MapReduce(期末速成版)
起初在B站看3分钟的速成视频,感觉很多细节没听懂。
具体例子解析(文件内容去重)
对于两个输入文件,即文件A 和文件B,请编写MapReduce 程序,对两个文件进行合并,并剔除
其中重复的内容,得到一个新的输出文件C。
📂 一、输入数据文件
文件 A:
20150101 x
20150102 y
20150103 x
20150104 y
20150105 z
20150106 x
文件 B:
20150101 y
20150102 y
20150103 x
20150104 z
20150105 y
🧠 二、MapReduce 执行流程和中间结果
MapReduce 分为三个主要阶段:
-
Map 阶段
-
Shuffle(分组 & 排序)阶段
-
Reduce 阶段
🔹2.1 Map 阶段(映射阶段)
我们先来看下 Mapper 的代码逻辑:
public static class Map extends Mapper<Object, Text, Text, Text> {private static Text text = new Text();public void map(Object key, Text value, Context context) {text = value;context.write(text, new Text(""));}
}
🔍 Mapper 做了什么?
-
每行文本被视为一个输入记录(
value),key是字节偏移量(无关紧要)。 -
该
Mapper不对数据做任何处理,直接原样输出value作为key,并给定空字符串作为value。 -
这样,相同行的数据(A、B 中相同的行)会生成相同的 key,从而可以在 Shuffle 阶段合并。
🔢 Map 输出结果(中间键值对)
我们对 A、B 两个文件的所有行执行一次 map() 操作,得到如下中间结果(<key, value> 形式):
| 来源 | key(Text) | value(Text) |
|---|---|---|
| A | 20150101 x | "" |
| A | 20150102 y | "" |
| A | 20150103 x | "" |
| A | 20150104 y | "" |
| A | 20150105 z | "" |
| A | 20150106 x | "" |
| B | 20150101 y | "" |
| B | 20150102 y | "" |
| B | 20150103 x | "" |
| B | 20150104 z | "" |
| B | 20150105 y | "" |
🔹2.2 Shuffle 阶段(分组 & 排序)
MapReduce 框架自动完成以下操作:
-
将所有 Mapper 输出结果根据 key 进行哈希分区、排序、去重分组。
-
每一个唯一的 key 会被送入一次 Reducer。
🎯 分组结果(Reducer 接收到的 key 和 values):
| key(唯一行) | values("" 的列表) |
|---|---|
20150101 x | ["",] |
20150101 y | ["",] |
20150102 y | ["", ""] |
20150103 x | ["", ""] |
20150104 y | ["",] |
20150104 z | ["",] |
20150105 y | ["",] |
20150105 z | ["",] |
20150106 x | ["",] |
⚠️ 注意:
-
20150102 y和20150103 x都在两个文件中出现了,所以它们的values有两个空字符串。 -
但 Reducer 并不关心这些
values,它只输出唯一的key。
🔹2.3 Reduce 阶段(归约阶段)
看一下 Reducer 的代码:
public static class Reduce extends Reducer<Text, Text, Text, Text> {public void reduce(Text key, Iterable<Text> values, Context context) {context.write(key, new Text(""));}
}
🔍 Reducer 做了什么?
-
对于每一个唯一的
key,Reducer 被调用一次。 -
它忽略 values,直接输出
key和空的Text("")。 -
实际效果是:只输出不重复的唯一行内容。
✅ 最终输出文件 C 的内容:
20150101 x
20150101 y
20150102 y
20150103 x
20150104 y
20150104 z
20150105 y
20150105 z
20150106 x
✅ 总结
| 步骤 | 说明 |
|---|---|
| Map | 对输入的每一行输出 <Text(该行), Text("")> |
| Shuffle | 根据行内容去重、分组、排序 |
| Reduce | 忽略 values,只输出唯一的 key(行内容) |
| 输出文件 | 文件 A 和 B 合并去重后的内容 |
问题一:Reduce端是如何输出文件的?
✅ Reduce中context.write(key, value) 的行为
在 Hadoop MapReduce 中:
context.write(new Text("s"), new Text("a"));
的输出行为是:
-
每一行输出格式为:
key \t value即,key 和 value 之间用一个制表符(Tab 字符
\t)分隔。
🔍 所以你举的例子
context.write(new Text("s"), new Text("a"));
最终输出文件中的一行会是:
s a
不是 sa,而是 s 和 a 之间有一个 Tab 分隔符。
🔧 那么在你的代码中:
context.write(key, new Text(""));
由于 value 是空字符串,所以每一行就是:
key
即没有显示的 value,只输出 key 的内容,所以:
20150101 x
这行实际上是 key 的原样内容,不是 key + "" 的拼接结果,而是 key 后面虽然有个空字符串作为 value,但由于 value 是空的,输出就是 key 自身。
✍️ 补充:可以自定义 key 和 value 的分隔符
在 Hadoop 中默认的 key/value 分隔符是 Tab(\t),但你可以通过设置:
-D mapreduce.output.textoutputformat.separator=","
来更改分隔符,比如改成逗号,则输出会变成:
s,a
✅ 是不是有几个 Reducer 就会产生几个输出文件?
是的,完全正确。
在 Hadoop MapReduce 中:
-
如果你设置了 N 个 Reducer 任务(比如
job.setNumReduceTasks(N)), -
那么就会产生 N 个输出文件。
这些输出文件的名称通常是:
part-r-00000
part-r-00001
...
part-r-00(N-1)
每个文件由一个 Reducer 任务写出。
❓ 那这些输出文件的内容一致吗?
不一致!每个文件的内容不同!
➤ 原因:
-
MapReduce 框架会按照 key 的 hash 值把数据**分区(Partition)**给不同的 Reducer。
-
每个 Reducer 只处理自己分到的 key 分区。
-
所以:
-
每个输出文件包含的是不同部分的 key-value 对。
-
输出文件之间是不重合的,也就是说每个 key 只会出现在一个 Reducer 的输出文件中。
-
🧠 举个例子(比如有 2 个 Reducer):
假设你有以下中间 key:
20150101 x
20150101 y
20150102 y
20150103 x
20150104 y
20150104 z
20150105 y
20150105 z
20150106 x
Hadoop 会通过 partitioner(比如默认的 HashPartitioner)决定:
-
Reducer 0 处理:
20150101 x 20150103 x 20150105 z 20150106 x -
Reducer 1 处理:
20150101 y 20150102 y 20150104 y 20150104 z 20150105 y
然后产生:
-
part-r-00000← Reducer 0 写入 -
part-r-00001← Reducer 1 写入
两个文件中的内容互不重复,但合起来是完整的结果。
✅ 1. 默认是不是只有一个 Reducer?
是的,默认情况下 Hadoop MapReduce 只使用 1 个 Reducer。
也就是说,如果你没有显式调用:
job.setNumReduceTasks(N);
则默认 N = 1,最终只会生成一个输出文件:part-r-00000。
✅ 2. 可以设置多个 Reducer 吗?
当然可以,而且非常常见。
你可以在驱动代码中显式设置 Reducer 个数,例如设置为 3:
job.setNumReduceTasks(3);
这样 Hadoop 会启用 3 个 Reducer 并行处理数据,输出三个文件:
part-r-00000
part-r-00001
part-r-00002
问题二:Shuffle过程的输出结果与Combiner函数本质是?
✅ 一、Shuffle 输出是啥?
默认情况下:
Map 阶段的输出会经过 Shuffle(排序 + 分区 + 组装) 后变成:
key1 → [v1, v2, v3, ...]
key2 → [v1, v2, ...]
...
这些最终被送入 Reducer。
❓ 问题:为什么会有重复的 value?
因为 同一个 key 可能在同一个 Mapper 中出现多次,比如:
hello → 1
hello → 1
hello → 1
这些数据在传输前就可以局部聚合,先加一加再传过去,不用浪费网络带宽。
✅ 二、Combiner 是什么?
Combiner 就是一个 “局部 Reduce”,在 Mapper 端执行,用来提前聚合。
它的作用是:
-
在 Mapper 本地 就先对 key 进行累加(或合并),
-
减少大量重复的
<key, 1>传给 Reducer, -
降低网络传输压力,提升性能。
✅ 三、怎么写一个 Combiner?
👉 很简单,其实你可以直接 复用 Reducer 逻辑,只要满足:聚合操作是可交换和结合的(比如加法)。
✅ 1. 定义 Combiner 类(和 Reducer 一样):
public static class IntSumCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result); // 输出 key sum}
}
✅ 2. 在 Driver 中设置:
job.setCombinerClass(IntSumCombiner.class);
⚠️ 注意:你也可以直接写成:
job.setCombinerClass(IntSumReducer.class);
因为本质一样(统计加法是符合条件的操作)。
✅ 四、添加了 Combiner 后的数据流是什么样?
假设有两个 Map 输出如下:
Mapper1 输出:
hello → 1
hello → 1
world → 1
经过 Combiner:
hello → 2
world → 1
Mapper2 输出:
hello → 1
world → 1
经过 Combiner:
hello → 1
world → 1
最终 Shuffle 输出给 Reducer:
hello → [2, 1]
world → [1, 1]
Reducer 再聚合:
hello → 3
world → 2
✅ 五、什么时候不要用 Combiner?
虽然 Combiner 很有用,但它不是 always-safe 的,只有在满足可交换、可结合的前提下才可用。
| 操作类型 | 适合使用 Combiner? | 示例 |
|---|---|---|
| 加法、计数、最大最小值 | ✅ 可以用 | WordCount、MaxTemperature |
| 求平均、TopN、排序 | ❌ 不建议 | 平均值不能分区计算后再平均 |
✅ 所以完整流程是:
Map → Combiner → Shuffle(聚合 + 分区)→ Reduce
相关文章:
)
MapReduce(期末速成版)
起初在B站看3分钟的速成视频,感觉很多细节没听懂。 具体例子解析(文件内容去重) 对于两个输入文件,即文件A 和文件B,请编写MapReduce 程序,对两个文件进行合并,并剔除 其中重复的内容,得到一个新的输出文件…...

鸿蒙OSUniApp 移动端直播流播放实战:打造符合鸿蒙设计风格的播放器#三方框架 #Uniapp
UniApp 移动端直播流播放实战:打造符合鸿蒙设计风格的播放器 在移动互联网时代,直播已经成为一种主流的内容形式。本文将详细介绍如何使用 UniApp 框架开发一个优雅的直播流播放器,并融入鸿蒙系统的设计理念,实现一个既美观又实用…...

C3、C2f、C3K2、C2PSA的具体结构
YOLOV5 C3 Bottleneck C2f...

2_MCU开发环境搭建-配置MDK兼容Keil4和C51
MCU开发环境搭建-配置MDK兼容Keil4和C51 一、概述 本文以MDK-ARM V5.36版本基础介绍DMK-ARM工程兼容Keil4和C51的配置。 注:在阅读本文前,请先安装和配置完成MDK-ARM(Keil5)。 二、工具包下载 链接: https://pan.baidu.com/s/1Tu2tDD6zRra4xb_PuA1Wsw 提取码: 81pp 三、…...

通过远程桌面连接Windows实例提示“出现身份验证错误,无法连接到本地安全机构”错误怎么办?
本文介绍通过远程桌面连接Windows实例提示“出现身份验证错误无法连接到本地安全机构”错误的解决方案。 问题现象 通过本地电脑内的远程桌面连接Windows实例提示“出现身份验证错误,无法连接到本地安全机构”错误。 问题原因 导致该问题的可能原因如下&#x…...

百度golang研发一面面经
输入一个网址,到显示界面,中间的过程是怎样的 IP 报文段的结构是什么 Innodb 的底层结构 知道几种设计模式 工厂模式 简单工厂模式:根据传入类型参数判断创建哪种类型对象工厂方法模式:由子类决定实例化哪个类抽象工厂模式&#…...
TC3xx学习笔记-启动过程详解(一)
文章目录 前言Firmware启动过程BMHD Check流程ABM启动Internal Flash启动Bootloader ModeProcessing in case no valid BMHD foundProcessing in case no Boot Mode configured by SSW 总结 前言 之前介绍过UCB BMHD的使用,它在启动过程中起着重要的作用࿰…...
Scratch节日 | 六一儿童节抓糖果
六一儿童节怎么能没有糖果?这款 六一儿童节抓糖果 小游戏,让你变身小猫,开启一场甜蜜大作战! 🎮 游戏玩法 帮助小猫收集所有丢失的糖果,收集越多分数越高! 小心虫子一样的“坏糖果”ÿ…...

系统调用与程序接口的关系
程序接口类型 系统调用:是操作系统提供给应用程序的接口 ,允许应用程序请求操作系统执行特定操作,像文件操作(打开、读写、关闭文件 )、进程管理(创建、终止进程 )、设备管理(操作磁…...
)
从线性方程组角度理解公式 s=n−r(3E−A)
从线性方程组角度理解公式 sn−r(3E−A) 这个公式本质上是 齐次线性方程组解空间维度 的直接体现。下面通过三个关键步骤解释其在线性方程组中的含义: 1. 公式对应的线性方程组 考虑矩阵方程: (3E−A)x0 其中: x 是 n 维未知向量3E−…...

通信算法之280:无人机侦测模块知识框架思维导图
1. 无人机侦测模块知识框架思维导图, 见文末章节。 2. OFDM参数估计,基于循环自相关特性。 3. 无人机其它参数估计...
【Doris基础】Apache Doris中的Coordinator节点作用详解
目录 1 Doris架构概述 2 Coordinator节点的核心作用 2.1 查询协调与调度 2.2 执行计划生成与优化 2.3 资源管理与负载均衡 2.4 容错与故障恢复 3 Coordinator节点的关键实现机制 3.1 两阶段执行模型 3.2 流水线执行引擎 3.3 分布式事务管理 4 Coordinator节点的高可…...

软考 系统架构设计师之考试感悟3
接前一篇文章:软考 系统架构设计师之考试感悟2 上周六(2025年5月24日),本人第三次参加了软考系统架构师的考试。和前两次一样,考了一天,身心俱疲。不过这次感觉比上一次要稍微好点,可能也是考的…...

【Kubernetes-1.30】--containerd部署
文章目录 一、环境准备1.1 三台服务器1.2 基础配置(三台机通用)1.3 关闭 Swap(必须)1.4 关闭防火墙(可选)1.5 加载必要模块 & 配置内核参数 二、安装容器运行时(containerd 推荐)…...

Flutter 嵌套H5 传参数
你可以通过在加载 H5 页面时,将 token 作为 URL 参数拼接,或者通过 WebView 的 JavaScript 通信功能(如 runJavaScript 或 addJavaScriptChannel)传递 token。常用方式如下: 方式一:URL 拼接参数 假设你的…...

什么是线程上下文切换?
导语: 线程上下文切换(Context Switch)是Java并发编程中一个常见但容易被忽视的概念。在高并发场景下,它直接影响系统性能。本文将从面试官角度深入剖析这个话题,帮你理解底层原理、掌握优化思路、规避项目中的常见陷阱…...

Jvm 元空间大小分配原则
JVM元空间(Metaspace)的大小分配原则与系统物理内存密切相关,但并不是直接等比例分配,而是通过一系列参数和JVM的动态管理机制来确定。下面从原理和实际行为两方面详细说明: 1. 元空间(Metaspace࿰…...
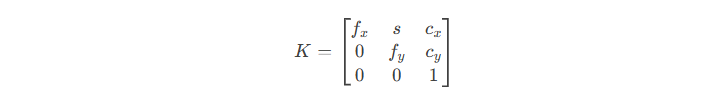
相机--相机标定
教程 内外参公式及讲解 相机标定分类 相机标定分为内参标定和外参标定。 相机成像原理 相机成像畸变 链接 四个坐标系的转变 内参标定 内参 相机内参通常用一个 33 矩阵(内参矩阵,KK)表示,形式如下: (1)焦距&…...

MongoDB(七) - MongoDB副本集安装与配置
文章目录 前言一、下载MongoDB1. 下载MongoDB2. 上传安装包3. 创建相关目录 二、安装配置MongoDB1. 解压MongoDB安装包2. 重命名MongoDB文件夹名称3. 修改配置文件4. 分发MongoDB文件夹5. 配置环境变量6. 启动副本集7. 进入MongoDB客户端8. 初始化副本集8.1 初始化副本集8.2 添…...

131. 分割回文串-两种回溯思路
我们可以将字符串分割成若干回文子串,返回所有可能的方案。如果将问题分解,可以表示为分割长度为n-1的子字符串,这与原问题性质相同,因此可以采用递归方法解决。 为什么回溯与递归存在联系?在解决这个问题时࿰…...
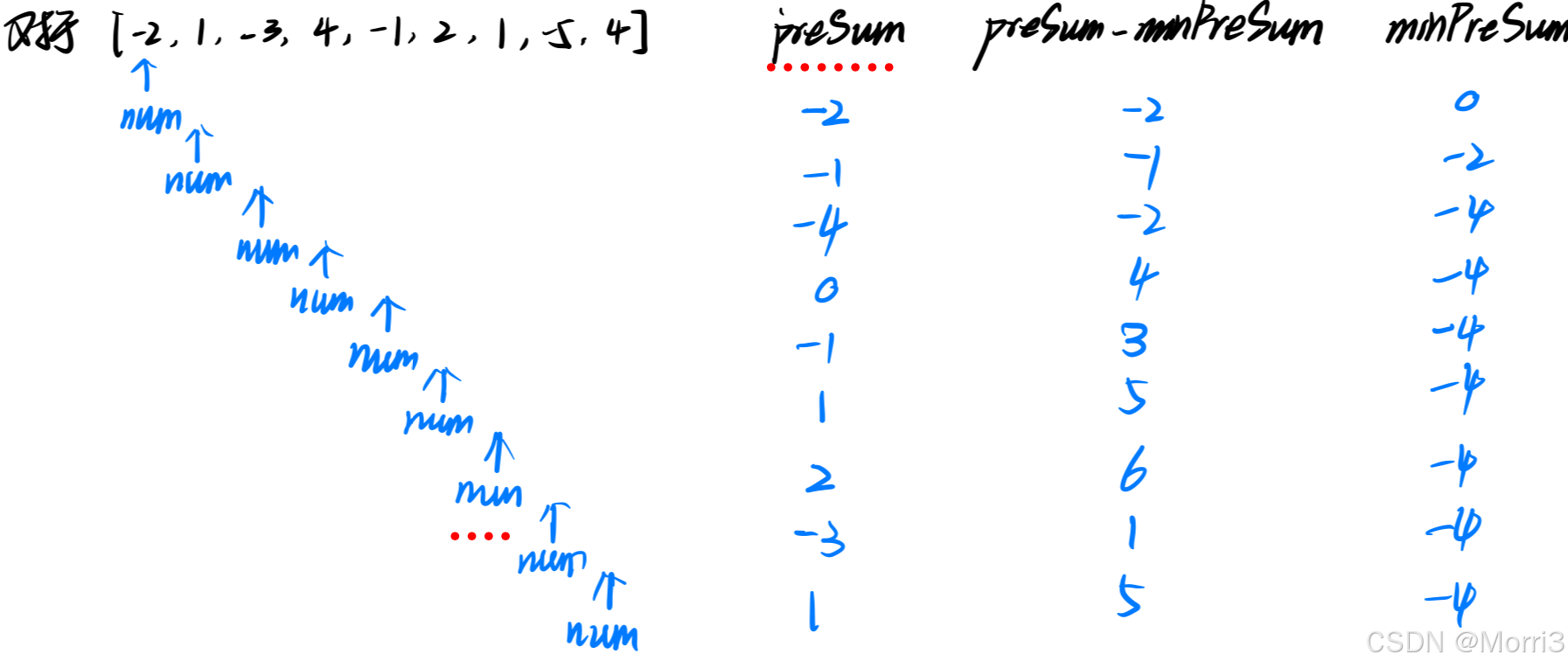
[Java恶补day13] 53. 最大子数组和
休息了一天,开始补上! 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 子数组是数组中的一个连续部分。 示例 1: 输入:nums …...

摩尔投票算法原理实现一文剖析
摩尔投票算法原理&实现一文剖析 一、算法原理1.1 基本思想1.2 数学原理 二、算法实现2.1 Python实现2.2 Java实现2.3 C实现 三、复杂度分析四、应用场景4.1 多数元素问题4.2 扩展应用:寻找出现次数超过n/3的元素 五、算法优势与注意事项5.1 优势5.2 注意事项 总…...

springboot项目下面的单元测试注入的RedisConnectionFactory类redisConnectionFactory值为什么为空呢?
你遇到的问题是: RedisConnectionFactory redisConnectionFactory 在单元测试中为 null 这是 Spring Boot 单元测试中非常常见的问题,根本原因是你的测试类没有启用 Spring 容器上下文,导致 Resource 注解无法注入 Bean。 ✅ 正确做法&…...

MyBatis操作数据库(2)
1.#{}和${}使用 Interger类型的参数可以看到这里显示的语句是:select username,password,age,gender,phone from userinfo where id? 输入的参数并没有在后面进行拼接,,id的值是使用?进行占位,这种sql称之为"预编译sql".这里,把#{}改成${}观察情况:这里可以看到…...

C++面向对象(二)
面向对象基础内容参考: C面向对象(一)-CSDN博客 友元函数 类的友元函数是定义在类外部,但有权访问类的所有私有(private)成员和保护(protected)成员。尽管友元函数的原型有在类的定…...
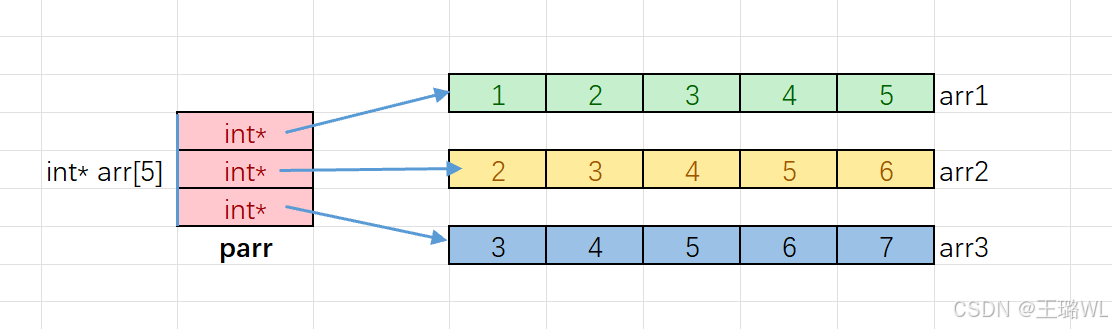
【C语言入门级教学】冒泡排序和指针数组
文章目录 1.冒泡排序2.⼆级指针3.指针数组4.指针数组模拟⼆维数组 1.冒泡排序 冒泡排序的核⼼思想:两两相邻的元素进⾏⽐较。 //⽅法1 void bubble_sort(int arr[], int sz)//参数接收数组元素个数 { int i 0;for(i0; i-1; i) { int j 0; for(j0; j-1; j) { …...

shell脚本中常用的命令
一、设置主机名称 通过文件的方式修改通过命令修改 二、nmcli 查看网卡 ip a s ens160 (网卡名称) ifconfig ens160 nmcli device show ens160 nmcli device status nmcli connection show ens160 2.设置网卡 a)当网卡没有被设置时 b)网卡被设定,需要修改 三…...
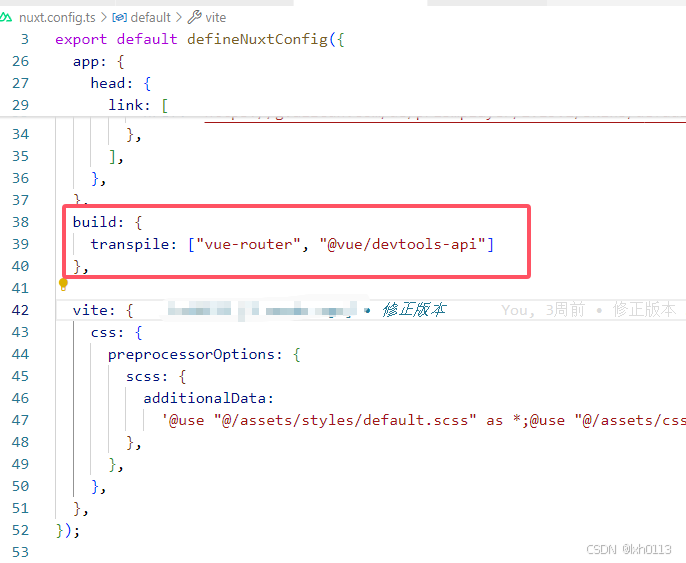
Nuxt3部署
最近接了一个项目,需要用到 nuxt3 技术来满足甲方所要求的需求,在部署的时候遇到了很多问题,这里我一一给大家讲述部署流程,以及所遇到的坑 打包部署 部署分为俩种方式: 静态(spa)部署 和 ssr部署 静态部署 静态部…...

网络攻防技术一:绪论
文章目录 一、网络空间CyberSpace1、定义2、基本四要素 二、网络空间安全1、定义2、保护对象3、安全属性4、作用空间 三、网络攻击1、攻击分类2、攻击过程 四、网络防护1、定义2、安全模型3、安全服务5类4、特定安全机制8种5、普遍性安全机制5种 五、网络安全技术发展简史1、第…...

【人工智能】deepseek七篇论文阅读笔记大纲
七篇文章看了整整五天,加上整理笔记和问ds优化,大致的框架是有了。具体的公式细节比较多,截图也比较麻烦,就不列入大纲去做笔记了。 DeepSeek-LLM:一切的起点,所以探索的东西比较多,包括&#x…...