf.transpose(w)) + vb)#Generate the sample probabilitydef sample_prob(self, probs):return tf.nn.relu(tf.sign(probs - tf.random.uniform(tf.shape(probs))))#Training method for the modeldef train(self, X, epochs=10): loss = []for epoch in range(epochs):#For each step/batchfor start, end in zip(range(0, len(X), self.batchsize),range(self.batchsize,len(X), self.batchsize)):batch = X[start:end]#Initialize with sample probabilitiesh0 = self.sample_prob(self.prob_h_given_v(batch, self.w, self.hb))v1 = self.sample_prob(self.prob_v_given_h(h0, self.w, self.vb))h1 = self.prob_h_given_v(v1, self.w, self.hb)#Create the Gradientspositive_grad = tf.matmul(tf.transpose(batch), h0)negative_grad = tf.matmul(tf.transpose(v1), h1)#Update learning rates self.w = self.w + self.learning_rate *(positive_grad - negative_grad) / tf.dtypes.cast(tf.shape(batch)[0],tf.float32)self.vb = self.vb + self.learning_rate * tf.reduce_mean(batch - v1, 0)self.hb = self.hb + self.learning_rate * tf.reduce_mean(h0 - h1, 0)#Find the error rateerr = tf.reduce_mean(tf.square(batch - v1))print ('Epoch: %d' % epoch,'reconstruction error: %f' % err)loss.append(err)return loss#Create expected output for our DBNdef rbm_output(self, X):out = tf.nn.sigmoid(tf.matmul(X, self.w) + self.hb)return outdef rbm_reconstruct(self,X):h = tf.nn.sigmoid(tf.matmul(X, self.w) + self.hb)reconstruct = tf.nn.sigmoid(tf.matmul(h, tf.transpose(self.w)) + self.vb)return reconstruct
(2) 使用 RBM 类创建一个堆叠的 RBM 结构,第一个 RBM 有 500 个隐单元,第二个有 200 个隐单元,第三个有 50 个隐单元:
RBM_hidden_sizes = [500, 200 , 50 ] #create 2 layers of RBM with size 400 and 100#Since we are training, set input as training data
inpX = train_data#Create list to hold our RBMs
rbm_list = []#Size of inputs is the number of inputs in the training set
input_size = train_data.shape[1]#For each RBM we want to generate
for i, size in enumerate(RBM_hidden_sizes):print ('RBM: ',i,' ',input_size,'->', size)rbm_list.append(RBM(input_size, size))input_size = size
"""
RBM: 0 784 -> 500
RBM: 1 500 -> 200
RBM: 2 200 -> 50
"""
(3) 对于第一个 RBM,MNIST 数据作为输入。第一个 RBM 的输出作为输入传递到第二个 RBM,以此类推,通过连续的 RBM 层:
#For each RBM in our list
for rbm in rbm_list:print ('Next RBM:')#Train a new onerbm.train(tf.cast(inpX,tf.float32)) #Return the output layerinpX = rbm.rbm_output(inpX)out = rbm_list[0].rbm_reconstruct(test_data)
# Plotting original and reconstructed images
row, col = 2, 8
idx = np.random.randint(0, 100, row * col // 2)
f, axarr = plt.subplots(row, col, sharex=True, sharey=True, figsize=(20,4))
for fig, row in zip([test_data,out], axarr):for i,ax in zip(idx,row):ax.imshow(tf.reshape(fig[i],[28, 28]), cmap='Greys_r')ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)
plt.show()
本节中,这三个堆叠的受限玻尔兹曼机以无监督学习方式进行训练。DBN 还可以通过监督学习进行训练,为此,需要对训练好的 RBM 的权重进行微调,并在最后添加一个全连接层。
小结
受限玻尔兹曼机 (Restricted Boltzmann Machine, RBM) 是一种强大的无监督学习模型,可以用于特征学习、数据降维、图像生成等任务。尽管其训练过程复杂且计算开销较大,但它为深度学习的发展奠定了基础,如深度信念网络 (Deep Belief Network, DBN)。
系列链接
TensorFlow深度学习实战(1)——神经网络与模型训练过程详解
TensorFlow深度学习实战(2)——使用TensorFlow构建神经网络
TensorFlow深度学习实战(3)——深度学习中常用激活函数详解
TensorFlow深度学习实战(4)——正则化技术详解
TensorFlow深度学习实战(5)——神经网络性能优化技术详解
TensorFlow深度学习实战(6)——回归分析详解
TensorFlow深度学习实战(7)——分类任务详解
TensorFlow深度学习实战(8)——卷积神经网络
TensorFlow深度学习实战(9)——构建VGG模型实现图像分类
TensorFlow深度学习实战(10)——迁移学习详解
TensorFlow深度学习实战(11)——风格迁移详解
TensorFlow深度学习实战(12)——词嵌入技术详解
TensorFlow深度学习实战(13)——神经嵌入详解
TensorFlow深度学习实战(14)——循环神经网络详解
TensorFlow深度学习实战(15)——编码器-解码器架构
TensorFlow深度学习实战(16)——注意力机制详解
TensorFlow深度学习实战(17)——主成分分析详解
TensorFlow深度学习实战(18)——K-means 聚类详解
相关文章:
TensorFlow深度学习实战(19)——受限玻尔兹曼机
TensorFlow深度学习实战(19)——受限玻尔兹曼机 0. 前言1. 受限玻尔兹曼机1.1 受限玻尔兹曼机架构1.2 受限玻尔兹曼机的数学原理 2. 使用受限玻尔兹曼机重建图像3. 深度信念网络小结系列链接 0. 前言 受限玻尔兹曼机 (Restricted Boltzmann Machine, RB…...
告别手动绘图!基于AI的Smart Mermaid自动可视化图表工具搭建与使用指南
以下是对Smart Mermaid的简单介绍: 一款基于 AI 技术的 Web 应用程序,可将文本内容智能转换为 Mermaid 格式的代码,并将其渲染成可视化图表可以智能制作流程图、序列图、甘特图、状态图等等,并且支持在线调整、图片导出可以Docke…...

【Oracle】安装单实例
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 安装前的准备工作1.1 硬件和系统要求1.2 检查系统环境1.3 下载Oracle软件 2. 系统配置2.1 创建Oracle用户和组2.2 配置内核参数2.3 配置用户资源限制2.4 安装必要的软件包 3. 目录结构和环境变量3.1 创建Ora…...
)
C++测开,自动化测试,业务(第一段实习)
目录 🌼前言 一,实习经历怎么写简历 🌹业务理解 🎂结构化表达 二,实习 🦂技术和流程卡点 🔑实习收获 / 代码风格 三,测试理论,用例设计,工具链 &…...
QT中更新或添加组件时出现“”qt操作至少需要一个处于启用状态的有效资料档案库“解决方法”
在MaintenanceTool.exe中点击下一步 第一个: 第二个: 第三个: 以上任意一个放入资料库中...
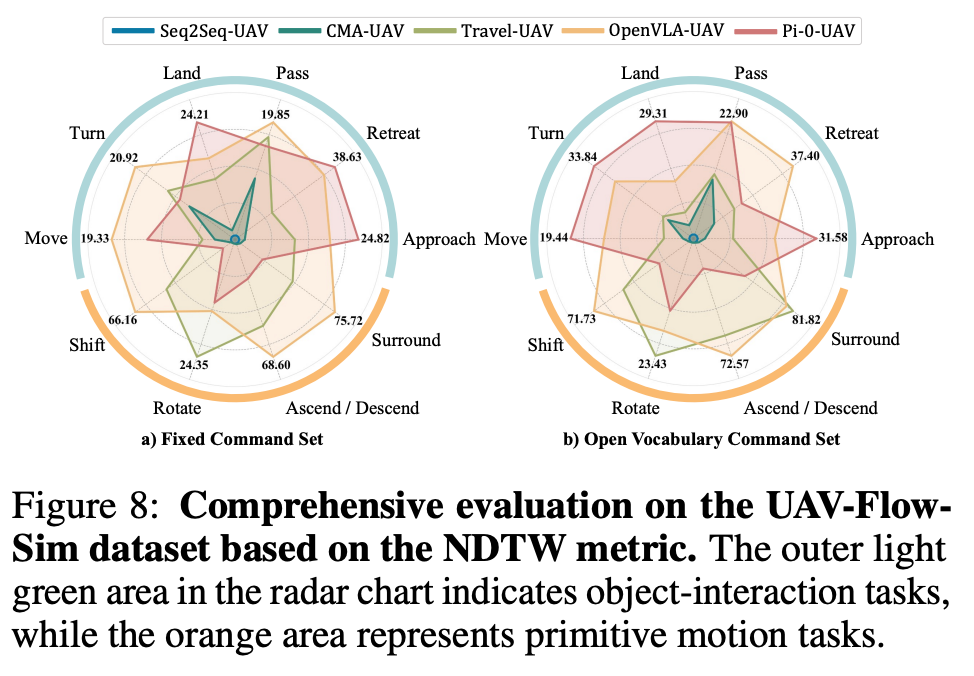
论文速读《UAV-Flow Colosseo: 自然语言控制无人机系统》
论文链接:https://arxiv.org/abs/2505.15725项目主页:https://prince687028.github.io/UAV-Flow/ 0. 简介 近年来,无人机技术蓬勃发展,但如何让无人机像智能助手一样理解并执行人类语言指令,仍是一个前沿挑战。现有研…...

ES6+中Promise 中错误捕捉详解——链式调用catch()或者async/await+try/catch
通过 unhandledrejection 捕捉未处理的 Promise 异常,手动将其抛出,最终让 window.onerror 捕捉,从而统一所有异常的处理逻辑 规范代码:catch(onRejected)、async...awaittry...catch 在 JavaScript 的 Pro…...

CDN安全加速:HTTPS加密最佳配置方案
CDN安全加速的HTTPS加密最佳配置方案需从证书管理、协议优化、安全策略到性能调优进行全链路设计,以下是核心实施步骤与注意事项: 一、证书配置与管理 证书选择与格式 证书类型:优先使用受信任CA机构颁发的DV/OV/EV证…...
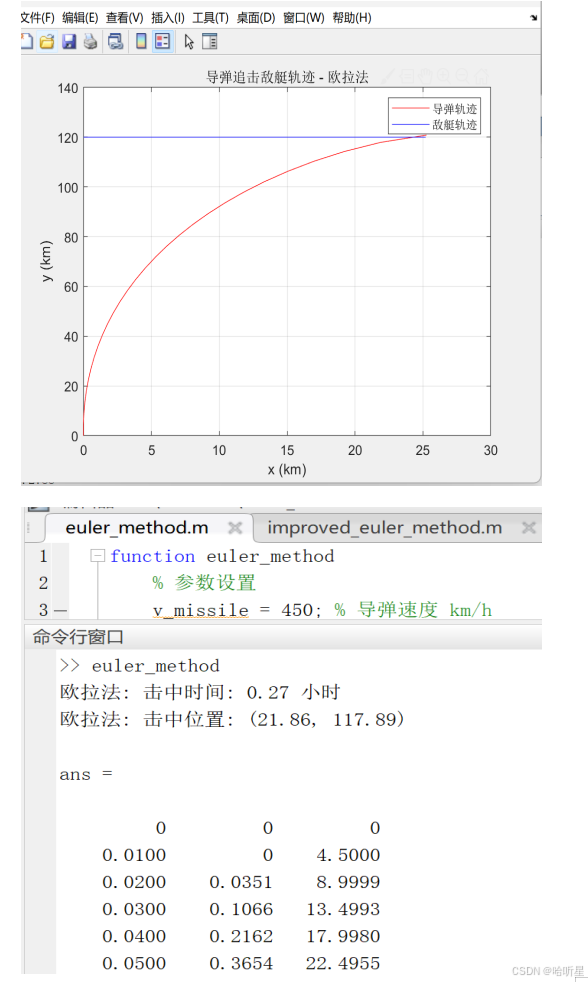
解常微分方程组
Euler法 function euler_method % 参数设置 v_missile 450; % 导弹速度 km/h v_enemy 90; % 敌艇速度 km/h % 初始条件 x0 0; % 导弹初始位置 x y0 0; % 导弹初始位置 y xe0 120; % 敌艇初始位置 y t0 0; % 初始时间 % 时间步长和总时间 dt 0.01; % 时间步长 t_final …...

C++实现汉诺塔游戏自动完成
目录 一、汉诺塔的规则二、数学递归推导式三、步骤实现(一)汉诺塔模型(二)递归实现(三)显示1.命令行显示2.SDL图形显示 四、处理用户输入及SDL环境配置五、总结六、源码下载 一、汉诺塔的规则 游戏由3根柱子和若干大小不一的圆盘组成,初始状态下,所有的…...

在 ABP VNext 中集成 Serilog:打造可观测、结构化日志系统
🚀 在 ABP VNext 中集成 Serilog:打造可观测、结构化日志系统 📚 目录 🚀 在 ABP VNext 中集成 Serilog:打造可观测、结构化日志系统1. 为什么要使用结构化日志? 🤔2. 核心集成步骤 Ὦ…...
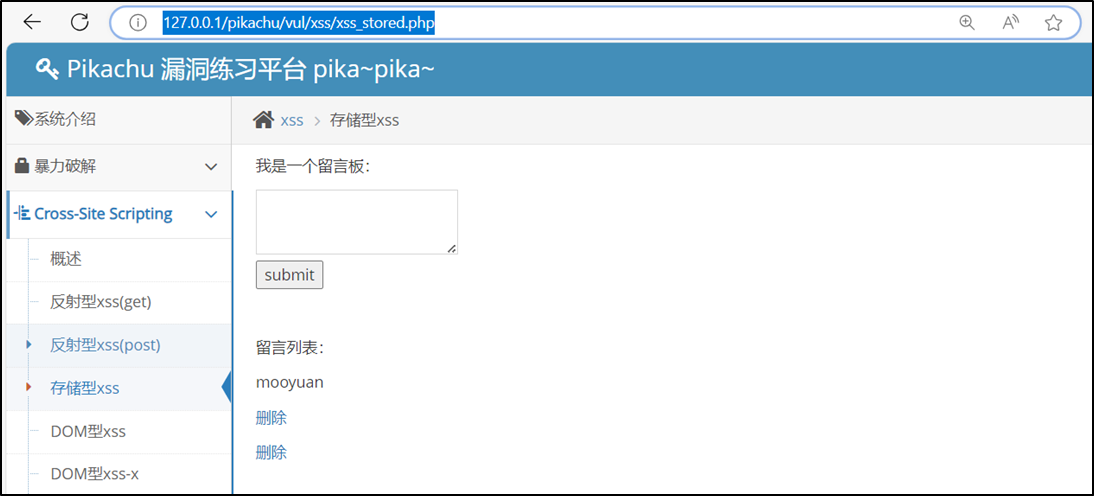
pikachu靶场通关笔记07 XSS关卡03-存储型XSS
目录 一、XSS 二、存储型XSS 三、源码分析 四、渗透实战 1、输入mooyuan试一试 2、注入Payload 3、查看数据库 4、再次进入留言板页面 本系列为通过《pikachu靶场通关笔记》的XSS关卡(共10关)渗透集合,通过对XSS关卡源码的代码审计找到XSS风险的…...

GitLab CI、GitHub Actions和Jenkins进行比较
特性/工具JenkinsGitLab CIGitHub Actions架构设计哲学Master/Agent分布式架构,通过插件扩展功能代码与CI/CD强耦合,内置Git仓库,基于Runner注册机制事件驱动,与GitHub深度集成,基于虚拟机的Job执行单元核心运行机制支…...

strcat及其模拟实现
#define _CRT_SECURE_NO_WARNINGS strcat 追加字符串 str "string"(字符串) cat "concatenate"(连接 / 追加) char* strcat(char* destination, const char* source); strcat的应用 方法一ÿ…...
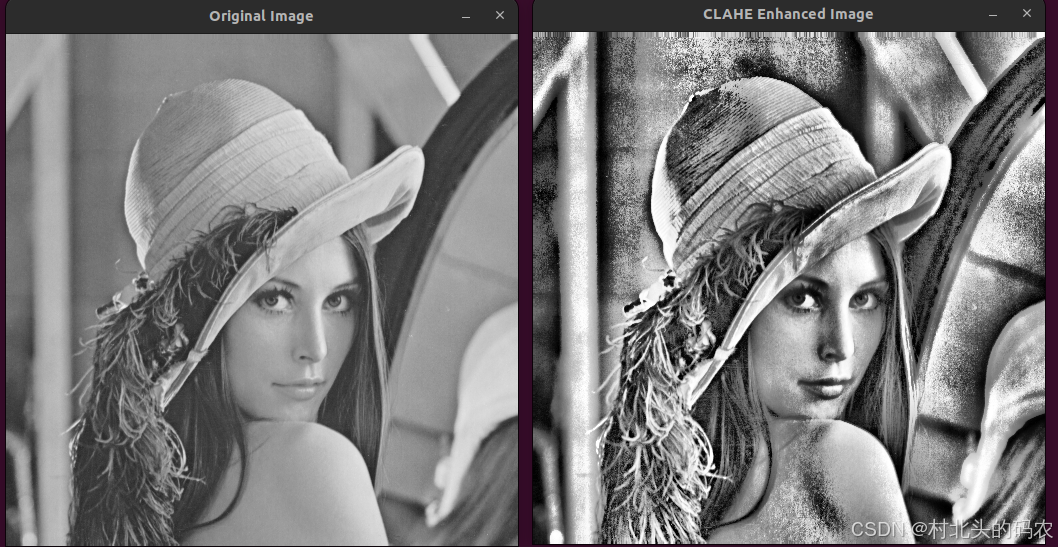
OpenCV CUDA模块直方图计算------用于在 GPU 上执行对比度受限的自适应直方图均衡类cv::cuda::CLAHE
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::CLAHE 是 OpenCV 的 CUDA 模块中提供的一个类,用于在 GPU 上执行对比度受限的自适应直方图均衡(Contrast Limi…...
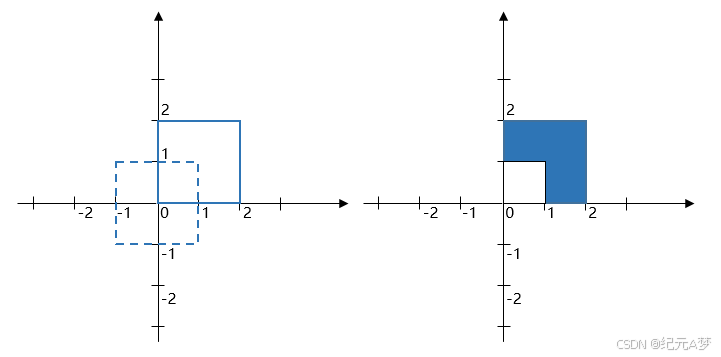
华为OD机试真题——矩形绘制(2025A卷:200分)Java/python/JavaScript/C/C++/GO最佳实现
2025 A卷 200分 题型 本专栏内全部题目均提供Java、python、JavaScript、C、C++、GO六种语言的最佳实现方式; 并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析; 本文收录于专栏:《2025华为OD真题目录+全流程解析+备考攻略+经验分…...

通义开源视觉感知多模态 RAG 推理框架 VRAG-RL:开启多模态推理新时代
通义实验室的自然语言智能团队,凭借深厚的技术积累与创新精神,成功研发并开源了视觉感知多模态 RAG 推理框架 VRAG-RL,为 AI 在复杂视觉信息处理领域带来了重大突破。 传统 RAG 方法的局限 传统的检索增强型生成(RAG࿰…...

爬虫入门:从基础到实战全攻略
🧠 一、爬虫基础概念 1.1 爬虫定义 爬虫(Web Crawler)是模拟浏览器行为,自动向服务器发送请求并获取响应数据的一种程序。主要用于从网页中提取结构化数据,供后续分析、展示或存储使用。 1.2 爬虫特点 数据碎片化&…...

qemu安装risc-V 64
参考这篇文章https://developer.aliyun.com/article/1323996,其中在wsl下面安装可能会报错环境变量中有空格。 # clean_path.sh#!/bin/bash# 备份旧 PATH OLD_PATH"$PATH"# 过滤掉包含空格、制表符、换行的路径 CLEAN_PATH"" IFS: read -ra PA…...
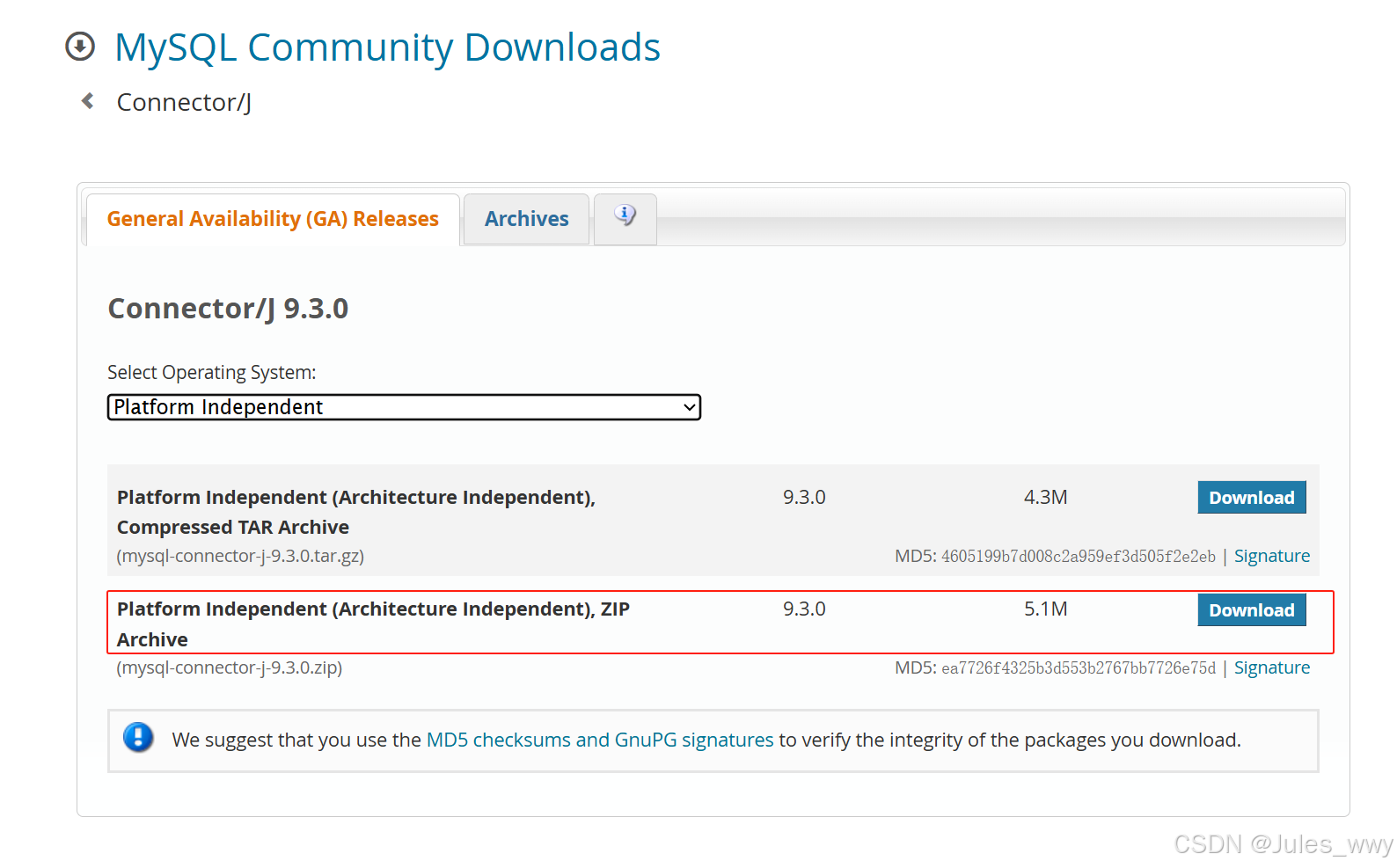
JDBC连不上mysql:Unable to load authentication plugin ‘caching_sha2_password‘.
最近为一个spring-boot项目下了mysql-9.3.0,结果因为mysql版本太新一直报错连不上。 错误如下: 2025-06-01 16:19:43.516 ERROR 22088 --- [http-nio-8080-exec-2] o.a.c.c.C.[.[.[/].[dispatcherServlet] : Servlet.service() for servlet [dispat…...

AsyncIOScheduler与BackgroundScheduler的线程模型对比
1. BackgroundScheduler的线程机制 多线程模型:BackgroundScheduler基于线程池执行任务,默认通过ThreadPoolExecutor创建独立线程处理任务,每个任务运行在单独的线程中,主线程不会被阻塞。适用场景:适合同步…...
)
Python+MongoDb使用手册(精简)
这里是学了下面链接的内容,加上一些自己学习的内容综合的,大家也可以去看看这篇文章,写的特别好 【python】在Python中操作MongoDB的详细用法教程与实战案例分享_python轻松入门,基础语法到高阶实战教学-CSDN专栏 1 库࿱…...

前端面经 协商缓存和强缓存
HHTTPTTP缓存 协商缓存和强缓存 核心区别是否向服务器发起请求验证资源过期 强缓存 浏览器直接读取本地缓存,不发请求 HTTP响应头 Cache-Control:max-age3600资源有效期 Expires优先级低 如果有效浏览器返回200(浏览器换伪造的200) 应用静态资源 协商缓存 OK如果 1强缓…...

MacOS安装Docker Desktop并汉化
1. 安装Docker Desktop 到Docker Desktop For Mac下载对应系统的Docker Desktop 安装包,下载后安装,没有账号需要注册,然后登陆即可。 2. 汉化 前往汉化包下载链接下载对应系统的.asar文件 然后将安装好的文件覆盖原先的文件app.asar文件…...
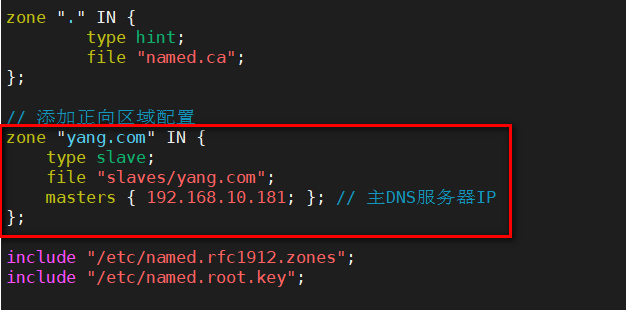
Centos系统搭建主备DNS服务
目录 一、主DNS服务器配置 1.安装 BIND 软件包 2.配置主配置文件 3.创建正向区域文件 4.创建区域数据文件 5.检查配置语法并重启服务 二、从DNS服务配置 1.安装 BIND 软件包 2.配置主配置文件 3.创建缓存目录 4.启动并设置开机自启 一、主DNS服务器配置 1.安装 BIN…...

VUE项目部署IIS服务器手册
IIS部署Vue项目完整手册 📋 目录 基础概念准备工作Vue项目构建web.config详解IIS部署步骤不同场景配置常见问题实用配置模板 基础概念 Vue单页应用(SPA)工作原理 重要理解:Vue项目是单页应用,这意味着:…...
使用 HTML + JavaScript 实现在线考试系统
在现代的在线教育平台中,在线考试系统是不可或缺的一部分。本文将通过一个完整的示例,演示如何使用 HTML、CSS 和 JavaScript 构建一个支持多种题型的在线考试系统。 效果演示 项目概述 本项目主要包含以下核心功能: 支持4种常见题型&…...
谷歌工作自动化——仙盟大衍灵机——仙盟创梦IDE
下载地址 https://chromewebstore.google.com/detail/selenium-ide/mooikfkahbdckldjjndioackbalphokd https://chrome.zzzmh.cn/info/mooikfkahbdckldjjndioackbalphokd...
Day13)
嵌入式(C语言篇)Day13
嵌入式Day13 一段话总结 文档主要介绍带有头指针和尾指针的单链表的实现及操作,涵盖创建、销毁、头插、尾插、按索引/数据增删查、遍历等核心操作,强调头插/尾插时间复杂度为O(1),按索引/数据操作需遍历链表、时间复杂度为O(n),并…...

Oracle 的V$LOCK 视图详解
Oracle 的V$LOCK 视图详解 V$LOCK 是 Oracle 数据库中最重要的动态性能视图之一,用于显示当前数据库中锁的持有和等待情况。 一、V$LOCK 视图结构 列名数据类型描述SIDNUMBER持有或等待锁的会话标识符TYPEVARCHAR2(2)锁类型标识符ID1NUMBER锁标识符1(…...