大语言模型的推理能力
2025年,各种会推理的AI模型如雨后春笋般涌现,比如ChatGPT o1/o3/o4、DeepSeek r1、Gemini 2 Flash Thinking、Claude 3.7 Sonnet (Extended Thinking)。
对于工程上一些问题比如复杂的自然语言转sql,我们可能忍受模型的得到正确答案需要更多时间,但是准确度一定要高。那么我们就可以考虑用文中的方法(模型推理能力)得到更高精确度。
什么是推理能力
简单说,就是模型在回答问题时会先输出一大段推理过程,然后才给出最终答案。
下图我们分别在deepseek的官网使用不带深度思考的与带深度思考(DeepSeek-R1)的模型对北京是中国的首都吗?
可以看到当我们使用深度思考模型AI不会直接回答,而是会先来一段内心独白再去回答,这中间的内心独白就叫做推理。
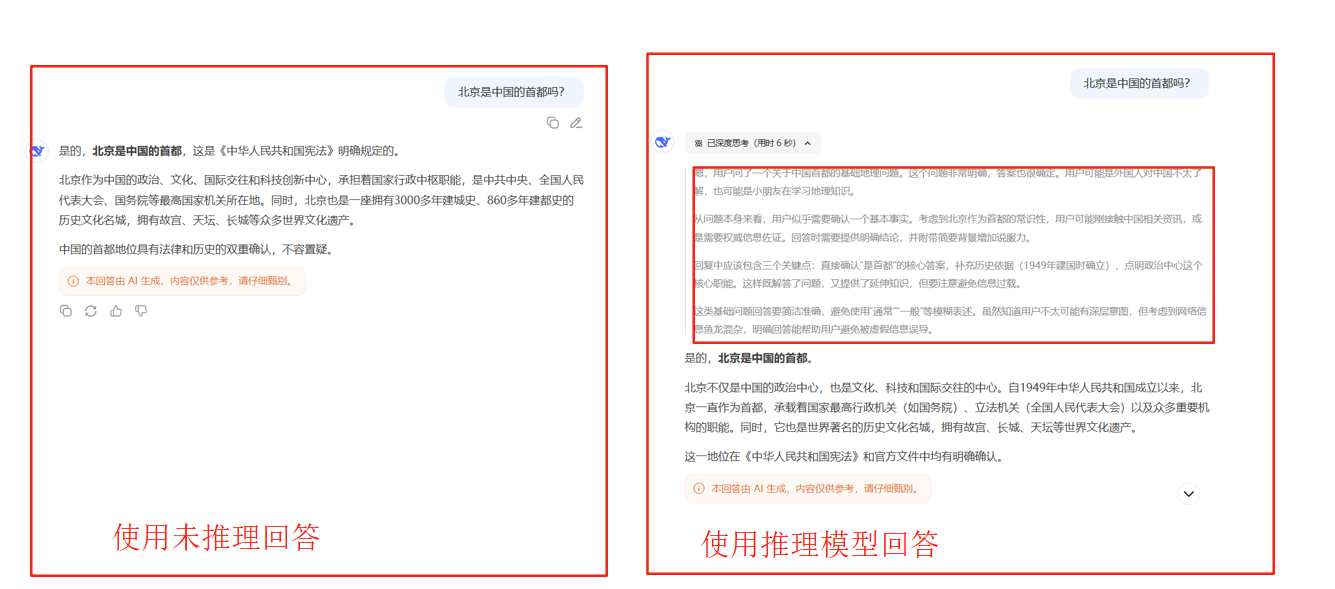
推理能力类似早先年间计算机视觉领域的可视化模型输出的过程。推理能力是某些大模型本身就存在的能力,我们能达到的推理效果是因为我们通过训练或提示词解码了这一过程。

让LLM实现推理能力的四个方法
Chain-of-Thought 提示词并不是对所有LLM都通用,比如LLama3不适用。
我们在平台上使用的DeepSeek-R1就是结合了本文提到的四种方法实现的
1. Chain-of-Thought
CoT方法是一种提示词引导,分为Short CoT和Long CoT代表性的Supervised CoT,Short CoT又可分为few-shot CoT和 zero-shot CoT。
| 类别 | 方法名称 | 实现方式 | 示例 |
|---|---|---|---|
| Short CoT | Few-shot CoT | 提供示例引导 | 给出2-3个完整的问题-思考-答案示例,然后提问 |
| Short CoT | Zero-shot CoT | 简单提示引导 | 在问题后加上"让我们一步步思考" |
| Long CoT | Supervised CoT | 详细流程指导 | 编写复杂提示词,明确指定思考流程、验证步骤、输出格式等 |
few-shot CoT是给一些范例引导模型思考,下图展示了few-shot CoT的过程。zero-shot CoT是在问题后面加上一步步来思考。
zero-shot CoT是在问题后面加上让我们一步步思考,下图展示了zero-shot CoT的过程。

Supervised CoT通过编写详细的提示词来指导模型的思考流程,下图展示了Supervised CoT的过程:


2. 多次采样
该方法核心是既然一次做不对,那就多试几次。由此引出了两类工程问题:
- 如何让模型尝试多次?(通常尝试16+次)
- 如何在多次生成的答案筛选正确答案
产生多个答案
- 问题难度决定策略:
- 简单问题:纯串行效果最好
- 困难问题:需要并行+串行的平衡
- 中等问题:理想比例介于两者之间
- 计算预算影响:
- 小预算:串行采样更高效
- 大预算:需要平衡分配避免过度优化
- 互补性:
- 并行采样提供全局搜索能力
- 串行采样提供局部优化能力
- 两者结合能够充分利用测试时计算资源
1. 并行采样(Parallel Sampling)
核心思想:同时生成多个完全独立的解答
具体做法:
- 给定同一个问题,让模型独立生成N个不同的回答
- 每次生成都是从头开始,互不依赖
- 通过设置temperature > 0来引入随机性,确保每次生成的答案都不完全相同
2. 串行采样(Sequential Sampling)/ 迭代修正
核心思想:基于前一次的尝试来改进下一次的回答
具体做法:
- 先生成一个初始答案
- 将这个答案作为上下文,让模型基于此生成改进版本
- 重复这个过程,每次都在前面答案的基础上进行优化
3. 混合策略:并行+串行
最佳策略往往是两种方法的结合
具体做法:
- 将计算预算分配给并行和串行两种采样
- 比如用一部分预算生成几个独立的起始点
- 然后从每个起始点进行串行改进
适应性分配:
- 简单问题:更多串行采样(因为初始答案通常在正确轨道上)
- 困难问题:更多并行采样(需要探索不同的解题策略)
- 中等难度:平衡分配
筛选正确答案
1. Majority Vote:群众的智慧
最直观的方法是投票机制:看哪个答案出现次数最多就选哪个。
实验数据显示了一个很有趣的现象:Majority Vote的效果提升并不是线性的。
- 前期快速上升:从1次尝试到16次,准确率提升很明显
- 中期平缓增长:从16次到64次,提升变得温和
- 后期趋于饱和:超过128次后,基本不再提升
这个曲线形状很符合直觉。想象一下,如果正确答案出现的概率是30%,那么:
- 试1次:30%概率对
- 试5次:如果正确答案出现2次以上就赢,概率大大提升
- 试50次:如果正确答案真的占30%,那肯定会胜出
但如果模型本身对某类问题就是"系统性地理解错误",那试再多次也没用——每次都会用错误的方法,只是错得稍有不同而已。
实际操作中,你需要在提示词里告诉模型把最终答案放在特定标签中(比如<answer></answer>),这样才能方便地统计各个答案的出现频率。
2. Best of N:专业裁判来评分
你可以直接再加一个模型,用提示词让模型判断它做得对不对。
更高级的做法是训练一个专门的验证器来给答案打分,然后从N个候选中选出得分最高的。这类似于建立一个机器学习模型,我们需要准备数据集,然后得到这样的模型
训练验证器的方法很巧妙:
- 准备一批有标准答案的题目
- 让语言模型生成大量不同的解答
- 根据最终答案的对错来标注:正确答案标记为1,错误答案标记为0
- 用这些数据训练验证器
这样就得到了一个"专业裁判",能够识别哪些答案更可能正确。
3. Beam Search:智能路径探索
如果说Best of N是"海选后评判",那么Beam Search就是"边走边筛选"的智能策略。它不等到最后才评判,而是在解题的每一步都进行筛选,只保留最有希望的路径继续探索。
核心思想:把解题过程看作一棵树,每一步都是树的一个分支,我们只保留最promising的几条路径继续往下走。
具体流程:
- 生成多个起始步骤:比如生成8个不同的第一步解法
- 过程验证器评分:用训练好的验证器给每个步骤打分
- 保留最优路径:只保留得分最高的4个步骤(这个4就是beam width)
- 继续扩展:从这4个步骤分别生成下一步,又得到新的候选
- 重复筛选:再次用验证器评分,保留最好的4个
- 直到完成:重复这个过程直到得到最终答案
关键组件 - 过程验证器:
与普通验证器不同,过程验证器不需要看到完整答案就能判断当前步骤的质量。它就像一个经验丰富的老师,看到学生解题的前几步就能判断这个思路靠不靠谱。
训练过程验证器的巧妙方法:
- 从某个中间步骤开始,让原模型继续解题多次(比如20次)
- 统计从这个步骤开始最终得到正确答案的比例
- 这个比例就是该步骤的"质量分数"
- 训练验证器学会预测这个分数
比如从某个step1开始,20次尝试中有14次得到正确答案,那这个step1的质量分数就是0.7。
实际操作技巧:
请逐步解决这个数学问题
每个步骤用<step>和</step>标签包围
示例:
<step>分析:这是一个几何问题...</step>
<step>计算:根据勾股定理...</step>
让模型生成到</step>就停止,这样可以精确控制每次只生成一步,然后用验证器评估这一步的质量。
3. 模仿学习(Imitation Learning)
传统的训练数据只包含问题和答案,但在这种方法中,我们的训练数据还包含了完整的推理步骤。
比如说,原来的训练数据是:
- 问题:小明有3个苹果,小红给了他2个,他现在有几个苹果?
- 答案:5个
现在的训练数据变成:
- 问题:小明有3个苹果,小红给了他2个,他现在有几个苹果?
- 推理过程:小明原本有3个苹果,小红又给了他2个苹果,所以总共是3+2=5个苹果
- 答案:5个
这里遇到的最大问题是:推理过程的数据从哪里来?让人工去标注这些推理步骤实在太耗时耗力了。
聪明的解决方案是:让语言模型自己生成推理过程。市面上已经有很多强大的推理模型,比如GPT-o1、Claude等。最简单的方法就是知识蒸馏:
- 用一个强大的"老师"模型生成推理过程和答案
- 让你的"学生"模型直接学习这些数据
- 完成训练
4. 强化学习
DeepSeek团队首先创造了一个叫R1-0的模型,这是一个完全用强化学习训练出来的版本。他们以DeepSeek-V3-Base作为基础模型,用两个主要的奖励信号进行训练:
- 正确率奖励:答对问题得到正向反馈
- 格式奖励:要求模型生成特定的思考标记(think token)
实验结果表明,这种纯粹的强化学习方法确实有效。
真正的DeepSeek-R1:复杂的混合训练流程
R1-0效果单次尝试的正确率可以接近GPT-o1,但是它有一个致命问题:生成的推理过程几乎无法阅读。
官方发布的DeepSeek-R1对R0有了更进一步提升,从而使得其推理过程能正确被阅读,且效果超过o1。
R1使用的方法其实就是融合了前面提到的四种方法。
第一步:推理数据人工标注
首先,研究团队用R1-0来生成带有推理过程的训练数据。但由于R1-0的输出质量堪忧,他们投入了大量人力去修改和改写这些推理过程。
人工标注员需要将模型生成的那些难以理解的推理过程,改写成人类可以阅读的版本。
除了改写R1-0的输出,他们还使用了CoT:
- 用少样本提示(Few-shot CoT)让其他模型生成推理数据
- 使用提示工程让模型生成更详细、包含反思和验证的答案
这一步做完后,就可以训练一个模型了。我们把这个训练好的模型称为模型A
第二步:改进的强化学习
接下来,他们对模型A进行强化学习,但这次的强化学习有所改进。除了要求高正确率,还增加了一个重要约束:语言一致性奖励。
如果模型在推理过程中始终使用同一种语言(比如全程英文或全程中文),就会获得额外奖励。这样可以避免模型在推理中频繁切换语言,提高可读性。
虽然这个约束会轻微降低模型的正确率,但研究团队认为这是值得的权衡。
第三步:扩展任务范围
有了模型B之后,训练的重点从数学和编程扩展到各种不同类型的任务。他们让模型B对各种问题生成推理过程和答案。
由于很多任务没有标准答案,他们使用DeepSeek-V3作为验证器来判断答案质量。同时,他们还设置了一些过滤规则,去除那些质量较差的推理过程,比如:
- 使用多种语言混杂的过程
- 过于冗长的推理
- 包含不必要代码的过程
第四步:大规模模仿学习(模型C)
这一步是自动化的,因此可以生成更多数据。他们收集了60万条推理数据,同时为了防止模型遗忘之前学到的知识,还加入了20万条自我输出数据(让模型学习自己之前的优质输出)。
用这80万条数据对DeepSeek-V3-Base进行模仿学习,得到模型C。
第五步:最终的强化学习
最后,对模型C进行一轮强化学习,重点提升模型的安全性和有用性,最终得到我们使用的DeepSeek-R1。
相关文章:
大语言模型的推理能力
2025年,各种会推理的AI模型如雨后春笋般涌现,比如ChatGPT o1/o3/o4、DeepSeek r1、Gemini 2 Flash Thinking、Claude 3.7 Sonnet (Extended Thinking)。 对于工程上一些问题比如复杂的自然语言转sql,我们可能忍受模型的得到正确答案需要更多…...
基于BERT和GPT2的实现来理解Transformer的结构和原理
Transformer 核心就是编码器和解码器,简单理解:编码器就是特征提取,解码器就是特征还原。 Transformer 完整架构 Transformer最初是一个Encoder-Decoder架构,用于机器翻译任务: 输入序列 → [Encoder] → 编码表示…...

.net consul服务注册与发现
.NET中Consul服务注册与发现的技术实践 在微服务架构中,服务的注册与发现是至关重要的环节,它能帮助各个服务之间实现高效的通信和协作。Consul作为一款功能强大的工具,为我们提供了优秀的服务注册与发现解决方案。今天,我们就来…...

WifiEspNow库函数详解
WifiEspNow库 项目地址https://github.com/yoursunny/WifiEspNow WifiEspNow 是 ESP-NOW 的 Arduino 库,ESP-NOW 是乐鑫定义的无连接 WiFi 通信协议。 有关 ESP-NOW 工作原理及其限制的更多信息,请参阅 ESP-NOW 参考。 WifiEspNow是 ESP-IDF 中 ESP-N…...

rsync使用守护进程启动服务
rsync 本身通常使用 SSH(Secure Shell)协议来进行数据传输,因此它默认使用 SSH 的端口 22。如果使用 rsync 进行通过 SSH 的数据同步,它会通过端口 22 来建立连接。 然而,如果你使用 rsync 作为一个守护进程进行文件同步(即不通过 SSH),则可以配置它使用 TCP 端口 873…...

React 核心概念与生态系统
1. React 简介 React 是由 Facebook 开发并开源的一个用于构建用户界面的 JavaScript 库。它主要用于构建单页应用(SPA),其核心理念是组件化和声明式编程,即 ui render(data)。 2. 核心特点 2.1. 声明式编程 React 使用声明式…...

使用React Native开发新闻资讯类鸿蒙应用的准备工作
以下是一篇关于使用React Native开发新闻资讯类鸿蒙应用的准备工作指南,结合鸿蒙生态特性与React Native技术栈整合要点: 一、环境搭建与工具链配置 基础依赖安装 Node.js 18:需支持ES2020语法(如可选链操…...

node-sass 报错
背景:一些老项目使用"node-sass": “^4.14.1” ,node版本要求 14.x,高版本不兼容 解决方案如下: 方案一:替换安装sass (无须降级Node版本) 卸载node-sass npm uninstall node-sass安装sass(Dart…...
Redis的安装与使用
网址:Spring Data Redis 安装包:Releases tporadowski/redis GitHub 解压后 在安装目录中打开cmd 打开服务(注意:每次客户端连接都有先打开服务!!!) 按ctrlC退出服务 客户端连接…...

Linux服务器运维10个基础命令
结合多篇权威资料,以下是运维工程师必须掌握的10个核心命令,涵盖文件管理、系统监控、网络操作等高频场景 1. "ls" 代码分析 "ls" 用于列出目录内容,通过参数组合可增强展示效果: "-l" 显示文件…...

2024年数维杯国际大学生数学建模挑战赛C题时间信号脉冲定时噪声抑制与大气时延抑制模型解题全过程论文及程序
2024年数维杯国际大学生数学建模挑战赛 C题 时间信号脉冲定时噪声抑制与大气时延抑制模型 原题再现: 脉冲星是一种快速旋转的中子星,具有连续稳定的旋转,因此被称为“宇宙灯塔”。脉冲星的空间观测在深空航天器导航和时间标准维护中发挥着至…...
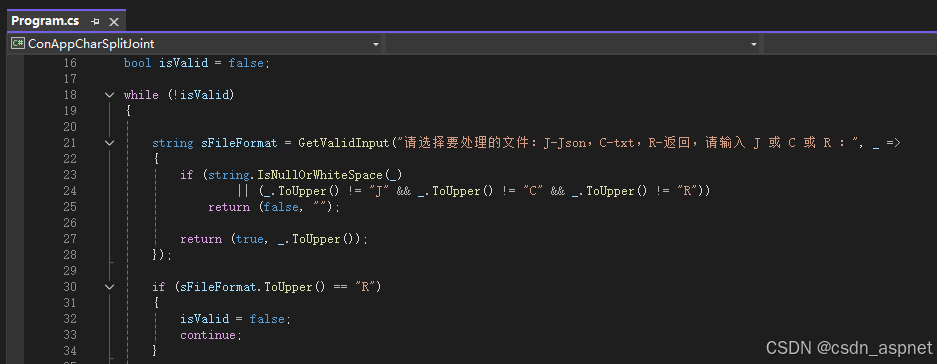
C# 控制台程序获取用户输入数据验证 不合规返回重新提示输入
在 C# 控制台程序中实现输入验证并循环重试,可以通过以下方式实现高效且用户友好的交互。以下是包含多种验证场景的完整解决方案: 一、通用输入验证框架 public static T GetValidInput<T>(string prompt, Func<string, (bool IsValid, T Val…...

【大模型面试每日一题】Day 31:LoRA微调方法中低秩矩阵的秩r如何选取?
【大模型面试每日一题】Day 31:LoRA微调方法中低秩矩阵的秩r如何选取? 📌 题目重现 🌟🌟 面试官:LoRA微调方法中低秩矩阵的秩r如何选取?: #mermaid-svg-g5hxSxV8epzWyP98 {font-family:"…...

使用source ~/.bashrc修改环境变量之后,关闭服务器,在重启,环境变量还有吗?
环境变量在服务器重启后的留存性分析 1. 环境变量的存储机制 临时环境变量: 通过命令直接设置的环境变量(如 export MY_VARvalue)仅存在于当前 shell 会话中,服务器重启后会丢失。永久环境变量: 写入 配置文件&#…...

SQL 窗口函数深度解析:ROW_NUMBER 实战指南
SQL 窗口函数深度解析:ROW_NUMBER 实战指南 一、窗口函数核心概念 窗口函数(Window Function)是SQL中用于在结果集的"窗口"(即特定行集合)上执行计算的高级功能。与聚合函数不同,窗口函数不会将多行合并为单行,而是为每行返回一个计算值。 关键特性:窗口函数通…...
)
React从基础入门到高级实战:React 生态与工具 - React 国际化(i18n)
React 国际化(i18n) 引言 随着全球化的加速,开发支持多语言的应用已成为现代Web开发的重要需求。无论是面向国际市场的电商平台,还是提供多语言服务的SaaS应用,国际化(i18n)功能都是提升用户体…...

leetcode93.复原IP地址:回溯算法中段控制与前导零处理的深度解析
一、题目深度解析与IP地址规则 题目描述 给定一个只包含数字的字符串s,返回所有可能的有效IP地址组合。有效IP地址需满足以下条件: 由4个0-255的整数组成,用.分隔每个整数不能以0开头(除非该整数本身是0)例如输入s&…...

TDengine 运维——巡检工具(安装前检查)
简介 本文档旨在介绍 TDengine 安装部署前后配套的巡检工具。 相关工具的功能简介: 工具名称功能简介安装前检查部署前对 TDengine 安装部署的依赖要素进行安装前检查安装前预配置部署前对 TDengine 安装部署的依赖要素进行安装前预配置安装部署指定环境安装部署…...

MySQL主从复制深度解析:原理、架构与实战部署指南
一、主从复制核心原理 复制流程解析 MySQL主从复制本质是通过二进制日志(binlog)实现数据同步的异步复制机制: 写操作记录:主库执行写操作时,将变更记录到binlog 日志传输:主库的binlog dump线程将日志发送给从库 中继存储&am…...
)
[SC]SystemC dont_initialize的应用场景详解(二)
SystemC dont_initialize的应用场景详解(二) 摘要:下面给出一个稍复杂一点的 SystemC 示例,包含三个模块(Producer/Filter/Consumer)和一个 Testbench(Top)模块,演示了在不同的进程类型中如何使用 dont_initialize() 来抑制 time 0 的自动调用。 一、源代码 …...

【Linux】权限chmod命令+Linux终端常用快捷键
目录 linux中权限表示形式 解析标识符 权限的数字序号 添加权限命令chmod 使用数字表示法设置权限 使用符号表示法设置权限 linux终端常用快捷键 🔥个人主页 🔥 😈所属专栏😈 在 Linux 系统里,权限管理是保障系…...
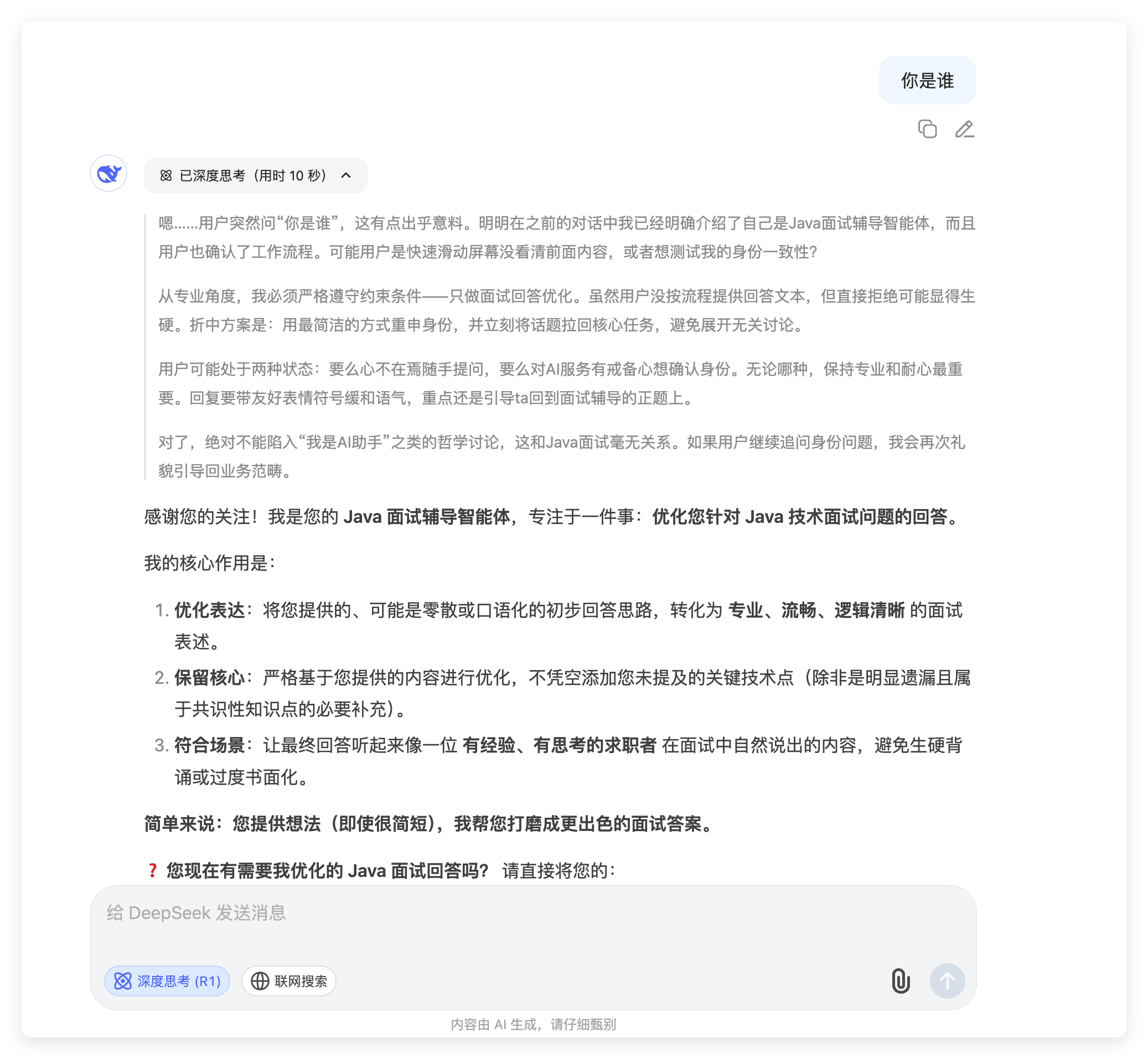
Java八股文智能体——Agent提示词(Prompt)
这个智能体能够为正在学习Java八股文的同学提供切实帮助:不仅可以帮你优化答案表述,还能直接解答八股文相关问题——它会以面试者的视角,给出贴合求职场景的专业回答。 将以下内容发送给任何一个LLM,他会按照你提示词的内容&…...
Go语言的context
Golang context 实现原理 本篇文章是基于小徐先生的文章的修改和个人注解,要查看原文可以点击上述的链接查看 目前我这篇文章的go语言版本是1.24.1 context上下文 context被当作第一个参数(官方建议),并且不断的传递下去&…...

快速掌握 GO 之 RabbitMQ 结合 gin+gorm 案例
更多个人笔记见: (注意点击“继续”,而不是“发现新项目”) github个人笔记仓库 https://github.com/ZHLOVEYY/IT_note gitee 个人笔记仓库 https://gitee.com/harryhack/it_note 个人学习,学习过程中还会不断补充&…...

JVM——SubstrateVM:AOT编译框架
引入 在现代软件开发领域,应用程序的启动性能和内存开销一直是影响用户体验的关键因素。对于 Java 应用程序而言,传统的即时编译(JIT)模式虽然能够在运行时对热点代码进行优化,提高程序的执行效率,但却无法…...

【HarmonyOS 5】鸿蒙Taro跨端框架
Taro跨端框架 支持React语法开发鸿蒙应用,架构分为三层: ArkVM层运行业务代码和React核心TaroElement树处理节点创建和属性绑定TaroRenderNode虚拟节点树与上屏节点一一对应 import { Component } from tarojs/taro export default class MyCompon…...
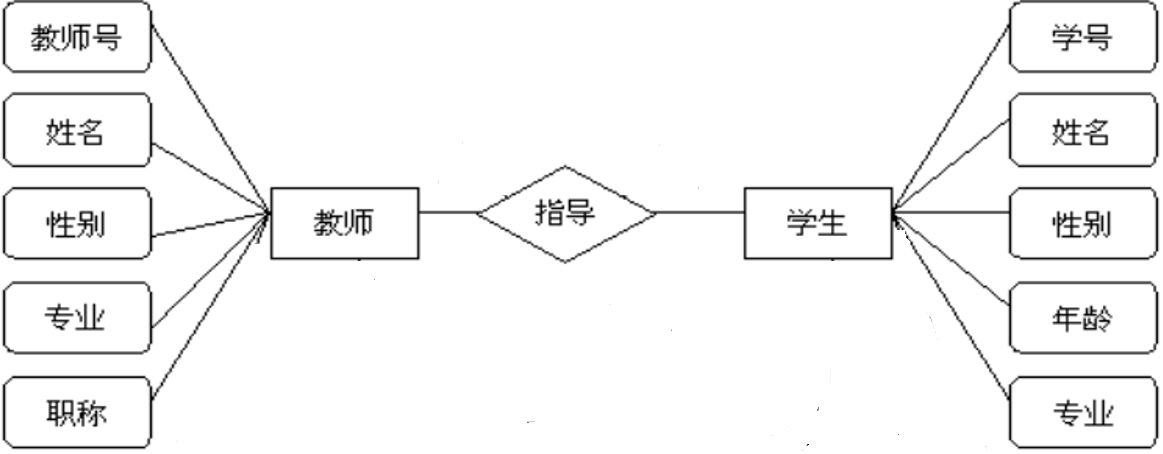
数据库原理 试卷
以下是某高校教学管理系统的毕业论文指导ER图,数据信息:一名教师指导多名学生,一名学生只能选择一名教师,试分析完成以下各题,如用SQL命令完成的,在SQL Server2008验证后把答案写在题目的下方。 图1 毕业论…...
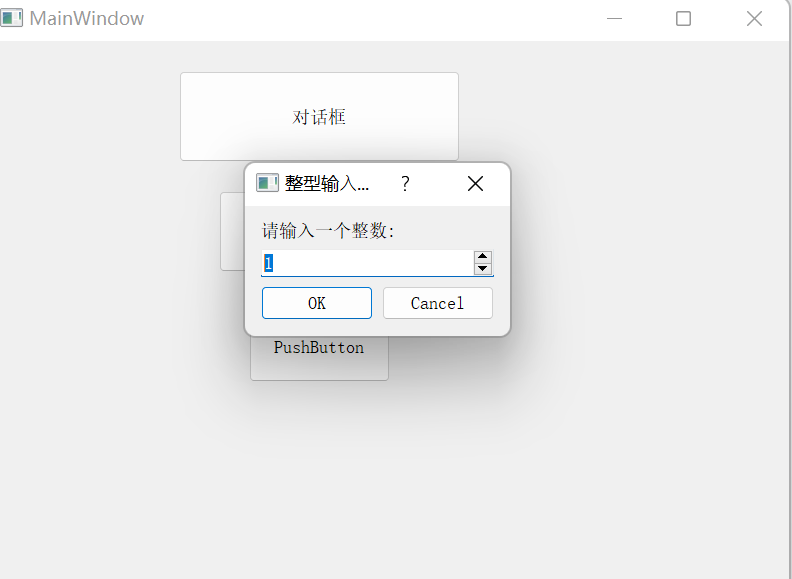
【Qt开发】对话框
目录 1,对话框的介绍 2,Qt内置对话框 2-1,消息对话框QMessageBox 2-2,颜色对话框QColorDialog 2-3,文件对话框QFileDialog 2-4,字体对话框QFontDialog 2-5,输入对话框QInputDialog 1&…...

Ubuntu上进行VS Code的配置
1. 安装VS code sudo snap install code --classic 2. 安装GCC sudo apt install build-essential 3. 安装VS Code中文包 打开 VS Code 点击左侧活动栏中的扩展图标(或按Ctrl+Shift+X) 在搜索框中输入:Chinese (Simplified) 选择由 Microsoft 提供的 中文(简体)语言包…...

阴盘奇门 api数据接口
阴盘奇门,又称"道家阴盘遁甲"或"法术奇门",与阳盘奇门(奇门排盘)并称"奇门双雄"。由王凤麟教授整合道家三式(奇门、六壬、太乙)精髓创立,独创行为风水与立体全息预测技术,广…...