数据结构之堆:解析与应用
一、堆的核心定义与性质
堆是一种特殊的完全二叉树,分为最大堆和最小堆:
- 最大堆:每个节点的值 ≥ 子节点值,根节点为最大值。
- 最小堆:每个节点的值 ≤ 子节点值,根节点为最小值。
关键性质:
- 完全二叉树:除最后一层外,其他层节点满,且最后一层节点靠左排列。
- 数组实现:通过索引计算父子节点关系:
- 父节点索引:
parent(i) = (i - 1) // 2 - 左子节点索引:
left(i) = 2 * i + 1 - 右子节点索引:
right(i) = 2 * i + 2
二、堆的存储结构与操作
1. 存储结构
堆通过数组实现,例如数组 [90, 15, 10, 7, 12, 2, 7, 3] 表示的最小堆:
90/ \15 10/ \ / \7 12 2 7/
32. 基本操作
- 插入(Insert):
- 将新元素添加到数组末尾。
- 通过上浮(Sift Up)调整堆序性:比较新节点与父节点,若违反堆序性则交换,直到满足条件。
- 时间复杂度:
O(log n)。
- 删除堆顶元素(Delete):
- 将堆顶元素与末尾元素交换,并删除末尾元素。
- 通过下沉(Sift Down)调整堆序性:比较当前节点与子节点,若违反堆序性则与较大(最大堆)或较小(最小堆)子节点交换,直到满足条件。
- 时间复杂度:
O(log n)。
- 建堆(Heapify):
- 自底向上建堆:从最后一个非叶子节点开始,对每个节点执行下沉操作。
- 时间复杂度:
O(n)(优于逐个插入的O(n log n))。
- 堆排序(Heap Sort):
- 构建最大堆。
- 反复将堆顶元素(最大值)与末尾元素交换,并缩小堆的范围,最后对新的堆顶执行下沉操作。
- 时间复杂度:
O(n log n)。 - 空间复杂度:
O(1)(原地排序)。
三、堆的实现
(一) 基于动态数组实现最大堆
1. 动态数组实现类
import org.omg.CORBA.Object;/*** 动态数组,数组二次封装*/
public class Array<E> {/*** 基于Java原生数组,保存数据的容器*/private E[] data;/*** 当前元素个数*/private int size;public Array(int capacity) {data = (E[]) new Object[capacity];size = 0;}/*** 默认数组容量capacity=10*/public Array() {this(10);}public Array(E[] arr) {data = (E[]) new Object[arr.length];for (int i = 0; i < arr.length; i++) {data[i] = arr[i];}size = arr.length;}/*** 获取数组中元素个数* @return*/public int getSize() {return size;}/*** 获取数组的容量* @return*/public int getCapacity() {return data.length;}/*** 判断数组是否为空* @return*/public boolean isEmpty() {return size == 0;}/*** 在所有元素后面添加新元素* @param e 元素*/public void addLast(E e) {add(size, e);}/*** 在所有元素前面添加新元素* @param e 元素*/public void addFirst(E e) {add(0, e);}/*** 向index索引位置插入一个新元素e* @param index 数组索引位置* @param e 元素*/public void add(int index, E e) {if (index < 0 || index > size) {throw new IllegalArgumentException("addList failed. index < 0 || index > size");}//空间不足,扩容if (size == data.length) {resize(2 * data.length);}for (int i = size - 1; i >= index; i--) {data[i + 1] = data[i];}data[index] = e;size++;}/*** 根据元素索引获取数组元素* @param index 索引* @return*/public E get(int index) {if (index < 0 || index >= size) {throw new IllegalArgumentException("get failed. index is illegal");}return data[index];}/*** 根据元素索引修改数组元素* @param index 索引* @param e 元素* @return*/public void set(int index, E e) {if (index < 0 || index >= size) {throw new IllegalArgumentException("get failed. index is illegal");}data[index] = e;}/*** 判断包含元素* @param e 元素* @return*/public boolean contains(E e) {for (int i = 0; i < size; i++) {if (data[i].equals(e)) {return true;}}return false;}/*** 查找元素索引* @param e 元素* @return 返回元素索引,如果不存在则返回-1*/public int find(E e) {for (int i = 0; i < size; i++) {if (data[i].equals(e)) {return i;}}return -1;}/*** 移除指定索引的元素* @param index 索引* @return 返回被移除的元素*/public E remove(int index) {if (index < 0 || index >= size) {throw new IllegalArgumentException("get failed. index is illegal");}E ret = data[index];for (int i = index + 1; i < size; i++) {data[i - 1] = data[i];}size--;data[size] = null;//空间利用率低,数组缩容,防止复杂度震荡if (size == data.length / 4 && data.length / 2 != 0) {resize(data.length / 2);}return ret;}/*** 移除第一个元素* @return 返回被移除元素*/public E removeFirst() {return remove(0);}/*** 移除最后一个元素* @return 返回被移除元素*/public E removeLast() {return remove(size - 1);}/*** 移除数组中一个元素* @param e 元素*/public void removeElement(E e) {int index = find(e);if (index != -1) {remove(index);}}/*** 数组容器扩容、缩容* @param newCapacity 新的容量*/private void resize(int newCapacity) {E[] newData = (E[]) new Object[newCapacity];for (int i = 0; i < size; i++) {newData[i] = data[i];}data = newData;}/*** 交换数组中两个索引对应的元素* @param i 元素* @param j 元素*/public void swap(int i, int j) {if (i < 0 || i >= size || j < 0 || j >= size) {throw new IllegalArgumentException("index is illegal");}E e = data[i];data[i] = data[j];data[j] = e;}@Overridepublic String toString() {StringBuilder res = new StringBuilder();res.append(String.format("Array: size = %d, capacity = %d\n", size, data.length));res.append("[");for (int i = 0; i < size; i++) {res.append(data[i]);if (i != size - 1) {res.append(", ");}}res.append("]");return res.toString();}}2. 基于动态数组实现最大堆
/*** 基于动态数组实现最大堆* @param <E>*/
public class MaxHeap<E extends Comparable<E>> {private Array<E> data;public MaxHeap(int capacity) {data = new Array<>(capacity);}public MaxHeap() {data = new Array<>();}/*** 普通数组堆化* @param arr*/public MaxHeap(E[] arr) {data = new Array<>(arr);//从第一个非叶子节点(叶子节点无需下沉操作)开始遍历,并且执行下沉操作,完成堆化for (int i = parent(arr.length - 1); i >= 0; i--) {siftDown(i);}}/*** 获取堆中元素个数* @return*/public int size() {return data.getSize();}/*** 判断堆中是否为空* @return*/public boolean isEmpty() {return data.isEmpty();}/*** 返回二叉堆的数组表示中,一个索引所表示的元素的父亲节点的索引* @param index 节点在数组中的索引* @return*/private int parent(int index) {if (index == 0) {throw new IllegalArgumentException("index-0 doesn't have parent");}return (index - 1) / 2;}/*** 返回二叉堆的数组表示中,一个索引所表示的元素的左孩子节点的索引* @param index 节点在数组中的索引* @return*/private int leftChild(int index) {return index * 2 + 1;}/*** 返回二叉堆的数组表示中,一个索引所表示的元素的右孩子节点的索引* @param index 节点在数组中的索引* @return*/private int rightChild(int index) {return index * 2 + 2;}/*** 向堆中添加元素* @param e 待添加元素*/public void add(E e) {data.addLast(e);siftUp(data.getSize() - 1);}/*** 堆中元素上浮* @param k 元素索引*/private void siftUp(int k) {//当前节点的元素比父亲节点的元素大则上浮while (k > 0 && data.get(parent(k)).compareTo(data.get(k)) < 0) {//交换数组中的元素data.swap(k, parent(k));k = parent(k);}}/*** 查询堆中最大元素* @return*/public E findMax() {if (data.getSize() == 0) {throw new IllegalArgumentException("can not finMax when heap is empty");}return data.get(0);}/*** 取出堆中最大元素* @return*/public E extractMax() {E max = findMax();//交换堆中最大的元素与堆尾元素data.swap(0, data.getSize() - 1);//删除堆尾元素data.removeLast();//元素下沉siftDown(0);return max;}/*** 堆中元素下沉* @param k 元素索引*/private void siftDown(int k) {//只要该元素的左孩子索引没有越界,继续处理while (leftChild(k) < data.getSize()) {int j = leftChild(k);if (j + 1 < data.getSize() && data.get(j + 1).compareTo(data.get(j)) > 0) {j = rightChild(k);}//data[j] 是leftChild 和 rightChild中的最大值if (data.get(k).compareTo(data.get(j)) >= 0) {break;}//下沉data.swap(k, j);k = j;}}/*** 取出堆中的最大元素,并且替换成元素e* @param e 待替换元素* @return 堆中最大元素*/public E replace(E e) {E max = findMax();//覆盖最大元素data.set(0, e);//被元素可能破坏了堆的结构,触发下沉操作siftDown(0);return max;}}四、堆的应用场景
(一) 优先队列:
- 堆是优先队列的天然实现,支持高效插入和删除最高优先级元素。
- 例如:任务调度、Dijkstra算法中的最短路径选择。
(二) Top-K问题:
- 维护一个大小为K的最小堆(求前K大)或最大堆(求前K小),快速找到极值。
- 例如:统计日志中的Top 100高频词。
(三) 中位数与百分位数:
- 使用两个堆(最大堆和最小堆)动态维护数据流的中位数或特定百分位值。
(四) 合并有序文件:
- 将多个有序小文件的头部元素插入最小堆,依次提取最小值合并到结果文件。
五、堆与其他数据结构的对比
| 特性 | 堆 | 二叉搜索树(BST) | 平衡二叉搜索树(如AVL树) |
| 有序性 | 仅保证堆序性(父子关系) | 中序遍历有序 | 完全有序 |
| 插入/删除 |
| 平均 |
|
| 查找 | 不支持高效查找 |
|
|
| 适用场景 | 优先队列、堆排序 | 需要频繁查找的场景 | 需要高效查找、插入、删除的场景 |
六、堆的变种与扩展
- 斐波那契堆:支持更高效的合并操作(均摊
O(1)),常用于动态图算法(如Prim算法)。 - 左偏树:具有高效的合并性能,适用于需要频繁合并堆的场景。
七、总结
堆是一种高效的树形数据结构,通过完全二叉树和数组的结合,实现了插入、删除和建堆等操作的高效性。其核心思想是通过“上浮”和“下沉”操作维护堆序性,适用于需要快速访问最大值或最小值的场景。理解堆的实现和操作是掌握高级算法(如堆排序、Dijkstra算法)的基础,也是解决大规模数据问题的关键工具。
相关文章:

数据结构之堆:解析与应用
一、堆的核心定义与性质 堆是一种特殊的完全二叉树,分为最大堆和最小堆: 最大堆:每个节点的值 ≥ 子节点值,根节点为最大值。最小堆:每个节点的值 ≤ 子节点值,根节点为最小值。 关键性质: …...
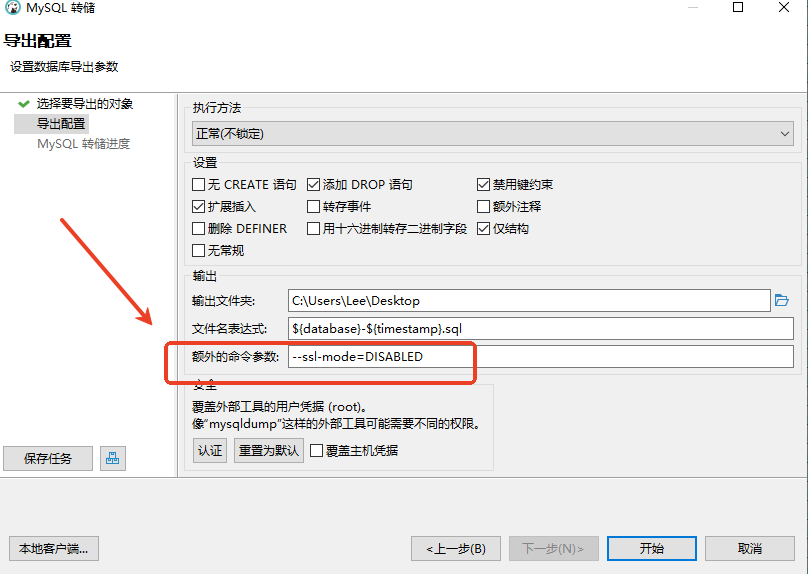
DBeaver导入/导出数据库时报错解决方案
导出: 报错:mysqldump: Got error: 2026: SSL connection error: error:0A000102:SSL routines::unsupported protocol when trying to connect 在额外的命令参数中添加"--ssl-modeDISABLED"可以关闭SSL服务,从而成功解决问题。这…...

GPIO模拟串口通信
在资源受限的嵌入式项目中,GPIO模拟串口(UART)仍有实际需求。尽管现代MCU多数具备多个硬件串口,但实际项目中仍可能遇到串口数量不足的情况,尤其在低成本、小封装芯片的应用场景中。 一、GPIO模拟串口的基本原理 GPIO模拟串口,顾名思义,就是通过软件控制普通IO口的高低…...
uniapp与微信小程序开发平台联调无法打开IDE
经测试属于网络问题。本机需要联网。否则会出现Hbuilder运行微信小程序到模拟器时无法打开 微信开发者工具 这个页面出不来会一直显示异常。这期间微信小程序开发工具的端口是通的 需要先联网...

第十二节:第五部分:集合框架:Set集合的特点、底层原理、哈希表、去重复原理
Set系列集合特点 哈希值 HashSet集合的底层原理 HashSet集合去重复 代码 代码一:整体了解一下Set系列集合的特点 package com.itheima.day20_Collection_set;import java.util.HashSet; import java.util.LinkedHashSet; import java.util.Set; import java.util.…...

【C++项目】:仿 muduo 库 One-Thread-One-Loop 式并发服务器
🌈 个人主页:Zfox_ 🔥 系列专栏:C从入门到精通 目录 🔥 前言 一:🔥 项目储备知识 🦋 HTTP 服务器🦋 Reactor 模型🎀 单 Reactor 单线程:单I/O多路…...

基于大数据的个性化购房推荐系统设计与实现(源码+定制+开发)面向房产电商的智能购房推荐与数据可视化系统 基于Spark与Hive的房源数据挖掘与推荐系统设计
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台…...

FFmpeg学习笔记
1. 播放器的架构 2. 播放器的渲染流程 3. ffmpeg下载与安装 3.0 查看PC是否已经安装了ffmpeg ffmpeg 3.1 下载 wget https://ffmpeg.org/releases/ffmpeg-7.0.tar.gz 3.2 解压 tar zxvf ffmpeg-7.0.tar.gz && cd ./ffmpeg-7.0 3.3 查看配置文件 ./configure …...
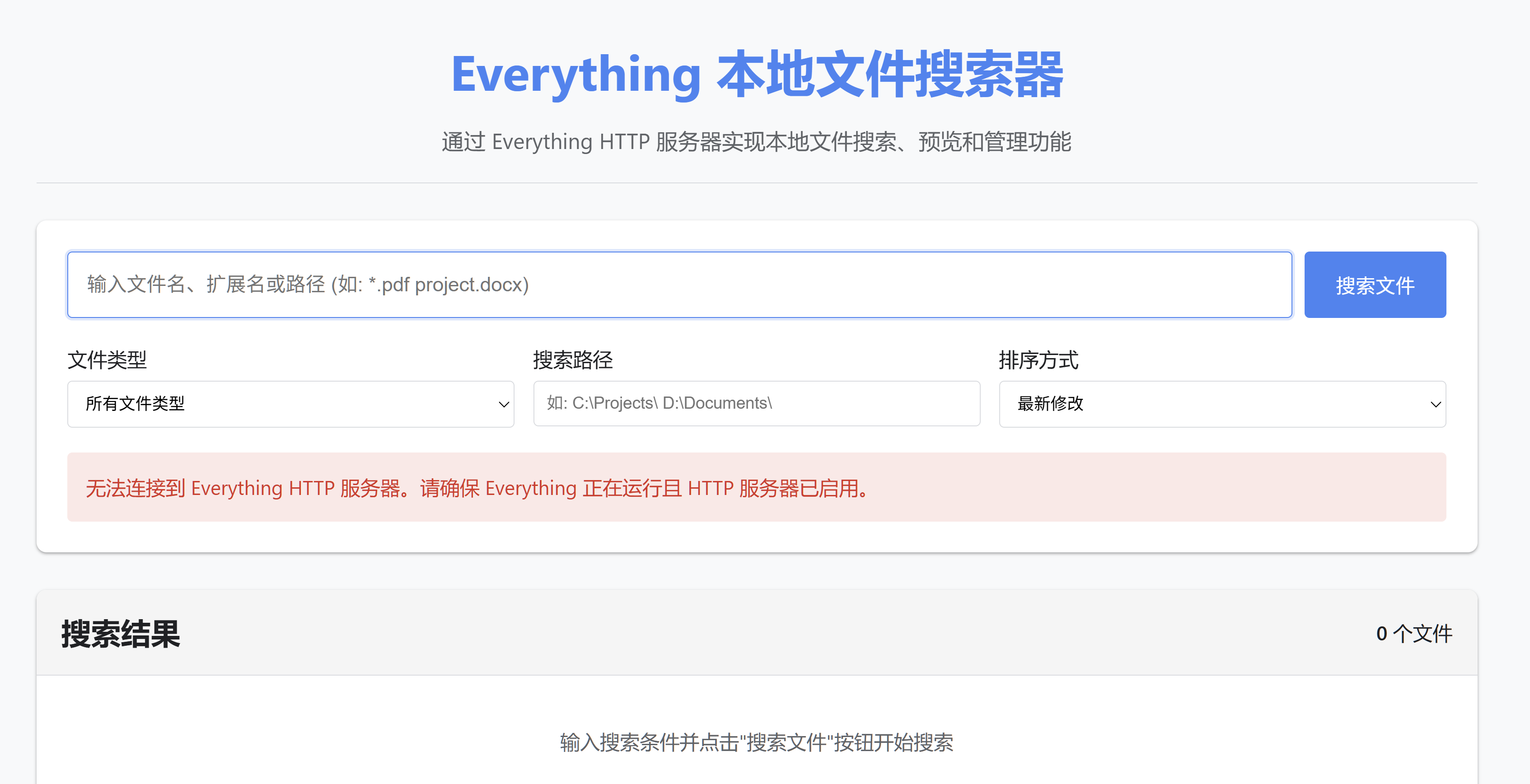
Chrome 通过FTP,HTTP 调用 Everything 浏览和搜索本地文件系统
【提问1】 Chrome调用本地 everything.exe, everything 好像有本地 FTP 服务器? 【DeepSeek R1 回答】 是的,Everything 确实内置了 HTTP/FTP 服务器功能,这提供了一种相对安全的浏览器与本地应用交互的方式。以下是完整的实现方案&#x…...
GpuGeek如何成为AI基础设施市场的中坚力量
AI时代,算力基础设施已成为支撑技术创新和产业升级的关键要素。作为国内专注服务算法工程师群体的智算平台,GpuGeek通过持续创新的服务模式、精准的市场定位和系统化的生态建设,正快速成长为AI基础设施领域的中坚力量。本文将深入分析GpuGeek…...

【Hot 100】45. 跳跃游戏 II
目录 引言跳跃游戏 IIdp解题贪心解题 🙋♂️ 作者:海码007📜 专栏:算法专栏💥 标题:【Hot 100】45. 跳跃游戏 II❣️ 寄语:书到用时方恨少,事非经过不知难! 引言 跳跃…...
 C. Racing)
Codeforces Round 1026 (Div. 2) C. Racing
Codeforces Round 1026 (Div. 2) C. Racing 题目 In 2077, a sport called hobby-droning is gaining popularity among robots. You already have a drone, and you want to win. For this, your drone needs to fly through a course with n n n obstacles. The i i i-…...
)
Python库CloudScraper详细使用(绕过 Cloudflare 的反机器人页面的 Python 模块)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、CloudScraper概述1.1 CloudScraper 介绍1.2 安装二、基本使用方法2.1 创建scraper实例2.2 发送请求2.3 带参数的请求2.4 自定义浏览器指纹2.5 设置代理2.6 自定义请求头三、高级配置3.1 处理Cloudflare挑战-自动处理…...

oracle sql 语句 优化方法
1、表尽量使用别名,字段尽量使用别名.字段名,这样子,可以减少oracle数据库解析字段名。而且把 不需要的字段名剔除掉,只保留有用的字段名,不要一直使用 select *。 2、关联查询时,选择好主表 。oracle解析…...

Python数学可视化——显函数、隐函数及复杂曲线的交互式绘图技术
Python数学可视化——显函数、隐函数及复杂曲线的交互式绘图技术 一、引言 在科学计算和数据分析中,函数与方程的可视化是理解数学关系和物理现象的重要工具。本文基于Python的Tkinter和Matplotlib库,实现一个功能完善的函数与方程可视化工具ÿ…...

代码随想录打卡|Day51 图论(dijkstra(堆优化版)精讲、Bellman_ford 算法精讲)
图论part09 dijkstra(堆优化版)精讲(不熟悉) 代码随想录链接 题目链接 import java.util.*;class Edge {int to; // 邻接顶点int val; // 边的权重Edge(int to, int val) {this.to to;this.val val;} }class MyComparison implements Comparator<…...

【深度剖析】流处理系统性能优化:解决维表JOIN、数据倾斜与数据膨胀问题
目录 前言:为什么你的流处理作业总是慢? 一、维表JOIN优化:从普通连接到高性能查询 1.1 时态表的双面性 1.2 Lookup Join 优化 1.3 多表JOIN优化策略 二、数据倾斜:单分区也会遇到的隐形杀手 2.1 单分区数据倾斜 2.2 热点键打散技术 2.3 时间窗口预聚合 三、数据…...

PostgreSQL优化实践:从查询到架构的性能提升指南
## 引言 PostgreSQL作为先进的开源关系型数据库,在复杂查询处理与高并发场景中表现卓越,但不当的使用仍会导致性能瓶颈。本文系统性梳理优化路径,覆盖SQL编写、索引策略、参数调优等关键环节,配合代码示例与量化建议,…...

AI入门——AI大模型、深度学习、机器学习总结
以下是对AI深度学习、机器学习相关核心技术的总结与拓展,结合技术演进逻辑与前沿趋势,以全新视角呈现关键知识点 一、深度学习:从感知到认知的技术革命 核心突破:自动化特征工程的范式变革 深度学习通过多层神经网络架构&#x…...

【AI论文】论文转海报:迈向从科学论文到多模态海报的自动化生成
摘要:学术海报生成是科学交流中一项关键但具有挑战性的任务,需要将长上下文交织的文档压缩成单一的、视觉上连贯的页面。 为了应对这一挑战,我们引入了第一个用于海报生成的基准和度量套件,该套件将最近的会议论文与作者设计的海报…...
智慧零工平台前端开发实战:从uni-app到跨平台应用
智慧零工平台前端开发实战:从uni-app到跨平台应用 本文将详细介绍我如何使用uni-app框架开发一个支持微信小程序和H5的零工平台前端应用,包含技术选型、架构设计、核心功能实现及部署经验。 前言 在当今移动互联网时代,跨平台开发已成为提高开发效率的重要手段。本次我选择…...
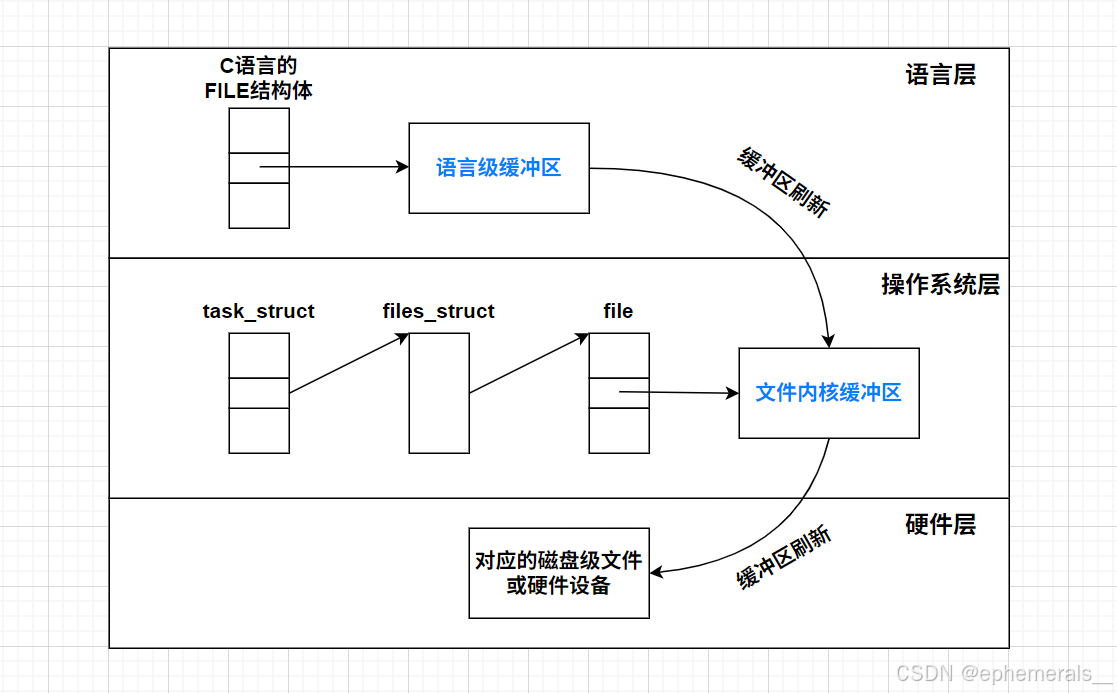
【Linux】基础文件IO
🌟🌟作者主页:ephemerals__ 🌟🌟所属专栏:Linux 前言 无论是日常使用还是系统管理,文件是Linux系统中最核心的概念之一。对于初学者来说,理解文件是如何被创建、读取、写入以及存储…...

opencv调用模型
在 C++ 中,OpenCV 的 cv::dnn::readNetFromONNX() 函数用于加载 ONNX 格式的深度学习模型,将其转换为 OpenCV DNN 模块可用的网络对象 (cv::dnn::Net)。以下是详细说明: 函数原型 #include <opencv2/dnn.hpp>cv::dnn::Net cv::dnn::readNetFromONNX(const String&am…...

由浅入深一文详解同余原理
由浅入深一文详解同余原理 一、同余原理的基本概念1.1 同余的定义1.2 剩余类与完全剩余系 二、同余原理的基本性质2.1 自反性2.2 对称性2.3 传递性2.4 加减性2.5 乘性2.6 幂性 三、同余原理的运算与应用3.1 同余运算在计算中的应用3.2 密码学中的应用3.3 日期与周期问题 四、案…...
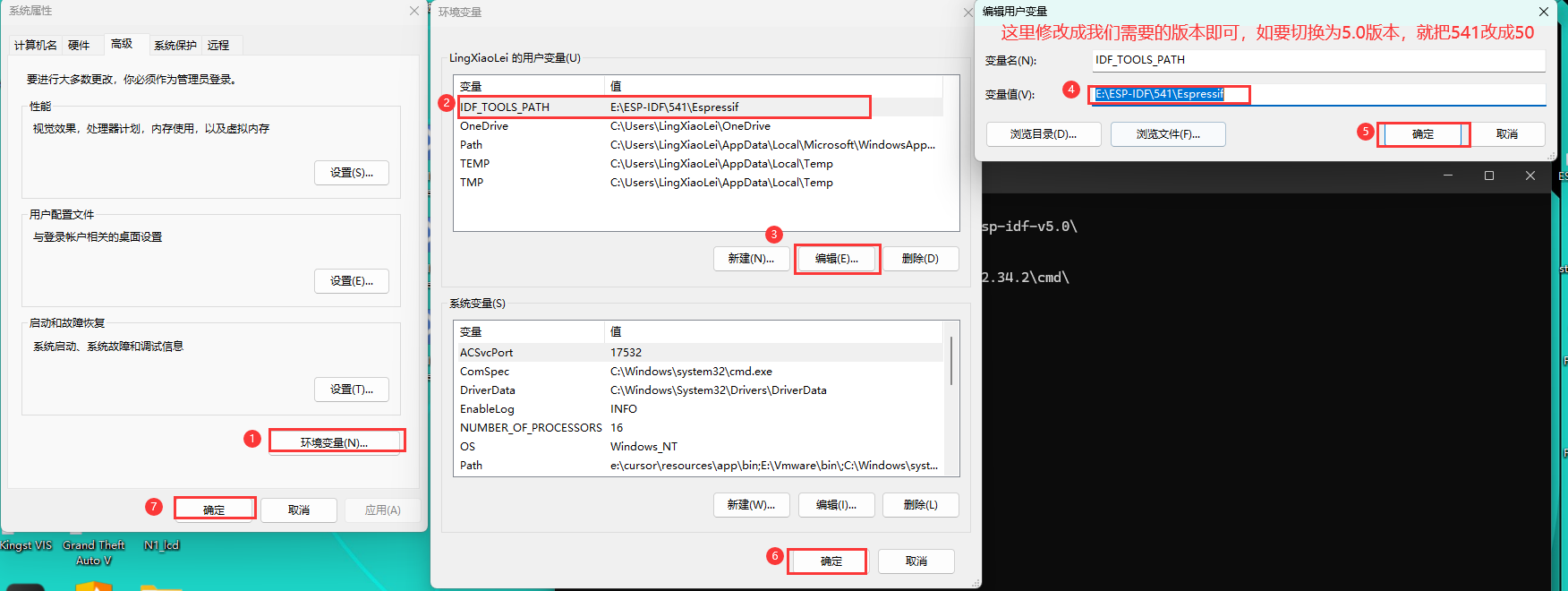
ESP-IDF 离线安装——同时存在多个版本以及进行版本切换的方法
一、离线安装包的下载方法 ESP-IDF离线安装包下载链接 我下载了下面三个版本进行测试 二、离线安装包的安装方法 1.创建文件夹 创建ESP-IDF文件夹,并为不同版本的IDF分别创建一个文件夹,如下图所示 2.双击离线安装包(以5.0版本为例&am…...
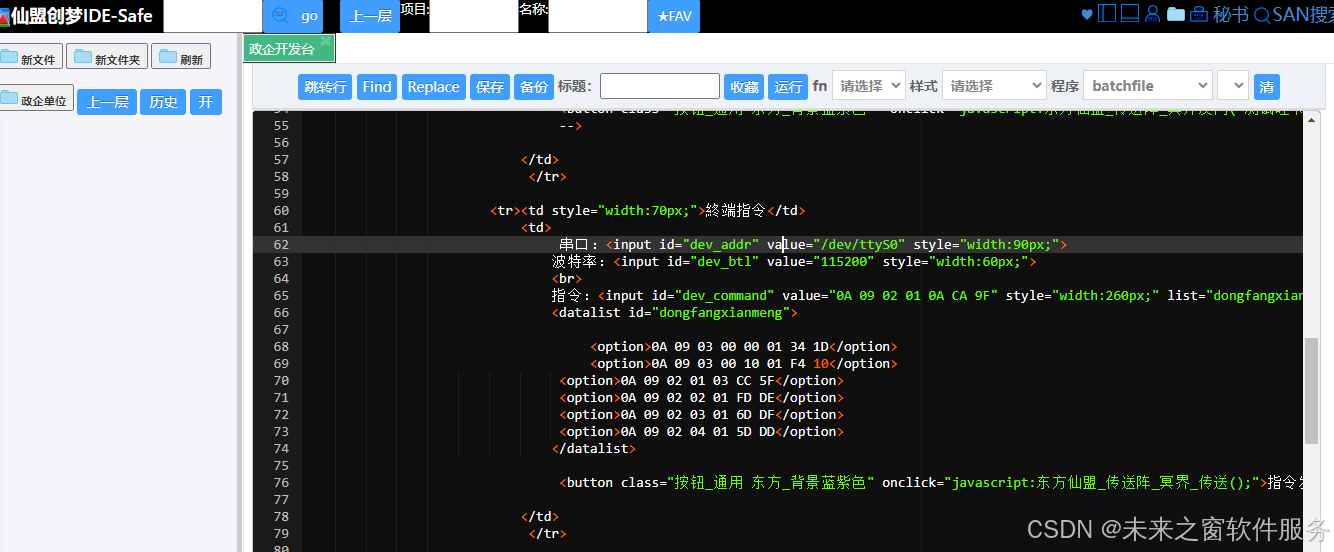
android 上位机调试软件-安卓串口 com ttl 调试——仙盟创梦IDE
在 Android 开发中,基于com.ttl库的串口调试 Web 编写意义非凡。它打破了硬件与软件之间的壁垒,让 Android 设备能够与外部串口设备通信。对于智能家居、工业控制等领域,这一功能使得手机或平板能成为控制终端,实现远程监控与操作…...
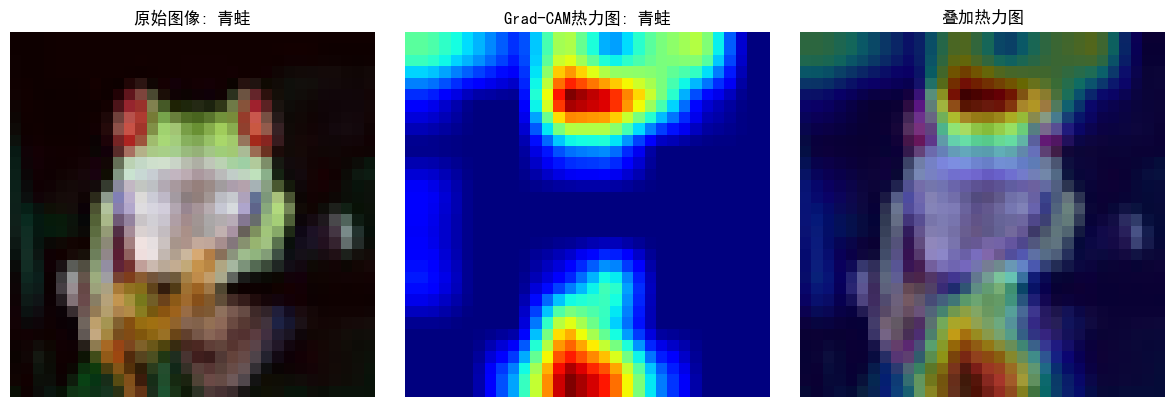
python打卡day42
Grad-CAM与Hook函数 知识点回顾 回调函数lambda函数hook函数的模块钩子和张量钩子Grad-CAM的示例 在深度学习中,我们经常需要查看或修改模型中间层的输出或梯度,但标准的前向传播和反向传播过程通常是一个黑盒,很难直接访问中间层的信息。PyT…...

XMOS以全新智能音频及边缘AI技术亮相广州国际专业灯光音响展
全球领先的边缘AI和智能音频解决方案提供商XMOS于5月27-30日亮相第23届广州国际专业灯光、音响展览会(prolight sound Guangzhou,以下简称“广州展”,XMOS展位号:5.2A66)。在本届展会上,XMOS将展出先进的音…...

Playwright 测试框架 - Node.js
🚀超全实战:基于 Playwright + Node.js 的自动化测试项目教程【附源码】 📌 本文适合自动化测试入门者 & 前端测试实战者。从零开始手把手教你搭建一个 Playwright + Node.js 项目,涵盖配置、测试用例编写、运行与调试、报告生成以及实用进阶技巧。建议收藏!👍 �…...

机器学习有监督学习sklearn实战二:六种算法对鸢尾花(Iris)数据集进行分类和特征可视化
本项目代码在个人github链接:https://github.com/KLWU07/Machine-learning-Project-practice 六种分类算法分别为逻辑回归LR、线性判别分析LDA、K近邻KNN、决策树CART、朴素贝叶斯NB、支持向量机SVM。 一、项目代码描述 1.数据准备和分析可视化 加载鸢尾花数据集&…...