D2-基于本地Ollama模型的多轮问答系统
本程序是一个基于 Gradio 和 Ollama API 构建的支持多轮对话的写作助手。相较于上一版本,本版本新增了对话历史记录、Token 计数、参数调节和清空对话功能,显著提升了用户体验和交互灵活性。
程序通过抽象基类 LLMAgent 实现模块化设计,当前使用 OllamaAgent 作为具体实现,调用本地部署的 Ollama 大语言模型(如 qwen3:8b)生成写作建议,并提供一个交互式的 Web 界面供用户操作。
设计支持未来扩展到其他 LLM 平台(如 OpenAI、HuggingFace),只需实现新的 LLMAgent 子类即可。
环境配置
依赖安装
需要以下 Python 库:
gradio:用于创建交互式 Web 界面。requests:向 Ollama API 发送 HTTP 请求。json:解析 API 响应数据(Python 内置)。logging:记录运行日志(Python 内置)。abc:定义抽象基类(Python 内置)。tiktoken:精确计算 Token 数量以管理输入和历史长度。
安装命令:
pip install gradio requests tiktoken
建议使用 Python 3.8 或更高版本。
Ollama 服务配置
-
安装 Ollama
从 https://ollama.ai/ 下载并安装。 -
启动 Ollama 服务
ollama serve- 默认监听地址:
http://localhost:11434。
- 默认监听地址:
-
下载模型
ollama pull qwen3:8b -
验证模型
ollama list
运行程序
- 将代码保存为
writing_assistant.py。 - 确保 Ollama 服务正在运行。
- 执行程序:
python writing_assistant.py - 打开浏览器访问界面(通常为
http://127.0.0.1:7860)。 - 输入写作提示,调整参数后点击“获取写作建议”,查看结果和对话历史。
代码说明
1. 依赖导入
import gradio as gr
import requests
import json
import logging
from abc import ABC, abstractmethod
import tiktoken
tiktoken:精确计算 Token 数量,优化输入控制。
2. 日志配置
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
- 配置日志级别为
INFO,记录 API 调用和错误信息,便于调试。
3. 抽象基类:LLMAgent
class LLMAgent(ABC):@abstractmethoddef generate_response(self, prompt):pass
- 定义通用 LLM 代理接口,要求实现
generate_response方法。 - 支持未来扩展到其他 LLM 平台(如 OpenAI、Anthropic)。
4. 具体实现:OllamaAgent
class OllamaAgent(LLMAgent):def __init__(self, config): ...def set_max_history_length(self, max_rounds): ...def set_parameters(self, max_tokens, temperature): ...def generate_response(self, prompt): ...def clear_history(self): ...
- 对话历史:维护
history列表,支持多轮对话。 - 参数调节:动态调整
max_tokens和temperature。 - Token 管理:自动截断历史记录,防止超出模型上下文限制。
- 错误处理:捕获网络请求失败和 JSON 解析错误,返回用户友好的提示。
5. Token 计数函数
def calculate_tokens(text): ...
def calculate_history_tokens(history): ...
- 使用
tiktoken精确估算 Token 数量,提升输入长度控制能力。
6. 历史格式化
def format_history_for_chatbot(history): ...
- 将内部
history结构转换为 Gradio 的Chatbot格式[user_msg, assistant_msg]。
7. 核心逻辑:generate_assistance
def generate_assistance(prompt, agent, max_rounds, max_tokens, temperature): ...
- 设置最大对话轮数和生成参数。
- 调用
agent.generate_response获取响应。 - 返回格式化的对话历史、最新回复和 Token 计数。
8. 辅助函数
def update_token_count(prompt): ...
def clear_conversation(agent): ...
- 实时更新输入 Token 数量。
- 清空对话历史并重置状态。
9. 主函数:main
def main():config = { ... }agent = OllamaAgent(config)with gr.Blocks(...) as demo:...demo.launch()
- 增强的 UI:包含输入框、Token 显示、参数调节滑块和清空按钮。
- Gradio 事件绑定:
prompt_input.change():动态更新 Token 计数。submit_button.click():触发写作建议生成。clear_button.click():重置对话历史。
运行流程图
graph TDA[用户输入提示] --> B[点击 submit_button]B --> C[调用 generate_assistance(prompt, agent, 参数)]C --> D[调用 agent.set_* 设置参数]D --> E[调用 agent.generate_response(prompt)]E --> F[向 Ollama API 发送 POST 请求]F --> G[接收并解析 JSON 响应]G --> H[更新聊天历史和输出结果]
注意事项
- Ollama 服务:确保服务运行并监听在
http://localhost:11434/v1。 - 模型可用性:确认
qwen3:8b已下载。 - Token 上限:注意模型的最大上下文长度(如 4096 Tokens),避免历史过长导致超限。
- 参数影响:
temperature:控制生成随机性(较低值更确定,较高值更具创造性)。max_tokens:限制输出长度。
- 调试信息:查看终端日志,确认 API 响应是否正常或是否有错误。
未来改进建议
- 多模型支持:添加
OpenAIAgent等子类,通过下拉菜单切换模型。 - 配置文件化:将硬编码配置移至 JSON/YAML 文件。
- 异步请求:使用
aiohttp替换requests,提升并发性能。 - 对话持久化:将历史对话保存到本地文件或数据库。
- 用户认证:区分不同用户的对话记录。
- 移动端适配:优化界面布局以适配手机端。
示例使用
- 启动程序后访问
http://127.0.0.1:7860。 - 输入提示:“帮我写一段关于环保的文章。”
- 调整参数(如
max_tokens=1000,temperature=0.2)。 - 点击“获取写作建议”,查看类似以下输出:
在这里插入图片描述
代码
import gradio as gr
import requests
import json
import logging
from abc import ABC, abstractmethod
import tiktoken# 设置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)# 抽象基类:定义通用的 LLM Agent 接口
class LLMAgent(ABC):@abstractmethoddef generate_response(self, prompt):pass# Ollama 特定的实现
class OllamaAgent(LLMAgent):def __init__(self, config):self.model = config["model"]self.base_url = config["base_url"]self.api_key = config["api_key"]self.max_tokens = config["max_tokens"]self.temperature = config["temperature"]self.history = []self.max_history_length = 10def set_max_history_length(self, max_rounds):self.max_history_length = int(max_rounds * 2)if len(self.history) > self.max_history_length:self.history = self.history[-self.max_history_length:]def set_parameters(self, max_tokens, temperature):self.max_tokens = int(max_tokens)self.temperature = float(temperature)def generate_response(self, prompt):self.history.append({"role": "user", "content": prompt})if len(self.history) > self.max_history_length:self.history = self.history[-self.max_history_length:]url = f"{self.base_url}/chat/completions"headers = {"Authorization": f"Bearer {self.api_key}","Content-Type": "application/json"}payload = {"model": self.model,"messages": self.history,"max_tokens": self.max_tokens,"temperature": self.temperature}try:response = requests.post(url, headers=headers, json=payload)response.raise_for_status()result = response.json()content = result['choices'][0]['message']['content']logger.info(f"API 响应: {content}")self.history.append({"role": "assistant", "content": content})return contentexcept requests.exceptions.RequestException as e:logger.error(f"API 请求失败: {str(e)}")return f"错误:无法连接到 Ollama API: {str(e)}"except KeyError as e:logger.error(f"解析响应失败: {str(e)}")return f"错误:解析响应失败: {str(e)}"def clear_history(self):self.history = []def calculate_tokens(text):if not text:return 0cleaned_text = text.strip().replace('\n', '')try:encoding = tiktoken.get_encoding("cl100k_base")tokens = encoding.encode(cleaned_text)return len(tokens)except Exception as e:logger.error(f"Token 计算失败: {str(e)}")return len(cleaned_text)def calculate_history_tokens(history):total_tokens = 0try:encoding = tiktoken.get_encoding("cl100k_base")for message in history:content = message["content"].strip()tokens = encoding.encode(content)total_tokens += len(tokens)return total_tokensexcept Exception as e:logger.error(f"历史 Token 计算失败: {str(e)}")return sum(len(msg["content"].strip()) for msg in history)def format_history_for_chatbot(history):"""将 agent.history 转换为 gr.Chatbot 所需格式:List[List[str, str]]"""messages = []for i in range(0, len(history) - 1, 2):if history[i]["role"] == "user" and history[i+1]["role"] == "assistant":messages.append([history[i]["content"], history[i+1]["content"]])return messagesdef generate_assistance(prompt, agent, max_rounds, max_tokens, temperature):agent.set_max_history_length(max_rounds)agent.set_parameters(max_tokens, temperature)response = agent.generate_response(prompt)history_tokens = calculate_history_tokens(agent.history)chatbot_format_history = format_history_for_chatbot(agent.history)return chatbot_format_history, response, f"历史总 token 数(估算):{history_tokens}"def update_token_count(prompt):return f"当前输入 token 数(精确):{calculate_tokens(prompt)}"def clear_conversation(agent):agent.clear_history()return [], "对话已清空", "历史总 token 数(估算):0"def main():config = {"api_type": "ollama","model": "qwen3:8b","base_url": "http://localhost:11434/v1","api_key": "ollama","max_tokens": 1000,"temperature": 0.2}agent = OllamaAgent(config)with gr.Blocks(title="写作助手") as demo:gr.Markdown("# 写作助手(支持多轮对话)")gr.Markdown("输入您的写作提示,获取建议和指导!支持连续对话,调整对话轮数、max_tokens 和 temperature,或点击“清空对话”重置。")with gr.Row():with gr.Column():prompt_input = gr.Textbox(label="请输入您的提示",placeholder="例如:帮我写一段关于环保的文章",lines=3)token_count = gr.Textbox(label="输入 token 数",value="当前输入 token 数(精确):0",interactive=False)history_token_count = gr.Textbox(label="历史 token 数",value="历史总 token 数(估算):0",interactive=False)max_rounds = gr.Slider(minimum=1,maximum=10,value=5,step=1,label="最大对话轮数",info="设置保留的对话轮数(每轮包含用户和模型消息)")max_tokens = gr.Slider(minimum=100,maximum=2000,value=1000,step=100,label="最大生成 token 数",info="控制单次生成的最大 token 数")temperature = gr.Slider(minimum=0.0,maximum=1.0,value=0.2,step=0.1,label="Temperature",info="控制生成随机性,0.0 为确定性,1.0 为较随机")submit_button = gr.Button("获取写作建议")clear_button = gr.Button("清空对话")with gr.Column():chatbot = gr.Chatbot(label="对话历史")output = gr.Textbox(label="最新生成结果", lines=5)prompt_input.change(fn=update_token_count,inputs=prompt_input,outputs=token_count)submit_button.click(fn=generate_assistance,inputs=[prompt_input, gr.State(value=agent), max_rounds, max_tokens, temperature],outputs=[chatbot, output, history_token_count])clear_button.click(fn=clear_conversation,inputs=gr.State(value=agent),outputs=[chatbot, output, history_token_count])demo.launch()if __name__ == "__main__":main()相关文章:

D2-基于本地Ollama模型的多轮问答系统
本程序是一个基于 Gradio 和 Ollama API 构建的支持多轮对话的写作助手。相较于上一版本,本版本新增了对话历史记录、Token 计数、参数调节和清空对话功能,显著提升了用户体验和交互灵活性。 程序通过抽象基类 LLMAgent 实现模块化设计,当前…...
HALCON 深度学习训练 3D 图像的几种方式优缺点
HALCON 深度学习训练 3D 图像的几种方式优缺点 ** 在计算机视觉和工业检测等领域,3D 图像数据的处理和分析变得越来越重要,HALCON 作为一款强大的机器视觉软件,提供了多种深度学习训练 3D 图像的方式。每种方式都有其独特的设计思路和应用场…...

123网盘SDK-npm包已发布
前言 大家好!今天想和大家分享一个我最近开源的项目:123 网盘 SDK。这个项目已经在 GitHub 开源,最近已经发布到 NPM,可以通过 npm i ked3/pan123-sdk 直接安装使用。 项目背景:为什么要开发这个 SDK? 在…...

强制卸载openssl-libs导致系统异常的修复方法
openssl升级比较麻烦,因为很多软件都会依赖它,一旦强制卸载(尤其是openssl-libs.rpm),就可能导致很多命令不可用,即使想用rpm命令重新安装都不行。 所以,除非万不得已,否则不要轻易去卸载openssl-libs。而且…...

乐播视频v4.0.0纯净版体验:高清流畅的视听盛宴
先放软件下载链接:夸克网盘下载 探索乐播视频v4.0.0纯净版:畅享精彩视听之旅 乐播视频v4.0.0纯净版为广大用户带来了优质的视频观看体验,是一款值得关注的视频类软件。 这款软件的资源丰富度令人惊喜,涵盖了电影、电视剧、综艺、动漫等多种…...

Linux 命令全讲解:从基础操作到高级运维的实战指南
Linux 命令全讲解:从基础操作到高级运维的实战指南 前言 Linux 作为开源操作系统的代表,凭借其稳定性、灵活性和强大的定制能力,广泛应用于服务器、云计算、嵌入式设备等领域。对于开发者、运维工程师甚至普通用户而言,熟练掌握…...
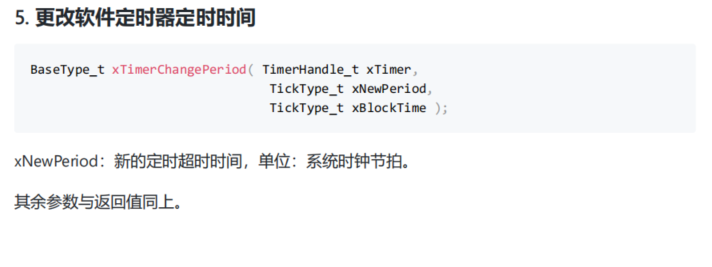
FreeRTOS的简单介绍
一、FreeRTOS介绍 FreeRTOS并不是实时操作系统,因为它是分时复用的 利用CubeMX快速移植 二、快速移植流程 1. 在 SYS 选项里,将 Debug 设为 Serial Wire ,并且将 Timebase Source 设为 TIM2 (其它定时器也行)。为何…...

DeepSeek模型安全部署与对抗防御全攻略
引言 随着DeepSeek模型在企业关键业务中的深入应用,模型安全已成为不可忽视的重要议题。本文将从实际攻防对抗经验出发,系统剖析DeepSeek模型面临的安全威胁,提供覆盖输入过滤、输出净化、权限控制等环节的立体防御方案,并分享红蓝对抗中的最佳实践,助力企业构建安全可靠…...

Docker容器使用手册
Docker是一种轻量级、可移植、自给自足的软件运行环境,用于打包和运行应用程序。它允许开发者将应用及其所有依赖打包成一个镜像(Image),然后基于这个镜像创建出容器(Container)来运行。与虚拟机相比不需要…...
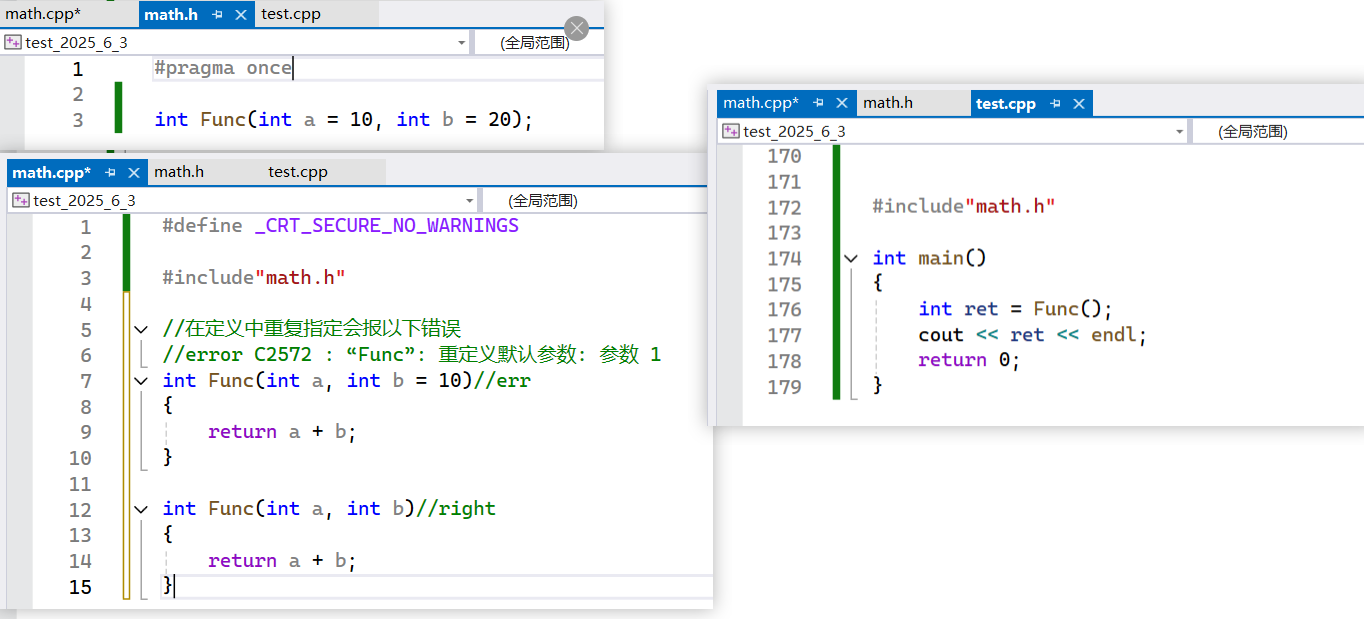
深入解析C++引用:从别名机制到函数特性实践
1.C引用 1.1引用的概念和定义 引用不是新定义⼀个变量,而是给已存在变量取了⼀个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同⼀块内存空间。比如四大名著中林冲,他有一个外号叫豹子头,类比到C里就…...

Fuse.js:打造极致模糊搜索体验
Fuse.js 完全学习指南:JavaScript模糊搜索库 🎯 什么是 Fuse.js? Fuse.js 是一个轻量、强大且无依赖的JavaScript模糊搜索库。它提供了简单而强大的模糊搜索功能,可以在任何 JavaScript 环境中使用,包括浏览器和 Nod…...
与MySQL分页语法的关系)
MyBatis分页插件(以PageHelper为例)与MySQL分页语法的关系
MyBatis分页插件(以PageHelper为例)与MySQL分页语法关系总结 MyBatis的分页插件(如PageHelper)底层实现依赖于数据库的分页语法。对于MySQL数据库来说,其分页逻辑最终会转化为LIMIT语句,下面展开详细说明&…...

CentOS 7.9 安装 宝塔面板
在 CentOS 7.9 上安装 宝塔面板(BT Panel) 的完整步骤如下: 1. 准备工作 系统要求: CentOS 7.x(推荐 7.9)内存 ≥ 1GB(建议 2GB)硬盘 ≥ 20GBroot 权限(需使用 root 用户…...

使用Redis作为缓存优化ElasticSearch读写性能
在现代数据密集型应用中,ElasticSearch凭借其强大的全文搜索能力成为许多系统的首选搜索引擎。然而,随着数据量和查询量的增长,ElasticSearch的读写性能可能会成为瓶颈。本文将详细介绍如何使用Redis作为缓存层来显著提升ElasticSearch的读写…...
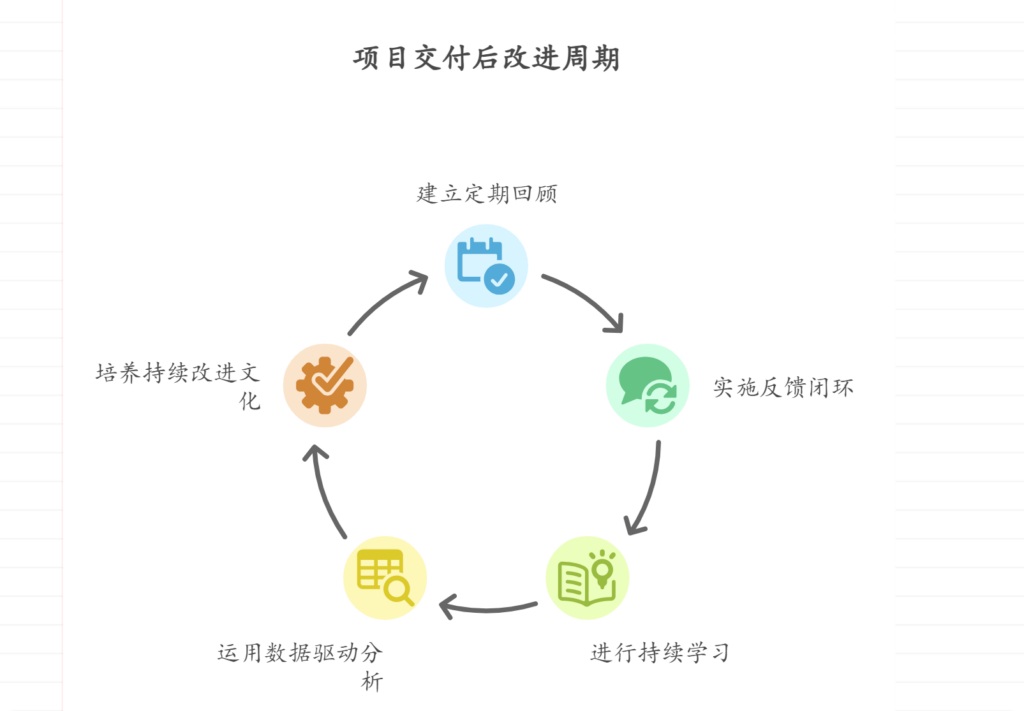
项目交付后缺乏回顾和改进,如何持续优化
项目交付后缺乏回顾和改进可通过建立定期回顾机制、实施反馈闭环流程、开展持续学习和培训、运用数据驱动分析、培养持续改进文化来持续优化。 其中,实施反馈闭环流程尤其重要,它能够确保反馈信息得到有效传递、处理与追踪,形成良好的改进生态…...
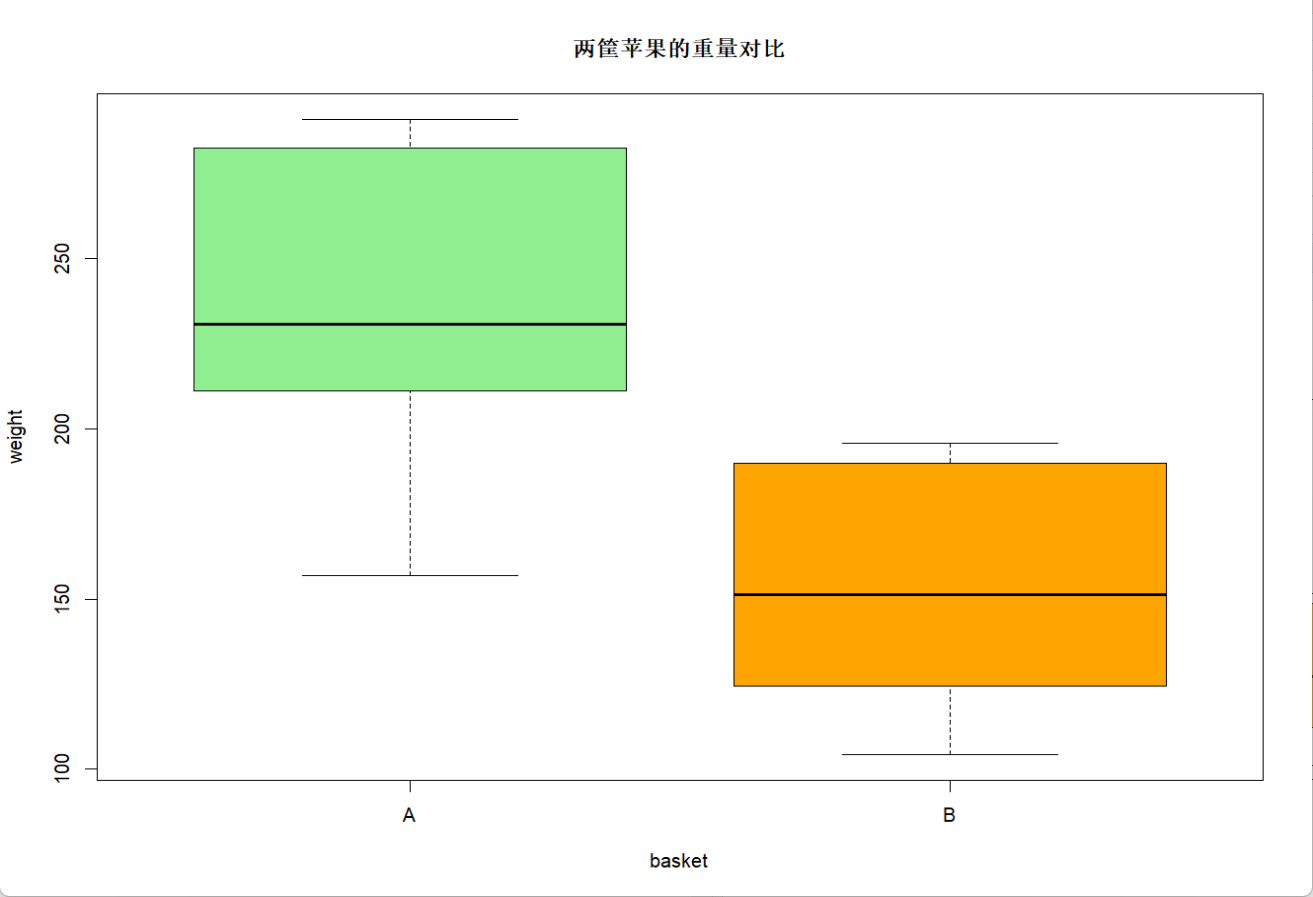
从0开始学习R语言--Day15--非参数检验
非参数检验 如果在进行T检验去比较两组数据差异时,假如数据里存在异常值,会把数据之间的差异拉的很大,影响正常的判断。那么这个时候,我们可以尝试用非参数检验的方式来比较数据。 假设我们有A,B两筐苹果,…...

Linux或者Windows下PHP版本查看方法总结
确定当前服务器或本地环境中 PHP 的版本,可以通过以下几种方法进行操作: 1. 通过命令行检查 这是最直接且常用的方法,适用于本地开发环境或有 SSH 访问权限的服务器。 方法一:php -v 命令 php -v输出示例:PHP 8.1.12 (cli) (built: Oct 12 2023 12:34:56) (NTS) Copyri…...

EC2 实例详解:AWS 的云服务器怎么玩?☁️
弹性计算、灵活计费、全球可用,AWS EC2 全攻略 在 AWS 生态中,有两个核心服务是非常关键的,一个是 S3(对象存储),另一个就是我们今天的主角 —— Amazon EC2(Elastic Compute Cloud)…...
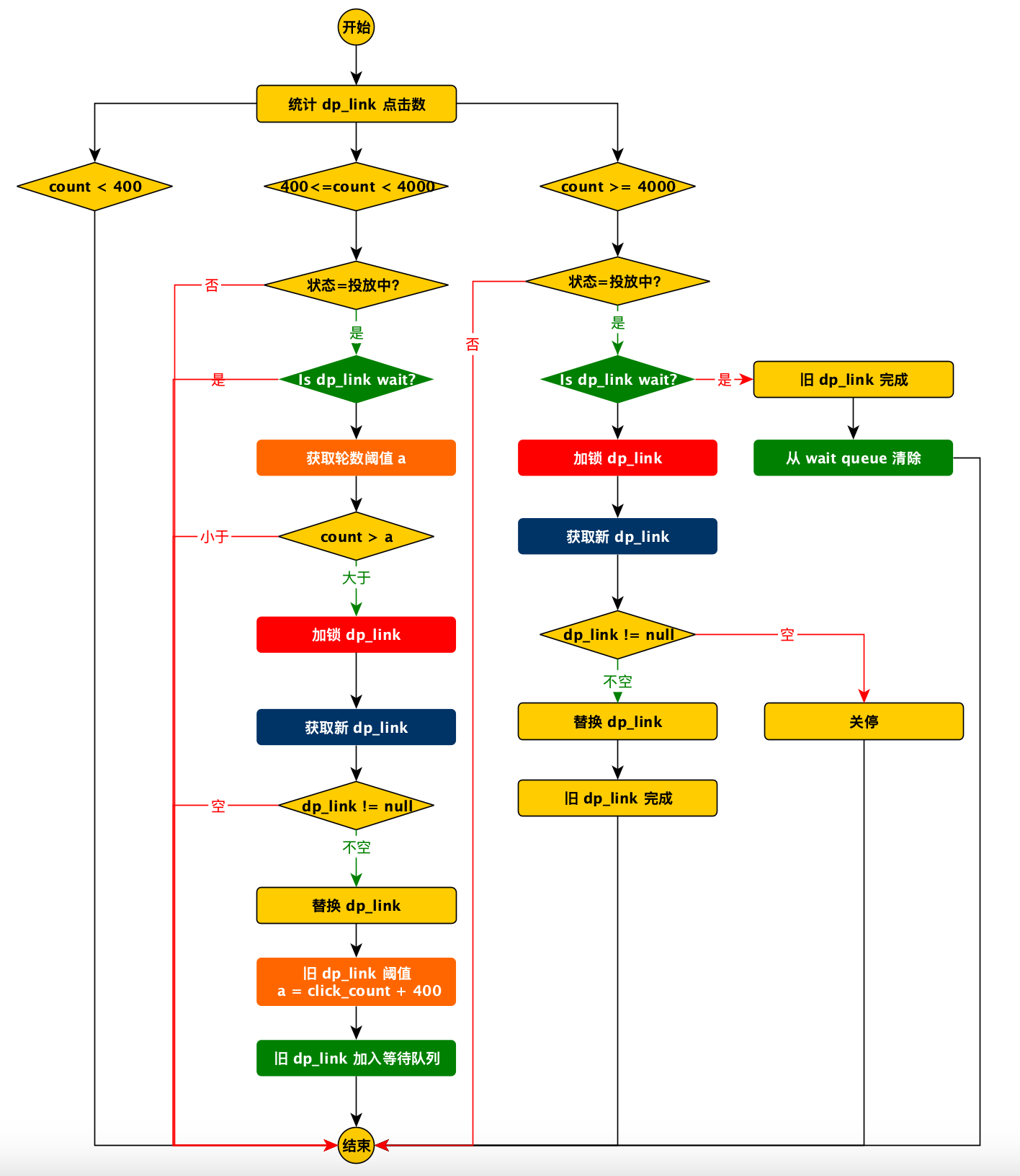
第三发 DSP 点击控制系统
背景 在第三方 DSP 上投放广告,需要根据 DP Link 的点击次数进行控制。比如当 DP Link 达到 5000 后,后续的点击将不能带来收益,但是后续的广告却要付出成本。因此需要建立一个 DP Link 池,当 DP Link 到达限制后,…...

saveOrUpdate 有个缺点,不会把值赋值为null,解决办法
针对 MyBatis-Plus 的 saveOrUpdate 方法无法将字段更新为 null 的问题,这是因为 MyBatis-Plus 默认会忽略 null 值字段。以下是几种解决方案: 方案 1:使用 update(entity, wrapper) 手动指定更新条件 原理:通过 UpdateWrapper …...

Java面试:企业协同SaaS中的技术挑战与解决方案
Java面试:企业协同SaaS中的技术挑战与解决方案 面试场景 在一家知名互联网大厂,面试官老王正在对一位应聘企业协同SaaS开发职位的程序员谢飞机进行技术面试。 第一轮提问:基础技术 老王:谢飞机,你好。首先…...

【笔记】在 MSYS2 MINGW64 环境中降级 NumPy 2.2.6 到 2.2.4
📝 在 MSYS2 MINGW64 环境中降级 NumPy 到 2.2.4 ✅ 目标说明 在 MSYS2 的 MINGW64 工具链环境中,将 NumPy 从 2.2.6 成功降级到 2.2.4。 🧰 环境信息 项目内容操作系统Windows 11MSYS2 终端类型MINGW64(默认终端)Py…...

前端限流如何实现,如何防止服务器过载
前端限流是一种控制请求频率的技术,旨在防止过多的请求在同一时间段内发送到服务器,避免造成服务器过载或触发反爬虫机制。实现前端限流的方法有很多,下面介绍几种常见的策略和技术: 1. 时间窗口算法 时间窗口算法是最简单的限流…...

基于大模型的慢性硬脑膜下血肿预测与诊疗系统技术方案
目录 一、术前阶段二、并发症风险预测三、手术方案制定四、麻醉方案生成五、术后护理与康复六、系统集成方案七、实验验证与统计分析八、健康教育与随访一、术前阶段 1. 数据预处理与特征提取 伪代码: # 输入:患者多模态影像数据(CT/MRI)、病史、生理指标 def preproce…...

vue入门环境搭建及demo运行
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 vue简介:第一步:安装node.jsnode简介第二步:安装vue.js第三步:安装vue-cli工具第四步 :安装webpack第五步…...

git checkout C1解释
git checkout C1 的意思是: 让 Git 切换到某个提交(commit)ID 为 C1 的状态。 🔍 更具体地说: C1 通常是一个 commit 的哈希值(可以是前几位,比如 6a3f9d2) git checkout C1 会让你…...
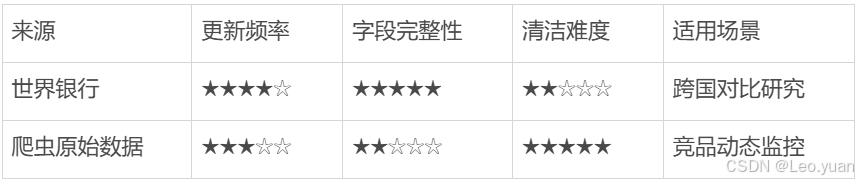
原始数据去哪找?分享15个免费官方网站
目录 一、找数据的免费官方网站 (一)国家级数据宝库:权威且全面 1.中国国家统计局 2.香港政府数据中心 3.OECD数据库 (二)企业情报中心:洞察商业本质 4.巨潮资讯 5.EDGAR数据库 6.天眼查/企查查&a…...
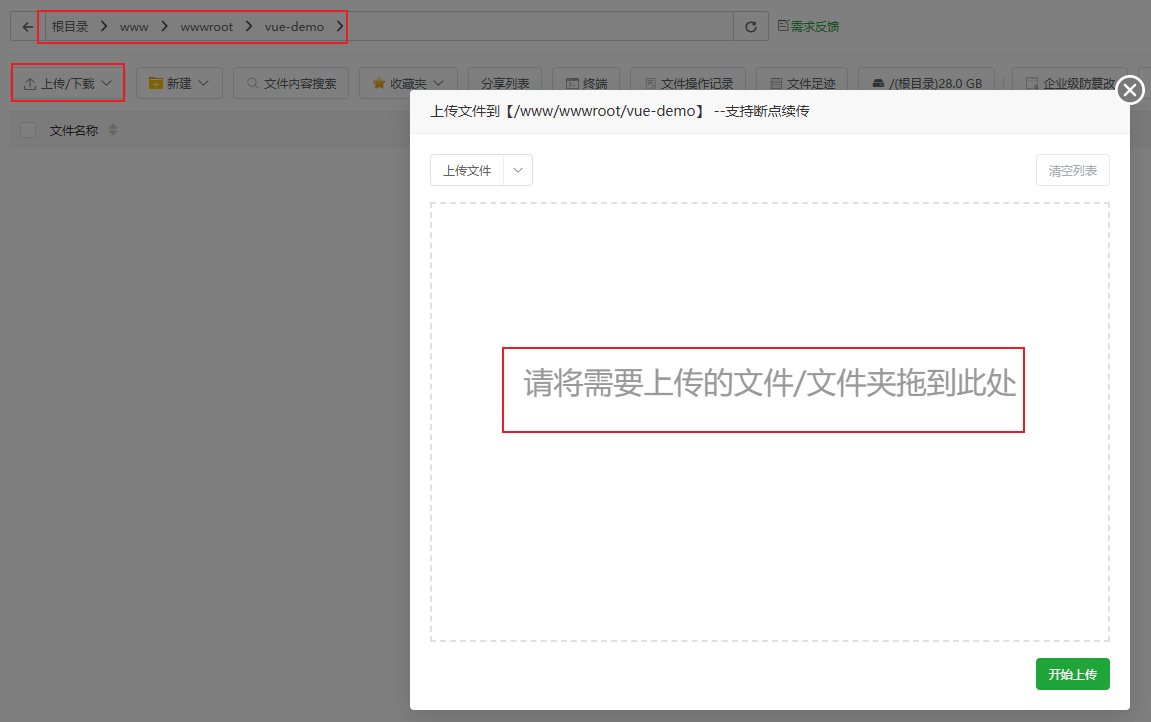
宝塔部署 Vue + NestJS 全栈项目
宝塔部署 Vue NestJS 全栈项目 前言一、Node.js版本管理器1、安装2、配置 二、NestJS项目管理(等同Node项目)1、Git安装2、拉取项目代码3、无法自动认证4、添加Node项目5、配置防火墙(两道) 三、Vue项目管理1、项目上传2、Nginx安…...
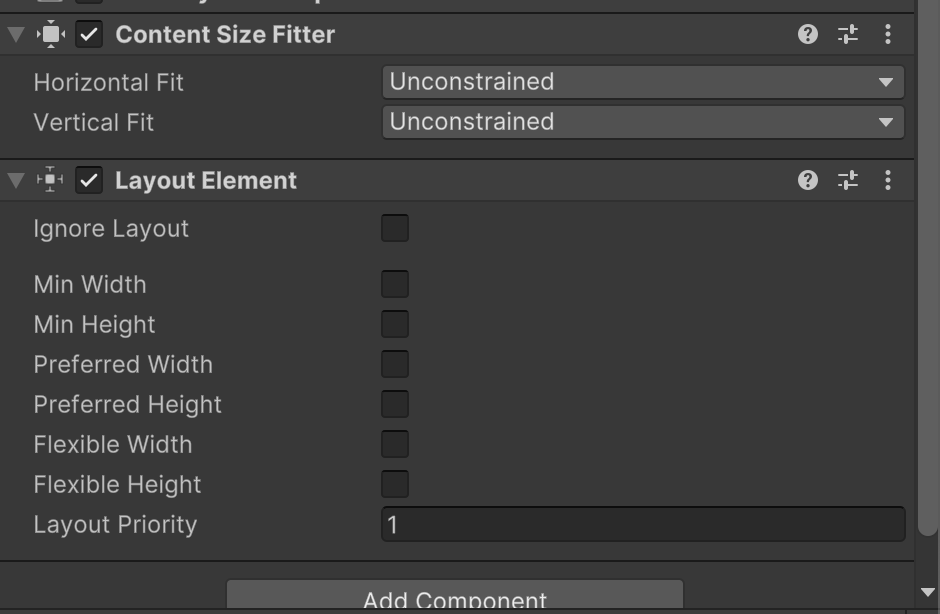
# [特殊字符] Unity UI 性能优化终极指南 — LayoutGroup篇
🎯 Unity UI 性能优化终极指南 — LayoutGroup篇 🧩 什么是 LayoutGroup? LayoutGroup 是一类用于 自动排列子节点 的UI组件。 代表组件: HorizontalLayoutGroupVerticalLayoutGroupGridLayoutGroup 可以搭配: Conte…...

Apache Iceberg 如何实现分布式 ACID 事务:深度解析大数据时代的可靠数据管理
引言:大数据时代的事务挑战 在大数据时代,传统数据库的 ACID 事务模型面临前所未有的挑战: 海量数据:PB 级数据难以使用传统事务机制管理多并发写入:数十甚至上百个作业同时写入同一数据集复杂分析:长时间运行的查询需要一致性视图混合负载:批处理和流处理同时访问相同…...