现代语言模型中的分词算法全解:从基础到高级
基础分词(Naive Tokenization)
最简单的分词方式是基于空格将文本拆分为单词。这是许多自然语言处理(NLP)任务中常用的一种分词方法。
text = "Hello, world! This is a test."
tokens = text.split()
print(f"Tokens: {tokens}")
输出结果为:
Tokens: ['Hello,', 'world!', 'This', 'is', 'a', 'test.']
虽然这种方法简单且快速,但存在诸多局限。例如,模型处理文本时需要了解其词汇表——即所有可能的分词集合。采用这种朴素分词,词汇表就是训练数据中出现的所有单词。当模型投入实际应用时,可能遇到词汇表外的新词,这时模型无法处理这些词,或者只能用特殊的“未知”标记替代。
此外,朴素分词对标点和特殊字符的处理也很糟糕。例如,“world!” 会视为一个整体分词,而在另一句中,“world” 可能是单独的分词,这样就会为本质相同的词在词汇表中分配两个不同的标记。类似问题还出现在大小写和连字符的处理上。

为什么要用空格分词?
在英语中,空格用于分隔单词,而单词是语言的基本单位。如果按字节分词,会得到毫无意义的字母序列,模型难以理解文本含义。同理,按句子分词也不可行,因为句子的数量比单词多得多,训练模型理解句子层面的文本需要成倍增加的数据量。
然而,单词真的是最佳分词单位吗?理想情况下,我们希望将文本拆解为最小的有意义单位。例如在德语中,由于大量复合词,基于空格的分词效果很差。即使在英语中,前缀和后缀也往往与其他单词组合表达特定含义,比如 “unhappy” 应该理解为 “un-” + “happy”。
因此,我们需要更好的分词方法。
词干提取与词形还原(Stemming and Lemmatization)
通过实现更复杂的分词算法,可以构建更优的词汇表。例如,以下正则表达式可将文本分割为单词、标点和数字:
import retext = "Hello, world! This is a test."
tokens = re.findall(r'\w+|[^\w\s]', text)
print(f"Tokens: {tokens}")
为了进一步减少词汇表大小,可以将所有内容转为小写:
import retext = "Hello, world! This is a test."
tokens = re.findall(r'\w+|[^\w\s]', text.lower())
print(f"Tokens: {tokens}")
输出结果为:
Tokens: ['hello', ',', 'world', '!', 'this', 'is', 'a', 'test', '.']
但这仍无法解决词形变化的问题。
**词干提取(Stemming)和词形还原(Lemmatization)**是两种将单词归约为词根的技术。
-
词干提取通过规则去除前后缀,操作较为激进,可能生成无效词。
-
词形还原则较为温和,借助词典将单词还原为基本形式,几乎总能得到有效词。两者都依赖具体语言。
在英语中,常用的 Porter 词干提取算法可借助 nltk 库实现:
import nltk
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenizenltk.download('punkt_tab')text = "These models may become unstable quickly if not initialized."
stemmer = PorterStemmer()
words = word_tokenize(text)
stemmed_words = [stemmer.stem(word) for word in words]
print(stemmed_words)
输出为:
['these', 'model', 'may', 'becom', 'unstabl', 'quickli', 'if', 'not', 'initi', '.']
可以看到,“unstabl” 并不是有效单词,但这是 Porter 算法的结果。
词形还原的效果更佳,基本总能得到有效单词。用 nltk 实现如下:
import nltk
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenizenltk.download('wordnet')text = "These models may become unstable quickly if not initialized."
lemmatizer = WordNetLemmatizer()
words = word_tokenize(text)
lemmatized_words = [lemmatizer.lemmatize(word) for word in words]
print(lemmatized_words)
输出为:
['These', 'model', 'may', 'become', 'unstable', 'quickly', 'if', 'not', 'initialized', '.']
无论哪种方法,都是先分词、后用词干/词形还原器归一化,构建更一致的词汇表。不过,像子词识别等根本性分词问题仍未解决。
字节对编码(Byte-Pair Encoding, BPE)
字节对编码(BPE)是现代语言模型中最广泛使用的分词算法之一。它最初是一种文本压缩算法,后被引入机器翻译领域,随后被 GPT 等模型采用。BPE 的核心思想是:在训练数据中,反复合并出现频率最高的相邻字符或分词对。
该算法以单个字符为初始词表,不断将最常见的相邻字符对合并为新分词。这个过程持续进行,直到达到期望的词表大小。对于英文文本,你可以仅以字母和少量标点作为初始字符集,然后逐步将常见字母组合引入词表。最终,词表既包含单个字符,也包含常见的子词单元。
BPE 需要在特定数据集上训练,因此其分词方式取决于训练数据。因此,你需要保存并加载 BPE 分词器模型,以便在项目中使用。
BPE 并未规定“单词”如何定义。例如,带连字符的“pre-trained”可以被视为一个单词,也可以拆为两个,这取决于“预分词器”(pre-tokenizer),最简单的形式就是按空格切分。
许多 Transformer 模型都采用 BPE,包括 GPT、BART 和 RoBERTa。你可以直接使用它们训练好的 BPE 分词器。例如调用 Hugging Face Transformers 库如下:
from transformers import GPT2Tokenizer# 加载 GPT-2 分词器(使用 BPE)
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")# 分词
text = "Pre-trained models are available."
tokens = tokenizer.encode(text)
print(f"Token IDs: {tokens}")
print(f"Tokens: {tokenizer.convert_ids_to_tokens(tokens)}")
print(f"Decoded: {tokenizer.decode(tokens)}")
输出如下:
Token IDs: [6719, 12, 35311, 4981, 389, 1695, 13]
Tokens: ['Pre', '-', 'trained', 'Ġmodels', 'Ġare', 'Ġavailable', '.']
Decoded: Pre-trained models are available.
可以看到,分词器用“Ġ”来表示单词间的空格,这是 BPE 用于标识词边界的特殊符号。注意,词语并未被词干提取或词形还原——“models” 保持原样。
OpenAI 的 tiktoken 库也是一个可选方案,示例如下:
import tiktokenencoding = tiktoken.get_encoding("cl100k_base")
text = "Pre-trained models are available."
tokens = encoding.encode(text)
print(f"Token IDs: {tokens}")
print(f"Tokens: {[encoding.decode_single_token_bytes(t) for t in tokens]}")
print(f"Decoded: {encoding.decode(tokens)}")
如需自定义训练 BPE 分词器,Hugging Face 的 Tokenizers 库非常方便。示例如下:
from datasets import load_dataset
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.pre_tokenizers import Whitespace
from tokenizers.trainers import BpeTrainerds = load_dataset("Salesforce/wikitext", "wikitext-103-raw-v1")
print(ds)tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
tokenizer.pre_tokenizer = Whitespace()
trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
print(tokenizer)tokenizer.train_from_iterator(ds["train"]["text"], trainer)
print(tokenizer)
tokenizer.save("my-tokenizer.json")# 重新加载训练好的分词器
tokenizer = Tokenizer.from_file("my-tokenizer.json")
运行结果显示:
DatasetDict({test: Dataset({features: ['text'],num_rows: 4358})train: Dataset({features: ['text'],num_rows: 1801350})validation: Dataset({features: ['text'],num_rows: 3760})
})
Tokenizer(version="1.0", truncation=None, padding=None, added_tokens=[], normalizer=None, pre_tokenizer=Whitespace(), post_processor=None, decoder=None, model=BPE(..., vocab={}, merges=[]))
[00:00:04] Pre-processing sequences ███████████████████████████ 0 / 0
[00:00:00] Tokenize words ███████████████████████████ 608587 / 608587
[00:00:00] Count pairs ███████████████████████████ 608587 / 608587
[00:00:02] Compute merges ███████████████████████████ 25018 / 25018
Tokenizer(version="1.0", ..., model=BPE(..., vocab={"[UNK]":0, "[CLS]":1, "[SEP]":2, "[PAD]":3, "[MASK]":4, ...}, merges=[("t", "h"), ("i", "n"), ("e", "r"), ...]))
BpeTrainer 对象支持更多训练参数。上述示例中,我们用 Hugging Face 的 datasets 库加载数据集,并在“train”数据上训练分词器。每个数据集结构略有不同——本例包含“test”、“train”和“validation”三部分,每部分有一个名为“text”的字段。我们用 ds["train"]["text"] 训练,训练器会自动合并直到达到目标词表大小。
训练前后分词器的状态明显不同——训练后,词表中新增了从训练数据中学习到的分词及其 ID。
BPE 分词器最大的优势之一,就是能将未登录词(未知词)拆分为已知的子词单元进行处理。
WordPiece
WordPiece 是 Google 于 2016 年提出的著名分词算法,被 BERT 及其变体广泛采用。它同样是一种子词分词算法。让我们看一个分词示例:
from transformers import BertTokenizer# 加载 BERT 的 WordPiece 分词器
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")# 分词
text = "These models are usually initialized with Gaussian random values."
tokens = tokenizer.encode(text)
print(f"Token IDs: {tokens}")
print(f"Tokens: {tokenizer.convert_ids_to_tokens(tokens)}")
print(f"Decoded: {tokenizer.decode(tokens)}")
输出如下:
Token IDs: [101, 2122, 4275, 2024, 2788, 3988, 3550, 2007, 11721, 17854, 2937, 6721, 5300, 1012, 102]
Tokens: ['[CLS]', 'these', 'models', 'are', 'usually', 'initial', '##ized', 'with', 'ga', '##uss', '##ian', 'random', 'values', '.', '[SEP]']
Decoded: [CLS] these models are usually initialized with gaussian random values. [SEP]
可以看到,“initialized” 被拆分为 “initial” 和 “##ized”,“##” 前缀表示当前分词是前一个词的一部分。如果分词没有前缀“##”,默认其前有空格。
该结果还包含 BERT 的设计细节。例如,BERT 模型自动将文本转为小写,分词器隐式完成。BERT 还假设序列以 [CLS] 开头,以 [SEP] 结尾,这些特殊符号由分词器自动添加。而这些并非 WordPiece 算法本身的要求,其他模型可能未必采用。
WordPiece 与 BPE 类似,都从所有字符出发,合并部分字符生成新的分词。区别在于:
-
BPE 总是合并出现频率最高的分词对;
-
WordPiece 则采用最大化似然的得分公式。
BPE 可能会将常见单词拆为子词,而 WordPiece 通常会保留常见单词为单一分词。
用 Hugging Face Tokenizers 训练 WordPiece 分词器的过程与 BPE 类似。例如:
from datasets import load_dataset
from tokenizers import Tokenizer
from tokenizers.models import WordPiece
from tokenizers.pre_tokenizers import Whitespace
from tokenizers.trainers import WordPieceTrainerds = load_dataset("Salesforce/wikitext", "wikitext-103-raw-v1")tokenizer = Tokenizer(WordPiece(unk_token="[UNK]"))
tokenizer.pre_tokenizer = Whitespace()
trainer = WordPieceTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])tokenizer.train_from_iterator(ds["train"]["text"], trainer)
tokenizer.save("my-tokenizer.json")
好的,以下是后续内容的翻译与整理:
SentencePiece 与 Unigram
BPE 和 WordPiece 都是自底向上的分词算法:它们从所有字符出发,通过合并得到新的词汇单元。与之相对,也可以采用自顶向下的方法,从训练数据的所有单词出发,不断修剪词表直至达到目标大小。
Unigram 就是这样一种算法。训练 Unigram 分词器时,每一步都会根据对数似然分数移除一部分词汇项。与 BPE 和 WordPiece 不同,训练好的 Unigram 分词器不是基于规则的,而是基于统计概率。它会保存每个分词的概率,在分词新文本时据此决策。
虽然理论上 Unigram 可以独立存在,但它最常见的实现形式是作为 SentencePiece 框架的一部分。
SentencePiece 是一种语言中立的分词算法,无需对输入文本进行预分词(如按空格切分)。这对于多语言场景尤其有用,例如英语使用空格分词,而中文没有空格。SentencePiece 将输入视为 Unicode 字符流,然后用 BPE 或 Unigram 来生成分词。
下面是在 Hugging Face Transformers 库中使用 SentencePiece 分词器的例子:
from transformers import T5Tokenizer# 加载 T5 分词器(使用 SentencePiece+Unigram)
tokenizer = T5Tokenizer.from_pretrained("t5-small")text = "SentencePiece is a subword tokenizer used in models such as XLNet and T5."
tokens = tokenizer.encode(text)
print(f"Token IDs: {tokens}")
print(f"Tokens: {tokenizer.convert_ids_to_tokens(tokens)}")
print(f"Decoded: {tokenizer.decode(tokens)}")
输出为:
Token IDs: [4892, 17, 1433, 345, 23, 15, 565, 19, 3, 9, 769, 6051, 14145, 8585, 261, 16, 2250, 224, 38, 3, 4, 434, 9688, 11, 332, 9125, 1]
Tokens: ['▁Sen', 't', 'ence', 'P', 'i', 'e', 'ce', '▁is', '▁', 'a', '▁sub', 'word', '▁token', 'izer', '▁used', '▁in', '▁models', '▁such', '▁as', '▁', 'X', 'L', 'Net', '▁and', '▁T', '5.', '']
Decoded: SentencePiece is a subword tokenizer used in models such as XLNet and T5.
可以看出,类似于 WordPiece,SentencePiece 用特殊的前缀字符(下划线“_”或“▁”)来区分词与词内子词。
训练 SentencePiece 分词器也同样简单,下面是使用 Hugging Face Tokenizers 库进行训练的例子:
from datasets import load_dataset
from tokenizers import SentencePieceUnigramTokenizerds = load_dataset("Salesforce/wikitext", "wikitext-103-raw-v1")
tokenizer = SentencePieceUnigramTokenizer()tokenizer.train_from_iterator(ds["train"]["text"])
tokenizer.save("my-tokenizer.json")
你也可以使用 Google 的 sentencepiece 库实现同样的功能。
延伸阅读
如需了解更多,推荐以下资料:
-
The Porter Stemming Algorithm
-
BPE 论文:Neural Machine Translation of Rare Words with Subword Units
-
WordPiece 论文:Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
-
Fast WordPiece Tokenization
-
Unigram 论文:Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates
-
SentencePiece 论文:A simple and language independent subword tokenizer and detokenizer for Neural Text Processing
-
Hugging Face Tokenizers 文档
-
Google SentencePiece 项目
总结
本文介绍了现代语言模型中常用的分词算法:
- BPE
:GPT 等模型广泛采用,通过合并高频相邻对实现子词分词。
- WordPiece
:BERT 模型采用,通过最大化训练数据似然分数来合并子词单元。
- SentencePiece
:更灵活,可无预分词直接处理多语言文本,底层可选用 BPE 或 Unigram。
-
现代分词器还包含特殊分词、截断、填充等重要功能。
相关文章:
现代语言模型中的分词算法全解:从基础到高级
基础分词(Naive Tokenization) 最简单的分词方式是基于空格将文本拆分为单词。这是许多自然语言处理(NLP)任务中常用的一种分词方法。 text "Hello, world! This is a test." tokens text.split() print(f"Tok…...

HttpServletResponse 对象用来做什么?
HttpServletResponse 对象是由 Servlet 容器创建并传递给 Servlet 的 service() 方法(以及间接传递给 doGet(), doPost() 等方法)的。它的核心作用是让 Servlet 能够向客户端(通常是浏览器)发送 HTTP 响应。 通过 HttpServletRes…...

第十三章 Java基础-特殊处理
文章目录 1.包和final2.权限修饰符和代码块3.抽象类1.包和final 2.权限修饰符和代码块 3.抽象类...

MTK的Download agent是什么下载程序?
MTK(MediaTek)的Download Agent(DA)是一种与MTK设备进行通信的协议代理程序,在MTK设备的固件下载与烧录过程中起着关键作用,以下为你展开介绍: 下载原理 在MTK平台的固件下载过程中,DA会被加载到MTK设备的内部RAM中运行。它负责配置Flash及RAM的时序,从而建立起PC端…...

ArcGIS Pro 3.4 二次开发 - 地图创作 2
环境:ArcGIS Pro SDK 3.4 + .NET 8 文章目录 ArcGIS Pro 3.4 二次开发 - 地图创作 224 注记24.1 创建标注构造工具24.2 通过属性更新注释文本。注意:TEXTSTRING 注释属性必须存在24.3 旋转或移动标注24.4 获取注释文本图形24.5 获取注记的轮廓几何24.6 获取标注的掩膜几何25 …...

【操作系统原理08】文件管理
文章目录 零.大纲一.文件管理0.大纲1.文件管理1.1 **文件属性**1.2 文件内部数据组织1.3 文件之间的组织1.4操作系统提供功能1.5 文件在外存存放 二.文件的逻辑结构0.大纲1.无结构文件2.有结构文件 三.文件目录0.大纲1.文件控制块2.目录结构3.索引节点(FCB改进) 四.文件共享0.大…...
图论学习笔记 5 - 最小树形图
我们不废话,直接进入正题:最小树形图,一个名字看起来很高级的东西。 声明:为了便于理解,可能图片数量会有亿点点多。图片尺寸可能有的较大。 概念 最小树形图的英文是 Directed Minimum Spanning Tree。 相信懂英文…...

VueUse:组合式API实用函数全集
VueUse 完全学习指南:组合式API实用函数集合 🎯 什么是 VueUse? VueUse 是基于 组合式API(Composition API) 的实用函数集合,为Vue 3开发者提供了丰富的可复用逻辑功能。它通过提供大量预构建的组合函数&…...
《自动驾驶轨迹规划实战:Lattice Planner实现避障路径生成(附可运行Python代码)》—— 零基础实现基于离散优化的避障路径规划
《自动驾驶轨迹规划实战:Lattice Planner实现避障路径生成(附可运行Python代码)》 —— 零基础实现基于离散优化的避障路径规划 一、为什么Lattice Planner成为自动驾驶的核心算法? 在自动驾驶的路径规划领域,Lattice…...

嵌入式笔试题+面试题
一、嵌入式笔试题 1) int a; 2) int *a; 3) int **a; 4) int a[10]; 5) int *a[10]; 6) int (*a)[10]; 7) int (*a)(int); 8) int (*a[10])(int); (1) 一个整型数 (2) 一个指向整型数的指针 (3) 一个指向指针的的指针,它指向的指针是指向一个整型数 (4) 一个有10个…...

【Go语言生态】
在Go语言生态中,以下工具和方法可以实现类似Laravel的dump()或Symfony的VarDumper的结构体美化打印和调试功能: 使用spew库 spew是Go社区广泛使用的结构化输出库,提供深度嵌套结构的可读性展示: import "github.com/davec…...
PyTorch——卷积操作(2)
二维矩阵 [[ ]] 这里面conv2d(N,C,H,W)里面的四个是 N就是batch size也就是输入图片的数量,C就是通道数这只是一个二维张量所以通道为1,H就是高,W就是宽,所以是1 1 5 5 卷积核 reshape 第一个参数是batch size样本数量 第二个参数…...
【JavaWeb】SpringBoot原理
1 配置优先级 在前面,已经学习了SpringBoot项目当中支持的三类配置文件: application.properties application.yml application.yaml 在SpringBoot项目当中,我们要想配置一个属性,通过这三种方式当中的任意一种来配置都可以&a…...

BSRR对比BRR对比ODR
✅ 三种操作方式的本质区别 寄存器功能原子操作特点BSRR同时支持置位(1)和复位(0)✔️ 是单指令完成任意位操作,无竞争风险ODR直接读写输出状态❌ 否需"读-改-写",多线程/中断中需关中断保护BRR只能复位(0)✔️ 是仅清零功能,无置…...
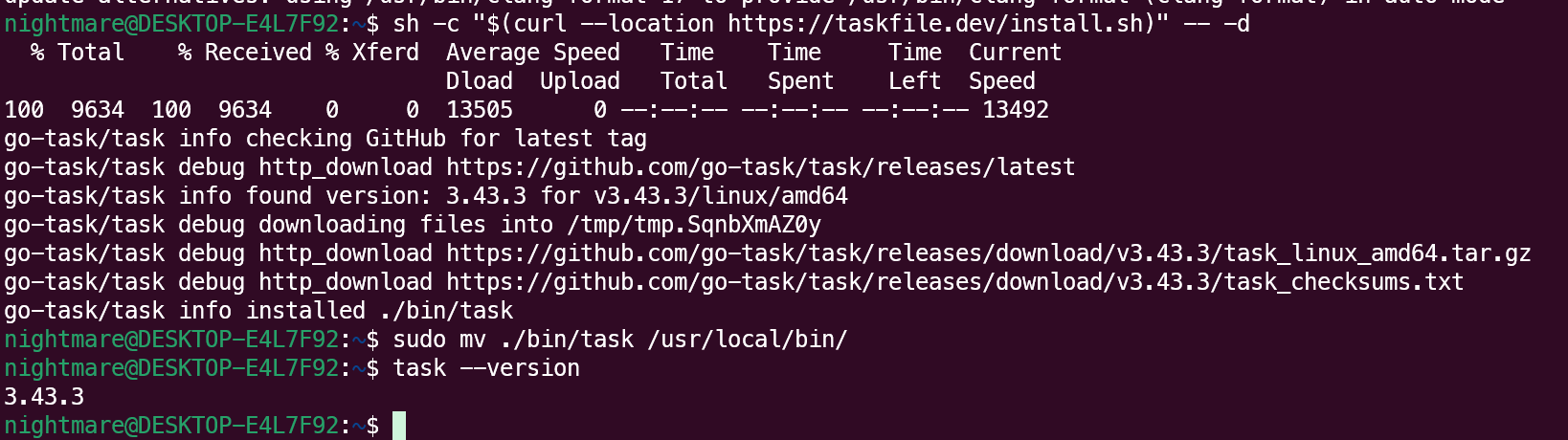
ubuntu22.04安装taskfile
sh -c "$(curl --location https://taskfile.dev/install.sh)" -- -dsudo mv ./bin/task /usr/local/bin/测试 task --version...

记录被mybatis一级缓存坑的问题
背景 我之前有个方法需要多次调用数据库拿数据,由于每次查询数据比较少,所以我前期都是直接查数据库拿的,准备后面再改缓存 // 查询代码 假设在A方法中 List<LeftOrderType> leftOrderTypes orderTypeMapper.selectList(wrapper); …...

遥感影像建筑物变化检测
文章目录 效果1、环境安装2、项目下载3、数据集下载4、模型训练5、模型推理6、推理结果7、批量推理效果 1、环境安装 参考文章 搭建Pytorch的GPU环境超详细 win10安装3DGS环境(GPU)超详细 测试GPU环境可用 2、项目下载 https://gitcode.com/gh_mirrors/ch/change_detectio…...

【数据库】《DBA实战手记》- 读书笔记
《DBA实战手记》基本介绍 作者:薛晓刚 等出版时间:2024年6月出版社:机械工业出版社ISBN:9787111757665 本书是一本指导DBA进行数据库开发和运维的实用手册,本书共9章,包括漫谈数据库、如何提升数据库性能…...

多模态大语言模型arxiv论文略读(103)
Are Bigger Encoders Always Better in Vision Large Models? ➡️ 论文标题:Are Bigger Encoders Always Better in Vision Large Models? ➡️ 论文作者:Bozhou Li, Hao Liang, Zimo Meng, Wentao Zhang ➡️ 研究机构: 北京大学 ➡️ 问题背景&…...
汇编语言基础: 搭建实验环境
环境配置 1.Visual Studio 创建空项目 创建成功 2.平台框架改为为WIN32 右键点击项目 点击属性 点击配置管理器 平台改为Win32(本文使用32位的汇编) 3.生成采用MASM 在项目属性里点击"生成依赖项"的"生成自定义" 勾选 masm 4.创建第一个汇编程序 右…...

SIFT 算法原理详解
SIFT 算法原理详解 SIFT(尺度不变特征变换,Scale-Invariant Feature Transform)是一种经典的局部特征检测和描述算法,它能够在不同的尺度、旋转和光照变化下稳定地检测图像特征。SIFT 主要包括以下几个步骤:尺度空间极…...
基于springboot的益智游戏系统的设计与实现
博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了六年的毕业设计程序开发,开发过上千套毕业设计程序,没有什么华丽的语言࿰…...

短剧系统开发文案:打造沉浸式互动娱乐新体验
一、项目背景 随着短视频与碎片化娱乐的兴起,短剧市场呈现爆发式增长。用户对剧情紧凑、节奏明快、互动性强的内容需求激增,传统影视平台已难以满足个性化与参与感需求。「XX短剧系统」应运而生,致力于打造集内容创作、分发、互动于一体的短…...

第十二节:第四部分:集合框架:List系列集合:LinkedList集合的底层原理、特有方法、栈、队列
LinkedList集合的底层原理 LinkedList集合的应用场景之一 代码:掌握LinkedList集合的使用 package com.itheima.day19_Collection_List;import java.util.LinkedList; import java.util.List;//掌握LinkedList集合的使用。 public class ListTest3 {public static …...

多模态大语言模型arxiv论文略读(104)
Talk Less, Interact Better: Evaluating In-context Conversational Adaptation in Multimodal LLMs ➡️ 论文标题:Talk Less, Interact Better: Evaluating In-context Conversational Adaptation in Multimodal LLMs ➡️ 论文作者:Yilun Hua, Yoav…...
【C++高级主题】多重继承下的类作用域
目录 一、类作用域与名字查找规则:理解二义性的根源 1.1 类作用域的基本概念 1.2 单继承的名字查找流程 1.3 多重继承的名字查找特殊性 1.4 关键规则:“最近” 作用域优先,但多重继承无 “最近” 二、多重继承二义性的典型类型与代码示…...
基于Android的一周穿搭APP的设计与实现 _springboot+vue
开发语言:Java框架:springboot AndroidJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7数据库工具:Navicat12开发软件:eclipse/myeclipse/ideaMaven包:Maven3.6 系统展示 APP登录 A…...
机器学习——使用多个决策树
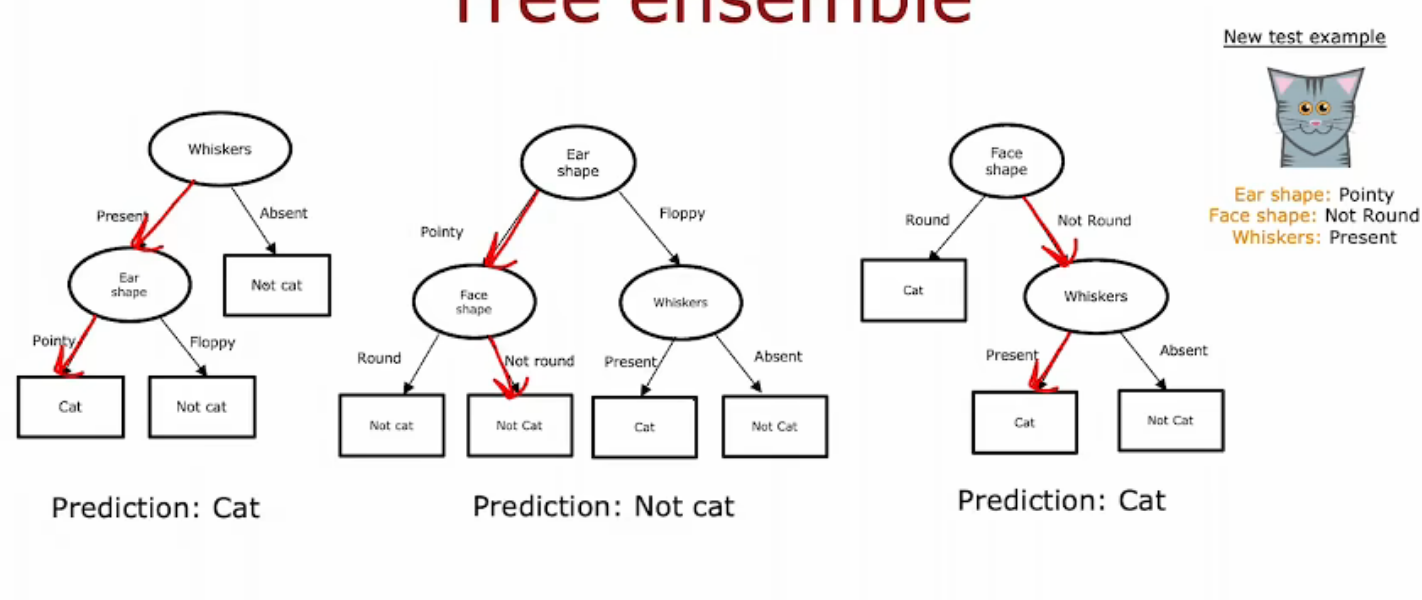
使用单一决策树的弱点之一是决策树对数据中的微小变化非常敏感,一个使算法不那么敏感或更健壮的解决方案,不是建立一个决策树,而是要建立大量的决策树,我们称之为树合奏。 在这个例子中,我们一直在使用最好的特性来分…...

C# 中的对话框与导航:构建流畅用户交互的完整指南
在现代应用程序开发中,良好的用户交互体验是成功的关键因素之一。作为.NET开发者,熟练掌握C#中的对话框与导航技术,能够显著提升应用程序的易用性和专业性。本文将全面探讨Windows Forms、WPF、ASP.NET Core和MAUI等平台下的对话框与导航实现…...
DeepSeek - 尝试一下GitHub Models中的DeepSeek
1.简单介绍 当前DeepSeek使用的人很多,各大AI平台中也快速引入了DeekSeek,比如Azure AI Foundary(以前名字是Azure AI Studio)中的Model Catalog, HuggingFace, GitHub Models等。同时也出现了一些支持DeepSeek的.NET类库。微软的Semantic Kernel也支持…...