【Python 算法零基础 4.排序 ⑥ 快速排序】
既有锦绣前程可奔赴,亦有往日岁月可回首
—— 25.5.25
选择排序回顾
① 遍历数组:从索引 0 到 n-1(n 为数组长度)。
② 每轮确定最小值:假设当前索引 i 为最小值索引 min_index。从 i+1 到 n-1 遍历,若找到更小元素,则更新 min_index。
③ 交换元素:若 min_index ≠ i,则交换 arr[i] 与 arr[min_index]。
'''
① 遍历数组:从索引 0 到 n-1(n 为数组长度)。② 每轮确定最小值:假设当前索引 i 为最小值索引 min_index。从 i+1 到 n-1 遍历,若找到更小元素,则更新 min_index。③ 交换元素:若 min_index ≠ i,则交换 arr[i] 与 arr[min_index]。
'''def selectionSort(arr: List[int]):n = len(arr)for i in range(n):min_index = ifor j in range(i+1, n):if arr[j] < arr[min_index]:min_index = jif min_index != i:arr[i], arr[min_index] = arr[min_index], arr[i]return arr冒泡排序回顾
① 初始化:设数组长度为 n。
② 外层循环:遍历 i 从 0 到 n-1(共 n 轮)。
③ 内层循环:对于每轮 i,遍历 j 从 0 到 n-i-2。
④ 比较与交换:若 arr[j] > arr[j+1],则交换两者。
⑤ 结束条件:重复步骤 2-4,直到所有轮次完成。
'''
① 初始化:设数组长度为 n。② 外层循环:遍历 i 从 0 到 n-1(共 n 轮)。③ 内层循环:对于每轮 i,遍历 j 从 0 到 n-i-1。④ 比较与交换:若 arr[j] > arr[j+1],则交换两者。⑤ 结束条件:重复步骤 2-4,直到所有轮次完成。
'''
def bubbleSort(arr: List[int]):n = len(arr)for i in range(n):for j in range(n-i-1):if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j]return arr插入排序回顾
① 遍历未排序元素:从索引 1 到 n-1。
② 保存当前元素:将 arr[i] 存入 current。
③ 元素后移:从已排序部分的末尾(索引 j = i-1)向前扫描,将比 current 大的元素后移。直到找到第一个不大于 current 的位置或扫描完所有元素。
④ 插入元素:将 current 放入 j+1 位置。
'''
① 遍历未排序元素:从索引 1 到 n-1。② 保存当前元素:将 arr[i] 存入 current。③ 元素后移:从已排序部分的末尾(索引 j = i-1)向前扫描,将比 current 大的元素后移。直到找到第一个不大于 current 的位置或扫描完所有元素。④ 插入元素:将 current 放入 j+1 位置。
'''
def insertSort(arr: List[int]):n = len(arr)for i in range(n):current = arr[i]j = i - 1while current < arr[j] and j >0:arr[j+1] = arr[j]j -= 1arr[j + 1] = currentreturn arr计数排序回顾
① 初始化:设数组长度为 n,元素最大值为 r。创建长度为 r+1 的计数数组 count,初始值全为 0。
② 统计元素频率:遍历原数组 arr,对每个元素 x,将 count[x] 加 1。
③ 重构有序数组:初始化索引 index = 0。遍历计数数组 count,索引 v 从 0 到 r,若 count[v] > 0,则将 v 填入原数组 arr[index],并将 index 加 1。count[v] - 1,重复此步骤直到 count[v] 为 0。
④ 结束条件:当计数数组遍历完成时,排序结束。
'''
输入全为非负整数,且所有元素 ≤ r① 初始化:设数组长度为 n,元素最大值为 r。创建长度为 r+1 的计数数组 count,初始值全为 0。② 统计元素频率:遍历原数组 arr,对每个元素 x,将 count[x] 加 1。③ 重构有序数组:初始化索引 index = 0。遍历计数数组 count,索引 v 从 0 到 r,
若 count[v] > 0,则将 v 填入原数组 arr[index],并将 index 加 1。
count[v] - 1,重复此步骤直到 count[v] 为 0。④ 结束条件:当计数数组遍历完成时,排序结束。
'''def countingSort(arr: List[int], r: int):# count = [0] * len(r + 1)count = [0 for i in range(r + 1)]for x in arr:count[x] += 1index = 0for v in range(r + 1):while count[v] > 0:arr[index] = vindex += 1count[v] -= 1return arr归并排序回顾
Ⅰ、递归分解列表
① 终止条件:若链表为空或只有一个节点(head is None 或 head.next is None),直接返回头节点。
② 快慢指针找中点:初始化 slow 和 fast 指针,slow 指向头节点,fast 指向头节点的下一个节点。fast 每次移动两步,slow 每次移动一步。当 fast 到达末尾时,slow 恰好指向链表的中间节点。
③ 分割链表:将链表从中点断开,head2 指向 slow.next(后半部分的头节点)。将 slow.next 置为 None,切断前半部分与后半部分的连接。
④ 递归排序子链表:对前半部分(head)和后半部分(head2)分别递归调用 mergesort 函数。
Ⅱ、合并两个有序列表
① 创建虚拟头节点:创建一个值为 -1 的虚拟节点 zero,用于简化边界处理。使用 current 指针指向 zero,用于构建合并后的链表。
② 比较并合并节点:遍历两个子链表 head1 和 head2,比较当前节点的值:若 head1.val <= head2.val,将 head1 接入合并链表,并移动 head1 指针。否则,将 head2 接入合并链表,并移动 head2 指针。每次接入节点后,移动 current 指针到新接入的节点。
③ 处理剩余节点:当其中一个子链表遍历完后,将另一个子链表的剩余部分直接接入合并链表的末尾。
④ 返回合并后的链表:虚拟节点 zero 的下一个节点即为合并后的有序链表的头节点。
'''
Ⅰ、递归分解列表① 终止条件:若链表为空或只有一个节点(head is None 或 head.next is None),直接返回头节点。② 快慢指针找中点:初始化 slow 和 fast 指针,slow 指向头节点,fast 指向头节点的下一个节点。fast 每次移动两步,slow 每次移动一步。当 fast 到达末尾时,slow 恰好指向链表的中间节点。③ 分割链表:将链表从中点断开,head2 指向 slow.next(后半部分的头节点)。将 slow.next 置为 None,切断前半部分与后半部分的连接。④ 递归排序子链表:对前半部分(head)和后半部分(head2)分别递归调用 mergesort 函数。Ⅱ、合并两个有序列表① 创建虚拟头节点:创建一个值为 -1 的虚拟节点 zero,用于简化边界处理。使用 current 指针指向 zero,用于构建合并后的链表。② 比较并合并节点:遍历两个子链表 head1 和 head2,比较当前节点的值:若 head1.val <= head2.val,将 head1 接入合并链表,并移动 head1 指针。否则,将 head2 接入合并链表,并移动 head2 指针。每次接入节点后,移动 current 指针到新接入的节点。③ 处理剩余节点:当其中一个子链表遍历完后,将另一个子链表的剩余部分直接接入合并链表的末尾。④ 返回合并后的链表:虚拟节点 zero 的下一个节点即为合并后的有序链表的头节点。
'''
def mergesort(self, head: ListNode):if head is None or head.next is None:return headslow, fast = head, head.nextwhile fast and fast.next:slow = slow.nextfast = fast.next.nexthead2 = slow.nextslow.next = Nonereturn self.merge(self.mergesort(head), self.mergesort(head2))def merge(self, head1: ListNode, head2: ListNode):zero = ListNode(-1)current = zerowhile head1 and head2:if head1.val <= head2.val:current.next = head1head1 = head1.nextelse:current.next = head2head2 = head2.nextcurrent = current.nextcurrent.next = head1 if head1 else head2return zero.next一、引言
快速排序(Quick Sort)是一种分而治之的排序算法。它通过选择一个基准元素,将数组分为两部分,一部分的元素都比基准小,另一部分的元素都比基准大,然后对这两部分再进行快速排序,最终得到有序的数组。
二、算法思想
① 选择基准元素:从数组中随机选择一个元素作为基准。将基准元素放在数组的最左边。
② 分割数组:从头遍历数组,将比基准小的元素放在基准的左边,比基准大的元素放在基准的右边。
③ 递归排序:对基准左边和右边的子数组分别进行快速排序。
④ 重复步骤 ① 至 ③:直到子数组的长度为 1 或 0。
首先随机选择了一个数字作为【基准数】,并且将它和最左边的数交换,然后依次遍历,小于这个数字的值存储在一起,大于这个数字的值存储在一起,遍历完毕后,将这个【基准数】和下标最大的那个比【基准数】小的数字交换位置,至此,这个 、基准数左边位置上的数都小于它,右边位置上的数字都大于它,左边与右边两部分数字继续递归求解即可
三、算法分析
1.时间复杂度
最优情况:当每次选择的基准元素正好将数组分成两等分时,快速排序的时间复杂度是 O(n*logn)
最坏情况:当每次选择的基准元素是最大或最小元素时,快速排序的时间复杂度是 O(n^2)
平均情况:在平均情况下,快速排序的时间复杂度也是 O(n*logn)
2.空间复杂度
快速排序的空间复杂度是 O(logn),因为在递归调用中需要使用栈来存储中间结果。这意味着在排序过程中,最多需要 O(logn) 的额外空间来保存递归调用的栈帧。
3.算法的优点
① 高效性:快速排序在大多数情况下具有较高的排序效率。
② 适应性:适用于各种数据类型的排序。
③ 原地排序:不需要额外的存储空间。
4.算法的缺点
① 最坏情况性能:在最坏情况下,快速排序的时间复杂度可能退化为 O(n^2)。
② 不稳定性:快速排序可能会破坏排序的稳定性,即相同元素的相对顺序可能会改变
四、实战练习
217. 存在重复元素
给你一个整数数组
nums。如果任一值在数组中出现 至少两次 ,返回true;如果数组中每个元素互不相同,返回false。示例 1:
输入:nums = [1,2,3,1]
输出:true
解释:
元素 1 在下标 0 和 3 出现。
示例 2:
输入:nums = [1,2,3,4]
输出:false
解释:
所有元素都不同。
示例 3:
输入:nums = [1,1,1,3,3,4,3,2,4,2]
输出:true
提示:
1 <= nums.length <= 105-109 <= nums[i] <= 109
思路与算法
Ⅰ、分区函数 Partition
① 随机选择基准元素:根据左右边界下标随机选择基准元素(选择的是元素并非下标),将基准元素赋值变量进行后续比较
② 交换基准元素:将基准元素移动到最左边,将基准元素存储在变量中,
③ 分区操作:对于基准元素右边的元素,找到第一个小于基准元素的值,移动到最左边;对于基准元素左边的元素,找到第一个大于基准元素的值,移动到最右边
④ 返回基准元素的最终位置:循环执行完毕后,基准元素左边的值都小于它,基准元素右边的值都大于它
Ⅱ、递归排序函数
① 定义递归终止条件:当左索引小于右索引时,结束递归
② 分区操作: 执行第一次分区操作,找到基准元素
③ 递归调用分区函数:将基准元素的左边、右边部分分别传入递归函数进行排序
Ⅲ、验证是否存在重复元素
① 排序数组:将数组传入快速排序的实现中,返回排好序的数组
② 遍历数组,寻找是否存在重复元素:遍历数组,如果发现相邻两个元素相等,则返回True,否则遍历完数组后,返回False
class Solution:def Partition(self, arr: List, left, right):index = random.randint(left, right)arr[left], arr[index] = arr[index], arr[left]i = leftj = rightx = arr[i]while i < j:while i < j and arr[j] > x:j -= 1if i < j:arr[i], arr[j] = arr[j], arr[i]i += 1while i < j and arr[i] < x:i += 1if i < j:arr[i], arr[j] = arr[j], arr[i]j -= 1return idef quickSort(self, arr: List, left: int, right: int) -> List[int]: if left >= right:returnnode = self.Partition(arr, left, right)self.quickSort(arr, left, node - 1)self.quickSort(arr, node + 1, right)def containsDuplicate(self, nums: List[int]) -> bool:n = len(nums)self.quickSort(nums, 0, n - 1)for i in range(1, n):if nums[i] == nums[i - 1]:return Truereturn False 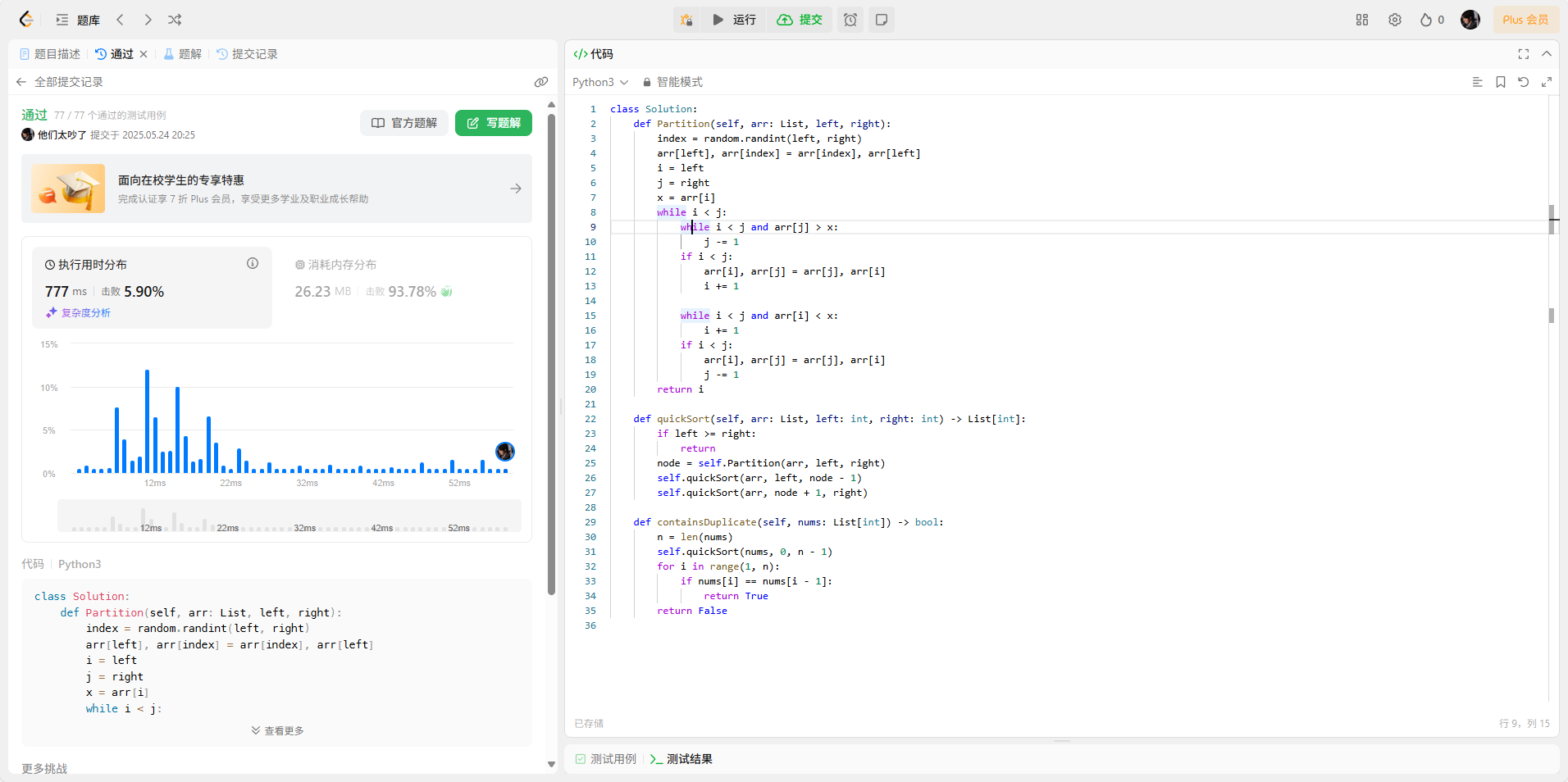
169. 多数元素
给定一个大小为
n的数组nums,返回其中的多数元素。多数元素是指在数组中出现次数 大于⌊ n/2 ⌋的元素。你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 1:
输入:nums = [3,2,3] 输出:3示例 2:
输入:nums = [2,2,1,1,1,2,2] 输出:2提示:
n == nums.length1 <= n <= 5 * 104-109 <= nums[i] <= 109进阶:尝试设计时间复杂度为 O(n)、空间复杂度为 O(1) 的算法解决此问题。
思路与算法
Ⅰ、分区函数 Partition
① 随机选择基准元素:根据左右边界下标随机选择基准元素
② 交换基准元素:将基准元素移动到最左边
③ 分区操作:对于基准元素右边的元素,找到第一个小于基准元素的值,移动到最左边;对于基准元素左边的元素,找到第一个大于基准元素的值,移动到最右边
④ 返回基准元素的最终位置:循环执行完毕后,基准元素左边的值都小于它,基准元素右边的值都大于它
Ⅱ、递归排序函数
① 定义递归终止条件:当左索引小于右索引时,结束递归
② 分区操作: 执行第一次分区操作,找到基准元素
③ 递归调用分区函数:将基准元素的左边、右边部分分别传入递归函数进行排序
Ⅲ、在排好序的数组中返回多数元素
① 排序数组:将数组传入实现的快速排序函数中,返回已排序的数组
② 返回多数元素:因为题目中保证一定存在多数元素,所以排序好的数组中,多数一定是多数元素,所以直接返回排序后数组中间位置的值即可
class Solution:def Partition(self, arr: List, left, right):index = random.randint(left, right)arr[left], arr[index] = arr[index], arr[left]i = leftj = rightx = arr[i]while i < j:while i < j and arr[j] > x:j -= 1if i < j:arr[i], arr[j] = arr[j], arr[i]i += 1while i < j and arr[i] < x:i += 1if i < j:arr[i], arr[j] = arr[j], arr[i]j -= 1return idef quickSort(self, arr: List, left: int, right: int) -> List[int]: if left >= right:returnnode = self.Partition(arr, left, right)self.quickSort(arr, left, node - 1)self.quickSort(arr, node + 1, right)def majorityElement(self, nums: List[int]) -> int:n = len(nums)self.quickSort(nums, 0, n - 1)return nums[n//2]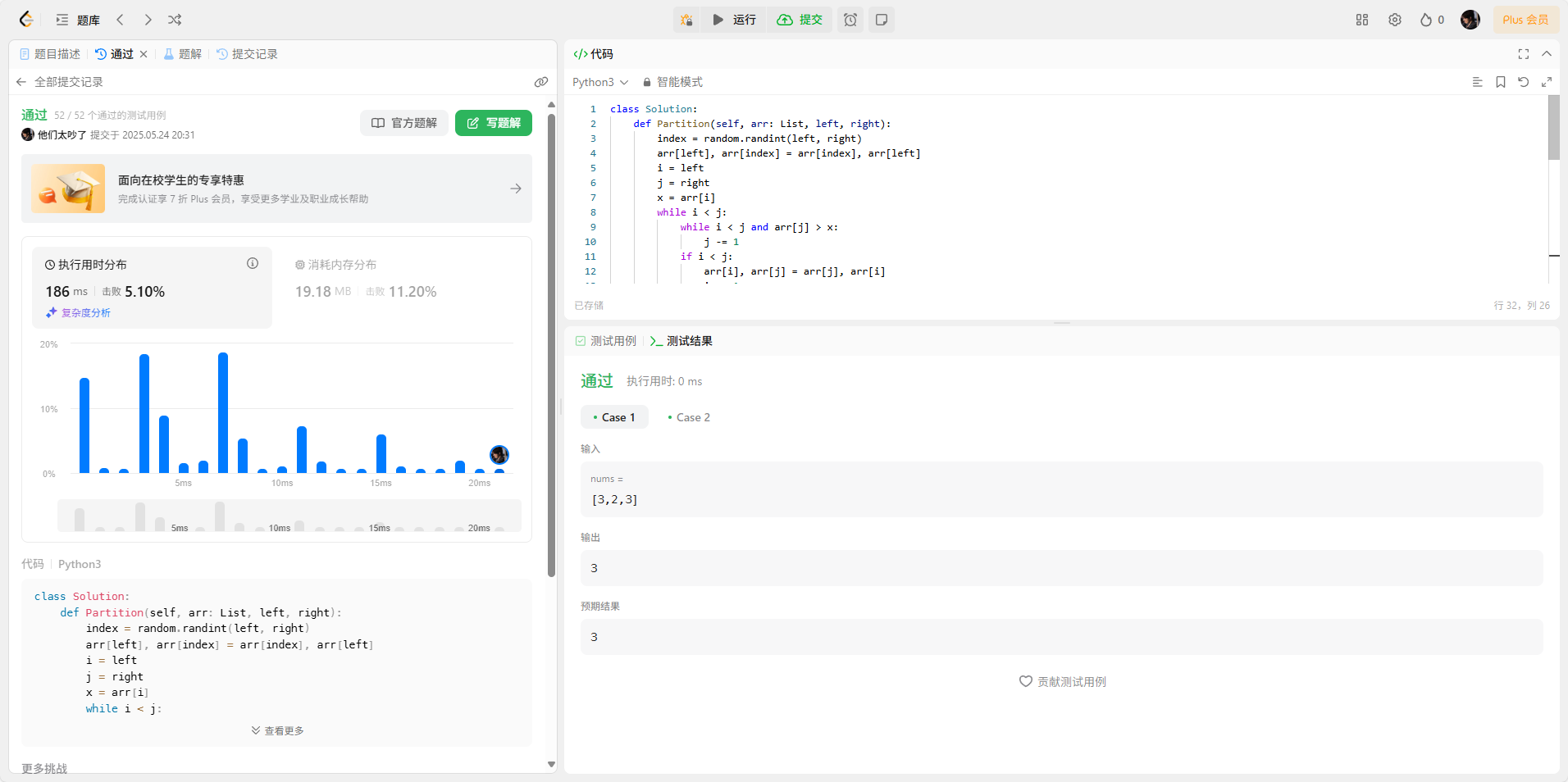
相关文章:
【Python 算法零基础 4.排序 ⑥ 快速排序】
既有锦绣前程可奔赴,亦有往日岁月可回首 —— 25.5.25 选择排序回顾 ① 遍历数组:从索引 0 到 n-1(n 为数组长度)。 ② 每轮确定最小值:假设当前索引 i 为最小值索引 min_index。从 i1 到 n-1 遍历,若找到…...

Java面试实战:从Spring Boot到微服务与AI的全栈挑战
场景一:初步了解和基本技术问题 面试官:我们先从基础开始,谢先生,你能简单介绍一下你在Java SE上的经验吗? 谢飞机:当然!Java就像是我的老朋友,尤其是8和11版本。我用它们做过很多…...
Go 即时通讯系统:日志模块重构,并从main函数开始
重构logger 上次写的logger.go过于繁琐,有很多没用到的功能;重构后只提供了简洁的日志接口,支持日志轮转、多级别日志记录等功能,并采用单例模式确保全局只有一个日志实例 全局变量 var (once sync.Once // 用于实现…...

CppCon 2014 学习:Exception-Safe Coding
以下是你提到的内容(例如 “Exception-Safe Coding 理解” 和 “Easier to Read!” 等)翻译成中文并进一步解释: 承诺:理解异常安全(Exception-Safe Coding) 什么是异常安全? 异常安全是指&a…...
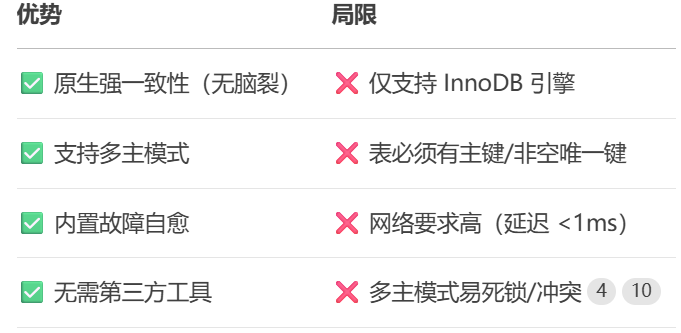
MYSQL MGR高可用
1,MYSQL MGR高可用是什么 简单来说,MySQL MGR 的核心目标就是:确保数据库服务在部分节点(服务器)发生故障时,整个数据库集群依然能够继续提供读写服务,最大限度地减少停机时间。 2. 核心优势 v…...

阿里通义实验室突破空间音频新纪元!OmniAudio让360°全景视频“声”临其境
在虚拟现实和沉浸式娱乐快速发展的今天,视觉体验已经远远不够,声音的沉浸感成为打动用户的关键。然而,传统的视频配音技术往往停留在“平面”的音频层面,难以提供真正的空间感。阿里巴巴通义实验室(Qwen Lab࿰…...
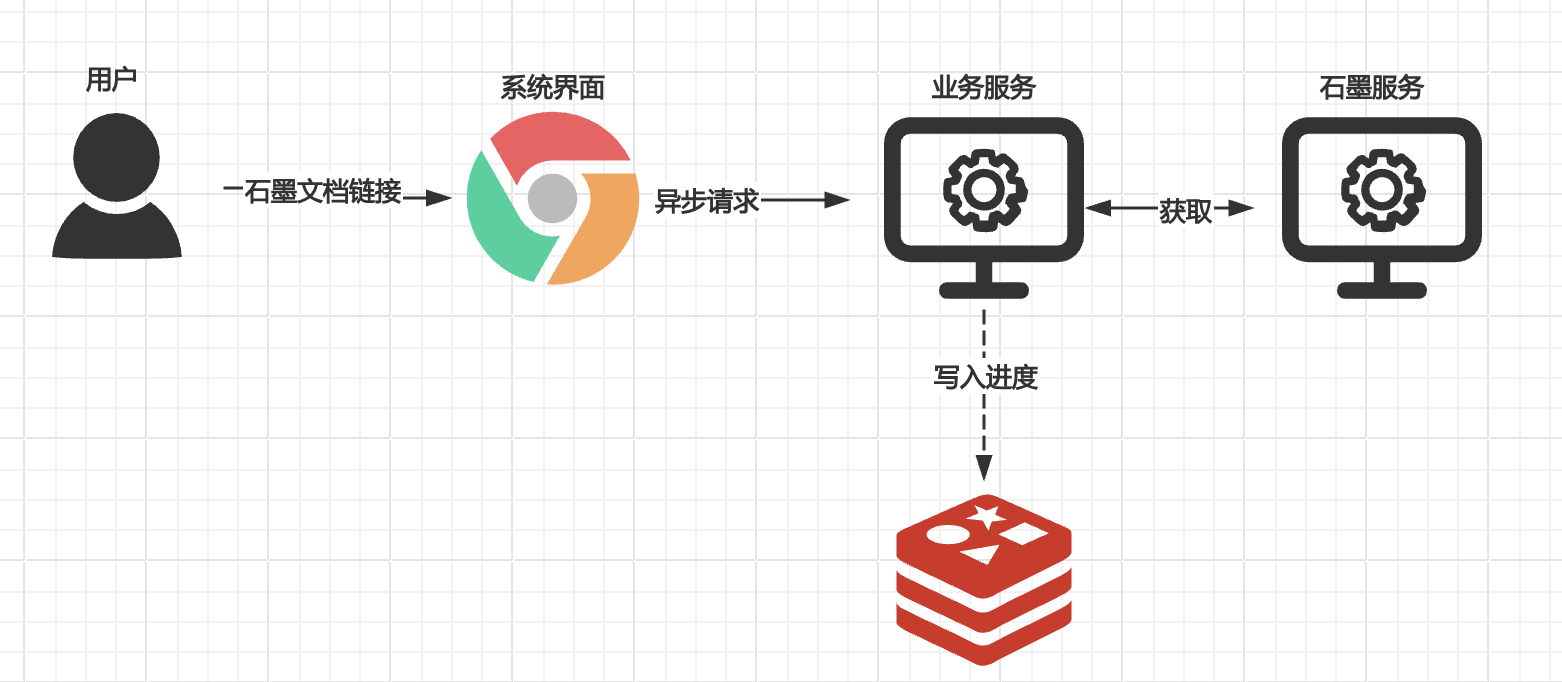
异步上传石墨文件进度条前端展示记录(采用Redis中String数据结构实现-苏东坡版本)
昔者,有客临门,亟需自石墨文库中撷取卷帙若干。此等文册,非止一卷,乃累牍连篇,亟需批量转置。然吾辈虑及用户体验,当效东坡"腹有诗书气自华"之雅意,使操作如行云流水,遂定…...
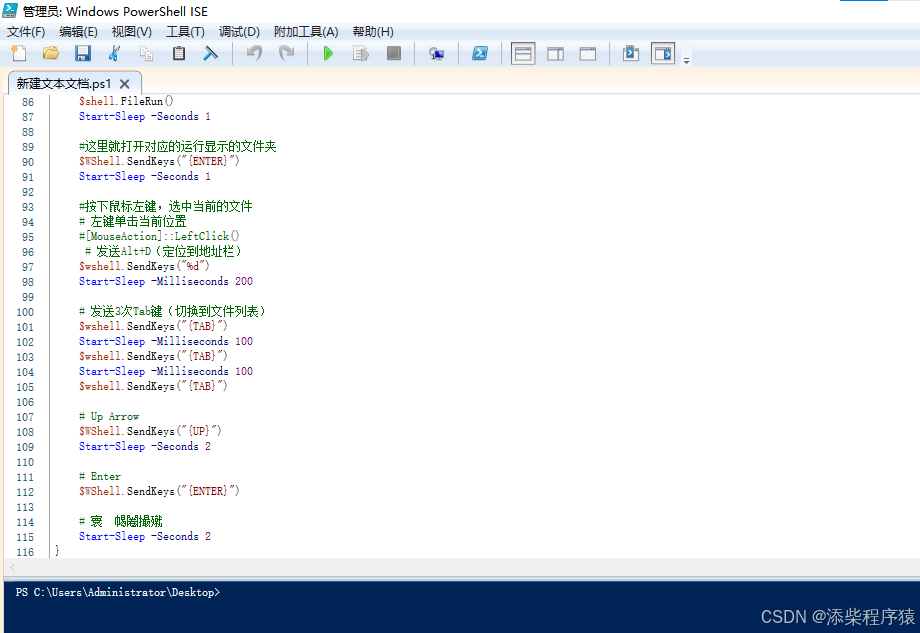
处理知识库文件_编写powershell脚本文件_批量转换其他格式文件到pdf文件---人工智能工作笔记0249
最近在做部门知识库,选用的dify,作为rag的工具,但是经过多个对比,最后发现, 比较好用的是,纳米搜索,但是可惜纳米搜索无法在内网使用,无法把知识库放到本地,导致 有信息…...
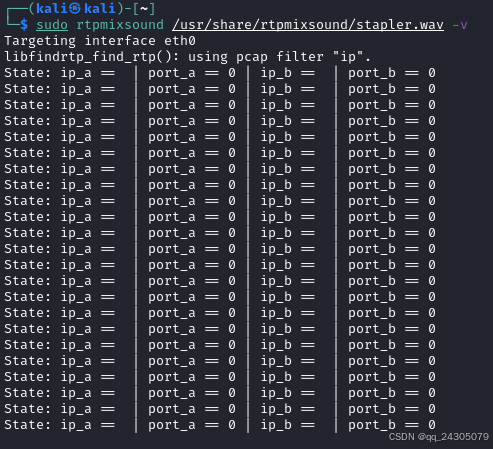
rtpmixsound:实现音频混音攻击!全参数详细教程!Kali Linux教程!
简介 一种将预先录制的音频与指定目标音频流中的音频(即 RTP)实时混合的工具。 一款用于将预先录制的音频与指定目标音频流中的音频(即 RTP)实时混合的工具。该工具创建于 2006 年 8 月至 9 月之间。该工具名为 rtpmixsound。它…...

【Netty系列】解决TCP粘包和拆包:LengthFieldBasedFrameDecoder
目录 如何使用? 1. 示例代码(基于Netty) 2. 关键参数解释 3. 协议格式示例 4. 常见配置场景 场景1:长度字段包含自身 场景2:长度字段在消息中间 5. 注意事项 举个例子 完整示例:客户端与服务端交互…...

stm与51单片机哪个更适合新手学
一句话总结 51单片机:像学骑自行车,简单便宜,但只能在小路上骑。 STM32:像学开汽车,复杂但功能强,能上高速公路,还能拉货载人(做复杂项目)。 1. 为啥有人说“先学51单片…...

【计算机网络】第3章:传输层—面向连接的传输:TCP
目录 一、PPT 二、总结 TCP(传输控制协议)详解 1. 概述 核心特性: 2. TCP报文段结构 关键字段说明: 3. TCP连接管理 3.1 三次握手(建立连接) 3.2 四次挥手(终止连接) 4. 可…...

从架构视角设计统一网络请求体系 —— 基于 uni-app 的前后端通信模型
在使用 uni-app 开发跨平台应用时,设计一套清晰、统一、可扩展的网络请求模块 是前期架构的关键环节。良好的请求模块不仅提高开发效率,更是保证后期维护、调试和业务扩展的基础。 一、网络请求设计目标 在uni-app中设计网络请求模块,应遵循…...
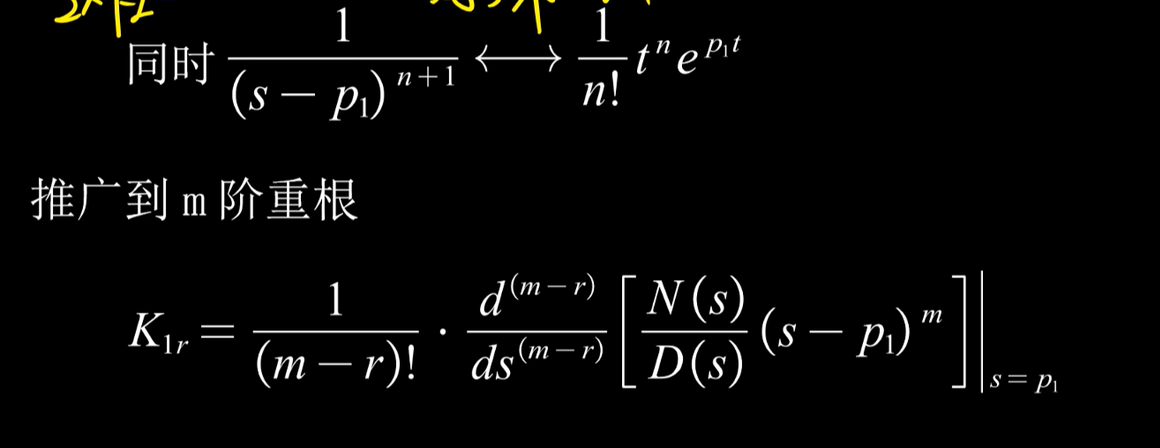
《信号与系统》--期末总结V1.0
《信号与系统》–期末总结V1.0 学习链接 入门:【拯救期末】期末必备!8小时速成信号与系统!【拯救期末】期末必备!8小时速成信号与系统!_哔哩哔哩_bilibili 精通:2022浙江大学信号与系统(含配…...

第32次CCF计算机软件能力认证-2-因子化简
因子化简 刷新 时间限制: 2.0 秒 空间限制: 512 MiB 下载题目目录(样例文件) 题目背景 质数(又称“素数”)是指在大于 11 的自然数中,除了 11 和它本身以外不再有其他因数的自然数。 题…...
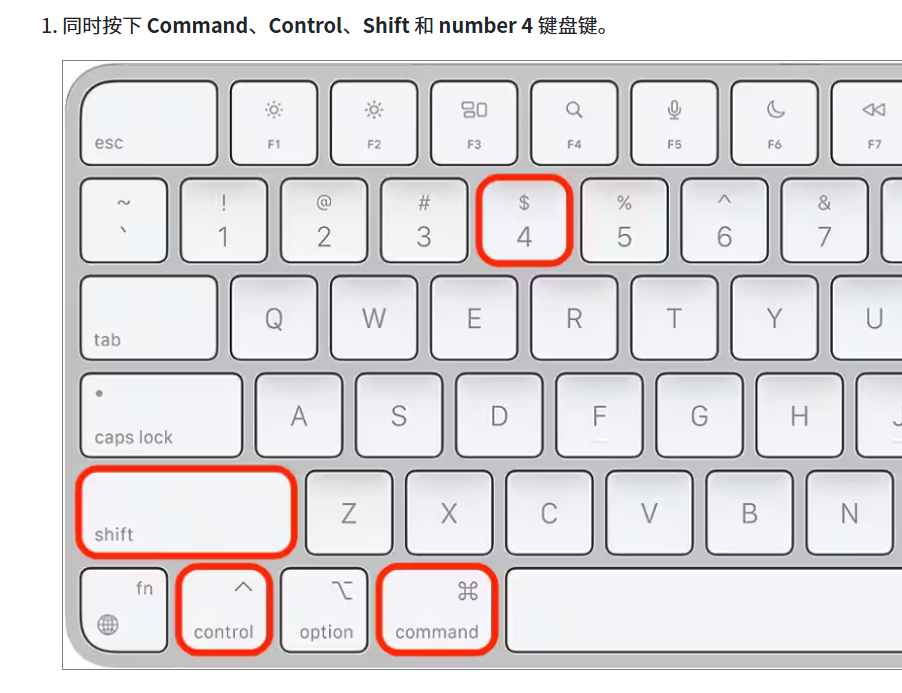
mac笔记本如何快捷键截图后自动复制到粘贴板
前提:之前只会进行部分区域截图操作(commandshift4)操作,截图后发现未自动保存在剪贴板,还要进行一步手动复制到剪贴板的操作。 mac笔记本如何快捷键截图后自动复制到粘贴板 截取 Mac 屏幕的一部分并将其自动复制到剪…...
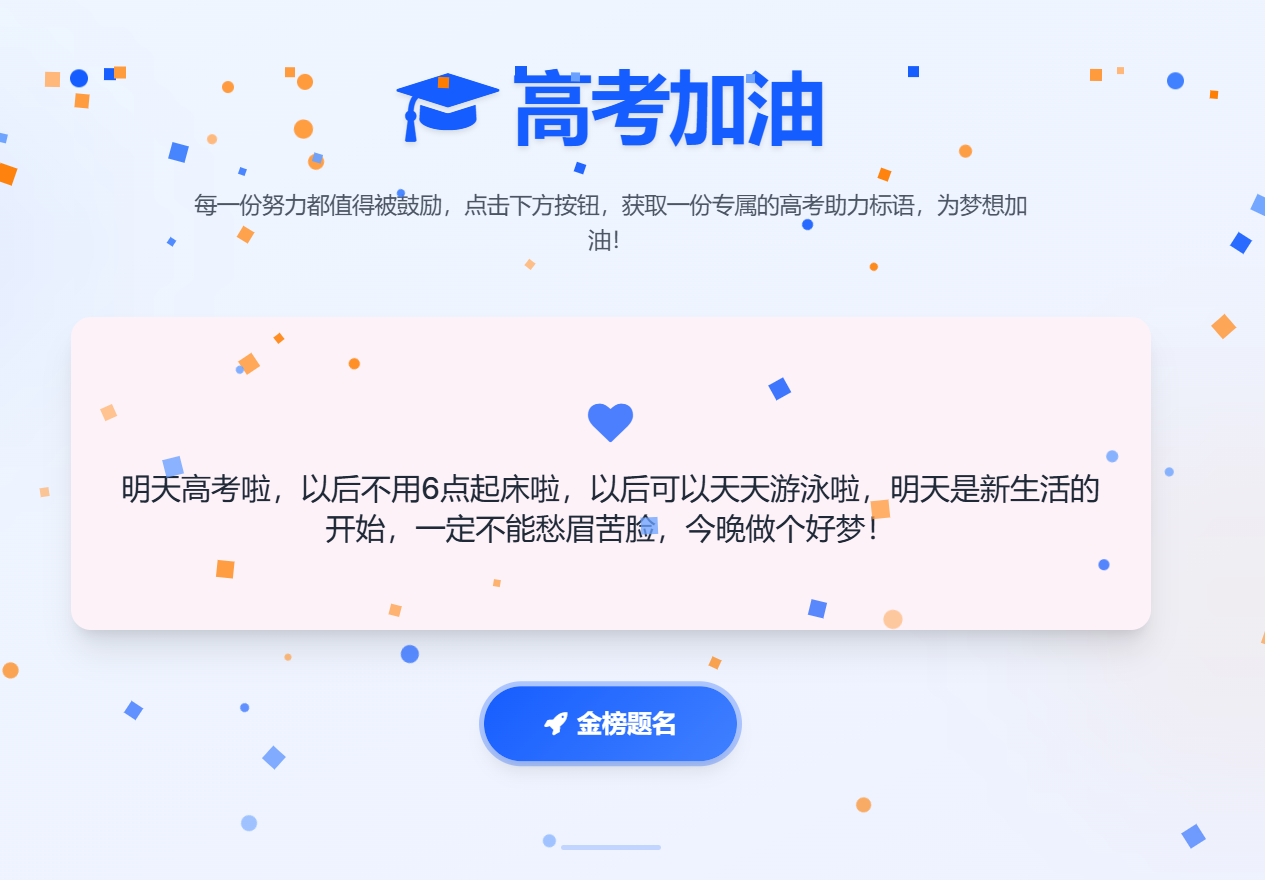
高考加油!UI界面生成器!
这个高考助力标语生成器具有以下特点: 视觉设计:采用了蓝色为主色调,搭配渐变背景和圆形装饰元素,营造出宁静而充满希望的氛围,非常适合高考主题。 标语生成:内置了超过 100 条精心挑选的高考加油标语&a…...
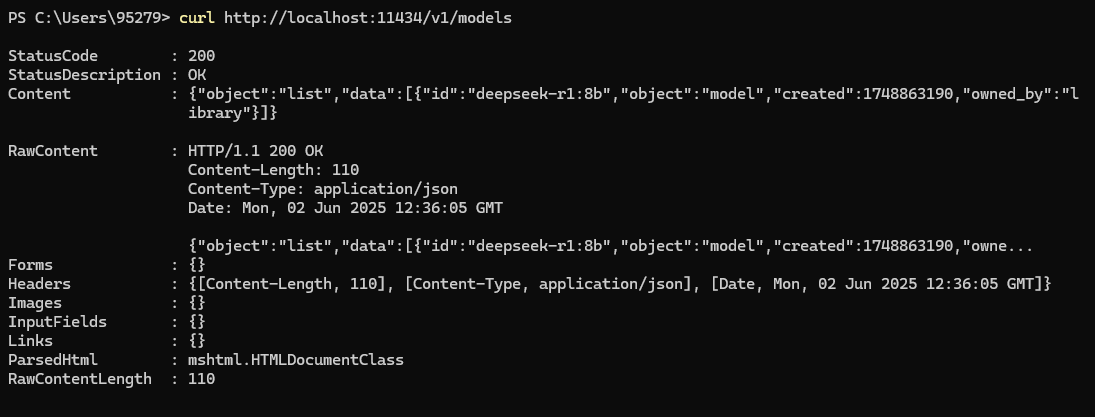
window ollama部署模型
注意去官网下载ollama,这个win和linux差别不大,win下载exe,linux用官网提供的curl命令 模型下载表:deepseek-r1 使用命令:Ollama API 交互 | 菜鸟教程 示例: 1.查看已加载模型: 2.文本生成接口 curl -X POST http://localhost:11434/v1/completions -H "Conte…...

用mediamtx搭建简易rtmp,rtsp视频服务器
简述: 平常测试的时候搭建rtmp服务器很麻烦,这个mediamtx服务器,只要下载就能运行,不用安装、编译、配置等,简单易用、ffmpeg推流、vlc拉流 基础环境: vmware17,centos10 64位,wi…...
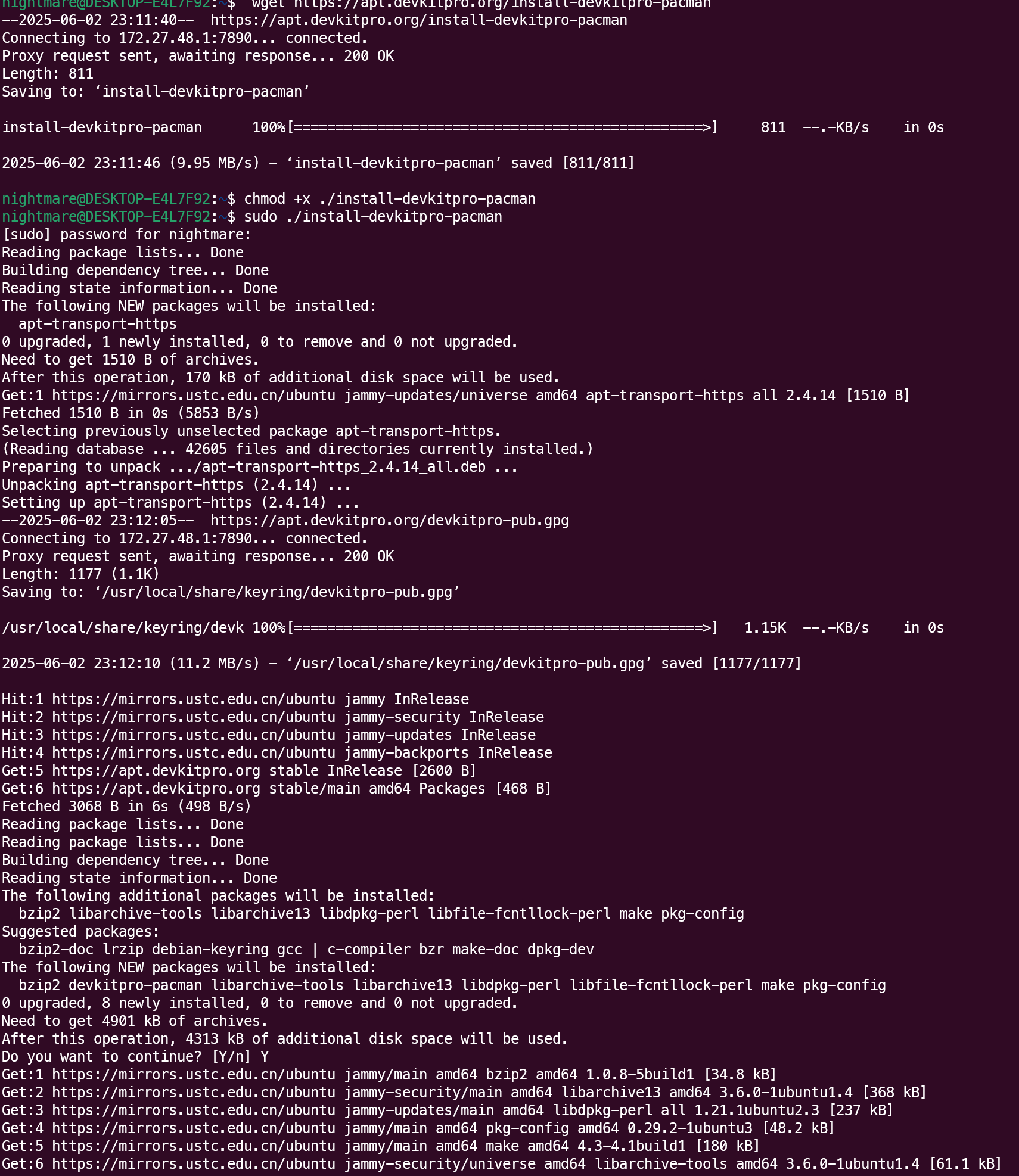
ubuntu安装devkitPro
建议开个魔法 wget https://apt.devkitpro.org/install-devkitpro-pacman chmod x ./install-devkitpro-pacman sudo ./install-devkitpro-pacman(下面这句如果报错也没事) sudo ln -s /proc/self/mounts /etc/mtab往~.bashrc添加 export DEVKITPRO/o…...

Linux(10)——第二个小程序(自制shell)
目录 编辑 一、引言与动机 📝背景 📝主要内容概括 二、全局数据 三、环境变量的初始化 ✅ 代码实现 四、构造动态提示符 ✅ 打印提示符函数 ✅ 提示符生成函数 ✅获取用户名函数 ✅获取主机名函数 ✅获取当前目录名函数 五、命令的读取与…...

github actions入门指南
GitHub Actions 是 GitHub 提供的持续集成和持续交付(CI/CD)平台,允许开发者自动化软件工作流程(如构建、测试、部署)。以下是详细介绍: 一、核心概念 Workflow(工作流程) 持续集成的…...
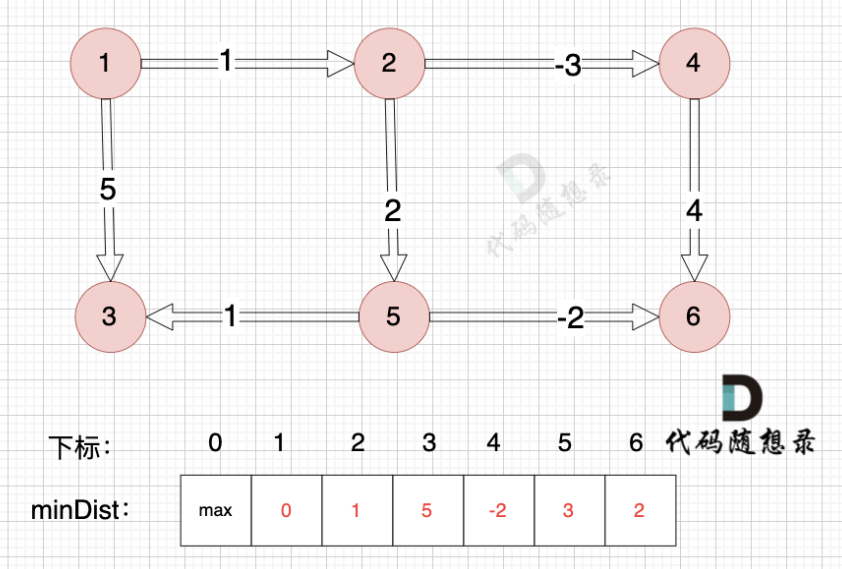
代码随想录算法训练营 Day59 图论Ⅸ dijkstra优化版 bellman_ford
图论 题目 47. 参加科学大会(第六期模拟笔试) 改进版本的 dijkstra 算法(堆优化版本) 朴素版本的 dijkstra 算法解法的时间复杂度为 O ( n 2 ) O(n^2) O(n2) 时间复杂度与 n 有关系,与边无关系 类似于 prim 对应点多…...

HTML实战:响应式个人资料页面
我将创建一个现代化的响应式个人资料页面,展示HTML在实际应用中的强大功能。这个页面将包含多个实战元素:导航栏、个人简介、技能展示、作品集和联系表单。 设计思路 使用Flexbox和Grid布局实现响应式设计 添加CSS过渡效果增强交互体验 实现深色/浅色模式切换功能 创建悬停动…...

Mac电脑上本地安装 MySQL并配置开启自启完整流程
文章目录 一、mysql安装1.1 使用 Homebrew 安装(推荐)1.2 手动下载 MySQL 社区版1.3 常见问题1.4 图形化管理工具(可选) 二、Mac 上配置 MySQL 开机自动启动2.1 使用 launchd 系统服务(原生支持)2.2 通过 H…...
)
JavaSE:面向对象进阶之内部类(Inner Class)
JavaSE 面向对象进阶之内部类(Inner Class) 一、内部类的核心概念 内部类是定义在另一个类内部的类,它与外部类存在紧密的逻辑关联,主要作用: 封装细节:隐藏实现细节,对外提供简洁接口。访问…...

【HW系列】—安全设备介绍(开源蜜罐的安装以及使用指南)
文章目录 蜜罐1. 什么是蜜罐?2. 开源蜜罐搭建与使用3. HFish 开源蜜罐详解安装步骤使用指南关闭方法 总结 蜜罐 1. 什么是蜜罐? 蜜罐(Honeypot)是一种主动防御技术,通过模拟存在漏洞的系统或服务(如数据库…...
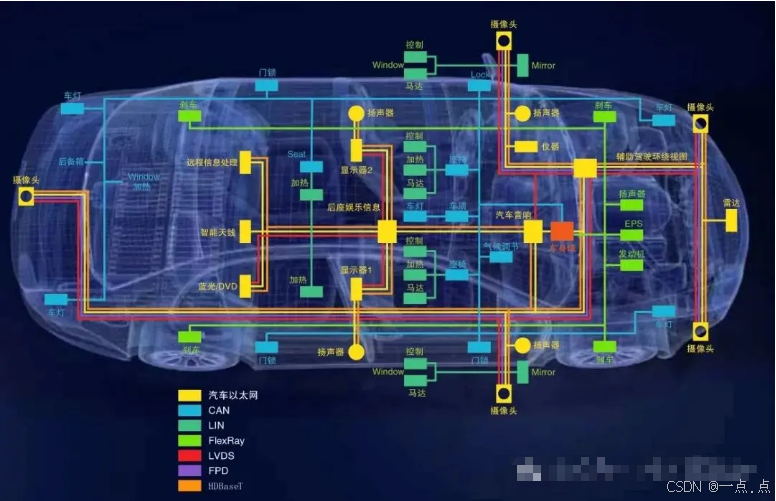
汽车总线分析总结(CAN、LIN、FlexRay、MOST、车载以太网)
目录 一、汽车总线技术概述 二、主流汽车总线技术对比分析 1. CAN总线(Controller Area Network) 2. LIN总线(Local Interconnect Network) 3. FlexRay总线 4. MOST总线(Media Oriented Systems Transport&#x…...
MyBatisPlus--条件构造器及自定义SQL详解
条件构造器 在前面学习快速入门的时候,练习的增删改查都是基于id去执行的,但是在实际开发业务中,增删改查的条件往往是比较复杂的,因此MyBatisPlus就提供了一个条件构造器来帮助构造复杂的条件。 MyBatisPlus支持各种复杂的wher…...
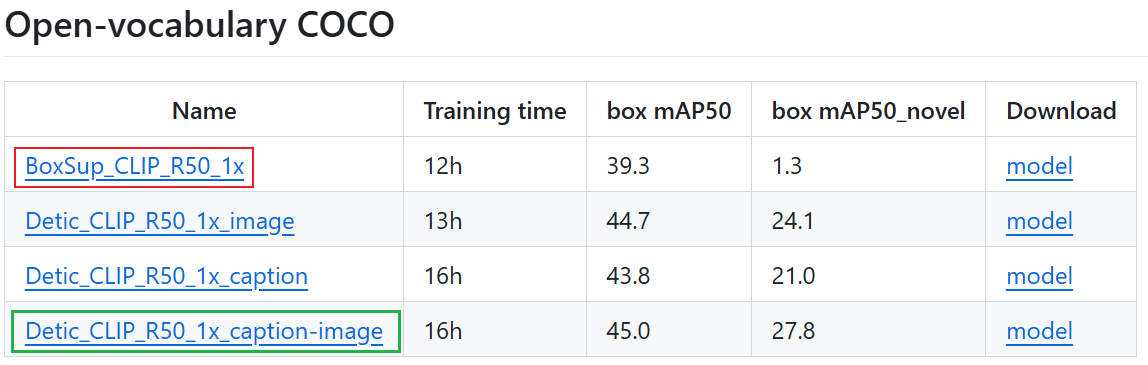
OVD开放词汇检测 Detic 训练COCO数据集实践
0、引言 纯视觉检测当前研究基本比较饱和,继续创新提升空间很小,除非在CNN和transformer上提出更强基础建模方式。和文本结合是当前的一大趋势,也是计算机视觉和自然语言处理结合的未来趋势,目前和文本结合的目标检测工作还是有很…...