深度学习---负样本训练
一、负样本的本质与核心作用
1. 定义与范畴
负样本(Negative Sample)是与目标样本(正样本)在语义、特征或任务目标上存在显著差异的样本。其核心价值在于通过对比学习引导模型学习样本间的判别性特征,而非仅记忆正样本分布。
- 场景差异:
- 分类任务:负样本为非目标类样本(如垃圾邮件分类中“非垃圾邮件”)。
- 排序/推荐系统:负样本为用户未交互但相关的项目(如未点击的商品)。
- 对比学习:负样本为同一数据增强空间中的非相似样本(如同一图像的不同失真版本)。
2. 核心目标
- 增强判别能力:迫使模型学习“区分边界”,而非仅记住正样本特征(如区分“猫”与“非猫”而非仅记住猫的外观)。
- 缓解过拟合:通过引入多样性样本(尤其是困难负样本),避免模型对正样本的过拟合。
- 优化损失函数:在对比损失、三元组损失等中,负样本直接影响梯度方向,引导模型拉近正样本距离、推远负样本距离。
二、负样本采集策略:从随机到智能
1. 基础采样方法
-
随机采样(Random Sampling)
- 原理:从非正样本中均匀随机选取负样本。
- 优缺点:简单易实现,但可能引入大量无关样本(如推荐系统中随机选取用户不感兴趣的类别商品),导致模型学习低效。
- 适用场景:数据量充足、正负样本分布均衡的简单任务。
-
分层采样(Stratified Sampling)
- 原理:按类别/特征分层采样,确保负样本覆盖各类别(如在图像分类中,负样本需包含所有非目标类的少量样本)。
- 优势:避免负样本偏向某一类,提升样本多样性。
2. 困难样本挖掘(Hard Negative Mining)
- 核心思想:聚焦“难分负样本”(模型易误判为正样本的负样本),优先训练此类样本以提升模型鲁棒性。
- 实现方式:
- 离线挖掘:训练后根据模型输出概率/距离筛选难样本,重新加入训练集(如Faster R-CNN中对候选框的loss排序)。
- 在线挖掘:在训练过程中动态选择难样本(如Siamese网络中实时计算样本间距离,选取最近的负样本)。
- 关键参数:难样本比例(通常控制在10%-30%,避免模型被噪声主导)。
3. 基于密度的采样
- 欠采样(Under-Sampling):对高频负样本(如背景类)减少采样比例,避免其主导损失函数(如医学图像中正常组织为负样本,数量远多于病变组织)。
- 过采样(Over-Sampling):对低频负样本(如罕见类别)增加采样或生成(如SMOTE算法合成少数类样本)。
4. 对抗生成负样本
- 对抗样本(Adversarial Examples):通过微小扰动生成接近正样本的负样本(如FGSM算法),迫使模型学习更鲁棒的特征(如对抗训练提升模型抗攻击能力)。
- 生成模型(GANs/VAE):利用生成模型合成逼真负样本(如在人脸验证中,生成与正样本相似但身份不同的人脸)。
三、负样本在模型训练中的技术实现
1. 损失函数设计
-
二元分类场景
-
交叉熵损失(Cross-Entropy Loss):
L = − 1 N ∑ i = 1 N [ y i log p i + ( 1 − y i ) log ( 1 − p i ) ] L = - \frac{1}{N} \sum_{i=1}^N \left[ y_i \log p_i + (1-y_i) \log (1-p_i) \right] L=−N1∑i=1N[yilogpi+(1−yi)log(1−pi)]
其中负样本 ( y i = 0 ) (y_i=0) (yi=0)通过 l o g ( 1 − p i ) log(1-p_i) log(1−pi)项驱动模型降低对其预测为正的概率。 -
焦点损失(Focal Loss):
L = − 1 N ∑ i = 1 N ( 1 − p i ) γ log p i ( 当 y i = 1 ) L = - \frac{1}{N} \sum_{i=1}^N (1-p_i)^\gamma \log p_i \quad (\text{当} \ y_i=1) L=−N1∑i=1N(1−pi)γlogpi(当 yi=1)
L = − 1 N ∑ i = 1 N p i γ log ( 1 − p i ) ( 当 y i = 0 ) L = - \frac{1}{N} \sum_{i=1}^N p_i^\gamma \log (1-p_i) \quad (\text{当} \ y_i=0) L=−N1∑i=1Npiγlog(1−pi)(当 yi=0)
通过 γ \gamma γ调节对难负样本的关注程度 ( γ > 0 (\gamma>0 (γ>0时,难负样本的权重更高)。 -
-
对比学习场景
-
三元组损失(Triplet Loss):
L = max ( 0 , d ( A , P ) − d ( A , N ) + margin ) L = \max(0, d(A,P) - d(A,N) + \text{margin}) L=max(0,d(A,P)−d(A,N)+margin)
要求正样本对(Anchor-Positive)的距离小于负样本对(Anchor-Negative)的距离至少 m a r g i n margin margin,其中(N)为负样本。 -
NT-Xent损失(对比学习标准损失):
L = − 1 2 N ∑ i = 1 N [ log e s i m ( z i , z i + ) / τ e s i m ( z i , z i + ) / τ + ∑ k = 1 2 N e s i m ( z i , z k − ) / τ ] L = - \frac{1}{2N} \sum_{i=1}^N \left[ \log \frac{e^{sim(z_i, z_i^+) / \tau}}{e^{sim(z_i, z_i^+) / \tau} + \sum_{k=1}^{2N} e^{sim(z_i, z_k^-) / \tau}} \right] L=−2N1∑i=1N[logesim(zi,zi+)/τ+∑k=12Nesim(zi,zk−)/τesim(zi,zi+)/τ]
其中 z i + z_i^+ zi+为正样本(同一数据的不同增强), z k − z_k^- zk−为负样本(其他数据的增强),通过温度参数 τ \tau τ调节对比难度。
-
2. 训练技巧
- 难样本挖掘时机:
- 早期训练优先使用简单负样本,避免模型因难样本梯度爆炸而难以收敛;后期逐步引入难样本,提升判别精度。
- 在线难样本挖掘(OHEM):
- 在目标检测中,对每个ROI(区域建议)计算loss,仅保留前(k%)高loss的负样本参与反向传播,提升训练效率。
- 负样本权重分配:
- 根据样本难度动态调整权重(如难负样本权重设为1,简单负样本设为0.1),平衡不同样本对损失的贡献。
四、负样本训练的核心挑战与解决方案
1. 负样本质量问题
- 挑战1:混淆样本(Ambiguous Negatives)
- 表现:负样本与正样本高度相似(如细粒度分类中“金渐层猫”与“银渐层猫”),导致模型难以区分。
- 解决方案:
- 人工标注难负样本边界(如在数据集中增加难负样本类别);
- 使用度量学习(如Siamese网络)显式建模样本间距离。
- 挑战2:无关负样本(Irrelevant Negatives)
- 表现:负样本与正样本语义无关(如推荐系统中为用户推荐跨品类商品),导致模型学习无效特征。
- 解决方案:
- 基于内容过滤负样本(如通过用户历史行为筛选相关类别);
- 引入注意力机制,让模型自动忽略无关特征。
2. 计算效率瓶颈
- 挑战:大规模数据中负样本数量庞大(如推荐系统中负样本数可达正样本的1000倍),导致计算成本激增。
- 解决方案:
- 分层抽样(Hierarchical Sampling):先按粗粒度类别(如商品大类)抽样,再在类内细选(如电子产品下的手机品类);
- 负样本共享(Negative Sharing):多个正样本共享同一批负样本(如对比学习中一个batch内的样本互为负样本);
- 近似最近邻(ANN):通过向量检索(如FAISS、NSW)快速找到难负样本,避免全局遍历。
3. 类别不平衡与偏差
- 挑战:负样本类别分布不均(如长尾分布),模型易偏向高频负类,忽视稀有负类。
- 解决方案:
- 类别加权损失:对低频负类赋予更高权重(如根据类别频率的倒数设置权重);
- 元学习(Meta-Learning):训练模型快速适应新出现的负类别(如小样本学习中的负样本泛化)。
五、负样本训练最佳实践与案例
1. 推荐系统中的负样本优化
- 场景:用户点击商品为正样本,未点击但曝光的商品为负样本(显式负样本),未曝光商品为隐式负样本。
- 策略:
- 优先采样“曝光未点击”的显式负样本(更具区分度);
- 使用逆 propensity 加权(IPW)校正负样本偏差(如曝光概率高但未点击的商品更可能为真负样本);
- 案例:YouTube Recommendations通过“均匀采样+热门负样本降权”提升推荐多样性。
2. 图像识别中的难负样本挖掘
- 场景:目标检测中,背景区域(负样本)数量远超前景,需筛选对边界框分类最具挑战性的负样本。
- 方法:
- Faster R-CNN的RPN网络中,对候选框按分类loss排序,保留前50%的负样本参与训练;
- SSD算法通过设定正负样本比例(如1:3),避免负样本过多主导训练。
3. 自然语言处理中的负采样
- 场景:Word2Vec训练中,通过负采样优化Skip-gram模型,区分目标词与噪声词。
- 实现:
- 根据词频的平方根概率采样负词(高频词如“the”更易被采样,但概率低于其实际频率);
- 案例:GloVe模型通过负采样加速训练,同时保留全局统计信息。
六、前沿趋势与未来方向
1. 自监督学习中的负样本创新
- 对比学习扩展:利用海量无标签数据构建负样本(如MoCo通过动态字典维护负样本队列);
- 负样本语义关联:引入知识图谱约束负样本的语义合理性(如在图像-文本对比中,负样本需为文本不相关的图像)。
2. 生成模型驱动的负样本革命
- GAN生成难负样本:通过对抗训练生成与正样本高度相似的负样本(如FaceForensics++生成逼真的伪造人脸作为负样本);
- 扩散模型(Diffusion Models):从潜在空间采样负样本,提升样本多样性(如在分子生成中,采样非活性分子作为负样本)。
3. 动态自适应负采样
- 元学习动态调整:根据当前模型状态实时调整负样本难度(如Meta-Sampling通过元网络预测最优负样本分布);
- 强化学习采样策略:使用RL智能体优化负样本采样路径(如在机器人训练中,通过奖励函数引导采样关键失败案例)。
七、总结:负样本训练的黄金法则
- 质量优先于数量:100个高质量难负样本的价值远超1000个随机负样本;
- 动态平衡策略:根据训练阶段调整负样本难度(前期简单,后期困难);
- 领域知识嵌入:结合业务逻辑设计负样本(如医疗影像中,负样本需包含相似病灶的正常组织);
- 评估体系配套:建立负样本质量评估指标(如负样本在模型空间中的分布熵、与正样本的平均距离)。
通过系统化设计负样本采集、训练与优化流程,模型可突破“记忆正样本”的局限,真正学会“理解差异”,在判别、生成、排序等任务中实现性能跃升。
相关文章:

深度学习---负样本训练
一、负样本的本质与核心作用 1. 定义与范畴 负样本(Negative Sample)是与目标样本(正样本)在语义、特征或任务目标上存在显著差异的样本。其核心价值在于通过对比学习引导模型学习样本间的判别性特征,而非仅记忆正样本…...
SpringAI+DeepSeek大模型应用开发实战
内容来自黑马程序员 这里写目录标题 认识AI和大模型大模型应用开发模型部署方案对比模型部署-云服务模型部署-本地部署调用大模型什么是大模型应用传统应用和大模型应用大模型应用 大模型应用开发技术架构 SpringAI对话机器人快速入门会话日志会话记忆 认识AI和大模型 AI的发…...
)
【Python Cookbook】文件与 IO(一)
文件与 IO(一) 1.读写文本数据2.打印输出至文件中3.使用其他分隔符或行终止符打印4.读写字节数据5.文件不存在才能写入 1.读写文本数据 你需要读写各种不同编码的文本数据,比如 ASCII,UTF-8 或 UTF-16 编码等。 使用带有 rt 模式…...

STM32 HAL库函数学习 GPIO篇
1、void HAL_GPIO_Init(GPIO_TypeDef *GPIOx, const GPIO_InitTypeDef *pGPIO_Init) GPIO外设属于是任何芯片的最基础功能 ,STM32各个系列的GPIO初始化都是一致的,有不同的是部分系列在IO复用使用了单独一个成员属性Alternate 来表明这个IO的具体复用功…...
如何以 9 种方式将照片从 iPhone 传输到笔记本电脑
您的 iPhone 可能充满了以照片和视频形式捕捉的珍贵回忆。无论您是想备份它们、在更大的屏幕上编辑它们,还是只是释放设备上的空间,您都需要将照片从 iPhone 传输到笔记本电脑。幸运的是,有 9 种方便的方法可供使用,同时满足 Wind…...
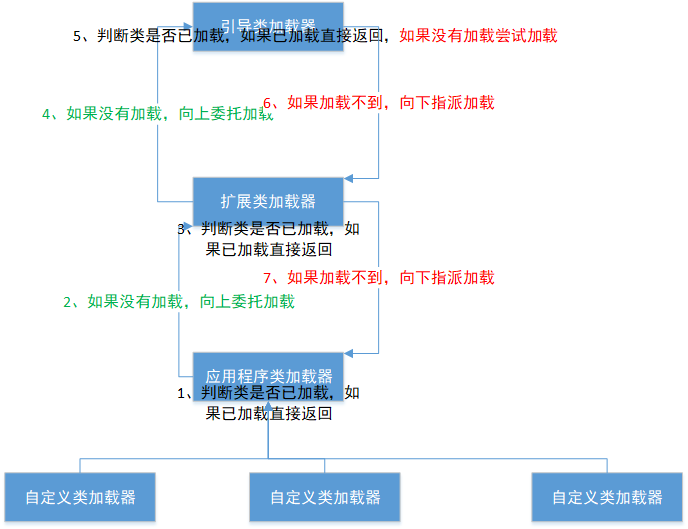
根据jvm源码剖析类加载机制
根据jvm源码剖析类加载机制 java Test.class之后的大致流程 java Test.class ----> 对于windows操作系统 ----> java.exe调用jvm.dll文件创建JVM, ----> 在创建JVM中先由C的代码创建Boostarp(引导)类加载器, ----&g…...
 安装教程及使用常见问题解决)
Mixly1.0/2.0/3.0 (windows系统) 安装教程及使用常见问题解决
大家好!长期以来,不少用户在使用 Mixly 软件过程中遇到了各类问题。为了帮助大家更顺畅地使用该软件,齐护机器人工程师结合自身丰富经验,精心总结并推出了本期教程。在本教程中,我们将从 Mixly 图形化编程软件的安装步…...

DDS通信中间件——DDS-TSN规范
DDS通信中间件——DDS-TSN规范 做了十年DDS通信中间件产品的程序员和大家分享一下对DDS这套规范的个人理解。预期本系列文章将包括以下内容陆续更新: DDS规范概述DCPS规范解读 & QoS策略XTypes规范解读RTPS规范解读DDS安全规范解读DDS-RPC规范解读(…...

JWT安全:弱签名测试.【实现越权绕过.】
JWT安全:假密钥【签名随便写实现越权绕过.】 JSON Web 令牌 (JWT)是一种在系统之间发送加密签名 JSON 数据的标准化格式。理论上,它们可以包含任何类型的数据,但最常用于在身份验证、会话处理和访问控制机制中发送有关用户的信息(“声明”)。…...

MATLAB实现井字棋
一、智能决策系统与博弈游戏概述 (一)智能决策系统核心概念 智能决策系统(Intelligent Decision System, IDS)是通过数据驱动和算法模型模拟人类决策过程的计算机系统,核心目标是在复杂环境中自动生成最优策略&#…...
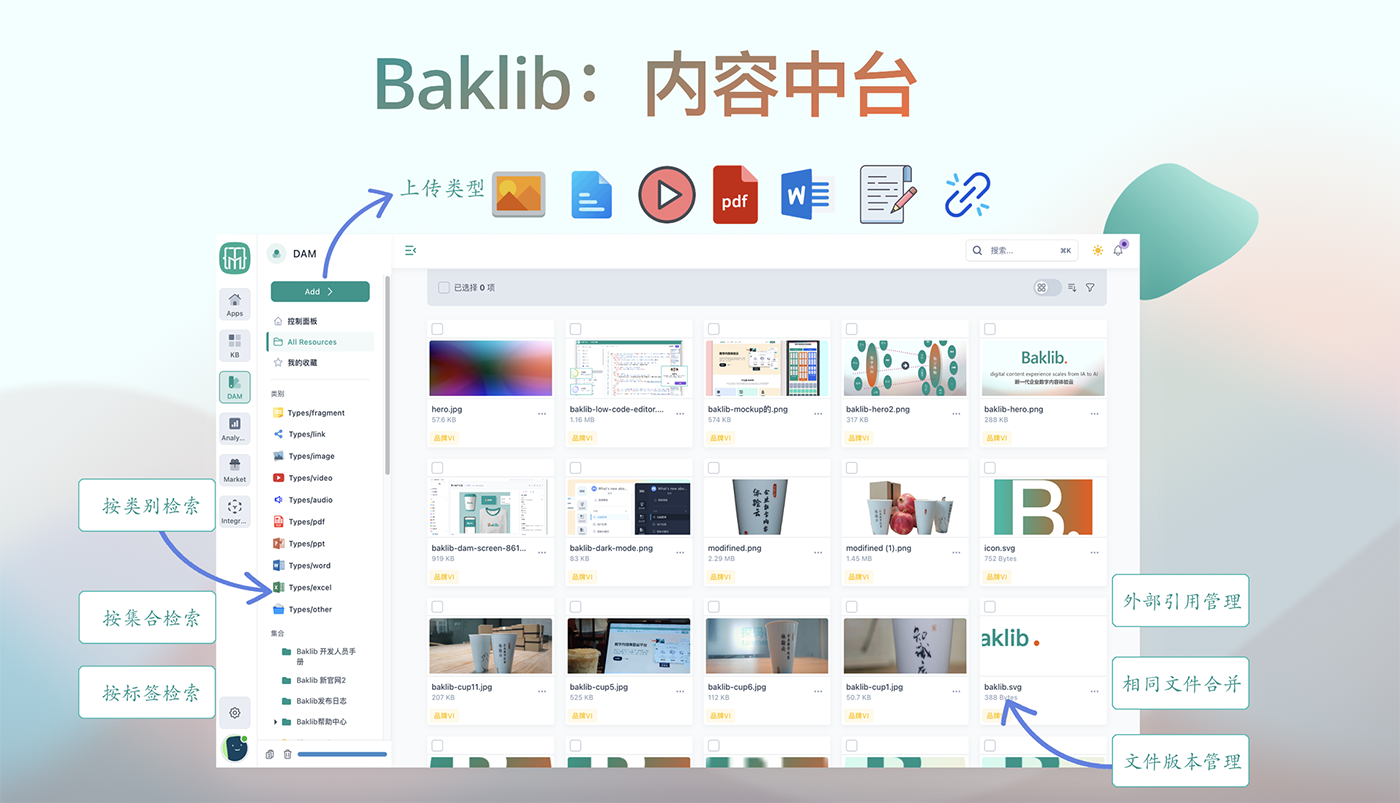
Baklib知识中台加速企业服务智能化实践
知识中台架构体系构建 Baklib 通过构建多层级架构体系实现知识中台的底层支撑,其核心包含数据采集层、知识加工层、服务输出层及智能应用层。在数据采集端,系统支持对接CRM、ERP等业务系统,结合NLP技术实现非结构化数据的自动抽取࿱…...

在AIX环境下修改oracle 11g rac的IP地址
0、当前环境 由于机房网络变更,客户要修改现在RAC的网络地址,这里记录一下。 主机操作系统:AIX 7.2 数据库版本:11.2.0.4 rac 数据库实例名:orcl1/orcl2 当前hosts文件配置 192.168.56.10 rac1 192.168.56.11 …...
VMware Tools 手动编译安装版
OWASPBWA安装VMware tools 安装时,显示如下提示 官方安装手册参考:https://knowledge.broadcom.com/external/article?legacyId1014294 按照提示,下载linux.iso文件,并连接到虚拟机的CDROM里,状态勾选已连接&#x…...
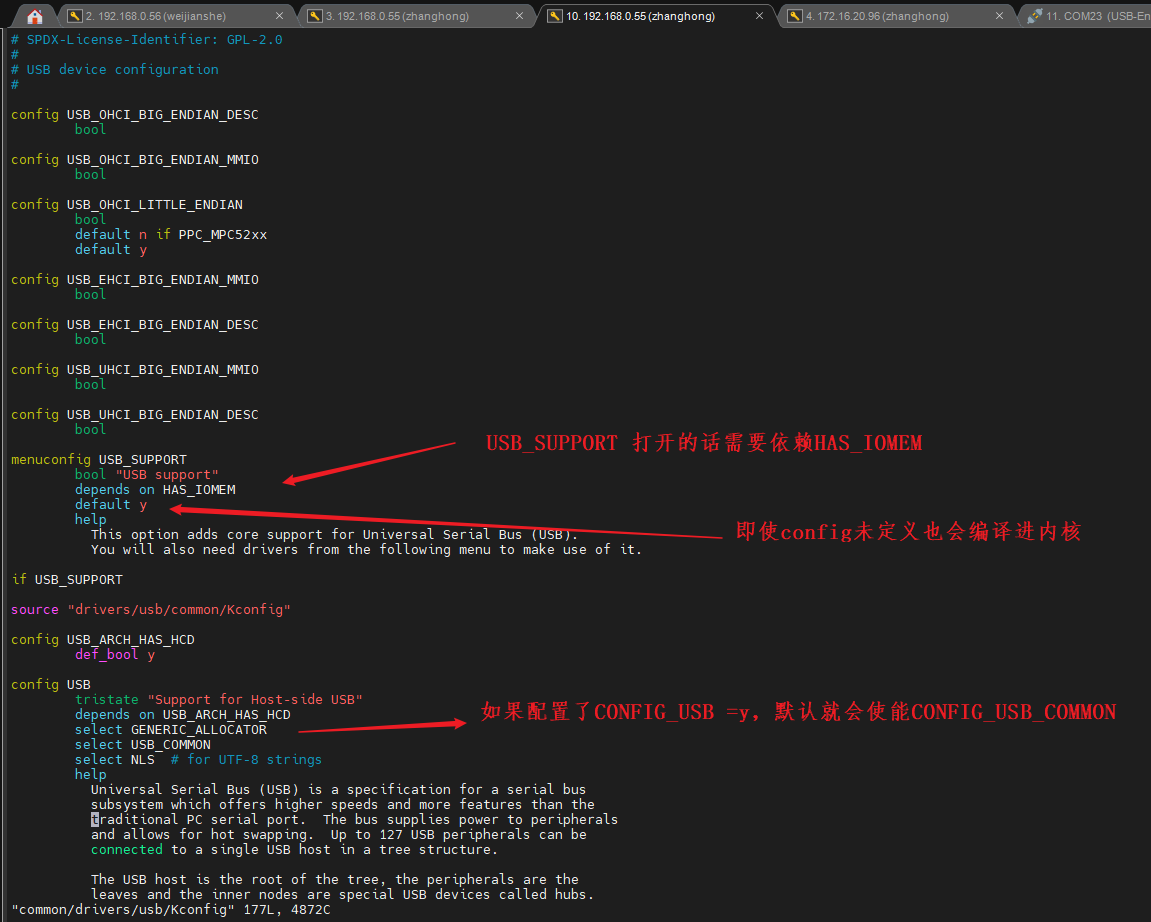
android平台驱动开发(六)--Makefile和Kconfig简介
Makefile: 1.编译进内核,还是以模块方式加载 模块方式编译成ko,通常是自己添加脚本方式insmod ,android 平台通常默认有modprobe加载,不需要额外添加insmod脚本 lsmod |grep test 可以查看是否安装成功 rmmod test-m.ko 可以删除ko 2.多…...

【手写系列】手写线程池
PS:本文的线程池为演示 Demo,皆在理解线程池的工作原理,并没有解决线程安全问题。 最简单一版的线程池 public class MyThreadPool {// 存放线程,复用已创建的线程List<Thread> threadList new ArrayList<>();publ…...

python学习打卡day40
DAY 40 训练和测试的规范写法 知识点回顾: 彩色和灰度图片测试和训练的规范写法:封装在函数中展平操作:除第一个维度batchsize外全部展平dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作业&#…...

redis高并发问题
Redlock原理和存在的问题 Redlock 基于以下假设: 有多个(一般建议是 5 个)彼此独立的 Redis 实例(不是主从复制,也不是集群模式),它们之间没有数据同步。客户端可以与所有 Redis 实例通信。 …...
Live Helper Chat 安装部署
Live Helper Chat(LHC)是一款开源的实时客服聊天系统,适用于网站和应用,帮助企业与访问者即时沟通。它功能丰富、灵活、可自托管,常被用于在线客户支持、销售咨询以及技术支持场景。 🧰 系统要求 安装要求 您提供的链接指向 Live Helper Chat 的官方安装指南页面,详细…...
ARXML解析与可视化工具
随着汽车电子行业的快速发展,AUTOSAR标准在车辆软件架构中发挥着越来越重要的作用。然而,传统的ARXML文件处理工具往往存在高昂的许可费用、封闭的数据格式和复杂的使用门槛等问题。本文介绍一种基于TXT格式输出的ARXML解析方案,为开发团队提供了一个高效的替代解决方案。 …...
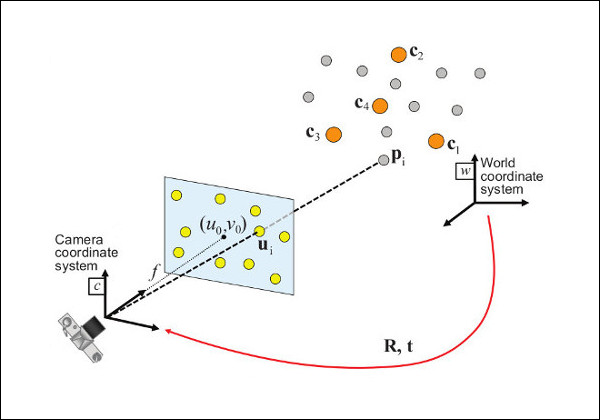
PnP(Perspective-n-Point)算法 | 用于求解已知n个3D点及其对应2D投影点的相机位姿
什么是PnP算法? PnP 全称是 Perspective-n-Point,中文叫“n点透视问题”。它的目标是: 已知一些空间中已知3D点的位置(世界坐标)和它们对应的2D图像像素坐标,求解摄像机的姿态(位置和平移&…...
)
LeetCode 热题 100 208. 实现 Trie (前缀树)
LeetCode 热题 100 | 208. 实现 Trie (前缀树) 大家好!今天我们来解决一道经典的算法题——实现 Trie (前缀树)。Trie(发音类似 “try”)是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构在自动补全和拼…...

python爬虫:RoboBrowser 的详细使用
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、RoboBrowser概述1.1 RoboBrowser 介绍1.2 安装 RoboBrowser1.3 与类似工具比较二、基本用法2.1 创建浏览器对象并访问网页2.2 查找元素2.3 填写和提交表单三、高级功能3.1 处理文件上传3.2 处理JavaScript重定向3.3…...

在日常管理服务器中如何防止SQL注入与XSS攻击?
在日常管理服务器时,防止SQL注入(Structured Query Language Injection)和XSS(Cross-Site Scripting)攻击是至关重要的,这些攻击可能会导致数据泄露、系统崩溃和信息泄露。以下是一份技术文章,介…...
Wkhtmltopdf使用
Wkhtmltopdf使用 1.windows本地使用2.golangwindows环境使用3.golangdocker容器中使用 1.windows本地使用 官网地址 https://wkhtmltopdf.org/,直接去里面下载自己想要的版本,这里以windows版本为例2.golangwindows环境使用 1.安装扩展go get -u githu…...
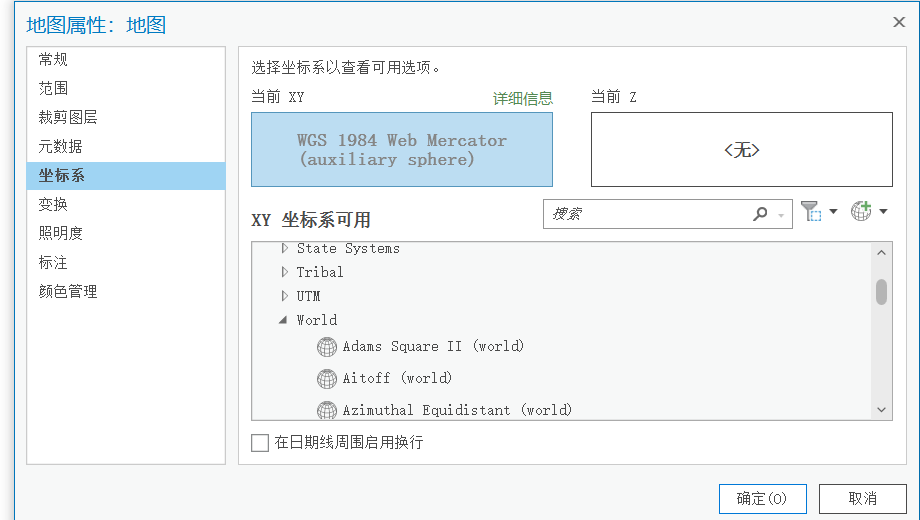
ArcGIS Pro 创建渔网格网过大,只有几个格网的解决方案
之前用ArcGIS Pro创建渔网的时候,发现创建出来格网过大,只有几个格网。 后来查阅资料,发现是坐标不对,导致设置格网大小时单位为度,而不是米,因此需要进行坐标系转换,网上有很多资料讲了ArcGIS …...
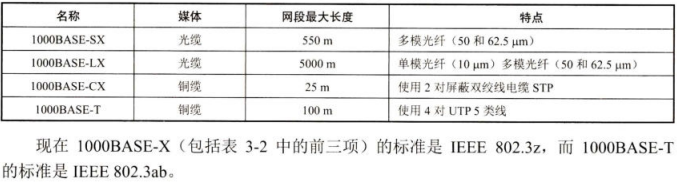
重学计算机网络之以太网
一:历史发展进程 DIX EtherNet V2 战胜IEEE802.3成为主流版本。总线型交换机拓扑机构代替集线器星型拓扑机构 1990年IEEE制定出星形以太网10BASE-T的标准**802.3i**。“10”代表10 Mbit/s 的数据率,BASE表示连接线上的信号是基带信号,T代表…...
《深度解构现代云原生微服务架构的七大支柱》
☁️《深度解构现代云原生微服务架构的七大支柱》 一线架构师实战总结,系统性拆解现代微服务架构中最核心的 7 大支柱模块,涵盖通信协议、容器编排、服务网格、弹性伸缩、安全治理、可观测性、CI/CD 等。文内附架构图、实操路径与真实案例,适…...

使用SCSS实现随机大小的方块在页面滚动
目录 一、scss中的插值语法 二、方块在界面上滚动的动画 一、scss中的插值语法 插值语法 #{} 是一种动态注入变量或表达式到选择器、属性名、属性值等位置的机制 .类名:nth-child(n) 表示需同时满足为父元素的第n个元素且类名为给定条件 效果图: <div class…...

AI 眼镜新纪元:贴片式TF卡与 SOC 芯片的黄金组合破局智能穿戴
目录 一、SD NAND:智能眼镜的“记忆中枢”突破空间限制的存储革命性能与可靠性的双重保障 二、SOC芯片:AI眼镜的“智慧大脑”从性能到能效的全面跃升多模态交互的底层支撑 三、SD NANDSOC:11>2的协同效应数据流水线的高效协同成本…...

论文阅读(六)Open Set Video HOI detection from Action-centric Chain-of-Look Prompting
论文来源:ICCV(2023) 项目地址:https://github.com/southnx/ACoLP 1.研究背景与问题 开放集场景下的泛化性:传统 HOI 检测假设训练集包含所有测试类别,但现实中存在大量未见过的 HOI 类别(如…...