【Python Cookbook】文件与 IO(一)
文件与 IO(一)
- 1.读写文本数据
- 2.打印输出至文件中
- 3.使用其他分隔符或行终止符打印
- 4.读写字节数据
- 5.文件不存在才能写入
1.读写文本数据
你需要读写各种不同编码的文本数据,比如 ASCII,UTF-8 或 UTF-16 编码等。
使用带有 rt 模式的 open() 函数读取文本文件。如下所示:
# Read the entire file as a single string
with open('somefile.txt', 'rt') as f:data = f.read()# Iterate over the lines of the file
with open('somefile.txt', 'rt') as f:for line in f:# process line...
🚀 在 Python 中,
open()函数的rt模式表示以 文本模式读取(read text)文件。
r:只读模式(默认模式),文件必须存在,否则会报错FileNotFoundError。t:文本模式(默认模式),文件内容会被解码为字符串(Python 3 中默认是str类型,Unicode 编码)。
因此,rt 等价于单独使用 r(因为 t 是默认值)。以下两种写法完全等效:
open('file.txt', 'rt') # 显式指定 rt
open('file.txt', 'r') # 隐式使用默认的 t 模式
类似的,为了写入一个文本文件,使用带有 wt 模式的 open() 函数,如果之前文件内容存在则清除并覆盖掉。如下所示:
# Write chunks of text data
with open('somefile.txt', 'wt') as f:f.write(text1)f.write(text2)...# Redirected print statement
with open('somefile.txt', 'wt') as f:print(line1, file=f)print(line2, file=f)...
🚀 在 Python 中,
open()函数的wt模式表示以 文本模式写入(write text)文件。
w:写入模式(如果文件已存在,会 清空内容;如果文件不存在,会 创建新文件)。t:文本模式(默认模式),写入的内容必须是字符串(str类型),而非二进制数据(bytes)。
因此,wt 等价于单独使用 w(因为 t 是默认值)。以下两种写法完全等效:
open('file.txt', 'wt') # 显式指定 wt
open('file.txt', 'w') # 隐式使用默认的 t 模式
如果是在已存在文件中添加内容,使用模式为 at 的 open() 函数。
| 模式 | 描述 |
|---|---|
wb | 二进制模式写入(需 bytes 类型数据) |
w+ 或 w+t | 可读写文本模式(先清空文件) |
a 或 at | 追加文本模式(不覆盖原内容) |
x 或 xt | 独占创建模式(文件存在则报错) |
文件的读写操作默认使用系统编码,可以通过调用 sys.getdefaultencoding() 来得到。在大多数机器上面都是 utf-8 编码。如果你已经知道你要读写的文本是其他编码方式,那么可以通过传递一个可选的 encoding 参数给 open() 函数。如下所示:
with open('somefile.txt', 'rt', encoding='latin-1') as f:...
Python 支持非常多的文本编码。几个常见的编码是 ascii、latin-1、utf-8 和 utf-16。
- 在 Web 应用程序中通常都使用的是 UTF-8。
ascii对应从U+0000到U+007F范围内的 7 位字符。latin-1是字节 0-255 到 U+0000 至 U+00FF 范围内 Unicode 字符的直接映射。
当读取一个未知编码的文本时使用 latin-1 编码永远不会产生解码错误。使用 latin-1 编码读取一个文件的时候也许不能产生完全正确的文本解码数据,但是它也能从中提取出足够多的有用数据。同时,如果你之后将数据回写回去,原先的数据还是会保留的。
🚀 Latin-1(也称为 ISO-8859-1)是一种单字节字符编码标准,属于 ISO/IEC 8859 系列编码的一部分。
- 编码范围:
- 使用 8 位(1字节)表示一个字符
- 共 256 个码位(
0x00-0xFF)- 其中
0x00-0x7F与 ASCII 完全一致0x80-0xFF用于扩展字符(西欧语言字符)
- 覆盖语言:
- 主要支持西欧语言(英语、法语、德语、西班牙语、葡萄牙语等)
- 包含重音字母、货币符号等特殊字符
- Unicode关系:
- Latin-1 字符集中的字符在 Unicode 中的码位与 Latin-1 编码值相同(
U+0000到U+00FF)
读写文本文件一般来讲是比较简单的。但是也有几点是需要注意的。首先,在例子程序中的 with 语句给被使用到的文件创建了一个上下文环境, 但 with 控制块结束时,文件会自动关闭。你也可以不使用 with 语句,但是这时候你就必须记得手动关闭文件:
f = open('somefile.txt', 'rt')
data = f.read()
f.close()
另外一个问题是关于换行符的识别问题,在 Unix 和 Windows 中是不一样的(分别是 \n 和 \r\n)。 默认情况下,Python 会以统一模式处理换行符。这种模式下,在读取文本的时候,Python 可以识别所有的普通换行符并将其转换为单个 \n 字符。 类似的,在输出时会将换行符 \n 转换为系统默认的换行符。如果你不希望这种默认的处理方式,可以给 open() 函数传入参数 newline='' ,就像下面这样:
# Read with disabled newline translation
with open('somefile.txt', 'rt', newline='') as f:...
在 Python 的
open()函数中,newline参数用于控制文本模式下的 换行符(行结束符)处理方式。它在不同操作系统的换行符兼容性中尤为重要。
为了说明两者之间的差异,下面我在 Unix 机器上面读取一个 Windows 上面的文本文件,里面的内容是 hello world!\r\n :
>>> # Newline translation enabled (the default)
>>> f = open('hello.txt', 'rt')
>>> f.read()
'hello world!\n'>>> # Newline translation disabled
>>> g = open('hello.txt', 'rt', newline='')
>>> g.read()
'hello world!\r\n'
>>>
| 取值 | 读取时(输入) | 写入时(输出) |
|---|---|---|
None(默认) | 自动将不同系统的换行符(\n、\r\n、\r)统一转换为 \n。 | 根据当前操作系统转换: (1)Unix/Linux: \n(2)Windows: \r\n(3)旧版 Mac: \r |
''(空字符串) | 保留原始换行符(不转换),文件中的 \n、\r\n、\r 会原样保留。 | 直接输出写入的 \n,不进行任何转换。 |
其他字符串(如 '\n'、'\r\n') | 强制将指定的字符串作为换行符解析(极少用)。 | 将所有的 \n 替换为指定的字符串(如 '\r\n')。 |
最后一个问题就是文本文件中可能出现的编码错误。但你读取或者写入一个文本文件时,你可能会遇到一个编码或者解码错误。比如:
>>> f = open('sample.txt', 'rt', encoding='ascii')
>>> f.read()
Traceback (most recent call last):File "<stdin>", line 1, in <module>File "/usr/local/lib/python3.3/encodings/ascii.py", line 26, in decodereturn codecs.ascii_decode(input, self.errors)[0]
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position
12: ordinal not in range(128)
>>>
如果出现这个错误,通常表示你读取文本时指定的编码不正确。你最好仔细阅读说明并确认你的文件编码是正确的(比如使用 UTF-8 而不是 Latin-1 编码或其他)。如果编码错误还是存在的话,你可以给 open() 函数传递一个可选的 errors 参数来处理这些错误。 下面是一些处理常见错误的方法:
>>> # Replace bad chars with Unicode U+fffd replacement char
>>> f = open('sample.txt', 'rt', encoding='ascii', errors='replace')
>>> f.read()
'Spicy Jalape?o!'
>>> # Ignore bad chars entirely
>>> g = open('sample.txt', 'rt', encoding='ascii', errors='ignore')
>>> g.read()
'Spicy Jalapeo!'
>>>
如果你经常使用 errors 参数来处理编码错误,可能会让你的生活变得很糟糕。对于文本处理的首要原则是确保你总是使用的是正确编码。当模棱两可的时候,就使用默认的设置(通常都是 UTF-8)。
注意事项
- 二进制模式无效:
newline仅在文本模式(如rt、wt)下生效,二进制模式(如rb、wb)会忽略它。- CSV 文件处理:
csv模块在写入时通常需要指定newline='',以避免额外空行(官方文档推荐)。- 性能影响:频繁的换行符转换可能轻微影响性能,但对大多数场景可忽略。
2.打印输出至文件中
你想将 print() 函数的输出重定向到一个文件中去。
在 print() 函数中指定 file 关键字参数,像下面这样:
with open('d:/work/test.txt', 'wt') as f:print('Hello World!', file=f)
关于输出重定向到文件中就这些了。但是有一点要注意的就是文件必须是以文本模式打开。如果文件是二进制模式的话,打印就会出错。
3.使用其他分隔符或行终止符打印
你想使用 print() 函数输出数据,但是想改变默认的分隔符或者行尾符。
可以使用在 print() 函数中使用 sep 和 end 关键字参数,以你想要的方式输出。比如:
>>> print('ACME', 50, 91.5)
ACME 50 91.5
>>> print('ACME', 50, 91.5, sep=',')
ACME,50,91.5
>>> print('ACME', 50, 91.5, sep=',', end='!!\n')
ACME,50,91.5!!
>>>
使用 end 参数也可以在输出中禁止换行。比如:
>>> for i in range(5):
... print(i)
...
0
1
2
3
4
>>> for i in range(5):
... print(i, end=' ')
...
0 1 2 3 4 >>>
当你想使用非空格分隔符来输出数据的时候,给 print() 函数传递一个 sep 参数是最简单的方案。 有时候你会看到一些程序员会使用 str.join() 来完成同样的事情。比如:
>>> print(','.join(('ACME','50','91.5')))
ACME,50,91.5
>>>
str.join() 的问题在于它仅仅适用于字符串。这意味着你通常需要执行另外一些转换才能让它正常工作。比如:
>>> row = ('ACME', 50, 91.5)
>>> print(','.join(row))
Traceback (most recent call last):File "<stdin>", line 1, in <module>
TypeError: sequence item 1: expected str instance, int found
>>> print(','.join(str(x) for x in row))
ACME,50,91.5
>>>
你当然可以不用那么麻烦,只需要像下面这样写:
>>> print(*row, sep=',')
ACME,50,91.5
>>>
4.读写字节数据
你想读写二进制文件,比如图片,声音文件等等。
使用模式为 rb 或 wb 的 open() 函数来读取或写入二进制数据。比如:
# Read the entire file as a single byte string
with open('somefile.bin', 'rb') as f:data = f.read()# Write binary data to a file
with open('somefile.bin', 'wb') as f:f.write(b'Hello World')
在读取二进制数据时,需要指明的是所有返回的数据都是字节字符串格式的,而不是文本字符串。类似的,在写入的时候,必须保证参数是以字节形式对外暴露数据的对象(比如字节字符串,字节数组对象等)。
在读取二进制数据的时候,字节字符串 和 文本字符串 的语义差异可能会导致一个潜在的陷阱。特别需要注意的是,索引和迭代动作返回的是字节的值而不是字节字符串。比如:
>>> # Text string
>>> t = 'Hello World'
>>> t[0]
'H'
>>> for c in t:
... print(c)
...
H
e
l
l
o
...
>>> # Byte string
>>> b = b'Hello World'
>>> b[0]
72
>>> for c in b:
... print(c)
...
72
101
108
108
111
...
>>>
如果你想从二进制模式的文件中读取或写入文本数据,必须确保要进行解码和编码操作。比如:
with open('somefile.bin', 'rb') as f: # 以二进制只读模式打开文件data = f.read(16) # 读取前16字节的二进制数据text = data.decode('utf-8') # 将二进制数据解码为字符串(UTF-8)with open('somefile.bin', 'wb') as f: # 以二进制写入模式打开文件text = 'Hello World' # 定义字符串f.write(text.encode('utf-8')) # 将字符串编码为二进制后写入文件
二进制 I/O 还有一个鲜为人知的特性,就是数组和 C 结构体类型能直接被写入,而不需要中间转换为自己对象。比如:
import array
nums = array.array('i', [1, 2, 3, 4])
with open('data.bin','wb') as f:f.write(nums)
这个适用于任何实现了被称之为 缓冲接口 的对象,这种对象会直接暴露其底层的内存缓冲区给能处理它的操作。二进制数据的写入就是这类操作之一。
很多对象还允许通过使用文件对象的 readinto() 方法直接读取二进制数据到其底层的内存中去。比如:
>>> import array
>>> a = array.array('i', [0, 0, 0, 0, 0, 0, 0, 0])
>>> with open('data.bin', 'rb') as f:
... f.readinto(a)
...
16
>>> a
array('i', [1, 2, 3, 4, 0, 0, 0, 0])
>>>
🚀
readinto()是 Python 文件对象(io.FileIO或二进制模式打开的文件)的一个方法,用于 高效地将文件数据读取到预分配的字节缓冲区(bytearray或memoryview),而不是返回一个新的bytes对象。它的主要用途是 减少内存分配,提高 I/O 性能,尤其是在处理大文件或高频读取时。
但是使用这种技术的时候需要格外小心,因为它通常具有平台相关性,并且可能会依赖字长和字节顺序(高位优先和低位优先)。
| 方法 | 返回值 | 内存分配 | 适用场景 |
|---|---|---|---|
read(n) | bytes | 每次返回新对象 | 简单读取 |
readinto(buffer) | int(实际读取字节数) | 复用现有缓冲区 | 高性能 I/O |
5.文件不存在才能写入
你想向一个文件中写入数据,但是前提必须是这个文件在文件系统上不存在。也就是不允许覆盖已存在的文件内容。
w模式(写入模式)
- 行为:
- 如果文件 已存在,会 直接覆盖(清空原有内容)。
- 如果文件 不存在,会 创建新文件。
- 风险:可能意外覆盖重要文件!
x模式(独占创建模式)
- 行为:
- 如果文件 已存在,会抛出
FileExistsError异常。- 如果文件 不存在,会 创建新文件。
- 用途:确保不会意外覆盖已有文件,适合需要安全写入的场景。
可以在 open() 函数中使用 x 模式来代替 w 模式的方法来解决这个问题。比如:
>>> with open('somefile', 'wt') as f:
... f.write('Hello\n')
...
>>> with open('somefile', 'xt') as f:
... f.write('Hello\n')
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
FileExistsError: [Errno 17] File exists: 'somefile'
>>>
如果文件是二进制的,使用 xb 来代替 xt。
这一小节演示了在写文件时通常会遇到的一个问题的完美解决方案(不小心覆盖一个已存在的文件)。一个替代方案是先测试这个文件是否存在,像下面这样:
>>> import os
>>> if not os.path.exists('somefile'):
... with open('somefile', 'wt') as f:
... f.write('Hello\n')
... else:
... print('File already exists!')
...
File already exists!
>>>
显而易见,使用 x 文件模式更加简单。要注意的是 x 模式是一个 Python3 对 open() 函数特有的扩展。在 Python 的旧版本或者是 Python 实现的底层 C 函数库中都是没有这个模式的。
相关文章:
)
【Python Cookbook】文件与 IO(一)
文件与 IO(一) 1.读写文本数据2.打印输出至文件中3.使用其他分隔符或行终止符打印4.读写字节数据5.文件不存在才能写入 1.读写文本数据 你需要读写各种不同编码的文本数据,比如 ASCII,UTF-8 或 UTF-16 编码等。 使用带有 rt 模式…...

STM32 HAL库函数学习 GPIO篇
1、void HAL_GPIO_Init(GPIO_TypeDef *GPIOx, const GPIO_InitTypeDef *pGPIO_Init) GPIO外设属于是任何芯片的最基础功能 ,STM32各个系列的GPIO初始化都是一致的,有不同的是部分系列在IO复用使用了单独一个成员属性Alternate 来表明这个IO的具体复用功…...
如何以 9 种方式将照片从 iPhone 传输到笔记本电脑
您的 iPhone 可能充满了以照片和视频形式捕捉的珍贵回忆。无论您是想备份它们、在更大的屏幕上编辑它们,还是只是释放设备上的空间,您都需要将照片从 iPhone 传输到笔记本电脑。幸运的是,有 9 种方便的方法可供使用,同时满足 Wind…...
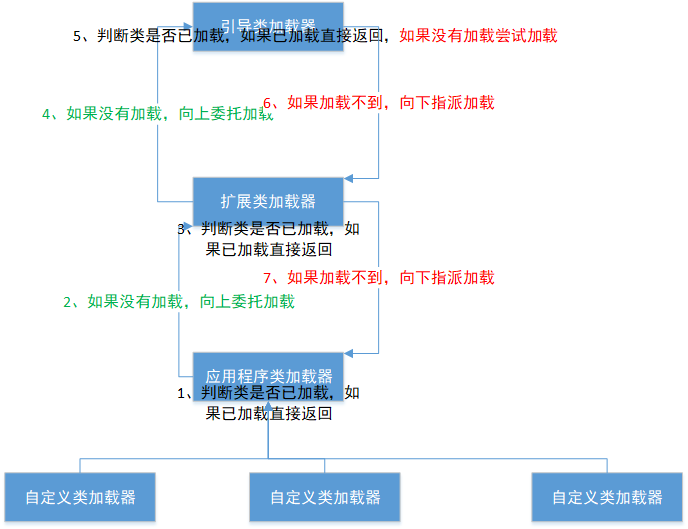
根据jvm源码剖析类加载机制
根据jvm源码剖析类加载机制 java Test.class之后的大致流程 java Test.class ----> 对于windows操作系统 ----> java.exe调用jvm.dll文件创建JVM, ----> 在创建JVM中先由C的代码创建Boostarp(引导)类加载器, ----&g…...
 安装教程及使用常见问题解决)
Mixly1.0/2.0/3.0 (windows系统) 安装教程及使用常见问题解决
大家好!长期以来,不少用户在使用 Mixly 软件过程中遇到了各类问题。为了帮助大家更顺畅地使用该软件,齐护机器人工程师结合自身丰富经验,精心总结并推出了本期教程。在本教程中,我们将从 Mixly 图形化编程软件的安装步…...

DDS通信中间件——DDS-TSN规范
DDS通信中间件——DDS-TSN规范 做了十年DDS通信中间件产品的程序员和大家分享一下对DDS这套规范的个人理解。预期本系列文章将包括以下内容陆续更新: DDS规范概述DCPS规范解读 & QoS策略XTypes规范解读RTPS规范解读DDS安全规范解读DDS-RPC规范解读(…...

JWT安全:弱签名测试.【实现越权绕过.】
JWT安全:假密钥【签名随便写实现越权绕过.】 JSON Web 令牌 (JWT)是一种在系统之间发送加密签名 JSON 数据的标准化格式。理论上,它们可以包含任何类型的数据,但最常用于在身份验证、会话处理和访问控制机制中发送有关用户的信息(“声明”)。…...

MATLAB实现井字棋
一、智能决策系统与博弈游戏概述 (一)智能决策系统核心概念 智能决策系统(Intelligent Decision System, IDS)是通过数据驱动和算法模型模拟人类决策过程的计算机系统,核心目标是在复杂环境中自动生成最优策略&#…...
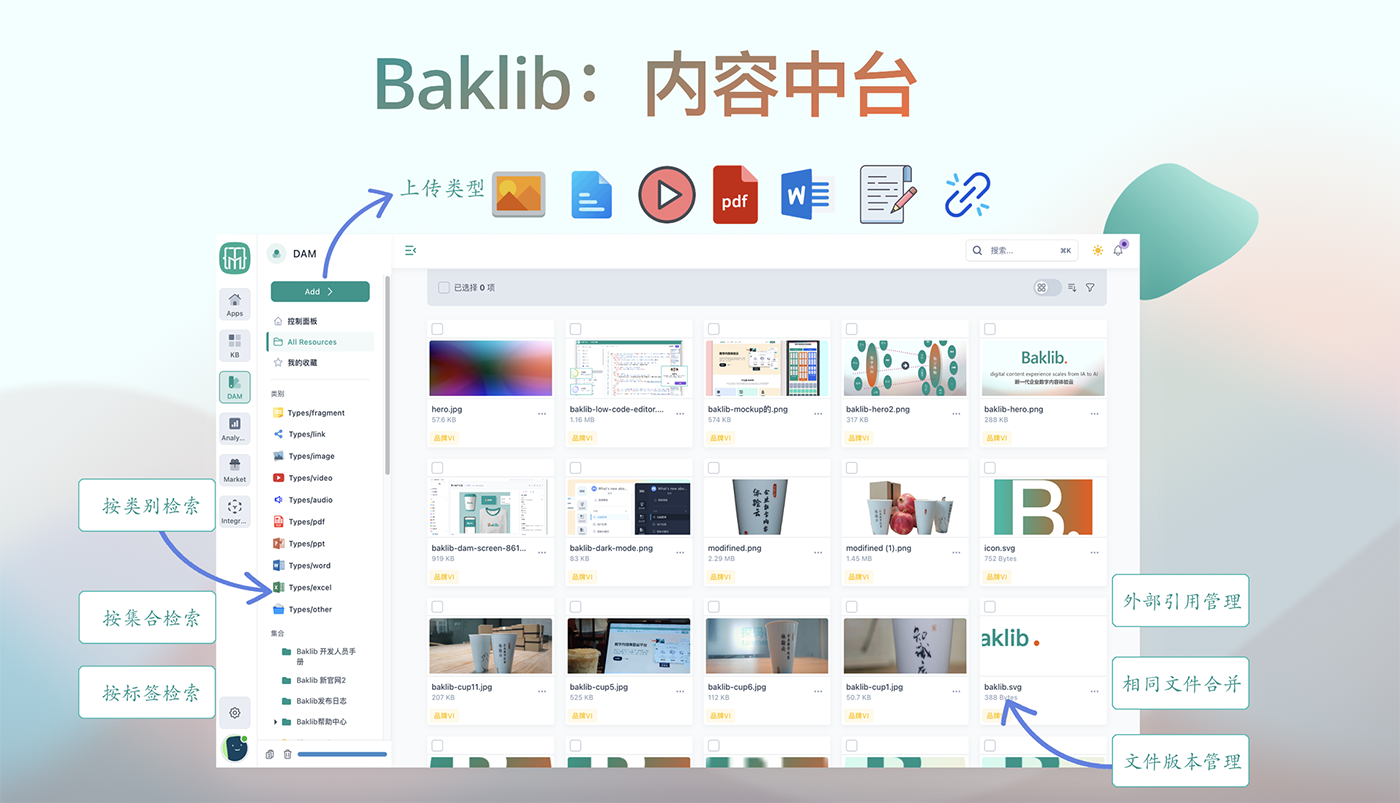
Baklib知识中台加速企业服务智能化实践
知识中台架构体系构建 Baklib 通过构建多层级架构体系实现知识中台的底层支撑,其核心包含数据采集层、知识加工层、服务输出层及智能应用层。在数据采集端,系统支持对接CRM、ERP等业务系统,结合NLP技术实现非结构化数据的自动抽取࿱…...

在AIX环境下修改oracle 11g rac的IP地址
0、当前环境 由于机房网络变更,客户要修改现在RAC的网络地址,这里记录一下。 主机操作系统:AIX 7.2 数据库版本:11.2.0.4 rac 数据库实例名:orcl1/orcl2 当前hosts文件配置 192.168.56.10 rac1 192.168.56.11 …...
VMware Tools 手动编译安装版
OWASPBWA安装VMware tools 安装时,显示如下提示 官方安装手册参考:https://knowledge.broadcom.com/external/article?legacyId1014294 按照提示,下载linux.iso文件,并连接到虚拟机的CDROM里,状态勾选已连接&#x…...
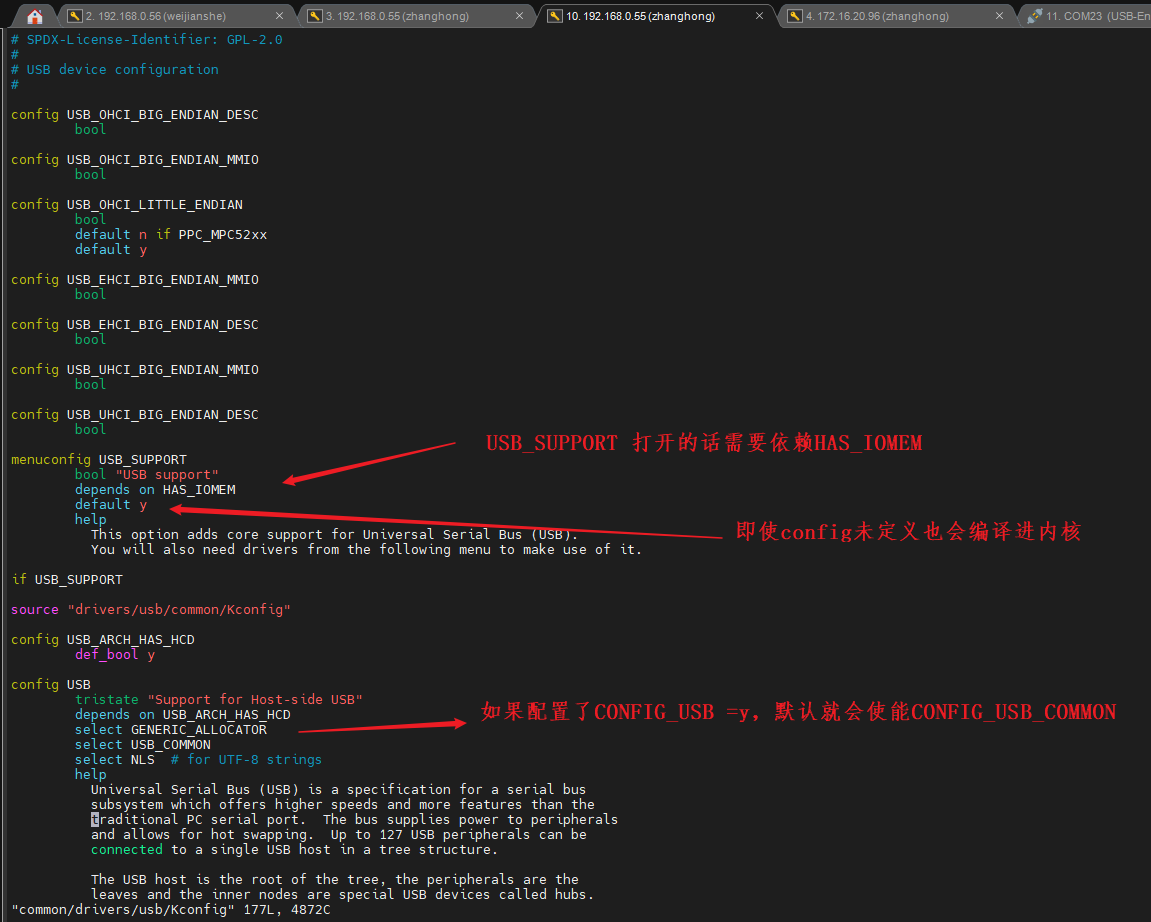
android平台驱动开发(六)--Makefile和Kconfig简介
Makefile: 1.编译进内核,还是以模块方式加载 模块方式编译成ko,通常是自己添加脚本方式insmod ,android 平台通常默认有modprobe加载,不需要额外添加insmod脚本 lsmod |grep test 可以查看是否安装成功 rmmod test-m.ko 可以删除ko 2.多…...

【手写系列】手写线程池
PS:本文的线程池为演示 Demo,皆在理解线程池的工作原理,并没有解决线程安全问题。 最简单一版的线程池 public class MyThreadPool {// 存放线程,复用已创建的线程List<Thread> threadList new ArrayList<>();publ…...

python学习打卡day40
DAY 40 训练和测试的规范写法 知识点回顾: 彩色和灰度图片测试和训练的规范写法:封装在函数中展平操作:除第一个维度batchsize外全部展平dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作业&#…...

redis高并发问题
Redlock原理和存在的问题 Redlock 基于以下假设: 有多个(一般建议是 5 个)彼此独立的 Redis 实例(不是主从复制,也不是集群模式),它们之间没有数据同步。客户端可以与所有 Redis 实例通信。 …...
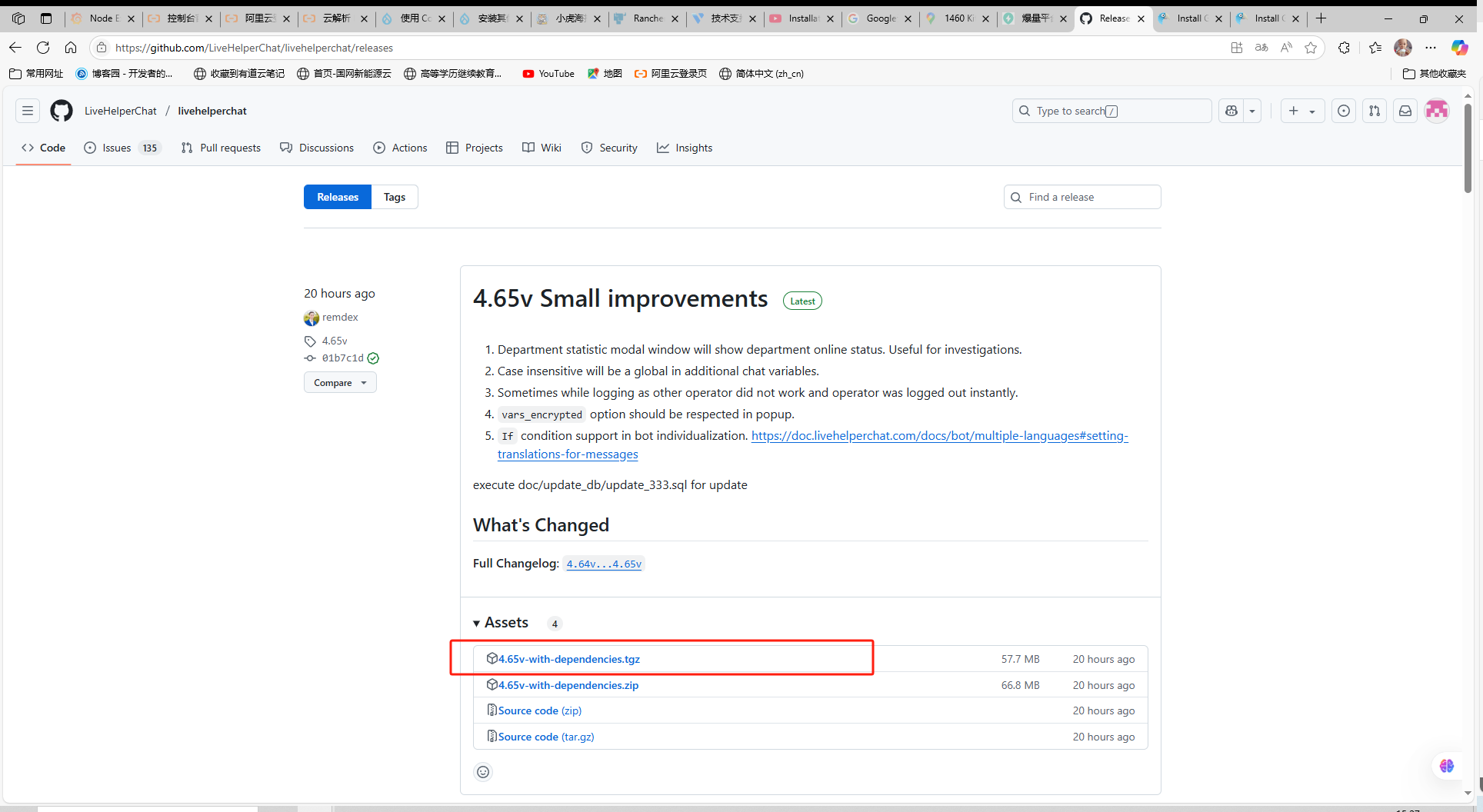
Live Helper Chat 安装部署
Live Helper Chat(LHC)是一款开源的实时客服聊天系统,适用于网站和应用,帮助企业与访问者即时沟通。它功能丰富、灵活、可自托管,常被用于在线客户支持、销售咨询以及技术支持场景。 🧰 系统要求 安装要求 您提供的链接指向 Live Helper Chat 的官方安装指南页面,详细…...
ARXML解析与可视化工具
随着汽车电子行业的快速发展,AUTOSAR标准在车辆软件架构中发挥着越来越重要的作用。然而,传统的ARXML文件处理工具往往存在高昂的许可费用、封闭的数据格式和复杂的使用门槛等问题。本文介绍一种基于TXT格式输出的ARXML解析方案,为开发团队提供了一个高效的替代解决方案。 …...
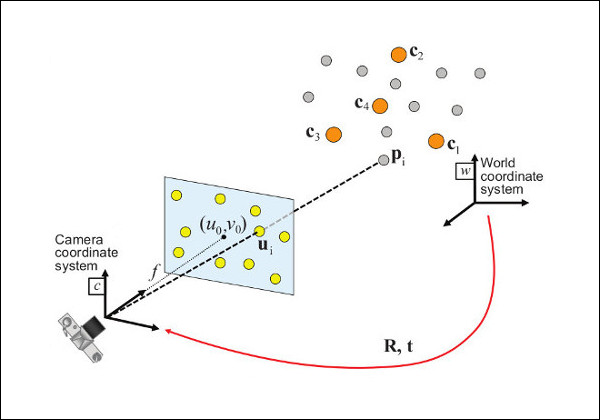
PnP(Perspective-n-Point)算法 | 用于求解已知n个3D点及其对应2D投影点的相机位姿
什么是PnP算法? PnP 全称是 Perspective-n-Point,中文叫“n点透视问题”。它的目标是: 已知一些空间中已知3D点的位置(世界坐标)和它们对应的2D图像像素坐标,求解摄像机的姿态(位置和平移&…...
)
LeetCode 热题 100 208. 实现 Trie (前缀树)
LeetCode 热题 100 | 208. 实现 Trie (前缀树) 大家好!今天我们来解决一道经典的算法题——实现 Trie (前缀树)。Trie(发音类似 “try”)是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构在自动补全和拼…...

python爬虫:RoboBrowser 的详细使用
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、RoboBrowser概述1.1 RoboBrowser 介绍1.2 安装 RoboBrowser1.3 与类似工具比较二、基本用法2.1 创建浏览器对象并访问网页2.2 查找元素2.3 填写和提交表单三、高级功能3.1 处理文件上传3.2 处理JavaScript重定向3.3…...

在日常管理服务器中如何防止SQL注入与XSS攻击?
在日常管理服务器时,防止SQL注入(Structured Query Language Injection)和XSS(Cross-Site Scripting)攻击是至关重要的,这些攻击可能会导致数据泄露、系统崩溃和信息泄露。以下是一份技术文章,介…...
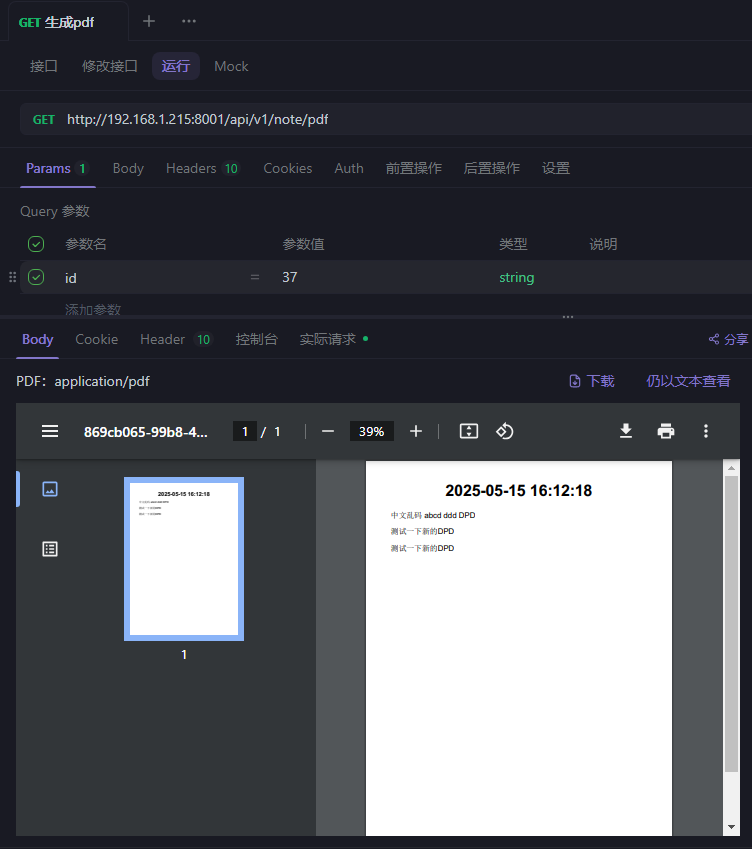
Wkhtmltopdf使用
Wkhtmltopdf使用 1.windows本地使用2.golangwindows环境使用3.golangdocker容器中使用 1.windows本地使用 官网地址 https://wkhtmltopdf.org/,直接去里面下载自己想要的版本,这里以windows版本为例2.golangwindows环境使用 1.安装扩展go get -u githu…...
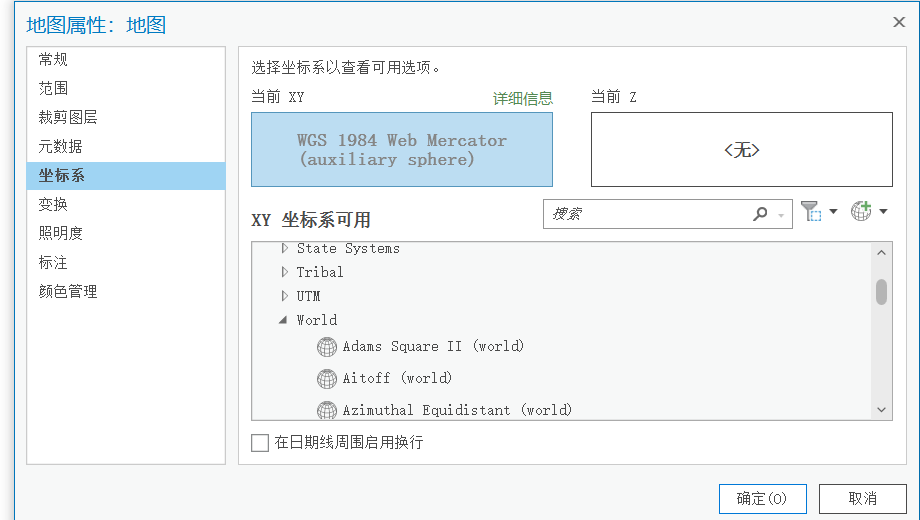
ArcGIS Pro 创建渔网格网过大,只有几个格网的解决方案
之前用ArcGIS Pro创建渔网的时候,发现创建出来格网过大,只有几个格网。 后来查阅资料,发现是坐标不对,导致设置格网大小时单位为度,而不是米,因此需要进行坐标系转换,网上有很多资料讲了ArcGIS …...
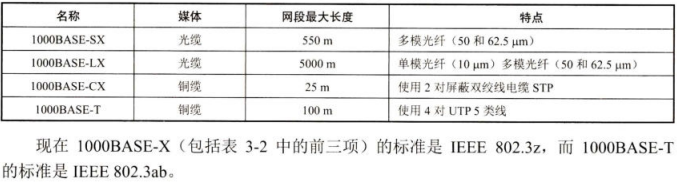
重学计算机网络之以太网
一:历史发展进程 DIX EtherNet V2 战胜IEEE802.3成为主流版本。总线型交换机拓扑机构代替集线器星型拓扑机构 1990年IEEE制定出星形以太网10BASE-T的标准**802.3i**。“10”代表10 Mbit/s 的数据率,BASE表示连接线上的信号是基带信号,T代表…...
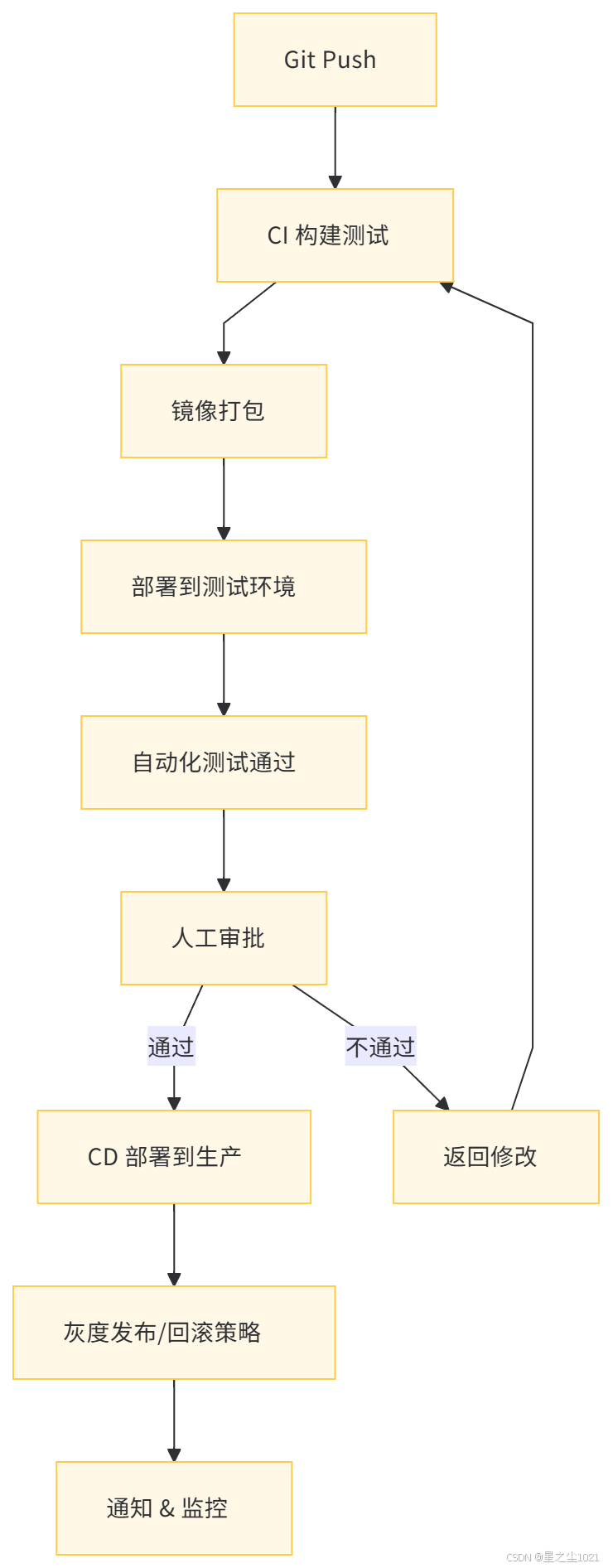
《深度解构现代云原生微服务架构的七大支柱》
☁️《深度解构现代云原生微服务架构的七大支柱》 一线架构师实战总结,系统性拆解现代微服务架构中最核心的 7 大支柱模块,涵盖通信协议、容器编排、服务网格、弹性伸缩、安全治理、可观测性、CI/CD 等。文内附架构图、实操路径与真实案例,适…...

使用SCSS实现随机大小的方块在页面滚动
目录 一、scss中的插值语法 二、方块在界面上滚动的动画 一、scss中的插值语法 插值语法 #{} 是一种动态注入变量或表达式到选择器、属性名、属性值等位置的机制 .类名:nth-child(n) 表示需同时满足为父元素的第n个元素且类名为给定条件 效果图: <div class…...

AI 眼镜新纪元:贴片式TF卡与 SOC 芯片的黄金组合破局智能穿戴
目录 一、SD NAND:智能眼镜的“记忆中枢”突破空间限制的存储革命性能与可靠性的双重保障 二、SOC芯片:AI眼镜的“智慧大脑”从性能到能效的全面跃升多模态交互的底层支撑 三、SD NANDSOC:11>2的协同效应数据流水线的高效协同成本…...

论文阅读(六)Open Set Video HOI detection from Action-centric Chain-of-Look Prompting
论文来源:ICCV(2023) 项目地址:https://github.com/southnx/ACoLP 1.研究背景与问题 开放集场景下的泛化性:传统 HOI 检测假设训练集包含所有测试类别,但现实中存在大量未见过的 HOI 类别(如…...

算法学习--持续更新
算法 2025年5月24日 完成:快速排序、快速排序基数优化、尾递归优化 快排 public class QuickSort {public void sort(int[] nums, int left, int right) {if(left>right){return;}int partiton quickSort(nums,left,right);sort(nums,left,partiton-1);sort(nu…...

Postman 发送 SOAP 请求步骤 归档
0.来源 https://apifox.com/apiskills/sending-soap-requests-with-postman/?utm_sourceopr&utm_mediuma2bobzhang&utm_contentpostman 再加上自己一点实践经验 1. 创建一个新的POST请求 postman 创建一个post请求, 请求url 怎么来的可以看第三步 2. post请求设…...