【数据结构】图论核心算法解析:深度优先搜索(DFS)的纵深遍历与生成树实战指南
深度优先搜索
- 导读:从广度到深度,探索图的遍历奥秘
- 一、深度优先搜索
- 二、算法思路
- 三、算法逻辑
- 四、算法评价
- 五、深度优先生成树
- 六、有向图与无向图
- 结语:深潜与回溯,揭开图论世界的另一面

导读:从广度到深度,探索图的遍历奥秘
大家好,很高兴又和大家见面啦!!!
在上一篇中,我们共同揭开了广度优先搜索(BFS)的神秘面纱:它以“分层扩散”的方式遍历图结构,借助队列实现层序遍历,擅长解决最短路径和连通性分析问题(例如社交网络中的好友推荐)。BFS如同一束光波,由近及远均匀覆盖每个角落,确保无遗漏地探索所有可能性。
而今天,我们将潜入另一种经典策略——深度优先搜索(DFS)。与BFS的“广撒网”不同,DFS更像一位执着探险家,认准一条路走到尽头,再回溯寻找新路径。这种策略在迷宫探索、拓扑排序、环路检测等场景中大放异彩。
为何需要DFS?关键差异一目了然👇
-
遍历逻辑:BFS用队列实现“先进先出”,逐层扫描;DFS用栈(或递归)实现“后进先出”,纵深突破。
-
适用场景:BFS适合最短路径,DFS擅长深入探测结构特性(如回溯问题、图的连通分量统计)。
-
空间效率:BFS在稠密图中可能内存暴增,DFS的空间消耗通常与路径深度成正比,更适合树形结构。
本文你将收获:
- DFS核心思想:从二叉树的先序/后序遍历,推演至图的深度优先法则,图解“一条路走到黑+回溯”的精髓。
- 代码与逻辑全解:递归与非递归实现对比,visited数组如何避免重复访问,连通图与非连通图的遍历陷阱。
- 深度优先生成树:如何用DFS“绘制”图的骨架,邻接矩阵与邻接表为何导致生成树不唯一?
- 实战思考:DFS在有向图(如依赖解析)与无向图中的不同表现,强连通分量的秘密。
阅读建议:搭配上一篇“BFS详解”食用更佳!通过对比两大算法,你将真正掌握“何时用BFS,何时选DFS”的决策智慧。文末附生成树案例详解,帮助你将抽象理论转化为直观洞察。🚀
现在,让我们一起潜入图论的深海,揭开DFS的层层奥秘吧!
一、深度优先搜索
深度优先搜索(Depth-First-Search, DFS),简单的理解就是尽可能深的进行遍历,用一句话来描述就是一条路走到黑。
在二叉树的遍历算法中,按照遍历的方式,我们可以将其分为4类:
- 先根遍历:根—>左—>右
- 中根遍历:左—>根—>右
- 后根遍历:左—>右—>根
- 层序遍历:分层遍历
其中层序遍历实际上就是我们所说的:广度优先搜索(BFS)在树中的一种实际应用。在上一篇的内容中我们已经详细介绍,这里就不再赘述。
下面我们就来分析一下其他的三种遍历;
- 先根遍历的核心是:先访问根结点,再访问子树,对应到图中,就是先访问当前顶点,再访问与其邻接的顶点;
- 中根遍历是二叉树这种特殊的树形结构独有的一种遍历方式,因此我们不能够通过该遍历方式来拓展到图的遍历中;
- 后根遍历的核心是:先访问子树,再访问根结点,对应到图中,就是先访问与当前顶点邻接的顶点,再访问当前顶点;
不管是先根遍历还是后根遍历,其遍历的方式都是沿着一条路径先找到最深的结点,再去找其他结点。
对于先根遍历与后根遍历这种每次遍历时都是沿着一条路径,往深处走的方式进行遍历,就是深度优先遍历(Depth-First-Traversal, DFT)。
当我们要查找具体的对象时,采用这种沿着一条路径,往深处走的方式进行查找,这就是深度优先搜索(Depth-First-Search, DFS)。
这里我们需要区分一下遍历与搜索:
- 遍历简单的理解就是无条件地对数据结构中的所有元素进行访问;
- 搜索简单的理解就是有条件地对数据结构中的特定元素进行访问;
由此可以看到,当所有元素都是搜索中的特定元素时,那么我们对存储这些数据元素的数据结构进行搜索时,实际上就是在遍历该数据结构。
因此我们可以简单的理解为,遍历与搜索的区别就是:对元素的访问条件不同。
深度优先遍历(DFT) 和 深度优先搜索(DFS) 是同一策略的不同应用场景,但术语上更常用 DFS 统称。
这里一定要注意,在下面的介绍中,我们说的 DFS 实际上是说的对图的遍历算法,而不是查找特定值的算法。
理解了深度优先遍历与深度优先搜索后,下面我们就来了解一下其算法思路;
二、算法思路
深度优先搜索的算法思路如下:
- 首先访问图中某一起始顶点 v v v
- 然后从 v v v 出发,访问与 v v v 邻接且未被访问的任意一个顶点 w 1 w_1 w1
- 再访问与 w 1 w_1 w1 邻接且未被访问的人一个顶点 w 2 w_2 w2
- 重复上述过程,直到 w i w_i wi 不存在与其邻接且未被访问的顶点
- 当无法继续访问时,依次退回到最近被访问的顶点
- 当退回后的顶点存在还未被访问的邻接顶点,则从该顶点继续上述搜索过程,直至所有顶点完成访问
这里我们以二叉树的先序遍历为例:

上图中使用的是先根遍历的方式进行展示:
- 二叉树:先访问根结点,再访问子树
- 图:先访问当前顶点,再访问当前顶点的邻接顶点
对于图而言,其遍历序列根据其存储结构的不同而有所不同:
- 邻接矩阵:同一起始顶点的遍历序列相同
- 邻接表:同一起始顶点的遍历序列不同
- 十字链表:同一起始点的遍历序列不同
- 邻接多重表:同一起始点的遍历序列不同
上图所示的遍历序列对于除邻接矩阵外的存储结构而言,只是其中的一种遍历序列,仅供大家参考。
三、算法逻辑
今天我们要介绍的图的深度优先搜索与树的先根遍历类似,都是先访问当前顶点,再对一条路径进行深入,直至该路径无法继续深入后,开始回溯,选择下一条路径进行深入;
在图的 DFS 中我们需要对已经完成访问的顶点进行标记,因此需要一个标记数组 visited[] 来记录当前顶点是否被访问。整个过程如下所示:
- 访问当前起始顶点,并对起始顶点进行标记
- 通过
FirstNeighbor(G, x)获取当前顶点x的下一个邻接顶点编号y,并通过visited[y]进行判断该顶点是否被访问:visited[y] == false则未被访问,继续对顶点y进行DFSvisited[y] == true则已被访问,则说明该路径上的顶点都已被访问,接下来通过NexttNeighbor(G, x, y)获取顶点x除了顶点y之外的下一个邻接顶点编号z,并对该顶点进行判断是否被访问:- 存在未被访问的顶点,继续对该顶点进行
DFS - 不存在未被访问的顶点,开始回溯
- 存在未被访问的顶点,继续对该顶点进行
其代码表达如下所示:
// 深度优先搜索
bool visited[MAXVERSIZE];
void DFS(graph* g, int x) {visit(g, x); // 访问当前顶点visited[x] = true; // 标记当前顶点for (int y = FirstNeighbor(g, x); y >= 0; y = NextNeighbor(g, x, y)) {// FirstNeighbor(g, x): 当前顶点x存在下一个邻接点,则返回对应顶点编号,否则,返回-1// NextNeighbor(g, x, y): 当前顶点x存在下一个除顶点y以外的邻接点,则返回对应顶点编号,否则,返回-1// y == -1时,说明此时该路径中不存在未被访问的邻接点if (!visited[y]) { // 判断当前顶点是否被访问DFS(g, y); // 未被访问,则对该点进行深度优先搜索}}
}
对于连通图而言,上述代码逻辑足以完成所有顶点的遍历,但是在非连通图中,从某一起始点开始进行 DFS 只能完成该点所在连通分量的所有顶点的遍历。
为了确保能够对非连通图完成所有顶点的遍历,我们需要借助 visited[] 数组来查找未被访问过的顶点信息,如下所示:
void DFSTraverse(graph* g) {// 初始化标记数组for (int i = 0; i < MAXVERSIZE; i++) {visited[i] = false;}for (int i = 0; i < MAXVERSIZE; i++) {if (!visited[i]) {DFS(g, i);}}
}
在该函数中,每一次调用 DFS 就是对图中的一个连通分量进行遍历,图中存在多少个连通分量,就会调用多少次 DFS;
四、算法评价
图的遍历算法的本质就是通过边来找顶点,因此对于 DFS 而言,其时间复杂度与 BFS 的时间复杂度一致:
- 邻接矩阵: O ( ∣ V ∣ 2 ) O(|V|^2) O(∣V∣2)
- 邻接表/十字链表/邻接多重表: O ( ∣ V ∣ + ∣ E ∣ ) O(|V| + |E|) O(∣V∣+∣E∣)
在 DFS 中,我们可以像上述展示的代码一样,通过递归实现,其对应的空间复杂度为: O ( ∣ V ∣ ) O(|V|) O(∣V∣)
同样也可以通过栈的方式来实现,对应的空间复杂度依然是: O ( ∣ V ∣ ) O(|V|) O(∣V∣)
五、深度优先生成树
与广度优先生成树一致,深度优先生成树也是在遍历图的过程中保留所有的顶点与其访问的边所得到的一棵生成树,我们以下面的例子来说明:
在上图中,其顶点集与边集如下所示:
- 顶点集: V = { a , b , c , d , e , f , g } V = \{a, b, c, d, e, f, g\} V={a,b,c,d,e,f,g}
- 边集: E = { ( a , b ) , ( a , c ) , ( b , d ) , ( b , e ) , ( c , e ) , ( e , f ) , ( e , g ) , ( f , g ) } E = \{(a, b), (a, c), (b, d), (b, e), (c, e), (e, f), (e, g), (f, g)\} E={(a,b),(a,c),(b,d),(b,e),(c,e),(e,f),(e,g),(f,g)}
当我们从起始点 a 开始进行遍历时,此时点a 会被标记,其对应的生成树为:
对于点a而言,其邻接点有两个:
- 点b:未访问
- 点c:未访问
当我们找到第一个邻接点b时,点b会被标记,所对应的边 ( a , b ) (a, b) (a,b) 被访问,对应的生成树为:
对于点b而言,其邻接点有3个:
- 点a:已访问
- 点d:未访问
- 点e:未访问
这时找到的邻接点a已经被访问,算法会继续寻找除了点a外的下一个邻接点d。
当找到点d后,点d会被标记,所对应的边 ( b , d ) (b, d) (b,d) 被访问,其对应的生成树为:
对于点d而言,其邻接点有1个:
- 点b:被访问
由于点d不存在未被访问的邻接点,算法会开始回溯到点b,这时会继续寻找与点b邻接的下一个邻接点e。
当找到点e后,点e会被标记,所对应的边 ( b , e ) (b, e) (b,e) 被访问,对应的生成树为:
对于点e而言,其邻接点有4个:
- 点b:已访问
- 点c:未访问
- 点f:未访问
- 点g:未访问
这时算法会重复上述的步骤依次找到并标记以下顶点与边:
- 顶点:c,对应边: ( e , c ) (e, c) (e,c)
- 顶点:f,对应边: ( e , f ) (e, f) (e,f)
- 顶点:g,对应边: ( f , g ) (f, g) (f,g)
此时所有的顶点都完成了标记,我们也就得到了该图的深度优先生成树:
深度优先生成树在不同的存储结构中,同样不相同:
- 邻接矩阵:深度优先生成树唯一
- 邻接表/十字链表/邻接多重表:深度优先生成树不唯一
具体的原因我这里再重复一遍:
- 在邻接表/十字链表/邻接多重表中,边的存储是以链表的形式进行存储,因此结点的位置可能发生变化,因此对应的生成树也会发生变化
六、有向图与无向图
现在我们已经了解了图的两种遍历方式:BFS 与 DFS ,不管是哪种方式,在对无向图进行遍历与对有向图进行遍历时,是有些许区别的:
- 在无向图中,两种遍历方式的调用次数 = 连通分量的数量
- 在有向图中,两种遍历方式的调用次数都需要根据实际情况进行分析:
- 起始点到其它顶点都有路径,则只需调用一次
- 起始点与其它的顶点之间不存在路径,则需多次调用
- 有向图为强连通图,无论从哪个顶点出发,都只需要调用一次
在这两个篇章中我们都是以无向图为例进行说明,但是在实际问题中,我们还是需要根据具体情况进行具体分析。
结语:深潜与回溯,揭开图论世界的另一面
通过本篇的探索,我们见证了深度优先搜索(DFS)如何以“不撞南墙不回头”的执着,在图结构中开辟出一条条纵深路径。与广度优先搜索(BFS)的“层层递进”不同,DFS以递归与回溯为利器,在迷宫寻路、拓扑排序、连通分量统计等场景中展现独特优势。
关键回顾🔍
-
DFS的核心逻辑:从二叉树的遍历(先序/后序)出发,推演至图的深度探索策略,通过visited数组避免重复访问,用递归或栈实现“一条路走到黑”的纵深突破。
-
生成树的多样性:DFS生成树的形态因存储结构(邻接矩阵 vs 邻接表)而异,揭示了算法执行路径的不确定性,也体现了图遍历的灵活性。
-
场景适应性:
-
无向图:DFS调用次数=连通分量数,天然适合检测图的连通性。
-
有向图:强连通分量需特殊处理,DFS在依赖解析、环路检测中表现卓越。
-
实践启示💡
-
代码实现:递归简洁但需警惕栈溢出,非递归栈实现更适合大规模图。
-
性能权衡:邻接表下DFS时间复杂度为 O ( V + E ) O(V + E) O(V+E),空间复杂度与递归深度正相关,树形图优化显著。
-
决策智慧:遇到回溯问题、连通分量分析时优先考虑DFS;追求最短路径或层序关系时转向BFS。
如果本文对你有所启发,欢迎互动支持!
👉 关注👆蒙奇D索大,获取更多算法深度解析
👉 点赞👍鼓励持续创作
👉 收藏📁备查实战应用
👉 转发📤分享给更多同行
图论的海洋浩瀚无垠,DFS与BFS仅是探索的起点。下一篇我们将深入《图的实际应用——最小生成树(Minimum Spanning Tree)》,揭秘如何在复杂网络中高效构建成本最低的连通骨架,无论是Kruskal的贪心策略,还是Prim的顶点扩展法,都将为你打开优化问题的新视野。敬请期待,一起用算法编织智慧之网! 🌟
相关文章:
【数据结构】图论核心算法解析:深度优先搜索(DFS)的纵深遍历与生成树实战指南
深度优先搜索 导读:从广度到深度,探索图的遍历奥秘一、深度优先搜索二、算法思路三、算法逻辑四、算法评价五、深度优先生成树六、有向图与无向图结语:深潜与回溯,揭开图论世界的另一面 导读:从广度到深度,…...

Mysql数据库 索引,事务
Mysql数据库 索引,事务 一.索引 简介 索引是数据库中用于提高查询效率的一种数据结构,它通过预先排序和存储特定列的值,帮助数据库快速定位符合条件的数据行,避免全表扫描。以下是关于索引的核心简介: 1. 核心作用…...
RESTful APInahamcon Fuzzies-write-up
RESTful API 路径详解 RESTful API(Representational State Transfer)是一种 基于 HTTP 协议的 API 设计风格,它通过 URL 路径 和 HTTP 方法(GET、POST、PUT、DELETE 等)来定义资源的访问方式。它的核心思想是 将数据…...

安装DockerDocker-Compose
Docker 1、换掉关键文件 vim /etc/yum.repos.d/CentOS-Base.repo ▽ [base] nameCentOS-$releasever - Base - Mirrors Aliyun baseurlhttp://mirrors.aliyun.com/centos/$releasever/os/$basearch/ gpgcheck1 enabled1 gpgkeyhttp://mirrors.aliyun.com/centos/RPM-GPG-KEY-C…...

2025年机械化设计制造与计算机工程国际会议(MDMCE 2025)
2025年机械化设计制造与计算机工程国际会议(MDMCE 2025) 2025 International Conference on Mechanized Design, Manufacturing, and Computer Engineering 一、大会信息 会议简称:MDMCE 2025 大会地点:中国贵阳 审稿通知&#…...

Java生态中的NLP框架
Java生态系统中提供了多个强大的自然语言处理(NLP)框架,以下是主要的NLP框架及其详细说明: 1、Apache OpenNLP 简介:Apache OpenNLP是Apache软件基金会的开源项目,提供了一系列常用的NLP工具。 主要功能: …...

NVM,Node.Js 管理工具
node_mirror: https://npmmirror.com/mirrors/node/ npm_mirror: https://npmmirror.com/mirrors/npm/ 一、什么是 NVM? NVM 是一个命令行工具,允许你在同一台机器上安装、切换和管理多个 Node.js 版本,解决项目间版本冲突问题。 二、安装 …...
Jmeter逻辑控制器、定时器
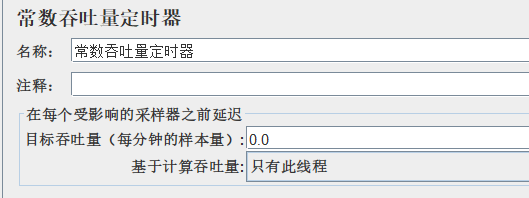
目录 一、Jmeter逻辑控制器 ①IF(如果)控制器 作用: 位置: 参数介绍: 步骤: ②循环控制器 作用: 位置: 步骤: 线程组属性VS循环控制器 ③ForEach控制器 作用: 位置&am…...

每日八股文6.2
每日八股-6.2 Go1.GMP调度原理(这部分多去看看golang三关加深理解)2.GC(同样多去看看golang三关加深理解)3.闭包4.go语言函数是一等公民是什么意思5.sync.Mutex和sync.RWMutex6.sync.WaitGroup7.sync.Cond8.sync.Pool9.panic和rec…...
R3GAN利用配置好的Pytorch训练自己的数据集
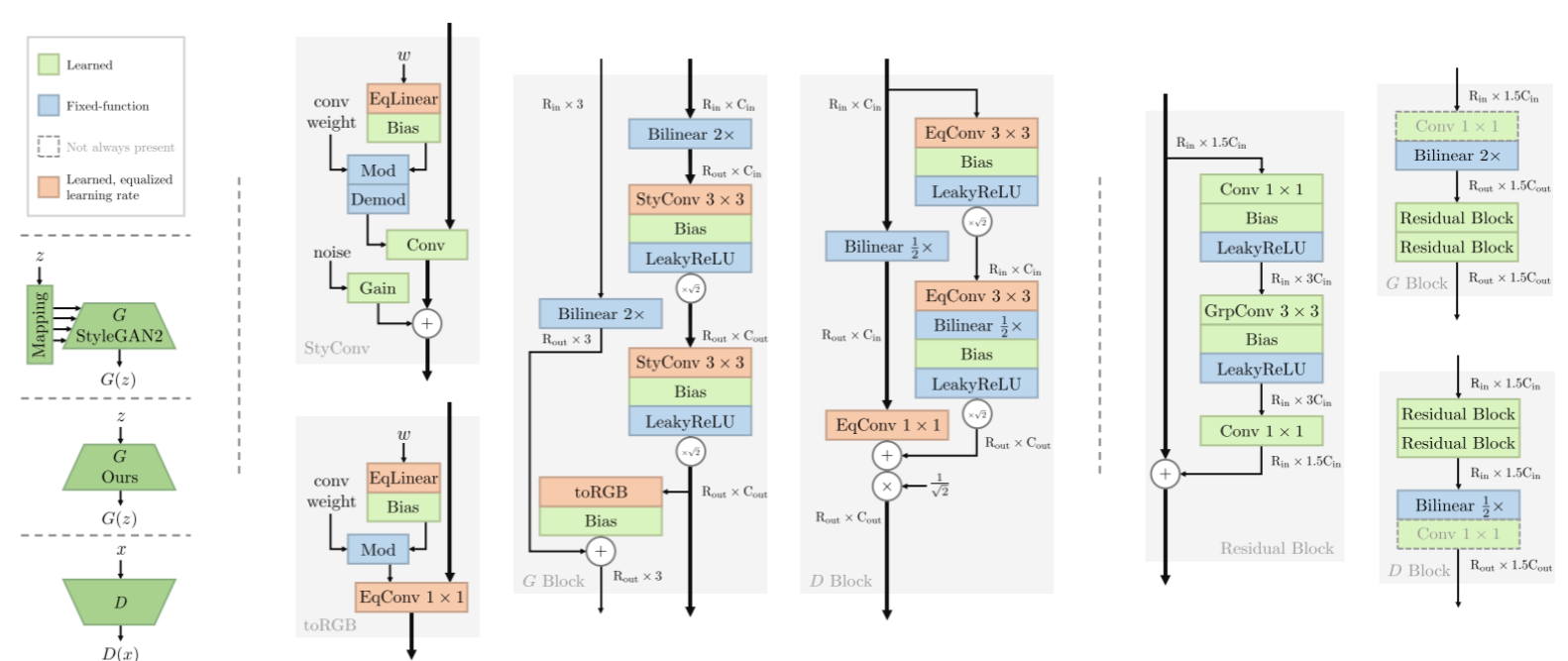
简介 简介:这篇论文挑战了"GANs难以训练"的广泛观点,通过提出一个更稳定的损失函数和现代化的网络架构,构建了一个简洁而高效的GAN基线模型R3GAN。作者证明了通过合适的理论基础和架构设计,GANs可以稳定训练并达到优异性能。 论文题目:The GAN is dead; long l…...
吴恩达机器学习笔记(1)—引言
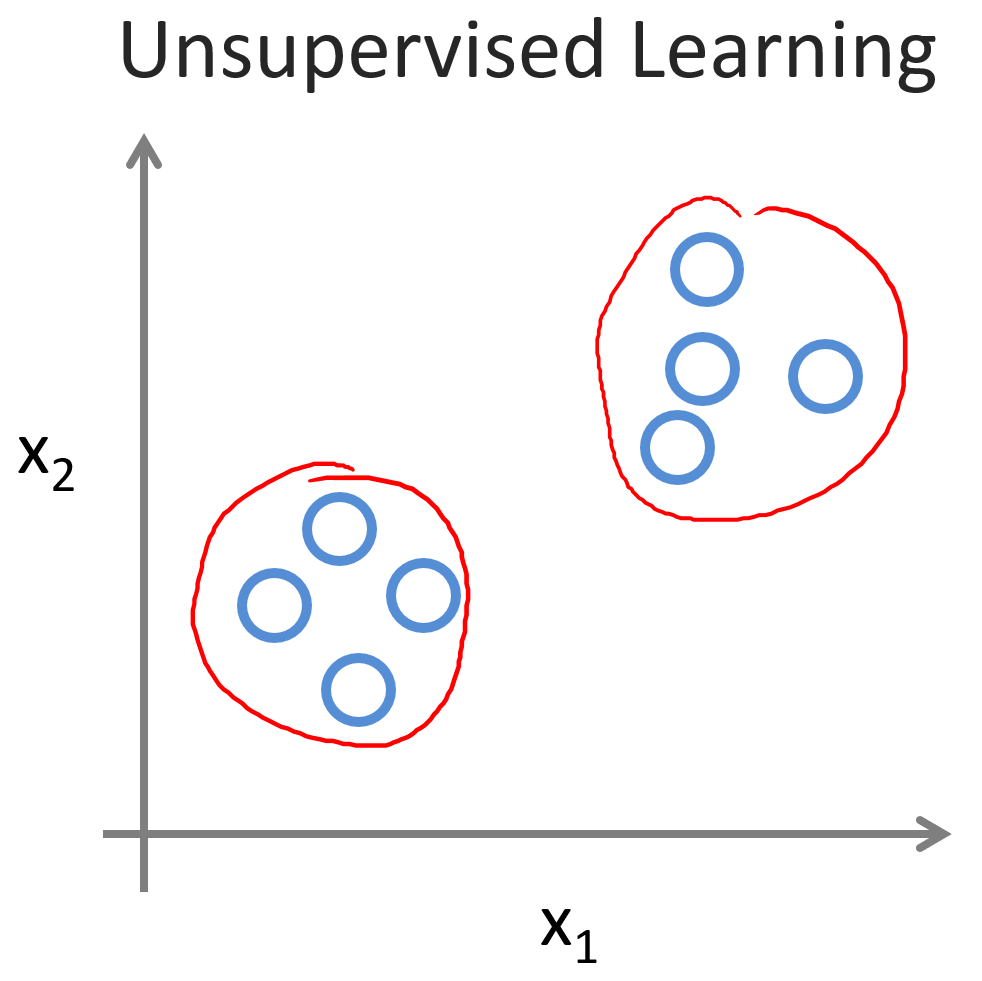
目录 一、欢迎 二、机器学习是什么 三、监督学习 四、无监督学习 一、欢迎 机器学习是当前信息技术领域中最令人兴奋的方向之一。在这门课程中,你不仅会学习机器学习的前沿知识,还将亲手实现相关算法,从而深入理解其内部机理。 事实上&…...

信贷风控规则策略累计增益lift测算
在大数据风控业务实践过程中,目前业内主要还是采用规则叠加的办法做策略,但是会遇到一些问题: 1.我们有10条规则,我上了前7条后,后面3条的绝对风险增益是多少? 2.我的规则之间应该做排序吗,最重…...
【笔记】Windows 部署 Suna 开源项目完整流程记录
#工作记录 因篇幅有限,所有涉及处理步骤的详细处理办法请参考文末资料。 Microsoft Windows [Version 10.0.27868.1000] (c) Microsoft Corporation. All rights reserved.(suna-py3.12) F:\PythonProjects\suna>python setup.py --admin███████╗██╗…...
【Elasticsearch】Elasticsearch 核心技术(一):索引
Elasticsearch 核心技术(一):索引 1.索引的定义2.索引的命名规范3.索引的增、删、改、查3.1 创建索引3.1.1 创建空索引 3.2 删除索引3.3 文档操作3.3.1 添加/更新文档(指定ID)3.3.2 添加文档(自动生成ID&am…...

AudioTrack的理解
采样率说的是一秒钟采样多少点 波形频率说的是一个采样周期内有多少个波形 pcm编码说的是 16 还是8 直接决定write的时候使用short还是byte 一、初始化配置 参数设定 需定义音频格式、采样率及缓冲区大小,确保符合硬件支持范围 // 音频参数配置 int sample…...

HTTP请求与HTTP响应介绍及其字段
HTTP请求 请求行:请求行主要包含请求方法、请求URI(统一资源标识符)和HTTP协议版本。例如: GET /index.html HTTP/1.1 请求头(Headers):包含客户端的元数据,为服务器提供了额外信息…...
Fullstack 面试复习笔记:操作系统 / 网络 / HTTP / 设计模式梳理
Fullstack 面试复习笔记:操作系统 / 网络 / HTTP / 设计模式梳理 面试周期就是要根据JD调整准备内容(挠头),最近会混合复习针对全栈这块的内容,目前是根据受伤的JD,优先选择一些基础的操作系统、Java、Nod…...

中科院报道铁电液晶:从实验室突破到多场景应用展望
2020年的时候,相信很多关注科技前沿的朋友都注意到,中国科学院一篇报道聚焦一项有望改写显示产业格局的新技术 —— 铁电液晶(FeLC)。这项被业内称为 "下一代显示核心材料" 的研究,究竟取得了哪些实质性进展…...
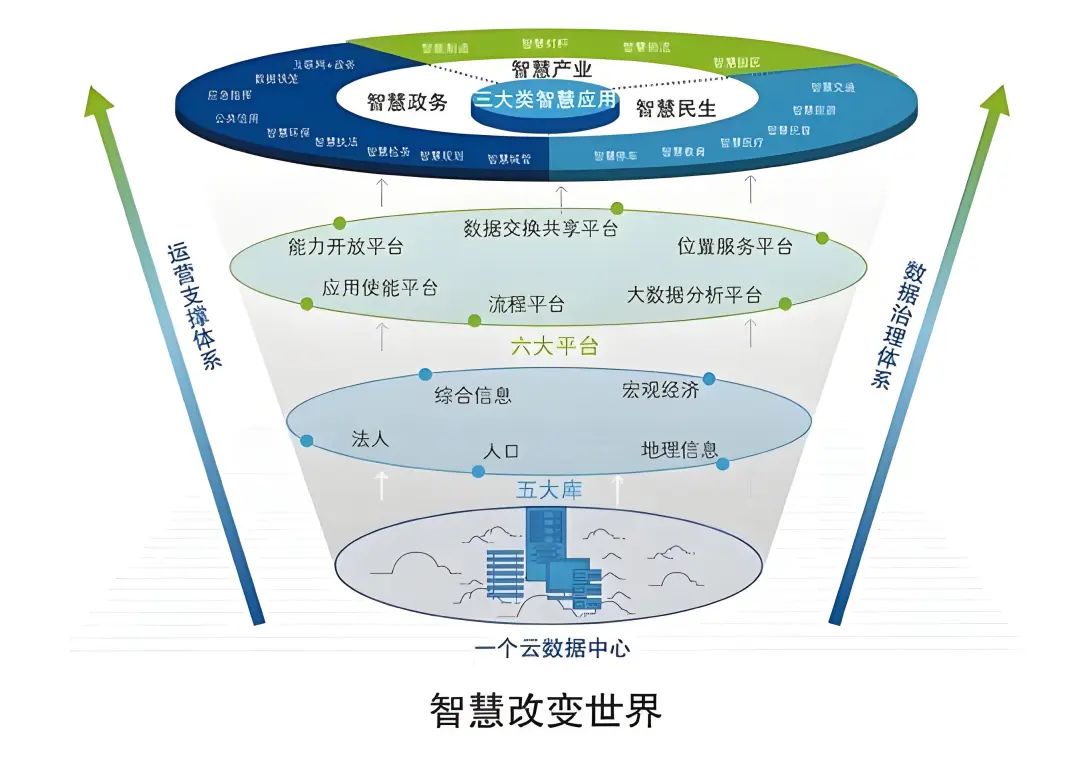
智慧政务标准规范介绍:构建高效、协同的政务信息体系
在当今信息化快速发展的时代,智慧政务作为政府数字化转型的重要方向,正逐步改变着政府管理和服务的方式。为了确保智慧政务系统的建设能够有序、高效地进行,国家制定了一系列标准规范,其中GB∕T 21062系列标准《政务信息资源交换体…...

6个月Python学习计划 Day 12 - 字符串处理 文件路径操作
第一周 Day 1 - Python 基础入门 & 开发环境搭建 Day 2 - 条件判断、用户输入、格式化输出 Day 3 - 循环语句 range 函数 Day 4 - 列表 & 元组基础 Day 5 - 字典(dict)与集合(set) Day 6 - 综合实战:学生信息…...

CSS篇-3
1. CSS 中哪些样式可以继承?哪些不可以继承? 可继承的样式: 与字体相关的样式,如:font-size、font-family、color 列表样式:list-style(如 UL、OL 的 list-style-type) 不可继承的样式: 与布局和尺寸相关的样式,如:border、padding、margin、width、height 总结: …...

Unity使用Lua框架和C#框架开发游戏的区别
在Unity中使用Lua框架和C#框架开发游戏有显著的区别,主要体现在性能、开发效率、热更新能力、维护成本等方面。 1. 语言类型与设计目标 维度LuaC#类型动态类型、解释型脚本语言静态类型、编译型面向对象语言设计初衷轻量级嵌入、配置和扩展宿主程序通用开发&#…...

Go开发简历优化指南
一、简历格式与排版 (一)简洁至上 去除多余装饰:在 Go 后台开发简历中,应摒弃那些花哨却无实际作用的元素,比如复杂的封面、页眉、页脚等。设想招聘人员每日要处理大量简历,若你的简历有繁杂的封面设计&a…...

手机照片太多了存哪里?
手机相册里塞满了旅行照片、生活碎片,每次清理都舍不得删?NAS——一款超实用的存储方案,让你的回忆安全又有序~ 1️⃣自动备份解放双手 手机 / 电脑 / 相机照片全自动同步到 NAS,再也不用手动传文件 2️⃣远程访问像…...

【论文笔记】SecAlign: Defending Against Prompt Injection with Preference Optimization
论文信息 论文标题:SecAlign: Defending Against Prompt Injection with Preference Optimization - CCS 25 论文作者: Sizhe Chen - UC Berkeley ;Meta, FAIR 论文链接:https://arxiv.org/abs/2410.05451 代码链接:h…...

IP Search Performance Tests dat/db/xdb/mmdb 结构性能差异对比
IP Search Performance Tests qqzeng-ip by 2025-06-01 测试环境: BenchmarkDotNet v0.15.0 macOS Sequoia 15.5 (24F74) [Darwin 24.5.0] Apple M4 Max, 1 CPU, 14 logical and 14 physical cores .NET SDK 10.0.100-preview.4.25258.110 [Host]: .NET…...
OpenRouter使用指南
OpenRouter 是一个专注于大模型(LLM)API 聚合和路由的服务平台,旨在帮助开发者便捷地访问多种主流大语言模型(如 GPT-4、Claude、Llama 等),并提供统一的接口、成本优化和智能路由功能。以下是它的核心功能…...

Linux 中 m、mm、mmm 函数和 make 的区别
在 Linux 内核开发和 Android 开发中,构建系统通常使用 make 命令来编译和构建项目。而在 Android 开发环境中,还有 m、mm 和 mmm 等命令,这些命令是 Android 构建系统的一部分,提供了更高效和便捷的构建方式。以下将详细介绍这些…...

【MAC】YOLOv8/11/12 转换为 CoreML 格式并实现实时目标检测
在本文中,我们将详细介绍如何将 YOLOv8/11/12 模型转换为 CoreML 格式,并使用该模型在摄像头实时检测中进行目标检测。主要适用于M1、M2、M3、M4芯片的产品。 以下教程在YOLOv8/11/12均适用,此处就以 YOLOv11 举例 目录 前提条件YOLOv8/11/12 转换为 CoreML实时目标检测结论…...

NodeJS全栈WEB3面试题——P7工具链 测试
📊 7.1 Truffle vs Hardhat:各自的优势? 项目TruffleHardhat📦 成熟度老牌框架,社区大,文档全面新一代框架,现代化设计🧪 测试支持内置 Mocha 测试框架支持 Mocha Chai,…...