基于FashionMnist数据集的自监督学习(生成式自监督学习AE算法)
目录
一,生成式自监督学习
1.1 简介
1.2 核心思想
1.3 常见算法
1.3.1 自动编码器(Autoencoder)
1.3.2 生成对抗网络(GANs)
1.3.3 变分自编码器(VAE)
1.3.4 Transformer-based 模型(如 BERT、GPT)
1.3.5 扩散模型(Diffusion Models)
1.3.6 自回归模型(Autoregressive Models)
1.3.7 对比总结
二,代码逻辑分析
2.1 数据处理
2.2 模型定义
2.3 模型训练
2.4 主函数逻辑
三,测试结果
3.1 图片重建效果
3.2 分类测试效果
3.3 总结
四,完整代码
一,生成式自监督学习
1.1 简介
生成式自监督学习(Generative Self-Supervised Learning)是机器学习中一种利用数据自身结构进行无监督学习的方法,其核心思想是通过生成模型构建自监督信号,让模型从无标注数据中自动学习数据的潜在规律和特征表示。这种方法无需人工标注标签,而是利用数据本身的内在关联(如上下文关系、时序依赖、结构特征等)生成训练目标,从而提升模型对数据的理解和生成能力。
1.2 核心思想
生成式自监督学习就像让机器自己跟自己玩 “猜谜游戏”—— 不用别人告诉它 “答案是什么”,它自己从海量无标注的数据(比如网上的文字、图片)里找规律。比如,给它一段被遮住几个词的句子,它会猜缺失的词是什么;给它一张模糊的图片,它会试着还原清晰的样子;甚至还能根据 “星空下的森林” 这样的描述画出一幅画。通过不断 “猜谜”“还原”“创造”,机器就能自己学会数据里的隐藏逻辑(比如语言的顺序、图像的色彩搭配),实现无师自通,现在很多 AI 写文章、生成图片的能力,背后靠的就是这种 “自己教自己” 的本事。
1.3 常见算法
1.3.1 自动编码器(Autoencoder)
自动编码器(Autoencoder,AE) 是一种简单且经典的无监督学习模型,核心思想是通过 “压缩 - 重建” 数据来学习数据的潜在特征。它特别适合用于 特征提取、数据压缩、去噪 等任务,尤其在图像领域应用广泛。假设你有一张 28x28 的服装图片(如 T 恤),AE 会先 “压缩” 图片成一个更小的 “特征向量”(比如 64 维),这个向量包含了图片的核心信息(如轮廓、纹理);然后再用这个向量 “重建” 出原始图片。让重建的图片尽可能接近原图,迫使模型学习到最关键的特征。通过自监督任务(重建自身),让模型自动挖掘数据的内在结构,无需人工标注标签。
输入图像 → 编码器 → 隐向量(特征) → 解码器 → 重建图像 → 与原图比较
1.3.2 生成对抗网络(GANs)
生成对抗网络(GANs)是一种通过 “对抗博弈” 机制实现数据生成的机器学习模型,其核心逻辑类似 “造假者” 与 “鉴伪专家” 的攻防战:生成器负责将随机噪声 “加工” 成假数据(如伪造的衣服图片),试图以假乱真;判别器则专注鉴别输入数据是真实样本(如 FashionMNIST 真实图片)还是生成器的 “伪造品”,力求火眼金睛。两者在训练中互相博弈 —— 生成器不断优化造假技术让假数据更逼真,判别器持续升级鉴别能力识破套路,最终当生成器的输出能让判别器无法区分真假(概率接近 50%)时,模型便成功学会生成以假乱真的新数据。GANs 的优势在于能创造全新样本(如 FashionMNIST 中不存在的服饰款式),常用于数据增强、图像生成、风格迁移等场景,但其训练难度高,需平衡两者能力以防 “崩溃”。与自动编码器(AE)相比,AE 侧重数据压缩与还原(类似复印机),而 GANs 专注 “无中生有” 的创造性生成(类似艺术家),更适合需要生成新样本的自监督任务,但直接用于分类时提取特征的效率可能不如 AE。
1.3.3 变分自编码器(VAE)
变分自动编码器(VAE)就像一个会 “猜可能性” 的智能画家:它先观察大量衣服图片(比如 FashionMNIST),学会把每张图 “翻译” 成一个带 “概率标签” 的密码(比如 “这件 T 恤有 70% 可能是蓝色、圆领,30% 可能有条纹”),这个密码不是一个固定的数字,而是一个 “可能性范围”(用均值和方差表示)。然后,它能从这个可能性范围里随机 “抽样”,画出符合这些特征的新衣服(比如生成一件没见过的蓝白条纹 T 恤)。
它的核心是让生成的新图既要 “像真的”(尽量接近原图,避免变成裤子),又要让所有密码的 “可能性范围” 均匀分布(避免只记住几种固定款式)。相比只能复制原图的 AE(像复印机),VAE 能生成多样化的新样本(比如不同花纹的鞋子);相比靠对抗博弈生成的 GANs(像造假者和警察打架),它更稳定,虽然生成的图可能没那么逼真,但胜在 “可控”(比如能按 “圆领”“长袖” 等特征生成)。在自监督分类里,它提取的密码自带 “衣服类型” 的隐藏信息(比如鞋子和包包的密码差异很大),可以直接用来训练分类器,是一种简单又实用的 “数据翻译官”。
1.3.4 Transformer-based 模型(如 BERT、GPT)
Transformer-based 模型是一种让 AI 拥有 “全局思维” 的智能架构,核心是通过 “自注意力机制” 让模型处理数据时能像人类一样 “抓重点、理关系”。比如读句子 “小狗叼着骨头跑向主人,因为它饿了”,模型会让 “它” 主动 “看向” 前面的 “小狗”,不管句子多长都能准确建立关联(解决长距离依赖难题)。它的结构分为 “分析员” Encoder 和 “创造者” Decoder:前者负责拆解输入数据(如文本、图像块),用自注意力给每个元素标上 “重点标签”(比如 “骨头” 是 “叼” 的宾语);后者则根据这些标签生成内容(如翻译后的中文句子、对应文字描述的图片),生成时还会反复 “回看” 分析结果,确保逻辑连贯(比如 “跑向主人” 要对应正确的动作方向)。
这种模型的厉害之处在于:
并行处理效率高:不像传统模型只能逐字逐句处理,它能同时分析所有元素的关系(比如同时判断 “小狗”“骨头”“主人” 的关联),处理长文本或大规模数据更快;
跨领域通用:在文本领域能让 ChatGPT 流畅聊天、帮 GPT 写文章,在图像领域能让 ViT 分类图片,甚至在多模态场景(如 Stable Diffusion)中,能把 “夕阳下的沙滩” 文字描述 “翻译” 成逼真图像,靠的就是自注意力把文字和图像块 “配对” 的能力;
长距离记忆强:哪怕前后文隔得很远(如开头的 “小猫” 和结尾的 “它”),也能精准 “牵线”,避免 “失忆”。
Transformer 就像给 AI 大脑装了一个 “全局导航系统”,让它看数据时能快速锁定重点、理清逻辑关系,无论是写文章、翻译、生成图片还是理解复杂内容,都能驾轻就熟,是如今 AI 领域的 “万能底座”,撑起了从聊天机器人到生成式 AI 的核心能力。
1.3.5 扩散模型(Diffusion Models)
扩散模型(Diffusion Models)是一种通过 “渐进去噪” 实现高质量数据生成的 AI 技术,核心原理类似 “从模糊到清晰还原画面” 的逆向修复过程。它先通过扩散过程(如往清水中滴墨水)将清晰数据(如图像)逐步转化为随机噪声(从隐约可见轮廓到完全杂乱像素),再通过逆扩散过程(反向去噪)让神经网络学会从噪声中逐层还原真实数据 —— 就像剥洋葱一样,每一步都用名为 U-Net 的 “对称漏斗状神经网络” 分析当前噪声图,预测并去除最关键的噪声颗粒,最终 “雕刻” 出逼真的图像、视频等内容。训练时,模型通过大量 “原图 + 不同噪声程度版本” 的数据对,学习 “噪声变化规律”(如 “猫的眼睛区域该去掉哪种噪声”),确保每一步去噪都符合真实数据的分布逻辑。其生成内容细节丰富(如 Stable Diffusion 能画出毛发纹理),稳定性远超传统对抗模型(如 GAN),但需数十步去噪计算,速度较慢。简单说,扩散模型是 AI 界的 “精细雕刻师”,通过数学上的渐进去噪魔法,从混沌噪声中还原或创造出高质量的视觉内容,成为当前图像生成、修复等领域的标杆技术。
1.3.6 自回归模型(Autoregressive Models)
自回归模型(Autoregressive Models)是一种让 AI 实现 “按顺序创作” 的核心技术,其本质是让模型像人类说话一样,根据已生成的内容逐步预测下一个元素—— 比如写 “今天天气” 时,会基于 “今天” 和 “天气” 的语境,推测下一个词可能是 “晴朗”“炎热” 或 “多变”。它的工作逻辑类似 “接龙游戏”,每一步生成都依赖于前面所有结果,通过数学上的概率计算(如极大似然估计)最大化 “下一词符合语境” 的可能性,例如先算 “猫” 出现的概率,再算 “追” 在 “猫” 之后的概率,以此类推串联成完整内容。现代自回归模型(如 GPT 系列)采用自注意力机制升级 “记忆系统”,让模型在生成时能 “全局回看” 所有历史内容(如开头的 “小猫” 和结尾的 “它” 直接关联),解决了传统循环神经网络(RNN)长距离依赖差的问题,使生成的文本、语音等序列数据逻辑更连贯。其应用覆盖文本生成(写文章、代码、对话)、语音合成等领域,特点是输出自然流畅,但因需逐个元素生成(如逐词写句子),速度较慢且无法并行处理。简单说,自回归模型是 AI 的‘顺序创作引擎’,通过‘步步依赖、层层生成’的方式,让机器学会像人类一样‘先说前半句,再顺理成章接后半句’,成为 ChatGPT 等生成式 AI 的底层技术支撑。
1.3.7 对比总结
| 方法 | 核心思想 | 生成特点 | 优缺点 | 典型应用场景 |
|---|---|---|---|---|
| 自动编码器(AE) | 压缩数据再还原,学关键特征(类似 “压缩包解压”) | - 还原输入,适合提取核心特征 - 生成新样本能力弱(只能模仿,难创新) | - 优点:简单高效,适合数据降维、去噪 - 缺点:生成能力差,新内容质量低 | 图像压缩、医学图像去噪、异常检测 |
| 生成对抗网络(GANs) | 两个模型对抗:一个造假,一个打假,越打越真(类似 “猫鼠游戏”) | - 生成样本逼真(如人脸、风景) - 容易 “偷懒”(只生成几种类型,缺乏多样性) | - 优点:图像效果逼真 - 缺点:训练难(易崩溃),结果不可控 | 虚拟人物生成、艺术创作、风格迁移 |
| 变分自编码器(VAE) | 给压缩的特征加 “概率滤镜”,能随机生成新样本(类似 “特征抽奖”) | - 生成多样新样本(如不同风格的猫) - 样本可能模糊(细节不清晰) | - 优点:能创造新样本,适合扩展数据 - 缺点:画质 / 音质一般,不够清晰 | 数据增强(生成同类变体)、药物分子设计 |
| Transformer(如 GPT) | 按顺序预测下一个词 / 元素,学长距离逻辑(类似 “接龙游戏”) | - 文本逻辑连贯(能写文章、对话) - 生成速度慢(一个字一个字蹦) | - 优点:擅长长文本,会 “理解” 上下文 - 缺点:耗算力(需要超大规模训练) | 写文章、聊天机器人、代码生成、翻译 |
| 扩散模型 | 从 “噪声” 中一点点还原清晰数据(类似 “擦除马赛克”) | - 生成质量极高(细节拉满,如复杂场景画图) - 计算慢(需要几十步 “擦除”) | - 优点:图像 / 视频生成天花板 - 缺点:耗时耗显卡(训练要几周,生成要几十步) | 高质量图像生成(DALL・E、MidJourney)、视频生成 |
| 自回归模型 | 按顺序生成(如先写第一个词,再根据第一个词写第二个词) | - 严格按顺序生成(适合文本、语音) - 长序列效率低(如生成很长的句子会变慢) | - 优点:适合 “按步骤” 生成(如逐字、逐像素) - 缺点:并行能力差(不能同时生成多个部分) | 文本生成、语音合成、图像逐块生成 |
二,代码逻辑分析
2.1 数据处理
# 设置随机种子
torch.manual_seed(42)
np.random.seed(42)# 数据预处理 - 调整为32×32输入
transform = transforms.Compose([transforms.Resize((32, 32)),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))
])# 加载FashionMNIST数据集
train_dataset = datasets.FashionMNIST(root='./data', train=True, download=True, transform=transform
)
test_dataset = datasets.FashionMNIST(root='./data', train=False, download=True, transform=transform
)# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=256, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=256, shuffle=False) 将 28×28 的 FashionMNIST 图像调整为 32×32,适配后续网络结构,随机水平翻转图像,增强数据多样性,将像素值归一化到 [-1, 1] 区间(均值 0.5,标准差 0.5),batch_size=256,训练集shuffle=True确保数据随机打乱,测试集不打乱以保持顺序。
2.2 模型定义
# 定义残差块
class ResidualBlock(nn.Module):...# 定义32×32输入的自动编码器模型
class AdvancedAutoencoder(nn.Module):def __init__(self):# 编码器(适配32×32输入)self.encoder = nn.Sequential(...)# 解码器(适配32×32输出)self.decoder = nn.Sequential(...)def forward(self, x):x = self.encoder(x)x = self.decoder(x)return xdef extract_features(self, x):return self.encoder(x)# 定义线性分类器
class LinearClassifier(nn.Module):def __init__(self, input_dim=512 * 2 * 2, num_classes=10):super().__init__()self.linear = nn.Linear(input_dim, num_classes)def forward(self, x):x = x.view(x.size(0), -1)return self.linear(x)ResidualBlock残差连接(Shortcut Connection),缓解深层网络的梯度消失问题,输入输出通道数或尺寸不一致时,通过 1×1 卷积调整维度。
AdvancedAutoencoder:编码器:通过 5 次下采样(卷积 + 残差块)将 32×32 图像压缩为 2×2×512 的特征表示。解码器:通过 5 次上采样(反卷积 + 残差块)将特征重构为 32×32 图像。extract_features方法:仅使用编码器提取特征,用于后续分类任务。
LinearClassifier:输入维度:512×2×2=2048(编码器输出展平后)。单层线性映射,直接连接到 10 个分类类别,用于评估特征质量。
2.3 模型训练
# 训练AE模型
def train_ae(model, train_loader, criterion, optimizer, epochs, device):...# 训练线性分类器
def train_linear_classifier(ae_model, train_loader, test_loader, num_classes, device):# 冻结AE参数for param in ae_model.parameters():param.requires_grad = False# 仅训练线性分类器feature_extractor = ae_model.extract_featuresclassifier = LinearClassifier(input_dim, num_classes).to(device)...train_ae():训练自动编码器,目标是最小化重构误差(MSE 损失)。使用 Adam 优化器,学习率 1e-3,训练 50 个 epochs。
train_linear_classifier():冻结 AE 的参数,仅训练线性分类器,使用预训练的 AE 提取特征,输入到线性层进行分类,评估特征的质量(线性分类准确率反映特征的判别能力)。
2.4 主函数逻辑
def main():# 1. 初始化设备device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 2. 训练自动编码器ae_model = AdvancedAutoencoder().to(device)ae_model = train_ae(ae_model, train_loader, ..., epochs=50)# 3. 可视化重构效果visualize_reconstructions(ae_model, test_loader, device)# 4. 训练线性分类器(评估特征质量)classifier, test_acc = train_linear_classifier(ae_model, ...)# 5. 保存模型torch.save(ae_model.state_dict(), 'fashion_mnist_32_ae.pth')torch.save(classifier.state_dict(), 'fashion_mnist_32_classifier.pth')自监督学习阶段:训练 AE 学习图像的特征表示(无标签数据),通过重构质量评估 AE 性能。
线性评估阶段:使用冻结的 AE 提取特征,训练线性分类器,分类准确率反映特征的质量(是否包含类别判别信息)。
三,测试结果
3.1 图片重建效果

经过50个epcho训练后,loss大概能到0.00x的水平,说明损失也是非常小了

可以看到这里推图片的还原程度还是很高的
3.2 分类测试效果

最终线性分类的准确度大概能到91%
3.3 总结
总的来看,AE方法的训练成本比较低而且准确度较高,在本次实验中,发现调参时epcho不能过大,不然最终的classifier acc基本会维持在百分之90以下。AE对Fashionminst数据集的处理也比较合适,如果想达到更好的准确度,就更需要细细调参,或者是改用效率更高的结构。
四,完整代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)# 数据预处理 - 将输入图像调整为32×32尺寸
transform = transforms.Compose([transforms.Resize((32, 32)), # 将原始28×28图像调整为32×32,便于后续卷积操作transforms.RandomHorizontalFlip(), # 随机水平翻转图像,增加数据多样性transforms.ToTensor(), # 将图像转换为Tensortransforms.Normalize((0.5,), (0.5,)) # 归一化处理,将像素值缩放到[-1, 1]范围
])# 加载FashionMNIST数据集(服装分类数据集,包含10个类别)
train_dataset = datasets.FashionMNIST(root='./data', train=True, download=True, transform=transform
)
test_dataset = datasets.FashionMNIST(root='./data', train=False, download=True, transform=transform
)# 创建数据加载器,用于批量加载数据
train_loader = DataLoader(train_dataset, batch_size=256, shuffle=True) # 训练集打乱顺序
test_loader = DataLoader(test_dataset, batch_size=256, shuffle=False) # 测试集不打乱顺序# 定义残差块,用于构建深度网络,解决梯度消失问题
class ResidualBlock(nn.Module):def __init__(self, in_channels, out_channels, stride=1):super(ResidualBlock, self).__init__()# 第一个卷积层:3×3卷积,保持特征图尺寸或减半(由stride控制)self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(out_channels) # 批量归一化,加速训练并提高稳定性self.relu = nn.ReLU(inplace=True) # ReLU激活函数,引入非线性# 第二个卷积层:3×3卷积,保持特征图尺寸不变self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channels)# 捷径连接:当输入输出通道数或尺寸不一致时,使用1×1卷积调整self.shortcut = nn.Sequential()if stride != 1 or in_channels != out_channels:self.shortcut = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(out_channels))def forward(self, x):# 前向传播:第一个卷积块out = self.relu(self.bn1(self.conv1(x)))# 第二个卷积块out = self.bn2(self.conv2(out))# 残差连接:将输入直接加到输出上out += self.shortcut(x)# 最后通过ReLU激活out = self.relu(out)return out# 定义32×32输入的自动编码器模型(自监督学习)
class AdvancedAutoencoder(nn.Module):def __init__(self):super(AdvancedAutoencoder, self).__init__()# 编码器:将输入图像压缩为低维特征表示self.encoder = nn.Sequential(# 第一层:保持尺寸32×32,增加通道数到32nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1), # 输出: 32×32×32nn.BatchNorm2d(32),nn.ReLU(),ResidualBlock(32, 32), # 残差块,保持通道数不变# 第一次下采样:尺寸减半为16×16,通道数翻倍到64nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1), # 输出: 16×16×64nn.BatchNorm2d(64),nn.ReLU(),ResidualBlock(64, 64),# 第二次下采样:尺寸减半为8×8,通道数翻倍到128nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1), # 输出: 8×8×128nn.BatchNorm2d(128),nn.ReLU(),ResidualBlock(128, 128),# 第三次下采样:尺寸减半为4×4,通道数翻倍到256nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1), # 输出: 4×4×256nn.BatchNorm2d(256),nn.ReLU(),ResidualBlock(256, 256),# 第四次下采样:尺寸减半为2×2,通道数翻倍到512nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1), # 输出: 2×2×512nn.BatchNorm2d(512),nn.ReLU())# 解码器:将低维特征重构为原始图像self.decoder = nn.Sequential(# 第一次上采样:尺寸翻倍为4×4,通道数减半到256nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, output_padding=1), # 输出: 4×4×256nn.BatchNorm2d(256),nn.ReLU(),ResidualBlock(256, 256),# 第二次上采样:尺寸翻倍为8×8,通道数减半到128nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, output_padding=1), # 输出: 8×8×128nn.BatchNorm2d(128),nn.ReLU(),ResidualBlock(128, 128),# 第三次上采样:尺寸翻倍为16×16,通道数减半到64nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, output_padding=1), # 输出: 16×16×64nn.BatchNorm2d(64),nn.ReLU(),ResidualBlock(64, 64),# 第四次上采样:尺寸翻倍为32×32,通道数减半到32nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, output_padding=1), # 输出: 32×32×32nn.BatchNorm2d(32),nn.ReLU(),ResidualBlock(32, 32),# 最后一层:保持尺寸32×32,将通道数压缩到1(原始图像通道数)nn.Conv2d(32, 1, kernel_size=3, stride=1, padding=1), # 输出: 32×32×1nn.Tanh() # 将输出值限制在[-1, 1]范围内,与输入归一化范围一致)def forward(self, x):# 完整的前向传播:编码 -> 解码x = self.encoder(x)x = self.decoder(x)return x# 提取特征的方法:仅使用编码器部分def extract_features(self, x):return self.encoder(x)# 定义线性分类器:用于评估自动编码器提取的特征质量
class LinearClassifier(nn.Module):def __init__(self, input_dim=512 * 2 * 2, num_classes=10):super(LinearClassifier, self).__init__()# 线性层:将编码器输出的特征向量映射到分类类别self.linear = nn.Linear(input_dim, num_classes)def forward(self, x):# 将特征张量展平为一维向量x = x.view(x.size(0), -1) # 从[batch_size, 512, 2, 2]变为[batch_size, 2048]return self.linear(x)# 训练自动编码器的函数
def train_ae(model, train_loader, criterion, optimizer, epochs, device):model.train() # 设置为训练模式for epoch in range(epochs):running_loss = 0.0for data, _ in train_loader: # 忽略标签(自监督学习)data = data.to(device) # 将数据移至GPU(如果可用)optimizer.zero_grad() # 清零梯度outputs = model(data) # 前向传播loss = criterion(outputs, data) # 计算重构损失loss.backward() # 反向传播optimizer.step() # 更新参数running_loss += loss.item()# 打印每个epoch的平均损失avg_loss = running_loss / len(train_loader)print(f'AE Epoch [{epoch + 1}/{epochs}], Loss: {avg_loss:.4f}')return model# 训练线性分类器的函数(使用预训练的自动编码器提取特征)
def train_linear_classifier(ae_model, train_loader, test_loader, num_classes, device):# 冻结自动编码器的所有参数,仅训练线性分类器for param in ae_model.parameters():param.requires_grad = Falsefeature_extractor = ae_model.extract_features # 获取特征提取器input_dim = 512 * 2 * 2 # 编码器输出的特征维度classifier = LinearClassifier(input_dim, num_classes).to(device) # 创建线性分类器criterion = nn.CrossEntropyLoss() # 分类任务使用交叉熵损失optimizer = optim.Adam(classifier.parameters(), lr=1e-3) # 仅优化分类器参数classifier.train() # 设置为训练模式epochs = 30for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for data, labels in train_loader:data, labels = data.to(device), labels.to(device) # 数据移至GPU# 使用预训练的AE提取特征(不需要梯度计算)with torch.no_grad():features = feature_extractor(data)outputs = classifier(features) # 通过分类器预测loss = criterion(outputs, labels) # 计算分类损失optimizer.zero_grad() # 清零梯度loss.backward() # 反向传播optimizer.step() # 更新参数# 计算准确率_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()running_loss += loss.item()# 打印每个epoch的损失和训练准确率train_acc = 100. * correct / totalavg_loss = running_loss / len(train_loader)print(f'Classifier Epoch [{epoch + 1}/{epochs}], Loss: {avg_loss:.4f}, Acc: {train_acc:.2f}%')# 在测试集上评估分类器性能test_acc = evaluate_classifier(classifier, feature_extractor, test_loader, device)print(f'Test Accuracy: {test_acc:.2f}%')return classifier, test_acc# 评估分类器性能的函数
def evaluate_classifier(classifier, feature_extractor, test_loader, device):classifier.eval() # 设置为评估模式correct = 0total = 0# 不计算梯度,加速推理with torch.no_grad():for data, labels in test_loader:data, labels = data.to(device), labels.to(device)features = feature_extractor(data) # 提取特征outputs = classifier(features) # 分类预测# 计算准确率_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()return 100. * correct / total# 可视化原始图像和重构图像的函数
def visualize_reconstructions(model, test_loader, device, num_samples=5):model.eval() # 设置为评估模式# 不计算梯度,加速推理with torch.no_grad():data, _ = next(iter(test_loader)) # 获取一批测试数据data = data[:num_samples].to(device) # 取前几个样本reconstructions = model(data) # 生成重构图像# 转换为CPU张量并调整维度,从[B,1,H,W]转为[B,H,W]data = data.cpu().numpy().squeeze(1)reconstructions = reconstructions.cpu().numpy().squeeze(1)# 创建图像对比图fig, axes = plt.subplots(2, num_samples, figsize=(15, 8))for i in range(num_samples):# 显示原始图像axes[0, i].imshow(data[i], cmap='gray')axes[0, i].set_title('Original (32×32)')axes[0, i].axis('off')# 显示重构图像axes[1, i].imshow(reconstructions[i], cmap='gray')axes[1, i].set_title('Reconstructed (32×32)')axes[1, i].axis('off')plt.tight_layout()plt.show()# 主函数:程序入口点
def main():device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"Using device: {device}")# 创建并训练自动编码器ae_model = AdvancedAutoencoder().to(device)criterion = nn.MSELoss() # 使用均方误差损失函数optimizer = optim.Adam(ae_model.parameters(), lr=1e-3) # Adam优化器print("Training Advanced Autoencoder...")ae_model = train_ae(ae_model, train_loader, criterion, optimizer, epochs=50, device=device)# 可视化重构效果,检查AE训练质量visualize_reconstructions(ae_model, test_loader, device)# 训练并评估线性分类器print("\nTraining Linear Classifier...")num_classes = len(train_dataset.classes) # 获取类别数量(10类)classifier, test_acc = train_linear_classifier(ae_model, train_loader, test_loader, num_classes, device)# 保存模型torch.save(ae_model.state_dict(), 'fashion_mnist_32_ae.pth')torch.save(classifier.state_dict(), 'fashion_mnist_32_classifier.pth')print(f"Models saved: fashion_mnist_32_ae.pth, fashion_mnist_32_classifier.pth")if __name__ == "__main__":main() # 执行主函数相关文章:
基于FashionMnist数据集的自监督学习(生成式自监督学习AE算法)
目录 一,生成式自监督学习 1.1 简介 1.2 核心思想 1.3 常见算法 1.3.1 自动编码器(Autoencoder) 1.3.2 生成对抗网络(GANs) 1.3.3 变分自编码器(VAE) 1.3.4 Transformer-based 模型&…...
从监控到告警:Prometheus+Grafana+Alertmanager+告警通知服务全链路落地实践
文章目录 一、引言1.1 监控告警的必要性1.2 监控告警的基本原理1.2.1 指标采集与存储1.2.2 告警规则与触发机制1.2.3 多渠道通知与闭环 二、技术选型与架构设计2.1 为什么选择 Prometheus 及其生态2.1.1 Prometheus 优势分析2.1.2 Grafana 可视化能力2.1.3 Alertmanager 灵活告…...

AUTOSAR图解==>AUTOSAR_EXP_AIADASAndVMC
AUTOSAR高级驾驶辅助系统与车辆运动控制接口详解 基于AUTOSAR R22-11标准的ADAS与VMC接口规范解析 目录 1. 引言2. 术语和概念说明 2.1 坐标系统2.2 定义 2.2.1 乘用车重心2.2.2 极坐标系统2.2.3 车辆加速度/推进力方向2.2.4 倾斜方向2.2.5 方向盘角度2.2.6 道路变量2.2.7 曲率…...
WPF【09】WPF基础入门 (三层架构与MVC架构)
9-2 【操作】WPF 基础入门 新建一项目 Create a new project - WPF Application (A project for creating a .NET Core WPF Application) - Next - .NET 5.0 (Current) - Create 项目创建完成,VS自动打开 GUI用户界面,格式是 .xaml文件,跟xm…...
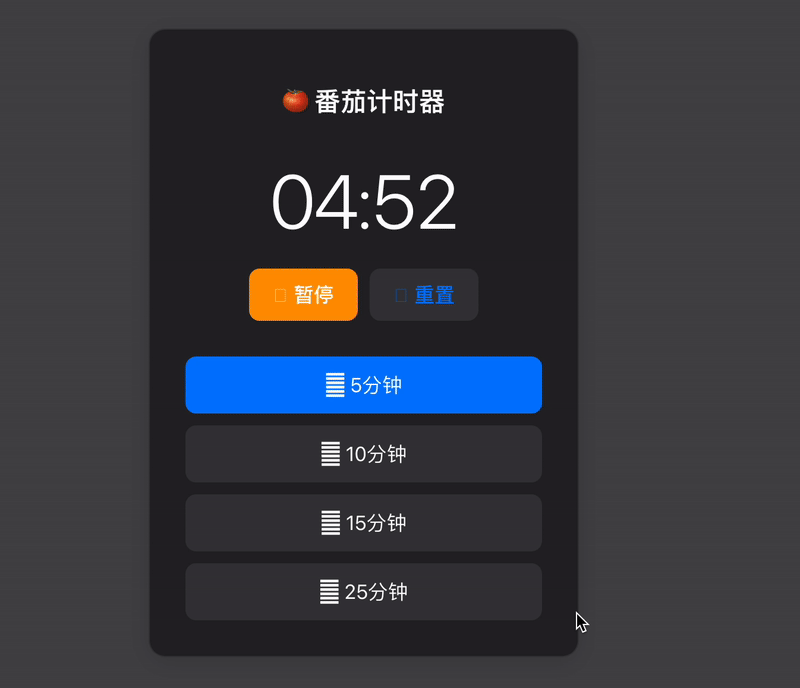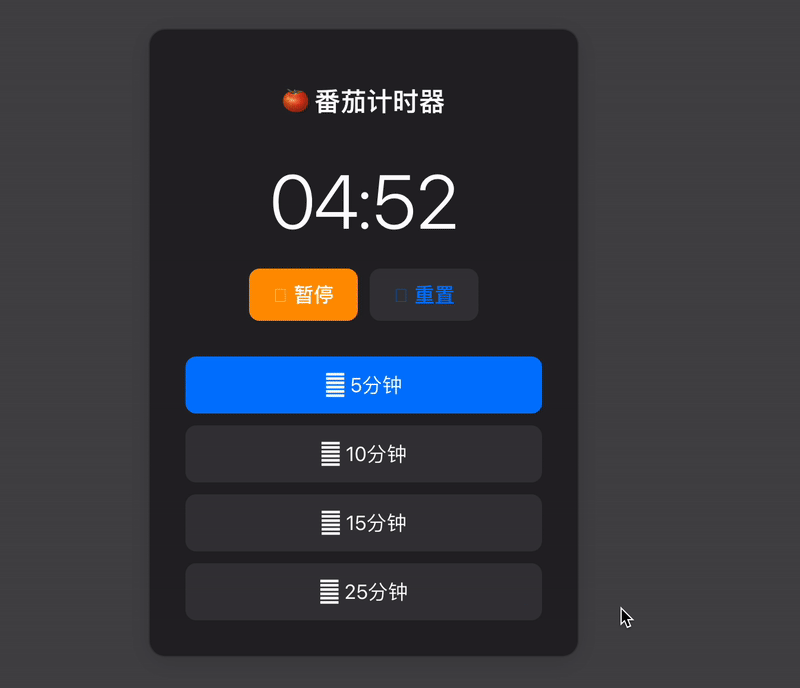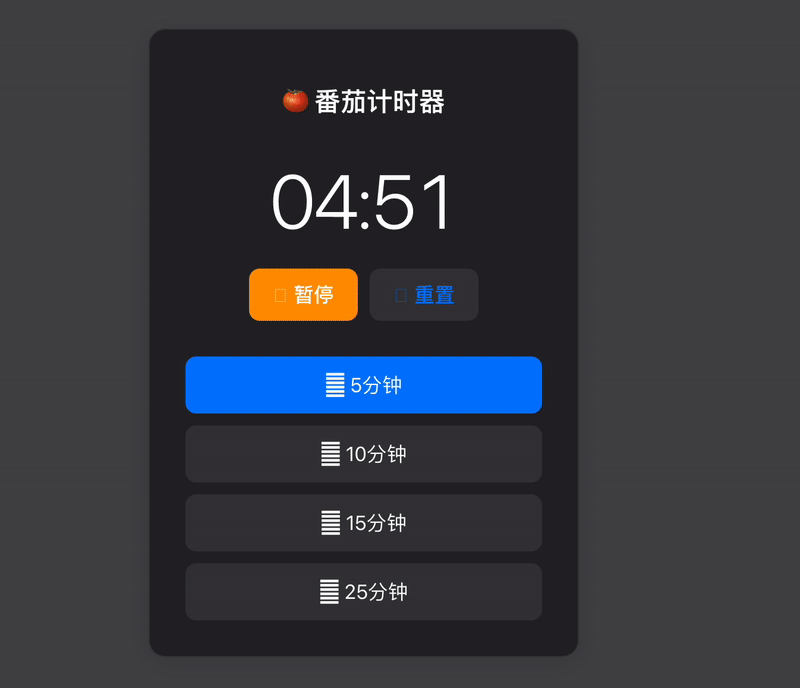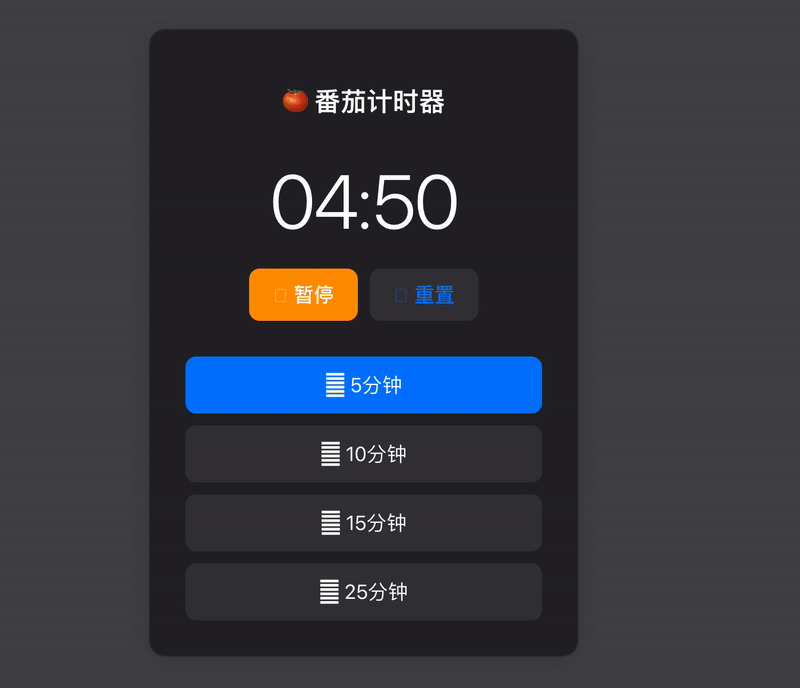
macOS 风格番茄计时器:设计与实现详解
macOS 风格番茄计时器:设计与实现详解 概述 本文介绍一款采用 macOS 设计语言的网页版番茄计时器实现。该计时器完全遵循苹果的人机界面指南(HIG),提供原汁原味的 macOS 使用体验,同时具备响应式设计和深色模式支持。 核心特性 原生 macOS…...

中文NLP with fastai - Fastai Part4
使用fastai进行自然语言处理 在之前的教程中,我们已经了解了如何利用预训练模型并对其进行微调,以执行图像分类任务(MNIST)。应用于图像的迁移学习原理同样也可以应用于NLP任务。在本教程中,我们将使用名为AWD_LSTM的预训练模型来对中文电影评论进行分类。AWD_LSTM是LSTM…...
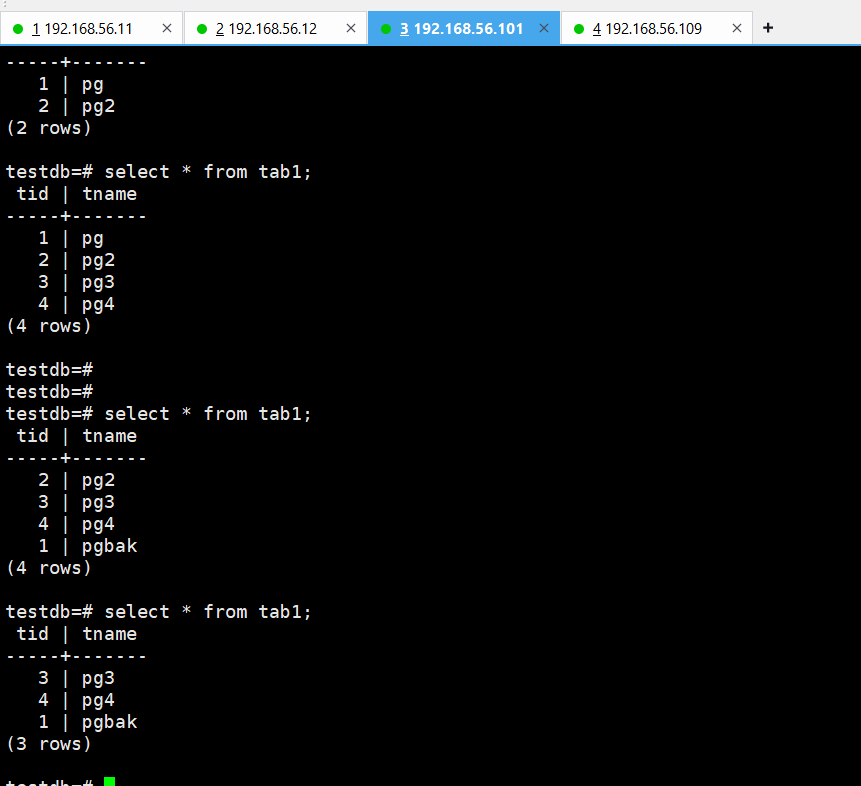
oracle goldengate实现远程抽取postgresql 到 postgresql的实时同步【绝对无坑版,亲测流程验证】
oracle goldengate实现postgresql 到 postgresql的实时同步 源端:postgresql1 -> postgresql2 流复制主备同步 目标端:postgresql 数据库版本:postgresql 12.14 ogg版本:21.3 架构图: 数据库安装以及流复制主备…...
)
【MYSQL】索引篇(一)
1.为什么要有索引 索引的本质是一种数据结构,她的作用其实就是更好更快的帮我们找到数据库中存储的数据,就好比一本书,你想要找到指定的内容,但是如果在没有目录的情况下,你只能一页页的进行寻找,这样效率…...
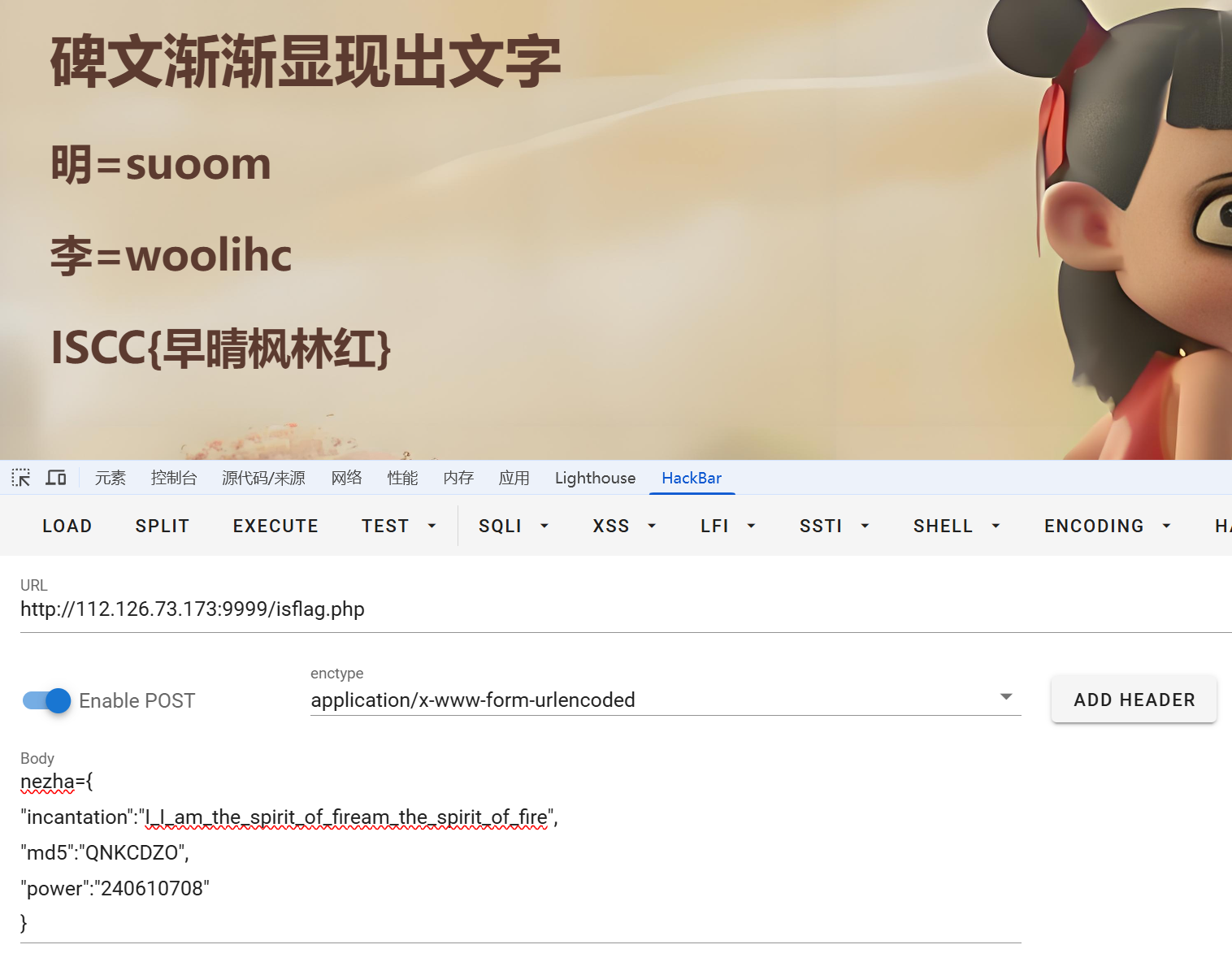
ISCC-2025-web-wp
web 校赛 校赛靠着ENOCH师傅发力,也是一路躺进了区域赛,E师傅不好意思发这抽象比赛的wp(这比赛确实啥必到让人大开眼界,反正明年我是肯定不会打了),我就顺手要过来连着区域赛的一起发了 web 150分 按照提示进入/includes/fla…...

鸿蒙分辨率
鸿蒙手机App界面开发,UI元素应该以什么哪种屏幕尺寸为基准?换言之,做鸿蒙手机APP UI设计时,应该以哪种屏 PX转VP 华为开发者问答 | 华为开发者联盟 各单位换算API 华为开发者问答 | 华为开发者联盟 开源鸿蒙更改DPI 如何在Op…...

@Docker Compose 部署 Pushgateway
文章目录 Docker Compose 部署 Pushgateway1. 目的2. 适用范围3. 先决条件4. 部署步骤4.1 创建项目目录4.2 创建 docker-compose.yml 文件4.3 启动 Pushgateway 服务4.4 验证服务运行状态4.5 测试 Pushgateway 访问 5. 配置 Prometheus 采集 Pushgateway 数据6. 日常维护6.1 查…...

我们来学mysql -- 从库重启,是否同步主库数据
从库重启后,通常不需要重新复制主库的全部数据,然后再开启复制。MySQL 的主从复制机制设计了优雅的恢复流程,可以在从库重启后继续从上次中断的位置继续复制,前提是相关的日志和状态信息完整。 以下是详细解释: 从库…...

King3399(ubuntu文件系统)iic(i2c)功能测试
0 引言 前面两篇博文简要介绍了板子上uart部分的内容,但在驱动开发时,我们遇到的外设更多的是以i2c或spi进行通信,本文将对king3399的i2c进行测试并对硬件电路、设备树与驱动程序进行分析 如果使用的i2c设备不是mma8452,建议先看…...

德思特新闻 | 德思特与es:saar正式建立合作伙伴关系
德思特新闻 2025年5月9日,德思特科技有限公司(以下简称“德思特”)与德国嵌入式系统专家es:saar GmbH正式达成合作伙伴关系。此次合作旨在将 es:saar 的先进嵌入式开发与测试工具引入中国及亚太市场,助力本地客户提升产品开发效率…...
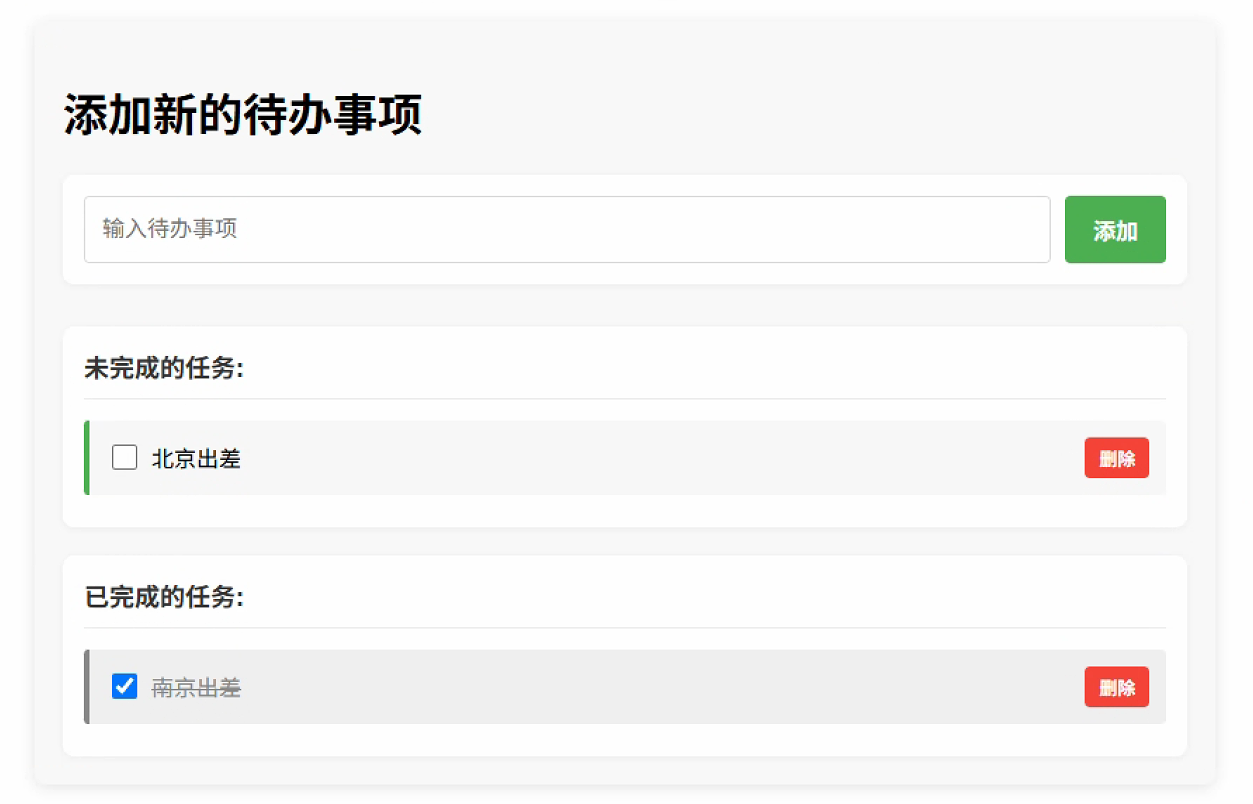
基于原生JavaScript前端和 Flask 后端的Todo 应用
Demo地址:https://gitcode.com/rmbnetlife/todo-app-js-flask.git Python Todo 应用 这是一个使用Python Flask框架开发的简单待办事项(Todo)应用,采用前后端分离架构。本项目实现了待办事项的添加、删除、状态切换等基本功能,并提供了直观…...

一些Dify聊天系统组件流程图架构图
分享一些有助于深入理解Dify聊天模块的架构图 整体组件架构图 #mermaid-svg-0e2XalGLqrRbH1Jy {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-0e2XalGLqrRbH1Jy .error-icon{fill:#552222;}#mermaid-svg-0e2XalGLq…...

jq处理日志数据
介绍 jq 是一个轻量级且灵活的命令行 JSON 处理器。它允许你使用简单的过滤器来处理 JSON 数据,提取、操作和转换 JSON 文档。jq 是处理 JSON 数据的强大工具,特别适合在命令行环境中使用。 简单将就是:专门处理 json结构的字符串的工具 我…...

Matlab程序设计基础
matlab程序设计基础 程序设计函数文件1.函数文件的基本结构2.创建并使用函数文件的示例3.带多个输出的函数示例4.包含子函数的函数文件 流程控制1. if 条件语句2. switch 多分支选择语句3. try-catch 异常处理语句ME与lasterr 4. while 循环语句5. for 循环语句break和continue…...
MIT 6.S081 2020 Lab6 Copy-on-Write Fork for xv6 个人全流程
文章目录 零、写在前面一、Implement copy-on write1.1 说明1.2 实现1.2.1 延迟复制与释放1.2.2 写时复制 零、写在前面 可以阅读下 《xv6 book》 的第五章中断和设备驱动。 问题 在 xv6 中,fork() 系统调用会将父进程的整个用户空间内存复制到子进程中。**如果父…...
第304个Vulnhub靶场演练攻略:digital world.local:FALL
digital world.local:FALL Vulnhub 演练 FALL (digitalworld.local: FALL) 是 Donavan 为 Vulnhub 打造的一款中型机器。这款实验室非常适合经验丰富的 CTF 玩家,他们希望在这类环境中检验自己的技能。那么,让我们开始吧,看看如何…...
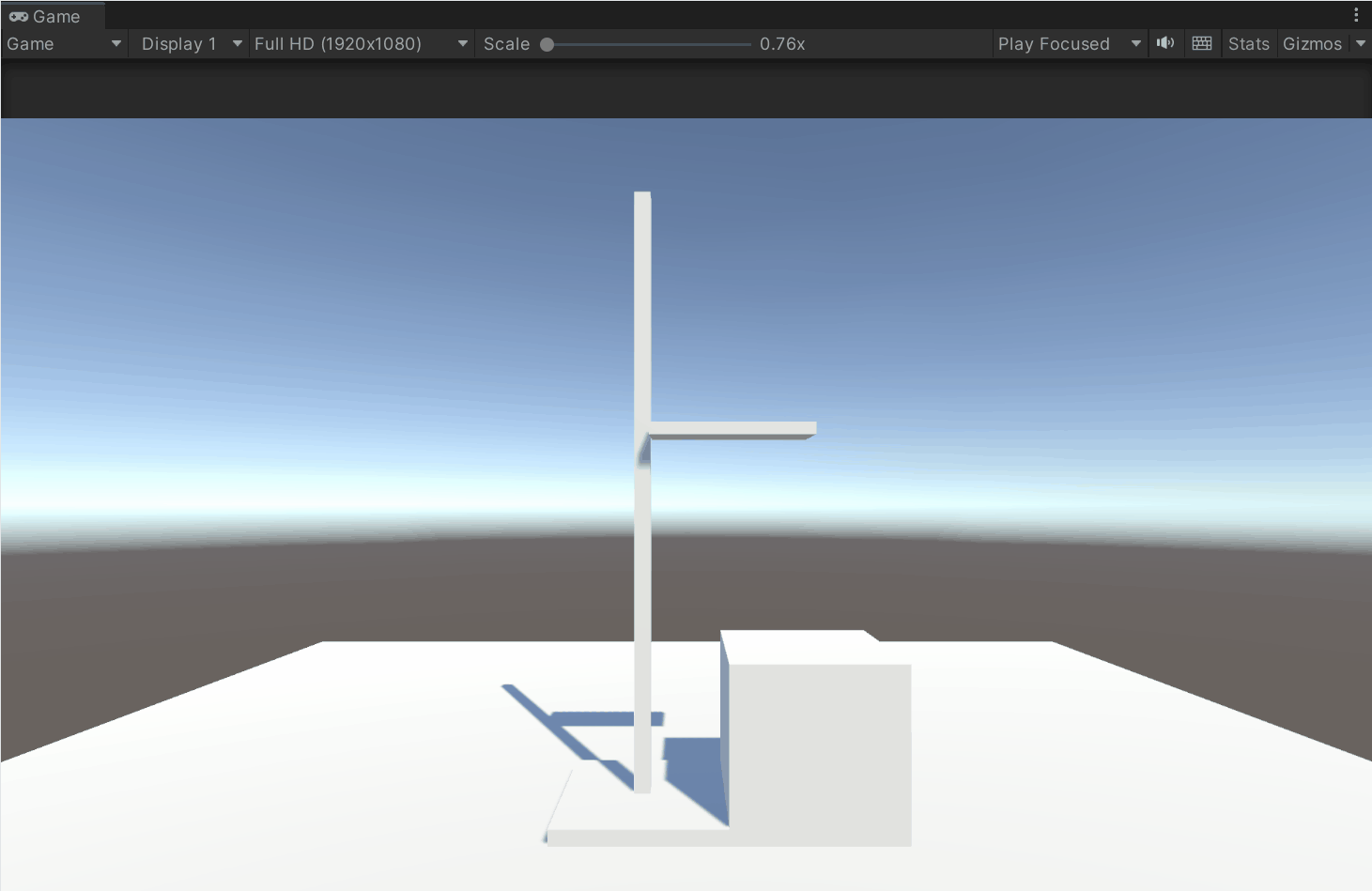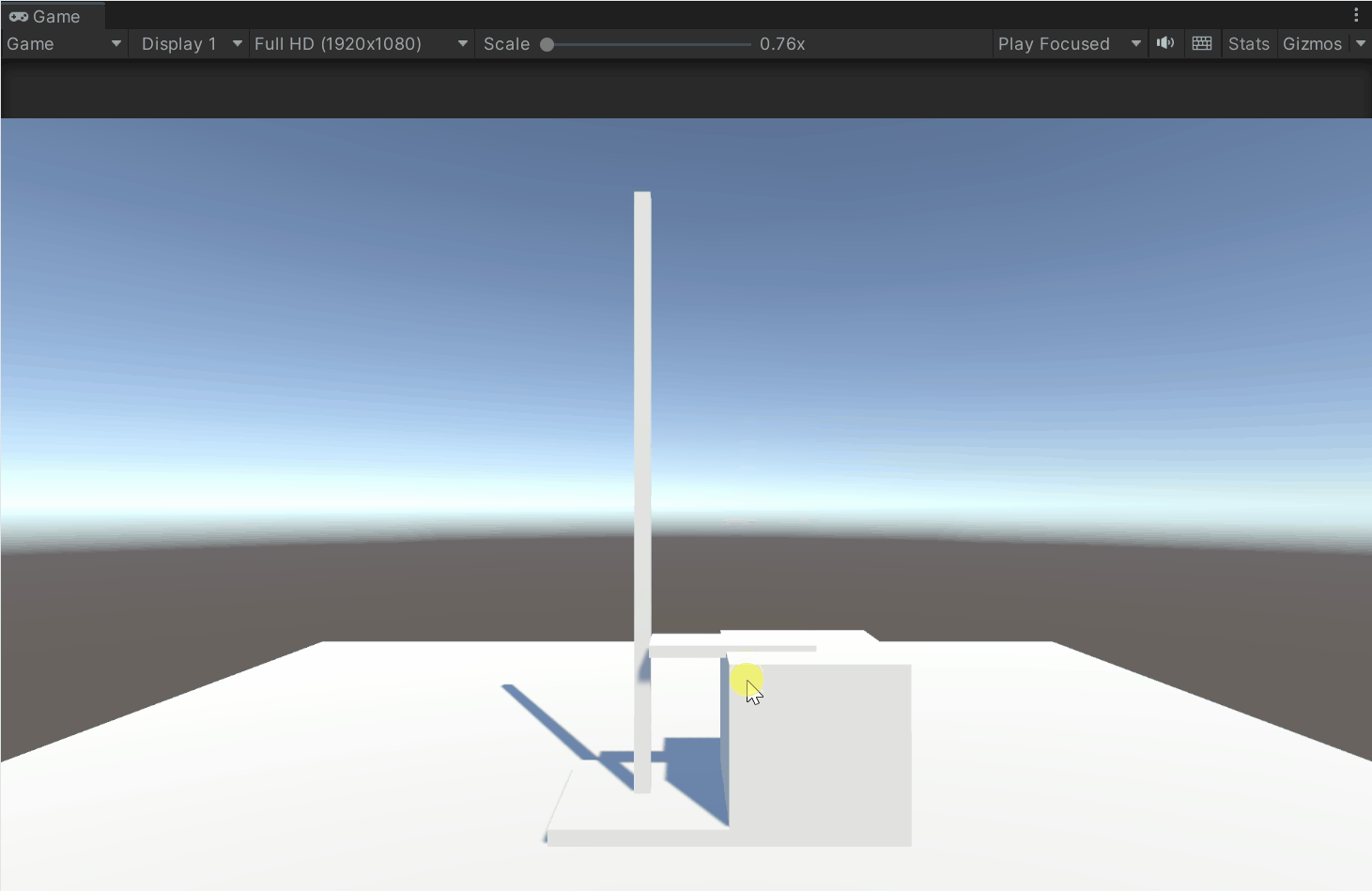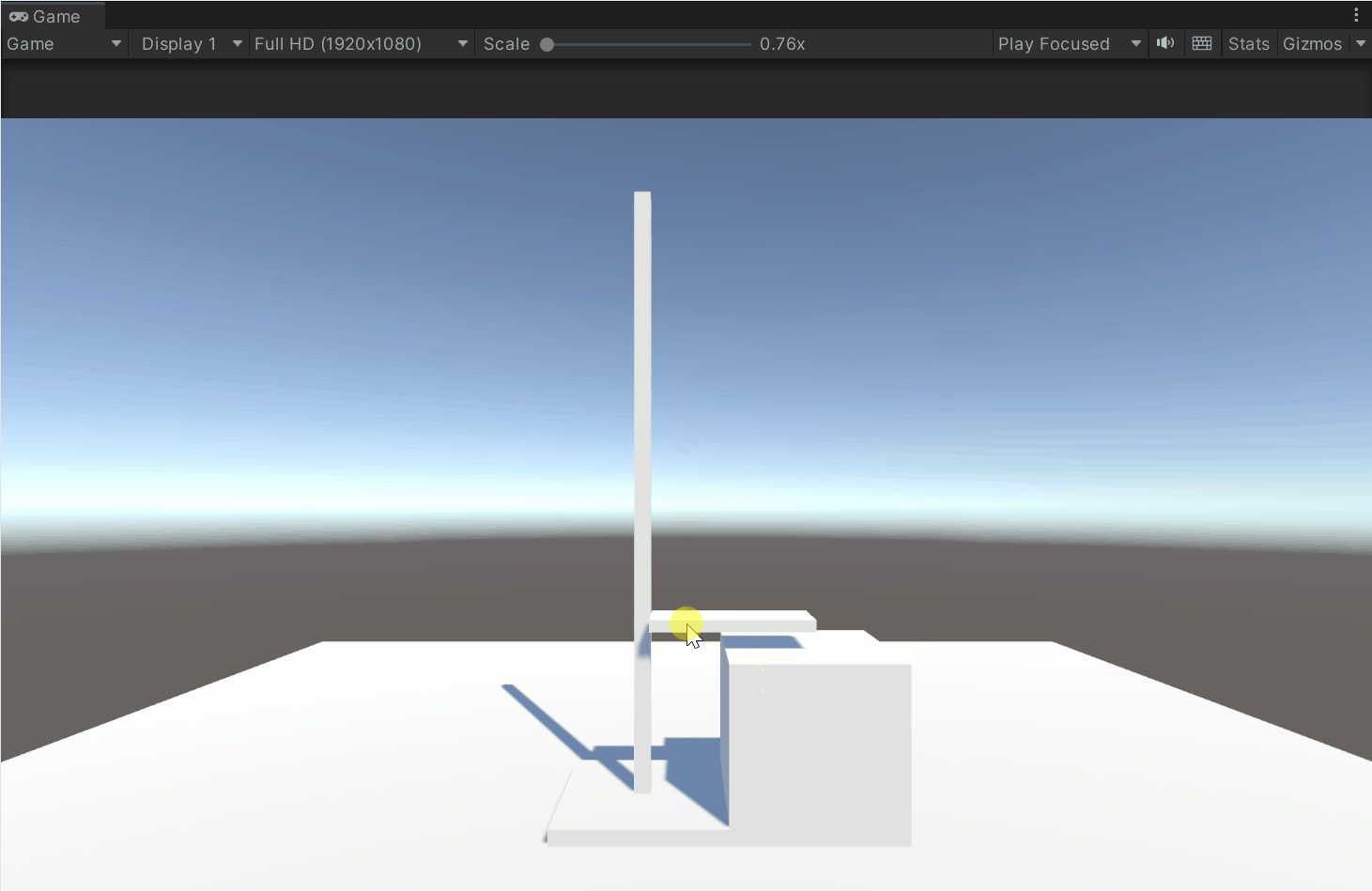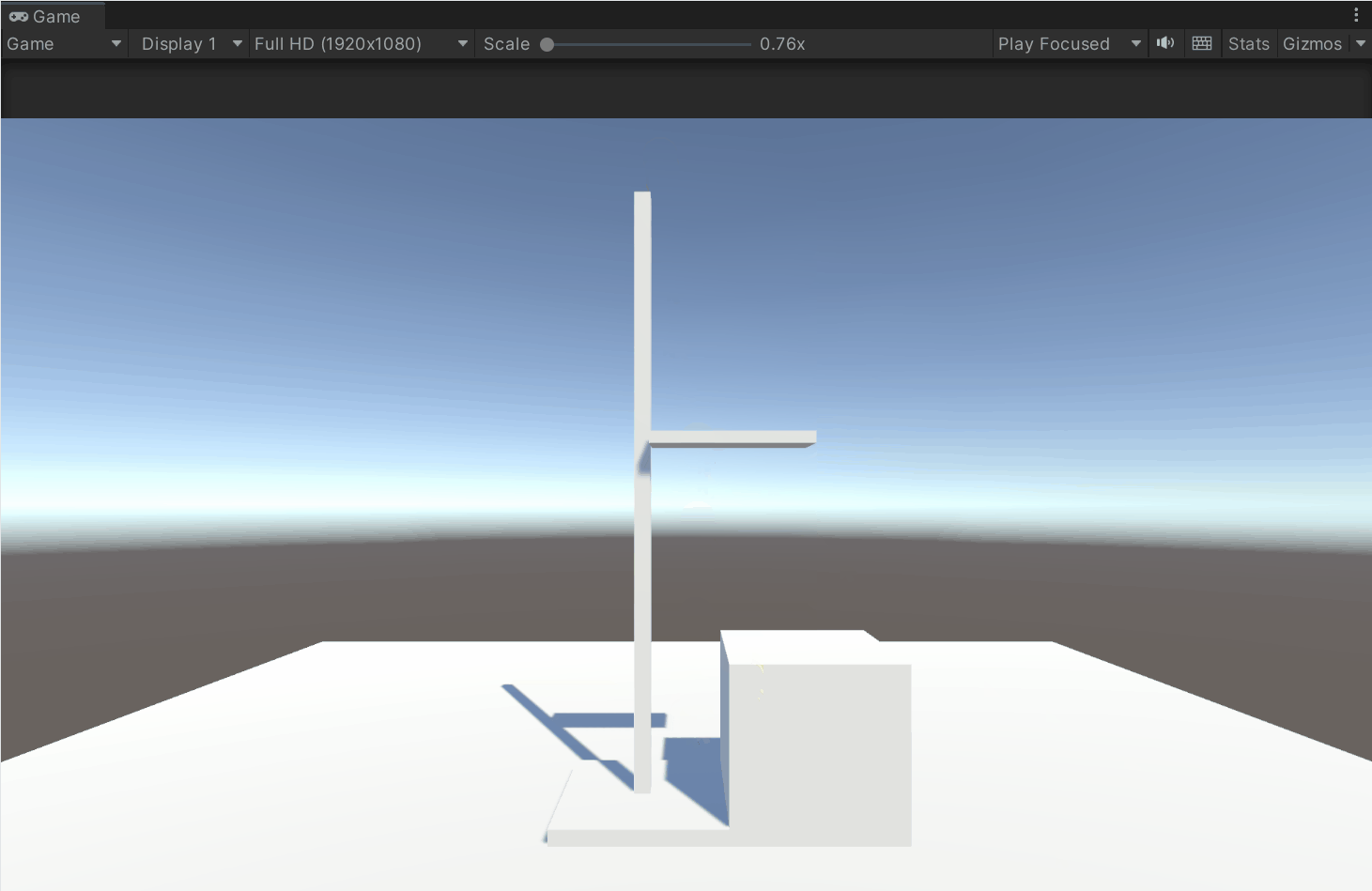
Unity 模拟高度尺系统开发详解——实现拖动、范围限制、碰撞吸附与本地坐标轴选择
内容将会持续更新,有错误的地方欢迎指正,谢谢! Unity 模拟高度尺系统开发详解——实现拖动、范围限制、碰撞吸附与本地坐标轴选择 TechX 坚持将创新的科技带给世界! 拥有更好的学习体验 —— 不断努力,不断进步,不…...
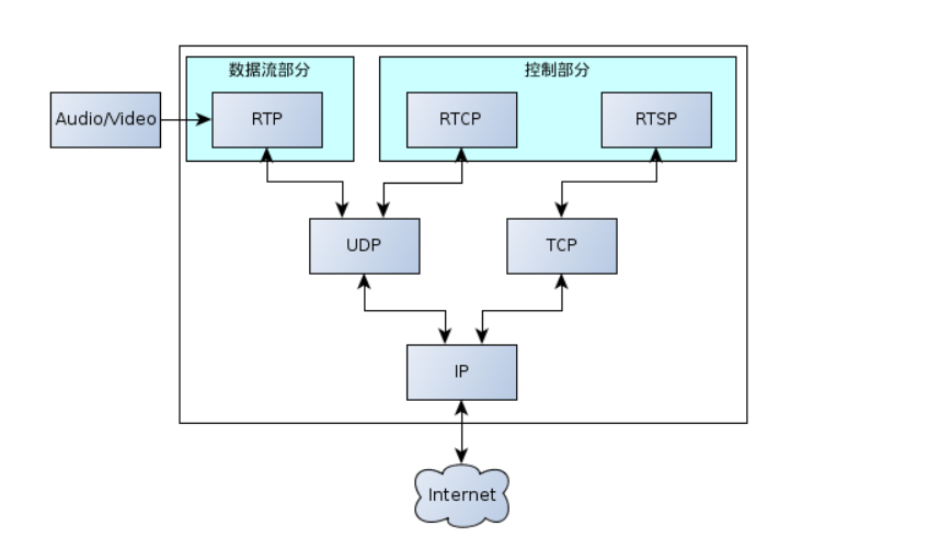
万字详解RTR RTSP SDP RTCP
目录 1 RTSP1.1 RTSP基本简介1.2 RSTP架构1.3 重点内容分析 2 RTR2.1 RTR简介2.2 RTP 封装 H.2642.3 RTP 解封装 H.2642.4 RTP封装 AAC2.5 RTP解封装AAC 3 SDP3.1 基础概念3.2 SDP协议示例解析3.3 重点知识 4 RTCP4.1 RTCP基础概念4.2 重点 5 总结 1 RTSP 1.1 RTSP基本简介 一…...

云服务器如何自动更新系统并保持安全?
云服务器自动更新系统是保障安全、修补漏洞的重要措施。下面是常见 Linux 系统(如 Ubuntu、Debian、CentOS)和 Windows 服务器自动更新的做法和建议: 1. Linux 云服务器自动更新及安全维护 Ubuntu / Debian 系统 手动更新命令 sudo apt up…...

训练中常见的运动强度分类
概述 有氧运动是耐力基础,乳酸阈值是耐力突破的关键,提升乳酸阈值可以延缓疲劳,无氧运动侧重速度和力量,混氧和最大摄氧量用于细化训练强度和评估潜力。 分类强度供能系统乳酸浓度训练目标有氧运动低(60%-80% HR&…...

java 递归地复制文件夹及其所有子文件夹和文件
java 递归地复制文件夹及其所有子文件夹和文件 根据你的需求,下面是一个 Java 代码示例,用于递归地复制文件夹及其所有子文件夹和文件。由于你提到文件夹是数据层面的,这里假设你可以通过 folderById 来获取文件夹的相关信息,并且…...
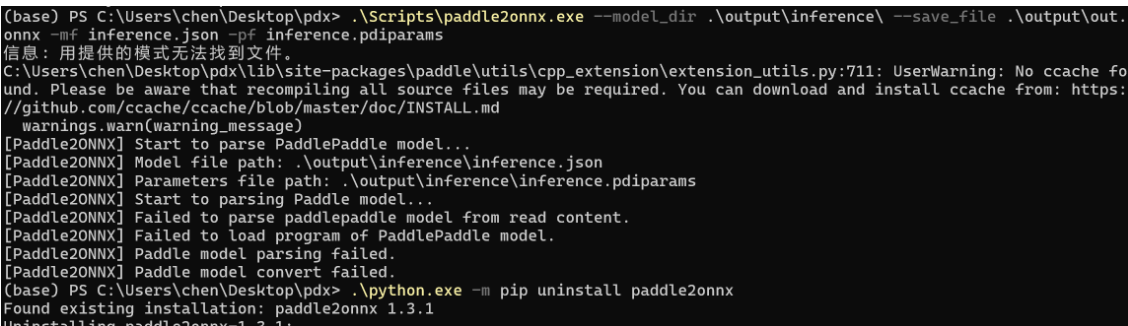
[paddle]paddle2onnx无法转换Paddle3.0.0的json格式paddle inference模型
使用PDX 3.0rc1 训练时序缺陷检测后导出的模型无法转换 Informations (please complete the following information): Inference engine for deployment: PD INFERENCE 3.0-->onnxruntime Why convert to onnx:在端侧设备上部署 Paddle2ONNX Version: 1.3.1 解…...

React项目在ios和安卓端要做一个渐变色背景,用css不支持,可使用react-native-linear-gradient
以上有个模块是灰色逐渐到白的背景色过渡 如果是css,以下代码就直接搞定 background: linear-gradient(180deg, #F6F6F6 0%, #FFF 100%);但是在RN中不支持这种写法,那应该写呢? 1.引入react-native-linear-gradient插件,我使用的是…...

【数据分析】特征工程-特征选择
【数据分析】特征工程-特征选择 (一)方差过滤法1.1 消除方差为0的特征1.2 保留一半的特征1.3 特征是二分类时 (二)相关性过滤法2.1 卡方过滤2.2 F检验2.3 互信息法 (三)其他3.1 包装法3.2 嵌入法3.3 衍生特…...

第4节 Node.js NPM 使用介绍
本文介绍了 Node.js 中 NPM 的使用,我们先来了解什么是 NPM。 NPM是随同NodeJS一起安装的包管理工具,能解决NodeJS代码部署上的很多问题,常见的使用场景有以下几种: 允许用户从NPM服务器下载别人编写的第三方包到本地使用。允许…...

RK3399 Android7.1增加应用安装白名单机制
通过设置应用包名白名单的方式限制未授权的应用软件安装。 diff --git a/frameworks/base/services/core/java/com/android/server/pm/PackageManagerService.java b/frameworks/base/services/core/java/com/android/server/pm/PackageManagerService.java index af9a533..ca…...