算法打开13天
41.前 K 个高频元素
(力扣347题)
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
示例 2:
输入: nums = [1], k = 1
输出: [1]
提示:
1 <= nums.length <= 105k的取值范围是[1, 数组中不相同的元素的个数]- 题目数据保证答案唯一,换句话说,数组中前
k个高频元素的集合是唯一的
**进阶:**你所设计算法的时间复杂度 必须 优于 O(n log n) ,其中 n 是数组大小。
解题思路
- 题目要求我们从一个整数数组
nums中找出出现频率最高的 k 个元素。为了实现这一目标,我们可以采用以下步骤:- 统计频率: 使用一个哈希表(
unordered_map)来统计每个数字的出现次数。遍历数组nums,对于每个数字,将其在哈希表中的计数加一。这样,我们可以快速得到每个数字的出现频率。 - 维护小顶堆: 使用一个优先队列(
priority_queue)来维护频率最高的 k 个元素。优先队列的第一个元素是根节点,即堆顶元素。默认情况下,std::priority_queue是一个大顶堆,但通过自定义比较函数mycomparison,我们可以将其转换为小顶堆。小顶堆的特性是堆顶元素是所有元素中最小的,这正好符合我们的需求,因为我们希望在堆中保留频率最高的 k 个元素。当堆的大小超过 k 时,弹出堆顶元素(频率最小的元素),从而保证堆中始终存储的是频率最高的 k 个元素。 - 提取结果: 将小顶堆中的元素依次弹出,并存入结果数组。由于小顶堆的特性,弹出的顺序是频率从小到大,因此需要从后向前填充结果数组。最终,结果数组中存储的就是频率最高的 k 个元素。
- 统计频率: 使用一个哈希表(
单调队列与优先队列的区别
首先,我们需要明确 单调队列 和 优先队列 是两种不同的数据结构,它们的行为和用途有所不同。
单调队列
- 单调队列通常用于处理滑动窗口问题,它维护一个单调递增或单调递减的队列。
- 单调队列的第一个元素通常是当前窗口的最小值或最大值。
- 单调队列的实现通常基于双端队列(
std::deque),而不是基于堆。
优先队列
- 优先队列是一种基于堆的数据结构,通常用于维护一个动态集合,使得每次可以高效地访问和删除具有最高优先级的元素。
- 优先队列的根节点(堆顶元素)是所有元素中优先级最高的元素。
- 默认情况下,
std::priority_queue是一个大顶堆,即堆顶元素是所有元素中最大的。
大顶堆的定义
在大顶堆中:
- 根节点(堆顶元素)是所有元素中最大的。
- 对于任意节点 i,其子节点的值都小于或等于节点 i 的值。
代码
// 给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。
// 你可以按 任意顺序 返回答案。
#include <iostream>
#include <vector>
#include <unordered_map>
#include <queue>
using namespace std;// 使用单调队列(基于小根堆(底层逻辑是完全二叉树)
class Solution
{
public:// 小顶堆(自定义比较函数)class mycomparison{// 重载比较运算符 std::less<T> 把默认的大顶堆变成小顶堆public:// pair<int, int>是类模板bool operator()(const pair<int, int> & lhs, const pair<int, int> & rhs){// 比较两个元素的频率,频率大的排在后面(小顶堆)return lhs.second > rhs.second;}};vector<int> topKFrequent(vector<int> &nums, int k){ // 使用哈希表统计每个数字出现的频率unordered_map<int, int> map;// 遍历数组,统计每个数字的出现次数for (int i = 0; i < nums.size(); i++){// 遍历数组,统计每个数字的出现次数map[nums[i]]++;}// 定义一个小顶堆,用于存储频率最高的 k 个元素// std::priority_queue 默认是一个大顶堆priority_queue<pair<int, int>, vector<pair<int, int>>, mycomparison> pri_que; // priority_queue优先队列// 遍历哈希表,将元素及其频率加入小顶堆for (unordered_map<int, int>::iterator it = map.begin(); it != map.end(); it++){// 将当前元素及其频率加入堆pri_que.push(*it);// 如果堆的大小超过 kif(pri_que.size() > k){pri_que.pop();}}// 将小顶堆中的元素依次弹出,存入结果数组vector<int> result(k);// / 从后向前填充结果数组for(int i = k - 1; i >= 0; i--){// 获取堆顶元素的数字部分result[i] = pri_que.top().first;// 弹出堆顶元素pri_que.pop();}// 返回结果数组return result;}
};- 时间复杂度: O(nlogk)
- 空间复杂度: O(n)
42.二叉树的前序遍历
(力扣94题)
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
示例 1:
**输入:**root = [1,null,2,3]
输出:[1,2,3]
解释:
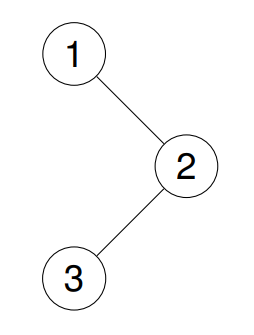
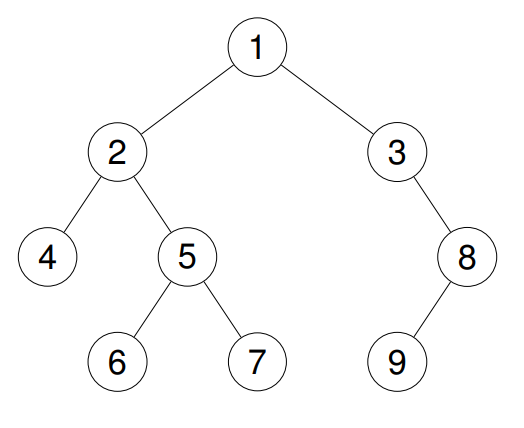
示例 2:
**输入:**root = [1,2,3,4,5,null,8,null,null,6,7,9]
输出:[1,2,4,5,6,7,3,8,9]
解释:
示例 3:
**输入:**root = []
输出:[]
示例 4:
**输入:**root = [1]
输出:[1]
提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
**进阶:**递归算法很简单,你可以通过迭代算法完成吗?
解题思路
前序遍历的顺序是“根-左-右”,即先访问根节点,然后递归遍历左子树,最后递归遍历右子树。实现前序遍历可以使用递归或**非递归(栈)**的方法。
递归方法
递归方法是最直观的实现方式,利用函数调用栈来实现遍历:
- 访问根节点:将当前节点的值加入结果向量。
- 递归左子树:对当前节点的左子树进行前序遍历。
- 递归右子树:对当前节点的右子树进行前序遍历。
- 终止条件:如果当前节点为空,直接返回。
递归方法的优点是代码简洁,但可能会受到递归深度的限制。
非递归方法(栈)
非递归方法使用显式的栈来模拟递归调用:
- 初始化栈:将根节点压入栈。
- 循环条件:当栈不为空时,执行以下操作:
- 弹出栈顶节点,访问其值,并将其值加入结果向量。
- 如果右子节点不为空,将其压入栈。
- 如果左子节点不为空,将其压入栈。
- 终止条件:栈为空时,遍历完成。
非递归方法的优点是避免了递归调用的开销,适合处理较深的树结构
代码
#include <iostream>
#include <vector>
#include <stack>
using namespace std;
struct TreeNode
{int val;TreeNode *left;TreeNode *right;TreeNode() : val(0), left(nullptr), right(nullptr) {}TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(nullptr), right(nullptr) {}
};class Solution
{
public:// 递归函数void traversak(TreeNode *cur, vector<int> &vec){if (cur == nullptr){return;}vec.push_back(cur->val); // 当前节点traversak(cur->left, vec); // 左traversak(cur->right, vec); // 右}// 前序遍历vector<int> preorderTraversal(TreeNode *root){vector<int> result;traversak(root, result);return result;}
};
class Solution
{
public:// 前序遍历vector<int> preorderTraversal(TreeNode *root){// 定义栈stack<TreeNode *> st;// 结果集vector<int> result;// 空节点 返回空if (root == NULL){return result;}// 根节点压入栈st.push(root);while (!st.empty()){TreeNode *node = st.top(); // 根节点st.pop();result.push_back(node->val);if (node->right){// 右(空节点不入栈st.push(node->right);}if (node->left){// 左(空节点不入栈st.push(node->left);}}return result;}
};return 只是结束当前栈帧的执行,并返回到调用它的函数。它不会影响其他栈帧的执行
43.二叉树的后序遍历
(力扣145题)
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:
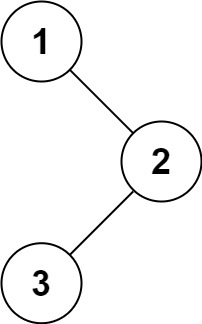
输入:root = [1,null,2,3]
输出:[1,3,2]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [1]
输出:[1]
提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
解题思路
后序遍历的顺序是“左-右-根”,即先递归遍历左子树,然后递归遍历右子树,最后访问根节点。实现后序遍历可以使用递归或**非递归(栈)**的方法。
递归方法
递归方法是最直观的实现方式,利用函数调用栈来实现遍历:
- 递归左子树:对当前节点的左子树进行后序遍历。
- 递归右子树:对当前节点的右子树进行后序遍历。
- 访问根节点:将当前节点的值加入结果向量。
- 终止条件:如果当前节点为空,直接返回。
递归方法的优点是代码简洁,但可能会受到递归深度的限制。
非递归方法(栈)
非递归方法使用显式的栈来模拟递归调用:
- 初始化栈:将根节点压入栈。
- 循环条件:当栈不为空时,执行以下操作:
- 弹出栈顶节点,访问其值,并将其值加入结果向量。
- 如果左子节点不为空,将其压入栈。
- 如果右子节点不为空,将其压入栈。
- 反转结果集:由于栈的后进先出特性,最终结果需要反转。
- 终止条件:栈为空时,遍历完成。
非递归方法的优点是避免了递归调用的开销,适合处理较深的树结构。
代码
#include <iostream>
#include <vector>
#include <stack>
#include <algorithm>
using namespace std;
struct TreeNode
{int val;TreeNode *left;TreeNode *right;TreeNode() : val(0), left(nullptr), right(nullptr) {}TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(nullptr), right(nullptr) {}
};class Solution
{
public:// 递归函数void traversak(TreeNode *cur, vector<int> &vec){if (cur == nullptr){return;}traversak(cur->left, vec); // 左traversak(cur->right, vec); // 右vec.push_back(cur->val); // 当前节点}// 后序遍历vector<int> postorderTraversal(TreeNode *root){vector<int> result;traversak(root, result);return result;}
};class Solution
{
public:// 后序遍历vector<int> postorderTraversal(TreeNode *root){// 定义栈stack<TreeNode *> st;// 结果集vector<int> result;// 空节点 返回空if (root == NULL){return result;}// 根节点压入栈st.push(root);while (!st.empty()){TreeNode *node = st.top(); // 根节点st.pop();result.push_back(node->val);if (node->left){// 左(空节点不入栈st.push(node->left);}if (node->right){// 右(空节点不入栈st.push(node->right);}}// 反转结果集reverse(result.begin(), result.end());return result;}
};
相关文章:
算法打开13天
41.前 K 个高频元素 (力扣347题) 给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。 示例 1: 输入: nums [1,1,1,2,2,3], k 2 输出: [1,2]示例 2: 输入: nums [1], k 1 输出: …...

Freeqwq 世界首个免费无限制 分布式 AI 算力平台 https://qwq.aigpu.cn/
官网:Free QWQ - 免费分布式 AI 算力平台 基于来自全国各地 50 台家用电脑的 3090、4080、4090 显卡分布式算力,我们为开发者提供完全免费、无限制的 QwQ 32B 大语言模型 API。无需注册,无需充值,立即获取 API Key 开始使用。 …...
广告拦截器:全方位拦截,畅享无广告体验
在数字时代,广告无处不在。无论是浏览网页、使用社交媒体,还是观看视频,广告的频繁弹出常常打断我们的体验,让人不胜其烦。更令人担忧的是,一些广告可能包含恶意软件,威胁我们的设备安全和个人隐私。AdGuar…...

.net Avalonia应用程序生命周期
.NET Avalonia 应用程序生命周期全解析 在 .NET 开发领域,Avalonia 作为一个跨平台的 UI 框架,为开发者提供了强大的功能和灵活性。了解 Avalonia 应用程序的生命周期,对于构建高效、稳定的应用至关重要。本文将深入探讨 Avalonia 应用程序生…...

主数据编码体系全景解析:从基础到高级的编码策略全指南
在数字化转型的浪潮中,主数据管理(MDM)已成为企业数字化转型的基石。而主数据编码作为MDM的核心环节,其设计质量直接关系到数据管理的效率、系统的可扩展性以及业务决策的准确性。本文将系统性地探讨主数据编码的七大核心策略&…...

Selenium操作指南(全)
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 大家好,今天带大家一起系统的学习下模拟浏览器运行库Selenium,它是一个用于Web自动化测试及爬虫应用的重要工具。 Selenium测试直接运行在…...

Go语言中的数据类型转换
Go 语言中只有强制类型转换,没有隐式类型转换。 1. 数值类型之间的相互转换 1.1. 整型和整型之间的转换 package main import "fmt"func main() {var a int8 20var b int16 40fmt.Println(int16(a) b)// 60 }1.2. 浮点型和浮点型之间的转换 packag…...

35、请求处理-【源码分析】-自定义参数绑定原理
35、请求处理-【源码分析】-自定义参数绑定原理 自定义参数绑定原理主要涉及Spring Boot如何将HTTP请求中的参数自动绑定到控制器方法的自定义对象参数上。以下是详细的解析: ### 1. 参数解析器的选择 - **HandlerMethodArgumentResolverComposite**: - …...

智绅科技——科技赋能健康养老,构建智慧晚年新生态
当老龄化浪潮与数字技术深度碰撞,智绅科技以 “科技赋能健康,智慧守护晚年” 为核心理念,锚定数字健康与养老服务赛道,通过人工智能、物联网、大数据等技术集成,为亚健康群体与中老年人群构建 “监测 - 预防 - 辅助 - …...
STM32通过KEIL pack包轻松移植LVGL,并学会使用GUI guider
先展示最终实现的功能效果如下: 1.目的与意义 之前在学习STM32移植LVGL图形库的时候,搜到的很多教程都是在官网下载LVGL的文件包,然后一个个文件包含进去,还要添加路径,还要给文件改名字,最后才能修改程序…...

day43 python Grad-CAM
目录 一、为什么需要 Grad-CAM? 二、Grad-CAM 的原理 三、Grad-CAM 的实现 1. 模块钩子(Module Hooks) 2. Grad-CAM 的实现代码 四、学习总结 在深度学习领域,神经网络模型常常被视为“黑盒”,因为其复杂的内部结…...

在 Ubuntu 上挂载其他硬盘的步骤
一、查看当前磁盘信息 打开终端,执行: lsblk 这个命令会列出所有的块设备(包括硬盘和分区)。比如输出可能如下: NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 1.8T 0 disk └─sda1 8:1 0 …...

SQL的查询优化
1. 查询优化器 1.1. SQL语句执行需要经历的环节 解析阶段:语法分析和语义检查,确保语句正确;优化阶段:通过优化器生成查询计划;执行阶段:由执行器根据查询计划实际执行操作。 1.2. 查询优化器 查询优化器…...
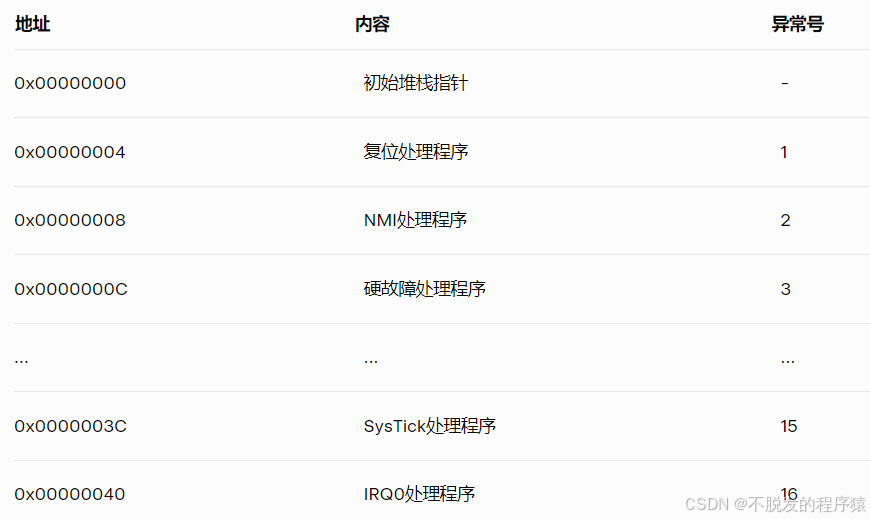
MCU如何从向量表到中断服务
目录 1、中断向量表 2、编写中断服务例程 中断处理的核心是中断向量表(IVT),它是一个存储中断服务例程(ISR)地址的内存结构。当中断发生时,MCU通过IVT找到对应的ISR地址并跳转执行。本文将深入探讨MCU&am…...

物联网基础概念
入行物联网两年半,想写点东西记录踩过的坑,能让自己反省的同时,也希望能帮到其他小伙伴。 本人仍是小白,请看客朋友谨慎参考。另,本人主要从事智慧用电和智慧医疗行业,其他行业不一定有参考性。 以下所有内…...

Linux线程同步实战:多线程程序的同步与调度
个人主页:chian-ocean 文章专栏-Linux Linux线程同步实战:多线程程序的同步与调度 个人主页:chian-ocean文章专栏-Linux 前言:为什么要实现线程同步线程饥饿(Thread Starvation)示例:抢票问题 …...
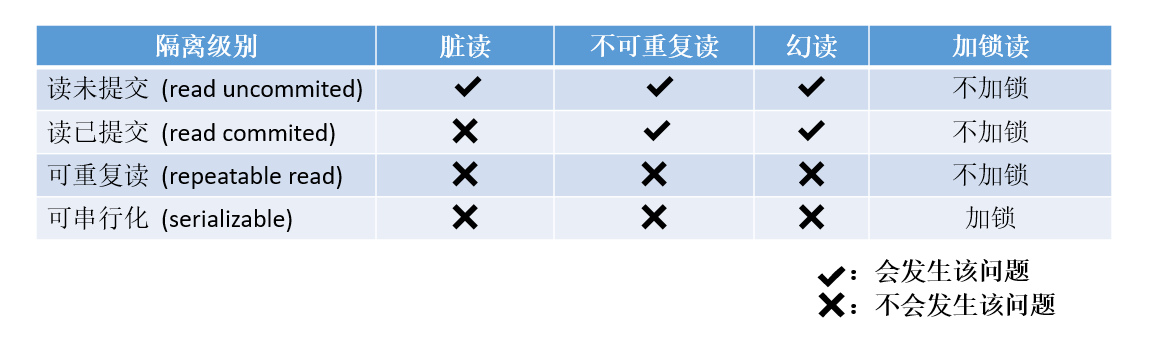
【MySQL】事务及隔离性
目录 一、什么是事务 (一)概念 (二)事务的四大属性 (三)事务的作用 (四)事务的提交方式 二、事务的启动、回滚与提交 (一)事务的启动、回滚与提交 &am…...

Leetcode 3566. Partition Array into Two Equal Product Subsets
Leetcode 3566. Partition Array into Two Equal Product Subsets 1. 解题思路2. 代码实现 题目链接:3566. Partition Array into Two Equal Product Subsets 1. 解题思路 这一题我的实现还是比较暴力的,首先显而易见的,若要满足题目要求&…...
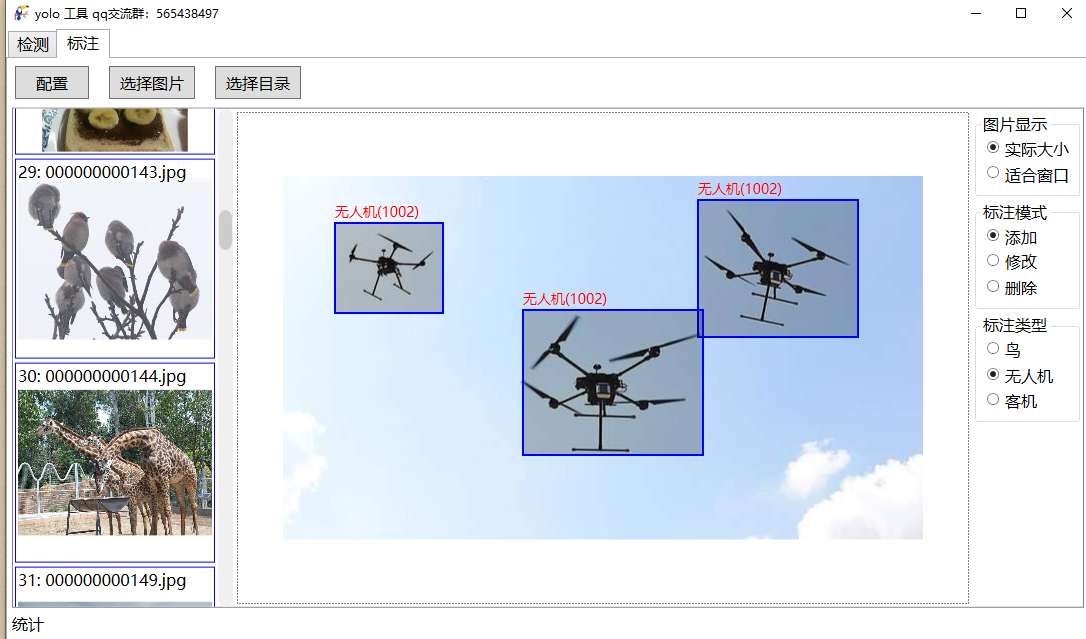
yolo目标检测助手:具有模型预测、图像标注功能
在人工智能浪潮席卷各行各业的今天,计算机视觉模型(如 YOLO)已成为目标检测领域的标杆。然而,模型的强大能力需要直观的界面和便捷的工具才能充分发挥其演示、验证与迭代优化的价值。为此,我开发了一款基于 WPF 的桌面…...

传统数据表设计与Prompt驱动设计的范式对比:以NBA投篮数据表为例
引言:数据表设计方法的演进 在数据库设计领域,传统的数据表设计方法与新兴的Prompt驱动设计方法代表了两种截然不同的思维方式。本文将以NBA赛季投篮数据表(shots)的设计为例,深入探讨这两种方法的差异、优劣及适用场景。随着AI技术在数据领…...

2022 RoboCom 世界机器人开发者大赛(睿抗 caip) -高职组(国赛)解题报告 | 科学家
前言 题解 2022 RoboCom 世界机器人开发者大赛(睿抗 caip) -高职组(国赛)。 最后一题还考验能力,需要找到合适的剪枝。 RC-v1 智能管家 分值: 20分 签到题,map的简单实用 #include <bits/stdc.h>using namespace std;int…...

WIN11 Docker Desktop 安装问题解决
windows version 打开windows 命令行,执行 ver显示 Microsoft Windows [版本 10.0.26100.4061]安装docker desktop 后,启动出问题,可以按下面步骤解决 安装 virtual machine plateform 开始 —》 控制面板 ----》程序 ----》启动或关闭w…...

网站服务器出现异常的原因是什么?
网站时企业和个人用户进行提供信息和服务的重要平台,随着时间的推移,网站服务器出现异常情况也是常见的问题之一,这可能会导致网站无法正常访问或者是运行缓慢,会严重影响到用户的体验感,本文就来介绍一下网站服务器出…...

Python实例题:Python3实现图片转彩色字符
目录 Python实例题 题目 代码实现 实现原理 图像预处理: 灰度值计算: 字符映射: 彩色输出: 关键代码解析 1. 字符映射和灰度计算 2. 图像模式输出 3. 命令行参数处理 使用说明 基本用法(终端输出&#x…...

同一机器下通过HTTP域名访问其他服务器进程返回504问题记录
我这边项目的服务器有好几个类型节点,每个节点为一个进程,不同节点间通过HTTP来通讯,当前这几个类型的节点都部署在同一台机器上,然后我再测试某个节点到另一个节点的http通讯时,发现一个奇怪的现象: 1. 我…...

基于物联网(IoT)的电动汽车(EVs)智能诊断
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从&#x…...
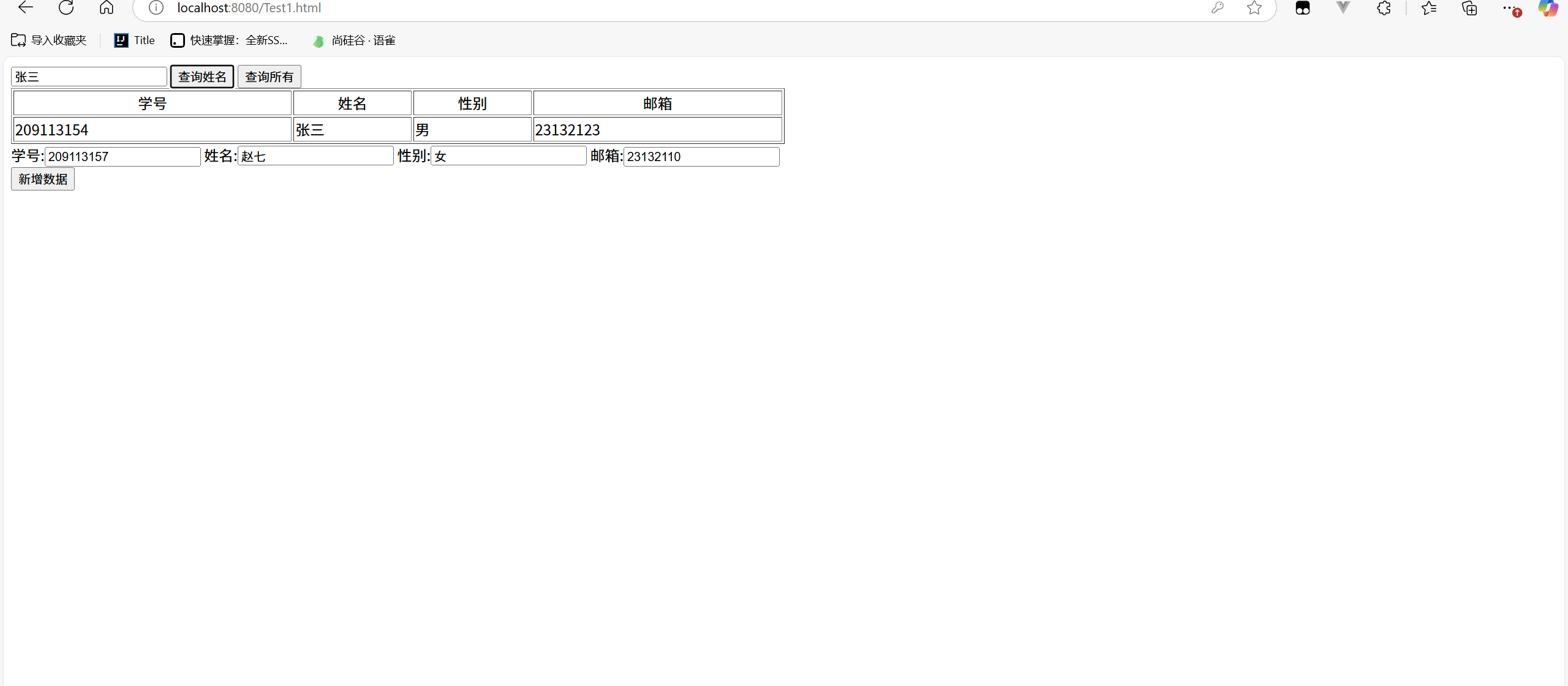
JDBC+HTML+AJAX实现登陆和单表的CRUD
JDBCHTMLAJAX实现登陆和单表的CRUD 导入maven依赖 <?xml version"1.0" encoding"UTF-8"?><project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocatio…...

Leetcode 3568. Minimum Moves to Clean the Classroom
Leetcode 3568. Minimum Moves to Clean the Classroom 1. 解题思路2. 代码实现 题目链接:3568. Minimum Moves to Clean the Classroom 1. 解题思路 这一题我的核心思路就是广度优先遍历遍历剪枝。 显然,我们可以给出一个广度优先遍历来给出所有可能…...

Kafka多线程Consumer
Apache Kafka作为一款分布式流处理平台,以其高吞吐量和可扩展性在大数据处理领域占据了重要地位。在实际应用中,为了提升数据处理的效率和灵活性,我们常常需要采用多线程的方式来消费Kafka中的数据。本文将通过一个案例分析,详细探…...

从零开始的git学习
基本概念:修改记录 1、每个修改记录都有对应的id 2、当发现修改有问题时,可以进行回滚操作。 3、回滚的本质是一次新的更新以复原修改。但是如果不是针对最新记录进行回滚,会出现冲突。 这里需要举例说明 基本概念:分支 1、分支…...