PyTorch 入门学习笔记
一、简介
PyTorch 是由 Meta(原 Facebook) 开源的深度学习框架。其前身 Torch 是一个基于 LuaJIT 的科学计算框架,核心功能是提供高效的张量(Tensor)操作和神经网络支持。由于 Lua 语言的生态限制,Torch 逐渐被 Google 的 TensorFlow 等框架取代。2016年,Meta 的 AI 研究团队基于 Torch 的核心设计理念,使用 Python 重构了动态计算图架构,并创新性地实现了自动微分系统(Autograd),最终发布了 PyTorch。如今 PyTorch 已成为最主流的 AI 框架之一。
二、安装
1 首先,确保已安装 python 和 pip,并且版本满足 PyTorch 的要求。最新版本的 PyTorch 需要 Python 3.9 及更高版本。
python --version pip --version2 使用 pip 安装 pytorch:
pip3 install torch torchvision
3 测试是否安装成功,将这段代码存储到 test.py 文件里,在终端运行 python3 test.py 查看是否正常运行并输出内容。
import torchprint("PyTorch version:", torch.__version__)
x = torch.rand(5, 3)
print("Random tensor:", x)三、概念
1 张量(Tensor)
PyTorch 中的核心数据结构,用于存储和操作多维数组。在 PyTorch 中,张量的概念类似于 NumPy 中的数组,但是 PyTorch 的张量可以运行在不同的设备上,比如 CPU 和 GPU,这使得它们非常适合于进行大规模并行计算,特别是在深度学习领域。
- 维度(Dimensionality)指数据的多维数组结构。例如,一个标量(0维张量)是一个单独的数字,一个向量(1维张量)是一个一维数组,一个矩阵(2维张量)是一个二维数组,以此类推。
- 形状(Shape)指每个维度上的大小。例如,一个形状为(3, 4)的张量意味着它有3行4列。
- 数据类型(Dtype)定义了存储每个元素所需的内存大小和解释方式。PyTorch 支持多种数据类型,包括整数型(如torch.int8、torch.int32)、浮点型(如torch.float32、torch.float64)和布尔型(torch.bool)。
import torch# 创建一个2x3的全0张量
a = torch.zeros(2, 3)
print(a)# 创建一个2x3的全1张量
b = torch.ones(2, 3)
print(b)# 创建一个2x3的随机数张量
c = torch.randn(2, 3)
print(c)# 从 NumPy 数组创建张量
import numpy as np
numpy_array = np.array([[1, 2], [3, 4]])
tensor_from_numpy = torch.from_numpy(numpy_array)
print(tensor_from_numpy)# 在指定设备(CPU/GPU)上创建张量
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
d = torch.randn(2, 3, device=device) print(d)输出结果:

再通俗一点的理解:

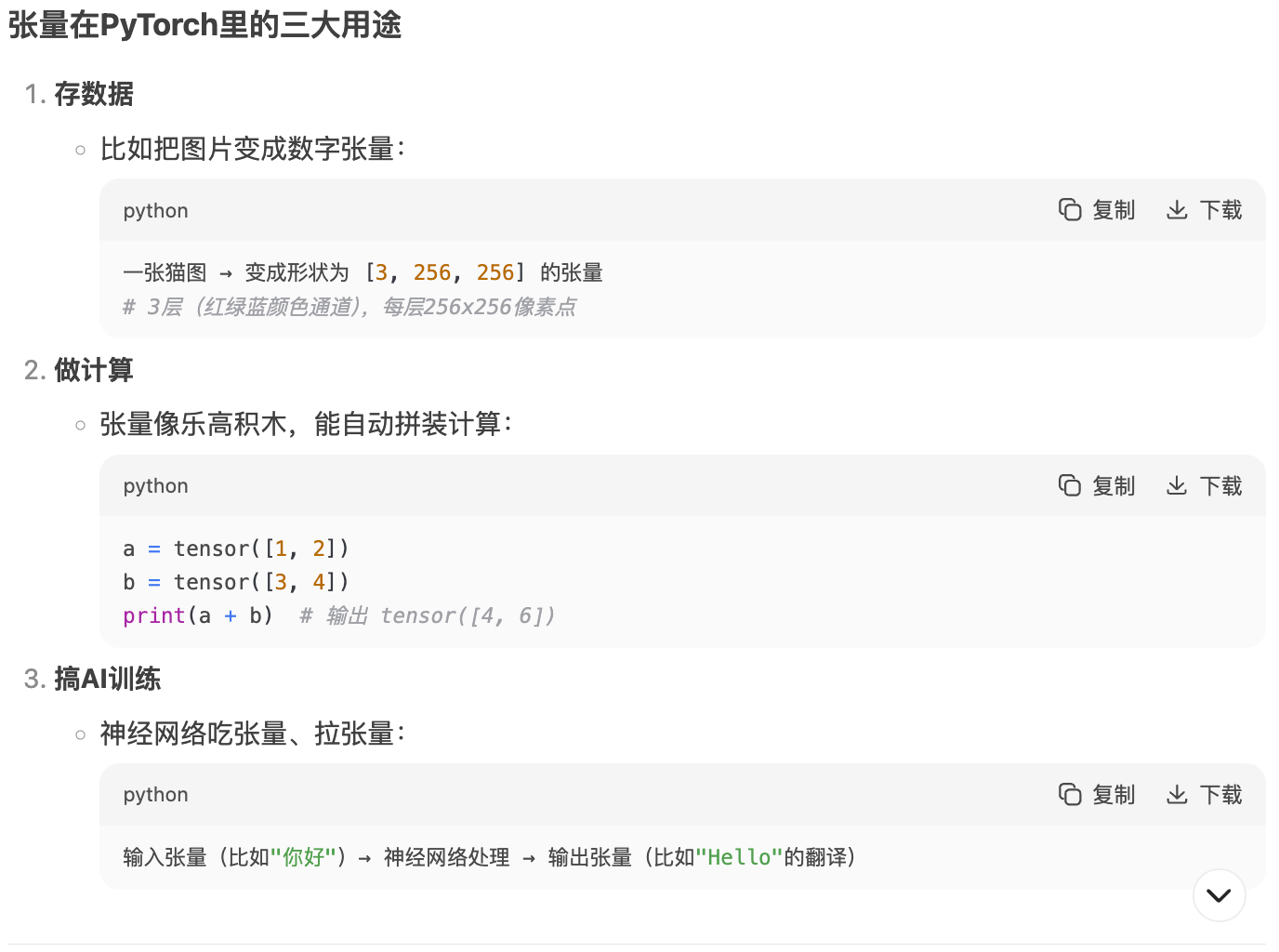

2 梯度和自动微分

import torch# 创建一个需要梯度的张量
# requires_grad=True 表示需要自动计算该张量的梯度(类似"请跟踪我的变化"标签)
x = torch.tensor([1.0], requires_grad=True)# 定义计算图:y = (x + 2)^2
# PyTorch 会自动跟踪所有涉及 x 的操作(相当于用荧光笔标记计算路径)
y = (x + 2) ** 2# 反向传播计算梯度
# 对于标量 y,不需要传入梯度参数(默认为1.0)
# 计算过程:dy/dx = 2*(x+2),当 x=1 时,dy/dx=2*(1+2)=6
y.backward()# 输出 x 的梯度,注意 x.grad 会累积梯度,重复计算时需要清零
print(x.grad) # 输出:tensor([6.])对于梯度的理解,可参考下面两个例子:
- 梯度=8 表示:「增大x会使y剧烈上升」
- 梯度=0.01 表示:「x对y几乎没影响」
3 自动求导(Autograd)
PyTorch 提供了自动求导功能,通过 autograd 模块来自动计算梯度。
在深度学习中,自动求导主要用于两个方面:一是在训练神经网络时计算梯度,二是进行反向传播算法的实现。
自动求导基于链式法则(Chain Rule),这是一个用于计算复杂函数导数的数学法则。链式法则表明,复合函数的导数是其各个组成部分导数的乘积。在深度学习中,模型通常是由许多层组成的复杂函数,自动求导能够高效地计算这些层的梯度。
自动求导和自动微分实际上是同一个概念的不同表述。自动求导是自动微分的一种实现方式,用于计算梯度,从而支持反向传播和模型参数的更新。
动态图与静态图:动态图(Dynamic Graph):在动态图中,计算图在运行时动态构建。每次执行操作时,计算图都会更新,这使得调试和修改模型变得更加容易。PyTorch 使用的是动态图。静态图(Static Graph):在静态图中,计算图在开始执行之前构建完成,并且不会改变。TensorFlow 最初使用的是静态图,但后来也支持动态图。
反向传播(Backpropagation):一旦定义了计算图,可以通过 .backward() 方法来计算梯度。
如果你不希望某些张量的梯度被计算(例如,当你不需要反向传播时),可以使用 torch.no_grad() 或设置 requires_grad=False。
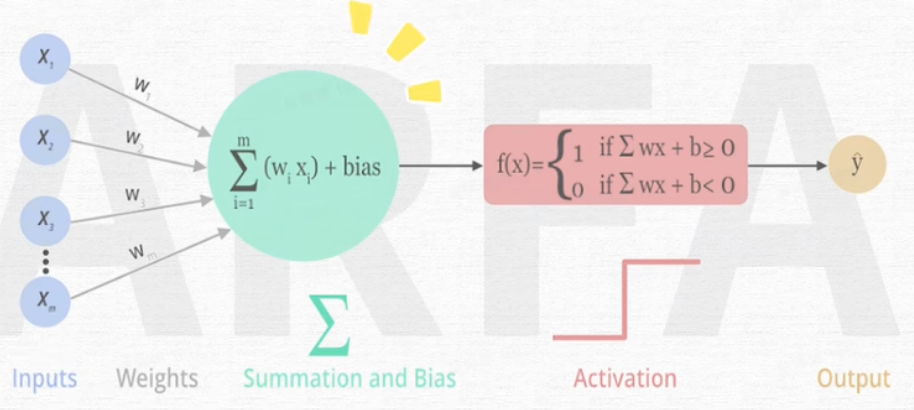
4 神经网络(nn.Module)
神经网络是一种模仿人脑神经元连接的计算模型,由多层节点(神经元)组成,用于学习数据之间的复杂模式和关系。神经网络通过调整神经元之间的连接权重来优化预测结果,这一过程涉及前向传播、损失计算、反向传播和参数更新。神经网络的类型包括前馈神经网络、卷积神经网络(CNN)、循环神经网络(RNN)和长短期记忆网络(LSTM),它们在图像识别、语音处理、自然语言处理等多个领域都有广泛应用。
PyTorch 提供了一个非常方便的接口来构建神经网络模型,即 torch.nn.Module。
我们可以继承 nn.Module 类并定义自己的网络层。
创建一个简单的神经网络:
import torch.nn as nn
import torch.optim as optim# 定义一个简单的全连接神经网络
class SimpleNN(nn.Module):def __init__(self):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(2, 2) # 输入层到隐藏层self.fc2 = nn.Linear(2, 1) # 隐藏层到输出层def forward(self, x):x = torch.relu(self.fc1(x)) # ReLU 激活函数x = self.fc2(x)return x# 创建网络实例
model = SimpleNN()# 打印模型结构
print(model)训练过程
1)前向传播(Forward Propagation): 在前向传播阶段,输入数据通过网络层传递,每层应用权重和激活函数,直到产生输出。
2)计算损失(Calculate Loss): 根据网络的输出和真实标签,计算损失函数的值。
3)反向传播(Backpropagation): 反向传播利用自动求导技术计算损失函数关于每个参数的梯度。
4)参数更新(Parameter Update): 使用优化器根据梯度更新网络的权重和偏置。
5)迭代(Iteration): 重复上述过程,直到模型在训练数据上的性能达到满意的水平。
总体:
Pythorch 解题思路(五步解题法):准备数据、定义模型、训练模型、评估模型、做出预测。
关于训练集和测试集,可以这样通俗地理解:

代码实例:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset# 创建一些随机数据作为示例
inputs = torch.randn(100, 10) # 100个样本,每个样本10个特征
labels = torch.randint(0, 2, (100,)) # 100个样本的标签,0或1# 创建数据集和数据加载器
dataset = TensorDataset(inputs, labels)
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)# 定义一个简单的神经网络
class SimpleNN(nn.Module):def __init__(self):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(10, 50) # 输入层到隐藏层self.fc2 = nn.Linear(50, 2) # 隐藏层到输出层def forward(self, x):x = torch.relu(self.fc1(x)) # 激活函数x = self.fc2(x)return x# 实例化模型、定义损失函数和优化器
model = SimpleNN()
criterion = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降# 训练模型
num_epochs = 10
for epoch in range(num_epochs):model.train() # 设置模型为训练模式running_loss = 0.0for inputs, labels in dataloader:optimizer.zero_grad() # 清空梯度outputs = model(inputs) # 前向传播loss = criterion(outputs, labels) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数running_loss += loss.item()print(f"Epoch {epoch+1}, Loss: {running_loss/len(dataloader)}")# 评估模型(这里简单使用训练数据作为示例)
model.eval() # 设置模型为评估模式
correct = 0
total = 0
with torch.no_grad(): # 禁用梯度计算for inputs, labels in dataloader:outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()
print(f"Accuracy: {100 * correct / total}%")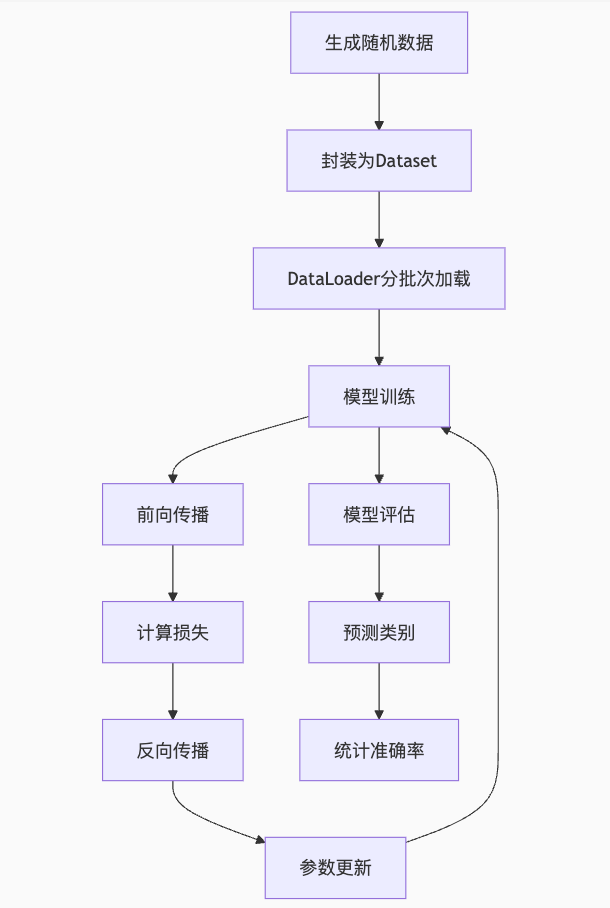
关于向前传播和向后传播的通俗理解:



(持续更新……)
相关文章:
PyTorch 入门学习笔记
一、简介 PyTorch 是由 Meta(原 Facebook) 开源的深度学习框架。其前身 Torch 是一个基于 LuaJIT 的科学计算框架,核心功能是提供高效的张量(Tensor)操作和神经网络支持。由于 Lua 语言的生态限制,Torch 逐…...

【 Samba】Windows 用户访问Docker服务器上当前A用户的 ~/aaa目录
要让 Windows 用户访问 ~/aaa目录,需要在 Linux 系统上配置 Samba 共享服务,并设置合适的权限。以下是具体步骤: 1. 安装 Samba bash sudo apt update sudo apt install samba 2. 创建 Samba 用户(可选) 如果你希望 …...
pycharm生成图片
文章目录 图片例子生成图片并储存,设置中文字体支持两条线绘制散点图和直方图绘制条形图(bar)绘制条形图(横着的)(plt.barh)分组的条形图 颜色和线条风格1. **颜色字符 (color)**其他颜色指定方…...
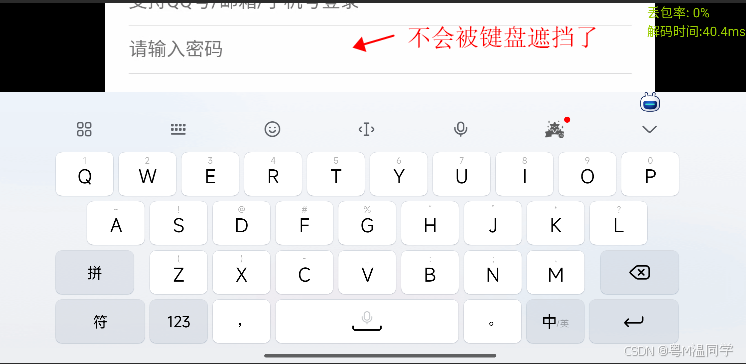
Android 云手机横屏模式下真机键盘遮挡输入框问题处理
一、背景 打开横屏应用,点击云机EditText输入框,输入框被键盘遮挡,如下图: 未打开键盘状态: 点击第二个输入框,键盘遮挡了输入框: 二、解决方案(推荐第三中方案,博主采用的也是第三种方案) 博主这里整理了三种方案:…...

Redis 中的 5 种数据类型和示例场景
Redis 作为一款高性能的键值对数据库,凭借其丰富的数据类型,在缓存、消息队列、排行榜等众多场景中发挥着重要作用。本文将详细介绍 Redis 的 5 种核心数据类型,并结合示例场景和代码,让你快速掌握它们的使用方法。 一、String&am…...
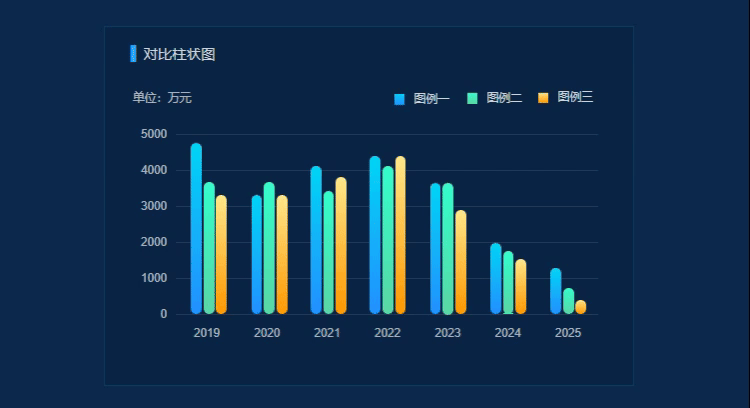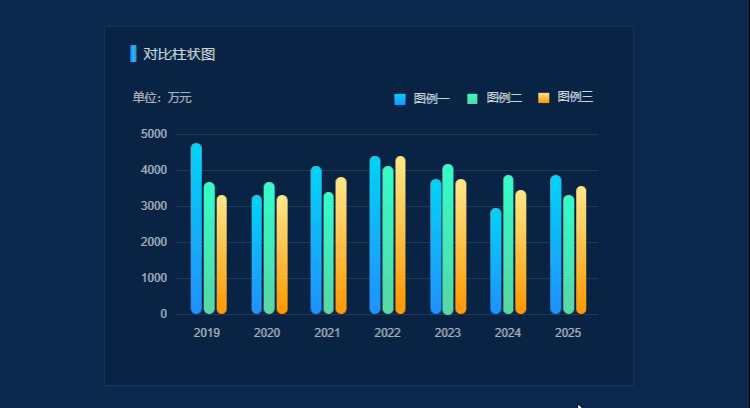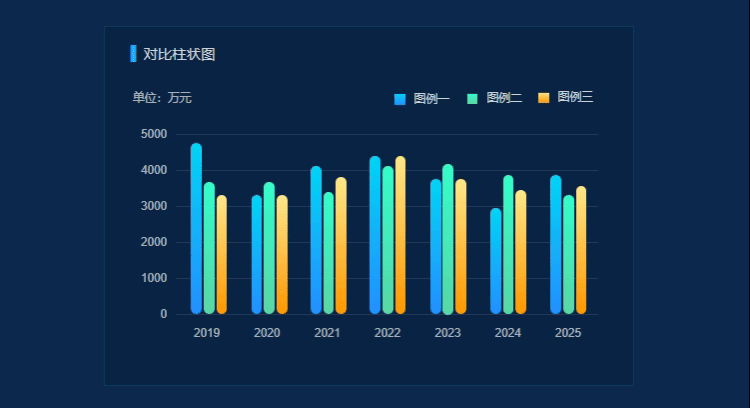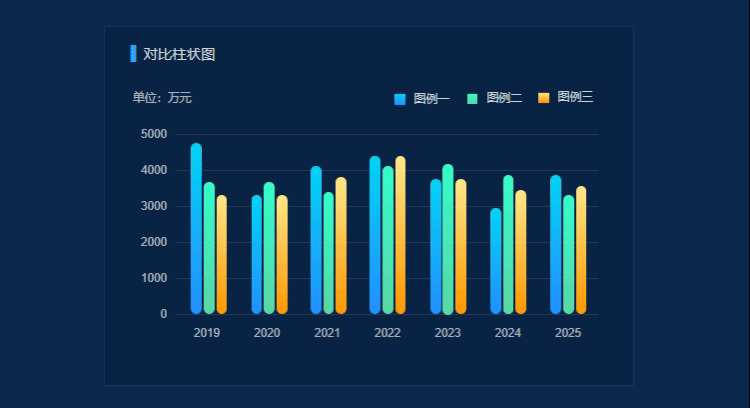
Axure设计案例——科技感对比柱状图
想让数据对比展示摆脱平淡无奇,瞬间抓住观众的眼球吗?那就来看看这个Axure设计的科技感对比柱状图案例!科技感设计风格运用独特元素打破传统对比柱状图的常规,营造出一种极具冲击力的视觉氛围。每一组柱状体都仿佛是科技战场上的士…...

SpringBoot项目搭建指南
SpringBoot项目搭建指南 文章目录 SpringBoot项目搭建指南一、SpringBoot项目搭建1.1 SpringBoot 版本选择1.2 SpringBoot 框架引入方式1.2.1 继承 Starter Parent POM1.2.2 不使用 Parent POM 来使用 Spring Boot 1.3 SpringBoot 打包插件 二、日志框架引入2.1 引入SpringBoot…...

分布式锁剖析
一、分布式锁 1. 为什么需要分布式锁? 在单体应用中,通过synchronized或ReentrantLock等进程内锁即可解决多线程资源竞争问题。但在分布式系统中,多个服务实例运行在不同进程中,传统进程内锁失效,此时需要一种跨进程…...

C语言中函数指针和指针函数的定义及用法
在C/C中,函数指针和指针函数是两个容易混淆但完全不同的概念。以下是它们的详细对比和学习指南,结合代码示例帮助你彻底掌握。 1. 函数指针(Function Pointer) 本质:一个指向函数的指针变量,用于动态调用…...

Spring Boot DevTools 热部署
在Spring Boot项目中加入 spring-boot-devtools 热部署依赖启动器后,通常不需要手动重启项目即可让更改生效。spring-boot-devtools 的核心特性之一就是自动重启或热加载。 Spring Boot DevTools 热部署关键知识点 🔥 目的:spring-boot-devt…...

unix/linux source 命令,其基本属性、语法、操作、api
现在像解剖精密仪器一样,来细致地审视 source (或 .) 命令的各个方面:它的属性、语法、操作方式,以及可以称之为“API”的交互接口。这种细致的分析有助于我们精确地理解和使用它。 让我们深入细节: 一、基本属性 (Core Attributes) 命令类型 (Command Type): Shell 内置…...
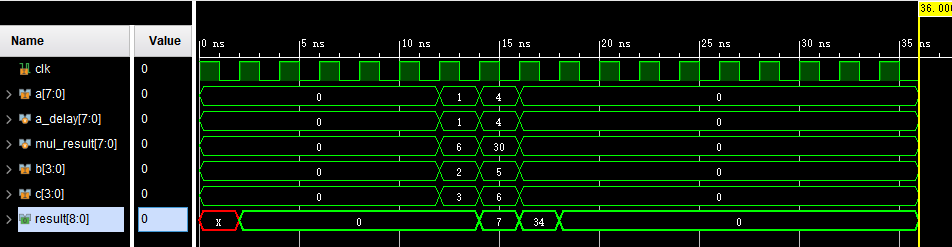
FPGA仿真中阻塞赋值(=)和非阻塞赋值(<=)区别
FPGA仿真中阻塞赋值和非阻塞赋值的区别 单独仿真小模块对但将小模块加入整个工程仿真不对就有可能是没有注意到仿真中阻塞赋值和非阻塞赋值的区别 目录 前言 一、简介 二、设计实例 三、仿真实例 1、仿真用非阻塞赋值 2、仿真用阻塞赋值 总结 前言 网上很多人介绍verilo…...
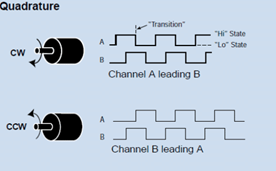
LabVIEW轴角编码器自动检测
LabVIEW 开发轴角编码器自动检测系统,针对指控系统中高故障率的轴角编码器性能检测需求,通过模块化硬件架构与软件设计,实现编码器运转状态模拟、扭矩 / 转速实时监测、19 位并行编码采集译码、数据自动分析及报告生成等功能,解决…...

MySQL数据库从0到1
目录 数据库概述 基本命令 查询命令 函数 表的操作 增删改数据和表结构 约束 事务 索引 视图 触发器 存储过程和函数 三范式 数据库概述 SQL语句的分类: DQL:查询语句,凡是select语句都是DQL。 DML:insert,delete,up…...
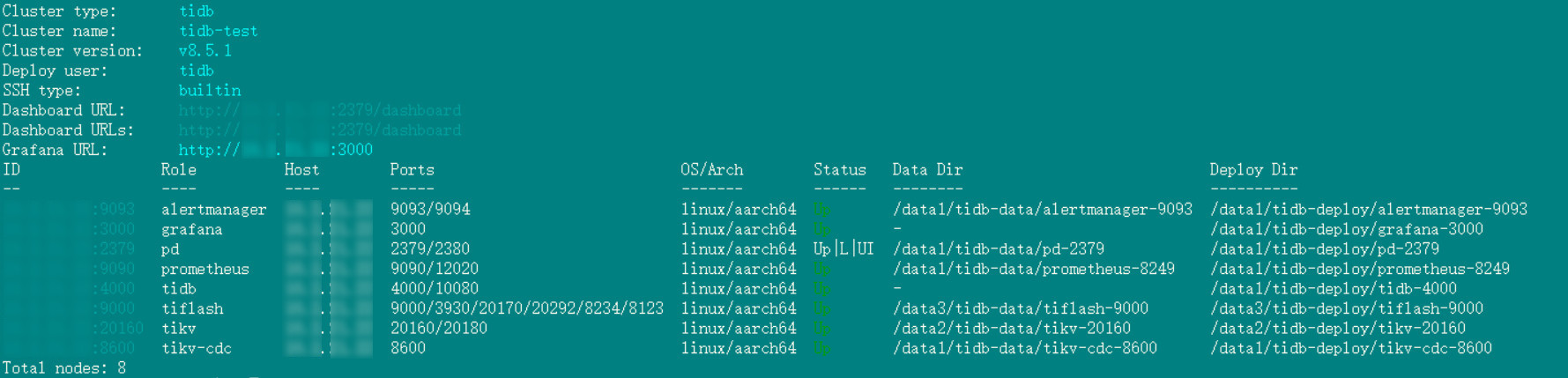
WiFi万能钥匙鲲鹏服务器部署 TiDB 集群实战指南
作者: TiDBer_yangxi 原文来源: https://tidb.net/blog/15a234d0 一、环境准备 1. 硬件要求 服务器架构 :鲲鹏服务器(ARM架构),TiDB 官方明确支持 ARM 架构服务器部署 推荐配置 (生产环…...

正则表达式的前世今生
当你熟练地用正则表达式查找替换代码时,这个工具的历史可以追溯到1943年。那时候还没有计算机,更别说编程语言了。 从神经网络到文本匹配 故事要从两个神经生理学家说起。1943年,Warren McCulloch和Walter Pitts发表了一篇论文《A logical ca…...
Vue 核心技术与实战智慧商城项目Day08-10
温馨提示:这个黑马的视频在b占可以找到,里面有完整的教学过程 然后这个项目有完整的代码,我已经上传了,如果审核成功大家就可以看了,但是需要审核多久我也不是很确定 1.项目演示 2. 项目收获 3. 创建项目 4. 调整初始化…...

TCP/IP协议精华总结pdf分享
hi ,大家好,应小伙伴们的要求,上次分享了个人的一些学习和职场经验,其中网络协议PDF文档是我之前学习协议的时候总结一些精华知识,网络属于基本功,是互联网必备知识,我深信掌握好核心20%知识&am…...

组件化:软件工程化的基础
在现代软件系统中,**组件化(Componentization)**不仅是一种设计技术,更是推动软件工程走向工业化、体系化的关键基础。随着业务复杂度、团队规模与生命周期成本的持续上升,软件开发从“写代码”演变为“构建系统”。而…...

⚡️ Linux grep 命令参数详解
⚡️ Linux grep 用法及参数详解 📘 1. grep 简介 grep 是 Linux/Unix 系统中用于文本搜索的命令,其全称为 Global Regular Expression Print,意为全局正则表达式打印器。 它根据给定的 模式(pattern) 对文件或标准…...

2025年第三届CCF·夜莺开源创新论坛通知
点击蓝字 关注我们 CCF Opensource Development Committee 01 大会简介 由中国计算机学会主办、CCF开源发展委员会及夜莺开源社区承办的第三届CCF夜莺开源创新论坛拟于2025年7月4日在北京召开。本次论坛以“AI 加速可观测”为主题,汇聚了开源夜莺核心开发团队&#…...
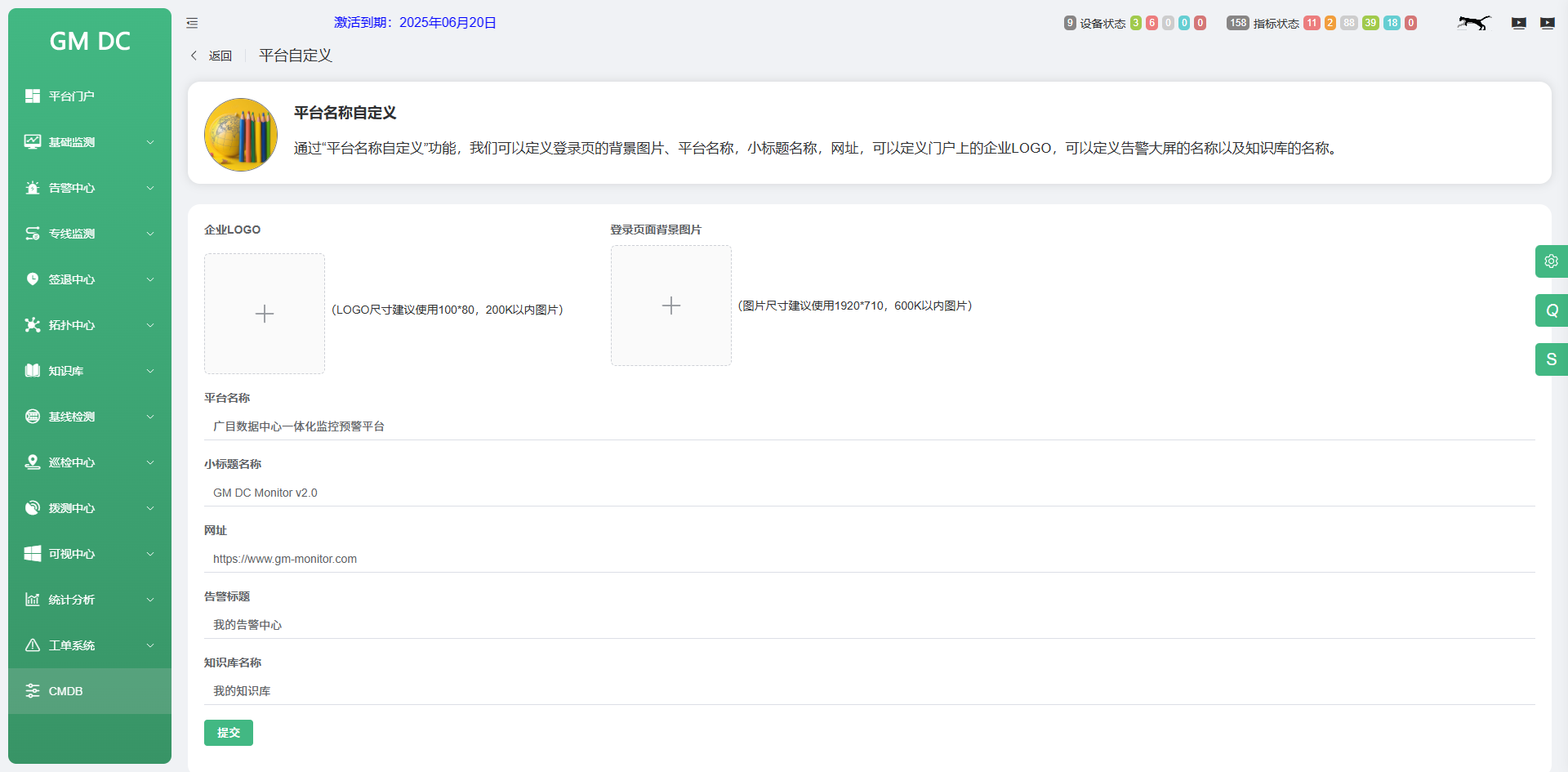
GMDCMonitor企业版功能分享0602
企业版包含了拓扑中心、签退中心、知识库、通知渠道配置、平台自定义,这5个功能 1)拓扑中心 拓扑中心绘制的时候需要注意2点: 1)要先选择 “矩形区域” 或 “圆形区域” 来添加各个背景区域,同时录入区域尺寸&#x…...

automa
网页版插件 https://extension.automa.site/(可能插件下架了) https://github.com/AutomaApp/automa/releases/tag/v1.29.9(可以直接在git上下载) automa官网地址: https://www.automa.site/ 官方的文档 https://docs.automa.si…...
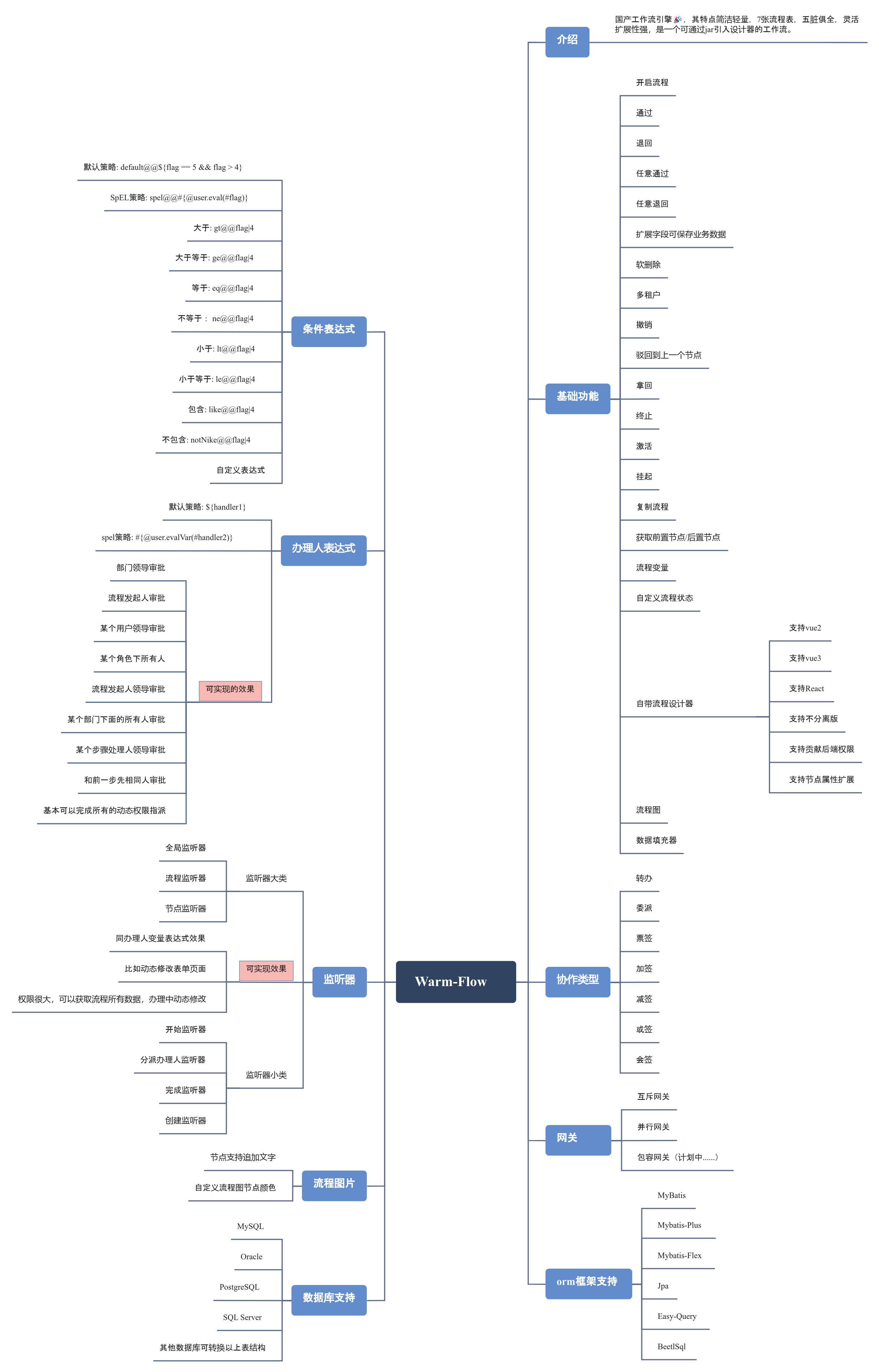
Warm-Flow发布1.7.3 端午节(设计器流和流程图大升级)
Warm-Flow发布1.7.3 端午节(设计器流和流程图大升级) 更新内容项目介绍功能思维导图演示地址官网Warm-Flow视频 更新内容 [feat] 新版流程图通过前端渲染[perf] 美化流程设计器ui[feat] 办理人权限处理器,新增办理人转换接口,比如…...

【存储基础】SAN存储基础知识
文章目录 1. 什么是SAN存储?2. SAN存储组网架构3. SAN存储的主要协议SCSI光纤通道(FC)协议iSCSIFCoENVMe-oFIB 4. SAN存储的关键技术Thin Provision:LUN空间按需分配Tier:分级存储Cache:缓存机制QoS&#x…...
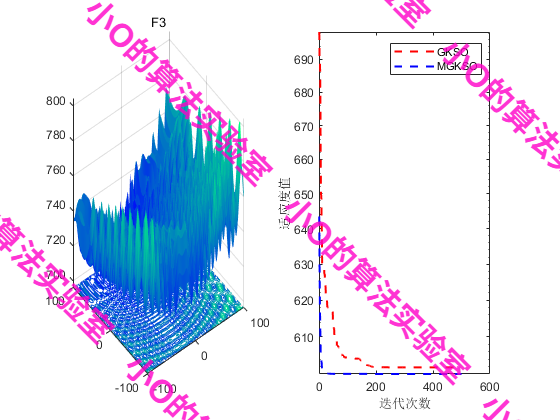
2025年ESWA SCI1区TOP,改进成吉思汗鲨鱼算法MGKSO+肝癌疾病预测,深度解析+性能实测
1.摘要 本文针对肝癌(HCC)早期诊断难题,提出了一种基于改进成吉思汗鲨鱼优化算法(MGKSO)的计算机辅助诊断系统。由于HCC在早期症状不明显且涉及高维复杂数据,传统机器学习方法易受噪声和冗余特征干扰。为提…...
:增长率的真相——从数据基准到科学增长策略)
精益数据分析(93/126):增长率的真相——从数据基准到科学增长策略
精益数据分析(93/126):增长率的真相——从数据基准到科学增长策略 在创业领域,增长率常被视为企业成功的核心指标,但多少才算“足够好”?如何避免陷入“盲目增长陷阱”?今天,我们将…...

MAC上怎么进入隐藏目录
在Mac上,由于系统保护的原因,一些系统目录如/usr默认是隐藏的,但可以通过以下方法进入: 方法一:使用Finder的“前往文件夹”功能 打开Finder。使用快捷键Command Shift G,或者在菜单栏中选择“前往”-“…...
Spark-TTS: AI语音合成的“变声大师“
嘿,各位AI爱好者!还记得那些机器人般毫无感情的合成语音吗?或者那些只能完全模仿但无法创造的语音克隆?今天我要介绍的Spark-TTS模型,可能会让这些问题成为历史。想象一下,你可以让AI不仅说出任何文字&…...

【Python 进阶3】常见的 call 和 forward 区别
在 Python 和深度学习框架(如 PyTorch)中,__call__ 和 forward 是两个不同的概念,它们的用途和实现方式有明显区别: 1. __call__ 方法(Python 内置特殊方法) 在 Python 中,__call_…...