嵌入式(C语言篇)Day13
嵌入式Day13
一段话总结
文档主要介绍带有头指针和尾指针的单链表的实现及操作,涵盖创建、销毁、头插、尾插、按索引/数据增删查、遍历等核心操作,强调头插/尾插时间复杂度为O(1),按索引/数据操作需遍历链表、时间复杂度为O(n),并对比提及双向链表因存储前后指针、操作更高效,是典型的空间换时间策略。
思维导图
## **单链表结构**
- 头指针(head)
- 尾指针(tail)
- 节点(Node):data+next指针
- 链表结构体(LinkedList):包含head、tail、size
## **核心操作**
- 创建:calloc分配LinkedList结构体
- 销毁:先释放所有节点,再释放结构体
- 遍历:按"x->y->z->NULL"格式打印
- 新增- 头插(add_before_head):更新head,首个节点时更新tail- 尾插(add_behind_tail):有节点时尾节点next指向新节点,否则更新head- 按索引(idx):idx=0头插,idx=size尾插,中间需找idx-1前驱节点
- 查询- 按索引(search_by_idx):遍历找idx节点- 按数据:遍历找匹配data节点
- 删除- 按索引(delete_by_idx):idx=0删头节点,其他找前驱节点,删尾节点需更新tail- 按数据(delete_by_data):遍历找节点及前驱,删头/尾节点特殊处理
## **时间复杂度**
- O(1):头插、尾插、删头节点
- O(n):按索引/数据增删查、删非头节点
## **双向链表对比**
- 节点增加前驱指针
- 操作更灵活,附近操作O(1)
- 空间换时间,如C++ list/Java LinkedList底层实现
详细总结
一、单链表结构与核心操作概述
- 结构组成:由
LinkedList结构体管理head(头指针)、tail(尾指针)、size(节点数),每个Node包含data(数据)和next(后继指针)。 - 核心操作:涵盖创建、销毁、遍历、增删查等,操作时需注意头/尾节点特殊情况(如首个节点需同时更新
head和tail)。
二、具体操作实现要点
- 创建与销毁
- 创建:使用
calloc分配LinkedList结构体,初始head=tail=NULL,size=0。 - 销毁:先遍历释放所有
Node节点,再释放LinkedList结构体。
- 创建:使用
- 新增操作
- 头插法:新节点直接指向原
head,更新head;若为首个节点,同时更新tail。 - 尾插法:若链表非空,原
tail->next指向新节点,更新tail;若为空,直接更新head和tail。 - 按索引插入:索引范围
[0, size],idx=0头插,idx=size尾插,中间需遍历找到idx-1前驱节点,时间复杂度O(n)。
- 头插法:新节点直接指向原
- 查询操作
- 按索引查询:索引范围
[0, size-1],遍历找到对应节点,时间复杂度O(n)。 - 按数据查询:遍历全链表匹配数据,时间复杂度O(n)。
- 按索引查询:索引范围
- 删除操作
- 按索引删除:
idx=0直接删头节点,更新head;若为尾节点(idx=size-1),需更新tail为前驱节点;其他情况遍历找前驱节点,时间复杂度O(n)(除删头节点为O(1))。 - 按数据删除:遍历找到节点及其前驱,删头节点时更新
head,删尾节点时更新tail,时间复杂度O(n)(除删头节点为O(1))。
- 按索引删除:
三、时间复杂度对比表
| 操作类型 | 具体操作 | 时间复杂度 | 是否需遍历 |
|---|---|---|---|
| 新增 | 头插/尾插 | O(1) | 否 |
| 按索引插入 | O(n) | 是(中间) | |
| 查询 | 按索引/数据查询 | O(n) | 是 |
| 删除 | 删头节点 | O(1) | 否 |
| 删非头节点(含尾) | O(n) | 是 |
四、双向链表对比
- 优势:节点增加前驱指针(
prev),可直接访问前后节点,附近操作(如删除当前节点)时间复杂度为O(1),性能更优。 - 应用:C++
list、JavaLinkedList底层均为双向链表,体现空间换时间策略。
关键问题
-
为什么头插法和尾插法的时间复杂度是O(1)?
答:头插法直接通过头指针操作首个节点,尾插法通过尾指针直接定位最后一个节点,无需遍历链表,因此时间复杂度为O(1)。 -
删除单链表尾节点的时间复杂度为什么是O(n)?
答:删除尾节点需先遍历找到其前驱节点(需O(n)时间),才能更新前驱节点的next指针为NULL,因此整体时间复杂度为O(n)。 -
双向链表相比单链表的核心优化点是什么?
答:双向链表每个节点增加前驱指针(prev),可直接访问前后节点,使在确定节点附近的操作(如删除当前节点)时间复杂度从O(n)降至O(1),以空间换时间提升性能。
文档主要介绍了单链表常见的五道经典面试题及解法,包括求中间结点、判断是否有环、反转链表、合并两条有序链表(两种方法),具体如下:
六、求链表中间结点
问题:给定单链表,找到中间结点(奇数长度取中间结点,偶数长度取中间偏右结点)。
解法:
- 遍历统计法
- 先遍历链表统计长度
list_len,再计算中间索引mid_idx = list_len / 2,再次遍历找到对应结点。 - 时间复杂度:O(n)(两次遍历)。
- 先遍历链表统计长度
- 快慢指针法(双指针法)
- 思路:定义两个指针
slow(每次走1步)和fast(每次走2步)。当fast到达链表末尾(fast == NULL或fast->next == NULL)时,slow指向中间结点。 - 代码逻辑:
int find_mid_ele2(Node *head) {Node *fast = head, *slow = head;while (fast != NULL && fast->next != NULL) { // 循环条件确保快慢指针有效移动slow = slow->next;fast = fast->next->next;}return slow->data; // 直接返回中间结点数据 } - 时间复杂度:O(n)(单次遍历),效率更高。
- 思路:定义两个指针
七、判断单链表是否有环
问题:判断单链表是否存在环(尾结点 next 指向链表中任意结点)。
解法:快慢指针法
- 思路:若链表有环,快慢指针最终会在环内相遇;若无环,
fast会先到达NULL,循环结束。 - 代码逻辑:
bool has_circle(Node *head) {Node *fast = head, *slow = head;while (fast != NULL && fast->next != NULL) {slow = slow->next;fast = fast->next->next;if (slow == fast) return true; // 相遇即有环}return false; // 循环正常结束,无环 } - 关键点:
- 环的形成:尾结点
next指向头结点、中间结点或自身。 - 快慢指针速度差确保在环内必然相遇(数学证明:快指针每次比慢指针多走1步,环长有限,最终会追上)。
- 环的形成:尾结点
八、单链表反转(循环迭代法)
问题:反转单链表,返回新链表的头指针(原尾结点)。
解法:三指针法(prev、curr、succ)
- 思路:
- 初始化
prev = NULL(前驱指针,指向反转后的尾部),curr = head(当前结点),succ = head->next(后继结点,防止链表断开)。 - 遍历链表,每次将
curr->next指向prev,然后prev、curr、succ依次后移。 - 遍历结束后,
prev指向新链表的头结点(原尾结点)。
- 初始化
- 代码实现:
Node *reverse(Node *head) {Node *prev = NULL, *curr = head, *succ = head ? head->next : NULL; // 处理头结点为空的情况while (curr != NULL) {curr->next = prev; // 反转当前结点指向prev = curr;curr = succ;succ = (succ != NULL) ? succ->next : NULL; // 避免空指针访问}return prev; // 返回新头指针 } - 变种:通过二级指针直接修改原头指针(
reverse2函数),适用于需要修改原始链表头指针的场景。
九、合并两条有序单链表(循环迭代法)
问题:合并两条升序单链表,返回合并后的升序链表头指针。
解法1:无虚拟头结点(需处理头部特殊情况)
- 步骤:
- 校验空链表,直接返回非空链表。
- 找到两条链表的最小结点,作为新链表的头指针
head和尾指针tail,并移动对应链表指针(list1或list2)。 - 循环比较
list1和list2的当前结点,将较小结点接入tail->next,更新tail和对应链表指针。 - 循环结束后,将剩余非空链表接入
tail。
- 代码逻辑:
Node *merge_lists(Node *list1, Node *list2) {if (!list1 || !list2) return list1 ? list1 : list2; // 处理空链表Node *head, *tail;if (list1->data < list2->data) {head = tail = list1;list1 = list1->next;} else {head = tail = list2;list2 = list2->next;}while (list1 && list2) { // 合并剩余结点if (list1->data < list2->data) {tail->next = list1;tail = list1;list1 = list1->next;} else {tail->next = list2;tail = list2;list2 = list2->next;}}tail->next = (list1 != NULL) ? list1 : list2; // 接入剩余链表return head; }
解法2:使用虚拟头结点(简化头部处理)
- 优化点:在链表头部添加一个虚拟结点
dummy_node,避免单独处理头指针初始化,统一逻辑。 - 代码逻辑:
Node *merge_lists2(Node *list1, Node *list2) {if (!list1 || !list2) return list1 ? list1 : list2;Node dummy_node = {0, NULL}; // 栈上创建虚拟头结点Node *tail = &dummy_node; // tail指向虚拟结点,作为初始尾结点while (list1 && list2) { // 直接合并所有结点,无需头部特殊处理if (list1->data < list2->data) {tail->next = list1;tail = list1;list1 = list1->next;} else {tail->next = list2;tail = list2;list2 = list2->next;}}tail->next = (list1 != NULL) ? list1 : list2;return dummy_node.next; // 返回虚拟结点的下一个结点(真正的头结点) } - 优势:虚拟头结点使头部和后续结点的处理逻辑一致,代码更简洁,减少边界条件判断。
十、核心算法总结
| 面试题 | 关键思路 | 时间复杂度 | 空间复杂度 |
|---|---|---|---|
| 求中间结点 | 快慢指针法(单次遍历) | O(n) | O(1) |
| 判断是否有环 | 快慢指针法(相遇即有环) | O(n) | O(1) |
| 反转链表 | 三指针迭代反转(prev、curr、succ) | O(n) | O(1) |
| 合并有序链表(无虚拟头) | 比较结点+尾插法(处理头部特殊情况) | O(n+m) | O(1) |
| 合并有序链表(有虚拟头) | 虚拟头结点统一逻辑 | O(n+m) | O(1) |
注意事项:
- 指针操作需避免空指针访问(如判断
succ != NULL再取值)。 - 处理边界条件(如空链表、单结点链表、环的特殊情况)。
- 虚拟头结点常用于简化链表操作的头部逻辑,提高代码鲁棒性。
文档主要介绍单链表反转与合并的递归实现方法,包括递归思路、代码实现及复杂度分析,以下是详细总结:
十一、单链表反转(递归实现)
核心思路:通过递归分解问题,将长链表反转拆解为短链表反转,逐步构建反转后的链表。
- 递归分解逻辑
- 问题分解:反转
n个结点的链表 = 反转第 1 个结点 + 反转后续n-1个结点。 - 递归出口:当链表为空或只剩一个结点时,直接返回头结点(无需反转)。
- 关键操作:
- 先递归反转后续结点(从第 2 个结点开始),得到新链表头指针
new_head。 - 修改第 2 个结点的指针,使其指向第 1 个结点(
head->next->next = head)。 - 将第 1 个结点的指针置为
NULL,使其成为新链表的尾结点。
- 先递归反转后续结点(从第 2 个结点开始),得到新链表头指针
- 问题分解:反转
- 代码实现
Node *reverse_recursion(Node *head) {// 递归出口:空链表或单结点链表if (head == NULL || head->next == NULL) {return head;}// 递归反转后续结点,得到新链表头指针Node *new_head = reverse_recursion(head->next);// 让第 2 个结点指向第 1 个结点head->next->next = head;// 第 1 个结点置为尾结点(指针域为 NULL)head->next = NULL;return new_head; // 返回新链表头指针 } - 复杂度分析
- 时间复杂度:O(n),每个结点递归处理一次。
- 空间复杂度:O(n),递归栈深度最多为
n(链表长度),存在栈溢出风险。
十二、合并两条有序单链表(递归实现)
核心思路:通过递归逐层比较两条链表的当前结点,将较小结点作为当前层结果,并递归合并剩余结点。
- 递归分解逻辑
- 问题分解:合并链表
list1和list2= 选择当前较小结点 + 递归合并剩余结点。 - 递归出口:当任一链表为空时,直接返回另一链表(已处理完所有结点)。
- 关键操作:
- 比较
list1和list2的当前结点,选择较小者作为当前层合并结果。 - 将较小结点的
next指针指向递归合并剩余结点的结果(形成链式合并)。
- 比较
- 问题分解:合并链表
- 代码实现
Node *merge_lists3(Node *list1, Node *list2) {// 递归出口:处理空链表if (list1 == NULL) return list2;if (list2 == NULL) return list1;// 选择较小结点,并递归合并剩余结点if (list1->data < list2->data) {list1->next = merge_lists3(list1->next, list2); // 递归合并 list1 剩余结点和 list2return list1; // 返回当前较小结点} else {list2->next = merge_lists3(list1, list2->next); // 递归合并 list1 和 list2 剩余结点return list2; // 返回当前较小结点} } - 复杂度分析
- 时间复杂度:O(m+n),每条链表的每个结点递归处理一次(m、n 为链表长度)。
- 空间复杂度:O(m+n),递归栈深度最多为
m+n,大链表场景下可能导致栈溢出。
十三、递归与迭代实现对比
| 操作 | 实现方式 | 时间复杂度 | 空间复杂度 | 优缺点对比 |
|---|---|---|---|---|
| 单链表反转 | 迭代 | O(n) | O(1)(原地算法) | 无额外空间,效率高,适合大链表;逻辑较直观,需维护三指针(prev、curr、succ)。 |
| 递归 | O(n) | O(n)(递归栈) | 代码简洁,利用递归分解问题;但存在栈溢出风险,大链表场景下不推荐。 | |
| 合并有序链表 | 迭代 | O(m+n) | O(1)(原地算法) | 需处理头部特殊情况(或用虚拟头结点简化),逻辑稍复杂,无栈风险。 |
| 递归 | O(m+n) | O(m+n)(递归栈) | 代码更简洁,递归分解自然;但栈空间占用随链表长度增长,大链表易栈溢出。 |
十四、注意事项与扩展
- 递归的局限性
- 递归深度受系统栈空间限制,处理长链表(如上万结点)时可能引发栈溢出错误。
- 迭代实现更适合生产环境,尤其对性能和稳定性要求高的场景。
- 虚拟头结点的应用
- 迭代合并链表时,虚拟头结点可统一头部和后续结点的处理逻辑,减少边界条件判断(如
merge_lists2函数)。
- 迭代合并链表时,虚拟头结点可统一头部和后续结点的处理逻辑,减少边界条件判断(如
- 其他反转思路
- 复制头插法:遍历原链表,复制每个结点并采用头插法构建新链表。时间复杂度 O(n),但需额外空间且涉及内存分配,效率较低。
十五、总结
- 递归的核心思想:将大问题分解为同类型小问题,通过递归出口终止分解,逐层构建结果。
- 适用场景:递归适合逻辑简洁、链表长度较小的场景;迭代更适合长链表或对性能敏感的场景。
- 指针操作要点:递归实现中需注意指针指向的正确性(如反转时避免链表断开),确保每一步递归调用后链表结构有效。
文档主要介绍七种基于比较的排序算法,包括简单排序(冒泡、选择、插入)、希尔排序及高级排序(归并、快速、堆排序),以下是从第十六条开始的详细总结:
十六、插入排序(重点)
- 核心思想:将未排序元素逐个插入到已排序序列的合适位置,类似扑克牌整理。
- 操作流程:
- 从第二个元素开始(视为未排序元素),与前序已排序元素比较。
- 若未排序元素小于前序元素,则前序元素后移,直至找到合适位置插入。
- 代码逻辑(伪代码):
for (i = 1; i < n; i++) { temp = arr[i]; j = i - 1; while (j >= 0 && arr[j] > temp) { arr[j+1] = arr[j]; j--; } arr[j+1] = temp; } - 复杂度:
- 时间复杂度:O(n²)(最坏/平均),但常数项和系数优于冒泡、选择排序,实际性能更好。
- 空间复杂度:O(1)(原地排序)。
- 稳定性:稳定(相邻交换,不改变相同元素相对顺序)。
- 适用场景:小规模数据排序的首选算法。
十七、希尔排序(了解)
- 核心思想:插入排序的改进版,通过增量递减将数组分组,对每组进行插入排序,逐步缩小增量至1。
- 操作流程:
- 选择初始增量(如
gap = n/2),将数组分为gap组(每组元素下标差为gap)。 - 对每组进行插入排序,缩小增量(如
gap = gap/2),重复直至gap=1(此时退化为插入排序)。
- 选择初始增量(如
- 复杂度:
- 时间复杂度:依赖增量选择,介于 O(nlogn) 到 O(n²) 之间(通常优于插入排序)。
- 空间复杂度:O(1)(原地排序)。
- 稳定性:不稳定(跨组交换可能改变相同元素相对顺序)。
- 评价:适用场景有限,大数据集下不如高级排序,小数据集下牺牲稳定性但性能提升不明显。
十八、归并排序(高级排序)
- 核心思想:分治策略,递归将数组分成两半,分别排序后合并有序子数组。
- 关键步骤:
- 分解:将数组从中间分成左右两部分,直至子数组长度为1(有序)。
- 合并:将两个有序子数组合并为一个有序数组(需额外空间存储临时合并结果)。
- 代码逻辑(伪代码):
void merge_sort(int arr[], int left, int right) { if (left < right) { mid = (left + right)/2; merge_sort(arr, left, mid); merge_sort(arr, mid+1, right); merge(arr, left, mid, right); // 合并两个有序子数组 } } - 复杂度:
- 时间复杂度:O(nlogn)(所有情况均稳定)。
- 空间复杂度:O(n)(需额外数组存储合并结果)。
- 稳定性:稳定(合并时保留相同元素顺序)。
- 适用场景:需要稳定排序的大数据集,如外部排序(磁盘数据排序)。
十九、快速排序(高级排序,重点)
- 核心思想:分治策略,选择基准值(pivot),将数组分为小于/大于基准值的左右两部分,递归排序子数组。
- 关键步骤:
- 分区:选择基准值,通过交换将数组分为左(< pivot)、中(= pivot)、右(> pivot)三部分。
- 递归:对左右子数组重复分区操作,直至子数组长度为1。
- 优化点:
- 基准值选择:随机选、三数取中(避免最坏情况O(n²))。
- 双向分区:从两端向中间扫描,减少交换次数。
- 复杂度:
- 时间复杂度:平均 O(nlogn),最坏 O(n²)(可通过基准值优化规避)。
- 空间复杂度:O(logn)(递归栈深度,平均情况),最坏 O(n)(退化为链表递归)。
- 稳定性:不稳定(跨区交换可能改变相同元素顺序)。
- 适用场景:大数据集排序的首选(性能最优),但需注意栈溢出风险(大递归深度)。
二十、堆排序(高级排序)
- 核心思想:基于堆(大顶堆/小顶堆)结构,每次将堆顶元素(最大值/最小值)与末尾元素交换,逐步构建有序数组。
- 关键步骤:
- 建堆:将数组转换为大顶堆(父节点≥子节点)。
- 排序:交换堆顶(最大值)与末尾元素,对前
n-1个元素重新建堆,重复直至排序完成。
- 复杂度:
- 时间复杂度:O(nlogn)(建堆 O(n),每次调整堆 O(logn))。
- 空间复杂度:O(1)(原地排序,仅利用数组本身空间)。
- 稳定性:不稳定(堆顶交换可能破坏相同元素顺序)。
- 适用场景:无需递归、空间受限的大数据集排序,如操作系统进程调度。
二十一、七种排序算法对比表
| 算法 | 时间复杂度(最坏) | 时间复杂度(平均) | 空间复杂度 | 稳定性 | 适用场景 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n²) | O(n²) | O(1) | 稳定 | 玩具算法,仅学习用途 |
| 选择排序 | O(n²) | O(n²) | O(1) | 不稳定 | 玩具算法,仅学习用途 |
| 插入排序 | O(n²) | O(n²) | O(1) | 稳定 | 小规模数据首选 |
| 希尔排序 | O(n²) | O(nlogn)~O(n²) | O(1) | 不稳定 | 了解即可,实际应用少 |
| 归并排序 | O(nlogn) | O(nlogn) | O(n) | 稳定 | 大数据集稳定排序 |
| 快速排序 | O(n²) | O(nlogn) | O(logn) | 不稳定 | 大数据集首选(性能最优) |
| 堆排序 | O(nlogn) | O(nlogn) | O(1) | 不稳定 | 无需递归、空间受限场景 |
二十二、总结与建议
- 简单排序选择:
- 小规模数据:优先使用插入排序(性能最佳,稳定)。
- 学习用途:了解冒泡、选择排序逻辑,但无需用于实际项目。
- 高级排序选择:
- 需要稳定性:选归并排序(如数据库排序、物流订单排序)。
- 性能优先:选快速排序(默认场景,需注意基准值优化)。
- 空间受限/禁止递归:选堆排序(如嵌入式系统、内核排序)。
- 算法实现建议:
- 必学:插入排序(简单高效)、快速排序(工业级应用)。
- 扩展学习:归并排序(分治思想)、堆排序(数据结构应用)。
- 复杂度注意点:
- 时间复杂度是趋势描述,O(n²) 算法在小规模下可能比 O(nlogn) 更快(如插入排序 vs 快排)。
- 空间复杂度需关注额外堆空间(如归并排序),栈空间(如递归快排)可能导致栈溢出。
相关文章:
Day13)
嵌入式(C语言篇)Day13
嵌入式Day13 一段话总结 文档主要介绍带有头指针和尾指针的单链表的实现及操作,涵盖创建、销毁、头插、尾插、按索引/数据增删查、遍历等核心操作,强调头插/尾插时间复杂度为O(1),按索引/数据操作需遍历链表、时间复杂度为O(n),并…...

Oracle 的V$LOCK 视图详解
Oracle 的V$LOCK 视图详解 V$LOCK 是 Oracle 数据库中最重要的动态性能视图之一,用于显示当前数据库中锁的持有和等待情况。 一、V$LOCK 视图结构 列名数据类型描述SIDNUMBER持有或等待锁的会话标识符TYPEVARCHAR2(2)锁类型标识符ID1NUMBER锁标识符1(…...
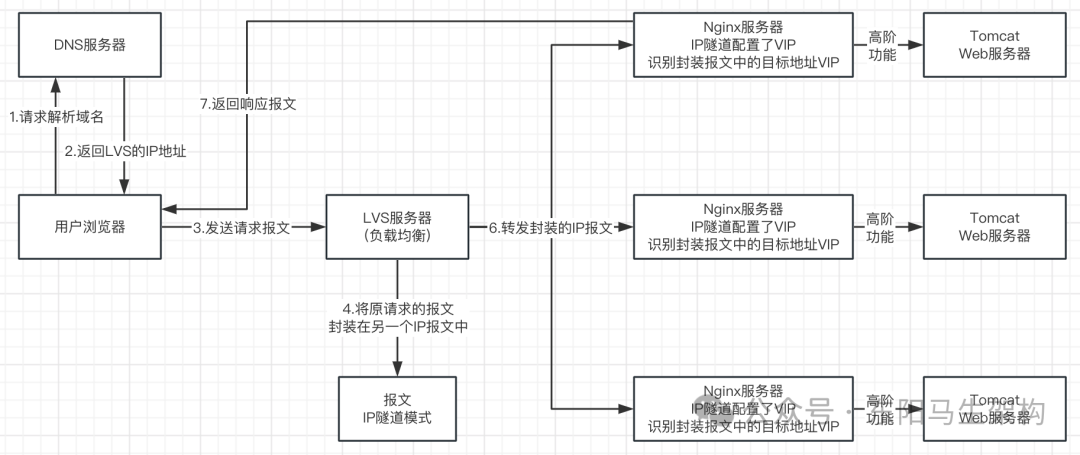
秒杀系统—1.架构设计和方案简介
大纲 1.秒杀系统的方案设计要点 2.秒杀系统的数据 页面 接口的处理方案 3.秒杀系统的负载均衡方案底层相关 4.秒杀系统的限流机制和超卖问题处理 5.秒杀系统的异步下单和高可用方案 1.秒杀系统的方案设计要点 (1)秒杀促销活动的数据处理 (2)秒杀促销活动的页面处理 (…...

基于FashionMnist数据集的自监督学习(生成式自监督学习AE算法)
目录 一,生成式自监督学习 1.1 简介 1.2 核心思想 1.3 常见算法 1.3.1 自动编码器(Autoencoder) 1.3.2 生成对抗网络(GANs) 1.3.3 变分自编码器(VAE) 1.3.4 Transformer-based 模型&…...
从监控到告警:Prometheus+Grafana+Alertmanager+告警通知服务全链路落地实践
文章目录 一、引言1.1 监控告警的必要性1.2 监控告警的基本原理1.2.1 指标采集与存储1.2.2 告警规则与触发机制1.2.3 多渠道通知与闭环 二、技术选型与架构设计2.1 为什么选择 Prometheus 及其生态2.1.1 Prometheus 优势分析2.1.2 Grafana 可视化能力2.1.3 Alertmanager 灵活告…...

AUTOSAR图解==>AUTOSAR_EXP_AIADASAndVMC
AUTOSAR高级驾驶辅助系统与车辆运动控制接口详解 基于AUTOSAR R22-11标准的ADAS与VMC接口规范解析 目录 1. 引言2. 术语和概念说明 2.1 坐标系统2.2 定义 2.2.1 乘用车重心2.2.2 极坐标系统2.2.3 车辆加速度/推进力方向2.2.4 倾斜方向2.2.5 方向盘角度2.2.6 道路变量2.2.7 曲率…...
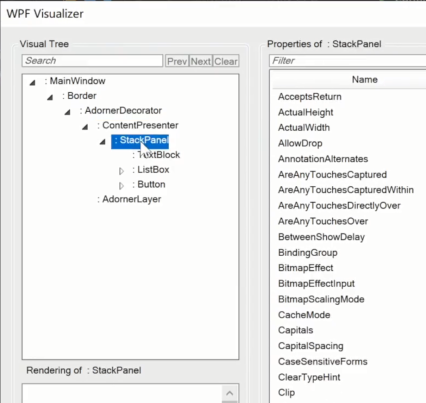
WPF【09】WPF基础入门 (三层架构与MVC架构)
9-2 【操作】WPF 基础入门 新建一项目 Create a new project - WPF Application (A project for creating a .NET Core WPF Application) - Next - .NET 5.0 (Current) - Create 项目创建完成,VS自动打开 GUI用户界面,格式是 .xaml文件,跟xm…...
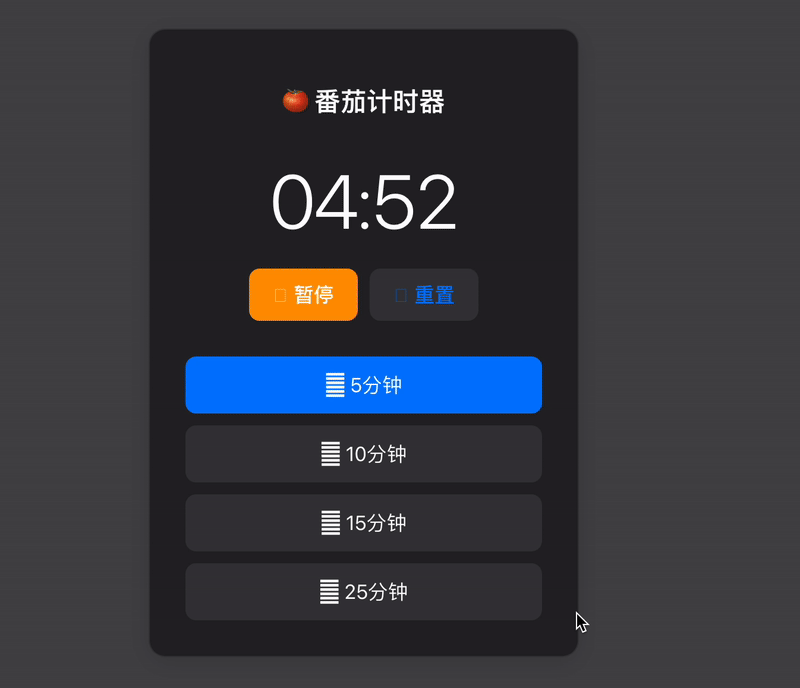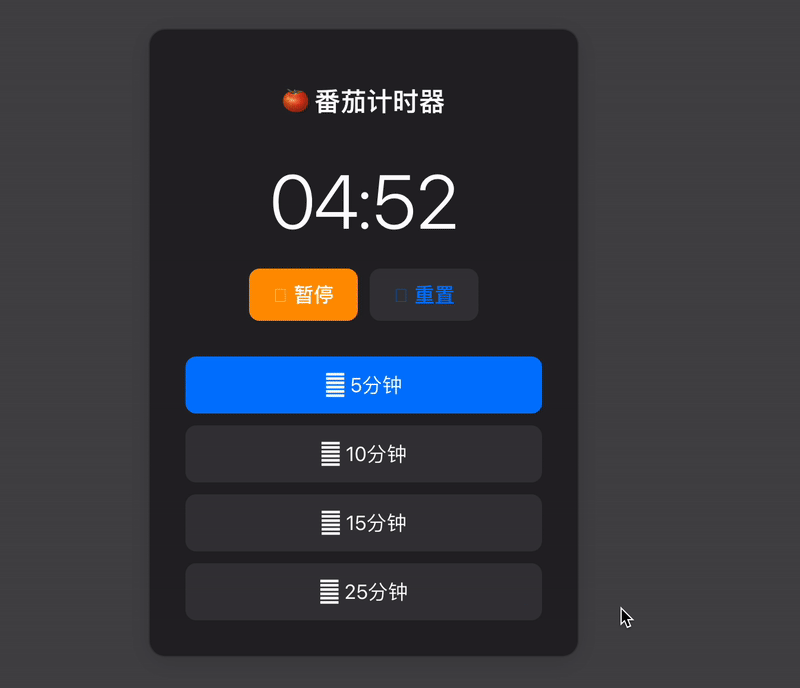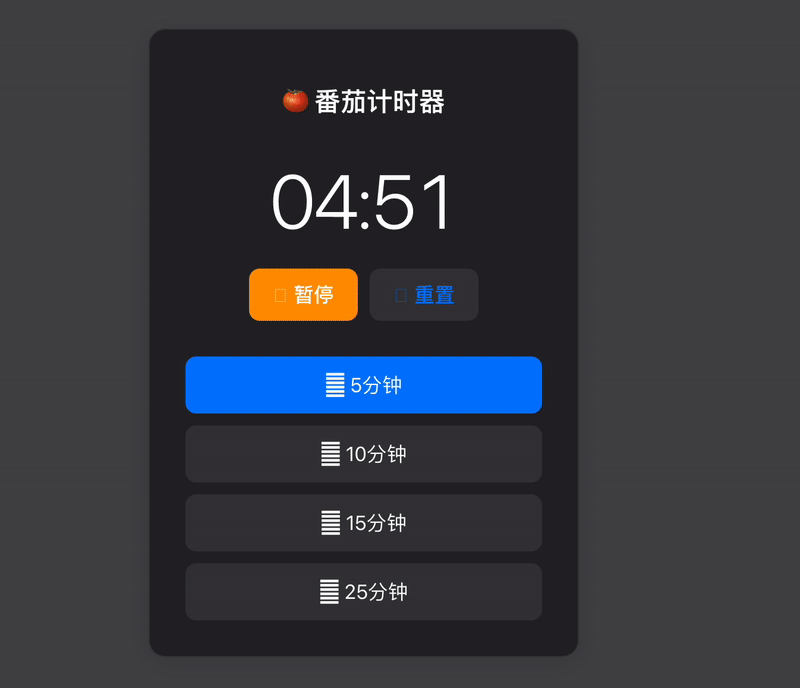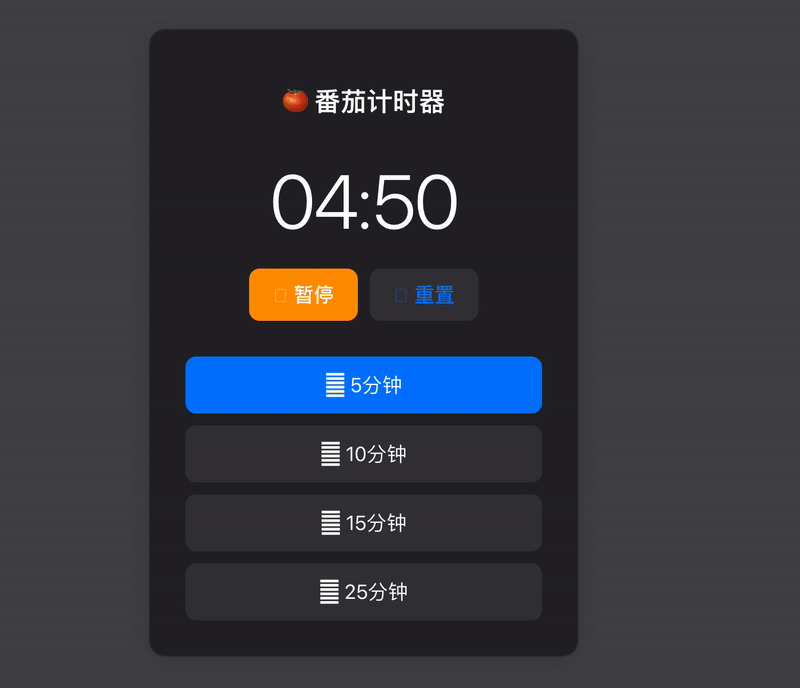
macOS 风格番茄计时器:设计与实现详解
macOS 风格番茄计时器:设计与实现详解 概述 本文介绍一款采用 macOS 设计语言的网页版番茄计时器实现。该计时器完全遵循苹果的人机界面指南(HIG),提供原汁原味的 macOS 使用体验,同时具备响应式设计和深色模式支持。 核心特性 原生 macOS…...

中文NLP with fastai - Fastai Part4
使用fastai进行自然语言处理 在之前的教程中,我们已经了解了如何利用预训练模型并对其进行微调,以执行图像分类任务(MNIST)。应用于图像的迁移学习原理同样也可以应用于NLP任务。在本教程中,我们将使用名为AWD_LSTM的预训练模型来对中文电影评论进行分类。AWD_LSTM是LSTM…...
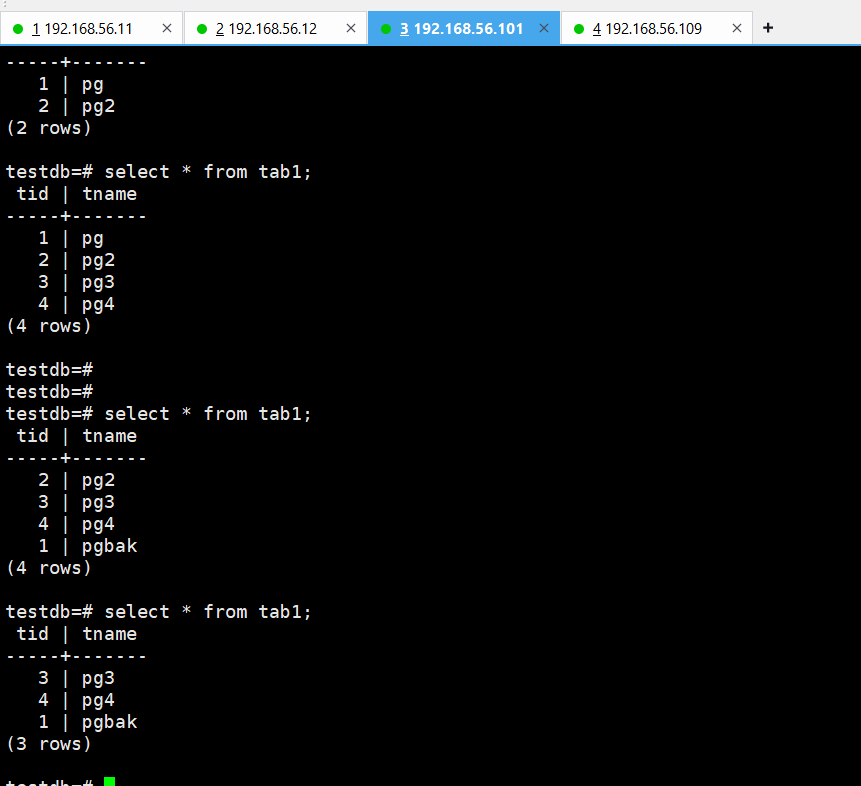
oracle goldengate实现远程抽取postgresql 到 postgresql的实时同步【绝对无坑版,亲测流程验证】
oracle goldengate实现postgresql 到 postgresql的实时同步 源端:postgresql1 -> postgresql2 流复制主备同步 目标端:postgresql 数据库版本:postgresql 12.14 ogg版本:21.3 架构图: 数据库安装以及流复制主备…...
)
【MYSQL】索引篇(一)
1.为什么要有索引 索引的本质是一种数据结构,她的作用其实就是更好更快的帮我们找到数据库中存储的数据,就好比一本书,你想要找到指定的内容,但是如果在没有目录的情况下,你只能一页页的进行寻找,这样效率…...
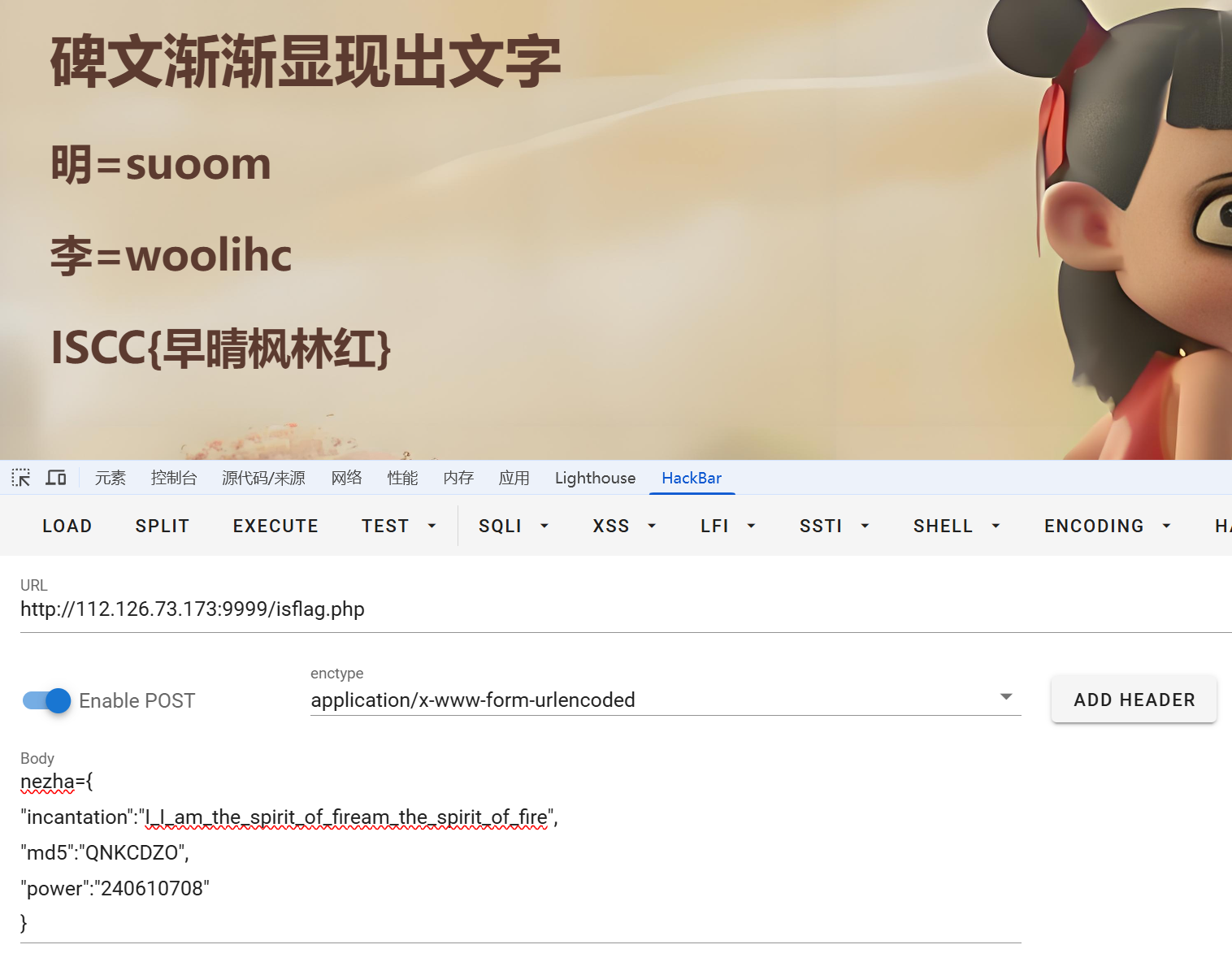
ISCC-2025-web-wp
web 校赛 校赛靠着ENOCH师傅发力,也是一路躺进了区域赛,E师傅不好意思发这抽象比赛的wp(这比赛确实啥必到让人大开眼界,反正明年我是肯定不会打了),我就顺手要过来连着区域赛的一起发了 web 150分 按照提示进入/includes/fla…...

鸿蒙分辨率
鸿蒙手机App界面开发,UI元素应该以什么哪种屏幕尺寸为基准?换言之,做鸿蒙手机APP UI设计时,应该以哪种屏 PX转VP 华为开发者问答 | 华为开发者联盟 各单位换算API 华为开发者问答 | 华为开发者联盟 开源鸿蒙更改DPI 如何在Op…...

@Docker Compose 部署 Pushgateway
文章目录 Docker Compose 部署 Pushgateway1. 目的2. 适用范围3. 先决条件4. 部署步骤4.1 创建项目目录4.2 创建 docker-compose.yml 文件4.3 启动 Pushgateway 服务4.4 验证服务运行状态4.5 测试 Pushgateway 访问 5. 配置 Prometheus 采集 Pushgateway 数据6. 日常维护6.1 查…...

我们来学mysql -- 从库重启,是否同步主库数据
从库重启后,通常不需要重新复制主库的全部数据,然后再开启复制。MySQL 的主从复制机制设计了优雅的恢复流程,可以在从库重启后继续从上次中断的位置继续复制,前提是相关的日志和状态信息完整。 以下是详细解释: 从库…...

King3399(ubuntu文件系统)iic(i2c)功能测试
0 引言 前面两篇博文简要介绍了板子上uart部分的内容,但在驱动开发时,我们遇到的外设更多的是以i2c或spi进行通信,本文将对king3399的i2c进行测试并对硬件电路、设备树与驱动程序进行分析 如果使用的i2c设备不是mma8452,建议先看…...

德思特新闻 | 德思特与es:saar正式建立合作伙伴关系
德思特新闻 2025年5月9日,德思特科技有限公司(以下简称“德思特”)与德国嵌入式系统专家es:saar GmbH正式达成合作伙伴关系。此次合作旨在将 es:saar 的先进嵌入式开发与测试工具引入中国及亚太市场,助力本地客户提升产品开发效率…...
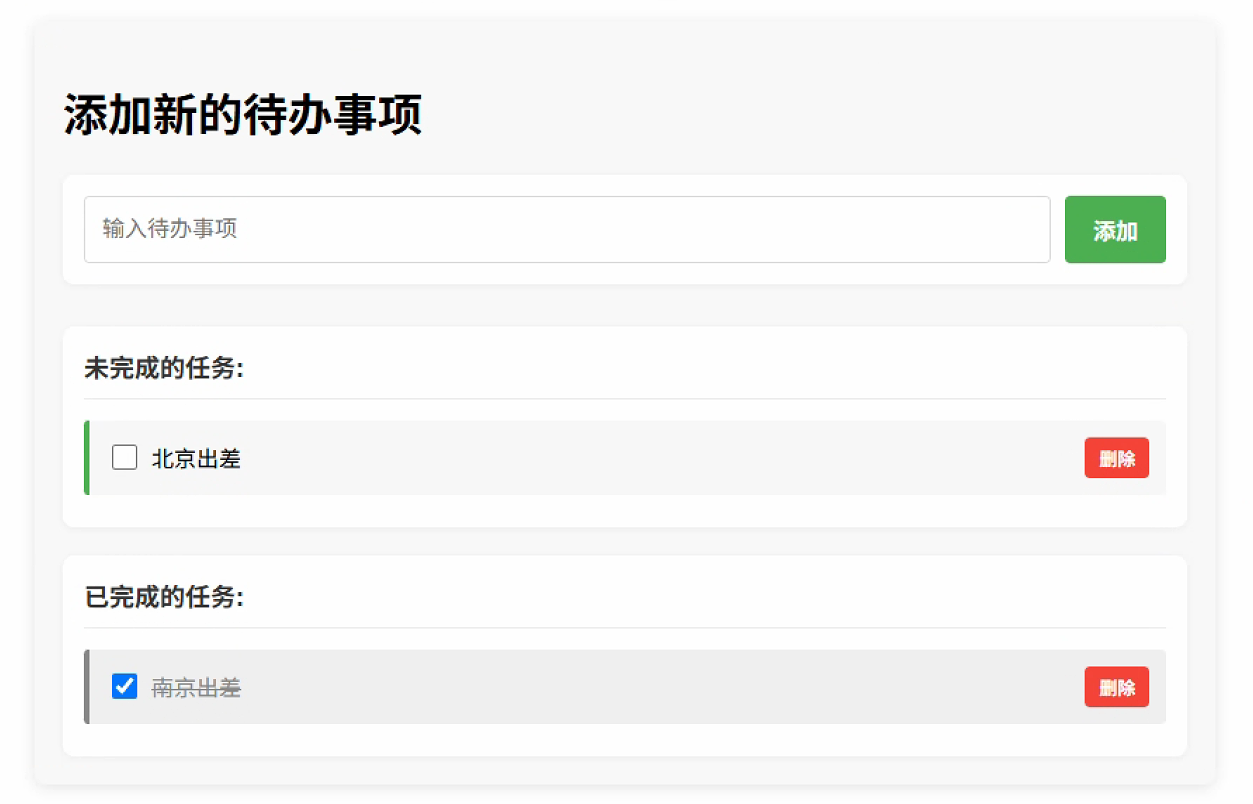
基于原生JavaScript前端和 Flask 后端的Todo 应用
Demo地址:https://gitcode.com/rmbnetlife/todo-app-js-flask.git Python Todo 应用 这是一个使用Python Flask框架开发的简单待办事项(Todo)应用,采用前后端分离架构。本项目实现了待办事项的添加、删除、状态切换等基本功能,并提供了直观…...

一些Dify聊天系统组件流程图架构图
分享一些有助于深入理解Dify聊天模块的架构图 整体组件架构图 #mermaid-svg-0e2XalGLqrRbH1Jy {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-0e2XalGLqrRbH1Jy .error-icon{fill:#552222;}#mermaid-svg-0e2XalGLq…...

jq处理日志数据
介绍 jq 是一个轻量级且灵活的命令行 JSON 处理器。它允许你使用简单的过滤器来处理 JSON 数据,提取、操作和转换 JSON 文档。jq 是处理 JSON 数据的强大工具,特别适合在命令行环境中使用。 简单将就是:专门处理 json结构的字符串的工具 我…...

Matlab程序设计基础
matlab程序设计基础 程序设计函数文件1.函数文件的基本结构2.创建并使用函数文件的示例3.带多个输出的函数示例4.包含子函数的函数文件 流程控制1. if 条件语句2. switch 多分支选择语句3. try-catch 异常处理语句ME与lasterr 4. while 循环语句5. for 循环语句break和continue…...
MIT 6.S081 2020 Lab6 Copy-on-Write Fork for xv6 个人全流程
文章目录 零、写在前面一、Implement copy-on write1.1 说明1.2 实现1.2.1 延迟复制与释放1.2.2 写时复制 零、写在前面 可以阅读下 《xv6 book》 的第五章中断和设备驱动。 问题 在 xv6 中,fork() 系统调用会将父进程的整个用户空间内存复制到子进程中。**如果父…...
第304个Vulnhub靶场演练攻略:digital world.local:FALL
digital world.local:FALL Vulnhub 演练 FALL (digitalworld.local: FALL) 是 Donavan 为 Vulnhub 打造的一款中型机器。这款实验室非常适合经验丰富的 CTF 玩家,他们希望在这类环境中检验自己的技能。那么,让我们开始吧,看看如何…...
Unity 模拟高度尺系统开发详解——实现拖动、范围限制、碰撞吸附与本地坐标轴选择
内容将会持续更新,有错误的地方欢迎指正,谢谢! Unity 模拟高度尺系统开发详解——实现拖动、范围限制、碰撞吸附与本地坐标轴选择 TechX 坚持将创新的科技带给世界! 拥有更好的学习体验 —— 不断努力,不断进步,不…...
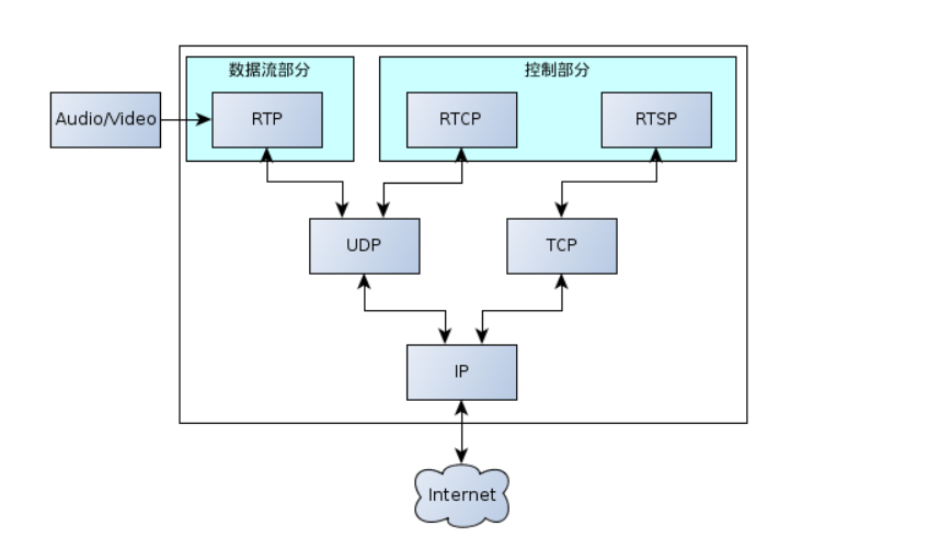
万字详解RTR RTSP SDP RTCP
目录 1 RTSP1.1 RTSP基本简介1.2 RSTP架构1.3 重点内容分析 2 RTR2.1 RTR简介2.2 RTP 封装 H.2642.3 RTP 解封装 H.2642.4 RTP封装 AAC2.5 RTP解封装AAC 3 SDP3.1 基础概念3.2 SDP协议示例解析3.3 重点知识 4 RTCP4.1 RTCP基础概念4.2 重点 5 总结 1 RTSP 1.1 RTSP基本简介 一…...

云服务器如何自动更新系统并保持安全?
云服务器自动更新系统是保障安全、修补漏洞的重要措施。下面是常见 Linux 系统(如 Ubuntu、Debian、CentOS)和 Windows 服务器自动更新的做法和建议: 1. Linux 云服务器自动更新及安全维护 Ubuntu / Debian 系统 手动更新命令 sudo apt up…...

训练中常见的运动强度分类
概述 有氧运动是耐力基础,乳酸阈值是耐力突破的关键,提升乳酸阈值可以延缓疲劳,无氧运动侧重速度和力量,混氧和最大摄氧量用于细化训练强度和评估潜力。 分类强度供能系统乳酸浓度训练目标有氧运动低(60%-80% HR&…...

java 递归地复制文件夹及其所有子文件夹和文件
java 递归地复制文件夹及其所有子文件夹和文件 根据你的需求,下面是一个 Java 代码示例,用于递归地复制文件夹及其所有子文件夹和文件。由于你提到文件夹是数据层面的,这里假设你可以通过 folderById 来获取文件夹的相关信息,并且…...
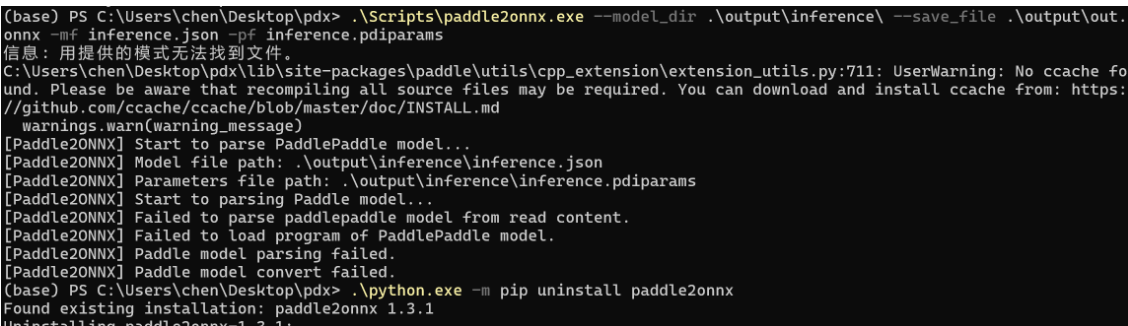
[paddle]paddle2onnx无法转换Paddle3.0.0的json格式paddle inference模型
使用PDX 3.0rc1 训练时序缺陷检测后导出的模型无法转换 Informations (please complete the following information): Inference engine for deployment: PD INFERENCE 3.0-->onnxruntime Why convert to onnx:在端侧设备上部署 Paddle2ONNX Version: 1.3.1 解…...

React项目在ios和安卓端要做一个渐变色背景,用css不支持,可使用react-native-linear-gradient
以上有个模块是灰色逐渐到白的背景色过渡 如果是css,以下代码就直接搞定 background: linear-gradient(180deg, #F6F6F6 0%, #FFF 100%);但是在RN中不支持这种写法,那应该写呢? 1.引入react-native-linear-gradient插件,我使用的是…...