西瓜书第十一章——降维与度量学习

文章目录
- 降维与度量学习
- k近邻学习原理
- 头歌实战-numpy实现KNN
- sklearn实现KNN
- 降维——多维缩放(Multidimensional Scaling, MDS,MDS)提出背景与原理重述
- 1.**提出背景**
- 2.**数学建模与原理推导**
- 3.**关键推导步骤**
- Principal Component Analysis, PCA 主成分分析
- 1.**提出背景与有效性基础**
- 2.**优化问题的等价性证明**
- 3.**数学求解与有效性保障**
降维与度量学习
k近邻学习原理
KNN有什么显著的特征?
第一是Lazy Learning,没有显式的训练阶段,实现非常简单
第二是直接支持多分类,而一些二分类模型例如SVM需要借助OvO或者OvM训练多个模型来进行多分类
KNN需要注意的点?
超参数k的选择非常非常重要,过小则过拟合,过大则欠拟合,因此需要进行进行多折交叉验证确定最佳的k
最后是需要对特征进行归一化防止大数吃小数
k近邻(k-Nearest Neighbor, kNN)是一种基于实例的监督学习算法,其核心机制为局部相似性归纳。给定测试样本,算法通过度量空间中的距离函数,从训练集中选取与之最近的k个样本,利用这些邻居的类别标签进行预测。最关键的是选取合适的k,k过小即过拟合,过大则欠拟合
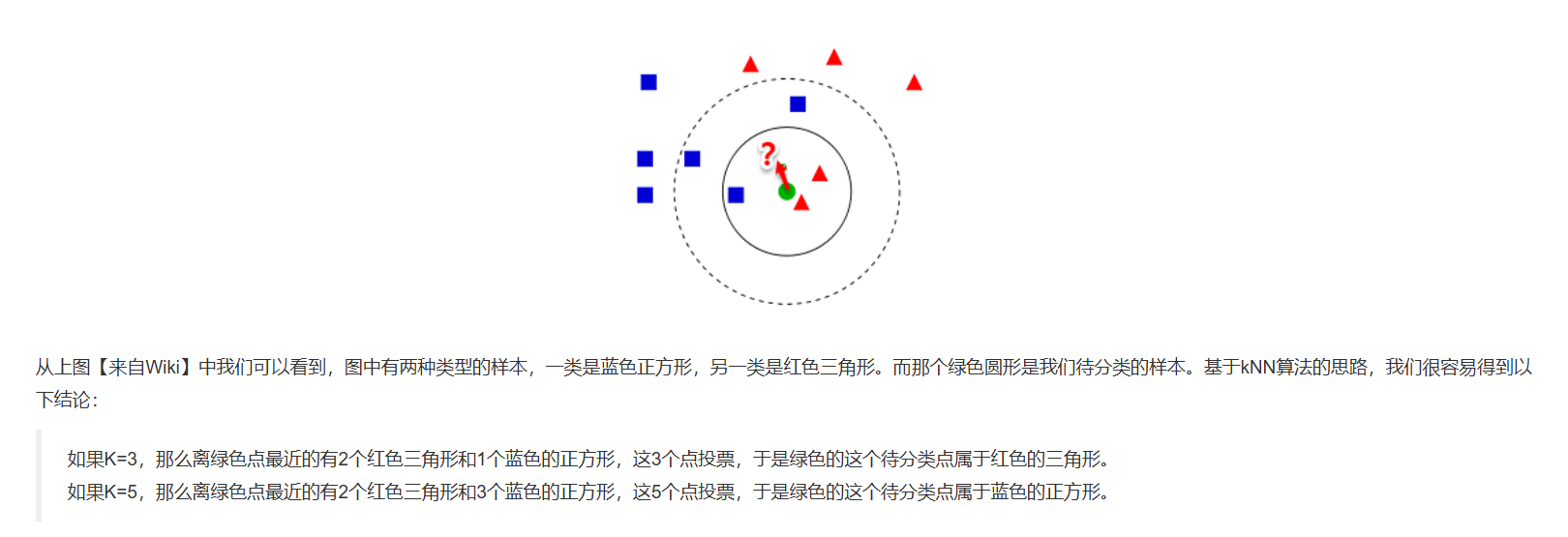
- 天然支持多分类!
- 原理实现简单
具体流程如下:
-
距离度量
设样本空间为 X ⊆ R n \mathcal{X} \subseteq \mathbb{R}^n X⊆Rn,给定距离函数 d : X × X → R + d:\mathcal{X} \times \mathcal{X} \rightarrow \mathbb{R}^+ d:X×X→R+(如闵可夫斯基距离 d p ( x i , x j ) = ( ∑ u = 1 n ∣ x i u − x j u ∣ p ) 1 / p d_{p}(\boldsymbol{x}_i,\boldsymbol{x}_j) = (\sum_{u=1}^n |x_{iu}-x_{ju}|^p)^{1/p} dp(xi,xj)=(∑u=1n∣xiu−xju∣p)1/p),计算测试样本与所有训练样本的相似性。常见特例包括:- 曼哈顿距离( p = 1 p=1 p=1)
- 欧氏距离( p = 2 p=2 p=2)
- 切比雪夫距离( p → ∞ p \rightarrow \infty p→∞)
-
近邻选择
根据距离排序,选择与测试样本距离最小的k个训练样本,构成邻域集合 N k ( x ) = { ( x i , y i ) ∈ D ∣ d ( x , x i ) ≤ d ( x , x ( k ) ) } N_k(\boldsymbol{x}) = \{ (\boldsymbol{x}_i,y_i) \in D \, | \, d(\boldsymbol{x},\boldsymbol{x}_i) \leq d(\boldsymbol{x},\boldsymbol{x}_{(k)}) \} Nk(x)={(xi,yi)∈D∣d(x,xi)≤d(x,x(k))},其中 D D D为训练集, d ( x , x ( k ) ) d(\boldsymbol{x},\boldsymbol{x}_{(k)}) d(x,x(k))为第k小的距离值。 -
决策函数
- 分类任务:采用多数投票法,即
y = arg max c ∈ Y ∑ ( x i , y i ) ∈ N k ( x ) I ( y i = c ) y = \arg\max_{c \in \mathcal{Y}} \sum_{(\boldsymbol{x}_i,y_i) \in N_k(\boldsymbol{x})} \mathbb{I}(y_i = c) y=argc∈Ymax(xi,yi)∈Nk(x)∑I(yi=c) - 回归任务:采用均值法,即
y = 1 k ∑ ( x i , y i ) ∈ N k ( x ) y i y = \frac{1}{k} \sum_{(\boldsymbol{x}_i,y_i) \in N_k(\boldsymbol{x})} y_i y=k1(xi,yi)∈Nk(x)∑yi
- 分类任务:采用多数投票法,即
-
关键参数与优化
- k值选择:通过交叉验证确定最优k值。较小k值易受噪声干扰(过拟合),较大k值导致决策边界模糊(欠拟合)。
- 维度归一化:对特征进行标准化处理(如Z-score),消除量纲差异对距离度量的影响。
- 距离加权:引入权值函数(如 w i = 1 / d ( x , x i ) w_i = 1/d(\boldsymbol{x},\boldsymbol{x}_i) wi=1/d(x,xi)),使近邻对决策的贡献度随距离衰减。
-
算法特性
- 懒惰学习(Lazy Learning):无显式训练阶段,计算延迟至预测时执行。
- 维度敏感性:高维数据下,样本稀疏性与距离计算复杂度显著增加,需结合降维技术(如PCA、LDA)优化性能。
- 决策边界:kNN生成的决策边界为非线性分段超平面,模型复杂度随k值增大而降低。
理论依据
kNN的泛化误差收敛性由Cover和Hart定理保证:当训练样本趋于无限且 k → ∞ k \rightarrow \infty k→∞、 k / n → 0 k/n \rightarrow 0 k/n→0时,分类错误率不超过贝叶斯最优错误率的两倍。该性质揭示了kNN在渐进意义下的统计合理性。
头歌实战-numpy实现KNN
#encoding=utf8
import numpy as np
from collections import Counterclass kNNClassifier(object):def __init__(self, k):'''初始化函数:param k:kNN算法中的k'''self.k = k# 用来存放训练数据,类型为ndarrayself.train_feature = None# 用来存放训练标签,类型为ndarrayself.train_label = Nonedef fit(self, feature, label):'''kNN算法的训练过程:param feature: 训练集数据,类型为ndarray:param label: 训练集标签,类型为ndarray:return: 无返回'''#********* Begin *********#self.train_feature=featureself.train_label=label#********* End *********#def predict(self, feature):'''kNN算法的预测过程:param feature: 测试集数据,类型为ndarray:return: 预测结果,类型为ndarray或list'''#********* Begin *********##测试集中的feature也是多个的predict=[]#需要遍历测试集中的featurefor sample in feature:distance=np.sum((sample-self.train_feature)**2,axis=1)**(1.0/2)#(samples,)#获取前k个近邻的索引index=np.argsort(distance)[:self.k] #获取这几个索引的labelpre_label=self.train_label[index]#统计每个标签的频次label_count=Counter(pre_label)#字典数据Counter({#label1: count1,#label2: count2,#...#})#找出次数最多的标签所对应的次数,因此这个max_count事实上是一个整数max_count = max(label_count.values())most_common_labels = [label for label , count in label_count.items() if count== max_count]#事实上,还需要处理频次相同的情况,但是此处只需要0.9的正确率就够了predict.append(most_common_labels[0])return predict#********* End *********#
sklearn实现KNN
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScalerdef classification(train_feature, train_label, test_feature):'''对test_feature进行红酒分类:param train_feature: 训练集数据,类型为ndarray:param train_label: 训练集标签,类型为ndarray:param test_feature: 测试集数据,类型为ndarray:return: 测试集数据的分类结果'''#********* Begin *********## 实例化StandardScaler对象scaler = StandardScaler()after_scaler_train = scaler.fit_transform(train_feature)after_scaler_test = scaler.fit_transform(test_feature)#生成K近邻分类器clf=KNeighborsClassifier(n_neighbors=8,p=2) #训练分类器clf.fit(after_scaler_train,train_label)#进行预测predict_result=clf.predict(after_scaler_test)return predict_result#********* End **********#降维——多维缩放(Multidimensional Scaling, MDS,MDS)提出背景与原理重述
1.提出背景
在高维数据分析中,降维操作需满足拓扑不变性约束:降维后的低维空间应保持原始高维空间中样本间距离的全局几何关系。多维缩放(Multidimensional Scaling, MDS)的核心目标即通过数学变换,将原始样本投影至低维嵌入空间,使得任意两样本在低维空间中的欧氏距离与原始空间中的广义距离严格一致,从而避免降维导致的样本分布畸变。
2.数学建模与原理推导
设原始空间存在 m m m个样本,其距离矩阵为 D ∈ R m × m \boldsymbol{D} \in \mathbb{R}^{m \times m} D∈Rm×m,其中 D i j D_{ij} Dij表示样本 x i \boldsymbol{x}_i xi与 x j \boldsymbol{x}_j xj的原始距离(不限定欧氏距离)。MDS要求构造低维坐标矩阵 Z ∈ R m × d ′ \boldsymbol{Z} \in \mathbb{R}^{m \times d'} Z∈Rm×d′( d ′ ≪ d d' \ll d d′≪d),使得两样本在高维空间的距离等于投影之后在低位空间中的欧式距离:
∥ z i − z j ∥ 2 = D i j , ∀ i , j ∈ { 1 , 2 , . . . , m } \|\boldsymbol{z}_i - \boldsymbol{z}_j\|_2 = D_{ij}, \quad \forall i,j \in \{1,2,...,m\} ∥zi−zj∥2=Dij,∀i,j∈{1,2,...,m}
3.关键推导步骤
-
中心化约束
令低维坐标矩阵 Z \boldsymbol{Z} Z满足中心化条件: ∑ i = 1 m z i = 0 \sum_{i=1}^m \boldsymbol{z}_i = \boldsymbol{0} ∑i=1mzi=0。此时,内积矩阵 B = Z Z ⊤ ∈ R m × m \boldsymbol{B} = \boldsymbol{Z}\boldsymbol{Z}^\top \in \mathbb{R}^{m \times m} B=ZZ⊤∈Rm×m的每行(列)和为0,即:
∑ i = 1 m B i j = ∑ j = 1 m B i j = 0 \sum_{i=1}^m B_{ij} = \sum_{j=1}^m B_{ij} = 0 i=1∑mBij=j=1∑mBij=0 -
距离与内积的转换
低维欧氏距离平方可展开为:
D i j 2 = ∥ z i ∥ 2 + ∥ z j ∥ 2 − 2 z i ⊤ z j D_{ij}^2 = \|\boldsymbol{z}_i\|^2 + \|\boldsymbol{z}_j\|^2 - 2\boldsymbol{z}_i^\top \boldsymbol{z}_j Dij2=∥zi∥2+∥zj∥2−2zi⊤zj
结合中心化条件,定义辅助变量:- 行内积均值: T i = 1 m ∑ j = 1 m B i j T_i = \frac{1}{m} \sum_{j=1}^m B_{ij} Ti=m1∑j=1mBij
- 全局内积均值: T = 1 m 2 ∑ i = 1 m ∑ j = 1 m B i j T = \frac{1}{m^2} \sum_{i=1}^m \sum_{j=1}^m B_{ij} T=m21∑i=1m∑j=1mBij
通过代数运算可得内积矩阵元素:
B i j = − 1 2 ( D i j 2 − T i − T j + T ) B_{ij} = -\frac{1}{2} \left( D_{ij}^2 - T_i - T_j + T \right) Bij=−21(Dij2−Ti−Tj+T) -
矩阵重构与特征分解
对 B \boldsymbol{B} B进行特征值分解:
B = V Λ V ⊤ \boldsymbol{B} = \boldsymbol{V} \boldsymbol{\Lambda} \boldsymbol{V}^\top B=VΛV⊤
其中 Λ = diag ( λ 1 , λ 2 , . . . , λ m ) \boldsymbol{\Lambda} = \text{diag}(\lambda_1, \lambda_2, ..., \lambda_m) Λ=diag(λ1,λ2,...,λm)为特征值对角矩阵(降序排列), V \boldsymbol{V} V为对应特征向量矩阵。选取前 d ′ d' d′个正特征值及其特征向量,则低维坐标为:
Z = V [ : , 1 : d ′ ] Λ [ 1 : d ′ , 1 : d ′ ] 1 / 2 \boldsymbol{Z} = \boldsymbol{V}_{[:,1:d']} \boldsymbol{\Lambda}_{[1:d',1:d']}^{1/2} Z=V[:,1:d′]Λ[1:d′,1:d′]1/2
算法流程
- 输入:距离矩阵 D ∈ R m × m \boldsymbol{D} \in \mathbb{R}^{m \times m} D∈Rm×m,目标维度 d ′ d' d′
- 计算内积矩阵
- 计算双中心化矩阵:
B i j = − 1 2 ( D i j 2 − 1 m ∑ k = 1 m D i k 2 − 1 m ∑ k = 1 m D k j 2 + 1 m 2 ∑ k = 1 m ∑ l = 1 m D k l 2 ) B_{ij} = -\frac{1}{2} \left( D_{ij}^2 - \frac{1}{m} \sum_{k=1}^m D_{ik}^2 - \frac{1}{m} \sum_{k=1}^m D_{kj}^2 + \frac{1}{m^2} \sum_{k=1}^m \sum_{l=1}^m D_{kl}^2 \right) Bij=−21(Dij2−m1k=1∑mDik2−m1k=1∑mDkj2+m21k=1∑ml=1∑mDkl2)
- 计算双中心化矩阵:
- 特征分解
- 对 B \boldsymbol{B} B进行特征分解,保留前 d ′ d' d′个最大正特征值及对应特征向量
- 输出:低维坐标矩阵 Z ∈ R m × d ′ \boldsymbol{Z} \in \mathbb{R}^{m \times d'} Z∈Rm×d′
理论意义与局限性
- 保距性:MDS严格保持样本间距离,适用于欧氏距离保持场景
- 计算复杂度:特征分解 复杂度为 O ( m 3 ) O(m^3) O(m3),不适用于大规模数据
- 扩展性:经典MDS假设原始距离为欧氏距离,对非度量型距离需采用非度量MDS变体
Principal Component Analysis, PCA 主成分分析
为什么PCA有效?
从最大可分性的角度理解,我们要求降维后的样本在低位空间上仍然能够做到坐标间的方差最大化,使得数据分布能尽可能分散以增强可分性。然而,以协方差矩阵的特征值最大的特征向量方向投影就是能够最大化可分性目标的做法两者是等价的。
PCA的过程是什么?
首先对每个样本点减去特征均值,然后 X X T XX^T XXT获得协方差矩阵。然后特征分解求得前d个最大的特征值,将这些特征值的特征向量作为投影的矩阵。达到降维的目的
PCA有什么局限?
只能捕捉线性结构的特征,对于非线性流形需要引入kernel PCA
1.提出背景与有效性基础
主成分分析(Principal Component Analysis, PCA)作为线性降维技术的代表,其有效性建立在统计最优性准则与几何投影理论的等价性上。面对高维数据中普遍存在的特征冗余与维度灾难问题,主成分分析(PCA)直接通过一个线性变换,将原始空间中的样本投影到新的低维空间中。简单来理解这一过程便是:PCA采用一组新的基来表示样本点,其中每一个基向量都是原来基向量的线性组合,通过使用尽可能少的新基向量来表出样本,从而达到降维的目的。
-
最近重构性(Minimum Reconstruction Error)
要求投影后的低维坐标能最大程度保留原始高维数据的拓扑结构,即样本点到投影超平面的垂直距离平方和最小:
min W ⊤ W = I ∑ i = 1 m ∥ x i − W W ⊤ x i ∥ 2 \min_{\boldsymbol{W}^\top\boldsymbol{W} = \boldsymbol{I}} \sum_{i=1}^m \|\boldsymbol{x}_i - \boldsymbol{W}\boldsymbol{W}^\top\boldsymbol{x}_i\|^2 W⊤W=Imini=1∑m∥xi−WW⊤xi∥2
其中 W ∈ R d × d ′ \boldsymbol{W} \in \mathbb{R}^{d \times d'} W∈Rd×d′为投影矩阵,约束条件 W ⊤ W = I \boldsymbol{W}^\top\boldsymbol{W} = \boldsymbol{I} W⊤W=I保证基向量正交归一化。 -
最大可分性(Maximum Variance Projection)
要求投影后样本在低维空间的坐标方差最大化,使数据分布尽可能分散以增强可分性:
max W ⊤ W = I tr ( W ⊤ X ⊤ X W ) \max_{\boldsymbol{W}^\top\boldsymbol{W} = \boldsymbol{I}} \text{tr}\left( \boldsymbol{W}^\top\boldsymbol{X}^\top\boldsymbol{X}\boldsymbol{W} \right) W⊤W=Imaxtr(W⊤X⊤XW)
此处 X ∈ R m × d \boldsymbol{X} \in \mathbb{R}^{m \times d} X∈Rm×d为数据中心化后的样本矩阵,协方差矩阵 Σ = 1 m X ⊤ X \boldsymbol{\Sigma} = \frac{1}{m}\boldsymbol{X}^\top\boldsymbol{X} Σ=m1X⊤X。因此事实上沿着协方差矩阵特征值较大的特征向量的方向投影就使得投影之后的方差较大
2.优化问题的等价性证明
通过代数变换可证上述两目标函数等价:
∑ i = 1 m ∥ x i − W W ⊤ x i ∥ 2 = tr ( X ⊤ X ) − tr ( W ⊤ X ⊤ X W ) \sum_{i=1}^m \|\boldsymbol{x}_i - \boldsymbol{W}\boldsymbol{W}^\top\boldsymbol{x}_i\|^2 = \text{tr}(\boldsymbol{X}^\top\boldsymbol{X}) - \text{tr}(\boldsymbol{W}^\top\boldsymbol{X}^\top\boldsymbol{X}\boldsymbol{W}) i=1∑m∥xi−WW⊤xi∥2=tr(X⊤X)−tr(W⊤X⊤XW)
因此,最小化重构误差等价于最大化投影方差。此等价性揭示了PCA在信息压缩与特征保持之间的根本一致性。
3.数学求解与有效性保障
对协方差矩阵 Σ \boldsymbol{\Sigma} Σ进行特征值分解:
Σ = V Λ V ⊤ \boldsymbol{\Sigma} = \boldsymbol{V} \boldsymbol{\Lambda} \boldsymbol{V}^\top Σ=VΛV⊤
其中特征向量矩阵 V = [ v 1 , v 2 , . . . , v d ] \boldsymbol{V} = [\boldsymbol{v}_1, \boldsymbol{v}_2, ..., \boldsymbol{v}_d] V=[v1,v2,...,vd]对应特征值降序排列 λ 1 ≥ λ 2 ≥ . . . ≥ λ d \lambda_1 \geq \lambda_2 \geq ... \geq \lambda_d λ1≥λ2≥...≥λd。选取前 d ′ d' d′个特征向量构成投影矩阵 W = [ v 1 , v 2 , . . . , v d ′ ] \boldsymbol{W} = [\boldsymbol{v}_1, \boldsymbol{v}_2, ..., \boldsymbol{v}_{d'}] W=[v1,v2,...,vd′],其有效性由以下理论保证:
- Karhunen-Loève定理:正交投影下,PCA是保留样本二阶统计量(协方差)的最优线性降维方法。
- 方差解释率:主成分方差 λ i \lambda_i λi反映数据在该方向的信息量,累计贡献率 ∑ i = 1 d ′ λ i / ∑ i = 1 d λ i \sum_{i=1}^{d'}\lambda_i / \sum_{i=1}^d \lambda_i ∑i=1d′λi/∑i=1dλi量化降维后的信息保留程度。
算法优势与适用性
- 去相关特性:主成分坐标间协方差为0,消除特征冗余。
- 计算高效性:基于协方差矩阵的特征分解,时间复杂度为 O ( d 3 ) O(d^3) O(d3),适合中等维度数据。
- 去噪能力:舍弃小特征值对应的成分,可滤除低方差方向的高频噪声。
局限性
- 仅捕捉线性结构,对非线性流形需引入核方法(Kernel PCA)。
- 方差最大化可能忽略判别信息,分类任务中需结合LDA等监督降维方法。

通过最大化数据内在方差与最小化信息损失的双重优化,PCA构建了高维数据在低维空间的最优线性表征,其数学严密性与计算可行性奠定了其作为基础降维技术的核心地位。
相关文章:
西瓜书第十一章——降维与度量学习
文章目录 降维与度量学习k近邻学习原理头歌实战-numpy实现KNNsklearn实现KNN 降维——多维缩放(Multidimensional Scaling, MDS,MDS)提出背景与原理重述1.**提出背景**2.**数学建模与原理推导**3.**关键推导步骤** Principal Component Analy…...
Portainer安装指南:多节点监控的docker管理面板-家庭云计算专家
背景 Portainer 是一个轻量级且功能强大的容器管理面板,专为 Docker 和 Kubernetes 环境设计。它通过直观的 Web 界面简化了容器的部署、管理和监控,即使是非技术用户也能轻松上手。Portainer 支持多节点管理,允许用户从一个中央控制台管理多…...

NanoGPT的BenchMarking.py
1.Benchmarking是一种评估和比较性能的过程。在深度学习领域,它通常涉及对模型的训练速度、推理速度、内存占用等指标进行测量,以便评估不同模型、不同硬件配置或者不同软件版本之间的性能差异。 例如,当你尝试比较两个不同架构的模型&#x…...

测试用例及黑盒测试方法
一、测试用例 1.1 基本要素 测试用例(Test Case)是为了实施测试而向被测试的系统提供的一组集合,这组集合包含:测试环境、操作步骤、测试数据、预期结果等4个主要要素。 1.1.1 测试环境 定义:测试执行所需的软硬件…...

CentOS 7 环境下部署 LAMP
在 CentOS 7 环境下部署 LAMP(Linux Apache MySQL 5.7 PHP 7.4) 环境的详细步骤如下: 1. 系统准备 1.1 更新系统 sudo yum update -y 1.2 安装依赖 sudo yum install -y gcc pcre pcre-devel zlib zlib-devel openssl openssl-devel e…...
vscode实用配置
前端开发安装插件: 1.可以更好看的显示文件图标 2.用户快速打开文件 使用步骤:在html文件下右键点击 open with live server 即可 刷力扣: 安装这个插件 还需要安装node.js即可...
React 项目中封装 Excel 导入导出组件:技术分享与实践
文章目录 前言一、为什么需要封装 Excel 组件?二、技术选型三、核心实现1. 安装依赖2. 封装Excel导出3. 封装导入组件 (UploadExcel) 总结 前言 在 React 项目中,处理 Excel 文件的导入和导出是常见的业务需求。无论是导出报表数…...
)
【PhysUnits】15.1 引入P1后的加一特质(add1.rs)
一、源码 代码实现了类型系统中的"加一"操作(Add1 trait),用于在编译期进行数字的增量计算。 //! 加一操作特质实现 / Increment operation trait implementation //! //! 说明: //! 1. Z0、P1,、N1 1࿰…...

【2025CCF中国开源大会】RISC-V 开源生态的挑战与机遇分论坛重磅来袭!共探开源芯片未来
点击蓝字 关注我们 CCF Opensource Development Committee 开源浪潮正从软件席卷硬件领域,RISC-V作为全球瞩目的开源芯片架构,正在重塑计算生态的版图!相较于成熟的x86与ARM,RISC-V生态虽处爆发初期,却蕴藏着无限可能。…...
python完成批量复制Excel文件并根据另一个Excel文件中的名称重命名
import openpyxl import shutil import os # 原始文件路径 original_file "C:/Users/Administrator/Desktop/事业联考面试名单/郑州.xlsx" # 读取包含名称的Excel文件 # 修改为您的文件名 wb openpyxl.load_workbook( "C:/Users/Administrator/Desktop/事…...
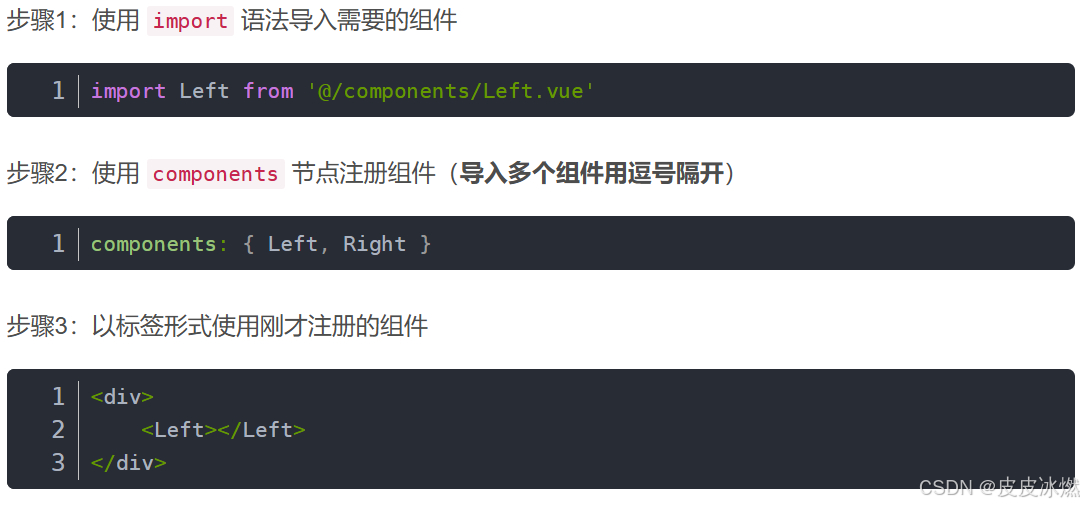
Vue-2-前端框架Vue基础入门之二
文章目录 1 计算属性1.1 计算属性简介1.2 计算属性示例 2 侦听器2.1 简单的侦听器2.2 深度监听2.3 监听对象单个属性 3 vue-cli3.1 工程化的Vue项目3.2 Vue项目的运行流程 4 vue组件4.1 Vue组件的三个部分4.1.1 template4.1.2 script4.1.3 style 4.2 组件之间的关系4.2.1 使用组…...

CPT208 Human-Centric Computing 人机交互 Pt.7 交互和交互界面
文章目录 1. 界面隐喻(Interface metaphors)1.1 界面隐喻的应用方式1.2 界面隐喻的优缺点 2. 交互类型2.1 Instructing(指令式交互)2.2 Conversing(对话式交互)2.3 Manipulating(操作式交互&…...

ubuntu20.04.5-arm64版安装robotjs
ubuntu20.04.5arm上使用robotjs #ssh,可选 sudo apt update sudo apt install openssh-server sudo systemctl status ssh sudo systemctl enable ssh sudo systemctl enable --now ssh #防火墙相关,可选 sudo ufw allow ssh sudo ufw allow 2222/tc…...
[网页五子棋][匹配模块]前后端交互接口(消息推送机制)、客户端开发(匹配页面、匹配功能)
让多个用户,在游戏大厅中能够进行匹配,系统会把实力相近的两个玩家凑成一桌,进行对战 约定前后端交互接口 消息推送机制 匹配这样的功能,也是依赖消息推送机制的 玩家 1 点击开始匹配按钮,就会告诉服务器࿱…...

【数据分析】Matplotlib+Pandas+Seaborn绘图
【数据分析】MatplotlibPandasSeaborn绘图 (一)Matplotlib绘图1.1 matplotlib绘图方式1: 状态接口1.2 matplotlib绘图方式2: 面向对象1.3 通过安斯科姆数据集, 说明可视化的重要性1.4 MatPlotlib绘图-单变量-直方图1.5 MatPlotlib绘图-双变量-散点图1.6 …...
NLP学习路线图(十五):TF-IDF(词频-逆文档频率)
在自然语言处理(NLP)的浩瀚宇宙中,TF-IDF(词频-逆文档频率) 犹如一颗恒星,虽古老却依然璀璨。当ChatGPT、BERT等大模型光芒四射时,TF-IDF作为传统方法的代表,其简洁性、高效性与可解…...

[Redis] Redis命令在Pycharm中的使用
初次学习,如有错误还请指正 目录 String命令 Hash命令 List命令 set命令 SortedSet命令 连接pycharm的过程见:[Redis] 在Linux中安装Redis并连接桌面客户端或Pycharm-CSDN博客 redis命令的使用见:[Redis] Redis命令(1…...

openpnp - 给M4x0.7mm的直油嘴加油的工具选择
文章目录 openpnp - 给M4x0.7mm的直油嘴加油的工具选择概述如果换上带卡口的M4x0.7直油嘴END openpnp - 给M4x0.7mm的直油嘴加油的工具选择 概述 X导轨用了一个HG15的滑块 滑块上的注油口的黄油嘴是M4x0.7mm的直油嘴。 外表面是6边形的柱子,没有可以卡住加油嘴工…...

Azure Devops 系列之三- vscode部署function app
Azure Function App 是 Microsoft Azure 提供的一项无服务器计算服务,它允许您运行事件驱动的应用程序,而无需管理底层基础架构。它使您能够执行代码来响应各种事件,例如 HTTP 请求、队列消息、计时器以及许多其他类型的触发器。 Azure Function App 的主要功能: 无服务器…...
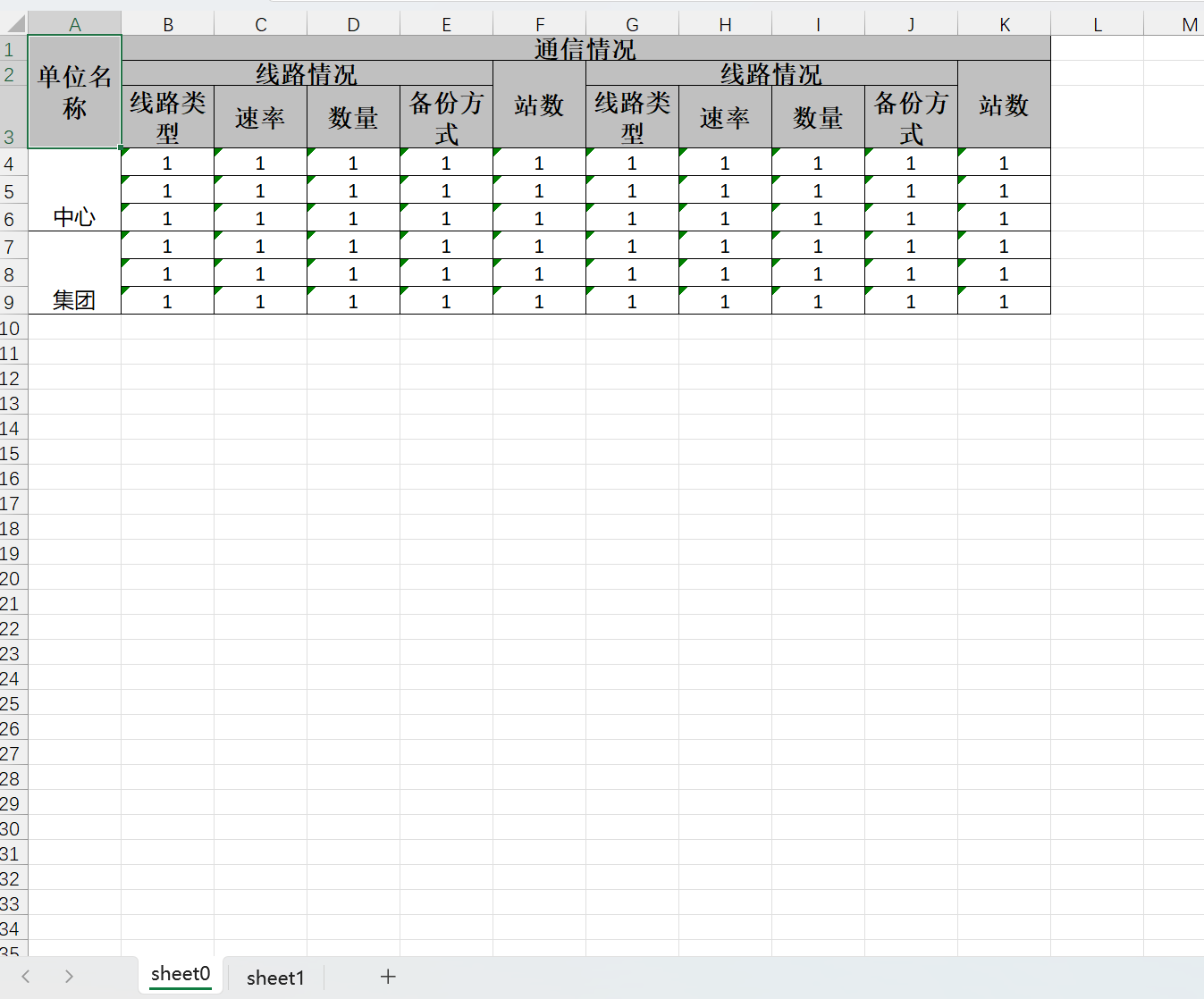
EasyExcel复杂Excel导出
效果图展示 1、引入依赖 <!-- easyExcel --> <dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>4.0.2</version> </dependency>2、实体类 import com.alibaba.excel.annotatio…...
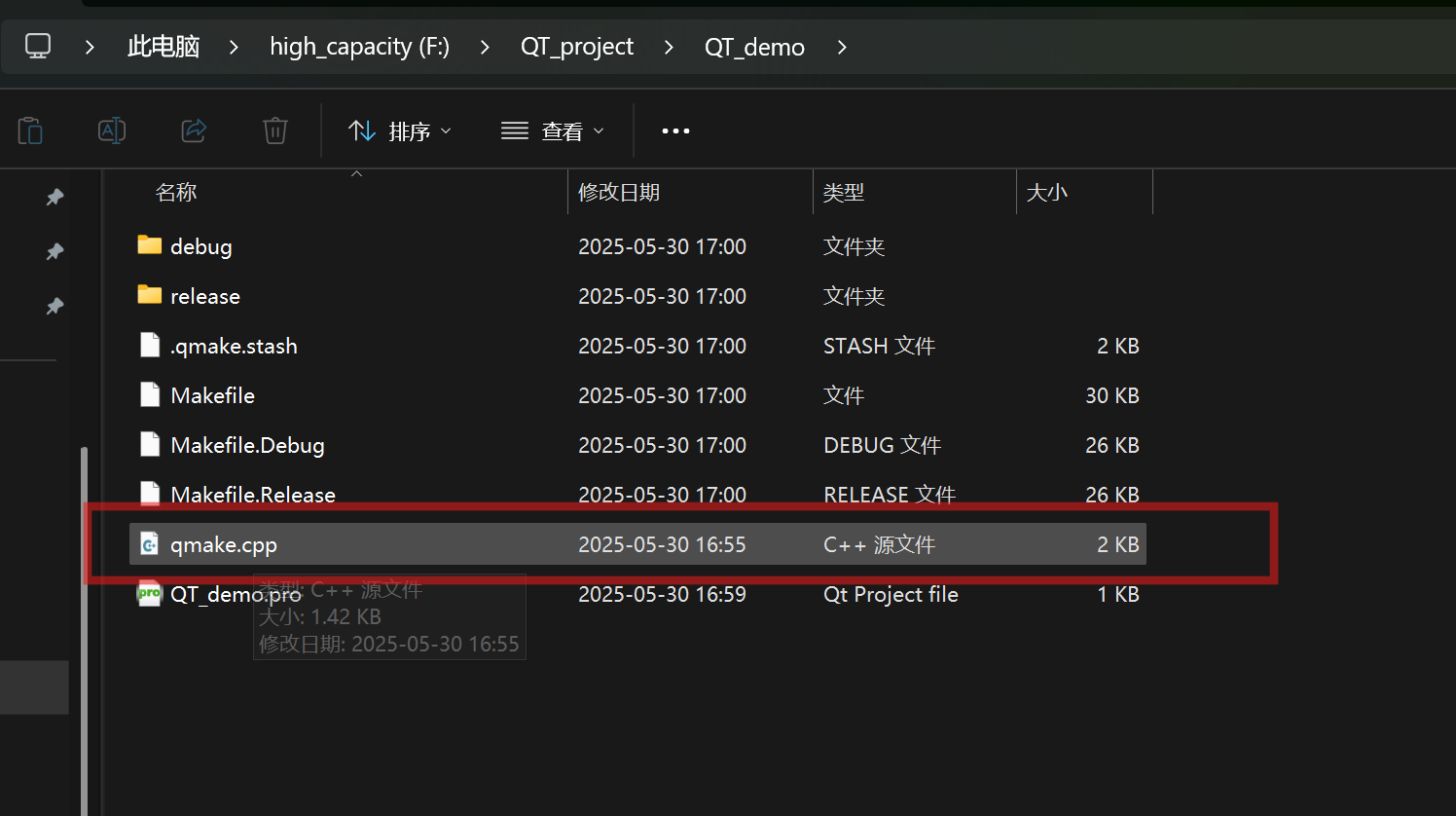
1,QT的编译教程
目录 整体流程: 1,新建project文件 2,编写源代码 3,打开QT的命令行窗口 4,生成工程文件(QT_demo.pro) 5,生成Make file 6,编译工程 7,运行编译好的可执行文件 整体流程: 1,新建project文件 新建文本文件,后缀改为.cpp 2,编写源代码...
)
C++基础算法————深度优先搜索(DFS)
一、DFS算法原理 (一)基本思想 深度优先搜索(Depth-First Search,DFS)是一种用于遍历或搜索树或图的算法。它从一个起始节点开始,沿着一个方向尽可能深入地探索,直到无法继续为止,然后回溯到上一个节点,继续探索其他方向。这一过程可以用递归或栈结构来实现。 (二…...

React 第五十节 Router 中useNavigationType的使用详细介绍
前言 useNavigationType 是 React Router v6 提供的一个钩子,用于确定用户如何导航到当前页面。 它提供了关于导航类型的洞察,有助于优化用户体验和实现特定导航行为。 一、useNavigationType 核心用途 1.1、检测导航方式: 判断用户是通过…...
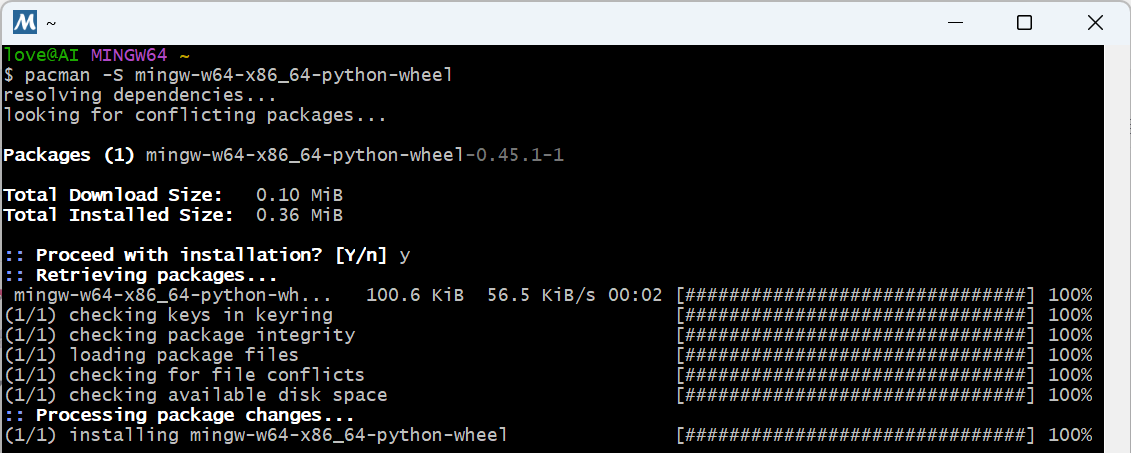
【笔记】在 MSYS2(MINGW64)中安装 Python 工具链的记录
#工作记录 📌 安装背景 操作系统:MSYS2 MINGW64当前时间:2025年6月1日Python 版本:3.12(默认通过 pacman 安装)目标工具链: pipxnumpypipsetuptoolswheel 🛠️ 安装过程与结果记录…...

npm install命令都做了哪些事情
npm install(或其简写 npm i)是 Node.js 项目中最重要的命令之一,它负责安装项目所需的所有依赖项。下面我将详细解释这个命令的完整执行过程和底层机制,让你彻底理解它背后的工作原理。 一、npm install 的完整工作流程 1. 依赖…...
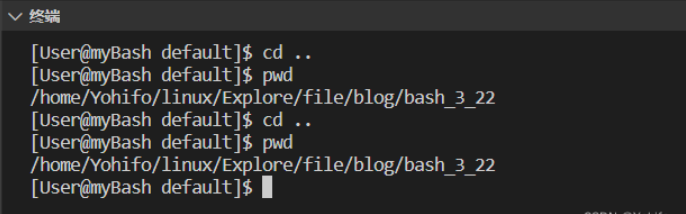
Linux 学习-模拟实现【简易版bash】
1、bash本质 在模拟实现前,先得了解 bash 的本质 bash 也是一个进程,并且是不断运行中的进程 证明:常显示的命令输入提示符就是 bash 不断打印输出的结果 输入指令后,bash 会创建子进程,并进行程序替换 证明&#x…...

【中国・珠海】2025 物联网与边缘计算国际研讨会(IoTEC2025)盛大来袭!
2025 物联网与边缘计算国际研讨会(IoTEC2025)盛大来袭! 科技浪潮奔涌向前,物联网与边缘计算已成为驱动各行业变革的核心力量。在此背景下,2025 物联网与边缘计算国际研讨会(IoTEC2025)即将震撼…...
)
企业级安全实践:SSL/TLS 加密与权限管理(二)
案例分析:成功与失败的经验教训 成功案例分析 以一家知名电商企业 ABC 为例,该企业每天处理数百万笔订单,涉及大量用户的个人信息、支付信息和商品数据。在网络安全建设方面,ABC 电商高度重视 SSL/TLS 加密与权限管理。 在 SSL…...

Java面试:从Spring Boot到分布式系统的技术探讨
场景一:电商平台的订单处理 面试官: “谢先生,假设我们在一个电商平台工作,你将如何使用Spring Boot构建一个订单处理服务?” 谢飞机: “这个简单,我会使用Spring Boot快速启动项目࿰…...

NodeJS全栈开发面试题讲解——P7 DevOps 与部署和跨域等
✅ 7.1 如何部署 Node.js 项目到生产环境?用过哪些工具? 面试官您好,我部署 Node.js 项目通常分为 构建 → 上传 → 启动服务 三步,常用工具包括 PM2、Nginx、Docker、Git Hooks、CI/CD 工具。 🛠️ 主要部署步骤&…...