【深度学习-pytorch篇】3. 优化器实现:momentum,NAG,AdaGrad,RMSProp,Adam
Optimization Algorithms Explained
1. Beale Function 与导数函数讲解
Beale 函数是一个著名的用于测试优化算法性能的函数,其具有多个局部极值点,适合评估不同优化器的表现:
def beale(x1, x2):"""Beale 函数定义:f(x1, x2) = (1.5 - x1 + x1*x2)^2 + (2.25 - x1 + x1*x2^2)^2 + (2.625 - x1 + x1*x2^3)^2参数:x1 (float or array): 第一个变量x2 (float or array): 第二个变量返回:函数值(float or array)"""return (1.5 - x1 + x1*x2)**2 + (2.25 - x1 + x1*x2**2)**2 + (2.625 - x1 + x1*x2**3)**2def dbeale_dx(x1, x2):"""Beale 函数的一阶偏导:返回 [df/dx1, df/dx2]。用于梯度下降算法中。参数:x1 (float): 当前 x1 位置x2 (float): 当前 x2 位置返回:dfdx1 (float): 对 x1 的偏导dfdx2 (float): 对 x2 的偏导"""dfdx1 = 2*(1.5 - x1 + x1*x2)*(x2-1) + \2*(2.25 - x1 + x1*x2**2)*(x2**2-1) + \2*(2.625 - x1 + x1*x2**3)*(x2**3-1)dfdx2 = 2*(1.5 - x1 + x1*x2)*x1 + \2*(2.25 - x1 + x1*x2**2)*(2*x1*x2) + \2*(2.625 - x1 + x1*x2**3)*(3*x1*x2**2)return dfdx1, dfdx2
调用方式说明:
x = np.array([1.0, 1.5])
dfdx = dbeale_dx(*x) # *x 解包为 x1, x2
这个解包调用方式是标准的 Python 用法,等价于 dbeale_dx(x[0], x[1])。
2. Momentum 优化器逐行讲解
Momentum 方法在普通梯度下降基础上引入了动量项,公式如下:
- 公式 (1): v t = γ v t − 1 − η ∇ f ( θ ) v_t = \gamma v_{t-1} - \eta \nabla f(\theta) vt=γvt−1−η∇f(θ)
- 公式 (2): θ = θ + v t \theta = \theta + v_t θ=θ+vt
代码实现:
def gd_momentum(df_dx, x0, conf_para=None):"""Momentum 优化器参数:df_dx: 梯度函数,形式为 df_dx(x1, x2),返回 (df/dx1, df/dx2)x0: 初始参数位置 (array)conf_para: 字典,包含如下超参数:- n_iter: 迭代次数- learning_rate: 学习率 η- momentum: 动量参数 γ返回:x_traj: 参数更新轨迹"""if conf_para is None:conf_para = {}conf_para.setdefault('n_iter', 1000)conf_para.setdefault('learning_rate', 0.001)conf_para.setdefault('momentum', 0.9)x_traj = [x0] # 保存轨迹v = np.zeros_like(x0) # 初始化速度向量 v0 = 0for _ in range(conf_para['n_iter']):dfdx = np.array(df_dx(*x_traj[-1]))v = conf_para['momentum'] * v - conf_para['learning_rate'] * dfdx # 公式 (1)x_traj.append(x_traj[-1] + v) # 公式 (2)return x_traj
3. Nesterov Accelerated Gradient 讲解
Nesterov 方法在计算梯度时先 “预判” 一步跳跃位置,公式如下:
- 公式 (3): θ ^ = θ + v t − 1 \hat{\theta} = \theta + v_{t-1} θ^=θ+vt−1
- 公式 (4): v t = γ v t − 1 − η ∇ f ( θ ^ ) v_t = \gamma v_{t-1} - \eta \nabla f(\hat{\theta}) vt=γvt−1−η∇f(θ^)
- 公式 (5): θ = θ + v t \theta = \theta + v_t θ=θ+vt
def gd_nesterov(df_dx, x0, conf_para=None):"""Nesterov 加速梯度方法参数:df_dx: 梯度函数x0: 初始参数位置conf_para: 参数字典(n_iter, learning_rate, momentum)返回:x_traj: 参数更新轨迹"""if conf_para is None:conf_para = {}conf_para.setdefault('n_iter', 1000)conf_para.setdefault('learning_rate', 0.001)conf_para.setdefault('momentum', 0.9)x_traj = [x0]v = np.zeros_like(x0)for _ in range(conf_para['n_iter']):x_jump = x_traj[-1] + v # 公式 (3)dfdx = np.array(df_dx(*x_jump)) # 在跳跃位置计算梯度 ∇f(θ + v)v = conf_para['momentum'] * v - conf_para['learning_rate'] * dfdx # 公式 (4)x_traj.append(x_traj[-1] + v) # 公式 (5)return x_traj
4. AdaGrad 讲解
AdaGrad 通过累积历史梯度的平方来自适应地缩小学习率,公式如下:
- r t = r t − 1 + ∇ f ( θ ) 2 r_t = r_{t-1} + \nabla f(\theta)^2 rt=rt−1+∇f(θ)2
- θ = θ − η r t + ϵ ∇ f ( θ ) \theta = \theta - \frac{\eta}{\sqrt{r_t} + \epsilon} \nabla f(\theta) θ=θ−rt+ϵη∇f(θ)
def gd_adagrad(df_dx, x0, conf_para=None):"""AdaGrad 自适应梯度优化器参数:df_dx: 梯度函数x0: 初始参数位置conf_para: 参数字典,包含 learning_rate, epsilon, n_iter返回:x_traj: 参数轨迹"""if conf_para is None:conf_para = {}conf_para.setdefault('n_iter', 1000)conf_para.setdefault('learning_rate', 0.001)conf_para.setdefault('epsilon', 1e-7)x_traj = [x0]r = np.zeros_like(x0)for _ in range(conf_para['n_iter']):dfdx = np.array(df_dx(*x_traj[-1]))r += dfdx**2 # 累积平方梯度x_traj.append(x_traj[-1] - conf_para['learning_rate'] * dfdx / (np.sqrt(r) + conf_para['epsilon']))return x_traj
5. RMSProp 讲解
RMSProp 是 AdaGrad 的改进,引入滑动平均:
- r t = γ r t − 1 + ( 1 − γ ) ∇ f ( θ ) 2 r_t = \gamma r_{t-1} + (1-\gamma) \nabla f(\theta)^2 rt=γrt−1+(1−γ)∇f(θ)2
- θ = θ − η r t + ϵ ∇ f ( θ ) \theta = \theta - \frac{\eta}{\sqrt{r_t} + \epsilon} \nabla f(\theta) θ=θ−rt+ϵη∇f(θ)
def gd_rmsprop(df_dx, x0, conf_para=None):"""RMSProp 优化器参数:df_dx: 梯度函数x0: 初始值conf_para: 参数字典,包括 gamma, learning_rate, epsilon"""if conf_para is None:conf_para = {}conf_para.setdefault('n_iter', 1000)conf_para.setdefault('learning_rate', 0.001)conf_para.setdefault('epsilon', 1e-7)conf_para.setdefault('gamma', 0.9)x_traj = [x0]r = np.zeros_like(x0)for _ in range(conf_para['n_iter']):dfdx = np.array(df_dx(*x_traj[-1]))r = conf_para['gamma'] * r + (1 - conf_para['gamma']) * dfdx**2x_traj.append(x_traj[-1] - conf_para['learning_rate'] * dfdx / (np.sqrt(r) + conf_para['epsilon']))return x_traj
6. Adam 讲解
Adam 同时融合了 Momentum 和 RMSProp 的优点:
- 一阶动量: s t = β 1 s t − 1 + ( 1 − β 1 ) ∇ f ( θ ) s_t = \beta_1 s_{t-1} + (1-\beta_1) \nabla f(\theta) st=β1st−1+(1−β1)∇f(θ)
- 二阶动量: r t = β 2 r t − 1 + ( 1 − β 2 ) ∇ f ( θ ) 2 r_t = \beta_2 r_{t-1} + (1-\beta_2) \nabla f(\theta)^2 rt=β2rt−1+(1−β2)∇f(θ)2
- 偏差修正: s ^ t = s t 1 − β 1 t , r ^ t = r t 1 − β 2 t \hat{s}_t = \frac{s_t}{1 - \beta_1^t}, \hat{r}_t = \frac{r_t}{1 - \beta_2^t} s^t=1−β1tst,r^t=1−β2trt
- 参数更新: θ = θ − η s ^ t r ^ t + ϵ \theta = \theta - \eta \frac{\hat{s}_t}{\sqrt{\hat{r}_t} + \epsilon} θ=θ−ηr^t+ϵs^t
def gd_adam(df_dx, x0, conf_para=None):"""Adam 优化器参数:df_dx: 梯度函数x0: 初始位置conf_para: 包含 rho1, rho2, epsilon, learning_rate"""if conf_para is None:conf_para = {}conf_para.setdefault('n_iter', 1000)conf_para.setdefault('learning_rate', 0.001)conf_para.setdefault('rho1', 0.9)conf_para.setdefault('rho2', 0.999)conf_para.setdefault('epsilon', 1e-8)x_traj = [x0]t = 0s = np.zeros_like(x0)r = np.zeros_like(x0)for _ in range(conf_para['n_iter']):dfdx = np.array(df_dx(*x_traj[-1]))t += 1s = conf_para['rho1'] * s + (1 - conf_para['rho1']) * dfdxr = conf_para['rho2'] * r + (1 - conf_para['rho2']) * (dfdx**2)st = s / (1 - conf_para['rho1']**t)rt = r / (1 - conf_para['rho2']**t)x_traj.append(x_traj[-1] - conf_para['learning_rate'] * st / (np.sqrt(rt) + conf_para['epsilon']))return x_traj
相关文章:

【深度学习-pytorch篇】3. 优化器实现:momentum,NAG,AdaGrad,RMSProp,Adam
Optimization Algorithms Explained 1. Beale Function 与导数函数讲解 Beale 函数是一个著名的用于测试优化算法性能的函数,其具有多个局部极值点,适合评估不同优化器的表现: def beale(x1, x2):"""Beale 函数定义&#x…...
C# NX二次开发-查找连续倒圆角面
在QQ群里有人问怎么通过一个选择一个倒圆角面来自动选中一组倒圆角面。 可以通过ufun函数 UF_MODL_ask_face_type 和 UF_MODL_ask_face_props 可判断处理选择相应的一组圆角面。 代码: Tag[] 查找连续倒圆角面(Tag faceTag) {theUf.Modl.AskFaceType(faceTag, out int typ…...

今天遇到的bug
先呈现一下BUG现象。 这主要是一个传参问题,参数一直传不过去。后来我才发现,问题所在。 我们这里用的RquestBody接收参数,所有请求的参数需要用在body体中接收,但是我们用postman,用的是字符串查询方式传参&#x…...

Go语言字符串类型详解
1. 定义字符串类型 package mainimport ("fmt");func main() {var str1 string "你好 GoLang 1"var str2 "你好 GoLang 2"str3 : "你好 GoLang 3"fmt.Printf("%v--%T\n", str1, str1)// 你好 GoLang 1--stringfmt.Printf…...
长安链智能合约命令解析(全集)
创建命令解析 ./cmc client contract user create \ --contract-namefact \ --runtime-typeWASMER \ --byte-code-path./testdata/claim-wasm-demo/rust-fact-2.0.0.wasm \ --version1.0 \ --sdk-conf-path./testdata/sdk_config.yml \ --admin-key-file-paths./testdata/cryp…...

一、OpenCV的基本操作
目录 1、OpenCV的模块 2、OpenCV的基础操作 2.1图像的IO操作 2.2绘制几何图形 2.3获取并修改图像中的像素点 2.4 获取图像的属性 2.5图像通道的拆分与合并 2.6色彩空间的改变 3、OpenCV的算数操作 3.1图像的加法 3.2图像的混合 3.3总结 1、OpenCV的模块 2、OpenCV的基…...

裂缝仪在线监测装置:工程安全领域的“实时守卫者”
在基础设施运维领域,裂缝扩展是威胁建筑结构安全的核心隐患之一。传统人工巡检方式存在效率低、时效性差、数据主观性强等局限,而裂缝仪在线监测装置通过技术迭代,实现了对结构裂缝的自动化、持续性追踪,为工程安全评估提供科学依…...

【论文精读】2024 ECCV--MGLD-VSR现实世界视频超分辨率(RealWorld VSR)
文章目录 一、摘要二、问题三、Method3.1 Latent Diffusion Model3.2 Motion-guided Diffusion Sampling3.3 Temporal-aware Decoder Fine-tuning 四、实验设置4.1 训练阶段4.2 训练数据 贡献总结 论文全称: Motion-Guided Latent Diffusion for Temporally Consis…...
SpringBoot简单体验
1 Helloworld 打开:https://start.spring.io/ 选择maven配置。增加SpringWeb的依赖。 Generate之后解压,代码大致如下: hpDESKTOP-430500P:~/springboot2/demo$ tree ├── HELP.md ├── mvnw ├── mvnw.cmd ├── pom.xml └── s…...
)
【系统架构设计师】2025年上半年真题论文回忆版: 论系统负载均衡设计方法(包括解题思路和参考素材)
更多内容请见: 备考系统架构设计师-专栏介绍和目录 文章目录 真题题目(2025年上半年 试题3)解题思路论文素材参考1、静态负载均衡策略2、动态负载均衡策略3、基于场景的负载均衡真题题目(2025年上半年 试题3) 请围绕 “论系统负载均衡设计方法” 论题,依次从以下三个方面…...

2025年通用 Linux 服务器操作系统该如何选择?
2025年通用 Linux 服务器操作系统该如何选择? 服务器操作系统的选择对一个企业IT和云服务影响很大,主推的操作系统在后期更换的成本很高,而且也有很大的迁移风险,所以企业在选择服务器操作系统时要尤为重视。 之前最流行的服务器…...
Azure devops 系统之五-部署ASP.NET web app
今天介绍如何通过vscode 来创建一个asp.net web app,并部署到azure 上。 创建 ASP.NET Web 应用 在您的计算机上打开一个终端窗口并进入工作目录。使用 dotnet new webapp 命令创建一个新的 .NET Web 应用,然后将目录切换到新创建的应用。 dotnet new webapp -n MyFirstAzu…...

Hadoop是什么
注:本人不懂Hadoop是什么,问的大模型,让它用生动浅显的语言向我解释。为了防止忘记,我把它说的记录下来。接下来的解释都是大模型生成的,如果有错误的地方欢迎指正 。 Hadoop 是什么?(一句…...
学习路之PHP--easyswoole_panel安装使用
学习路之PHP--easyswoole_panel安装使用 一、新建文件夹二、安装三、改配置地址四、访问 IP:Port 自动进入index.html页面 一、新建文件夹 /www/wwwroot/easyswoole_panel 及配置ftp 解压easyswoole_panel源码 https://github.com/easyswoole-panel/easyswoole_panel 二、安…...

结合 AI 编程,让前端开发更简单:趋势、方法与实践
在 AI 迅猛发展的浪潮中,前端开发正在迎来范式转变。本文将深入探讨如何将 AI 编程能力嵌入前端工程体系中,重塑前端生产力工具链与开发方式。 一、前端开发的核心痛点 尽管前端框架(如 Vue、React)已经大大简化了 UI 构建&#…...
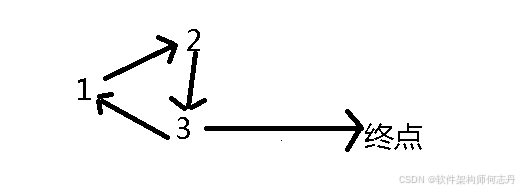
【拓扑排序】P6560 [SBCOI2020] 时光的流逝|普及+
本文涉及知识点 C图论 拓扑排序 P6560 [SBCOI2020] 时光的流逝 题目背景 时间一分一秒的过着,伴随着雪一同消融在了这个冬天, 或许,要是时光能停留在这一刻,该有多好啊。 … “这是…我在这个小镇的最后一个冬天了吧。” “嗯…...
SSRF 接收器
接收请求 IP.php <?php // 定义日志文件路径 $logFile hackip.txt;// 处理删除请求 if (isset($_POST[delete])) {$ipToDelete $_POST[ip];$lines file($logFile, FILE_IGNORE_NEW_LINES);$newLines array();foreach ($lines as $line) {$parts explode( | , $line);…...

【设计模式】责任链
【设计模式】责任链 在实际开发中,我们经常遇到这样的需求:某个请求需要经过多个处理者,但处理的顺序、方式可能会变化或扩展。这时候,责任链模式就能派上用场。 责任链模式(Chain of Responsibility) 是…...

unix/linux source 命令,其高级使用
就像在物理学中,掌握了基本定律后,我们可以开始研究更复杂的系统和现象,source 的高级用法也是建立在对其基本行为深刻理解之上的。 让我们一起探索 source 的高级应用领域: 1. 条件化加载 (Conditional Sourcing) 根据某些条件来决定是否 source 一个文件,或者 source…...

邮件验证码存储推荐方式
邮件验证码的存储方案需要兼顾 安全性、性能 和 可维护性,以下是详细分析和推荐方案: 1. 推荐方案:Redis(首选) 为什么选择 Redis? 优势说明高性能内存读写,毫秒级响应,适合高频验…...

Allegro 输出生产数据详解
说明 用于PCB裸板的生产可以分别单独创建文件 光绘数据(Gerber)、钻孔(NC Drill)、IPC网表;或者通过ODB++或IPC2581文件(这是一个新格式),它包含生产裸板所需要的所有信息 光绘数据 Artwork Gerber 光绘数据一般包含设计中各个层面的蚀刻线路、阻焊、铅锡、字符等信…...
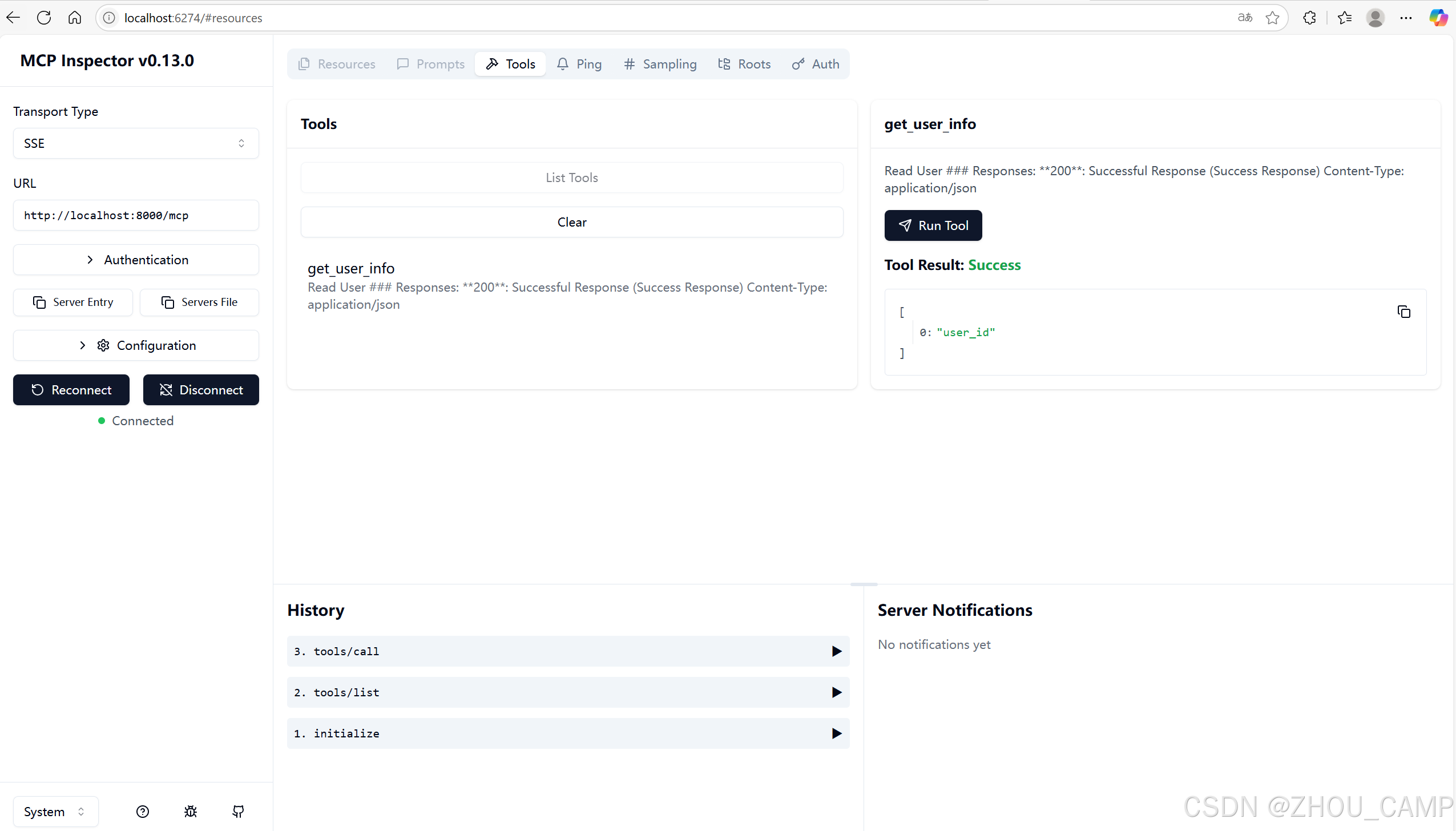
FastAPI MCP 快速入门教程
目录 什么是 FastAPI MCP?项目设置1. 初始化项目2. 安装依赖3. 项目结构 编写代码创建主应用文件 运行和测试1. 启动服务器2. 使用 MCP Inspector 测试 什么是 FastAPI MCP? FastAPI MCP 是一个将 FastAPI 应用程序转换为 Model Context Protocol (MCP)…...
uni-app学习笔记二十一--pages.json中tabBar设置底部菜单项和图标
如果应用是一个多 tab 应用,可以通过 tabBar 配置项指定一级导航栏,以及 tab 切换时显示的对应页。 在 pages.json 中提供 tabBar 配置,不仅仅是为了方便快速开发导航,更重要的是在App和小程序端提升性能。在这两个平台ÿ…...
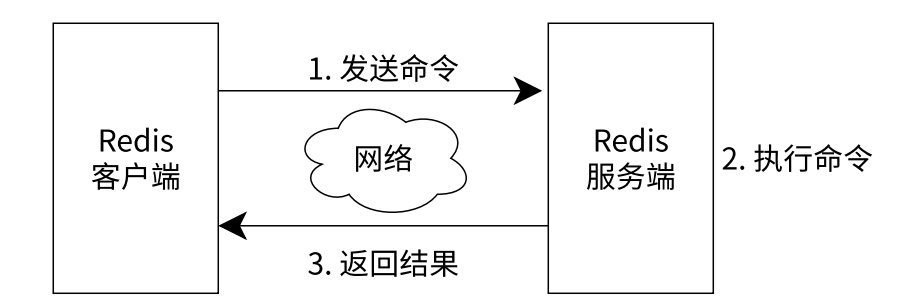
【Redis】基本命令
Redis命令行客户端 现在我们已经启动了Redis服务,下面将介绍如何使用redis - cli连接、操作Redis服务。客户端和服务端的交互过程如图1 - 3所示。 redis - cli可以使用两种方式连接Redis服务器。 第一种是交互式方式:通过redis - cli -h {host} -p {p…...

爬虫工具链的详细分类解析
以下是针对爬虫工具链的详细分类解析,涵盖静态页面、动态渲染和框架开发三大场景的技术选型与核心特性: 🧩 一、静态页面抓取(HTML结构固定) 工具组合:Requests BeautifulSoup 适用场景:目标数…...

鸿蒙编译ffmpeg库
下载 ffmpeg 项目 基于如下项目编译的 ffmpeg git clone https://gitcode.com/openharmony-sig/tpc_c_cplusplus.git 配置编译环境 下载 command line tools https://developer.huawei.com/consumer/cn/download/ 导出 OHOS_SDK 环境变量 export OHOS_SDK~/command-line-…...
哈希:闭散列的开放定址法
我还是曾经的那个少年 1.概念 通过其要存储的值与存储的位置建立映射关系。 如:基数排序也是运用了哈希开放定址法的的思想。 弊端:仅适用于数据集中的情况 2.开放定址法 问题:按照上述哈希的方式,向集合插入数据为44ÿ…...
Unity-QFramework框架学习-MVC、Command、Event、Utility、System、BindableProperty
QFramework QFramework简介 QFramework是一套渐进式、快速开发框架,适用于任何类型的游戏及应用项目,它包含一套开发架构和大量的工具集 QFramework的特性 简洁性:QFramework 强调代码的简洁性和易用性,让开发者能够快速上手&a…...

FPGA实现CNN卷积层:高效窗口生成模块设计与验证
我最近在从事一项很有意思的项目,我想在PFGA上部署CNN并实现手写图片的识别。而本篇文章,是我迈出的第一步。具体代码已发布在github上 模块介绍 卷积神经网络(CNN)可以分为卷积层、池化层、激活层、全链接层结构,本篇要实现的&…...
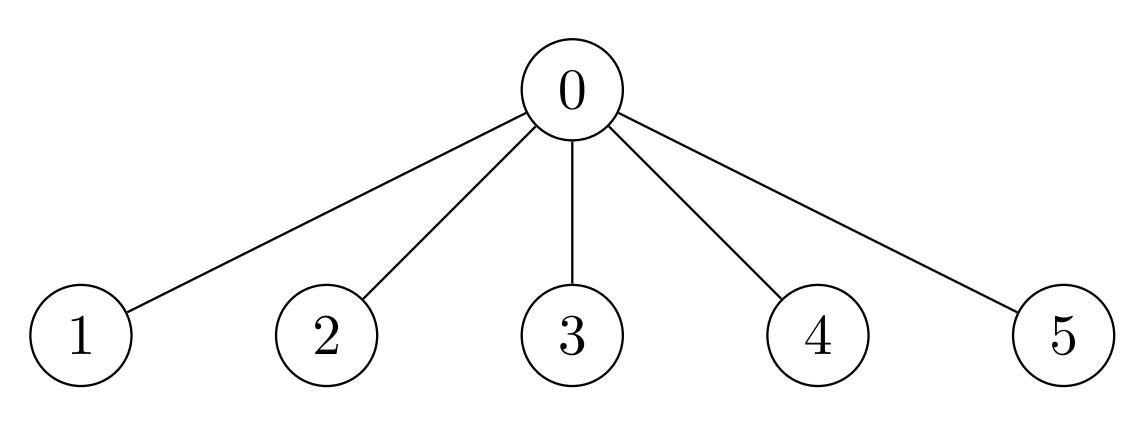
LeetCode 3068.最大节点价值之和:脑筋急转弯+动态规划(O(1)空间)
【LetMeFly】3068.最大节点价值之和:脑筋急转弯动态规划(O(1)空间) 力扣题目链接:https://leetcode.cn/problems/find-the-maximum-sum-of-node-values/ 给你一棵 n 个节点的 无向 树,节点从 0 到 n - 1 编号。树以长…...