使用langchain实现五种分块策略:语义分块、父文档分块、递归分块、特殊格式、固定长度分块
文章目录
- 分块策略详解
- 1. 固定长度拆分(简单粗暴)
- 2. 递归字符拆分(智能切割)
- 3. 特殊格式拆分(定向打击)
- Markdown分块
- 4. 语义分割(更智能切割)
- 基于Embedding的语义分块
- 基于模型的端到端语义分块
- 5. 父文档检索(分层切割)
- 方式一:返回完整文档
- 方式二:分层块结构
分块策略详解
文档拆分策略有多种,每种策略都有其自身的优势。
但是粗略来说我们1~5的分块策略是由差到好的,具体可以根据项目多方面测试下
1. 固定长度拆分(简单粗暴)
最直观的策略是根据固定长度进行拆分。
就像用刀切面包一样,每100个字符就切一刀,不管切到哪里。
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0, separator="")document="""One of the most important things I didn't understand about the world when I was a child is the degree to which the returns for performance are superlinear.Teachers and coaches implicitly told us the returns were linear. "You get out," I heard a thousand times, "what you put in." They meant well, but this is rarely true. If your product is only half as good as your competitor's, you don't get half as many customers. You get no customers, and you go out of business.It's obviously true that the returns for performance are superlinear in business. Some think this is a flaw of capitalism, and that if we changed the rules it would stop being true. But superlinear returns for performance are a feature of the world, not an artifact of rules we've invented. We see the same pattern in fame, power, military victories, knowledge, and even benefit to humanity. In all of these, the rich get richer. [1]You can't understand the world without understanding the concept of superlinear returns. And if you're ambitious you definitely should, because this will be the wave you surf on.It may seem as if there are a lot of different situations with superlinear returns, but as far as I can tell they reduce to two fundamental causes: exponential growth and thresholds.The most obvious case of superlinear returns is when you're working on something that grows exponentially. For example, growing bacterial cultures. When they grow at all, they grow exponentially. But they're tricky to grow. Which means the difference in outcome between someone who's adept at it and someone who's not is very great.Startups can also grow exponentially, and we see the same pattern there. Some manage to achieve high growth rates. Most don't. And as a result you get qualitatively different outcomes: the companies with high growth rates tend to become immensely valuable, while the ones with lower growth rates may not even survive.Y Combinator encourages founders to focus on growth rate rather than absolute numbers. It prevents them from being discouraged early on, when the absolute numbers are still low. It also helps them decide what to focus on: you can use growth rate as a compass to tell you how to evolve the company. But the main advantage is that by focusing on growth rate you tend to get something that grows exponentially.YC doesn't explicitly tell founders that with growth rate "you get out what you put in," but it's not far from the truth. And if growth rate were proportional to performance, then the reward for performance p over time t would be proportional to pt.Even after decades of thinking about this, I find that sentence startling."""
texts = text_splitter.split_text(document)
total_characters = len(document)
num_chunks = len(texts)
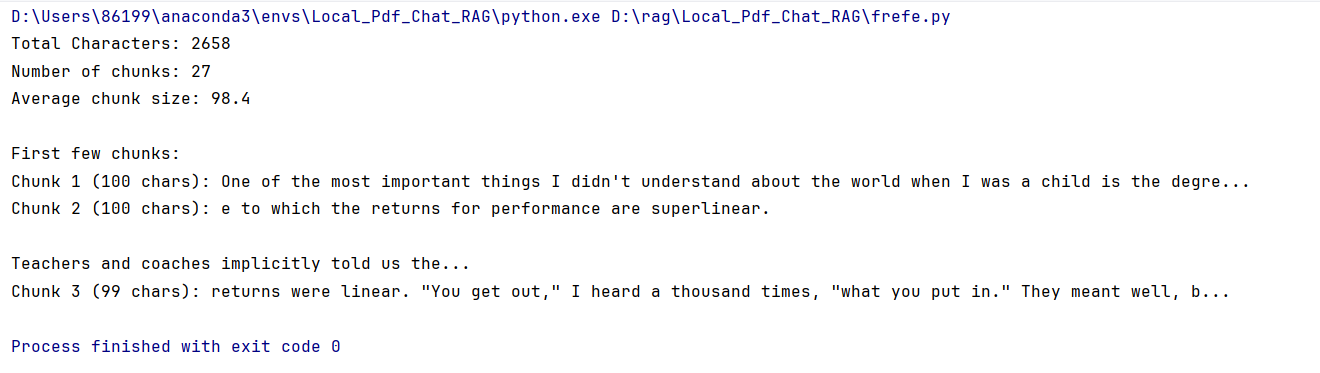
average_chunk_size = total_characters/len(texts)print(f"Total Characters: {total_characters}")
print(f"Number of chunks: {num_chunks}")
print(f"Average chunk size: {average_chunk_size:.1f}")
print(f"\nFirst few chunks:")
for i, chunk in enumerate(texts[:3]):print(f"Chunk {i+1} ({len(chunk)} chars): {chunk[:100]}...")
控制台会输出:
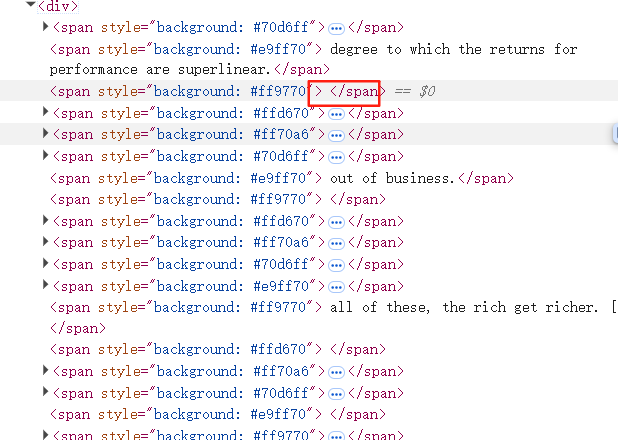
以上结果我们可以在https://chunkviz.up.railway.app/ 看到,如下图:

一般实战中我们会设置约10%-20%做重叠窗口,这样可以使得模型分块之后可以具备连续上下文逻辑。
2. 递归字符拆分(智能切割)
最直观的策略是根据固定长度进行拆分。这种简单而有效的方法可以确保每个块不超过指定的大小限制。
就像用刀切面包一样,每100个字符就切一刀,不管切到哪里。
1. 首先尝试按最大单位切割(段落)
# 就像先按整个萝卜来分
段落1 = "这是第一段内容..."
段落2 = "这是第二段内容..."
段落3 = "这是第三段内容..."
2. 如果段落太大,就切成句子
# 萝卜太大了,按句子切
句子1 = "这是第一个句子。"
句子2 = "这是第二个句子。"
句子3 = "这是第三个句子。"
3. 如果句子还是太大,就切成单词
# 句子还是太长,按单词切
单词1 = "这是"
单词2 = "第一个"
单词3 = "很长的"
单词4 = "句子"
4. 最后实在没办法,才按字符切
# 实在没办法了,按字符切
字符1 = "这"
字符2 = "是"
字符3 = "一"
字符4 = "个"
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)document="""One of the most important things I didn't understand about the world when I was a child is the degree to which the returns for performance are superlinear.Teachers and coaches implicitly told us the returns were linear. "You get out," I heard a thousand times, "what you put in." They meant well, but this is rarely true. If your product is only half as good as your competitor's, you don't get half as many customers. You get no customers, and you go out of business.It's obviously true that the returns for performance are superlinear in business. Some think this is a flaw of capitalism, and that if we changed the rules it would stop being true. But superlinear returns for performance are a feature of the world, not an artifact of rules we've invented. We see the same pattern in fame, power, military victories, knowledge, and even benefit to humanity. In all of these, the rich get richer. [1]You can't understand the world without understanding the concept of superlinear returns. And if you're ambitious you definitely should, because this will be the wave you surf on.It may seem as if there are a lot of different situations with superlinear returns, but as far as I can tell they reduce to two fundamental causes: exponential growth and thresholds.The most obvious case of superlinear returns is when you're working on something that grows exponentially. For example, growing bacterial cultures. When they grow at all, they grow exponentially. But they're tricky to grow. Which means the difference in outcome between someone who's adept at it and someone who's not is very great.Startups can also grow exponentially, and we see the same pattern there. Some manage to achieve high growth rates. Most don't. And as a result you get qualitatively different outcomes: the companies with high growth rates tend to become immensely valuable, while the ones with lower growth rates may not even survive.Y Combinator encourages founders to focus on growth rate rather than absolute numbers. It prevents them from being discouraged early on, when the absolute numbers are still low. It also helps them decide what to focus on: you can use growth rate as a compass to tell you how to evolve the company. But the main advantage is that by focusing on growth rate you tend to get something that grows exponentially.YC doesn't explicitly tell founders that with growth rate "you get out what you put in," but it's not far from the truth. And if growth rate were proportional to performance, then the reward for performance p over time t would be proportional to pt.Even after decades of thinking about this, I find that sentence startling."""texts = text_splitter.split_text(document)
total_characters = len(document)
num_chunks = len(texts)
average_chunk_size = total_characters/len(texts)print(f"Total Characters: {total_characters}")
print(f"Number of chunks: {num_chunks}")
print(f"Average chunk size: {average_chunk_size:.1f}")
print(f"\nFirst few chunks:")
for i, chunk in enumerate(texts[:3]):print(f"Chunk {i+1} ({len(chunk)}字符): {chunk}")
控制台会输出:

以上结果我们可以在https://chunkviz.up.railway.app/ 看到,如下图:

这个网站开发者将空格也视为了分割块,可忽略它的span数计算总数与我们不一样(它的bug):
该方法是dify的默认方法。我们可以修改分割符从而快速简单达到效果,比如
separators 分隔符设置:
默认的separators 是"\n\n"(即回车)。比如:
- 中文文档:应增加中文标点符号(如"。“、”,")作为分隔符
- Markdown文档:可使用标题标记(#、##)、代码块标记(```)等作为分隔符
3. 特殊格式拆分(定向打击)
某些文档具有固有的结构,例如 HTML、Markdown 或 JSON 文件。
这里我就先介绍下Markdown ,其他我遇到了再跟大家补充。
Markdown分块
MarkdownHeaderTextSplitter是对RecursiveCharacterTextSplitter用了多个不同符号使得其能适应格式。
包含了以下符号作为分隔符:
-
#到###### -
````lang` - 三个反引号开始的代码块
-
~~~lang- 三个波浪号开始的代码块 -
***- 星号分割线(3个或更多) -
---- 短横线分割线(3个或更多) -
___- 下划线分割线(3个或更多)
4. 语义分割(更智能切割)
递归文本分块基于预定义规则工作,虽然简单高效,但可能无法准确捕捉语义变化。
基于语义的分块策略则直接分析文本内容,根据语义相似度判断分块位置。
基于Embedding的语义分块
但从概念上讲,该方法是在文本含义发生显著变化时对文本进行拆分。例如,我们可以使用滑动窗口方法生成嵌入向量,并比较嵌入以发现显著差异:
1. 句子分割 首先将整个文本按句子分割(默认按句号、问号、感叹号分割)。
2. 创建语义窗口 为了获得更稳定的语义表示,不是单独分析每个句子,而是创建"滑动窗口"。默认情况下,每个窗口包含3个句子:当前句子加上前后各一个句子。这样做可以减少单个短句造成的噪音。
3. 生成嵌入向量 对每个滑动窗口的组合句子生成嵌入向量,这些向量能够捕获文本的语义含义。
4. 计算语义距离 计算相邻窗口之间的余弦距离。余弦距离越大,说明两个窗口的语义差异越大。
5. 确定断点阈值 系统提供4种方法来确定什么程度的语义距离算作"断点":
- 百分位数法:找出距离最大的前5%作为断点
- 标准差法:超过平均值加3倍标准差的距离作为断点
- 四分位数法:基于四分位距离的统计方法
- 梯度法:分析距离变化的梯度来找断点
6. 执行分割 在语义距离超过阈值的位置进行分割,形成最终的语义块。
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'model_name = "BAAI/bge-small-en"
model_kwargs = {"device": "cpu"}
encode_kwargs = {"normalize_embeddings": True}
hf = HuggingFaceBgeEmbeddings(model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs
)text_splitter = SemanticChunker(hf)
document="""One of the most important things I didn't understand about the world when I was a child is the degree to which the returns for performance are superlinear.Teachers and coaches implicitly told us the returns were linear. "You get out," I heard a thousand times, "what you put in." They meant well, but this is rarely true. If your product is only half as good as your competitor's, you don't get half as many customers. You get no customers, and you go out of business.It's obviously true that the returns for performance are superlinear in business. Some think this is a flaw of capitalism, and that if we changed the rules it would stop being true. But superlinear returns for performance are a feature of the world, not an artifact of rules we've invented. We see the same pattern in fame, power, military victories, knowledge, and even benefit to humanity. In all of these, the rich get richer. [1]You can't understand the world without understanding the concept of superlinear returns. And if you're ambitious you definitely should, because this will be the wave you surf on.It may seem as if there are a lot of different situations with superlinear returns, but as far as I can tell they reduce to two fundamental causes: exponential growth and thresholds.The most obvious case of superlinear returns is when you're working on something that grows exponentially. For example, growing bacterial cultures. When they grow at all, they grow exponentially. But they're tricky to grow. Which means the difference in outcome between someone who's adept at it and someone who's not is very great.Startups can also grow exponentially, and we see the same pattern there. Some manage to achieve high growth rates. Most don't. And as a result you get qualitatively different outcomes: the companies with high growth rates tend to become immensely valuable, while the ones with lower growth rates may not even survive.Y Combinator encourages founders to focus on growth rate rather than absolute numbers. It prevents them from being discouraged early on, when the absolute numbers are still low. It also helps them decide what to focus on: you can use growth rate as a compass to tell you how to evolve the company. But the main advantage is that by focusing on growth rate you tend to get something that grows exponentially.YC doesn't explicitly tell founders that with growth rate "you get out what you put in," but it's not far from the truth. And if growth rate were proportional to performance, then the reward for performance p over time t would be proportional to pt.Even after decades of thinking about this, I find that sentence startling."""
texts = text_splitter.create_documents([document])
print(texts[0].page_content)
print(len(texts))total_characters = len(document)
num_chunks = len(texts)
average_chunk_size = total_characters/len(texts)print(f"Total Characters: {total_characters}")
print(f"Number of chunks: {num_chunks}")
print(f"Average chunk size: {average_chunk_size:.1f}")
print(f"\nFirst few chunks:")
for i, chunk in enumerate(texts[:3]):print(f"Chunk {i+1}: {chunk}\n")

由于文本是英文的,可能我们还是不太能直观看明白Embedding模型做了什么,由此我又写了以下代码,这个代码将会从语义分割的实现到绘制图(工程上用上面那份代码即可,这份代码只是做解释)
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
import os
import re
import numpy as np
import matplotlib.pyplot as plt
from langchain_community.utils.math import cosine_similarity# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False# 设置环境
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'# 初始化嵌入模型
model_name = "BAAI/bge-small-en"
model_kwargs = {"device": "cpu"}
encode_kwargs = {"normalize_embeddings": True}
hf = HuggingFaceBgeEmbeddings(model_name=model_name,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs
)# 你的文档内容
document = """One of the most important things I didn't understand about the world when I was a child is the degree to which the returns for performance are superlinear.Teachers and coaches implicitly told us the returns were linear. "You get out," I heard a thousand times, "what you put in." They meant well, but this is rarely true. If your product is only half as good as your competitor's, you don't get half as many customers. You get no customers, and you go out of business.It's obviously true that the returns for performance are superlinear in business. Some think this is a flaw of capitalism, and that if we changed the rules it would stop being true. But superlinear returns for performance are a feature of the world, not an artifact of rules we've invented. We see the same pattern in fame, power, military victories, knowledge, and even benefit to humanity. In all of these, the rich get richer. [1]You can't understand the world without understanding the concept of superlinear returns. And if you're ambitious you definitely should, because this will be the wave you surf on.It may seem as if there are a lot of different situations with superlinear returns, but as far as I can tell they reduce to two fundamental causes: exponential growth and thresholds.The most obvious case of superlinear returns is when you're working on something that grows exponentially. For example, growing bacterial cultures. When they grow at all, they grow exponentially. But they're tricky to grow. Which means the difference in outcome between someone who's adept at it and someone who's not is very great.Startups can also grow exponentially, and we see the same pattern there. Some manage to achieve high growth rates. Most don't. And as a result you get qualitatively different outcomes: the companies with high growth rates tend to become immensely valuable, while the ones with lower growth rates may not even survive.Y Combinator encourages founders to focus on growth rate rather than absolute numbers. It prevents them from being discouraged early on, when the absolute numbers are still low. It also helps them decide what to focus on: you can use growth rate as a compass to tell you how to evolve the company. But the main advantage is that by focusing on growth rate you tend to get something that grows exponentially.YC doesn't explicitly tell founders that with growth rate "you get out what you put in," but it's not far from the truth. And if growth rate were proportional to performance, then the reward for performance p over time t would be proportional to pt.Even after decades of thinking about this, I find that sentence startling."""def combine_sentences(sentences, buffer_size=1):"""组合句子,创建滑动窗口"""for i in range(len(sentences)):combined_sentence = ""# 添加前面的句子for j in range(i - buffer_size, i):if j >= 0:combined_sentence += sentences[j]["sentence"] + " "# 添加当前句子combined_sentence += sentences[i]["sentence"]# 添加后面的句子for j in range(i + 1, i + 1 + buffer_size):if j < len(sentences):combined_sentence += " " + sentences[j]["sentence"]sentences[i]["combined_sentence"] = combined_sentencereturn sentencesdef calculate_cosine_distances(sentences):"""计算余弦距离"""distances = []for i in range(len(sentences) - 1):embedding_current = sentences[i]["combined_sentence_embedding"]embedding_next = sentences[i + 1]["combined_sentence_embedding"]# 计算余弦相似度similarity = cosine_similarity([embedding_current], [embedding_next])[0][0]# 转换为余弦距离distance = 1 - similaritydistances.append(distance)sentences[i]["distance_to_next"] = distancereturn distances, sentences# 手动实现语义距离计算
def calculate_semantic_distances(text, embeddings_model, buffer_size=1):"""计算文本的语义距离"""# 按句子分割sentence_split_regex = r"(?<=[.?!])\s+"single_sentences_list = re.split(sentence_split_regex, text)single_sentences_list = [s.strip() for s in single_sentences_list if s.strip()]print(f"分割出 {len(single_sentences_list)} 个句子:")for i, sentence in enumerate(single_sentences_list):print(f"{i + 1}. {sentence[:100]}...")print()# 创建句子字典sentences = [{"sentence": x, "index": i} for i, x in enumerate(single_sentences_list)]# 组合句子(滑动窗口)sentences = combine_sentences(sentences, buffer_size)# 获取嵌入向量print("生成嵌入向量...")embeddings = embeddings_model.embed_documents([x["combined_sentence"] for x in sentences])for i, sentence in enumerate(sentences):sentence["combined_sentence_embedding"] = embeddings[i]# 计算距离distances, sentences = calculate_cosine_distances(sentences)return distances, sentences, single_sentences_list# 计算语义距离
print("开始计算语义距离...")
distances, sentences_with_embeddings, original_sentences = calculate_semantic_distances(document, hf)print(f"计算出 {len(distances)} 个距离值")
print("距离值:", [f"{d:.3f}" for d in distances])
print()# 绘制图表
plt.figure(figsize=(15, 8))# 绘制距离线
plt.plot(distances, linewidth=2, marker='o', markersize=4)# 设置y轴上限
y_upper_bound = max(distances) * 1.2
plt.ylim(0, y_upper_bound)
plt.xlim(0, len(distances))# 计算阈值
breakpoint_percentile_threshold = 95
breakpoint_distance_threshold = np.percentile(distances, breakpoint_percentile_threshold)print(f"95%分位数阈值: {breakpoint_distance_threshold:.3f}")# 绘制阈值线
plt.axhline(y=breakpoint_distance_threshold, color='r', linestyle='-', linewidth=2,label=f'95%阈值: {breakpoint_distance_threshold:.3f}')# 计算超过阈值的距离数量
num_distances_above_threshold = len([x for x in distances if x > breakpoint_distance_threshold])
num_chunks = num_distances_above_threshold + 1print(f"超过阈值的距离数量: {num_distances_above_threshold}")
print(f"最终块数: {num_chunks}")# 显示块数量
plt.text(x=(len(distances) * 0.01), y=y_upper_bound * 0.9, s=f"{num_chunks} 个分块",fontsize=14, bbox=dict(boxstyle="round,pad=0.3", facecolor="yellow", alpha=0.7))# 获取超过阈值的索引
indices_above_thresh = [i for i, x in enumerate(distances) if x > breakpoint_distance_threshold]
print(f"断点位置: {indices_above_thresh}")# 为每个块着色和标注
colors = ['lightblue', 'lightgreen', 'lightcoral', 'lightyellow', 'lightpink', 'lightgray', 'lightcyan']# 处理第一个块
if indices_above_thresh:# 第一个块:从开始到第一个断点plt.axvspan(0, indices_above_thresh[0], facecolor=colors[0], alpha=0.3)plt.text(x=indices_above_thresh[0] / 2,y=breakpoint_distance_threshold + y_upper_bound / 20,s=f"块 1", horizontalalignment='center', fontsize=10,bbox=dict(boxstyle="round,pad=0.2", facecolor=colors[0], alpha=0.8))# 中间的块for i in range(1, len(indices_above_thresh)):start_idx = indices_above_thresh[i - 1]end_idx = indices_above_thresh[i]plt.axvspan(start_idx, end_idx, facecolor=colors[i % len(colors)], alpha=0.3)plt.text(x=(start_idx + end_idx) / 2,y=breakpoint_distance_threshold + y_upper_bound / 20,s=f"块 {i + 1}", horizontalalignment='center', fontsize=10,bbox=dict(boxstyle="round,pad=0.2", facecolor=colors[i % len(colors)], alpha=0.8))# 最后一个块:从最后一个断点到结束last_breakpoint = indices_above_thresh[-1]plt.axvspan(last_breakpoint, len(distances),facecolor=colors[len(indices_above_thresh) % len(colors)], alpha=0.3)plt.text(x=(last_breakpoint + len(distances)) / 2,y=breakpoint_distance_threshold + y_upper_bound / 20,s=f"块 {len(indices_above_thresh) + 1}", horizontalalignment='center', fontsize=10,bbox=dict(boxstyle="round,pad=0.2",facecolor=colors[len(indices_above_thresh) % len(colors)], alpha=0.8))
else:# 如果没有断点,整个文档就是一块plt.axvspan(0, len(distances), facecolor=colors[0], alpha=0.3)plt.text(x=len(distances) / 2,y=y_upper_bound / 2,s="块 1", horizontalalignment='center', fontsize=12,bbox=dict(boxstyle="round,pad=0.3", facecolor=colors[0], alpha=0.8))# 标记超过阈值的点
for i, distance in enumerate(distances):if distance > breakpoint_distance_threshold:plt.plot(i, distance, 'ro', markersize=8, markerfacecolor='red', markeredgecolor='darkred', markeredgewidth=2)plt.annotate(f'断点\n{distance:.3f}',xy=(i, distance),xytext=(i, distance + y_upper_bound / 10),arrowprops=dict(arrowstyle='->', color='red', lw=1.5),ha='center', fontsize=9,bbox=dict(boxstyle="round,pad=0.2", facecolor="red", alpha=0.7, edgecolor="darkred"))plt.title("超线性回报文章的语义距离分析", fontsize=16, fontweight='bold')
plt.xlabel("句子位置索引", fontsize=12)
plt.ylabel("连续句子间的余弦距离", fontsize=12)
plt.grid(True, alpha=0.3)
plt.legend()# 添加距离统计信息
stats_text = f"""距离统计:
最小值: {min(distances):.3f}
最大值: {max(distances):.3f}
平均值: {np.mean(distances):.3f}
标准差: {np.std(distances):.3f}"""plt.text(x=len(distances) * 0.7, y=y_upper_bound * 0.7, s=stats_text,fontsize=10, bbox=dict(boxstyle="round,pad=0.5", facecolor="white", alpha=0.8, edgecolor="gray"))plt.tight_layout()
plt.show()# 使用SemanticChunker进行实际分割验证
print("\n" + "=" * 50)
print("使用SemanticChunker验证结果:")
text_splitter = SemanticChunker(hf)
chunks = text_splitter.split_text(document)print(f"SemanticChunker分割结果: {len(chunks)} 个块")
for i, chunk in enumerate(chunks):print(f"\n块 {i + 1} ({len(chunk)} 字符):")print(chunk[:200] + "..." if len(chunk) > 200 else chunk)print(f"\n总字符数: {len(document)}")
print(f"平均块大小: {len(document) / len(chunks):.1f} 字符")
控制台输出为如下。
-
句子分割 ✅
首先按标点符号(句号、问号、感叹号)拆分文本,得到了29个独立句子。 -
创建滑动窗口 (buffer_size=1) ✅
为每个句子添加上下文,构建包含前后邻句的组合文本:- 句子1:只包含句子1+句子2(没有前句)
- 句子2:包含句子1+句子2+句子3
- 句子3:包含句子2+句子3+句子4
- …
- 句子29:只包含句子28+句子29(没有后句)
-
生成嵌入向量
使用BGE模型为29个组合句子生成768维的向量表示,每个向量捕获了句子及其上下文的语义信息。 -
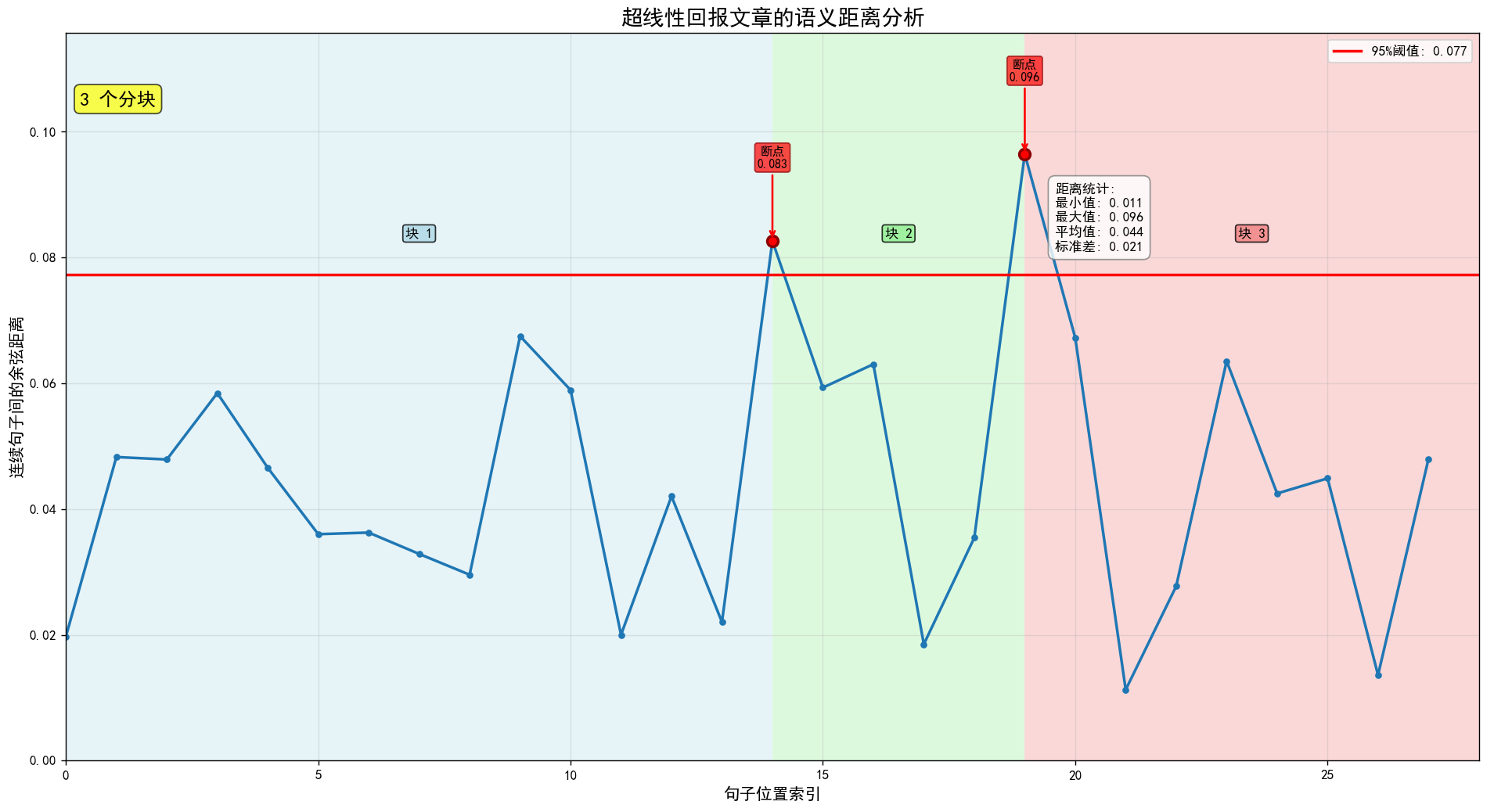
计算余弦距离
计算相邻句子间的语义距离,得到28个距离值(两两之间计算29句就会变为28个距离):- 距离值范围:0.011 到 0.096
- 距离越大表示语义跳跃越明显
-
确定分块阈值
使用95%分位数作为分块阈值:- 计算所有距离的95%分位数
- 超过这个阈值的位置被认为是语义断点
-
识别分块点
找出距离值超过阈值的位置,这些就是文本的语义转折点,用于分割不同的主题块。 -
可视化展示
生成图表显示:- 蓝色曲线:28个位置的语义距离变化
- 红色水平线:95%分位数阈值
- 彩色区域:不同的语义块
- 红色圆点:标记的断点位置
开始计算语义距离...
分割出 29 个句子:
1. One of the most important things I didn't understand about the world when I was a child is the degre...
2. Teachers and coaches implicitly told us the returns were linear....
3. "You get out," I heard a thousand times, "what you put in." They meant well, but this is rarely true...
4. If your product is only half as good as your competitor's, you don't get half as many customers....
5. You get no customers, and you go out of business....
6. It's obviously true that the returns for performance are superlinear in business....
7. Some think this is a flaw of capitalism, and that if we changed the rules it would stop being true....
8. But superlinear returns for performance are a feature of the world, not an artifact of rules we've i...
9. We see the same pattern in fame, power, military victories, knowledge, and even benefit to humanity....
10. In all of these, the rich get richer....
11. [1]You can't understand the world without understanding the concept of superlinear returns....
12. And if you're ambitious you definitely should, because this will be the wave you surf on....
13. It may seem as if there are a lot of different situations with superlinear returns, but as far as I ...
14. The most obvious case of superlinear returns is when you're working on something that grows exponent...
15. For example, growing bacterial cultures....
16. When they grow at all, they grow exponentially....
17. But they're tricky to grow....
18. Which means the difference in outcome between someone who's adept at it and someone who's not is ver...
19. Startups can also grow exponentially, and we see the same pattern there....
20. Some manage to achieve high growth rates....
21. Most don't....
22. And as a result you get qualitatively different outcomes: the companies with high growth rates tend ...
23. Y Combinator encourages founders to focus on growth rate rather than absolute numbers....
24. It prevents them from being discouraged early on, when the absolute numbers are still low....
25. It also helps them decide what to focus on: you can use growth rate as a compass to tell you how to ...
26. But the main advantage is that by focusing on growth rate you tend to get something that grows expon...
27. YC doesn't explicitly tell founders that with growth rate "you get out what you put in," but it's no...
28. And if growth rate were proportional to performance, then the reward for performance p over time t w...
29. Even after decades of thinking about this, I find that sentence startling....生成嵌入向量...
计算出 28 个距离值
距离值: ['0.020', '0.048', '0.048', '0.058', '0.047', '0.036', '0.036', '0.033', '0.030', '0.068', '0.059', '0.020', '0.042', '0.022', '0.083', '0.059', '0.063', '0.019', '0.035', '0.096', '0.067', '0.011', '0.028', '0.064', '0.042', '0.045', '0.014', '0.048']95%分位数阈值: 0.077
超过阈值的距离数量: 2
最终块数: 3
断点位置: [14, 19]==================================================
使用SemanticChunker验证结果:
SemanticChunker分割结果: 3 个块块 1 (1414 字符):
One of the most important things I didn't understand about the world when I was a child is the degree to which the returns for performance are superlinear. Teachers and coaches implicitly told us the ...块 2 (299 字符):
When they grow at all, they grow exponentially. But they're tricky to grow. Which means the difference in outcome between someone who's adept at it and someone who's not is very great. Startups can al...块 3 (935 字符):
Most don't. And as a result you get qualitatively different outcomes: the companies with high growth rates tend to become immensely valuable, while the ones with lower growth rates may not even surviv...总字符数: 2658
平均块大小: 886.0 字符
基于模型的端到端语义分块
更先进的方法是使用专门训练的神经网络模型,直接判断每个句子是否应作为分块点。这种方法无需手动设置阈值,而是由模型端到端地完成分块决策。
以阿里达摩院开发的语义分块模型为例,其工作流程为:
- 将文本窗口中的N个句子输入模型
- 模型为每个句子生成表示向量
- 通过二分类层直接判断每个句子是否为分块点
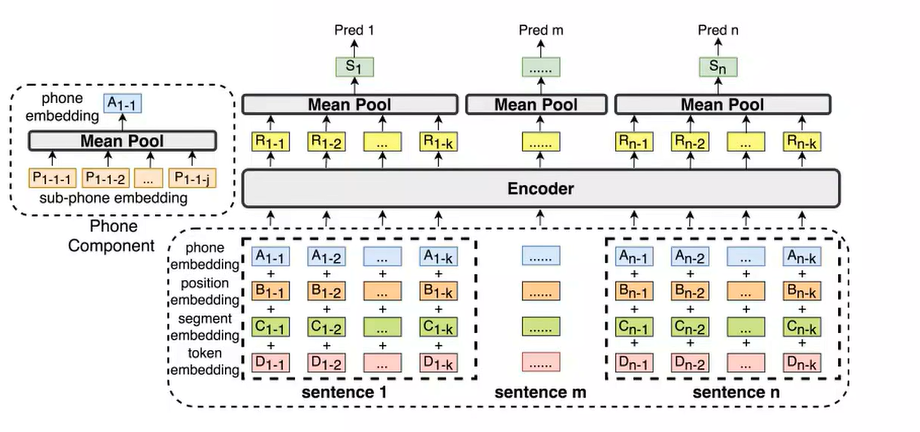
from modelscope.pipelines import pipeline# 加载语义分块模型
semantic_segmentation = pipeline('text-semantic-segmentation',model='damo/nlp_bert_semantic-segmentation_chinese-base'
)# 进行分块
result = semantic_segmentation(long_text)
segments = result['text']
这种方法的优势在于模型已经学习了语义变化的复杂模式,无需手动调整参数。但需注意模型的泛化能力,应在特定领域文档上进行验证。
5. 父文档检索(分层切割)
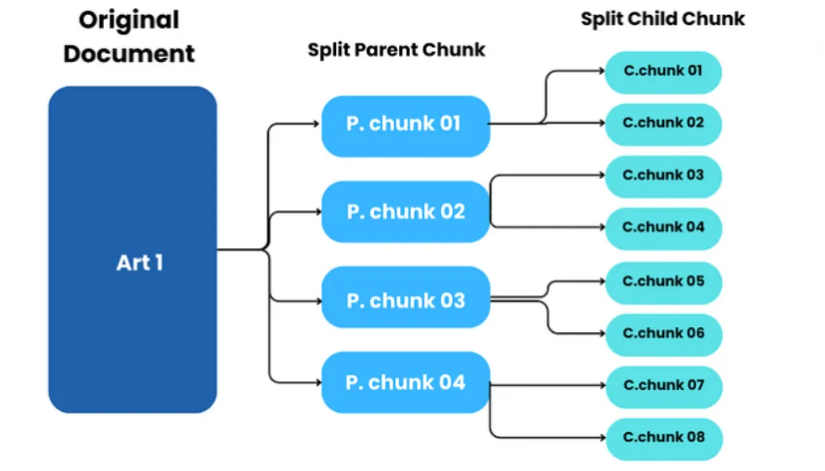
父文档检索器的核心思想其实很简单:用小块来检索,用大块来回答。这样做的好处显而易见:我们获得了子块级别的检索精度,同时保持了父块级别的上下文丰富度。
具体的工作流程是这样的:
- 分层分块:首先将原始文档分成较大的父块,然后将每个父块进一步分割成更小的子块。若是不分块即为全文,若是分块即分层。
- 索引子块:对这些小的子块进行向量化并建立索引
- 检索时的魔法:当用户提问时,系统会基于子块的嵌入进行相似度搜索,但返回的不是子块本身,而是包含该子块的父块
下图展示了分层的父文档构建过程:
举个例子,假设用户问"腾讯的广告收入是多少",系统可能会匹配到一个专门讨论广告收入数字的小块,但返回的是包含完整财务分析上下文的大块,这样LLM就能基于更全面的信息来回答问题。涉及到向量检索,我们通常是采用向量数据库存储从而实现检索(后续代码可以体现)。
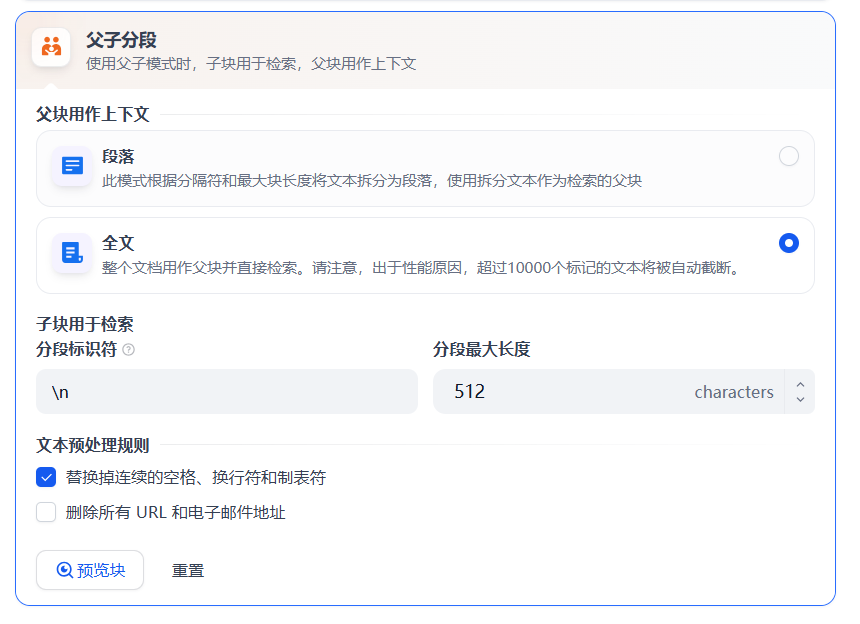
dify中2025年集成了父子检索,且将其作为推荐分块,如下图:
父文档检索器有两种常见的实现方式:
方式一:返回完整文档
如果你的原始文档本身就不是特别长(比如产品说明书、新闻文章等),可以直接将完整文档作为"父块"。这种情况下:
- 子块:文档的段落或句子
- 父块:完整的文档
这种方式特别适合处理大量相对短小的文档集合,比如FAQ数据库、产品目录等。
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
import osos.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'model_name = "BAAI/bge-small-en"
model_kwargs = {"device": "cpu"}
encode_kwargs = {"normalize_embeddings": True}
bge_embeddings = HuggingFaceBgeEmbeddings(model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs
)document="""One of the most important things I didn't understand about the world when I was a child is the degree to which the returns for performance are superlinear.Teachers and coaches implicitly told us the returns were linear. "You get out," I heard a thousand times, "what you put in." They meant well, but this is rarely true. If your product is only half as good as your competitor's, you don't get half as many customers. You get no customers, and you go out of business.It's obviously true that the returns for performance are superlinear in business. Some think this is a flaw of capitalism, and that if we changed the rules it would stop being true. But superlinear returns for performance are a feature of the world, not an artifact of rules we've invented. We see the same pattern in fame, power, military victories, knowledge, and even benefit to humanity. In all of these, the rich get richer. [1]You can't understand the world without understanding the concept of superlinear returns. And if you're ambitious you definitely should, because this will be the wave you surf on.It may seem as if there are a lot of different situations with superlinear returns, but as far as I can tell they reduce to two fundamental causes: exponential growth and thresholds.The most obvious case of superlinear returns is when you're working on something that grows exponentially. For example, growing bacterial cultures. When they grow at all, they grow exponentially. But they're tricky to grow. Which means the difference in outcome between someone who's adept at it and someone who's not is very great.Startups can also grow exponentially, and we see the same pattern there. Some manage to achieve high growth rates. Most don't. And as a result you get qualitatively different outcomes: the companies with high growth rates tend to become immensely valuable, while the ones with lower growth rates may not even survive.Y Combinator encourages founders to focus on growth rate rather than absolute numbers. It prevents them from being discouraged early on, when the absolute numbers are still low. It also helps them decide what to focus on: you can use growth rate as a compass to tell you how to evolve the company. But the main advantage is that by focusing on growth rate you tend to get something that grows exponentially.YC doesn't explicitly tell founders that with growth rate "you get out what you put in," but it's not far from the truth. And if growth rate were proportional to performance, then the reward for performance p over time t would be proportional to pt.Even after decades of thinking about this, I find that sentence startling."""child_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
docs = child_splitter.create_documents([document])vectorstore = Chroma(collection_name="documents", embedding_function=bge_embeddings
)store = InMemoryStore()
retriever = ParentDocumentRetriever(vectorstore=vectorstore,docstore=store,child_splitter=child_splitter
)retriever.add_documents([Document(page_content=document)], ids=None)# 返回小文档检索,问题:什么原因造成了超线性回报?
sub_docs = vectorstore.similarity_search("What causes superlinear returns?")# 返回大文档检索
retrieved_docs = retriever.get_relevant_documents("What causes superlinear returns?")
print(sub_docs[0].page_content)
print('='*40)
print(retrieved_docs[0].page_content)
控制台的输出:

方式二:分层块结构
对于长文档,我们需要建立真正的分层结构:
- 原始文档 → 父块(比如400字符)→ 子块(比如100字符)
这种方式更适合处理长报告、学术论文、技术文档等。
这部分代码与方式一很类似:
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
import osos.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'model_name = "BAAI/bge-small-en"
model_kwargs = {"device": "cpu"}
encode_kwargs = {"normalize_embeddings": True}
bge_embeddings = HuggingFaceBgeEmbeddings(model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs
)document="""One of the most important things I didn't understand about the world when I was a child is the degree to which the returns for performance are superlinear.Teachers and coaches implicitly told us the returns were linear. "You get out," I heard a thousand times, "what you put in." They meant well, but this is rarely true. If your product is only half as good as your competitor's, you don't get half as many customers. You get no customers, and you go out of business.It's obviously true that the returns for performance are superlinear in business. Some think this is a flaw of capitalism, and that if we changed the rules it would stop being true. But superlinear returns for performance are a feature of the world, not an artifact of rules we've invented. We see the same pattern in fame, power, military victories, knowledge, and even benefit to humanity. In all of these, the rich get richer. [1]You can't understand the world without understanding the concept of superlinear returns. And if you're ambitious you definitely should, because this will be the wave you surf on.It may seem as if there are a lot of different situations with superlinear returns, but as far as I can tell they reduce to two fundamental causes: exponential growth and thresholds.The most obvious case of superlinear returns is when you're working on something that grows exponentially. For example, growing bacterial cultures. When they grow at all, they grow exponentially. But they're tricky to grow. Which means the difference in outcome between someone who's adept at it and someone who's not is very great.Startups can also grow exponentially, and we see the same pattern there. Some manage to achieve high growth rates. Most don't. And as a result you get qualitatively different outcomes: the companies with high growth rates tend to become immensely valuable, while the ones with lower growth rates may not even survive.Y Combinator encourages founders to focus on growth rate rather than absolute numbers. It prevents them from being discouraged early on, when the absolute numbers are still low. It also helps them decide what to focus on: you can use growth rate as a compass to tell you how to evolve the company. But the main advantage is that by focusing on growth rate you tend to get something that grows exponentially.YC doesn't explicitly tell founders that with growth rate "you get out what you put in," but it's not far from the truth. And if growth rate were proportional to performance, then the reward for performance p over time t would be proportional to pt.Even after decades of thinking about this, I find that sentence startling."""child_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
docs = child_splitter.create_documents([document])# add:增加了parent_splitter这句
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
vectorstore = Chroma(collection_name="documents", embedding_function=bge_embeddings
)store = InMemoryStore()
retriever = ParentDocumentRetriever(vectorstore=vectorstore,docstore=store,child_splitter=child_splitter,# addparent_splitter=parent_splitter
)retriever.add_documents([Document(page_content=document)], ids=None)# 返回小文档检索,问题:什么原因造成了超线性回报?
sub_docs = vectorstore.similarity_search("What causes superlinear returns?")# 返回大文档检索
retrieved_docs = retriever.get_relevant_documents("What causes superlinear returns?")
print(sub_docs[0].page_content)
print('='*40)
print(retrieved_docs[0].page_content)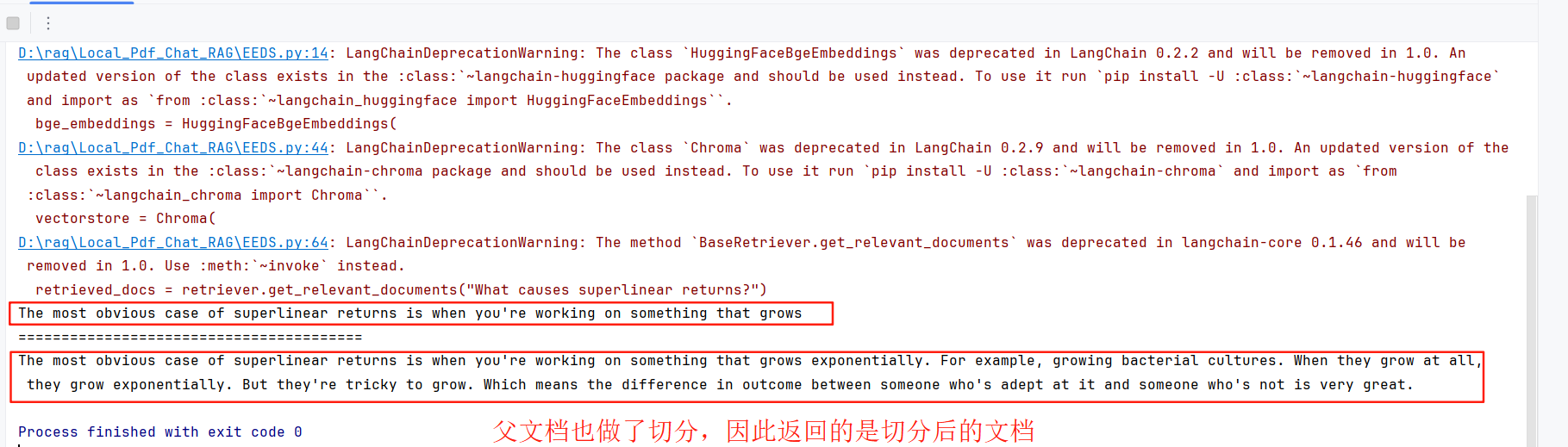
相关文章:
使用langchain实现五种分块策略:语义分块、父文档分块、递归分块、特殊格式、固定长度分块
文章目录 分块策略详解1. 固定长度拆分(简单粗暴)2. 递归字符拆分(智能切割)3. 特殊格式拆分(定向打击)Markdown分块 4. 语义分割(更智能切割)基于Embedding的语义分块基于模型的端到…...
【项目记录】登录认证(下)
1 过滤器 Filter 刚才通过浏览器的开发者工具,可以看到在后续的请求当中,都会在请求头中携带JWT令牌到服务端,而服务端需要统一拦截所有的请求,从而判断是否携带的有合法的JWT令牌。 那怎么样来统一拦截到所有的请求校验令牌的有…...

Debian上安装PostgreSQL的故障和排除
命令如下: apt install postgresql#可能是apt信息错误,报错 E: Failed to fetch http://deb.debian.org/debian/pool/main/p/postgresql-15/postgresql-client-15_15.12-0%2bdeb12u2_amd64.deb 404 Not Found [IP: 146.75.46.132 80] E: Failed to f…...
linux文件管理(补充)
1、查看文件命令 1.1 cat 用于连接文件并打印到标准输出设备上,它的主要作用是用于查看和连接文件。 用法: cat 参数 文件名 参数: -n:显示行号,会在输出的每一行前加上行号。 -b:显示行号,…...
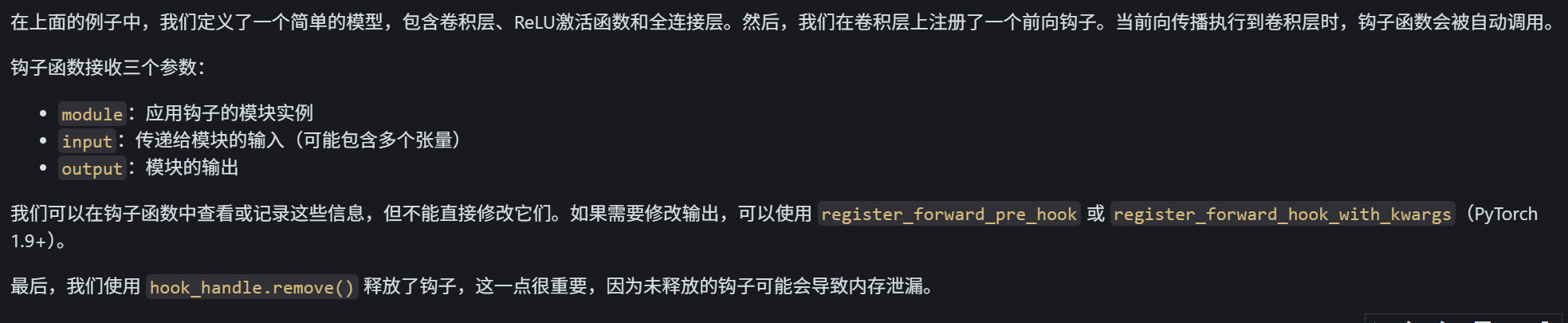
Python训练营---Day42
DAY 42 Grad-CAM与Hook函数 知识点回顾 回调函数lambda函数hook函数的模块钩子和张量钩子Grad-CAM的示例 作业:理解下今天的代码即可 1、回调函数 回调函数(Callback Function)是一种特殊的函数,它作为参数传递给另一个函数&#…...

基于空天地一体化网络的通信系统matlab性能分析
目录 1.引言 2.算法仿真效果演示 3.数据集格式或算法参数简介 4.MATLAB核心程序 5.算法涉及理论知识概要 5.1 QPSK调制原理 5.2 空天地一体化网络信道模型 5.3 空天地一体化网络信道特性 6.参考文献 7.完整算法代码文件获得 1.引言 空天地一体化网络是一种将卫星通信…...
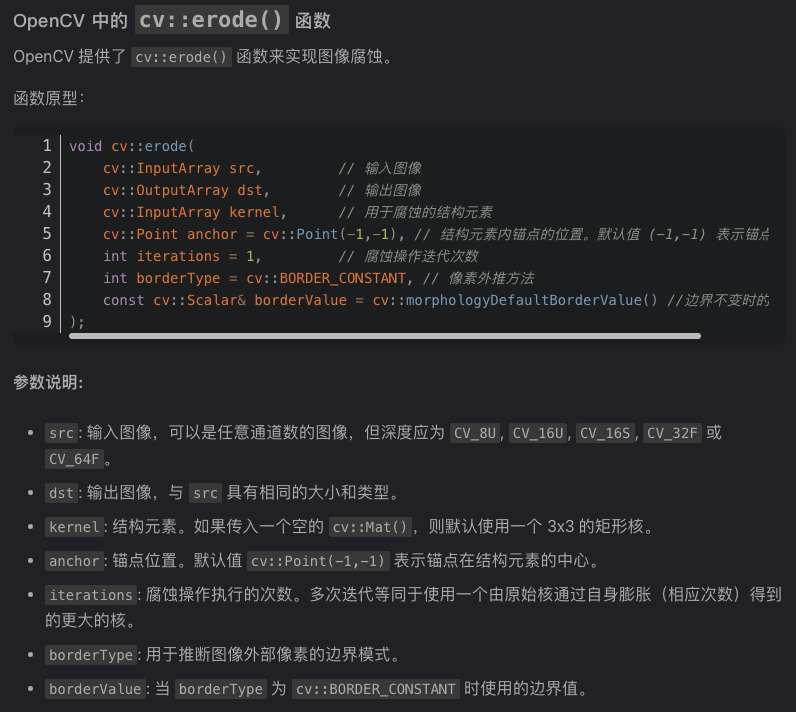
c++ opencv 形态学操作腐蚀和膨胀
https://www.jb51.net/article/247894.htm(上图图片来自这个博客) https://codec.wang/docs/opencv/basic/erode-and-dilate(上图图片参考博客) cv::Mat kernel cv::getStructuringElement(cv::MORPH_RECT, cv::Size(3, 3)); cv::erode(src, dst, kern…...
)
Axure组件即拖即用:横向拖动菜单(支持左右拖动选中交互)
亲爱的小伙伴,在您浏览之前,请关注一下,在此深表感谢!如有帮助请订阅专栏!免费哦! Axure横向菜单拖不动?一拖就乱?你缺的是这个"防手残"组件! 💢…...

Hadoop MapReduce:大数据处理利器
Hadoop 的 MapReduce 是一种用于处理大规模数据集的分布式计算框架,基于“分而治之”思想设计。以下从核心概念、工作流程、代码结构、优缺点和应用场景等方面详细讲解: 一、MapReduce 核心概念 核心思想: Map࿰…...

RabbitMQ-Go 性能分析
更多个人笔记见: github个人笔记仓库 gitee 个人笔记仓库 个人学习,学习过程中还会不断补充~ (后续会更新在github和 gitee上) 文章目录 对比功能没有rabbitMQ有rabbitMQwrk 测试分析 链接: 项目连接,完整…...

【c++】【数据结构】红黑树
目录 红黑树的定义红黑树的部分模拟实现颜色的向上更新旋转算法单旋算法双旋算法 红黑树与AVL树的对比 红黑树的定义 红黑树是一种自平衡的二叉搜索树,通过特定的规则维持树的平衡。红黑树在每个结点上都增加一个存储位表示结点的颜色,结点的颜色可以是…...
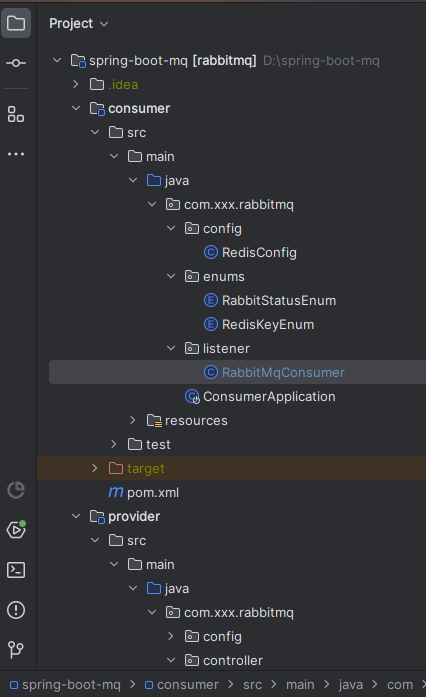
基于SpringBoot+Redis实现RabbitMQ幂等性设计,解决MQ重复消费问题
解决MQ重复消费问题 一、实现方案 本方案参考 「RabbitMQ消息可靠性深度解析|从零构建高可靠消息系统的实战指南」,向开源致敬! 1、业务层幂等处理: 每个消息携带一个全局唯一ID,在业务处理过程中,首先检查…...

React从基础入门到高级实战:React 生态与工具 - React 单元测试
React 单元测试 引言 在现代软件开发中,单元测试是确保代码质量和可靠性的关键环节。对于React开发者而言,单元测试不仅能帮助捕获潜在的错误,还能提升代码的可维护性和团队协作效率。随着React应用的复杂性不断增加,掌握单元测…...

使用lighttpd和开发板进行交互
文章目录 🧠 一、Lighttpd 与开发板的交互原理1. 什么是 Lighttpd?2. 与开发板交互的方式? 🧾 二、lighttpd.conf 配置文件讲解⚠️ 注意事项: 📁 三、目录结构说明💡 四、使用 C 编写 CGI 脚本…...
DRF的使用
1. DRF概述 DRF即django rest framework,是一个基于Django的Web API框架,专门用于构建RESTful API接口。DRF的核心特点包括: 序列化:通过序列化工具,DRF能够轻松地将Django模型转换为JSON格式,也可以将JS…...

2024年09月 C/C++(四级)真题解析#中国电子学会#全国青少年软件编程等级考试
C/C++编程(1~8级)全部真题・点这里 第1题:有几个PAT 字符串 APPAPT 中包含了两个单词 PAT,其中第一个 PAT 是第 2 位,第 4 位(A),第 6 位(T);第二个 PAT 是第 3 位,第 4 位(A),第 6 位(T)。 现给定字符串,问一共可以形成多少个 PAT? 时间限制:1000 内存限制:26214…...
免费且好用的PDF水印添加工具
软件介绍 琥珀扫描.zip下载链接:https://pan.quark.cn/s/3a8f432b29aa 今天要给大家推荐一款超实用的PDF添加水印工具,它能够满足用户给PDF文件添加水印的需求,而且完全免费。 这款PDF添加水印的软件有着简洁的界面,操作简便&a…...

mqtt协议连接阿里云平台
首先现在的阿里云物联网平台已经不在新购了,如下图所示: 解决办法:在咸鱼上租用一个账号,先用起来。 搭建阿里云平台,参考博客: (一)MQTT连接阿里云物联网平台(小白向&…...
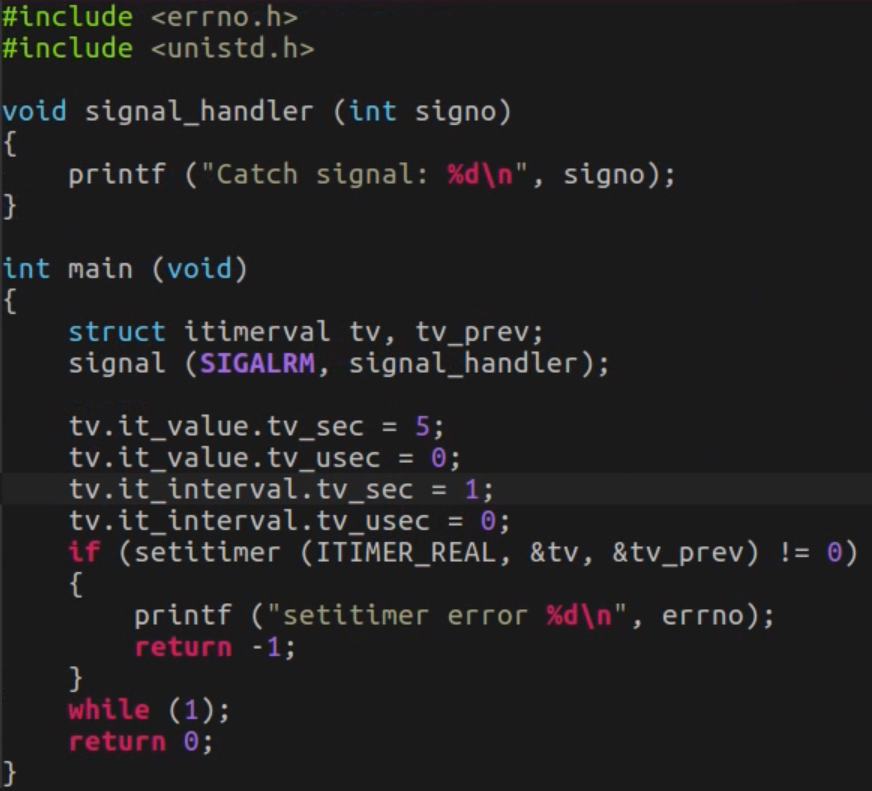
一文详谈Linux中的时间管理和定时器编程
(目录) 先说一些在计算机中需要用到时间的地方:系统日志log、OS调度(时间片、定时器)等等~~ 时间的计量 计时的方式发展:日晷、沙漏 -> 机械钟 -> 石英振荡器、晶振 -> 铯原子钟 -> 氢原子钟 计算机中的计时方式&…...

Ubuntu 安装 Miniconda 及配置国内镜像源完整指南
目录 Miniconda 安装Conda 镜像源配置Pip 镜像源配置验证配置基本使用常见问题 1. Miniconda 安装 1.1 下载安装脚本 wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh1.2 执行安装 bash Miniconda3-latest-Linux-x86_64.sh按回车查看许可协议…...

性能优化 - 理论篇:常见指标及切入点
文章目录 引言一、 Java 性能优化的核心思路二、为什么要度量?三、常用性能衡量指标详解3.1 吞吐量与响应速度3.2 响应时间的具体度量:平均响应时间与百分位数3.3 并发量3.4 秒开率(页面秒开)3.5 正确性(功能可用性&am…...

青少年编程与数学 02-020 C#程序设计基础 08课题、字符和字符串
青少年编程与数学 02-020 C#程序设计基础 08课题、字符和字符串 一、字符和字符集1. 字符(Character)定义特点示例 2. 字符集(Character Set)定义特点常见字符集 小结 二、char数据类型1. 定义2. 特点3. 声明和初始化4. 转义字符示…...

【论文阅读 | PR 2024 |ICAFusion:迭代交叉注意力引导的多光谱目标检测特征融合】
论文阅读 | PR 2024 |ICAFusion:迭代交叉注意力引导的多光谱目标检测特征融合 1.摘要&&引言2.方法2.1 架构2.2 双模态特征融合(DMFF)2.2.1 跨模态特征增强(CFE)2.2.2 空间特征压缩(SFS)…...

Spring Security加密模块深度解析
Spring Security加密模块概述 Spring Security Crypto模块(简称SSCM)是Spring Security框架中专门处理密码学相关操作的组件。由于Java语言本身并未提供开箱即用的加密/解密功能及密钥生成能力,开发者在实现这些功能时往往需要引入额外依赖库。SSCM通过提供内置解决方案,有…...

华为OD机试真题——模拟消息队列(2025A卷:100分)Java/python/JavaScript/C++/C语言/GO六种最佳实现
2025 A卷 100分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C++、C语言、GO六种语言的最佳实现方式! 2025华为OD真题目录+全流程解析/备考攻略/经验分享 华为OD机试真题《模拟消息队列》: 目录 题…...
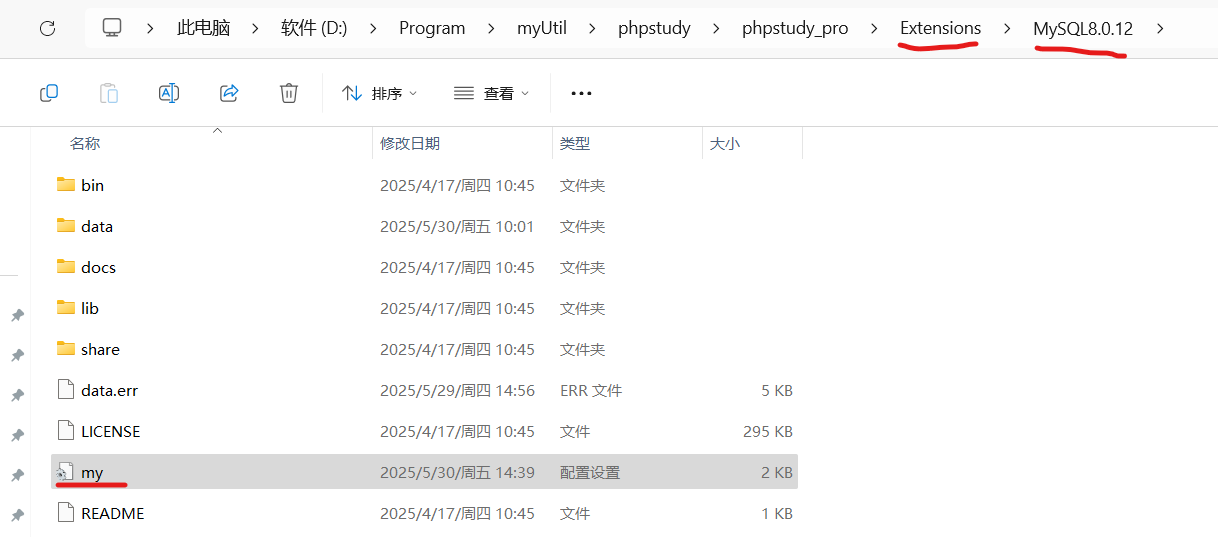
MySql(十三)
目录 mysql外键约束 准备工作 创建表 插入数据 创建表时添加外键 1..格式 2..创建表student表时,为其添加外键 3.插入数据测试 正常数据 异常数据 3.使用alter添加外键 删除外键 添加外键 4.Mysql外键不生效的原因 修改引擎 phpystudy的mysql位置 mysql外键约束 注&…...
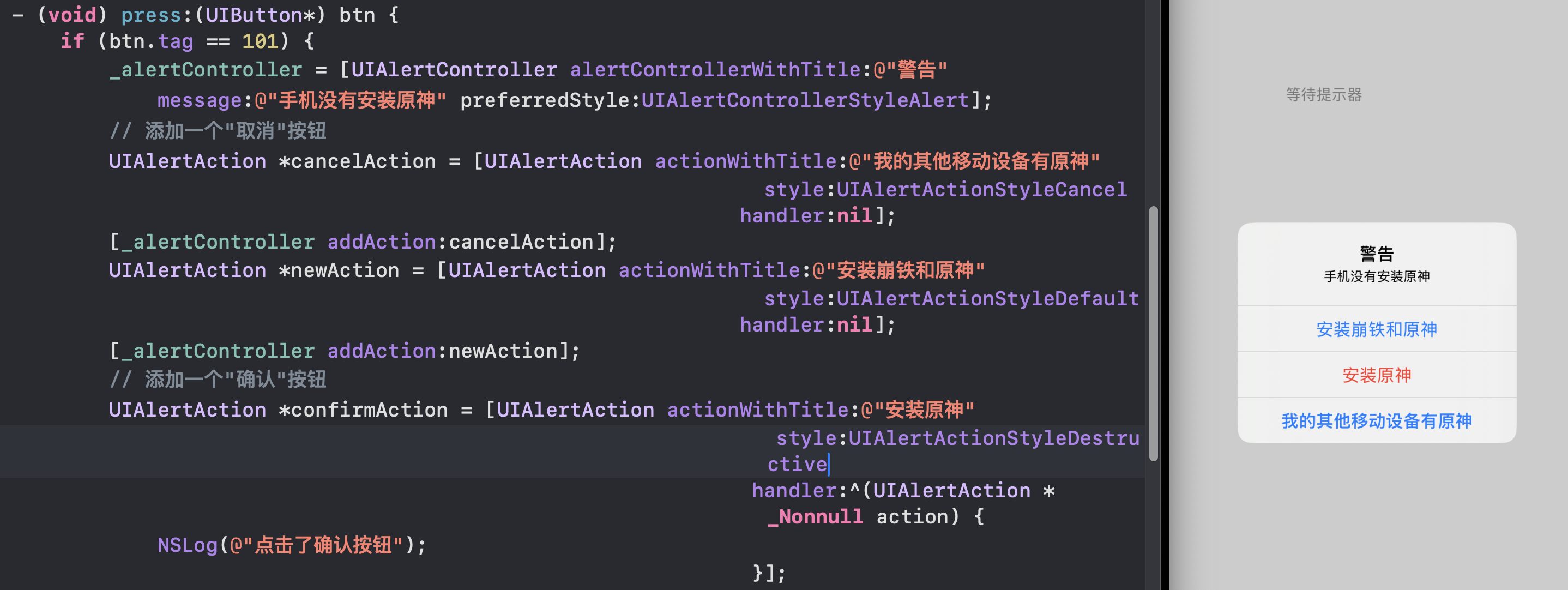
iOS —— UI 初探
简介 第一次新建时,你可能会好奇。为什么有这么多文件,他们都有什么用? App 启动与生命周期管理相关 文件名 类型 作用 main.m m 程序入口,main() 函数定义在这里 AppDelegate.h/.m h/m App 启动/进入后台/退出等全局事…...

day23-计算机网络-1
1. 网络简介 1.1. 网络介质 网线:cat5,cat5e 六类网线,七类网线,芭蕾网线光纤:wifi:无线路由器,ap5G 1.2. 常见网线类型 1.2.1. 双绞线(Twisted Pair Cable)【最常用】 按性能主…...

C语言基础(09)【数组的概念 与一维数组】
数组 数组的概念 什么是数组 数组是相同类型、有序数据的集合。 数组的特征 数组中的数据称之为数组的元素(数组中的每一个匿名变量空间,是同构的)数组中的元素存放在内存空间建立。 衍生概念:下标(索引) 下标或者索引代表…...

【JavaScript】Ajax 侠客行:axios 轻功穿梭服务器间
一、AJAX 概念和 axios 使用讲解 什么是 AJAX ? 使用浏览器的 XMLHttpRequest 对象与服务器通信 浏览器网页中,使用 AJAX技术(XHR对象)发起获取省份列表数据的请求,服务器代码响应准备好的省份列表数据给前端,前端…...