【深度学习】实验四 卷积神经网络CNN
实验四 卷积神经网络CNN
一、实验学时: 2学时
二、实验目的
- 掌握卷积神经网络CNN的基本结构;
- 掌握数据预处理、模型构建、训练与调参;
- 探索CNN在MNIST数据集中的性能表现;
三、实验内容
实现深度神经网络CNN。
四、主要实验步骤及结果
1.搭建一个CNN网络,使用MNIST手写数字数据集进行训练与测试,并体现模型最终结果,CNN网络的具体框架可参考下图,也可自己设计:
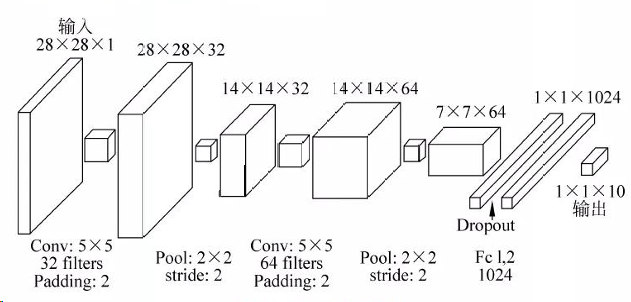
图4-1 CNN架构图
(1)该图表示输入层为28*28*1的尺寸,符合MNIST数据集的标准尺寸。
(2)第一个卷积层,使用5*5卷积核,32个滤波器,填充(Padding)为2。输出尺寸为28*28*32。
(3)第一个池化层,使用2*2池化窗口,步长(stride)为2。输出尺寸为14*14*32。
(4)第二个卷积层,使用5*5卷积核,64个滤波器,填充(Padding)为2。输出尺寸为14*14*64。
(5)第二个池化层,使用2*2池化窗口,步长(stride)为2。输出尺寸为7*7*64。
(6)全连接层包含1024个神经元,输出尺寸为1*1*1024。
(7)Dropout层用于防止过拟合。
(8)输出层包含10个神经元,对应手写数字的0-9。输出尺寸为1*1*10。
模型实现:
以该架构图搭建CNN网络,使用MNIST手写数字数据集进行训练与测试,训练和测试结果如图4-2所示:
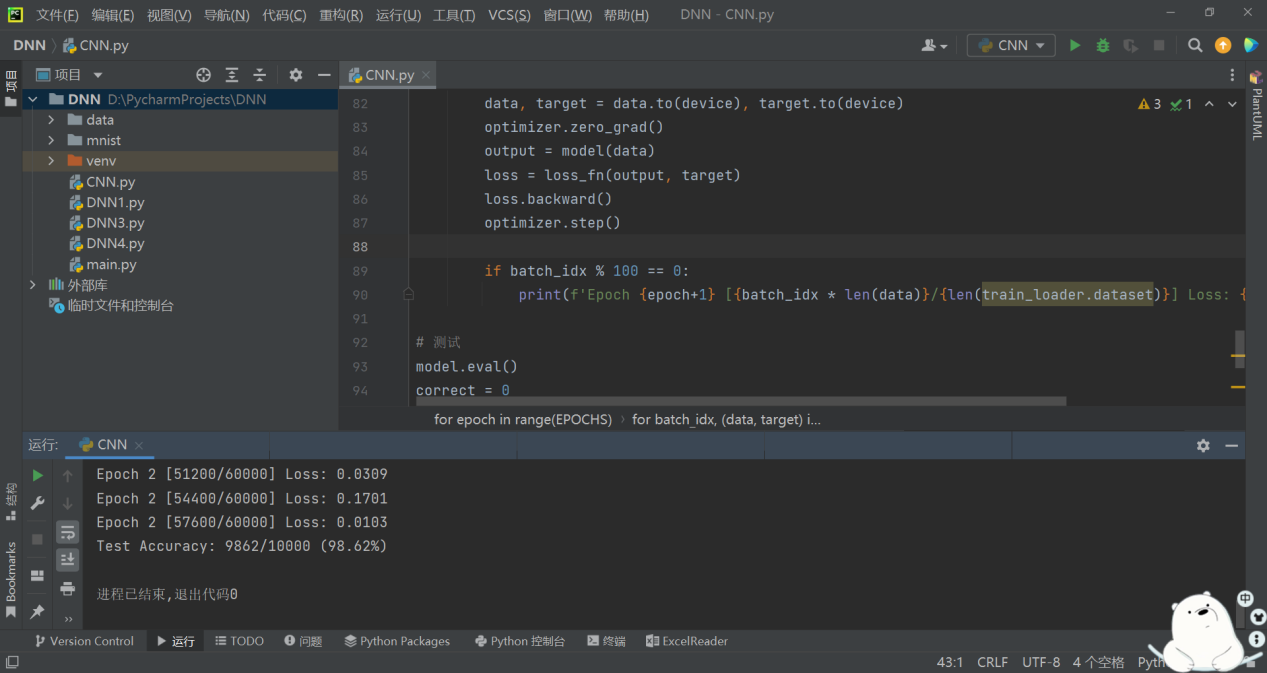
图4-2 CNN测试结果
2.尝试使用不同的数据增强方法、优化器、损失函数、学习率、batch size和迭代次数来进行训练,记录训练过程,评估模型性能,保存最佳模型。
| 编号 | batch size | 训练轮次 | 学习率 | 数据增强方法 | 优化器 | 实验结果 |
| 1 | 32 | 2 | 1e-4 | 无 | Adam | 98.62% |
| 2 | 64 | 2 | 1e-4 | 无 | Adam | 98.56% |
| 3 | 64 | 4 | 1e-4 | 无 | Adam | 99.08% |
| 4 | 64 | 4 | 3e-4 | 无 | Adam | 99.08% |
| 5 | 64 | 4 | 3e-4 | 旋转+平移 | Adam | 98.90% |
| 5 | 64 | 4 | 3e-4 | 无 | Adam(L2正则化) | 99.23% |
| 6 | 64 | 4 | 1e-4 | 无 | SGD+momentum | 97.30% |
其中数据增强方法采用随机旋转和平移吗,原始代码中包含ToTensor()和Normalize(),给原始代码添加随机旋转10度和随机平移10%,代码如下:
# 数据加载(归一化)
transform = torchvision.transforms.Compose([torchvision.transforms.RandomRotation(10), # 随机旋转10度torchvision.transforms.RandomAffine(0, translate=(0.1, 0.1)), # 随机平移10%torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))
])优化器选择方面使用SGD+momentum(0.9)替代原Adam优化器,
# 使用SGD+momentum
optimizer = torch.optim.SGD(model.parameters(), lr=LEARN_RATE, momentum=0.9)根据训练过程记录的数据,最佳模型尊却绿为99.23%,最佳模型代码如下:
import torch
import torchvision
import torch.nn as nn
from torch.utils.data import DataLoaderBATCH_SIZE = 64
EPOCHS = 4
LEARN_RATE = 3e-4
DROPOUT_RATE = 0.5device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')# 数据加载(归一化)
transform = torchvision.transforms.Compose([# torchvision.transforms.RandomRotation(10), # 随机旋转10度# torchvision.transforms.RandomAffine(0, translate=(0.1, 0.1)), # 随机平移10%torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))
])train_data = torchvision.datasets.MNIST(root='./mnist',train=True,download=True,transform=transform
)
train_loader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)test_data = torchvision.datasets.MNIST(root='./mnist',train=False,transform=transform
)
test_loader = DataLoader(test_data, batch_size=1000, shuffle=False)class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv_layers = nn.Sequential(# 第一层卷积:5x5 卷积核,32 个过滤器,padding=2nn.Conv2d(1, 32, kernel_size=5, padding=2),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2), # 池化后 14x14x32# 第二层卷积:5x5 卷积核,64 个过滤器,padding=2nn.Conv2d(32, 64, kernel_size=5, padding=2),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2) # 池化后 7x7x64)self.fc_layers = nn.Sequential(nn.Linear(64 * 7 * 7, 1024), # 全连接层:7x7x64 → 1024nn.ReLU(),nn.Dropout(DROPOUT_RATE), # Dropout层nn.Linear(1024, 10) # 输出层:1024 → 10)self._initialize_weights()def _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='relu')nn.init.constant_(m.bias, 0)def forward(self, x):x = self.conv_layers(x)x = x.view(x.size(0), -1) # 展平操作x = self.fc_layers(x)return xmodel = CNN().to(device)
loss_fn = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=LEARN_RATE, weight_decay=1e-5)
# optimizer = torch.optim.SGD(model.parameters(), lr=LEARN_RATE, momentum=0.9) # 使用SGD+momentum
# 训练循环
for epoch in range(EPOCHS):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = loss_fn(output, target)loss.backward()optimizer.step()if batch_idx % 100 == 0:print(f'Epoch {epoch + 1} [{batch_idx * len(data)}/{len(train_loader.dataset)}] Loss: {loss.item():.4f}')# 测试
model.eval()
correct = 0
with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)pred = output.argmax(dim=1)correct += pred.eq(target).sum().item()print(f'Test Accuracy: {correct}/{len(test_loader.dataset)} ({100. * correct / len(test_loader.dataset):.2f}%)')3.使用画图工具将自己的学号逐个写出,使用保存的最佳模型对每个数字进行推理,比较模型对每个数字的准确率预测,也可以尝试实现一个实时识别手写数字的demo。
(1)使用画图工具将自己的学号逐个写出,进行反色处理,并将图片命名为“x_001.png”格式。
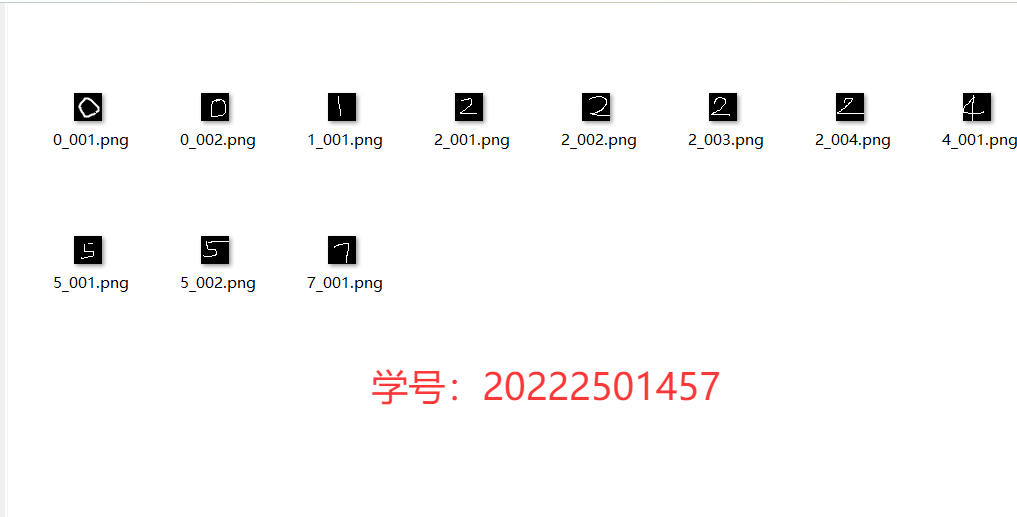
图4-3手写数字
(2)在训练代码(CNN.py)中添加模型保存代码。
torch.save(model.state_dict(), 'mnist_cnn.pth')(3)编写推理代码读取img文件夹中的手写图片并预测,预测代码如下所示:
import torch
import torch.nn as nn
from torchvision import transforms
from PIL import Image
import numpy as np
import os# 定义模型结构(需与训练代码一致)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv_layers = nn.Sequential(nn.Conv2d(1, 32, kernel_size=5, padding=2),nn.ReLU(),nn.MaxPool2d(2, 2),nn.Conv2d(32, 64, kernel_size=5, padding=2),nn.ReLU(),nn.MaxPool2d(2, 2))self.fc_layers = nn.Sequential(nn.Linear(64 * 7 * 7, 1024),nn.ReLU(),nn.Dropout(0.5),nn.Linear(1024, 10))def forward(self, x):x = self.conv_layers(x)x = x.view(x.size(0), -1)x = self.fc_layers(x)return x# 加载模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = CNN().to(device)
model.load_state_dict(torch.load('mnist_cnn.pth', map_location=device))
model.eval()# 定义预处理(与训练一致)
transform = transforms.Compose([transforms.Resize((28, 28)), # 确保输入为28x28transforms.Grayscale(num_output_channels=1), # 转换为单通道transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])# 遍历img文件夹中的图片并推理
img_dir = 'img'
digit_stats = {str(i): {'correct': 0, 'total': 0} for i in range(10)}for filename in os.listdir(img_dir):if filename.lower().endswith(('.png', '.jpg', '.jpeg')):# 从文件名中提取真实标签(假设文件名为 "label_xxx.png")try:true_label = filename.split('_')[0] # 例如文件名 "3_001.png" → 标签为3true_label = int(true_label)if true_label < 0 or true_label > 9:continueexcept:print(f"跳过文件 {filename}(文件名格式错误)")continue# 加载并预处理图像img_path = os.path.join(img_dir, filename)image = Image.open(img_path)image = transform(image).unsqueeze(0).to(device) # 添加batch维度# 推理with torch.no_grad():output = model(image)pred = output.argmax(dim=1).item()# 统计结果digit_stats[str(true_label)]['total'] += 1if pred == true_label:digit_stats[str(true_label)]['correct'] += 1print(f"图片 {filename} 真实标签: {true_label}, 预测: {pred} → {'正确' if pred == true_label else '错误'}")# 计算每个数字的准确率
accuracies = {}
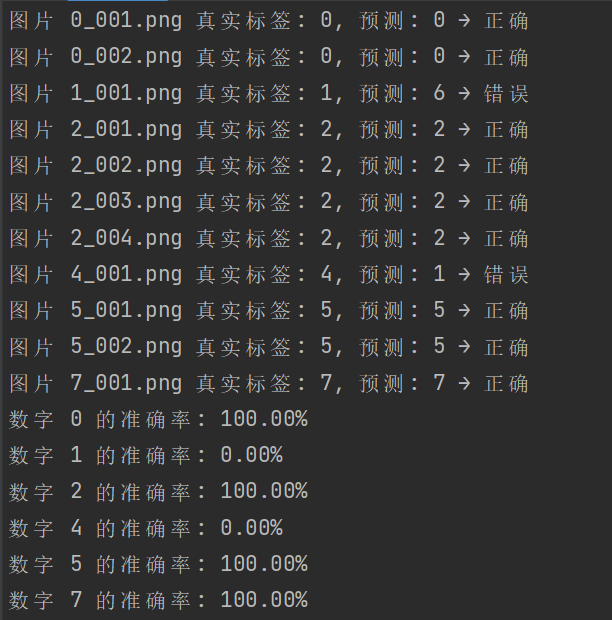
for digit in digit_stats:if digit_stats[digit]['total'] > 0:acc = digit_stats[digit]['correct'] / digit_stats[digit]['total']accuracies[digit] = accprint(f"数字 {digit} 的准确率: {acc:.2%}")预测结果如图4-4所示:
图4-4预测结果
预测结果显示“1”和“4”预测结果错误,其他均正确。
五、实验小结(包括问题和解决办法、心得体会、意见与建议等)
1.问题和解决办法:
问题1:RuntimeError: Dataset not found. You can use download=True to download it。
解决方法:添加下载训练集的参数download=True。
问题2:使用SGD+momentum优化器后,准确率反而下降了。
解决方法:因为SGD对学习率比较敏感,学习率没有适配,使用StepLR梯度衰减,另外也可以增加训练轮次。
问题3:预测结果全部错误。
解决方法:图片要像素28*28,且黑色背景,白色笔迹,对Windows画图的图片反色处理即可。
2.心得体会:通过本次CNN手写数字识别实验的完整实践,我深刻体会到深度学习模型性能的提升是一个系统工程,需要从数据、模型、训练策略到结果分析的全流程精细化把控,尝试使用不同的数据增强方法、优化器、损失函数、学习率、batch size和迭代次数来进行训练,迭代出最佳模型,再手写数字进行测试。通过以上的学习和实践,我对神经网络的原理和应用有了更深入的理解。神经网络的发展给人工智能带来了巨大的影响,它在图像识别、自然语言处理等领域发挥着重要的作用。我相信,随着技术的进步,神经网络将会有更广泛的应用。
相关文章:
【深度学习】实验四 卷积神经网络CNN
实验四 卷积神经网络CNN 一、实验学时: 2学时 二、实验目的 掌握卷积神经网络CNN的基本结构;掌握数据预处理、模型构建、训练与调参;探索CNN在MNIST数据集中的性能表现; 三、实验内容 实现深度神经网络CNN。 四、主要实验步…...
实现一个免费可用的文生图的MCP Server
概述 文生图模型为使用 Cloudflare Worker AI 部署 Flux 模型,是参照视频https://www.bilibili.com/video/BV1UbkcYcE24/?spm_id_from333.337.search-card.all.click&vd_source9ca2da6b1848bc903db417c336f9cb6b的复现Cursor MCP Server实现是参照文章https:/…...

无公网ip远程桌面连接不了怎么办?内网计算机让外网访问方法和问题分析
无公网IP时,可以通过内网穿透技术实现远程桌面连接。 具体方法包括使用 NAT123 或类似端口映射软件将内网IP和端口映射到公网域名和端口上。用户需要在本地安装NAT123客户端,并登录添加设置映射,将内网的远程桌面连接IP和3389端口映射到一…...
【手搓一个原生全局loading组件解决页面闪烁问题】
页面闪烁效果1 页面闪烁效果2 封装一个全局loading组件 class GlobalLoading extends HTMLElement {constructor() {super();this.attachShadow({ mode: open });}connectedCallback() {this.render();this.init();}render() {this.shadowRoot.innerHTML <style>.load…...

CSS基础巩固-基础-选择
目录 CSS是如何工作的? 当浏览器遇到无法解析的CSS代码时 如何导入CSS样式? 改变元素的默认样式 选择 前缀符号(后面会具体介绍) 优先级 同时应用样式到多个类上 属性选择器 伪类 伪元素 关系选择器 后代选择器 子代…...

一种在SQL Server中传递多行数据的方法
这是一种比较偷懒的方法,其实各种数据库对Json 支持的很好。sql server 、oracle都不错。所以可以直接传json declare 这是一个json varchar(max) set 这是一个json{"data":[{"code":"1","name":"啥1"},{"…...
【Docker 从入门到实战全攻略(一):核心概念 + 命令详解 + 部署案例】
1. 是什么 Docker 是一个用于开发、部署和运行应用程序的开源平台,它使用 容器化技术 将应用及其依赖打包成独立的容器,确保应用在不同环境中一致运行。 2. Docker与虚拟机 2.1 Docker(容器化) 容器化是一种轻量级的虚拟化技术…...
github 提交失败,连接不上
1. 第一种情况,开了加速器,导致代理错误 删除hosts文件里相关的github代理地址 2. 有些ip不支持22端口连接,改为443连接 ssh -vT gitgithub.com // 命令执行结果 OpenSSH_for_Windows_9.5p1, LibreSSL 3.8.2 debug1: C…...

系统架构设计师(一):计算机系统基础知识
系统架构设计师(一):计算机系统基础知识 引言计算机系统概述计算机硬件处理器处理器指令集常见处理器 存储器总线总线性能指标总线分类按照总线在计算机中所处的位置划分按照连接方式分类按照功能分类 接口接口分类 计算机软件文件系统文件类…...

VMware安装Ubuntu全攻略
VMware安装Ubuntu实战分享大纲 准备工作 列出安装前的必要条件和工具,包括硬件要求、软件下载链接等。 VMware Workstation Pro/Player的安装与激活Ubuntu镜像文件下载(官方推荐版本)确保主机系统满足虚拟化技术(VT-x/AMD-V)要求创建虚拟机 详细描述在VMware中创建新虚…...
清理 pycharm 无效解释器
1. 起因, 目的: 经常使用 pycharm 来调试深度学习项目,每次新建虚拟环境,都是显示一堆不存在的名称,删也删不掉。 总觉得很烦,是个痛点。决定深入研究一下。 2. 先看效果 效果是能行,而且清爽多了。 3. …...
:指标基准化——如何判断你的数据表现是否足够优秀)
精益数据分析(92/126):指标基准化——如何判断你的数据表现是否足够优秀
精益数据分析(92/126):指标基准化——如何判断你的数据表现是否足够优秀 在创业过程中,面对纷繁复杂的指标数据,创业者常常困惑于“什么样的表现算优秀”“我的数据是否达标”。今天,我们将通过WP Engine的…...

手机如何压缩文件为 RAR 格式:详细教程与工具推荐
在如今这个数字化时代,手机已经成为我们生活中不可或缺的工具。随着我们使用手机的频率越来越高,手机中的文件也越来越多,照片、视频、文档等各种类型的文件不断占据着手机的存储空间。 据统计,普通用户的手机存储空间中…...

Elasticsearch集群管理的相关工具介绍
Elasticsearch 集群管理涉及节点监控、配置管理、故障排查、性能优化等多个环节,依赖一系列官方工具和社区方案实现高效运维。以下从 官方工具链、生态集成工具、社区辅助工具 三个维度介绍核心工具及其应用场景: 一、官方核心工具链 1. Elasticsearch 内置功能 _cluster 接…...

基于多尺度卷积和扩张卷积-LSTM的多变量时间序列预测
时间序列预测是机器学习和数据分析中的重要领域,广泛应用于金融、气象、交通等领域。本文将介绍一种结合多尺度卷积、扩张卷积和LSTM的混合神经网络模型,用于多变量时间序列预测,并提供完整的代码实现和详细讲解。 1. 模型架构概述 我们提出的模型结合了三种强大的神经网络…...

Java 注解式限流教程(使用 Redis + AOP)
Java 注解式限流教程(使用 Redis AOP) 在上一节中,我们已经实现了基于 Redis 的请求频率控制。现在我们将进一步升级功能,使用 Spring AOP 自定义注解 实现一个更优雅、可复用的限流方式 —— 即通过 RateLimiter 注解…...

C# XAML 基础:构建现代 Windows 应用程序的 UI 语言
在现代 Windows 应用程序开发中,XAML (eXtensible Application Markup Language) 扮演着至关重要的角色。作为一种基于 XML 的声明性语言,XAML 为 WPF (Windows Presentation Foundation)、UWP (Universal Windows Platform) 和 Xamarin.Forms 应用程序提…...

Linux运维笔记:服务器感染 netools 病毒案例
文章目录 背景排查过程1. 发现异常2. 检测隐藏进程3. 尝试终止进程4. 深入分析进程 处理步骤1. 禁用 Cron 任务2. 删除恶意文件3. 终止恶意进程4. 重启系统 注意事项总结 提示:本文记录了一起 Linux 服务器感染恶意软件(疑似挖矿病毒)的排查与…...
获取View宽高的几种方式)
(面试)获取View宽高的几种方式
Android 中获取 View 宽高的几种方式,以及它们的适用场景和注意事项: 1. View.getWidth() 和 View.getHeight() 原理: 直接从 View 对象中获取已经计算好的宽度和高度。 优点: 简单直接。 缺点: 在 onCreate()、onStart() 等生命周期方法中࿰…...
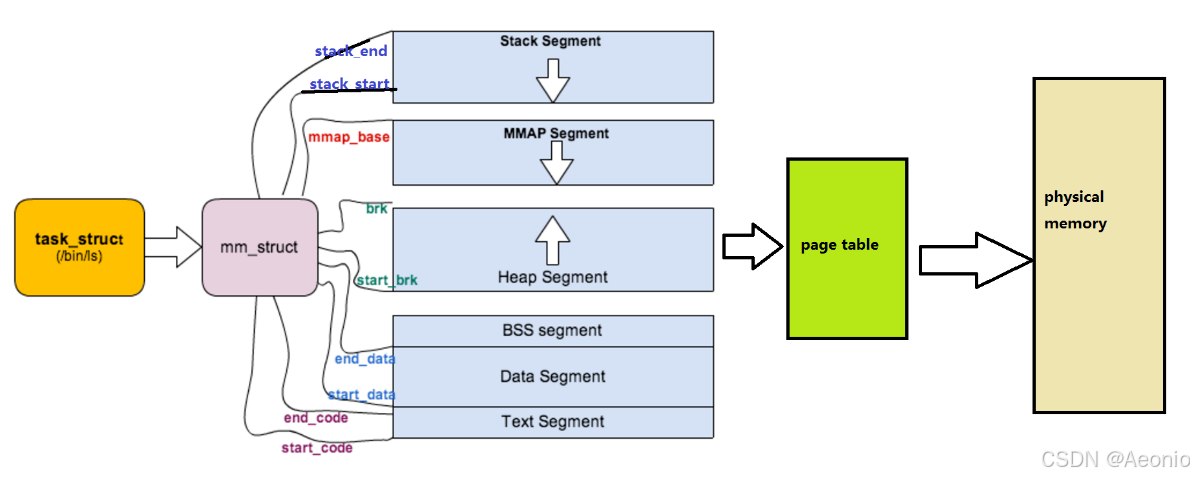
【Linux】进程地址空间揭秘(初步认识)
10.进程地址空间(初步认识) 文章目录 10.进程地址空间(初步认识)一、进程地址空间的实验现象解析二、进程地址空间三、虚拟内存管理补充:数据的写时拷贝(浅谈)补充:页表(…...
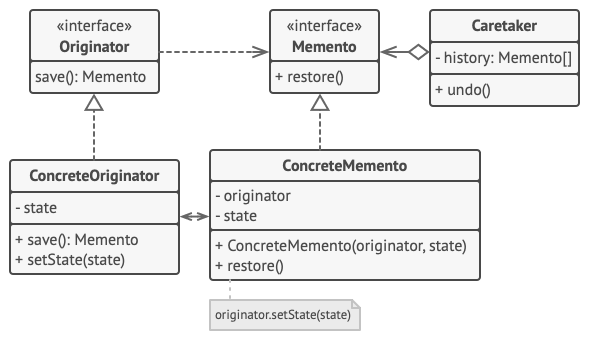
设计模式——备忘录设计模式(行为型)
摘要 备忘录设计模式是一种行为型设计模式,用于在不破坏封装性的前提下,捕获对象的内部状态并在需要时恢复。它包含三个关键角色:原发器(Originator)、备忘录(Memento)和负责人(Car…...

吴恩达:构建自动化评估并不需要大量投入,从一些简单快速的示例入手,然后逐步迭代!
吴恩达老师又来信了。 这次他分享了一个重要观点:构建自动化评估并不需要大量投入。从一些简单快速的示例入手,然后逐步迭代! 以下是我对原文的翻译: 亲爱的朋友们: 我注意到,许多生成式 AI 应用项目在系…...

鸿蒙OSUniApp内存管理优化实战:从入门到精通#三方框架 #Uniapp
UniApp内存管理优化实战:从入门到精通 在开发 UniApp 应用时,特别是针对鸿蒙设备的开发过程中,内存管理往往成为影响应用性能的关键因素。本文将结合实际项目经验,深入探讨 UniApp 应用的内存优化策略,帮助开发者构建…...

Vue-5-基于JavaScript和plotly.js绘制数据分析类图表
文章目录 1 折线图示例1.1 网页基本结构1.2 绘图流程1.2.1 type图表类型1.2.2 mode显示方式1.2.3 marker数据点的样式1.3 横坐标为时间戳1.3.1 xaxis.type坐标值类型1.3.2 xaxis.tickformat格式1.4 悬停时展示毫秒数2 一个变量2.1 箱线图2.2 小提琴图2.3 直方图3 两个变量3.1 折…...
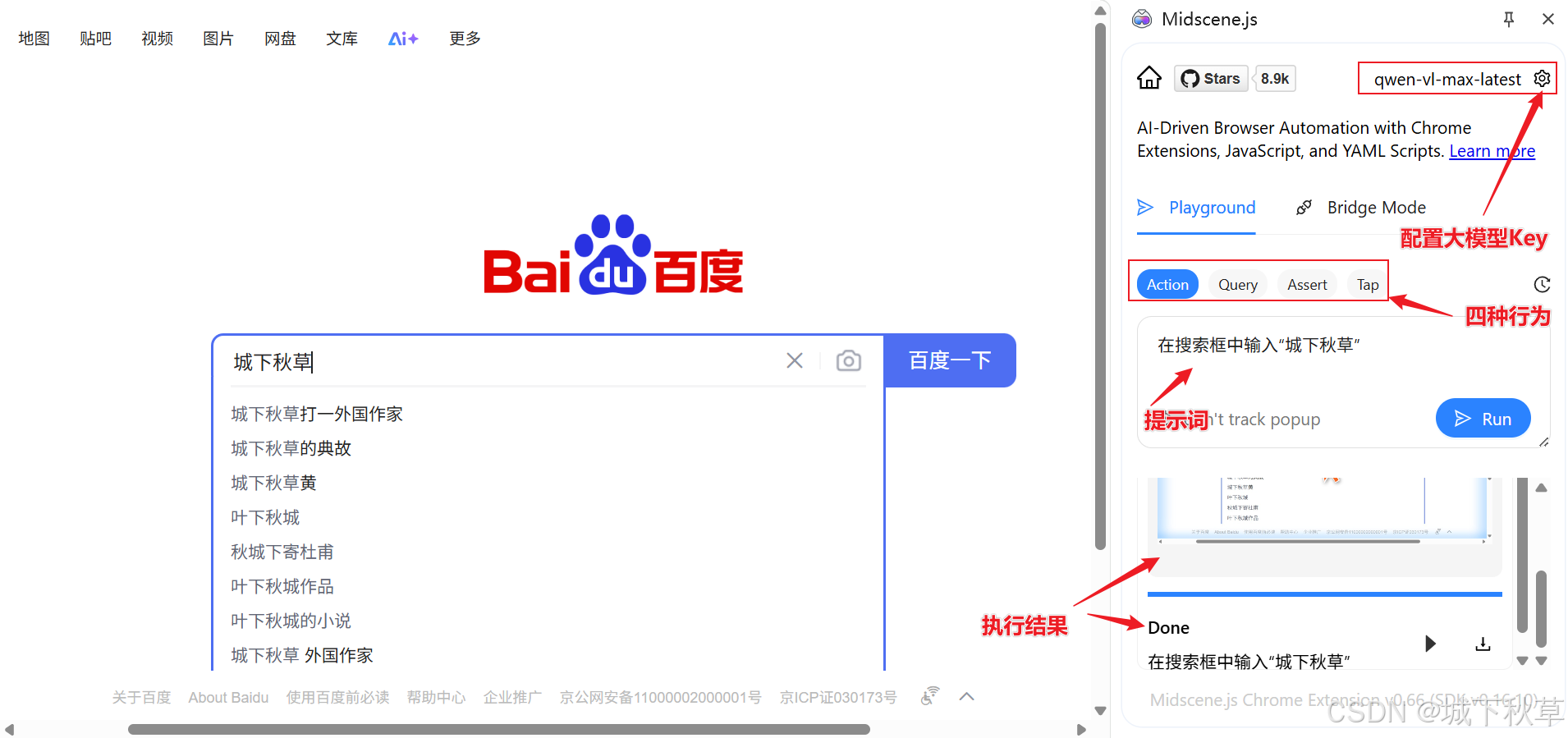
UI自动化测试的革新,新一代AI工具MidScene.js实测!
前言 AI已经越来越深入地走入我们的实际工作,在软件测试领域,和AI相关的新测试工具、方法也层出不穷。在之前我们介绍过结合 mcp server 实现 AI 驱动测试的案例,本文我们将介绍一个近期崭露头角的国产AI测试工具 Midscene.js Midscene.js简介 MidScene.js 是由字节跳动 w…...

StarRocks的几种表模型
## 一、引言:OLAP场景下的表模型挑战 在实时分析领域,数据表的设计直接影响查询性能、存储效率和更新灵活性。StarRocks作为新一代极速全场景MPP数据库,针对不同的业务场景提供了多样化的表模型解决方案。每种模型通过独特的存储结构和预计算…...
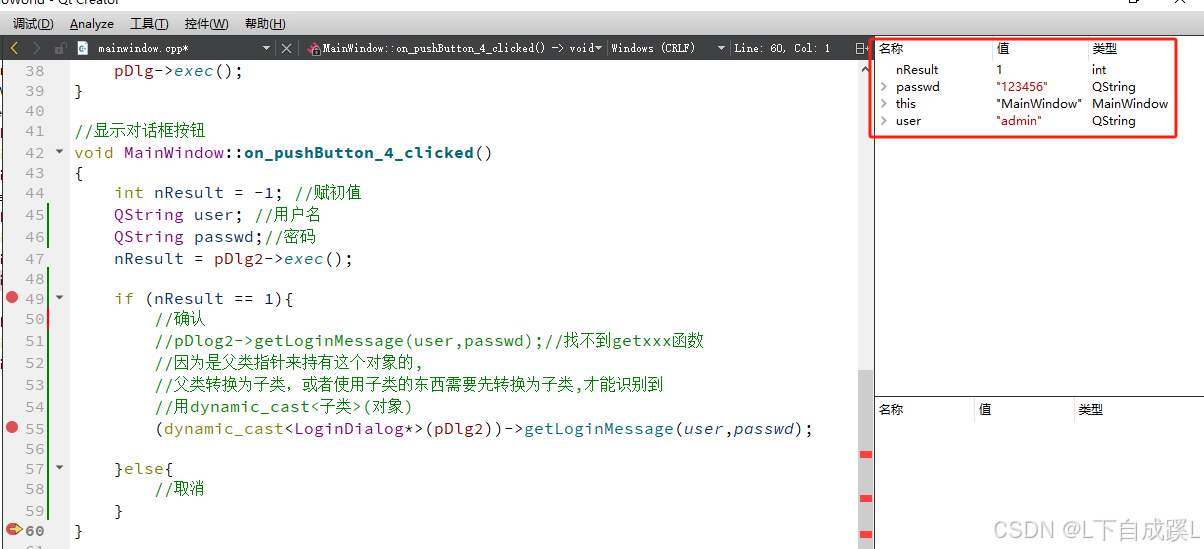
4. Qt对话框(2)
在上节中已经学习了对话框的确认和取消,本节内容继续接上节完成登录对话框实例并得到登录信息。 本文部分ppt、视频截图原链接:[萌马工作室的个人空间-萌马工作室个人主页-哔哩哔哩视频] 1 实现登录对话框 1.1 功能需要 得到登录信息,需要…...
)
2025-5-31-C++ 学习 字符串(终)
字符串 2025-5-31-C 学习 字符串(终)P1200 [USACO1.1] 你的飞碟在这儿 Your Ride Is Here题目描述输入格式输出格式输入输出样例 #1输入 #1输出 #1 输入输出样例 #2输入 #2输出 #2 说明/提示题解代码 P1597 语句解析题目背景题目描述输入格式输出格式输入…...

Android Studio 2022.2.1.20 汉化教程
查看Android Studio 版本 Android Studio Flamingo | 2022.2.1 Patch 2 下载:https://plugins.jetbrains.com/plugin/13710-chinese-simplified-language-pack----/versions/stable...

第17讲、odoo18可视化操作代码生成模块
1. 模块概述 代码框架生成模块是一个专为Odoo开发者设计的工具,旨在简化模块开发过程中的重复性工作。该模块允许开发者通过定义模型名称和字段,自动生成相应的Python代码、XML视图和CSV权限配置文件,从而大幅提高开发效率。通过这种方式&am…...