TDengine 的 AI 应用实战——电力需求预测

作者: derekchen
Demo数据集准备
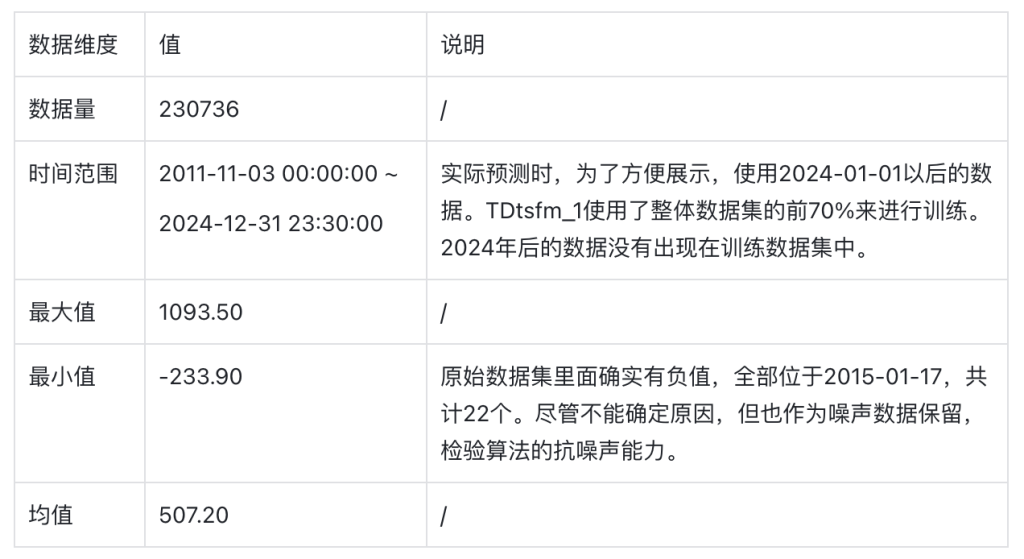
我们使用公开的UTSD数据集里面的电力需求数据,作为预测算法的数据来源,基于历史数据预测未来若干小时的电力需求。数据集的采集频次为30分钟,单位与时间戳未提供。为了方便演示,按照频率从2025-01-01 00:00:00开始向前倒推生成时间戳,并存储在TDengine对应的表里。
数据集中包含5个文件,我们使用编号最大的一个子集来完成演示。该数据文件,放置于https://github.com/taosdata/TDgpt-demo仓库的demo_data目录下,请参考下文的步骤导入TDengine以完成演示。数据集的统计信息如下:
演示环境准备
环境要求
您可基于Linux、Mac以及Windows操作系统完成Demo系统的运行。但为使用docker-compose,您计算机上需要安装有下属软件:
- Git
- Docker Engine: v20.10+
- Docker Compose: v2.20+
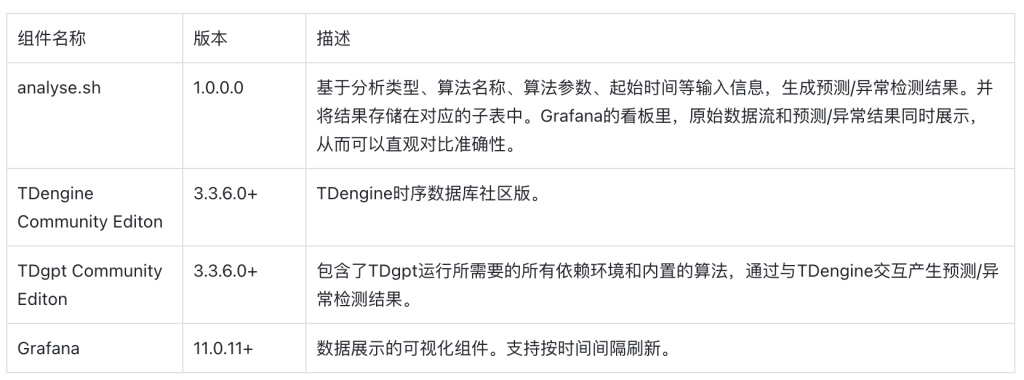
Demo中包含3个docker镜像 (TDengine, TDgpt, Grafana),以及一组用于产生预测/异常检测结果的shell脚本。组件版本的要求如下:
克隆Demo仓库到本地
git clone https://github.com/taosdata/TDgpt-democd TDgpt-demochmod 775 analyse.sh
文件夹下包含docker-compose.yml、tdengine.yml两个yml文件。docker-compose.yml 包含了所有一键启动demo所需的镜像配置信息,其引用tdengine.yml作为Grafana的数据源配置。
TDgpt-demo/demo_data下包含三个csv文件(electricity_demand.csv、wind_power.csv、ec2_failure.csv),以及三个同前缀sql脚本,分别对应电力需求预测、风力发电预测和运维监控异常检测场景。
TDgpt-demo/demo_dashboard下包含了三个json文件(electricity_demand_forecast.json、wind_power_forecast.json、ec2_failure_anomaly.json),分别对应三个场景的看板。
docker-compose.yml中已经定义了TDengine容器的持久化卷:tdengine-data,待容器启动后,使用docker cp命令将demo_data拷贝至容器内使用。
运行和关闭Demo
注意:在运行demo前,请根据您宿主机的架构(CPU类型),编辑docker-compose.yml文件,为TDengine指定对应的platform参数:linux/amd64(Intel/AMD CPU)或linux/arm64(ARM CPU)。TDgpt必须统一使用linux/amd64参数。
进入docker-compose.yml文件所在的目录执行如下命令,启动TDengine、TDgpt和Grafana一体化演示环境:
docker-compose up -d
首次运行时,等待10s后请执行如下命令将TDgpt的Anode节点注册到TDengine:
docker exec -it tdengine taos -s "create anode 'tdgpt:6090'"
在宿主机执行下列命令,初始化体验测试环境的数据:
docker cp analyse.sh tdengine:/var/lib/taosdocker cp demo_data tdengine:/var/lib/taosdocker exec -it tdengine taos -s "source /var/lib/taos/demo_data/init_electricity_demand.sql"
关闭演示环境,请使用:
docker-compose down
进行演示
- 打开浏览器,输入http://localhost:3000,并用默认的用户名口令 admin/admin 登录Grafana。
- 登录成功后,进入路径”Home → Dashboards”页面,并且导入electricity_demand_forecast.json文件。
- 导入后,选择“electricity_demand”这个面板。面板已经配置好了真实值、TDtsfm_1以及HoltWinters的预测结果。当前只有真实值的数据曲线。
- 我们以analyze.sh脚本,来进行预测。首先完成TDtsfm_1算法的演示:
docker exec -it tdengine /var/lib/taos/analyse.sh --type forecast --db tdgpt_demo --table electricity_demand --stable single_val --algorithm tdtsfm_1 --params "fc_rows=48,wncheck=0" --start "2024-01-01" --window 30d --step 1d
上述shell脚本,将从指定的起始时间开始(2024-01-01)以前一个月的数据为输入,使用TDtsfm_1算法预测当前下一天的每30mins的电力需求(共计48个数据点),直到达到electricity_demand 表中最后一天的记录,并将结果写入electricity_demand_tdtsfm_1_result 表中。执行新的预测前,脚本会新建/清空对应的结果表。执行过程中将持续在控制台上,按照天为单位推进输出如下的执行结果:
taos> INSERT INTO tdgpt_demo.electricity_demand_tdtsfm_1_result SELECT _frowts, forecast(val, 'algorithm=tdtsfm_1,fc_rows=48,wncheck=0')FROM tdgpt_demo.electricity_demanWHERE ts >= '2024-01-12 00:00:00' AND ts < '2024-02-11 00:00:00'Insert OK, 48 row(s) affected (0.238208s)
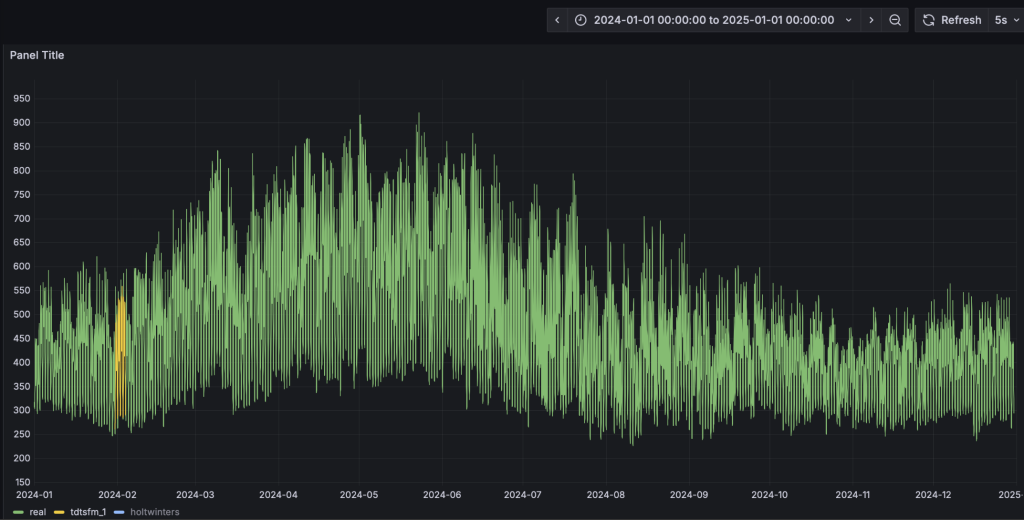
- Grafana的看板上,配置刷新频率为5s,将动态显示预测结果的黄色曲线,直观呈现与实际值的对比。为了展示清晰,请按住command键点击左下角的Real以及TDtsfm_1图例(Mac下,Windows下请使用win键),从而只保留这两条曲线展示。
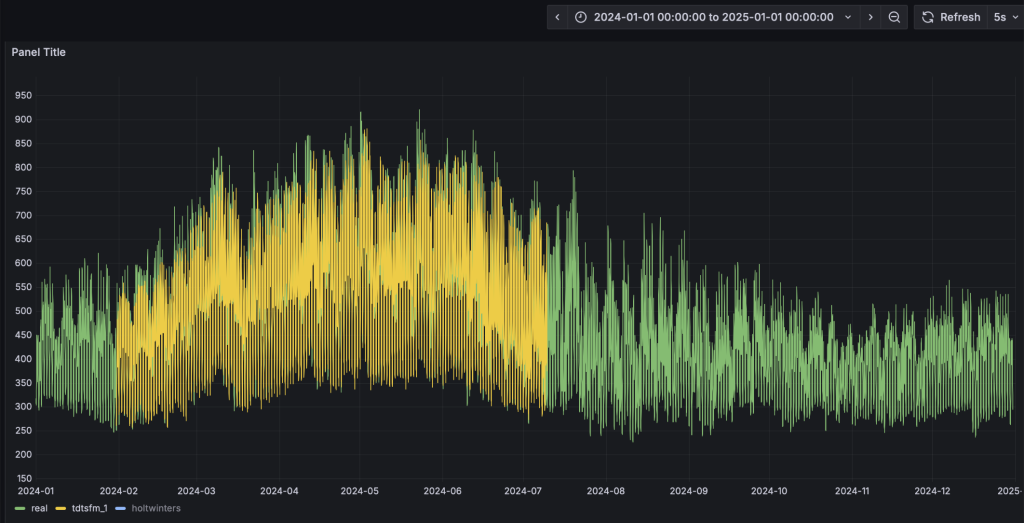
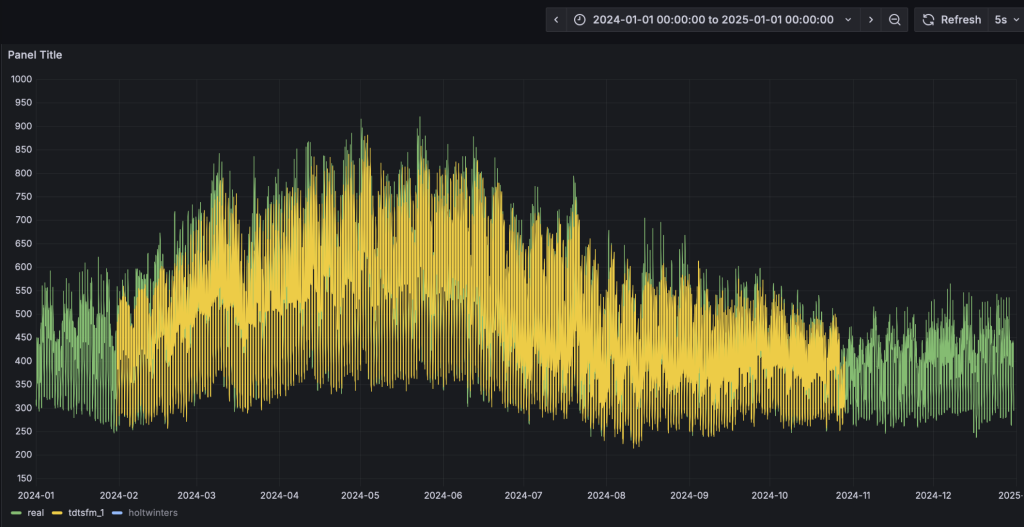
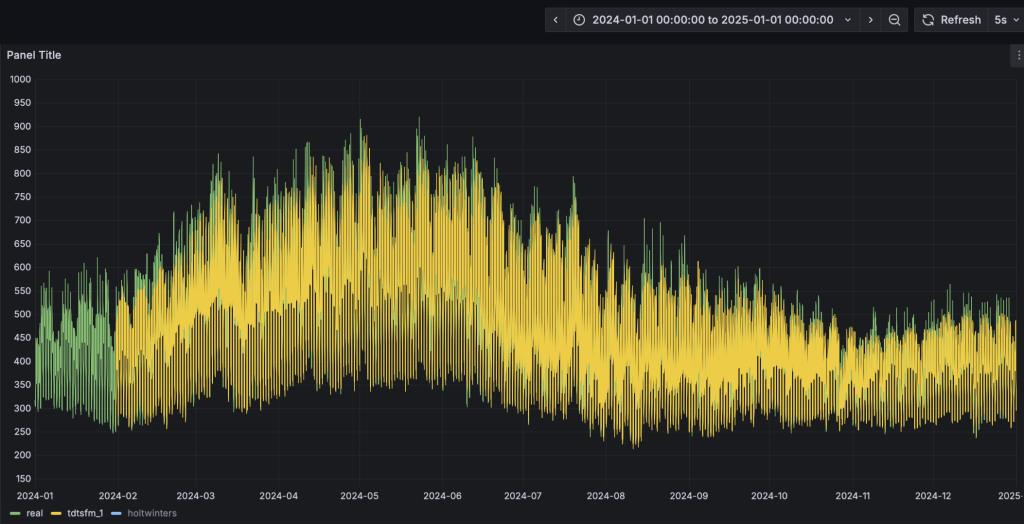
- 完成HoltWinters模型的演示:
docker exec -it tdengine /var/lib/taos/analyse.sh --type forecast --db tdgpt_demo --table electricity_demand --stable single_val --algorithm holtwinters --params "rows=48,period=48,wncheck=0,trend=add,seasonal=add" --start "2024-01-01" --window 30d --step 1d
与第四步类似,HoltWinters模型将动态输出预测结果并呈现在看板上。从预测结果中可以看到,TDtsfm_1对数据的预测精度显著优于传统的统计学方法HoltWinters。除了预测精度外,HoltWinters算法的最大问题是需要非常精细化的对参数进行调整评估,否则还容易出现下图中这种频繁发生的预测值奇异点。
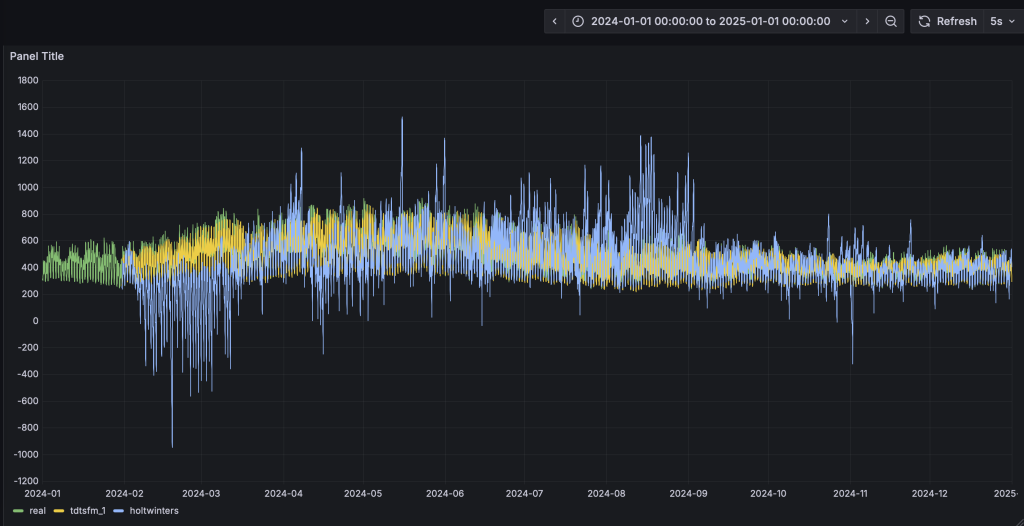
基于鼠标圈选的方式,我们可以查看一段时间内的细粒度预测结果对比:
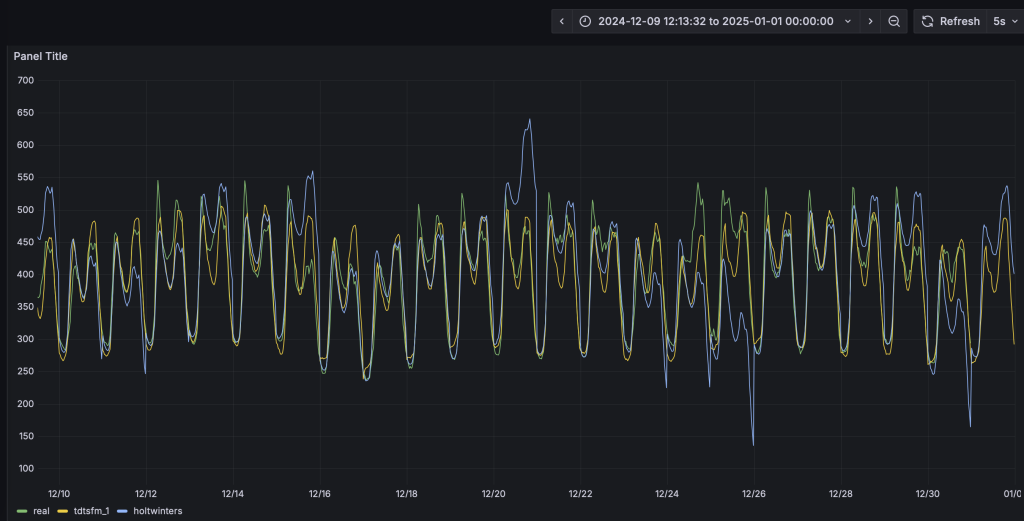
您也可以尝试其他算法或模型,来找到最合适自己场景的算法和模型。
Demo脚本使用详解
脚本概述
analyse.sh脚本用于在 TDengine 数据库上执行时间序列预测和异常检测分析,支持滑动窗口算法处理。主要功能包括:
- 时间序列预测 :使用 HoltWinters 等算法进行未来值预测 。
- 异常检测 :使用 k-Sigma 等算法识别数据异常点 。
- 自动窗口滑动 :支持自定义窗口大小和步长进行连续分析。
参数说明
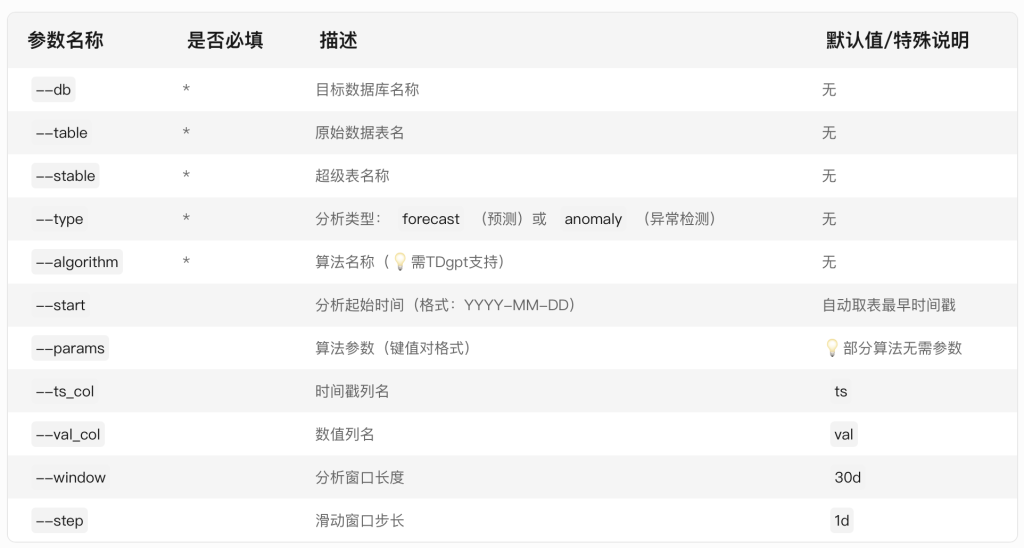
TDengine推荐使用超级表来进行数据建模。因此,Demo中建立了一个名为 single_val 的超级表,包含ts (timestamp类型) 和val (float类型),以及标签定义scene (varchar (64) )。现阶段TDgpt只支持单列值输入输出,因此这个超级表可以作为所有源数据表和结果表的结构定义。子表的表名与tag名称保持一致即可。
db参数指定了源数据表和结果表隶属的数据库。结果表将以【源表名称】_【算法名称】_【result】格式存储。Grafana里面通过查询结果表实现分析结果和原始数据的对比。
一般情况下,对于非必填项,用户在demo过程中只需要设置–start参数以节省运行时间。对于必填项,请参考示例值进行设置。
时间格式说明
step和window参数指定的滑动步长和分析窗口大小需符合如下参数约定:

脚本执行流程
graph TDgpt_DemoA[开始] --> B[参数解析与验证]B --> C{是否指定start?}C -->|否| D[查询最小时间戳]C -->|是| E[转换时间格式]D --> EE --> F[计算时间窗口]F --> G[生成结果表]G --> H{是否到达数据终点?}H -->|否| I[生成并执行SQL]I --> HH -->|是| J[输出完成信息]
使用更多的数据
参考「运行和关闭Demo」章节里electricity_demand.sql脚本的内容,确保按照规定格式将数据准备为csv格式(逗号分隔,值需要用英文双引号括起来),即可将数据导入TDengine。然后,请使用「进行演示」章节中的方法来生成预测结果,并调整Grafana中的看板以实现和实际数据的对比。
结论
在本文中,我们展示了使用TDgpt来进行电力需求预测的完整流程。从中可以看到,基于TDgpt 来构建时序数据分析,能够以SQL方式实现与应用的便捷集成,还可以用Grafana 进行展示,大大降低开发和应用时序数据预测和异常检测的成本。
从预测效果来看,基于transformer架构的预训练模型TDtsfm_1在使用的数据集上展示出显著优于Holtwinters模型的效果。在不同的实际场景下,用户需要针对数据特点,针对模型算法进行选择和参数调优,也可以选择不同的算法或模型进行尝试。
TDengine 的企业版中,TDgpt 将为用户提供更多的选择:
- 模型选择器。模型选择器可以自动根据用户的历史数据集,对购买的所有模型进行准确性评估。用户可选择最适合自己场景的模型或算法进行部署和应用。
- TDtsfm_1自研模型的重训练及微调。TDtsfm_1基于海量时序数据进行了预训练,在大部分场景下相比于传统的机器学习和统计预测模型都会有显著的准确率优势。如果用户对于模型预测准确度有更高的要求,可以申请购买 TDgpt 企业版的预训练服务。使用用户的场景历史数据进行预训练,在特定场景下的预测效果可能更佳。
- 第三方解决方案。涛思数据联合国内外时序分析/异常检测专业厂家、研究机构,为用户提供专业的分析解决方案,包括落地过程中的实施服务等。
关于背景
电力需求预测作为现代能源管理的核心工具,其核心价值贯穿电力系统的全生命周期。在资源配置层面,通过精准预判用电趋势,可优化发电设施布局与电网升级节奏,避免超前投资造成的资源闲置或滞后建设引发的供应缺口,典型场景中可使基础设施投资效率提升15%-20%。对于电力运营商而言,负荷预测支撑着从燃料采购到机组调度的动态优化,在火力发电领域已实现吨煤发电量2%以上的能效提升,同时通过削峰填谷降低电网备用容量需求,显著压缩系统运行成本。
在能源安全维度,预测技术构建起电力供需的缓冲机制。短期预测误差每降低1个百分点,对应减少的紧急调峰成本可达区域电网日均运营费用的3%-5%,这在应对极端天气或突发事件时尤为关键。而中长期预测则为跨区域电力互济、储能设施配置提供决策基线,有效缓解结构性缺电风险。市场环境中,预测能力直接转化为经济收益,发电企业通过日前96时段负荷预测优化报价策略,在电力现货市场中可额外获取10%-18%的价格套利空间,工商用户则借助负荷特性分析制定用能方案,实现年度电费支出5%-10%的降幅。
本文提供基于 docker-compose 快速部署 TDgp 体验测试环境的指引,并基于这个环境和真实的数据,展示日前预测电力需求的全过程,便于大家快速掌握 TDgpt,迅速让自己拥有AI驱动的时序数据预测与异常检测的能力。
关于TDgpt
TDgpt 是 TDengine 内置的时序数据分析智能体,它基于 TDengine 的时序数据查询功能,通过 SQL 提供运行时可动态扩展和切换的时序数据高级分析的能力,包括时序数据预测和时序数据异常检测。通过预置的时序大模型、大语言模型、机器学习、传统的算法,TDgpt 能帮助工程师在10分钟内完成时序预测与异常检测模型的上线,降低至少80%的时序分析模型研发和维护成本。
截止到3.3.6.0版本,TDgpt 提供Arima、HoltWinters、LSTM、MLP 以及基于Transformer架构自研的TDtsfm (TDengine time series foundation model) v1版和其他时序模型,以及k-Sigma、Interquartile range(IQR)、Grubbs、SHESD、Local Outlier Factor(LOF)、Autoencoder这六种异常检测模型。用户可以根据TDgpt开发指南自行接入自研或其他开源的时序模型或算法。
相关文章:
TDengine 的 AI 应用实战——电力需求预测
作者: derekchen Demo数据集准备 我们使用公开的UTSD数据集里面的电力需求数据,作为预测算法的数据来源,基于历史数据预测未来若干小时的电力需求。数据集的采集频次为30分钟,单位与时间戳未提供。为了方便演示,按…...
NLP学习路线图(二十一): 词向量可视化与分析
在自然语言处理(NLP)的世界里,词向量(Word Embeddings)犹如一场静默的革命。它将原本离散、难以捉摸的词语,转化为稠密、富含语义的连续向量,为机器理解语言铺平了道路。然而,这些向…...

【分布式技术】KeepAlived高可用架构科普
KeepAlived高可用架构 Keepalived 架构详解一、核心架构组件二、VRRP 协议详解1. **VRRP 核心概念**2. **VRRP 工作流程**3. **VRRP 通信机制** 三、高可用架构模型四、健康检查机制五、配置文件详解配置文件关键参数说明: 六、高可用实现流程七、脑裂问题与解决方案…...

如何配置mvn镜像源为华为云
如何配置mvn镜像源为华为云 # 查找mvn 配置文件 mvn -X help:effective-settings | grep settings.xml# 配置mvn镜像源为华为云,/home/apache-maven-3.9.5/conf/settings.xml文件路径需要根据上一步中查询结果调整 cat > /home/apache-maven-3.9.5/conf/setting…...

Linux平台排查CPU占用高的进程和线程指南
基础排查工具 1. top命令 - 实时进程监控 top操作指令: 按 P:按CPU使用率排序按 1:显示每个CPU核心的使用情况按 H:切换显示线程视图按 M:按内存使用排序按 q:退出 2. htop命令 - 增强版top(…...

多模态大语言模型arxiv论文略读(105)
UnifiedMLLM: Enabling Unified Representation for Multi-modal Multi-tasks With Large Language Model ➡️ 论文标题:UnifiedMLLM: Enabling Unified Representation for Multi-modal Multi-tasks With Large Language Model ➡️ 论文作者:Zhaowei…...

简述MySQL 超大分页怎么处理 ?
针对MySQL超大分页(深度分页)的性能问题,核心优化方案如下: 1. 子查询 覆盖索引(延迟关联) 原理: 子查询仅扫描覆盖索引(如主键),避免回表操作…...

Pyhton中的命名空间包(Namespace Package)您了解吗?
在 Python 中,命名空间包(Namespace Package) 是一种特殊的包结构,它允许将模块分散在多个独立的目录中,但这些目录在逻辑上属于同一个包命名空间。命名空间包的核心特点是:没有 __init__.py 文件ÿ…...

Java设计模式之备忘录模式详解
Java设计模式之备忘录模式详解 一、备忘录模式核心思想 核心目标:捕获对象内部状态并在需要时恢复,同时不破坏对象的封装性。如同游戏存档系统,允许玩家保存当前进度并在需要时回退到之前的状态。 二、备忘录模式类图(Mermaid&am…...

Azure DevOps Server 2022.2 补丁(Patch 5)
微软Azure DevOps Server的产品组在4月8日发布了2022.2 的第5个补丁。下载路径为:https://aka.ms/devops2022.2patch5 这个补丁的主要功能是修改了代理(Agent)二进制安装文件的下载路径;之前,微软使用这个CND(域名为vstsagentpackage.azuree…...

手摸手还原vue3中reactive的get陷阱以及receiver的作用
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、实例是什么?二、new Prxoy三、实现代码1.引入代码2.读入数据 总结 前言 receiver不是为解决get陷阱而生,而是为解决Proxy中的this绑…...

小明的Java面试奇遇之互联网保险系统架构与性能优化
一、文章标题 小明的Java面试奇遇之互联网保险系统架构与性能优化🚀 二、文章标签 Java,Spring Boot,MyBatis,Redis,Kafka,JVM,多线程,互联网保险,系统架构,性能优化 三、文章概述 本文模拟了程序员小明在应聘互联网保险系统开发岗位时,参与的一场深…...
C++学习-入门到精通【13】标准库的容器和迭代器
C学习-入门到精通【13】标准库的容器和迭代器 目录 C学习-入门到精通【13】标准库的容器和迭代器一、标准模板库简介1.容器简介2.STL容器总览3.近容器4.STL容器的通用函数5.首类容器的通用typedef6.对容器元素的要求 二、迭代器简介1.使用istream_iterator输入,使用…...
C# 面向对象特性
面向对象编程的三大基本特性是:封装、继承和多态。下面将详细介绍这三大特性在C#中的体现方式。 封装 定义:把对象的数据和操作代码组合在同一个结构中,这就是对象的封装性。 体现方式: 使用访问修饰符控制成员的可见性 通过属…...
ElasticStack技术之logstash介绍
一、什么是Logstash Logstash 是 Elastic Stack(ELK Stack)中的一个开源数据处理管道工具,主要用于收集、解析、过滤和传输数据。它支持多种输入源,如文件、网络、数据库等,能够灵活地对数据进行处理,比如…...

前端与后端
实例一 处理登录页面请求 # 处理登录页面请求 app.route(/c, methods[GET, POST]) # /c是网页地址 def login(): usernameaa passwordbb print(username,password) if request.method POST: username request.form.get(yhm) password requ…...

CI/CD 持续集成、持续交付、持续部署
CI/CD 是 持续集成(Continuous Integration) 和 持续交付/持续部署(Continuous Delivery/Deployment) 的缩写,代表现代软件开发中通过自动化流程快速、可靠地构建、测试和发布代码的实践。其核心目标是 减少人工干预、…...

代码随想录60期day54
岛屿dfs #include<iostream> #include<vector> using namespace std;int dir[4][2] {0,1,1,0,-1,0,0,-1};void dfs(const vector<vector<int>>&grid,vector<vecotr<bool>>&visited,int x,int y){for(int i 0 ; i < 4; i){in…...

关于easyx头文件
一、窗口创建 (1)几种创建方式 #include<easyx.h>//easyx的头文件 #include<iostream> using namespace std;int main() {//创建一个500*500的窗口//参数为:长度,宽度,是否显示黑框(无参为不…...

Java 中执行命令并使用指定配置文件的最佳实践
在Java开发中,有时需要从Java应用程序中执行系统命令,并使用指定的配置文件来控制这些命令的行为。本文将详细介绍在Java中执行命令并使用指定配置文件的最佳实践,包括如何设置环境变量、重定向输入输出以及处理可能出现的异常。 一、基本实…...
django入门-orm数据库操作
一:下载数据库依赖项mysqlclient pip install mysqlclient 二:django配置文件配置数据库链接 路径:mysite2\mysite2\settings.py DATABASES {default: {ENGINE: django.db.backends.mysql,NAME: data, # 数据库名称USER: root, …...

食品电商突围战!品融电商全平台代运营,助您抢占天猫京东抖音红利!
食品电商突围战!品融电商全平台代运营,助您抢占天猫京东抖音红利! 一、食品电商的黄金时代:机遇与挑战并存 随着消费升级和线上渗透率的持续攀升,食品行业正迎来前所未有的发展机遇。2023年ÿ…...

Termux下如何使用MATLAB
实际上,termux 目前无法运行MATLAB,但是可以运行MATLAB的平替octave ,可以完全在终端环境运行,方便运算和查看模型拟合结果等,完全兼容MATLAB命令。 食用方法: //pkg install wget wget https://its-poin…...
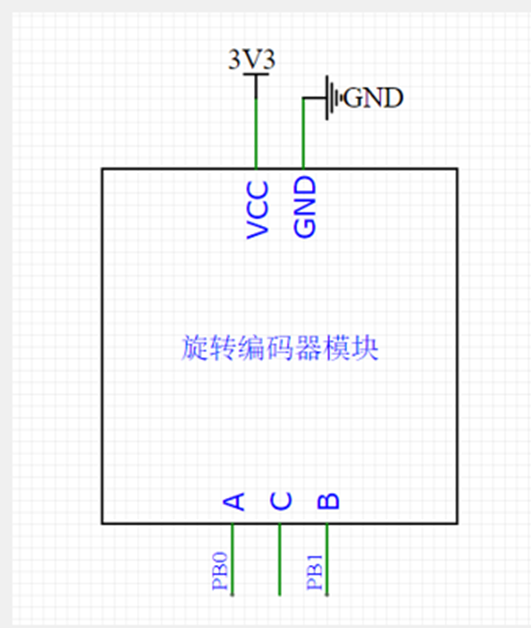
STM32外部中断(EXTI)以及旋转编码器的简介
一、外部中断机制概述 中断是指当主程序执行期间出现特定触发条件(即中断源)时,CPU将暂停当前任务,转而执行相应的中断服务程序(ISR),待处理完成后恢复原程序的运行流程。该机制通过事件驱动…...

双擎驱动:华为云数字人与DeepSeek大模型的智能交互升级方案
一、技术融合概述 华为云数字人 华为云数字人,全称:数字内容生产线 MetaStudio。数字内容生产线,提供数字人视频制作、视频直播、智能交互、企业代言等多种服务能力,使能千行百业降本增效。另外,数字内容生产线&#…...

Unity Version Control UVC报错:Not connected. Trying to re-connect…
问题背景 今天备份项目的时候遇到了这个问题,起因是Unity停用了原始的Plastic SCM的项目管理功能,我使用新的Unity Version Control系统时遇到了无法新建workspace的问题,即使新建之后进入Unity也无法连接到仓库,点击重试也无反应…...

场景题-1
场景题-1 订单到期关闭 1、DelayQueue 无界阻塞队列,用于放置实现了Delayed接口的对象,基于PriorityQueue实现,可用于实现在指定的延迟时间之后处理元素。订单创建后放入队列中,然后使用一个常驻任务不停地执行扫描取出超时订单…...

Java复习Day26
Lambda表达式简介 Lambda表达式是Java 8的重要特性,允许使用简洁的表达式代替功能接口。它类似于方法,包含参数列表和执行主体(可以是表达式或代码块)。Lambda可以视为匿名内部类的语法糖,也被称为闭包。 优点 代码…...
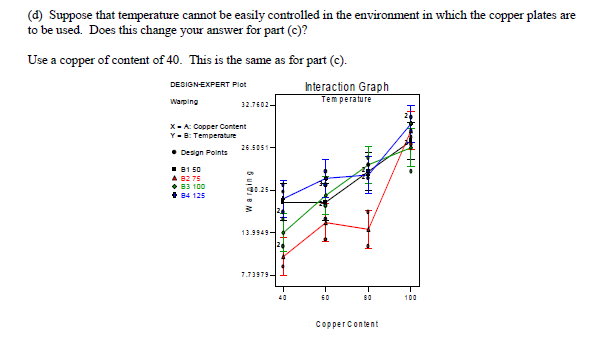
实验设计与分析(第6版,Montgomery)第5章析因设计引导5.7节思考题5.5 R语言解题
本文是实验设计与分析(第6版,Montgomery著,傅珏生译) 第5章析因设计引导5.7节思考题5.5 R语言解题。主要涉及方差分析,正态假设检验,残差分析,交互作用图。 dataframe <-data.frame( wrapc(17,20,12,9,…...

阿里云百炼全解析:一站式大模型开发平台的架构与行业实践
目录 大模型开发范式的革新平台核心架构与技术解析全生命周期开发工作流企业级安全与合规体系行业应用场景与最佳实践未来演进与技术展望1. 大模型开发范式的革新 1.1 从碎片化到平台化的演进 传统大模型开发面临三大核心挑战:算力管理复杂、工具链割裂、安全合规风险高。阿…...