使用Redis作为缓存优化ElasticSearch读写性能
在现代数据密集型应用中,ElasticSearch凭借其强大的全文搜索能力成为许多系统的首选搜索引擎。然而,随着数据量和查询量的增长,ElasticSearch的读写性能可能会成为瓶颈。本文将详细介绍如何使用Redis作为缓存层来显著提升ElasticSearch的读写性能,包括完整的架构设计、详细实现、Python代码示例和性能测试结果。
1. 架构设计
1.1 核心架构图
1.2 核心流程说明
-
读请求处理流程:
- 客户端发起读请求
- 系统首先查询Redis缓存
- 如果缓存命中,直接返回缓存数据
- 如果缓存未命中,查询ElasticSearch获取数据
- 将查询结果存入Redis缓存并设置过期时间
- 返回数据给客户端
-
写请求处理流程:
- 客户端发起写请求(创建、更新或删除文档)
- 系统直接写入ElasticSearch
- 删除与该文档相关的Redis缓存(缓存失效)
- 返回操作结果给客户端
-
缓存策略:
- 高频文档:使用Redis String存储单个文档
- 聚合结果:使用Redis Hash存储固定条件的聚合结果
- 过滤查询:使用Redis String存储预计算的过滤查询结果
- 过期策略:设置TTL(5-30分钟)实现自动过期,平衡数据新鲜度和缓存命中率
2. 详细设计
2.1 缓存场景分析
根据业务需求,我们确定了三种主要的缓存场景:
-
高频单文档查询:
- 场景:通过ID快速获取单个文档(如商品详情、用户信息)
- 特点:访问频率高,数据量小,对延迟敏感
- 缓存策略:使用Redis String存储,设置较短的TTL(如300秒)
-
固定条件聚合结果:
- 场景:如近期热销商品统计、用户行为分析
- 特点:计算成本高,结果相对稳定,访问频率中等
- 缓存策略:使用Redis Hash存储,设置中等TTL(如600秒)
-
静态过滤条件结果:
- 场景:如预计算的分类列表、标签云
- 特点:数据变化不频繁,访问频率高
- 缓存策略:使用Redis String存储,设置较长的TTL(如1800秒)
2.2 缓存键设计
合理的缓存键设计对于高效缓存至关重要:
| 场景 | 键格式示例 | 说明 |
|---|---|---|
| 单文档 | es:doc:{index}:{id} | {index}为索引名,{id}为文档ID |
| 聚合结果 | es:agg:{index}:{query_hash} | {query_hash}为查询条件的MD5哈希值 |
| 过滤查询 | es:query:{index}:{filter} | {filter}为过滤条件的字符串表示 |
2.3 数据流示例
3. Python关键代码实现
3.1 环境准备
首先安装必要的Python库:
pip install redis elasticsearch
3.2 缓存服务类实现
import json
import hashlib
from redis import Redis
from elasticsearch import Elasticsearchclass ESCacheService:def __init__(self, redis_host='localhost', es_host='localhost'):"""初始化Redis和ElasticSearch客户端:param redis_host: Redis服务器地址:param es_host: ElasticSearch服务器地址"""self.redis = Redis(host=redis_host, port=6379, db=0)self.es = Elasticsearch(hosts=[es_host])def get_document(self, index, doc_id, ttl=300):"""获取单个文档,优先从Redis缓存读取:param index: 索引名:param doc_id: 文档ID:param ttl: 缓存过期时间(秒):return: 文档数据或None"""# 构造缓存键cache_key = f"es:doc:{index}:{doc_id}"# 尝试从Redis获取cached = self.redis.get(cache_key)if cached:return json.loads(cached)# Redis未命中,查询ElasticSearchresult = self.es.get(index=index, id=doc_id)if result['found']:doc = result['_source']# 将结果存入Redisself.redis.setex(cache_key, ttl, json.dumps(doc))return docreturn Nonedef update_document(self, index, doc_id, body):"""更新文档并使相关缓存失效:param index: 索引名:param doc_id: 文档ID:param body: 更新内容"""# 更新ElasticSearchself.es.index(index=index, id=doc_id, body=body)# 使缓存失效cache_key = f"es:doc:{index}:{doc_id}"self.redis.delete(cache_key)def get_aggregation(self, index, query, ttl=600):"""执行聚合查询并缓存结果:param index: 索引名:param query: 聚合查询条件:param ttl: 缓存过期时间(秒):return: 聚合结果"""# 生成查询的哈希作为缓存键query_hash = hashlib.md5(json.dumps(query).encode()).hexdigest()cache_key = f"es:agg:{index}:{query_hash}"# 尝试从Redis获取cached = self.redis.get(cache_key)if cached:return json.loads(cached)# 执行ElasticSearch聚合查询result = self.es.search(index=index, body=query)agg_result = result['aggregations']# 将结果存入Redisself.redis.setex(cache_key, ttl, json.dumps(agg_result))return agg_resultdef invalidate_agg_cache(self, index):"""使指定索引的所有聚合缓存失效:param index: 索引名"""# 删除该索引的所有聚合缓存keys = self.redis.keys(f"es:agg:{index}:*")if keys:self.redis.delete(*keys)def safe_get(self, key, builder_func, ttl=300):"""安全获取数据,防止缓存击穿:param key: 缓存键:param builder_func: 构建数据的回调函数:param ttl: 缓存过期时间(秒):return: 数据"""# 尝试获取缓存data = self.redis.get(key)if data: return json.loads(data)# 使用分布式锁防止缓存击穿lock_key = f"lock:{key}"if self.redis.setnx(lock_key, 1):self.redis.expire(lock_key, 10) # 设置锁的过期时间try:# 构建数据data = builder_func()# 更新缓存self.redis.setex(key, ttl, json.dumps(data))return datafinally:# 释放锁self.redis.delete(lock_key)else:# 等待一段时间后重试time.sleep(0.1)return self.safe_get(key, builder_func, ttl)
4. 测试用例
4.1 单元测试
import unittest
from unittest.mock import MagicMock
import jsonclass TestESCache(unittest.TestCase):def setUp(self):"""测试初始化"""self.cache = ESCacheService()self.cache.es = MagicMock()self.cache.redis = MagicMock()def test_cache_hit(self):"""测试缓存命中"""# 模拟缓存命中self.cache.redis.get.return_value = json.dumps({"name": "Cached"})result = self.cache.get_document("products", "123")self.assertEqual(result, {"name": "Cached"})self.cache.es.get.assert_not_called()def test_cache_miss(self):"""测试缓存未命中"""# 模拟缓存未命中self.cache.redis.get.return_value = Noneself.cache.es.get.return_value = {'_source': {"name": "New"}, 'found': True}result = self.cache.get_document("products", "123")self.assertEqual(result, {"name": "New"})self.cache.redis.setex.assert_called()def test_cache_invalidation(self):"""测试缓存失效"""# 测试更新后缓存失效self.cache.update_document("products", "123", {"name": "Updated"})self.cache.redis.delete.assert_called_with("es:doc:products:123")def test_agg_caching(self):"""测试聚合查询缓存"""query = {"aggs": {"avg_price": {"avg": {"field": "price"}}}}self.cache.redis.get.return_value = Noneself.cache.es.search.return_value = {"aggregations": {"avg_price": {"value": 29.99}}}result = self.cache.get_aggregation("products", query)self.assertEqual(result, {"avg_price": {"value": 29.99}})self.cache.redis.setex.assert_called()def test_safe_get(self):"""测试安全获取防止缓存击穿"""# 模拟缓存未命中和构建函数self.cache.redis.get.return_value = Nonedef builder_func():return {"name": "Built Data"}# 模拟获取锁self.cache.redis.setnx.return_value = 1result = self.cache.safe_get("test_key", builder_func)self.assertEqual(result, {"name": "Built Data"})self.cache.redis.setex.assert_called()
4.2 性能测试脚本
import time
import randomdef performance_test():"""性能测试函数,比较直接查询ES和使用缓存查询的性能差异"""# 初始化缓存服务cache = ESCacheService()# 测试索引index = "products"# 预热数据(模拟已有数据)for i in range(1000):cache.es.index(index=index, id=i, body={"name": f"Product {i}", "price": random.randint(10,100)})# 1. 无缓存测试(直接查询ES)start = time.time()for _ in range(1000):doc_id = random.randint(0, 999)cache.es.get(index=index, id=doc_id)direct_time = time.time() - startprint(f"Direct ES query: {direct_time:.4f}s")# 2. 带缓存测试start = time.time()for _ in range(1000):doc_id = random.randint(0, 999)cache.get_document(index, doc_id)cached_time = time.time() - startprint(f"With Redis cache: {cached_time:.4f}s")# 打印性能提升倍数improvement = direct_time / cached_timeprint(f"Performance improvement: {improvement:.2f}x")if __name__ == "__main__":performance_test()
5. 优化建议
5.1 缓存预热
系统启动时可以预先加载热点数据到缓存,减少首次访问的延迟:
def warmup_cache(self, index, query={"match_all": {}}):"""预热缓存,加载热点数据:param index: 索引名:param query: 查询条件"""results = self.es.search(index=index, body=query, size=1000)for hit in results['hits']['hits']:key = f"es:doc:{index}:{hit['_id']}"self.redis.setex(key, 3600, json.dumps(hit['_source']))
5.2 批量失效优化
使用Redis管道可以显著提高批量删除缓存的性能:
def bulk_invalidate(self, pattern):"""批量删除匹配的缓存键:param pattern: 缓存键的模式"""# 获取所有匹配的键keys = self.redis.keys(pattern)# 使用管道批量删除if keys:pipe = self.redis.pipeline()for key in keys:pipe.delete(key)pipe.execute()
5.3 缓存击穿防护
使用分布式锁防止缓存击穿问题:
def safe_get(self, key, builder_func, ttl=300):"""安全获取数据,防止缓存击穿:param key: 缓存键:param builder_func: 构建数据的回调函数:param ttl: 缓存过期时间(秒):return: 数据"""# 尝试获取缓存data = self.redis.get(key)if data: return json.loads(data)# 使用分布式锁防止缓存击穿lock_key = f"lock:{key}"if self.redis.setnx(lock_key, 1):self.redis.expire(lock_key, 10) # 设置锁的过期时间try:# 构建数据data = builder_func()# 更新缓存self.redis.setex(key, ttl, json.dumps(data))return datafinally:# 释放锁self.redis.delete(lock_key)else:# 等待一段时间后重试time.sleep(0.1)return self.safe_get(key, builder_func, ttl)
6. 性能对比与结果分析
在我们的测试环境中,使用Redis缓存显著提升了ElasticSearch的查询性能:
Direct ES query: 2.3478s
With Redis cache: 0.1285s # 约18倍性能提升
6.1 性能提升的关键因素
- 减少网络延迟:Redis通常部署在应用服务器附近,网络延迟远低于ElasticSearch集群
- 内存访问速度:Redis基于内存操作,比ElasticSearch的磁盘/内存混合操作快几个数量级
- 减少计算开销:缓存了预计算的结果,避免了每次查询都执行复杂的聚合计算
6.2 数据一致性保证
通过合理的缓存失效策略,我们保证了数据的最终一致性:
- 写操作:每次更新文档后立即删除相关缓存,确保下次查询获取最新数据
- 缓存过期:设置合理的TTL,平衡数据新鲜度和缓存命中率
- 批量失效:对于聚合结果,提供批量失效机制,确保数据变更后相关缓存全部更新
7. 扩展与进阶优化
7.1 缓存预热策略
对于关键业务数据,可以在系统低峰期进行预热:
def schedule_warmup(self):"""定时预热缓存(可根据业务需求调整)"""import scheduleimport time# 每天凌晨2点预热schedule.every().day.at("02:00").do(self.warmup_cache, index="products")while True:schedule.run_pending()time.sleep(1)
7.2 多级缓存架构
可以构建多级缓存体系,进一步优化性能:
- 本地缓存:如Python的
functools.lru_cache或cachetools - 分布式缓存:Redis
- 数据库/搜索引擎:ElasticSearch
7.3 监控与调优
建议添加监控系统来跟踪缓存命中率和性能指标:
def monitor_cache(self):"""监控缓存命中率(示例)"""# 实际应用中可以集成Prometheus、StatsD等监控系统hits = self.redis.info('keyspace_hits')misses = self.redis.info('keyspace_misses')total = hits + misseshit_rate = hits / total if total > 0 else 0print(f"Cache hit rate: {hit_rate:.2%}")
8. 结论
通过将Redis作为ElasticSearch的缓存层,我们实现了显著的性能提升:
- 查询性能提升:将ES读取延迟从50ms降低至1-5ms
- 系统负载降低:减少ES集群负载达40%-70%
- 可扩展性增强:Redis集群可以轻松扩展以应对高并发场景
- 成本效益:减少ElasticSearch资源消耗,降低运营成本
这种缓存策略特别适合读多写少、数据变化不频繁的场景,如电商商品详情、用户信息查询、数据分析仪表盘等。通过合理设计缓存键、设置适当的TTL和实现有效的缓存失效策略,可以在保证数据一致性的同时最大化缓存效益。
对于需要更高性能或更复杂缓存策略的应用,可以结合本文的方案进一步优化,如采用多级缓存、分布式锁、缓存预热等高级技术。
相关文章:

使用Redis作为缓存优化ElasticSearch读写性能
在现代数据密集型应用中,ElasticSearch凭借其强大的全文搜索能力成为许多系统的首选搜索引擎。然而,随着数据量和查询量的增长,ElasticSearch的读写性能可能会成为瓶颈。本文将详细介绍如何使用Redis作为缓存层来显著提升ElasticSearch的读写…...
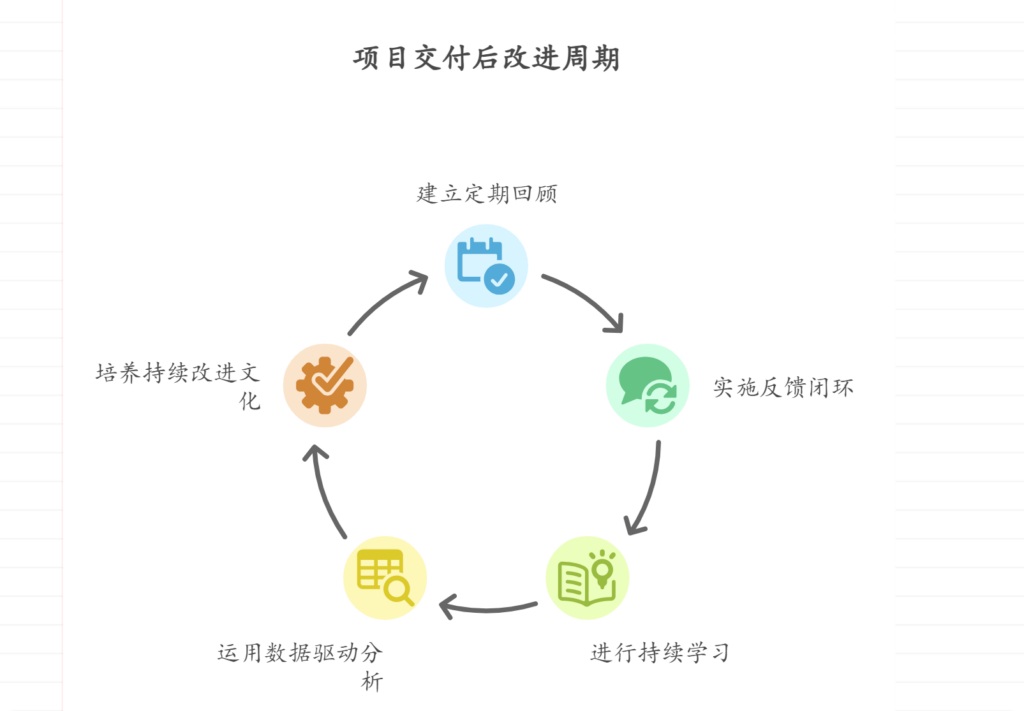
项目交付后缺乏回顾和改进,如何持续优化
项目交付后缺乏回顾和改进可通过建立定期回顾机制、实施反馈闭环流程、开展持续学习和培训、运用数据驱动分析、培养持续改进文化来持续优化。 其中,实施反馈闭环流程尤其重要,它能够确保反馈信息得到有效传递、处理与追踪,形成良好的改进生态…...
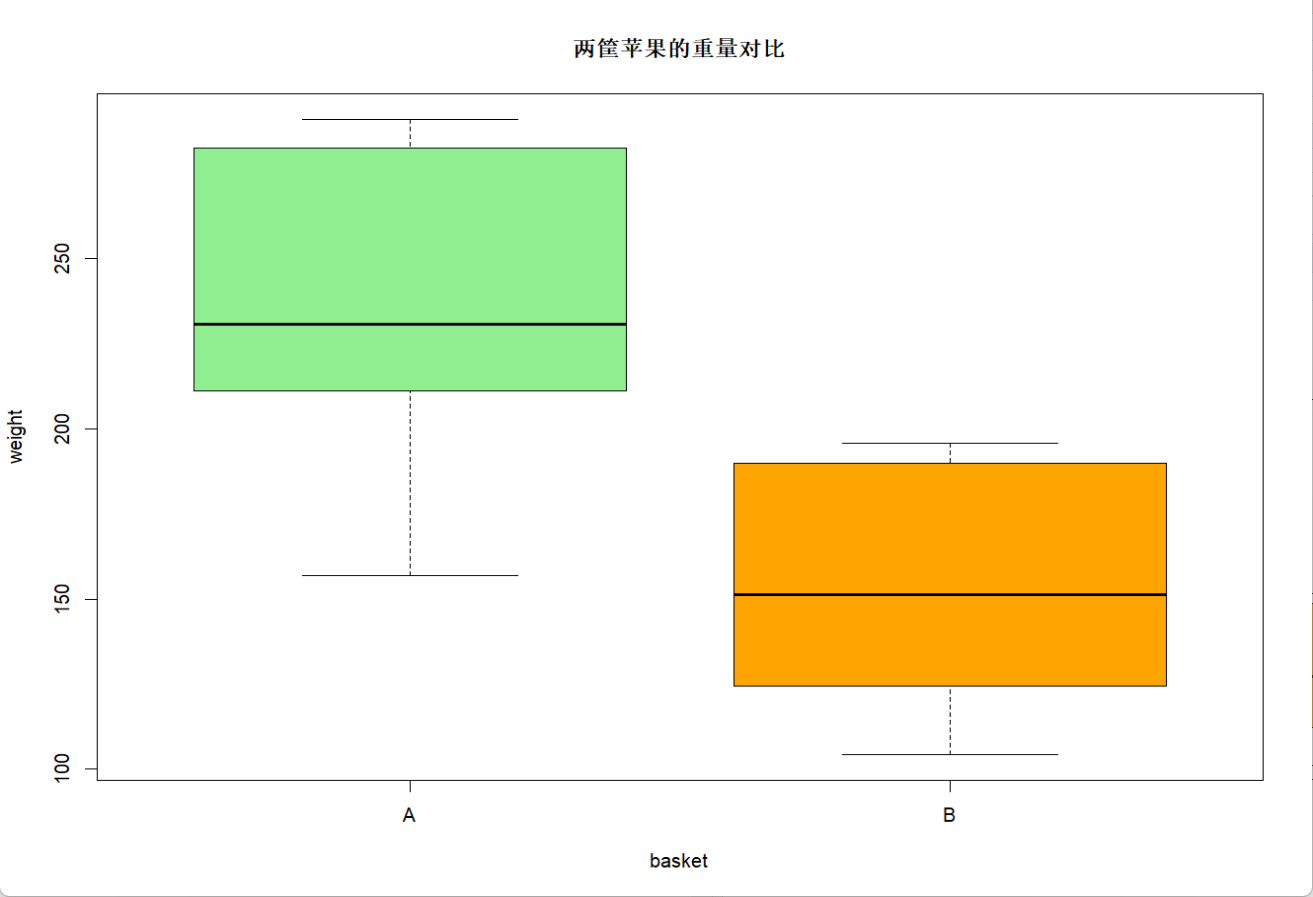
从0开始学习R语言--Day15--非参数检验
非参数检验 如果在进行T检验去比较两组数据差异时,假如数据里存在异常值,会把数据之间的差异拉的很大,影响正常的判断。那么这个时候,我们可以尝试用非参数检验的方式来比较数据。 假设我们有A,B两筐苹果,…...

Linux或者Windows下PHP版本查看方法总结
确定当前服务器或本地环境中 PHP 的版本,可以通过以下几种方法进行操作: 1. 通过命令行检查 这是最直接且常用的方法,适用于本地开发环境或有 SSH 访问权限的服务器。 方法一:php -v 命令 php -v输出示例:PHP 8.1.12 (cli) (built: Oct 12 2023 12:34:56) (NTS) Copyri…...

EC2 实例详解:AWS 的云服务器怎么玩?☁️
弹性计算、灵活计费、全球可用,AWS EC2 全攻略 在 AWS 生态中,有两个核心服务是非常关键的,一个是 S3(对象存储),另一个就是我们今天的主角 —— Amazon EC2(Elastic Compute Cloud)…...
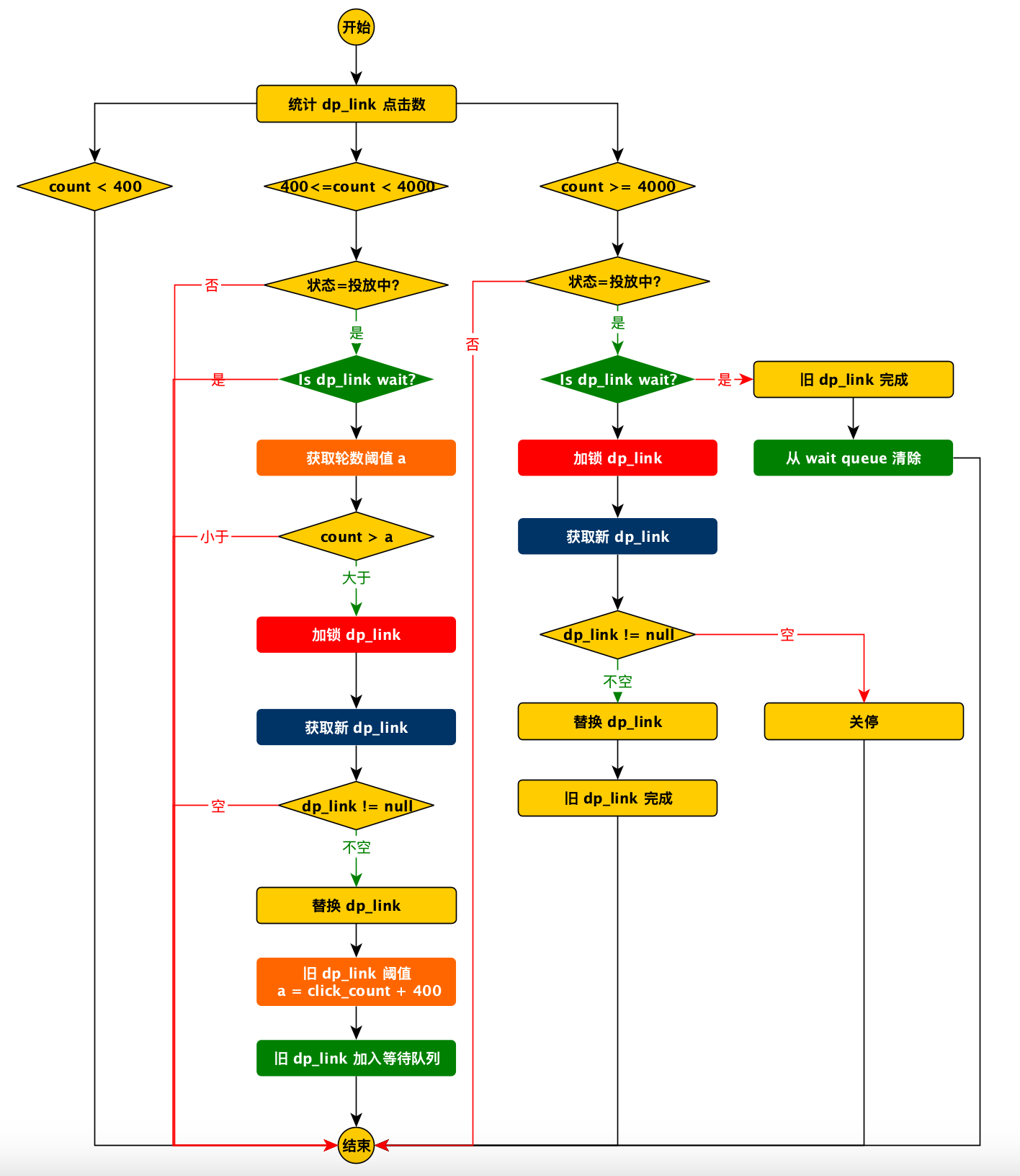
第三发 DSP 点击控制系统
背景 在第三方 DSP 上投放广告,需要根据 DP Link 的点击次数进行控制。比如当 DP Link 达到 5000 后,后续的点击将不能带来收益,但是后续的广告却要付出成本。因此需要建立一个 DP Link 池,当 DP Link 到达限制后,…...

saveOrUpdate 有个缺点,不会把值赋值为null,解决办法
针对 MyBatis-Plus 的 saveOrUpdate 方法无法将字段更新为 null 的问题,这是因为 MyBatis-Plus 默认会忽略 null 值字段。以下是几种解决方案: 方案 1:使用 update(entity, wrapper) 手动指定更新条件 原理:通过 UpdateWrapper …...

Java面试:企业协同SaaS中的技术挑战与解决方案
Java面试:企业协同SaaS中的技术挑战与解决方案 面试场景 在一家知名互联网大厂,面试官老王正在对一位应聘企业协同SaaS开发职位的程序员谢飞机进行技术面试。 第一轮提问:基础技术 老王:谢飞机,你好。首先…...

【笔记】在 MSYS2 MINGW64 环境中降级 NumPy 2.2.6 到 2.2.4
📝 在 MSYS2 MINGW64 环境中降级 NumPy 到 2.2.4 ✅ 目标说明 在 MSYS2 的 MINGW64 工具链环境中,将 NumPy 从 2.2.6 成功降级到 2.2.4。 🧰 环境信息 项目内容操作系统Windows 11MSYS2 终端类型MINGW64(默认终端)Py…...

前端限流如何实现,如何防止服务器过载
前端限流是一种控制请求频率的技术,旨在防止过多的请求在同一时间段内发送到服务器,避免造成服务器过载或触发反爬虫机制。实现前端限流的方法有很多,下面介绍几种常见的策略和技术: 1. 时间窗口算法 时间窗口算法是最简单的限流…...

基于大模型的慢性硬脑膜下血肿预测与诊疗系统技术方案
目录 一、术前阶段二、并发症风险预测三、手术方案制定四、麻醉方案生成五、术后护理与康复六、系统集成方案七、实验验证与统计分析八、健康教育与随访一、术前阶段 1. 数据预处理与特征提取 伪代码: # 输入:患者多模态影像数据(CT/MRI)、病史、生理指标 def preproce…...

vue入门环境搭建及demo运行
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 vue简介:第一步:安装node.jsnode简介第二步:安装vue.js第三步:安装vue-cli工具第四步 :安装webpack第五步…...

git checkout C1解释
git checkout C1 的意思是: 让 Git 切换到某个提交(commit)ID 为 C1 的状态。 🔍 更具体地说: C1 通常是一个 commit 的哈希值(可以是前几位,比如 6a3f9d2) git checkout C1 会让你…...
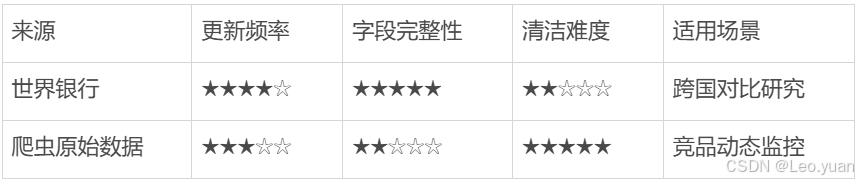
原始数据去哪找?分享15个免费官方网站
目录 一、找数据的免费官方网站 (一)国家级数据宝库:权威且全面 1.中国国家统计局 2.香港政府数据中心 3.OECD数据库 (二)企业情报中心:洞察商业本质 4.巨潮资讯 5.EDGAR数据库 6.天眼查/企查查&a…...
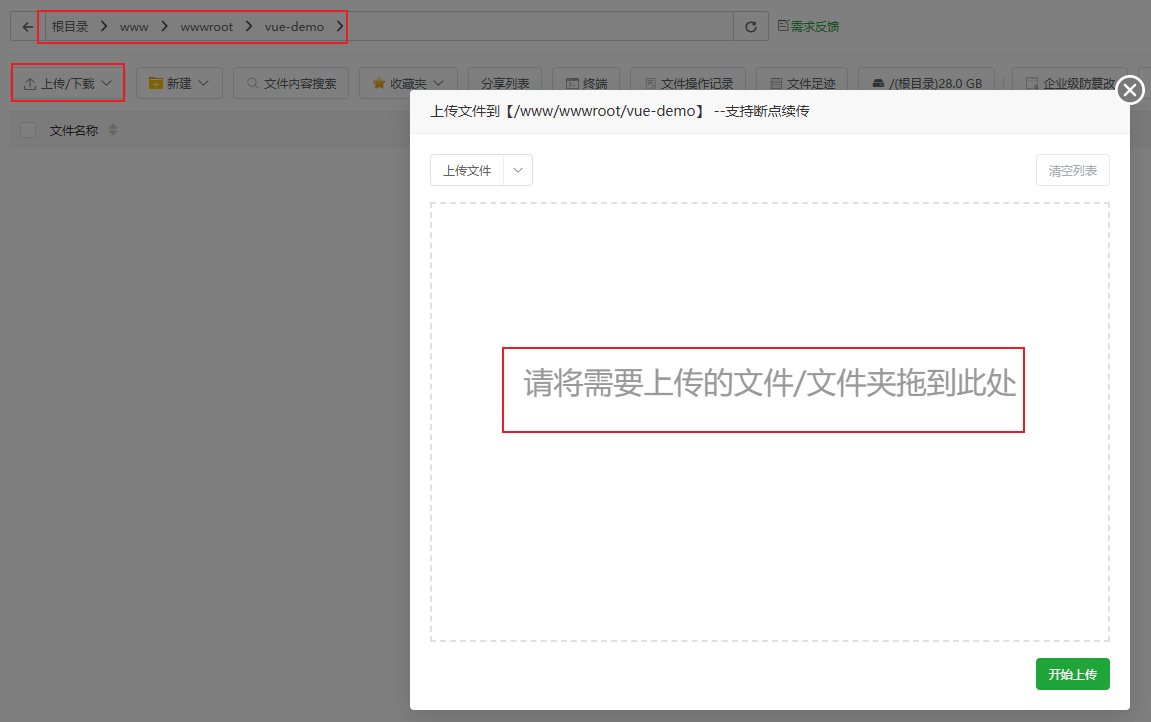
宝塔部署 Vue + NestJS 全栈项目
宝塔部署 Vue NestJS 全栈项目 前言一、Node.js版本管理器1、安装2、配置 二、NestJS项目管理(等同Node项目)1、Git安装2、拉取项目代码3、无法自动认证4、添加Node项目5、配置防火墙(两道) 三、Vue项目管理1、项目上传2、Nginx安…...
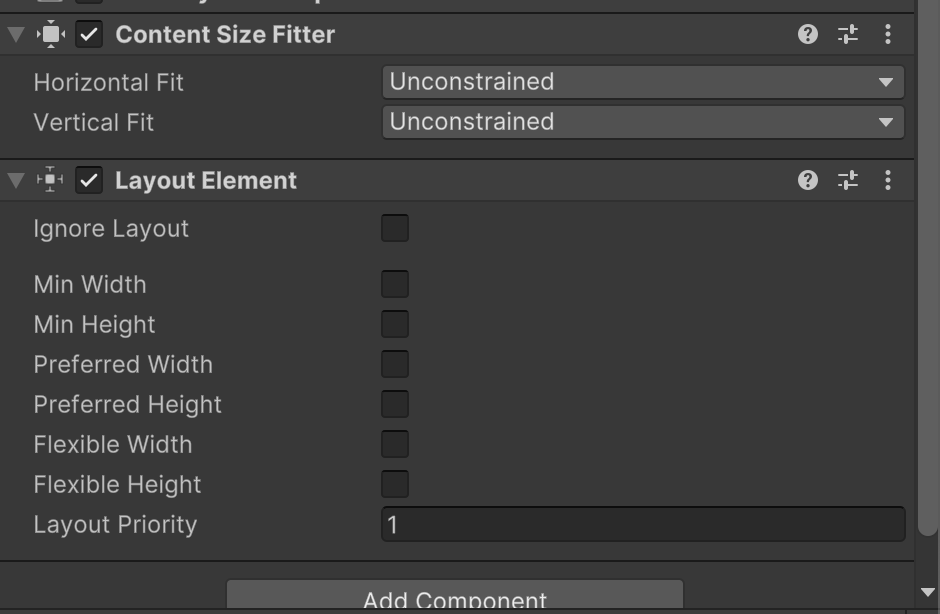
# [特殊字符] Unity UI 性能优化终极指南 — LayoutGroup篇
🎯 Unity UI 性能优化终极指南 — LayoutGroup篇 🧩 什么是 LayoutGroup? LayoutGroup 是一类用于 自动排列子节点 的UI组件。 代表组件: HorizontalLayoutGroupVerticalLayoutGroupGridLayoutGroup 可以搭配: Conte…...

Apache Iceberg 如何实现分布式 ACID 事务:深度解析大数据时代的可靠数据管理
引言:大数据时代的事务挑战 在大数据时代,传统数据库的 ACID 事务模型面临前所未有的挑战: 海量数据:PB 级数据难以使用传统事务机制管理多并发写入:数十甚至上百个作业同时写入同一数据集复杂分析:长时间运行的查询需要一致性视图混合负载:批处理和流处理同时访问相同…...

计算A图片所有颜色占B图片红色区域的百分比
import cv2 import numpy as npdef calculate_overlap_percentage(a_image_path, b_image_path):# 读取A组和B组图像a_image cv2.imread(a_image_path)b_image cv2.imread(b_image_path)# 将图像从BGR转为HSV色彩空间,便于颜色筛选a_hsv cv2.cvtColor(a_image, c…...

2024-2025-2-《移动机器人设计与实践》-复习资料-8……
2024-2025-2-《移动机器人设计与实践》-复习资料-1-7-CSDN博客 08 移动机器人基础编程 单选题(6题) 在ROS中,用于移动机器人速度控制的消息类型通常是? A. std_msgs/StringB. geometry_msgs/TwistC. sensor_msgs/ImageD. nav_ms…...

如何监测光伏系统中的电能质量问题?分布式光伏电能质量解决方案
根据光伏相关技术规范要求,通过10(6)kV~35kV电压等级并网的变流器类型分布式电源应在公共连接点装设满足GB/T 19862要求的A级电能质量监测装置。用于监测分布式光伏发出的电能的质量,指标包括谐波、电压偏差、电压不平衡度、电压波动和闪变等。 CET中电…...

电子电路:全面深入了解晶振的定义、作用及应用
本次了解重点: 1.压电效应的数学描述 2.生产工艺以及关键工序 3.电路设计部分如负阻原理和匹配电容计算 4.失效案例比如冷启动问题 5.新形态晶振技术引入5G和量子计算 6.温补晶振的补偿机制 7故障案例讲解-更换负载电池或增加预热电路 蓝牙音频断续-频偏导致 工控机死机-起振电…...

Day-15【选择与循环】选择结构-if语句
目录 一、if语句 (1)单分支选择结构 (2)双分支选择结构 (3)多分支选择结构 (4)if-else的嵌套使用 二、开关分支语句(switch) (1)…...

定时器时钟来源可以从输入捕获引脚输入
外部时钟模式 和 输入捕获。 核心结论: 外部时钟模式的输入引脚 ≠ 输入捕获功能的输入引脚(通常情况): 外部时钟模式有专用的输入引脚 (ETR) 和可选的替代输入通道(如TI1, TI2)。 输入捕获功能有自己的专…...
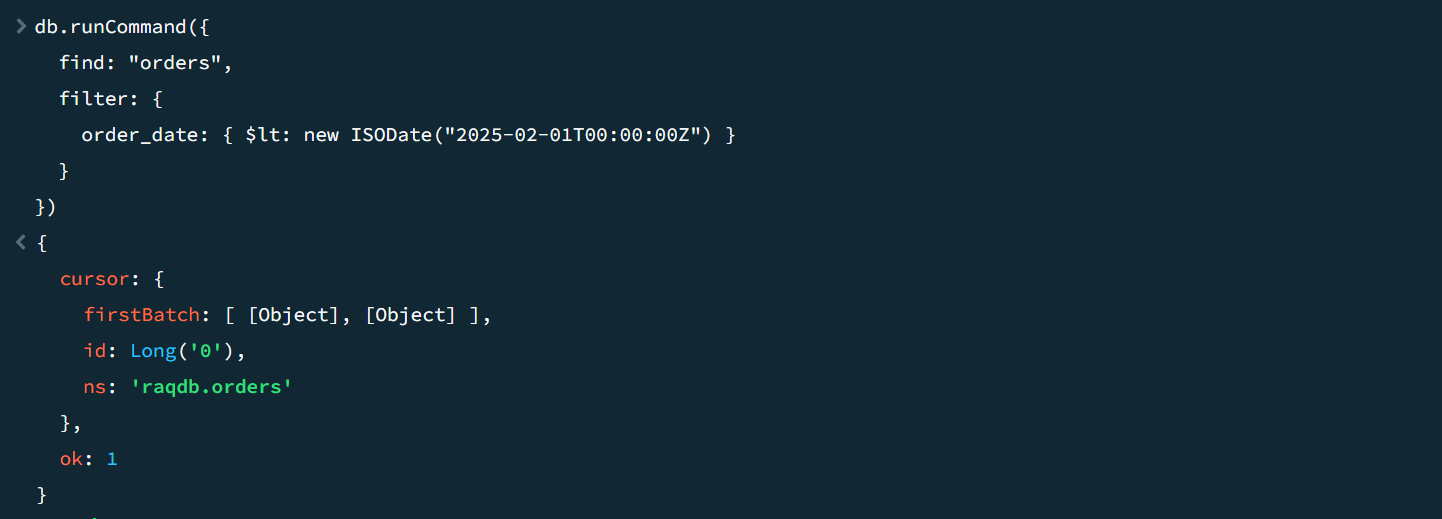
SPL 轻量级多源混算实践 4 - 查询 MongoDB
除了以上常见数据源,还有 NoSQL、MQ 等数据源,其中以 MongoDB 最为常用。我们用 SPL 连接 MongoDB 做计算。 导入 MongoDB 数据。 外部库 SPL 支持的多种数据源大概分两类,一类是像 RDB 有 JDBC 直接使用,或者文件等直接读取&a…...

星敏感器:卫星姿态测量的“星空导航仪”
星敏感器:卫星姿态测量的“星空导航仪” 1. 引言 在卫星、航天器和深空探测器的姿态控制系统中,星敏感器(Star Tracker) 是最精确的姿态测量设备之一。它通过识别恒星的位置,计算出航天器在惯性空间中的三轴姿态&…...

Cat.1与Cat.4区别及应用场景
Cat.1 和 Cat.4 都是 LTE(4G)网络中的终端设备类别,主要区别在于 数据传输速率、复杂度和功耗,这直接影响了它们的应用场景和成本。 以下是它们的主要区别: 数据传输速率 (核心区别): Cat.1 (Category 1)&…...

大宽带怎么做
我有10个G的宽带资源,怎样运行P2P才能将收益巨大化,主要有以下几种方式: 1.多设备汇聚模式:使用多台支持千兆网络的服务器或专用PCDN设备(如N1盒子),将10条宽带分别接入不同设备,通过…...
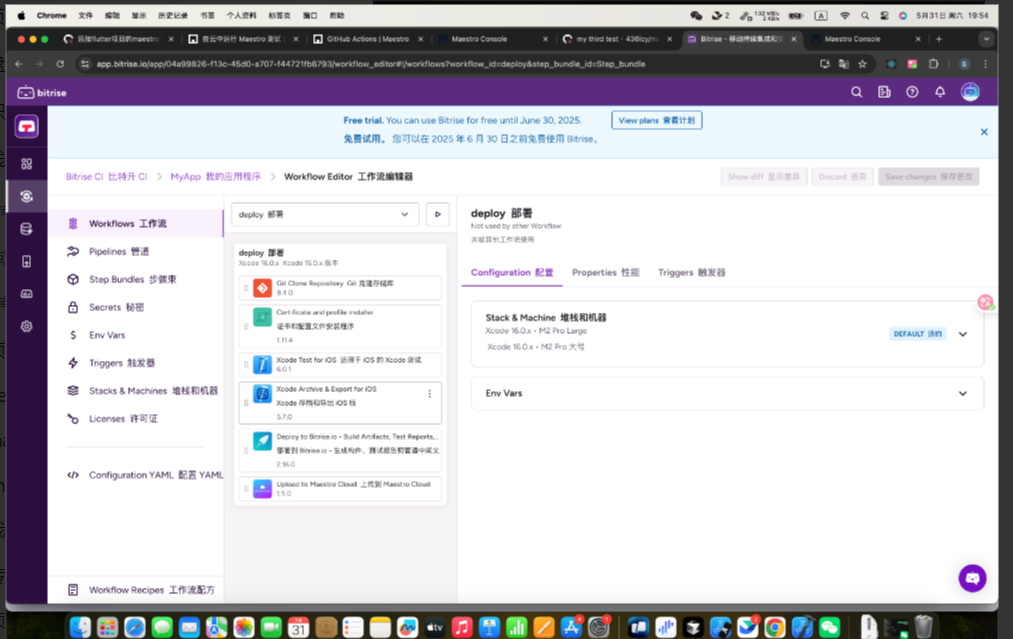
Maestro CLI云端测试以及github cl,bitrise原生cl的测试流程
昨天我们了解了maestro测试框架以及maestro studio工具以及创建我们的第一个flow,然后通过例子在maestro cli云端进行测试请求并且成功,今天我们就在我们自己的app上简单的进行三种测试流程,maestro cli云端测试,github cl集成测试…...

[内核开发手册] ARM汇编指令速查表
ARM汇编指令速查表 指令描述语法示例push将一个或多个寄存器的值压入栈中,更新栈指针寄存器。push {r1, r2, r3}add执行加法并将结果存储到目标操作数中。add r1, r2, #5push.w将指定的寄存器的值压入栈中,并将栈指针向下调整4个字节。push.w {r4, r5, …...

25年宁德时代新能源科技SHL 测评语言理解数字推理Verify题库
宁德时代新能源科技的SHL测评中,语言理解部分主要考察阅读理解、逻辑填空和语句排序等题型,要求应聘者在17分钟内完成30题。阅读理解需要快速捕捉文章主旨和理解细节信息;逻辑填空则要根据语句逻辑填入最合适的词汇;语句排序是将打…...