PyTorch中 torch.utils.data.DataLoader 的详细解析和读取点云数据示例
一、DataLoader 是什么?
torch.utils.data.DataLoader 是 PyTorch 中用于加载数据的核心接口,它支持:
- 批量读取(batch)
- 数据打乱(shuffle)
- 多线程并行加载(num_workers)
- 自动将数据打包成 batch
- 数据预处理和增强(搭配 Dataset 使用)
二、常见参数详解
| 参数 | 含义 |
|---|---|
dataset | 传入的 Dataset 对象(如自定义或 torchvision.datasets) |
batch_size | 每个 batch 的样本数量 |
shuffle | 是否打乱数据(通常训练集为 True) |
num_workers | 并行加载数据的线程数(越大越快,但依机器决定) |
drop_last | 是否丢弃最后一个不足 batch_size 的 batch |
pin_memory | 若为 True,会将数据复制到 CUDA 的 page-locked 内存中(加速 GPU 训练) |
collate_fn | 自定义打包 batch 的函数(可用于变长序列、图神经网络等) |
sampler | 控制数据采样策略,不能与 shuffle 同时使用 |
persistent_workers | 若为 True,worker 在 epoch 间保持运行状态(提高效率,PyTorch 1.7+) |
三、基本使用示例
搭配 Dataset 使用
from torch.utils.data import Dataset, DataLoaderclass MyDataset(Dataset):def __init__(self):self.data = [i for i in range(100)]def __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]dataset = MyDataset()
loader = DataLoader(dataset, batch_size=8, shuffle=True, num_workers=2)for batch in loader:print(batch)
四、自定义 collate_fn 示例
适用于:变长数据(如文本、点云)或特殊处理需求
from torch.nn.utils.rnn import pad_sequencedef my_collate_fn(batch):# 假设每个样本是 list 或 tensor(变长)batch = [torch.tensor(item) for item in batch]padded = pad_sequence(batch, batch_first=True, padding_value=0)return paddedloader = DataLoader(dataset, batch_size=4, collate_fn=my_collate_fn)
五、使用注意事项
-
Windows 平台注意:
-
设置
num_workers > 0时,必须使用:if __name__ == '__main__':DataLoader(...)
-
-
过多线程数可能导致瓶颈:
- 通常
num_workers = cpu_count() // 2较稳定
- 通常
-
GPU 加速:
- 训练时推荐设置
pin_memory=True可提高 GPU 训练数据传输效率。
- 训练时推荐设置
-
不要同时设置
shuffle=True和sampler:- 否则会报错,二者功能冲突。
六、训练中的典型使用方式
for epoch in range(num_epochs):for i, batch in enumerate(train_loader):inputs, labels = batchinputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()
七、调试技巧与加速建议
| 场景 | 建议 |
|---|---|
| 数据加载慢 | 增加 num_workers |
| GPU 等数据 | 设置 pin_memory=True |
| Dataset 中有耗时操作 | 考虑预处理或使用缓存 |
| debug 模式 | 设置 num_workers=0,禁用多进程 |
八、与 TensorDataset、ImageFolder 配合
from torchvision.datasets import ImageFolder
from torchvision import transformstransform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),
])dataset = ImageFolder(root='your/image/folder', transform=transform)
loader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4)
九、点云数据处理场景应用实例
在 点云数据处理 场景中,使用 torch.utils.data.DataLoader 时,常遇到如下需求:
- 每帧点云大小不同(变长 Tensor)
- 点云数据 + 标签(如语义、实例)
- 使用
.bin、.pcd或.npy等格式加载 - 数据增强(如旋转、裁剪、噪声)
- GPU 加速 + 批量训练
1. 点云数据 Dataset 示例(以 .npy 文件为例)
import os
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoaderclass PointCloudDataset(Dataset):def __init__(self, root_dir, transform=None):self.root_dir = root_dirself.files = sorted([f for f in os.listdir(root_dir) if f.endswith('.npy')])self.transform = transformdef __len__(self):return len(self.files)def __getitem__(self, idx):point_cloud = np.load(os.path.join(self.root_dir, self.files[idx])) # shape: [N, 3] or [N, 6]point_cloud = torch.tensor(point_cloud, dtype=torch.float32)if self.transform:point_cloud = self.transform(point_cloud)return point_cloud
2. 自定义 collate_fn(处理变长点云)
def collate_pointcloud_fn(batch):"""输入: List of [N_i x 3] tensors输出: - 合并后的 [B x N_max x 3] tensor- 每个样本的真实点数 list"""max_points = max(pc.shape[0] for pc in batch)padded = torch.zeros((len(batch), max_points, batch[0].shape[1]))lengths = []for i, pc in enumerate(batch):lengths.append(pc.shape[0])padded[i, :pc.shape[0], :] = pcreturn padded, torch.tensor(lengths)
3. 加载器构建示例
dataset = PointCloudDataset("/path/to/your/pointclouds")loader = DataLoader(dataset,batch_size=8,shuffle=True,num_workers=4,pin_memory=True,collate_fn=collate_pointcloud_fn
)for batch_points, batch_lengths in loader:# batch_points: [B, N_max, 3]# batch_lengths: [B]print(batch_points.shape)
4. 可选扩展功能
| 功能 | 实现方法 |
|---|---|
| 点云旋转/缩放 | 自定义 transform(例如随机旋转矩阵乘点云) |
加载 .pcd | 使用 open3d, pypcd, 或 pclpy |
| 同时加载标签 | 在 Dataset 中返回 (point_cloud, label),修改 collate_fn |
| voxel downsampling | 使用 open3d.geometry.VoxelDownSample |
| GPU 加速 | point_cloud = point_cloud.cuda(non_blocking=True) |
5. 训练循环中使用
for epoch in range(num_epochs):for batch_pc, batch_len in loader:batch_pc = batch_pc.to(device)# 可用 batch_len 做 mask 或 attention maskout = model(batch_pc)...
相关文章:

PyTorch中 torch.utils.data.DataLoader 的详细解析和读取点云数据示例
一、DataLoader 是什么? torch.utils.data.DataLoader 是 PyTorch 中用于加载数据的核心接口,它支持: 批量读取(batch)数据打乱(shuffle)多线程并行加载(num_workers)自…...

直线模组在手术机器人中有哪些技术挑战?
手术机器人在现代医疗领域发挥着越来越重要的作用,直线模组作为其关键部件,对手术机器人的性能有着至关重要的影响。然而,在手术机器人中使用直线模组面临着诸多技术挑战,具体如下: 1、高精度要求:手术…...

RK3568DAYU开发板-平台驱动开发--UART
1、程序介绍 本程序是基于OpenHarmony标准系统编写的平台驱动案例:UART 系统版本:openharmony5.0.0 开发板:dayu200 编译环境:ubuntu22 部署路径: //sample/06_platform_uart 2、基础知识 2.1、UART简介 UART指异步收发传输器(Univer…...

ubuntu 安装 Redis 5.0.8 的完整步骤
以下是根据前面的沟通记录整理的完整安装过程和依赖项,确保在 Ubuntu 22 上成功安装 Redis 5.0.8。 安装 Redis 5.0.8 的完整步骤 1. 安装依赖 在编译和运行 Redis 之前,需要安装一些必要的工具和库: sudo apt update sudo apt install bu…...

制造企业搭建AI智能生产线怎么部署?
制造商需要精准协调生产和发货,确保订单及时交付。MES、ERP、CRM 系统与生产线集成,对生产管理流程、物料跟踪、品控、确定货期至关重要。如果某个系统发生延迟或者效率低下,会在造成整个生产环节停滞,影响最终交付,导…...
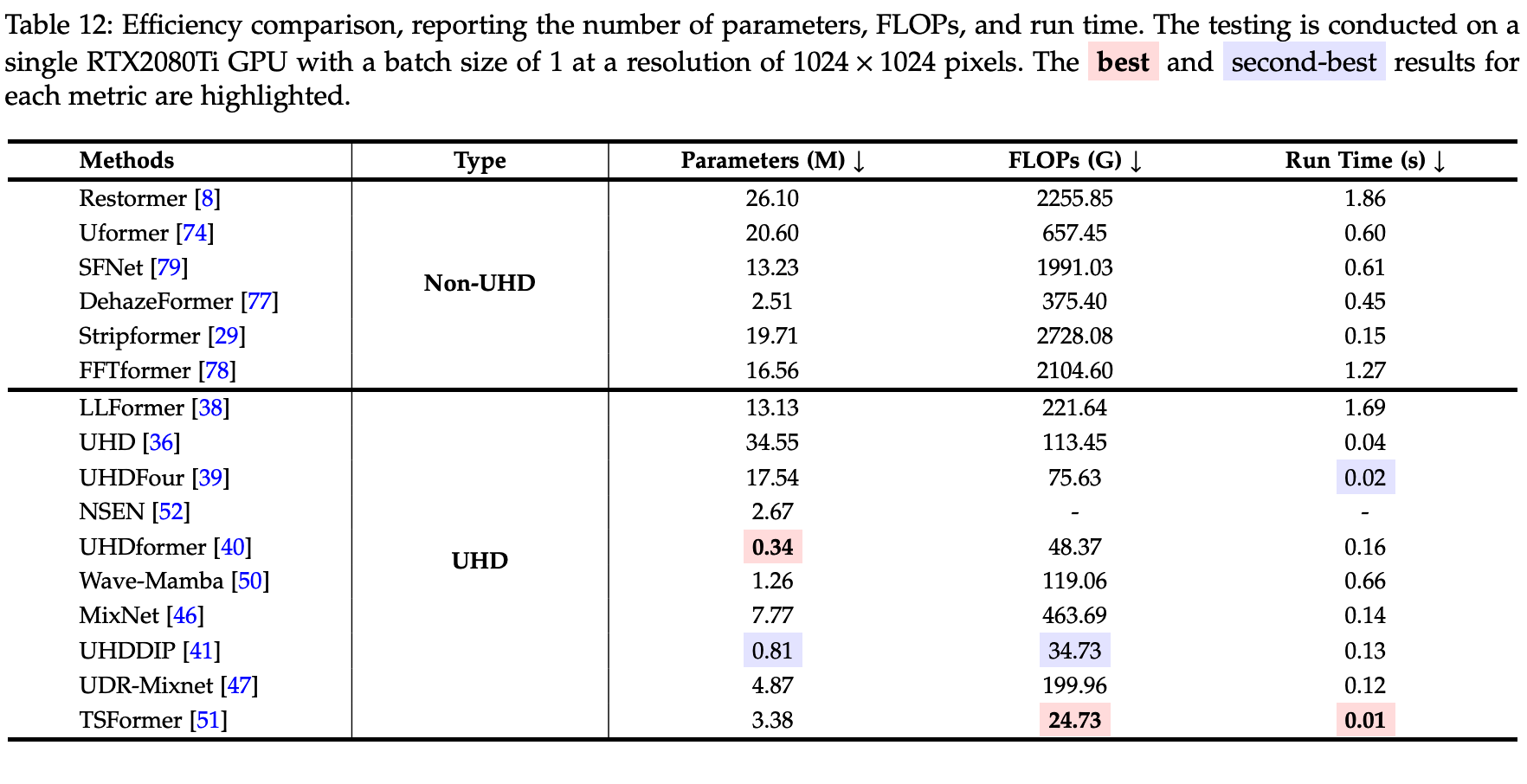
深度学习驱动的超高清图修复技术——综述
Deep Learning-Driven Ultra-High-Definition Image Restoration: A Survey Liyan Wang, Weixiang Zhou, Cong Wang, Kin-Man Lam, Zhixun Su, Jinshan Pan Abstract Ultra-high-definition (UHD) image restoration aims to specifically solve the problem of quali…...

unix/linux source 命令,其内部结构机制
要理解 source (或 .) 命令的内部结构机制,我们需要戴上“操作系统”和“解释器设计”的眼镜,深入到 Shell 如何管理其状态以及如何执行命令的层面。 虽然我们无法直接看到 Shell 内部的 C 代码(除非我们去阅读 Bash 或 Zsh 的源码),但我们可以基于其行为和操作系统的原理…...

【LLM】FastAPI入门教程
note FastAPI 是一个现代的、快速(高性能)的 Web 框架,用于构建 API(应用程序编程接口)。它基于 Python 3.7,使用了 Python 类型提示(type hints),并且具有自动化的文档…...

进程同步机制-信号量机制-记录型信号量机制中的的wait和signal操作
wait和signal是记录型信号量机制中用于实现进程同步与互斥的两个重要操作, wait 操作 wait(semaphores *S) {S->value --;if (S->value<0) block(S->list) }请求资源:S->value --; 这一步表示进程请求一个单位的资源,将信号…...

gitlib 常见命令
git clone <项目URL> # 从 GitLab 拉取代码到本地 git status 查看状态 git diff 文件路径 查看修改位置 git diff 文件路径 查看修改位置 black -l 180 路径 格式化文件 git add 路径 (可以多个) 添加修改到暂存区 git commit -m “提交说明…...
Azure DevOps 管道部署系列之二IIS
本博客旨在提供如何使用 Azure DevOps YAML 管道部署到虚拟机上的 IIS 的实用指南。 开始之前,您需要做好以下准备: 您拥有要部署的服务器的访问权限以及 PowerShell 的管理员访问权限。您拥有要部署的远程服务器的互联网访问权限。您拥有在服务器上安装 .NET Core 托管包的…...

Vue.js教学第十七章:Vue 与后端交互(一),Axios 基础
Vue 与后端交互(一):Axios 基础 在现代前端开发中,Vue 应用通常需要与后端 API 进行数据交互,以实现动态数据的获取和提交。Axios 是一个基于 Promise 的 HTTP 客户端,广泛用于 Vue 项目中与后端进行通信。本文将深入讲解 Axios 的基本用法,包括如何通过 Axios 发送 GE…...

人工智能浪潮下,制造企业如何借力DeepSeek实现数字化转型?
一、DeepSeek技术概述 DeepSeek,凭借其强大的深度学习和自然语言处理能力,能够理解复杂问题并提供精准解决方案。它不仅能够作为学习、工作、生活的助手,满足用户在不同场景下的需求,更能在制造业中发挥重要作用。通过自然语言交…...

NodeJS全栈开发面试题讲解——P2Express / Nest 后端开发
✅ 2.1 Express 的中间件机制?如何组织一个 RESTful API 项目? 面试官好,我来讲讲 Express 的中间件机制,它是 Express 架构的核心,也是组织 RESTful 项目的基础。 🧩 什么是中间件? 中间件&am…...

从线性代数到线性回归——机器学习视角
真正不懂数学就能理解机器学习其实是个神话。我认为,AI 在商业世界可以不懂数学甚至不懂编程也能应用,但对于技术人员来说,一些基础数学是必须的。本文收集了我认为理解学习本质所必需的数学基础,至少在概念层面要掌握。毕竟&…...

计算机网络相关发展以及常见性能指标
目录 一、因特网概述 1.1 基本概念 1.2 因特网发展的三个阶段 1.3 英特网服务提供者ISP 1.4 英特网的标准化工作 1.5 因特网的组成 1.6 简单总结 二、3种交换方式 2.1 电路交换(Circuit Switching) 2.2 分组交换(Packet Switching&…...

通义灵码:基于MCP的火车票小助手系统全流程设计与技术总结
具体操作步骤请访问:https://blog.csdn.net/ailuloo/article/details/148319336?spm1001.2014.3001.5502 前沿技术应用全景图 一、项目背景与需求分析 目标:基于12306 MCP接口,开发一款解决高峰出行(春运/节假日)痛…...
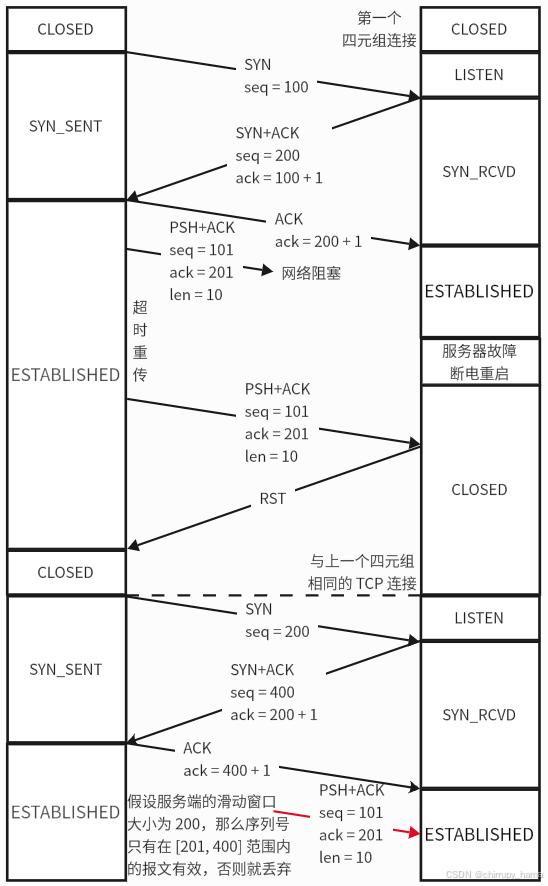
为什么建立 TCP 连接时,初始序列号不固定?
主要原因有两个方面: 很大程度上避免历史报文被下一个相同四元组的 TCP 连接接收问题(主要方面)防止黑客伪造相同序列号的 TCP 报文被接收 接下来,详细说说第一点 假设每次建立 TCP 连接时,客户端和服务端的初始序列…...
VBA数据库解决方案二十:Select表达式From区域Where条件Order by
《VBA数据库解决方案》教程(版权10090845)是我推出的第二套教程,目前已经是第二版修订了。这套教程定位于中级,是学完字典后的另一个专题讲解。数据库是数据处理的利器,教程中详细介绍了利用ADO连接ACCDB和EXCEL的方法…...

NX753NX756美光科技闪存NX784NX785
技术解读与产品特性 美光科技的NX系列闪存,包括NX753、NX756、NX784、NX785等型号,代表了当前存储技术的前沿水平。这些产品基于先进的NAND闪存技术,采用业界领先的3D TLC NAND技术,实现了高速的数据读写能力。3D TLC NAND技术通…...

使用 pytesseract 构建一个简单 OCR demo
简介 pytesseract 库是 Google Tesseract OCR (光学字符识别)引擎的一个 Python 封装库,使用广泛且功能强大。 构建 使用 pytesseract 构建一个简单 OCR demo。 步骤一:安装必要的库 您需要在您的 Python 环境中安装 pytessera…...

Cesium快速入门到精通系列教程三:添加物体与3D建筑物
Cesium中添加物体与3D建筑物,对于大规模城市模型,推荐使用 3D Tileset;对于简单几何图形,可以使用 Entity API;对于复杂模型,可以使用 GLTF 格式: 一、添加一个点: 在 Cesium 1.93…...
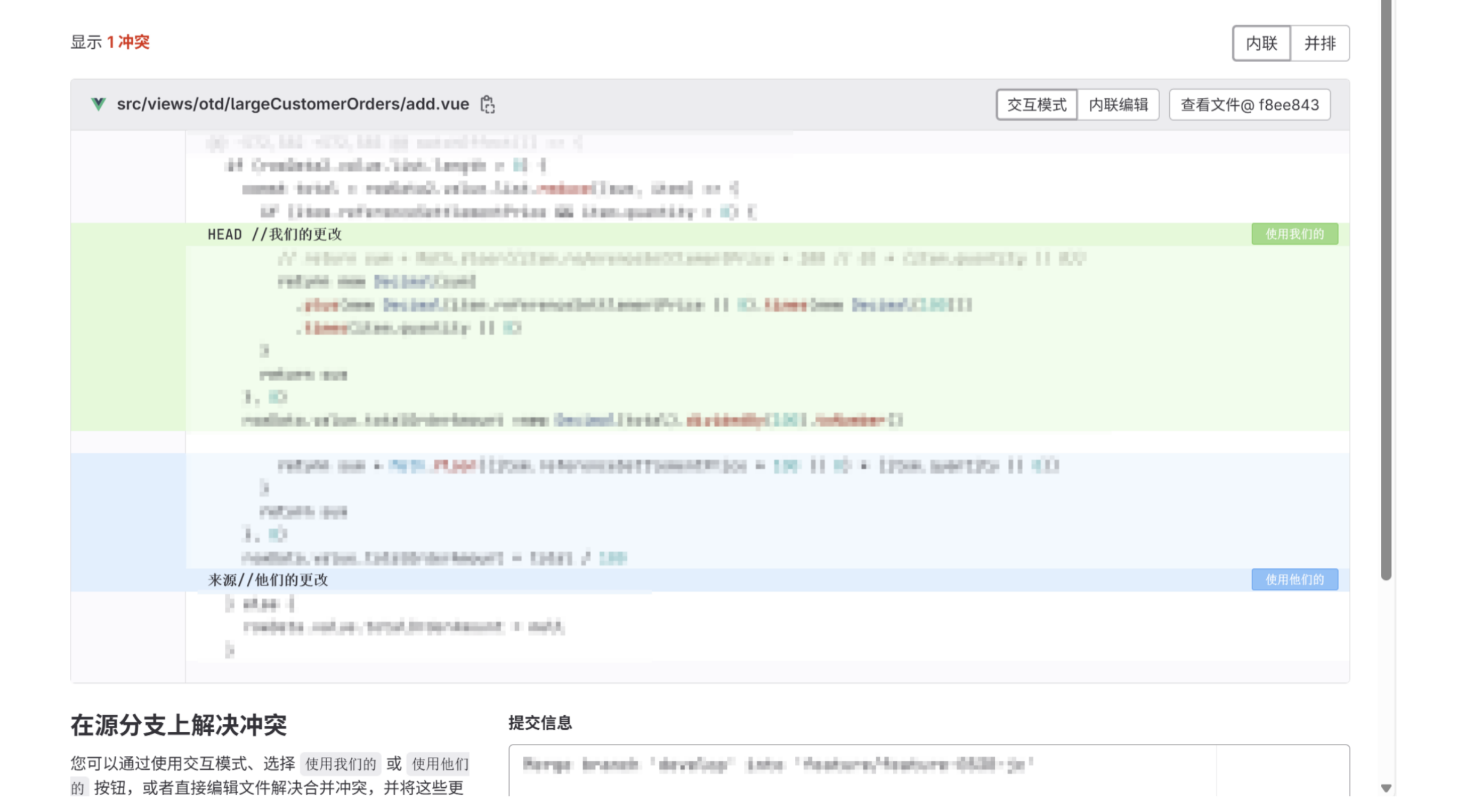
git 如何解决分支合并冲突(VS code可视化解决+gitLab网页解决)
1、定义:两个分支修改了同一文件的同一行代码,无法自动决定如何合并代码,需要人工干预的情况。(假设A提交了文件a,此时B在未拉取代码的情况下,直接提交是会报错的,此时需要拉取之后再提交才会成功ÿ…...
【CF】Day72——Codeforces Round 890 (Div. 2) CDE1 (二分答案 | 交互 + 分治 | ⭐树上背包)
C. To Become Max 题目: 思路: 二分挺好想的,但是check有点不好写 看到最大值,试试二分,如果 x 可以,那么 x - 1 肯定也可以,所以具有单调性,考虑二分 如何check呢?由于…...

单片机寄存器的四种主要类型!
1. 控制寄存器(Control Registers) 专业定义:用于配置硬件行为或触发操作的寄存器。 大白话: 相当于设备的“控制面板”,通过写入特定值来开关功能或调整参数。例如&am…...

智能嗅探AJAX触发:机器学习在动态渲染中的创新应用
一、问题描述:数据加载变“隐形”,采集举步维艰 随着Web技术不断发展,越来越多网站采用了AJAX、动态渲染等技术来加载数据。以今日头条(https://www.toutiao.com)为例,用户打开网页时并不会一次性加载所有…...
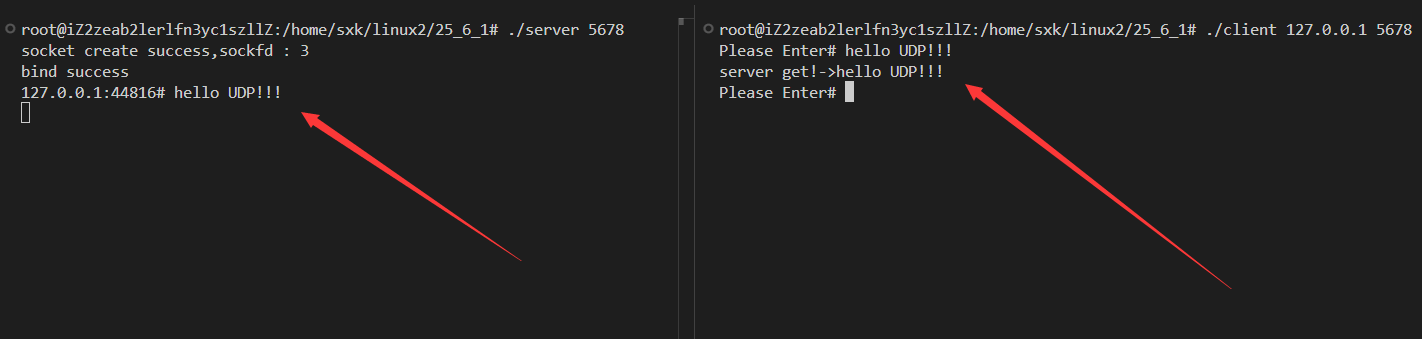
【计算机网络】Linux下简单的UDP服务器(超详细)
套接字接口 我们把服务器封装成一个类,当我们定义出一个服务器对象后需要马上初始化服务器,而初始化服务器需要做的第一件事就是创建套接字。 🌎socket函数 这是Linux中创建套接字的系统调用,函数原型如下: int socket(int domain, int typ…...

Java并发编程实战 Day 3:volatile关键字与内存可见性
【Java并发编程实战 Day 3】volatile关键字与内存可见性 开篇 欢迎来到《Java并发编程实战》系列的第3天!本系列旨在带领你从基础到高级逐步掌握Java并发编程的核心概念和最佳实践。 今天我们将重点探讨volatile关键字及其在多线程程序中确保内存可见性的作用。我…...

华为OD机试真题——报文回路(2025A卷:100分)Java/python/JavaScript/C/C++/GO最佳实现
2025 A卷 100分 题型 本专栏内全部题目均提供Java、python、JavaScript、C、C++、GO六种语言的最佳实现方式; 并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析; 本文收录于专栏:《2025华为OD真题目录+全流程解析+备考攻略+经验分…...

K8s工作流程与YAML实用指南
K8s 工作流程 K8s 采用声明式管理(用户说"要什么",K8s 负责"怎么做")方式,通过 YAML 文件描述期望的状态,K8s控制平面会自动确保实际状态与期望状态一致。 核心工作流程如下: 用户提交…...