自适应移动平均(Adaptive Moving Average, AMA)
文章目录
- 1. 考夫曼自适应移动平均 (KAMA)算法推导及Python实现
- 2. 对 (KAMA)算法参数进行优化及实现
自适应移动平均(Adaptive Moving Average, AMA)由Perry Kaufman在其著作《Trading Systems and Methods》中提出,它通过动态调整平滑系数来适应不同的市场状况:
在趋势明显时,AMA更像快速移动平均线,紧跟价格变化
在震荡市场时,AMA更像慢速移动平均线,过滤噪音。
是一种动态调整平滑系数的移动平均方法,适用于非线性、非平稳的【时间序列数据预测场景】(如负荷受温度、节假日等因素影响),其核心是通过波动率或趋势指标自动调整权重,提高预测灵敏度。
在接触过程中记录一下。
1. 考夫曼自适应移动平均 (KAMA)算法推导及Python实现

import numpy as np
import pandas as pd
import matplotlib.pyplot as pltdef ama(close_prices, n=10, fast_sc=2, slow_sc=30):"""计算自适应移动平均线(AMA)参数:close_prices: 收盘价序列 (list, np.array或pd.Series)n: 计算效率比率(ER)的周期 (默认10)fast_sc: 快速平滑常数周期 (默认2)slow_sc: 慢速平滑常数周期 (默认30)返回:AMA值 (np.array)"""close = np.array(close_prices)length = len(close)ama_values = np.zeros(length)sc = np.zeros(length)er = np.zeros(length)fast_alpha = 2 / (fast_sc + 1)slow_alpha = 2 / (slow_sc + 1)# 初始AMA值为第一个收盘价ama_values[0] = close[0]for i in range(1, length):# 计算方向变化和波动总和direction = abs(close[i] - close[i - n if i >= n else 0])volatility = sum(abs(close[j] - close[j-1]) for j in range(max(1, i-n+1), i+1))# 计算效率比率(ER)er[i] = direction / volatility if volatility != 0 else 0# 计算平滑系数(SC)temp_sc = er[i] * (fast_alpha - slow_alpha) + slow_alphasc[i] = temp_sc * temp_sc # 平方使变化更平滑# 计算AMAama_values[i] = ama_values[i-1] + sc[i] * (close[i] - ama_values[i-1])return ama_values# 示例使用
if __name__ == "__main__":# 生成示例数据(正弦波+随机噪声)np.random.seed(42)x = np.linspace(0, 10, 200)prices = np.sin(x) * 10 + np.random.normal(0, 1, 200) + 20# 计算AMAama_values = ama(prices, n=2, fast_sc=2, slow_sc=30)# 绘图plt.figure(figsize=(12, 6))plt.plot(prices, label='Data', alpha=0.5)plt.plot(ama_values, label='AMA(2,2,30)', color='red', linewidth=2)plt.title("Adaptive Moving Average (AMA)")plt.legend()plt.grid()plt.show()
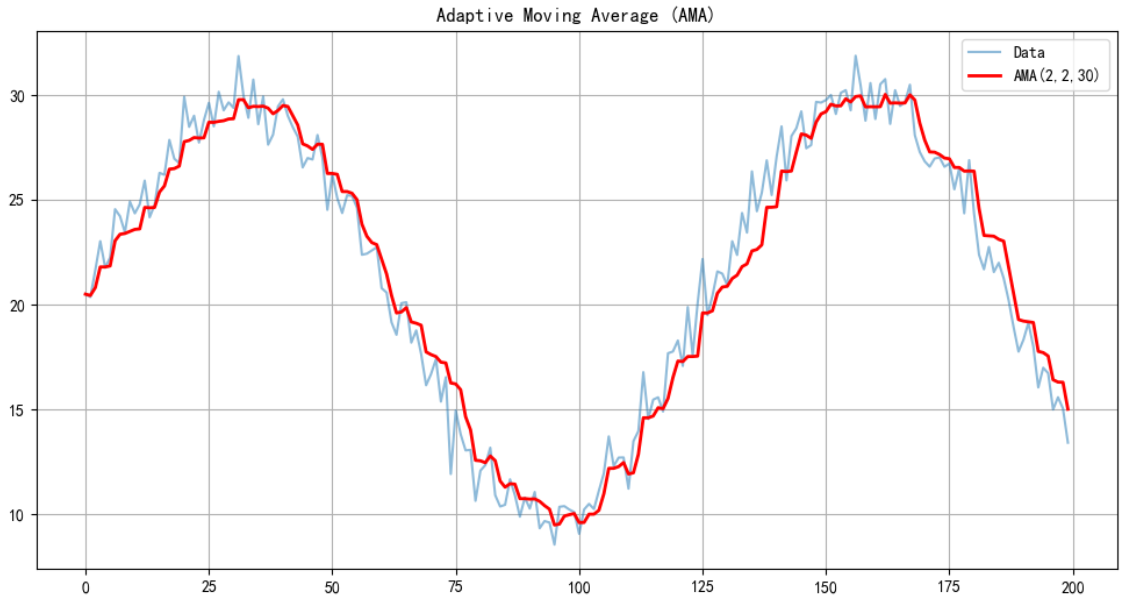
2. 对 (KAMA)算法参数进行优化及实现
## 基于上面方法的对参数进行优化
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_errordef ama(close_prices, n=10, fast_sc=2, slow_sc=30):"""计算自适应移动平均线(AMA)参数:close_prices: 收盘价序列 (list, np.array或pd.Series)n: 计算效率比率(ER)的周期 (默认10)fast_sc: 快速平滑常数周期 (默认2)slow_sc: 慢速平滑常数周期 (默认30)返回:AMA值 (np.array)"""close = np.array(close_prices)length = len(close)ama_values = np.zeros(length)sc = np.zeros(length)er = np.zeros(length)fast_alpha = 2 / (fast_sc + 1)slow_alpha = 2 / (slow_sc + 1)# 初始AMA值为第一个收盘价ama_values[0] = close[0]for i in range(1, length):# 计算方向变化和波动总和direction = abs(close[i] - close[i - n if i >= n else 0])volatility = sum(abs(close[j] - close[j-1]) for j in range(max(1, i-n+1), i+1))# 计算效率比率(ER)er[i] = direction / volatility if volatility != 0 else 0# 计算平滑系数(SC)temp_sc = er[i] * (fast_alpha - slow_alpha) + slow_alphasc[i] = temp_sc * temp_sc # 平方使变化更平滑# 计算AMAama_values[i] = ama_values[i-1] + sc[i] * (close[i] - ama_values[i-1])return ama_valuesdef optimize_ama(close_prices, n_range, fast_range, slow_range):best_params = {}min_mse = float('inf')for n in n_range:for fast in fast_range:for slow in slow_range:ama_vals = ama(close_prices, n, fast, slow)mse = mean_squared_error(close_prices[n:], ama_vals[n:])if mse < min_mse:min_mse = msebest_params = {'n': n, 'fast': fast, 'slow': slow}return best_paramsparams = optimize_ama(prices, n_range=range(2, 21, 3),fast_range=range(2, 6),slow_range=range(10, 31, 3))
print("最佳参数:", params)# 示例使用
if __name__ == "__main__":# 生成示例数据(正弦波+随机噪声)np.random.seed(42)x = np.linspace(0, 10, 200)prices = np.sin(x) * 10 + np.random.normal(0, 1, 200) + 20# 计算AMAn = params['n']fast_sc = params['fast']slow_sc = params['slow']ama_values = ama(prices, n= n, fast_sc =fast_sc , slow_sc=slow_sc)# 绘图plt.figure(figsize=(12, 6))plt.plot(prices, label='Data', alpha=0.5)plt.plot(ama_values, label=f'AMA({n},{fast_sc},{slow_sc})', color='red', linewidth=2)plt.title("Adaptive Moving Average (AMA)")plt.legend()plt.grid()plt.show()
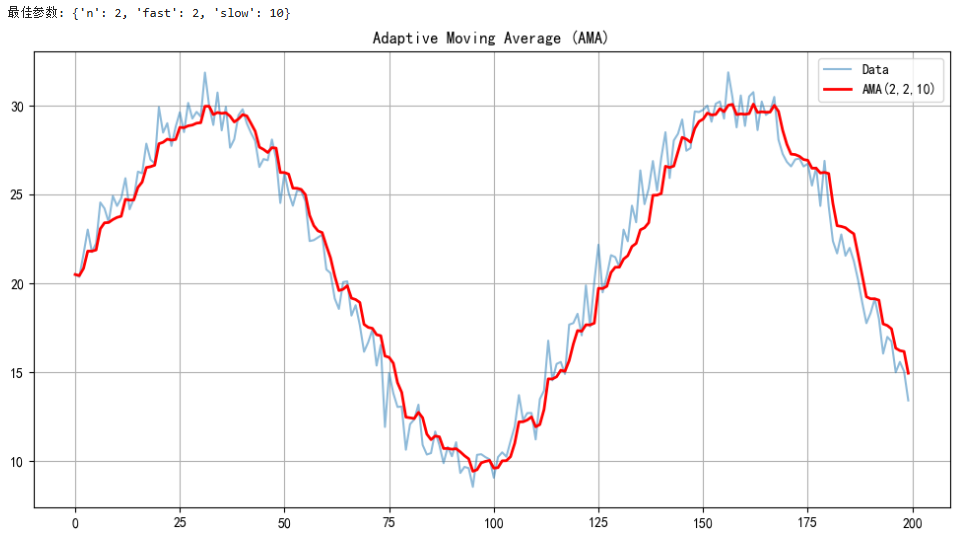
## 方法2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import ParameterGrid
from sklearn.metrics import mean_absolute_error, mean_squared_error
import logging
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 配置日志
logging.getLogger('prophet').setLevel(logging.WARNING)
logging.getLogger('cmdstanpy').setLevel(logging.WARNING)# =================================== 1. 模拟数据生成(若已有真实数据,可跳过此步) ====================
def data_row_column(hourly_loads): #将数据1*96转换成96*1# 计算时间戳(每15分钟一个点)hourly_loads["point_idx"] = hourly_loads["point"].str.extract("(\d+)").astype(int)hourly_loads["hour"] = (hourly_loads["point_idx"] - 1) // 4 # 计算小时(0-23)hourly_loads["minute"] = ((hourly_loads["point_idx"] - 1) % 4) * 15 # 计算分钟(0, 15, 30, 45)hourly_loads["timestamp"] = hourly_loads["amt_ym"] + pd.to_timedelta(hourly_loads["hour"], unit="h") + pd.to_timedelta(hourly_loads["minute"], unit="m")# 按时间戳排序hourly_loads = hourly_loads.sort_values("timestamp")ts_df = hourly_loads[["timestamp", "load"]].set_index("timestamp")return ts_dfRAWcus_df = pd.read_excel("D:\\data_example.xlsx",engine='openpyxl')
cus_df = RAWcus_df.copy()
cus_df['年月'] = cus_df['amt_ym'].dt.strftime('%Y-%m')
load_series1 = data_row_column(cus_df).squeeze()
train_data = load_series1[:-96] # 训练集(排除最后96点)
test_data = load_series1[-96:] # 测试集(最后96点)# =================================== 2. AMA模型实现 ====================
def ama_forecast(data, forecast_steps=96, window=24*4, alpha_min=0.05, alpha_max=0.95, initial_window=100):"""AMA模型预测(带动态平滑系数调整):param data: 历史负荷序列(Series):param forecast_steps: 预测步长:param window: 计算效率比率(ER)的窗口大小 =n:param alpha_min: 平滑系数下限 =s:param alpha_max: 平滑系数上限 =f:param initial_window: 初始化AMA的窗口( warm-up 阶段):return: 预测结果数组(numpy.ndarray)"""history = data.values.copy()n = len(history)ama = np.zeros(n + forecast_steps)ama[:n] = history# Warm-up阶段:用简单移动平均初始化AMAif initial_window > 0:ama[:initial_window] = np.convolve(history[:initial_window], np.ones(5)/5, mode='same')for t in range(n, n + forecast_steps):# 计算效率比率(ER)start_idx = max(0, t - window)direction = abs(ama[t-1] - ama[start_idx])volatility = sum(abs(ama[i] - ama[i-1]) for i in range(start_idx + 1, t))er = direction / (volatility + 1e-6) # 避免除零# 动态平滑系数alpha = er * (alpha_max - alpha_min) + alpha_minalpha = np.clip(alpha, alpha_min, alpha_max) # 限制在[min, max]范围内# 更新AMA(假设未来变化与最近变化相同)recent_change = ama[t-1] - ama[t-2] if t >= 2 else 0ama[t] = ama[t-1] + alpha * recent_changereturn ama[n:]# =================================== 3. 参数调优(网格搜索) ====================
def grid_search_ama(train_data, test_data, param_grid):"""网格搜索最优AMA参数"""best_params = Nonebest_mae = float('inf')results = []for params in ParameterGrid(param_grid):# 滚动预测验证forecasts = []for i in range(len(test_data)):history = pd.concat([train_data, test_data[:i]])pred = ama_forecast(history, forecast_steps=1, **params)forecasts.append(pred[0])# 计算指标mae = mean_absolute_error(test_data, forecasts)results.append({'params': params, 'MAE': mae})if mae < best_mae:best_mae = maebest_params = paramsreturn best_params, best_mae, pd.DataFrame(results)# 定义参数搜索空间
param_grid = {'window': [10,24*1, 24*2, 24*4,24*10,24*15], # 等效窗口大小 n: 1天、2天、4天窗口 'alpha_min': [0.01, 0.05, 0.1,0.5], # s'alpha_max': [0.8, 0.9, 0.95], # f'initial_window': [50, 100, 200]
}# 执行网格搜索(耗时操作,实际使用时建议缩小参数范围)
best_params, best_mae, search_results = grid_search_ama(train_data, test_data, param_grid)
print(f"最佳参数: {best_params}, 最优MAE: {best_mae:.2f}")# =================================== 4. 使用最优参数预测 ====================
final_forecast = ama_forecast(train_data, forecast_steps=96, **best_params)# =================================== 5. 评估与可视化 ====================
# 计算指标
mae = mean_absolute_error(test_data, final_forecast)
rmse = np.sqrt(mean_squared_error(test_data, final_forecast))
print(f"测试集 MAE: {mae:.2f}, RMSE: {rmse:.2f}")# 绘图
plt.figure(figsize=(14, 6))
plt.plot(train_data.index[-200:], train_data.values[-200:], label="历史负荷", color="blue", alpha=0.7)
plt.plot(test_data.index, test_data.values, label="真实值", color="green", marker='o', markersize=3)
plt.plot(test_data.index, final_forecast, label="AMA预测", linestyle="--", color="red", linewidth=2)
plt.fill_between(test_data.index, final_forecast - rmse, final_forecast + rmse, color="red", alpha=0.1, label="±RMSE误差带")
plt.title(f"负荷预测 (AMA模型)\n最优参数: {best_params}, MAE: {mae:.2f}, RMSE: {rmse:.2f}")
plt.xlabel("时间")
plt.ylabel("负荷")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()# 保存预测结果
forecast_df = pd.DataFrame({"时间": test_data.index,"真实值": test_data.values,"预测值": final_forecast,"绝对误差": np.abs(test_data.values - final_forecast),"误差百分比":np.abs(test_data.values - final_forecast)/test_data.values*100
})
# forecast_df.to_csv("ama_load_forecast_results.csv", index=False)
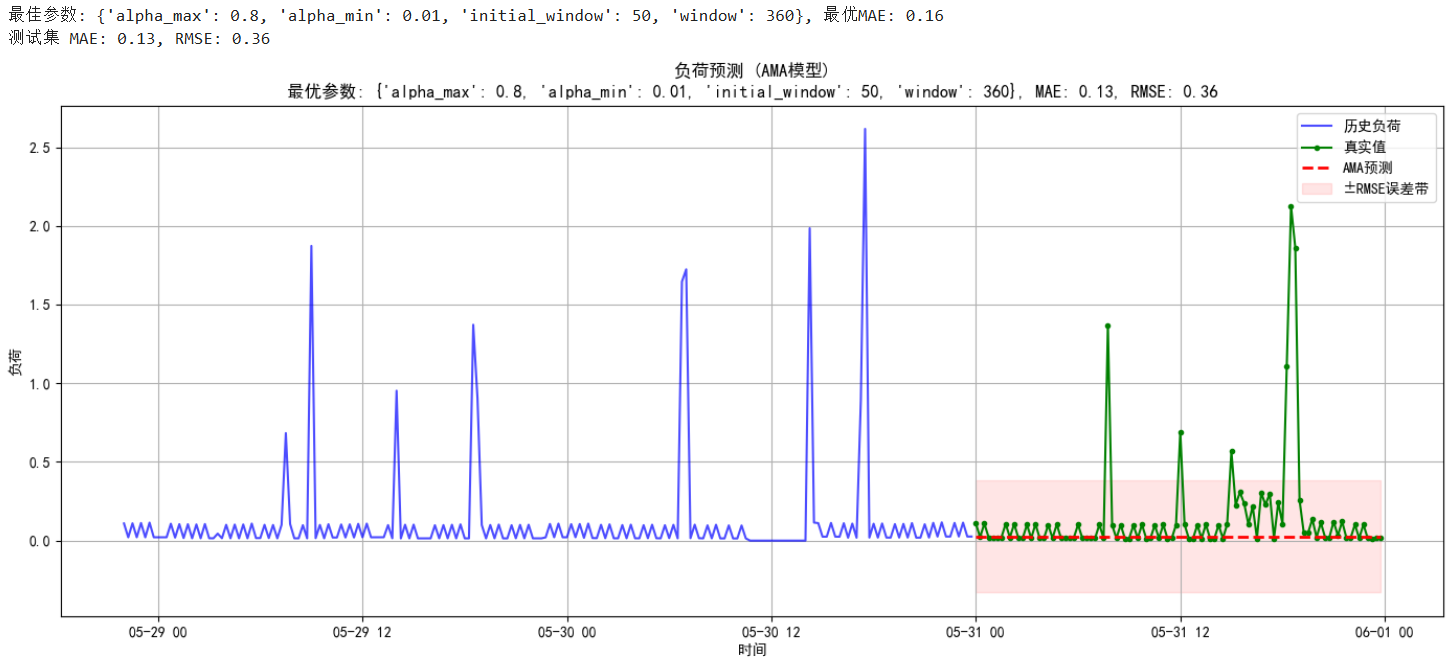
预测值与真实对比
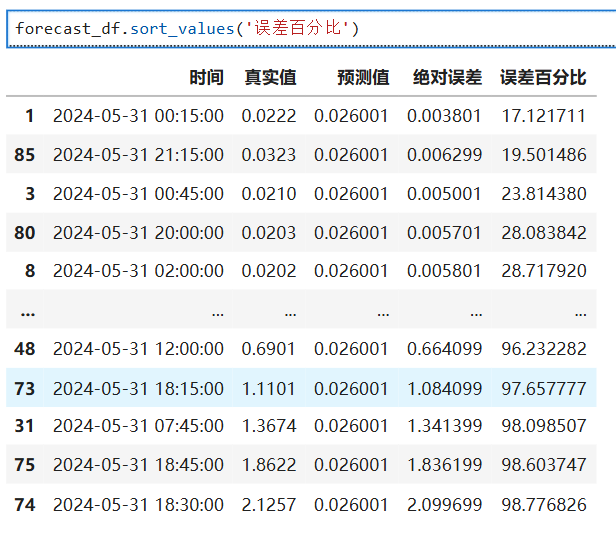
相关文章:
自适应移动平均(Adaptive Moving Average, AMA)
文章目录 1. 考夫曼自适应移动平均 (KAMA)算法推导及Python实现2. 对 (KAMA)算法参数进行优化及实现 自适应移动平均(Adaptive Moving Average, AMA)由Perry Kaufman在其著作《Trading Systems and Methods》中提出,它通过动态调整平滑系数来…...

Java密码加密存储算法,SpringBoot 实现密码安全存储
文章目录 一、写在前面二、密码加密存储方式1、基于MD5加盐方式2、SHA-256 Salt(不需要第三方依赖包)3、使用 BCrypt 进行哈希4、使用 PBKDF2 进行哈希5、使用 Argon2 进行哈希6、SCrypt 一、写在前面 日常开发中,用户密码存储是严禁明文存…...
)
使用 Version Catalogs统一配置版本 (Gradle 7.0+ 特性)
1.在 gradle/libs.versions.toml 文件中定义: [versions] compileSdk "34" minSdk "21" targetSdk "34" 2. 在 build.gradle 中使用: android {compileSdkVersion libs.versions.compileSdk.get().toInteger()defaul…...

涨薪技术|0到1学会性能测试第95课-全链路脚本开发实例
至此关于系统资源监控、apache监控调优、Tomcat监控调优、JVM调优、Mysql调优、前端监控调优、接口性能监控调优的知识已分享完,今天学习全链路脚本开发知识。后续文章都会系统分享干货,带大家从0到1学会性能测试。 前面章节介绍了如何封装.h头文件,现在通过一个实例来介绍…...

C++文件和流基础
C文件和流基础 1. C文件和流基础1.1 文件和流的概念1.2 标准库支持1.3 常用文件流类ifstream 类ofstream 类fstream 类 2.1 打开文件使用构造函数打开文件使用 open() 成员函数打开文件打开文件的模式标志 2.2 关闭文件使用 close() 成员函数关闭文件关闭文件的重要性 3.1 写入…...
Spring AI Alibaba + Nacos 动态 MCP Server 代理方案
作者:刘宏宇,Spring AI Alibaba Contributor 文章概览 Spring AI Alibaba MCP 可基于 Nacos 提供的 MCP server registry 信息,建立一个中间代理层 Java 应用,将 Nacos 中注册的服务信息转换成 MCP 协议的服务器信息,…...
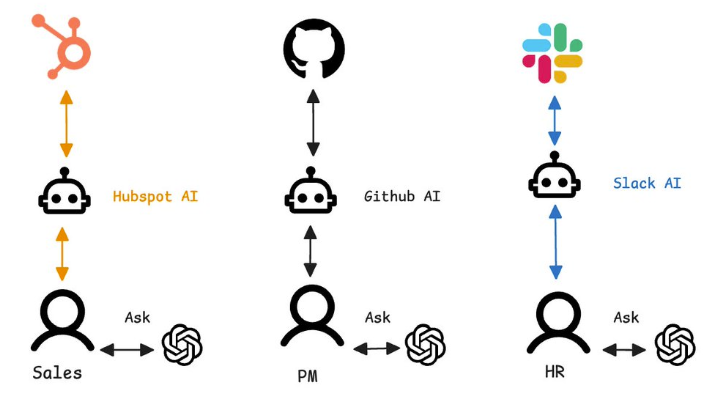
MCP:让AI工具协作变得像聊天一样简单 [特殊字符]
想象一下,你正在处理一个项目,需要从A平台查看团队讨论,从B平台获取客户信息,还要在GitHub上检查代码进度。传统做法是什么?打开三个不同的网页,在各个平台间来回切换,复制粘贴数据,最后还可能因为信息分散而遗漏重要细节。 听起来很熟悉?这正是当前工作流程的痛点所…...

C++ Learning string类模拟实现
string类模拟实现 std::string 类作为 C 标准库中非常重要的一个类型,它封装了字符串的动态分配、内存管理以及其他字符串操作。 基本构思与设计 一个简化版的 string 类需要满足以下基本功能: 存储一个字符数组(char*)。记录…...

Message=“HalconDotNet.HHandleBase”的类型初始值设定项引发异常
该异常通常与HalconDotNet库的版本冲突或环境配置问题有关,以下是常见解决方案: 版本冲突处理 检查项目中是否同时存在多个HalconDotNet引用(如NuGet安装和本地引用混用),需删除所有冲突引用并统一版本2确保工具…...
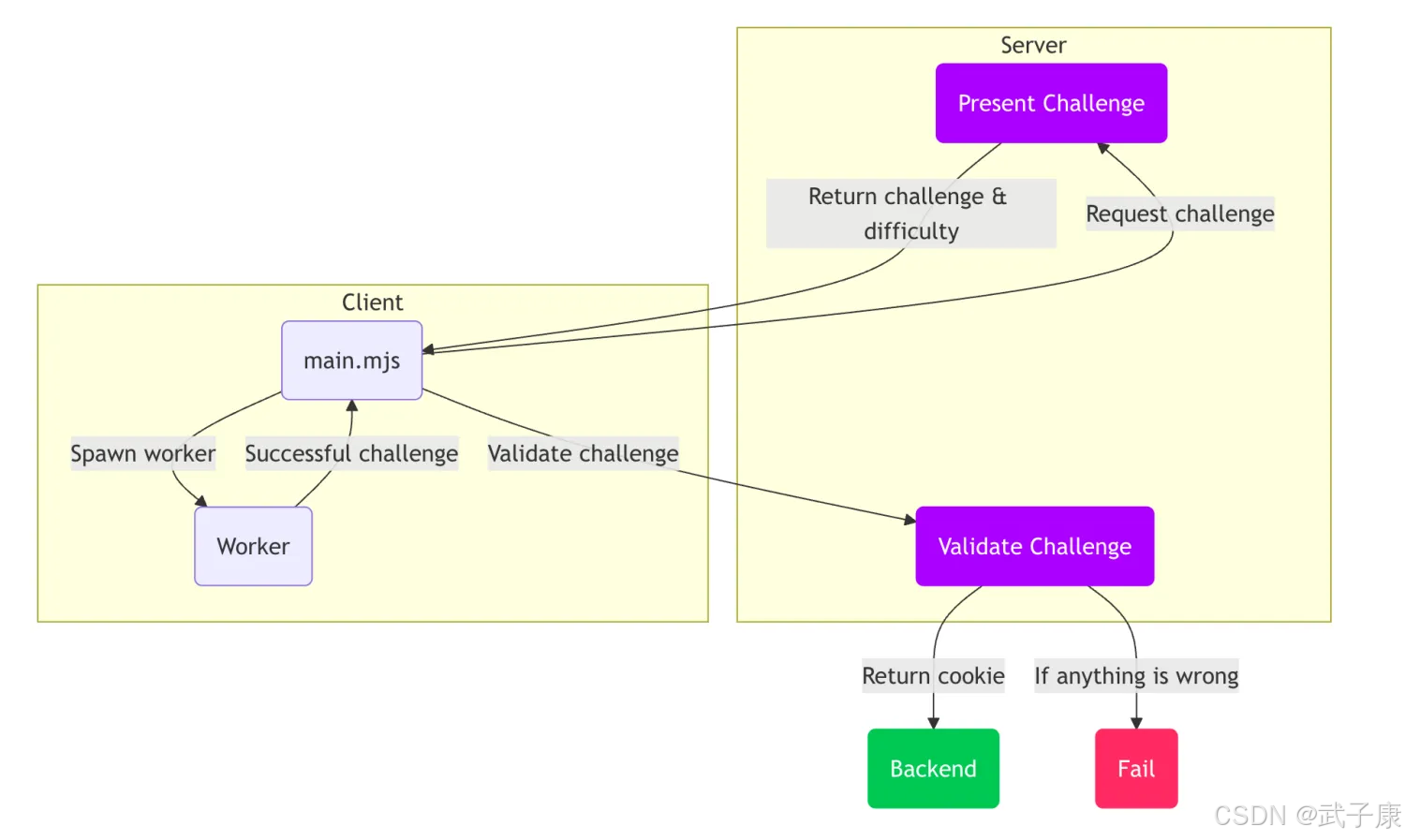
AI炼丹日志-27 - Anubis 通过 PoW工作量证明的反爬虫组件 上手指南 原理解析
点一下关注吧!!!非常感谢!!持续更新!!! Java篇: MyBatis 更新完毕目前开始更新 Spring,一起深入浅出! 大数据篇 300: Hadoop&…...

阿姆达尔定律的演进:古斯塔夫森定律
前言 在上一篇文章《使用阿姆达尔定律来提升效率》中提到的阿姆达尔定律前提是假设问题的规模保持不变,并且给定一台速度更快的机器,目标是更快地解决问题。然而,在大多数情况下,这并不完全正确。当有一台更快的机器时࿰…...

JavaScript极致性能优化全攻略
JavaScript性能优化深度指南 1 引言 JavaScript性能优化在现代Web开发中至关重要。随着Web应用日益复杂,性能直接影响用户体验、搜索引擎排名和业务转化率。研究表明,页面加载时间每增加1秒,转化率下降7%,跳出率增加32%。通过优化JavaScript性能,开发者可以: 提升用户满…...
)
批量大数据并发处理中的内存安全与高效调度设计(以Qt为例)
背景 在批量处理大型文件(如高分辨率图片、视频片段、科学数据块)时,开发者通常希望利用多核CPU并行计算以提升处理效率。然而,如果每个任务对象的数据量很大,直接批量并发处理极易导致系统内存被迅速耗尽,出现程序假死、崩溃,甚至系统级“死机”。 Qt自带的线程池(Q…...
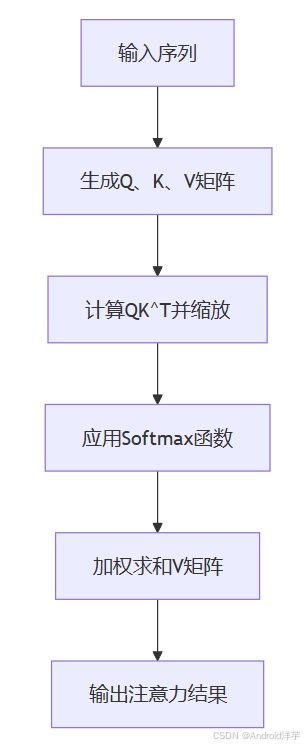
Transformer核心原理
简介 在人工智能技术飞速发展的今天,Transformer模型凭借其强大的序列处理能力和自注意力机制,成为自然语言处理、计算机视觉、语音识别等领域的核心技术。本文将从基础理论出发,结合企业级开发实践,深入解析Transformer模型的原…...

Grafana-State timeline状态时间线
显示随时间推移的状态变化 状态区域:即状态时间线上的状态显示的条或带,区域长度表示状态持续时间或频率 数据格式要求(可视化效果最佳): 时间戳实体名称(即:正在监控的目标对应名称…...
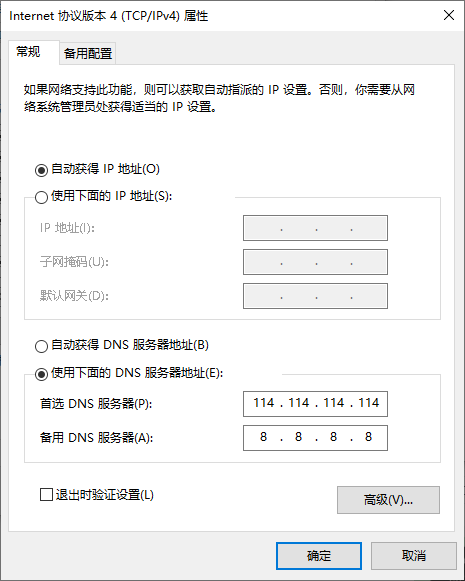
解决CSDN等网站访问不了的问题
原文网址:解决CSDN等网站访问不了的问题-CSDN博客 简介 本文介绍解决CSDN等网站访问不了的方法。 问题描述 CSDN访问不了了,页面是空的。 问题解决 方案1:修改DNS 可能是dns的问题,需要重新配置。 国内常用的dns是&#x…...
)
【华为云Astro Zero】组装设备管理页面开发(图形拖拽 + 脚本绑定)
目录 🧠 一、核心原理概览(类比说明) 🛠 二、完整操作步骤(详细图形拖拽流程) 1. 创建项目页面骨架 2. 定义设备信息的数据模型 equipmentInstance 3. 定义服务模型(接口绑定机器人搬运逻辑) 4. 拖拽组件搭建界面结构 4.1 表格: 4.2 工具栏按钮(新增) 4.…...

PopupImageMenuItem 无响应
Popup Menu | GNOME JavaScript let menuItem new PopupMenu.PopupImageMenuItem(设置, settings, {}); 第三个参数 params (Object) — Additional item properties 写了个 {},我就以为是 function,我还改成了 () > {} ! 正常是通过 connect 响…...

C++ Vector算法精讲与底层探秘:从经典例题到性能优化全解析
前引:在C标准模板库(STL)中,vector作为动态数组的实现,既是算法题解的基石,也是性能优化的关键战场。其连续内存布局、动态扩容机制和丰富的成员函数,使其在面试高频题(如LeetCode、…...

Flowith,有一种Agent叫无限
大家好,我是羊仔,专注AI工具、智能体、编程。 今天羊仔要和大家聊聊一个最近发现的超级实用的Agent平台,名字叫Flowith。 这篇文章会带你从零了解到实战体验,搞清楚Flowith是如何让工作效率飙升好几倍,甚至重新定义未…...

系统思考:短期利益与长期系统影响
一个决策难题:一家公司接到了一个大订单,客户提出了10%的降价要求,而企业的产能还无法满足客户的需求。你会选择增加产能,接受这个订单,还是拒绝?从系统思考的角度来看,这个决策不仅仅是一个简单…...

大数据 ETL 工具 Sqoop 深度解析与实战指南
一、Sqoop 核心理论与应用场景 1.1 设计思想与技术定位 Sqoop 是 Apache 旗下的开源数据传输工具,核心设计基于MapReduce 分布式计算框架,通过并行化的 Map 任务实现高效的数据批量迁移。其特点包括: 批处理特性:基于 MapReduc…...

【学习记录】Django Channels + WebSocket 异步推流开发常用命令汇总
文章目录 📌 摘要🧰 虚拟环境管理✅ 创建虚拟环境✅ 删除虚拟环境✅ 激活/切换虚拟环境 🛠️ Django 项目管理✅ 查看 Django 版本✅ 创建 Django 项目✅ 创建 Django App 💬 Channels 常用操作✅ 查看 Channels 版本 ὐ…...
动手实现多层感知机:深度学习中的非线性建模实战)
(四)动手实现多层感知机:深度学习中的非线性建模实战
1 多层感知机(MLP) 多层感知机(Multilayer Perceptron, MLP)是一种前馈神经网络,包含一个或多个隐藏层。它能够学习数据中的非线性关系,广泛应用于分类和回归任务。MLP的每个神经元对输入信号进行加权求和…...
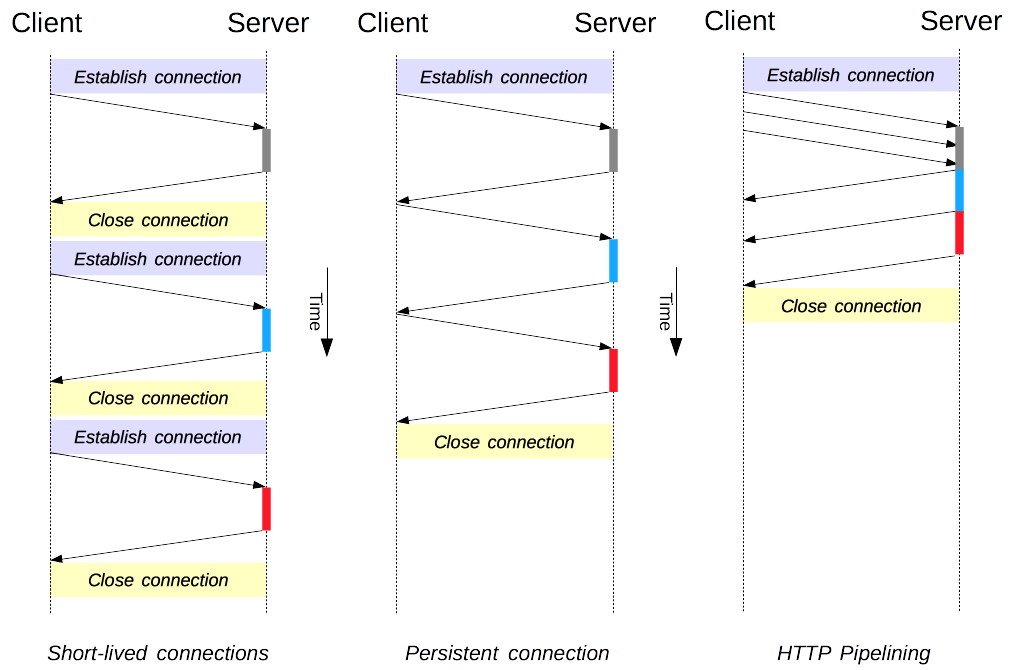
HTTP连接管理——短连接,长连接,HTTP 流水线
连接管理是一个 HTTP 的关键话题:打开和保持连接在很大程度上影响着网站和 Web 应用程序的性能。在 HTTP/1.x 里有多种模型:短连接、_长连接_和 HTTP 流水线。 下面分别来详细解释 短连接 HTTP 协议最初(0.9/1.0)是个非常简单的…...
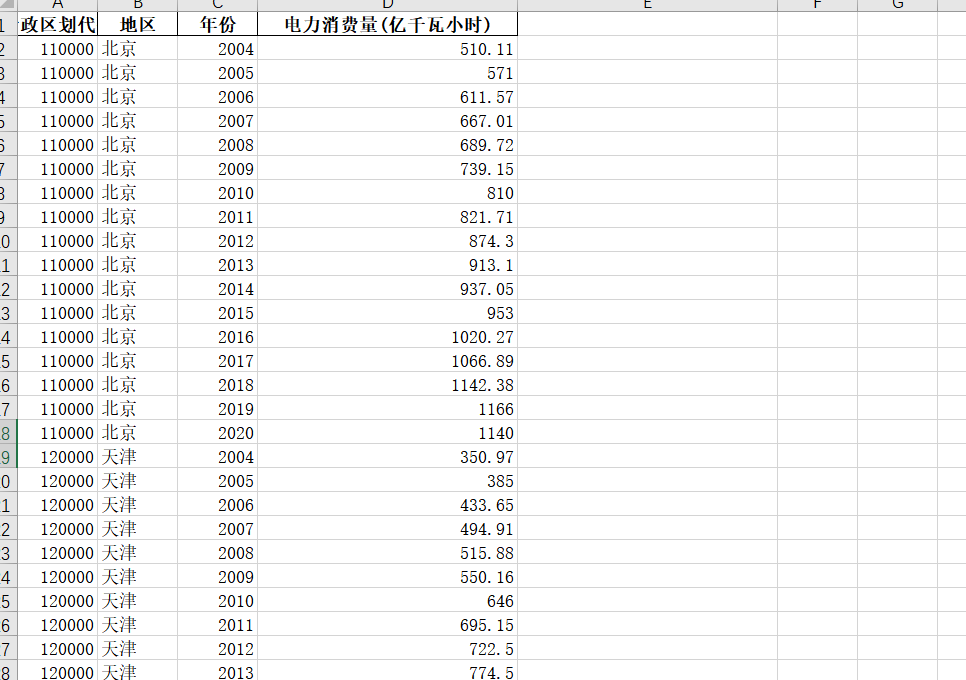
【免费】2004-2020年各省电力消费量数据
2004-2020年各省电力消费量数据 1、时间:2004-2020年 2、来源:国家统计局、统计年鉴 3、指标:行政区划代码、地区、年份、电力消费量(亿千瓦小时) 4、范围:31省 5、指标说明:电力消费量是指在一定时期内ÿ…...
 | if语句)
Python编程基础(四) | if语句
引言:很久没有写 Python 了,有一点生疏。这是学习《Python 编程:从入门到实践(第3版)》的课后练习记录,主要目的是快速回顾基础知识。 练习1:条件测试 编写一系列条件测试,将每个条…...

登录的写法,routerHook具体配置,流程
routerHook挂在在index.js/main.js下的,找不到可以去那边看一下 vuex需要做的: //创建token的sate,从本地取 let token window.localStorage.getItem(token) // 存储用户登录信息let currentUserInfo reactive({userinfo: {}}) //存根据不…...

Java-IO流之字节输出流详解
Java-IO流之字节输出流详解 一、Java字节输出流基础概念1.1 Java IO体系与字节输出流的位置1.2 字节输出流的核心类层次结构 二、OutputStream接口核心方法详解2.1 void write(int b)2.2 void write(byte[] b)2.3 void write(byte[] b, int off, int len)2.4 void flush()2.5 v…...
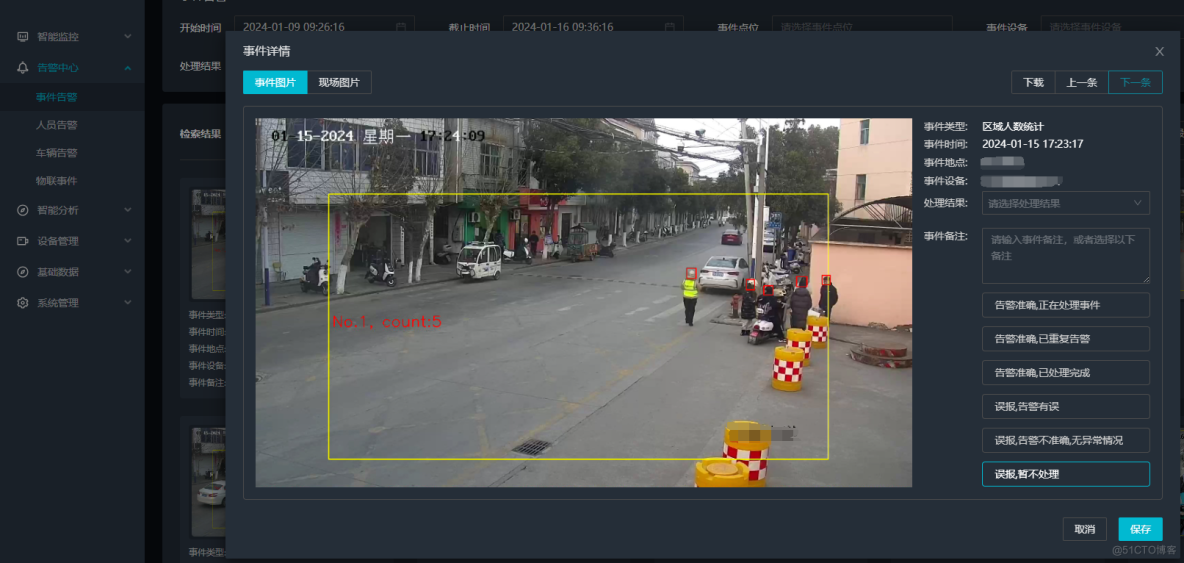
工作服/反光衣检测算法AI智能分析网关V4安全作业风险预警方案:筑牢矿山/工地/工厂等多场景安全防线
一、方案背景 在工地、矿山、工厂等高危作业场景,反光衣是保障人员安全的必备装备。但传统人工巡查存在效率低、易疏漏等问题,难以实现实时监管。AI智能分析网关V4基于人工智能技术,可自动识别人员着装状态,精准定位未穿反光衣…...