头歌之动手学人工智能-Pytorch 之优化
目录
第1关:如何使用optimizer
任务描述
编程要求
测试说明
真正的科学家应当是个幻想家;谁不是幻想家,谁就只能把自己称为实践家。 —— 巴尔扎克开始你的任务吧,祝你成功!
第2关:optim.SGD
任务描述
编程要求
测试说明
真正的科学家应当是个幻想家;谁不是幻想家,谁就只能把自己称为实践家。 —— 巴尔扎克开始你的任务吧,祝你成功!
第3关:RMSprop
任务描述
编程要求
测试说明
真正的科学家应当是个幻想家;谁不是幻想家,谁就只能把自己称为实践家。 —— 巴尔扎克开始你的任务吧,祝你成功!
第4关:Adam
任务描述
编程要求
测试说明
知识有如人体血液一样的宝贵。人缺少了血液,身体就要衰弱,人缺少了知识,头脑就要枯竭。——高士其开始你的任务吧,祝你成功!
第5关:优化器总结
任务描述
编程要求
测试说明
开始你的任务吧,祝你成功!
第1关:如何使用optimizer
torch.optim是一个实现了各种优化算法的库。大部分常用的方法得到支持,并且接口具备足够的通用性,使得未来能够集成更加复杂的方法。
-
任务描述
本关任务:
本关卡要求同学们声明一个 SGD 优化器 optimizer,按照要求传入优化器的参数。同时,为了便于观察,利用optimizer.param_groups方法查看优化器的各项参数并输出。
-
编程要求
本关涉及的代码文件为optimizer.py,本次编程任务是补全右侧代码片段中Begin至End中间的代码。其中,本关声明了一个线性模型 linear,将该模型的相关参数进行操作,具体要求如下:
声明一个 SGD 优化器 optimizer,将 linear 的参数作为优化器的参数传入其中,其学习率lr设为0.1;
利用optimizer.param_groups即可查看优化器的各项参数并输出lr的值。
具体请参见后续测试样例。
-
测试说明
测试过程:
本关涉及的测试文件为optimizerTest.py,运行用户填写后的程序判断正误。
根据程序是否包含创建正则化的关键语句来判断程序是否正确,如是否含有optimizer.param_groups、optim.SGD等语句。
若正确则输出下面的预期输出,否则报错,打印 Sorry ! Check again please!。
以下是测试样例:
测试输入:
预期输出:
lr: 0.1Congratulation!
真正的科学家应当是个幻想家;谁不是幻想家,谁就只能把自己称为实践家。 —— 巴尔扎克
开始你的任务吧,祝你成功!
import torch.nn as nn
import torch.optim
import torch
from torch.autograd import Variable# Linear Regression Model
class LinearRegression(nn.Module):def __init__(self):super(LinearRegression, self).__init__()self.linear = nn.Linear(2, 2) # input and output is 2 dimensiondef forward(self, x):out = self.linear(x)return out
model = LinearRegression()#/********** Begin *********/#声明一个 SGD优化器 optimizer,传入参数#利用optimizer.param_groups查看优化器的各项参数并输出lr的值。#/********** End *********/
第2关:optim.SGD
-
任务描述
本关任务:
本次关卡要求同学们声明一个 SGD优化器 optimizer, 掌握为不同的子网络参数设置不同的学习率,并按照相关格式要求输出相应语句。
-
编程要求
本关涉及的代码文件为 SGDoptimizer.py,本次编程任务是补全右侧代码片段中Begin至End中间的代码,其中,程序提前声明了一个线性模型为model,按照要求利用该模型完成实验,具体要求如下:
声明一个 SGD优化器 optimizer, 其中,模型model中的linear层学习率为默认值1e-5,linear2层的学习率为0.01;
按照“The len of param_groups list:...”格式输出 optimizer.param _groups的长度;
按照“linear's lr:...”格式输出linear层的lr;
按照“linear2's lr:...”格式输出linear2层的lr;
具体请参见后续测试样例。
-
测试说明
测试过程:
本关涉及的测试文件为SGDoptimizerTest.py,运行用户填写后的程序判断正误。
根据程序是否包含创建正则化的关键语句来判断程序是否正确,如是否含有optim.SGD,len(),optimizer.param_groups等语句。
若正确则输出下面的预期输出,否则报错,打印 Sorry ! Check again please!。
注意,在声明变量时请按照提示命名,否则将会报错。
以下是测试样例:
测试输入:
预期输出:
The len of param_groups list: 2
linear's lr: 1e-05
linear2's lr: 0.01
Congratulation!
真正的科学家应当是个幻想家;谁不是幻想家,谁就只能把自己称为实践家。 —— 巴尔扎克
开始你的任务吧,祝你成功!
import torch.nn as nn
import torch.optim
import torch
from torch.autograd import Variable# Linear Regression Model
class LinearRegression(nn.Module):def __init__(self):super(LinearRegression, self).__init__()self.linear = nn.Linear(2, 2) # input and output is 1 dimensionself.linear2 = nn.Linear(2, 2)def forward(self, x):out = self.linear(x)out = self.linear2(out)return out
model = LinearRegression()#/********** Begin *********/#声明一个 SGD优化器 optimizer, 按要求设置 lr 的值
optimizer = torch.optim.SGD([{'params': model.linear.parameters(), 'lr': 1e-5},{'params':model.linear2.parameters()}], lr=0.01, momentum=0.9)
#按照格式输出optimizer.param_groups的长度
print('The len of param_groups list:',len(optimizer.param_groups))
#按照格式输出linear层的lr
print("linear's lr:",optimizer.param_groups[0]['lr'])
#按照格式输出linear2层的lr
print("linear2's lr:",optimizer.param_groups[1]['lr'])#/********** End *********/
第3关:RMSprop
-
任务描述
本关任务:
本关要求同学们声明一个 RMSprop优化器optimizer,设置其lr和alpha的数值。并补充优化器基本使用方法的相关步骤:清空梯度和更新参数。最后,按照格式输出相关信息。
-
编程要求
本关涉及的代码文件为RMSprop.py,本次编程任务是补全右侧代码片段中Begin至End中间的代码。其中,程序提前声明了一个线性模型为model,和训练数据x_train、y_train,按照要求利用这些信息完成实验,具体要求如下:
声明一个 RMSprop优化器optimizer,设置 lr为0.1,alpha为 0.9;
补充优化器基本使用方法的相关步骤:清空梯度,计算Loss,反向传播,更新参数。其中,计算Loss,反向传播两步骤的相关代码已给出;
按照格式“optimizer's lr:... ”输出optimizer的lr;
按照格式“optimizer's alpha:... ”输出optimizer的alpha。
具体请参见后续测试样例。
-
测试说明
测试过程:
本关涉及的测试文件为RMSpropTest.py,运行用户填写后的程序判断正误。
根据程序是否包含创建正则化的关键语句来判断程序是否正确,如是否含有 optim.SGD ,len(),optimizer.param_groups等语句。
若正确则输出下面的预期输出,否则报错,打印 Sorry ! Check again please!。 注意,在声明变量时请按照提示命名,否则将会报错。
以下是测试样例:
测试输入:
预期输出:
optimizer's lr: 0.1
optimizer's alpha: 0.9Congratulation!
真正的科学家应当是个幻想家;谁不是幻想家,谁就只能把自己称为实践家。 —— 巴尔扎克
开始你的任务吧,祝你成功!
import torch
from torch import nn, optim
from torch.autograd import Variable
import numpy as np
# Linear Regression Model
class LinearRegression(nn.Module):def __init__(self):super(LinearRegression, self).__init__()self.linear = nn.Linear(1,1) # input and output is 1 dimensiondef forward(self, x):out = self.linear(x)return outx_train = Variable(torch.randn(1,1))
y_train = Variable(torch.randn(1,1))
criterion = nn.MSELoss()model = LinearRegression()#/********** Begin *********/#声明一个 RMSprop 优化器 optimizer, 按要求设置 lr,alpha 的值
optimizer = torch.optim.RMSprop(model.parameters(), lr=0.1, alpha=0.9)
#清空梯度
optimizer.zero_grad()
#计算Loss
loss = criterion(model(x_train), y_train)
#反向传播
loss.backward()
#更新参数
optimizer.step()
#按照格式输出optimizer的lr
print("optimizer's lr:",optimizer.param_groups[0]['lr'])
##按照格式输出optimizer的alpha
print("optimizer's alpha:",optimizer.param_groups[0]['alpha'])#/********** End *********/第4关:Adam
-
任务描述
本关任务:
本关要求同学们声明两个 Adam 优化器optimizer1和 optimizer2, 分别传入程序提前声明好的线性模型model_Adam1和model_Adam2的参数值,分别设置他们lr和beats的数值。并对每个优化器, 优化属于他的神经网络。从而,根据 loss的值判断哪个优化器表现较好,按照格式输出相关信息。
-
编程要求
本关涉及的代码文件为adam.py,本次编程任务是补全右侧代码片段中Begin至End中间的代码,其中,程序提前声明好的线性模型model_Adam1和model_Adam2,和训练数据x_train、y_train,按照要求利用这些信息完成实验,具体要求如下:
声明一个Adam优化器 optimizer1, 传入model_Adam1的属性值,设置 lr为0.2,betas为(0.9,0.9);
声明一个Adam优化器 optimizer2, 传入model_Adam2的属性值,设置 lr为0.001, betas为(0.9,0.9);
程序对 迭代十次的loss值求和。要求同学们按要求输出相应语句。
若 loss1小于loss2,输出“opt_Adam1 is better than opt_Adam2”;
否则输出“opt_Adam2 is better than opt_Adam1”。
具体请参见后续测试样例。
-
测试说明
测试过程:
本关涉及的测试文件为adamTest.py,运行用户填写后的程序判断正误。
根据程序是否包含创建正则化的关键语句来判断程序是否正确,如是否含有Adam,if,else,lr,betas等语句。
若正确则输出下面的预期输出,否则报错,打印 Sorry ! Check again please!。 注意,在声明变量时请按照提示命名,否则将会报错。
以下是测试样例:
测试输入:
预期输出:
opt_Adam1 is better than opt_Adam2Congratulation!
知识有如人体血液一样的宝贵。人缺少了血液,身体就要衰弱,人缺少了知识,头脑就要枯竭。——高士其
开始你的任务吧,祝你成功!
import torch
from torch import nn, optim
from torch.autograd import Variable
import numpy as np
# Linear Regression Model
class LinearRegression(nn.Module):def __init__(self):super(LinearRegression, self).__init__()self.linear = nn.Linear(2,2) # input and output is 2 dimensiondef forward(self, x):out = self.linear(x)return outx_train = Variable(torch.from_numpy(np.array([[1,2],[3,4]], dtype=np.float32)))
y_train = Variable(torch.from_numpy(np.array([[1,5],[2,8]], dtype=np.float32)))model_Adam1 = LinearRegression()
model_Adam2 = LinearRegression()
models = [model_Adam1,model_Adam2]
#/********** Begin *********/#声明一个Adam优化器 optimizer1, 设置 lr为0.2,betas为(0.9,0.9)
opt_Adam1 = torch.optim.Adam(model_Adam1.parameters(),lr=0.2,betas=(0.9,0.9))
#声明一个Adam优化器 optimizer2, 设置 lr为0.001,betas为(0.9,0.9)
opt_Adam2 = torch.optim.Adam(model_Adam2.parameters(),lr=0.001,betas=(0.9,0.9))optimizers = [opt_Adam1,opt_Adam2]
losses_his = [[],[]]
loss_func = nn.MSELoss()for epoch in range(10):# 对每个优化器, 优化属于他的神经网络for model,opt, l_his in zip(models,optimizers, losses_his):output = model(x_train)loss = loss_func(output, y_train)opt.zero_grad()loss.backward()opt.step()l_his.append(loss.item())
loss1 = sum(losses_his[0])
loss2 = sum(losses_his[1])#利用 if-else 结构判断 loss1、loss2的大小
#若loss1小于loss2,输出“opt_Adam1 is better than opt_Adam2”;
#否则输出“opt_Adam2 is better than opt_Adam1”。
if loss1 > loss2:print("opt_Adam2 is better than opt_Adam1")
else:print("opt_Adam1 is better than opt_Adam2")#/********** End *********/第5关:优化器总结
-
任务描述
本关任务:
本关要求同学们掌握不同优化器的特点,根据提示,利用不同的优化器进行训练,并利用loss 画图。
-
编程要求
本关涉及的代码文件为compare.py,本次编程任务是补全右侧代码片段中Begin至End中间的代码。根据提示,计算并利用loss 画图。
-
测试说明
我会对你编写的代码进行测试:
测试过程:
本关涉及的测试文件为compareTest.py,运行用户填写后的程序判断正误。
根据程序是否包含创建正则化的关键语句来判断程序是否正确。
若正确则输出下面的预期输出,否则报错。
注意,在声明变量时请按照提示命名,否则将会报错。
测试输入:
预期输出:
Congratulation!
开始你的任务吧,祝你成功!
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variableimport matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as pltimport warnings
warnings.filterwarnings('ignore')import os,sys
path = os.path.split(os.path.abspath(os.path.realpath(sys.argv[0])))[0] + os.path.sep
print("validation path:" ,path)#定义参数
LR = 0.01
BATCH_SIZE = 32
EPOCH = 10x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1)
y = x.pow(2) + 0.1*torch.randn(x.size())
# torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)# 默认的 network 形式
class Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.hidden = torch.nn.Linear(1, 40)self.predict = torch.nn.Linear(40, 1)def forward(self, x):#隐藏层的激活函数x = F.relu(self.hidden(x))#线性输出x = self.predict(x)return xnet_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]#/********** Begin *********/opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)# 声明优化器opt_Momentum,传入对应的模型参数,lr 赋值为 LR,momentum为0.7
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(),lr=LR,momentum=0.7)
# 声明优化器opt_RMSprop,传入对应的模型参数,lr 赋值为 LR,alpha为0.9
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(),lr=LR,alpha=0.9)
# 声明优化器opt_Adam,传入对应的模型参数,lr 赋值为 LR,betas为(0.9, 0.99)
opt_Adam = torch.optim.Adam(net_Adam.parameters(),lr=LR,betas=(0.9,0.99))#/********** End *********/
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
loss_func = torch.nn.MSELoss()losses_his = [[], [], [], []]#训练循环
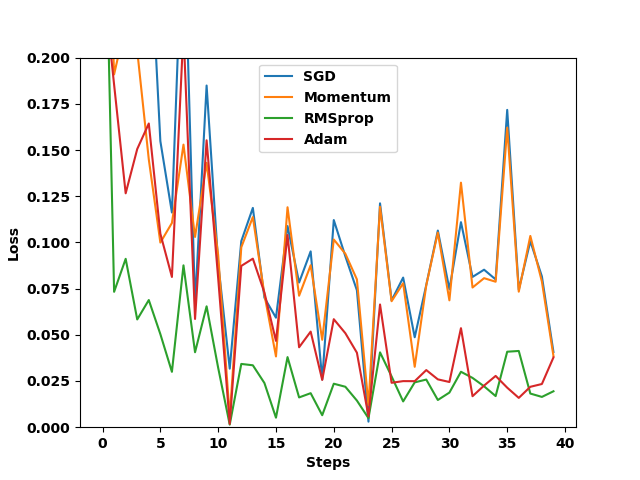
for epoch in range(EPOCH):for step, (batch_x, batch_y) in enumerate(loader):b_x = Variable(batch_x)b_y = Variable(batch_y)for net, opt, l_his in zip(nets, optimizers, losses_his):output = net(b_x)loss = loss_func(output, b_y)#/********** Begin *********/opt.zero_grad()# 反向传播loss.backward()# 更新参数 opt.step()# 记录损失 l_his.append(loss.item()) #/********** End *********/#画图
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_his):plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.savefig(path + "outputimages/mylossTest.png")
相关文章:
头歌之动手学人工智能-Pytorch 之优化
目录 第1关:如何使用optimizer 任务描述 编程要求 测试说明 真正的科学家应当是个幻想家;谁不是幻想家,谁就只能把自己称为实践家。 —— 巴尔扎克开始你的任务吧,祝你成功! 第2关:optim.SGD 任务描述…...

基于谷歌ADK的智能客服系统简介
Google的智能体开发工具包(Agent Development Kit,简称ADK)是一个开源的、以代码为中心的Python工具包,旨在帮助开发者更轻松、更灵活地构建、评估和部署复杂的人工智能智能体(AI Agent)。ADK 是一个灵活的…...

(一)视觉——工业相机(以海康威视为例)
一、工业相机介绍 工业相机是机器视觉系统中的一个关键组件,其最本质的功能就是将光信号转变成有序的电信号。选择合适的相机也是机器视觉系统设计中的重要环节,相机的选择不仅直接决定所采集到的图像分辨率、图像质量等,同时也与整个系统的运…...
DAY 36 超大力王爱学Python
仔细回顾一下神经网络到目前的内容,没跟上进度的同学补一下进度。 作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。探索性作业(随意完成):尝试进入nn.Mo…...

基于React + TypeScript构建高度可定制的QR码生成器
前言 在现代Web应用中,QR码已成为连接线上线下的重要桥梁。本文将详细介绍如何使用React TypeScript Vite构建一个功能强大、高度可定制的QR码生成器,支持背景图片、文本叠加、HTML模块、圆角导出等高级功能。 前往试试 项目概述 技术栈 前端框架:…...

DeepSeek进阶教程:实时数据分析与自动化决策系统
进阶教程:实时数据分析与自动化决策系统 1. 实时数据流处理架构 class StreamProcessor:def __init__(self):self.window_size = 60 # 滑动窗口大小(秒)self.analytics_engine = AnalyticsEngine() # 复用之前的分析引擎def process_kafka_stream(self, topic):"&quo…...

visual studio 2022 初学流程
本文采用总-分的形式讲述流程 1.前端外部可以使用的接口 ExternalDataWebService.asmx?opReportWaterForWayder 新建ExternalDataWebService.asmx 文件 <% WebService Language"C#" CodeBehind"~/App_Code/ExternalDataWebService.cs" Class…...
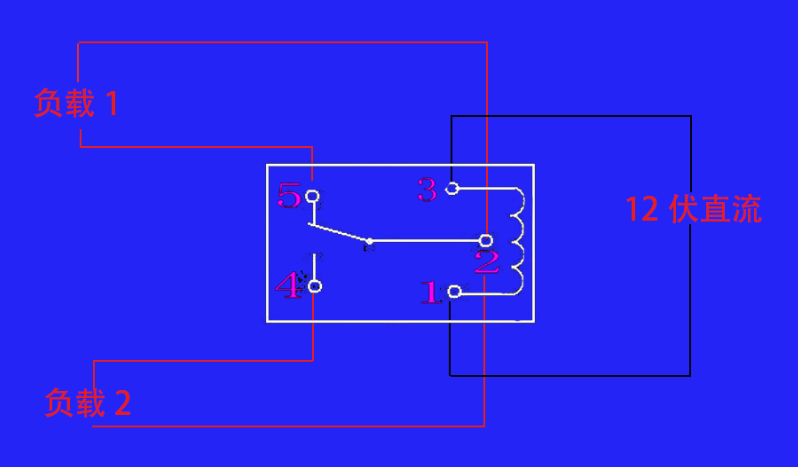
SRD-12VDC-SL-C 继电器接线图解
这个继电器可以使用12伏的直流电源控制250伏和125伏的交流电,也可以控制30伏和28伏的直流电,电流都为10安。 此继电器有5个引脚,各个的作用如下: 引脚4和引脚5为触点, 引脚1和引脚3为线圈引脚,接12伏的直…...

基于开源链动2+1模式AI智能名片S2B2C商城小程序的企业组织生态化重构研究
摘要:本文以互联网时代企业组织结构变革为背景,探讨开源链动21模式AI智能名片S2B2C商城小程序在推动企业从封闭式向开放式生态转型中的核心作用。通过分析传统企业资源获取模式与网络化组织生态的差异,结合开源链动21模式的裂变机制、AI智能名…...

前端面经 两栏布局
两栏布局 float实现 1.给父盒子加float:hidden实现BFC 2.给左盒子加浮动float:left 给宽度 flex布局 1父盒子 display:flex 2左盒子 固定宽度 3.右盒子 flex:1 三栏布局 法1:浮动实现 1 父盒子overflow:hidden 实现BFC 2左盒子:float:left 3右盒子 :floa…...
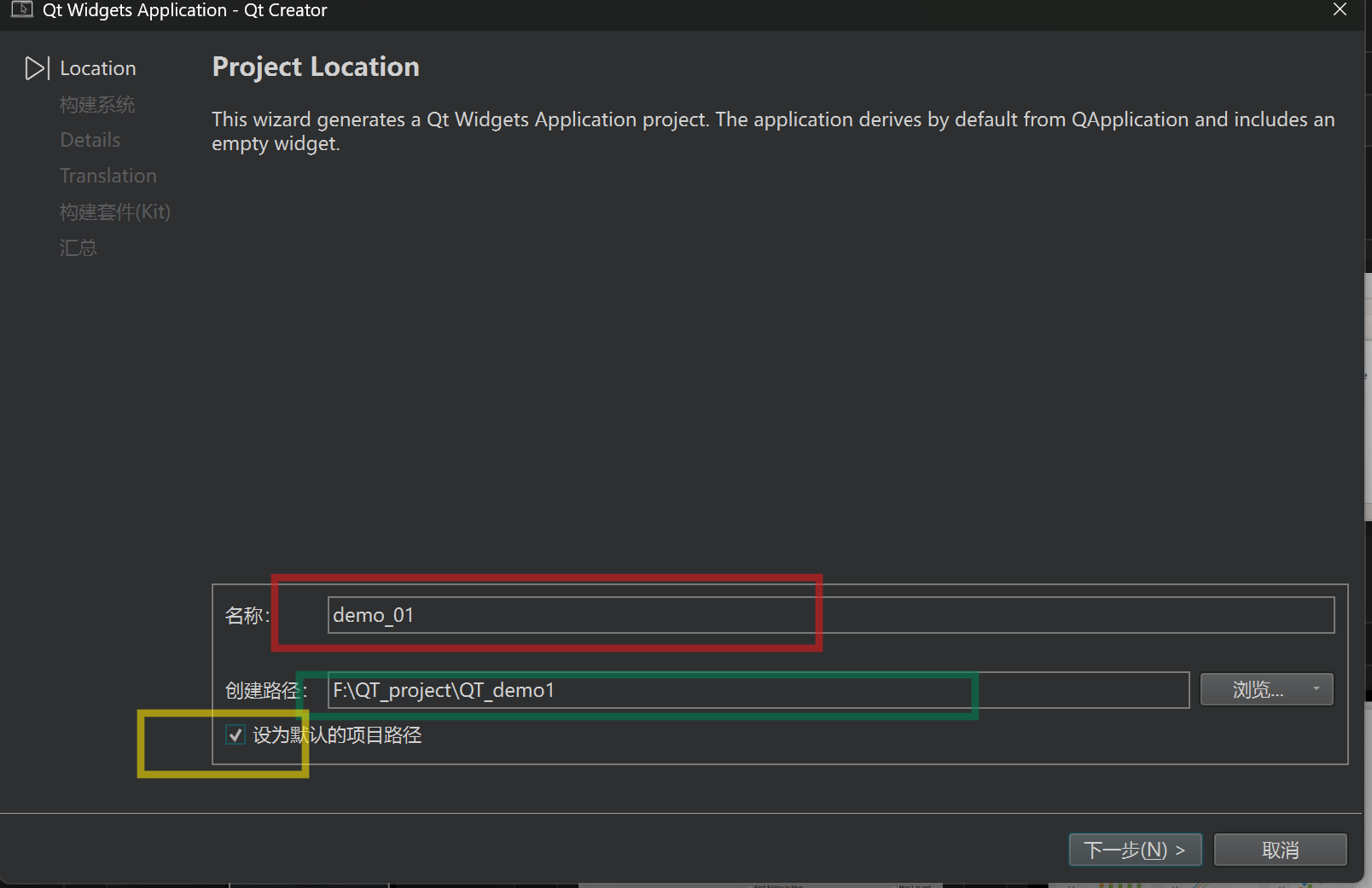
2,QT-Creator工具创建新项目教程
目录 1,创建一个新项目 demo_01.pro(项目配置文件) 类似 CMakeList.txt widget.h(头文件) main.cpp(程序入口) widget.cpp(源文件) widget.ui(界面设计文件) 1,创建一个新项目 依次选择: 设置路径: 选择编译器: 如果选择CMake, 就会生成cmakel…...
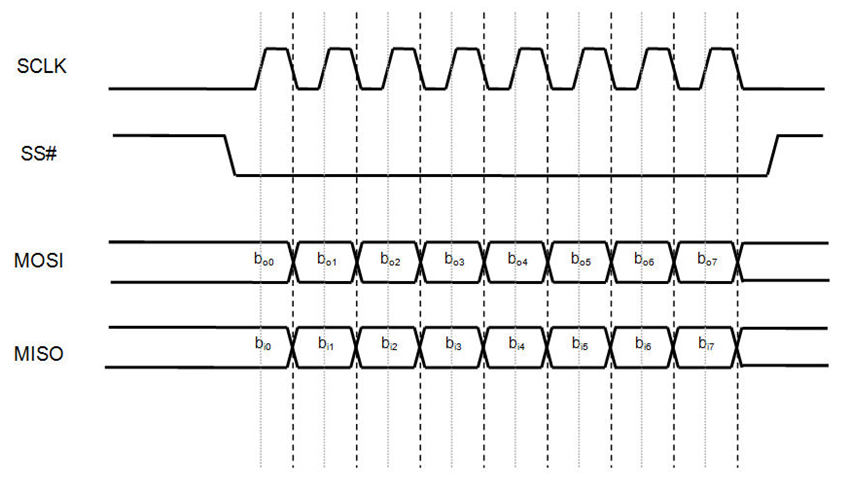
《深入解析SPI协议及其FPGA高效实现》-- 第一篇:SPI协议基础与工作机制
第一篇:SPI协议基础与工作机制 1. 串行外设接口导论 1.1 SPI的核心定位 协议本质 : 全双工同步串行协议(对比UART异步、IC半双工)核心优势 : 无寻址开销(通过片选直连)时钟速率可达100MHz&…...
2025年5月6日 飞猪Java一面
锐评 鸡蛋鸭蛋荷包蛋 我的蛋仔什么时候才能上巅峰凤凰蛋? 1. 如何保证数据库数据和redis数据一致性 数据库数据和 redis 数据不一致是在 高并发场景下更新数据的情况 首先我们要根据当前保持数据一致性的策略来决定方案 如果采取的策略是先删除缓存 更新数据库 我们假设现…...

技术深度解析:《鸿蒙5.0+:AI驱动的全场景功耗革命》
引言:鸿蒙5.0的能效革新目标 行业挑战: 移动设备多设备协同需求激增,传统系统面临分布式通信开销、AI算力碎片化、边缘设备能效瓶颈等问题。鸿蒙5.0突破: 引入方舟引擎3.0(ArkTS编译优化…...

Nodejs+http-server 使用 http-server 快速搭建本地图片访问服务
在开发过程中,我们经常需要临时查看或分享本地的图片资源,比如设计稿、截图、素材等。虽然可以通过压缩发送,但效率不高。本文将教你使用 Node.js 的一个轻量级工具 —— http-server,快速搭建一个本地 HTTP 图片预览服务…...

Zsh/Bash Conda设置延迟启动,启动速度优化
Zsh/Bash 启动速度优化 在安装完 Conda 之后,会发现每次启动 Zsh/Bash 的时候都需要加载时间,这个时候就会发现没有以前流畅了,原因是因为每次启动 Shell 时都需要去加载 Conda 环境,才能保证每次可以使用工具。然而官方自带的安…...
【AI论文】推理语言模型的强化学习熵机制
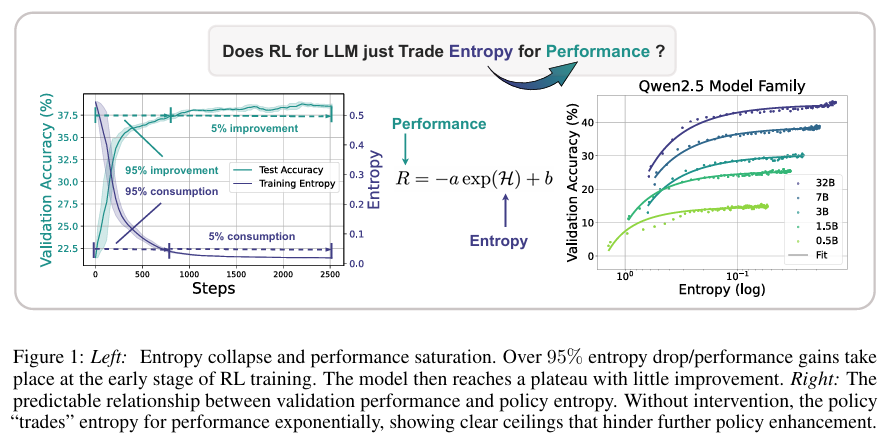
摘要:本文旨在克服将强化学习扩展到使用 LLM 进行推理的主要障碍,即策略熵的崩溃。 这种现象在没有熵干预的RL运行中一直存在,其中策略熵在早期训练阶段急剧下降,这种探索能力的减弱总是伴随着策略性能的饱和。 在实践中ÿ…...

Java中的JSONObject详解:从基础到高级应用
Java中的JSONObject详解:从基础到高级应用 在当今前后端分离的架构中,JSONObject已成为Java开发者处理JSON数据的瑞士军刀。本文将深入解析JSONObject的核心机制与实战技巧。 一、JSONObject的本质与实现库 1.1 核心定位 JSONObject是Java中表示JSON对…...
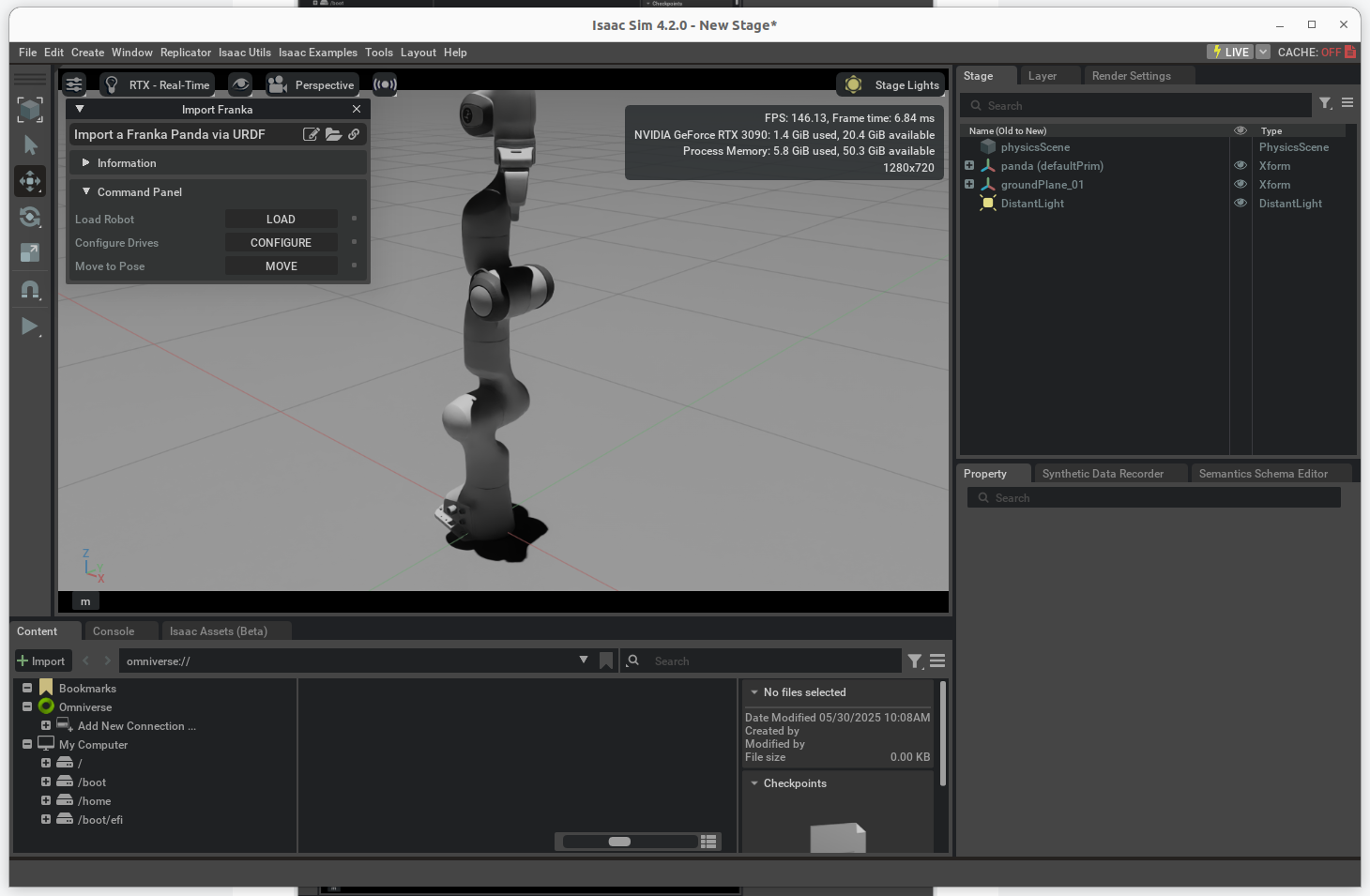
Ubuntu22.04 安装 IsaacSim 4.2.0
1. 从官网下载 IsaacSim 4.2.0 安装包 https://download.isaacsim.omniverse.nvidia.com/isaac-sim-standalone%404.2.0-rc.18%2Brelease.16044.3b2ed111.gl.linux-x86_64.release.zip 2. 查阅 Workstation Installation 安装方式 Workstation Installation — Isaac Sim Do…...

子串题解——和为 K 的子数组【LeetCode】
谨记: 数组不是单调的话,不要用滑动窗口,考虑用前缀和 写法一:两次遍历 代码的核心思想是通过 前缀和 和 哈希表 来高效地统计符合条件的子数组个数。具体步骤如下: 计算前缀和数组 s: s[i] 表示 nums 的前…...

深入理解设计模式之访问者模式
深入理解设计模式之访问者模式(Visitor Pattern) 一、什么是访问者模式? 访问者模式(Visitor Pattern)是一种行为型设计模式。它的主要作用是将数据结构与数据操作分离,使得在不改变数据结构的前提下&…...

Java代码重构:如何提升项目的可维护性和扩展性?
Java代码重构:如何提升项目的可维护性和扩展性? 在Java开发领域,随着项目规模的不断扩大和业务需求的频繁变更,代码的可维护性和扩展性逐渐成为了项目成功的关键因素。代码重构作为一种优化代码质量的重要手段,能够在…...
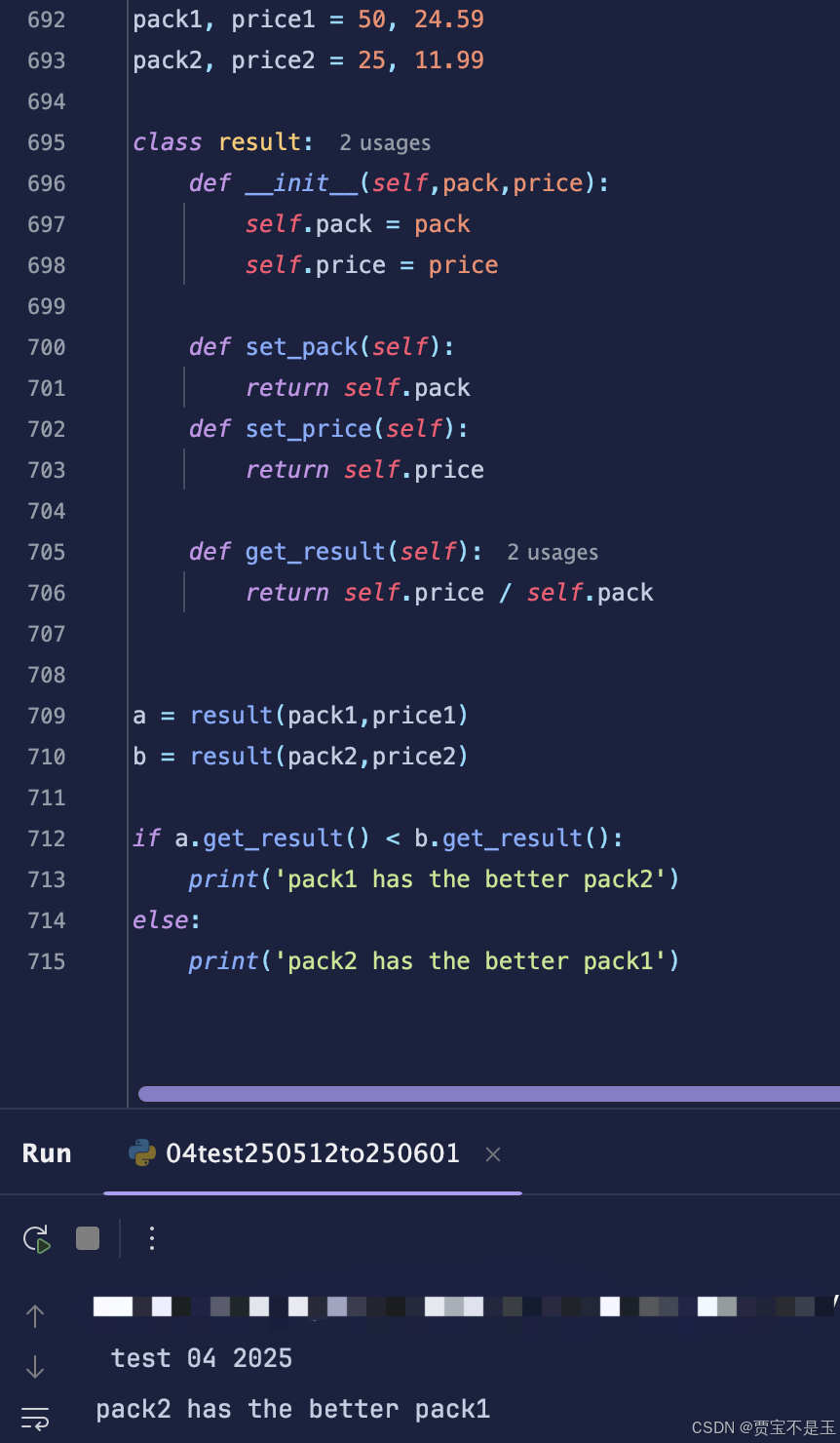
《Python语言程序设计》2018 第4章第9题3重量和价钱的对比,利用第7章的概念来解答你
利用类来解答这个问题。 pack1, price1 50, 24.59 pack2, price2 25, 11.99class result:def __init__(self,pack,price):self.pack packself.price pricedef set_pack(self):return self.packdef set_price(self):return self.pricedef get_result(self):return self.pric…...

Nginx安装操作命令
Nginx官网:https://nginx.org/ Nginx下载地址:http://nginx.org/en/download.html # 重载nginx服务 systemctl reload nginx # 启动nginx服务 systemctl start nginx # 关闭nginx服务 systemctl stop nginx # 设置nginx服务开机自启动 systemctl enable…...
在IIS上无法使用PUT等请求
错误来源: chat:1 Access to XMLHttpRequest at http://101.126.139.3:11000/api/receiver/message from origin http://101.126.139.3 has been blocked by CORS policy: No Access-Control-Allow-Origin header is present on the requested resource. 其实我的后…...
 B. Gellyfish and Baby‘s Breath)
Codeforces Round 1028 (Div. 2) B. Gellyfish and Baby‘s Breath
Codeforces Round 1028 (Div. 2) B. Gellyfish and Baby’s Breath 题目 Flower gives Gellyfish two permutations ∗ ^{\text{∗}} ∗ of [ 0 , 1 , … , n − 1 ] [0, 1, \ldots, n-1] [0,1,…,n−1]: p 0 , p 1 , … , p n − 1 p_0, p_1, \ldots, p_{n-1} p0,p1,……...

数据基座觉醒!大数据+AI如何重构企业智能决策金字塔(上)
1. 数据金字塔的千年进化史 1.1 从地窖到云端的存储革命 某家电企业在2010年遭遇库存危机时,市场部门需要三天才能从纸质单据中统计出全国滞销型号。当他们的数据工程师在2023年轻声唤醒对话式分析机器人,同样的需求响应时间缩短至9秒。 数据分层架构的…...

前端八股HTTP和https大全套
htttp 超文本传输协议 特点 1.CS 支持客户端服务器端模式 2.灵活 传输任意形式的数据 content-type规定 3.明文传输,https解决 4.无连接:每次连接仅处理一个请求 解决:1.1长连接 5.无状态,无法保存两次http连接之间的关联信…...

使用 DeepSeek API 搭建智能体《无间》- 卓伊凡的完整指南 -优雅草卓伊凡
使用 DeepSeek API 搭建智能体《无间》- 卓伊凡的完整指南 -优雅草卓伊凡 作者:卓伊凡 前言:为什么选择 DeepSeek API,而非私有化部署? 在开始搭建智能体之前,我想先说明 为什么推荐使用 DeepSeek API,而…...

量子语言模型——where to go
1️⃣ 在大语言模型(LLM)高度发达的今天,还研究这些小模型(如n-gram、RNN、量子语言模型)是否有意义? ✅ 有意义,但意义已经转变了——不再是用于「直接生产 SOTA 应用」,而是&…...