学习日记-day20-6.1
完成目标:
知识点:
1.集合_Collections集合工具类
方法:static <T> boolean addAll(Collection<? super T> c, T... elements)->批量添加元素 static void shuffle(List<?> list) ->将集合中的元素顺序打乱static <T> void sort(List<T> list) ->将集合中的元素按照默认规则排序static <T> void sort(List<T> list, Comparator<? super T> c)->将集合中的元素按照指定规则排序 public class Demo01Collections {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();//static <T> boolean addAll(Collection<? super T> c, T... elements)->批量添加元素Collections.addAll(list,"张三","李四","王五","赵六","田七","朱八");System.out.println(list);//static void shuffle(List<?> list) ->将集合中的元素顺序打乱Collections.shuffle(list);System.out.println(list);//static <T> void sort(List<T> list) ->将集合中的元素按照默认规则排序-> ASCII码表ArrayList<String> list1 = new ArrayList<>();list1.add("c.举头望明月");list1.add("a.床前明月光");list1.add("d.低头思故乡");list1.add("b.疑是地上霜");Collections.sort(list1);System.out.println(list1);}
}=========================================================================================
1.方法:static <T> void sort(List<T> list, Comparator<? super T> c)->将集合中的元素按照指定规则排序2.Comparator比较器a.方法:int compare(T o1,T o2)o1-o2 -> 升序o2-o1 -> 降序 public class Person {private String name;private Integer age;public Person() {}public Person(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}
}public class Demo02Collections {public static void main(String[] args) {ArrayList<Person> list = new ArrayList<>();list.add(new Person("柳岩",18));list.add(new Person("涛哥",16));list.add(new Person("金莲",20));Collections.sort(list, new Comparator<Person>() {@Overridepublic int compare(Person o1, Person o2) {return o1.getAge()-o2.getAge();}});System.out.println(list);}
}===============================================================================
1.接口:Comparable接口
2.方法: int compareTo(T o) -> this-o (升序) o-this(降序)public class Student implements Comparable<Student>{private String name;private Integer score;public Student() {}public Student(String name, Integer score) {this.name = name;this.score = score;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getScore() {return score;}public void setScore(Integer score) {this.score = score;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", score=" + score +'}';}@Overridepublic int compareTo(Student o) {return this.getScore()-o.getScore();}
}public class Demo03Collections {public static void main(String[] args) {ArrayList<Student> list = new ArrayList<>();list.add(new Student("涛哥",100));list.add(new Student("柳岩",150));list.add(new Student("张宇",80));Collections.sort(list);System.out.println(list);}
}Arrays中的静态方法:static <T> List<T> asList(T...a) -> 直接指定元素,转存到list集合中public class Demo04Collections {public static void main(String[] args) {List<String> list = Arrays.asList("张三", "李四", "王五");System.out.println(list);}}| 知识点 | 核心内容 | 重点 |
| collections集合工具类 | 集合的工具类,用于操作集合 | 与Array工具类(arise)的对比 |
| 特点 | 构造私有、方法静态 | 构造私有确保工具类不能被实例化,方法静态便于直接调用 |
| addAll方法 | 批量添加元素到集合中 | 可变参数,可添加多个元素 |
| shuffle方法 | 打乱集合中元素的顺序 | 每次执行结果都不同 |
| sort方法(默认排序) | 按照默认规则(ASCII码表)排序 | 对字符串等实现了Comparable接口的对象有效 |
| sort方法(自定义排序) | 使用Comparator比较器进行排序 | 需要实现Comparator接口的compare方法 |
| Comparable接口 | 对象实现该接口后,可直接使用sort方法排序 | 需重写compareTo方法指定排序规则 |
| Arrays.asList方法 | 将指定元素转存到List集合中 | 静态方法,返回固定大小的List |

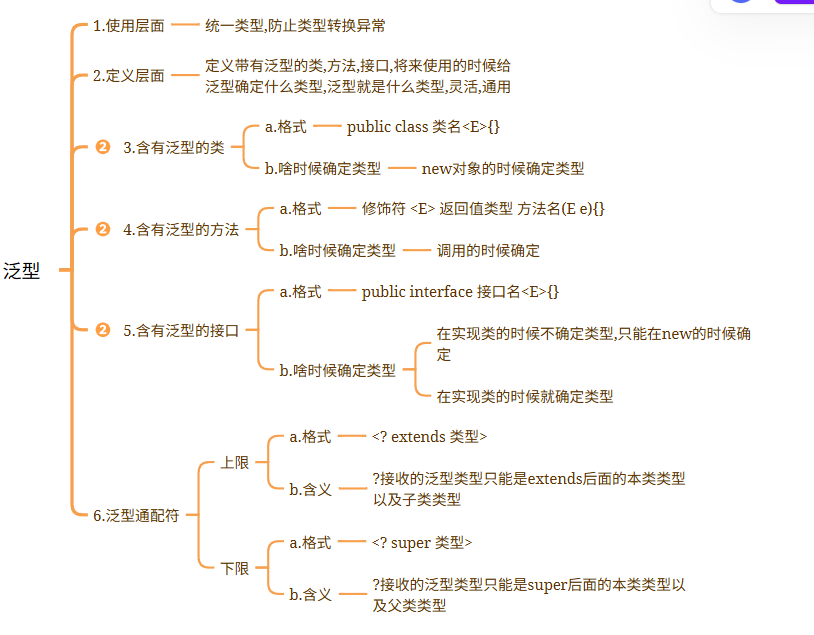
2.集合_泛型的定义和使用&泛型通配符
泛型1.泛型:<>
2.作用:统一数据类型,防止将来的数据转换异常
3.注意:a.泛型中的类型必须是引用类型b.如果泛型不写,默认类型为Object ===============================================================================
## 1.为什么要使用泛型1.从使用层面上来说:统一数据类型,防止将来的数据类型转换异常
2.从定义层面上来看:定义带泛型的类,方法等,将来使用的时候给泛型确定什么类型,泛型就会变成什么类型,凡是涉及到泛型的都会变成确定的类型,代码更灵活public class Demo01Genericity {public static void main(String[] args) {ArrayList list = new ArrayList();list.add("1");list.add(1);list.add("abc");list.add(2.5);list.add(true);//获取元素中为String类型的字符串长度for (Object o : list) {String s = (String) o;System.out.println(s.length());//ClassCastException}}
}============================================================================## 2.泛型的定义### 2.1含有泛型的类1.定义:public class 类名<E>{}2.什么时候确定类型new对象的时候确定类型 public class MyArrayList <E>{//定义一个数组,充当ArrayList底层的数组,长度直接规定为10Object[] obj = new Object[10];//定义size,代表集合元素个数int size;/*** 定义一个add方法,参数类型需要和泛型类型保持一致** 数据类型为E 变量名随便取*/public boolean add(E e){obj[size] = e;size++;return true;}/*** 定义一个get方法,根据索引获取元素*/public E get(int index){return (E) obj[index];}@Overridepublic String toString() {return Arrays.toString(obj);}
}public class Demo02Genericity {public static void main(String[] args) {MyArrayList<String> list1 = new MyArrayList<>();list1.add("aaa");list1.add("bbb");System.out.println(list1);//直接输出对象名,默认调用toStringSystem.out.println("===========");MyArrayList<Integer> list2 = new MyArrayList<>();list2.add(1);list2.add(2);Integer element = list2.get(0);System.out.println(element);System.out.println(list2);}
}===========================================================================### 2.2含有泛型的方法1.格式:修饰符 <E> 返回值类型 方法名(E e)2.什么时候确定类型调用的时候确定类型public class ListUtils {//定义一个静态方法addAll,添加多个集合的元素public static <E> void addAll(ArrayList<E> list,E...e){for (E element : e) {list.add(element);}}}public class Demo03Genericity {public static void main(String[] args) {ArrayList<String> list1 = new ArrayList<>();ListUtils.addAll(list1,"a","b","c");System.out.println(list1);System.out.println("================");ArrayList<Integer> list2 = new ArrayList<>();ListUtils.addAll(list2,1,2,3,4,5);System.out.println(list2);}
}============================================================================### 2.3含有泛型的接口1.格式:public interface 接口名<E>{}
2.什么时候确定类型:a.在实现类的时候还没有确定类型,只能在new实现类的时候确定类型了 ->比如 ArrayListb.在实现类的时候直接确定类型了 -> 比如Scanner public interface MyList <E>{public boolean add(E e);
}public class MyArrayList1<E> implements MyList<E>{//定义一个数组,充当ArrayList底层的数组,长度直接规定为10Object[] obj = new Object[10];//定义size,代表集合元素个数int size;/*** 定义一个add方法,参数类型需要和泛型类型保持一致** 数据类型为E 变量名随便取*/public boolean add(E e){obj[size] = e;size++;return true;}/*** 定义一个get方法,根据索引获取元素*/public E get(int index){return (E) obj[index];}@Overridepublic String toString() {return Arrays.toString(obj);}
}public class Demo04Genericity {public static void main(String[] args) {MyArrayList1<String> list1 = new MyArrayList1<>();list1.add("张三");list1.add("李四");System.out.println(list1.get(0));}
}public interface MyIterator <E>{E next();
}public class MyScanner implements MyIterator<String>{@Overridepublic String next() {return "涛哥和金莲的故事";}
}public class Demo05Genericity {public static void main(String[] args) {MyScanner myScanner = new MyScanner();String result = myScanner.next();System.out.println("result = " + result);}
}======================================================================## 3.泛型的高级使用### 3.1 泛型通配符 ?public class Demo01Genericity {public static void main(String[] args) {ArrayList<String> list1 = new ArrayList<>();list1.add("张三");list1.add("李四");ArrayList<Integer> list2 = new ArrayList<>();list2.add(1);list2.add(2);method(list1);method(list2);}public static void method(ArrayList<?> list){for (Object o : list) {System.out.println(o);}}}===================================================================================
### 3.2 泛型的上限下限1.作用:可以规定泛型的范围
2.上限:a.格式:<? extends 类型>b.含义:?只能接收extends后面的本类类型以及子类类型
3.下限:a.格式:<? super 类型>b.含义:?只能接收super后面的本类类型以及父类类型 /*** Integer -> Number -> Object* String -> Object*/
public class Demo02Genericity {public static void main(String[] args) {ArrayList<Integer> list1 = new ArrayList<>();ArrayList<String> list2 = new ArrayList<>();ArrayList<Number> list3 = new ArrayList<>();ArrayList<Object> list4 = new ArrayList<>();get1(list1);//get1(list2);错误get1(list3);//get1(list4);错误System.out.println("=================");//get2(list1);错误//get2(list2);错误get2(list3);get2(list4);}//上限 ?只能接收extends后面的本类类型以及子类类型public static void get1(Collection<? extends Number> collection){}//下限 ?只能接收super后面的本类类型以及父类类型public static void get2(Collection<? super Number> collection){}
}===================================================================================应用场景:1.如果我们在定义类,方法,接口的时候,如果类型不确定,我们可以考虑定义含有泛型的类,方法,接口2.如果类型不确定,但是能知道以后只能传递某个类的继承体系中的子类或者父类,就可以使用泛型的通配符| 知识点 | 核心内容 | 重点 |
| 泛型基本概念 | 使用尖括号声明引用数据类型,统一集合元素类型 | 必须使用引用类型,基本类型需用包装类 |
| 泛型作用 | 1. 统一数据类型; 2. 防止类型转换异常 | 未指定泛型时默认Object类型 |
| 泛型类定义 | 类声明时添加<E>,成员方法可使用E作为类型 | new对象时确定具体类型 |
| 泛型方法定义 | 方法修饰符后声明<E>,可接受任意类型参数 | 调用时确定类型,注意与返回值类型区分 |
| 泛型接口实现 | 1. 实现时不指定类型(new时确定); 2. 实现时直接指定具体类型 | Iterator接口的两种实现方式对比 |
| 通配符(?)使用 | 接收任意泛型类型,常用于方法参数 | 与不声明泛型的区别(编译检查) |
| 泛型上下限 | 上限:<? extends T>(接收T及其子类); 下限:<? super T>(接收T及其父类) | Number与Integer的继承关系应用 |
| 类型擦除机制 | 编译后泛型信息被擦除,转为Object类型 | 运行时无法获取泛型具体类型 |
| 泛型应用场景 | 1. 类型不确定时定义泛型类/方法; 2. 知道继承体系时使用通配符 | ArrayList源码中的泛型设计 |
3.集合_二叉树&查找树&红黑树说明
| 知识点 | 核心内容 | 重点 |
| 树的基本概念 | 计算机中的树与生活场景相反(树根朝上),由根节点、子树、叶子节点构成 | 生活场景与数据结构的差异(树根位置) |
| 二叉树 | 每个节点最多有两个子节点(左子树/右子树),分支数≤2 | 分支数量限制(超过两个则非二叉树) |
| 平衡树 | 左右子树节点数量相等,查询效率高 | 不平衡树的缺陷(如左子树过长导致查询效率低) |
| 排序树(查找树) | 左子树值<根节点<右子树值,利用大小关系加速查询(如查找2时无需遍历右子树) | 存储规则(新节点按大小插入左右子树) |
| 红黑树 | 趋近平衡的二叉查找树,通过颜色规则(根黑、红节点子节点必黑等)和旋转保持平衡 | 旋转操作(左旋/右旋调整不平衡结构) |
| 哈希表结构演进 | JDK8前:数组+链表; JDK8后:数组+链表+红黑树(优化查询效率) | 红黑树在哈希表中的应用场景 |
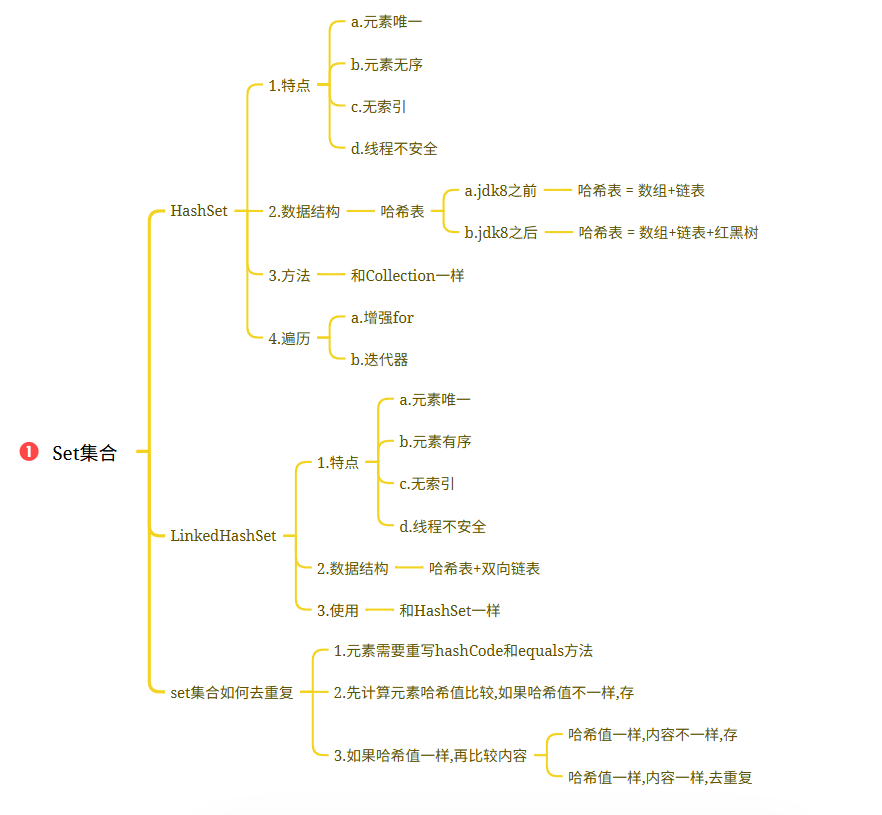
4.集合_Set接口_HashSet&LinkedHashSet
# Set集合Set接口并没有对Collection接口进行功能上的扩充,而且所有的Set集合底层都是依靠Map实现## 1.Set集合介绍Set和Map密切相关的
Map的遍历需要先变成单列集合,只能变成set集合## 2.HashSet集合的介绍和使用1.概述:HashSet是Set接口的实现类
2.特点:a.元素唯一b.元素无序c.无索引d.线程不安全
3.数据结构:哈希表a.jdk8之前:哈希表 = 数组+链表b.jdk8之后:哈希表 = 数组+链表+红黑树加入红黑树目的:查询快
4.方法:和Collection一样
5.遍历:a.增强forb.迭代器public class Demo01HashSet {public static void main(String[] args) {HashSet<String> set = new HashSet<>();set.add("张三");set.add("李四");set.add("王五");set.add("赵六");set.add("田七");set.add("张三");System.out.println(set);//迭代器Iterator<String> iterator = set.iterator();while(iterator.hasNext()){System.out.println(iterator.next());}System.out.println("============");//增强forfor (String s : set) {System.out.println(s);}}
}## 3.LinkedHashSet的介绍以及使用1.概述:LinkedHashSet extends HashSet
2.特点:a.元素唯一b.元素有序c.无索引d.线程不安全
3.数据结构:哈希表+双向链表
4.使用:和HashSet一样 public class Demo02LinkedHashSet {public static void main(String[] args) {LinkedHashSet<String> set = new LinkedHashSet<>();set.add("张三");set.add("李四");set.add("王五");set.add("赵六");set.add("田七");set.add("张三");System.out.println(set);//迭代器Iterator<String> iterator = set.iterator();while(iterator.hasNext()){System.out.println(iterator.next());}System.out.println("============");//增强forfor (String s : set) {System.out.println(s);}}
}| 知识点 | 核心内容 | 重点 |
| Set集合概述 | Set是Collection接口的子接口,未扩展新功能,完全依赖Map实现(如HashSet底层为HashMap) | 无特有方法,方法签名与Collection完全一致(对比JDK6/8源码) |
| HashSet特点 | 1. 元素唯一(自动去重); 2. 无序性(存取顺序不一致); 3. 无索引、线程不安全; 4. 哈希表结构(JDK8前:数组+链表;JDK8+:数组+链表+红黑树) | 哈希表有数组但无索引(需结合底层原理理解); 去重应用场景(如手机号快速去重) |
| LinkedHashSet特点 | 1. 继承HashSet,元素唯一; 2. 有序性(双向链表维护插入顺序); 3. 数据结构:哈希表+双向链表 | 与HashSet的核心差异在有序性; 底层通过双向链表实现顺序追踪 |
| Set实现类对比 | HashSet:无序、哈希表; LinkedHashSet:有序、哈希表+双向链表; 共同点:线程不安全、无索引、依赖Map实现(如add()调用map.put()) | 底层依赖Map(HashSet→HashMap,LinkedHashSet→LinkedHashMap); 遍历方式仅限迭代器/增强for(无普通for循环) |
| 源码关联性 | Set与Map强关联: 1. Set底层调用Map方法(如add()→map.put()); 2. Map遍历需转为Set集合 | 设计模式:Set是Map的"傀儡接口"(功能完全委托) |
5.集合_哈希值&字符串哈希算法
## 4.哈希值1.概述:是由计算机算出来的一个十进制数,可以看做是对象的地址值
2.获取对象的哈希值,使用的是Object中的方法public native int hashCode()
3.注意:如果重写了hashCode方法,那计算的就是对象内容的哈希值了
4.总结:a.哈希值不一样,内容肯定不一样b.哈希值一样,内容也有可能不一样 public class Person {private String name;private Integer age;public Person() {}public Person(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return Objects.equals(name, person.name) && Objects.equals(age, person.age);}@Overridepublic int hashCode() {return Objects.hash(name, age);}
}public class Demo01Hash {public static void main(String[] args) {Person p1 = new Person("涛哥", 18);Person p2 = new Person("涛哥", 18);System.out.println(p1);//com.atguigu.f_hash.Person@4eec7777System.out.println(p2);//com.atguigu.f_hash.Person@3b07d329System.out.println(p1.hashCode());System.out.println(p2.hashCode());//System.out.println(Integer.toHexString(1324119927));//4eec7777//System.out.println(Integer.toHexString(990368553));//3b07d329System.out.println("======================");String s1 = "abc";String s2 = new String("abc");System.out.println(s1.hashCode());//96354System.out.println(s2.hashCode());//96354System.out.println("=========================");String s3 = "通话";String s4 = "重地";System.out.println(s3.hashCode());//1179395System.out.println(s4.hashCode());//1179395}
}如果不重写hashCode方法,默认计算对象的哈希值如果重写了hashCode方法,计算的是对象内容的哈希值## 5.字符串的哈希值时如何算出来的String s = "abc"
byte[] value = {97,98,99} public int hashCode() {int h = hash;if (h == 0 && !hashIsZero) {h = isLatin1() ? StringLatin1.hashCode(value): StringUTF16.hashCode(value);if (h == 0) {hashIsZero = true;} else {hash = h;}}return h;
}
====================================================
StringLatin1.hashCode(value)底层源码,String中的哈希算法public static int hashCode(byte[] value) {int h = 0;for (byte v : value) {h = 31 * h + (v & 0xff);}return h;
}直接跑到StringLatin1.hashCode(value)底层源码,计算abc的哈希值-> 0xff这个十六进制对应的十进制255
任何数据和255做&运算,都是原值第一圈:h = 31*0+97 = 97
第二圈:h = 31*97+98 = 3105
第三圈:h = 31*3105+99 = 96354问题:在计算哈希值的时候,有一个定值就是31,为啥?31是一个质数,31这个数通过大量的计算,统计,认为用31,可以尽量降低内容不一样但是哈希值一样的情况内容不一样,哈希值一样(哈希冲突,哈希碰撞)| 知识点 | 核心内容 | 考试重点/易混淆点 |
| 希值概念 | 哈希值是由计算机算出的十进制数,可看作对象的地址值 | 哈希值与对象地址值的关系 |
| 获取哈希值 | 使用object中的hashCode方法,返回值为int类型 | hashCode方法是本地方法 |
| 哈希值与地址值 | 未重写hashCode时,对象的哈希值不同,地址值也不同 | 哈希值影响地址值 |
| String重写hashCode | String类重写了hashCode方法,计算对象内容的哈希值 | 重写后哈希值与内容相关 |
| 哈希冲突 | 内容不一样但哈希值可能一样,称为哈希冲突或哈希碰撞 | 31作为乘数可降低哈希冲突的概率 |
| 哈希算法 | String的哈希算法是通过遍历字符数组,使用31作为乘数进行计算 | 哈希算法的具体实现过程 |
| 重写hashCode的意义 | 重写hashCode方法后,可计算对象内容的哈希值,便于哈希存储和去重 | 重写hashCode与哈希存储的关系 |
| 特例说明 | 存在特殊字符串(如"通话"和"重力"),内容不同但哈希值相同 | 特例的存在不影响哈希算法的正确性 |
6.集合_HashSet去重复过程说明
## HashSet的存储去重复的过程1.先计算元素的哈希值(重写hashCode方法),再比较内容(重写equals方法)
2.先比较哈希值,如果哈希值不一样,存
3.如果哈希值一样,再比较内容a.如果哈希值一样,内容不一样,存b.如果哈希值一样,内容也一样,去重复 public class Test02 {public static void main(String[] args) {HashSet<String> set = new HashSet<>();set.add("abc");set.add("通话");set.add("重地");set.add("abc");System.out.println(set);//[通话, 重地, abc]}
}===================================================================================## HashSet存储自定义类型如何去重复public class Person {private String name;private Integer age;public Person() {}public Person(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return Objects.equals(name, person.name) && Objects.equals(age, person.age);}@Overridepublic int hashCode() {return Objects.hash(name, age);}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}
}public class Test03 {public static void main(String[] args) {HashSet<Person> set = new HashSet<>();set.add(new Person("涛哥",16));set.add(new Person("金莲",24));set.add(new Person("涛哥",16));System.out.println(set);}
}总结:
1.如果HashSet存储自定义类型,如何去重复呢?重写hashCode和equals方法,让HashSet比较属性的哈希值以及属性的内容
2.如果不重写hashCode和equals方法,默认调用的是Object中的,不同的对象,肯定哈希值不一样,equals比较对象的地址值也不一样,所以此时即使对象的属性值一样,也不能去重复 | 知识点 | 核心内容 | 重点 |
| HashSet去重原理 | 通过计算元素哈希值并比较内容实现去重,需重写hashCode()和equals()方法 | 哈希值相同但内容不同仍存储(如“通话”和“重地”) |
| 自定义类型存储 | 存储自定义类(如Person)时,必须重写hashCode()和equals()方法,否则默认比较对象地址 | 未重写方法时,属性相同仍视为不同对象 |
| 字符串去重特性 | 字符串因底层已重写hashCode()和equals(),可直接用于HashSet去重 | 重复字符串(如“ABC”)自动去重 |
| 源码关联性 | HashSet底层依赖HashMap实现,去重逻辑与HashMap一致 | 需结合Map源码理解Set实现 |
| 方法重写工具 | 使用IDE(如Alt+Insert)快速生成hashCode()和equals()方法 | 无脑下一步即可完成重写 |
7.集合_双列集合框架
## 1.Map的介绍1.概述:是双列集合的顶级接口
2.元素特点:元素都是由key(键),value(值)组成 -> 键值对## 2.HashMap的介绍和使用1.概述:HashMap是Map的实现类
2.特点:a.key唯一,value可重复 -> 如果key重复了,会发生value覆盖b.无序c.无索引d.线程不安全e.可以存null键null值
3.数据结构:哈希表
4.方法:V put(K key, V value) -> 添加元素,返回的是V remove(Object key) ->根据key删除键值对,返回的是被删除的valueV get(Object key) -> 根据key获取valueboolean containsKey(Object key) -> 判断集合中是否包含指定的keyCollection<V> values() -> 获取集合中所有的value,转存到Collection集合中Set<K> keySet()->将Map中的key获取出来,转存到Set集合中 Set<Map.Entry<K,V>> entrySet()->获取Map集合中的键值对,转存到Set集合中public class Demo01HashMap {public static void main(String[] args) {HashMap<String, String> map = new HashMap<>();//V put(K key, V value) -> 添加元素,返回的是被覆盖的valueString value1 = map.put("猪八", "嫦娥");System.out.println(value1);String value2 = map.put("猪八", "高翠兰");System.out.println(value2);System.out.println(map);map.put("后裔","嫦娥");map.put("二郎神","嫦娥");map.put("唐僧","女儿国国王");map.put("涛哥","金莲");map.put(null,null);System.out.println(map);//V remove(Object key) ->根据key删除键值对,返回的是被删除的valueString value3 = map.remove("涛哥");System.out.println(value3);System.out.println(map);//V get(Object key) -> 根据key获取valueSystem.out.println(map.get("唐僧"));//boolean containsKey(Object key) -> 判断集合中是否包含指定的keySystem.out.println(map.containsKey("二郎神"));//Collection<V> values() -> 获取集合中所有的value,转存到Collection集合中Collection<String> collection = map.values();System.out.println(collection);}
}1.概述:LinkedHashMap extends HashMap
2.特点:a.key唯一,value可重复 -> 如果key重复了,会发生value覆盖b.有序c.无索引d.线程不安全e.可以存null键null值
3.数据结构:哈希表+双向链表
4.使用:和HashMap一样 public class Demo02LinkedHashMap {public static void main(String[] args) {LinkedHashMap<String, String> map = new LinkedHashMap<>();map.put("八戒","嫦娥");map.put("涛哥","金莲");map.put("涛哥","三上");map.put("唐僧","女儿国国王");System.out.println(map);}
}| 知识点 | 核心内容 | 重点 |
| Map集合概述 | 双列集合顶级接口,与单列集合相对 | 区分单列集合(Collection)与双列集合(Map)的结构差异 |
| HashMap | - KV键值对结构; - 值可重复; - 无序/无索引; - 线程不安全; - 允许null键null值; - 哈希表数据结构 | 重点记忆哈希冲突处理机制 |
| LinkedHashMap | - 继承HashMap; - 有序存储(双向链表+哈希表); - 其他特性与HashMap一致 | 与HashMap的核心差异在于有序性实现原理 |
| Hashtable | - 线程安全版本; - 禁止null键值; - 哈希表结构 | 对比HashMap的线程安全实现方式 |
| Properties | - Hashtable子类; - 专用于配置文件; - 键值强制String类型; - IO流配合使用 | 配置文件读取时的编码处理问题 |
| TreeMap | - 红黑树结构; - 按键排序; - 禁止null键值; - 线程不安全 | 排序规则实现与Comparator的关系 |
8.集合_HashMap和LinkedHashMap特点和使用
## 1.Map的介绍1.概述:是双列集合的顶级接口
2.元素特点:元素都是由key(键),value(值)组成 -> 键值对## 2.HashMap的介绍和使用1.概述:HashMap是Map的实现类
2.特点:a.key唯一,value可重复 -> 如果key重复了,会发生value覆盖b.无序c.无索引d.线程不安全e.可以存null键null值
3.数据结构:哈希表
4.方法:V put(K key, V value) -> 添加元素,返回的是V remove(Object key) ->根据key删除键值对,返回的是被删除的valueV get(Object key) -> 根据key获取valueboolean containsKey(Object key) -> 判断集合中是否包含指定的keyCollection<V> values() -> 获取集合中所有的value,转存到Collection集合中Set<K> keySet()->将Map中的key获取出来,转存到Set集合中 Set<Map.Entry<K,V>> entrySet()->获取Map集合中的键值对,转存到Set集合中public class Demo01HashMap {public static void main(String[] args) {HashMap<String, String> map = new HashMap<>();//V put(K key, V value) -> 添加元素,返回的是被覆盖的valueString value1 = map.put("猪八", "嫦娥");System.out.println(value1);String value2 = map.put("猪八", "高翠兰");System.out.println(value2);System.out.println(map);map.put("后裔","嫦娥");map.put("二郎神","嫦娥");map.put("唐僧","女儿国国王");map.put("涛哥","金莲");map.put(null,null);System.out.println(map);//V remove(Object key) ->根据key删除键值对,返回的是被删除的valueString value3 = map.remove("涛哥");System.out.println(value3);System.out.println(map);//V get(Object key) -> 根据key获取valueSystem.out.println(map.get("唐僧"));//boolean containsKey(Object key) -> 判断集合中是否包含指定的keySystem.out.println(map.containsKey("二郎神"));//Collection<V> values() -> 获取集合中所有的value,转存到Collection集合中Collection<String> collection = map.values();System.out.println(collection);}
}1.概述:LinkedHashMap extends HashMap
2.特点:a.key唯一,value可重复 -> 如果key重复了,会发生value覆盖b.有序c.无索引d.线程不安全e.可以存null键null值
3.数据结构:哈希表+双向链表
4.使用:和HashMap一样 public class Demo02LinkedHashMap {public static void main(String[] args) {LinkedHashMap<String, String> map = new LinkedHashMap<>();map.put("八戒","嫦娥");map.put("涛哥","金莲");map.put("涛哥","三上");map.put("唐僧","女儿国国王");System.out.println(map);}
}## 3.HashMap的两种遍历方式### 3.1.方式1:获取key,根据key再获取valueSet<K> keySet()->将Map中的key获取出来,转存到Set集合中 public class Demo03HashMap {public static void main(String[] args) {HashMap<String, String> map = new HashMap<>();map.put("猪八", "嫦娥");map.put("猪八", "高翠兰");map.put("后裔","嫦娥");map.put("二郎神","嫦娥");map.put("唐僧","女儿国国王");map.put("涛哥","金莲");Set<String> set = map.keySet();//获取所有的key,保存到set集合中for (String key : set) {//根据key获取valueSystem.out.println(key+".."+map.get(key));}}
}### 3.2.方式2:同时获取key和valueSet<Map.Entry<K,V>> entrySet()->获取Map集合中的键值对,转存到Set集合中public class Demo04HashMap {public static void main(String[] args) {HashMap<String, String> map = new HashMap<>();map.put("猪八", "嫦娥");map.put("猪八", "高翠兰");map.put("后裔","嫦娥");map.put("二郎神","嫦娥");map.put("唐僧","女儿国国王");map.put("涛哥","金莲");/*Set集合中保存的都是"结婚证"-> Map.Entry我们需要将"结婚证"从set集合中遍历出来*/Set<Map.Entry<String, String>> set = map.entrySet();for (Map.Entry<String, String> entry : set) {String key = entry.getKey();String value = entry.getValue();System.out.println(key+"..."+value);}}
}## 1.Map存储自定义对象时如何去重复public class Person {private String name;private Integer age;public Person() {}public Person(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return Objects.equals(name, person.name) && Objects.equals(age, person.age);}@Overridepublic int hashCode() {return Objects.hash(name, age);}
}public class Demo05HashMap {public static void main(String[] args) {HashMap<Person, String> map = new HashMap<>();map.put(new Person("涛哥",18),"河北省");map.put(new Person("三上",26),"日本");map.put(new Person("涛哥",18),"北京市");System.out.println(map);}
}如果key为自定义类型,去重复的话,重写hashCode和equals方法,去重复过程和set一样一样的
因为set集合的元素到了底层都是保存到了map的key位置上## 2.Map的练习需求:用Map集合统计字符串中每一个字符出现的次数
步骤:1.创建Scanner和HashMap2.遍历字符串,将每一个字符获取出来3.判断,map中是否包含遍历出来的字符 -> containsKey4.如果不包含,证明此字符第一次出现,直接将此字符和1存储到map中5.如果包含,根据字符获取对应的value,让value++6.将此字符和改变后的value重新保存到map集合中7.输出public class Demo06HashMap {public static void main(String[] args) {//1.创建Scanner和HashMapScanner sc = new Scanner(System.in);HashMap<String, Integer> map = new HashMap<>();String data = sc.next();//2.遍历字符串,将每一个字符获取出来char[] chars = data.toCharArray();for (char aChar : chars) {String key = aChar+"";//3.判断,map中是否包含遍历出来的字符 -> containsKeyif (!map.containsKey(key)){//4.如果不包含,证明此字符第一次出现,直接将此字符和1存储到map中map.put(key,1);}else{//5.如果包含,根据字符获取对应的value,让value++//6.将此字符和改变后的value重新保存到map集合中Integer value = map.get(key);value++;map.put(key,value);}}//7.输出System.out.println(map);}
}| 知识点 | 核心内容 | 重点 |
| Map接口基础 | 双列集合顶级接口,元素由键值对(k-v)构成 | 区分单列集合(Collection)与双列集合(Map)的结构差异 |
| HashMap特点 | 1. k唯一 value可重复; 2. 无序无索引; 3. 线程不安全; 4. 允许null键null值; 5. 哈希表结构(数组+链表+红黑树) | 值覆盖机制:k重复时新value覆盖旧value |
| LinkedHashMap特点 | 继承HashMap,双向链表保持有序 | 与HashMap的唯一区别是有序性实现原理 |
| 遍历方式 | 1. keySet():先取k再取v; 2. entrySet():直接获取键值对对象(Map.Entry) | entrySet效率更高(比喻:结婚证包含完整键值信息) |
| 自定义对象去重 | 必须重写hashCode()和equals()方法 | 去重原理与Set集合完全相同(底层共用实现) |
| 核心方法 | put(): 返回被覆盖的value; remove(): 返回被删除的value; get()/containsKey()/values() | put返回值的特殊处理逻辑 |
| 数据结构对比 | HashMap:哈希表+单向链表; LinkedHashMap:哈希表+双向链表 | 链表结构差异导致有序性不同 |
相关文章:
学习日记-day20-6.1
完成目标: 知识点: 1.集合_Collections集合工具类 方法:static <T> boolean addAll(Collection<? super T> c, T... elements)->批量添加元素 static void shuffle(List<?> list) ->将集合中的元素顺序打乱static <T>…...

【音视频】 FFmpeg 解码H265
一、概述 实现了使用FFmpeg读取对应H265文件,并且保存为对应的yuv文件 二、实现流程 读取文件 将H265/H264文件放在build路径下,然后指定输出为yuv格式 在main函数中读取外部参数 if (argc < 2){fprintf(stderr, "Usage: %s <input file&…...

Linux 系统 Docker Compose 安装
个人博客地址:Linux 系统 Docker Compose 安装 | 一张假钞的真实世界 本文方法是直接下载 GitHub 项目的 release 版本。项目地址:GitHub - docker/compose: Define and run multi-container applications with Docker。 执行以下命令将发布程序加载至…...

软件测试|FIT故障注入测试工具——ISO 26262合规下的智能汽车安全验证引擎
FIT(Fault Injection Tester)是SURESOFT专为汽车电子与工业控制设计的自动化故障注入测试工具,基于ISO 26262等国际安全标准开发,旨在解决传统测试中效率低、成本高、安全隐患难以复现的问题,其核心功能包括…...
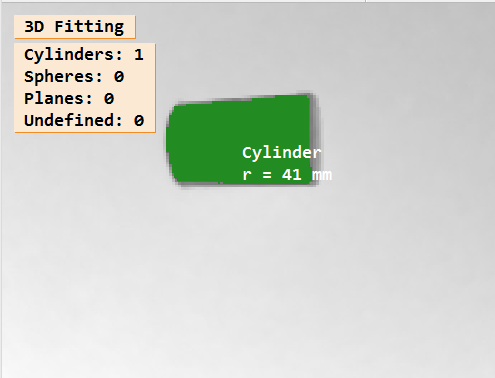
3D拟合测量水杯半径
1,目的。 测量水杯的半径 如图所示: 2,原理。 对 3D 点云对象 进行圆柱体拟合,获取拟合后的半径。 3,注意事项。 在Halcon中使用fit_primitives_object_model_3d进行圆柱体拟合时,输出的primitive_para…...
量子计算对密码学的影响)
(21)量子计算对密码学的影响
文章目录 2️⃣1️⃣ 量子计算对密码学的影响 🌌🔍 TL;DR🚀 量子计算:密码学的终结者?⚡ 量子计算的破坏力 🔐 Java密码学体系面临的量子威胁🔥 受影响最严重的Java安全组件 🛡️ 后…...

Python训练打卡Day38
Dataset和Dataloader类 知识点回顾: Dataset类的__getitem__和__len__方法(本质是python的特殊方法)Dataloader类minist手写数据集的了解 在遇到大规模数据集时,显存常常无法一次性存储所有数据,所以需要使用分批训练的…...
Selenium基础操作方法详解
Selenium基础操作方法详解:从零开始编写自动化脚本(附完整代码) 引言 Selenium是自动化测试和网页操作的利器,但对于新手来说,掌握基础操作是成功的第一步。本文将手把手教你使用Selenium完成浏览器初始化、元素定位、…...

Kali Linux从入门到实战:系统详解与工具指南
一、Kali Linux简介 Kali Linux是一款基于Debian的Linux发行版,专为渗透测试和网络安全审计设计,由Offensive Security团队维护。其前身是BackTrack,目前集成了超过600款安全工具,覆盖渗透测试全流程,是网络安全领域…...

【大模型】Bert变种
1. RoBERTa(Robustly optimized BERT approach) 核心改动 取消 NSP(Next Sentence Prediction)任务,研究发现 NSP 对多数下游任务贡献有限。动态遮蔽(dynamic masking):每个 epoch …...
)
vue-09(使用自定义事件和作用域插槽构建可重用组件)
实践练习:使用自定义事件和作用域插槽构建可重用组件 构建可重用的组件是高效 Vue.js 开发的基石。本课重点介绍如何通过自定义事件和范围插槽来增强组件的可重用性,从而实现更灵活和动态的组件交互。我们将探索如何定义和发出自定义事件,使…...
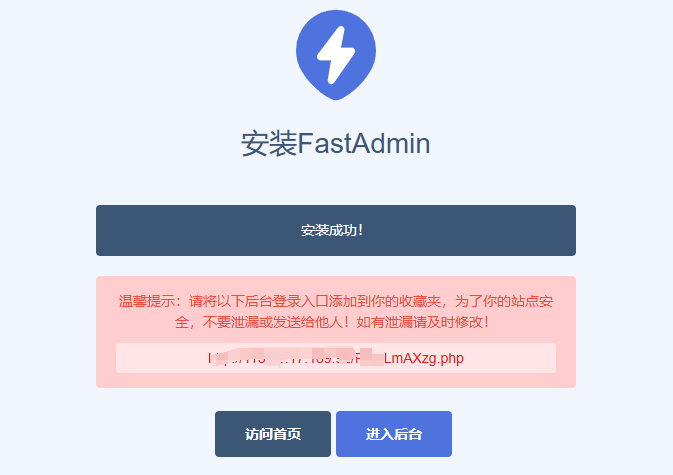
简单三步FastAdmin 开源框架的安装
简单三步FastAdmin 开源框架的安装 第一步:新建站点1,在宝塔面板中,创建一个新的站点,并填写项目域名。 第二步:上传框架1,框架下载2,上传解压缩 第三步:配置并安装1,进入…...
RISC-V 开发板 MUSE Pi Pro 搭建 Spacengine AI模型部署环境
视频讲解: RISC-V 开发板 MUSE Pi Pro 搭建 Spacengine AI模型部署环境 Spacengine 是由 进迭时空 研发的一套 AI 算法模型部署工具,可以方便的帮助用户部署自己的模型在端侧, 环境部署的方式,官方提供了两种方式: do…...

C++面试5——对象存储区域详解
C++对象存储区域详解 核心观点:内存是程序员的战场,存储区域决定对象的生杀大权!栈对象自动赴死,堆对象生死由你,全局对象永生不死,常量区对象只读不灭。 一、四大地域生死簿 栈区(Stack) • 特点:自动分配释放,速度极快(类似高铁进出站) • 生存期:函数大括号{}就…...
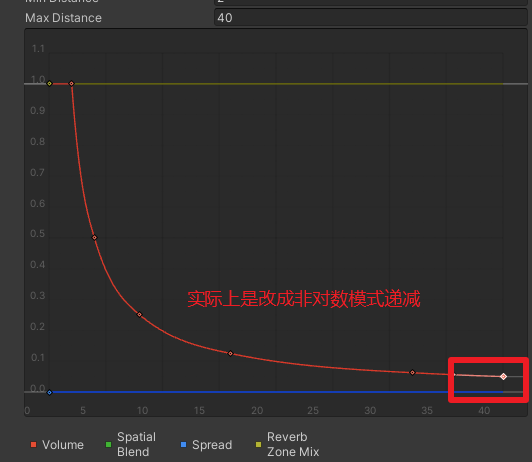
【Unity】AudioSource超过MaxDistance还是能听见
unity版本:2022.3.51f1c1 将SpatialBlend拉到1即可 或者这里改到0 Hearing audio outside max distance - #11 by wderstine - Questions & Answers - Unity Discussions...

基于 51 单片机的智能饮水机控制系统设计与实现
一、引言 随着物联网技术的发展,传统家电的智能化升级成为趋势。本文提出一种基于 51 单片机的智能饮水机设计方案,实现水温精准控制、水位监测、人机交互等功能,具有成本低、稳定性高的特点,适用于家庭和小型办公场景。 二、硬件设计 2.1 核心芯片选型 单片机:选用STC…...
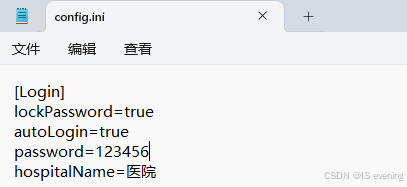
Qt 读取和写入 INI 格式的配置文件
Qt 读取和写入 INI 格式的配置文件 前言:INI 配置文件在 Qt 开发中的重要性基础夯实:INI 文件结构与 QSettings 核心概念1. INI 文件的基本结构2. QSettings 类概述3. 初始化 QSettings 对象4. 基本读写操作5. 高级操作技巧5.1 处理数组和列表5.2 检查键…...

互联网大厂Java求职面试:AI与云原生架构实战解析
互联网大厂Java求职面试:AI与云原生架构实战解析 面试背景设定 场景:某互联网头部企业技术总监办公室,窗外是城市夜景,室内灯光柔和。面试官是一位经验丰富的技术总监,面前摆着一杯黑咖啡和候选人的简历。 候选人&a…...
Spring:从青铜到王者,你的Java修炼手册
一、Spring家族宇宙:原来你是这样的框架(青铜段位) 1.1 Spring的"前世今生":从泡面到满汉全席 2002年的泡面哲学:Rod Johnson在厨房煮泡面时突然顿悟:"Java开发为什么不能像泡面一…...

React和原生事件的区别
一、核心差异对比表 维度原生事件React 事件绑定语法HTML 属性(onclick)或 DOM API(addEventListener)JSX 中使用驼峰式属性(onClick)绑定位置直接绑定到具体 DOM 元素统一委托到根节点(React …...
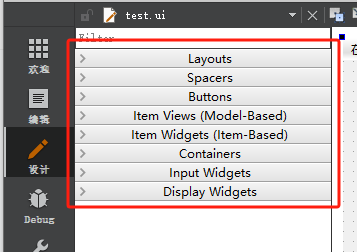
Qt creator 设计页面控件认识与了解
记录一下 Qt 中的认识与了解: 在 Qt 中,这些功能属于 Qt Designer 的组件过滤系统,旨在帮助开发者在对象浏览器中快速定位和使用不同类型的控件和组件。以下是每个功能的详细讲解: Layouts(布局)&…...

命象架构法 02|你的系统有“用神”吗?
命理中说:“八字无用神,是虚命。” 系统架构中说:“模块无主线,是垃圾桶。” 你设计了无数类,却不知道哪个是核心。 那么你的系统,很可能是没有“用神”的。 01|什么是“用神”?不是你以为的“最好” 命理中,“用神”不是“最强的”,而是对命主最有帮助的。 比如一…...

NVIDIA Mellanox BlueField-2 DPU(Data Processing Unit)智能网卡的调试和使用
专有名词 OOB: BMC: BFB: EMMC: 关键词解释eMMCEmbedded Multi-Media Card——把 NAND 闪存颗粒与控制器封装在一起的板载存储件,类似手机里的“内置储存” .deb:文件是Debian软件包格式的专…...

Tomcat- AJP协议文件读取/命令执行漏洞(幽灵猫复现)详细步骤
一、漏洞描述 Apache Tomcat是由Apache软件基金会属下Jakarta项目开发的Servlet容器.默认情况下,Apache Tomcat会开启AJP连接器,方便与其他Web服务器通过AJP协议进行交互.但Apache Tomcat在AJP协议的实现上存在漏洞,导致攻击者可以通过发送恶意的AJP请求,可以读取或者包含Web应…...

B1、进度汇报(— 25/05/31)
本文档汇总了各成员在 2025 年 5 月 11 日 ~ 5 月 31 日完成的工作。我们遇到了进度问题(收工后需反思): 本学期第十四周(05/19 ~ 05/25)有相当多课程需要提交实验结果或上台展示。本学期第十六周(06/02 ~…...

工作流引擎-11-开源 BPM 项目 jbpm
工作流引擎系列 工作流引擎-00-流程引擎概览 工作流引擎-01-Activiti 是领先的轻量级、以 Java 为中心的开源 BPMN 引擎,支持现实世界的流程自动化需求 工作流引擎-02-BPM OA ERP 区别和联系 工作流引擎-03-聊一聊流程引擎 工作流引擎-04-流程引擎 activiti 优…...

【Prompt Engineering】摸索出的一些小套路
prompt 优化方法 🔹 1. 通用结构模板 模块化的Prompt:Prompt 划分成边界清晰的模块,不同模块间都应有明确的分隔符 以下是通用 Prompt 的推荐结构: [角色设定] [任务描述] [输出格式要求] [补充上下文]角色设定:…...

CSS强制div单行显示不换行
在CSS中,要让<div>的内容强制单行显示且不换行,可通过以下属性组合实现: 核心解决方案: css 复制 下载 div {white-space: nowrap; /* 禁止文本换行 */overflow: hidden; /* 隐藏溢出内容 */text-overflow: e…...

js的时间循环的讲解
JavaScript 事件循环(Event Loop)是其运行时的核心机制,负责处理异步操作,确保单线程的 JavaScript 能够高效地处理并发任务。下面从多个角度详细解析事件循环机制: 1. 核心概念 (1)执行栈(Call Stack) 定义:JavaScript 是单线程的,所有同步任务都在执行栈中依次执…...

Flutter实现不规则瀑布流布局拖拽重排序
因为业务,所以需要用flutter去实现一种不规则图形的瀑布流,但是同时需要支持拖拽并重新排序。效果类似如下。 查询过现有的插件,要么是仅支持同样大小的组件进行排序,要么就是动画效果不是很满意,有点死板,…...