【搭建 Transformer】
搭建 Transformer 的基本步骤
Transformer 是一种基于自注意力机制的深度学习模型,广泛应用于自然语言处理任务。以下为搭建 Transformer 的关键步骤和代码示例。
自注意力机制
自注意力机制是 Transformer 的核心,计算输入序列中每个元素与其他元素的关联度。公式如下:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$
其中,$Q$ 为查询矩阵,$K$ 为键矩阵,$V$ 为值矩阵,$d_k$ 为键的维度。
import torch
import torch.nn as nnclass SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_sizeself.heads = headsself.head_dim = embed_size // headsself.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)self.fc_out = nn.Linear(embed_size, embed_size)def forward(self, values, keys, queries, mask):N = queries.shape[0]value_len, key_len, query_len = values.shape[1], keys.shape[1], queries.shape[1]values = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = queries.reshape(N, query_len, self.heads, self.head_dim)energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])if mask is not None:energy = energy.masked_fill(mask == 0, float("-1e20"))attention = torch.softmax(energy / (self.embed_size ** (0.5)), dim=3)out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(N, query_len, self.embed_size)return self.fc_out(out)
多头注意力
多头注意力通过并行计算多个自注意力头,增强模型的表达能力。
class MultiHeadAttention(nn.Module):def __init__(self, embed_size, heads):super(MultiHeadAttention, self).__init__()self.attention = SelfAttention(embed_size, heads)self.norm = nn.LayerNorm(embed_size)self.dropout = nn.Dropout(0.1)def forward(self, x, mask):attention = self.attention(x, x, x, mask)x = self.dropout(self.norm(attention + x))return x
前馈神经网络
前馈神经网络用于进一步处理自注意力层的输出。
class FeedForward(nn.Module):def __init__(self, embed_size, ff_dim):super(FeedForward, self).__init__()self.ff = nn.Sequential(nn.Linear(embed_size, ff_dim),nn.ReLU(),nn.Linear(ff_dim, embed_size),)self.norm = nn.LayerNorm(embed_size)self.dropout = nn.Dropout(0.1)def forward(self, x):out = self.ff(x)x = self.dropout(self.norm(out + x))return x
编码器层
编码器层由多头注意力和前馈神经网络组成。
class EncoderLayer(nn.Module):def __init__(self, embed_size, heads, ff_dim):super(EncoderLayer, self).__init__()self.attention = MultiHeadAttention(embed_size, heads)self.ff = FeedForward(embed_size, ff_dim)def forward(self, x, mask):x = self.attention(x, mask)x = self.ff(x)return x
解码器层
解码器层包含掩码多头注意力、编码器-解码器注意力和前馈神经网络。
class DecoderLayer(nn.Module):def __init__(self, embed_size, heads, ff_dim):super(DecoderLayer, self).__init__()self.masked_attention = MultiHeadAttention(embed_size, heads)self.attention = MultiHeadAttention(embed_size, heads)self.ff = FeedForward(embed_size, ff_dim)def forward(self, x, enc_out, src_mask, trg_mask):x = self.masked_attention(x, trg_mask)x = self.attention(enc_out, src_mask)x = self.ff(x)return x
完整 Transformer
整合编码器和解码器,构建完整的 Transformer 模型。
class Transformer(nn.Module):def __init__(self,src_vocab_size,trg_vocab_size,embed_size=512,num_layers=6,heads=8,ff_dim=2048,max_len=100,):super(Transformer, self).__init__()self.encoder_embed = nn.Embedding(src_vocab_size, embed_size)self.decoder_embed = nn.Embedding(trg_vocab_size, embed_size)self.pos_embed = PositionalEncoding(embed_size, max_len)self.encoder_layers = nn.ModuleList([EncoderLayer(embed_size, heads, ff_dim) for _ in range(num_layers)])self.decoder_layers = nn.ModuleList([DecoderLayer(embed_size, heads, ff_dim) for _ in range(num_layers)])self.fc_out = nn.Linear(embed_size, trg_vocab_size)def forward(self, src, trg, src_mask, trg_mask):src_embed = self.pos_embed(self.encoder_embed(src))trg_embed = self.pos_embed(self.decoder_embed(trg))for layer in self.encoder_layers:src_embed = layer(src_embed, src_mask)for layer in self.decoder_layers:trg_embed = layer(trg_embed, src_embed, src_mask, trg_mask)return self.fc_out(trg_embed)
位置编码
位置编码用于注入序列的位置信息。
class PositionalEncoding(nn.Module):def __init__(self, embed_size, max_len):super(PositionalEncoding, self).__init__()pe = torch.zeros(max_len, embed_size)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, embed_size, 2).float() * (-math.log(10000.0) / embed_size))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)self.register_buffer("pe", pe.unsqueeze(0))def forward(self, x):return x + self.pe[:, :x.shape[1], :]
相关文章:
【搭建 Transformer】
搭建 Transformer 的基本步骤 Transformer 是一种基于自注意力机制的深度学习模型,广泛应用于自然语言处理任务。以下为搭建 Transformer 的关键步骤和代码示例。 自注意力机制 自注意力机制是 Transformer 的核心,计算输入序列中每个元素与其他元素的…...

自然图像数据集
目录 CIFAR-10 数据集CIFAR-100 数据集AFHQ 数据集FFHQ 数据集 CIFAR-10 数据集 简介: CIFAR-10 是一个经典的图像分类数据集,广泛用于机器学习领域的计算机视觉算法基准测试。它包含60000幅32x32的彩色图像,分为10个类,每类6000…...

Linux下使用nmcli连接网络
Linux下使用nmcli连接网络 介绍 在使用ubuntu系统的时候,有时候不方便使用桌面,使用ssh远程连接,可能需要使用nmcli命令来连接网络。本文将介绍如何使用nmcli命令连接网络。nmcli 是 NetworkManager 的命令行工具,用于管理网络连…...
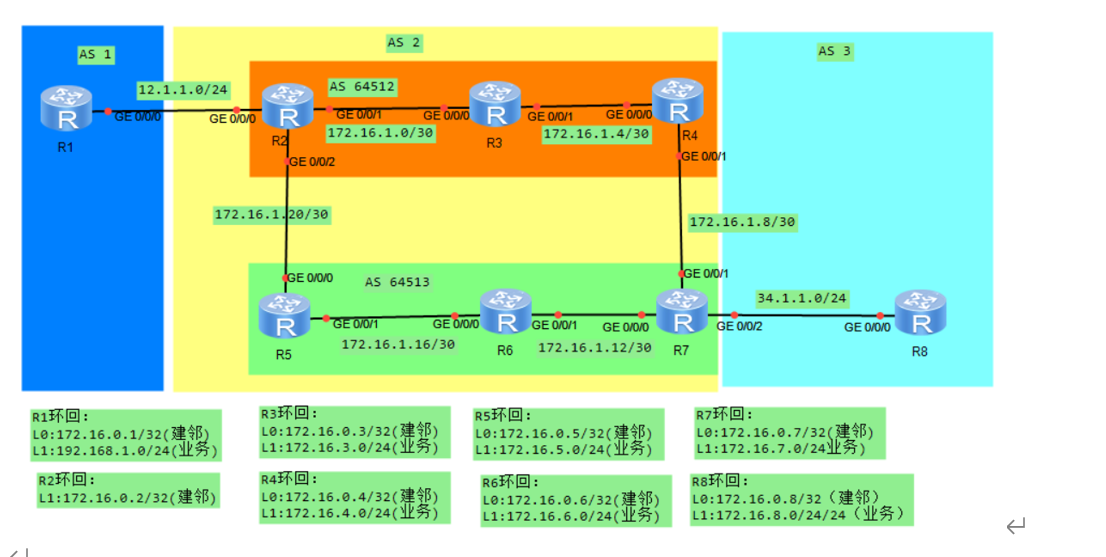
HCIP(BGP综合实验)
一、实验拓扑 AS 划分: AS1:R1(环回 L0:172.16.0.1/32,L1:192.168.1.0/24)AS2:R2、R3、R4、R5、R6、R7(内部运行 OSPF,AS 号为 64512 和 64513 的联盟)AS3:R…...

Attention Is All You Need (Transformer) 以及Transformer pytorch实现
参考https://zhuanlan.zhihu.com/p/569527564 Attention Is All You Need (Transformer) 是当今深度学习初学者必读的一篇论文。 一. Attention Is All You Need (Transformer) 论文精读 1. 知识准备 机器翻译,就是将某种语言的一段文字翻译成另一段文字。 由…...
uniapp+vue2+uView项目学习知识点记录
持续更新中... 1、发送给朋友,分享到朋友圈功能开启 利用onShareAppMessage和onShareTimeline生命周期函数,在script中与data同级去写 // 发送给朋友 onShareAppMessage() {return {title: 清清前端, // 分享标题path: /pages/index/index, // 分享路…...

精美的软件下载页面HTML源码:现代UI与动画效果的完美结合
精美的软件下载页面HTML源码:现代UI与动画效果的完美结合 在数字化产品推广中,一个设计精良的下载页面不仅能提升品牌专业度,还能显著提高用户转化率。本文介绍的精美软件下载页面HTML源码,通过现代化UI设计与丰富的动画效果&…...

车载诊断架构 --- DTC消抖参数(Trip Counter DTCConfirmLimit )
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...
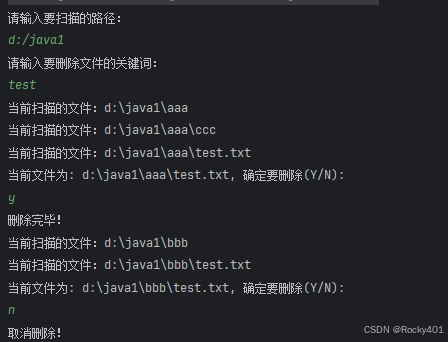
javaEE->IO:
文件: 操作系统中会把很多 硬件设备 和 软件资源 抽象成“文件”,统一进行管理。 大部分谈到的文件,都是指 硬盘的文件,文件就相当于是针对“硬盘”数据的一种抽象 硬盘: 1.机械硬盘:便宜 2.固态硬盘&…...

Oracle 用户/权限/角色管理
1. 用户 1.1. 用户的创建和删除 1.1.1. 创建用户 create user user identified {by password | externally} [ default tablespace tablespace ] [ temporary tablespace tablespace ] [ quota {integer [k | m ] | unlimited } on tablespace [ quota {integer [k | m ] | …...

使用免费wordpress成品网站模板需要注意点什么
在使用免费 WordPress 成品网站模板时,需要从版权、安全性、兼容性、功能限制等多个方面谨慎考量,避免后续出现问题。以下是具体需要注意的要点: 一、版权与授权问题 明确授权类型 免费模板可能分为「开源免费」「限个人使用」「禁止商业用…...

深入理解 JSX:React 的核心语法
1. 什么是 JSX? JSX(JavaScript And XML)是 React 中最核心的概念之一,也是区别于 Vue 的一个重要特征(尽管 Vue 现在也支持 JSX 语法)。JSX 是一种在 JavaScript 中编写 HTML 代码片段的语法协议…...
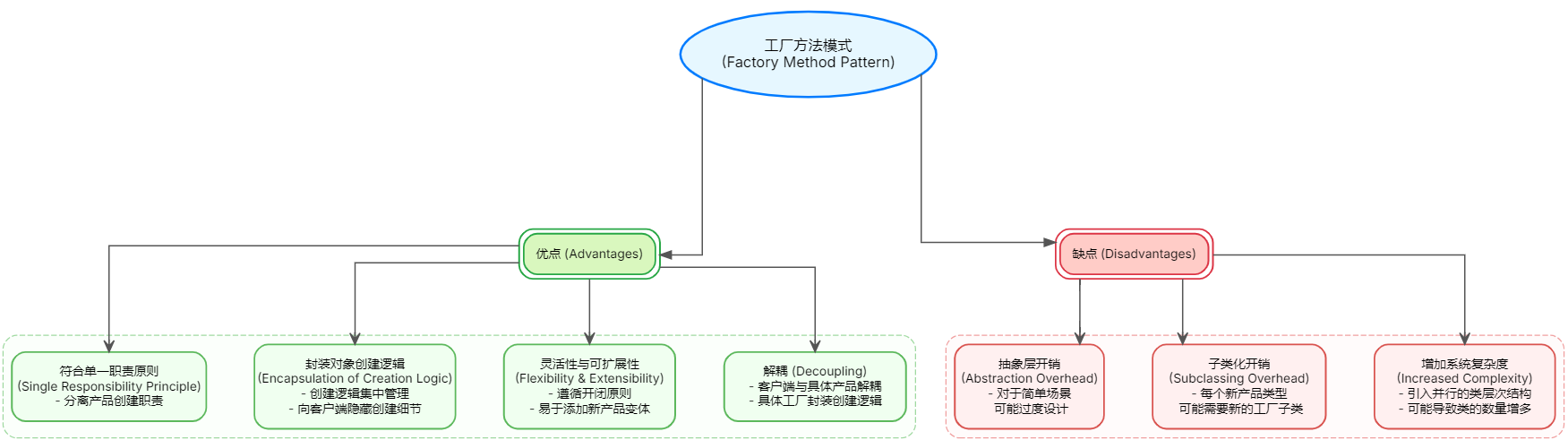
工厂方法模式深度解析:从原理到应用实战
作者简介 我是摘星,一名全栈开发者,专注 Java后端开发、AI工程化 与 云计算架构 领域,擅长Python技术栈。热衷于探索前沿技术,包括大模型应用、云原生解决方案及自动化工具开发。日常深耕技术实践,乐于分享实战经验与…...

TS 星际通信指南:从 TCP 到 UDP 的宇宙漫游
文章目录 一、计算机网络通信1、基本概念2、核心要素(一)终端设备(二)通信介质(三)网络协议 3、常用通信模型(一)OSI 七层模型(理论框架)(二&…...

python可视化:端午假期旅游火爆原因分析
python可视化:端午假期旅游火爆原因分析 2025年的旅游市场表现强劲: 2025年端午假期全社会跨区域人员流动量累计6.57亿人次,日均2.19亿人次,同比增长3.0%。入境游订单同比大涨近90%,门票交易额(GMV&#…...

Missashe考研日记—Day51-Day57
Missashe考研日记—Day51-Day57 写在面前 本系列博客用于记录博主一周的学习进度。线代题型总结 专业课408 这周简直是拼命学计网,花了两三天速通传输层和应用层内容,又臭又长的网课听不下去一点了,赶紧结束准备开二轮进行复习和刷题了。…...

electron-vite_18桌面共享
electron默认不支持桌面共享,需要添加desktopCapturer配置,这样在使用navigator.mediaDevices.getUserMedia API访问可用于从桌面捕获音频和视频的媒体源的信息。 electron版本 "electron": "^31.0.2",在main.js中添加desktopCaptu…...

SOC-ESP32S3部分:28-BLE低功耗蓝牙
飞书文档https://x509p6c8to.feishu.cn/wiki/CHcowZMLtiinuBkRhExcZN7Ynmc 蓝牙是一种短距的无线通讯技术,可实现固定设备、移动设备之间的数据交换,下图是一个蓝牙应用的分层架构,Application部分则是我们需要实现的内容,Protoc…...
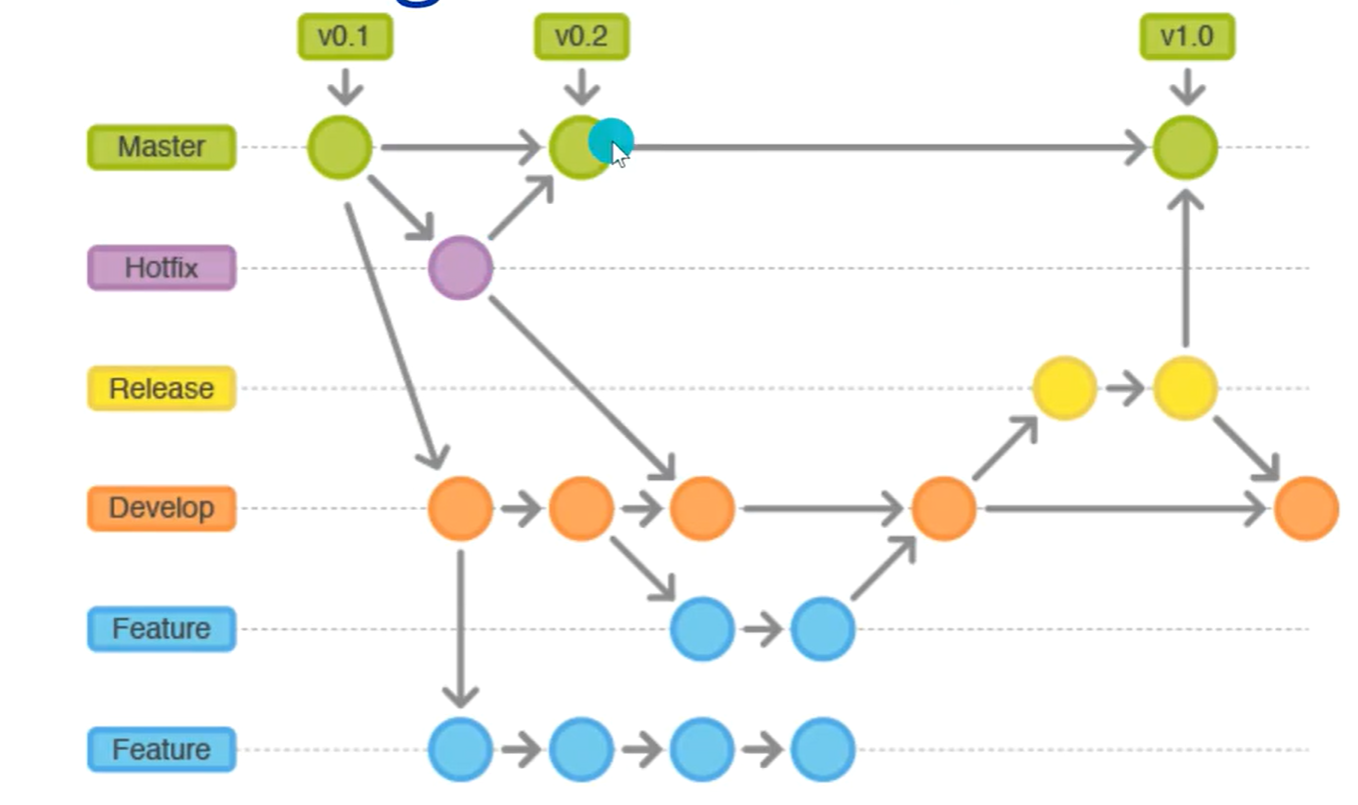
Git-flow流
Git git是版本控制软件,一般用来做代码版本控制 github是一个免费版本控制仓库是国内外很多开源项目的集中地,其本体是一个git服务器 Git初始化操作 git init 初始化仓库 git status 查看当前仓库的状态 git add . 将改动的文件加到暂存区 gi…...
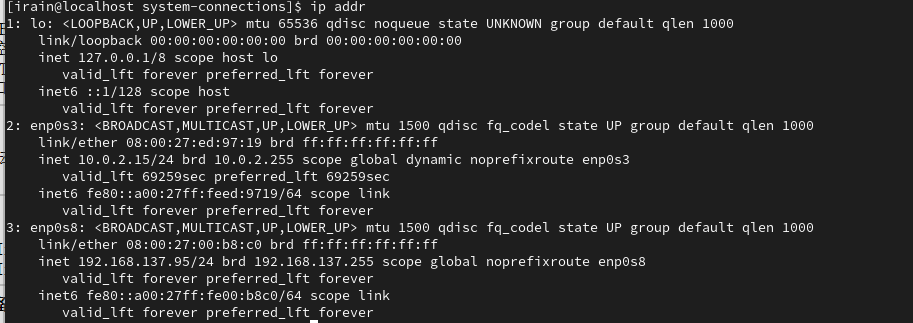
VirtualBox给Rock Linux9.x配置网络
写这篇文章之前,先说明一下,我参考的是我之前写的《VirtualBox Linux网络配置》 我从CentOS7转到了Rock9,和配置Centos7一样,主流程没有变化,变化的是Rock9.x中的配置文件和使用的命令。 我再说一次,因为主…...

知识图谱增强的大型语言模型编辑
https://arxiv.org/pdf/2402.13593 摘要 大型语言模型(LLM)是推进自然语言处理(NLP)任务的关键,但其效率受到不准确和过时知识的阻碍。模型编辑是解决这些挑战的一个有前途的解决方案。然而,现有的编辑方法…...

.NET 原生驾驭 AI 新基建实战系列(一):向量数据库的应用与畅想
在当今数据驱动的时代,向量数据库(Vector Database)作为一种新兴的数据库技术,正逐渐成为软件开发领域的重要组成部分。特别是在 .NET 生态系统中,向量数据库的应用为开发者提供了构建智能、高效应用程序的新途径。 一…...
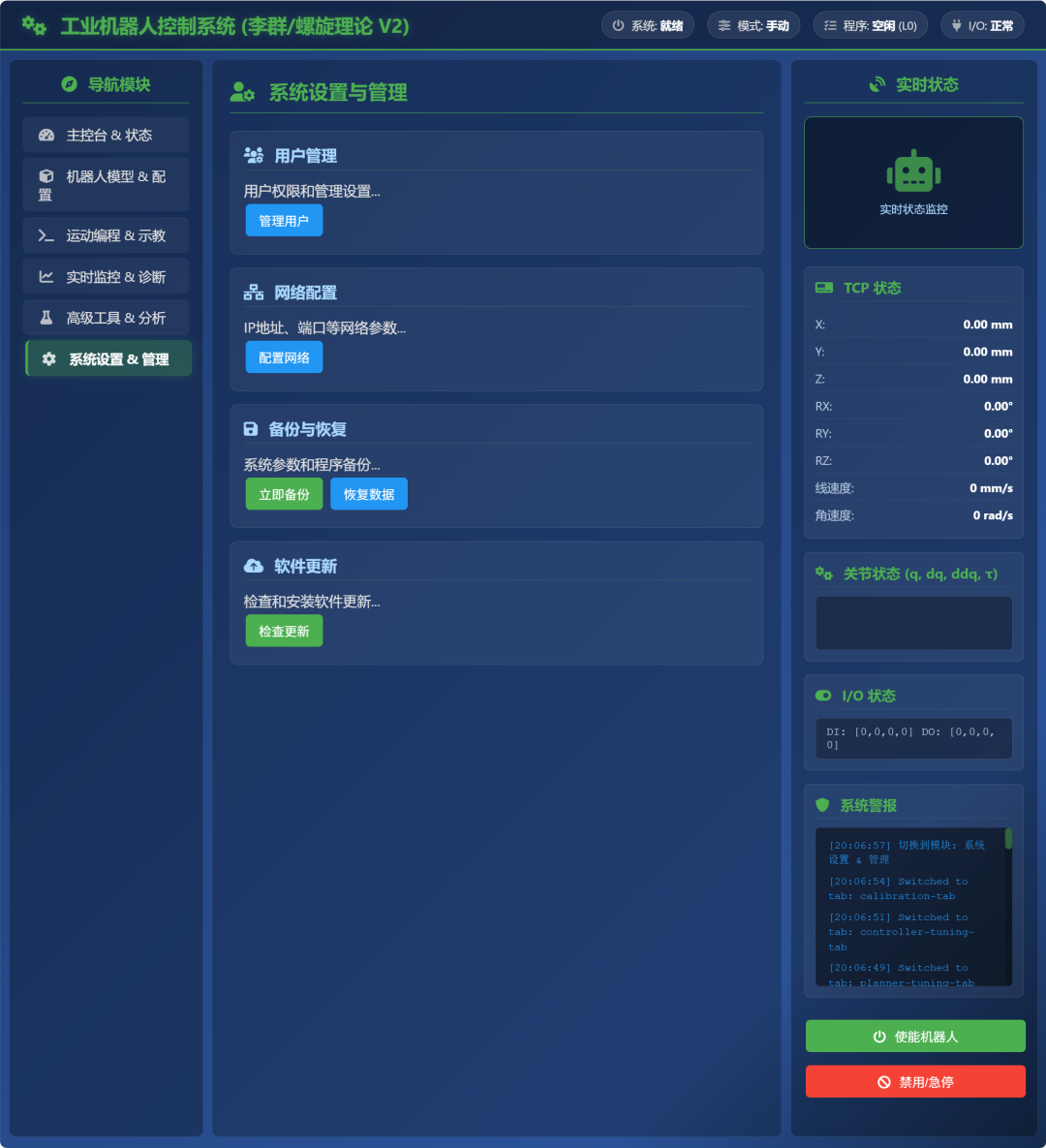
【claude+deepseek+gemini】基于李群李代数和螺旋理论工业机器人控制系统软件UI设计
claude的首次设计html是最佳的。之后让deepseek和gemini根据claude的UI设计进行改进设计。。。当然可以尝试很多次,也可以让他们之间来回不断改进…… claude deepseek-r1 0528 上图为deepseek首次设计,下面为改进设计 …… Gemini 2.5 Pro 0506 &#x…...
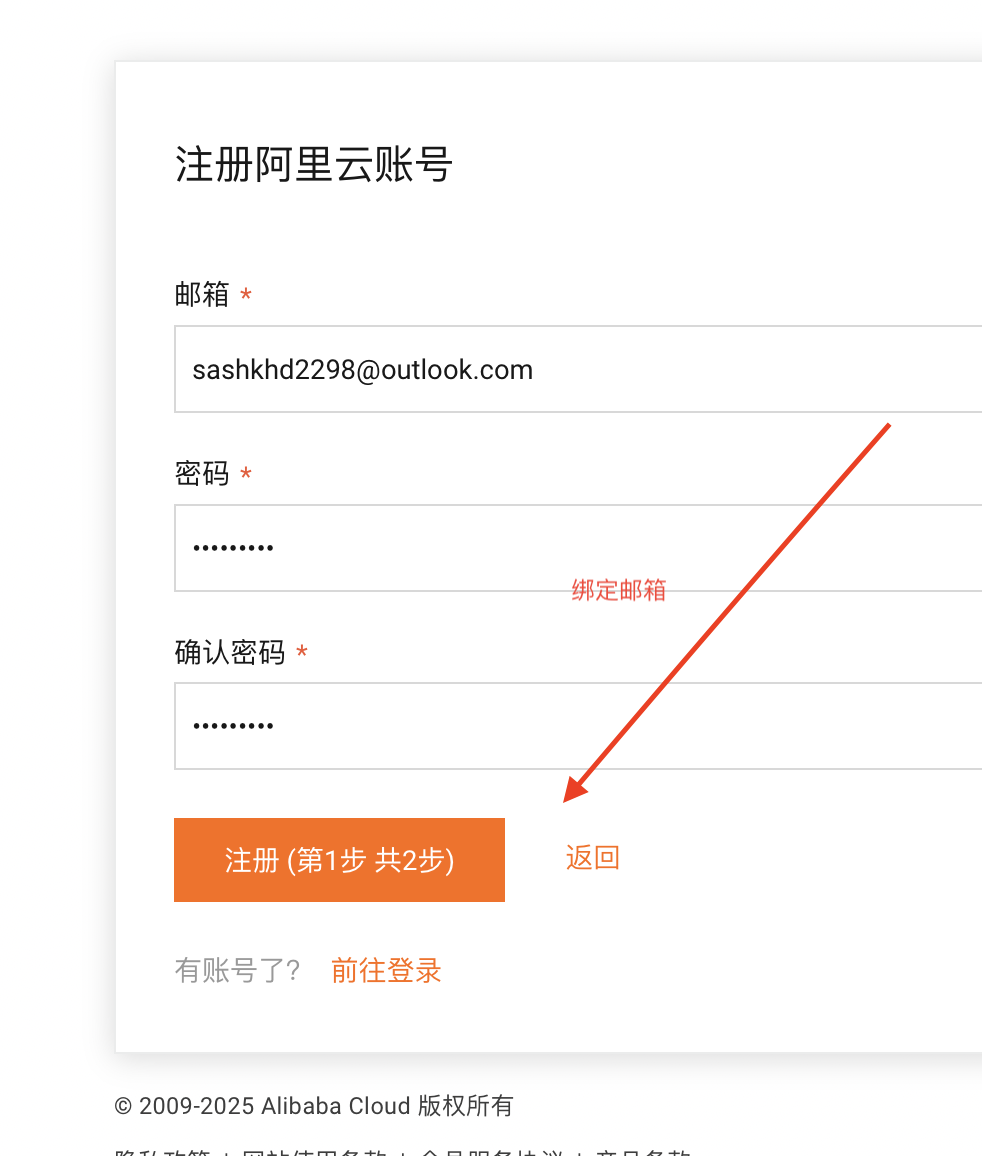
阿里云国际站,如何通过代理商邀请的链接注册账号
阿里云国际站:如何通过代理商邀请链接注册,解锁“云端超能力”与专属福利? 渴望在全球化浪潮中抢占先机?想获得阿里云国际站的海量云资源、遍布全球的加速节点与前沿AI服务,同时又能享受专属折扣、VIP级增值服务支持或…...

乾坤qiankun的使用
vue2 为主应用 react 为子应用 在项目中安装乾坤 yarn add qiankun # 或者 npm i qiankun -Svue主应用 在main.js中新增 (需要注意的是路由模型为history模式) registerMicroApps([{name: reactApp,entry: //localhost:3011,container: #container,/…...

从仿射矩阵得到旋转量平移量缩放量
仿射变换原理 仿射变换是一种线性变换,可以包括平移、旋转、缩放和剪切等操作。其一般公式可以表示为: $$\mathbf{x’} A \mathbf{x} \mathbf{b} ] 其中: (\mathbf{x}) 是输入向量,通常表示一个点在二维或三维空间中的坐标。(…...
后端配置)
Dockerfile 使用多阶段构建(build 阶段 → release 阶段)后端配置
错误Dockerfile配置示例: FROM python:3.11 as buildENV http_proxyhttp://172.17.0.1:7890 ENV https_proxyhttp://172.17.0.1:7890WORKDIR /appENV PYTHONPATH/app# Install Poetry # RUN curl -sSL https://install.python-poetry.org | POETRY_HOME/opt/poetry…...

Docker 镜像深度剖析:构建、管理与优化
一、前言 在容器化浪潮中,Docker镜像已成为构建可移植、标准化部署服务的基石。优质的镜像不仅能提升构建效率,更显著影响运行时性能和资源利用率。 本文将深入剖析Docker镜像的底层架构与工作原理,并通过实战案例详细演示镜像构建与优化技巧…...

使用 Flutter 开发 App 时,想要根据 Figma 设计稿开发出响应式 UI 界面
在使用 Flutter 开发 App 时,想要根据 Figma 设计稿开发出响应式 UI 界面(Responsive UI),以适配不同尺寸和分辨率的手机设备,需要从 设计阶段 和 编码实现阶段 双向配合。以下是详细的实现思路与方法: &am…...

Flink2.0及Flink-operater在K8S上部署
1.查找镜像 dockerhub访问不了的可以访问这个查找镜像 https://docker.aityp.com/ 在docker服务器上拉取flink镜像到本地 拉取镜像到你的docker服务器本地 docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/apache/flink:2.0.0-scala_2.12-java17 将docker服…...