python训练营打卡第41天
简单CNN
知识回顾
- 数据增强
- 卷积神经网络定义的写法
- batch归一化:调整一个批次的分布,常用与图像数据
- 特征图:只有卷积操作输出的才叫特征图
- 调度器:直接修改基础学习率
卷积操作常见流程如下:
1. 输入 → 卷积层 → Batch归一化层(可选) → 池化层 → 激活函数 → 下一层
2. Flatten -> Dense (with Dropout,可选) -> Dense (Output)
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([# 随机裁剪图像,从原图中随机截取32x32大小的区域transforms.RandomCrop(32, padding=4),# 随机水平翻转图像(概率0.5)transforms.RandomHorizontalFlip(),# 随机颜色抖动:亮度、对比度、饱和度和色调随机变化transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),# 随机旋转图像(最大角度15度)transforms.RandomRotation(15),# 将PIL图像或numpy数组转换为张量transforms.ToTensor(),# 标准化处理:每个通道的均值和标准差,使数据分布更合理transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 测试集:仅进行必要的标准化,保持数据原始特性,标准化不损失数据信息,可还原
test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform # 使用增强后的预处理
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform # 测试集不使用增强
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义CNN模型的定义(替代原MLP)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # 继承父类初始化# ---------------------- 第一个卷积块 ----------------------# 卷积层1:输入3通道(RGB),输出32个特征图,卷积核3x3,边缘填充1像素self.conv1 = nn.Conv2d(in_channels=3, # 输入通道数(图像的RGB通道)out_channels=32, # 输出通道数(生成32个新特征图)kernel_size=3, # 卷积核尺寸(3x3像素)padding=1 # 边缘填充1像素,保持输出尺寸与输入相同)# 批量归一化层:对32个输出通道进行归一化,加速训练self.bn1 = nn.BatchNorm2d(num_features=32)# ReLU激活函数:引入非线性,公式:max(0, x)self.relu1 = nn.ReLU()# 最大池化层:窗口2x2,步长2,特征图尺寸减半(32x32→16x16)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # stride默认等于kernel_size# ---------------------- 第二个卷积块 ----------------------# 卷积层2:输入32通道(来自conv1的输出),输出64通道self.conv2 = nn.Conv2d(in_channels=32, # 输入通道数(前一层的输出通道数)out_channels=64, # 输出通道数(特征图数量翻倍)kernel_size=3, # 卷积核尺寸不变padding=1 # 保持尺寸:16x16→16x16(卷积后)→8x8(池化后))self.bn2 = nn.BatchNorm2d(num_features=64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:16x16→8x8# ---------------------- 第三个卷积块 ----------------------# 卷积层3:输入64通道,输出128通道self.conv3 = nn.Conv2d(in_channels=64, # 输入通道数(前一层的输出通道数)out_channels=128, # 输出通道数(特征图数量再次翻倍)kernel_size=3,padding=1 # 保持尺寸:8x8→8x8(卷积后)→4x4(池化后))self.bn3 = nn.BatchNorm2d(num_features=128)self.relu3 = nn.ReLU() # 复用激活函数对象(节省内存)self.pool3 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:8x8→4x4# ---------------------- 全连接层(分类器) ----------------------# 计算展平后的特征维度:128通道 × 4x4尺寸 = 128×16=2048维self.fc1 = nn.Linear(in_features=128 * 4 * 4, # 输入维度(卷积层输出的特征数)out_features=512 # 输出维度(隐藏层神经元数))# Dropout层:训练时随机丢弃50%神经元,防止过拟合self.dropout = nn.Dropout(p=0.5)# 输出层:将512维特征映射到10个类别(CIFAR-10的类别数)self.fc2 = nn.Linear(in_features=512, out_features=10)def forward(self, x):# 输入尺寸:[batch_size, 3, 32, 32](batch_size=批量大小,3=通道数,32x32=图像尺寸)# ---------- 卷积块1处理 ----------x = self.conv1(x) # 卷积后尺寸:[batch_size, 32, 32, 32](padding=1保持尺寸)x = self.bn1(x) # 批量归一化,不改变尺寸x = self.relu1(x) # 激活函数,不改变尺寸x = self.pool1(x) # 池化后尺寸:[batch_size, 32, 16, 16](32→16是因为池化窗口2x2)# ---------- 卷积块2处理 ----------x = self.conv2(x) # 卷积后尺寸:[batch_size, 64, 16, 16](padding=1保持尺寸)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x) # 池化后尺寸:[batch_size, 64, 8, 8]# ---------- 卷积块3处理 ----------x = self.conv3(x) # 卷积后尺寸:[batch_size, 128, 8, 8](padding=1保持尺寸)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x) # 池化后尺寸:[batch_size, 128, 4, 4]# ---------- 展平与全连接层 ----------# 将多维特征图展平为一维向量:[batch_size, 128*4*4] = [batch_size, 2048]x = x.view(-1, 128 * 4 * 4) # -1自动计算批量维度,保持批量大小不变x = self.fc1(x) # 全连接层:2048→512,尺寸变为[batch_size, 512]x = self.relu3(x) # 激活函数(复用relu3,与卷积块3共用)x = self.dropout(x) # Dropout随机丢弃神经元,不改变尺寸x = self.fc2(x) # 全连接层:512→10,尺寸变为[batch_size, 10](未激活,直接输出logits)return x # 输出未经过Softmax的logits,适用于交叉熵损失函数# 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号# 记录每个 epoch 的准确率和损失train_acc_history = []test_acc_history = []train_loss_history = []test_loss_history = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_acc_history.append(epoch_train_acc)train_loss_history.append(epoch_train_loss)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_acc_history.append(epoch_test_acc)test_loss_history.append(epoch_test_loss)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 绘制每个 epoch 的准确率和损失曲线plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 绘制每个 epoch 的准确率和损失曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))# 绘制准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend()plt.grid(True)# 绘制损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始使用CNN训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
torch.save(model.state_dict(), 'cifar10_cnn_model.pth')
print("模型已保存为: cifar10_cnn_model.pth")输出结果:
使用设备: cpu
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████| 170M/170M [2:35:15<00:00, 18.3kB/s]
开始使用CNN训练模型...
Epoch: 1/20 | Batch: 100/782 | 单Batch损失: 1.9777 | 累计平均损失: 2.0057
Epoch: 1/20 | Batch: 200/782 | 单Batch损失: 1.6204 | 累计平均损失: 1.8880
Epoch: 1/20 | Batch: 300/782 | 单Batch损失: 1.7299 | 累计平均损失: 1.8201
Epoch: 1/20 | Batch: 400/782 | 单Batch损失: 1.6091 | 累计平均损失: 1.7746
Epoch: 1/20 | Batch: 500/782 | 单Batch损失: 1.6772 | 累计平均损失: 1.7437
Epoch: 1/20 | Batch: 600/782 | 单Batch损失: 1.4562 | 累计平均损失: 1.7158
Epoch: 1/20 | Batch: 700/782 | 单Batch损失: 1.7877 | 累计平均损失: 1.6911
Epoch 1/20 完成 | 训练准确率: 38.04% | 测试准确率: 52.76%
Epoch: 2/20 | Batch: 100/782 | 单Batch损失: 1.3830 | 累计平均损失: 1.4543
Epoch: 2/20 | Batch: 200/782 | 单Batch损失: 1.4006 | 累计平均损失: 1.4024
Epoch: 2/20 | Batch: 300/782 | 单Batch损失: 1.3910 | 累计平均损失: 1.3811
Epoch: 2/20 | Batch: 400/782 | 单Batch损失: 1.4579 | 累计平均损失: 1.3645
Epoch: 2/20 | Batch: 500/782 | 单Batch损失: 1.1114 | 累计平均损失: 1.3383
Epoch: 2/20 | Batch: 600/782 | 单Batch损失: 1.5332 | 累计平均损失: 1.3200
Epoch: 2/20 | Batch: 700/782 | 单Batch损失: 1.0414 | 累计平均损失: 1.2985
Epoch 2/20 完成 | 训练准确率: 53.50% | 测试准确率: 61.99%
Epoch: 3/20 | Batch: 100/782 | 单Batch损失: 1.2217 | 累计平均损失: 1.1599
Epoch: 3/20 | Batch: 200/782 | 单Batch损失: 1.1079 | 累计平均损失: 1.1518
Epoch: 3/20 | Batch: 300/782 | 单Batch损失: 1.2212 | 累计平均损失: 1.1452
Epoch: 3/20 | Batch: 400/782 | 单Batch损失: 1.2502 | 累计平均损失: 1.1357
Epoch: 3/20 | Batch: 500/782 | 单Batch损失: 0.7482 | 累计平均损失: 1.1227
Epoch: 3/20 | Batch: 600/782 | 单Batch损失: 1.0918 | 累计平均损失: 1.1133
Epoch: 3/20 | Batch: 700/782 | 单Batch损失: 0.9135 | 累计平均损失: 1.1041
Epoch 3/20 完成 | 训练准确率: 60.86% | 测试准确率: 69.86%
Epoch: 4/20 | Batch: 100/782 | 单Batch损失: 0.8592 | 累计平均损失: 1.0361
Epoch: 4/20 | Batch: 200/782 | 单Batch损失: 0.7710 | 累计平均损失: 1.0218
Epoch: 4/20 | Batch: 300/782 | 单Batch损失: 0.7764 | 累计平均损失: 1.0221
Epoch: 4/20 | Batch: 400/782 | 单Batch损失: 1.0345 | 累计平均损失: 1.0122
Epoch: 4/20 | Batch: 500/782 | 单Batch损失: 0.9350 | 累计平均损失: 1.0076
Epoch: 4/20 | Batch: 600/782 | 单Batch损失: 0.8809 | 累计平均损失: 1.0044
Epoch: 4/20 | Batch: 700/782 | 单Batch损失: 0.7959 | 累计平均损失: 0.9978
Epoch 4/20 完成 | 训练准确率: 64.80% | 测试准确率: 71.14%
Epoch: 5/20 | Batch: 100/782 | 单Batch损失: 1.0453 | 累计平均损失: 0.9381
Epoch: 5/20 | Batch: 200/782 | 单Batch损失: 0.8142 | 累计平均损失: 0.9390
Epoch: 5/20 | Batch: 300/782 | 单Batch损失: 1.1331 | 累计平均损失: 0.9349
Epoch: 5/20 | Batch: 400/782 | 单Batch损失: 1.0204 | 累计平均损失: 0.9336
Epoch: 5/20 | Batch: 500/782 | 单Batch损失: 0.7933 | 累计平均损失: 0.9294
Epoch: 5/20 | Batch: 600/782 | 单Batch损失: 1.0409 | 累计平均损失: 0.9300
Epoch: 5/20 | Batch: 700/782 | 单Batch损失: 0.7061 | 累计平均损失: 0.9265
Epoch 5/20 完成 | 训练准确率: 67.23% | 测试准确率: 72.77%
Epoch: 6/20 | Batch: 100/782 | 单Batch损失: 0.9459 | 累计平均损失: 0.9026
Epoch: 6/20 | Batch: 200/782 | 单Batch损失: 0.9639 | 累计平均损失: 0.8838
Epoch: 6/20 | Batch: 300/782 | 单Batch损失: 0.8213 | 累计平均损失: 0.8805
Epoch: 6/20 | Batch: 400/782 | 单Batch损失: 1.1107 | 累计平均损失: 0.8805
Epoch: 6/20 | Batch: 500/782 | 单Batch损失: 0.6813 | 累计平均损失: 0.8779
Epoch: 6/20 | Batch: 600/782 | 单Batch损失: 1.0904 | 累计平均损失: 0.8801
Epoch: 6/20 | Batch: 700/782 | 单Batch损失: 0.9470 | 累计平均损失: 0.8820
Epoch 6/20 完成 | 训练准确率: 69.05% | 测试准确率: 74.45%
Epoch: 7/20 | Batch: 100/782 | 单Batch损失: 0.6600 | 累计平均损失: 0.8492
Epoch: 7/20 | Batch: 200/782 | 单Batch损失: 0.9984 | 累计平均损失: 0.8343
Epoch: 7/20 | Batch: 300/782 | 单Batch损失: 0.9071 | 累计平均损失: 0.8481
Epoch: 7/20 | Batch: 400/782 | 单Batch损失: 0.8838 | 累计平均损失: 0.8467
Epoch: 7/20 | Batch: 500/782 | 单Batch损失: 1.1298 | 累计平均损失: 0.8448
Epoch: 7/20 | Batch: 600/782 | 单Batch损失: 0.8678 | 累计平均损失: 0.8463
Epoch: 7/20 | Batch: 700/782 | 单Batch损失: 0.8116 | 累计平均损失: 0.8446
Epoch 7/20 完成 | 训练准确率: 70.22% | 测试准确率: 74.77%
Epoch: 8/20 | Batch: 100/782 | 单Batch损失: 0.8443 | 累计平均损失: 0.8203
Epoch: 8/20 | Batch: 200/782 | 单Batch损失: 0.8219 | 累计平均损失: 0.8119
Epoch: 8/20 | Batch: 300/782 | 单Batch损失: 0.9490 | 累计平均损失: 0.8191
Epoch: 8/20 | Batch: 400/782 | 单Batch损失: 0.6975 | 累计平均损失: 0.8150
Epoch: 8/20 | Batch: 500/782 | 单Batch损失: 0.9863 | 累计平均损失: 0.8163
Epoch: 8/20 | Batch: 600/782 | 单Batch损失: 0.8835 | 累计平均损失: 0.8173
Epoch: 8/20 | Batch: 700/782 | 单Batch损失: 0.9080 | 累计平均损失: 0.8163
Epoch 8/20 完成 | 训练准确率: 71.32% | 测试准确率: 75.56%
Epoch: 9/20 | Batch: 100/782 | 单Batch损失: 0.7591 | 累计平均损失: 0.7930
Epoch: 9/20 | Batch: 200/782 | 单Batch损失: 0.8791 | 累计平均损失: 0.7982
Epoch: 9/20 | Batch: 300/782 | 单Batch损失: 0.8607 | 累计平均损失: 0.7932
Epoch: 9/20 | Batch: 400/782 | 单Batch损失: 0.9582 | 累计平均损失: 0.7926
Epoch: 9/20 | Batch: 500/782 | 单Batch损失: 0.8388 | 累计平均损失: 0.7962
Epoch: 9/20 | Batch: 600/782 | 单Batch损失: 0.8563 | 累计平均损失: 0.7962
Epoch: 9/20 | Batch: 700/782 | 单Batch损失: 0.7313 | 累计平均损失: 0.7930
Epoch 9/20 完成 | 训练准确率: 72.18% | 测试准确率: 76.50%
Epoch: 10/20 | Batch: 100/782 | 单Batch损失: 0.9776 | 累计平均损失: 0.7650
Epoch: 10/20 | Batch: 200/782 | 单Batch损失: 0.8844 | 累计平均损失: 0.7662
Epoch: 10/20 | Batch: 300/782 | 单Batch损失: 0.8675 | 累计平均损失: 0.7713
Epoch: 10/20 | Batch: 400/782 | 单Batch损失: 0.7129 | 累计平均损失: 0.7783
Epoch: 10/20 | Batch: 500/782 | 单Batch损失: 0.8208 | 累计平均损失: 0.7755
Epoch: 10/20 | Batch: 600/782 | 单Batch损失: 0.6194 | 累计平均损失: 0.7719
Epoch: 10/20 | Batch: 700/782 | 单Batch损失: 0.8767 | 累计平均损失: 0.7721
Epoch 10/20 完成 | 训练准确率: 72.93% | 测试准确率: 76.78%
Epoch: 11/20 | Batch: 100/782 | 单Batch损失: 0.9397 | 累计平均损失: 0.7650
Epoch: 11/20 | Batch: 200/782 | 单Batch损失: 0.6596 | 累计平均损失: 0.7479
Epoch: 11/20 | Batch: 300/782 | 单Batch损失: 0.6678 | 累计平均损失: 0.7525
Epoch: 11/20 | Batch: 400/782 | 单Batch损失: 0.7369 | 累计平均损失: 0.7468
Epoch: 11/20 | Batch: 500/782 | 单Batch损失: 0.5968 | 累计平均损失: 0.7456
Epoch: 11/20 | Batch: 600/782 | 单Batch损失: 0.7618 | 累计平均损失: 0.7482
Epoch: 11/20 | Batch: 700/782 | 单Batch损失: 0.5952 | 累计平均损失: 0.7468
Epoch 11/20 完成 | 训练准确率: 73.76% | 测试准确率: 77.75%
Epoch: 12/20 | Batch: 100/782 | 单Batch损失: 0.6831 | 累计平均损失: 0.7307
Epoch: 12/20 | Batch: 200/782 | 单Batch损失: 1.0081 | 累计平均损失: 0.7396
Epoch: 12/20 | Batch: 300/782 | 单Batch损失: 0.7043 | 累计平均损失: 0.7319
Epoch: 12/20 | Batch: 400/782 | 单Batch损失: 0.7510 | 累计平均损失: 0.7373
Epoch: 12/20 | Batch: 500/782 | 单Batch损失: 0.6491 | 累计平均损失: 0.7328
Epoch: 12/20 | Batch: 600/782 | 单Batch损失: 0.7510 | 累计平均损失: 0.7338
Epoch: 12/20 | Batch: 700/782 | 单Batch损失: 0.5930 | 累计平均损失: 0.7348
Epoch 12/20 完成 | 训练准确率: 74.27% | 测试准确率: 78.12%
Epoch: 13/20 | Batch: 100/782 | 单Batch损失: 0.6943 | 累计平均损失: 0.7011
Epoch: 13/20 | Batch: 200/782 | 单Batch损失: 0.6623 | 累计平均损失: 0.7131
Epoch: 13/20 | Batch: 300/782 | 单Batch损失: 0.6798 | 累计平均损失: 0.7113
Epoch: 13/20 | Batch: 400/782 | 单Batch损失: 0.7274 | 累计平均损失: 0.7166
Epoch: 13/20 | Batch: 500/782 | 单Batch损失: 0.7826 | 累计平均损失: 0.7161
Epoch: 13/20 | Batch: 600/782 | 单Batch损失: 0.7504 | 累计平均损失: 0.7173
Epoch: 13/20 | Batch: 700/782 | 单Batch损失: 0.7069 | 累计平均损失: 0.7152
Epoch 13/20 完成 | 训练准确率: 74.70% | 测试准确率: 78.06%
Epoch: 14/20 | Batch: 100/782 | 单Batch损失: 0.7636 | 累计平均损失: 0.7224
Epoch: 14/20 | Batch: 200/782 | 单Batch损失: 0.6530 | 累计平均损失: 0.7117
Epoch: 14/20 | Batch: 300/782 | 单Batch损失: 0.8442 | 累计平均损失: 0.7096
Epoch: 14/20 | Batch: 400/782 | 单Batch损失: 0.6878 | 累计平均损失: 0.7081
Epoch: 14/20 | Batch: 500/782 | 单Batch损失: 0.6114 | 累计平均损失: 0.7047
Epoch: 14/20 | Batch: 600/782 | 单Batch损失: 0.7571 | 累计平均损失: 0.7039
Epoch: 14/20 | Batch: 700/782 | 单Batch损失: 0.6249 | 累计平均损失: 0.7035
Epoch 14/20 完成 | 训练准确率: 75.43% | 测试准确率: 77.57%
Epoch: 15/20 | Batch: 100/782 | 单Batch损失: 0.5851 | 累计平均损失: 0.6991
Epoch: 15/20 | Batch: 200/782 | 单Batch损失: 0.4987 | 累计平均损失: 0.6924
Epoch: 15/20 | Batch: 300/782 | 单Batch损失: 0.6194 | 累计平均损失: 0.6968
Epoch: 15/20 | Batch: 400/782 | 单Batch损失: 0.7770 | 累计平均损失: 0.6955
Epoch: 15/20 | Batch: 500/782 | 单Batch损失: 0.7774 | 累计平均损失: 0.6949
Epoch: 15/20 | Batch: 600/782 | 单Batch损失: 0.5769 | 累计平均损失: 0.6957
Epoch: 15/20 | Batch: 700/782 | 单Batch损失: 0.8801 | 累计平均损失: 0.6915
Epoch 15/20 完成 | 训练准确率: 75.65% | 测试准确率: 78.43%
Epoch: 16/20 | Batch: 100/782 | 单Batch损失: 0.5745 | 累计平均损失: 0.6677
Epoch: 16/20 | Batch: 200/782 | 单Batch损失: 0.5646 | 累计平均损失: 0.6759
Epoch: 16/20 | Batch: 300/782 | 单Batch损失: 0.5587 | 累计平均损失: 0.6737
Epoch: 16/20 | Batch: 400/782 | 单Batch损失: 0.7392 | 累计平均损失: 0.6799
Epoch: 16/20 | Batch: 500/782 | 单Batch损失: 0.7110 | 累计平均损失: 0.6784
Epoch: 16/20 | Batch: 600/782 | 单Batch损失: 0.6812 | 累计平均损失: 0.6743
Epoch: 16/20 | Batch: 700/782 | 单Batch损失: 0.5018 | 累计平均损失: 0.6737
Epoch 16/20 完成 | 训练准确率: 76.24% | 测试准确率: 79.31%
Epoch: 17/20 | Batch: 100/782 | 单Batch损失: 0.6641 | 累计平均损失: 0.6629
Epoch: 17/20 | Batch: 200/782 | 单Batch损失: 0.8051 | 累计平均损失: 0.6559
Epoch: 17/20 | Batch: 300/782 | 单Batch损失: 0.9051 | 累计平均损失: 0.6629
Epoch: 17/20 | Batch: 400/782 | 单Batch损失: 0.5781 | 累计平均损失: 0.6598
Epoch: 17/20 | Batch: 500/782 | 单Batch损失: 0.7231 | 累计平均损失: 0.6574
Epoch: 17/20 | Batch: 600/782 | 单Batch损失: 0.5777 | 累计平均损失: 0.6603
Epoch: 17/20 | Batch: 700/782 | 单Batch损失: 0.9671 | 累计平均损失: 0.6628
Epoch 17/20 完成 | 训练准确率: 76.85% | 测试准确率: 78.49%
Epoch: 18/20 | Batch: 100/782 | 单Batch损失: 0.6666 | 累计平均损失: 0.6729
Epoch: 18/20 | Batch: 200/782 | 单Batch损失: 0.5626 | 累计平均损失: 0.6737
Epoch: 18/20 | Batch: 300/782 | 单Batch损失: 0.4289 | 累计平均损失: 0.6661
Epoch: 18/20 | Batch: 400/782 | 单Batch损失: 0.7499 | 累计平均损失: 0.6611
Epoch: 18/20 | Batch: 500/782 | 单Batch损失: 0.6759 | 累计平均损失: 0.6619
Epoch: 18/20 | Batch: 600/782 | 单Batch损失: 0.6288 | 累计平均损失: 0.6585
Epoch: 18/20 | Batch: 700/782 | 单Batch损失: 0.6190 | 累计平均损失: 0.6603
Epoch 18/20 完成 | 训练准确率: 76.76% | 测试准确率: 78.82%
Epoch: 19/20 | Batch: 100/782 | 单Batch损失: 0.5597 | 累计平均损失: 0.6393
Epoch: 19/20 | Batch: 200/782 | 单Batch损失: 0.7296 | 累计平均损失: 0.6434
Epoch: 19/20 | Batch: 300/782 | 单Batch损失: 0.5335 | 累计平均损失: 0.6350
Epoch: 19/20 | Batch: 400/782 | 单Batch损失: 0.7613 | 累计平均损失: 0.6358
Epoch: 19/20 | Batch: 500/782 | 单Batch损失: 0.7232 | 累计平均损失: 0.6382
Epoch: 19/20 | Batch: 600/782 | 单Batch损失: 0.7425 | 累计平均损失: 0.6445
Epoch: 19/20 | Batch: 700/782 | 单Batch损失: 0.4579 | 累计平均损失: 0.6460
Epoch 19/20 完成 | 训练准确率: 77.39% | 测试准确率: 80.34%
Epoch: 20/20 | Batch: 100/782 | 单Batch损失: 0.6894 | 累计平均损失: 0.6250
Epoch: 20/20 | Batch: 200/782 | 单Batch损失: 0.6279 | 累计平均损失: 0.6234
Epoch: 20/20 | Batch: 300/782 | 单Batch损失: 0.6294 | 累计平均损失: 0.6268
Epoch: 20/20 | Batch: 400/782 | 单Batch损失: 0.7378 | 累计平均损失: 0.6291
Epoch: 20/20 | Batch: 500/782 | 单Batch损失: 0.7755 | 累计平均损失: 0.6328
Epoch: 20/20 | Batch: 600/782 | 单Batch损失: 0.4936 | 累计平均损失: 0.6303
Epoch: 20/20 | Batch: 700/782 | 单Batch损失: 0.5084 | 累计平均损失: 0.6347
Epoch 20/20 完成 | 训练准确率: 78.11% | 测试准确率: 79.24%@浙大疏锦行
相关文章:

python训练营打卡第41天
简单CNN 知识回顾 数据增强卷积神经网络定义的写法batch归一化:调整一个批次的分布,常用与图像数据特征图:只有卷积操作输出的才叫特征图调度器:直接修改基础学习率 卷积操作常见流程如下: 1. 输入 → 卷积层 → Batch…...

1.3HarmonyOS NEXT统一开发范式与跨端适配:开启高效跨设备应用开发新时代
HarmonyOS NEXT统一开发范式与跨端适配:开启高效跨设备应用开发新时代 在HarmonyOS NEXT的技术体系中,统一开发范式与跨端适配是两大关键特性,它们为开发者打破了设备边界,极大地提升了开发效率与应用体验。本章节将深入探讨方舟…...

麒麟v10,arm64架构,编译安装Qt5.12.8
Window和麒麟x86_64架构,官网提供安装包,麒麟arm64架构的,只能自己用编码编译安装。 注意,“桌面”路径是中文,所以不要把源码放在桌面上编译。 1. 下载源码 从官网下载源码:https://download.qt.io/arc…...

ArcGIS Pro 3.4 二次开发 - 布局
环境:ArcGIS Pro SDK 3.4 + .NET 8 文章目录 布局1 布局工程项1.1 引用布局工程项及其关联的布局1.2 在新视图中打开布局工程项1.3 激活已打开的布局视图1.4 引用活动布局视图1.5 将 pagx 导入工程1.6 移除布局工程项1.7 创建并打开一个新的基本布局1.8 使用修改后的CIM创建新…...
的锂电池健康状态(SOH)预测)
基于随机函数链接神经网络(RVFL)的锂电池健康状态(SOH)预测
基于随机函数链接神经网络(RVFL)的锂电池健康状态(SOH)预测 一、RVFL网络的基本原理与结构 随机向量功能链接(Random Vector Functional Link, RVFL)网络是一种单隐藏层前馈神经网络的随机化版本,其核心特征在于输入层到隐藏层的权重随机生成且固定,输出层权重通过最…...

爱其实很简单
初春时,元元买来两只芙蓉鸟。一只白色的,是雄鸟;另一只黄色的,是雌鸟。 每天清晨日出之前,雄鸟便开始“啁啾——啁啾”地啼鸣,鸣声清脆婉转,充满喜悦,仿佛在迎接日出,又…...

2025年渗透测试面试题总结-匿名[校招]安全工程师(甲方)(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 匿名[校招]安全工程师(甲方) 1. 介绍自己熟悉的渗透领域 2. 编程语言与开发能力 3. 实习工作内容与流程 …...
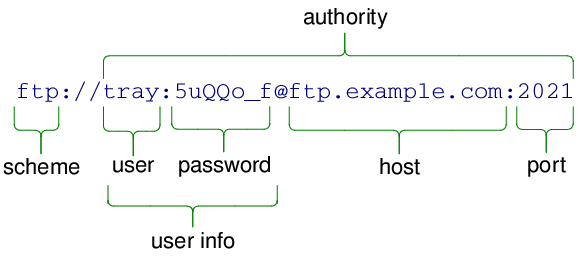
PySide6 GUI 学习笔记——常用类及控件使用方法(地址类QUrl)
文章目录 地址类QUrl主要功能URL 格式介绍常见 scheme(协议)类型QUrl 类常用方法常用方法示例典型应用场景 地址类QUrl QUrl 是 PySide6.QtCore 模块中的一个类,用于处理和操作 URL(统一资源定位符)。它可以解析、构建…...

任务23:创建天气信息大屏Django项目
任务描述 知识点: Django 重 点: Django创建项目Django视图函数Django路由Django静态文件Django渲染模板 内 容: 使用PyCharm创建大屏项目渲染大屏主页 任务指导 1. 使用PyCharm创建大屏项目。 创建weather项目配置虚拟环境创建ch…...
数学分析——一致性(均匀性)和收敛
目录 1. 连续函数 1.1 连续函数的定义 1.2 连续函数的性质 1.2.1 性质一 1.2.2 性质二 1.2.3 性质三 1.2.4 性质四 2. 一致连续函数 2.1 一致连续函数的定义 2.2 一致连续性定理(小间距定理)(一致连续函数的另一种定义) 2.3 一致连续性判定法 2.4 连…...
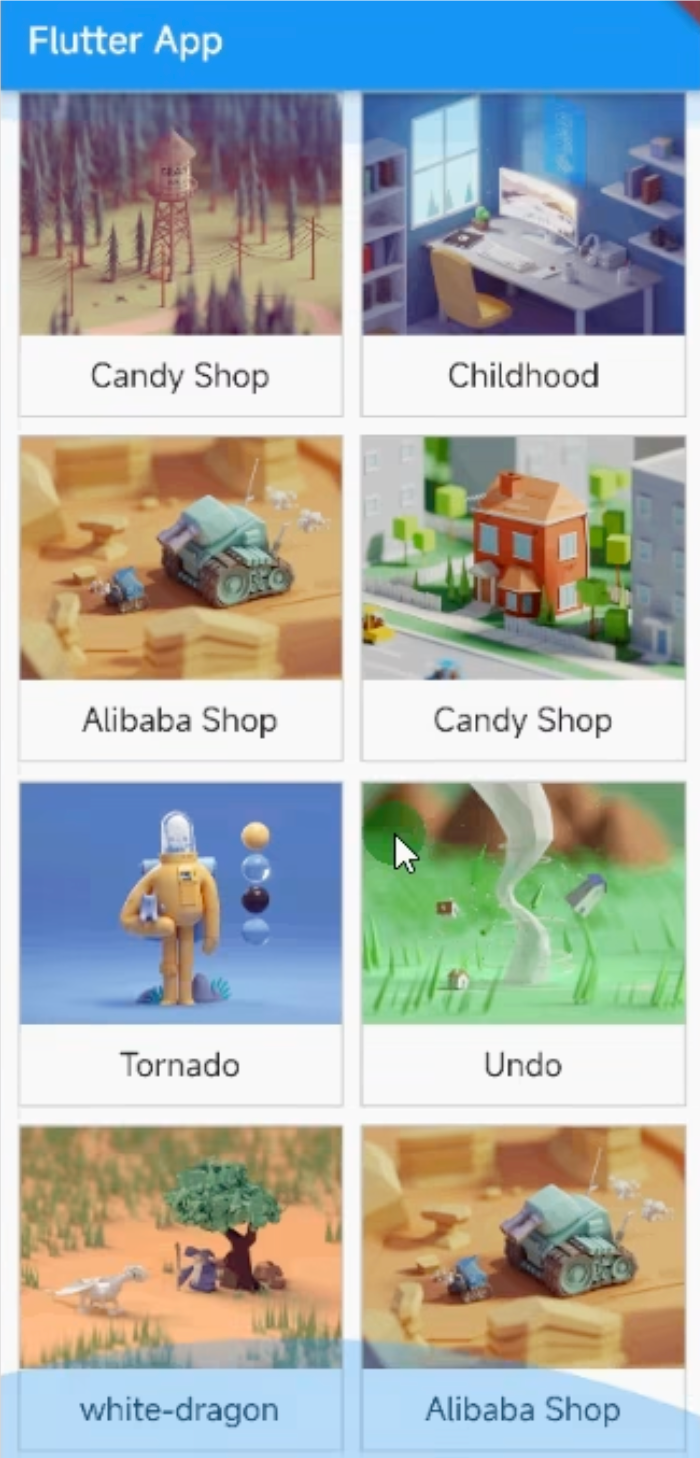
Flutter GridView网格组件
目录 常用属性 GridView使用配置 GridView.count使用 GridView.extent使用 GridView.count Container 实现列表 GridView.extent Container 实现列表 GridView.builder使用 GridView网格布局在实际项目中用的也是非常多的,当我们想让可以滚动的元素使用矩阵…...
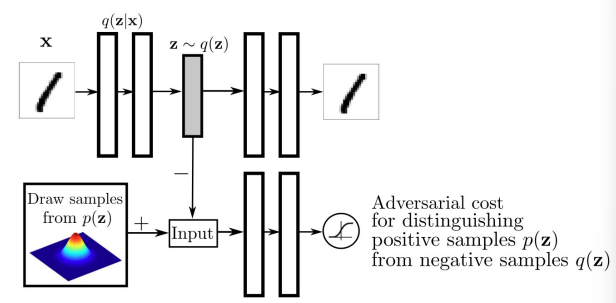
【深度学习】18. 生成模型:Variational Auto-Encoder(VAE)详解
Variational Auto-Encoder(VAE)详解 本节内容完整介绍 VAE 的模型结构、优化目标、重参数化技巧及其生成机制。 回顾:Autoencoder(自编码器) Autoencoder 是一种无监督学习模型,旨在从未标注的数据中学习压…...

NodeJS全栈开发面试题讲解——P6安全与鉴权
✅ 6.1 如何防止 SQL 注入 / XSS / CSRF? 面试官您好,Web 安全三大经典问题分别从不同层面入手: 🔸 SQL 注入(Server端) 原理:恶意用户将 SQL 注入查询语句拼接,导致数据泄露或破坏…...

C# 密封类和密封方法
密封(sealed)是C#中用于限制继承和多态行为的关键字,它可以应用于类和方法,提供了一种控制继承层次的方式。 密封类 特点 使用 sealed 关键字修饰的类密封类不能被其他类继承,但可以继承其他类或接口主要用于防止派生所有结构(struct)都是…...

为什么badmin reconfig以后始终不能提交任务
最近遇到的怪事:修改了openlava配置以后运行badmin reconfig激活配置变更,但是长时间始终不能提交任务。 首先查看进程,发现openlava管理节点上的所有服务进程都在运行状态;查看mbd日志没有发现错误信息;再看mbd进程的…...
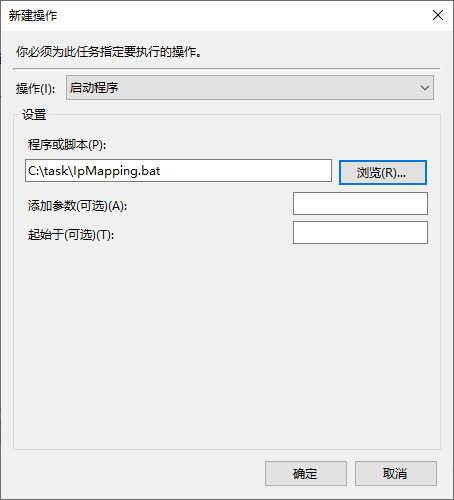
解决Window10上IP映射重启失效的问题
问题 在实际网络搭建过程中,大家有可能会遇到在局域网范围内,在自己本机上搭建一个网站或者应用时,其他设备通过本机的IP地址无法访问的问题,这个问题可以通过设置IP映射来解决,但是通过netsh interface命令设置的IP映射…...
)
力扣刷题(第四十四天)
灵感来源 - 保持更新,努力学习 - python脚本学习 删除重复的电子邮箱 解题思路 这个问题要求我们删除表中所有重复的电子邮箱,只保留每个唯一电子邮箱对应的最小id记录。解决这个问题的关键在于识别出哪些记录是重复的,并确定需要删除的…...

MyBatis-Plus高级用法:最优化持久层开发
MyBatis-Plus 是 MyBatis 的增强工具,旨在简化开发、提高效率并保持 MyBatis 的灵活性。本文将详细介绍 MyBatis-Plus 的高级用法,帮助开发者最优化持久层开发。 一、MyBatis-Plus 简介 MyBatis-Plus 是一个 ORM 框架,提供了 CRUD 接口、条…...

c++之循环
目录 C循环结构完全解析:从基础到实战应用 一、for循环结构 二、while循环结构 三、do-while循环结构 四、范围for循环(C11) 五、循环控制语句 C循环结构完全解析:从基础到实战应用 循环结构是编程语言的核心控制结构之一&a…...

python h5py 读取mat文件的<HDF5 object reference> 问题
我用python加载matlab的mat文件 mat文件: 加载方式: mat_file h5py.File(base_dir str(N) _nodes_dataset_snr- str(snr) _M_ str(M) .mat, r) Signals mat_file["Signals"][()] Tp mat_file["Tp"][()] Tp_list mat_fil…...
linux命令 systemctl 和 supervisord 区别及用法解读
目录 基础与背景服务管理范围配置文件和管理方式监控与日志依赖管理适用场景常用命令对照表实际应用场景举例优缺点对比小结参考链接 1. 基础与背景 systemctl 和 supervisord 都是用于管理和控制服务(进程)的工具,但它们在设计、使用场景和…...

Spring Boot + MyBatis 实现的简单用户管理项目的完整目录结构示例
📁 示例项目结构(基于 Maven) user-management/ ├── src/ │ ├── main/ │ │ ├── java/ │ │ │ └── com/example/usermanagement/ │ │ │ ├── controller/ │ │ │ │ └── UserC…...
)
NodeJS全栈开发面试题讲解——P5前端能力(React/Vue + API调用)
✅ 5.1 如何使用 React/Vue 发起后端请求?用什么库? 面试官您好,在实际项目中我们通常使用 axios、fetch 或框架提供的封装库发起后端请求。 🔧 常用库对比: 库框架适配优点axios通用默认支持拦截器、取消请求、请求体…...

[001]从操作系统层面看锁的逻辑
从操作系统层面,锁 (Lock) 是一种同步机制,用于控制多个线程或线程对共享资源的访问,防止竞态条件(race condition).常见的锁包括互斥锁(mutex)、读写锁(read-write lock)、自旋锁(spinlock)等。…...

初识 Pytest:测试世界的智能助手
概述 在编写程序的过程中,我们常常需要确认代码是否按照预期工作。为了提高效率并减少人为错误,我们可以借助工具来帮助我们完成这一过程。Pytest 就是这样一个用于编写和运行测试的 Python 工具。 什么是 Pytest? Pytest 是一个用于 Pyth…...

stm32 + ads1292心率检测报警设置上下限
这个项目是在做心率检测的时候一个小伙伴提出来的,今年五一的时候提出来的想法,五一假期的时候没时间,也没心情做这个,就把这个事情搁置了,在月中做工作计划的时候,就把这个小项目排进来了,五一…...

项目练习:element ui 的icon放在button的右侧
文章目录 一、需求描述二、左侧实现三、右侧实现 一、需求描述 我们知道,element ui的button一般都会配置一个icon 这个icon默认是放在左侧的。 如何让它放在右侧了? 二、左侧实现 <el-buttontype"primary"plainicon"el-icon-d-arr…...
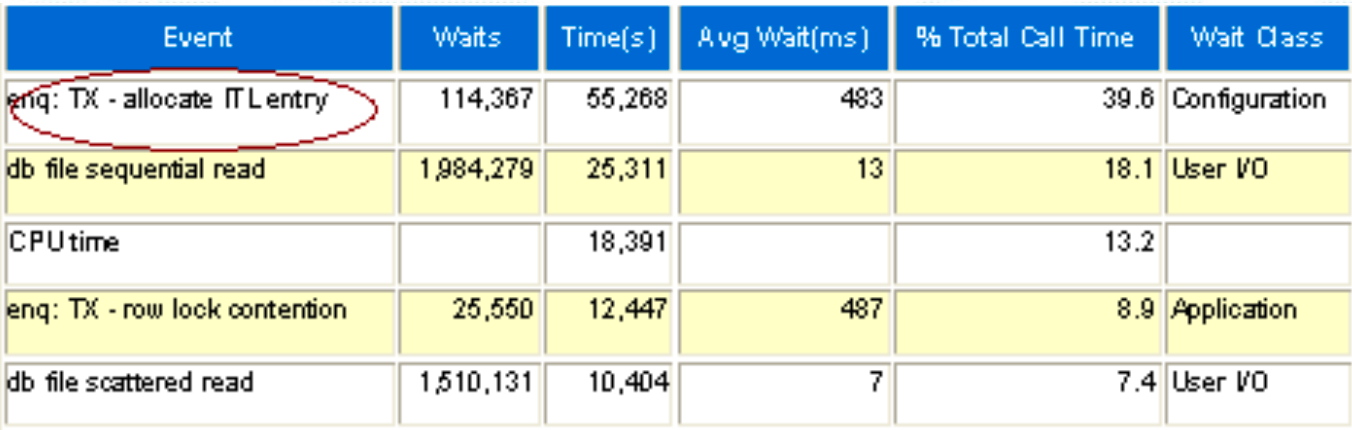
性能诊断工具AWR配置策略与报告内容解析
AWR(Automatic Workload Repository)是 Oracle 数据库中的一个重要性能诊断工具。AWR 会按照固定的时间间隔自动收集数据库系统的性能统计信息。这些信息涵盖了数据库运行状态的方方面面,像SQL 执行情况、系统资源利用率、等待事件等。AWR抓取…...
Tailwind CSS 实战,基于 Kooboo 构建 AI 对话框页面(三):实现暗黑模式主题切换
基于前两篇的内容,为页面添加主题切换功能,实现网站页面的暗黑模式: Tailwind css实战,基于Kooboo构建AI对话框页面(一)-CSDN博客 Tailwind css实战,基于Kooboo构建AI对话框页面(…...

OleDbParameter.Value 与 DataTable.Rows.Item.Value 的性能对比
OleDbParameter.Value 与 DataTable.Rows.Item.Value 的性能对比 您提到的两种赋值操作属于不同场景,它们的性能和稳定性取决于具体使用方式。下面从几个维度进行分析: 1. 操作本质对比 (1)OleDbParameter.Value 用途…...