python学习打卡day40
知识点回顾:
- 彩色和灰度图片测试和训练的规范写法:封装在函数中
- 展平操作:除第一个维度batchsize外全部展平
- dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout
作业:仔细学习下测试和训练代码的逻辑,这是基础,这个代码框架后续会一直沿用,后续的重点慢慢就是转向模型定义阶段了。
1.彩色和灰度图片测试和训练的规范写法:封装在函数中
# 先继续之前的代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader , Dataset # DataLoader 是 PyTorch 中用于加载数据的工具
from torchvision import datasets, transforms # torchvision 是一个用于计算机视觉的库,datasets 和 transforms 是其中的模块
import matplotlib.pyplot as plt
import warnings
# 忽略警告信息
warnings.filterwarnings("ignore")
# 设置随机种子,确保结果可复现
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")灰度图像的规范写法:
# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])# 2. 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)#3. 创建数据加载器
train_loader = DataLoader(train_dataset,batch_size=64, # 每个批次64张图片,一般是2的幂次方,这与GPU的计算效率有关shuffle=True # 随机打乱数据
)test_loader = DataLoader(test_dataset,batch_size=1000 # 每个批次1000张图片# shuffle=False # 测试时不需要打乱数据
)
# 4. 定义模型、损失函数和优化器
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)# from torchsummary import summary # 导入torchsummary库
# print("\n模型结构信息:")
# summary(model, input_size=(1, 28, 28)) # 输入尺寸为MNIST图像尺寸criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于多分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器彩色图像的规范写法:
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器训练模型:
# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')模型测试
# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testprint(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_acc # 返回最终测试准确率绘制损失曲线
# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()执行训练和测试:
# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")@浙大疏锦行
相关文章:

python学习打卡day40
DAY 40 训练和测试的规范写法 知识点回顾: 彩色和灰度图片测试和训练的规范写法:封装在函数中展平操作:除第一个维度batchsize外全部展平dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作业&#…...

redis高并发问题
Redlock原理和存在的问题 Redlock 基于以下假设: 有多个(一般建议是 5 个)彼此独立的 Redis 实例(不是主从复制,也不是集群模式),它们之间没有数据同步。客户端可以与所有 Redis 实例通信。 …...
Live Helper Chat 安装部署
Live Helper Chat(LHC)是一款开源的实时客服聊天系统,适用于网站和应用,帮助企业与访问者即时沟通。它功能丰富、灵活、可自托管,常被用于在线客户支持、销售咨询以及技术支持场景。 🧰 系统要求 安装要求 您提供的链接指向 Live Helper Chat 的官方安装指南页面,详细…...
ARXML解析与可视化工具
随着汽车电子行业的快速发展,AUTOSAR标准在车辆软件架构中发挥着越来越重要的作用。然而,传统的ARXML文件处理工具往往存在高昂的许可费用、封闭的数据格式和复杂的使用门槛等问题。本文介绍一种基于TXT格式输出的ARXML解析方案,为开发团队提供了一个高效的替代解决方案。 …...
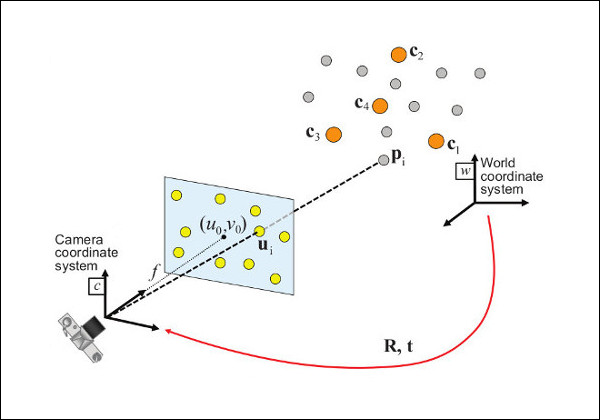
PnP(Perspective-n-Point)算法 | 用于求解已知n个3D点及其对应2D投影点的相机位姿
什么是PnP算法? PnP 全称是 Perspective-n-Point,中文叫“n点透视问题”。它的目标是: 已知一些空间中已知3D点的位置(世界坐标)和它们对应的2D图像像素坐标,求解摄像机的姿态(位置和平移&…...
)
LeetCode 热题 100 208. 实现 Trie (前缀树)
LeetCode 热题 100 | 208. 实现 Trie (前缀树) 大家好!今天我们来解决一道经典的算法题——实现 Trie (前缀树)。Trie(发音类似 “try”)是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构在自动补全和拼…...

python爬虫:RoboBrowser 的详细使用
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、RoboBrowser概述1.1 RoboBrowser 介绍1.2 安装 RoboBrowser1.3 与类似工具比较二、基本用法2.1 创建浏览器对象并访问网页2.2 查找元素2.3 填写和提交表单三、高级功能3.1 处理文件上传3.2 处理JavaScript重定向3.3…...

在日常管理服务器中如何防止SQL注入与XSS攻击?
在日常管理服务器时,防止SQL注入(Structured Query Language Injection)和XSS(Cross-Site Scripting)攻击是至关重要的,这些攻击可能会导致数据泄露、系统崩溃和信息泄露。以下是一份技术文章,介…...
Wkhtmltopdf使用
Wkhtmltopdf使用 1.windows本地使用2.golangwindows环境使用3.golangdocker容器中使用 1.windows本地使用 官网地址 https://wkhtmltopdf.org/,直接去里面下载自己想要的版本,这里以windows版本为例2.golangwindows环境使用 1.安装扩展go get -u githu…...
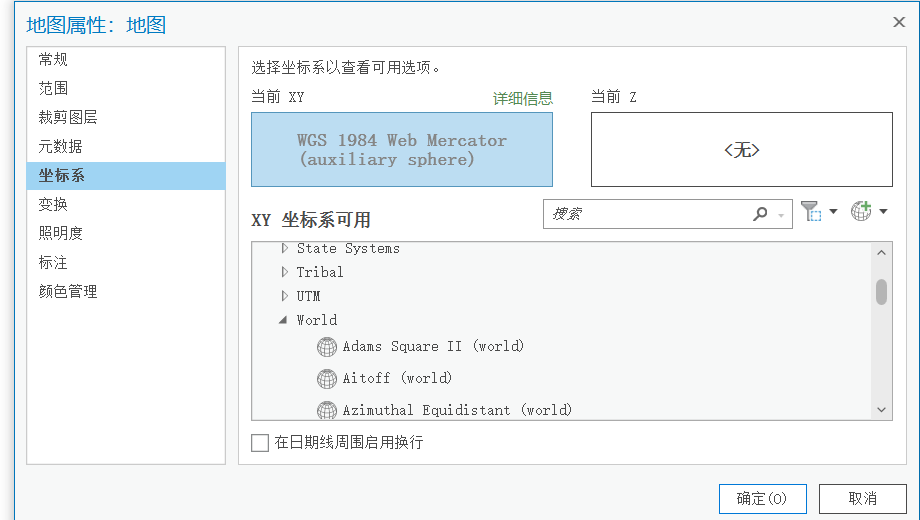
ArcGIS Pro 创建渔网格网过大,只有几个格网的解决方案
之前用ArcGIS Pro创建渔网的时候,发现创建出来格网过大,只有几个格网。 后来查阅资料,发现是坐标不对,导致设置格网大小时单位为度,而不是米,因此需要进行坐标系转换,网上有很多资料讲了ArcGIS …...
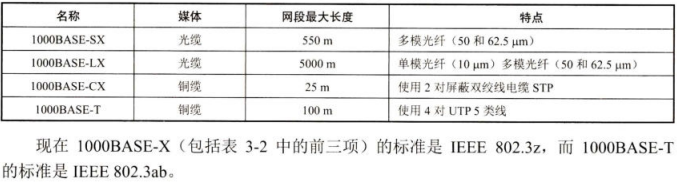
重学计算机网络之以太网
一:历史发展进程 DIX EtherNet V2 战胜IEEE802.3成为主流版本。总线型交换机拓扑机构代替集线器星型拓扑机构 1990年IEEE制定出星形以太网10BASE-T的标准**802.3i**。“10”代表10 Mbit/s 的数据率,BASE表示连接线上的信号是基带信号,T代表…...
《深度解构现代云原生微服务架构的七大支柱》
☁️《深度解构现代云原生微服务架构的七大支柱》 一线架构师实战总结,系统性拆解现代微服务架构中最核心的 7 大支柱模块,涵盖通信协议、容器编排、服务网格、弹性伸缩、安全治理、可观测性、CI/CD 等。文内附架构图、实操路径与真实案例,适…...

使用SCSS实现随机大小的方块在页面滚动
目录 一、scss中的插值语法 二、方块在界面上滚动的动画 一、scss中的插值语法 插值语法 #{} 是一种动态注入变量或表达式到选择器、属性名、属性值等位置的机制 .类名:nth-child(n) 表示需同时满足为父元素的第n个元素且类名为给定条件 效果图: <div class…...

AI 眼镜新纪元:贴片式TF卡与 SOC 芯片的黄金组合破局智能穿戴
目录 一、SD NAND:智能眼镜的“记忆中枢”突破空间限制的存储革命性能与可靠性的双重保障 二、SOC芯片:AI眼镜的“智慧大脑”从性能到能效的全面跃升多模态交互的底层支撑 三、SD NANDSOC:11>2的协同效应数据流水线的高效协同成本…...

论文阅读(六)Open Set Video HOI detection from Action-centric Chain-of-Look Prompting
论文来源:ICCV(2023) 项目地址:https://github.com/southnx/ACoLP 1.研究背景与问题 开放集场景下的泛化性:传统 HOI 检测假设训练集包含所有测试类别,但现实中存在大量未见过的 HOI 类别(如…...

算法学习--持续更新
算法 2025年5月24日 完成:快速排序、快速排序基数优化、尾递归优化 快排 public class QuickSort {public void sort(int[] nums, int left, int right) {if(left>right){return;}int partiton quickSort(nums,left,right);sort(nums,left,partiton-1);sort(nu…...

Postman 发送 SOAP 请求步骤 归档
0.来源 https://apifox.com/apiskills/sending-soap-requests-with-postman/?utm_sourceopr&utm_mediuma2bobzhang&utm_contentpostman 再加上自己一点实践经验 1. 创建一个新的POST请求 postman 创建一个post请求, 请求url 怎么来的可以看第三步 2. post请求设…...

Python Day39 学习(复习日志Day4)
复习Day4日志内容 浙大疏锦行 补充: 关于“类”和“类的实例”的通俗易懂的例子 补充:如何判断是用“众数”还是“中位数”填补空缺值? 今日复习了日志Day4的内容,感觉还是得在纸上写一写印象更深刻,接下来几日都采取“纸质化复…...
[Python] Python自动化:PyAutoGUI的基本操作
初次学习,如有错误还请指正 目录 PyAutoGUI介绍 PyAutoGUI安装 鼠标相关操作 鼠标移动 鼠标偏移 获取屏幕分辨率 获取鼠标位置 案例:实时获取鼠标位置 鼠标点击 左键单击 点击次数 多次有时间间隔的点击 右键/中键点击 移动时间 总结 鼠…...

课程介绍:《ReactNative基础与实战指南2025》
学习如何使用 ReactJS 构建适用于 iOS 和 Android 的 React Native 移动应用,无需 ReactJS 经验。无需掌握 Swift、Objective-C 或 Java/Android,也能开发跨平台(iOS 和 Android)移动应用。 全面掌握 React Native 的核心与进阶内…...
概念)
“候选对话链”(Candidate Dialogue Chain)概念
目录 一、定义与形式 二、生成过程详解 1. 语言模型生成(LLM-Based Generation) 2. 知识图谱支持(KG-Augmented Generation) 3. 策略调控(Policy-Driven Planning) 三、候选对话链的属性 四、候选对…...
应急响应靶机-web2-知攻善防实验室
题目: 前景需要:小李在某单位驻场值守,深夜12点,甲方已经回家了,小李刚偷偷摸鱼后,发现安全设备有告警,于是立刻停掉了机器开始排查。 这是他的服务器系统,请你找出以下内容&#…...
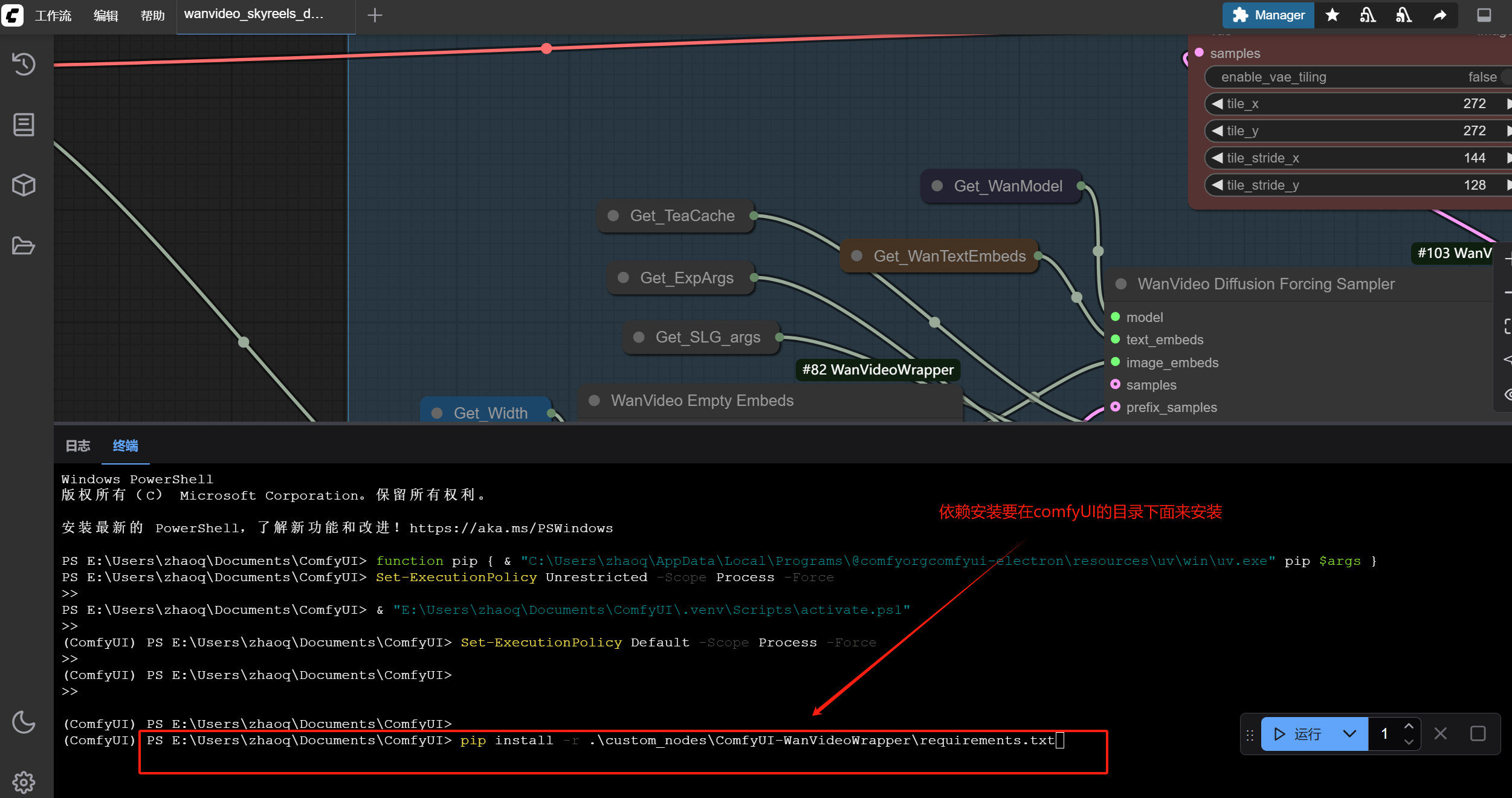
comfyui利用 SkyReels-V2直接生成长视频本地部署问题总结 1
在通过桌面版comfyUI 安装ComfyUI-WanVideoWrapper 进行SkyReels-V2 生成长视频的过程中,出现了,很多错误。 总结一下,让大家少走点弯路 下面是基于搜索结果的 ComfyUI 本地部署 SkyReels-V2 实现长视频生成的完整指南,涵盖环境配…...

UV 包管理工具:替代 pip 的现代化解决方案
安装 方法一:使用安装脚本 # macOS 和 Linux curl -LsSf https://astral.sh/uv/install.sh | sh# Windows PowerShell powershell -c "irm https://astral.sh/uv/install.ps1 | iex" 方法二:使用包管理器 # macOS (Homebrew) brew install uv#…...

css3 新增属性/滤镜效果/裁剪元素/图片适应盒子/定义和使用变量/恢复默认initial
从 CSS3 发布至今,CSS 标准引入了大量新特性,极大地丰富了前端开发的能力。以下是 CSS3 之后的重要新增属性、模块与特性总结,涵盖布局、动画、交互、视觉、选择器、单位等多个领域。 🎨 视觉与效果增强 属性/功能作用示例filte…...

YOLOv8 实战指南:如何实现视频区域内的目标统计与计数
文章目录 YOLOv8改进 | 进阶实战篇:利用YOLOv8进行视频划定区域目标统计计数1. 引言2. YOLOv8基础回顾2.1 YOLOv8架构概述2.2 YOLOv8的安装与基本使用 3. 视频划定区域目标统计的实现3.1 核心思路3.2 完整实现代码 4. 代码深度解析4.1 关键组件分析4.2 性能优化技巧…...

matlab实现VMD去噪、SVD去噪,源代码详解
为了更好的利用MATLAB自带的vmd、svd函数,本期作者将详细讲解一下MATLAB自带的这两个分解函数如何使用,以及如何画漂亮的模态分解图。 VMD函数用法详解 首先给出官方vmd函数的调用格式。 [imf,residual,info] vmd(x) 函数的输入: 这里的x是待…...
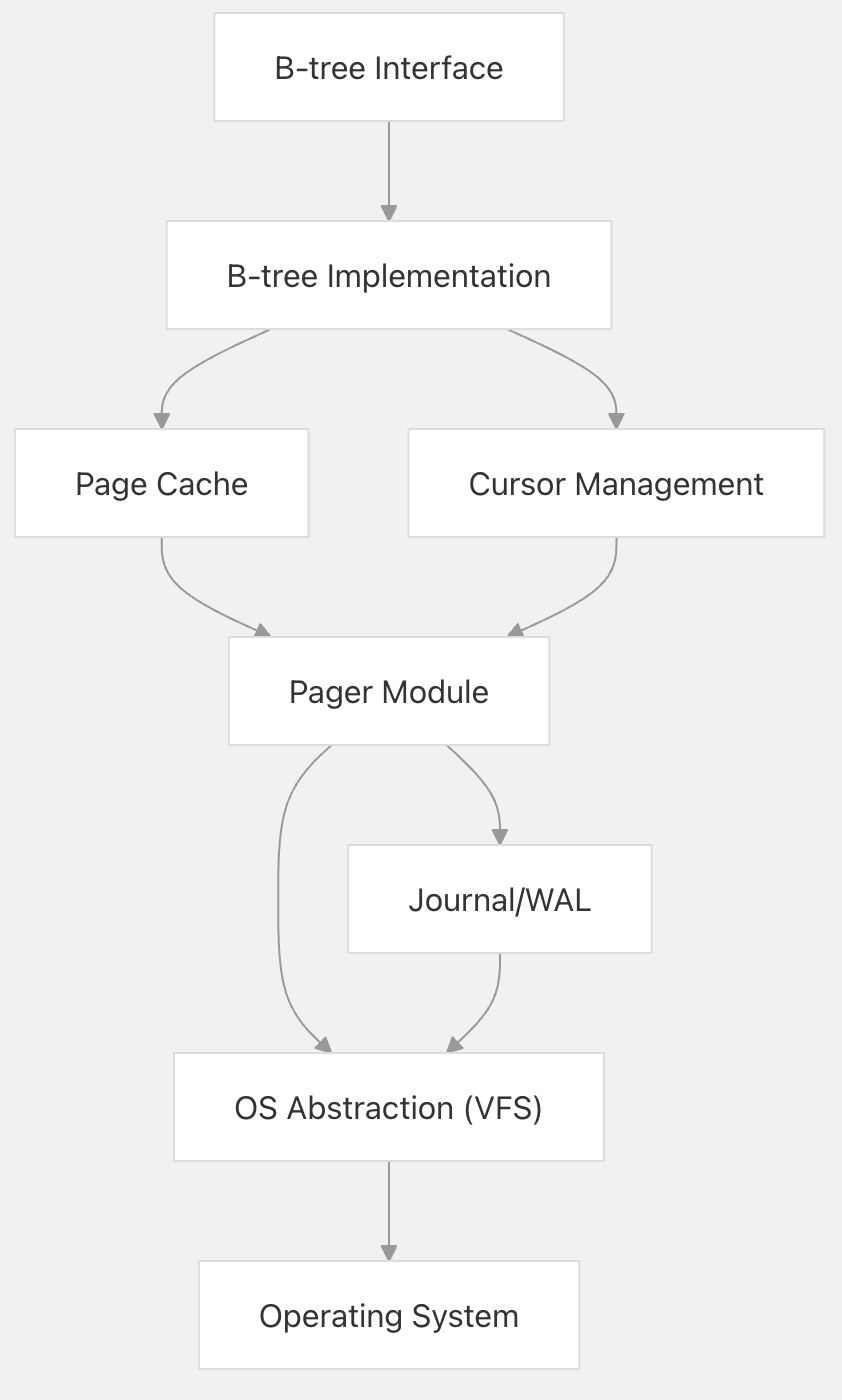
SQLite软件架构与实现源代码浅析
概述 SQLite 是一个用 C 语言编写的库,它成功打造出了一款小型、快速、独立、具备高可靠性且功能完备的 SQL 数据库引擎。本文档将为您简要介绍其架构、关键组件及其协同运作模式。 SQLite 显著特点之一是无服务器架构。不同于常规数据库,它并非以单独进…...
JAVA实战开源项目:精简博客系统 (Vue+SpringBoot) 附源码
本文项目编号 T 215 ,文末自助获取源码 \color{red}{T215,文末自助获取源码} T215,文末自助获取源码 目录 一、系统介绍二、数据库设计三、配套教程3.1 启动教程3.2 讲解视频3.3 二次开发教程 四、功能截图五、文案资料5.1 选题背景5.2 国内…...

Flink SQL 编程详解:从入门到实战难题与解决方案
Flink SQL 编程详解:从入门到实战难题与解决方案 Apache Flink 是当前流批一体实时计算的主流框架之一,而 Flink SQL 则为开发者提供了用 SQL 语言处理流式和批量数据的能力。本文将全面介绍 Flink SQL 的基础概念、编程流程、典型应用场景、常见难题及…...