pyspark实践
1。pyspark是什么
PySpark 是 Apache Spark 的官方 Python 接口,它使得 Python 开发者能够访问 Spark 的核心功能,如:
Spark SQL:用于执行 SQL 查询以及读取数据的库,支持多种数据格式和存储系统。py.qizhen.xyz
DataFrame API:提供了一个分布式数据集合,使得数据处理和分析更加直观和高效。py.qizhen.xyz+1CSDN 博客+1
MLlib:用于进行机器学习的库。py.qizhen.xyz+1维基百科+1
GraphX:用于图形处理的库(在 PySpark 中通过第三方库如 GraphFrames 访问)。py.qizhen.xyz
Spark Streaming:用于实时数据流处理的库。py.qizhen.xyz
通过 PySpark,Python 开发者可以方便地进行大规模数据分析和数据挖掘工作,而无需深入了解分布式计算的复杂性。
2.实战
创建和管理 Spark 会话所需的类from pyspark.sql import SparkSessionimport pyspark.sql.functions as F
#从 pyspark.sql.functions 模块中导入所有函数,并将其简写为 F
from pyspark.sql.types import *
#从 pyspark.sql.types 模块中导入所有的数据类型类。from pyspark.sql.functions import udf
#使用 PySpark 创建和注册用户定义函数的第一步,允许将自定义的 Python 函数应用于 Spark 的数据处理流程中spark = SparkSession.builder.appName('data_processing').getOrCreate()
#创建或获取一个 SparkSession 实例schema = StructType().add('user_id',"string").add("country","string").add("browser","string").add("OS","string").add("age","integer")
#创建的 DataFrame 将具有预定义的列名和数据类型,有助于确保数据一致性和便于后续的数据处理操作df_custom = spark.createDataFrame([("A203",'India',"Chrome","WIN",33),("A201",'China',"Safari","MacOS",35),("A205",'UK',"Mozilla","Linux",25)],schema = schema)
#这行代码使用 PySpark 创建了一个带有指定模式(schema)的 DataFrame。df_custom.printSchema()
#用于以可读的层次结构格式展示 DataFrame 的结构信息。
df_custom.show()
#将 DataFrame 的前几行数据显示在控制台上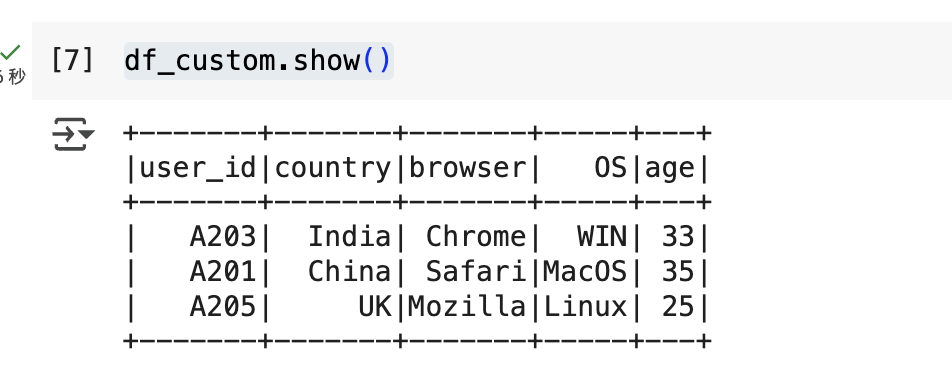
df_na=spark.createDataFrame([("A203",None,"Chrome","WIN",33),("A201",'China',None,"MacOS",35),("A205",'UK',"Mozilla","Linux",25)],schema=schema)
#使用指定的模式(schema)创建一个包含部分缺失值(None)的 DataFrame。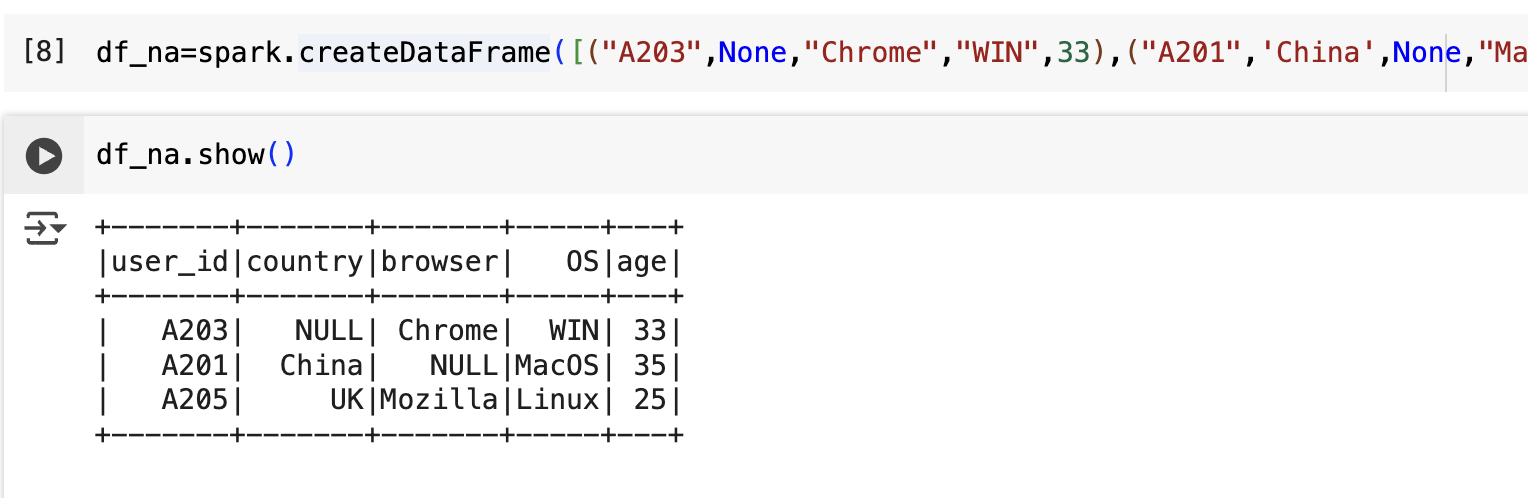
df_na.fillna('0').show()
#将 DataFrame df_na 中所有列的缺失值(null 或 None)替换为字符串 '0',然后以表格形式在控制台上显示前 20 行数据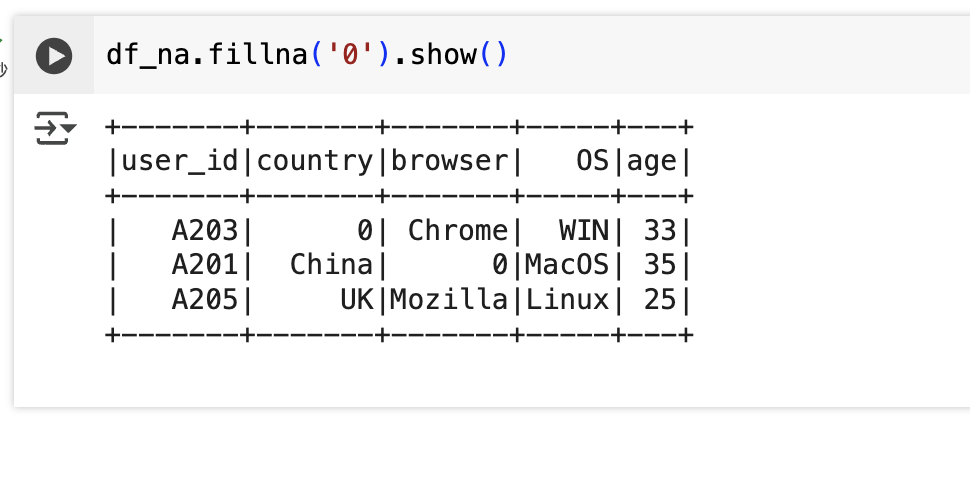
df_na.fillna({'country':'USA','browser':'Google Chrome'}).show()
#使用 fillna() 方法,将 DataFrame df_na 中 country 列的缺失值替换为 'USA',browser 列的缺失值替换为 'Google Chrome'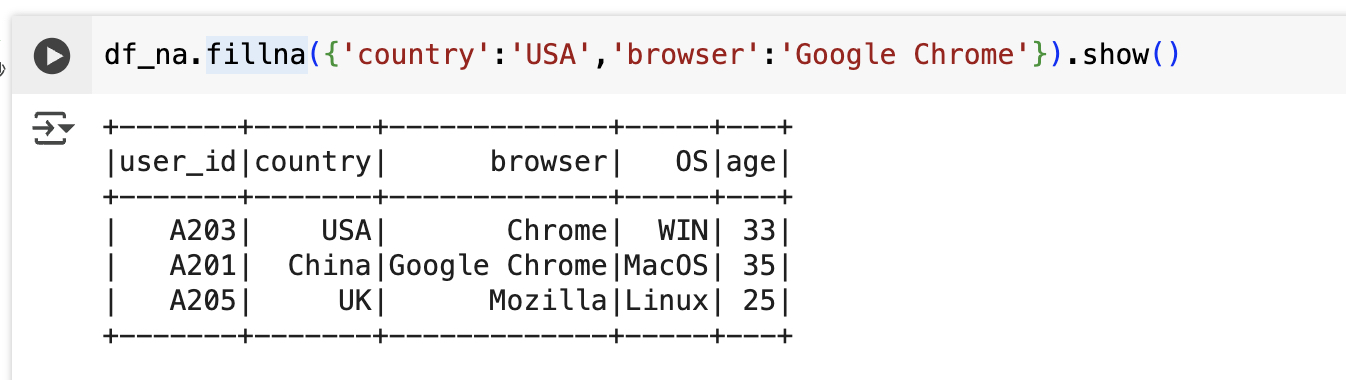
df_na.na.drop().show()
#删除包含缺失值的行:df_na.na.drop() 会从 DataFrame df_na 中删除任何包含 null(或 None)值的行。默认情况下,drop() 方法会移除任何列中存在缺失值的行。df_na.na.drop(subset='country').show()
#删除特定列中包含缺失值的行:df_na.na.drop(subset='country') 会从 DataFrame df_na 中删除 country 列中包含 null 或 None 值的行。对csv文件进行处理
df = spark.read.csv("customer_data.csv",header = True, inferSchema=True)
#读取名为 customer_data.csv 的 CSV 文件,并将其加载为 DataFramedf.count()
查看数量
len(df.columns)
#查看列数df.columns
#查看列名df.filter(df['Avg_Salary']>500000).filter(df['Number_of_houses']>2).show()
#筛选df.where((df['Avg_Salary']>500000)&(df['Number_of_houses']>2)).show()
#where() 是 PySpark DataFrame 的方法,用于根据指定的条件筛选行。它是 filter() 方法的别名,两者功能相同df.groupBy('Customer_subtype').count().show()
#按客户子类型分组并统计每组数量的常用方法,有助于了解不同客户子类型的分布情况。for col in df.columns:if col!='Avg_Salary':print(f" Aggregation for {col}")df.groupBy(col).count().orderBy('count',ascending=False).show(truncate=False)
#对 DataFrame df 中除 'Avg_Salary' 列以外的每一列进行分组计数,并按计数降序显示结果。df.groupBy('Customer_main_type').agg(F.mean('Avg_Salary')).show()
#对 DataFrame df 按照 Customer_main_type 列进行分组,并计算每个主类型的平均薪资:df.groupBy('Customer_main_type').agg(F.max('Avg_Salary')).orderBy('max(Avg_Salary)',ascending=False).show()
#用于对 DataFrame df 按照 Customer_main_type 列进行分组,并计算每个主类型的最高平均薪资,然后按降序排列结果df.groupBy('Customer_subtype').agg(F.max('Avg_Salary').alias('max_salary')).orderBy('max_salary',ascending=False).show()
#在 PySpark 中,以下代码用于对 DataFrame df 按照 Customer_subtype 列进行分组,并计算每个子类型的最高平均薪资,然后按降序排列结果df.groupBy("Customer_subtype").agg(F.collect_set("Number_of_houses")).show()
#是在 PySpark 中用于按客户子类型分组并收集每组房屋数量的唯一值的常用方法,有助于了解不同客户子类型的房屋数量分布情况。1. 初始化与数据创建
使用
SparkSession.builder.getOrCreate()初始化 Spark 环境。使用
StructType明确定义 schema。用
spark.createDataFrame()构造了两个 DataFrame(一个有缺失值)。2. DataFrame 基本操作
.printSchema():打印 schema 信息。
.show():展示数据内容。
.fillna():填充缺失值。
.na.drop()/.na.drop(subset=...):删除缺失值行。
.replace():替换字段值。
.drop():删除某一列。3. CSV 文件读取
spark.read.csv(..., header=True, inferSchema=True)读取并自动推断数据类型。4. 基础探索与过滤
.count()/len(df.columns)/df.columns:了解数据结构。
.summary().show():生成描述性统计。
.filter()/.where():条件筛选数据。
.select():选择列。5. 分组与聚合操作
.groupBy(...).count():分组计数。
.groupBy(...).agg(F.mean(...)):分组平均值。
.groupBy(...).agg(F.max(...)):分组最大值。
.agg(F.collect_set(...)):收集唯一值列表。
.orderBy(...):排序显示。6. 列操作
.withColumn("new_col", F.lit(...)):添加常量列。
.withColumn("new_col", udf(col)):使用自定义 UDF 添加新列。7. UDF / Pandas UDF
使用标准
udf()创建 age 分类函数。使用
pandas_udf()实现归一化薪资计算(注释掉了实际调用)。
相关文章:
pyspark实践
1。pyspark是什么 PySpark 是 Apache Spark 的官方 Python 接口,它使得 Python 开发者能够访问 Spark 的核心功能,如: Spark SQL:用于执行 SQL 查询以及读取数据的库,支持多种数据格式和存储系统。py.qizhen.xyz Data…...

内网怎么映射外网ip? 内网的地址快速映射给外网访问用方法
本文章向大家介绍内网怎么映射外网ip,主要包括如何将内网 IP 端口的网络服务映射到外网使用实例、应用技巧、基本知识点总结和需要注意事项,具有一定的参考价值,需要的朋友可以参考一下。内容主要包括路由映射公网IP和无公网IP通过nat123映射…...

【深度学习新浪潮】多模态模型如何处理任意分辨率输入?
多模态模型处理任意分辨率输入的能力主要依赖于架构设计的灵活性和预处理技术的结合。以下是核心方法及技术细节: 一、图像模态的分辨率处理 1. 基于Transformer的可变补丁划分(ViT架构) 补丁化(Patch Embedding): 将图像分割为固定大小的补丁(如1616或3232像素),不…...

ZYNQ移植FreeRTOS和固化和openAMP双核
想象一下:一颗拥有“双脑”的ZYNQ芯片,左脑运行Linux处理复杂网络协议,右脑运行FreeRTOS以微秒级精度控制电机,双脑通过“量子纠缠”般的技术实时对话——这就是OpenAMP框架创造的工程奇迹!今天,我们将揭开这项技术的神秘面纱,带你从零构建一个双核异构的智能系统。 🧠…...

K-匿名模型
K-匿名模型是隐私保护领域的一项基础技术,防止通过链接攻击从公开数据中重新识别特定个体。其核心思想是让每个个体在发布的数据中“隐匿于人群”,确保任意一条记录至少与其他K-1条记录在准标识符(Quasi-Identifiers, QIDs)上不可…...
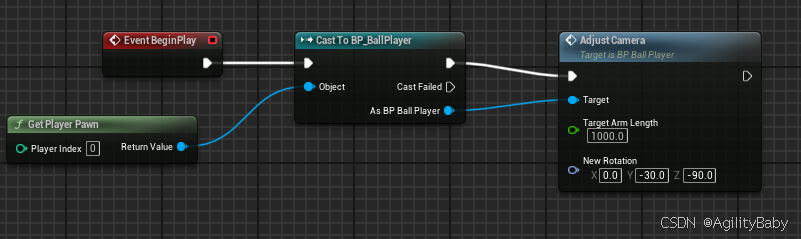
UE5蓝图暴露变量,在游戏运行时修改变量实时变化、看向目标跟随目标Find Look at Rotation、修改玩家自身弹簧臂
UE5蓝图中暴露变量,类似Unity中public一个变量,在游戏运行时修改变量实时变化 1,添加变量 2,设置变量的值 3,点开小眼睛,此变量显示在编辑器中,可以运行时修改 看向目标跟随目标Find Look at R…...

C语言进阶知识:深入探索编程的奥秘
一、指针:C语言的灵魂 指针是C语言中最核心的概念之一,它为程序员提供了对内存的直接操作能力。指针变量存储的是一个地址,通过这个地址可以访问和修改内存中的数据。 (一)指针的基本操作 指针的声明 指针的声明格式…...

机器视觉2D定位引导一般步骤
机器视觉的2D定位引导是工业自动化中的核心应用,主要用于精确确定目标物体的位置(X, Y坐标)和角度(旋转角度θ),并引导机器人或运动机构进行抓取、装配、对位、检测等操作。其一般步骤可概括如下: 一、系统规划与硬件选型 明确需求: 定位精度要求(多少毫米/像素,多少…...
Python-matplotlib中的Pyplot API和面向对象 API
matplotlib中的Pyplot API和面向对象 API Pyplot API(状态机模式)面向对象 API 详解二者差别核心区别方法命名差异注意事项差别举例 🍅 Pyplot API(状态机模式)和面向对象 API 是两种不同的编程接口.🍅 它们…...

FastAPI安全认证:从密码到令牌的魔法之旅
title: FastAPI安全认证:从密码到令牌的魔法之旅 date: 2025/06/02 13:24:43 updated: 2025/06/02 13:24:43 author: cmdragon excerpt: 在FastAPI中实现OAuth2密码流程的认证机制。通过创建令牌端点,用户可以使用用户名和密码获取JWT访问令牌。代码示例展示了如何使用Cry…...

人工智能时代教师角色的重塑与应对策略研究:从理论到实践的转型
一、引言 1.1 研究背景 近年来,人工智能技术迅猛发展,已经逐渐渗透到社会的各个领域,对人类的生产、生活和学习方式产生了深远影响。作为社会发展的重要组成部分,教育领域也不可避免地受到人工智能的冲击,正经历着前…...
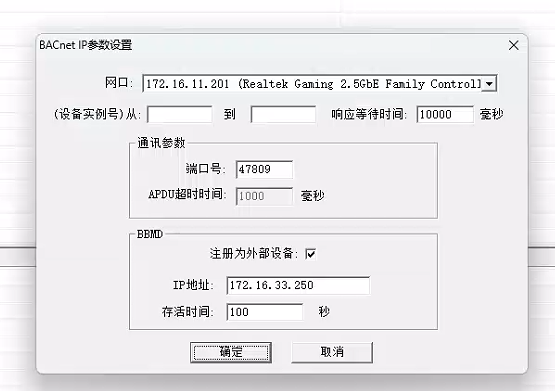
java对接bacnet ip协议(跨网段方式)
1、环境准备 #maven环境<repositories><repository><id>ias-releases</id><url>https://maven.mangoautomation.net/repository/ias-release/</url></repository></repositories><dependencies><dependency><…...
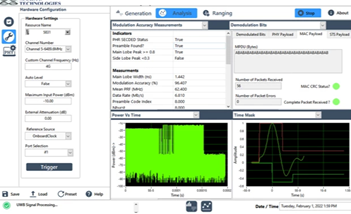
LabVIEW超宽带紧凑场测量系统
采用 LabVIEW 开发超宽带紧凑场测量系统,实现天线方向图、目标雷达散射截面(RCS)及天线增益的自动化测量。通过品牌硬件设备,优化系统架构,解决传统测量系统在兼容性、数据处理效率及操作便捷性等方面的问题࿰…...
编译rustdesk,使用flutter、hwcodec硬件编解码、支持Windows 7系统
目录 安装相应的环境安装visual studio安装vpkg安装rust开发环境安装llvm和clang编译源码下载源码使用Sciter作为UI的(已弃用)使用flutter作为UI的(主流)下载flutter sdk桥接静默安装支持Windows 7系统最近某desk免费的限制越来越多,实在没办法,平时远程控制用的比较多,…...
ROS机器人和NPU的往事和新知-250602
往事: 回顾一篇五年前的博客: ROS2机器人笔记20-12-04_ros2 移植到vxworks-CSDN博客 里面提及专用的机器人处理器,那时候只有那么1-2款专用机器人处理器。 无关: 01: 每代人的智商和注意力差异是如何出现的-250602-…...

【从零开始学习QT】信号和槽
目录 一、信号和槽概述 信号的本质 槽的本质 二、信号和槽的使用 2.1 连接信号和槽 2.2 查看内置信号和槽 2.3 通过 Qt Creator 生成信号槽代码 自定义槽函数 自定义信号 自定义信号和槽 2.4 带参数的信号和槽 三、信号与槽的连接方式 3.1 一对一 (1&…...
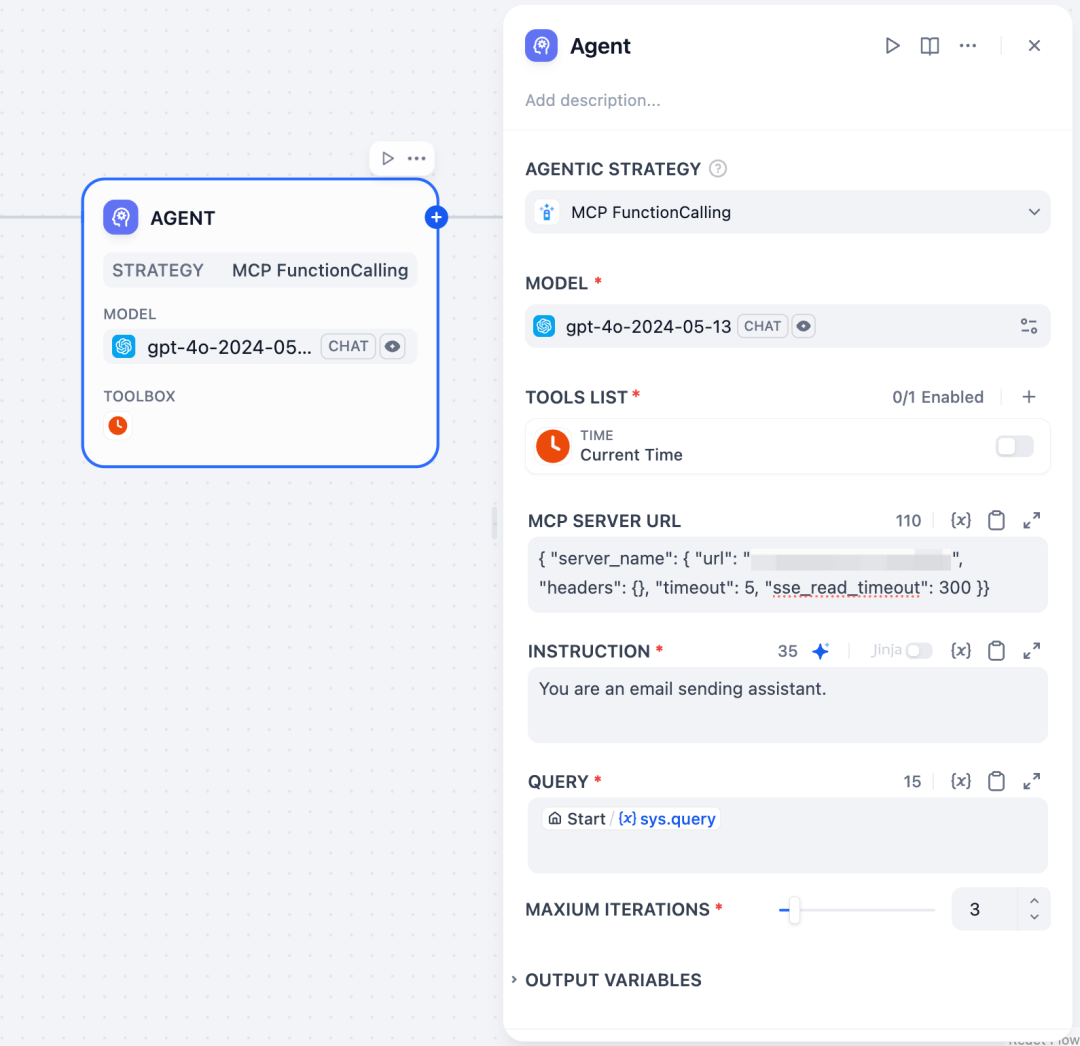
MCP调研
什么是 MCP MCP(Model Context Protocol,模型上下文协议),是由 Anthropic 在 2024 年 11 月底推出的开放标准协议,旨在统一大型语言模型(LLM)与外部数据源、工具的通信方式。MCP 的主要目的在于…...

TDengine 运维——巡检工具(定期检查)
背景 TDengine 在运行一段时间后需要针对运行环境和 TDengine 本身的运行状态进行定期巡检,本文档旨在说明如何使用巡检工具对 TDengine 的运行环境进行自动化检查。 安装工具使用方法 工具支持通过 help 参数查看支持的语法 Usage: taosinspect [OPTIONS]Check…...

8.7 基于EAP-AKA的订阅转移
8.7 基于EAP-AKA的订阅转移 以下场景描述如下情况: • 主ODSA设备应用程序被允许用于该类型主设备,且已获得服务提供商(SP)授权。 • 终端用户在存有活跃订阅的旧主设备上发起订阅转移请求,且可访问eSIM数据。 • 由于…...
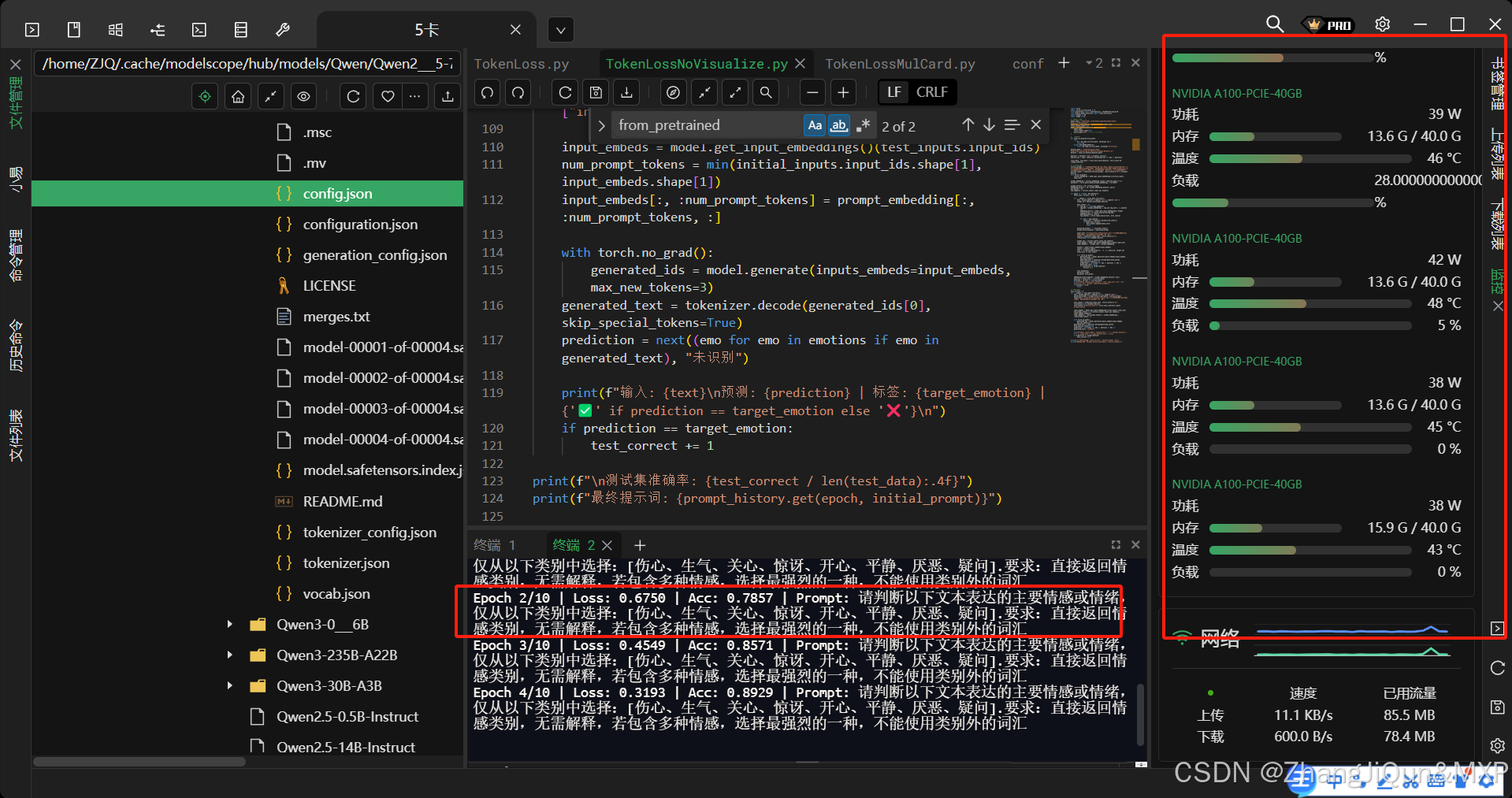
qwen 2.5 并行计算机制:依靠 PyTorch 和 Transformers 库的分布式能力
qwen 2.5 并行计算机制:依靠 PyTorch 和 Transformers 库的分布式能力 完整可运行代码: import torch import torch.nn.functional as F from transformers...

调整数据集的方法
我们对worldquant中的数据, 对数据频率怎么算 在 WorldQuant 平台中,数据更新频率是影响量化策略有效性、回测准确性和实盘交易表现的核心因素之一。它决定了数据的时效性和连续性,直接关系到策略能否捕捉市场动态、应对突发事件或适应不同…...

TCP 四次挥手
引言:优雅的告别 在网络通信中,建立连接需要三次握手,而终止连接则需要四次挥手。这种设计体现了 TCP 协议的可靠性和完整性原则。本文将用通俗易懂的方式,深入解析四次挥手的原理、状态转换和实际应用,帮助您掌握这一…...
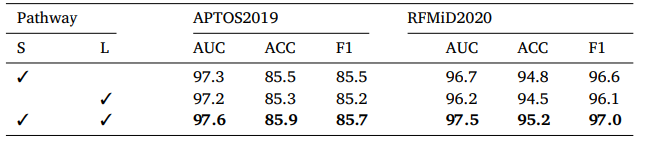
MSTNet:用于糖尿病视网膜病变分类的多尺度空间感知 Transformer 与多实例学习方法|文献速递-深度学习医疗AI最新文献
Title 题目 MSTNet: Multi-scale spatial-aware transformer with multi-instance learning for diabetic retinopathy classification MSTNet:用于糖尿病视网膜病变分类的多尺度空间感知 Transformer 与多实例学习方法 01 文献速递介绍 糖尿病视网膜病变&#…...
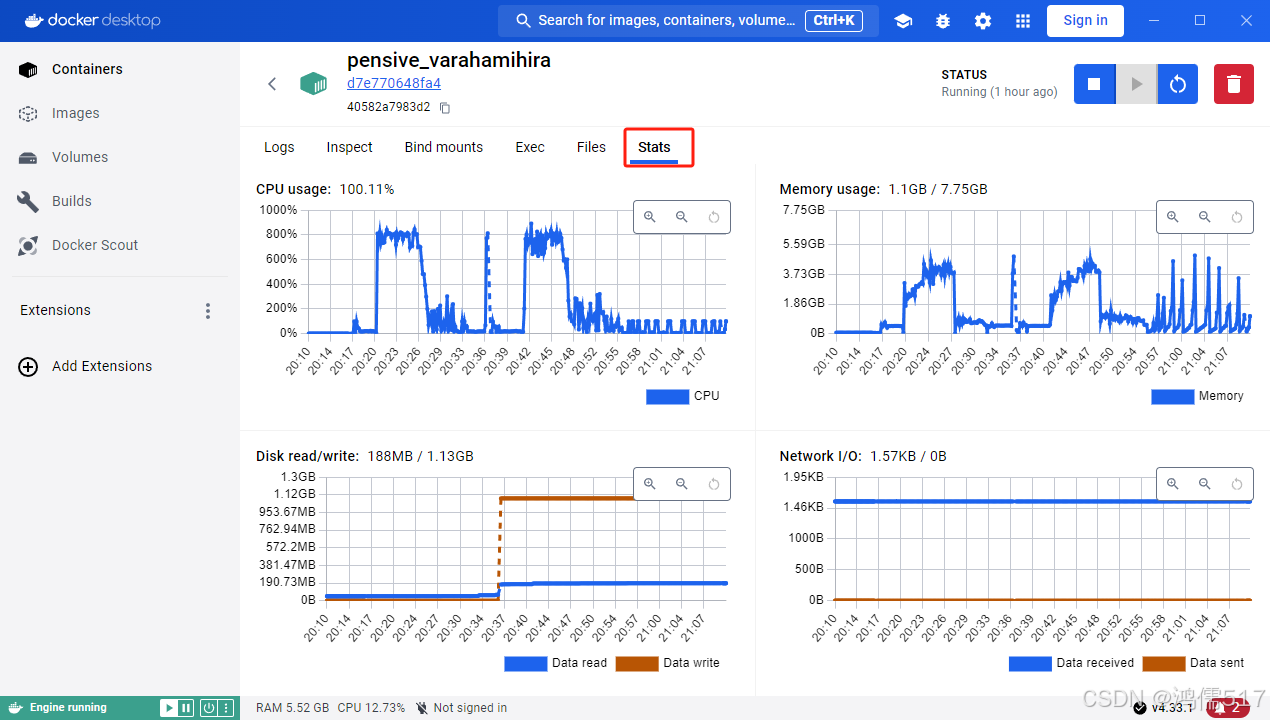
docker运行程序Killed异常排查
问题描述 我最近开发了一个C 多线程程序,测试没有问题,封装docker测试也没有问题,然后提交给客户了,然后在他那边测试有问题,不定时、不定位置异常中断,以前一直认为只要封装了docker就万事大吉࿰…...

【数学 逆序对 构造】P12386 [蓝桥杯 2023 省 Python B] 混乱的数组|普及+
本文涉及知识点 数学 构造 P12386 [蓝桥杯 2023 省 Python B] 混乱的数组 题目描述 给定一个正整数 x x x,请找出一个尽可能短的仅含正整数的数组 A A A 使得 A A A 中恰好有 x x x 对 i , j i, j i,j 满足 i < j i < j i<j 且 A i > A j A_…...
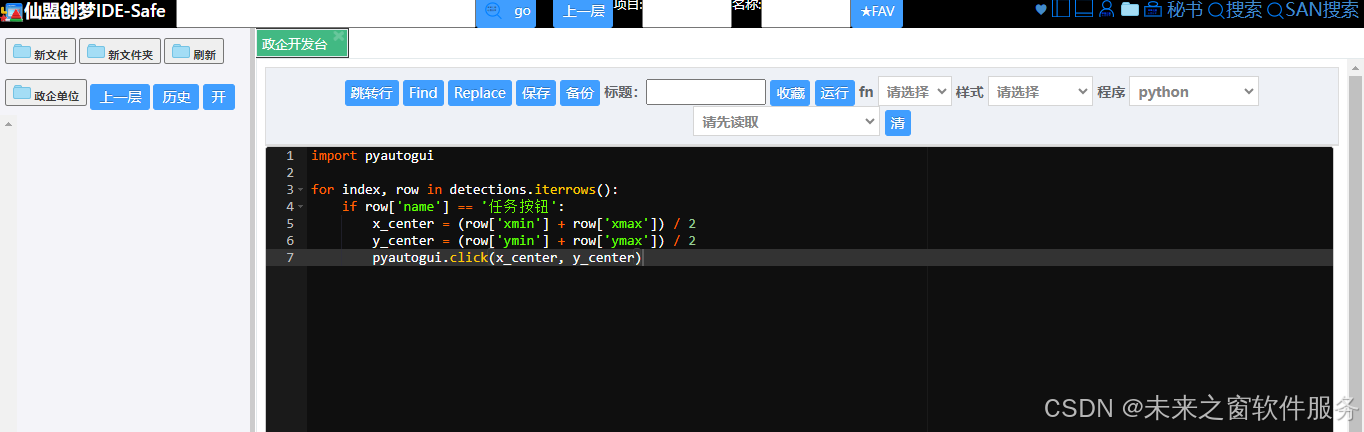
Excel 批量下载PDF、批量下载考勤图片——仙盟创梦IDE
在办公场景中,借助应用软件实现 Excel 批量处理考勤图片、电子文档与 PDF,具有诸多显著优势。 从考勤图片处理来看,通过 Excel 批量操作,能快速提取图片中的考勤信息,如员工打卡时间、面部识别数据等,节省…...
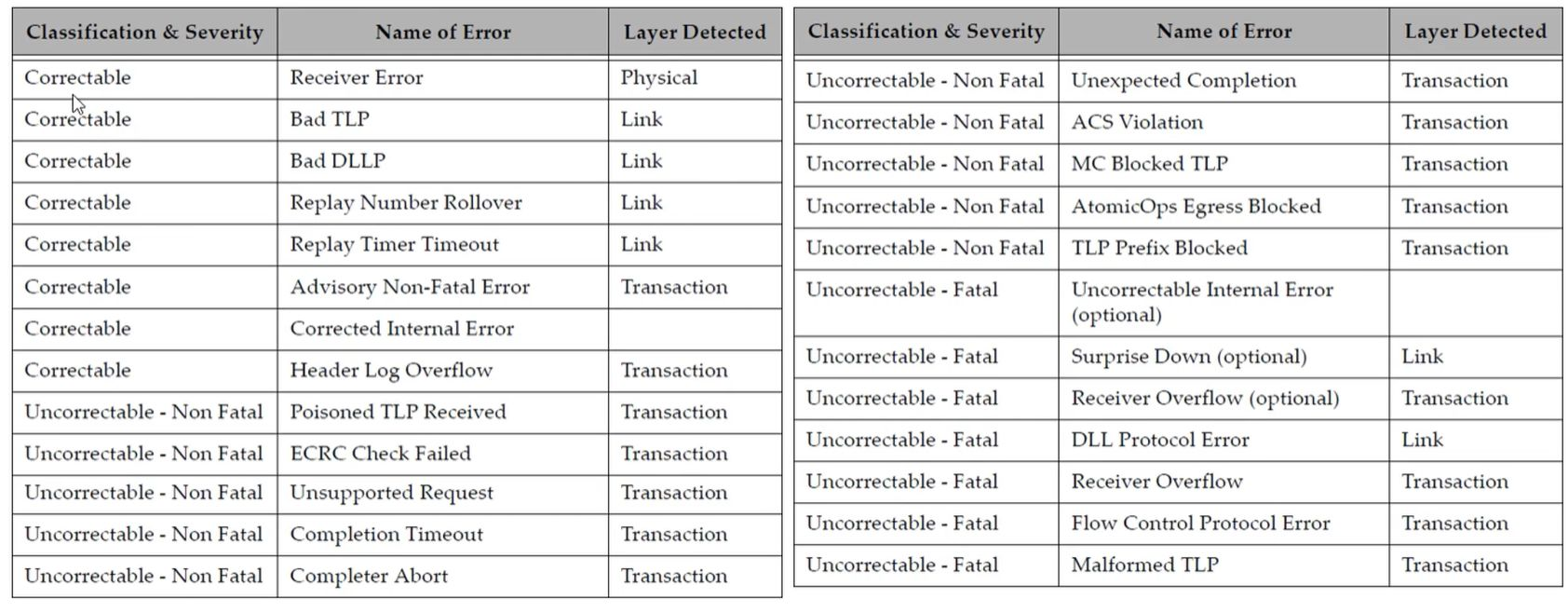
PCIe-Error Detection(一)
下表为PCIe协议中给出的错误: 一、可纠正错误(Correctable Errors,8种) 检错机制 错误名称检测层级触发条件Receiver ErrorPhysical接收端均衡器(EQ)监测到…...
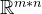
向量空间的练习题目
1.考虑 中的向量x1 和x2 求每一向量的长度 令x3x1x2,求x3的长度,它的长度与x1和x2的和有什么关系? 2.重复练习1,取向量 3.令C为复数集合,定义C上的加法为 (abi)(cdi)(ac)(bd)i 并定义标量乘法为对所有实数a (abi) a bi 证明&…...
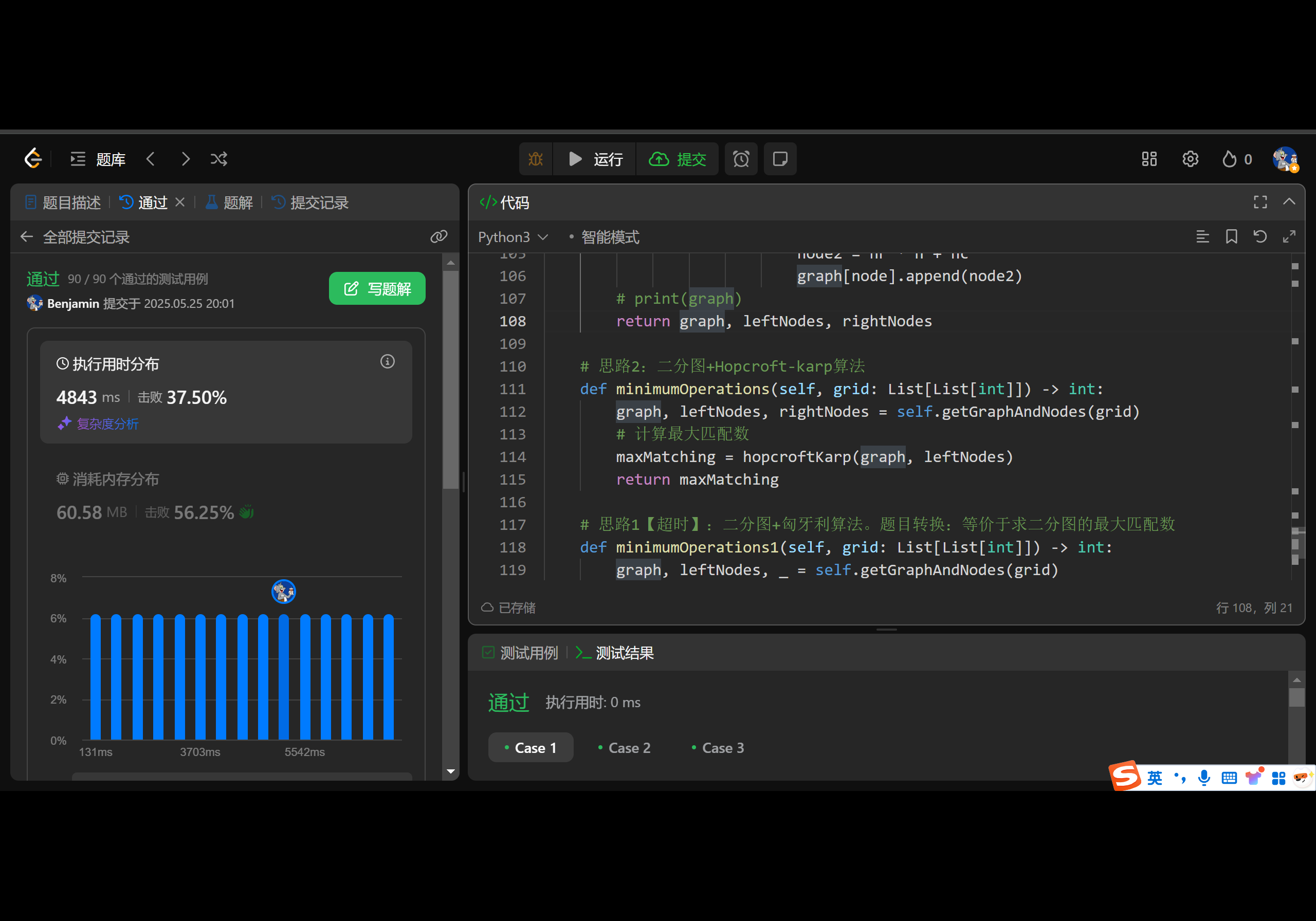
Leetcode 2123. 使矩阵中的 1 互不相邻的最小操作数
1.题目基本信息 1.1.题目描述 给你一个 下标从 0 开始 的矩阵 grid。每次操作,你可以把 grid 中的 一个 1 变成 0 。 如果一个矩阵中,没有 1 与其它的 1 四连通(也就是说所有 1 在上下左右四个方向上不能与其他 1 相邻)&#x…...
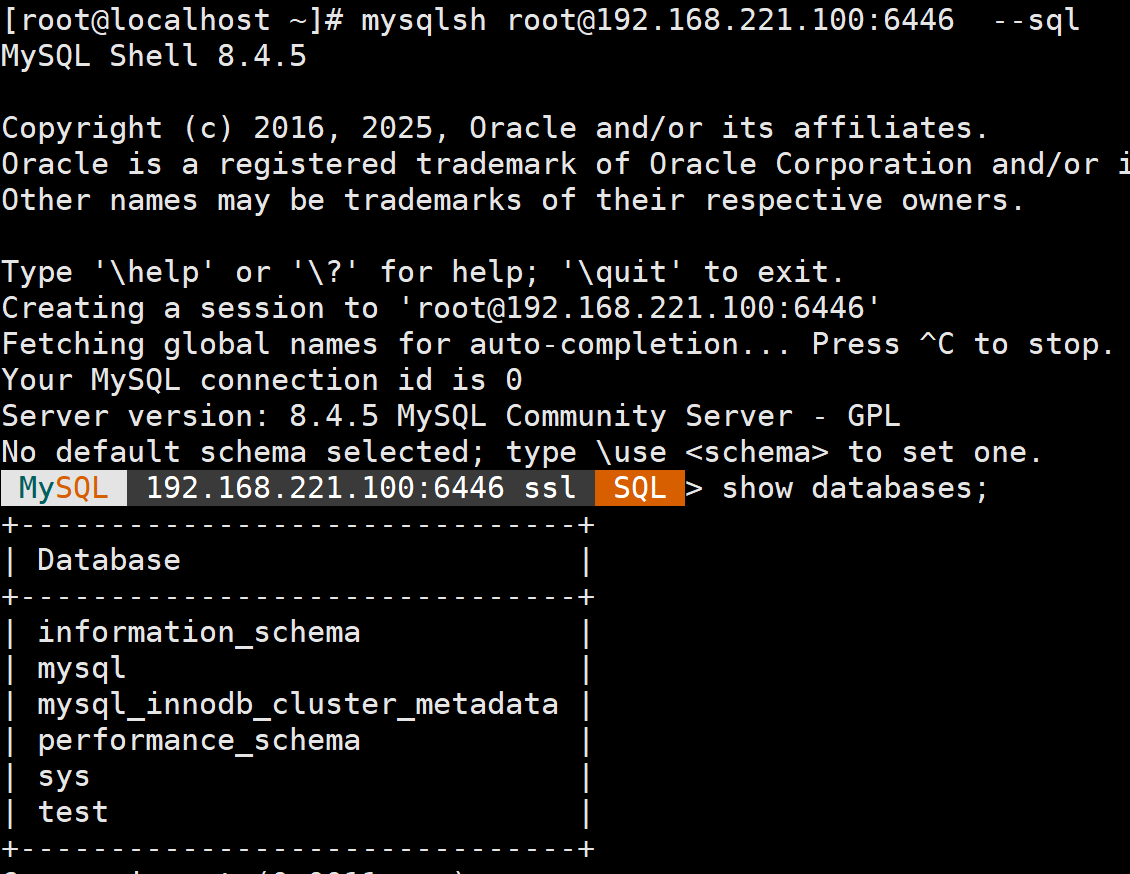
MySQL高可用集群
https://dev.mysql.com/doc/mysql-shell/8.4/en/mysql-innodb-cluster.html 1 什么是MySQL高可用集群 MySQL高可用集群:MySQL InnoDB ClusterInnoDB Cluster是MySQL官方实现高可用读写分离的架构方案,包含以下组件 MySQL Group Replication:简…...