superior哥AI系列第6期:Transformer注意力机制:AI界的“注意力革命“
🎭 superior哥AI系列第6期:Transformer注意力机制:AI界的"注意力革命"
嘿!小伙伴们!👋 今天superior哥要带你们探索AI界最火的技术——Transformer!这个家伙可了不得,它不仅改变了自然语言处理,还在计算机视觉、语音识别等领域掀起了革命!🚀 准备好了吗?我们一起来揭开注意力机制的神秘面纱!
🎯 今天我们要征服什么?
看看这个学习菜单,保证让你从"Transformer是什么鬼?“变成"我也能设计attention!”:
- 👁️ 注意力机制:AI的"专注力"是怎么炼成的?
- 🏗️ Transformer架构:现代AI的"建筑蓝图"
- 🚀 实际应用:从翻译到ChatGPT,都靠它!
- 💻 动手实战:搭建你的第一个迷你GPT
🧠 开胃菜:为什么我们需要"注意力"?
🤔 想象一个场景
superior哥问你:“昨天晚上你做了什么?”
你会怎么回答?你的大脑会:
- 🕐 回忆昨天晚上的时间段
- 🏠 聚焦在"晚上"这个关键信息
- 🎯 忽略其他不相关的白天活动
- 💭 组织语言进行回答
这就是注意力机制的本质!🎉
📚 传统RNN的"健忘症"
还记得我们上期讲的RNN吗?它有个老毛病:
# RNN处理长句子的痛苦
sentence = "我喜欢在阳光明媚的春天里,和朋友们一起去公园里踢足球,因为运动让我感到快乐"# RNN处理过程:
# Step 1: 记住"我喜欢" ✅
# Step 2: 记住"在阳光明媚" ✅
# Step 3: 记住"春天里" ✅
# Step 4: 记住"和朋友们" ✅
# Step 5: 记住"一起去公园" ❌ (开始忘记前面的内容)
# Step 6: 记住"踢足球" ❌ (几乎忘了开头说什么)
问题出现了! 当处理到"踢足球"时,RNN已经"忘记"了开头的"我喜欢"!😵
👁️ 注意力机制:AI的"聚光灯"
🔍 什么是注意力机制?
把注意力机制想象成一个智能聚光灯:
# 🎭 舞台上的表演者(输入序列)
performers = ["我", "喜欢", "在", "阳光", "明媚", "的", "春天", "踢", "足球"]# 🔦 聚光灯的选择(注意力权重)
attention_weights = {"我": 0.8, # 🔥 主角,重点关注!"喜欢": 0.7, # 🔥 关键动词"踢": 0.9, # 🔥 核心动作"足球": 0.9, # 🔥 目标对象"在": 0.1, # 💤 介词,不太重要"阳光": 0.3, # 💤 背景信息"明媚": 0.2, # 💤 修饰词"的": 0.1, # 💤 虚词"春天": 0.4 # 💤 时间信息
}
🎯 Self-Attention:自己和自己的对话
Self-Attention是Transformer的核心,就像每个词都在问其他词:
“嘿,朋友们!我想理解这句话,你们谁和我最相关?”
# 🗣️ "踢"这个词的内心独白:
def 踢_的_自我_attention():print("我是'踢',让我看看...")print("'我'说的是谁在踢?权重给你0.8!🎯")print("'足球'是我踢的对象?权重给你0.9!⚽")print("'喜欢'表达情感?权重给你0.7!❤️")print("'的''在'这些词?算了,权重给你们0.1吧 😴")return "现在我明白了!这句话的核心是:'我喜欢踢足球'!"
💡 注意力计算的三兄弟:Q、K、V
这三个字母看起来很神秘,其实很简单:
# 🎭 把每个词想象成一个人
class 词语角色:def __init__(self, word):self.word = wordself.Q = self.生成_Query() # 🤔 "我想找什么?"self.K = self.生成_Key() # 🔑 "我能提供什么信息?"self.V = self.生成_Value() # 💎 "我的真实内容是什么?"def 生成_Query(self):return f"{self.word}想要寻找相关信息"def 生成_Key(self):return f"{self.word}可以提供的特征"def 生成_Value(self):return f"{self.word}的实际含义"# 🔍 注意力计算过程
def calculate_attention(query, keys, values):"""就像在图书馆找书:- Query:你想找什么书?- Keys:书架上的目录标签- Values:书的实际内容"""similarity_scores = []for key in keys:# 🤝 计算相似度(Query和Key的匹配程度)score = compute_similarity(query, key)similarity_scores.append(score)# 🎯 Softmax归一化(让所有权重加起来等于1)attention_weights = softmax(similarity_scores)# 🎪 加权求和(根据权重组合Value)output = weighted_sum(values, attention_weights)return output, attention_weights
🏗️ Transformer架构:现代AI的"建筑蓝图"
🎯 整体结构:编码器+解码器
把Transformer想象成一个翻译公司:
class 翻译公司_Transformer:def __init__(self):self.编码器 = Encoder() # 🇨🇳 理解中文部门self.解码器 = Decoder() # 🇺🇸 生成英文部门def 翻译(self, 中文句子):# 🔍 第一步:编码器理解中文中文理解 = self.编码器.understand(中文句子)print(f"编码器: 我理解了!{中文句子} 的意思是...")# 🎯 第二步:解码器生成英文英文句子 = self.解码器.generate(中文理解)print(f"解码器: 翻译结果是: {英文句子}")return 英文句子# 🚀 实际使用
translator = 翻译公司_Transformer()
result = translator.翻译("我爱深度学习")
# 输出: "I love deep learning"
🧠 多头注意力:一心多用的超能力
想象你的大脑同时关注不同的信息:
class 多头注意力_MultiHead:def __init__(self, num_heads=8):self.heads = []for i in range(num_heads):self.heads.append(f"注意力头_{i+1}")def process(self, sentence):results = {}# 🎯 每个头关注不同的方面results["语法头"] = "关注主谓宾结构"results["语义头"] = "关注词汇含义"results["情感头"] = "关注情感色彩"results["时态头"] = "关注时间信息"results["实体头"] = "关注人名地名"results["关系头"] = "关注词汇关系"results["主题头"] = "关注主要话题"results["细节头"] = "关注修饰信息"print("🎭 8个注意力头同时工作中...")for head, focus in results.items():print(f" {head}: {focus}")return "综合所有头的信息,得到完整理解!"# 🎪 实际演示
multi_head = 多头注意力_MultiHead()
result = multi_head.process("昨天我在北京的咖啡厅里开心地写代码")
⚡ 位置编码:给词汇"安排座位"
Transformer没有RNN的时序性,所以需要告诉每个词它的位置:
import mathdef 位置编码_生动版(句子, d_model=512):"""就像给电影院的观众安排座位号!"""positions = {}for pos, word in enumerate(句子):# 🎫 为每个位置生成独特的"座位号"位置向量 = []for i in range(d_model):if i % 2 == 0:# 🎵 偶数维度用sin函数(像音乐的节拍)value = math.sin(pos / (10000 ** (i / d_model)))else:# 🎶 奇数维度用cos函数(像音乐的旋律)value = math.cos(pos / (10000 ** ((i-1) / d_model)))位置向量.append(value)positions[word] = {"座位号": pos,"位置向量": 位置向量[:8], # 只显示前8维"含义": f"我是第{pos+1}个出现的词"}return positions# 🎬 演示
sentence = ["我", "爱", "学习", "AI"]
pos_encodings = 位置编码_生动版(sentence)for word, info in pos_encodings.items():print(f"🎭 {word}: {info['含义']}")print(f" 位置向量预览: {info['位置向量'][:4]}...")
🚀 Transformer的超能力应用
🌍 机器翻译:全球语言无障碍
# 🌐 Google翻译背后的秘密
class TransformerTranslator:def translate(self, text, source_lang, target_lang):print(f"🔍 分析{source_lang}语法结构...")print(f"🧠 理解语义含义...")print(f"🎯 生成{target_lang}表达...")# 实际的注意力工作过程attention_map = {"我": ["I"],"爱": ["love"],"深度学习": ["deep", "learning"]}return "翻译完成!质量堪比专业译员!"# 📚 文本摘要:一键提取重点
class TransformerSummarizer:def summarize(self, long_text):print("🔍 扫描全文,寻找关键信息...")print("🎯 提取核心观点...")print("✨ 生成精炼摘要...")return "长文档 → 精华摘要,效率提升10倍!"
🤖 ChatGPT的大脑:GPT模型
class MiniGPT:"""GPT就是只有解码器的Transformer!"""def __init__(self):self.name = "迷你GPT"self.decoder_layers = 12 # 12层解码器self.attention_heads = 12 # 12个注意力头def chat(self, user_input):print(f"🎭 用户说: {user_input}")print("🧠 大脑活动中...")# 🎯 注意力机制工作流程steps = ["🔍 理解用户意图","🧠 激活相关知识","🎯 规划回答结构", "✨ 生成自然回复"]for step in steps:print(f" {step} ✅")return "这是一个基于Transformer的智能回复!"# 🎮 试试我们的迷你GPT
mini_gpt = MiniGPT()
response = mini_gpt.chat("什么是深度学习?")
💻 动手实战:搭建你的第一个注意力机制
🛠️ 简化版Self-Attention实现
import numpy as np
import torch
import torch.nn as nnclass SimpleAttention(nn.Module):"""superior哥的简化版注意力机制让你一目了然地理解核心原理!"""def __init__(self, d_model):super().__init__()self.d_model = d_model# 🎯 三兄弟的线性变换self.W_q = nn.Linear(d_model, d_model) # Query投影self.W_k = nn.Linear(d_model, d_model) # Key投影 self.W_v = nn.Linear(d_model, d_model) # Value投影# 🎪 输出投影self.W_o = nn.Linear(d_model, d_model)def forward(self, x):# 📐 输入形状: (batch_size, seq_len, d_model)batch_size, seq_len, d_model = x.shape# 🎯 第一步:生成Q、K、VQ = self.W_q(x) # 🤔 "我想找什么?"K = self.W_k(x) # 🔑 "我能提供什么?"V = self.W_v(x) # 💎 "我的真实内容"print(f"🎭 Q形状: {Q.shape}")print(f"🔑 K形状: {K.shape}")print(f"💎 V形状: {V.shape}")# 🤝 第二步:计算注意力分数attention_scores = torch.matmul(Q, K.transpose(-2, -1))attention_scores = attention_scores / np.sqrt(d_model) # 缩放# 🎯 第三步:Softmax归一化attention_weights = torch.softmax(attention_scores, dim=-1)print(f"🎯 注意力权重形状: {attention_weights.shape}")# 🎪 第四步:加权求和attended_values = torch.matmul(attention_weights, V)# ✨ 第五步:输出投影output = self.W_o(attended_values)return output, attention_weights# 🎮 测试我们的注意力机制
def test_attention():print("🚀 测试superior哥的注意力机制...")# 🎭 创建测试数据batch_size, seq_len, d_model = 1, 5, 64x = torch.randn(batch_size, seq_len, d_model)# 🏗️ 创建模型attention = SimpleAttention(d_model)# 🎯 前向传播output, weights = attention(x)print(f"✅ 输入形状: {x.shape}")print(f"✅ 输出形状: {output.shape}")print(f"✅ 注意力权重形状: {weights.shape}")# 🎪 可视化注意力权重print("\n🎭 注意力权重矩阵(前3x3):")print(weights[0, :3, :3].detach().numpy())# 运行测试
test_attention()
🎯 迷你Transformer块
class TransformerBlock(nn.Module):"""完整的Transformer块= Self-Attention + Feed-Forward + 残差连接 + Layer Norm"""def __init__(self, d_model, num_heads, d_ff):super().__init__()# 🎭 多头自注意力self.self_attention = nn.MultiheadAttention(d_model, num_heads)# 🍔 前馈网络(两层线性层)self.feed_forward = nn.Sequential(nn.Linear(d_model, d_ff),nn.ReLU(),nn.Linear(d_ff, d_model))# 🔄 层归一化self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)# 💧 Dropout防过拟合self.dropout = nn.Dropout(0.1)def forward(self, x):# 🎯 第一个子层:Self-Attention + 残差连接attn_output, _ = self.self_attention(x, x, x)x = self.norm1(x + self.dropout(attn_output))# 🍔 第二个子层:Feed-Forward + 残差连接ff_output = self.feed_forward(x)x = self.norm2(x + self.dropout(ff_output))return x# 🎮 测试完整的Transformer块
def test_transformer_block():print("🎯 测试完整的Transformer块...")# 🎭 参数设置d_model, num_heads, d_ff = 128, 8, 512seq_len, batch_size = 10, 2# 🏗️ 创建模型和数据transformer_block = TransformerBlock(d_model, num_heads, d_ff)x = torch.randn(seq_len, batch_size, d_model)# 🚀 前向传播output = transformer_block(x)print(f"✅ 输入形状: {x.shape}")print(f"✅ 输出形状: {output.shape}")print("🎉 Transformer块工作正常!")test_transformer_block()
🎯 实战项目:构建文本分类器
让我们用Transformer做一个情感分析项目:
class SentimentTransformer(nn.Module):"""基于Transformer的情感分析器判断文本是正面😊还是负面😞情感"""def __init__(self, vocab_size, d_model=128, num_heads=8, num_layers=2):super().__init__()# 📚 词嵌入层self.embedding = nn.Embedding(vocab_size, d_model)# 🎯 位置编码self.pos_encoding = self.create_position_encoding(1000, d_model)# 🏗️ Transformer层self.transformer_blocks = nn.ModuleList([TransformerBlock(d_model, num_heads, d_model*4)for _ in range(num_layers)])# 🎯 分类头self.classifier = nn.Sequential(nn.Linear(d_model, 64),nn.ReLU(),nn.Dropout(0.1),nn.Linear(64, 2) # 2个类别:正面/负面)def create_position_encoding(self, max_len, d_model):"""创建位置编码"""pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1).float()div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(np.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)return pedef forward(self, x):seq_len = x.size(1)# 📚 词嵌入 + 位置编码x = self.embedding(x) + self.pos_encoding[:seq_len, :].unsqueeze(0)# 🎭 通过Transformer层for transformer in self.transformer_blocks:x = transformer(x)# 🎯 全局平均池化 + 分类x = x.mean(dim=1) # 对序列维度取平均logits = self.classifier(x)return logits# 🎮 训练函数
def train_sentiment_model():print("🎯 开始训练情感分析模型...")# 🎭 模拟数据vocab_size = 1000model = SentimentTransformer(vocab_size)# 📊 损失函数和优化器criterion = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 🎮 模拟训练数据fake_texts = torch.randint(0, vocab_size, (32, 20)) # 32个样本,每个20个词fake_labels = torch.randint(0, 2, (32,)) # 32个标签# 🚀 训练一个步骤model.train()optimizer.zero_grad()logits = model(fake_texts)loss = criterion(logits, fake_labels)loss.backward()optimizer.step()print(f"✅ 训练损失: {loss.item():.4f}")print("🎉 模型训练成功!")train_sentiment_model()
🌟 Transformer的未来:无限可能
🚀 发展趋势
class TransformerEvolution:"""Transformer的进化历程"""def __init__(self):self.evolution = {"2017": "Transformer诞生 - 'Attention Is All You Need'","2018": "BERT横空出世 - 双向编码器称霸NLP","2019": "GPT-2震惊世界 - 生成能力爆表","2020": "GPT-3改变游戏 - 1750亿参数的巨兽","2021": "Vision Transformer - 征服计算机视觉","2022": "ChatGPT引爆全球 - AI助手走进千家万户","2023": "GPT-4多模态 - 文本图像齐飞","2024": "Sora视频生成 - AI创造力爆发","2025": "未来无限 - 你的想象就是边界!"}def show_evolution(self):print("🎯 Transformer进化史:")for year, milestone in self.evolution.items():print(f" {year}: {milestone}")# 🎪 应用领域大爆发
applications = {"🌍 自然语言处理": ["机器翻译", "文本摘要", "问答系统", "对话机器人"],"👁️ 计算机视觉": ["图像分类", "目标检测", "图像生成", "视频理解"],"🎵 语音技术": ["语音识别", "语音合成", "音乐生成", "声音克隆"],"🧬 科学研究": ["蛋白质折叠", "药物发现", "基因分析", "天体物理"],"🎮 创意产业": ["内容创作", "游戏AI", "艺术生成", "影视制作"]
}print("🚀 Transformer应用领域:")
for field, apps in applications.items():print(f"{field}: {', '.join(apps)}")
🎓 学习建议与下期预告
📚 深入学习资源
learning_resources = {"📖 必读论文": ["Attention Is All You Need (原始论文)","BERT: Pre-training of Deep Bidirectional Transformers","Language Models are Few-Shot Learners (GPT-3)"],"💻 实践项目": ["从零实现Transformer","构建中文聊天机器人", "多语言翻译系统","文档智能问答"],"🛠️ 推荐工具": ["Hugging Face Transformers","PyTorch官方教程","TensorFlow/Keras","OpenAI API"]
}for category, items in learning_resources.items():print(f"{category}:")for item in items:print(f" • {item}")
🎯 下期预告:第7期
下期superior哥要和大家深入探讨:
🎯 模型训练与优化:让AI学得又快又好
我们将学习:
- 📊 损失函数选择指南 - 分类回归问题的最佳拍档
- 🚀 优化器大比拼 - SGD、Adam谁更强?
- 🛡️ 正则化技术 - 防止过拟合的武器库
- ⚡ 训练加速技巧 - 让GPU发挥最大性能
💭 今天的思考题
在评论区告诉superior哥:
- 🤔 Transformer最吸引你的特性是什么?
- 🎯 你想用注意力机制解决什么实际问题?
- 🚀 对于下期的训练优化,你最期待哪个话题?
🎉 总结:你已经掌握了现代AI的核心!
今天我们一起探索了Transformer这个改变AI世界的神奇架构!从注意力机制的基本原理,到多头注意力的精妙设计,再到位置编码的巧思,你已经掌握了现代AI的核心技术!🎉
今天的收获清单:
- ✅ 理解了注意力机制的本质
- ✅ 掌握了Self-Attention的计算过程
- ✅ 学会了Transformer的整体架构
- ✅ 动手实现了简化版模型
- ✅ 构建了实用的情感分析器
记住:Transformer不仅仅是一个模型,更是一种思想革命! 它告诉我们,有时候最重要的不是复杂的结构,而是找到问题的核心机制。
准备好迎接下期的训练优化挑战了吗?我们要让模型不仅聪明,还要高效!🚀
🔥 如果这篇文章对你有帮助,记得点赞收藏哦!
💌 有问题随时在评论区找superior哥交流!
🚀 我们下期见,继续征服AI的世界!
superior哥AI系列 - 让每个人都能轻松掌握人工智能! 🎯
相关文章:
superior哥AI系列第6期:Transformer注意力机制:AI界的“注意力革命“
🎭 superior哥AI系列第6期:Transformer注意力机制:AI界的"注意力革命" 嘿!小伙伴们!👋 今天superior哥要带你们探索AI界最火的技术——Transformer!这个家伙可了不得,它不…...

【java面试】redis篇
redis篇 一、适用场景(一)缓存1、缓存穿透1.1 解决方案1:缓存空数据,查询返回的数据为空,将空结果缓存1.2 解决方案2:布隆过滤器 2、缓存击穿1.1 解决方案1:互斥锁1.2 解决方案2:逻辑…...
高效易用的 MAC 版 SVN 客户端:macSvn 使用体验
高效易用的 MAC 版 SVN 客户端:macSvn 使用体验 下载安装使用总结 最近有个项目要使用svn, 但是mac缺乏一款像 Windows 平台 TortoiseSVN 那样全面、高效且便捷的 SVN 客户端工具, 直到博主找到了该工具本文将结合实际使用体验,详细介绍 macSvn工具的核心…...
【搭建 Transformer】
搭建 Transformer 的基本步骤 Transformer 是一种基于自注意力机制的深度学习模型,广泛应用于自然语言处理任务。以下为搭建 Transformer 的关键步骤和代码示例。 自注意力机制 自注意力机制是 Transformer 的核心,计算输入序列中每个元素与其他元素的…...

自然图像数据集
目录 CIFAR-10 数据集CIFAR-100 数据集AFHQ 数据集FFHQ 数据集 CIFAR-10 数据集 简介: CIFAR-10 是一个经典的图像分类数据集,广泛用于机器学习领域的计算机视觉算法基准测试。它包含60000幅32x32的彩色图像,分为10个类,每类6000…...

Linux下使用nmcli连接网络
Linux下使用nmcli连接网络 介绍 在使用ubuntu系统的时候,有时候不方便使用桌面,使用ssh远程连接,可能需要使用nmcli命令来连接网络。本文将介绍如何使用nmcli命令连接网络。nmcli 是 NetworkManager 的命令行工具,用于管理网络连…...
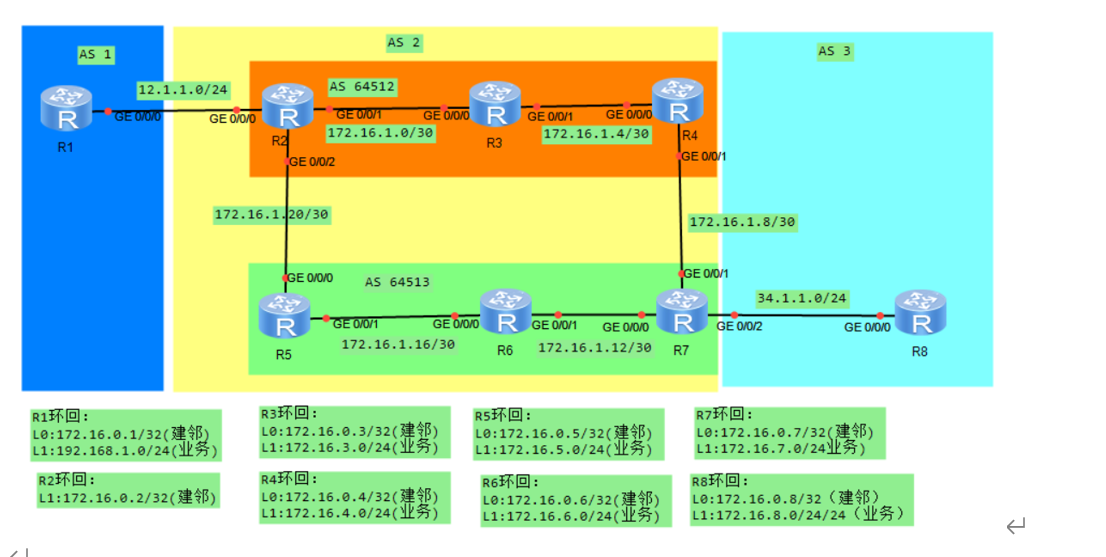
HCIP(BGP综合实验)
一、实验拓扑 AS 划分: AS1:R1(环回 L0:172.16.0.1/32,L1:192.168.1.0/24)AS2:R2、R3、R4、R5、R6、R7(内部运行 OSPF,AS 号为 64512 和 64513 的联盟)AS3:R…...

Attention Is All You Need (Transformer) 以及Transformer pytorch实现
参考https://zhuanlan.zhihu.com/p/569527564 Attention Is All You Need (Transformer) 是当今深度学习初学者必读的一篇论文。 一. Attention Is All You Need (Transformer) 论文精读 1. 知识准备 机器翻译,就是将某种语言的一段文字翻译成另一段文字。 由…...
uniapp+vue2+uView项目学习知识点记录
持续更新中... 1、发送给朋友,分享到朋友圈功能开启 利用onShareAppMessage和onShareTimeline生命周期函数,在script中与data同级去写 // 发送给朋友 onShareAppMessage() {return {title: 清清前端, // 分享标题path: /pages/index/index, // 分享路…...

精美的软件下载页面HTML源码:现代UI与动画效果的完美结合
精美的软件下载页面HTML源码:现代UI与动画效果的完美结合 在数字化产品推广中,一个设计精良的下载页面不仅能提升品牌专业度,还能显著提高用户转化率。本文介绍的精美软件下载页面HTML源码,通过现代化UI设计与丰富的动画效果&…...

车载诊断架构 --- DTC消抖参数(Trip Counter DTCConfirmLimit )
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...
javaEE->IO:
文件: 操作系统中会把很多 硬件设备 和 软件资源 抽象成“文件”,统一进行管理。 大部分谈到的文件,都是指 硬盘的文件,文件就相当于是针对“硬盘”数据的一种抽象 硬盘: 1.机械硬盘:便宜 2.固态硬盘&…...

Oracle 用户/权限/角色管理
1. 用户 1.1. 用户的创建和删除 1.1.1. 创建用户 create user user identified {by password | externally} [ default tablespace tablespace ] [ temporary tablespace tablespace ] [ quota {integer [k | m ] | unlimited } on tablespace [ quota {integer [k | m ] | …...

使用免费wordpress成品网站模板需要注意点什么
在使用免费 WordPress 成品网站模板时,需要从版权、安全性、兼容性、功能限制等多个方面谨慎考量,避免后续出现问题。以下是具体需要注意的要点: 一、版权与授权问题 明确授权类型 免费模板可能分为「开源免费」「限个人使用」「禁止商业用…...

深入理解 JSX:React 的核心语法
1. 什么是 JSX? JSX(JavaScript And XML)是 React 中最核心的概念之一,也是区别于 Vue 的一个重要特征(尽管 Vue 现在也支持 JSX 语法)。JSX 是一种在 JavaScript 中编写 HTML 代码片段的语法协议…...
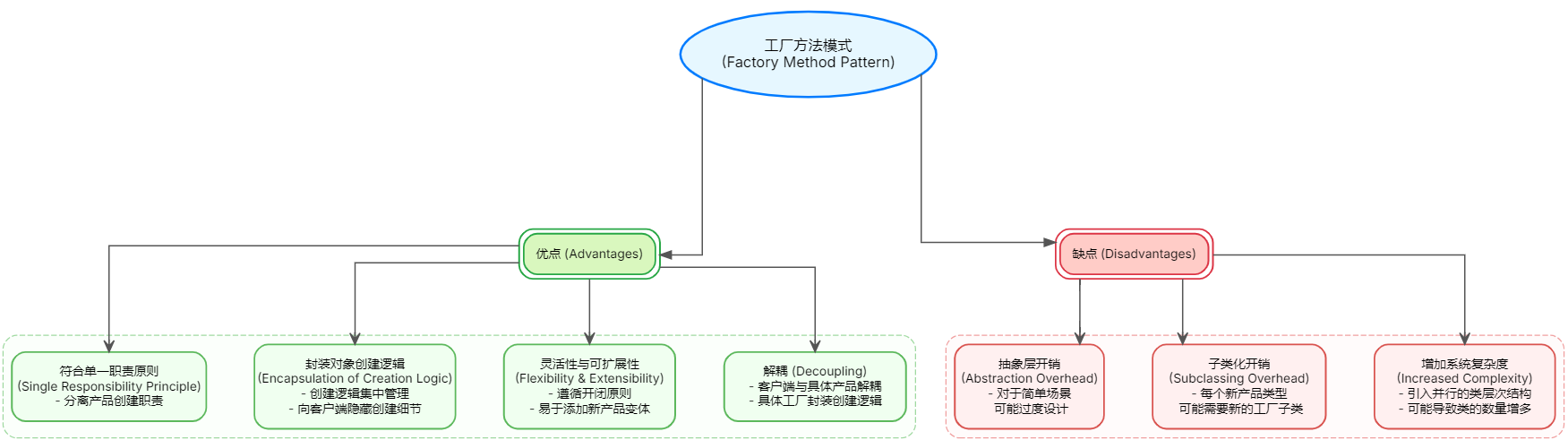
工厂方法模式深度解析:从原理到应用实战
作者简介 我是摘星,一名全栈开发者,专注 Java后端开发、AI工程化 与 云计算架构 领域,擅长Python技术栈。热衷于探索前沿技术,包括大模型应用、云原生解决方案及自动化工具开发。日常深耕技术实践,乐于分享实战经验与…...

TS 星际通信指南:从 TCP 到 UDP 的宇宙漫游
文章目录 一、计算机网络通信1、基本概念2、核心要素(一)终端设备(二)通信介质(三)网络协议 3、常用通信模型(一)OSI 七层模型(理论框架)(二&…...

python可视化:端午假期旅游火爆原因分析
python可视化:端午假期旅游火爆原因分析 2025年的旅游市场表现强劲: 2025年端午假期全社会跨区域人员流动量累计6.57亿人次,日均2.19亿人次,同比增长3.0%。入境游订单同比大涨近90%,门票交易额(GMV&#…...

Missashe考研日记—Day51-Day57
Missashe考研日记—Day51-Day57 写在面前 本系列博客用于记录博主一周的学习进度。线代题型总结 专业课408 这周简直是拼命学计网,花了两三天速通传输层和应用层内容,又臭又长的网课听不下去一点了,赶紧结束准备开二轮进行复习和刷题了。…...

electron-vite_18桌面共享
electron默认不支持桌面共享,需要添加desktopCapturer配置,这样在使用navigator.mediaDevices.getUserMedia API访问可用于从桌面捕获音频和视频的媒体源的信息。 electron版本 "electron": "^31.0.2",在main.js中添加desktopCaptu…...

SOC-ESP32S3部分:28-BLE低功耗蓝牙
飞书文档https://x509p6c8to.feishu.cn/wiki/CHcowZMLtiinuBkRhExcZN7Ynmc 蓝牙是一种短距的无线通讯技术,可实现固定设备、移动设备之间的数据交换,下图是一个蓝牙应用的分层架构,Application部分则是我们需要实现的内容,Protoc…...
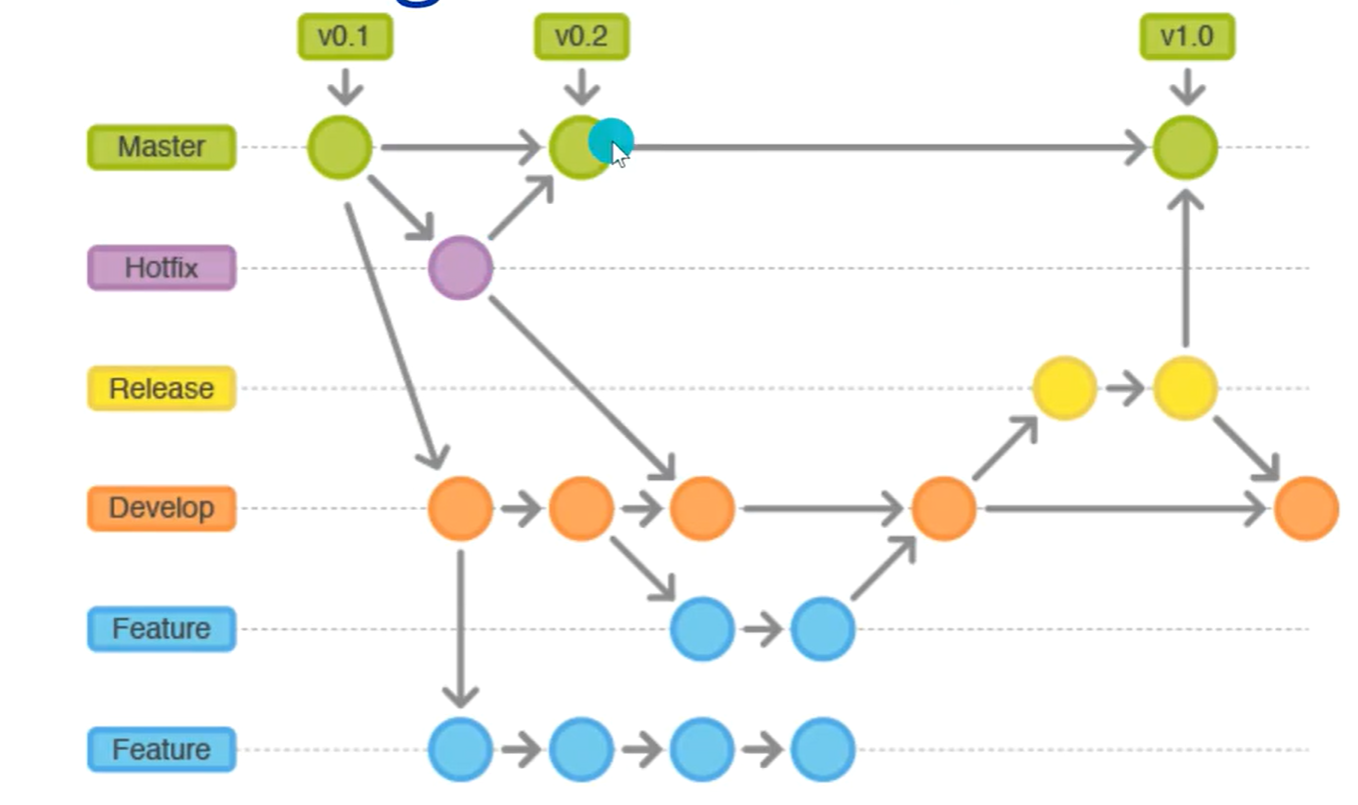
Git-flow流
Git git是版本控制软件,一般用来做代码版本控制 github是一个免费版本控制仓库是国内外很多开源项目的集中地,其本体是一个git服务器 Git初始化操作 git init 初始化仓库 git status 查看当前仓库的状态 git add . 将改动的文件加到暂存区 gi…...
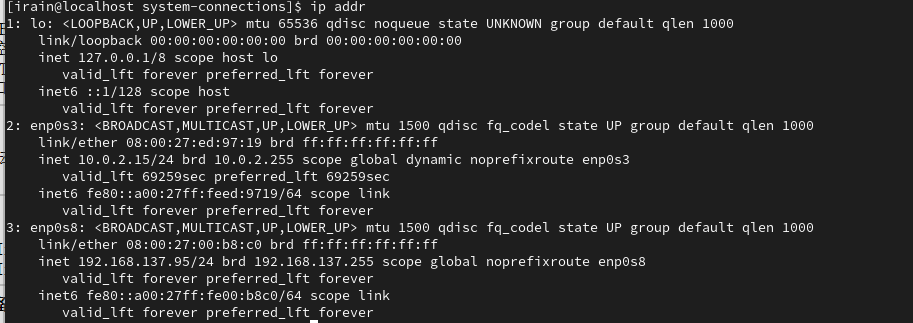
VirtualBox给Rock Linux9.x配置网络
写这篇文章之前,先说明一下,我参考的是我之前写的《VirtualBox Linux网络配置》 我从CentOS7转到了Rock9,和配置Centos7一样,主流程没有变化,变化的是Rock9.x中的配置文件和使用的命令。 我再说一次,因为主…...

知识图谱增强的大型语言模型编辑
https://arxiv.org/pdf/2402.13593 摘要 大型语言模型(LLM)是推进自然语言处理(NLP)任务的关键,但其效率受到不准确和过时知识的阻碍。模型编辑是解决这些挑战的一个有前途的解决方案。然而,现有的编辑方法…...

.NET 原生驾驭 AI 新基建实战系列(一):向量数据库的应用与畅想
在当今数据驱动的时代,向量数据库(Vector Database)作为一种新兴的数据库技术,正逐渐成为软件开发领域的重要组成部分。特别是在 .NET 生态系统中,向量数据库的应用为开发者提供了构建智能、高效应用程序的新途径。 一…...
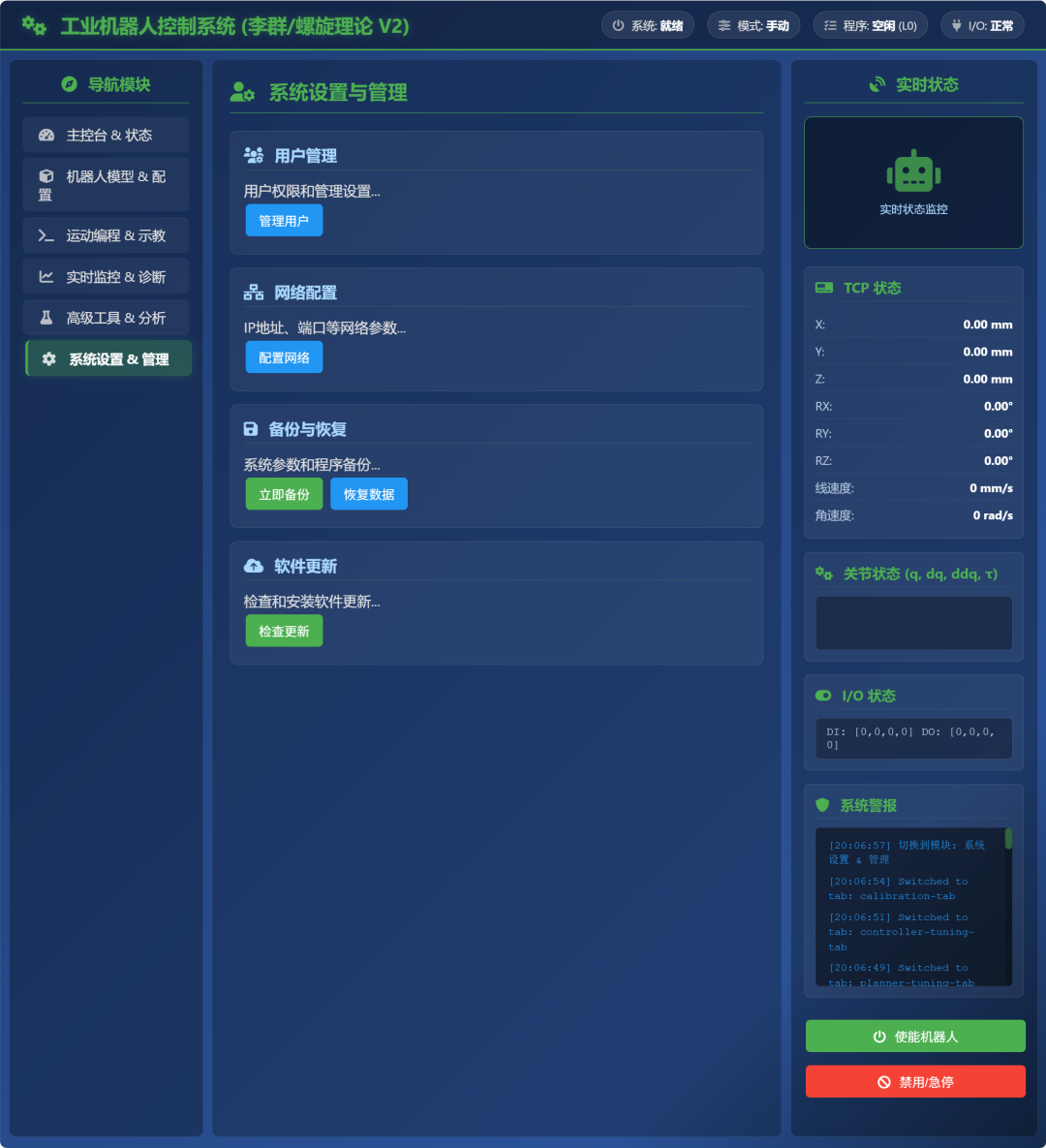
【claude+deepseek+gemini】基于李群李代数和螺旋理论工业机器人控制系统软件UI设计
claude的首次设计html是最佳的。之后让deepseek和gemini根据claude的UI设计进行改进设计。。。当然可以尝试很多次,也可以让他们之间来回不断改进…… claude deepseek-r1 0528 上图为deepseek首次设计,下面为改进设计 …… Gemini 2.5 Pro 0506 &#x…...
阿里云国际站,如何通过代理商邀请的链接注册账号
阿里云国际站:如何通过代理商邀请链接注册,解锁“云端超能力”与专属福利? 渴望在全球化浪潮中抢占先机?想获得阿里云国际站的海量云资源、遍布全球的加速节点与前沿AI服务,同时又能享受专属折扣、VIP级增值服务支持或…...

乾坤qiankun的使用
vue2 为主应用 react 为子应用 在项目中安装乾坤 yarn add qiankun # 或者 npm i qiankun -Svue主应用 在main.js中新增 (需要注意的是路由模型为history模式) registerMicroApps([{name: reactApp,entry: //localhost:3011,container: #container,/…...

从仿射矩阵得到旋转量平移量缩放量
仿射变换原理 仿射变换是一种线性变换,可以包括平移、旋转、缩放和剪切等操作。其一般公式可以表示为: $$\mathbf{x’} A \mathbf{x} \mathbf{b} ] 其中: (\mathbf{x}) 是输入向量,通常表示一个点在二维或三维空间中的坐标。(…...
后端配置)
Dockerfile 使用多阶段构建(build 阶段 → release 阶段)后端配置
错误Dockerfile配置示例: FROM python:3.11 as buildENV http_proxyhttp://172.17.0.1:7890 ENV https_proxyhttp://172.17.0.1:7890WORKDIR /appENV PYTHONPATH/app# Install Poetry # RUN curl -sSL https://install.python-poetry.org | POETRY_HOME/opt/poetry…...