雪花算法:分布式ID生成的优雅解决方案
一、雪花算法的核心机制与设计思想
雪花算法(Snowflake)是由Twitter开源的分布式ID生成算法,它通过巧妙的位运算设计,能够在分布式系统中快速生成全局唯一且趋势递增的ID。
1. 基本结构
雪花算法生成的是一个64位(long型)的整数,这个整数被划分为不同的部分,每个部分代表不同的含义:
- 符号位(1位):固定为0,表示正数。
- 时间戳部分(41位):记录的是时间戳的差值(当前时间戳 - 开始时间戳),而非当前时间戳本身。
- 工作机器ID部分(10位):用于标识不同的机器或节点,可进一步细分为:
- 数据中心ID(5位):最多支持32个数据中心
- 机器ID(5位):每个数据中心最多支持32台机器
- 序列号部分(12位):同一毫秒内的自增序列,最多支持4096个序列号
2. 设计思想
2.1 位运算的高效性
雪花算法通过位运算来组合各个部分,形成最终的ID。位运算的效率非常高,能够满足高并发场景下的ID生成需求。基本原理是将各部分数值通过左移操作放置到对应的位置,然后通过按位或运算组合成最终的ID。
2.2 时间戳的使用
- 选择41位时间戳:能够表示约69年的时间范围((1L<<41)/(1000L360024*365) ≈ 69年)
- 毫秒级精度:满足大多数应用场景的时间精度需求
- 趋势递增特性:由于高位是时间戳,整体ID呈现递增趋势,有利于数据库索引性能
2.3 机器ID的设计
- 分布式支持:通过10位的机器ID,最多可支持1024台机器同时生成ID,满足分布式系统需求
- 灵活的划分方式:可根据实际需求,灵活划分数据中心ID和机器ID的位数
2.4 序列号的设计
- 毫秒内并发:12位序列号支持同一毫秒内生成4096个不同的ID
- 循环利用:当序列号达到最大值时,通过等待下一毫秒来重置序列号
- 高并发支持:理论上单机每秒可生成约409.6万个ID(4096 * 1000)
3. 核心算法流程
- 获取当前时间戳
- 检查时钟回拨:如果当前时间戳小于上一次的时间戳,说明发生了时钟回拨,需要进行特殊处理
- 生成序列号:
- 如果当前时间戳与上一次相同,序列号加1
- 如果序列号超过最大值(4095),则等待下一毫秒
- 如果当前时间戳大于上一次时间戳,序列号重置为0
- 更新上一次时间戳
- 组合ID:通过位运算将时间戳、数据中心ID、机器ID和序列号组合成最终的ID
4. 算法优势
- 全局唯一性:通过时间戳、机器ID和序列号的组合,确保生成的ID在分布式环境中全局唯一
- 趋势递增:高位是时间戳,使得生成的ID整体呈现递增趋势,有利于数据库索引性能
- 高性能:基于位运算的实现,性能极高,且不依赖外部系统
- 自治性:每台机器独立生成ID,不需要中央服务器协调,避免了单点故障
- 灵活性:可根据业务需求调整各部分的位数分配
5. 算法局限
- 强依赖机器时钟:如果发生时钟回拨,可能会导致ID重复或服务不可用
- 机器ID的配置:需要手动配置机器ID,确保在分布式环境中唯一
雪花算法通过简洁而巧妙的设计,提供了一种高效、可靠的分布式ID生成方案,被广泛应用于各类分布式系统中。其核心思想也启发了许多其他分布式ID生成算法的设计和优化。
6. 雪花算法的实现机制
雪花算法的实现相对简单,主要依靠位运算来组合各个部分,形成最终的ID。下面是算法的核心流程:
-
首先,获取当前时间戳。这一步通常使用系统的毫秒级时间戳函数,如Java中的System.currentTimeMillis()。
-
接着,检查时钟回拨问题。如果当前时间戳小于上一次生成ID时的时间戳,说明发生了时钟回拨,需要进行特殊处理。标准的雪花算法会在这种情况下抛出异常,但在实际应用中,通常会有更复杂的处理机制。
-
然后,生成序列号。如果当前时间戳与上一次相同,序列号加1;如果序列号超过最大值(4095),则需要等待下一毫秒;如果当前时间戳大于上一次时间戳,序列号重置为0。
最后,通过位运算将时间戳、数据中心ID、机器ID和序列号组合成最终的ID。具体来说,将时间戳左移22位(10位机器ID + 12位序列号),将数据中心ID左移17位(5位机器ID + 12位序列号),将机器ID左移12位,然后将这些结果与序列号进行按位或运算,得到最终的ID。
下面是一个简化的Java实现示例:
public class SnowflakeIdGenerator {// 起始时间戳,可设定为系统上线时间private final long startTimestamp = 1420041600000L; // 2015-01-01// 各部分占用的位数private final long datacenterIdBits = 5L;private final long workerIdBits = 5L;private final long sequenceBits = 12L;// 各部分最大值private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);private final long maxWorkerId = -1L ^ (-1L << workerIdBits);private final long sequenceMask = -1L ^ (-1L << sequenceBits);// 各部分向左的位移private final long workerIdShift = sequenceBits;private final long datacenterIdShift = sequenceBits + workerIdBits;private final long timestampShift = sequenceBits + workerIdBits + datacenterIdBits;private long datacenterId;private long workerId;private long sequence = 0L;private long lastTimestamp = -1L;public SnowflakeIdGenerator(long datacenterId, long workerId) {// 参数校验if (datacenterId > maxDatacenterId || datacenterId < 0) {throw new IllegalArgumentException("Datacenter ID can't be greater than " + maxDatacenterId + " or less than 0");}if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException("Worker ID can't be greater than " + maxWorkerId + " or less than 0");}this.datacenterId = datacenterId;this.workerId = workerId;}public synchronized long nextId() {long timestamp = System.currentTimeMillis();// 检查时钟回拨if (timestamp < lastTimestamp) {throw new RuntimeException("Clock moved backwards. Refusing to generate ID");}// 同一毫秒内序列号递增if (timestamp == lastTimestamp) {sequence = (sequence + 1) & sequenceMask;// 同一毫秒内序列号用尽if (sequence == 0) {// 等待下一毫秒timestamp = waitForNextMillis(lastTimestamp);}} else {// 不同毫秒,序列号重置sequence = 0L;}lastTimestamp = timestamp;// 组合IDreturn ((timestamp - startTimestamp) << timestampShift) |(datacenterId << datacenterIdShift) |(workerId << workerIdShift) |sequence;}private long waitForNextMillis(long lastTimestamp) {long timestamp = System.currentTimeMillis();while (timestamp <= lastTimestamp) {timestamp = System.currentTimeMillis();}return timestamp;}
}
二、雪花算法使用注意事项
在实际应用雪花算法(Snowflake)生成分布式ID时,需要注意以下几个关键问题和最佳实践,以确保系统的稳定性和ID的唯一性。
1. 时钟回拨问题
1.1 问题描述
时钟回拨是雪花算法面临的最大挑战。由于算法强依赖机器时钟,当服务器时间发生回调(例如NTP同步、人为调整等)时,可能导致生成重复的ID。
1.2 解决方案
-
拒绝服务策略:
- 最简单的方法是检测到时钟回拨时直接抛出异常,拒绝服务
- 适用于时钟回拨概率低且短暂不可用影响较小的场景
-
等待策略:
- 当检测到时钟回拨时,算法等待直到当前时间追上之前记录的最大时间
- 适用于回拨时间较短的情况,但如果回拨时间较长,会导致服务长时间不可用
-
时间回拨容忍度:
- 设置一个可容忍的回拨时间阈值(如5毫秒)
- 当回拨时间在阈值内,使用上一次的时间戳
-
备用位方案:
- 使用序列号中的部分位作为回拨位
- 当发生时钟回拨时,回拨位加1,序列号清零
- 这种方法可以容忍一定次数的时钟回拨
-
外部时间源:
- 使用外部时间源如数据库或专门的时间服务器
- 减少对本地时钟的依赖
2. 机器ID分配问题
2.1 问题描述
在分布式环境中,如何确保每台机器分配到唯一的机器ID是一个挑战,特别是在动态扩缩容的云环境中。
2.2 解决方案
-
配置文件分配:
- 通过配置文件为每台机器静态分配ID
- 简单但不适合频繁变动的环境
-
中心化分配:
- 使用ZooKeeper、Etcd等分布式协调服务动态分配机器ID
- 机器启动时向中心服务申请ID,关闭时释放
- 适合动态变化的环境
-
网络标识分配:
- 基于机器的IP、MAC地址等网络标识生成机器ID
- 需要确保生成的ID在指定位数内且唯一
-
数据库分配:
- 使用数据库表记录和分配机器ID
- 需要考虑数据库可用性问题
3. 时间位数与系统使用寿命
3.1 问题描述
标准雪花算法使用41位表示时间戳,可以使用约69年。但在某些特殊场景下,可能需要调整时间位数。
3.2 解决方案
-
自定义起始时间:
- 选择接近系统上线时间的时间点作为起始时间
- 最大化算法的可用时间范围
-
调整位分配:
- 根据业务需求,调整时间戳、机器ID和序列号的位数分配
- 例如,减少机器ID位数,增加时间戳位数
-
定期迁移策略:
- 制定长期迁移计划,在算法接近使用寿命时进行系统升级
4. 性能与并发问题
4.1 问题描述
在高并发环境下,如何确保雪花算法的性能和ID生成的唯一性是一个挑战。
4.2 解决方案
-
序列号缓冲区:
- 使用缓冲区预先生成一批ID
- 减少实时生成的压力
-
多级缓存:
- 实现多级缓存机制,减少锁竞争
- 提高并发性能
-
异步生成:
- 使用异步方式生成ID
- 适用于对ID生成实时性要求不高的场景
-
批量生成:
- 支持一次请求生成多个ID
- 减少网络交互次数
5. 安全性考虑
5.1 问题描述
标准雪花算法生成的ID包含时间信息和机器信息,在某些场景下可能存在信息泄露风险。
5.2 解决方案
-
ID混淆:
- 对生成的ID进行加密或混淆处理
- 防止通过ID反推系统信息
-
非连续ID:
- 引入随机因子,使生成的ID不完全连续
- 增加ID的不可预测性
-
业务分离:
- 对敏感业务使用独立的ID生成策略
- 降低信息泄露的影响范围
6. 分布式部署最佳实践
-
合理规划数据中心和机器ID:
- 预留足够的扩展空间
- 考虑未来的扩容需求
-
监控时钟偏移:
- 定期检查和记录服务器时钟偏移情况
- 设置时钟偏移告警机制
-
高可用部署:
- 部署多个ID生成服务实例
- 实现负载均衡和故障转移
-
定期演练:
- 模拟时钟回拨等异常情况
- 验证系统的容错能力
-
完善的监控和日志:
- 记录ID生成的关键指标
- 便于问题排查和性能优化
通过合理应对这些挑战并采用最佳实践,可以确保雪花算法在分布式系统中稳定、高效地生成全局唯一ID。
三、雪花算法的实际应用案例
雪花算法在实际应用中已经被广泛采用,许多知名公司和开源项目都基于雪花算法实现了自己的分布式ID生成方案。
-
Twitter作为雪花算法的发明者,自然是最早的应用者。他们使用雪花算法为Twitter平台上的每条推文、每个用户操作生成唯一ID,支撑了海量数据的处理需求。
-
百度的UidGenerator是基于雪花算法的开源实现,它对原始算法进行了一系列优化,包括更高效的时钟回拨处理、RingBuffer缓冲区设计等,提高了ID生成的性能和可靠性。
-
美团的Leaf系统提供了两种ID生成方案:基于号段模式的分布式ID生成和基于雪花算法的分布式ID生成。其中,雪花算法部分针对时钟回拨问题进行了特殊处理,增强了系统的稳定性。
-
滴滴的TinyID也是一个基于雪花算法的分布式ID生成系统,它支持多种发号模式,并提供了REST API和SDK等多种接入方式,方便不同系统集成使用。
这些实际应用案例表明,雪花算法已经成为分布式ID生成领域的主流解决方案,并在实践中不断演进和完善。
相关文章:

雪花算法:分布式ID生成的优雅解决方案
一、雪花算法的核心机制与设计思想 雪花算法(Snowflake)是由Twitter开源的分布式ID生成算法,它通过巧妙的位运算设计,能够在分布式系统中快速生成全局唯一且趋势递增的ID。 1. 基本结构 雪花算法生成的是一个64位(lo…...

针对PostgreSQL中pg_wal目录占用过大的系统性解决方案
一、问题现象与根本原因 当pg_wal目录占用超过预期(如数十GB甚至占满磁盘),通常由以下原因导致 长事务未提交:未完成的事务会阻塞WAL日志清理。复制槽未释放:逻辑复制或流复制槽未及时清理,导…...

git push Git远端意外挂断
git push Git远端意外挂断 枚举对象中: 99, 完成. 对象计数中: 100% (99/99), 完成. 使用 8 个线程进行压缩 压缩对象中: 100% (78/78), 完成. send-pack: unexpected disconnect while reading sideband packet 写入对象中: 100% (82/82), 2.78 MiB | 5.56 MiB/s, 完成. 总共…...

python学习day34
GPU训练及类的call方法 知识点回归: CPU性能的查看:看架构代际、核心数、线程数GPU性能的查看:看显存、看级别、看架构代际GPU训练的方法:数据和模型移动到GPU device上类的call方法:为什么定义前向传播时可以直接写作…...
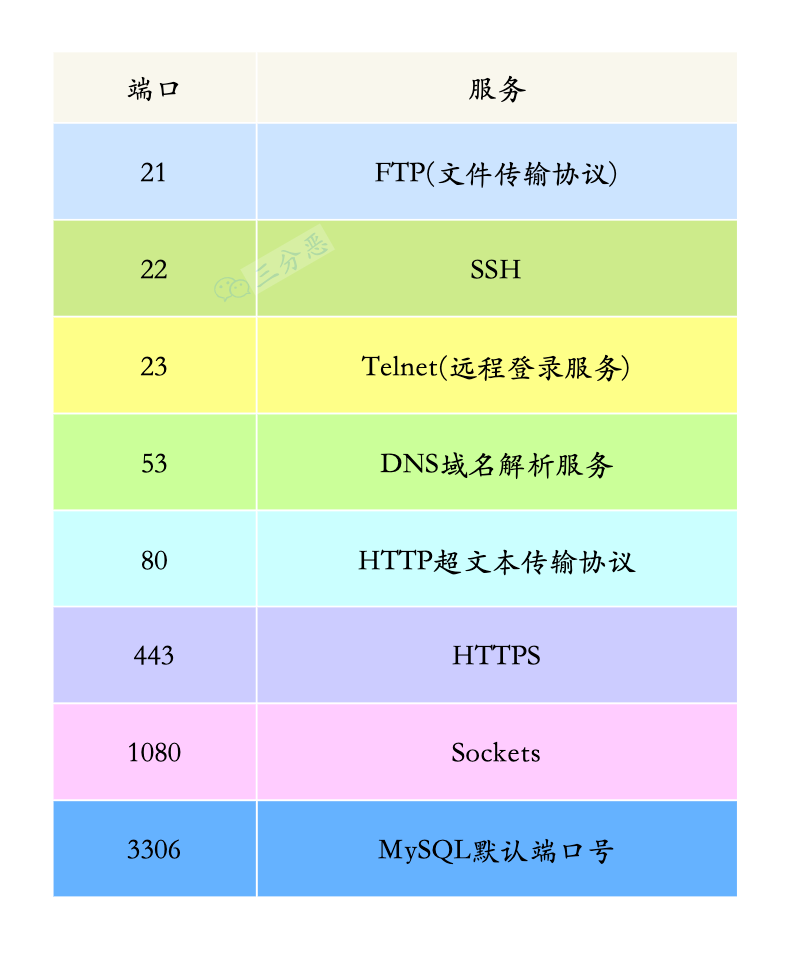
秋招Day12 - 计算机网络 - 网络综合
从浏览器地址栏输入URL到显示网页的过程了解吗? 从在浏览器地址栏输入 URL 到显示网页的完整过程,并不是一个单一的数据包从头到尾、一次性地完成七层封装再七层解析的过程。 而是涉及到多次、针对不同目的、与不同服务器进行的、独立的网络通信交互&a…...

QT-JSON
#include <QJsonDocument>#include <QJsonObject>#include <QJsonArray>#include <QFile>#include <QDebug>void createJsonFile() {// 创建一个JSON对象 键值对QJsonObject jsonObj;jsonObj["name"] "John Doe";jsonObj[…...

IP 风险画像技术略解
IP 风险画像的技术定义与价值 IP 风险画像通过整合 IP 查询数据与 IP 离线库信息,结合机器学习算法,为每个 IP 地址生成多维度风险评估模型。其核心价值在于将传统的静态 IP 黑名单升级为动态风险评估体系,可实时识别新型网络威胁࿰…...
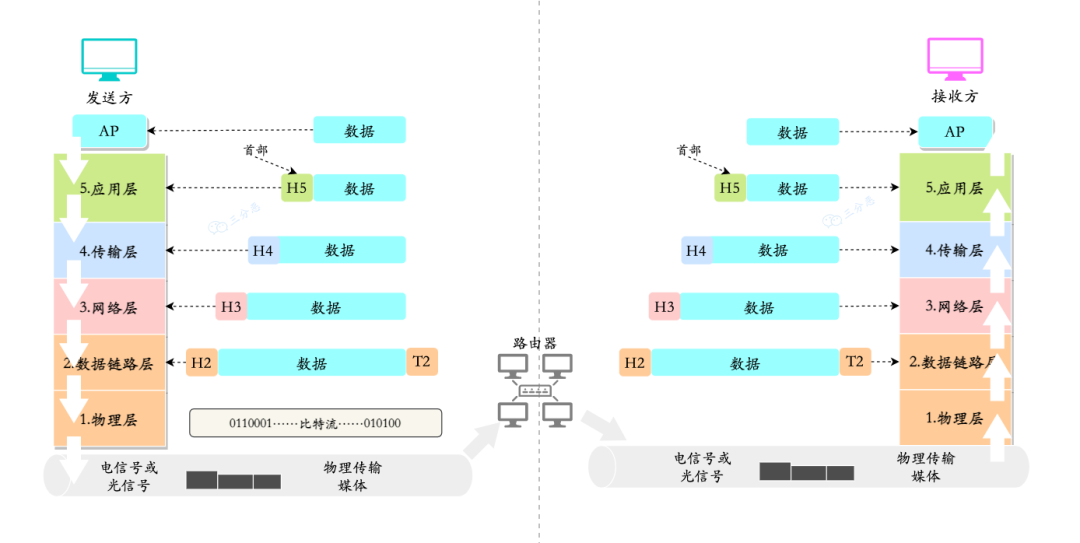
秋招Day12 - 计算机网络 - 基础
说一下计算机网络体系结构 OSI七层模型,TCP/IP四层模型和五层体系结构 说说OSI七层模型? 应用层:最靠近用户的层,用于处理特定应用程序的细节,提供了应用程序和网络服务之间的接口。表示层:确保从一个系…...
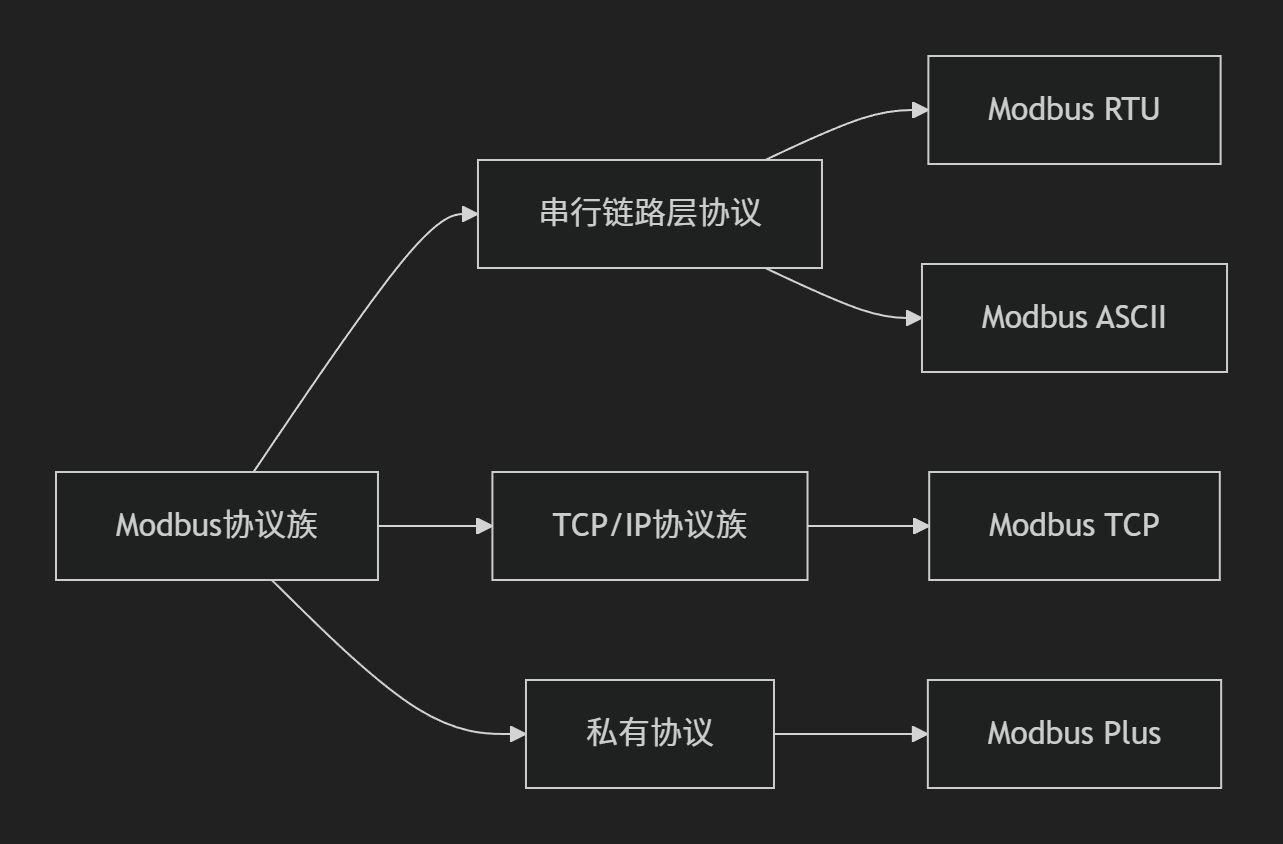
【网络安全】——Modbus协议详解:工业通信的“通用语言”
目录 一、初识Modbus:工业通信的基石 1.1 协议全称 1.2 协议简史 二、核心特性解析 2.1 架构设计 2.2 典型应用场景 三、协议族全景图 3.1 协议栈分类 3.2 版本演进对比 四、协议报文深度解析 4.1 Modbus RTU帧结构 4.2 Modbus TCP报文 五、通信机制实…...

MySQL 数据库备份与恢复利器:Percona XtraBackup 详解
一、XtraBackup 简介 1. 什么是 XtraBackup? XtraBackup 是 Percona 公司推出的免费开源工具,专为 InnoDB/XtraDB 引擎设计,支持 在线物理热备,具备以下核心特性: 非阻塞备份:备份过程中数据库仍可读写。…...

【GlobalMapper精品教程】095:如何获取无人机照片的拍摄方位角
文章目录 一、加载无人机照片二、计算方位角三、Globalmapper符号化显示方向四、arcgis符号化显示方向一、加载无人机照片 打开软件,加载无人机照片,在GLobalmapperV26中文版中,默认显示如下的航线信息。 关于航线的起止问题,可以直接从照片名称来确定。 二、计算方位角 …...

小提琴图绘制-Graph prism
在 GraphPad Prism 中为小提琴图添加显著性标记(如*P<0.05)的步骤如下: 步骤1:完成统计检验 选择数据表:确保数据已按分组排列(如A列=Group1,B列=Group2)。执行统计检验: 点击工具栏 Analyze → Column analyses → Mann-Whitney test(非参数检验,适用于非正态数…...

写作即是生活
一个问题 “我是什么时候开始写作的呢?”请你先暂停一下,别往下读,先想想这个问题。 什么才是写作? 或许在想上个问题之后,你就会开始想问另外一个问题,什么才算是写作呢? 我的回答是&#x…...

进阶知识:Selenium底层原理深度解析
Selenium底层原理深度解析:网络IO密集型系统揭秘 一、Selenium核心组件解析 1.1 三大核心角色 客户端(Client) 扮演"指挥官"角色,负责: 编写测试脚本(模拟用户点击、输入等操作)发送…...

基于 Flickr30k-Entities 数据集 的 Phrase Localization
以下示例基于 Flickr30k-Entities 数据集中的标注,以及近期(以 TransVG (Li et al. 2021)为例)在短语定位(Phrase Grounding)任务上的评测结果,展示了单张图片中若干名词短语的定位情…...
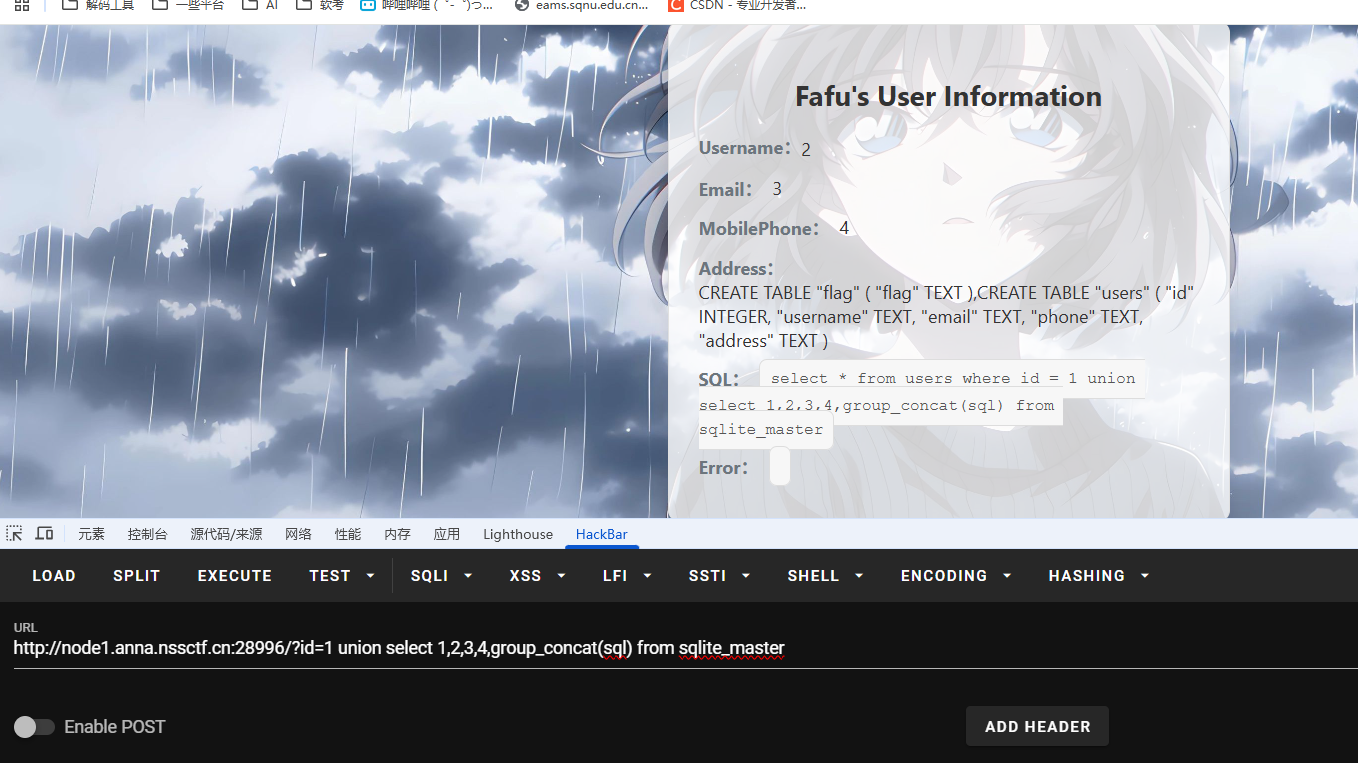
[GHCTF 2025]SQL???
打开题目在线环境: 先尝试注入: id1;show databases; 发现报错,后来看了wp才知道这个题目是SQLite注入。 我看的是这个师傅的wp: https://blog.csdn.net/2401_86190146/article/details/146164505?ops_request_misc%257B%2522request%255Fid…...
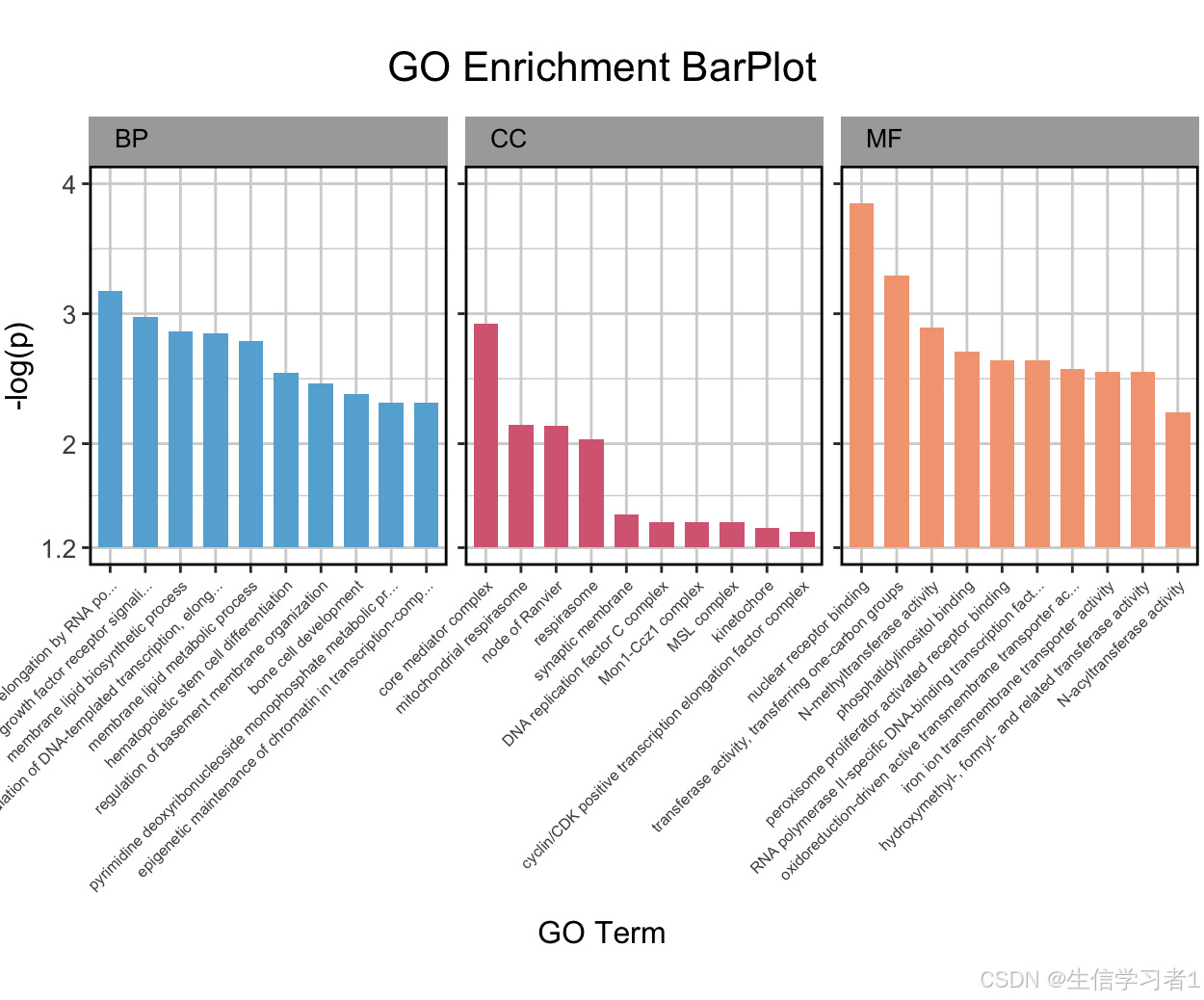
【科研绘图系列】R语言绘制GO term 富集分析图(enrichment barplot)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍加载R包数据下载导入数据数据预处理画图code 2code 3系统信息介绍 本文介绍了使用R语言绘制GO富集分析条形图的方法。通过加载ggplot2等R包,对GO term数据进行预处理,包括p值转换…...

JavaScript 性能优化实战指南
JavaScript 性能优化实战指南 一、引言 JavaScript 是一种广泛使用的编程语言,尤其在前端开发中占据重要地位。随着 Web 应用的复杂度不断增加,性能优化成为开发过程中不可或缺的一部分。性能优化不仅可以提升用户体验,还能减少服务器负载,提高应用的响应速度。本文将从多…...

达梦数据库:同1台服务器如何启动不同版本的DMAP服务
需求背景: 用户使用资源比较高的服务器,作为测试环境提供服务器,因为在这台服务器,运行了很多个数据库版本实例的情况,但是当dmap版本和数据库版本不一致时,通过dmap备份会报错。 解决办法: 1…...
Laravel单元测试使用示例
Date: 2025-05-28 17:35:46 author: lijianzhan 在 Laravel 框架中,单元测试是一种常用的测试方法,它是允许你测试应用程序中的最小可测试单元,通常是方法或函数。Laravel 提供了内置的测试工具PHPUnit,实践中进行单元测试是保障代…...
Kotlin委托机制使用方式和原理
目录 类委托属性委托简单的实现属性委托Kotlin标准库中提供的几个委托延迟属性LazyLazy委托参数可观察属性Observable委托vetoable委托属性储存在Map中 实践方式双击back退出Fragment/Activity传参ViewBinding和委托 类委托 类委托有点类似于Java中的代理模式 interface Base…...

鸿蒙OSUniApp集成WebAssembly实现高性能计算:从入门到实践#三方框架 #Uniapp
UniApp集成WebAssembly实现高性能计算:从入门到实践 引言 在移动应用开发领域,性能始终是一个永恒的话题。随着计算需求的不断增加,特别是在图像处理、数据分析等领域,如何在跨平台应用中实现高性能计算成为了一个重要课题。本文…...
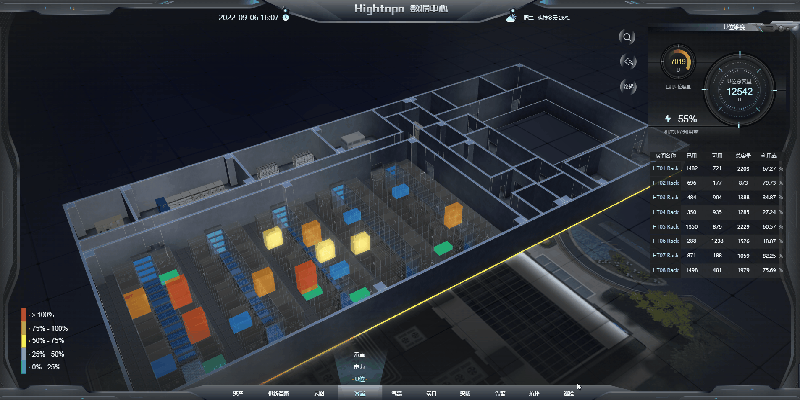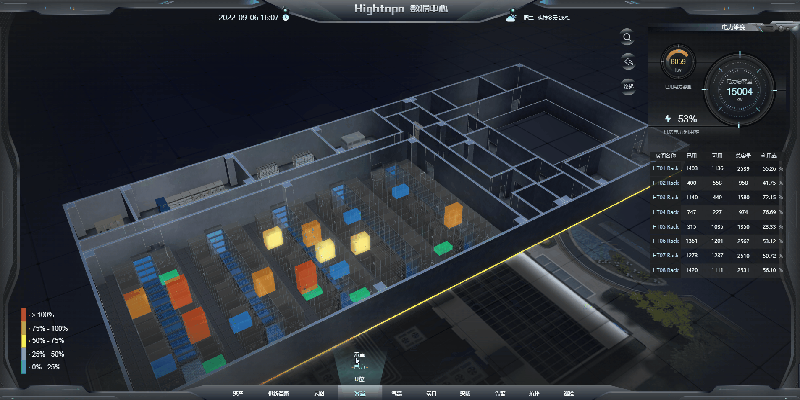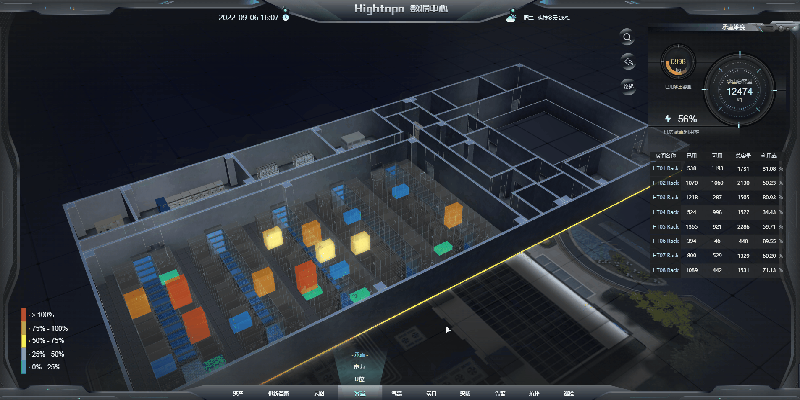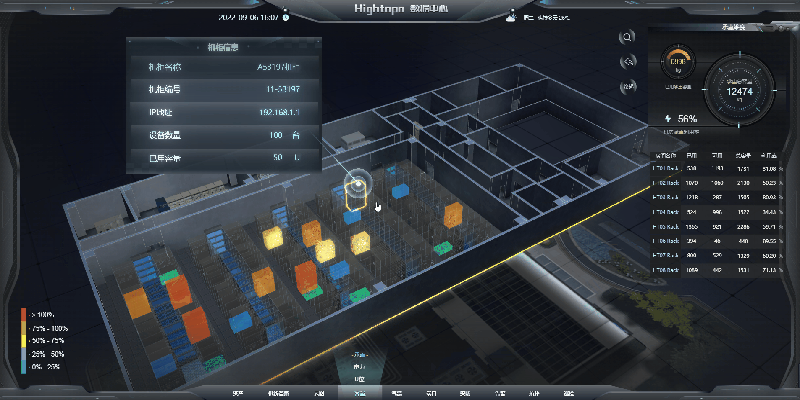
基于 HT for Web 轻量化 3D 数字孪生数据中心解决方案
一、技术架构:HT for Web 的核心能力 图扑软件自主研发的 HT for Web 是基于 HTML5 的 2D/3D 可视化引擎,核心技术特性包括: 跨平台渲染:采用 WebGL 技术,支持 PC、移动端浏览器直接访问,兼容主流操作系统…...
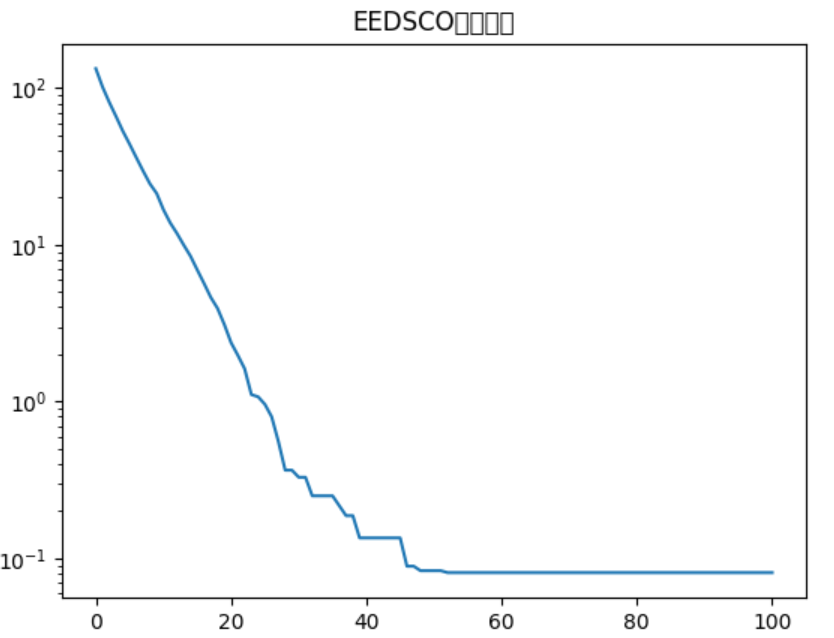
精英-探索双群协同优化(Elite-Exploration Dual Swarm Cooperative Optimization, EEDSCO)
一种多群体智能优化算法,其核心思想是通过两个分工明确的群体——精英群和探索群——协同工作,平衡算法的全局探索与局部开发能力,从而提高收敛精度并避免早熟收敛。 一 核心概念 在传统优化算法(如粒子群优化、遗传算法…...

解决Ubuntu20.04上Qt串口通信 QSerialPort 打开失败的问题
运行Qt串口通信 open(QIODevice::ReadWrite) 时,总是失败。 1、打印失败原因 QString QSerialHelper::openSerail() {if(this->open(QIODevice::ReadWrite) true){return this->portName();}else{return "打开失败";//return this->errorStri…...

深入浅出:使用DeepSeek开发小程序的完整指南
深入浅出:使用DeepSeek开发小程序的完整指南 1. 《从零开始:DeepSeek小程序开发环境搭建》 引言: "工欲善其事,必先利其器",在开始DeepSeek小程序开发之旅前,搭建一个高效的开发环境是至关重要的第一步。本文将手把手带你完成从软件安装到第一个&quo…...
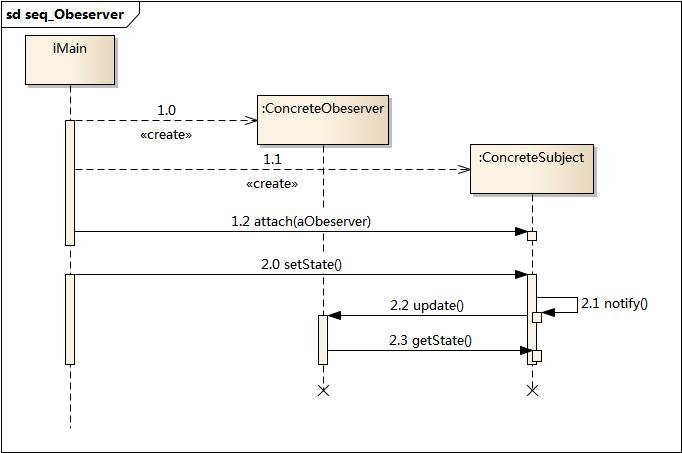
设计模式——观察者设计模式(行为型)
摘要 本文详细介绍了观察者设计模式,包括其定义、结构、实现方式、适用场景以及实战示例。通过代码示例展示了如何在Spring框架下实现观察者模式,以及如何通过该模式实现状态变化通知。同时,对比了观察者模式与消息中间件在设计理念、耦合程…...

【前端】Vue中使用CKeditor作为富文本编辑器
官网https://ckeditor.com/ 此处记录一下我在使用的时候具体初始化的代码。 <template><div><textarea :id"id"></textarea></div> </template><script> export default {name: CkEditor,data: function () {return {id:…...

CSS篇-6
1. 如果将<html>元素的font-size设置为10rem,那么当用户调整或拖曳浏览器窗口时,其文本大小会受到影响吗? 不会受到影响。rem单位是相对于根元素(即<html>元素)的font-size计算的。一旦<html>的fon…...
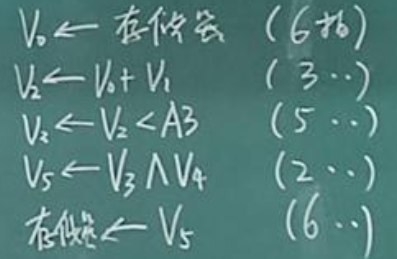
【计算机系统结构】习题2
目录 1.有一条静态多功能流水线由5段组成,加法用1、2、4、5段,乘法用1、3、5段,第3段时间为,其余各段为,且流水线的输出可直接返回输入端或暂存器,若计算,试计算吞吐量、加速比、效率 2.有一动…...