【C++】位图详解(一文彻底搞懂位图的使用方法与底层原理)
🌈 个人主页:谁在夜里看海.
🔥 个人专栏:《C++系列》《Linux系列》
⛰️ 天高地阔,欲往观之。


目录
1.位图的概念
2.位图的使用方法
定义与创建
设置和清除
位访问和检查
转换为其他格式
3.位图的使用场景
1.快速的查找某个数据是否在一个集合中
2.排序+去重
3.求两个集合的交集和并集
4.位图的底层实现
私有成员定义与初始化
set和reset的实现
前面的博客我们介绍了哈希结构以及以哈希为底层结构的容器unordered_map和unordered_set,相较于以红黑树为底层的map和set,它们的优势是更高效的查找(平均为O(1))不过代价是更多内存的消耗,这些内存的消耗在某些场景下会变得致命:
这是一道腾讯的面试题:
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。
既然是追求高效的查询,显然哈希结构更具优势,但是在这里如果使用哈希表,会占用大量的内存。40亿个整数键需要16GB的内存,为了解决哈希冲突,实际所需容量会更多(1.5倍以上)。这是什么概念呢?

这是博主的笔记本规格,可以看到RAM(运行内存)刚好是16GB(加上虚拟内存也不过20GB左右),也就是说即使我“倾家荡产”也不足以实现上述操作。
用其他办法(比如压缩数据结构)的确可以节省内存的占用,但是并无法达到快速查询的效果。现在存在如下矛盾:
①:更快查询效率的需要
②:更少内存占用的需要
我们需要寻找一种办法,同时满足上述两种需求,以解决这个问题。于是乎,位图闪亮登场~
1.位图的概念
所谓位图,是一种使用二进制位(bit位)来表示数据状态的数据结构。其每一个二进制位(bit)可以表示一个数据的存在与否,从而通过极少的内存实现大规模数据的存储与处理。
比如,存储1个整形需要4个字节的空间,现在我用存储1个整形的空间,就可以表示32个整形元素的存储状态:

1个整形有32个bit位,每一位都可以表示一个数据的状态(数据1存在就让第一位bit值变成1),因此我们可以把每一个比特位都看成一个bool值,bool值为1表示数据存在,为0表示不存在。
现在我们回到上面那道问题:
原本需要16GB的空间存储40亿个整数,而1个整形的空间可以表示32个数据的存在状态,所以现在只需要 16GB/32 = 512KB 的存储空间,而且由于数据是映射存储的,我们想知道 整数x 存不存在,只需要看第 x 个比特位是否为1即可,所以查询的时间复杂度是O(1)。这种映射关系和哈希结构很像,所以位图实际上就是哈希的一种应用。
 总结:位图是如何查询到数据的
总结:位图是如何查询到数据的
位图只存储数据的状态(即是否存在),而不存储数据本身的值,但是我们仍可以根据位图的位索引位置间接查询到数据本身。比如要记录整数 5 是否存在,则位图第 5 位会被置为 1,看到第 5 位是 1,可以知道 5 存在,但位图中并没有存储“5”的数值。总之,我们并不是根据数据本身进行查询,而是通过位置映射关系进行查询。

2.位图的使用方法
C++标准库提供了一个名为 bitset 的数据结构,用于管理和操作bit数组,可用于实现位图。
以下是bitset使用方法的介绍:
定义与创建
bitset 是一个模版类,模版参数表示位数,在编译时确定大小,例如:
#include <bitset>
#include <iostream>
using namespace std;int main()
{bitset<8> bits; // 定义一个大小为 8 位的位图(位数组)bitset<16> bits16(0xF0F0); // 定义一个大小为 16 位的位图,并初始化为二进制 1111 0000 1111 0000bitset<8> bitsFromStr("10101010"); // 从字符串创建一个 8 位位图return 0;
}

设置和清除
bitset 提供了很多方法用于位操作和状态管理:
| set() | 将所有位设置为 1 |
| set(size_t pos, bool value = true) | 将指定位置 pos 的位设置为 value |
| reset() | 将所有位重置为 0 |
| reset(size_t pos) | 将指定位置 pos 的位重置为 0 |
| flip() | 将所有位翻转(0 变 1,1 变 0) |
| flip(size_t pos) | 将指定位置 pos 的位翻转 |
bitset<8> bits("10101010");bits.set(0); // 将第 0 位设置为 1,结果为 10101011bits.reset(1); // 将第 1 位设置为 0,结果为 10101001bits.flip(); // 翻转所有位,结果为 01010110bits.flip(2); // 翻转第 2 位,结果为 01010010
位访问和检查
| operator[] | 使用 [] 访问位 |
| test(size_t pos) | 测试指定位置的位是否为 1,返回 true 表示为 1,返回 false 表示为 0 |
| all() | 检查所有位是否都为 1,是返回 true,否则返回 false |
| any() | 检查是否存在至少一位为 1,是则返回 true |
| none() | 检查是否所有位都是 0,是则返回 true |
| count() | 返回所有 1 的数量 |

转换为其他格式
| to_string() | 将位图转换为字符串 |
| to_ulong() | 将位图转换为 unsigned long 类型 |
| to_ullong() | 将位图转换为 unsigned long long 类型 |

3.位图的使用场景
1.快速的查找某个数据是否在一个集合中
现在随机生成10000个范围在0~15000的整数,检验某些数据是否存在:
#include <bitset>
#include <iostream>
#include <vector>
#include <random>
#include <chrono>using namespace std;int main() {const int num_elements = 10000; // 元素数量const int min_value = 0; // 最小值const int max_value = 15000; // 最大值// 获取当前时间作为种子unsigned seed = static_cast<unsigned>(std::chrono::system_clock::now().time_since_epoch().count());std::mt19937 gen(seed); // 使用当前时间作为种子生成随机数std::uniform_int_distribution<> dis(min_value, max_value); // 均匀分布// 创建一个 vector 并填充随机数std::vector<int> nums(num_elements);for (int& number : nums) {number = dis(gen); // 生成随机数并赋值}// 创建位图,范围是 0 到 max_valuebitset<max_value + 1> bitset;// 将生成的随机数映射到位图中for (const auto& it : nums) {bitset.set(it);}// 检查某个数是否存在vector<int> num_test = { 5, 64, 862, 1356, 45, 236, 856, 12, 489, 6116, 1648, 216, 1554, 335, 795, 211 };cout << "存在性检查结果:\n";for (const auto& it : num_test) {if (bitset.test(it)) { // 检查 num 的位是否为 1cout << it << " 存在.\n";}else {cout << it << " 不存在.\n";}}return 0;
}分别运行三次的结果:



2.排序+去重
位图和哈希表底层都是哈希结构,为什么哈希表不能实现排序而位图可以呢?
因为哈希表的存储位置是通过哈希函数求得的的哈希值决定的,不同的元素可能有相同的哈希值,因此元素的存储是非线性的。
而位图的存储位置就是数据本身决定的,每个比特位对于一个元素,因此元素的存储是线性的。
下面来看示例:
#include <iostream>
using namespace std;
#include <bitset>
#include <vector>const size_t MAX_SIZE = 1000; // 数据范围是 0 到 1,000,000int main() {bitset<MAX_SIZE> bitset;// 模拟数据插入(包括重复数据)vector<int> data = { 566,254,4,26,326,2,495,56,98,26,254,566,235,66 };cout << "排序+去重前的数据:\n";for (auto it : data) {cout << it << " ";}cout << "\n";for (int num : data) {bitset.set(num); // 将数据映射到位图中}// 遍历位图,输出所有置位为 1 的位置(即有序的、去重的数据)cout << "排序+去重后的数据:\n";for (size_t i = 0; i < MAX_SIZE; ++i) {if (bitset.test(i)) {cout << i << " ";}}cout << "\n";return 0;
}

3.求两个集合的交集和并集
位图是如何完成交集并集运算的呢?由于位图的每一个bit位存储对应元素的bool值(0或1),而相同元素在不同位图中的存储位置是一样的,我们对两个位图进行按位与运算,就可以得到交集;进行按位或运算,就可以得到并集。


#include <iostream>
#include <bitset>
const size_t MAX_SIZE = 1000000;
using namespace std;int main() {bitset<MAX_SIZE> setA;bitset<MAX_SIZE> setB;// 插入一些数据到集合 AsetA.set(123456);setA.set(654321);setA.set(500);// 插入一些数据到集合 BsetB.set(654321);setB.set(500);setB.set(999999);// 求交集(A & B)bitset<MAX_SIZE> intersection = setA & setB;cout << "交集:\n";for (size_t i = 0; i < MAX_SIZE; ++i) {if (intersection.test(i)) {cout << i << " ";}}cout << "\n";// 求并集(A | B)bitset<MAX_SIZE> unionSet = setA | setB;cout << "并集:\n";for (size_t i = 0; i < MAX_SIZE; ++i) {if (unionSet.test(i)) {cout << i << " ";}}cout << "\n";return 0;
}
4.位图的底层实现
位图的底层其实是一个vector容器,容器内部存放整形元素,一个整形元素可以存放32个对应元素的状态(bool值),并且通过位运算实现映射关系的对应。
底层存储结构:

私有成员定义与初始化
在bitset类中,我们需要一个_bitCount成员表示比特位的总个数用于对bitset的初始化,以及一个_bit(vector<int>类型的容器 )用于存储元素。
class bitset
{private:vector<int> _bit;size_t _bitCount;
};位图的大小是固定的,根据_bitCount的大小进行空间开辟,而_bitCount的大小是由待存储元素的最大值决定的。但是_bitCount的单位是bit,而vector中存储单位是整形,所以我们需要进行换算,将_bitCount>>5(也就是除以2^5)并+1(由于除法会向下取整,例如 bitCount 是 33,33 >> 5 计算结果是 1,但我们实际上需要 2 个整型来存储 33 个比特位)
bitset(size_t bitCount): _bit((bitCount >> 5) + 1), _bitCount(bitCount){}set和reset的实现
假设用which表示要存储的元素,我们需要求得映射位置。我们可以把每个元素当成一个数组,数组中包含32个比特位,此时将which/32就可以得出存储在第几个数组中,并用which%32得到在该数组下的具体比特位,假设which = 152:

存储位置为v[4]的第24个比特位:

如此一来就找到了对应的映射关系。下面是代码部分:
// 将which比特位置1void set(size_t which){if (which > _bitCount)return;size_t index = (which >> 5);size_t pos = which % 32;_bit[index] |= (1 << pos); // 将对应bit位改为1}// 将which比特位置0void reset(size_t which){if (which > _bitCount)return;size_t index = (which >> 5);size_t pos = which % 32;_bit[index] &= ~(1 << pos); // 将对应bit位改为0}// 检测位图中which是否为1bool test(size_t which){if (which > _bitCount)return false;size_t index = (which >> 5);size_t pos = which % 32;return _bit[index] & (1 << pos);}// 获取位图中比特位的总个数size_t size()const { return _bitCount; }以上就是对位图的详细介绍说明,欢迎指正~
码文不易,还请多多关注支持,这是我持续创作的最大动力!
相关文章:
【C++】位图详解(一文彻底搞懂位图的使用方法与底层原理)
🌈 个人主页:谁在夜里看海. 🔥 个人专栏:《C系列》《Linux系列》 ⛰️ 天高地阔,欲往观之。 目录 1.位图的概念 2.位图的使用方法 定义与创建 设置和清除 位访问和检查 转换为其他格式 3.位图的使用场景 1.快速…...

Spring Boot 整合 JdbcTemplate,JdbcTemplate 与 MyBatis 的区别
DAY29.1 Java核心基础 Spring Boot 整合 JdbcTemplate JdbcTemplate是一个轻量级JDBC封装的组件 JdbcTemplate 是 Spring 自带的JDBC的封装,和Mybatis类似,需要自己封装sql语句 JdbcTemplate 帮助我们来连接数据库,SQL的执行,…...

sass基础语法
Sass(Syntactically Awesome Style Sheets)是一种 CSS 预处理器,提供了比原生 CSS 更强大、更灵活的语法功能。它有两种语法格式: Sass(缩进语法,.sass 文件)SCSS(CSS-like 语法&am…...

【EF Core】 EF Core 批量操作的进化之路——从传统变更跟踪到无跟踪更新
文章目录 前言一、批量操作(Rang)1.1 AddRange()1.2 UpdateRange()1.3 AttachRange()1.4 RemoveRange() 二、Range操作的底层优化2.1 EF Core 7 前举步维艰2.2 EF Core 7后焕然一新 三、无跟踪的批量更新与删除3.1 ExecuteUpdate3.2 ExecuteDelete3.3 状…...

[Go] Option选项设计模式 — — 编程方式基础入门
[Go] Option选项设计模式 — — 编程方式基础入门 全部代码地址,欢迎⭐️ Github:https://github.com/ziyifast/ziyifast-code_instruction/tree/main/go-demo/go-option 1 介绍 在 Go 开发中,我们经常遇到需要处理多参数配置的场景。传统方…...

Vue 项目命名规范指南
📚 Vue 项目命名规范指南(适用于 Vue 3 Pinia Vue Router) 目的:统一命名风格,提升可读性、可维护性和团队协作效率。 一、通用原则 类型命名风格示例变量camelCaseuserName, isLoading常量UPPER_SNAKE_CASEMAX_RET…...
【笔记】开源通用人工智能代理 Suna 部署全流程准备清单(Windows 系统)
#工作记录 一、基础工具与环境 开发工具 Git 或 GitHub Desktop(代码管理)Docker Desktop(需启用 WSL2,容器化部署)Python 3.11(推荐版本,需添加到系统环境变量)Node.js LTS…...

海康工业相机SDK二次开发(VS+QT+海康SDK+C++)
前言 工业相机在现代制造和工业自动化中扮演了至关重要的角色,尤其是在高精度、高速度检测中。海康威视工业相机以其性能稳定、图像质量高、兼容性强而受到广泛青睐。特别是搞机器视觉的小伙伴们跟海康打交道肯定不在少数,笔者在平常项目中跟海康相关人…...

前端面试准备-5
1.Node.js中的process.nectTick()有什么作用 将一个回调函数插入到当前执行栈的尾部,在下一次事件轮询之前调用这个回调函数 2.什么是Node.js中的事件发射器,作用是什么,如何使用 提供一种机制,可以创建、触发和监听自定义事件…...

Spring Boot 启动流程深度解析:从源码到实践
Spring Boot 启动流程深度解析:从源码到实践 Spring Boot 作为 Java 开发的主流框架,其 “约定大于配置” 的理念极大提升了开发效率。本文将从源码层面深入解析 Spring Boot 的启动流程,并通过代码示例展示其工作机制。 一、Spring Boot 启…...
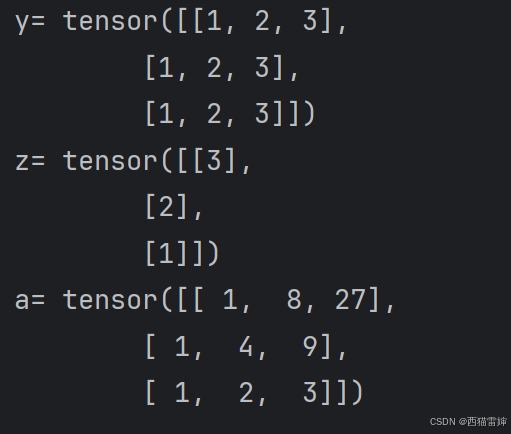
深度学习|pytorch基本运算-乘除法和幂运算
【1】引言 前序学习进程中,已经对pytorch张量数据的生成和广播做了详细探究,文章链接为: 深度学习|pytorch基本运算-CSDN博客 深度学习|pytorch基本运算-广播失效-CSDN博客 上述探索的内容还止步于张量的加减法,在此基础上&am…...

嵌入式通用集成电路卡市场潜力报告:物联网浪潮下的机遇与挑战剖析
一、嵌入式通用集成电路卡概述 嵌入式通用集成电路卡(Embedded Universal Integrated Circuit Card,简称 eUICC),是一种将传统 SIM 卡功能直接嵌入到设备主板上的芯片解决方案 。与传统可插拔式 SIM 卡不同,eUICC 采…...

4.2.4 Spark SQL 数据写入模式
在本节实战中,我们详细探讨了Spark SQL中数据写入的四种模式:ErrorIfExists、Append、Overwrite和Ignore。通过具体案例,我们演示了如何使用mode()方法结合SaveMode枚举类来控制数据写入行为。我们首先读取了一个JSON文件生成DataFrame&#…...
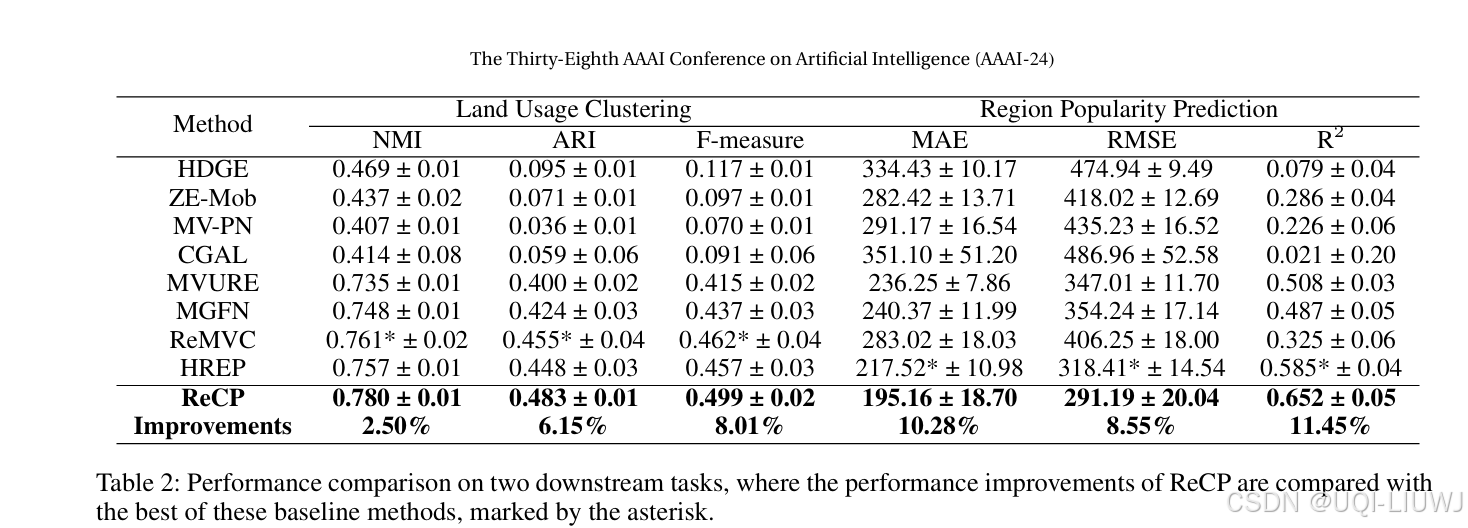
论文笔记: Urban Region Embedding via Multi-View Contrastive Prediction
AAAI 2024 1 INTRO 之前基于多视图的region embedding工作大多遵循相同的模式 单独的单视图表示多视图融合 但这种方法存在明显的局限性:忽略了不同视图之间的信息一致性 一个区域的多个视图所携带的信息是高度相关的,因此它们的表示应该是一致的如果能…...
)
Android 缓存应用冻结器(Cached Apps Freezer)
一、核心功能与原理 1. 功能概述 目标:通过冻结后台缓存应用的进程,减少其对 CPU、内存等系统资源的消耗,优化设备性能与续航。适用场景:针对行为不当的后台应用(如后台偷偷运行代码、占用 CPU)ÿ…...

初学者如何微调大模型?从0到1详解
本文将手把手带你从0到1,详细解析初学者如何微调大模型,让你也能驾驭这些强大的AI工具。 1. 什么是大模型微调? 想象一下,预训练大模型就像一位博览群书但缺乏专业知识的通才。它掌握了海量的通用知识,但可能无法完美…...

西瓜书第十一章——降维与度量学习
文章目录 降维与度量学习k近邻学习原理头歌实战-numpy实现KNNsklearn实现KNN 降维——多维缩放(Multidimensional Scaling, MDS,MDS)提出背景与原理重述1.**提出背景**2.**数学建模与原理推导**3.**关键推导步骤** Principal Component Analy…...
Portainer安装指南:多节点监控的docker管理面板-家庭云计算专家
背景 Portainer 是一个轻量级且功能强大的容器管理面板,专为 Docker 和 Kubernetes 环境设计。它通过直观的 Web 界面简化了容器的部署、管理和监控,即使是非技术用户也能轻松上手。Portainer 支持多节点管理,允许用户从一个中央控制台管理多…...

NanoGPT的BenchMarking.py
1.Benchmarking是一种评估和比较性能的过程。在深度学习领域,它通常涉及对模型的训练速度、推理速度、内存占用等指标进行测量,以便评估不同模型、不同硬件配置或者不同软件版本之间的性能差异。 例如,当你尝试比较两个不同架构的模型&#x…...

测试用例及黑盒测试方法
一、测试用例 1.1 基本要素 测试用例(Test Case)是为了实施测试而向被测试的系统提供的一组集合,这组集合包含:测试环境、操作步骤、测试数据、预期结果等4个主要要素。 1.1.1 测试环境 定义:测试执行所需的软硬件…...

CentOS 7 环境下部署 LAMP
在 CentOS 7 环境下部署 LAMP(Linux Apache MySQL 5.7 PHP 7.4) 环境的详细步骤如下: 1. 系统准备 1.1 更新系统 sudo yum update -y 1.2 安装依赖 sudo yum install -y gcc pcre pcre-devel zlib zlib-devel openssl openssl-devel e…...
vscode实用配置
前端开发安装插件: 1.可以更好看的显示文件图标 2.用户快速打开文件 使用步骤:在html文件下右键点击 open with live server 即可 刷力扣: 安装这个插件 还需要安装node.js即可...
React 项目中封装 Excel 导入导出组件:技术分享与实践
文章目录 前言一、为什么需要封装 Excel 组件?二、技术选型三、核心实现1. 安装依赖2. 封装Excel导出3. 封装导入组件 (UploadExcel) 总结 前言 在 React 项目中,处理 Excel 文件的导入和导出是常见的业务需求。无论是导出报表数…...
)
【PhysUnits】15.1 引入P1后的加一特质(add1.rs)
一、源码 代码实现了类型系统中的"加一"操作(Add1 trait),用于在编译期进行数字的增量计算。 //! 加一操作特质实现 / Increment operation trait implementation //! //! 说明: //! 1. Z0、P1,、N1 1࿰…...

【2025CCF中国开源大会】RISC-V 开源生态的挑战与机遇分论坛重磅来袭!共探开源芯片未来
点击蓝字 关注我们 CCF Opensource Development Committee 开源浪潮正从软件席卷硬件领域,RISC-V作为全球瞩目的开源芯片架构,正在重塑计算生态的版图!相较于成熟的x86与ARM,RISC-V生态虽处爆发初期,却蕴藏着无限可能。…...
python完成批量复制Excel文件并根据另一个Excel文件中的名称重命名
import openpyxl import shutil import os # 原始文件路径 original_file "C:/Users/Administrator/Desktop/事业联考面试名单/郑州.xlsx" # 读取包含名称的Excel文件 # 修改为您的文件名 wb openpyxl.load_workbook( "C:/Users/Administrator/Desktop/事…...
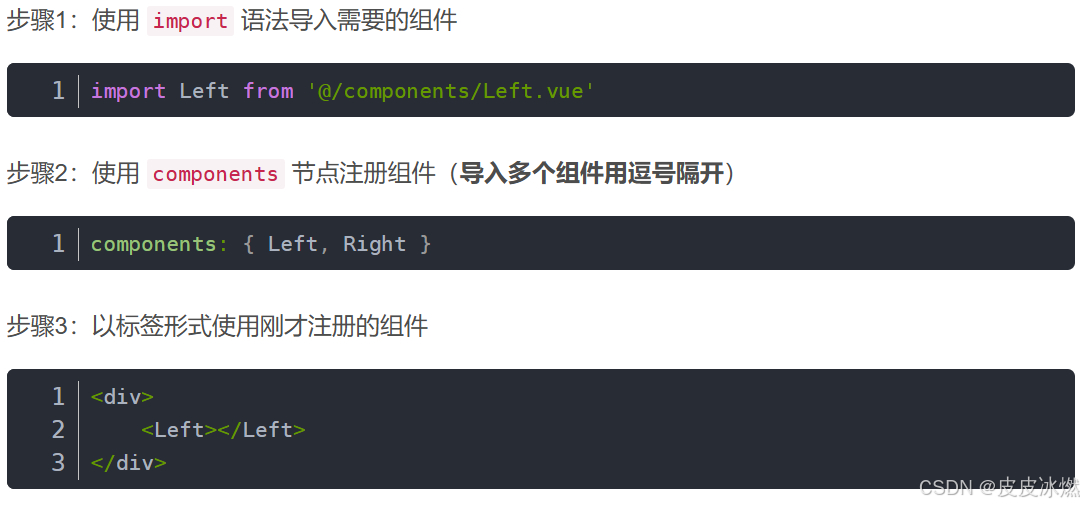
Vue-2-前端框架Vue基础入门之二
文章目录 1 计算属性1.1 计算属性简介1.2 计算属性示例 2 侦听器2.1 简单的侦听器2.2 深度监听2.3 监听对象单个属性 3 vue-cli3.1 工程化的Vue项目3.2 Vue项目的运行流程 4 vue组件4.1 Vue组件的三个部分4.1.1 template4.1.2 script4.1.3 style 4.2 组件之间的关系4.2.1 使用组…...

CPT208 Human-Centric Computing 人机交互 Pt.7 交互和交互界面
文章目录 1. 界面隐喻(Interface metaphors)1.1 界面隐喻的应用方式1.2 界面隐喻的优缺点 2. 交互类型2.1 Instructing(指令式交互)2.2 Conversing(对话式交互)2.3 Manipulating(操作式交互&…...

ubuntu20.04.5-arm64版安装robotjs
ubuntu20.04.5arm上使用robotjs #ssh,可选 sudo apt update sudo apt install openssh-server sudo systemctl status ssh sudo systemctl enable ssh sudo systemctl enable --now ssh #防火墙相关,可选 sudo ufw allow ssh sudo ufw allow 2222/tc…...
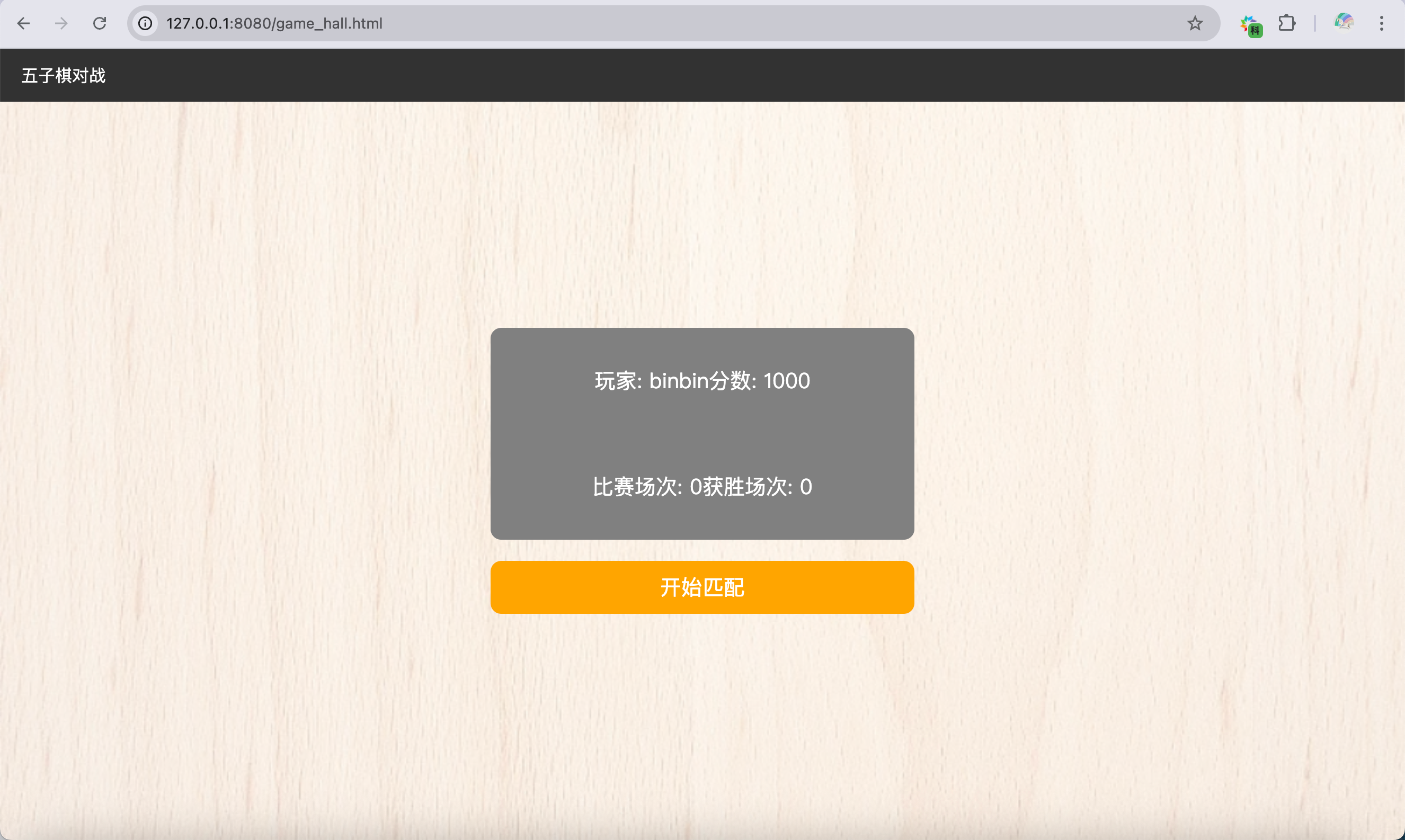
[网页五子棋][匹配模块]前后端交互接口(消息推送机制)、客户端开发(匹配页面、匹配功能)
让多个用户,在游戏大厅中能够进行匹配,系统会把实力相近的两个玩家凑成一桌,进行对战 约定前后端交互接口 消息推送机制 匹配这样的功能,也是依赖消息推送机制的 玩家 1 点击开始匹配按钮,就会告诉服务器࿱…...