【数据结构】顺序表和链表详解(上)
前言:上期我们介绍了算法的复杂度,知道的算法的重要性同时也了解到了评判一个算法的好与坏就去看他的复杂度(主要看时间复杂度),这一期我们就从顺序表和链表开始讲起。
文章目录
- 一,顺序表
- 1,线性表
- 2,顺序表
- 3,顺序表的分类
- 4,动态顺序表的实现
- 1,增
- 1,头插
- 2,尾插
- 2,在指定位置前插入数据
- 2,删
- 1,头删
- 2,尾删
- 3,删除pos位置(指定位置)的数据
- 3,查
- 4,改
- 5,销毁
- 二,顺序表的总结和问题的思考
- 三,链表
- 1,什么是链表?
- 2,什么是结点?
- 3,链表的分类
- 4,单链表的实现
- 1,增
- 1,头插
- 2,尾插
- 3,在指定位置之前插入数据
- 4,在指定位置之后插入数据
- 1,删
- 1,头删
- 2,尾删
- 3,删除pos位置之前的结点
- 4,删除pos位置之后的结点
- 3,查
- 4 ,链表的销毁
一,顺序表
在介绍顺序表之前我们先引出一个概念:线性表
1,线性表
什么是线性表?
线性表(linear list)是n个具有相同特性的数据元素的有限序列。
线性表是⼀种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串…。
· 线性表在逻辑上是线性结构也就是连续的一条直线;但在物理结构上并不一定是连续的,线性表在物理上储存时通常以数组或者链式结构的形式储存。
2,顺序表
什么是顺序表?
概念:顺序表是⽤⼀段物理地址连续的存储单元依次存储数据元素的线性结构,⼀般情况下采⽤数组存储。
通过概念不难发现顺序表它也是一个线性表,那就有线性表所对应的性质。那么线性表既然采用数组存储那么就说明它的底层就是一个数组,我们对于顺序表的操作就是对数组的操作。
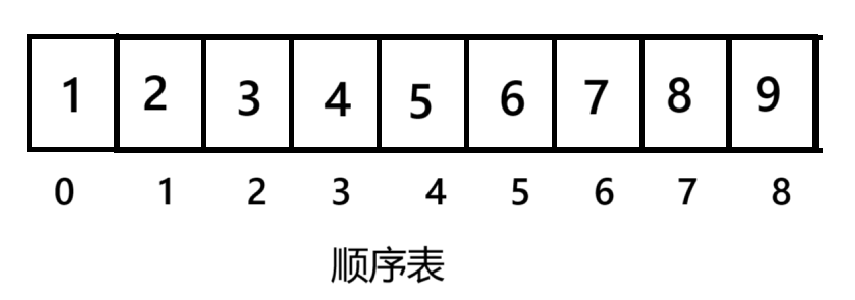
从上图我们可以看地出来,顺序表地逻辑结构是线性的,物理结构也是线性的。
逻辑结构是认为构想出来的的,比如上图就是人为想象出来的。
而物理结构是线性的是因为顺序表底层是数组,数组它本身就是连续存放数据的。
看到这有人就会有疑问了说顺序表和数组到底有什么区别呢?
首先数组是一个可以存放n个相同特性元素的集合,顺序表底层使用的是数组所以顺序也可以存放n个具有相同特性元素的集合,但是顺序表可以对它的底层数组执行一些操作比如对数组内部的数据进行增,删,查,改等操作。
所以可以理解为顺序表是对数组的一个封装,可以直接操作数组。
3,顺序表的分类
顺序表分为动态顺序表和静态顺序表两种。
静态顺序表 即使用定长数组
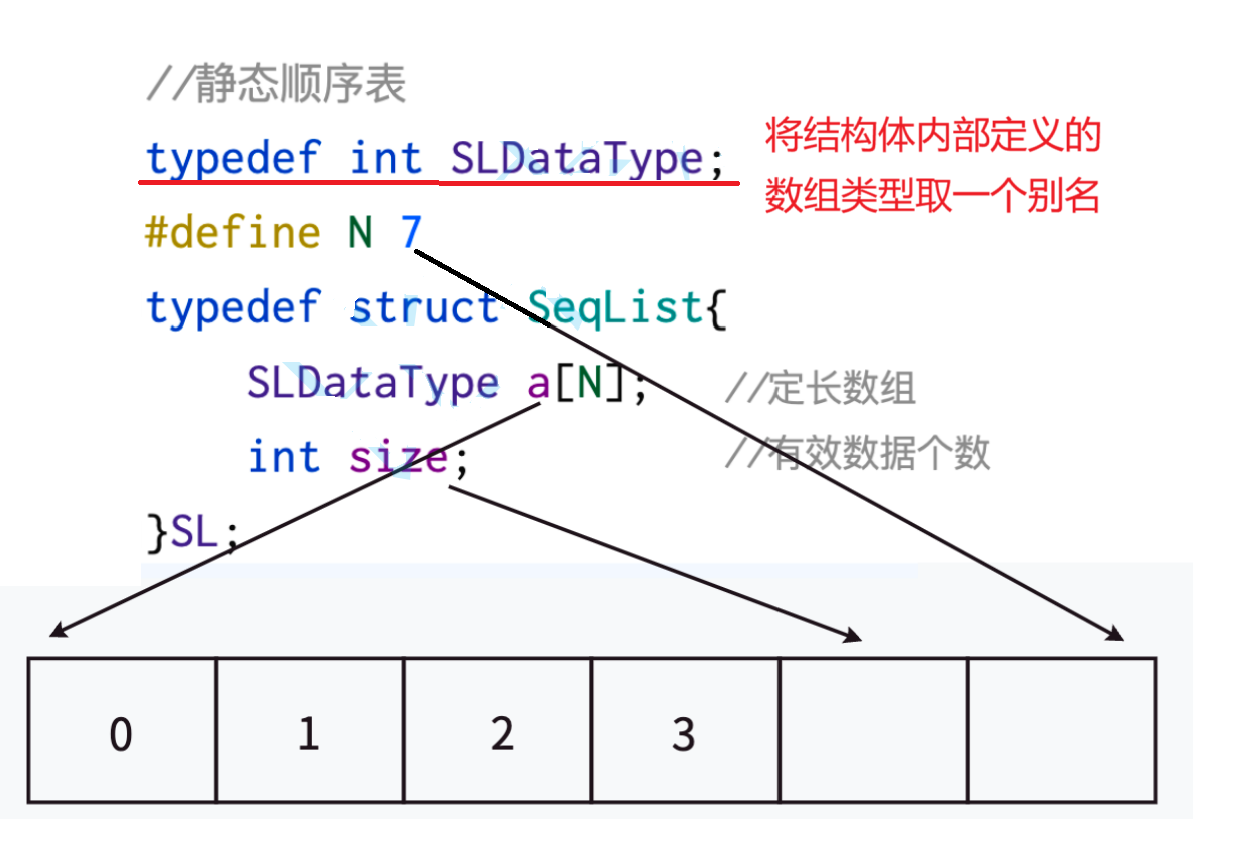
我们很容易发现它的缺点就是数组空间的问题,如果我们初始时的空间给大了却只存储很少的数据就造成了空间的浪费,如果我们初始时给的空间太小如果要存储大量的数据有会存在空间不足的问题,所以在实现顺序表时一般不采用静态顺序表的方式。
再来看下一种
动态顺序表 即空间大小可以随时变化
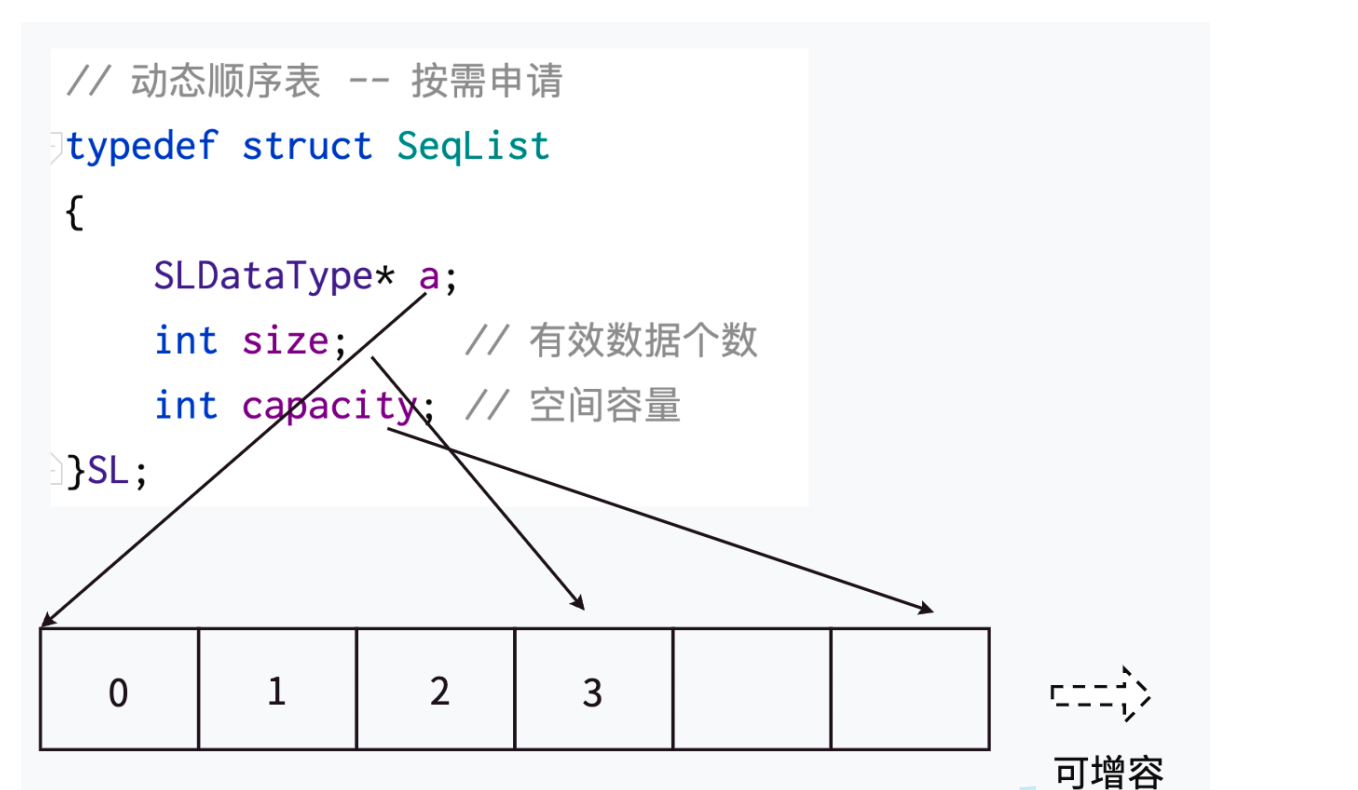
将数组改成指针的形式之后就可以通过malloc,realloc和calloc函数来扩展空间了,就很好的解决了静态顺序表对于空间的担忧。所以在实现顺序表的时候就使用动态顺序表。
注意:如果上面代码看不懂的话可以去看看博主写的C语言有关结构体,内存函数,指针的内容,因为数据结构就是使用他们来实现的!!!
4,动态顺序表的实现
首先需要定义一个顺序表在哪定义呢?
数据结构中的结构就是结构体,当然要在结构体内部定义了。
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
//定义一个顺序表
typedef int SLtype;
typedef struct sqelist
{SLtype* arr;//顺序表底层的数组int size;//size用于记录有效数据个数int capacity;//capacity用于管理空间
}SL;
下面是在定义时需要注意的一些细节:
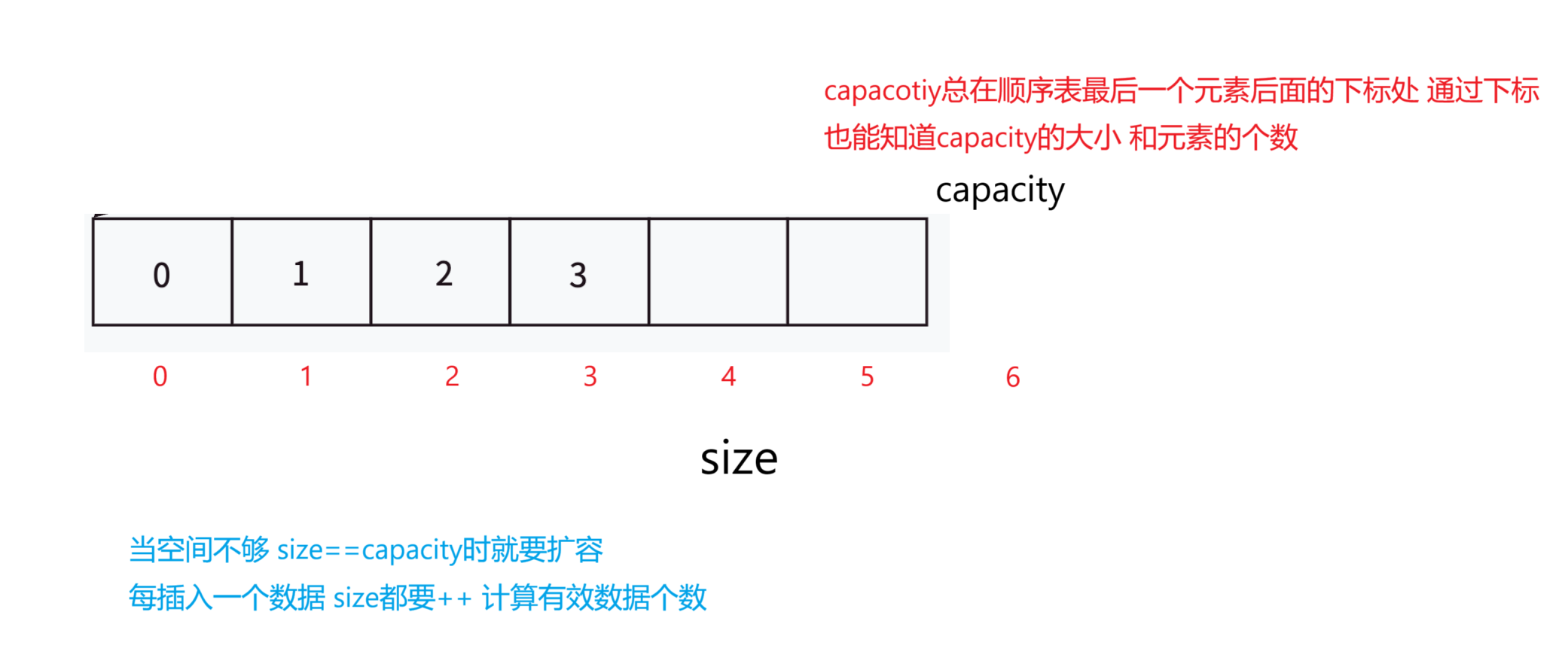
定义好了顺序表之后我们就来说说增,删,查,改的实现。
增(插入数据):头插,尾插,在指定位置前后插入数据。
删(删除数据):头删,尾删,在指定位置前后删除数据。
查(查找数据):查找指定位置的数据。
改(修改数据):修改指定位置的数据。
在进行这些操作之前我们要对顺序表进行初始化。
//初始化结构体
void SLinit(SL*ps);
//初始化
void SLinit(SL* ps)
{ps->arr = NULL;ps->size = ps->capacity = 0;
}
1,增
在插入数据之前我们首先要检查一下,顺序表的空间是否足够不够的话就扩容。
只要是设计插入,就要考虑空间是否足够的问题 所以我们将检查空间是否够封装成一个函数如下:
//判断内存是否足够 封装成一个函数
void SLCheckCapacity(SL*ps);
//检查空间是否足够
void SLCheckCapacity(SL* ps)
{if (ps == NULL){perror("init fial!");return;}//判断空间是否足够 空间不足需要扩容 扩容需要定义一个新的容量 因为capacity总是指向顺序表最后一个元素的后面if (ps->size == ps->capacity){int newcapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity;//创建一个临时指针指向扩展空间的首地址SLtype* tmp = (SLtype*)realloc(ps->arr, newcapacity * sizeof(SLtype));//扩容的是新空间//判断是否开辟成功if (tmp == NULL){perror("realloc fail!");return;}//走到这开辟成功ps->arr = tmp;//将新开辟空间的地址给arr 让arr指向新开辟的空间ps->capacity = newcapacity;//更新容量}
}
1,头插
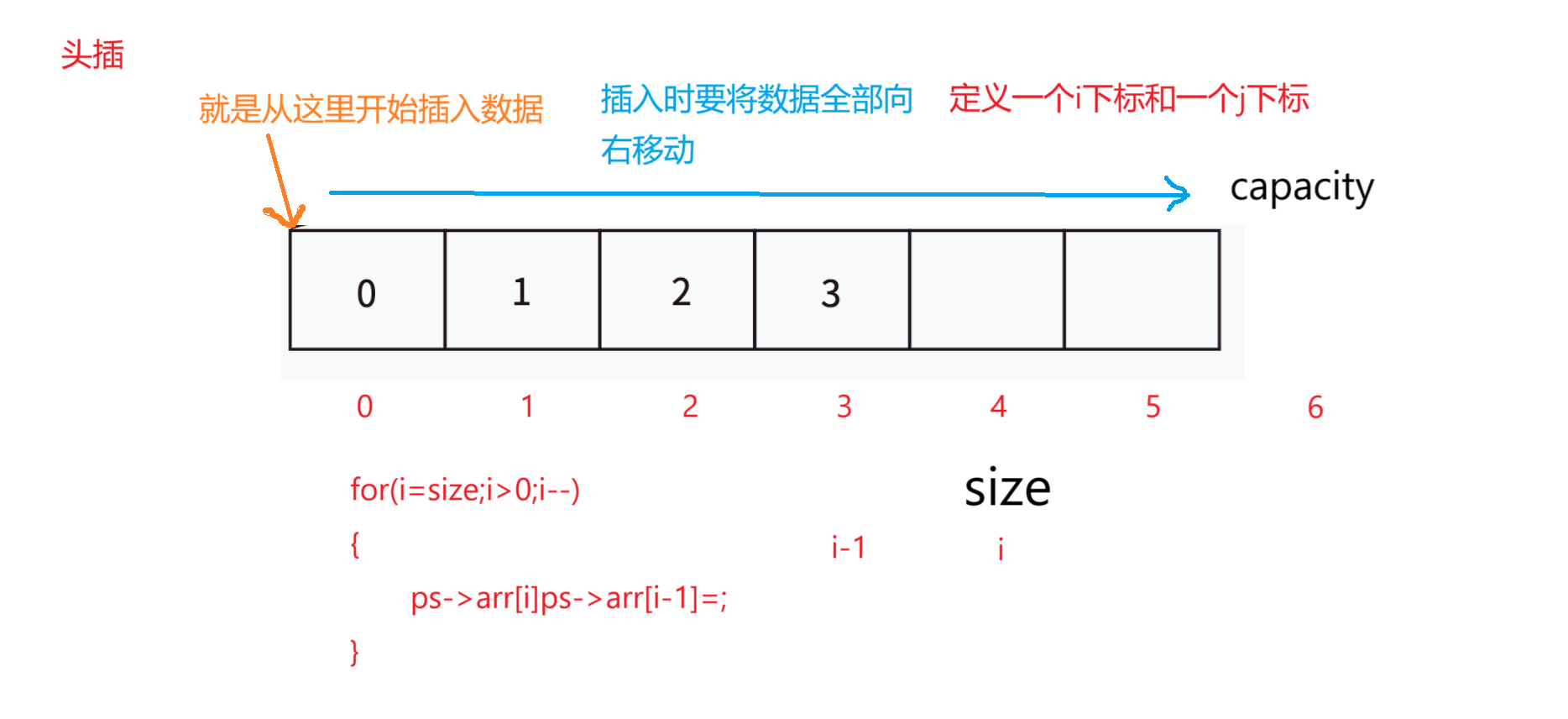
具体的代码如下:
头文件中:
//头插
void SLPushFornt(SL* ps, SLtype x);
实现文件中:
//头插
void SLPushFornt(SL* ps, SLtype x)
{//判断ps是否为空指针NULLif (ps == NULL){perror("fail!");return ;}//assert(ps);//如果内存不足SLCheckCapacity(ps);//如果内存足够int i = 0;for (i = ps->size;i > 0;i--){ps->arr[i] = ps->arr[i-1];}//程序走到这说明 ps->arr[0]的位置已经被空出来了ps->arr[0] = x;++ps->size;
}
2,尾插
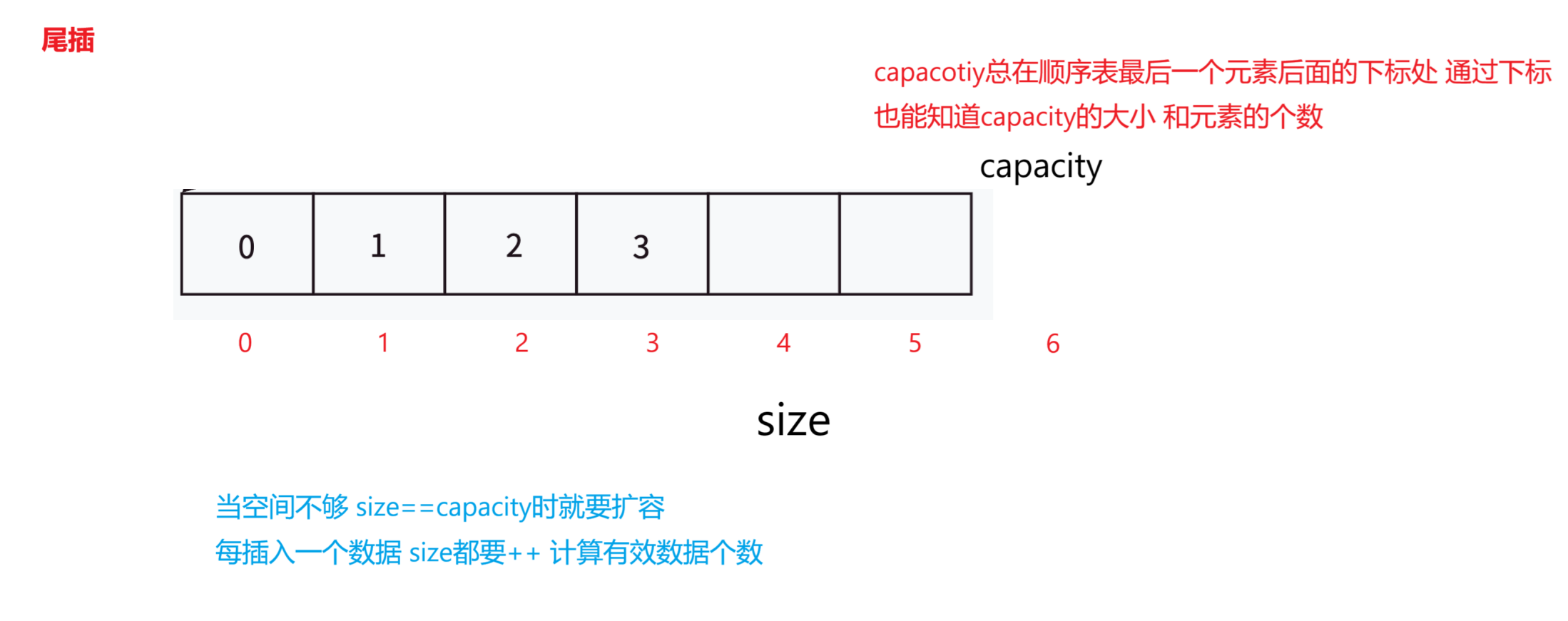
头文件中:
//尾插
void SLPushBack(SL* ps, SLtype x);
实现文件中:
//尾插
void SLPushBack(SL* ps, SLtype x)
{if (ps == NULL){perror("init fial!");return;}//判断空间是否足够 空间不足需要扩容 扩容需要定义一个新的容量 因为capacity总是指向顺序表最后一个元素的后面if (ps->size == ps->capacity){int newcapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity;//创建一个临时指针指向扩展空间的首地址SLtype* tmp = (SLtype*)realloc(ps->arr, newcapacity * sizeof(SLtype));//扩容的是新空间//判断是否开辟成功if (tmp == NULL){perror("realloc fail!");return ;}//走到这开辟成功ps->arr = tmp;//将新开辟空间的地址给arr 让arr指向新开辟的空间ps->capacity = newcapacity;//更新容量}//空间足够的情况下ps->arr[ps->size++] = x;//等价于 ps->arr[ps->size]=x;size++ 这两段代码
}
2,在指定位置前插入数据
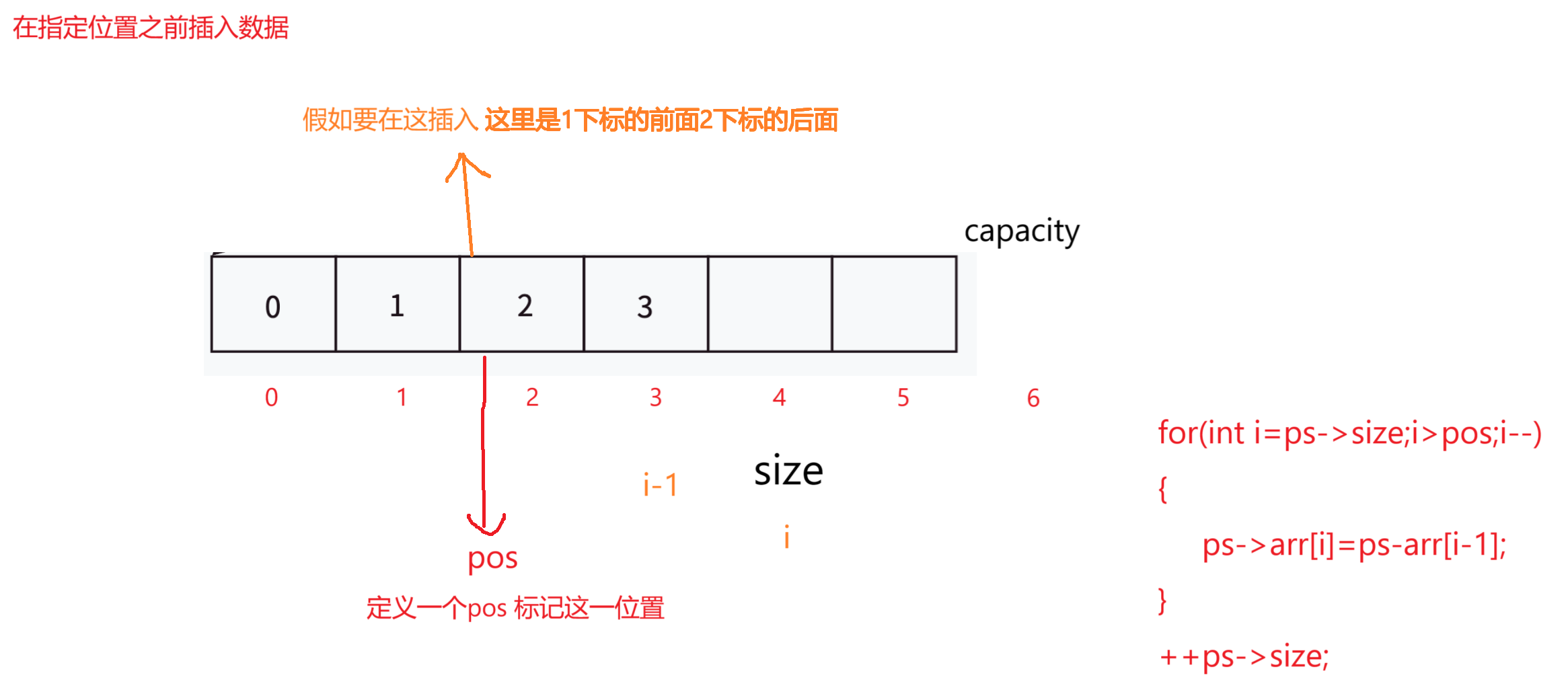
//在指定位置之前插入数据
void SLInsert(SL* ps, SLtype pos, SLtype x);
//在指定位置插入数据
void SLInsert(SL* ps, SLtype pos, SLtype x)
{//判断ps是否为空指针NULLif (ps == NULL){perror("fail!");return ;}//assert(ps);// 如果内存不足SLCheckCapacity(ps);//如果空间足够for (int i = ps ->size;i > pos;i--){ps->arr[i] = ps->arr[i - 1];}ps->arr[pos] = x;//将空出来的位置给xps->size = ps->size++;//插入数据 size要++ 即有效数据要++
}
2,删
1,头删

//头删
void SLPopFornt(SL* ps);
//头删
void SLPopFornt(SL* ps)
{//判断ps是否为空指针NULLif (ps == NULL){perror("fail!");return ;}//assert(ps);for (int i = 0;i < ps->size;i++){ps->arr[i] = ps->arr[i + 1];}ps->size = ps->size--;
}
2,尾删
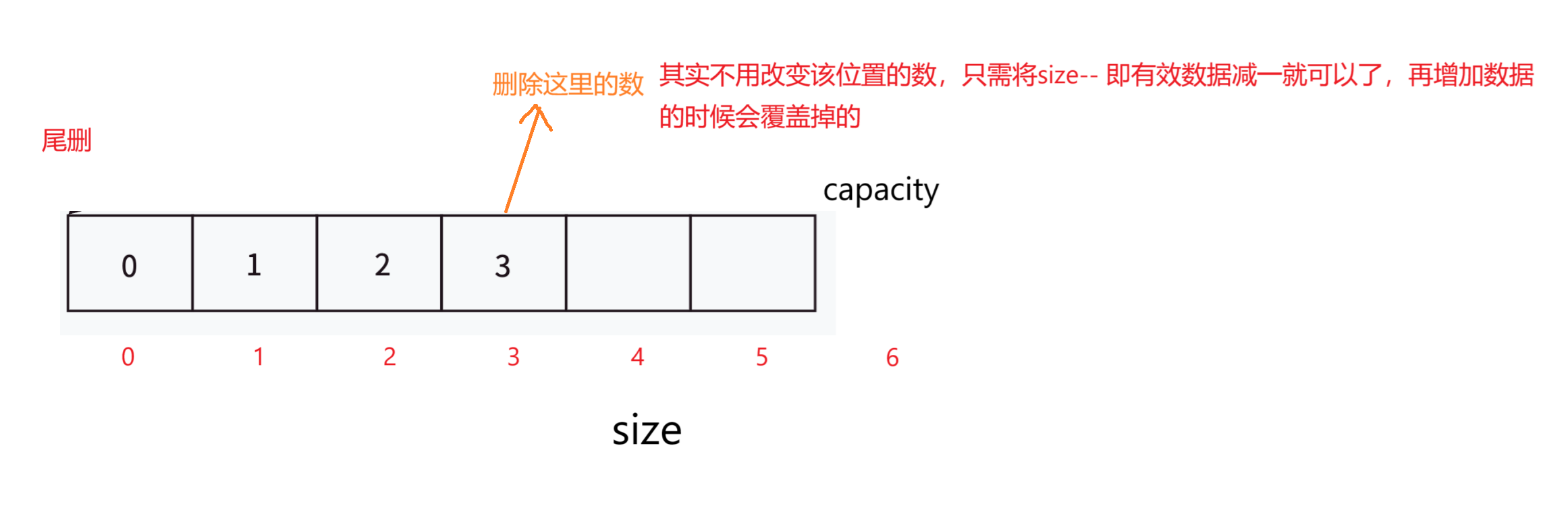
//尾删
void SLPopBack(SL* ps);
//尾删
void SLPopBack(SL* ps)
{//判断ps是否为空指针NULLif (ps == NULL){perror("fail!");return ;}//assert(ps);ps->size = --ps->size;
}
3,删除pos位置(指定位置)的数据
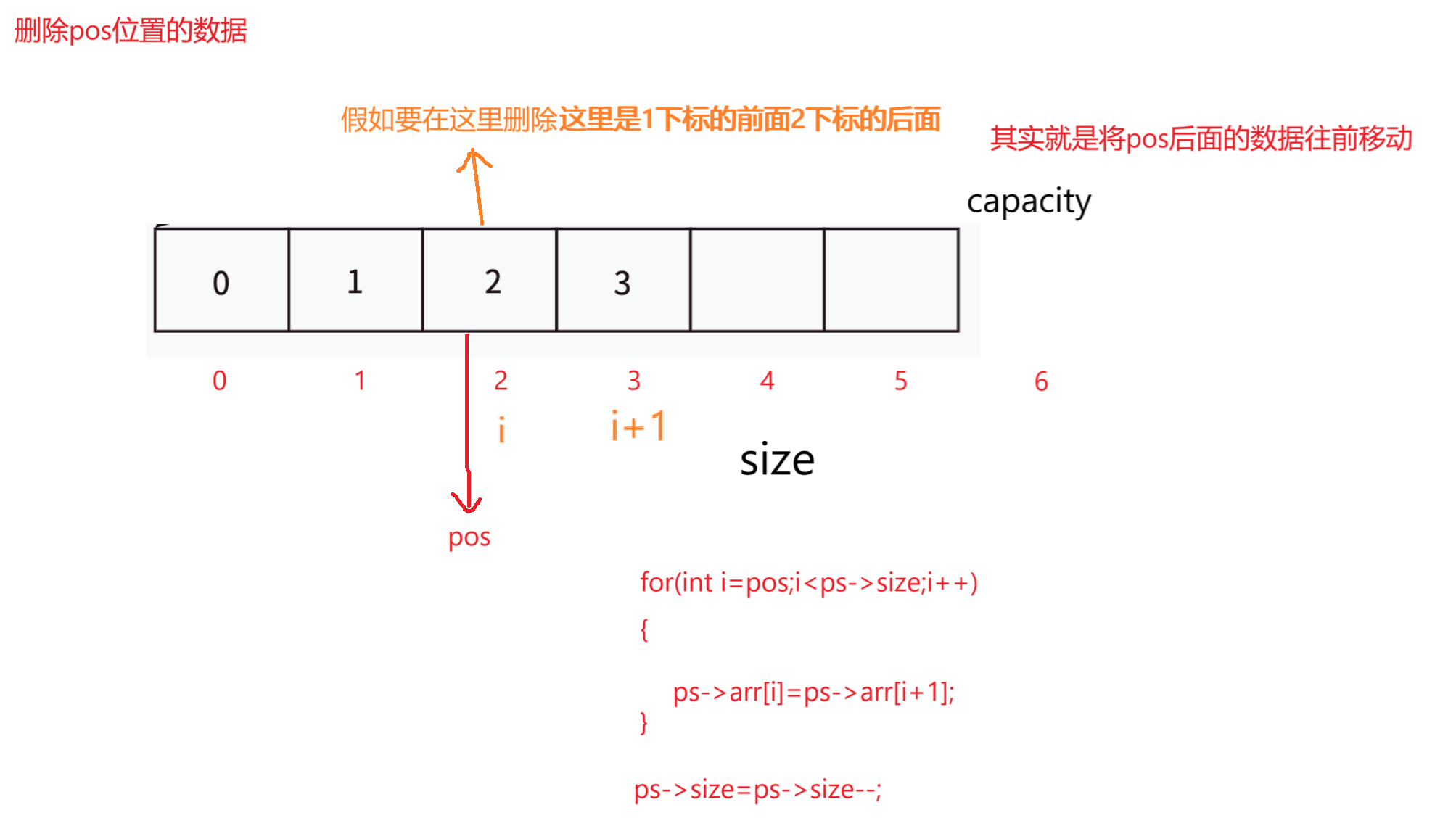
//删除pos位置的数据
void SLErase(SL* ps, SLtype pos, SLtype x);
/删除pos位置的数据
void SLErase(SL* ps, SLtype pos, SLtype x)
{//判断ps是否为空指针NULLif (ps == NULL){perror("fail!");return;}//assert(ps);// 如果内存不足SLCheckCapacity(ps);for (int i = pos;i < ps->size;i++){ps->arr[i] = ps->arr[i + 1];}ps->size = ps->size--;
}
3,查
查找的思路很简单,就是遍历循序表看能否找到我们给定的数据。
//查找
int SLFind(SL* ps, SLtype x);
//查找
int SLFind(SL* ps, SLtype x)
{//判断ps是否为空指针NULLif (ps == NULL){perror("fail!");return;}//assert(ps);//遍历数组查找for (int i = 0;i < ps->size;i++){if (ps->arr[i] == x){//进来说明找到了return i;}}//到这说明没找到return -1;
}
上面函数的返回值之所以是int是为了在测试文件中使用该函数的返回值去判断是否找到了。
4,改
修改的话很简单,根据从查找的方法我们找到指定位置后就可以直接修改数据。代码很简单这里就不再展示。
5,销毁
我们在C语言内存函数中说过,在堆区申请的空间不使用时要释放掉避免造成空间的浪费,动态顺序表是使用malloc开辟的所以不使用时要释放掉。
//销毁
void Destroy(SL* ps);
//销毁
void Destroy(SL* ps)
{assert(ps);if (ps->arr)//如果ps—>的arr不为空指针{free(ps->arr);//则释放}ps->arr = NULL;//释放完后arr变成了野指针 及时将其置为空指针NULLps->size = ps->capacity = 0;//释放内存以后顺序表将不复存在 所以将有效数据个数 容量都置为0
}
二,顺序表的总结和问题的思考
时间复杂度:中间/头部的插⼊删除,时间复杂度为O(N)
关于增容的问题:增容需要申请新空间,拷⻉数据,释放旧空间。会有不小的消耗。
增容的注意事项:增容⼀般是呈2倍的增长,势必会有⼀定的空间浪费。例如当前容量 为100,满了以后增容到200,
我们再继续插⼊了5个数据,后⾯没有数据插入了,那么就浪费了95个数据空间。
为了解决以上空间浪费,和增容和时间复杂度优化的问题我们就引出了链表。
三,链表
1,什么是链表?
概念:链表是⼀种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
光从概念上去看链表还是不好理解,举个例子:链表就是像是一个火车由一个火车头连接着很多节车厢;每节车厢之间都是独立的;且增加或减少车厢对其他的车厢都没有影响。
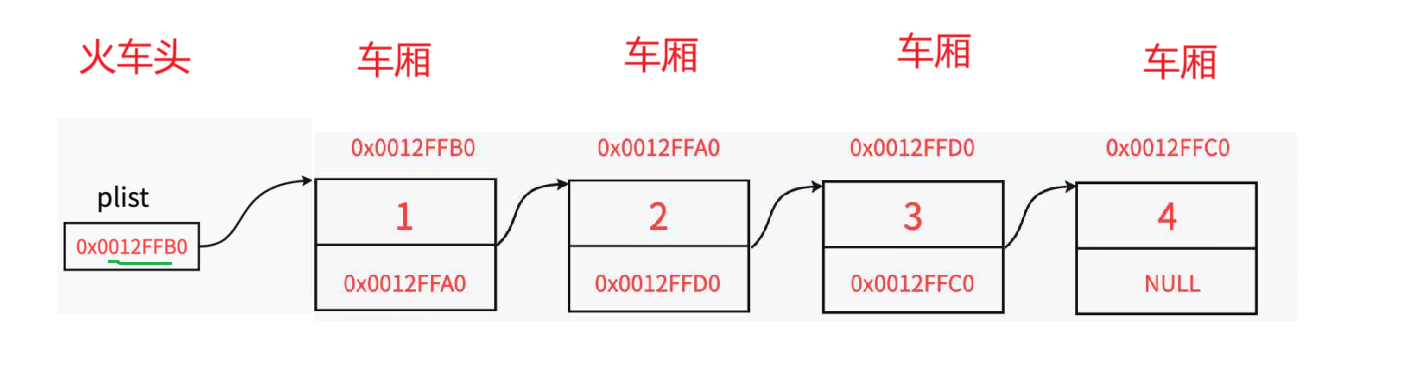
通过上图我们还发现链表与顺序不一样的点就是链表元素之间是指向关系,而顺序表底层是数组,数组是一块连续的空间。而链表就不一样了,链表在逻辑上是线性的也就是我们人为将他看作是连续的;但在物理空间上链表就是不连续的了。
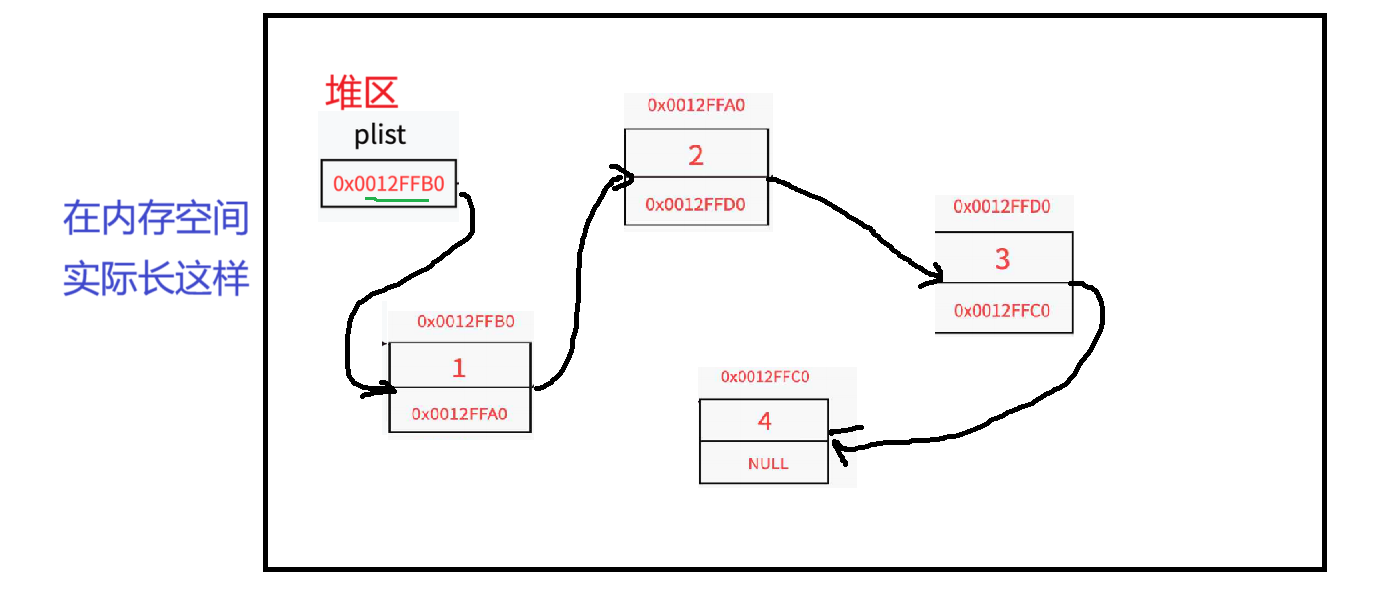
2,什么是结点?
上图我们看到了链表的结构,链表是由头和结点(车厢)组成的,那么什么是结点呢?
结点就是我们人为的在操作系统的堆区开辟的一块空间,这块空间有连个组成部分一是保存的数据,二是保存下一个结点的地址(指针变量)。
有了上面的认识我们就可以给出结点对应的代码:
typedef struct SListNode //加上typdef修改名字 可以简化代码
{ //结点的两个组成部分 1,保存的数据 2,保存下一个结点的地址int data; //结点数据 struct SListNode* next; //指针变量⽤保存下⼀个结点的地址
}SL;//将struct ListNode 改名为SL
对于结点(结构体)的解释:
当我们想要保存⼀个整型数据时,实际是向操作系统申请了⼀块内存,这个内存不仅要保存整型数据,也需要保存下⼀个结点的地址(当下⼀个结点为空时保存的地址为空)。
当我们想要从第⼀个结点走到最后一个结点时,只需要在当前结点拿上下一个结点的地址就可以了。
而头结点从图上看就是只存储下一个结点的地址,不存储数据的一个结构体。
从上面的结构我们可以看出链表与顺序表有明显的差异了,顺序表底层使用的是数组;链表使用的是指针。
有了上面的理解,如果给定一个链表让我们打印我们如何实现呢?
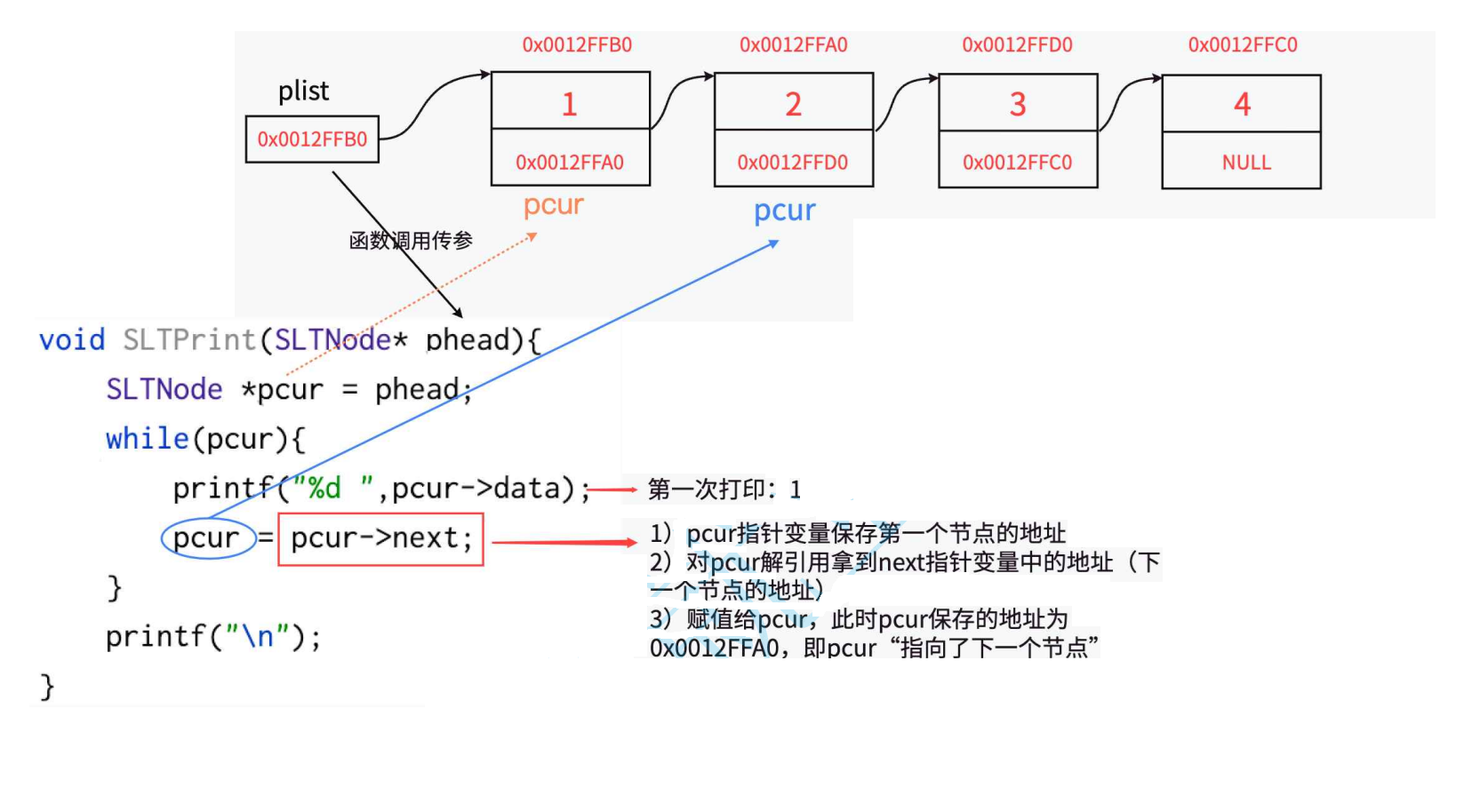
//打印函数
void STLPrint(STLNode* phead)
{STLNode* pcur = phead;//这里重复定义一个pcur是为了避免phead的值发生该变 便于找到链表的头(火车头)while (pcur){printf("%d -> ", pcur->date);pcur = pcur->next;//打印完第一个结构体的date数据 就让pcur指向下一个结构体}//走到这里说明pcur走到了尽头 此时pcur存的是NULL空指针printf("NULL\n");
}
3,链表的分类
链表的结构⾮常多样,以下情况组合起来就有8种(2 x 2 x 2)链表结构:
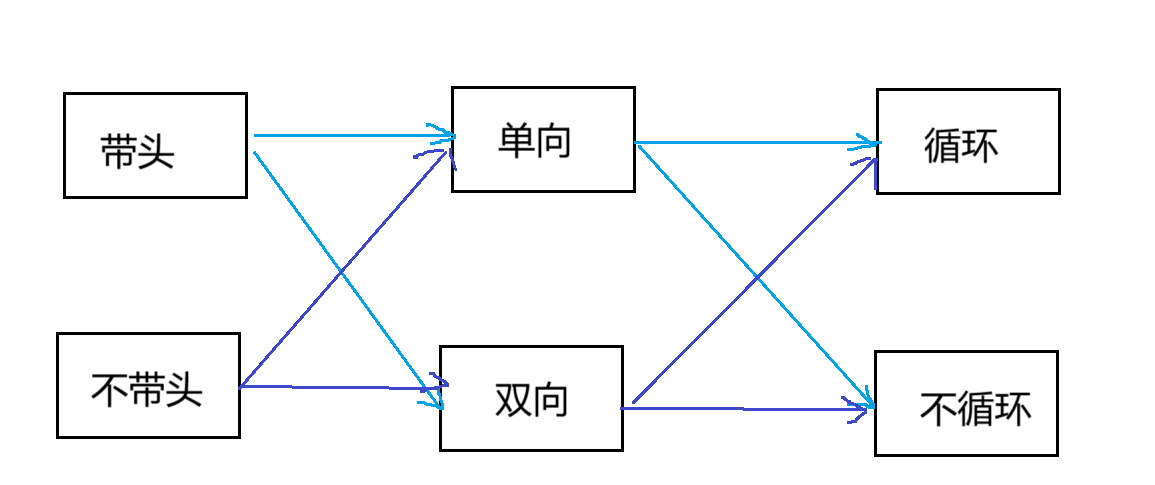
虽然链表有这么多结构但是最常用的有两种单链表(不带头单向不循环链表)和双向链表(双向带头循环链表)。
我们先从单链表开始讲起,下面我们就来讲讲怎么实现单链表:
4,单链表的实现
单链表与顺序表一样,也能实现对数据的增,删,查,改等功能,要实现这些功能我们首先要创建一个链表,在我们定义好结点(结构体)后我们就可以人为的往里面放数据和地址,如下图:
先定义好结点:
//定义链表的结构
typedef int STLDateType;
typedef struct SListNode
{STLDateType date;struct SListNode* next; //指向下一个结构体的指针
}STLNode;
创建好了链表以后我们就可以来实现增,删,查,改等功能了。
1,增
在增之前我们肯定要考虑空间问题,由于单链表是动态申请内存的,不会浪费空间需要增加结点的时候才开辟空间,所以我们要设计一个动态申请内存的函数,方便在增加数据的函数中调用。
//定义一个SLTLbuyNode函数用于动态申请内存
STLNode* STLbuyNode(STLDateType x)
{STLNode* NewNode = (STLNode*)malloc(sizeof(STLNode));//开辟一个结点大小的空间 结点->结构体if (NewNode == NULL){perror("malloc fail!");exit(1);}//走到这说明开辟结点成功了 将新结点的成员初始化NewNode->date = x;//x为我们想要传入的值NewNode->next = NULL;//由于不知道后面还有没有结构体 所以默认置为空指针return NewNode;//返回新创建好的结点的地址
}
有了这个函数我们就可以开始增加数据了:
1,头插
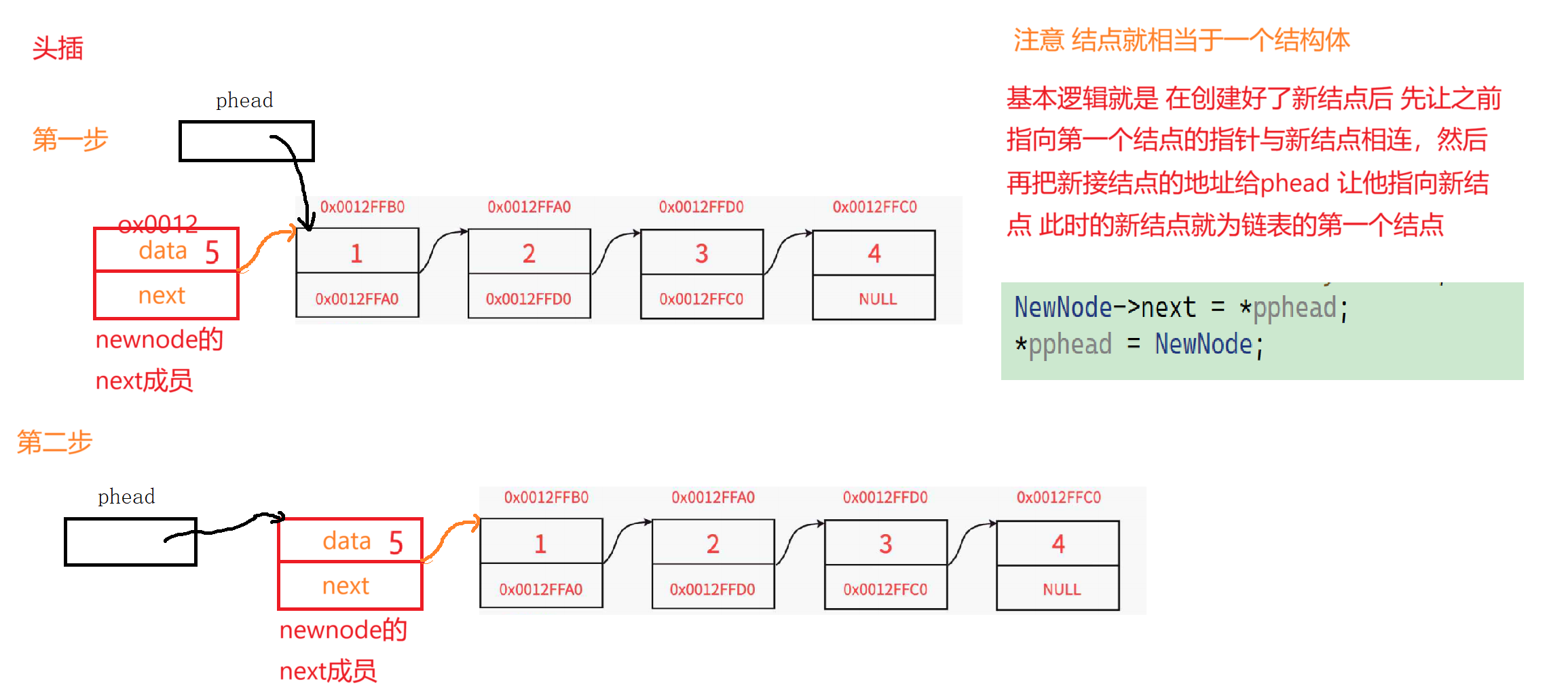
在.H文件中
//头插
void STLPushFront(STLNode** pphead, STLDateType x);
在.c文件中
//头插
void STLPushFront(STLNode** pphead, STLDateType x)
{assert(pphead);//如果链表为空 则改变链表的值STLNode*NewNode= STLbuyNode(x);NewNode->next = *pphead;//这是将新的结点与老的第一个结点相连接 *pphead = NewNode;//相连之后让*phead走到前面指向刚创建好的新结点 相当于让pphead往前走}
2,尾插
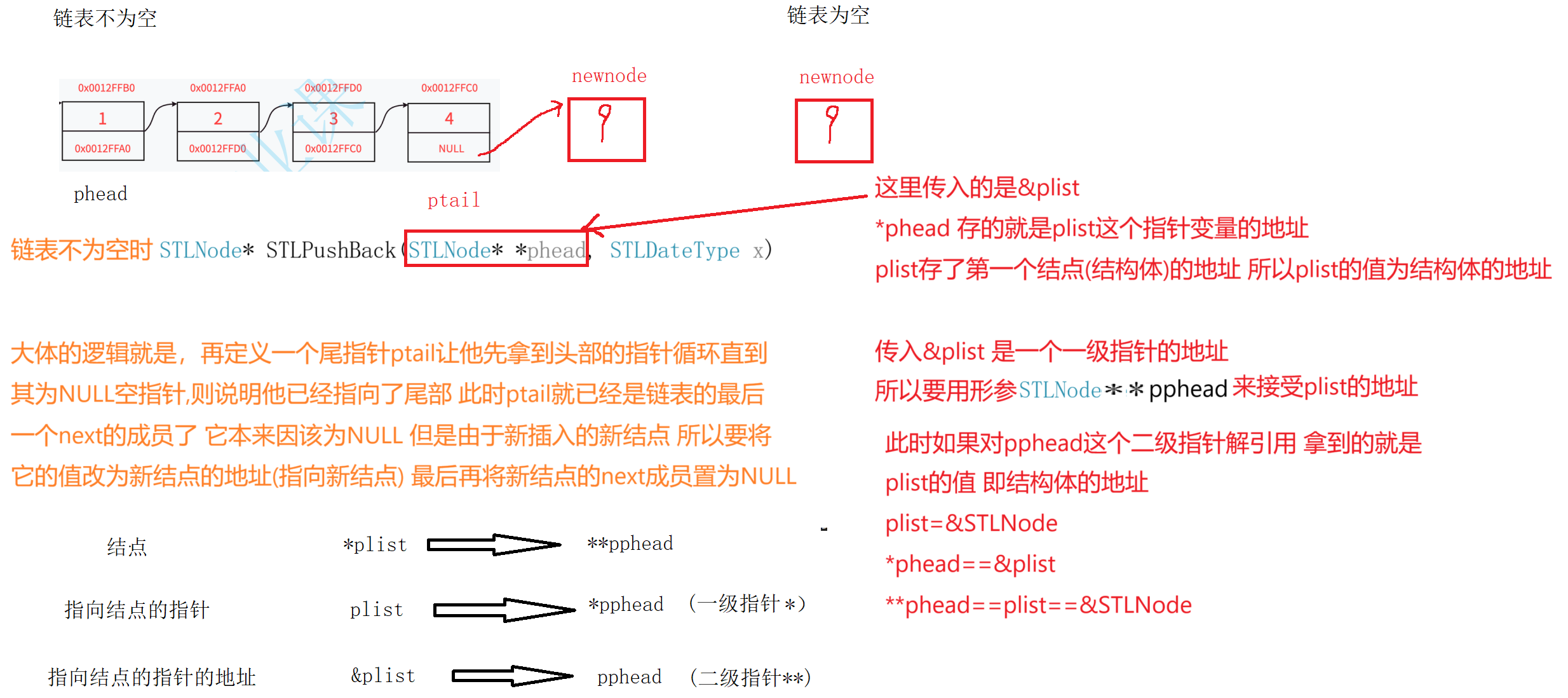
尾插这里需要注意到底是传值还是传地址,其实大家在目前阶段可以直接记住只要形参的改变不影响实参就传值,否则就传地址。
//尾插
void STLPushBack(STLNode** pphead, STLDateType x);//尾插
void STLPushBack(STLNode** pphead, STLDateType x)//由于传进来的plist是一级指针 所以要用二级指针来接收
{//注意phead传进来的是链表的头节点STLNode* NewNode = STLbuyNode(x);//直接调用STLbuyNode函数创建一个新的结点//链表为空的情况 此时头结点就应该是我们插入的新结点if (*pphead == NULL){//要想该百年实从参还得是使用指针 传址调用*pphead = NewNode;//这种 变化也是无效的变化 因为我们的目的是要让我们传进来的plist 指向我们创建好的这个新结点 作为第一个结点//phead = NewNode;//下面这种方法是错误的 空链表内什么都没有 哪里来的next成员//phead->next = NewNode;}else{//链表不为空的情况STLNode* ptail = *pphead;//定义一个找尾的指针 让他找到最后一个结点的最后一个成员while (ptail->next != NULL){ptail = ptail->next;}//走到这说明 ptail已经为最后一个结点的next成员了 要将ptail与新结点链接起来ptail->next = NewNode;//NewNode里边存了新结点的地址}
}3,在指定位置之前插入数据
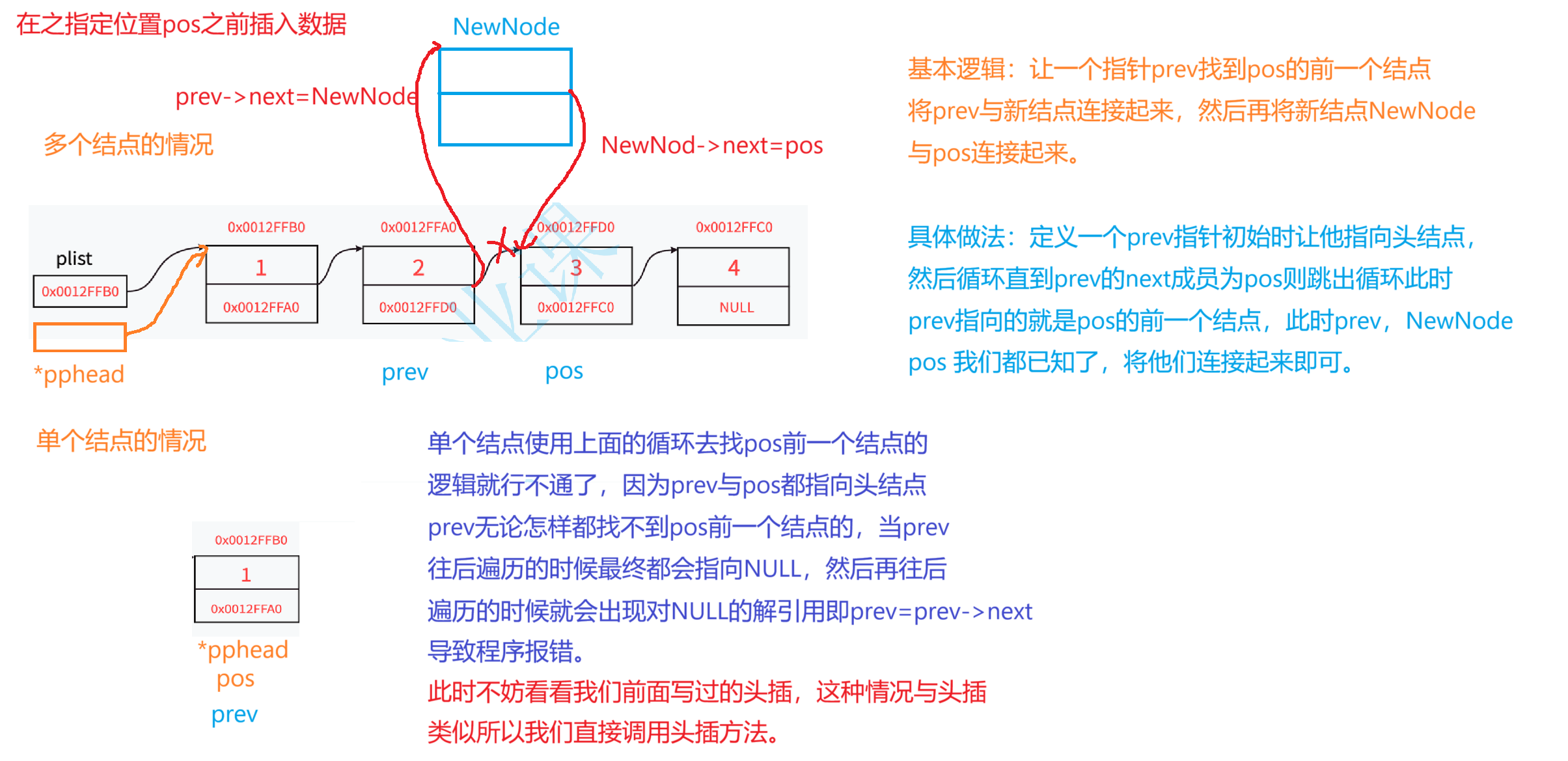
//在指定位置前插入数据
void STLInsert(STLNode** pphead, STLNode*Pos,STLDateType x);
//在指定位置之前插入数据
void STLInsert(STLNode** pphead, STLNode* pos, STLDateType x)
{assert(pphead && pos && *pphead);//当pos指向第一个结点 就是头插if (pos == *pphead){STLPushFront(*pphead,x);}//开辟一个新结点STLNode* NewNode = STLbuyNode(x);STLNode* prev = *pphead;//定义一个prev来遍历链表//找到pos的前一个结点while (prev->next != pos)//注意这里只是判断{prev = prev->next;}//走到这里 此时prev->next成员指向的是pos位置之后的结点的地址//走到这里prev->next==pos 注意这里是prev的成员指向了pos位置 说明prev已经走到了pos的前一个结点的位置prev->next=NewNode;NewNode->next=pos;
}4,在指定位置之后插入数据
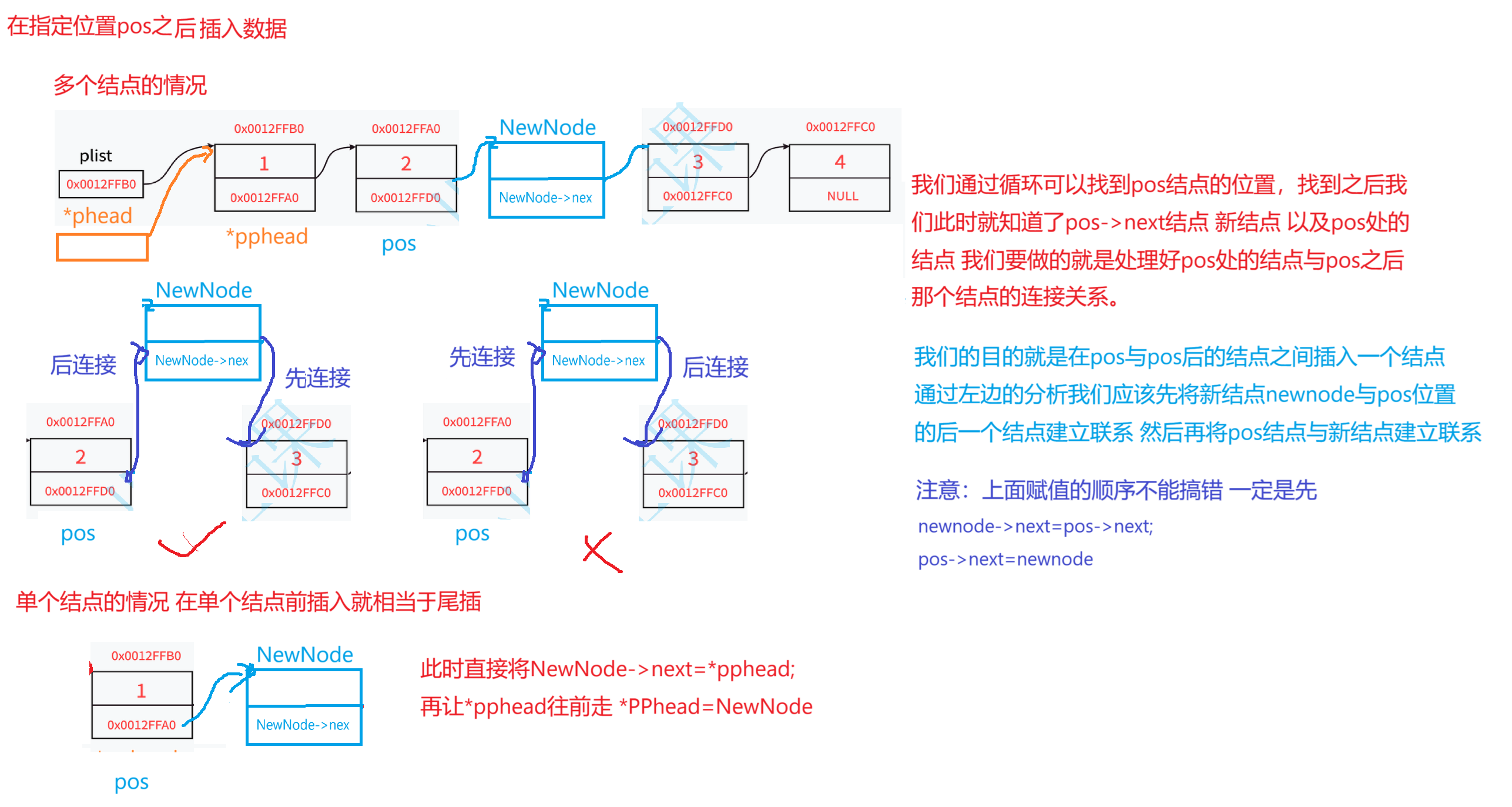
//在指定位置之后插入数据
void STLInsertAfter(STLNode* pos, STLDateType x);
//在指定位置之后插入数据
void STLInsertAfter(STLNode* pos, STLDateType x)
{assert(pos);STLNode* NewNode = STLbuyNode(x);//pos NewNode pos->nextNewNode->next = pos->next;pos->next = NewNode;
}
1,删
1,头删
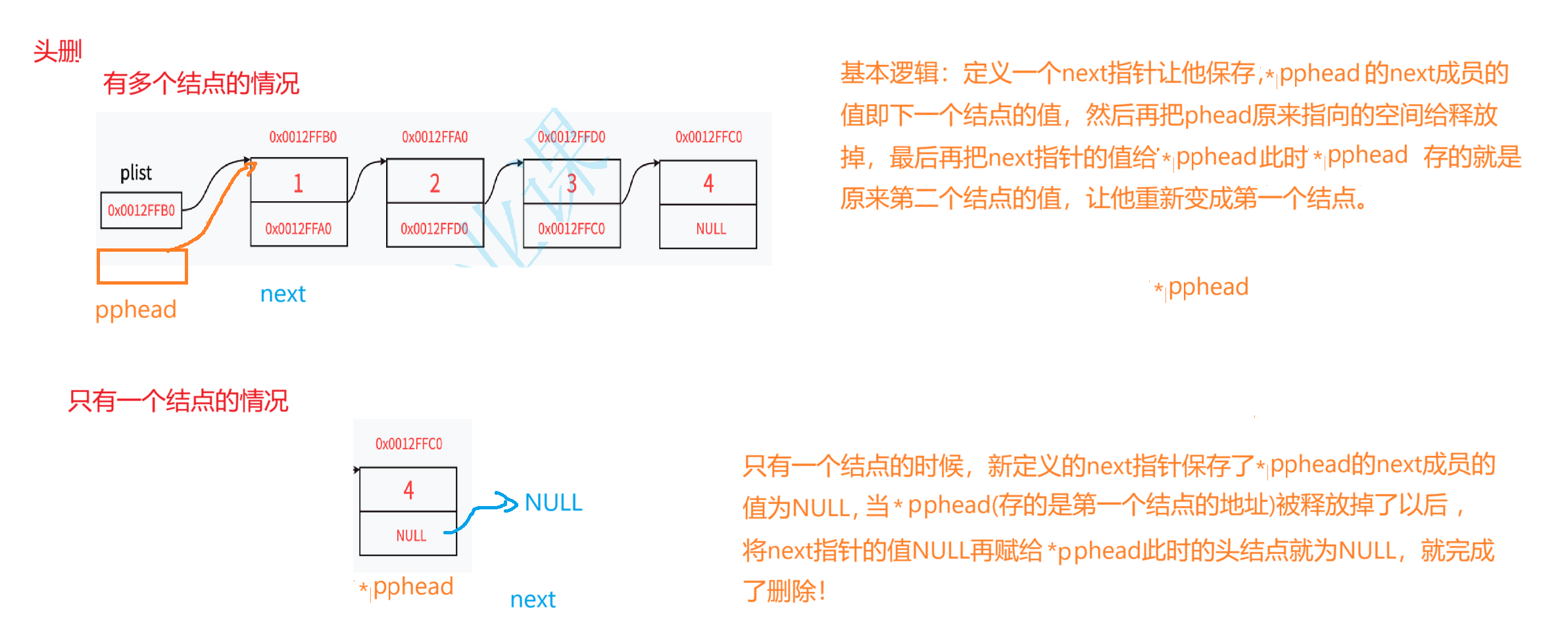
//头删
void STLPopFront(STLNode** pphead);
//头删
void STLPopFront(STLNode** pphead)
{assert(pphead && *pphead);STLNode* next = (*pphead)->next;//定义一个next指针来保存*pphead的next成员的值free(*pphead);*pphead = next;
}
2,尾删
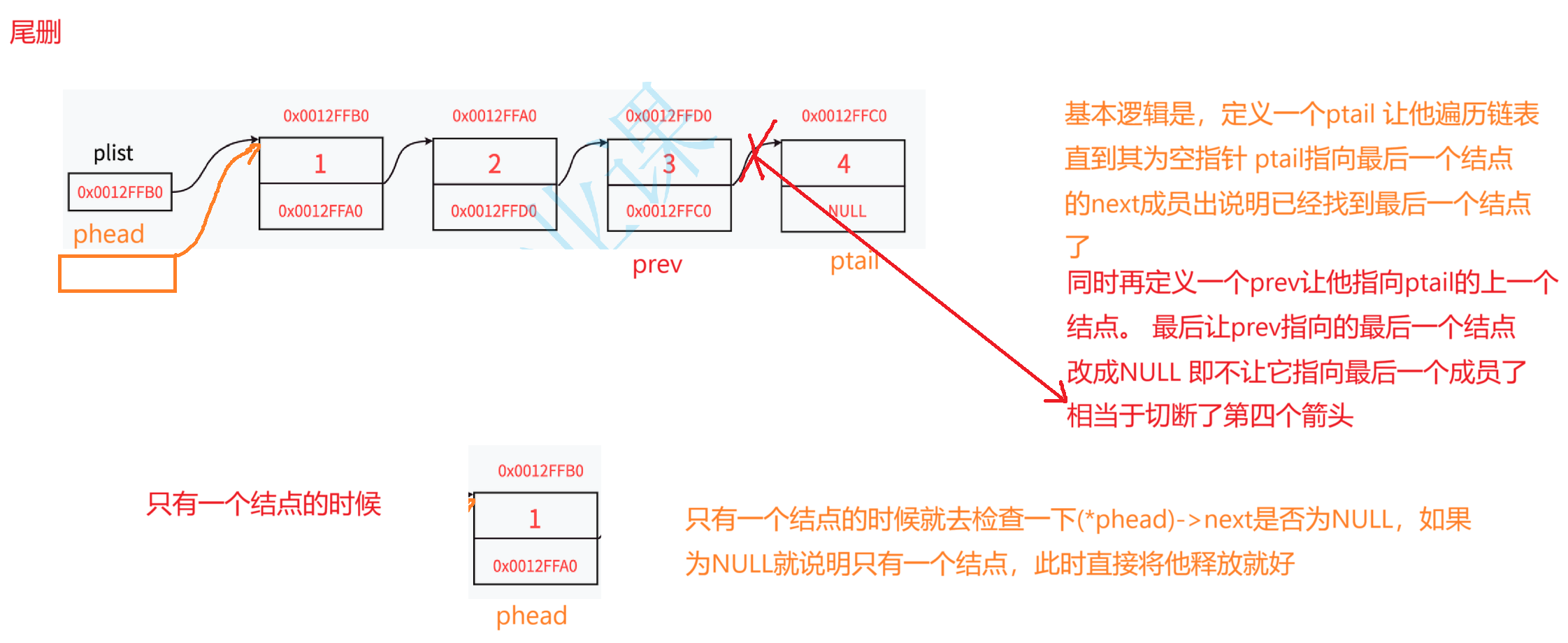
//尾删
void STLPopBack(STLNode** pphead);
//尾删
void STLPopBack(STLNode** pphead)
{assert(pphead && *pphead);////只有一个结点的情况if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}//有多个结点的情况else{STLNode* ptail = *pphead;STLNode* prev = NULL;//定义一个prev跟在ptail的后面while (ptail->next){prev = ptail;ptail = ptail->next;}//循环结束时,ptail为NULL,prev指向最后一个结点prev->next = NULL;//将倒数第二个结点的next指针置为空 free(ptail);//释放原本最后一个结点(结构体)的空间ptail = NULL;//最后一个结点被释放了 避免野指针所以置为空}
}
3,删除pos位置之前的结点
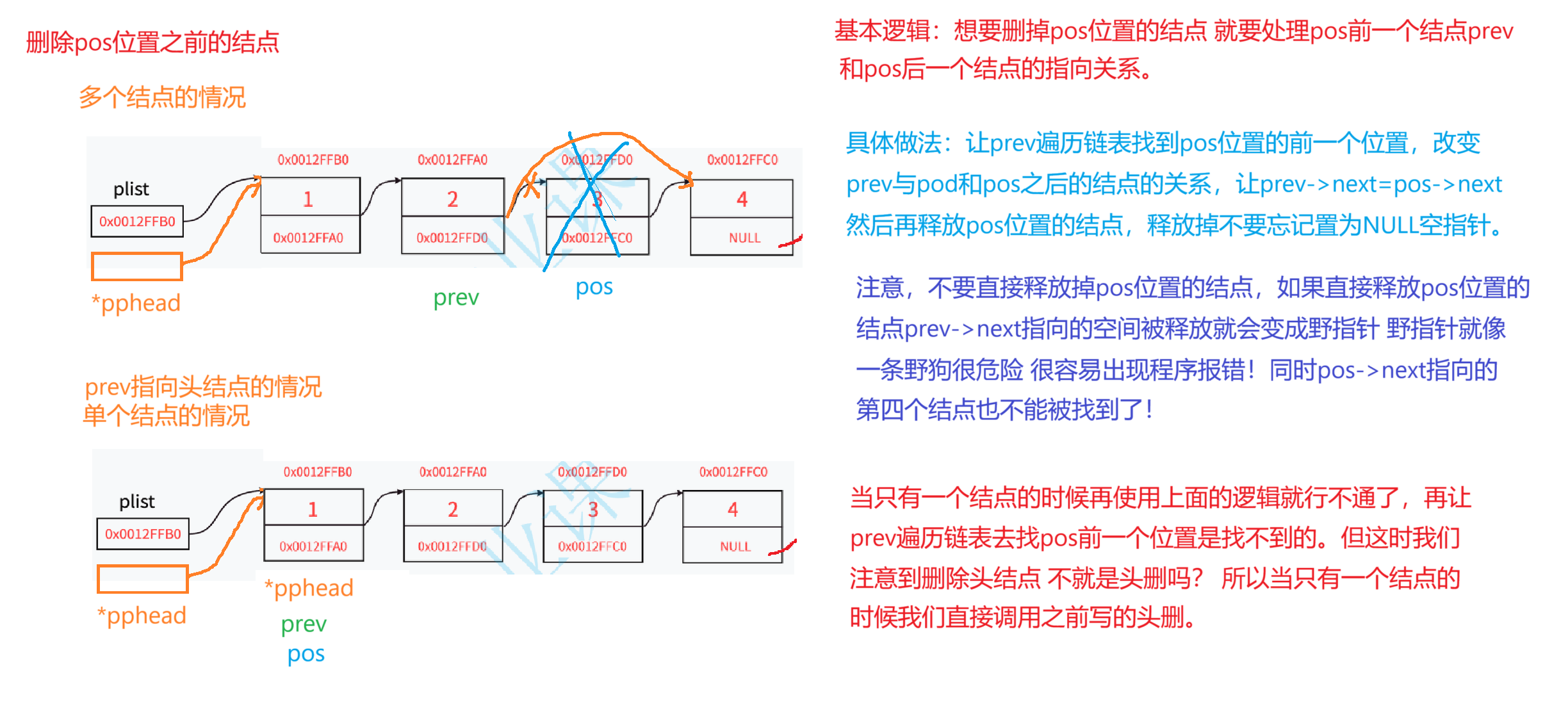
//删除pos位置的结点
void STLErase(STLNode** pphead, STLNode* pos);
//删除pos位置的结点
void STLErase(STLNode** pphead, STLNode* pos)
{assert(pphead && pos);//判断prev是不是指向头结点if (pos == *pphead){STLPopFront(pphead);}else{STLNode* prev = *pphead;while (prev->next != pos)//注意循环条件{prev = prev->next;}//走到这 prev就已经找到pos前一个位置了prev->next = pos->next;//将prev位置处的结点与pos后的结点相连free(pos);pos = NULL;//防止pos为野指针}
}
4,删除pos位置之后的结点
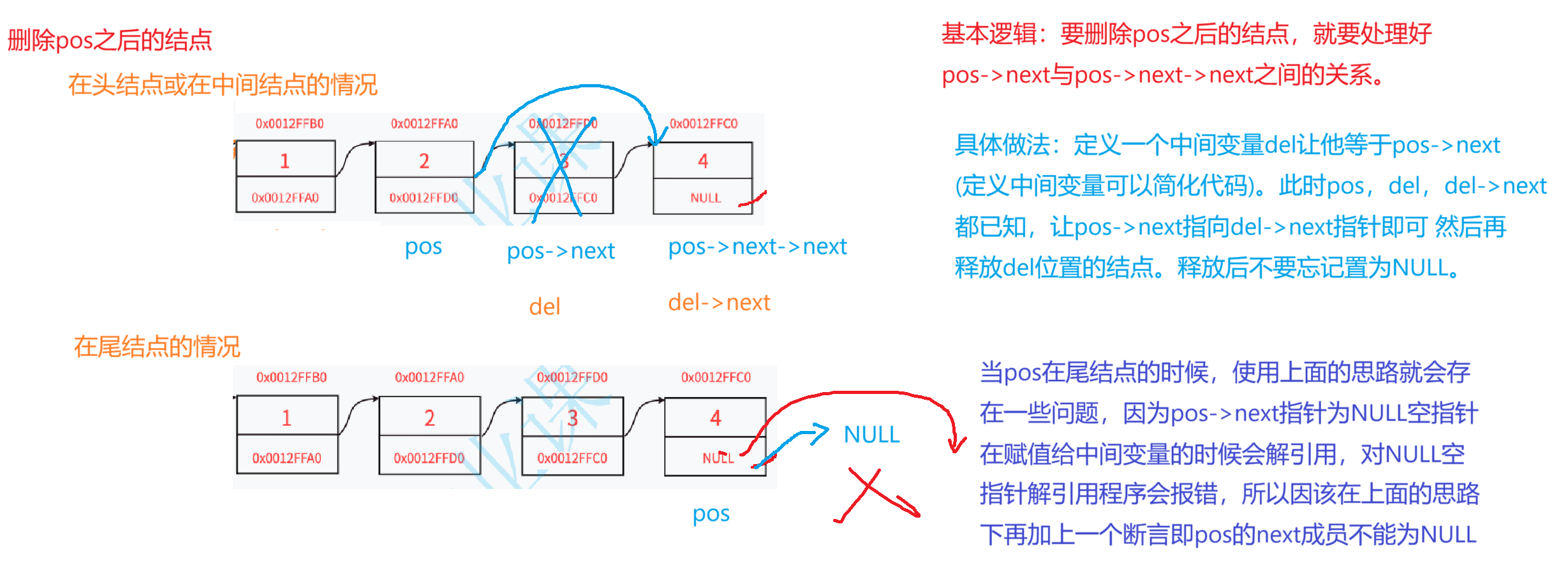
//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos);
//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos)
{assert(pos && pos->next);//pos del del->nextSLTNode* del = pos->next;pos->next = del->next;free(del);del = NULL;
}
3,查
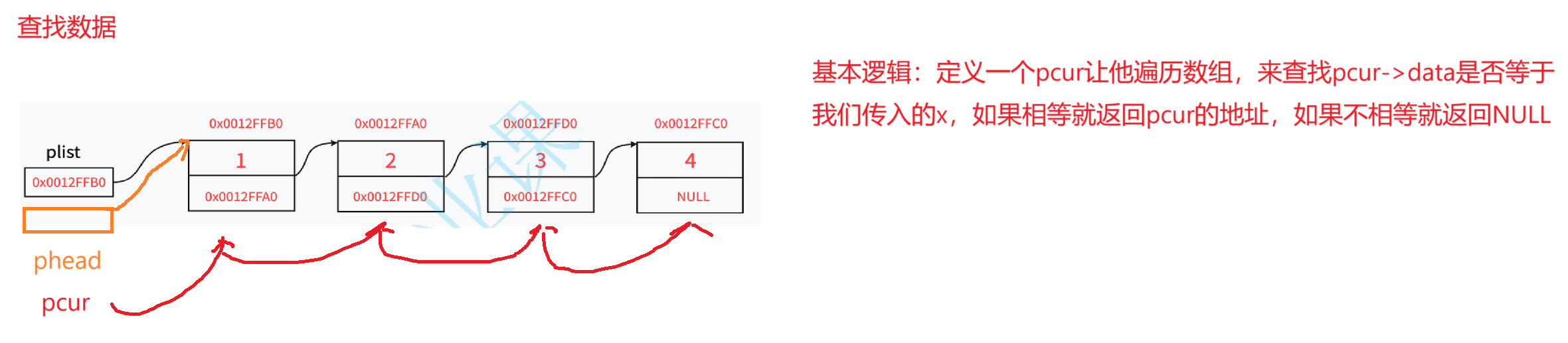
//查找数据
STLNode* STLFind(STLNode* phead, STLDateType x);
//查找数据
STLNode* STLFind(STLNode* phead, STLDateType x)
{STLNode* pcur = phead;while (pcur->next != NULL)//让pcur去遍历链表{if (pcur->date == x){return pcur;}pcur = pcur->next;//让pcur偏移}return NULL;
}
4 ,链表的销毁
链表是我们人为开辟的空间,所以为了避免空间的浪费在我们不使用链表时就手动将他销毁。
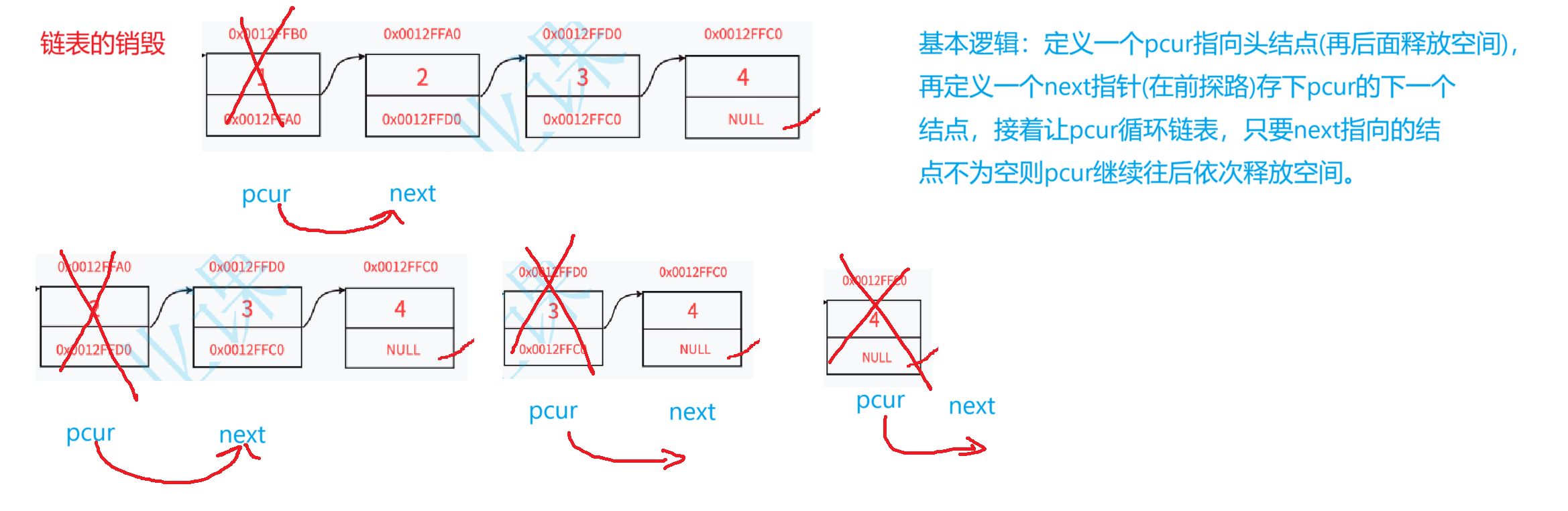
//销毁链表
void SListDestroy(SLTNode** pphead);
//销毁链表
void SListDestroy(SLTNode** pphead)
{SLTNode* pcur = *pphead;while (pcur){SLTNode* next = pcur->next;free(pcur);pcur = next;}*pphead = NULL;
}
以上就是所有单链表的实现了,由于篇幅有限剩下的双链表我们下期再介绍。
以上就是本章的全部内容啦!
最后感谢能够看到这里的读者,如果我的文章能够帮到你那我甚是荣幸,文章有任何问题都欢迎指出!制作不易还望给一个免费的三连,你们的支持就是我最大的动力!

相关文章:
【数据结构】顺序表和链表详解(上)
前言:上期我们介绍了算法的复杂度,知道的算法的重要性同时也了解到了评判一个算法的好与坏就去看他的复杂度(主要看时间复杂度),这一期我们就从顺序表和链表开始讲起。 文章目录 一,顺序表1,线性表2,顺序表…...

唯创WT2606B TFT显示灵动方案,重构电子锁人机互动界面,赋能智能门锁全场景交互!
在智能家居的浪潮中,门锁搭载显示屏已成为行业创新的焦点。据行业数据显示,2023年全球智能门锁出货量中,搭载显示屏的型号占比已突破40%,且年复合增长率达25%。而2024年国内智能门锁销量突破2200万套,预计2025年市场规…...

WPF的UI交互基石:数据绑定基础
数据绑定基础 1 Binding的Path属性2 ElementName绑定3 DataContext的作用4 绑定模式(Binding Mode)5 实用技巧集合1. 默认值处理2. 设计时数据3. 绑定验证4. 多级路径监控 6 常见错误排查 数据绑定是WPF的核心特性之一,它实现了界面ÿ…...

智能穿戴新标杆:SD NAND (贴片式SD卡)与 SOC 如何定义 AI 眼镜未来技术路径
目录 一、SD NAND:智能眼镜的“记忆中枢”突破空间限制的存储革命性能与可靠性的双重保障 二、SOC芯片:AI眼镜的“智慧大脑”从性能到能效的全面跃升多模态交互的底层支撑 三、SD NANDSOC:11>2的协同效应数据流水线的高效协同端侧…...

TCP/IP四层模型
TCP/IP四层模型 TCP/IP四层模型将网络通信分为四个层次: 1. 网络接口层:负责计算机与网络硬件间的数据传输,在物理网络上发送/接收数据帧(如以太网、Wi-Fi协议)。 2. 互联网层(网络层)&…...

深入浅出Nacos:微服务架构中的服务发现与配置管理利器
在当今的软件开发领域,随着微服务架构的普及,如何有效地进行服务治理和服务配置管理成为了开发者面临的重要挑战之一。阿里巴巴开源的 Nacos(Dynamic Naming and Configuration Service)应运而生,旨在帮助开发者更轻松地构建云原生应用。本文将详细介绍 Nacos 的核心功能、…...
node_modules包下载不下来
如果项目里面的package-lock.json有resolved ,就指向了包的下载来源,如果这个网址挂了,那npm i 就会一直卡着。而且,在终端去修改 npm的镜像是没有用的 解决办法是:把项目里面的 lock文件 .npmrc都删了 然后重新下载就可以了...
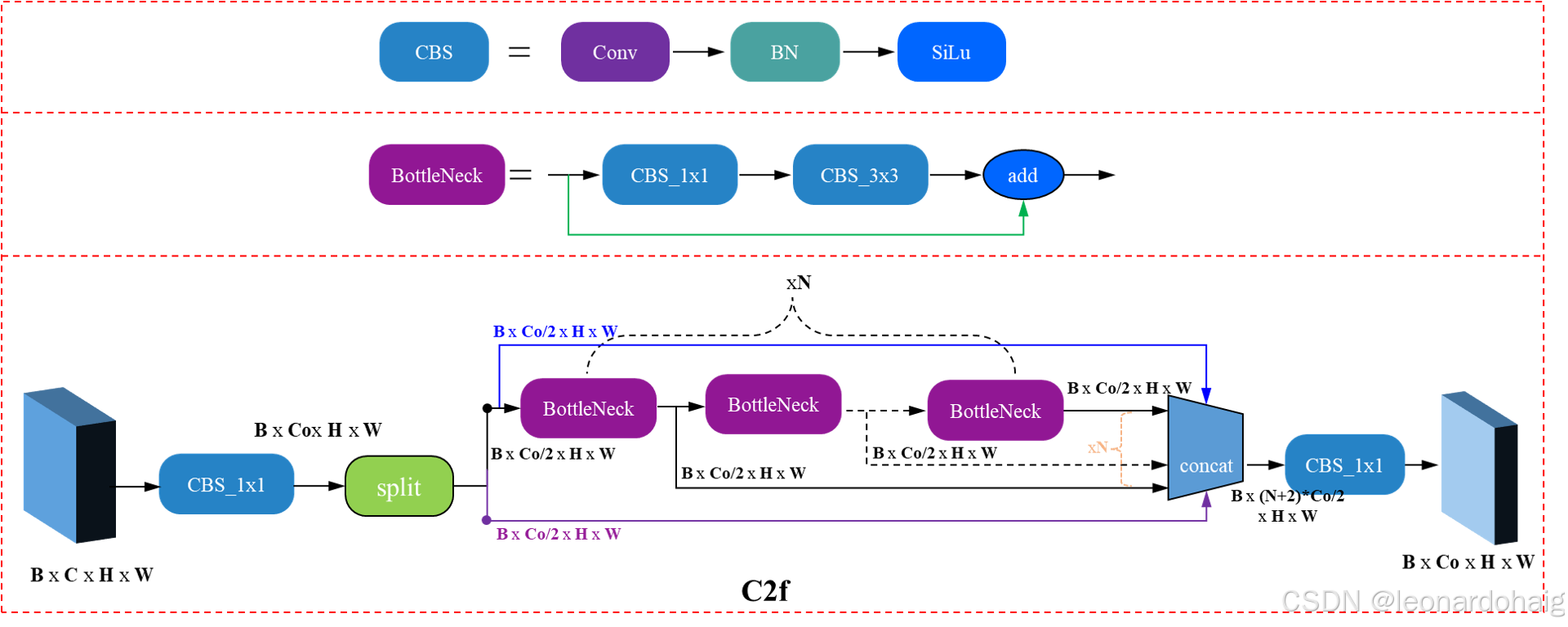
yolo个人深入理解
卷积层的理解,通过云端服务器训练模型,模型构建的重要性,针对极低像素的处理,模型训练召回率提高技巧,卷积层2,4,8,16,32的小模型与大模型的理解 一.关于backbone,neck,head深入理解 1,backbone的主要组成部分是sppf和conv,这是backbone的核心,其中yolov5和yolov8…...

Go语言中的布尔类型详解
布尔类型是Go语言中最基本的数据类型之一,用于表示逻辑值。下面详细介绍Go语言中的布尔类型。 1. 基本概念 Go语言中的布尔类型用关键字bool表示,它只有两个预定义的常量值: true // 真 false // 假 2. 声明布尔变量 var b1 bool …...

三方接口设计注意事项
前言 随着业务系统间集成需求的增加,三方接口设计已成为现代软件架构中的关键环节。一个设计良好的三方接口不仅能够提供稳定可靠的服务,还能确保数据安全、提升系统性能并支持业务的持续发展。 一、设计原则 1. 统一接口原则 三方接口设计应遵循统一…...

从0开始学vue:Element Plus详解
一、核心架构解析二、技术实现指南三、高级特性实现四、性能优化方案五、生态扩展方案六、调试与测试七、版本演进路线 Element Plus 是专为 Vue 3 设计的桌面端 UI 组件库,基于 Vue 3 的 Composition API 重构,在保持与 Element UI 兼容性的同时&#x…...
互联网向左,区块链向右
2008年,中本聪首次提出了比特币的设想,这打开了去中心化的大门。 比特币白皮书清晰的描述了去中心化支付的解决方案,并分别从以下几个方面阐述了他的理念: 一、由转账双方点对点的通讯,而不通过中心化的第三方…...
Python6.1打卡(day33)
DAY 33 MLP神经网络的训练 知识点回顾: 1.PyTorch和cuda的安装 2.查看显卡信息的命令行命令(cmd中使用) 3.cuda的检查 4.简单神经网络的流程 1.数据预处理(归一化、转换成张量) 2.模型的定义 …...

金融全业务场景的系统分层与微服务域架构切分
构建一个支持金融全业务场景的会员账户体系,是一项复杂但极具战略价值的工程。为了支持跨国收付款、供应链金融、信用账户、票据、银行卡发卡等场景,需要采用清晰的分层架构和服务划分策略,确保系统具备可扩展性、合规性、安全性和高可用性。…...

POJO、DTO和VO:Java应用中的三种关键对象详解
在软件开发特别是Java开发中,常常会遇到POJO、DTO和VO这三类对象。它们在不同场景下扮演着重要角色,有助于优化代码结构、增强系统安全性和提升性能。本文将全面解析这三者的定义、区别及常见使用场景,帮助你更好地理解和应用。 1. POJO&…...
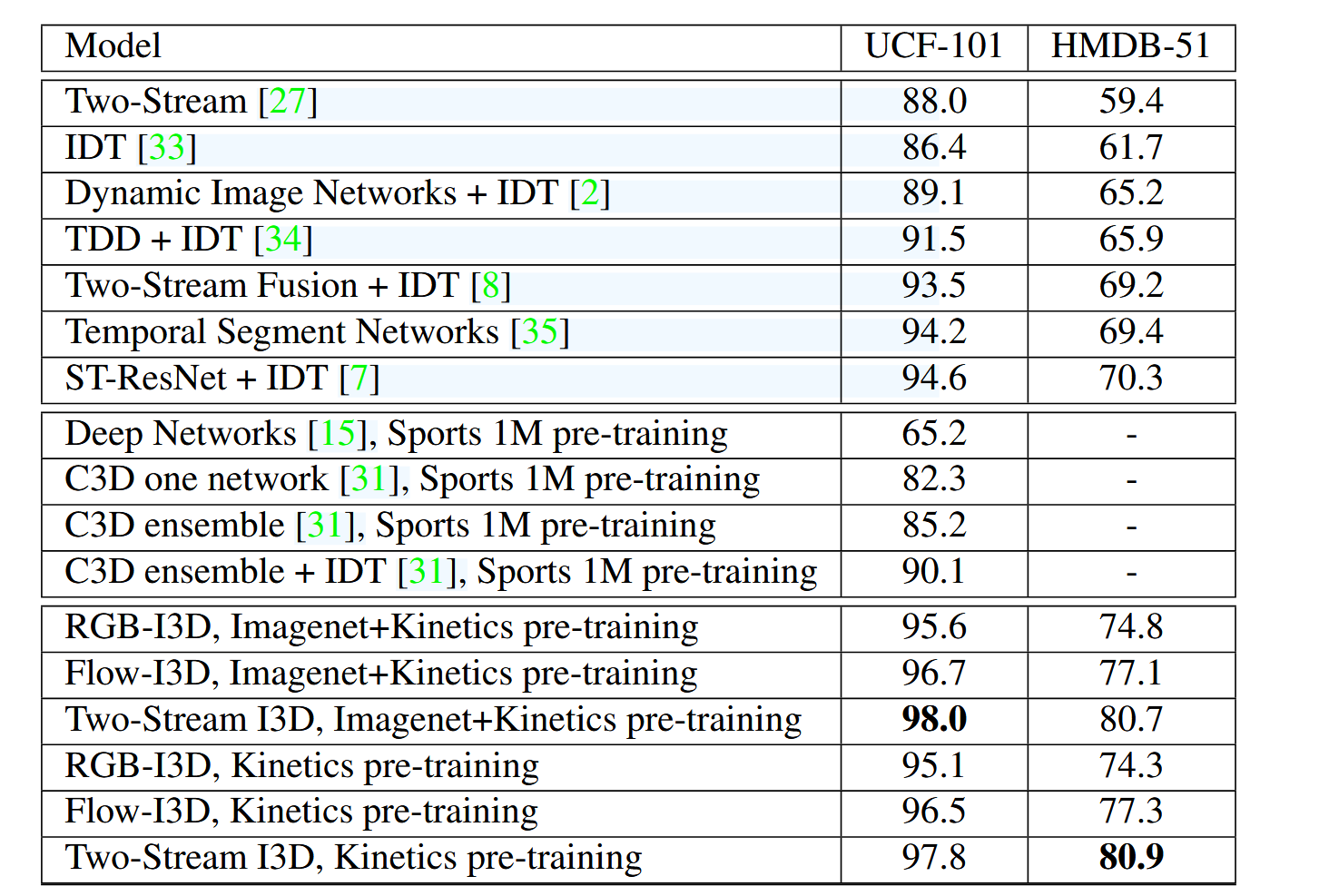
论文阅读笔记——Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
I3D 论文 UCF-101(13000多个视频)和 HMDB-51(7000多个视频)数据集过小,提出了 Kinetics 数据集,并且在其之上预训练之后能够迁移到其他小的数据集。 2DLSTM:使用2D CNN的好处是可以直接从 Ima…...

IDEA,Spring Boot,类路径
在 IDEA 中开发 Spring Boot 项目时,类路径 (classpath) 的正确配置至关重要,它直接影响项目的编译、运行和依赖管理。以下是关于此问题的关键知识点: IDEA 与 Spring Boot 类路径核心概念 类路径定义: 类路径是 JVM 用来搜索类文件 (.class…...
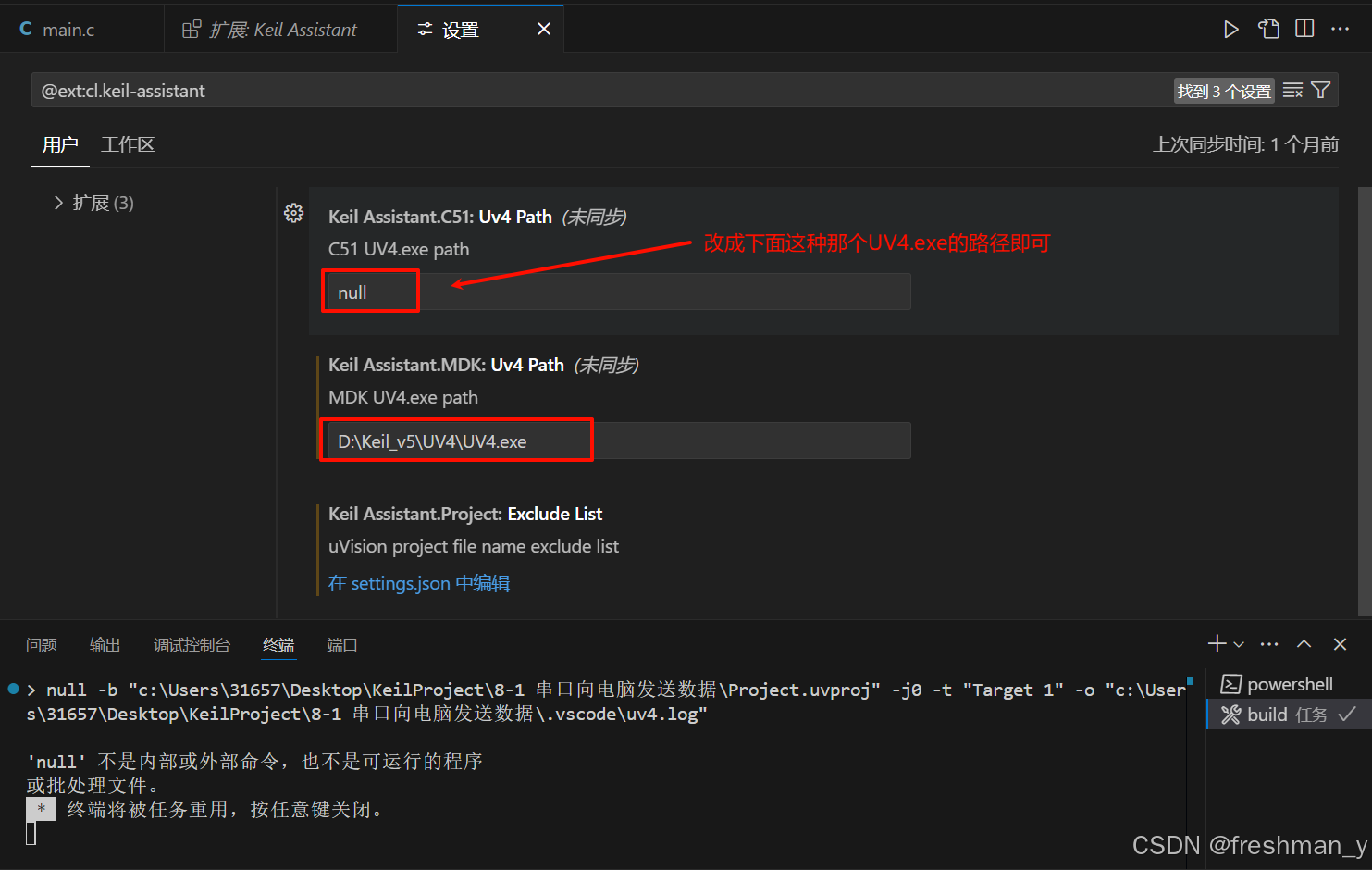
vscode编辑器怎么使用提高开发uVision 项目的效率,如何编译Keil MDK项目?
用vscode编译uVision 项目只需要安装一个Keil Assistant插件,即可用vscode开发“keil 项目”。极大提高开发速度! 1.安装Keil Assistant插件 安装插件成功之后,应该会让安装一个东西,点击安装即可 2.配置安装包路径 3.打开 uVi…...

Beta分布Dirichlet分布
目录 Beta分布Dirichlet分布Beta分布&Dirichlet分布从Dirichlet分布生成Beta样本Beta分布&Dirichlet分布应用 Beta分布 Beta分布是定义在区间 [ 0 , 1 ] [0, 1] [0,1]上的连续概率分布,通常用于模拟概率或比例的随机变量。Beta分布的概率密度函数ÿ…...
AR测量工具:精准测量,多功能集成
在日常生活中,我们常常会遇到需要测量物体长度、距离或角度的情况。无论是装修房屋、制作家具,还是进行户外活动,一个精准的测量工具都能大大提高我们的工作效率。AR测量工具就是这样一款集多种功能于一体的实用测量软件,它利用增…...
【Go-补充】Sync包
并发编程-Sync包 sync.WaitGroup 在代码中生硬的使用time.Sleep肯定是不合适的,Go语言中可以使用sync.WaitGroup来实现并发任务的同步。 sync.WaitGroup有以下几个方法: 方法名功能(wg * WaitGroup) Add(delta int)计数器delta(wg *WaitGroup) Done()…...

云服务器是什么,和服务器有什么区别?
云服务器 vs 传统服务器:通俗对比 一句话总结: 云服务器是「租用」的虚拟服务器(像租房),传统服务器是「自购」的物理机器(像买房)。 1. 本质区别 对比项云服务器传统服务器物理形态虚拟的&am…...

【HTML-14】HTML 列表:从基础到高级的完整指南
列表是HTML中用于组织和展示信息的重要元素。无论是导航菜单、产品特性还是步骤说明,列表都能帮助我们以结构化的方式呈现内容。本文将全面介绍HTML中的列表类型、语法、最佳实践以及一些高级技巧。 1. HTML列表的三种类型 HTML提供了三种主要的列表类型ÿ…...
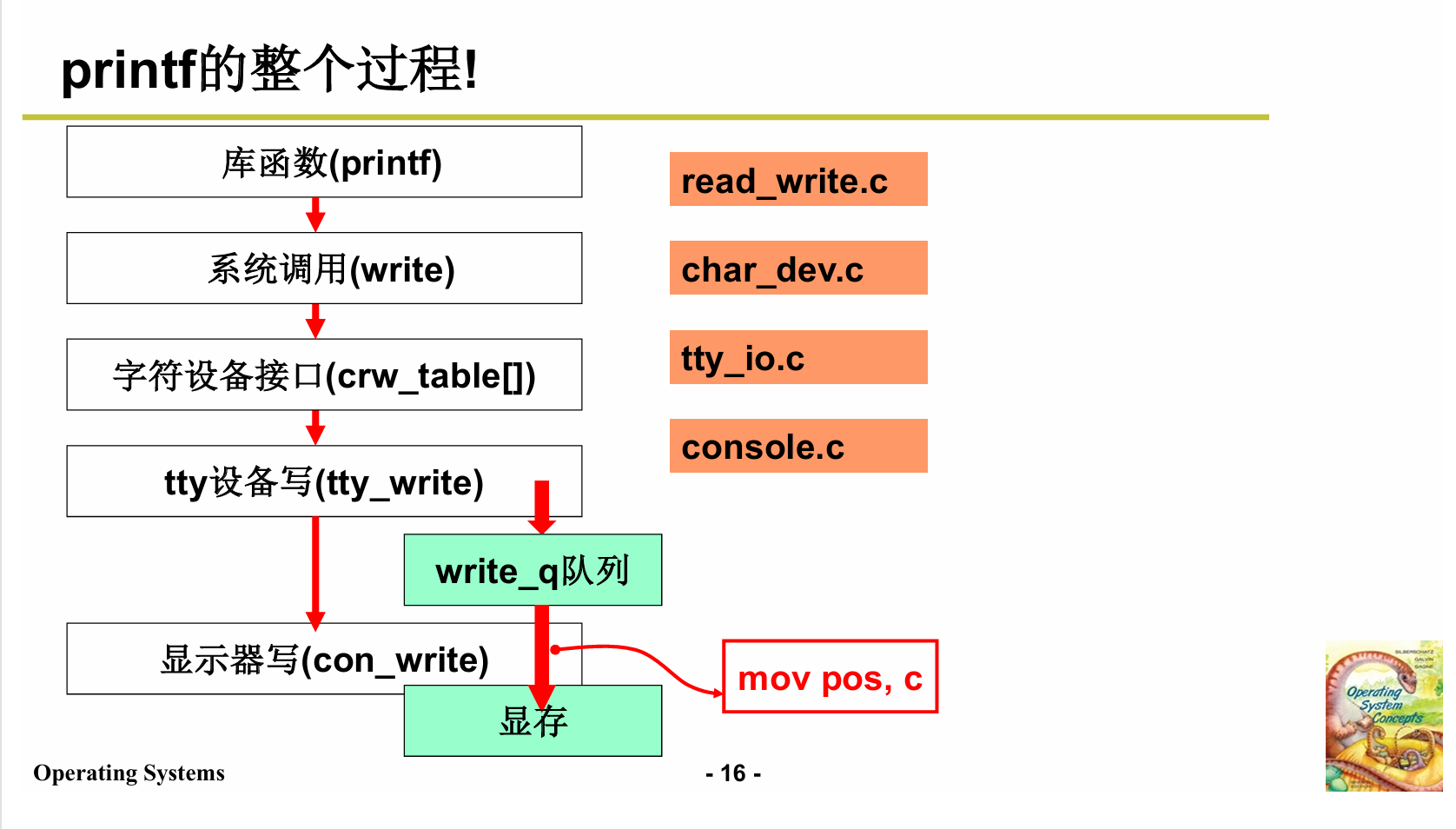
设备驱动与文件系统:01 I/O与显示器
操作系统设备驱动学习之旅——以显示器驱动为例 从这一节开始,我要学习操作系统的第四个部分,就是i o设备的驱动。今天要讲的是第26讲,内容围绕i o设备中的显示器展开,探究显示器是如何被驱动的,也就是操作系统怎样让…...

.NET 9正式发布,亮点是.NET Aspire和AI
.NET 9 正式发布:.NET Aspire 与 AI 引领新潮流 一、.NET 9 发布概览 Microsoft 正式发布了 .NET 9,这一版本堪称迄今为止最高效、最现代、最安全、最智能且性能最高的 .NET 版本。它凝聚了全球数千名开发人员一年的心血,带来了数千项性能、…...

vue+mitt的简便使用
突然注意到 onMounted 在一个组件中可以多次调用,这不得发挥一下: 把绑定/解绑的逻辑封装到同一个模块中不就简化了吗,只需要在组件中注册一下子再传递一个回调就完事了。简单的组件中甚至不用引入onMounted和onUnmounted cnpm i mitt /src/utils/emi…...

Java正则表达式完全指南
Java正则表达式完全指南 一、正则表达式基础概念1.1 什么是正则表达式1.2 Java中的正则表达式支持 二、正则表达式基本语法2.1 普通字符2.2 元字符2.3 预定义字符类 三、Java中正则表达式的基本用法3.1 编译正则表达式3.2 创建Matcher对象并执行匹配3.3 常用的Matcher方法 四、…...

Windows搭建Swift语言编译环境?如何构建ObjC语言编译环境?Swift如何引入ObjC框架?Interface Builder的历史?
目录 Windows搭建Swift语言编译环境 如何构建ObjC语言编译环境? Swift如何引入ObjC框架? Swift和ObjC中IBOutlet和IBAction代表什么? Interface Builder的历史 Xcode的“Use Storyboards"的作用? Xcode的Playground是什么? Windows搭建Swift语言编译环境 Windo…...
:结构化厨房的原材料管理系统)
第七部分:第四节 - 在 NestJS 应用中集成 MySQL (使用 TypeORM):结构化厨房的原材料管理系统
在 NestJS 这样一个结构化的框架中,我们更倾向于使用 ORM (Object-Relational Mapper) 来与关系型数据库交互。ORM 就像中央厨房里一套智能化的原材料管理系统,它将数据库中的表格和行映射到我们熟悉的对象和类的实例。我们可以使用面向对象的方式来操作…...

Bug 背后的隐藏剧情
Bug 背后的隐藏剧情 flyfish 1. 「bug」:70多年前那只被拍进史书的飞蛾 故事原型:1947年哈佛实验室的「昆虫命案」 1947年的计算机长啥样?像一间教室那么大,塞满了几万根继电器(类似老式开关)ÿ…...