大数据学习(124)-spark数据倾斜
🍋🍋大数据学习🍋🍋
🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博主哦🤞
1. 倾斜表现
- 某些Task执行时间远超其他Task(通常超过平均时间10倍以上)
- 集群资源利用率不均(部分Executor负载过高)
- 作业执行时间主要由少数几个Task决定
- 频繁出现GC超时或OOM错误
2. 诊断方法
scala
// 通过Spark UI观察Stage和Task的执行时间 | |
// 查看Shuffle Read/Write数据量分布 | |
// 使用以下代码定位倾斜键: | |
val skewedKeys = rdd.mapPartitions(iter => { | |
val counts = scala.collection.mutable.HashMap[String, Int]() | |
iter.foreach(x => counts.put(getKey(x), counts.getOrElse(getKey(x), 0) + 1)) | |
counts.filter(_._2 > threshold).iterator | |
}).collect() |
二、核心解决方案
1. 数据预处理策略
(1) 过滤无效倾斜数据
scala
// 过滤掉明显异常的倾斜键(如空值、默认值等) | |
val filteredData = rawData.filter(row => !isSkewKey(getKey(row))) |
(2) 数据采样分析
scala
// 采样分析数据分布 | |
val sampledData = rawData.sample(false, 0.1) | |
val keyDistribution = sampledData.map(row => (getKey(row), 1)) | |
.reduceByKey(_ + _) | |
.collect() | |
.sortBy(-_._2) |
2. Join操作优化
(1) 广播小表(Broadcast Join)
scala
// 当小表小于spark.sql.autoBroadcastJoinThreshold(默认10MB)时自动触发 | |
// 可手动设置: | |
val smallDF = spark.table("small_table").cache() | |
val largeDF = spark.table("large_table") | |
val result = largeDF.join(broadcast(smallDF), "join_key") |
(2) 盐值加盐法(Salting)
scala
// 对倾斜键添加随机前缀分散数据 | |
import org.apache.spark.sql.functions._ | |
// 生成随机盐值(0-99) | |
val saltedDF = largeDF.withColumn("salted_key", | |
concat(lit("salt_"), (rand() * 100).cast("int")), | |
col("key"))) | |
// 同样处理小表 | |
val saltedSmallDF = smallDF.withColumn("salted_key", | |
concat(lit("salt_"), (rand() * 100).cast("int")), | |
col("key"))) | |
// 执行Join后去除盐值 | |
val joined = saltedDF.join(saltedSmallDF, "salted_key") | |
.drop("salted_key") | |
.groupBy("key").agg(...) // 可能需要聚合去除重复 |
(3) 倾斜键单独处理
scala
// 分离倾斜键和非倾斜键分别处理 | |
val (skewKeys, nonSkewKeys) = getSkewKeys(largeDF) // 自定义方法获取倾斜键 | |
// 处理非倾斜键 | |
val nonSkewJoin = largeDF.filter(!col("key").isin(skewKeys:_*)) | |
.join(smallDF, "key") | |
// 处理倾斜键(可能使用更细粒度分区或特殊处理) | |
val skewJoin = largeDF.filter(col("key").isin(skewKeys:_*)) | |
.repartition(100, col("key")) // 增加分区数 | |
.join(smallDF.repartition(100, col("key")), "key") | |
// 合并结果 | |
val result = nonSkewJoin.union(skewJoin) |
3. 聚合操作优化
(1) 两阶段聚合
scala
// 第一阶段:添加随机前缀分散数据 | |
val firstStage = df.withColumn("prefix", (rand() * 100).cast("int")) | |
.groupBy("prefix", "key").agg(...) | |
// 第二阶段:去除前缀聚合 | |
val secondStage = firstStage.groupBy("key").agg(...) |
(2) 自定义分区器
scala
// 实现自定义分区器,将倾斜键分散到不同分区 | |
class SkewAwarePartitioner(partitions: Int) extends Partitioner { | |
override def numPartitions: Int = partitions | |
override def getPartition(key: Any): Int = { | |
val strKey = key.toString | |
if (isSkewKey(strKey)) { | |
// 对倾斜键进行哈希分散 | |
math.abs(strKey.hashCode) % partitions | |
} else { | |
// 非倾斜键使用默认分区 | |
math.abs(strKey.hashCode) % (partitions / 10) // 减少非倾斜键分区数 | |
} | |
} | |
} | |
// 使用自定义分区器 | |
val partitionedRDD = rdd.partitionBy(new SkewAwarePartitioner(100)) |
4. Shuffle相关优化
(1) 调整并行度
scala
// 增加Shuffle时的并行度 | |
val repartitionedDF = df.repartition(200, col("skew_key")) | |
// 或在join时指定 | |
df1.join(df2, Seq("key"), "inner").repartition(200) |
(2) 使用SkewJoin优化器(Spark 3.0+)
scala
// Spark 3.0+ 自动检测并优化倾斜Join | |
spark.conf.set("spark.sql.adaptive.enabled", "true") | |
spark.conf.set("spark.sql.adaptive.skewJoin.enabled", "true") | |
spark.conf.set("spark.sql.adaptive.skewJoin.skewedPartitionFactor", "5") // 倾斜阈值 | |
spark.conf.set("spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes", "256MB") |
5. 其他高级技术
(1) 增量计算
scala
// 对倾斜键采用增量计算方式,分批处理 | |
val batchSize = 10000 | |
val skewKeys = getSkewKeys(df) // 获取所有倾斜键 | |
val results = skewKeys.grouped(batchSize).flatMap { batch => | |
val batchDF = df.filter(col("key").isin(batch:_*)) | |
// 处理当前批次 | |
processBatch(batchDF) | |
}.toDF() |
(2) 外部系统辅助
scala
// 对极端倾斜数据,可考虑将数据导出到外部系统(如Redis、HBase)处理 | |
// 或使用Spark结合专门处理倾斜键的系统 |
三、最佳实践建议
-
预防为主:
- 在ETL阶段就识别并处理可能的倾斜键
- 对业务数据分布有充分了解
-
监控常态化:
- 建立作业性能基线
- 监控关键Stage的Shuffle数据量
-
参数调优:
properties# 常见相关参数spark.sql.shuffle.partitions=200 # 默认200,根据集群规模调整spark.default.parallelism=200spark.sql.adaptive.coalescePartitions.enabled=truespark.sql.adaptive.coalescePartitions.minPartitionNum=10 -
测试验证:
- 在开发环境使用生产规模数据测试
- 比较不同方案的性能差异
相关文章:
-spark数据倾斜)
大数据学习(124)-spark数据倾斜
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一…...
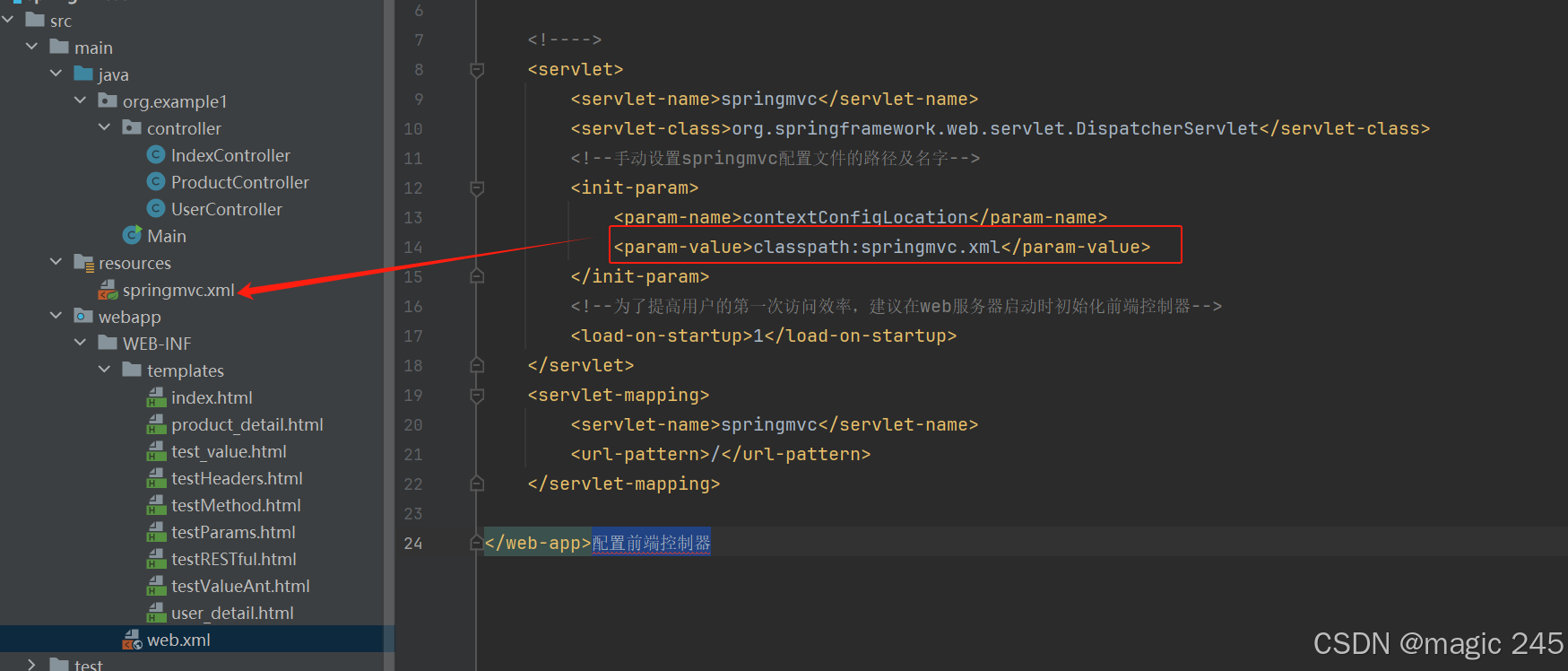
配置前端控制器
一、DispatcherServlet 详解 在使用 Spring MVC 框架构建 Web 应用时,DispatcherServlet是整个请求处理流程的核心。本文将深入解析DispatcherServlet的作用、工作原理及其在 Spring MVC 架构中的关键地位。 1.DispatcherServlet 是什么? DispatcherS…...

lua注意事项
感觉是lua的一大坑啊,它还不如函数内部就局部变量呢 注意函数等内部,全部给加上local得了...
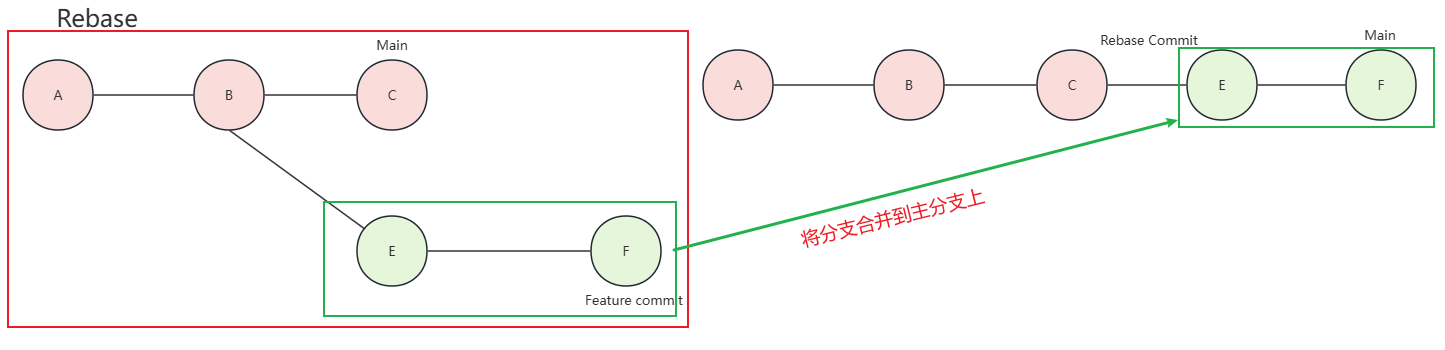
Git的三种合并方式
在 Gitee(码云)中合并分支主要有三种方式:普通合并(Merge Commit)、压缩合并(Squash Merge)和变基合并(Rebase Merge)。每种方式适用于不同的场景,各有…...

从零到一:我的技术博客导航(持续更新)
作者:冰茶 最后更新:2025年6月3日 本文收录了我的C#编程学习心得与技术探索,将持续更新 前言 作为一名.NET开发者,C#语言的学习与探索一直是我技术成长的核心路径。本文集整理了我在C#学习过程中的思考与实践,希望能够…...

SpringBoot整合Flowable【08】- 前后端如何交互
引子 在第02篇中,我通过 Flowable-UI 绘制了一个简单的绩效流程,并在后续章节中基于这个流程演示了 Flowable 的各种API调用。然而,在实际业务场景中,如果要求前端将用户绘制的流程文件发送给后端再进行解析处理,这种…...

DM达梦数据库开启SQL日志记录功能
DM达梦数据库开启SQL日志记录功能 配置SQL日志(非必须的配置步骤,与主备集群配置无关,如果没有需求可以跳过配置SQL日志) sqllog.ini 配置文件用于SQL日志的配置,当且仅当 INI(dm.ini) 参数 SV…...
)
00 QEMU源码分析中文注释与架构讲解(v8.2.4版本)
QEMU-v8.2.4源码中文注释与架构讲解 文档会不定期更新 注释作者将狼才鲸创建日期2025-05-30更新日期2025-06-02 CSDN阅读地址:QEMU源码中文注释与架构讲解Gitee源码仓库地址:才鲸嵌入式/qemu 一、前言 其它参考教程的网址: QEMU 源码目录…...
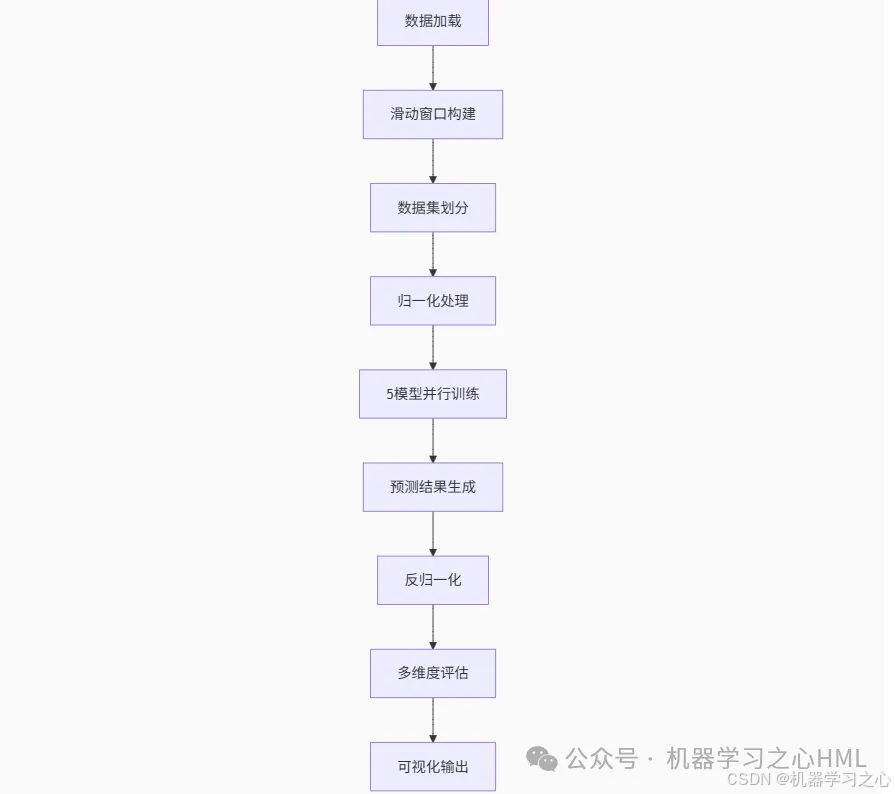
【五模型时间序列预测对比】Transformer-LSTM、Transformer、CNN-LSTM、LSTM、CNN
【五模型时间序列预测对比】Transformer-LSTM、Transformer、CNN-LSTM、LSTM、CNN 目录 【五模型时间序列预测对比】Transformer-LSTM、Transformer、CNN-LSTM、LSTM、CNN预测效果基本介绍程序设计参考资料 预测效果 基本介绍 Transformer-LSTM、Transformer、CNN-LSTM、LSTM、…...
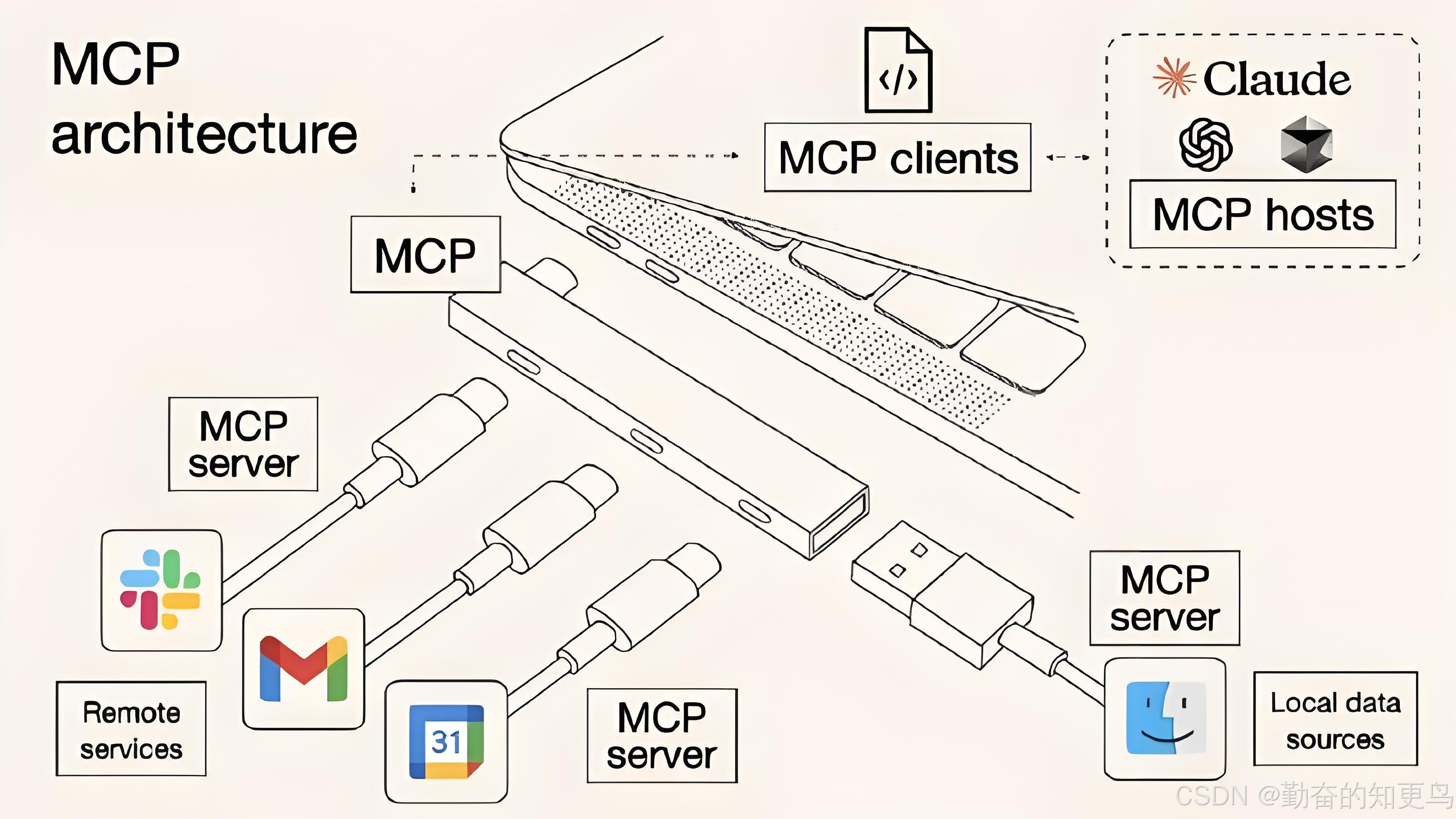
深入了解MCP基础与架构
一、引言 在人工智能技术以指数级速度渗透各行业领域的今天,我们正站在一个关键的技术拐点。当ChatGPT月活突破亿级、Gemini Pro实现多模态实时交互、Claude 3.5 Sonnet突破百万上下文长度,这些里程碑事件背后,一个崭新的大门逐步打开&#…...
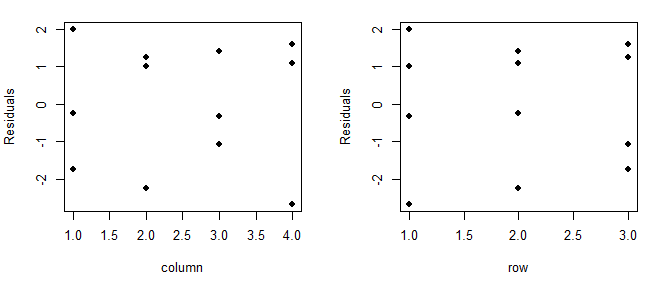
实验设计与分析(第6版,Montgomery)第5章析因设计引导5.7节思考题5.13 R语言解题
本文是实验设计与分析(第6版,Montgomery著,傅珏生译) 第5章析因设计引导5.7节思考题5.13 R语言解题。主要涉及方差分析,正态假设检验,残差分析,交互作用图。 dataframe<-data.frame( yc(36,18,30,39,20…...

怎么选择合适的高防IP
选择合适的高防IP需要综合考虑业务需求、防护能力、服务稳定性、成本效益等多方面因素。以下是从多个权威来源整理的关键要点,帮助您做出科学决策: 一、明确业务需求 业务类型与规模 网站/应用类:需支持HTTP/HTTPS协议,并配置域名…...

【java面试】MySQL篇
MySQL篇 一、总体结构二、优化(一)定位慢查询1.1 开源工具1.2Mysql自带的慢日志查询1.3 总结 (二)定位后优化2.1 优化2.2 总结 (三)索引3.1 索引3.2 索引底层数据结构——B树3.3 总结 (四&#…...

贪心算法应用:欧拉路径(Fleury算法)详解
Java中的贪心算法应用:欧拉路径(Fleury算法)详解 一、欧拉路径与欧拉回路基础 1.1 基本概念 欧拉路径(Eulerian Path)是指在一个图中,经过图中每一条边且每一条边只经过一次的路径。如果这条路径的起点和…...
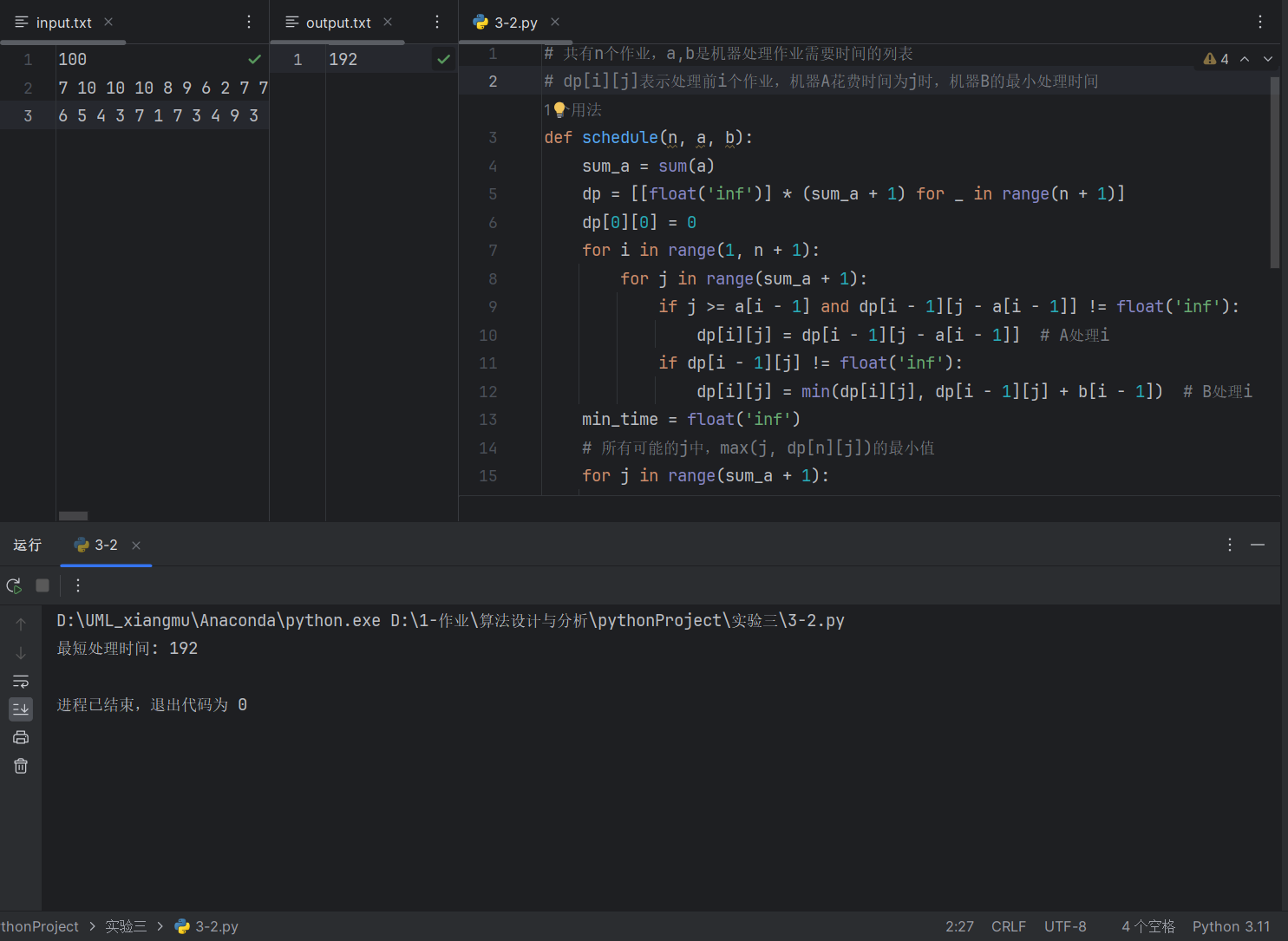
【算法设计与分析】实验——二维0-1背包问题(算法分析题:算法思路),独立任务最优调度问题(算法实现题:实验过程,描述,小结)
说明:博主是大学生,有一门课是算法设计与分析,这是博主记录课程实验报告的内容,题目是老师给的,其他内容和代码均为原创,可以参考学习,转载和搬运需评论吱声并注明出处哦。 要求:3-…...

P12592题解
题目传送门 思路 由于题目中说了可以任意交换两个字符的位置,我们只需要判断这个字符串是否满足回文串的条件即可。 代码: #include<bits/stdc.h> using namespace std; int a[30]; int main(){int T;cin>>T;while(T--){fill(a,a29,0);/…...
:分解与复用命令)
ffmpeg命令(二):分解与复用命令
分解(Demuxing) 提取视频流(不含音频) ffmpeg -i input.mp4 -an -vcodec copy video.h264-an:去掉音频 -vcodec copy:拷贝视频码流,不重新编码 提取音频流(不含视频)…...

【Git】View Submitted Updates——diff、show、log
在 Git 中查看更新的内容(即工作区、暂存区或提交之间的差异)是日常开发中的常见操作。以下是常用的命令和场景说明: 文章目录 1、查看工作区与暂存区的差异2、查看提交历史中的差异3、查看工作区与最新提交的差异4、查看两个提交之间的差异5…...
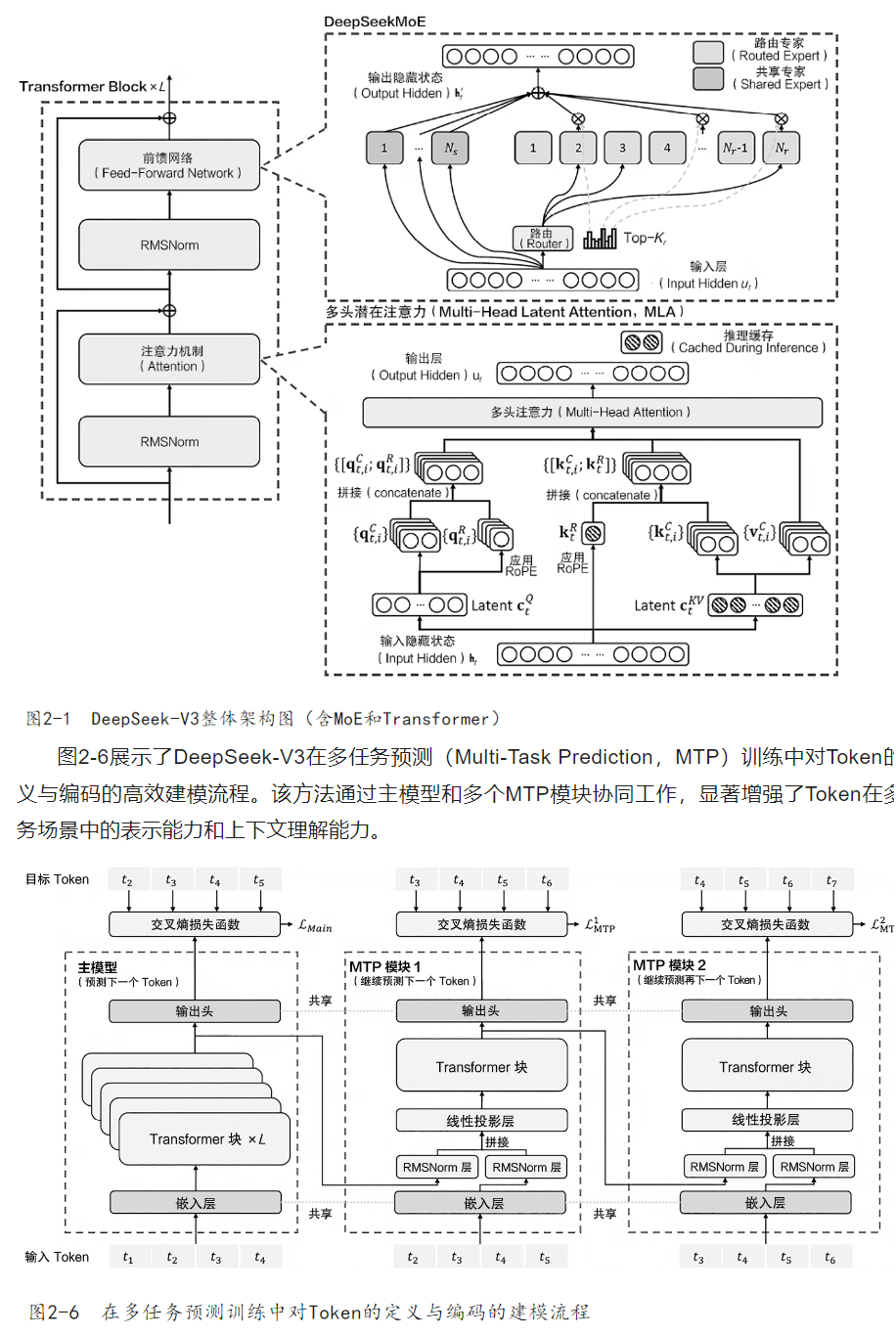
deepseek原理和项目实战笔记2 -- deepseek核心架构
混合专家(MoE) 混合专家(Mixture of Experts, MoE) 是一种机器学习模型架构,其核心思想是通过组合多个“专家”子模型(通常为小型神经网络)来处理不同输入,从而提高模型的容…...

在 MATLAB 2015a 中如何调用 Python
在 MATLAB 2015a 中调用 Python 可通过系统命令调用、.NET 交互层包装、MEX 接口间接桥接、环境变量配置四种方式,但因该版本对 Python 支持有限,主要依赖的是系统命令调用与间接脚本交互。其中,通过 system() 函数调用 Python 脚本是最简单且…...

房屋租赁系统 Java+Vue.js+SpringBoot,包括房屋类型、房屋信息、预约看房、合同信息、房屋报修、房屋评价、房主管理模块
房屋租赁系统 JavaVue.jsSpringBoot,包括房屋类型、房屋信息、预约看房、合同信息、房屋报修、房屋评价、房主管理模块 百度云盘链接:https://pan.baidu.com/s/1KmwOFzN9qogyaLQei3b6qw 密码:l2yn 摘 要 社会的发展和科学技术的进步…...

华为OD机试真题——生成哈夫曼树(2025B卷:100分)Java/python/JavaScript/C/C++/GO六种最佳实现
2025 B卷 100分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C++、C语言、GO六种语言的最佳实现方式! 本文收录于专栏:《2025华为OD真题目录+全流程解析/备考攻略/经验分享》 华为OD机试真题《生成…...

react与vue的渲染原理
vue:响应式驱动模板编译 (1)模板编译 将模板(.vue 文件或 HTML 模板)编译为 渲染函数(Render Function); (2)响应式依赖收集 初始化时,通过 Ob…...

我提出结构学习的思路,意图用结构学习代替机器学习
我提出结构学习的思路,意图用结构学习代替机器学习 1.机器学习的本质和缺点 机器学习的规律是设计算法、用数据训练算法、让算法学会产生正确的数据回答问题,其缺点在于,需要大规模训练数据和巨大算力还其次,机器学习不能产生智…...

Outbox模式:确保微服务间数据可靠交换的设计方案
https://debezium.io/blog/2019/02/19/reliable-microservices-data-exchange-with-the-outbox-pattern/ Outbox模式是一种在微服务架构中确保数据更改和消息/事件发布之间可靠性的设计模式。它解决了在更新数据库和发送消息这两个独立操作中可能出现的不一致问题(…...

数据可视化的定义和类型
数据可视化是一种将数据转换为图形或视觉表示的方法。想象一下,你面前有一堆数字和表格,看着这些,可能会让人头大。数据可视化就像是给这些枯燥的数字画上一幅画。它用图表、地图和各种有趣的图形,帮我们把难懂的数字变得容易看懂…...

sqlite-vec:谁说SQLite不是向量数据库?
sqlite-vec 是一个 SQLite 向量搜索插件,具有以零依赖、轻量级、跨平台和高效 KNN 搜索等优势,是本地化向量检索(例如 RAG)、轻量级 AI 应用以及边缘计算等场景的理想工具。 sqlite-vec 使用纯 C 语言实现,零外部依赖…...

Redis最佳实践——性能优化技巧之监控与告警详解
Redis 在电商应用的性能优化技巧之监控与告警全面详解 一、监控体系构建 1. 核心监控指标矩阵 指标类别关键指标计算方式/说明健康阈值(参考值)内存相关used_memoryINFO Memory 获取不超过 maxmemory 的 80%mem_fragmentation_ratio内存碎片率 used_m…...
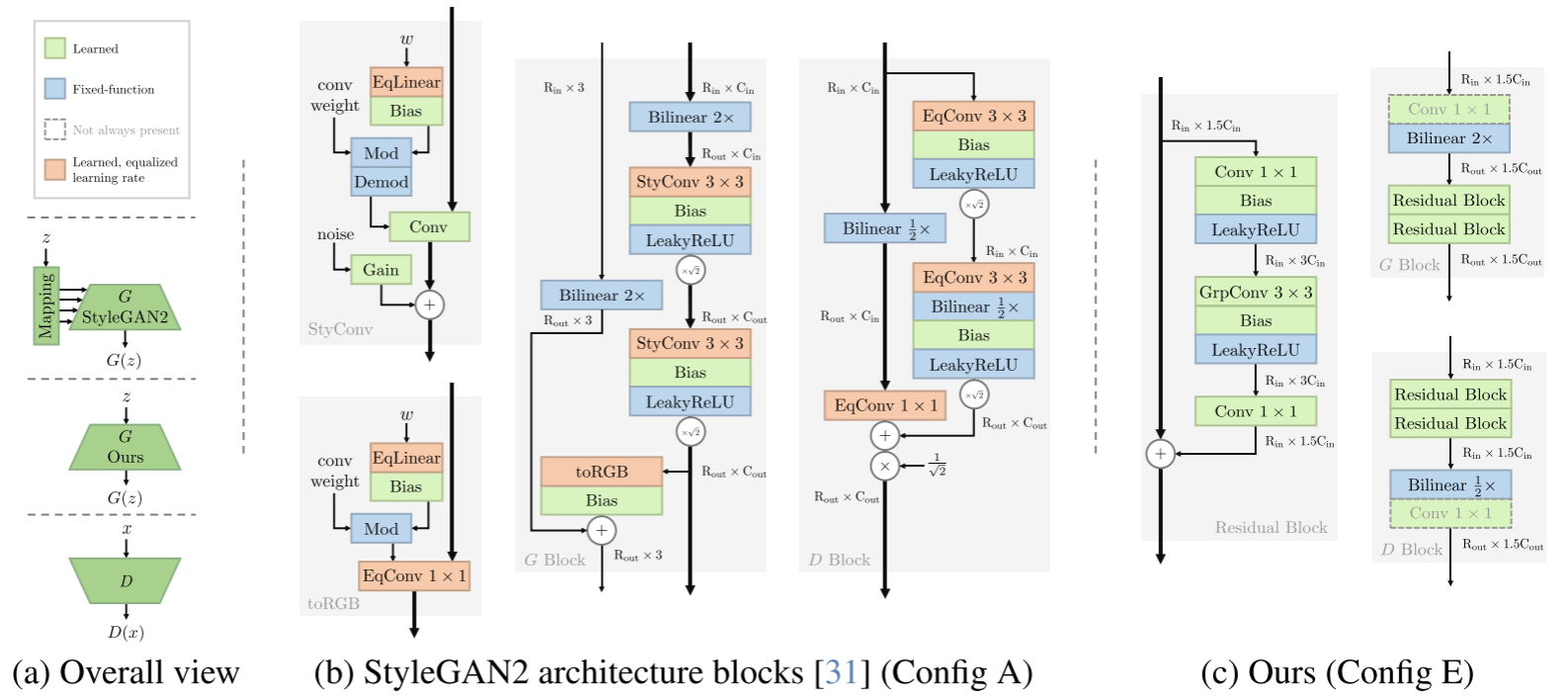
R3GAN训练自己的数据集
简介 简介:这篇论文挑战了"GANs难以训练"的广泛观点,通过提出一个更稳定的损失函数和现代化的网络架构,构建了一个简洁而高效的GAN基线模型R3GAN。作者证明了通过合适的理论基础和架构设计,GANs可以稳定训练并达到优异…...

MATLAB实战:Arduino硬件交互项目方案
以下是一个使用MATLAB与Arduino进行硬件交互的项目方案,涵盖传感器数据采集和执行器控制。本方案使用MATLAB的Arduino硬件支持包,无需额外编写Arduino固件。 系统组成 硬件: Arduino Uno 温度传感器(如LM35) 光敏电…...