数据结构(7)树-二叉树-堆
一、树
1.树的概述
现实生活中可以说处处有树。

在计算机里,有一种数据结构就是像现实中的树一样,有根,有分支,有叶子;一大片树就叫做森林。
这些性质抽象到计算机里也叫树,大致长这个样子:
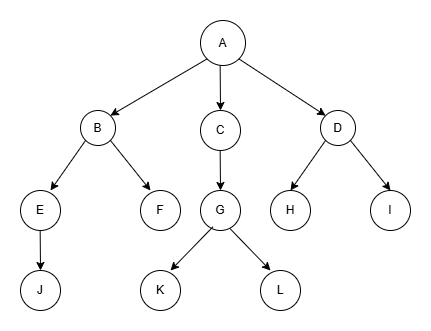
很明显,树是一个非线性的结构。也就是说,结点与结点之间不仅仅是一对一的关系(比如链表里谁是谁的前驱,谁是谁的后继都是唯一的),而是一对多的关系,就算我们还没开始学树,就看上面这个图,就能看出来A既是B的前驱结点,又是C、D的后继结点,不再是一对一的关系。
树是一个具有n个结点组成一个具有层级关系的集合,叫做树是因为它的根在最上面,枝干和叶子都在下面,宛如一个倒挂的树。
最上面的结点一般称为根结点,可以从根节点到达这个树上任意一个结点,但是根节点并没有前驱结点。
删去根结点以后其余结点又可以分成互不相交的n个集合,这些结构实际上还是树:
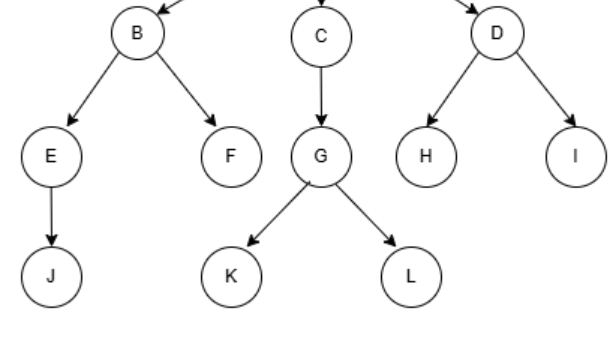
我们一般称这些树为子树。每棵子树的根结点有且仅有一个前驱结点,可以有0个或多个后继结点。因此,树是递归定义的。
2.树的相关术语
为了方便以后的学习,先来学习一系列关于树的术语。
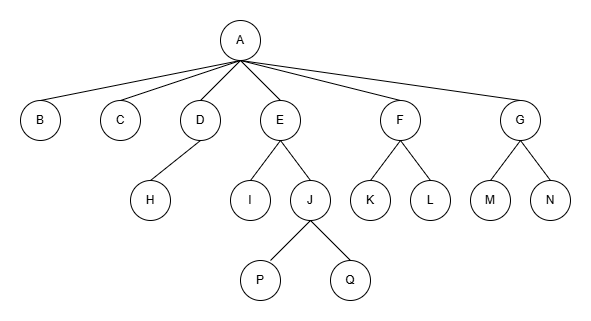
依照上面这棵树给出相关术语:
父结点/双亲结点:一个拥有子结点的结点就是子结点的父亲结点,如A是下面B、C、D、E、F、G的父结点,这也符合我们日常生活中的叫法,一个男人有了孩子才能叫做父亲(至于双亲结点纯粹政治正确,以后叫父结点就行,当然,本人对性别等无任何歧视,只是叫法方便而已)。
子结点/孩子结点:一个结点的子树的根结点是该结点的子结点,如:
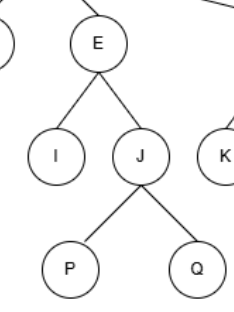
很明显,E有两个子树,子树结点有4个,但是只有两个子树根结点,也就是只有I J才是子结点
结点的度:结点的度就是看有几个子结点,比如A的度就是6,D的度就是1,H的度就是0
树的度:树中所有结点的度的最大值就是树的度
叶子结点/终端结点:没有子结点的结点就是叶子结点
分支结点/非终端结点:有子结点的结点就是分支结点
兄弟结点:同一个父结点就是兄弟结点,比如I和J的父结点都是E,那么I和J就是兄弟结点
结点的层次:从根开始,根结点为第一层,根的子结点为第二层,依此类推
树的高度或深度:结点的最大层次就是树的高度
结点的祖先:从根结点到该结点的分支上所有结点都是祖先,比如A这个根结点是所有结点的祖先
路径:从一个结点出发,到达另一个结点的序列,比如你要这么来:
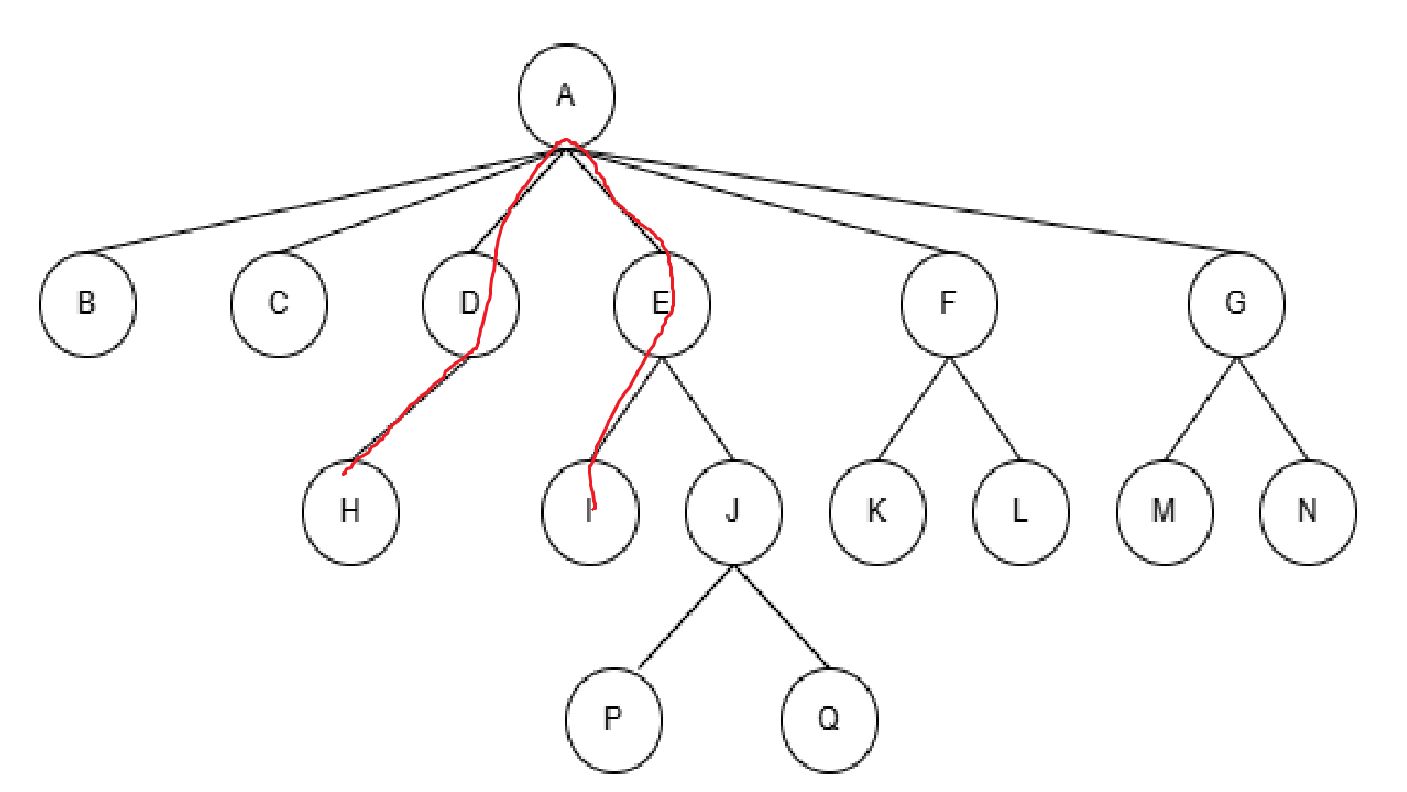
从H到I的路径就是HDAEI,一看便知
子孙:以某结点为子树的根结点是这个树里面所有结点都为该结点的子孙
森林:m个不相关的树组成的集合就是森林。
3.树的表示
看了这么多术语,很明显,树的结构相较于链表了,顺序表了都是无比的复杂。
那么树的结构体怎么写呢,如果还是一个一个元素全部体现,就像单链表里不是可以存next指针和数据data,按照这个思路的话一个结点有几个孩子就得写几个孩子指针,但是事先我怎么知道有几个孩子,这个思路还是有待商榷。
不过都已经21世纪了,我们更应该站在巨人的肩膀上看世界,先人给我们提供了:双亲表示法,孩子表示法、孩子双亲表示法以及孩子兄弟表示法等。
这里我们就以孩子兄弟表示法为示例:
struct TreeNode
{
struct TreeNode* child;//左边的第一个孩子结点struct TreeNode* brother;//第一个孩子结点右边的兄弟结点
TreeDataType data;//该结点存储的数据
}
光看这确实有点抽象,从百度拿过来一张图:
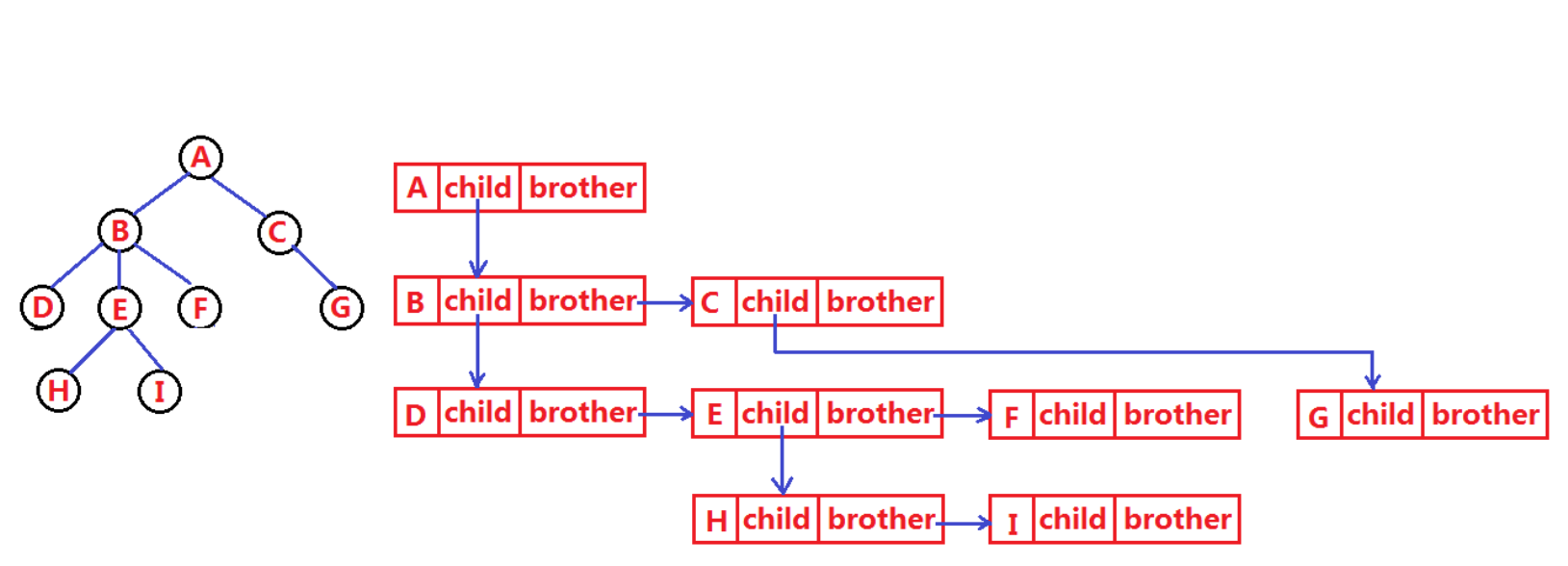
这张图很好的解释了,孩子兄弟表示法存的指针是干什么的,顺着指针就可以便利到树的每一个结点了。
4.树的应用场景
其实可以说是非常常见,我们磁盘管理文件的时候有个C盘和D盘,里面可以存文件夹,文件夹里面可以存文件夹,也可以存文件,至于更多的场景,以后应用自然就懂,目前的重点就是了解大概还挺有用,然后学习怎么实现。
二、二叉树
1.二叉树概述
树还是太难了,所以我们初阶阶段就把目光放在二叉树上,二叉树顾名思义,最多就分两个叉,也就是一个结点的子结点不得超过两个:
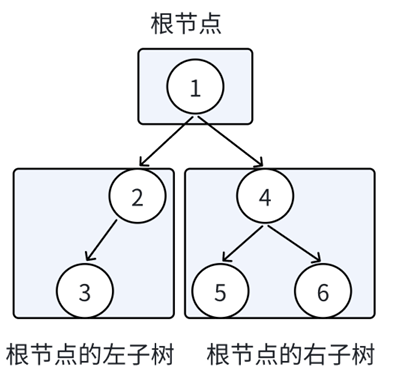
即结点的度不能超过2。
且二叉树的子树有左右之分,顺序不能随意调换。
这样看起来可以说是舒服多了,在树形结构中应用最多的就是二叉树,这也确实比树好区分一点,毕竟人习惯分左右,我真的在日常生活中见过很多人不分东南西北,更别提那些东北了,西南了这些方向,如果实现分好多叉的树那不更晕了。
2.特殊的二叉树
①满二叉树
如果一个二叉树每一层的结点都打到最大值,这个树就是满二叉树。
满二叉树的性质
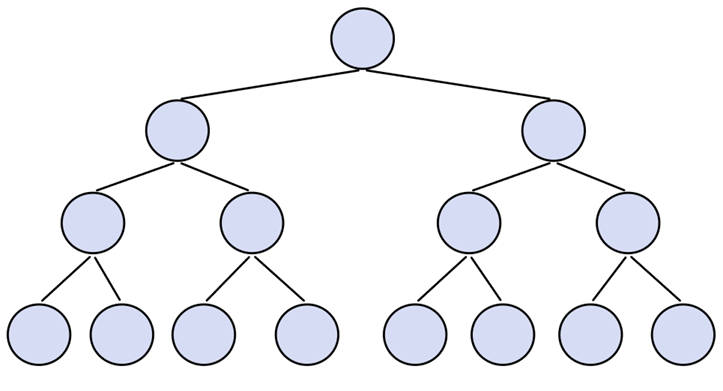
容易观察到这样的结论:
| 层数 | 结点个数 |
| 1 | 2^(1 - 1) |
| 2 | 2^(2 - 1) |
| 3 | 2^(3 - 1) |
| …… | …… |
| k | 2 ^(k - 1) |
得到层数为k的满二叉树有2^k - 1个结点。
②完全二叉树
完全二叉树是从满二叉树得来的概念,死扣定义的话就是完全二叉树的n个结点与满二叉树1~n的结点完全相同,如下图。
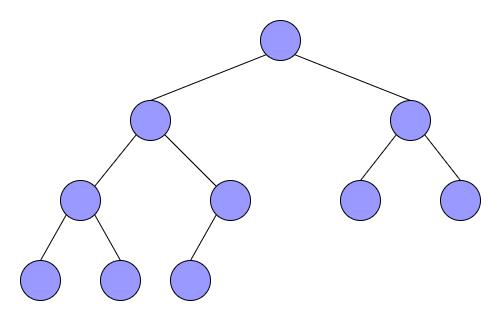
咱们自己看完全二叉树的话就是每层严格从左到右往上加结点的二叉树就是完全二叉树,容易得到,完全二叉树和满二叉树的关系是:
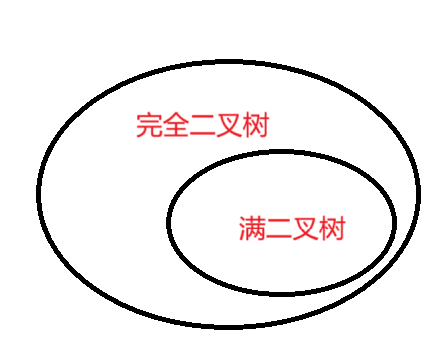
即满二叉树一定是完全二叉树,完全二叉树不一定是满二叉树。
完全二叉树的性质
完全二叉树的性质完全是根据满二叉树的性质得来的,如:
1)若规定根结点的层次为1,那么完全二叉树第i层的结点个数不超过个
2)若规定根结点的层次为1,那么深度为h的完全二叉树的结点个数最多为个
3)若规定根结点的层次为1,那么结点为n的完全二叉树深度为![]()
性质1和2一个是等比数列的通项公式,一个是等比数列的前n项和公式,这个好理解。
这个深度实在是在文章里写不出来,实际上应该是log向下取整再加一,举几个例子:
根据n = ,很容易得到上述3这个性质,但是真正算的时候满二叉树的性质可不能直接拿过来用。
比如只有两个结点,不用说就知道是只有两层,实际上算的是几,是以2为底3的对数向下取整就是1,因为多了几个结点,虽然并没有铺满下一层,但肯定就成一层的下一层了,就是向下取整再加一,也就是一共两层。当然,如果直接就是整数的话,那是几就是几了。
4)对于一个具有n个结点的完全二叉树,从上到下,从左到右依次将结点的序号从0开始排列,直到n-1。
则对于序号为i的结点有:
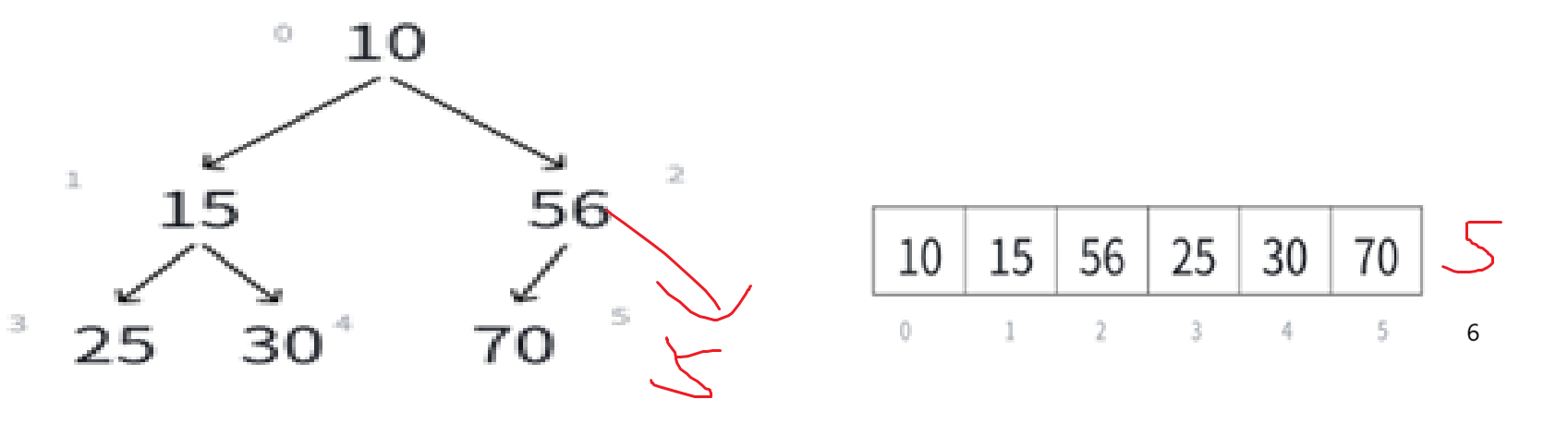
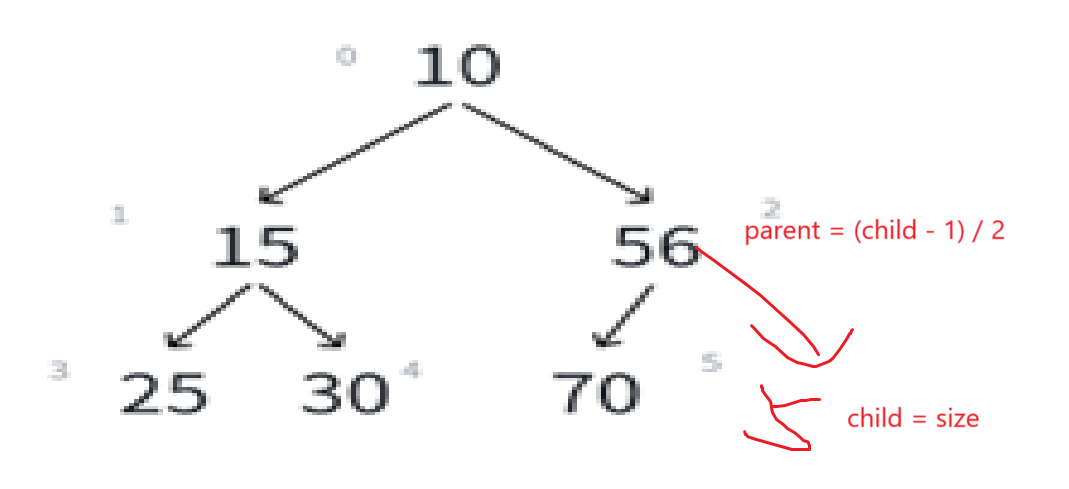
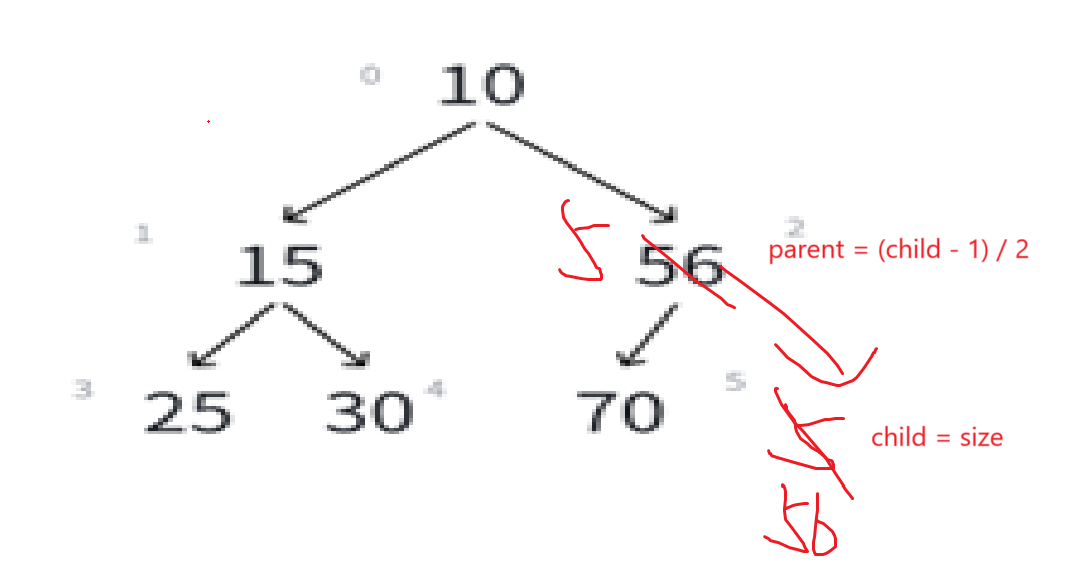
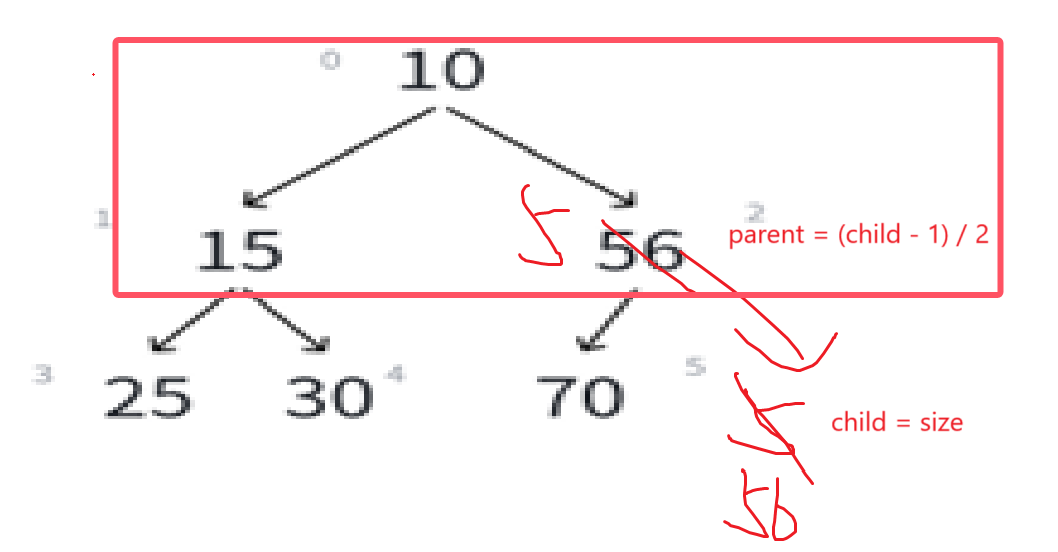
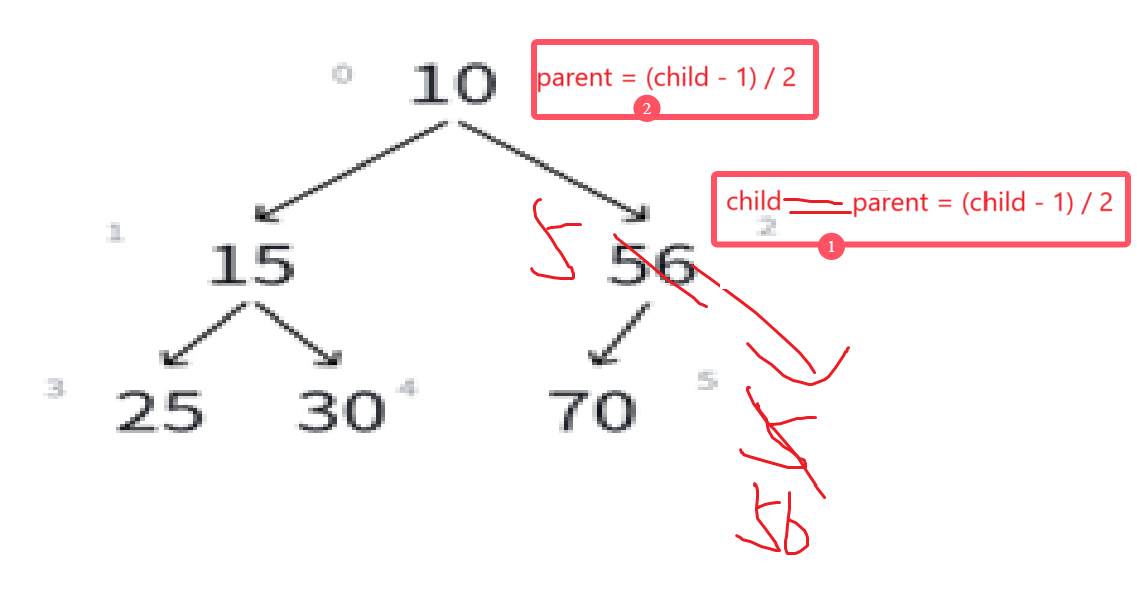
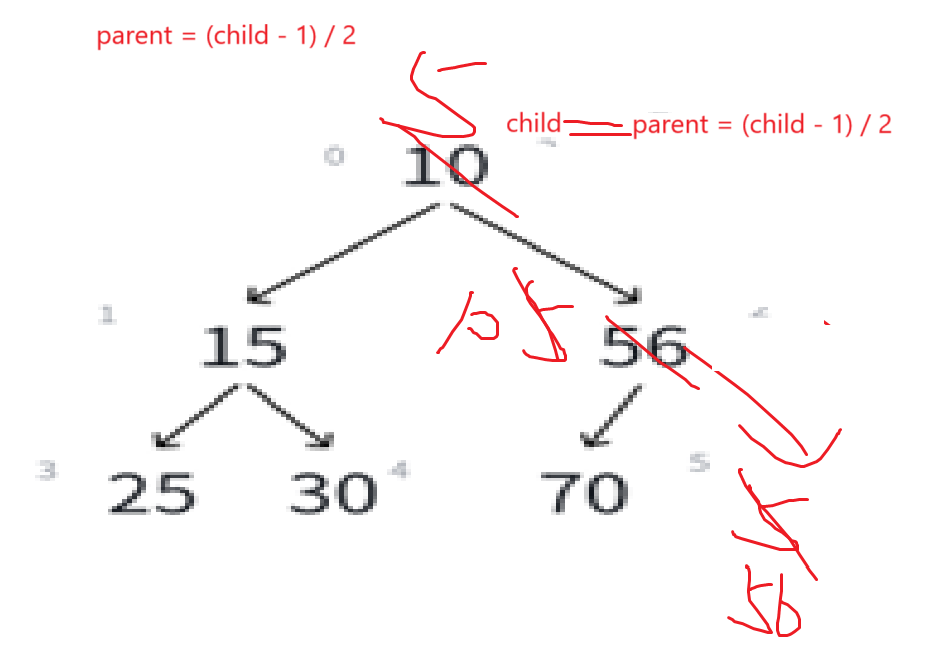
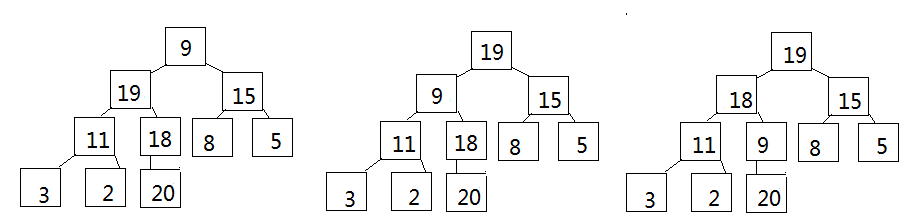
若i>0,则i位置的父结点序号为:(i - 1)/2也就是我们的向下取整除法,举例:
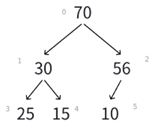
比如看最下面那个子树,左孩子25序号是3,(3 - 1)/2就是1,右孩子15序号为4,(4-1)/2就是1。非常正确。
可以由此推导左孩子结点的序号,明显左孩子和父亲结点的关系是:(leftchild - 1)/2 = parent
如果知道一个结点的序号为i,可推i*2+1为左孩子结点。
同理可知右孩子结点为i*2+1+1至于为什么是+1+1而不是+2,到后面写代码就能理解了。
3.二叉树的存储结构
二叉树的存储一般可以用两种结构,一个结构是顺序存储,一个结构是链式存储,也就是说一种存储底层是数组,一种存储底层是链表。
而对于一般的二叉树我们用的一般是链式存储,而完全二叉树用的就是顺序存储,为什么有这样的区别呢?
顺序存储
画图来看:
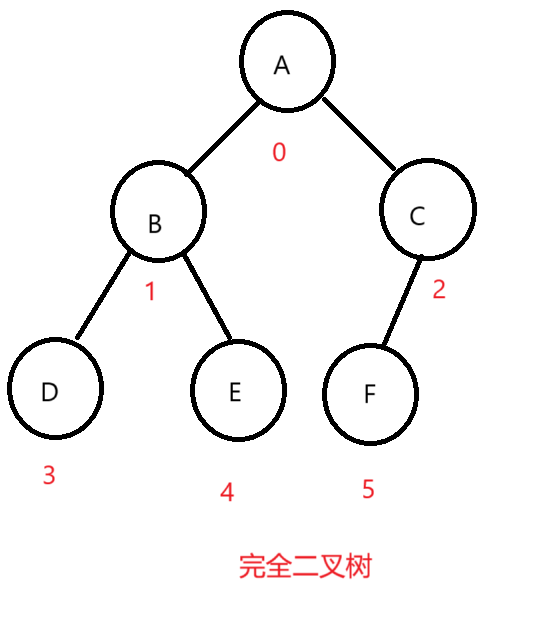
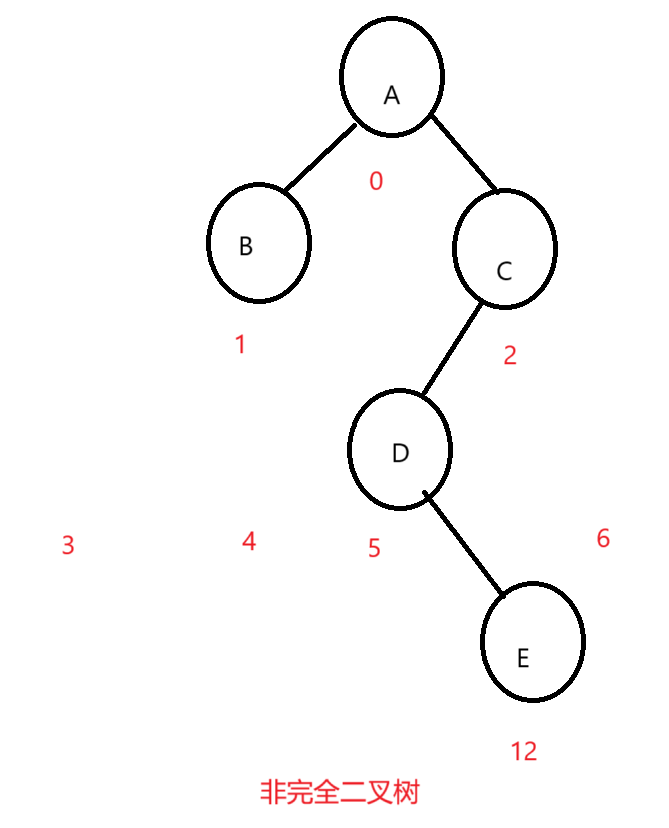
我们定存储的结点的下标都按照满二叉树来的话就是这样的两个图,放到数组里面是这样的:
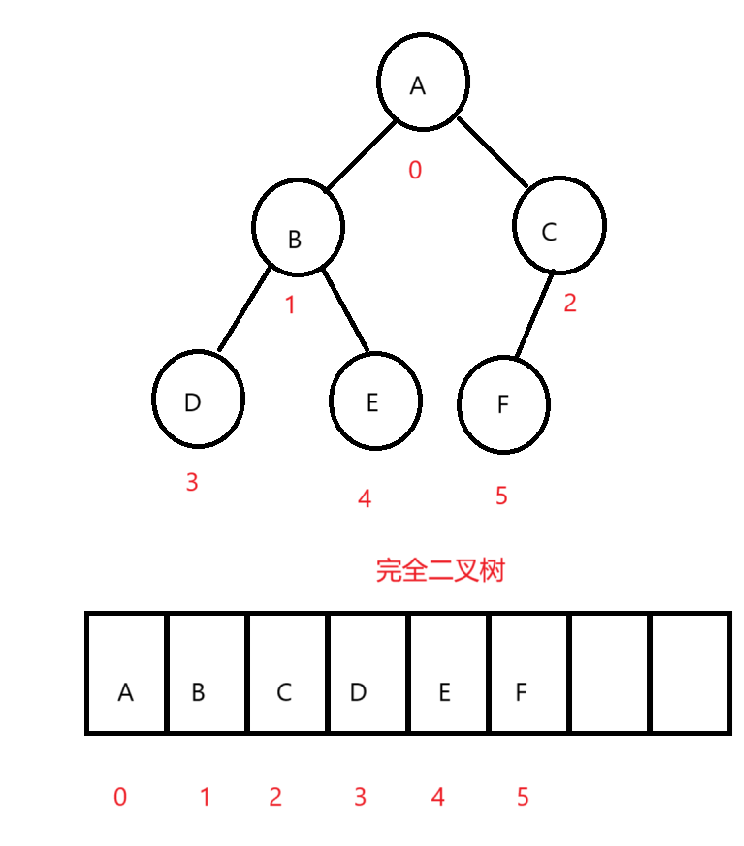
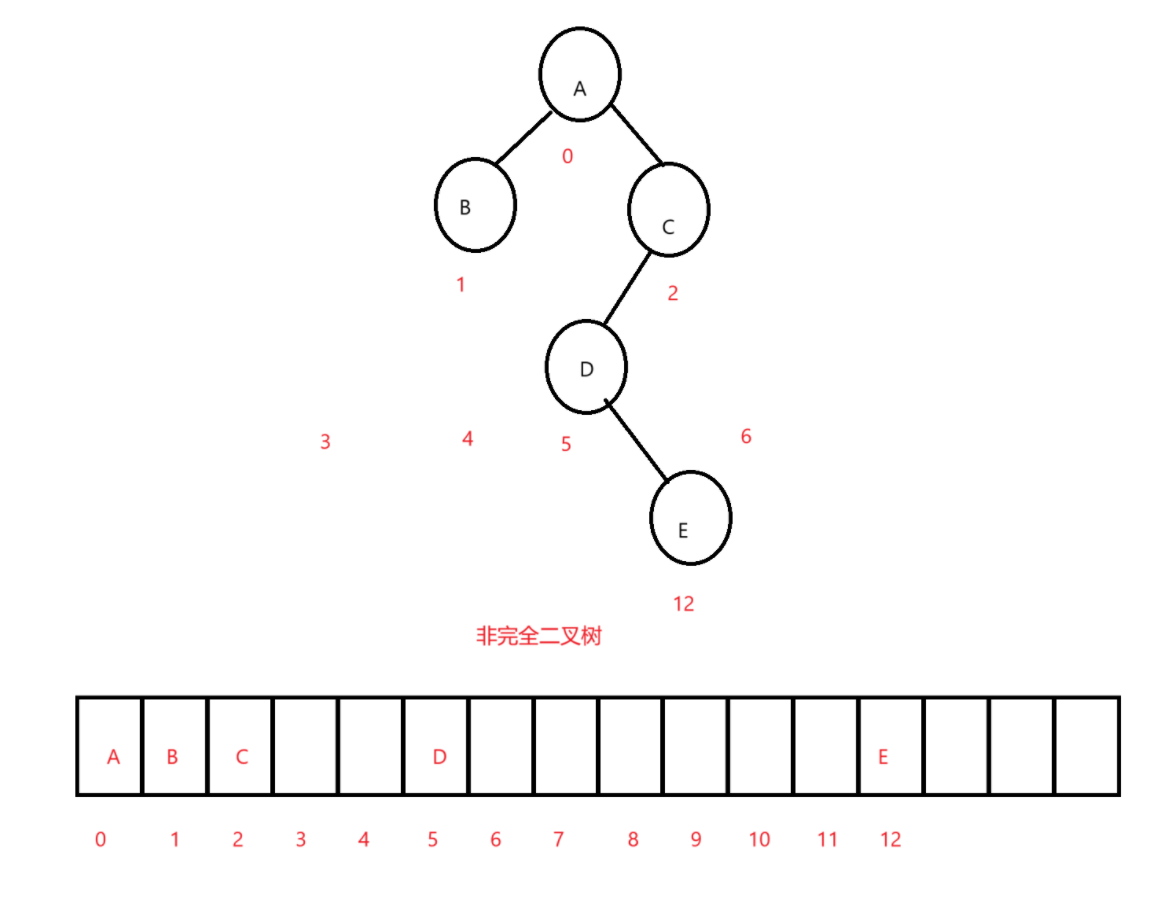
画出来图一目了然,很明显,我们的完全二叉树结点下标就是连续的,在数组中存储至少不会存在中间元素为空的情况,非完全二叉树就是存在为空的情况。
注意,这里千万不要有错误的认识,那你顺着放能咋地呢?
当然是一旦顺着放,二叉树的结构就被破坏了,这里不再画图了,就盯着第二张图看,很明显啊,假如你说不留空,存储空间中把D放到了下标为3的位置,那么将来还原的时候下标为1的左孩子就是下标为3的D,好家伙,我让你先给我存起来,结果你钻空子把我空的给去掉了,那我的东西不就坏了嘛,很好的理解就是如果你真的这么做了,就成了赛博“白蚁”了,你把树杈子给它“吃了”树的结构就改变了。
故非完全二叉树一般都用链式存储,防止空间的浪费。
链式存储
了解了以后就知道了,什么时候用顺序存储,什么时候用链式存储,接下来看看链式存储的两种形式:
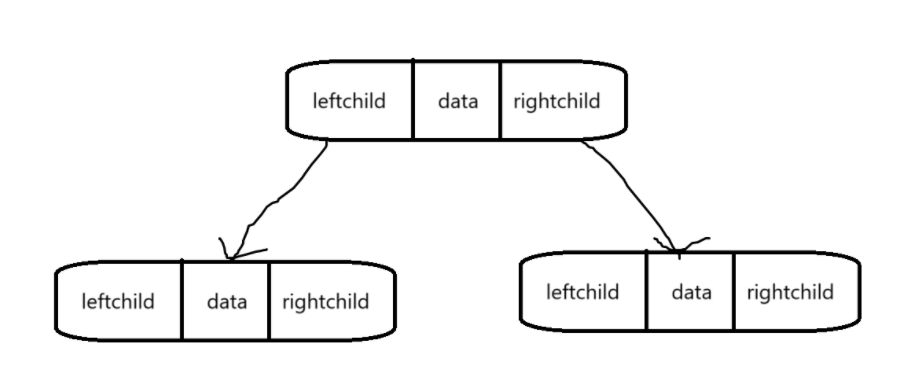
这种形式叫做二叉链表,二叉树的每个结点有三个成员,一个是变量来存数据,剩下两个是指针,分别存左孩子和右孩子结点的地址。
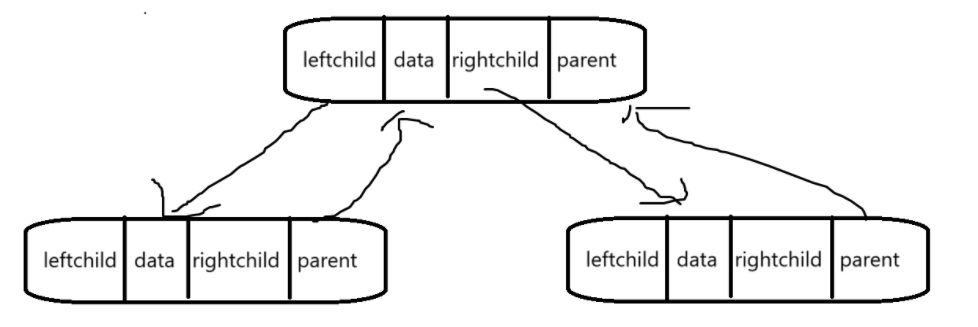
这种形式叫做三叉链表,三叉链表存储下二叉树的每个结点有四个成员,比二叉链表多了一个回指父结点的指针。
三、堆
1.堆的概述
其实多少有点喧宾夺主了啊,标题就是堆,结果说了说树,树说完还不过瘾,又说了说二叉树,二叉树还专门搞了特殊的二叉树来看了看,当然,心急吃不了热豆腐嘛,有了前面的铺垫,是为了让我们更好的理解堆这个结构。
首先说明,堆就是一个完全二叉树。
完全二叉树的特点也就告诉我们底层用顺序存储来实现堆数据的存放。
在完全二叉树的基础上堆结点间还有一个大小关系:
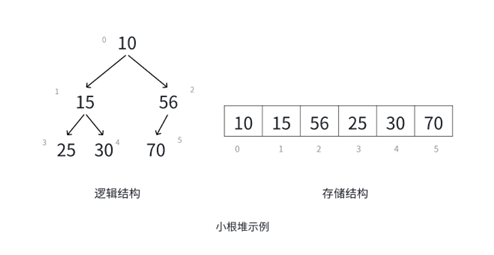
这张图是小根堆,小根堆的特点就是父结点的数据一定小于其孩子结点的数据,不信可以一个一个去对照。
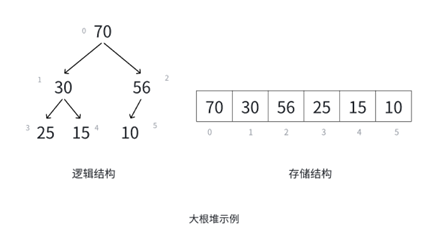
这张图是大根堆,大根堆的特点就是父结点的数据一定大于其孩子结点的数据。
所以说堆就是在完全二叉树的情况下对父结点与孩子结点的大小加以限制。
注意
这里的堆指的是数据结构里面一种,内存划分不是说有什么堆区栈区静态区嘛,这个是内存的一块区域,二者不能混为一谈。
另外,可能有的人一看有大小关系,就开始想当然了,那么小根堆按序号就是升序序列,大根堆按照序号就是降序序列,这个观点是错误的,致误原因也非常简单,大根堆小根堆只是定义了根结点比其分支要大或者小,这俩分支谁大谁小可没有硬性的规定啊。
2.堆的实现
堆的底层是数组,那基本上和顺序表一样了,直接给出来:

暴风雨前的平静。
3.堆的初始化
不必多说:

测试代码:
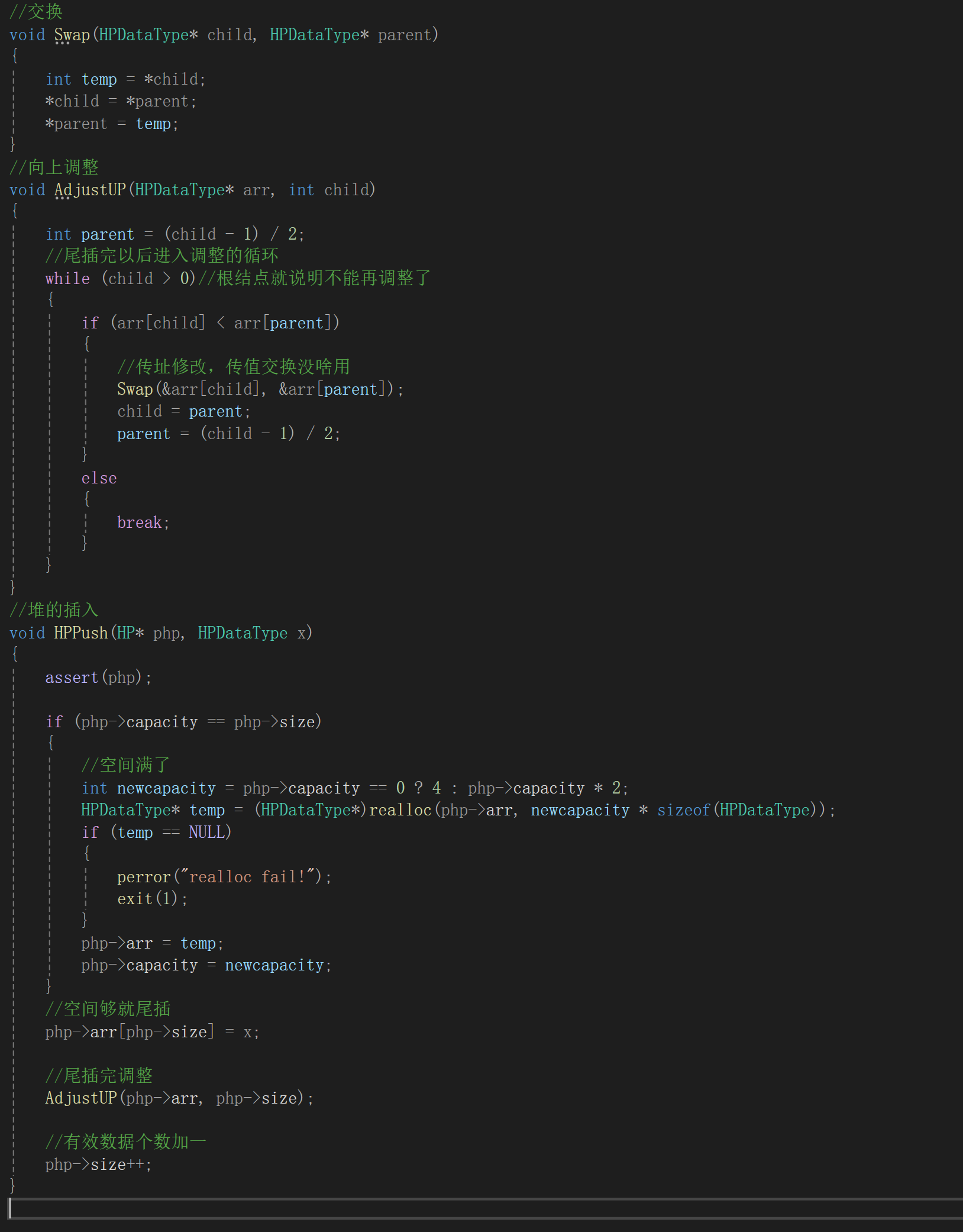
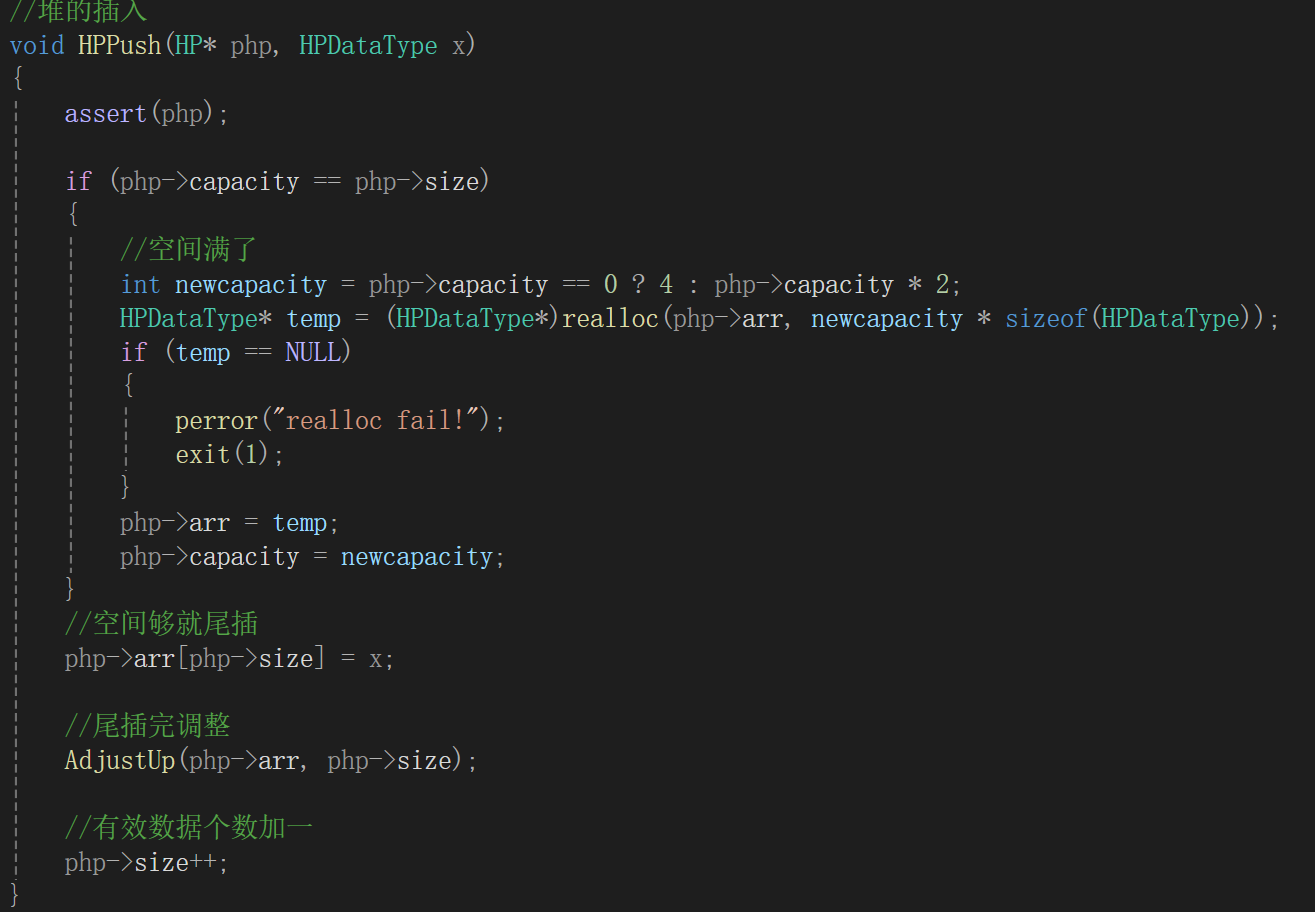
4.堆的插入
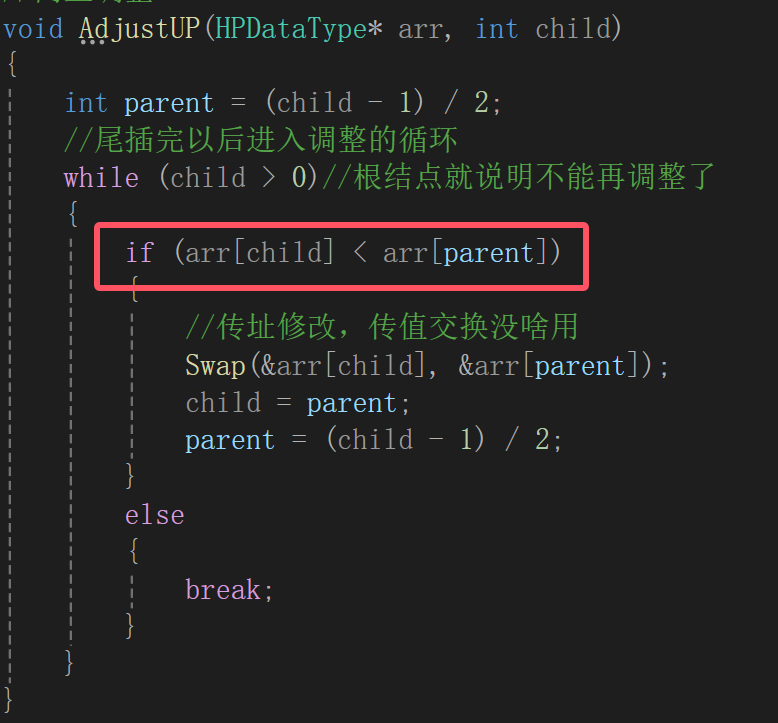
堆的插入可就麻烦了,因为你得保证一个性质,父结点比孩子结点的值要大,所以免不了有调整的环节,堆的部分有序性造成了代码的复杂:
而且小根堆和大根堆的大小不一样,所以还得有很多讲究,画图一一来研究:
小根堆为例:
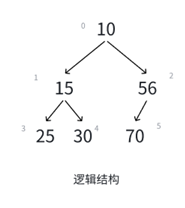
插入检查空间是否足够,删除检查是否为空。这个不再讲解。
根据顺序表插入数据的经验,头插是非常麻烦的,还得把已有的元素后移,时间复杂度也会更高,所以就尾插,比如给小根堆插入一个5。
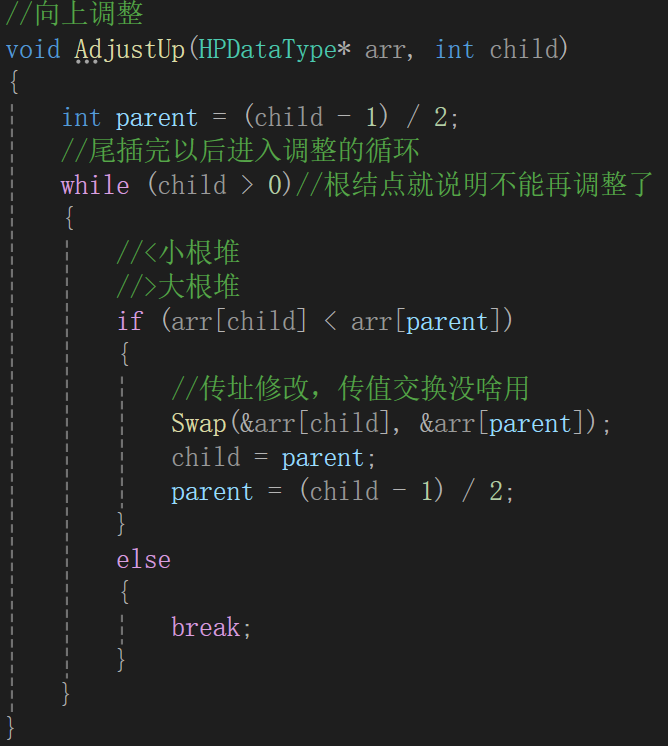
接下来我们肯定就得执行向上调整的操作,调整前明确我们知道什么,由于数组下标是从0开始的,所以新插入的数据刚好就应该是size位置的数据,即新插入数据的序号为size。
它一定是一个孩子结点,因为插入到了右下角的小子树里面了,所以应该首要跟根结点比,根据孩子结点算父结点是(i - 1)/2:
这种情况是父结点比孩子结点要大,又是小根堆,所以child和parent的数据就应该就该互换位置:
要注意,根比分支小,所以一旦新插入的比根小,那么一定比兄弟结点小,不需要再比较新插入的结点与兄弟结点的关系(如果有的话),如果比根大,那不就不用调整了嘛。
继续:
现在需要调整的部分就是这里,很明显,还是跟上次一样的效果,比根结点小,就得互换,这个时候的child应该是上一次的parent,这次的parent再用新的child计算即可:
最后结果就是:
child遍历到数组的头,或者说parent已经为负了,那就停止循环就行,基本思路有了,来看代码的表达:
测试代码:
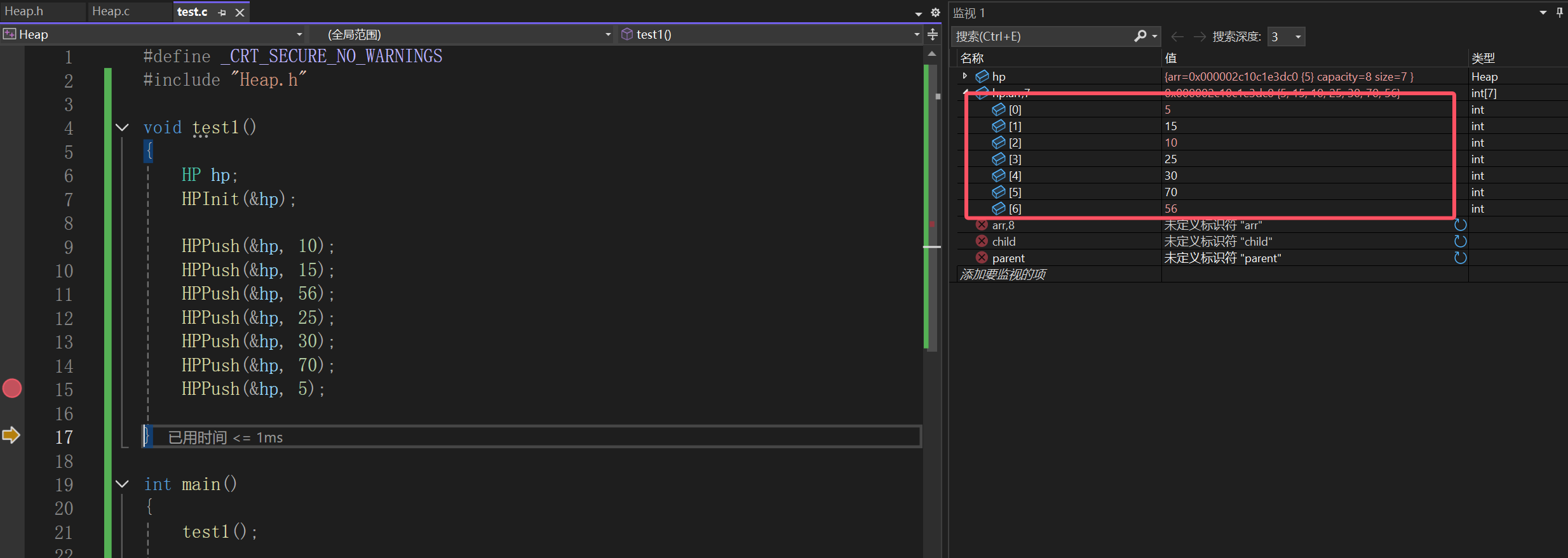
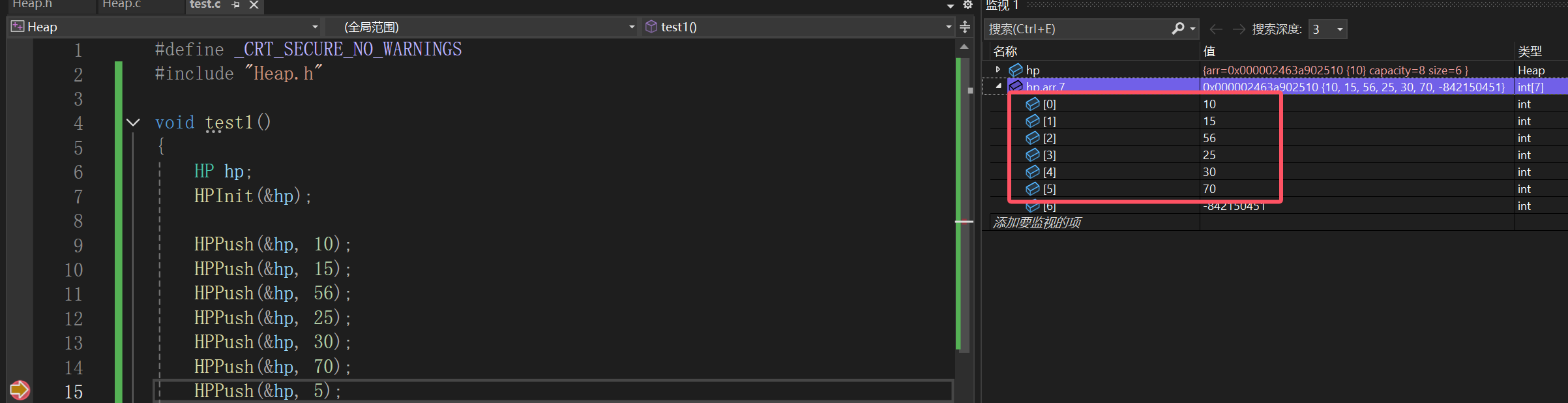
不过我们上面写的包括测试的都是为了生成一个小根堆:
因为我们的思路是,尾插数组,尾插数组也就造成某颗子树,被改变了关系,所以就看这个子树需不需要修改,一旦需要修改,肯定是变根结点了:
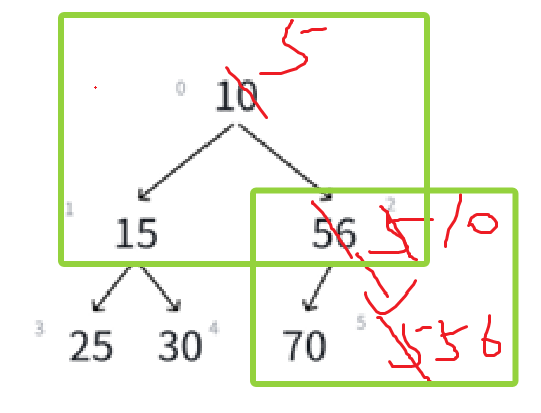
如果子比根小才交换,所以才是创造了小根堆。
那么很明显,如果要创造大根堆,那么就需要修改这个逻辑:
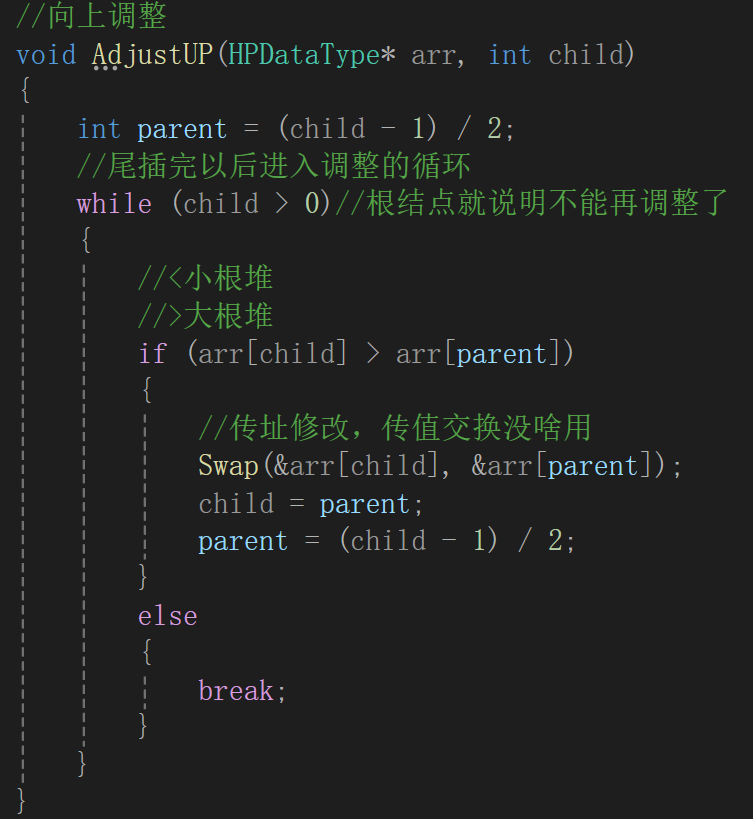
同样的数据,原封不动的插入:

可以看到调试的结果确实相当于生成了一个大根堆。
时间复杂度
其它的操作大多很简单,基本都是O(1),也就没必要浪费时间去分析时间复杂度,难度不说,堆的插入的代码长度反正不太小,所以分析一下时间复杂度:
内存空间的管理、以及尾插、有效数据个数等没有循环之类的,看来插入的时间复杂度取决于AdjustUp的时间复杂度:
可不要说,上来就是一个循环,那时间复杂度就写O(n)了,在我们学习时间复杂度那节里面,有这样一个循环:
void Func(int n)
{
int i = 1;
while(i <= n)
{
i *= 2;
}
}
这个很明显也有一个循环,难道有一层循环,时间复杂度就是O(n)吗?
我们所说的时间复杂度可是根据输入的n,看执行次数,这里的执行次数很明显就是:
logn,时间复杂度就该是O(logn)。
最差不就是child从最底层的叶子结点遍历到根结点,这个执行次数很显然基本等同于堆的层数也就是O(logn)的时间复杂度。
5.堆的删除
首先明确出堆操作只能出堆顶元素,其实我刚开始对此也深表怀疑,什么鬼,直接告诉我出堆顶就行,后续相关操作中我确实体会到了这样的好处,在这里就简述:出堆顶意味着出的是小根堆里面最小的元素,大根堆里面的最大元素,因为你随便找一个堆,就能验证这个说法。
如果不理解,就先记住,看看后续的操作。
现在非常明确就要删堆顶元素,但问题是怎么删才能让时间复杂度最小,才能让操作最简单:
我们知道堆顶元素底层是数组的下标为0的元素(堆不为空的情况下),根据删除顺序表头部元素的经验,如果要删数组第一个元素,删完就得前移,这么删时间复杂度首先就得是O(n)。
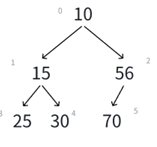
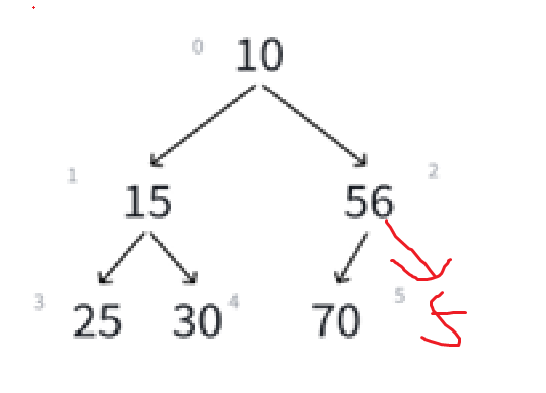
再者,一旦前移关系实在是太乱了,比如以上面的二叉树为例:
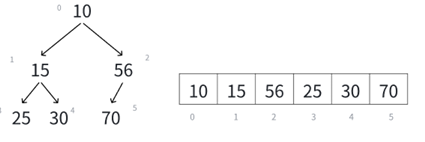
这样一个堆一旦删除堆顶,首先底层就变成这样:
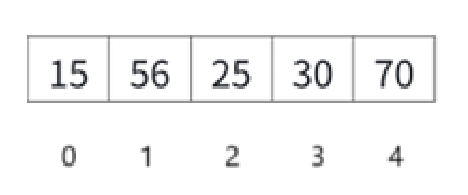
直接还原成二叉树:
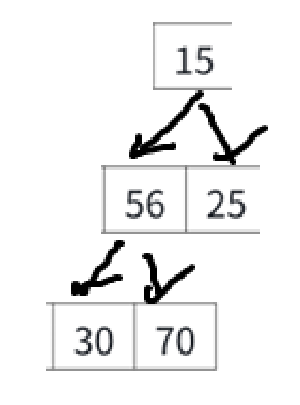
对照着原图看,就看15,原来的父结点是10被删了,兄弟结点是56,孩子结点是25和30。
把10一删,兄弟56变孩子,孩子30变成孩子56的孩子了,直接把堆的关系搞乱完了。
实际上的删除我们就来类比我们堆的插入,我们就这么做,数组当然是尾删舒服一点了,尾删的话只用size--即可,但是刚才已经说过了,删除堆的数据要求删堆顶就是因为堆顶元素的极值性,也就是这个例子里必须先删10,所以尾删前将第一个元素和最后一个元素先互换再删就可以了:
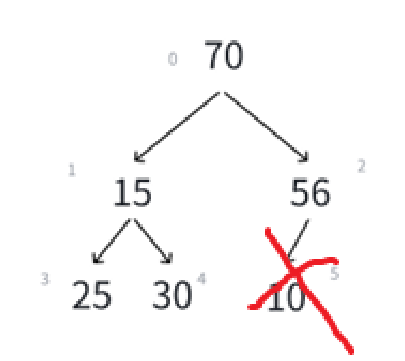
先不说后续操作,就单看这里,其实只动了最后一个叶子结点和根结点,左下角那棵子树还是该咋样咋样,一点没有动。
顺着想,因为根结点变了,可能不再维持堆的特性了,为了保证原堆的特性,肯定免不了调整,这次调整其实是从上往下调整,接下来我们画一画这个关系:
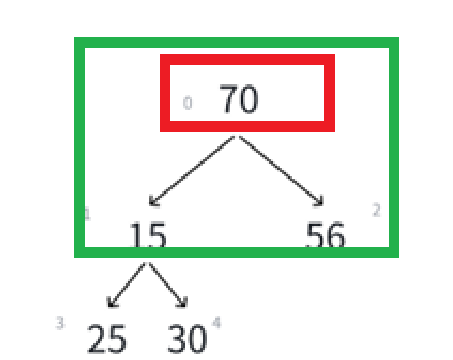
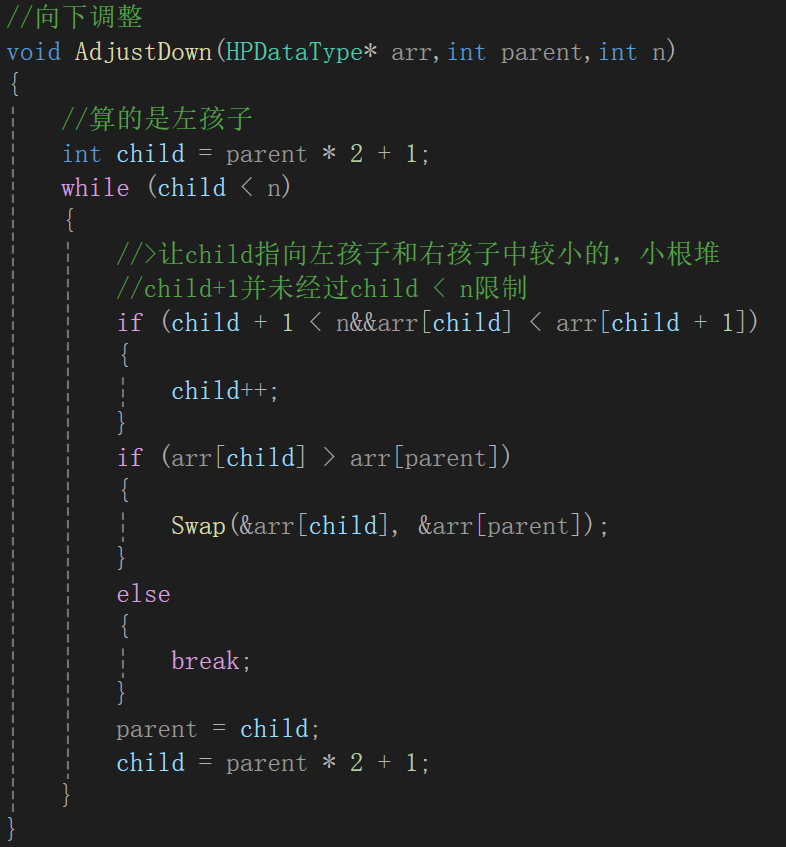
很明显现在跟原堆不一样的地方就是根结点,也就影响到绿色框里这棵树需要替换,很明显,我们的已知条件就是下标0,它在这棵树里面相当于parent结点,而调整需要和两个child的比较,由父结点求孩子结点是parent * 2 + 1(左孩子),parent * 2 + 1 + 1(右孩子 = 左孩子 + 1)。
经过上面的比较,调整,最后的结果应该是:
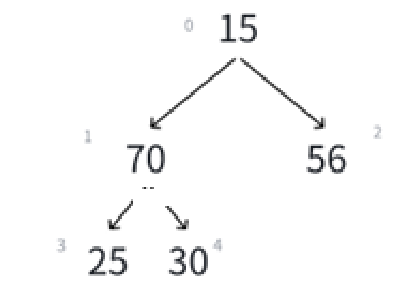
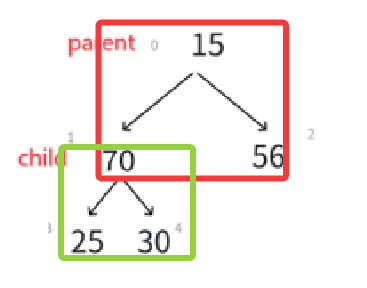
接下来就肯定得循环,循环条件和循环变量有谁呢?
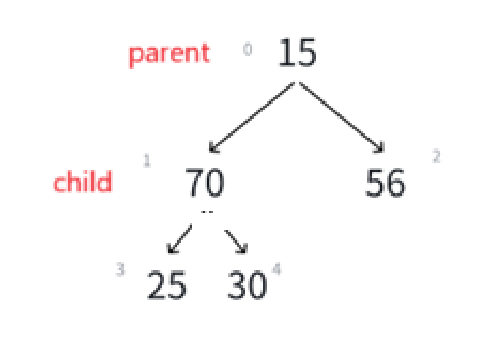
调换过的child是左结点,那么下一个可能需要调整的就变成了左孩子的那棵子树,所以这次的循环的parent就是child,至于哪个child需要调换,计算即可:
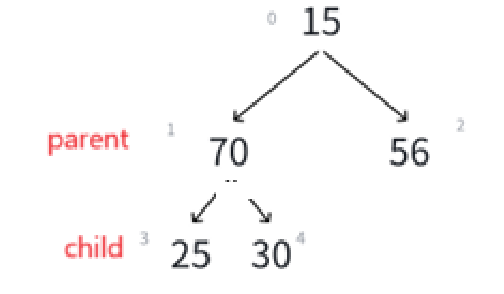
通过代码我们要实现parent的调换,和child(小根堆要求最小)的定位,也就是上图所示。
再交换:

并且很明显,child更先越界,所以循环条件也有了

给出大致代码:
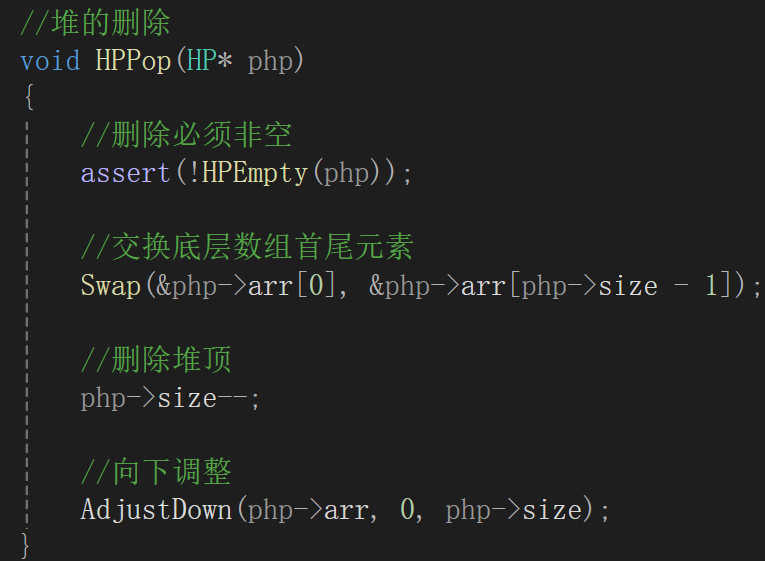
因为向下调整肯定是从数组下标为0开始的,其实不用跟向上调整一样传child(向下调整肯定传的parent),但是为了参数差不多,还是传一下。
传有效数据个数当然是为了循环条件,不用多解释。
重点肯定还是向下调整的循环:
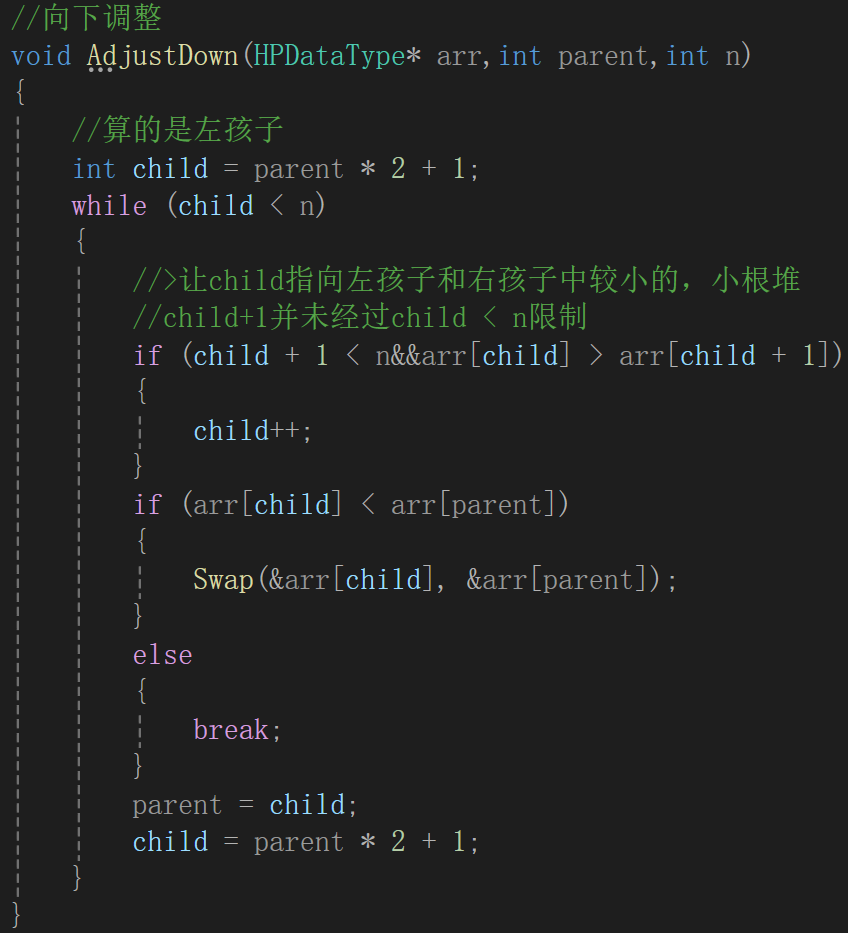
细节处理是,每次进入下一次循环前,默认child为左孩子,但可能要求的不是,进入循环先调整,并且防止了child + 1没有越界,其它的逻辑跟思路都一样了。
测试代码:
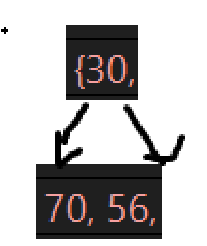
删除前的堆为:
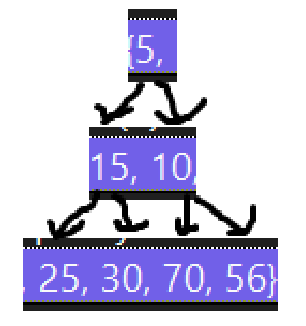
第一次删5,最后上位的肯定是10:
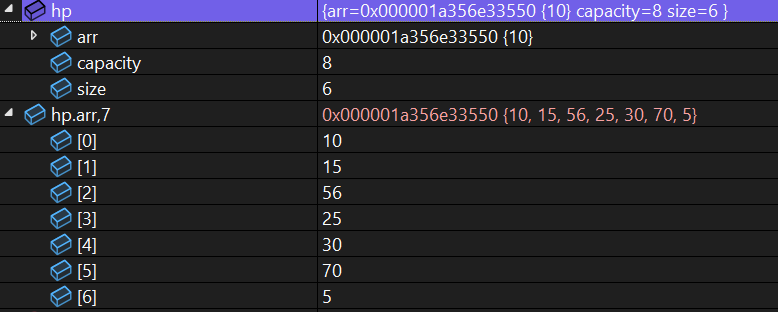
size已经是6了,画出来删除后的树:
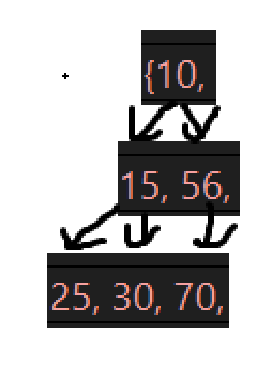
接下来几次的删除后的树为:
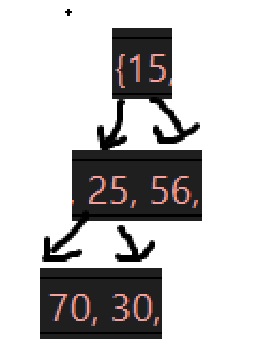
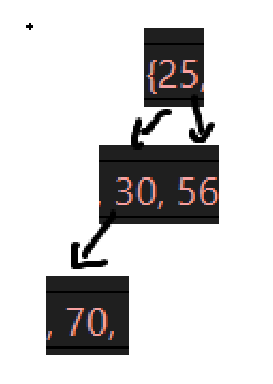

不再验证了,非常明确了,接下来就是一个小问题,看看断言是不是真的有用:
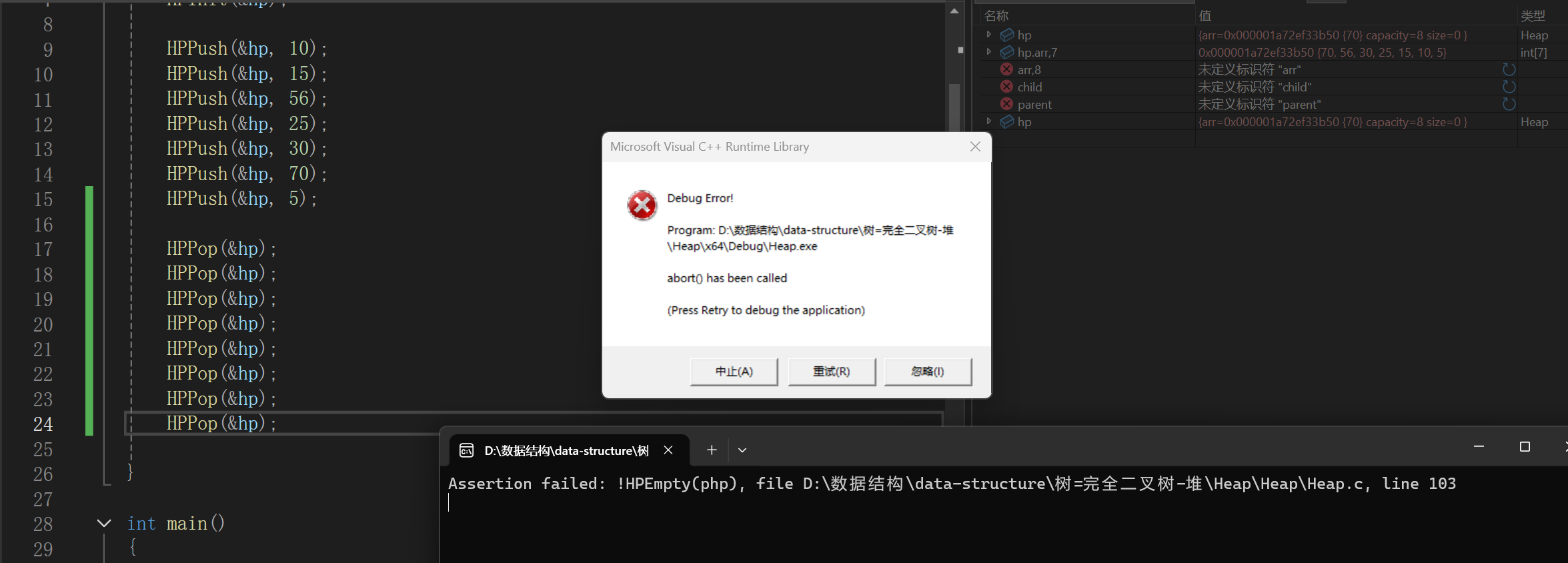
删了7次,第八次直接报错。
时间复杂度
还是分析一下时间复杂度,基本同理,因为只有AdjustDown含有循环,而这个循环的次数最坏还是堆的层数,也就是O(logn)
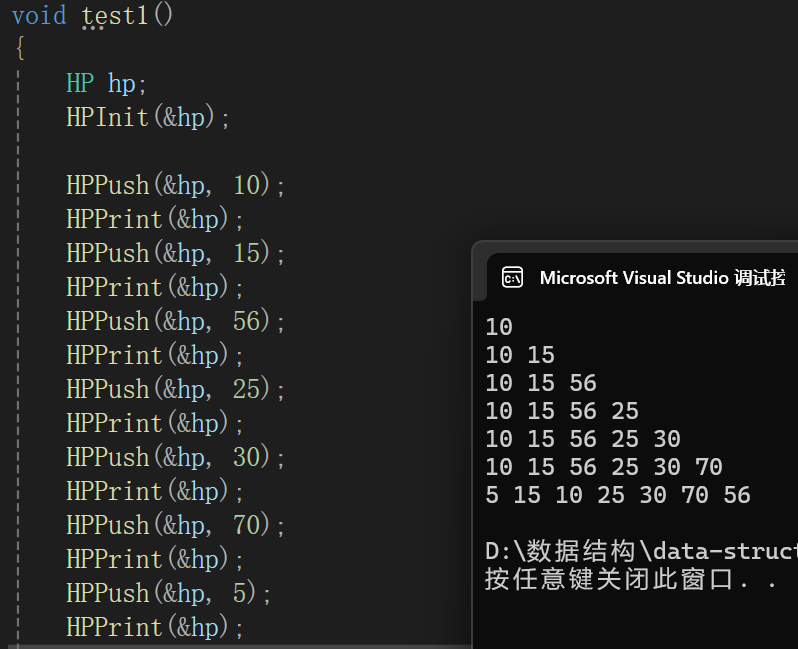
6.堆的遍历打印
一般没有这个操作,因为没啥必要,这里是懒得设断点,一点一点调试了,写个遍历打印便于分析:

测试代码:
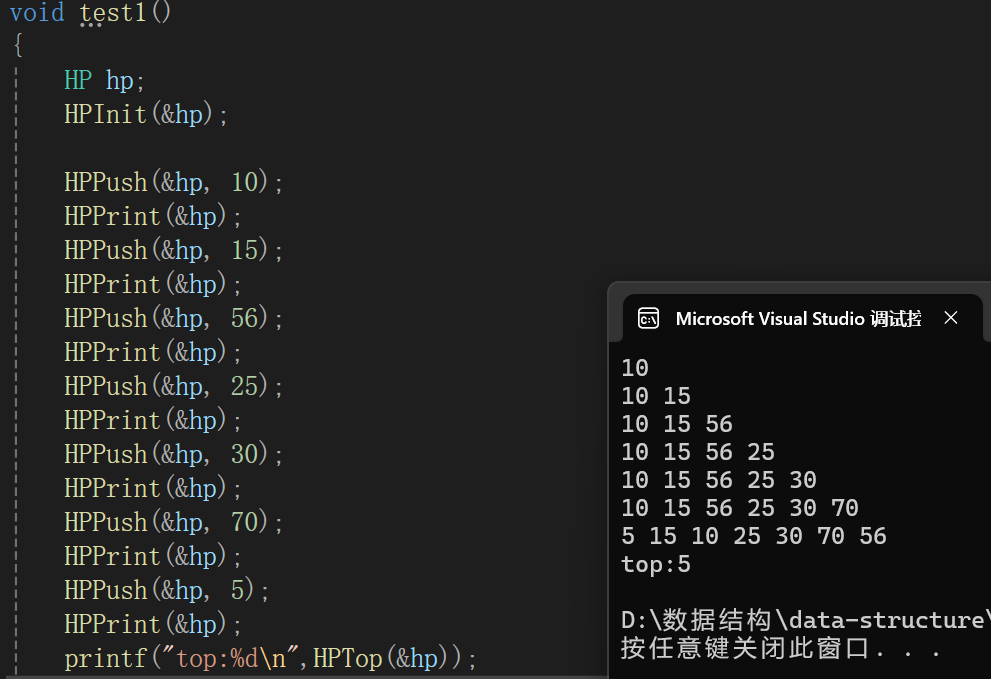
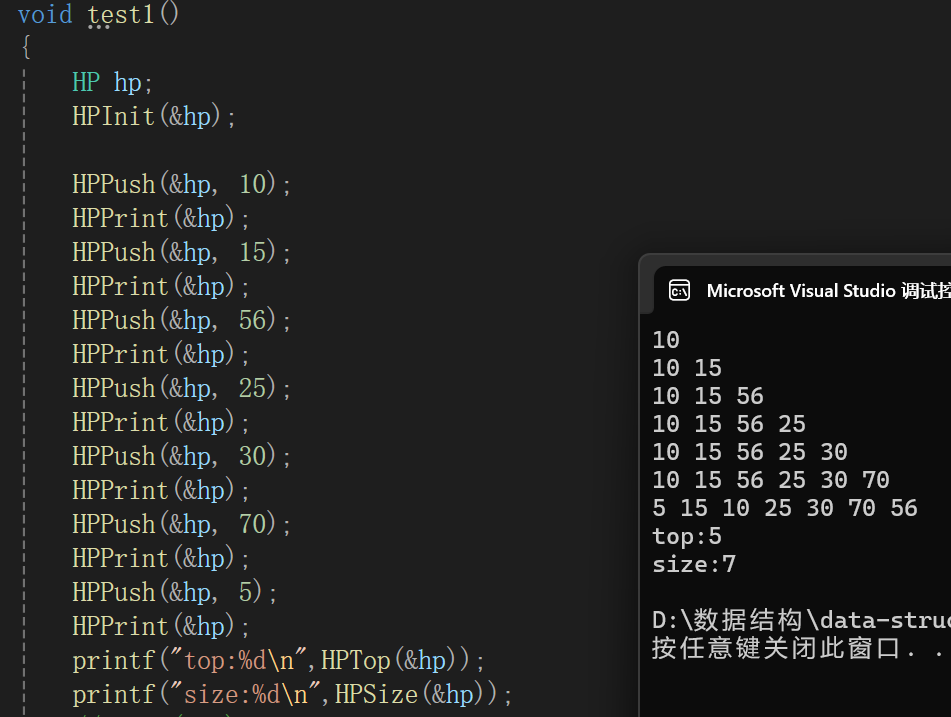
7.获取堆顶元素

测试代码:
8.获取堆有效元素个数

测试代码:
四、堆排序
虽然不知道堆排序怎么来的,但是一般只要学编程的,肯定听过什么冒泡排序了,堆排序了,快速排序了,归并排序了,希尔排序了等等。
1.堆排序的思想
为什么讲堆的操作完了,却不结束呢,又整过来一个堆排序,回答这个问题就先看一个现象:
借助堆的打印和遍历出堆打印出来的堆顶元素。
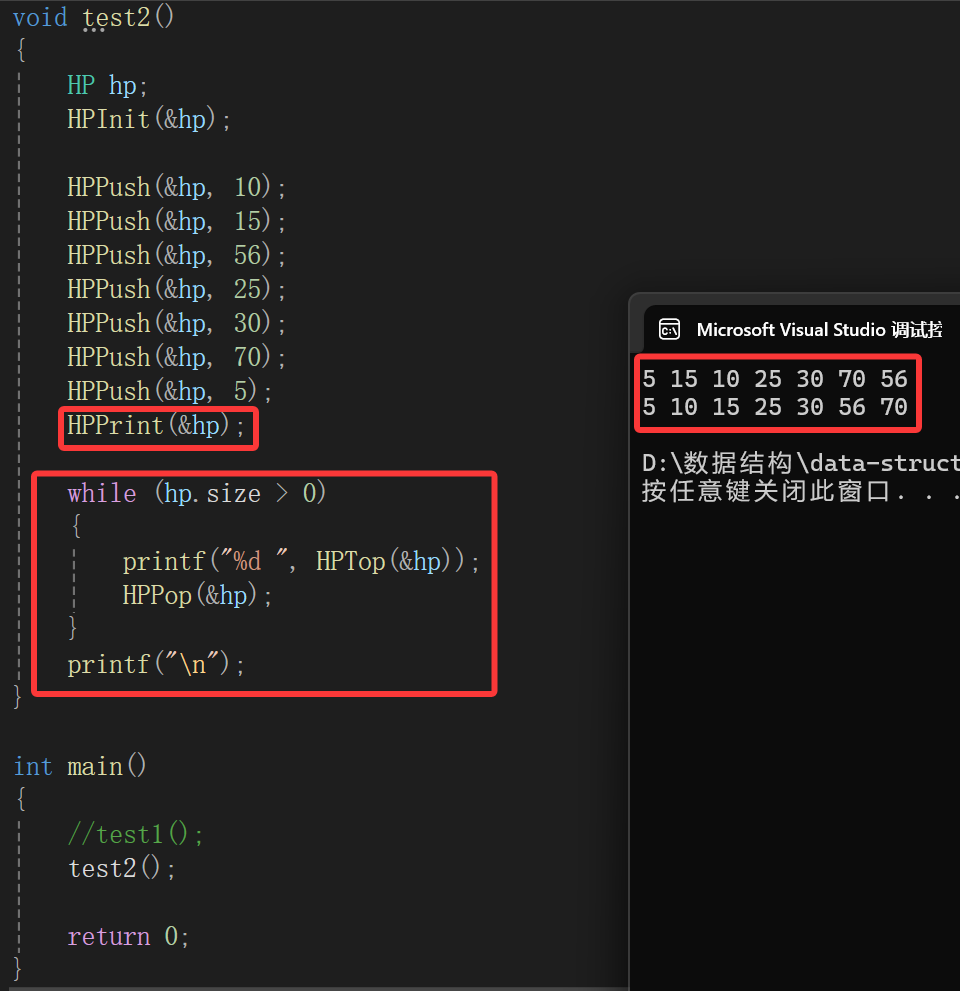
我们的Push和Pop两个函数都是维护小根堆的基础上建立的,每次删除的元素刚好就是堆里的最小的元素,这样的话最终生成的序列就是一个升序的数列,诶!难道这就是堆排序吗。
答案肯定是否定的,第一,排序算法我们也不是没见过,传参传的是待排序的数组,以及其他所需要参数,比如冒泡排序:

最后数组的元素应该被修改,如果直接用堆实现,最后还得把数据一个一个塞回数组里,肯定不是这么麻烦。
第二,难道排序前我们还得把什么Push,什么Init之类的方法去一一实现吗,太不现实了,我们需要的是算法思想,排序不应该借助数据结构。
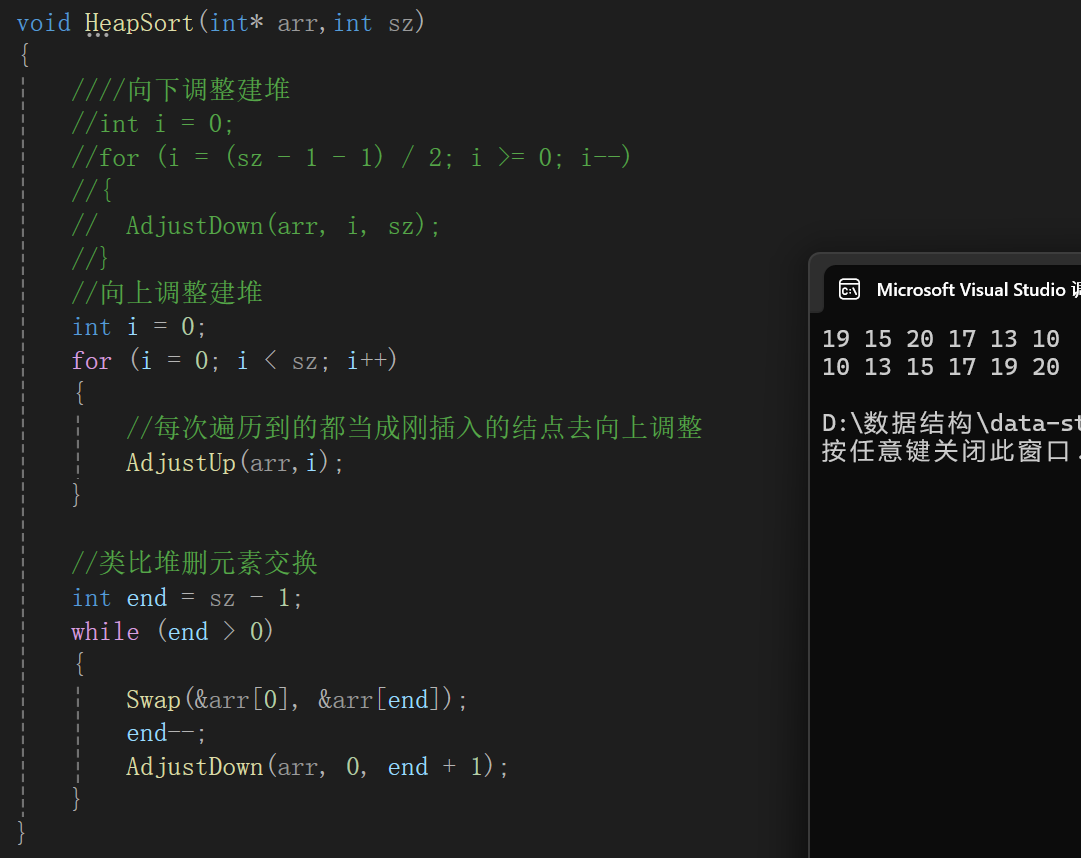
2.堆排序的实现(向下调整建堆)
根据分析,堆排序只借助堆的性质,而不借助堆的结构,怎么借助呢?
我们在上面进行堆删的时候是怎么做的,借助尾删的思想,为了尾删,所以就让底层数组的首元素和最后一个元素互相交换,然后再调整前n个元素的顺序,使其又成堆,重复以上操作。
根据这个性质,很容易得到,如果想要执行类似堆删的操作,首先就应该先将乱序数组郭建成堆,至于大根堆还是小根堆,取决你的要求,每次堆顶的元素是要放到数组的最后的,那么这样的话,升序就应该是大根堆,因为大的要放在后,反之,降序就应该是小根堆,因为小的要放在后。
所以代码大体上就两块,一块将无序数组调整成堆,一块做类似于出堆顶元素的操作(实际上是将堆顶的极值放到目前数组的末尾)。
思路有了以后,借助具体例子看看代码如何落地:
比如这样一个数组:
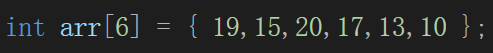
现在画成二叉树就应该是:
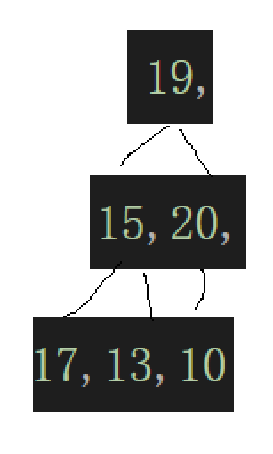
很明显,并不是堆,我们用向下调整算法给它调成堆是怎么来的呢?
第一次见向下调整是在堆底层的数组的首元素和尾元素进行了交换。
 变成
变成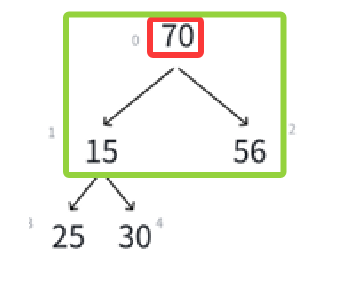
可以确定的是,以这个堆为根结点的那棵小子树,也就是第一层和第二层那棵树很可能因为互换而失去了堆的特性,所以需要比较并且如果需要互换就互换,这个互换使得第一层第二层的这棵树肯定符合堆的特性了:
但是被交换的,那个孩子结点,也就是这个例子的70,很明显就影响下面的那棵子树了,还得循环去检测并出现问题交换,直到越界。
这是我们之前接触过的向下调整,可知,向下调整前由于其它子树原来就是堆而保证了只需要修改根结点的子树,其它的如果被换了再去管。
我们现在面临的情况就是,实际上根本不是堆,每个子树都不能保证堆的特性,所以这个时候不能再从根节点的子树开始维护堆的特性,而是从倒数第一个子树开始,比如:
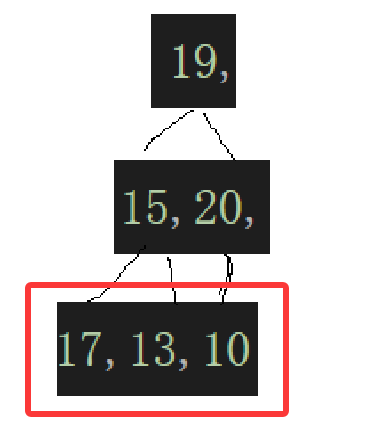
可知乱序数组的叶子结点没有后继结点,根本不会违背堆的特性,最少得从倒数第一个非叶子结点开始调整:
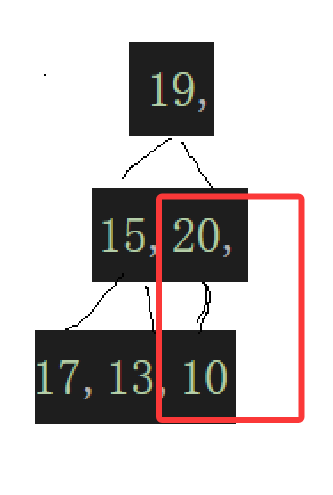
这个20这个结点应该是由最后一个结点算出来的,不然你怎么会知道是多少,也就是:
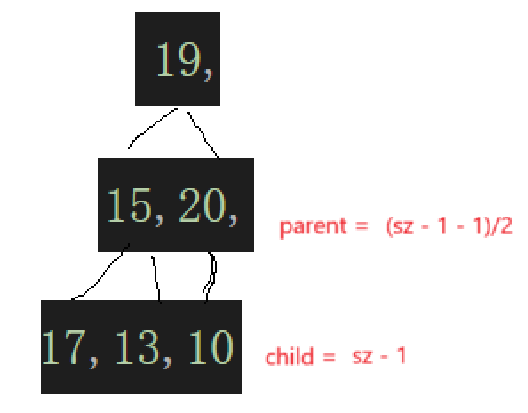
然后这个调整完,就检查上一个非叶子结点的子树:
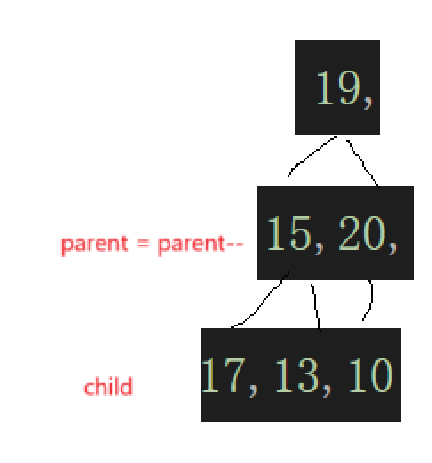
到这一步就看出来了,最开始根据数组元素个数算出来个子树的根结点下标检测子树,然后这棵子树遍历完,遍历上一颗,直接parent--,通过parent去算child,然后根据需要去交换:
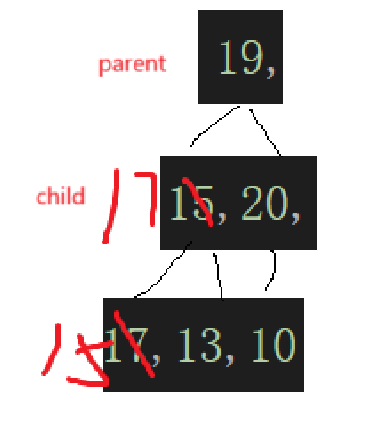
parent再--就到了19这个结点,一检测,就发现:
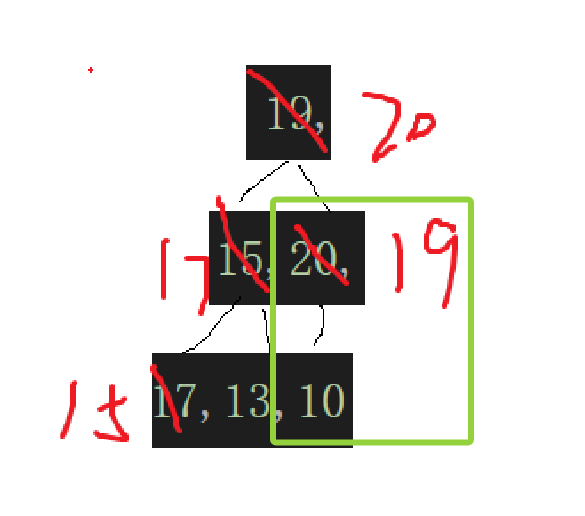
但是由于孩子结点可能还是某棵子树的根结点,你还必须一直检查到child越界不可。
思路有了,代码开写:

for循环的循环变量i做的是堆的非叶子结点的下标,从倒数第一个开始遍历,这样遍历到根结点的时候相当于只有根结点那棵子树可能有问题,这样就和我们堆删的场景相同了。
传参其实我犹豫了一下,调整的是arr数组的元素不用犹豫,parent是i也不用说,我写n的时候忘了,n代表的是数组有效元素个数,那就直接传sz就行。
然后就是每次数组的首元素与尾元素交换,保证了极值在数组末尾以后,那个元素位置就不用再变了,就像堆删除的元素肯定不能再一起调整了,所以end--,又考虑到end作的是最后一个元素的下标,而AdjustDown最后一个参数应该是堆中有效元素个数,所以传个end + 1。
测试代码:
当然,我为了方便看,写了个数组的遍历打印,一个循环而已,不多解释了。
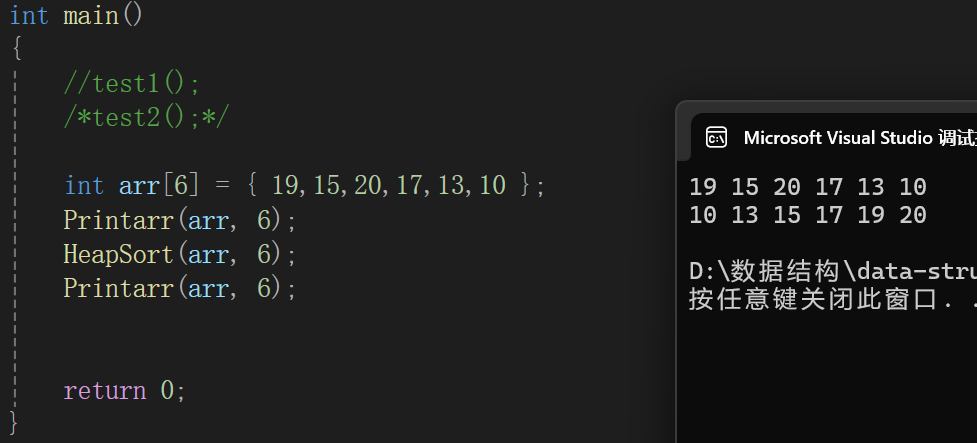
最后再强调一下,我们升序建大堆,降序建小堆,因为堆排序是将堆顶元素放到本次数组的最后,如果升序就得后放大,放大的应该是大堆,反之同理。
3.堆排序的实现(向上调整建堆)
还是回顾一下我们第一次见向上调整建堆:
当时是在堆的底层尾插了一个数据,这样以这个数据所在的子树就可能不符合堆的特性,也就可能导致一系列的子树的性质的改变,所以需要从下向上检测子树,例如:
这时我们是已知child,求parent,最终parent < 0或者child == 0说明根结点都检测过了,就停止向上调整,还是一样的问题,能够向上调整的前提肯定是本身就是一个堆。
我们类比插入的情境去建堆:
还是向下调整建堆的那个数组
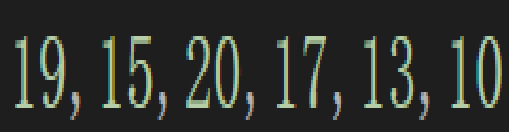
这次当成一个一个去尾插即可,也就是:
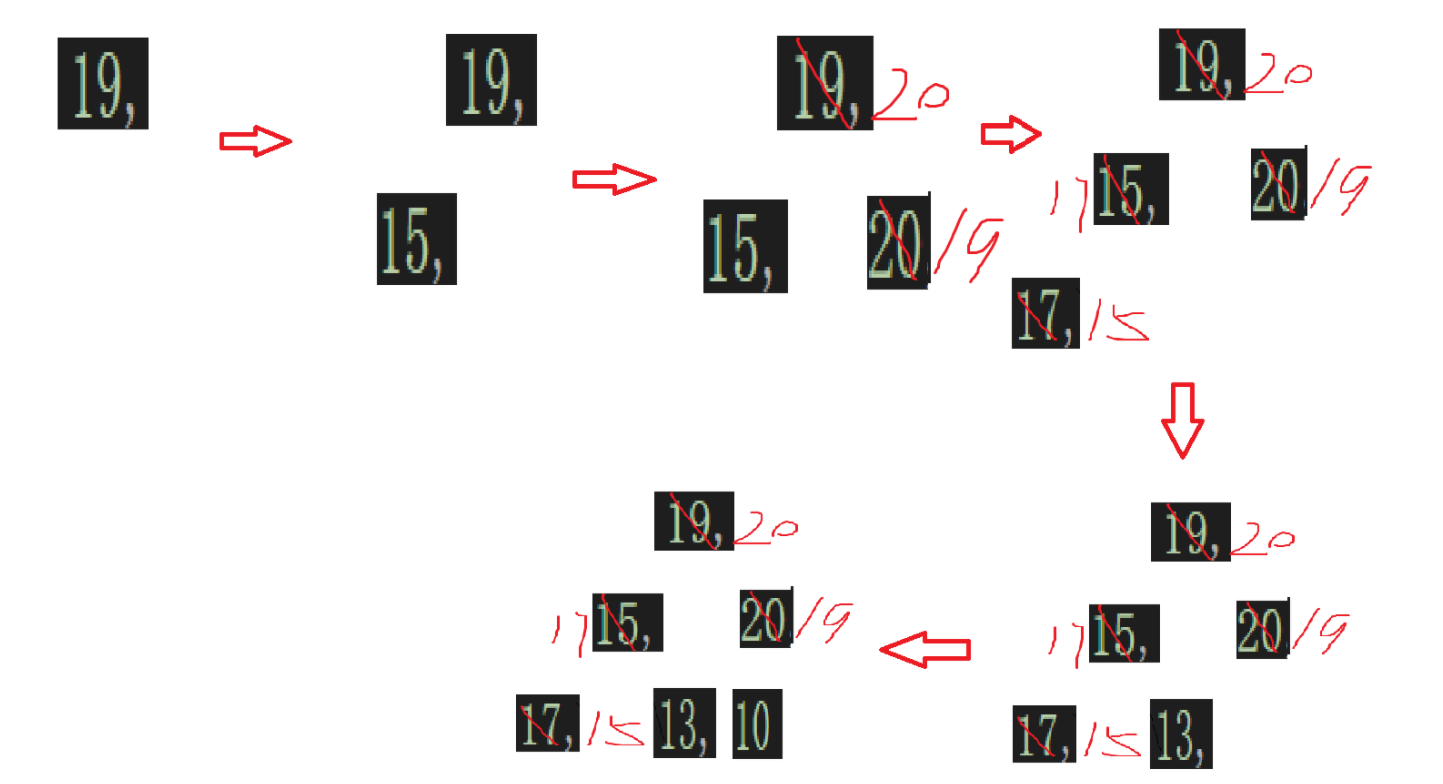
4.分析堆排序的时间复杂度
最终排序复杂度
首先分析相同点,最终用一个循环遍历完整个数组的数据,while循环的时间复杂度就应该是n,内层只有AdjustDown的时间复杂度不是O(1),分析可知:
循环的次数为层数,而层数与结点数的关系为:log(n)。
但是每次都还得n--,因为未排序的数肯定是循环一次少一次,所以最后时间复杂度就这么算:
log(n)+log(n-1)+……+log(2) = log(n!)≈nlogn - n。
这个公式左半边倒没啥,最后约等我确实也第一次见,大概知道最后排序加调整的时间复杂度为O(nlogn)即可。
向下调整建堆时间复杂度
我们为了便于计算,借用满二叉树来推理,完全二叉树和满二叉树顶多差几个有限的结点,不太影响总体时间复杂度。
而向下排序是什么,整个二叉树已经确定了,除了叶子结点的非叶子结点都得调整,假设满二叉树一共有h层,并且假设原二叉树的每个结点都需要向下移动到h层,那么每层结点个数以及调整的层数分别为:
| 每层结点个数 | 需要调整的层数 |
| h - 1 | |
| h - 2 | |
| h - 3 | |
| …… | …… |
| 1 |
弄清向下调整是除了最底层叶子结点的1到h - 1层都得向下调整。
其他操作都可视为O(1)只有这里是在循环的步骤,求和
T(h) = * (h - 1) +
* (h - 2) +
* (h - 3) + ……+
* 1
差比数列求和了:
2T(h) = * (h - 1) +
* (h - 2) +
* (h - 3) + ……+
* 1
可得T(h)= +
+
+……+
+
- h
化简为T(h) = - h
但是输入的时候看的是无序数组的元素个数,还得代换一下:
n =
h = log(n + 1)
等量代换:
T(n)= n - log(n + 1)
根据大O的原则,很明显只保留最高次项,那为O(n),由于其他的操作都是O(1),与输入无关,所以我们向下调整建堆的时间复杂度就是O(n)。
向上调整建堆时间复杂度
有了向下调整的经验,那就容易看向上调整建堆的时间复杂度了:
还是借助满二叉树的性质,向上调整可就相当于往上挂结点,再向上调整,还是假设满二叉树一共h层,每个挂上的结点都得向上调整至根结点。
还是给出每层结点与结点向上调整的层数:
| 每层结点个数 | 需要调整的层数 |
| 1 | |
| 2 | |
| …… | …… |
| h - 1 |
弄清向上调整是从第2层到第h层都得调整。
还是求和:
T(h)= * 1 +
* 2 +……+
*(h - 1)
差比还是乘公比
2T(h)= * 1 +
* 2 +……+
*(h - 1)
相减:
T(h)= -(+
+
+……+
+
)+h*
化简得:
T(h)= h* -
+ 2
还是代换成结点个数:
T(n)= (n+1)log(n+1)-2n
只保留最高项,可知时间复杂度为O(nlogn)。
也就是说向上调整建堆的时间复杂度为O(nlogn)
堆排序时间复杂度
综上所述,可知堆排序时间复杂度是:
O(n + nlogn)或O(nlogn + nlogn)
所以总体来看,时间复杂度就是O(nlogn)
五、TOP-K问题
简述什么叫TOP-K问题,比如现在给几十亿个数据,请你求前100个最小的数,在现实生活中的例子就是,福布斯富豪榜,咱一般不都爱说什么世界第一富豪,世界前几富豪嘛;又如,评价一个公司,老爱说什么世界五百强,这不还是前K个数嘛。
给一个数据超级大的问题,要求求前K个数据(可能是求最小的前K个,也可能求最大的前K个)。怎么解决?
其实借助的数据结构,或者说借助的思想基本就是堆了,但是具体怎么实现,难道真得建堆吗?
我们来看一个具体的例子,比如现在给了10亿个整型,那存放到内存里就是40亿个字节,基本上得4个G来存放,假如说现在程序只让你用1kb,那你不炸了嘛。
所以还是借助堆来实现,但是可不是简简单单把所有的数据都入堆,这样的话跟我们上面说的不就一样了嘛,憋说话,看操作:
如果堆里只存n个数据中前k的元素,其他元素只放在文件里,也就是先读取文件(或者说所给数据,在这里就以文件里的数据为例)k个数据构建成堆,再调换堆顶元素,因为堆顶元素就是极值。
不妨想一下什么情况建立什么样的堆,比如我们要求前K个最大的数,根据前k个数据建立堆,如果是小根堆的话,堆顶元素就是最小的元素,那就遍历剩下的n-k个元素,因为要求最大的几个数,碰见这次遍历的元素比堆顶大的话,就互换(这样至少保证在最开始的k个元素与之后n-k的遍历过的这些数据里,堆里的数据是最大的),这样的话还需要再调整堆,那么堆顶还是堆内最小的元素,这样遍历循环下去,因为每次都把堆里最小的换为每次遍历到的比堆顶大的,最终堆顶应该是在剩下的所有元素里最大的,而又因小根堆的特性,分支一定比根结点大,所以最后得到的堆就是要求的K个最大的数,反之如果要求k个最小的数,那就应该建大根堆。
理论成立,实践开始:
首先模拟一下情境:
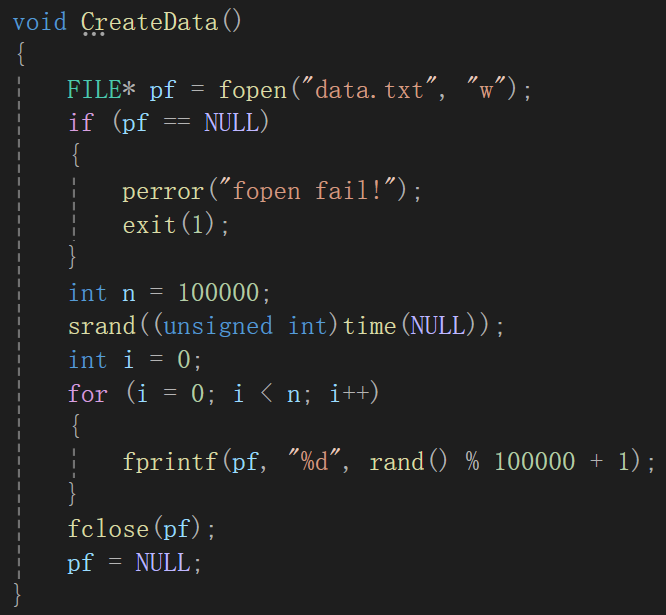
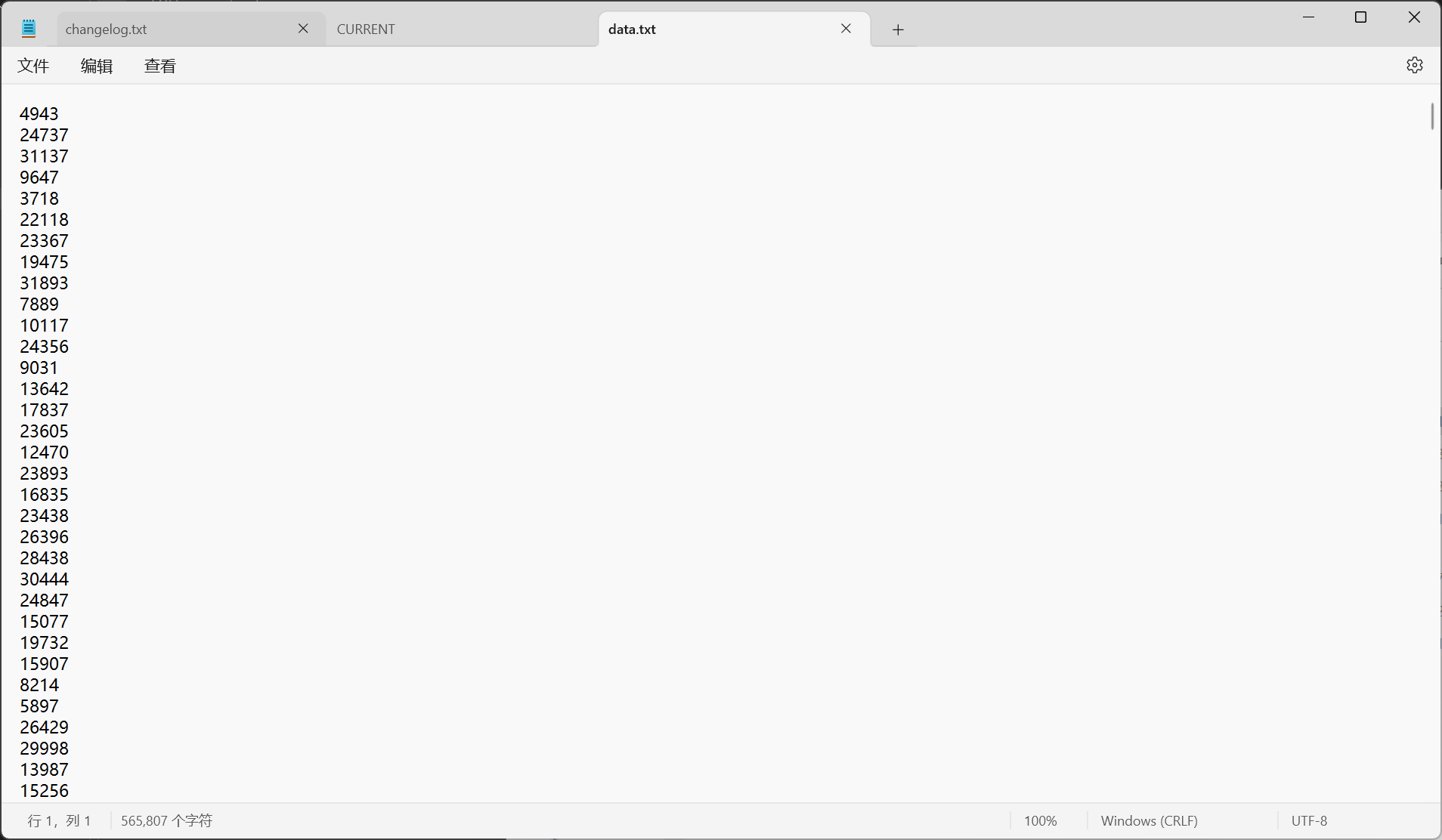
借助几个我们学过用过的函数来实现情景的模拟,即先创造100000个(不创造几个亿那么大的文件了,主要是展示思想)数据。
复习一下:
fopen第一个参数是一个字符串,传的是文件名(带后缀),当然,也可以带上路径,如果没有路径默认从程序所在文件夹里找;第二个参数是打开方式,比如"r","w"等,如果是以''w‘’即写的形式打开文件,就可以输出到文件数据,当然,如果指定文件不存在,系统会自动生成一个对应名字的文件。
srand函数是为了rand函数作准备的,rand函数生成的随机数序列取决于seed,如果不用srand函数的话,默认种子为1,这样的话,序列就只会固定,所以我们将seed根据程序运行的时间设定为时间戳time,只不过time函数参数为一个指针(传空即可),返回值默认unsigned int,强转是为防止报错。
fprintf函数类比printf函数,标准的输出函数,只不过printf函数是将数据输出到标准输出流即屏幕,而fprintf函数是将数据输入到文件,参数只是在printf("内容与格式",占位符的替换内容)前加了个文件指针,fprintf(FLIE* p,"内容与格式",占位符的替换内容),这样理解就不用解释了。
fclose函数与fopen的关系类似于malloc calloc realloc与free的关系,有借有还,有开有关。
当然,为了更好的查看最后得出的结果,我们自己再输入几个数据:
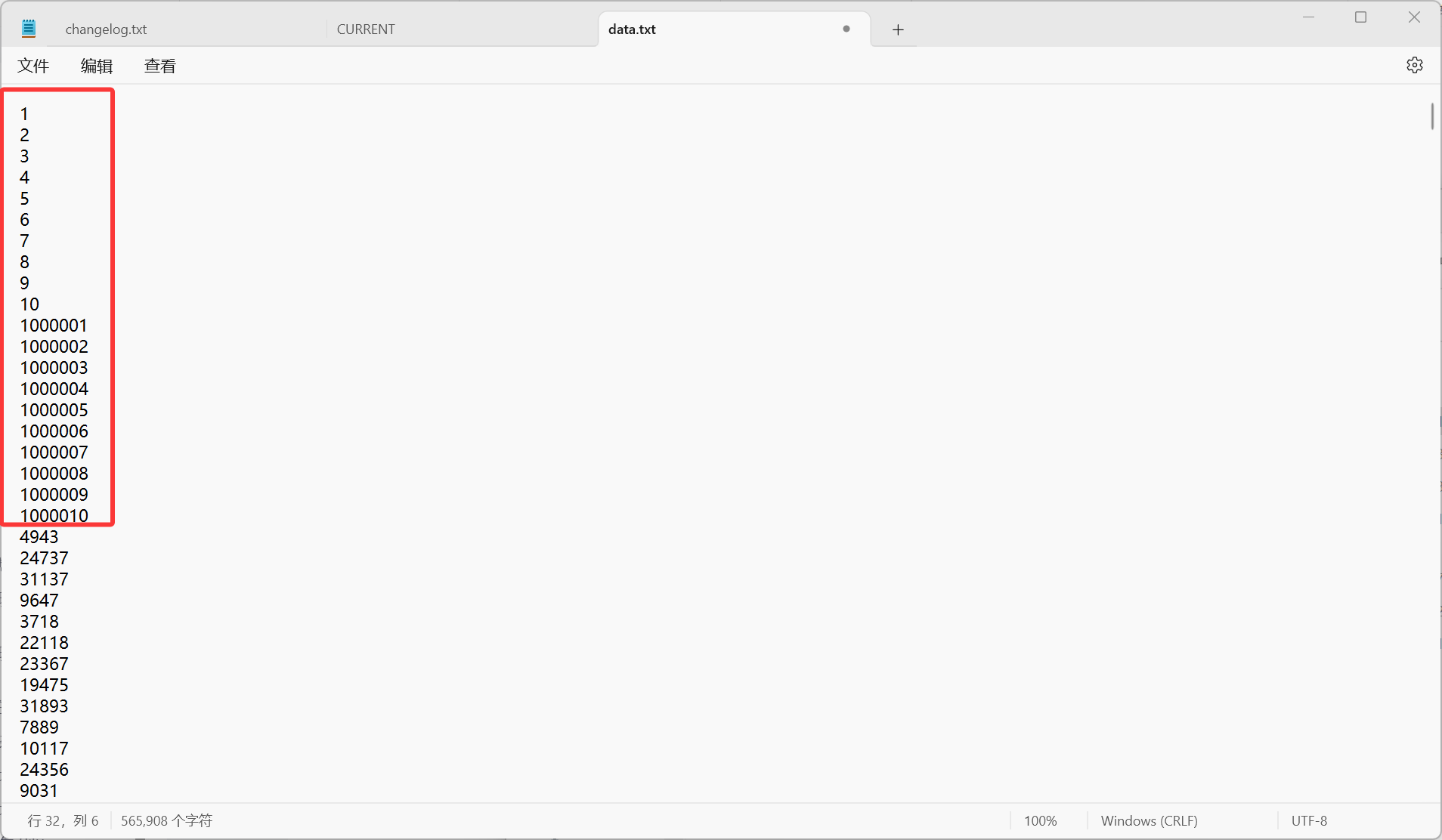
到时候输入K为10,就可以看到最大/最小就是我们人工插入的,便于验证我们代码的有效性。
准备工作做好了正式开始用代码实现求n个数据中前k个最大/最小的元素:
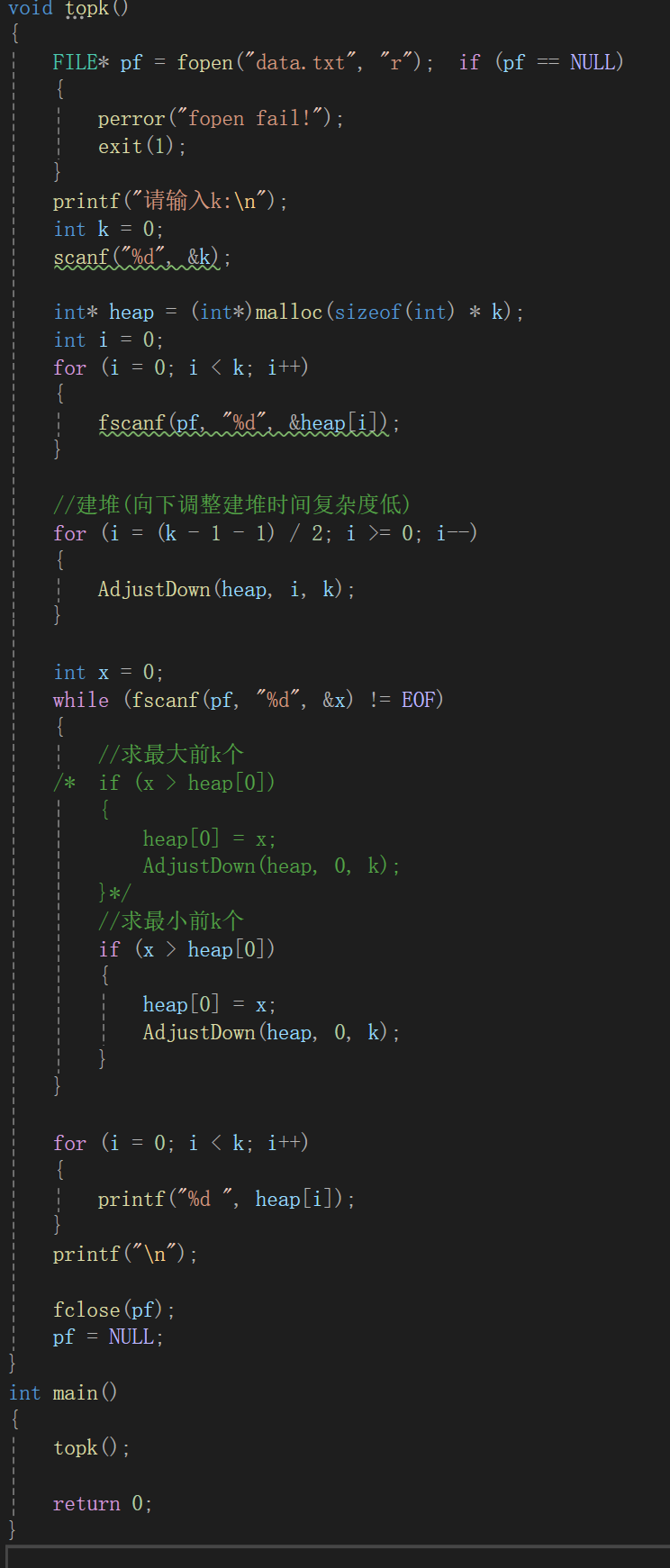
思路清晰了代码不必多说,场景模拟为从文件中读取数据,前两个循环先建小堆(因为后续比较是为了求k个最大)。
然后疯狂的读取文件后的数据(之前说过,FILE*这个结构体指针有很多类型,没读一次,指针自动后移,所以每次scanf后,就会自动移动向下一个数),如果需要调换,那就调整堆,最后一个循环不属于top-k问题,只是为了便于查看。
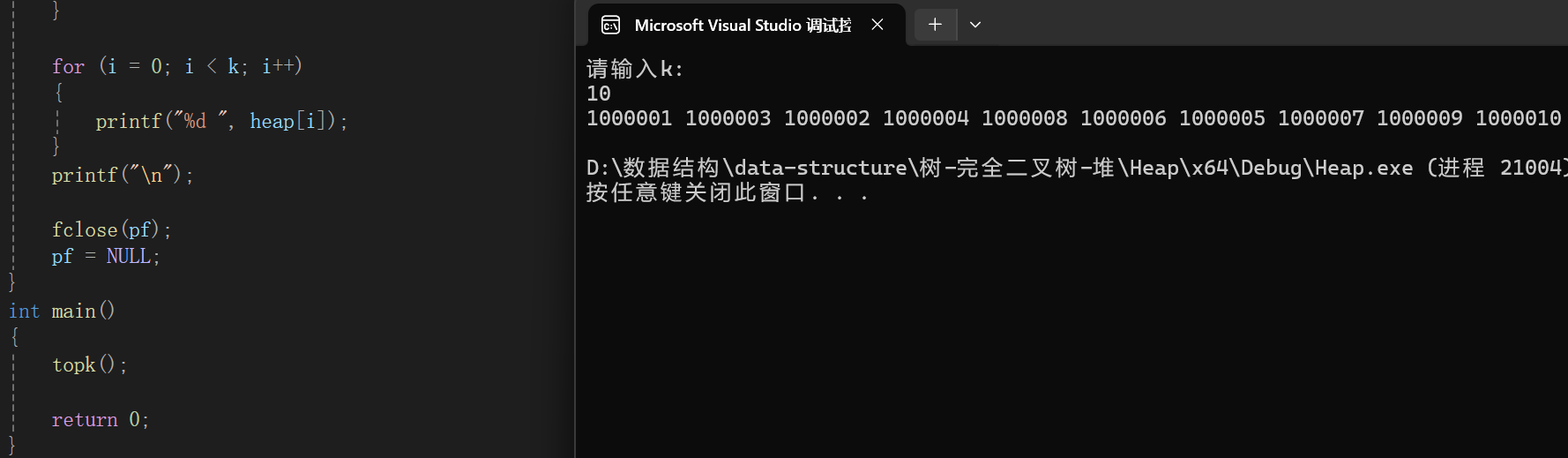
最终测试结果也不出所料,就是我们设置的要求,当然,把小根堆换大根堆,并且修改检查的逻辑,即可求最小的前k个:
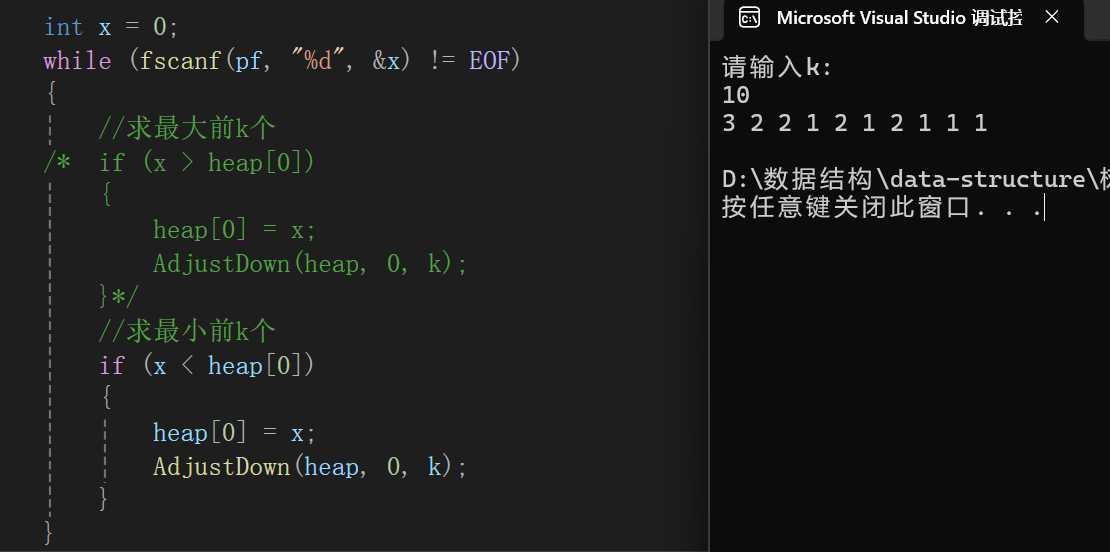
不过有点招笑了,以为没想到自然生成的还有1 2 3,还这么多,为了体现,我们在data.txt这个文件手动插入5个0:
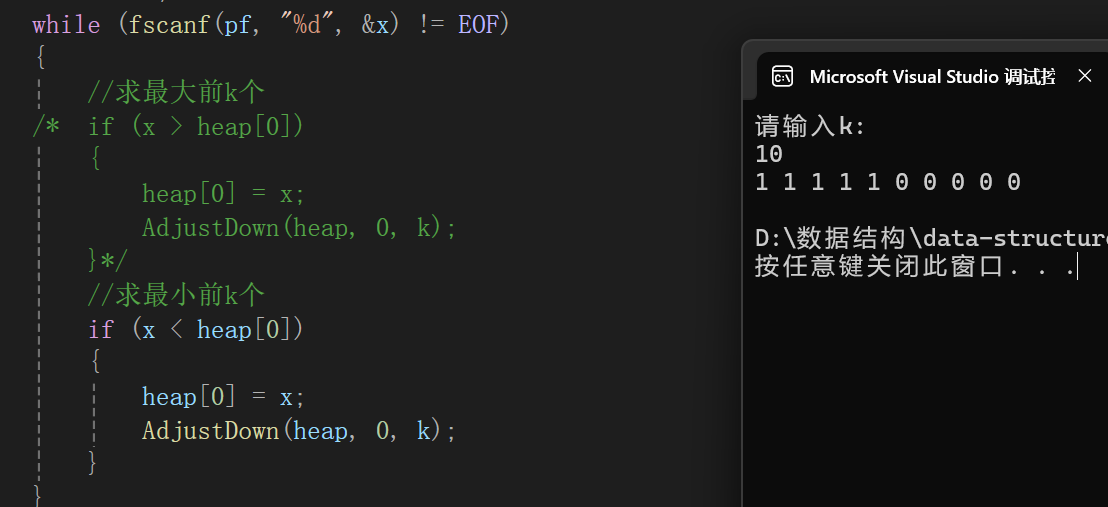
算法基本没有问题。
最后来分析一下这个算法的时间复杂度,直接在图上标注出来了:
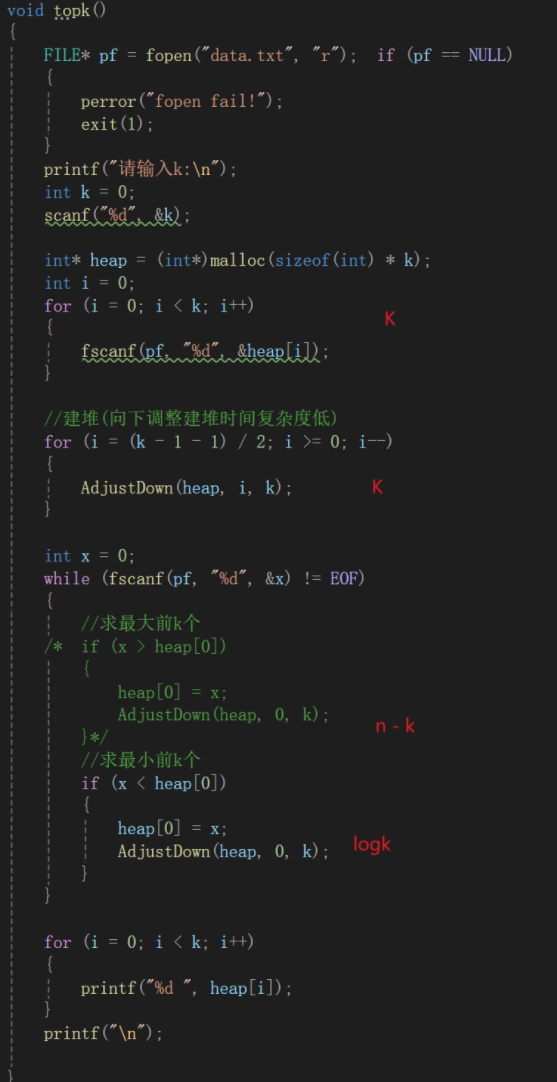
就是k + k + (n - k)logk
按照大O就是O(k + (n - k)logk)
k不确定,万一跟n对半那不就老大,无法忽略,所以就带上了。
相关文章:
数据结构(7)树-二叉树-堆
一、树 1.树的概述 现实生活中可以说处处有树。 在计算机里,有一种数据结构就是像现实中的树一样,有根,有分支,有叶子;一大片树就叫做森林。 这些性质抽象到计算机里也叫树,大致长这个样子: …...

时序数据库IoTDB基于云原生的创新与实践
概述 Apache IoTDB 是一款独立自研的物联网时序数据库,作为 Apache 基金会的顶级项目,它融合了产学研的优势,拥有深厚的科研基底。IoTDB 采用了端边云协同的架构,专为物联网设计,致力于提供极致的性能。 数据模型 I…...

怎么快速判断一款MCU能否跑RTOS系统
最近有朋友在后台中私信我,说现在做项目的时候有时候总是会考虑要不要用RTOS,或者怎么考量什么时候该用RTOS比较好、 关于这个问题,我个人也是深有感触的,做开发这么久了,大大小小的产品都做过不少了。有用RTOS开发的…...
使用原生前端技术封装一个组件
封装导航栏 navbar-template.html <header><nav><ul><li><a href"index.html"><i class"fas fa-home"></i> 主页</a></li><li><a href"#"><i class"fas fa-theate…...

lesson04-简单回归案例实战(理论+代码)
理解线性回归及梯度下降优化 引言 在机器学习的基础课程中,我们经常遇到的一个重要概念就是线性回归。今天,我们将深入探讨这一主题,并通过具体的例子来了解如何利用梯度下降方法对模型进行优化。 线性回归简介 线性回归是一种统计方法&a…...

Java 面试中的数据库设计深度解析
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Java 面试中的数据库设计深度解析一、数据库…...

国内首发!具有GPU算力的AI扫描仪
奥普思凯重磅推出的具有GPU算力的扫描仪,是一款真正意义上的AI扫描仪,奥普思凯将嵌有OCR发票识别核心的高性能NPU算力棒与高速扫描仪相结合,实现软件硬件相结合,采用一体化外观设计,实现高速扫描、快速识别表单&#x…...
【开发技巧指北】IDEA修改默认绑定Maven的仓库地址
【开发技巧指北】IDEA修改默认绑定Maven的仓库地址 Microsoft Windows 11 家庭中文版 IIntelliJ IDEA 2025.1.1.1 默认的IDEA是有自己捆绑的Maven的(这是修改完毕的截图) 修改默认的Maven配置,路径是IDEA安装路径下的plugins D:\Softwares\I…...

数据存储与运算
计算机中的数据存储与运算 输出地址后看不懂格式,为什么? 第一节:进制转换基础 ✅ 常见进制: 十进制(Decimal):日常使用的 0~9二进制(Binary):计算机底层使…...
【2025最新】Java图书借阅管理系统:从课程作业到实战应用的完整解决方案
【2025最新】Java图书借阅管理系统:从课程作业到实战应用的完整解决方案 目录 【2025最新】Java图书借阅管理系统:从课程作业到实战应用的完整解决方案**系统概述** **核心功能模块详解****1. 系统登录与权限控制****2. 借阅管理模块****3. 用户角色管理…...
springcloud openfeign 请求报错 java.net.UnknownHostException:
现象 背景 项目内部服务之间使用openfeign通过eureka注册中心进行服务间调用,与外部通过http直接调用。外部调用某个业务方提供的接口需要证书校验,因对方未提供证书故设置了忽略证书校验代码如下 Configuration public class IgnoreHttpsSSLClient {B…...
【harbor】--配置https
使用自建的 CA 证书来自签署和启用 HTTPS 通信。 (1)生成 CA认证 使用 OpenSSL 生成一个 2048位的私钥这是 自建 CA(证书颁发机构) 的私钥,后续会用它来签发证书。 # 1创建CA认证 cd 到harbor [rootlocalhost harbo…...

Oracle 临时表空间详解
Oracle 临时表空间详解 一 临时表空间概述 临时表空间(Temporary Tablespace)是Oracle数据库中用于存储临时数据的专用空间,主要用于: 排序操作(ORDER BY, GROUP BY等)哈希连接(HASH JOIN)临时表数据某些类型的索引创建临时LOB对象存储 二 临时表空间…...

深入理解享元模式:用Java实现高效对象共享
享元模式(Flyweight)的核心思想是对象复用,通过共享技术减少内存占用,就像"共享单车"一样让多个调用者共享同一组细粒度对象。 什么是享元模式? 享元模式是一种结构型设计模式,它通过共享技术有…...
OptiStruct实例:消声器前盖ERP分析(2)RADSND基础理论
13.2 Radiated Sound Output Analysis( RADSND ) RADSND 方法通过瑞利积分来求解结构对外的辐射噪声。其基本思路是分为两个阶段,如图 13-12 所示。 图13-12 结构辐射噪声计算示意图 第一阶段采用有限元方法,通过频响分析(模态叠加法、直接法)工况计算结…...

barker-OFDM模糊函数原理及仿真
文章目录 前言一、巴克码序列二、barker-OFDM 信号1、OFDM 信号表达式2、模糊函数表达式 三、MATLAB 仿真1、MATLAB 核心源码2、仿真结果①、barker-OFDM 模糊函数②、barker-OFDM 距离分辨率③、barker-OFDM 速度分辨率④、barker-OFDM 等高线图 四、资源自取 前言 本文进行 …...

Linux.docker.k8s基础概念
1.Linux基本命令 cat 查看文件内容。 cd 进入目标目录。 ll 查询当前路劲下文件的详细信息。 ls 查询当前路劲下的文件。 touch 建立一个文件。 mkdir 建立一个文件夹。 rm 删除文件或者目录。 mv 移动目录和重新命名文件。 unzip 解压。 top 查看当前线程的信息。 find …...

GIT命令行的一些常规操作
放弃修改 git checkout . 修改commit信息 git commit --amend 撤销上次本地commit 1、通过git log查看上次提交的哈希值 2、git reset --soft 哈希值 分支 1.创建本地分支 git branch 分支名 2.切换本地分支 git checkout mybranch; 3.创建一个新分支并…...

近期知识库开发过程中遇到的一些问题
我们正在使用Rust开发一个知识库系统,遇到了一些问题,在此记录备忘。 错误:Unable to make method calls because underlying connection is closed 场景:在docker中调用headless_chrome时出错 原因:为减小镜像大小&am…...
3.RV1126-OPENCV 图像叠加
一.功能介绍 图像叠加:就是在一张图片上放上自己想要的图片,如LOGO,时间等。有点像之前提到的OSD原理一样。例如:下图一张图片,在左上角增加其他图片。 二.OPENCV中图像叠加常用的API 1. copyTo方法进行图像叠加 原理…...
使用 HTML + JavaScript 实现一个日历任务管理系统
在现代快节奏的生活中,有效的时间管理变得越来越重要。本项目是一个基于 HTML 和 JavaScript 开发的日历任务管理系统,旨在为用户提供一个直观、便捷的时间管理工具。系统不仅能够清晰地展示当月日期,还支持事件的添加、编辑和删除操作&#…...

车载诊断架构SOVD --- 车辆发现与建连
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...

Notepad++找回自动暂存的文件
场景: 当你没有保存就退出Notepad,下次进来Notepad会自动把你上次编辑的内容显示出来,以便你继续编辑。除非你手动关掉当前页面,这样Notepad就会删除掉自动保存的内容。 问题: Notepad会将自动保存的文件地址,打开Note…...
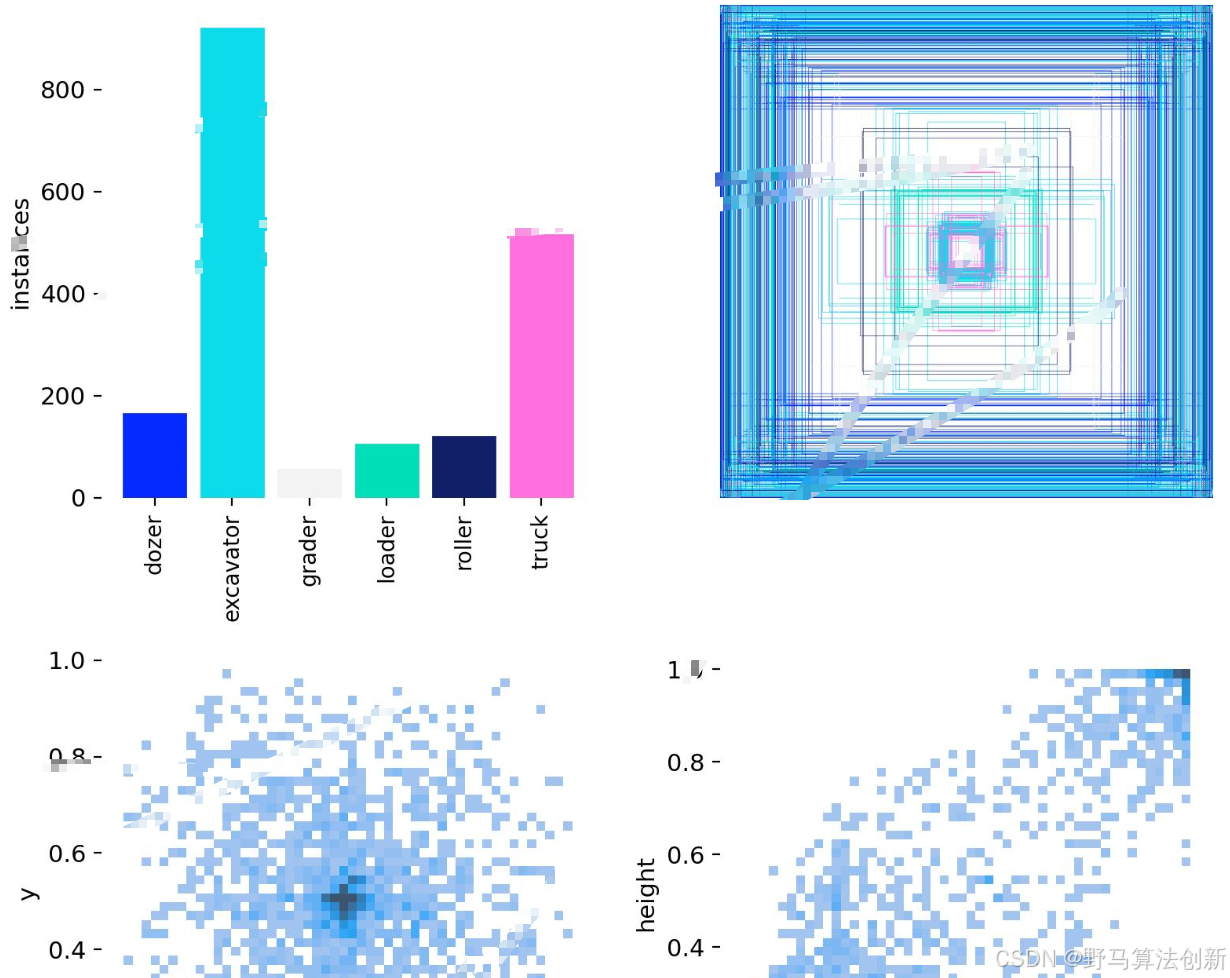
DL00924-基于深度学习YOLOv11的工程车辆目标检测含数据集
文末有代码完整出处 🚗 基于深度学习YOLOv11的工程车辆目标检测——引领智能识别新潮流! 🚀 随着人工智能技术的飞速发展, 目标检测 已经在各个领域取得了显著突破,尤其是在 工程车辆识别 这一关键技术上。今天&#…...
Axure RP11安装、激活、汉化
一:注册码 Axure RP11.0.0.4122在2025-5-29日亲测有效: 49bb9513c40444b9bcc3ce49a7a022f9...
)
【PhysUnits】15.6 引入P1后的左移运算(shl.rs)
一、源码 代码实现了Rust的类型级二进制数的左移运算(<<),使用类型系统在编译期进行计算。 use super::basic::{Z0, P1, N1, B0, B1, NonZero, NonOne, Unsigned}; use super::sub1::Sub1; use core::ops::Shl;// 左移运算(<<)…...
自编码器Auto-encoder(李宏毅)
目录 编码器的概念: 为什么需要编码器? 编码器什么原理? 去噪自编码器: 自编码器的应用: 特征解耦 离散隐表征 编码器的概念: 重构:输入一张图片,通过编码器转化成向量,要求再…...
数据结构之堆(topk问题、堆排序)
一、堆的初步认识 堆虽然是用数组存储数据的数据结构,但是它的底层却是另一种表现形式。 堆分为大堆和小堆,大堆是所有父亲大于孩子,小堆是所有孩子大于父亲。 通过分析我们能得出父子关系的计算公式,parent(child-1)/2ÿ…...

SpringBoot使用ffmpeg实现视频压缩
ffmpeg简介 FFmpeg 是一个开源的跨平台多媒体处理工具集,用于录制、转换、编辑和流式传输音频和视频。它功能强大,支持几乎所有常见的音视频格式,是多媒体处理领域的核心工具之一。 官方文档:https://ffmpeg.org/documentation.h…...

【Elasticsearch】exists` 查询用于判断文档中是否存在某个指定字段。它检查字段是否存在于文档中,并且字段的值不为 `null`
在 Elasticsearch 中,exists 查询用于判断文档中是否存在某个指定字段。它检查字段是否存在于文档中,并且字段的值不为 null。如果字段存在且有值(即使是空字符串或空数组),则 exists 查询会匹配该文档;如果…...