传统数据表设计与Prompt驱动设计的范式对比:以NBA投篮数据表为例
引言:数据表设计方法的演进
在数据库设计领域,传统的数据表设计方法与新兴的Prompt驱动设计方法代表了两种截然不同的思维方式。本文将以NBA赛季投篮数据表(shots)的设计为例,深入探讨这两种方法的差异、优劣及适用场景。随着AI技术在数据领域的渗透,Prompt工程正在重塑我们设计和实现数据模型的方式,这种转变不仅体现在效率上,更体现在思维模式上。
一、传统数据表设计方法论
1.1 传统设计流程的特点
传统数据表设计是一个高度结构化、线性化的过程,通常遵循以下步骤:
- 需求收集与分析:与领域专家(如篮球分析师)深入交流,理解业务需求
- 概念模型设计:绘制ER图,确定实体、属性和关系
- 逻辑模型设计:将概念模型转化为表结构,定义字段、类型和约束
- 物理模型设计:针对特定DBMS(如MySQL)优化实现
- 验证与迭代:通过样本数据和查询测试设计合理性
以NBA投篮表为例,传统方式会先定义核心实体:球员(Player)、球队(Team)、比赛(Game)、投篮事件(Shot),然后逐步细化属性。
1.2 传统设计的典型产出
CREATE TABLE shots (shot_id INT PRIMARY KEY,game_id INT REFERENCES games(game_id),player_id INT REFERENCES players(player_id),team_id INT REFERENCES teams(team_id),quarter INT CHECK (quarter BETWEEN 1 AND 7),shot_made BOOLEAN,shot_type ENUM('2PT','3PT'),action_type VARCHAR(20),shot_distance DECIMAL(5,2),game_time_remaining INT,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
1.3 传统方法的优势与局限
优势:
- 结构严谨,符合数据库规范化原则
- 关系明确,外键约束保证数据完整性
- 设计过程可文档化,便于团队协作
局限:
- 周期长,从需求到实现可能需要多次迭代
- 高度依赖设计者的经验和技术水平
- 灵活性不足,后期修改成本高
二、Prompt驱动设计的新范式
2.1 Prompt设计的基本原理
Prompt工程作为AI时代的新技能,其核心是通过结构化、精确的指令引导AI生成专业输出。吴恩达提出的Prompt设计原则强调:
- 角色指定:赋予AI特定专业身份(如"数据库工程师")
- 任务明确:清晰定义交付物要求
- 约束条件:明确技术边界和限制条件
2.2 典型Prompt示例
“假设你是一位专业的数据库工程师,请为MySQL设计NBA赛季投篮数据表。必须包含以下字段:赛季、球队、球员、得分情况(是否命中、得分值、投篮动作类型、得分原因)、投篮位置坐标、球员场上位置(PG/SG等)、比赛剩余时间(分+秒)。只需返回规范的SQL语句,并附简短设计理由。”
2.3 AI生成的典型产出
CREATE TABLE shots (shot_id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,season VARCHAR(7) NOT NULL COMMENT '赛季如2022-23',player_id INT UNSIGNED NOT NULL,player_name VARCHAR(50) NOT NULL,player_position ENUM('PG','SG','SF','PF','C') NOT NULL,is_made BOOLEAN NOT NULL COMMENT '是否命中',points TINYINT UNSIGNED NOT NULL COMMENT '得分值',shot_type VARCHAR(30) NOT NULL COMMENT '投篮动作类型',shot_result_reason VARCHAR(50) COMMENT '得分原因',shot_location_x DECIMAL(6,2) NOT NULL,shot_location_y DECIMAL(6,2) NOT NULL,game_time_remaining_min TINYINT UNSIGNED NOT NULL,game_time_remaining_sec TINYINT UNSIGNED NOT NULL,INDEX idx_player_season (player_id, season)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2.4 Prompt方法的创新价值
- 知识蒸馏:将专家的隐性知识通过Prompt显性化表达
- 快速原型:分钟级产出可执行方案,加速迭代
- 跨领域协同:非技术专家也能参与技术设计
- 模式发现:AI可能提出设计者未考虑的优秀实践
三、两种方法的深度对比
3.1 设计思维差异
| 维度 | 传统方法 | Prompt驱动方法 |
|---|---|---|
| 设计主体 | 人类专家主导 | 人机协同 |
| 知识来源 | 个人经验+文档资料 | 内化的海量最佳实践 |
| 迭代方式 | 线性循环 | 平行探索多方案 |
| 产出形式 | 完整设计方案 | 即用型代码片段 |
3.2 NBA投篮表设计对比
传统设计特点:
- 强调关系完整性,使用外键约束
- 字段类型相对保守(如使用INT而非TINYINT)
- 通常缺少注释和索引建议
- 设计周期可能需要数天
Prompt设计特点:
- 包含实用优化(如utf8mb4字符集)
- 自动添加性能相关索引
- 字段注释完善,增强可读性
- 即时响应(秒级产出)
- 可能忽略某些规范化原则
3.3 适用场景分析
传统方法更适合:
- 复杂业务系统的核心数据模型
- 需要严格数据治理的场景
- 长期演进的大型项目
Prompt方法更擅长:
- 快速原型开发
- 数据探索性分析
- 中小型项目初期
- 跨领域协作场景
四、AI时代的数据设计新实践
4.1 混合工作流建议
- 初步构思阶段:使用Prompt快速生成候选方案
- 专家评审阶段:人工校验AI设计的合理性
- 优化调整阶段:通过迭代Prompt完善细节
- 文档生成阶段:让AI基于最终设计生成说明文档
4.2 优秀Prompt设计技巧
-
角色精准定位:
“你是一位精通篮球数据分析的MySQL专家,曾为NBA球队设计过数据系统…” -
约束明确具体:
“字段必须满足第三范式,使用InnoDB引擎,包含所有外键关系…” -
示例引导输出:
“参考以下格式:字段名 类型 约束 COMMENT ‘解释说明’…” -
分阶段Prompt:
先获取概念模型,再转化为物理模型,最后优化查询性能
4.3 篮球数据设计的特殊考量
-
时空维度处理:
- 比赛时间表示法(剩余时间vs绝对时间)
- 投篮位置坐标系统(相对坐标vs绝对坐标)
-
篮球专业语义:
- 投篮动作类型的标准化表达
- 特殊事件编码(如压哨球、绝杀球)
-
分析友好设计:
- 便于计算投篮热区
- 支持时间序列分析
- 兼容机器学习特征工程
五、未来展望
随着LLM技术的进步,数据设计领域可能出现:
- 智能辅助设计系统:实时建议优化方案
- 自然语言到Schema:用业务语言直接生成数据模型
- 自适应数据模型:根据查询模式自动调整结构
- 多模态数据设计:结合图表、示例数据等综合设计
结语
传统数据设计方法与Prompt驱动方法并非对立关系,而是互补的技术体系。在NBA投篮数据表这个典型案例中,我们看到:
- 传统方法提供了严谨的理论基础和完整性保障
- Prompt方法带来了效率革命和知识民主化
- 二者的有机结合可能催生新一代数据设计范式
最终,优秀的数据工程师应当掌握这两种方法,根据具体场景灵活运用,就像篮球运动员既要掌握基本功又要具备临场创造力一样。数据设计正在从一门纯粹的技术艺术,演变为技术与AI协同的智能实践。
相关文章:

传统数据表设计与Prompt驱动设计的范式对比:以NBA投篮数据表为例
引言:数据表设计方法的演进 在数据库设计领域,传统的数据表设计方法与新兴的Prompt驱动设计方法代表了两种截然不同的思维方式。本文将以NBA赛季投篮数据表(shots)的设计为例,深入探讨这两种方法的差异、优劣及适用场景。随着AI技术在数据领…...

2022 RoboCom 世界机器人开发者大赛(睿抗 caip) -高职组(国赛)解题报告 | 科学家
前言 题解 2022 RoboCom 世界机器人开发者大赛(睿抗 caip) -高职组(国赛)。 最后一题还考验能力,需要找到合适的剪枝。 RC-v1 智能管家 分值: 20分 签到题,map的简单实用 #include <bits/stdc.h>using namespace std;int…...

WIN11 Docker Desktop 安装问题解决
windows version 打开windows 命令行,执行 ver显示 Microsoft Windows [版本 10.0.26100.4061]安装docker desktop 后,启动出问题,可以按下面步骤解决 安装 virtual machine plateform 开始 —》 控制面板 ----》程序 ----》启动或关闭w…...

网站服务器出现异常的原因是什么?
网站时企业和个人用户进行提供信息和服务的重要平台,随着时间的推移,网站服务器出现异常情况也是常见的问题之一,这可能会导致网站无法正常访问或者是运行缓慢,会严重影响到用户的体验感,本文就来介绍一下网站服务器出…...

Python实例题:Python3实现图片转彩色字符
目录 Python实例题 题目 代码实现 实现原理 图像预处理: 灰度值计算: 字符映射: 彩色输出: 关键代码解析 1. 字符映射和灰度计算 2. 图像模式输出 3. 命令行参数处理 使用说明 基本用法(终端输出&#x…...

同一机器下通过HTTP域名访问其他服务器进程返回504问题记录
我这边项目的服务器有好几个类型节点,每个节点为一个进程,不同节点间通过HTTP来通讯,当前这几个类型的节点都部署在同一台机器上,然后我再测试某个节点到另一个节点的http通讯时,发现一个奇怪的现象: 1. 我…...

基于物联网(IoT)的电动汽车(EVs)智能诊断
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从&#x…...
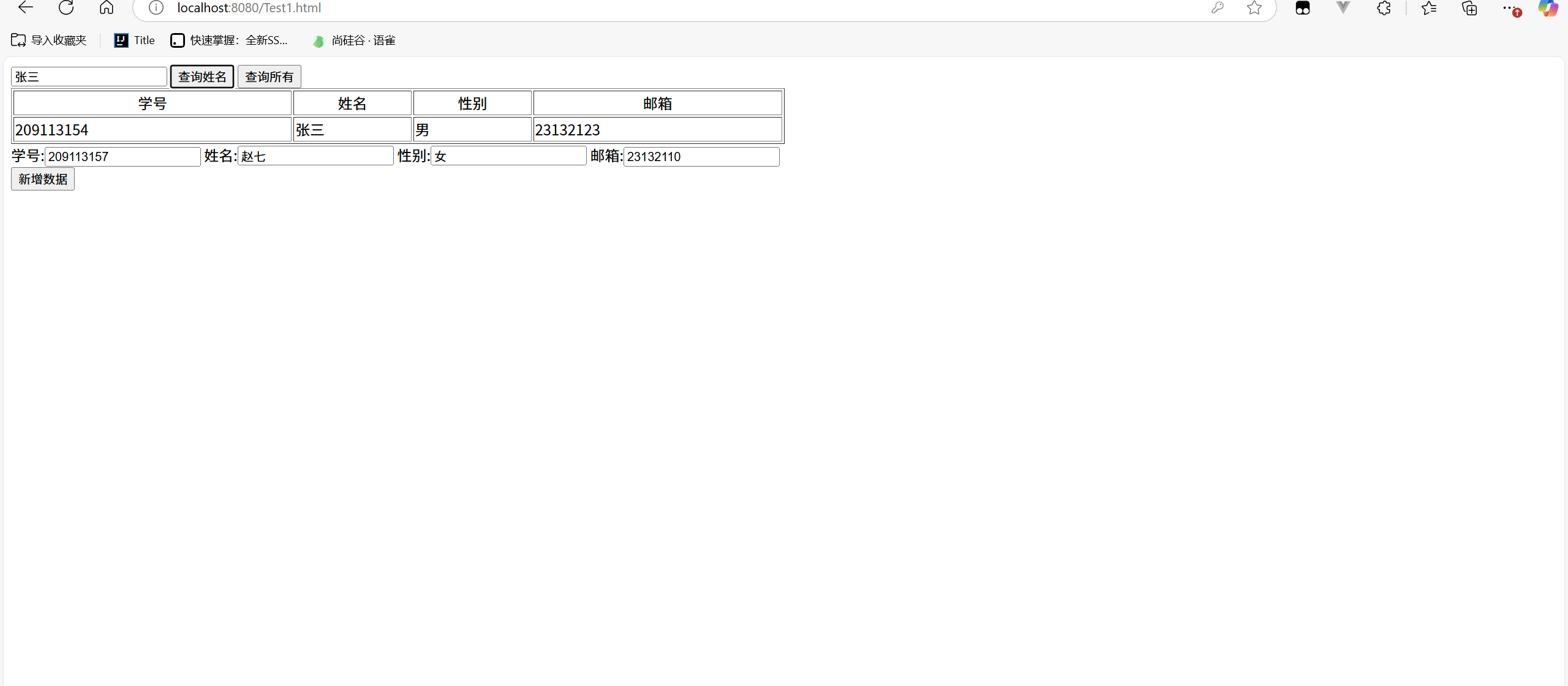
JDBC+HTML+AJAX实现登陆和单表的CRUD
JDBCHTMLAJAX实现登陆和单表的CRUD 导入maven依赖 <?xml version"1.0" encoding"UTF-8"?><project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocatio…...

Leetcode 3568. Minimum Moves to Clean the Classroom
Leetcode 3568. Minimum Moves to Clean the Classroom 1. 解题思路2. 代码实现 题目链接:3568. Minimum Moves to Clean the Classroom 1. 解题思路 这一题我的核心思路就是广度优先遍历遍历剪枝。 显然,我们可以给出一个广度优先遍历来给出所有可能…...

Kafka多线程Consumer
Apache Kafka作为一款分布式流处理平台,以其高吞吐量和可扩展性在大数据处理领域占据了重要地位。在实际应用中,为了提升数据处理的效率和灵活性,我们常常需要采用多线程的方式来消费Kafka中的数据。本文将通过一个案例分析,详细探…...

从零开始的git学习
基本概念:修改记录 1、每个修改记录都有对应的id 2、当发现修改有问题时,可以进行回滚操作。 3、回滚的本质是一次新的更新以复原修改。但是如果不是针对最新记录进行回滚,会出现冲突。 这里需要举例说明 基本概念:分支 1、分支…...

【C++】位图详解(一文彻底搞懂位图的使用方法与底层原理)
🌈 个人主页:谁在夜里看海. 🔥 个人专栏:《C系列》《Linux系列》 ⛰️ 天高地阔,欲往观之。 目录 1.位图的概念 2.位图的使用方法 定义与创建 设置和清除 位访问和检查 转换为其他格式 3.位图的使用场景 1.快速…...

Spring Boot 整合 JdbcTemplate,JdbcTemplate 与 MyBatis 的区别
DAY29.1 Java核心基础 Spring Boot 整合 JdbcTemplate JdbcTemplate是一个轻量级JDBC封装的组件 JdbcTemplate 是 Spring 自带的JDBC的封装,和Mybatis类似,需要自己封装sql语句 JdbcTemplate 帮助我们来连接数据库,SQL的执行,…...

sass基础语法
Sass(Syntactically Awesome Style Sheets)是一种 CSS 预处理器,提供了比原生 CSS 更强大、更灵活的语法功能。它有两种语法格式: Sass(缩进语法,.sass 文件)SCSS(CSS-like 语法&am…...

【EF Core】 EF Core 批量操作的进化之路——从传统变更跟踪到无跟踪更新
文章目录 前言一、批量操作(Rang)1.1 AddRange()1.2 UpdateRange()1.3 AttachRange()1.4 RemoveRange() 二、Range操作的底层优化2.1 EF Core 7 前举步维艰2.2 EF Core 7后焕然一新 三、无跟踪的批量更新与删除3.1 ExecuteUpdate3.2 ExecuteDelete3.3 状…...

[Go] Option选项设计模式 — — 编程方式基础入门
[Go] Option选项设计模式 — — 编程方式基础入门 全部代码地址,欢迎⭐️ Github:https://github.com/ziyifast/ziyifast-code_instruction/tree/main/go-demo/go-option 1 介绍 在 Go 开发中,我们经常遇到需要处理多参数配置的场景。传统方…...

Vue 项目命名规范指南
📚 Vue 项目命名规范指南(适用于 Vue 3 Pinia Vue Router) 目的:统一命名风格,提升可读性、可维护性和团队协作效率。 一、通用原则 类型命名风格示例变量camelCaseuserName, isLoading常量UPPER_SNAKE_CASEMAX_RET…...
【笔记】开源通用人工智能代理 Suna 部署全流程准备清单(Windows 系统)
#工作记录 一、基础工具与环境 开发工具 Git 或 GitHub Desktop(代码管理)Docker Desktop(需启用 WSL2,容器化部署)Python 3.11(推荐版本,需添加到系统环境变量)Node.js LTS…...

海康工业相机SDK二次开发(VS+QT+海康SDK+C++)
前言 工业相机在现代制造和工业自动化中扮演了至关重要的角色,尤其是在高精度、高速度检测中。海康威视工业相机以其性能稳定、图像质量高、兼容性强而受到广泛青睐。特别是搞机器视觉的小伙伴们跟海康打交道肯定不在少数,笔者在平常项目中跟海康相关人…...

前端面试准备-5
1.Node.js中的process.nectTick()有什么作用 将一个回调函数插入到当前执行栈的尾部,在下一次事件轮询之前调用这个回调函数 2.什么是Node.js中的事件发射器,作用是什么,如何使用 提供一种机制,可以创建、触发和监听自定义事件…...

Spring Boot 启动流程深度解析:从源码到实践
Spring Boot 启动流程深度解析:从源码到实践 Spring Boot 作为 Java 开发的主流框架,其 “约定大于配置” 的理念极大提升了开发效率。本文将从源码层面深入解析 Spring Boot 的启动流程,并通过代码示例展示其工作机制。 一、Spring Boot 启…...
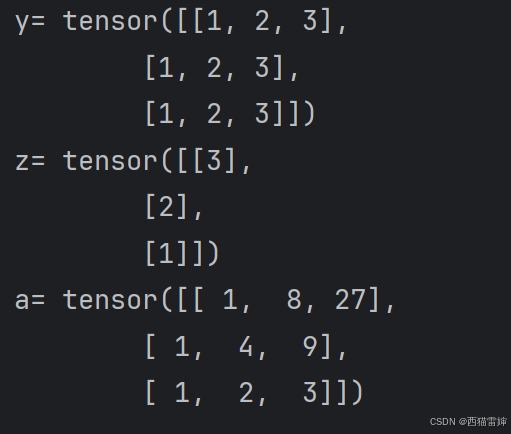
深度学习|pytorch基本运算-乘除法和幂运算
【1】引言 前序学习进程中,已经对pytorch张量数据的生成和广播做了详细探究,文章链接为: 深度学习|pytorch基本运算-CSDN博客 深度学习|pytorch基本运算-广播失效-CSDN博客 上述探索的内容还止步于张量的加减法,在此基础上&am…...

嵌入式通用集成电路卡市场潜力报告:物联网浪潮下的机遇与挑战剖析
一、嵌入式通用集成电路卡概述 嵌入式通用集成电路卡(Embedded Universal Integrated Circuit Card,简称 eUICC),是一种将传统 SIM 卡功能直接嵌入到设备主板上的芯片解决方案 。与传统可插拔式 SIM 卡不同,eUICC 采…...

4.2.4 Spark SQL 数据写入模式
在本节实战中,我们详细探讨了Spark SQL中数据写入的四种模式:ErrorIfExists、Append、Overwrite和Ignore。通过具体案例,我们演示了如何使用mode()方法结合SaveMode枚举类来控制数据写入行为。我们首先读取了一个JSON文件生成DataFrame&#…...
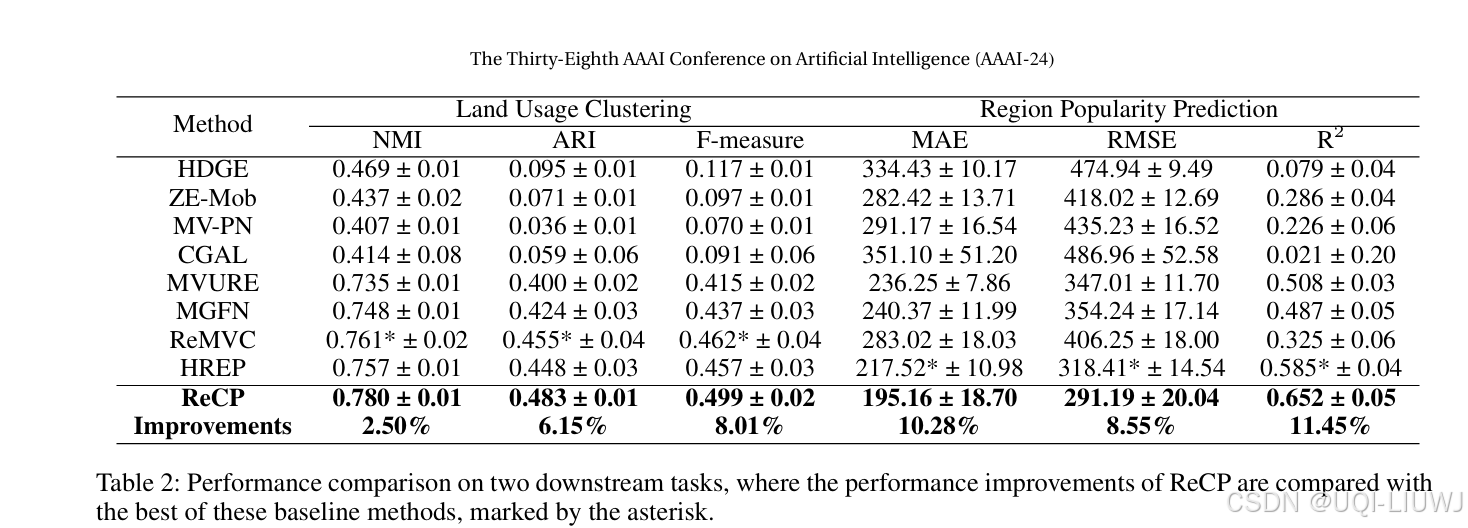
论文笔记: Urban Region Embedding via Multi-View Contrastive Prediction
AAAI 2024 1 INTRO 之前基于多视图的region embedding工作大多遵循相同的模式 单独的单视图表示多视图融合 但这种方法存在明显的局限性:忽略了不同视图之间的信息一致性 一个区域的多个视图所携带的信息是高度相关的,因此它们的表示应该是一致的如果能…...
)
Android 缓存应用冻结器(Cached Apps Freezer)
一、核心功能与原理 1. 功能概述 目标:通过冻结后台缓存应用的进程,减少其对 CPU、内存等系统资源的消耗,优化设备性能与续航。适用场景:针对行为不当的后台应用(如后台偷偷运行代码、占用 CPU)ÿ…...

初学者如何微调大模型?从0到1详解
本文将手把手带你从0到1,详细解析初学者如何微调大模型,让你也能驾驭这些强大的AI工具。 1. 什么是大模型微调? 想象一下,预训练大模型就像一位博览群书但缺乏专业知识的通才。它掌握了海量的通用知识,但可能无法完美…...

西瓜书第十一章——降维与度量学习
文章目录 降维与度量学习k近邻学习原理头歌实战-numpy实现KNNsklearn实现KNN 降维——多维缩放(Multidimensional Scaling, MDS,MDS)提出背景与原理重述1.**提出背景**2.**数学建模与原理推导**3.**关键推导步骤** Principal Component Analy…...
Portainer安装指南:多节点监控的docker管理面板-家庭云计算专家
背景 Portainer 是一个轻量级且功能强大的容器管理面板,专为 Docker 和 Kubernetes 环境设计。它通过直观的 Web 界面简化了容器的部署、管理和监控,即使是非技术用户也能轻松上手。Portainer 支持多节点管理,允许用户从一个中央控制台管理多…...

NanoGPT的BenchMarking.py
1.Benchmarking是一种评估和比较性能的过程。在深度学习领域,它通常涉及对模型的训练速度、推理速度、内存占用等指标进行测量,以便评估不同模型、不同硬件配置或者不同软件版本之间的性能差异。 例如,当你尝试比较两个不同架构的模型&#x…...