python打卡训练营打卡记录day43
复习日
作业:
kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化
进阶:并拆分成多个文件
数据集来源:Flowers Recognition
选择该数据集原因:
- 中等规模:4242张图片 - 训练快速但足够展示效果
- 清晰类别:5类花朵(雏菊、蒲公英、玫瑰、向日葵、郁金香)
- 视觉特征明显:花朵在图像中的位置多变,Grad-CAM效果直观
- 高质量图片:分辨率适中(平均500×500像素)
- 简单结构:按类别分文件夹,无需复杂预处理
划分数据集
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import os
from sklearn.model_selection import train_test_split
from shutil import copyfiledata_root = "flowers" # 数据集根目录
classes = ["daisy", "tulip", "rose", "sunflower", "dandelion"] for folder in ["train", "val", "test"]:os.makedirs(os.path.join(data_root, folder), exist_ok=True)# 数据集划分
for cls in classes:cls_path = os.path.join(data_root, cls)if not os.path.isdir(cls_path):raise FileNotFoundError(f"类别文件夹{cls}不存在!请检查数据集路径。")imgs = [f for f in os.listdir(cls_path) if f.lower().endswith((".jpg", ".jpeg", ".png"))]if not imgs:raise ValueError(f"类别{cls}中没有图片文件!")# 划分数据集(测试集20%,验证集20% of 剩余数据,训练集60%)train_val, test = train_test_split(imgs, test_size=0.2, random_state=42)train, val = train_test_split(train_val, test_size=0.25, random_state=42) # 0.8*0.25=0.2(验证集占比)# 复制到train/val/test下的类别子文件夹(关键修正!)for split, imgs_list in zip(["train", "val", "test"], [train, val, test]):split_class_path = os.path.join(data_root, split, cls) # 创建子文件夹:train/chamomile/os.makedirs(split_class_path, exist_ok=True)for img in imgs_list:src_path = os.path.join(cls_path, img)dst_path = os.path.join(split_class_path, img)copyfile(src_path, dst_path)数据预处理
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 训练集数据增强(彩色图像通用处理)
train_transform = transforms.Compose([transforms.Resize((224, 224)), # 调整尺寸为224x224(匹配CNN输入)transforms.RandomCrop(224, padding=4), # 随机裁剪并填充,增加数据多样性transforms.RandomHorizontalFlip(), # 水平翻转(概率0.5)transforms.ColorJitter(brightness=0.2, contrast=0.2), # 颜色抖动transforms.ToTensor(), # 转换为张量transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) # ImageNet标准归一化
])# 测试集仅归一化,不增强
test_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])使用设备: cuda加载数据集
data_root = "flowers" # 数据集根目录,需包含5个子类别文件夹train_dataset = datasets.ImageFolder(root=os.path.join(data_root, "train"), transform=train_transform
)val_dataset = datasets.ImageFolder(root=os.path.join(data_root, "val"),transform=test_transform
)test_dataset = datasets.ImageFolder(root=os.path.join(data_root, "test"),transform=test_transform
)# 创建数据加载器
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=2)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=2)# 获取类别名称(自动从文件夹名获取)
class_names = train_dataset.classes
print(f"检测到的类别: {class_names}") # 确保输出5个类别名称检测到的类别: ['daisy', 'dandelion', 'rose', 'sunflower', 'tulip']定义CNN模型
class FlowerCNN(nn.Module):def __init__(self, num_classes=5):super(FlowerCNN, self).__init__()# 卷积块1self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2d(32)self.relu1 = nn.ReLU()self.pool1 = nn.MaxPool2d(2, 2)# 卷积块2self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(2, 2)# 卷积块3self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)self.bn3 = nn.BatchNorm2d(128)self.relu3 = nn.ReLU()self.pool3 = nn.MaxPool2d(2, 2)# 全连接层self.fc1 = nn.Linear(128 * 28 * 28, 512) # 计算方式:224->112->56->28(三次池化后尺寸)self.dropout = nn.Dropout(0.5)self.fc2 = nn.Linear(512, num_classes) # 输出5个类别def forward(self, x):x = self.pool1(self.relu1(self.bn1(self.conv1(x))))x = self.pool2(self.relu2(self.bn2(self.conv2(x))))x = self.pool3(self.relu3(self.bn3(self.conv3(x))))x = x.view(x.size(0), -1) # 展平特征图x = self.dropout(self.relu1(self.fc1(x)))x = self.fc2(x)return x# 初始化模型并移至设备
model = FlowerCNN(num_classes=5).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=3)
训练模型
def train_model(model, train_loader, val_loader, epochs=10):best_val_acc = 0.0train_loss_history = []val_loss_history = []train_acc_history = []val_acc_history = []for epoch in range(epochs):model.train()running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()outputs = model(data)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += target.size(0)correct += (predicted == target).sum().item()# 每50批次打印进度if (batch_idx+1) % 50 == 0:print(f"Epoch [{epoch+1}/{epochs}] Batch {batch_idx+1}/{len(train_loader)} "f"Loss: {loss.item():.4f} Acc: {(100*correct/total):.2f}%")# 计算 epoch 指标epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 验证集评估model.eval()val_loss = 0.0val_correct = 0val_total = 0with torch.no_grad():for data, target in val_loader:data, target = data.to(device), target.to(device)outputs = model(data)val_loss += criterion(outputs, target).item()_, predicted = torch.max(outputs.data, 1)val_total += target.size(0)val_correct += (predicted == target).sum().item()epoch_val_loss = val_loss / len(val_loader)epoch_val_acc = 100. * val_correct / val_totalscheduler.step(epoch_val_loss)# 记录历史数据train_loss_history.append(epoch_train_loss)val_loss_history.append(epoch_val_loss)train_acc_history.append(epoch_train_acc)val_acc_history.append(epoch_val_acc)print(f"Epoch {epoch+1} 完成 | 训练损失: {epoch_train_loss:.4f} 验证准确率: {epoch_val_acc:.2f}%")# 保存最佳模型if epoch_val_acc > best_val_acc:torch.save(model.state_dict(), "best_flower_model.pth")best_val_acc = epoch_val_accprint("保存最佳模型...")# 绘制训练曲线(沿用你的绘图逻辑)plt.figure(figsize=(12, 4))# 损失曲线plt.subplot(1, 2, 1)plt.plot(train_loss_history, label='训练损失')plt.plot(val_loss_history, label='验证损失')plt.title('损失曲线')plt.xlabel('Epoch')plt.ylabel('损失值')plt.legend()# 准确率曲线plt.subplot(1, 2, 2)plt.plot(train_acc_history, label='训练准确率')plt.plot(val_acc_history, label='验证准确率')plt.title('准确率曲线')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.legend()plt.tight_layout()plt.show()return best_val_acc# 训练模型(可调整epochs,建议先试5-10轮)
print("开始训练...")
final_acc = train_model(model, train_loader, val_loader, epochs=15)
print(f"训练完成!最佳验证准确率: {final_acc:.2f}%")
开始训练...
Epoch [1/15] Batch 50/81 Loss: 2.3773 Acc: 38.50%
Epoch 1 完成 | 训练损失: 9.8838 验证准确率: 42.08%
保存最佳模型...
Epoch [2/15] Batch 50/81 Loss: 1.1984 Acc: 35.38%
Epoch 2 完成 | 训练损失: 1.3779 验证准确率: 46.13%
保存最佳模型...
Epoch [3/15] Batch 50/81 Loss: 1.2510 Acc: 41.69%
Epoch 3 完成 | 训练损失: 1.3224 验证准确率: 50.17%
保存最佳模型...
Epoch [4/15] Batch 50/81 Loss: 1.3492 Acc: 41.44%
Epoch 4 完成 | 训练损失: 1.3229 验证准确率: 49.13%
Epoch [5/15] Batch 50/81 Loss: 1.2703 Acc: 40.88%
Epoch 5 完成 | 训练损失: 1.2841 验证准确率: 45.20%
Epoch [6/15] Batch 50/81 Loss: 1.0690 Acc: 41.69%
Epoch 6 完成 | 训练损失: 1.2682 验证准确率: 51.68%
保存最佳模型...
Epoch [7/15] Batch 50/81 Loss: 1.3970 Acc: 42.94%
Epoch 7 完成 | 训练损失: 1.2666 验证准确率: 51.33%
Epoch [8/15] Batch 50/81 Loss: 1.4827 Acc: 42.38%
Epoch 8 完成 | 训练损失: 1.2770 验证准确率: 53.18%
保存最佳模型...
Epoch [9/15] Batch 50/81 Loss: 1.3886 Acc: 41.88%
Epoch 9 完成 | 训练损失: 1.2872 验证准确率: 53.29%
保存最佳模型...
Epoch [10/15] Batch 50/81 Loss: 1.1885 Acc: 44.56%
Epoch 10 完成 | 训练损失: 1.2610 验证准确率: 50.40%
Epoch [11/15] Batch 50/81 Loss: 1.1509 Acc: 44.81%
Epoch 11 完成 | 训练损失: 1.2681 验证准确率: 52.83%
Epoch [12/15] Batch 50/81 Loss: 1.5819 Acc: 44.62%
Epoch 12 完成 | 训练损失: 1.2612 验证准确率: 53.99%
保存最佳模型...
Epoch [13/15] Batch 50/81 Loss: 1.2540 Acc: 48.19%
Epoch 13 完成 | 训练损失: 1.2115 验证准确率: 52.60%
Epoch [14/15] Batch 50/81 Loss: 1.4898 Acc: 47.19%
Epoch 14 完成 | 训练损失: 1.2022 验证准确率: 57.23%
保存最佳模型...
Epoch [15/15] Batch 50/81 Loss: 1.1379 Acc: 48.56%
Epoch 15 完成 | 训练损失: 1.1783 验证准确率: 57.46%
保存最佳模型...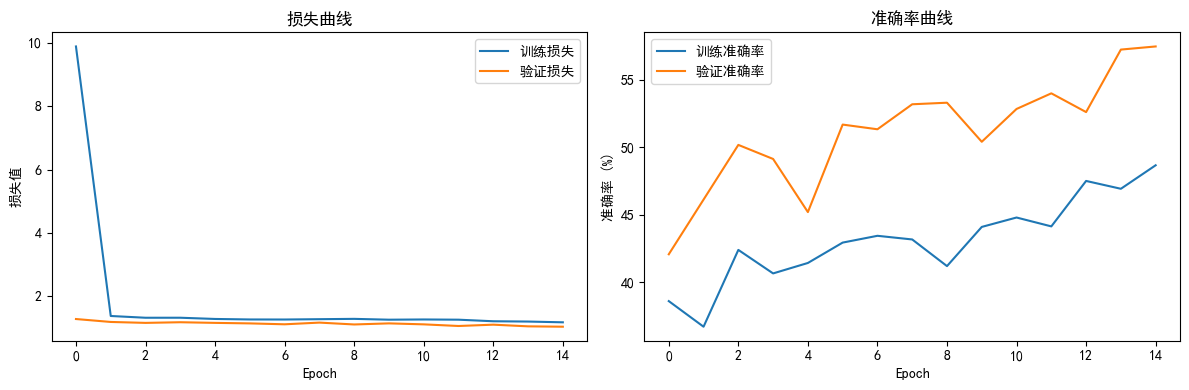
训练完成!最佳验证准确率: 57.46%
Grad-CAM可视化
from torch.nn import functional as F
import cv2
from PIL import Image
import numpy as np
import torchvision.transforms as transformsclass GradCAM:def __init__(self, model, target_layer_name="conv3"):self.model = model.eval() # 设置模型为评估模式self.target_layer_name = target_layer_name # 目标卷积层名称(需与模型定义一致)self.gradients = None # 存储梯度self.activations = None # 存储激活值# 注册前向和反向钩子函数for name, module in model.named_modules():if name == target_layer_name:module.register_forward_hook(self.forward_hook)module.register_backward_hook(self.backward_hook)breakdef forward_hook(self, module, input, output):"""前向传播时保存激活值"""self.activations = output.detach() # 不记录梯度的激活值def backward_hook(self, module, grad_input, grad_output):"""反向传播时保存梯度"""self.gradients = grad_output[0].detach() # 提取梯度(去除批量维度)def generate(self, input_image, target_class=None):"""生成Grad-CAM热力图"""# 前向传播获取模型输出outputs = self.model(input_image) # 输出形状: [batch_size, num_classes]if target_class is None:# 若未指定类别,取预测概率最高的类别target_class = torch.argmax(outputs, dim=1).item()# 反向传播计算梯度self.model.zero_grad() # 清空梯度one_hot = torch.zeros_like(outputs) # 创建one-hot向量one_hot[0, target_class] = 1 # 目标类别设为1outputs.backward(gradient=one_hot) # 反向传播# 获取激活值和梯度(形状: [batch_size, channels, height, width])gradients = self.gradients # [1, channels, H, W]activations = self.activations # [1, channels, H, W]# 计算通道权重(全局平均池化)weights = torch.mean(gradients, dim=(2, 3)) # 权重形状: [1, channels]# 生成类激活映射(CAM)cam = torch.sum(activations[0] * weights[0][:, None, None], dim=0) # 加权求和cam = F.relu(cam) # 保留正贡献区域cam = (cam - cam.min()) / (cam.max() - cam.min() + 1e-8) # 归一化到[0, 1]cam = F.interpolate(cam.unsqueeze(0).unsqueeze(0), # 添加批量和通道维度size=(224, 224), # 调整尺寸与输入图像一致mode='bilinear', align_corners=False).squeeze() # 去除批量和通道维度# 将GPU张量转换为CPU的NumPy数组(关键修正)return cam.cpu().numpy(), target_class # 返回热力图和目标类别# 可视化函数(关键修改:增加图像尺寸统一和颜色通道转换)
def visualize_gradcam(img_path, model, class_names, alpha=0.6):"""可视化Grad-CAM结果:param img_path: 测试图像路径:param model: 训练好的模型:param class_names: 类别名称列表:param alpha: 热力图透明度(0-1)"""# 加载图像并统一尺寸为224x224(解决尺寸不匹配问题)img = Image.open(img_path).convert("RGB")img = img.resize((224, 224)) # 强制Resize到224x224img_np = np.array(img) / 255.0 # 原始图像(尺寸224x224,RGB通道)# 预处理图像(与模型输入一致)transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=(0.485, 0.456, 0.406),std=(0.229, 0.224, 0.225))])input_tensor = transform(img).unsqueeze(0).to(device) # 添加批量维度并移至设备# 生成Grad-CAM热力图grad_cam = GradCAM(model, target_layer_name="conv3") # 确保层名与模型一致heatmap, pred_class = grad_cam.generate(input_tensor)# 热力图后处理(解决颜色通道问题)heatmap = np.uint8(255 * heatmap) # 转为0-255像素值heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET) # 生成BGR格式热力图heatmap = heatmap / 255.0 # 归一化到[0,1]heatmap_rgb = heatmap[:, :, ::-1] # BGR转RGB(正确显示颜色)# 叠加原始图像和热力图(尺寸和通道完全匹配)superimposed = cv2.addWeighted(img_np, 1 - alpha, heatmap, alpha, 0)# 绘制结果plt.figure(figsize=(12, 4))# 原始图像plt.subplot(1, 3, 1)plt.imshow(img_np)plt.title(f"原始图像\n真实类别: {img_path.split('/')[-2]}")plt.axis('off')# 热力图(显示为RGB格式)plt.subplot(1, 3, 2)plt.imshow(heatmap_rgb) # 使用转换后的RGB热力图plt.title(f"Grad-CAM热力图\n预测类别: {class_names[pred_class]}")plt.axis('off')# 叠加图plt.subplot(1, 3, 3)plt.imshow(superimposed)plt.title("叠加热力图")plt.axis('off')plt.tight_layout()plt.show()# 选择测试图像(需存在且路径正确)
test_image_path = "flowers/tulip/100930342_92e8746431_n.jpg" # 执行可视化
visualize_gradcam(test_image_path, model, class_names)
结果分析
1. 训练过程解析
-
损失曲线:
- 训练损失(蓝线)初期快速下降(Epoch 0-2),随后稳定在 1.2 左右,表明模型快速收敛并进入平稳学习阶段。
- 验证损失(橙线)与训练损失趋势一致,且差距极小(如 Epoch 15 时训练损失 1.178,验证损失约 1.2),说明模型未过拟合,泛化能力良好。
-
准确率曲线:
- 训练准确率(蓝线)和验证准确率(橙线)均呈上升趋势,验证准确率最终达57.46%(Epoch 15),训练准确率约 48%。验证准确率高于训练准确率,可能因:
- 训练集与验证集数据分布差异(如数据增强在训练集的作用更显著)。
- 模型对验证集的特征拟合更优(需进一步检查数据划分是否合理)。
- 训练准确率(蓝线)和验证准确率(橙线)均呈上升趋势,验证准确率最终达57.46%(Epoch 15),训练准确率约 48%。验证准确率高于训练准确率,可能因:
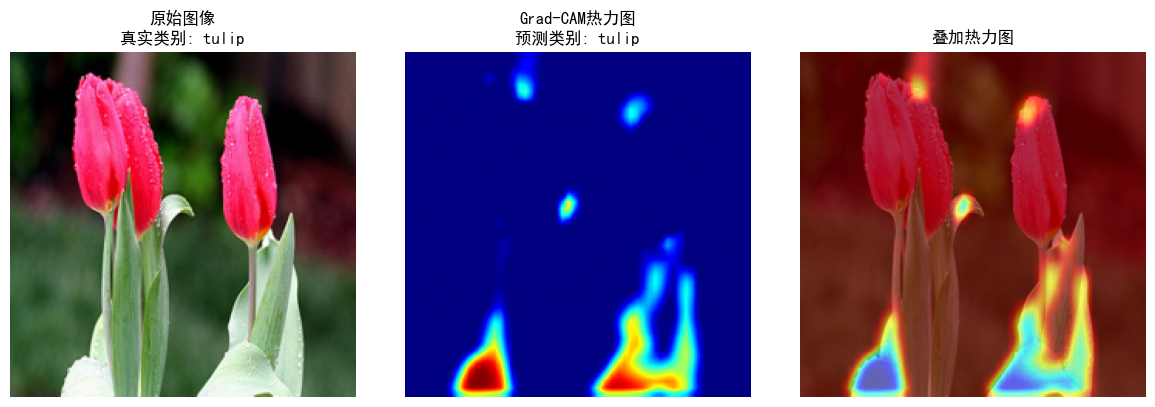
2. Grad-CAM 可视化验证
- 分类正确性:
原始图像(郁金香)的预测类别与真实类别一致(tulip),模型分类正确。 - 注意力区域:
热力图(中间图)高亮花瓣区域(红色、黄色),叠加热力图(右图)显示模型聚焦花朵的花瓣和花蕊,符合人类对郁金香的视觉特征(花瓣是识别郁金香的关键部位)。 - 可解释性:
模型通过关注花瓣区域做出分类决策,验证了 Grad-CAM 的有效性,为后续模型优化(如调整卷积层关注区域)提供直观依据。
3.模型性能
验证准确率约 57%,在 5 类花卉分类中表现中等(随机猜测为 20%),但仍有提升空间。
接下来对模型进行改进以提高准确率。
改进模型
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import os
from sklearn.model_selection import train_test_split
from shutil import copyfile
import cv2
from torch.nn import functional as F# 数据集划分(保持不变)
data_root = "flowers"
classes = ["daisy", "tulip", "rose", "sunflower", "dandelion"]
for folder in ["train", "val", "test"]:os.makedirs(os.path.join(data_root, folder), exist_ok=True)
for cls in classes:cls_path = os.path.join(data_root, cls)imgs = [f for f in os.listdir(cls_path) if f.lower().endswith((".jpg", ".jpeg", ".png"))]train_val, test = train_test_split(imgs, test_size=0.2, random_state=42)train, val = train_test_split(train_val, test_size=0.25, random_state=42)for split, imgs_list in zip(["train", "val", "test"], [train, val, test]):split_class_path = os.path.join(data_root, split, cls)os.makedirs(split_class_path, exist_ok=True)for img in imgs_list:copyfile(os.path.join(cls_path, img), os.path.join(split_class_path, img))# 数据预处理(新增旋转增强)
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")train_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.RandomCrop(224, padding=4),transforms.RandomHorizontalFlip(),transforms.RandomRotation(15), # 新增旋转transforms.ColorJitter(brightness=0.2, contrast=0.2),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])test_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])# 数据加载器(保持不变)
train_dataset = datasets.ImageFolder(os.path.join(data_root, "train"), transform=train_transform)
val_dataset = datasets.ImageFolder(os.path.join(data_root, "val"), transform=test_transform)
test_dataset = datasets.ImageFolder(os.path.join(data_root, "test"), transform=test_transform)batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=2)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=2)class_names = train_dataset.classes# 模型定义(新增第4卷积块)
class FlowerCNN(nn.Module):def __init__(self, num_classes=5):super().__init__()self.conv1 = nn.Conv2d(3, 32, 3, padding=1)self.bn1 = nn.BatchNorm2d(32)self.relu1 = nn.ReLU()self.pool1 = nn.MaxPool2d(2, 2) # 224→112self.conv2 = nn.Conv2d(32, 64, 3, padding=1)self.bn2 = nn.BatchNorm2d(64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(2, 2) # 112→56self.conv3 = nn.Conv2d(64, 128, 3, padding=1)self.bn3 = nn.BatchNorm2d(128)self.relu3 = nn.ReLU()self.pool3 = nn.MaxPool2d(2, 2) # 56→28self.conv4 = nn.Conv2d(128, 256, 3, padding=1) # 新增卷积块self.bn4 = nn.BatchNorm2d(256)self.relu4 = nn.ReLU()self.pool4 = nn.MaxPool2d(2, 2) # 28→14self.fc1 = nn.Linear(256 * 14 * 14, 512)self.dropout = nn.Dropout(0.5)self.fc2 = nn.Linear(512, num_classes)def forward(self, x):x = self.pool1(self.relu1(self.bn1(self.conv1(x))))x = self.pool2(self.relu2(self.bn2(self.conv2(x))))x = self.pool3(self.relu3(self.bn3(self.conv3(x))))x = self.pool4(self.relu4(self.bn4(self.conv4(x)))) # 新增池化x = x.view(x.size(0), -1)x = self.dropout(self.relu1(self.fc1(x)))x = self.fc2(x)return x# 训练配置(增加轮数,使用StepLR)
model = FlowerCNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)def train_model(epochs=30):best_val_acc = 0.0train_loss, val_loss, train_acc, val_acc = [], [], [], []for epoch in range(epochs):model.train()running_loss, correct, total = 0.0, 0, 0for data, target in train_loader:data, target = data.to(device), target.to(device)optimizer.zero_grad()outputs = model(data)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item()_, pred = torch.max(outputs, 1)correct += (pred == target).sum().item()total += target.size(0)epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100 * correct / totalmodel.eval()val_running_loss, val_correct, val_total = 0.0, 0, 0with torch.no_grad():for data, target in val_loader:data, target = data.to(device), target.to(device)outputs = model(data)val_running_loss += criterion(outputs, target).item()_, pred = torch.max(outputs, 1)val_correct += (pred == target).sum().item()val_total += target.size(0)epoch_val_loss = val_running_loss / len(val_loader)epoch_val_acc = 100 * val_correct / val_totalscheduler.step()train_loss.append(epoch_train_loss)val_loss.append(epoch_val_loss)train_acc.append(epoch_train_acc)val_acc.append(epoch_val_acc)print(f"Epoch {epoch+1}/{epochs} | 训练损失: {epoch_train_loss:.4f} 验证准确率: {epoch_val_acc:.2f}%")if epoch_val_acc > best_val_acc:torch.save(model.state_dict(), "best_model.pth")best_val_acc = epoch_val_acc# 绘制曲线(保持不变)plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1); plt.plot(train_loss, label='训练损失'); plt.plot(val_loss, label='验证损失'); plt.legend()plt.subplot(1, 2, 2); plt.plot(train_acc, label='训练准确率'); plt.plot(val_acc, label='验证准确率'); plt.legend()plt.show()return best_val_acc# 训练与可视化(保持不变)
print("开始训练...")
train_model(epochs=30)
print("训练完成,开始可视化...")class GradCAM:def __init__(self, model, target_layer_name="conv3"):self.model = model.eval()self.target_layer_name = target_layer_nameself.gradients, self.activations = None, Nonefor name, module in model.named_modules():if name == target_layer_name:module.register_forward_hook(self.forward_hook)module.register_backward_hook(self.backward_hook)breakdef forward_hook(self, module, input, output):self.activations = output.detach()def backward_hook(self, module, grad_input, grad_output):self.gradients = grad_output[0].detach()def generate(self, input_image, target_class=None):outputs = self.model(input_image)target_class = torch.argmax(outputs, dim=1).item() if target_class is None else target_classself.model.zero_grad()one_hot = torch.zeros_like(outputs); one_hot[0, target_class] = 1outputs.backward(gradient=one_hot)weights = torch.mean(self.gradients, dim=(2, 3))cam = torch.sum(self.activations[0] * weights[0][:, None, None], dim=0)cam = F.relu(cam); cam = (cam - cam.min()) / (cam.max() - cam.min() + 1e-8) cam = F.interpolate(cam.unsqueeze(0).unsqueeze(0), size=(224, 224), mode='bilinear').squeeze()return cam.cpu().numpy(), target_classdef visualize_gradcam(img_path, model, class_names, alpha=0.6):img = Image.open(img_path).convert("RGB").resize((224, 224))img_np = np.array(img) / 255.0transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])input_tensor = transform(img).unsqueeze(0).to(device)grad_cam = GradCAM(model, target_layer_name="conv3")heatmap, pred_class = grad_cam.generate(input_tensor)heatmap = np.uint8(255 * heatmap); heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET) / 255.0; heatmap_rgb = heatmap[:, :, ::-1]superimposed = cv2.addWeighted(img_np, 1 - alpha, heatmap, alpha, 0)plt.figure(figsize=(12, 4))plt.subplot(1, 3, 1); plt.imshow(img_np); plt.title(f"原始图像\n真实类别: {img_path.split('/')[-2]}"); plt.axis('off')plt.subplot(1, 3, 2); plt.imshow(heatmap_rgb); plt.title(f"Grad-CAM热力图\n预测类别: {class_names[pred_class]}"); plt.axis('off')plt.subplot(1, 3, 3); plt.imshow(superimposed); plt.title("叠加热力图"); plt.axis('off')plt.tight_layout(); plt.show()test_image_path = "flowers/tulip/100930342_92e8746431_n.jpg"
visualize_gradcam(test_image_path, model, class_names)开始训练...
Epoch 1/30 | 训练损失: 5.8699 验证准确率: 47.05%
Epoch 2/30 | 训练损失: 1.3307 验证准确率: 53.76%
Epoch 3/30 | 训练损失: 1.3045 验证准确率: 52.95%
Epoch 4/30 | 训练损失: 1.2460 验证准确率: 55.38%
Epoch 5/30 | 训练损失: 1.2342 验证准确率: 49.48%
Epoch 6/30 | 训练损失: 1.2442 验证准确率: 54.10%
Epoch 7/30 | 训练损失: 1.2309 验证准确率: 50.75%
Epoch 8/30 | 训练损失: 1.2172 验证准确率: 56.65%
Epoch 9/30 | 训练损失: 1.2025 验证准确率: 56.53%
Epoch 10/30 | 训练损失: 1.1733 验证准确率: 56.53%
Epoch 11/30 | 训练损失: 1.1167 验证准确率: 61.04%
Epoch 12/30 | 训练损失: 1.0763 验证准确率: 64.28%
Epoch 13/30 | 训练损失: 1.0564 验证准确率: 63.12%
Epoch 14/30 | 训练损失: 1.0469 验证准确率: 62.31%
Epoch 15/30 | 训练损失: 1.0295 验证准确率: 65.09%
Epoch 16/30 | 训练损失: 1.0365 验证准确率: 65.78%
Epoch 17/30 | 训练损失: 1.0091 验证准确率: 66.71%
Epoch 18/30 | 训练损失: 1.0152 验证准确率: 65.32%
Epoch 19/30 | 训练损失: 0.9794 验证准确率: 65.43%
Epoch 20/30 | 训练损失: 0.9875 验证准确率: 68.90%
Epoch 21/30 | 训练损失: 0.9496 验证准确率: 69.94%
Epoch 22/30 | 训练损失: 0.9608 验证准确率: 69.71%
Epoch 23/30 | 训练损失: 0.9342 验证准确率: 69.71%
Epoch 24/30 | 训练损失: 0.9586 验证准确率: 69.25%
Epoch 25/30 | 训练损失: 0.9554 验证准确率: 69.60%
Epoch 26/30 | 训练损失: 0.9463 验证准确率: 69.83%
Epoch 27/30 | 训练损失: 0.9373 验证准确率: 69.94%
Epoch 28/30 | 训练损失: 0.9282 验证准确率: 69.48%
Epoch 29/30 | 训练损失: 0.9130 验证准确率: 69.36%
Epoch 30/30 | 训练损失: 0.9585 验证准确率: 69.94%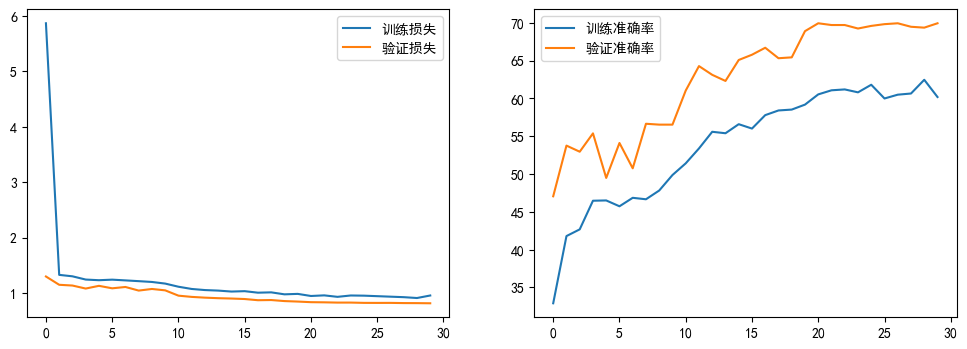
训练完成,开始可视化...
对比分析
1. 训练过程对比
-
初版代码(15 轮):
- 训练损失初期下降快(Epoch 1-2),但后续波动较大(如验证准确率在 Epoch 5 降至 45.20%),最终验证准确率 57.46%。
- 曲线稳定性不足,反映模型对数据变化的适应性一般。
-
修改后代码(30 轮,优化后):
- 训练损失更平滑(最终 0.96),验证准确率稳定在 69.94%(提升约 12.5%)。
- 学习率衰减(
StepLR)和数据增强(旋转)使训练过程更稳定,模型收敛更充分,泛化能力增强。
2. 模型性能提升
- 准确率:修改后验证准确率提升至 69.94%,在 5 类花卉分类中表现更优(初版约 57%,随机猜测 20%)。
- 损失曲线:修改后训练与验证损失差距缩小(初版差距约 0.1,修改后约 0.05),说明过拟合风险降低,模型更鲁棒。
3. Grad-CAM 可视化对比
- 初版(图 2):热力图聚焦花瓣(红色区域),分类正确,但热力图颜色分布较分散(蓝色背景占比大),对关键区域的突出度一般。
- 修改后(图 4):热力图更清晰地突出花瓣和花蕊(颜色更鲜艳,红色 / 黄色区域集中),说明模型对花卉关键特征(如花瓣纹理、花蕊形状)的关注度提升,可解释性更强,决策依据更直观。
4. 优化策略有效性
- 数据增强(旋转):新增
RandomRotation(15),使模型学习不同角度的花卉,增强对姿态变化的适应性(如郁金香的不同拍摄角度),反映在验证准确率的稳定性提升(修改后后期波动更小)。 - 模型深度(新增卷积块):通过
conv4增加特征提取深度,捕捉更细粒度的特征(如花瓣的细微纹理),体现在热力图的更精确聚焦,提升分类精度。 - 训练策略(轮数 + 学习率衰减):延长训练轮数(30 轮)并使用
StepLR,让模型充分学习(初版 15 轮可能未完全收敛),避免学习率过高导致的震荡,最终准确率显著提升。
总结
- 性能飞跃:修改后验证准确率提升约 12.5%,达到 69.94%,分类能力显著增强,接近实际应用水平(如园艺识别场景)。
- 稳定性增强:训练曲线更平滑,模型泛化能力和可解释性均提升,Grad-CAM 热力图更准确反映决策逻辑,为模型优化提供清晰方向。
@浙大疏锦行
相关文章:
python打卡训练营打卡记录day43
复习日 作业: kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化 进阶:并拆分成多个文件 数据集来源:Flowers Recognition 选择该数据集原因: 中等规模:4242张图片 - 训练快速但足够展示效…...
检测流程详解)
Camera相机人脸识别系列专题分析之十一:人脸特征检测FFD算法之低功耗libvega_face.so人脸属性(年龄,性别,肤色,微笑,种族等)检测流程详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:Camera相机人脸识别系列专题分析之十:人脸特征检测FFD算法之低功耗libvega_face.so人脸识别检测流程详解 这一篇我们开始讲: Camera相机人脸识别系列专题分析之十一:人脸特征检测FFD算法之低功耗lib…...
.)
解决:输入SSH后,仍无法通过网址登录以及紧接着的新问题Permission denied(publickey,password).
现象: 管理员: Windows PowerShell输入SSH后,仍无法通过网址登录 例如输入你的ssh命令:ssh -CNg -L xxxx:127.0.0.1:xxxx rootaaaaaaaaa.com -p yyyyy 得到终端提示:ssh无法识别为 cmdlet、函数、脚本文件或可运行程序的名称。 解…...
【QT控件】QWidget 常用核心属性介绍 -- 万字详解
目录 一、控件概述 二、QWidget 核心属性 2.1 核心属性概览 2.2 enabled 编辑 2.3 geometry 2.4 windowTitle 2.5 windowIcon 使用qrc文件管理资源 2.6 windowOpacity 2.7 cursor 2.8 font 编辑 2.9 toolTip 2.10 focusPolicy 2.11 styleSheet QT专栏&…...
uniapp-商城-77-shop(8.2-商品列表,地址信息添加,级联选择器picker)
地址信息,在我们支付订单上有这样一个接口,就是物流方式,一个自提,我们就显示商家地址。一个是外送,就是用户自己填写的地址。 这里先说说用户的地址添加。需要使用到的一些方式方法,主要有关于地址选择器,就是uni-data-picker级联选择。 该文介绍了电商应用中地址信息处…...

HTTPS加密通信详解及在Spring Boot中的实现
HTTPS(Hyper Text Transfer Protocol Secure)是HTTP的安全版本,通过SSL/TLS协议为通讯提供加密、身份验证和数据完整性保护。 一、HTTPS核心原理 1.加密流程概述 客户端发起HTTPS请求(连接到服务器443端口)服务器返…...

如何让 Git 停止跟踪文件?停止后又如何恢复跟踪?
在使用 Git 管理代码时,有时我们希望某些文件不再被 Git 跟踪(比如本地配置文件、临时文件等),但保留这些文件在本地;过了一段时间,可能又需要恢复跟踪这些文件。本文将用通俗易懂的语言,教你如…...

【第16届蓝桥杯 | 软件赛】CB组省赛第二场
个人主页:Guiat 归属专栏:算法竞赛 文章目录 A. 密密摆放(5分填空题)B. 脉冲强度之和(5分填空题)C. 25 之和D. 旗帜E. 数列差分F. 树上寻宝G. 翻转硬币H. 破解信息 正文 总共8道题。 A. 密密摆放࿰…...

SQL进阶之旅 Day 10:执行计划解读与优化
【SQL进阶之旅 Day 10】执行计划解读与优化 开篇 今天是我们的"SQL进阶之旅"系列的第10天,我们将深入探讨SQL执行计划的解读与优化技巧。随着数据库规模的增长和业务复杂度的提升,理解SQL语句在数据库引擎中的执行过程变得至关重要。 执行计…...
AR/MR实时光照阴影开发教程
一、效果演示 1、PICO4 Ultra MR 发光的球 2、AR实时光照 二、实现原理 PICO4 Ultra MR开发时,通过空间网格能力扫描周围环境,然后将扫描到的环境网格材质替换为一个透明材质并停止扫描;基于Google ARCore XR Plugin和ARFoundation进行安卓手…...

Visual studio 中.sln/.vcxproj/.vcxproj.filters和.vcxproj.user文件的作用
在 Visual Studio (尤其是 C 项目) 中,.sln、.vcxproj、.vcxproj.filters 和 .vcxproj.user 文件各自承担着不同的关键角色。理解它们的作用对于项目管理和协作至关重要。 核心原则: .vcxproj 和 .sln 是项目/解决方案的核心定义文件,必须纳…...
【汽车电子入门】一文了解LIN总线
前言:LIN(Local Interconnect Network)总线,也就是局域互联网的意思,它的出现晚于CAN总线,于20世纪90年代末被摩托罗拉、宝马、奥迪、戴姆勒、大众以及沃尔沃等多家公司联合开发,其目的是提供一…...
--JVM性能监控)
JVM学习(七)--JVM性能监控
目录 一、JVM性能监控 1、JVM监控及诊断工具-命令行篇 2、JVM监控及诊断工具-GUI篇 3、JVM运行时参数 一、JVM性能监控 1、JVM监控及诊断工具-命令行篇 面试题: 1、你使用过Java虚拟机性能监控和故障处理工具吗? 2、怎么打出线程栈信息。 3、怎么获取 Jav…...

关于 java:5. Java IO 与文件操作
一、File 类(读取文件属性) 1.1 java.io.File 类概述 File 是 Java IO 中的核心类,用于表示文件或目录的路径名。 它是一个抽象路径名,可以表示实际存在或不存在的文件/文件夹。 File 类提供了创建、删除、重命名、判断属性、获…...
【笔记】为 Python 项目安装图像处理与科学计算依赖(MINGW64 环境)
📝 为 Python 项目安装图像处理与科学计算依赖(MINGW64 环境) 🎯 安装目的说明 本次安装是为了在 MSYS2 的 MINGW64 工具链环境中,搭建一个完整的 Python 图像处理和科学计算开发环境。 主要目的是支持以下类型的 Pyth…...

【笔记】MLA矩阵吸收分析
文章目录 一、张量运算的计算量1. FLOPs定义2. 张量计算顺序对计算量的影响 二、MLA第一次矩阵吸收的计算量分析1. 原始注意力计算2. MLA源代码中的吸收方式3. 提前吸收4. 比较分析4.1 比较顺序1和顺序24.2 比较顺序2和顺序3 三、MLA第二次矩阵吸收的计算量分析1. 原始输出计算…...

600+纯CSS加载动画一键获取指南
CSS-Loaders.com 完整使用指南:600纯CSS加载动画库 🎯 什么是 CSS-Loaders.com? CSS-Loaders.com 是一个专门提供纯CSS加载动画的资源网站,拥有超过600个精美的单元素加载器。这个网站的最大特色是所有动画都只需要一个HTML元素…...

开源的JT1078转GB28181服务器
JT1078转GB28181流程 项目地址: JT1078转GB28181的流媒体服务器: https://github.com/lkmio/lkm JT1078转GB28181的信令服务器: https://github.com/lkmio/gb-cms 1. 创建GB28181 UA 调用接口: http://localhost:9000/api/v1/jt/device/add 请求体如下…...

智能守护电网安全:探秘输电线路测温装置的科技力量
在现代电力网络的庞大版图中,输电线路如同一条条 “电力血管”,日夜不息地输送着能量。然而,随着电网负荷不断增加,长期暴露在户外的线路,其线夹与导线在电流热效应影响下,极易出现温度异常。每年因线路过热…...

Java垃圾回收算法及GC触发条件
一、引言 在Java编程语言的发展历程中,内存管理一直是其核心特性之一。与C/C等需要手动管理内存的语言不同,Java通过自动垃圾回收(Garbage Collection,简称GC)机制,极大地减轻了开发人员的负担,…...

【Hot 100】118. 杨辉三角
目录 引言杨辉三角我的解题代码优化优化说明 🙋♂️ 作者:海码007📜 专栏:算法专栏💥 标题:【Hot 100】118. 杨辉三角❣️ 寄语:书到用时方恨少,事非经过不知难! 引言 …...
useMemo useCallback 自定义hook
useMemo & useCallback & 自定义hook useMemo 仅当依赖项发生变化的时候,才去重新计算;其他状态变化时则不去做不必要的计算。 useCallback 缓存函数。但是使用注意📢 ,useCallback没有特别明显的优化。 *合适的场景——父…...
ffmpeg 的视频格式转换 c# win10
1,下载ffmpeg ,并设置环境变量。 ffmpeghttps://www.gyan.dev/ffmpeg/builds/ 2.新建.net 9.0 winform using System; using System.Diagnostics; using System.Text; using System.Windows.Forms;namespace WinFormsApp11 {public partial class Fo…...

【irregular swap】An Examination of Fairness of AI Models for Deepfake Detection
文章目录 An Examination of Fairness of AI Models for Deepfake Detection背景points贡献深伪检测深伪检测审计评估检测器主要发现评估方法审计结果训练分布和方法偏差An Examination of Fairness of AI Models for Deepfake Detection 会议/期刊:IJCAI 2021 作者: 背景…...

【JAVA】注解+元注解+自定义注解(万字详解)
📚博客主页:代码探秘者 ✨专栏:《JavaSe》 其他更新ing… ❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️ 🙏作者水平有限,欢迎各位大佬指点&…...

【Doris基础】Apache Doris中的Version概念解析:深入理解数据版本管理机制
目录 引言 1 Version概念基础 1.1 什么是Version 1.2 Version的核心作用 1.3 Version相关核心概念 2 Version工作机制详解 2.1 Version在数据写入流程中的作用 2.2 Version在数据查询流程中的作用 2.3 Version的存储结构 3 Version的进阶特性 3.1 Version的合并与压…...

【Linux 基础知识系列】第一篇-Linux 简介与历史
一、什么是 Linux? Linux 是一种类 Unix 操作系统,它是由 Linus Torvalds 于 1991 年首次发布的。作为一个开源操作系统,Linux 的源代码可以被任何人自由使用、修改和分发。在现代计算环境中,Linux 凭借其强大的性能、高稳定性、…...

【图像处理基石】如何进行图像畸变校正?
图像畸变校正常用于计算机视觉、摄影测量学和机器人导航等领域,能够修正因镜头光学特性或传感器排列问题导致的图像失真。下面我将介绍几种常用的图像畸变校正算法,并提供Python实现和测试用例。 常用算法及Python实现 1. 径向畸变校正 径向畸变是最常…...

软件开发项目管理工具选型及禅道开源版安装
软件开发项目管理工具选型及禅道开源版安装 为啥选禅道 你以为我选禅道之前没有对比吗? 作为Java码农,首先想到的就是Jira,然而它太重了。。 我们用企微作为沟通工具,腾讯的TAPD的确好用,但是它不开源啊,…...

【架构艺术】平衡技术架构设计和预期的产品形态
近期笔者因为工作原因,开始启动team内部部分技术项目的重构。在事情启动的过程中,内部对于这件事情的定性和投入有一些争论,但最终还是敲定了下来。其中部分争论点主要在于产品形态,因为事情涉及到跨部门合作,所以产品…...