【深度学习】18. 生成模型:Variational Auto-Encoder(VAE)详解
Variational Auto-Encoder(VAE)详解
本节内容完整介绍 VAE 的模型结构、优化目标、重参数化技巧及其生成机制。
回顾:Autoencoder(自编码器)
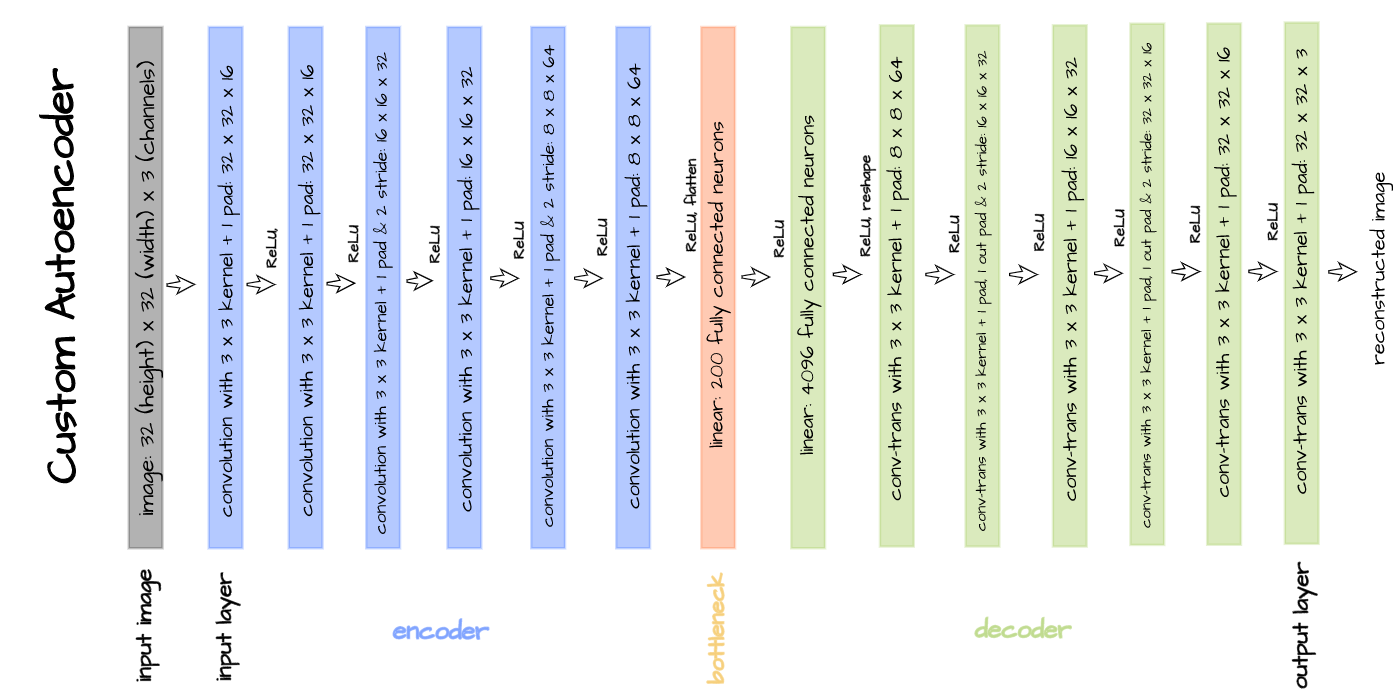
Autoencoder 是一种无监督学习模型,旨在从未标注的数据中学习压缩表示。其结构包括:
- Encoder:将输入 x x x 映射为潜在空间的表示 z z z
- Decoder:将 z z z 重构为 x ^ \hat{x} x^,使其尽可能接近原始输入 x x x
通常设置潜在变量 z z z 的维度低于 x x x,实现降维和特征提取。
Autoencoder 的训练目标
目标是最小化重构误差:
L ( x , x ^ ) = ∥ x − x ^ ∥ 2 L(x, \hat{x}) = \| x - \hat{x} \|^2 L(x,x^)=∥x−x^∥2
模型通过优化参数使得 x ^ = f ( g ( x ) ) \hat{x} = f(g(x)) x^=f(g(x)) 尽可能接近 x x x,其中 g g g 是 Encoder, f f f 是 Decoder。
Encoder 的用途
自动编码器可以重构数据,并且可以学习特征来初始化监督模型。特征捕获训练数据中的变化因素
训练完成后,Encoder 可以作为特征提取器用于其他下游任务。通常在分类等监督任务中:
- 预训练阶段训练 Autoencoder
- 丢弃 Decoder,仅保留 Encoder
- 添加分类器,进行微调训练
这种方式可利用无标签数据提升有标签任务效果。
Variational Auto-Encoder(VAE)的提出
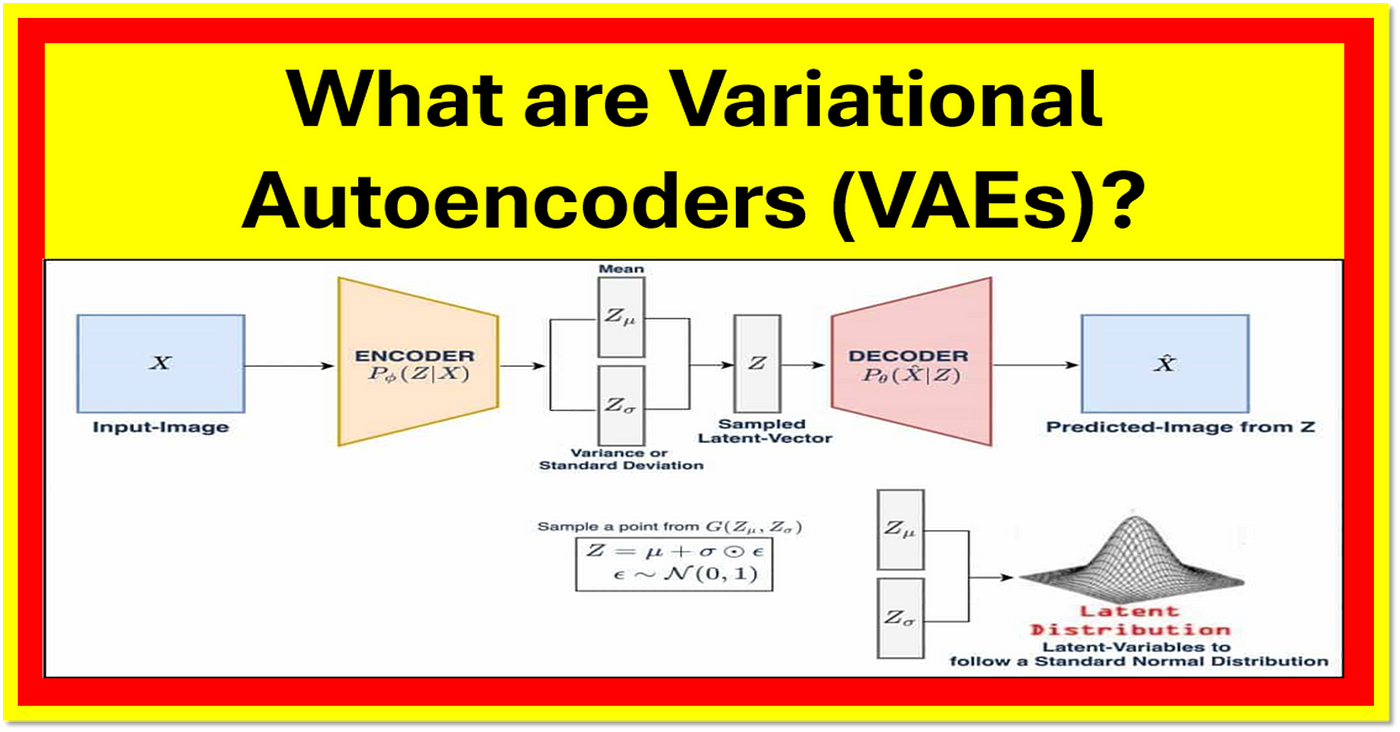
注意图中写的Variance or standard deviation有误,应该是log_var!
Autoencoder 能学习数据表示,但无法从潜在空间采样生成新样本。为此,VAE 将其扩展为生成模型:
- 假设存在潜变量 z z z,从先验分布 p ( z ) p(z) p(z)(通常是 N ( 0 , I ) \mathcal{N}(0, I) N(0,I),高斯分布)中采样
- 使用生成网络从 p θ ( x ∣ z ) p_\theta(x|z) pθ(x∣z) 中生成 x x x
完整生成过程为:
- 从 p ( z ) p(z) p(z) 中采样 z z z
- 用 p θ ( x ∣ z ) p_\theta(x|z) pθ(x∣z) 生成样本 x x x
但 p ( z ∣ x ) p(z|x) p(z∣x) 往往难以直接推导,因此采用变分推断,引入近似后验分布 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x)。
1. 输入与编码(Encoder)
输入样本 x x x 被送入编码器(Encoder),输出两个变量:
- z mean = μ z_{\text{mean}} = \mu zmean=μ
- z log_var = log σ 2 z_{\text{log\_var}} = \log \sigma^2 zlog_var=logσ2
这些构成了潜在变量 z z z 的高斯分布参数。
2. KL 散度项(先验正则化)
使用高斯分布的 KL 散度公式计算 q ϕ ( z ∣ x ) ∼ N ( μ , σ 2 ) q_\phi(z|x) \sim \mathcal{N}(\mu, \sigma^2) qϕ(z∣x)∼N(μ,σ2) 与 p ( z ) ∼ N ( 0 , 1 ) p(z) \sim \mathcal{N}(0,1) p(z)∼N(0,1) 之间的距离:
D K L ( N ( μ , σ 2 ) ∥ N ( 0 , 1 ) ) = − 1 2 ( 1 + log σ 2 − μ 2 − σ 2 ) D_{KL}(\mathcal{N}(\mu, \sigma^2) \| \mathcal{N}(0,1)) = -\frac{1}{2} \left( 1 + \log \sigma^2 - \mu^2 - \sigma^2 \right) DKL(N(μ,σ2)∥N(0,1))=−21(1+logσ2−μ2−σ2)
这项鼓励 q ( z ∣ x ) q(z|x) q(z∣x) 与标准高斯分布接近,使得从 p ( z ) p(z) p(z) 中采样具有可行性。
3. 重参数化技巧(Reparameterization Trick)
为了使得 z z z 可导,引入噪声变量 ϵ ∼ N ( 0 , 1 ) \epsilon \sim \mathcal{N}(0, 1) ϵ∼N(0,1),用如下方式采样 z z z:
z = μ + σ ⋅ ϵ z = \mu + \sigma \cdot \epsilon z=μ+σ⋅ϵ
这样,整个采样过程对网络参数 μ , σ \mu, \sigma μ,σ 可导,允许使用反向传播训练网络。
我们知道在神经网络中,如果某个操作是“不可导的”或者“不确定的(stochastic)”,我们就无法对它的参数进行梯度传播。
而在 VAE 中,如果我们直接从 z ∼ N ( μ , σ 2 ) z \sim \mathcal{N}(\mu, \sigma^2) z∼N(μ,σ2) 中采样,那么这个采样过程本身是随机的、不可导的,无法对 μ \mu μ 和 σ \sigma σ 求导!
所以怎么解决?
我们使用重参数化技巧,将随机性“从参数中移除”,变成一个确定性的函数:
z = μ + σ ⋅ ϵ , ϵ ∼ N ( 0 , 1 ) z = \mu + \sigma \cdot \epsilon,\quad \epsilon \sim \mathcal{N}(0,1) z=μ+σ⋅ϵ,ϵ∼N(0,1)
这个时候:
- ϵ \epsilon ϵ 是一个常量样本(在每次前向传播时采一次)
- z z z 是 μ \mu μ 和 σ \sigma σ 的一个确定函数(因为 ϵ \epsilon ϵ 视为已知)
为什么 ϵ \epsilon ϵ 不影响反向传播?
因为反向传播的目标是对损失函数 L L L 关于参数 μ \mu μ 和 σ \sigma σ 求导,比如:
$ ∂μ∂L=∂z∂L⋅∂μ∂z,∂μ∂z=1$
∂ L ∂ σ = ∂ L ∂ z ⋅ ∂ z ∂ σ , ∂ z ∂ σ = ϵ ∂L∂σ=∂L∂z⋅∂z∂σ,∂z∂σ=ϵ ∂L∂σ=∂L∂z⋅∂z∂σ,∂z∂σ=ϵ
- 虽然 ϵ \epsilon ϵ 是随机变量,但在一次前向过程中是常数(采样好了)
- 所以我们仍然可以对 μ \mu μ 和 σ \sigma σ 使用链式法则求导,反向传播不需要对 ϵ \epsilon ϵ 求导!
每次前向传播时, ϵ \epsilon ϵ 都要重新采样一次!
为什么?
在 VAE 中,我们采样的目的是从一个 随机潜在变量 z z z 中生成样本。为了能让 z z z 具有“随机性”,我们必须在每次前向传播时,从 ϵ ∼ N ( 0 , 1 ) \epsilon \sim \mathcal{N}(0,1) ϵ∼N(0,1) 中重新采样,否则模型生成的 z z z 就是确定的了,完全失去生成模型的意义。
4. 解码与重建误差
将 z z z 输入 Decoder 得到重建样本 x ^ \hat{x} x^。再与原始输入 x x x 比较,计算重建误差:
- 若像素值为 [ 0 , 1 ] [0, 1] [0,1],常使用 二值交叉熵损失(Binary Cross Entropy):
L recon = ∑ i = 1 n [ − x i log x ^ i − ( 1 − x i ) log ( 1 − x ^ i ) ] L_{\text{recon}} = \sum_{i=1}^n \left[ -x_i \log \hat{x}_i - (1 - x_i) \log(1 - \hat{x}_i) \right] Lrecon=i=1∑n[−xilogx^i−(1−xi)log(1−x^i)]
- 若为连续实值向量(如图像灰度),可使用 均方误差(MSE):
L recon = ∑ i = 1 n ( x i − x ^ i ) 2 L_{\text{recon}} = \sum_{i=1}^n (x_i - \hat{x}_i)^2 Lrecon=i=1∑n(xi−x^i)2
VAE 的完整损失函数
VAE 的最终损失函数由两个部分组成:
L VAE = L recon + D K L ( q ϕ ( z ∣ x ) ∥ p ( z ) ) \mathcal{L}_{\text{VAE}} = L_{\text{recon}} + D_{KL}(q_\phi(z|x) \| p(z)) LVAE=Lrecon+DKL(qϕ(z∣x)∥p(z))
其中:
- L recon L_{\text{recon}} Lrecon:重建误差(衡量生成的 x ^ \hat{x} x^ 与 x x x 的差距)
- D K L D_{KL} DKL:先验正则化项(限制潜变量空间服从 N ( 0 , 1 ) \mathcal{N}(0, 1) N(0,1))
最终优化目标:
min θ , ϕ E q ϕ ( z ∣ x ) [ − log p θ ( x ∣ z ) ] + D K L ( q ϕ ( z ∣ x ) ∥ p ( z ) ) \min_{\theta, \phi} \mathbb{E}_{q_\phi(z|x)}[-\log p_\theta(x|z)] + D_{KL}(q_\phi(z|x) \| p(z)) θ,ϕminEqϕ(z∣x)[−logpθ(x∣z)]+DKL(qϕ(z∣x)∥p(z))
VAE + GAN:Variational Autoencoder 与 GAN 的结合
本图展示了由 Makhzani 等人于 2015 年提出的 Adversarial Autoencoders (AAE) 架构,它结合了 Variational Autoencoder (VAE) 的编码思想与 Generative Adversarial Network (GAN) 的对抗训练机制。
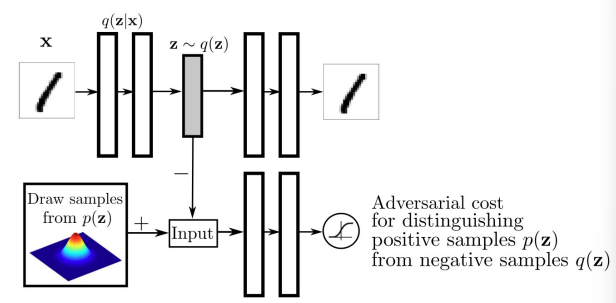
模型结构解析
1. 编码器(Encoder)
-
输入图像 x x x(如 MNIST 的手写数字图像)
-
编码器输出两个向量: z mean z_{\text{mean}} zmean 和 z log_var z_{\text{log\_var}} zlog_var
-
通过重参数技巧采样得到 z z z:
z = μ + σ ⋅ ϵ , ϵ ∼ N ( 0 , 1 ) z = \mu + \sigma \cdot \epsilon, \quad \epsilon \sim \mathcal{N}(0, 1) z=μ+σ⋅ϵ,ϵ∼N(0,1)
2. 解码器(Decoder)
- 接收采样的隐变量 z z z,重建图像 x ^ \hat{x} x^
- 使用重建误差(如 CrossEntropy 或 MSE)作为训练信号
3. 判别器(Discriminator)
-
判别器用于判断隐变量 z z z 是否来自:
- 编码器生成的 q ( z ) q(z) q(z),即编码器输出的 z z z
- 还是先验分布 p ( z ) p(z) p(z),如 N ( 0 , I ) \mathcal{N}(0, I) N(0,I)
-
编码器的目标是欺骗判别器,使 q ( z ) q(z) q(z) 与 p ( z ) p(z) p(z) 的样本无法区分,从而用 GAN 的方式逼近先验分布。
数学公式说明
图中展示了边缘分布 q ( z ) q(z) q(z) 的定义:
q ( z ) = ∫ x q ( z ∣ x ) p data ( x ) d x q(z) = \int_x q(z|x) \, p_{\text{data}}(x) \, dx q(z)=∫xq(z∣x)pdata(x)dx
即:将所有数据 x x x 编码后的隐变量 z z z 分布汇总起来形成 q ( z ) q(z) q(z)。我们希望 q ( z ) q(z) q(z) 与先验 p ( z ) p(z) p(z) 尽可能接近。
而对抗目标则是:
最小化判别器无法区分 q ( z ) q(z) q(z) 与 p ( z ) p(z) p(z) 的能力
用 GAN 代替 KL 散度进行对齐。
总结
- 传统 VAE 使用 KL 散度来匹配 q ( z ) q(z) q(z) 与 p ( z ) p(z) p(z),容易不稳定
- VAE + GAN (或 AAE) 使用判别器对抗训练,让隐空间更贴合先验分布
- 优势:
- 更高质量生成样本
- 更结构化的 latent space
- 支持复杂先验(如高斯混合)
这种结构为生成建模提供了更加稳定与表达力强的框架。
相关文章:
【深度学习】18. 生成模型:Variational Auto-Encoder(VAE)详解
Variational Auto-Encoder(VAE)详解 本节内容完整介绍 VAE 的模型结构、优化目标、重参数化技巧及其生成机制。 回顾:Autoencoder(自编码器) Autoencoder 是一种无监督学习模型,旨在从未标注的数据中学习压…...

NodeJS全栈开发面试题讲解——P6安全与鉴权
✅ 6.1 如何防止 SQL 注入 / XSS / CSRF? 面试官您好,Web 安全三大经典问题分别从不同层面入手: 🔸 SQL 注入(Server端) 原理:恶意用户将 SQL 注入查询语句拼接,导致数据泄露或破坏…...

C# 密封类和密封方法
密封(sealed)是C#中用于限制继承和多态行为的关键字,它可以应用于类和方法,提供了一种控制继承层次的方式。 密封类 特点 使用 sealed 关键字修饰的类密封类不能被其他类继承,但可以继承其他类或接口主要用于防止派生所有结构(struct)都是…...

为什么badmin reconfig以后始终不能提交任务
最近遇到的怪事:修改了openlava配置以后运行badmin reconfig激活配置变更,但是长时间始终不能提交任务。 首先查看进程,发现openlava管理节点上的所有服务进程都在运行状态;查看mbd日志没有发现错误信息;再看mbd进程的…...
解决Window10上IP映射重启失效的问题
问题 在实际网络搭建过程中,大家有可能会遇到在局域网范围内,在自己本机上搭建一个网站或者应用时,其他设备通过本机的IP地址无法访问的问题,这个问题可以通过设置IP映射来解决,但是通过netsh interface命令设置的IP映射…...
)
力扣刷题(第四十四天)
灵感来源 - 保持更新,努力学习 - python脚本学习 删除重复的电子邮箱 解题思路 这个问题要求我们删除表中所有重复的电子邮箱,只保留每个唯一电子邮箱对应的最小id记录。解决这个问题的关键在于识别出哪些记录是重复的,并确定需要删除的…...

MyBatis-Plus高级用法:最优化持久层开发
MyBatis-Plus 是 MyBatis 的增强工具,旨在简化开发、提高效率并保持 MyBatis 的灵活性。本文将详细介绍 MyBatis-Plus 的高级用法,帮助开发者最优化持久层开发。 一、MyBatis-Plus 简介 MyBatis-Plus 是一个 ORM 框架,提供了 CRUD 接口、条…...

c++之循环
目录 C循环结构完全解析:从基础到实战应用 一、for循环结构 二、while循环结构 三、do-while循环结构 四、范围for循环(C11) 五、循环控制语句 C循环结构完全解析:从基础到实战应用 循环结构是编程语言的核心控制结构之一&a…...

python h5py 读取mat文件的<HDF5 object reference> 问题
我用python加载matlab的mat文件 mat文件: 加载方式: mat_file h5py.File(base_dir str(N) _nodes_dataset_snr- str(snr) _M_ str(M) .mat, r) Signals mat_file["Signals"][()] Tp mat_file["Tp"][()] Tp_list mat_fil…...
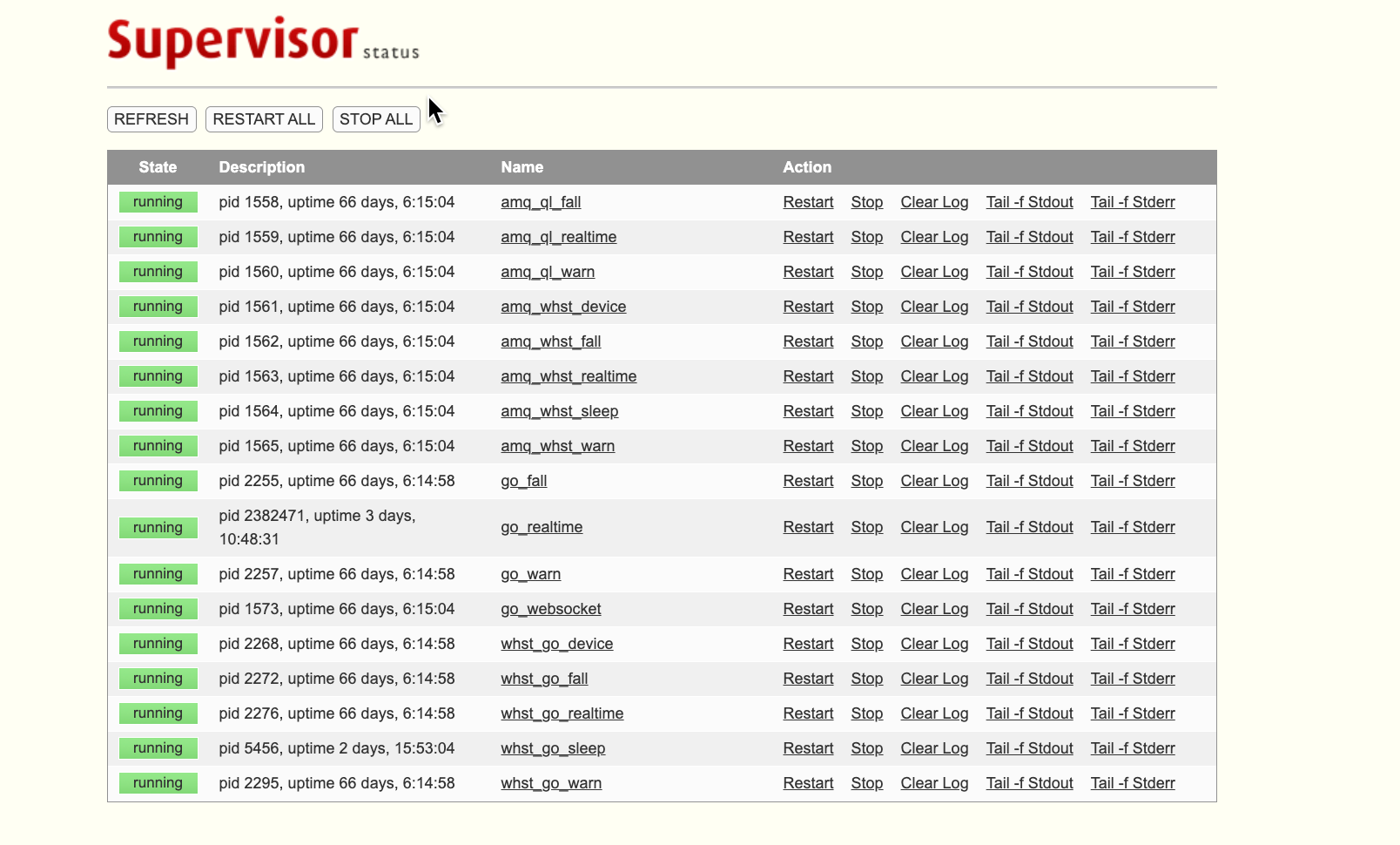
linux命令 systemctl 和 supervisord 区别及用法解读
目录 基础与背景服务管理范围配置文件和管理方式监控与日志依赖管理适用场景常用命令对照表实际应用场景举例优缺点对比小结参考链接 1. 基础与背景 systemctl 和 supervisord 都是用于管理和控制服务(进程)的工具,但它们在设计、使用场景和…...

Spring Boot + MyBatis 实现的简单用户管理项目的完整目录结构示例
📁 示例项目结构(基于 Maven) user-management/ ├── src/ │ ├── main/ │ │ ├── java/ │ │ │ └── com/example/usermanagement/ │ │ │ ├── controller/ │ │ │ │ └── UserC…...
)
NodeJS全栈开发面试题讲解——P5前端能力(React/Vue + API调用)
✅ 5.1 如何使用 React/Vue 发起后端请求?用什么库? 面试官您好,在实际项目中我们通常使用 axios、fetch 或框架提供的封装库发起后端请求。 🔧 常用库对比: 库框架适配优点axios通用默认支持拦截器、取消请求、请求体…...

[001]从操作系统层面看锁的逻辑
从操作系统层面,锁 (Lock) 是一种同步机制,用于控制多个线程或线程对共享资源的访问,防止竞态条件(race condition).常见的锁包括互斥锁(mutex)、读写锁(read-write lock)、自旋锁(spinlock)等。…...

初识 Pytest:测试世界的智能助手
概述 在编写程序的过程中,我们常常需要确认代码是否按照预期工作。为了提高效率并减少人为错误,我们可以借助工具来帮助我们完成这一过程。Pytest 就是这样一个用于编写和运行测试的 Python 工具。 什么是 Pytest? Pytest 是一个用于 Pyth…...

stm32 + ads1292心率检测报警设置上下限
这个项目是在做心率检测的时候一个小伙伴提出来的,今年五一的时候提出来的想法,五一假期的时候没时间,也没心情做这个,就把这个事情搁置了,在月中做工作计划的时候,就把这个小项目排进来了,五一…...

项目练习:element ui 的icon放在button的右侧
文章目录 一、需求描述二、左侧实现三、右侧实现 一、需求描述 我们知道,element ui的button一般都会配置一个icon 这个icon默认是放在左侧的。 如何让它放在右侧了? 二、左侧实现 <el-buttontype"primary"plainicon"el-icon-d-arr…...
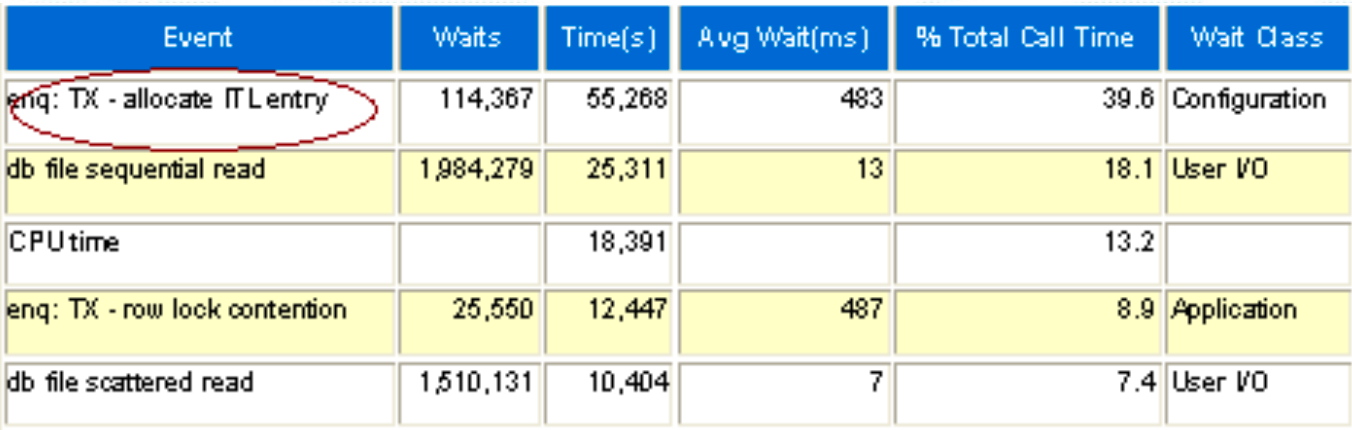
性能诊断工具AWR配置策略与报告内容解析
AWR(Automatic Workload Repository)是 Oracle 数据库中的一个重要性能诊断工具。AWR 会按照固定的时间间隔自动收集数据库系统的性能统计信息。这些信息涵盖了数据库运行状态的方方面面,像SQL 执行情况、系统资源利用率、等待事件等。AWR抓取…...
Tailwind CSS 实战,基于 Kooboo 构建 AI 对话框页面(三):实现暗黑模式主题切换
基于前两篇的内容,为页面添加主题切换功能,实现网站页面的暗黑模式: Tailwind css实战,基于Kooboo构建AI对话框页面(一)-CSDN博客 Tailwind css实战,基于Kooboo构建AI对话框页面(…...

OleDbParameter.Value 与 DataTable.Rows.Item.Value 的性能对比
OleDbParameter.Value 与 DataTable.Rows.Item.Value 的性能对比 您提到的两种赋值操作属于不同场景,它们的性能和稳定性取决于具体使用方式。下面从几个维度进行分析: 1. 操作本质对比 (1)OleDbParameter.Value 用途…...

Unity3D ET框架游戏脚本系统解析
前言 ET框架在Unity3D中实现的GamePlay脚本系统是一种革命性的、基于ECS(实体-组件-系统)架构的设计,它彻底改变了传统的基于MonoBehaviour的游戏逻辑编写方式。其核心思想是追求高性能、高解耦、易热更新,特别适合大型复杂的网络…...

函数的定义、调用、值传递、声明、非安全函数
函数 函数(英文“function”)把一些经常用到的代码封装起来,这样可以减少一些冗余代码、重复的代码。一个大的程序,它是由很多很多程序块组成的,每个模块实现一个特定的功能。 函数的定义 格式 英文版 return_typ…...

MySQL 8.0 OCP 英文题库解析(十一)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题91~100 试题91…...

机器学习算法-k-means
今天我们用 「超市顾客分组」 的例子来讲解K-means算法,从原理到实现一步步拆解,保证零基础也能懂! 🛒 例子背景 假设你是超市经理,手上有顾客的以下数据: 顾客ID每月消费金额(元)…...

ADQ36-2通道2.5G,4通道5G采样PXIE
ADQ36是一款高端12位四通道灵活数据采集板,针对高通道数科学应用进行了优化。ADQ36具有以下特性: 4 / 2模拟输入通道每通道2.5 / 5 GSPS7gb/秒的持续数据传输速率两个外部触发器通用输入/输出(GPIO)ADQ36数字化仪包括固件FWDAQ ADQ36简介 特…...

LLM:decoder-only 思考
文章目录 前言一、KV-cache1、为什么使用KV-cache2、KV-cache的运作原理 二、Decoder-only VS Encoder-Decoder1、Decoder-only2、Encoder-Decoder 三、Causal LM VS PrefixLM总结 前言 decoder-only模型是目前大模型的主流架构,由于OpenAI勇于挖坑踩坑,…...
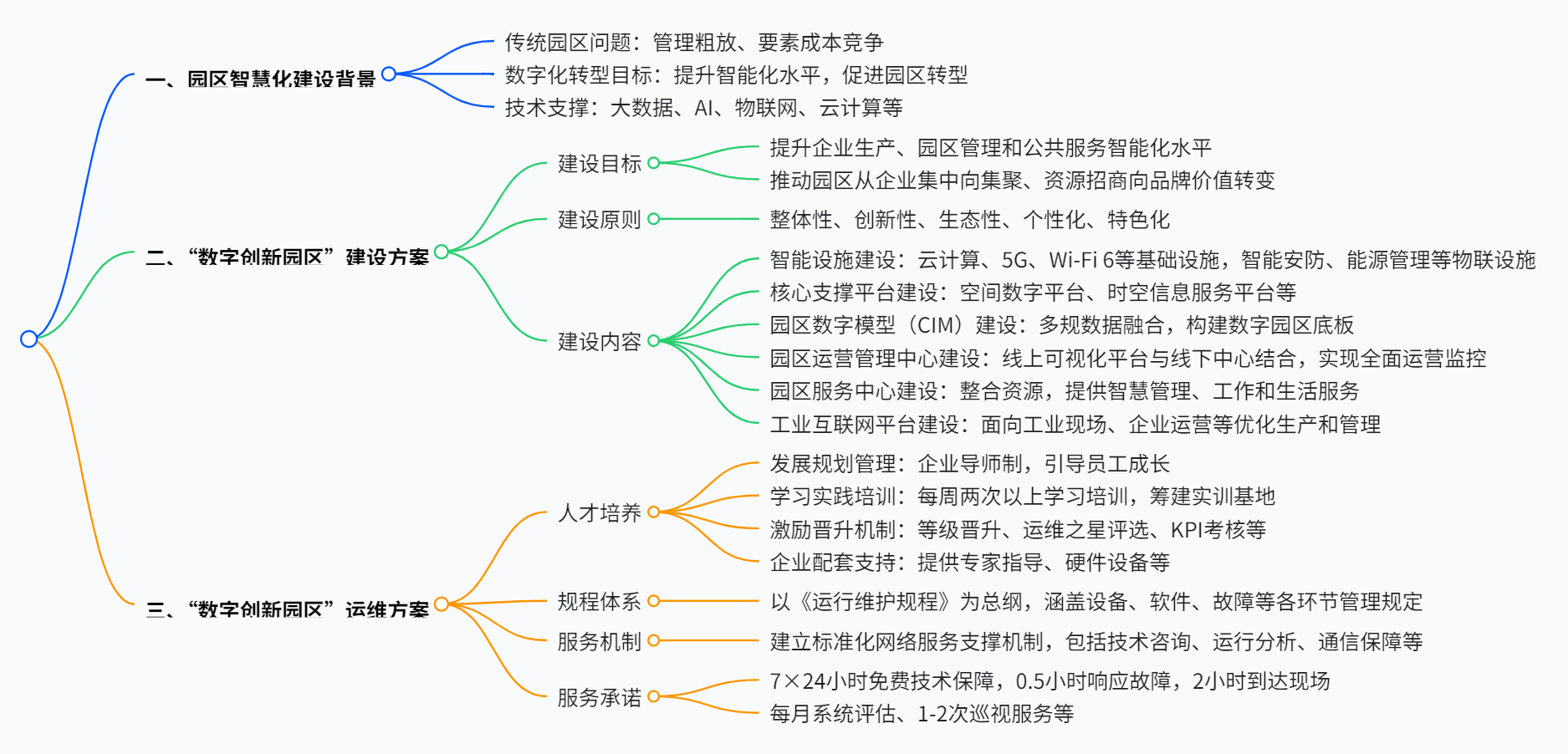
数字创新智慧园区建设及运维方案
该文档是 “数字创新智慧园区” 建设及运维方案,指出传统产业园区存在管理粗放等问题,“数字创新园区” 通过大数据、AI、物联网、云计算等数字化技术,旨在提升园区产业服务、运营管理水平,增强竞争力,实现绿色节能、高效管理等目标。建设内容包括智能设施、核心支撑平台、…...
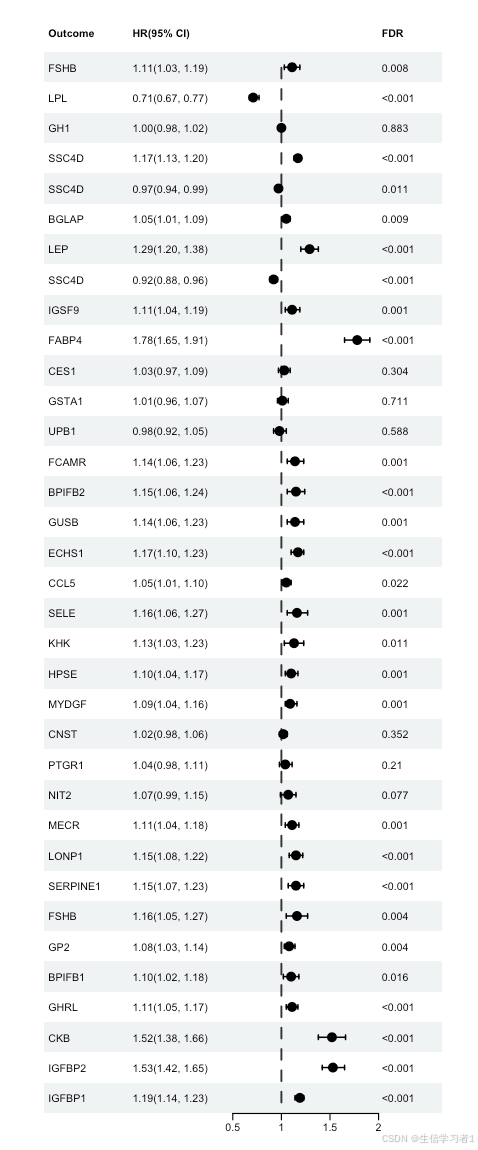
【科研绘图系列】R语言绘制森林图(forest plot)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍加载R包数据下载导入数据数据预处理画图系统信息介绍 本文介绍使用R语言绘制森林图(forest plot)的方法。首先加载必要的R包(grid、forestploter、openxlsx、stringr),导入并预处…...

Springcloud Alibaba自定义负载均衡详解
主要说一下springcloud alibaba 在使用nacos注册中心过程中,请求服务负载均衡的配置方法 引入依赖包 这个依赖包是springcloud在新版本的负载均衡实现,2020版本以上 <dependency><groupId>org.springframework.cloud</groupId><ar…...

深度学习---负样本训练
一、负样本的本质与核心作用 1. 定义与范畴 负样本(Negative Sample)是与目标样本(正样本)在语义、特征或任务目标上存在显著差异的样本。其核心价值在于通过对比学习引导模型学习样本间的判别性特征,而非仅记忆正样本…...
SpringAI+DeepSeek大模型应用开发实战
内容来自黑马程序员 这里写目录标题 认识AI和大模型大模型应用开发模型部署方案对比模型部署-云服务模型部署-本地部署调用大模型什么是大模型应用传统应用和大模型应用大模型应用 大模型应用开发技术架构 SpringAI对话机器人快速入门会话日志会话记忆 认识AI和大模型 AI的发…...