python打卡day43
作业:
kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化
进阶:并拆分成多个文件
找了个街头食物图像分类的数据集Popular Street Foods(其实写代码的时候就开始后悔了),原因在于:
1、如果是比较规整的图像分类数据集,自己划分了train和test目录,就可以直接用pytorch内置的ImageFolder类,不用自己再辛辛苦苦定义数据集类了,但很遗憾这个数据集不规整,图片在类别下面,标签用一个csv文件存储,所以不仅要自己定义数据类,训练测试的时候还要自己划分数据集
2、图片尺寸非常不统一,需要自己预先处理,遍历了一遍这个数据集,最后决定全部统一成140x140的
from PIL import Image
import os
from collections import defaultdict# 替换为你的数据集路径
dataset_path = "/kaggle/input/popular-street-foods/popular_street_foods/dataset"size_dict = defaultdict(int)for root, _, files in os.walk(dataset_path):for file in files:if file.lower().endswith(('png', 'jpg', 'jpeg')):try:with Image.open(os.path.join(root, file)) as img:size_dict[img.size] += 1 # (width, height)except:print(f"Error reading: {file}")# 打印尺寸统计
print("Top 10 common sizes:")
for size, count in sorted(size_dict.items(), key=lambda x: x[1], reverse=True)[:10]:print(f"{size}: {count} images")# -----------------------------------------------------
Top 10 common sizes:
(140, 140): 851 images
(93, 140): 574 images
(162, 108): 548 images
(162, 121): 308 images
(162, 91): 295 images
(105, 140): 119 images
(112, 140): 90 images
(100, 140): 30 images
(154, 140): 28 images
(162, 85): 26 images完成代码:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import Dataset, DataLoader, random_split
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
# 图像尺寸统一成140x140
class PhotoResizer:def __init__(self, target_size=140, fill_color=114): # target_size: 目标正方形尺寸,fill_color: 填充使用的灰度值self.target_size = target_sizeself.fill_color = fill_color# 预定义转换方法self.to_tensor = transforms.ToTensor()self.normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])def __call__(self, img):"""智能处理流程:1. 对小图像进行填充,对大图像进行智能裁剪2. 保持长宽比的情况下进行保护性处理"""w, h = img.sizeif w == h == self.target_size: # 情况1:已经是目标尺寸pass # 无需处理elif min(w, h) < self.target_size: # 情况2:至少有一个维度小于目标尺寸(需要填充)img = self.padding_resize(img)else: # 情况3:两个维度都大于目标尺寸(智能裁剪)img = self.crop_resize(img)# 最终统一转换return self.normalize(self.to_tensor(img))def padding_resize(self, img): # 等比缩放后居中填充不足部分w, h = img.sizescale = self.target_size / min(w, h)new_w, new_h = int(w * scale), int(h * scale)img = img.resize((new_w, new_h), Image.BILINEAR)# 等比缩放 + 居中填充# 计算需要填充的像素数(4个值:左、上、右、下)pad_left = (self.target_size - new_w) // 2pad_top = (self.target_size - new_h) // 2pad_right = self.target_size - new_w - pad_leftpad_bottom = self.target_size - new_h - pad_topreturn transforms.functional.pad(img, [pad_left, pad_top, pad_right, pad_bottom], self.fill_color)def crop_resize(self, img): # 等比缩放后中心裁剪w, h = img.sizeratio = w / h# 计算新尺寸(保护长边)if ratio < 0.9: # 竖图new_size = (self.target_size, int(h * self.target_size / w))elif ratio > 1.1: # 横图new_size = (int(w * self.target_size / h), self.target_size)else: # 近似正方形new_size = (self.target_size, self.target_size)img = img.resize(new_size, Image.BILINEAR)return transforms.functional.center_crop(img, self.target_size)# 训练集测试集预处理
train_transform = transforms.Compose([PhotoResizer(target_size=140), # 自动处理所有情况transforms.RandomHorizontalFlip(), # 随机水平翻转图像(概率0.5)transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 随机颜色抖动:亮度、对比度、饱和度和色调随机变化transforms.RandomRotation(15), # 随机旋转图像(最大角度15度)
])test_transform = transforms.Compose([PhotoResizer(target_size=140)
])# 2. 创建dataset和dataloader实例
class StreetFoodDataset(Dataset):def __init__(self, root_dir, transform=None):self.root_dir = root_dirself.transform = transformself.image_paths = []self.labels = []self.class_to_idx = {}# 遍历目录获取类别映射classes = sorted(entry.name for entry in os.scandir(root_dir) if entry.is_dir())self.class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}# 收集图像路径和标签for class_name in classes:class_dir = os.path.join(root_dir, class_name)for img_name in os.listdir(class_dir):if img_name.lower().endswith(('.png', '.jpg', '.jpeg')):self.image_paths.append(os.path.join(class_dir, img_name))self.labels.append(self.class_to_idx[class_name])def __len__(self):return len(self.image_paths)def __getitem__(self, idx):img_path = self.image_paths[idx]image = Image.open(img_path).convert('RGB')label = self.labels[idx]if self.transform:image = self.transform(image)return image, label# 数据集路径(Kaggle路径示例)
dataset_path = '/kaggle/input/popular-street-foods/popular_street_foods/dataset'# 创建数据集实例
# 先创建基础数据集
full_dataset = StreetFoodDataset(root_dir=dataset_path)# 分割数据集
train_size = int(0.8 * len(full_dataset))
test_size = len(full_dataset) - train_size
train_dataset, test_dataset = random_split(full_dataset, [train_size, test_size])
train_dataset.dataset.transform = train_transform
test_dataset.dataset.transform = test_transform# 创建数据加载器
train_loader = DataLoader(train_dataset,batch_size=32,shuffle=True,num_workers=2,pin_memory=True
)test_loader = DataLoader(test_dataset,batch_size=32,shuffle=False,num_workers=2,pin_memory=True
)# 3. 定义CNN模型
class CNN(nn.Module):def __init__(self, num_classes=20): super(CNN, self).__init__()# 第一个卷积块self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2d(32)self.relu1 = nn.ReLU()self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # 140x140 → 70x70# 第二个卷积块self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2) # 70x70 → 35x35# 第三个卷积块self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)self.bn3 = nn.BatchNorm2d(128)self.relu3 = nn.ReLU()self.pool3 = nn.MaxPool2d(kernel_size=2) # 35x35 → 17x17(下采样时尺寸向下取整)# 第四个卷积块(新增,处理更大尺寸)self.conv4 = nn.Conv2d(128, 256, kernel_size=3, padding=1)self.bn4 = nn.BatchNorm2d(256)self.relu4 = nn.ReLU()self.pool4 = nn.MaxPool2d(kernel_size=2) # 17x17 → 8x8# 全连接层(分类器)# 修改:计算展平后的特征维度 256通道 × 8x8尺寸 = 16384self.fc1 = nn.Linear(256 * 8 * 8, 512)self.dropout = nn.Dropout(p=0.5)self.fc2 = nn.Linear(512, num_classes) # 使用num_classes参数def forward(self, x):# 输入尺寸:[batch_size, 3, 140, 140]# 卷积块1处理x = self.conv1(x) # [batch_size, 32, 140, 140]x = self.bn1(x)x = self.relu1(x)x = self.pool1(x) # [batch_size, 32, 70, 70]# 卷积块2处理x = self.conv2(x) # [batch_size, 64, 70, 70]x = self.bn2(x)x = self.relu2(x)x = self.pool2(x) # [batch_size, 64, 35, 35]# 卷积块3处理x = self.conv3(x) # [batch_size, 128, 35, 35]x = self.bn3(x)x = self.relu3(x)x = self.pool3(x) # [batch_size, 128, 17, 17]# 卷积块4处理(新增)x = self.conv4(x) # [batch_size, 256, 17, 17]x = self.bn4(x)x = self.relu4(x)x = self.pool4(x) # [batch_size, 256, 8, 8]# 展平与全连接层x = x.view(-1, 256 * 8 * 8) # [batch_size, 16384]x = self.fc1(x) # [batch_size, 512]x = self.relu3(x) # 复用relu3x = self.dropout(x)x = self.fc2(x) # [batch_size, num_classes]return x # 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)# 4. 训练测试
# 定义损失函数、优化器、调度器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'max', patience=5, factor=0.5)# 训练过程封装
def train_epoch(model, loader, criterion, optimizer):model.train()running_loss = 0.0correct = 0total = 0for images, labels in loader:images, labels = images.to(device), labels.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()return running_loss/len(loader), 100.*correct/total# 测试过程封装
def test(model, loader, criterion):model.eval()running_loss = 0.0correct = 0total = 0with torch.no_grad():for images, labels in loader:images, labels = images.to(device), labels.to(device)outputs = model(images)loss = criterion(outputs, labels)running_loss += loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()return running_loss/len(loader), 100.*correct/total# 训练循环
epochs = 1000
best_acc = 0.0
patience = 10 # 早停耐心值
no_improve = 0 # 没有提升的epoch计数# 创建保存目录
os.makedirs("checkpoints", exist_ok=True)for epoch in range(epochs):train_loss, train_acc = train_epoch(model, train_loader, criterion, optimizer)test_loss, test_acc = test(model, test_loader, criterion)scheduler.step(test_acc) # 根据测试准确率调整学习率# 每200个epoch打印一次信息if (epoch + 1) % 200 == 0 or epoch == 0 or (epoch + 1) == epochs:print(f"\nEpoch {epoch+1}/{epochs}")print(f"Train Loss: {train_loss:.4f} | Acc: {train_acc:.2f}%")print(f"Test Loss: {test_loss:.4f} | Acc: {test_acc:.2f}%")print(f"Current LR: {optimizer.param_groups[0]['lr']:.6f}")print("-"*50)# 保存最佳模型if test_acc > best_acc:best_acc = test_acctorch.save(model.state_dict(), "checkpoints/best_model.pth")no_improve = 0else:no_improve += 1# 定期保存检查点if (epoch + 1) % 200 == 0:torch.save({'epoch': epoch,'model_state_dict': model.state_dict(),'optimizer_state_dict': optimizer.state_dict(),'best_acc': best_acc,}, f"checkpoints/checkpoint_{epoch+1}.pth")# 早停检查if no_improve >= patience:print(f"\nEarly stopping at epoch {epoch+1}, no improvement for {patience} epochs")print(f"Best test accuracy: {best_acc:.2f}%")breakprint(f"\n训练完成,最佳测试准确率: {best_acc:.2f}%")# 5. Grad-CAM实现
model.eval()# Grad-CAM实现
class GradCAM:def __init__(self, model, target_layer):self.model = modelself.target_layer = target_layerself.gradients = Noneself.activations = None# 注册钩子,用于获取目标层的前向传播输出和反向传播梯度self.register_hooks()def register_hooks(self):# 前向钩子函数,在目标层前向传播后被调用,保存目标层的输出(激活值)def forward_hook(module, input, output):self.activations = output.detach()# 反向钩子函数,在目标层反向传播后被调用,保存目标层的梯度def backward_hook(module, grad_input, grad_output):self.gradients = grad_output[0].detach()# 在目标层注册前向钩子和反向钩子self.target_layer.register_forward_hook(forward_hook)self.target_layer.register_backward_hook(backward_hook)def generate_cam(self, input_image, target_class=None):# 前向传播,得到模型输出model_output = self.model(input_image)if target_class is None:# 如果未指定目标类别,则取模型预测概率最大的类别作为目标类别target_class = torch.argmax(model_output, dim=1).item()# 清除模型梯度,避免之前的梯度影响self.model.zero_grad()# 反向传播,构造one-hot向量,使得目标类别对应的梯度为1,其余为0,然后进行反向传播计算梯度one_hot = torch.zeros_like(model_output)one_hot[0, target_class] = 1model_output.backward(gradient=one_hot)# 获取之前保存的目标层的梯度和激活值gradients = self.gradientsactivations = self.activations# 对梯度进行全局平均池化,得到每个通道的权重,用于衡量每个通道的重要性weights = torch.mean(gradients, dim=(2, 3), keepdim=True)# 加权激活映射,将权重与激活值相乘并求和,得到类激活映射的初步结果cam = torch.sum(weights * activations, dim=1, keepdim=True)# ReLU激活,只保留对目标类别有正贡献的区域,去除负贡献的影响cam = F.relu(cam)# 调整大小并归一化,将类激活映射调整为与输入图像相同的尺寸(140x140),并归一化到[0, 1]范围cam = F.interpolate(cam, size=(140, 140), mode='bilinear', align_corners=False)cam = cam - cam.min()cam = cam / cam.max() if cam.max() > 0 else camreturn cam.cpu().squeeze().numpy(), target_class# 选择一个随机图像
idx = np.random.randint(len(test_dataset))
image, label = test_dataset[idx]
classes = sorted(os.listdir('/kaggle/input/popular-street-foods/popular_street_foods/dataset'))
print(f"选择的图像类别: {classes[label]}")# 转换图像以便可视化
def tensor_to_np(tensor):img = tensor.cpu().numpy().transpose(1, 2, 0)mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])img = std * img + meanimg = np.clip(img, 0, 1)return img# 添加批次维度并移动到设备
input_tensor = image.unsqueeze(0).to(device)# 初始化Grad-CAM(选择最后一个卷积层)
grad_cam = GradCAM(model, model.conv4 )# 生成热力图
heatmap, pred_class = grad_cam.generate_cam(input_tensor)# 可视化
plt.figure(figsize=(12, 4))# 原始图像
plt.subplot(1, 3, 1)
plt.imshow(tensor_to_np(image))
plt.title(f"原始图像: {classes[label]}")
plt.axis('off')# 热力图
plt.subplot(1, 3, 2)
plt.imshow(heatmap, cmap='jet')
plt.title(f"Grad-CAM热力图: {classes[pred_class]}")
plt.axis('off')# 叠加的图像
plt.subplot(1, 3, 3)
img = tensor_to_np(image)
heatmap_resized = np.uint8(255 * heatmap)
heatmap_colored = plt.cm.jet(heatmap_resized)[:, :, :3]
superimposed_img = heatmap_colored * 0.4 + img * 0.6
plt.imshow(superimposed_img)
plt.title("叠加热力图")
plt.axis('off')plt.tight_layout()
plt.savefig('grad_cam_result.png')
plt.show()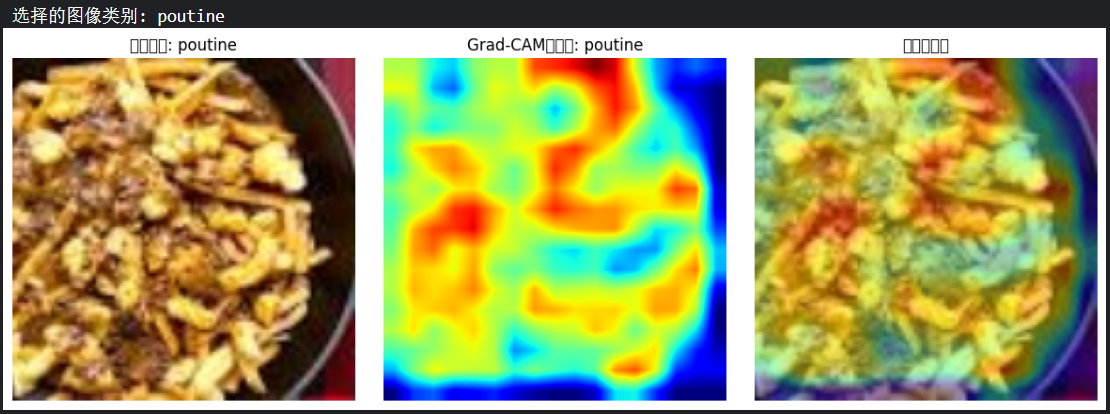
收获心得:
1、就是为了训练有更好的效果,所以图片尺寸处理的时候那么费劲(不然完全可以全部裁剪成一个更小的尺寸),但是最后训练出来的准确率还是不尽人意,可能是cnn结构的问题?下次再看看怎么调整
2、之前的数据集创建dataset和dataloader的时候都很轻松,到了这个数据集就成了比较困难的一个点了,首先是文件路径的问题,其次就是在数据集类的定义里对图像和标签的处理
3、训练的时候没有画损失曲线,所以过程比较简单,就想着加上早停策略,然后一直报错,debug有点de麻了,最后也不知道怎么就解决了,管他的能跑就行(
4、Grag-CAM部分的改动不大,之前的拿过来用,最后不想拆分文件了,比较懒
@浙大疏锦行
相关文章:
python打卡day43
复习日 作业: kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化 进阶:并拆分成多个文件 找了个街头食物图像分类的数据集Popular Street Foods(其实写代码的时候就开始后悔了),原因在于&…...

MySQL 如何判断某个表中是否存在某个字段
在MySQL中,判断某个表中是否存在某个字段,可以通过查询系统数据库 INFORMATION_SCHEMA.COLUMNS 实现。以下是详细步骤和示例: 方法:使用 INFORMATION_SCHEMA.COLUMNS 通过查询系统元数据表 COLUMNS,检查目标字段是否存…...

Linux --进程优先级
概念 什么是进程优先级,为什么需要进程优先级,怎么做到进程优先级这是本文需要解释清楚的。 优先级的本质其实就是排队,为了去争夺有限的资源,比如cpu的调度。cpu资源分配的先后性就是指进程的优先级。优先级高的进程有优先执行的…...
安装和配置 Nginx 和 Mysql —— 一步一步配置 Ubuntu Server 的 NodeJS 服务器详细实录6
前言 昨天更新了四篇博客,我们顺利的 安装了 ubuntu server 服务器,并且配置好了 ssh 免密登录服务器,安装好了 服务器常用软件安装, 配置好了 zsh 和 vim 以及 通过 NVM 安装好Nodejs,还有PNPM包管理工具 。 作为服务器的运行…...

Linux 测试本机与192.168.1.130 主机161/udp端口连通性
Linux 测试本机与 192.168.1.130 主机 161/UDP 端口连通性 161/UDP 端口是 SNMP(简单网络管理协议)的标准端口。以下是多种测试方法: 🛠️ 1. 使用 nmap 进行专业测试(推荐) sudo nmap -sU -p 161 -Pn 1…...

OpenCV 滑动条调整图像亮度
一、知识点 1、int createTrackbar(const String & trackbarname, const String & winname, int * value, int count, TrackbarCallback onChange 0, void * userdata 0); (1)、创建一个滑动条并将其附在指定窗口上。 (2)、参数说明: trackbarname: 创建的…...
图解gpt之注意力机制原理与应用
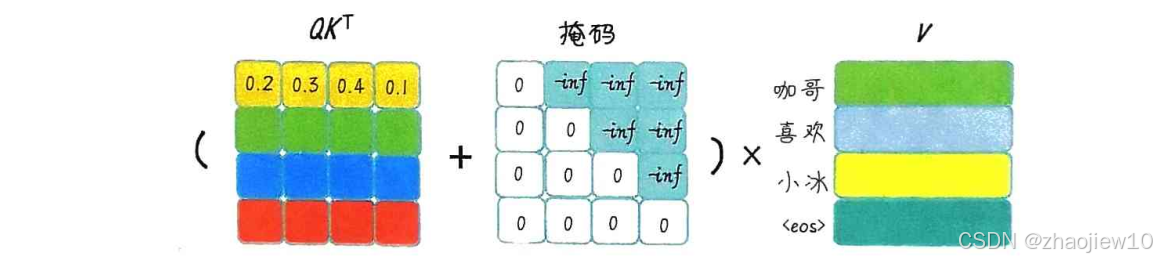
大家有没有注意到,当序列变长时,比如翻译一篇长文章,或者处理一个长句子,RNN这种编码器就有点力不从心了。它把整个序列信息压缩到一个固定大小的向量里,信息丢失严重,而且很难记住前面的细节,特…...

硬件学习笔记--65 MCU的RAM及FLash简介
MCU(微控制器单元)内部的 RAM 和 Flash 是最关键的两种存储器,它们直接影响MCU的性能、功耗和编程方式。以下是它们的详细讲解及作用: 1. RAM(随机存取存储器) 1.1 特性 1)易失性:…...

【Oracle】视图
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 视图基础概述1.1 视图的概念与特点1.2 视图的工作原理1.3 视图的分类 2. 简单视图2.1 创建简单视图2.1.1 基本简单视图2.1.2 带计算列的简单视图 2.2 简单视图的DML操作2.2.1 通过视图进行INSERT操作2.2.2 通…...
 与 MySQL (SQL) 的写法对比)
数据库 MongoDB (NoSQL) 与 MySQL (SQL) 的写法对比
MongoDB (NoSQL) 与 MySQL (SQL) 的写法对比及优劣势分析 基本概念差异 MySQL/SQL:关系型数据库,使用结构化查询语言(SQL),数据以表格形式存储,有预定义的模式(schema)MongoDB/NoSQL:文档型数据库,无固定…...

基于粒子滤波的PSK信号解调实现
基于粒子滤波的PSK信号解调实现 一、引言 相移键控(PSK)是数字通信中广泛应用的调制技术。在非高斯噪声和动态相位偏移环境下,传统锁相环(PLL)性能受限。粒子滤波(Particle Filter)作为一种序列蒙特卡洛方法,能有效处理非线性/非高斯系统的状态估计问题。本文将详细阐…...

更强劲,更高效:智源研究院开源轻量级超长视频理解模型Video-XL-2
长视频理解是多模态大模型关键能力之一。尽管OpenAI GPT-4o、Google Gemini等私有模型已在该领域取得显著进展,当前的开源模型在效果、计算开销和运行效率等方面仍存在明显短板。近日,智源研究院联合上海交通大学等机构,正式发布新一代超长视…...

2025.6.3学习日记 Nginx 基本概念 配置 指令 文件
1.初始nginx Nginx(发音为 “engine x”)是一款高性能的开源 Web 服务器软件,同时也具备反向代理、负载均衡、邮件代理等功能。它由俄罗斯工程师 Igor Sysoev 开发,最初用于解决高并发场景下的性能问题,因其轻量级、高…...
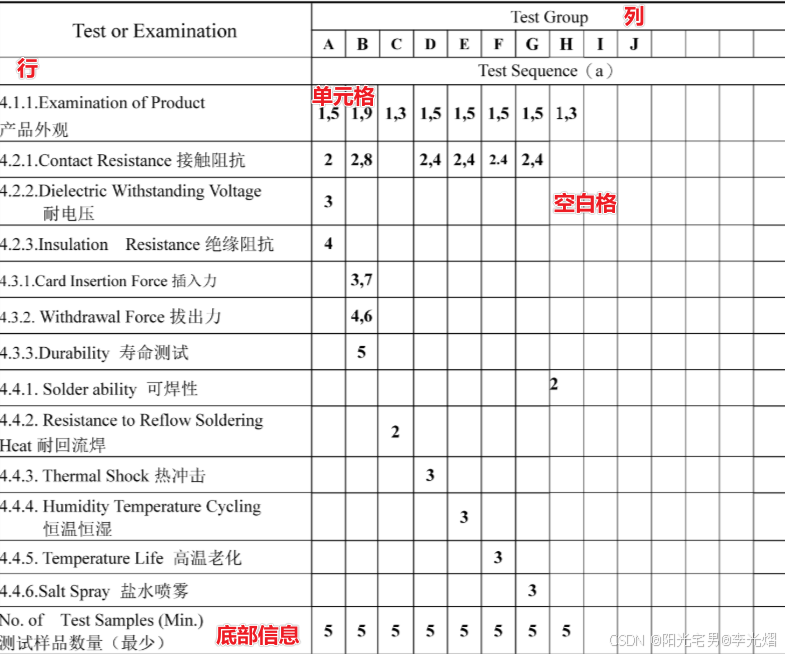
【连接器专题】案例:产品测试顺序表解读与应用
在查看SD卡座连接器的规格书,一些测试报告时,你可能会看到如下一张产品测试顺序表。为什么会出现一张测试顺序表呢? 测试顺序表的使用其实定义测试环节的验证的“路线图”和“游戏规则”,本文就以我人个经验带领大家一起看懂这张表并理解其设计逻辑。 测试顺序表结构 测试…...

星动纪元的机器人大模型 VPP,泛化能力效果如何?与 VLA 技术的区别是什么?
点击上方关注 “终端研发部” 设为“星标”,和你一起掌握更多数据库知识 VPP 利用了大量互联网视频数据进行训练,直接学习人类动作,减轻了对于高质量机器人真机数据的依赖,且可在不同人形机器人本体之间自如切换,这有望…...

4000万日订单背后,饿了么再掀即时零售的“效率革命”
当即时零售转向价值深耕,赢面就是综合实力的强弱。 文|郭梦仪 编|王一粟 在硝烟弥漫的外卖行业“三国杀”中,饿了么与淘宝闪购的日订单量竟然突破了4000万单。 而距淘宝闪购正式上线,还不到一个月。 在大额福利优惠…...
入门AJAX——XMLHttpRequest(Get)
一、什么是 AJAX AJAX Asynchronous JavaScript And XML(异步的 JavaScript 和 XML)。 1、XML与异步JS XML: 是一种比较老的前后端数据传输格式(已经几乎被 JSON 代替)。它的格式与HTML类似,通过严格的闭合自定义标…...

5分钟申请edu邮箱【方案本周有效】
这篇文章主要展示的是成果。如果你是第1次看见我的内容,具体的步骤请翻看往期的两篇作品。先看更正补全,再看下一个。 建议你边看边操作。 【更正补全】edu教育申请通过方案 本周 edu教育邮箱注册可行方案 #edu邮箱 伟大无需多言 我已经验证了四个了…...
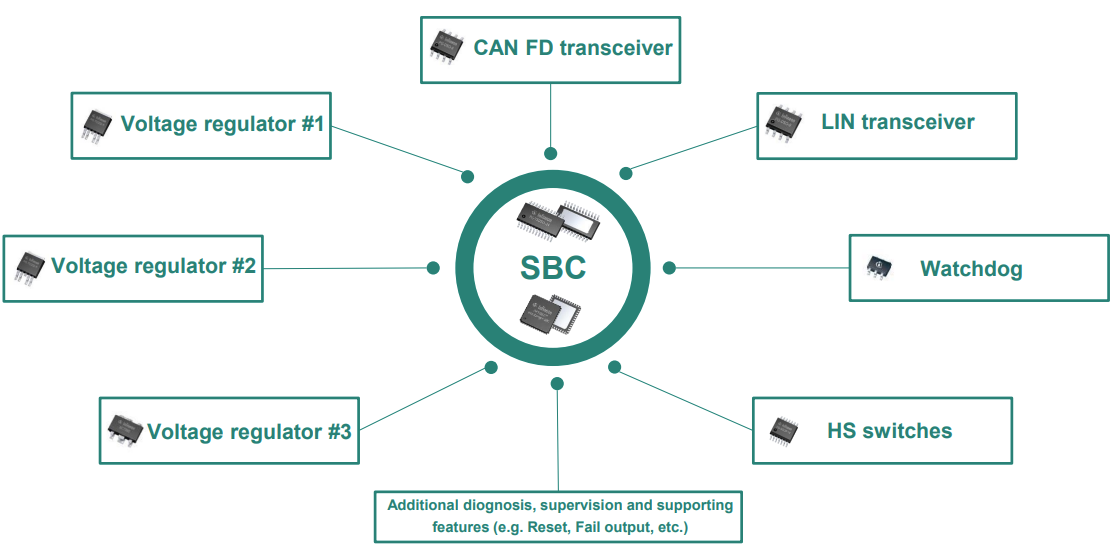
闲谈PMIC和SBC
今天不卷,简单写点。 在ECU设计里,供电芯片选型是逃不开的话题,所以聊聊PMIC或者SBC的各自特点,小小总结下。 PMIC,全称Power Management Intergrated Circuits,听名字就很专业:电源管理&…...
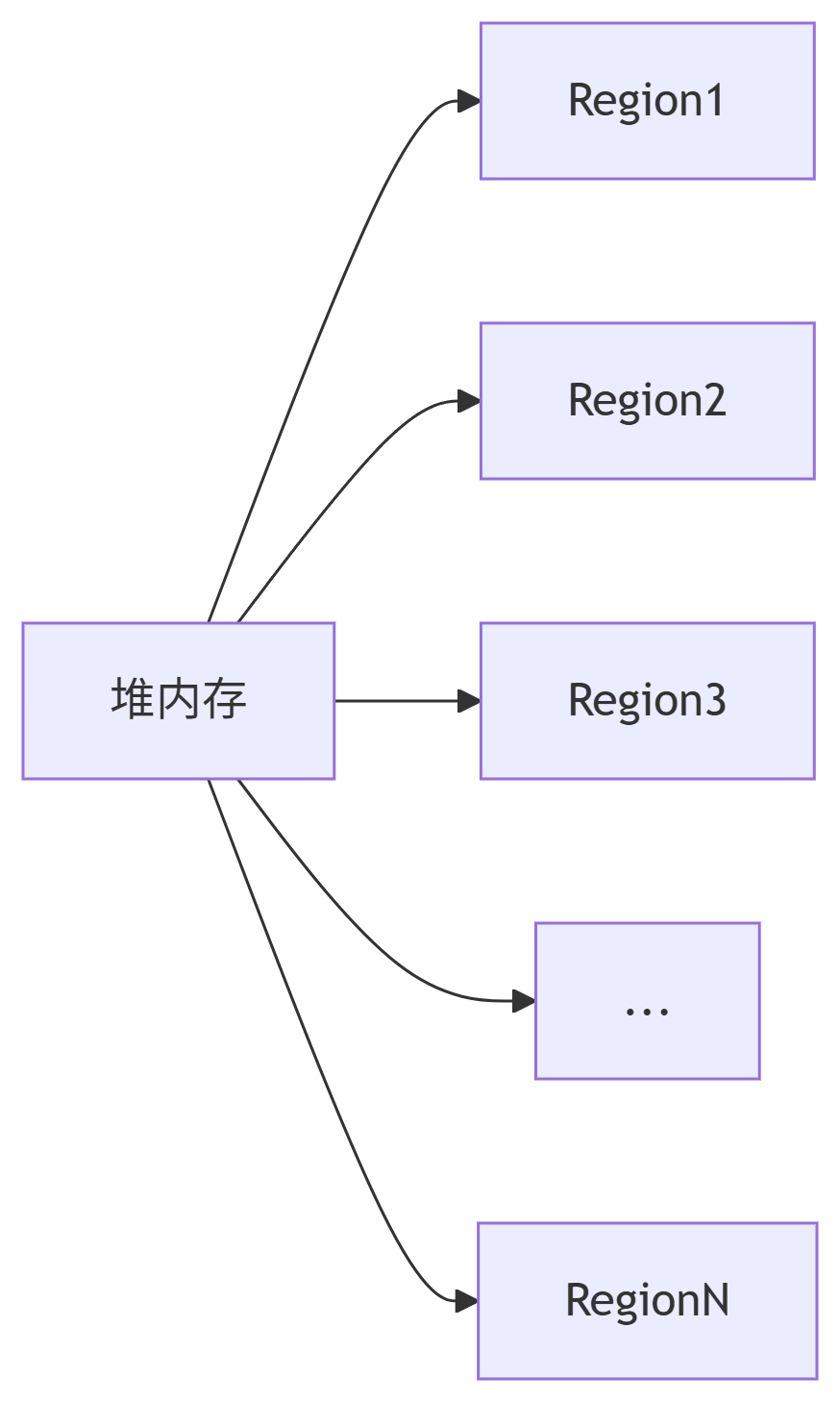
Java垃圾回收机制深度解析:从理论到实践的全方位指南
Java垃圾回收(GC)是Java虚拟机(JVM)的核心功能,它自动管理内存分配与回收,避免了C/C中常见的内存泄漏问题。本文将深入剖析Java垃圾回收的工作原理、算法实现、收集器类型及调优策略,助你全面掌握JVM内存管理的精髓。 一、垃圾回收基础概念 …...

Ubuntu系统 | 本地部署ollama+deepseek
1、Ollama介绍 Ollama是由Llama开发团队推出的开源项目,旨在为用户提供高效、灵活的本地化大型语言模型(LLM)运行环境。作为Llama系列模型的重要配套工具,Ollama解决了传统云服务对计算资源和网络连接的依赖问题,让用户能够在个人电脑或私有服务器上部署和运行如Llama 3等…...
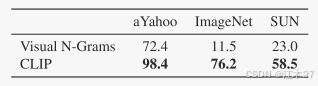
论文阅读:CLIP:Learning Transferable Visual Models From Natural Language Supervision
从自然语言监督中学习可迁移的视觉模型 虽然有点data/gpu is all you need的味道,但是整体实验和谈论丰富度上还是很多的,也是一篇让我多次想放弃的文章,因为真的是非常长的原文和超级多的实验讨论,隔着屏幕感受到了实验的工作量之…...
在图像分析算法部署中应对流行趋势的变化|文献速递-深度学习医疗AI最新文献
Title 题目 Navigating prevalence shifts in image analysis algorithm deployment 在图像分析算法部署中应对流行趋势的变化 01 文献速递介绍 机器学习(ML)已开始革新成像研究与实践的诸多领域。然而,医学图像分析领域存在显著的转化鸿…...
CAMEL-AI开源自动化任务执行助手OWL一键整合包下载
OWL 是由 CAMEL-AI 团队开发的开源多智能体协作框架,旨在通过动态智能体交互实现复杂任务的自动化处理,在 GAIA 基准测试中以 69.09 分位列开源框架榜首,被誉为“Manus 的开源平替”。我基于当前最新版本制作了免安装一键启动整合包。 CAMEL-…...

Selenium 中 JavaScript 点击的优势及使用场景
*在 Selenium 自动化测试中,使用 JavaScript 执行点击操作(如driver.execute_script("arguments[0].click();", element))相比直接调用element.click()有以下几个主要优势: 1. 绕过元素不可点击的限制 问题场景&#x…...
Linux系统-基本指令(5)
文章目录 mv 指令cat 指令(查看小文件)知识点(简单阐述日志)more 和 less 指令(查看大文件)head 和 tail 指令(跟查看文件有关)知识点(管道)时间相关的指令&a…...

C++ set数据插入、set数据查找、set数据删除、set数据统计、set排序规则、代码练习1、2
set数据插入,代码见下 #include<iostream> #include<set> #include<vector>using namespace std;void printSet(const set<int>& s) {for (set<int>::const_iterator it s.begin(); it ! s.end(); it) {cout << *it <…...

[android]MT6835 Android 指令启动MT6631 wifi操作说明
问题说明 MT6835使用指令启动wifi 使用andorid指令启动 2.4G启动方式 cmd wifi start-softap ctltest wpa2 11111111 -b 2 5G启动指令 cmd wifi start-softap ctltest wpa2 11111111 -b 5 使用linux指令启动 指令启动wifi 新建br-lan brctl addbr br-lan 关闭wifi a…...
C# winform教程(二)
一、基础控件 常用的基础控件主要有按钮,文本,文本输入,组,进度条,等等。 基础控件 名称含义详细用法Button按钮Buttoncheckbox多选按钮Combobox下拉选择groupbox组控件label标签,显示文字panel控件集合&a…...
:LeetCode 141. 环形链表(Linked List Cycle)详解)
Java详解LeetCode 热题 100(25):LeetCode 141. 环形链表(Linked List Cycle)详解
文章目录 1. 题目描述1.1 链表节点定义 2. 理解题目2.1 环形链表的可视化2.2 核心难点 3. 解法一:HashSet 标记访问法3.1 算法思路3.2 Java代码实现3.3 详细执行过程演示3.4 执行结果示例3.5 复杂度分析3.6 优缺点分析 4. 解法二:快慢指针法(…...