Kafka 的优势是什么?
Kafka 作为分布式流处理平台的核心组件,其设计哲学围绕高吞吐、低延迟、高可扩展性展开,在实时数据管道和大数据生态中具有不可替代的地位。
一、超高吞吐量与低延迟
1. 磁盘顺序 I/O 优化
- 突破磁盘瓶颈:Kafka 将消息持久化到磁盘(而非内存),但通过顺序写入大幅提升效率(比随机写快 6000 倍)。
- 页缓存技术:利用操作系统 Page Cache 减少磁盘访问,读写操作直接与内存交互。
2. 零拷贝(Zero-Copy)技术
- 减少数据复制:通过
sendfile()系统调用,数据直接从磁盘文件 → 网卡缓冲区,跳过应用层与内核层的多次拷贝。 - 效果:降低 CPU 开销,提升网络传输效率。
3. 批量处理(Batching)
- 生产者/消费者均支持批量发送与拉取消息,减少网络 I/O 次数。
- 典型吞吐:单集群可达 每秒百万级消息(依赖硬件配置)。
✅ 适用场景:日志收集、实时监控、金融交易流水等海量数据场景。
二、分布式架构与水平扩展
1. 分片(Partition)机制
- Topic 被划分为多个 Partition,分散在不同 Broker 上。
- 优势:
- 并行读写:生产者/消费者可同时操作多个 Partition。
- 负载均衡:Partition 可动态迁移。
2. 无缝扩容
- 新增 Broker 后,通过
kafka-reassign-partitions.sh工具自动平衡 Partition 分布。 - 无需停机:扩容过程不影响服务可用性。
3. 副本(Replication)机制
- 每个 Partition 有多个副本(Leader + Followers),保障数据高可用。
- ISR(In-Sync Replicas):仅同步的副本参与故障切换,避免脏数据。
三、持久化存储与数据可靠性
1. 消息持久化
- 数据默认保留 7 天(可配置为永久保留),支持按时间/大小滚动清理。
- 消费解耦:消费者可随时重放历史数据(区别于传统 MQ 的“阅后即焚”)。
2. 端到端数据保证
- 生产者:
acks=all:确保消息写入所有 ISR 副本后才返回成功。- 幂等生产者(Idempotent Producer):避免网络重试导致重复消息。
- 消费者:
- 位移(Offset)提交到 Kafka 内部 Topic(
__consumer_offsets),避免丢失。
- 位移(Offset)提交到 Kafka 内部 Topic(
四、流处理生态整合
1. Kafka Streams 原生流处理
- 轻量级库,无需额外集群,直接在应用中构建实时流处理管道。
- 支持 Exactly-Once 语义(通过事务 + 幂等写入)。
2. Connector 生态
- 官方提供上百种 Kafka Connect 插件:
- 输入:MySQL、MongoDB、Elasticsearch、S3 等。
- 输出:HDFS、Snowflake、Redis 等。
- 开箱即用的数据集成方案。
3. 与大数据栈无缝协作
- 流批一体:作为 Flink、Spark Streaming 的数据源/汇。
- 替代传统 ETL:实时数据管道取代 T+1 批处理。
五、高可用性与容错
1. Controller 选举机制
- 依赖 ZooKeeper(或 KRaft 模式)选举 Controller Broker,管理 Partition 状态。
- Controller 故障时自动切换(秒级恢复)。
2. 无单点故障
- 所有组件(Broker、Producer、Consumer)均分布式部署。
- 客户端自动发现集群拓扑变化(Metadata 更新)。
六、灵活的消息模型
1. 发布/订阅(Pub-Sub)与队列(Queue)融合
- 消费者组(Consumer Group) 机制:
- 同组内消费者竞争消费(Queue 模式)。
- 不同组独立消费全量数据(Pub-Sub 模式)。
2. 消息回溯与重放
- 通过调整 Offset 重新消费历史数据(如:修复程序 BUG 后重新计算)。
3. 多租户支持
- ACL + Quota 机制控制 Topic 访问权限与资源配额。
七、与传统消息队列的对比优势
| 特性 | Kafka | RabbitMQ / ActiveMQ |
|---|---|---|
| 吞吐量 | 100k+/s(单 Broker) | 10k~50k/s |
| 数据保留 | 持久化存储(TB 级) | 内存/临时存储(通常 GB 级) |
| 消费模型 | 支持多订阅组 + 回溯 | 阅后即焚(需手动持久化) |
| 扩展性 | 水平扩展(增 Broker 即可) | 垂直扩展或复杂集群配置 |
| 生态整合 | 流处理 + 大数据生态原生支持 | 需额外组件(如 Flink 适配) |
八、典型应用场景
- 实时数据管道
- 用户行为日志采集 → Kafka → Flink 实时分析 → 大屏展示。
- 事件驱动架构(EDA)
- 微服务间通过 Kafka Topic 解耦(如:订单创建 → 库存扣减 → 支付通知)。
- 流式 ETL
- 替代传统 Sqoop,实时同步数据库变更到数仓。
- Commit Log 存储
- 作为分布式系统的持久化日志(如:CDC 场景)。
九、注意事项
- 运维复杂度:需监控 ISR 状态、Leader 均衡、磁盘容量。
- 非强有序场景:Partition 内有序,跨 Partition 无序(需业务层处理)。
- 资源消耗:高吞吐需匹配高性能磁盘与网络。
🐮🐎
Kafka 的核心优势在于:
✅ 海量数据下的超高吞吐与低延迟(磁盘顺序 I/O + 零拷贝)
✅ 水平扩展能力(Partition 分片 + 无缝扩容)
✅ 流式生态整合(Kafka Streams + Connect + Flink/Spark)
✅ 企业级可靠性(副本机制 + Exactly-Once 语义)
选择 Kafka 而非传统 MQ 的关键判断点:
⚠️ 是否需处理 TB 级/百万 TPS 数据流?
⚠️ 是否需长期存储消息并支持回溯?
⚠️ 是否与实时计算引擎(如 Flink)深度集成?
若答案为“是”,Kafka 通常是无可争议的最佳选择。
你想要的我全都有:https://pan.q删掉憨子uark.cn/s/75a5a07b45a2

相关文章:
Kafka 的优势是什么?
Kafka 作为分布式流处理平台的核心组件,其设计哲学围绕高吞吐、低延迟、高可扩展性展开,在实时数据管道和大数据生态中具有不可替代的地位。 一、超高吞吐量与低延迟 1. 磁盘顺序 I/O 优化 突破磁盘瓶颈:Kafka 将消息持久化到磁盘ÿ…...

基于FPGA + JESD204B协议+高速ADC数据采集系统设计
摘 要: 针对激光扫描共聚焦显微镜的大视场、高分辨率需求,为在振镜扫描的时间内获取更多数据量,设计一种基 于 FPGA 的高速数据采集系统。该系统采用 Xilinx 的 A7 系列 FPGA 作为主控芯片,同时选用 TI 公司提供的 LM…...

微服务中引入公共拦截器
本文使用的微服务版本为springcloudAlbaba :2021.0.4.0 微服务工程,一般公共的东西都放入一个工程,别的微服务都会引入这个工程,比如common-service,那么就可以在这个工程编写一个拦截器:,比如: public cla…...
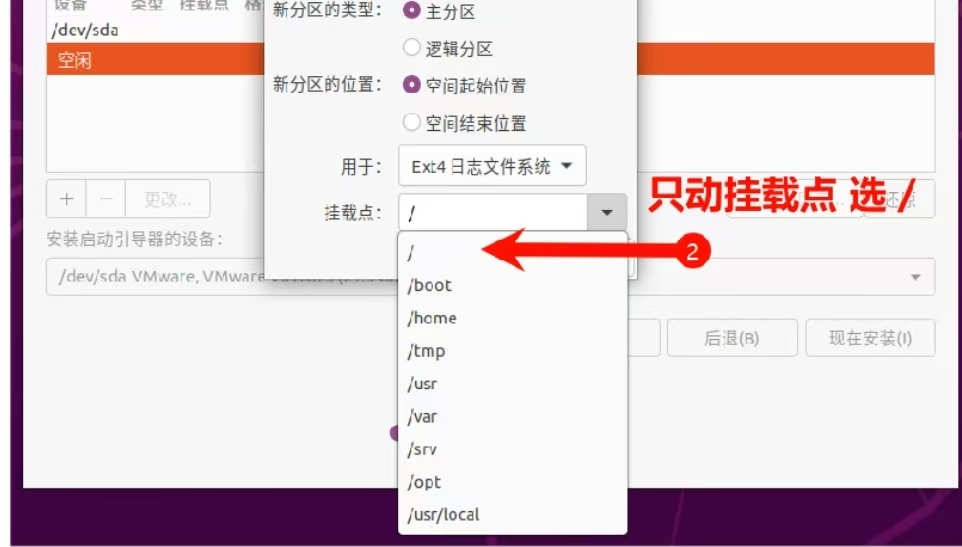
Ubuntu20.04 LTS 升级Ubuntu22.04LTS 依赖错误 系统崩溃重装 Ubuntu22.04 LTS
服务器系统为PowerEdge R740 BIOS Version 2.10.2 DELL EMC 1、关机 开机时连续按键盘F2 2、System Setup选择第一个 System BIOS 3、System BIOS Setting 选择 Boot Setting 4、System BIOS Setting-Boot Setting 选择 BIOS Boot Settings 5、重启 开启时连续按键盘F11 …...

C++11:unique_ptr的基本用法、使用场景和最佳使用指南
文章目录 1. 简介2. 基本语法和用法2.1. 创建unique_ptr2.2. 访问指向的对象2.3. 所有权管理 3. 自定义删除器4. 数组支持5. 常见使用场景5.1. RAII资源管理5.2. 工厂模式5.3. 容器中存储多态对象5.4. Pimpl(指针到实现)习惯用法 6. 与其他智能指针的比较…...

测量3D翼片的距离与角度
1,目的。 测量3D翼片的距离与角度。说明: 标注A 红色框选的区域即为翼片,本示例的3D 对象共有3个翼片待测。L1与L2的距离、L1与L2的角度即为所求的翼片距离与角度。 2,原理。 使用线结构光模型(标定模式࿰…...

零基础学习计算机网络编程----socket实现UDP协议
本章将会详细的介绍如何使用 socket 实现 UDP 协议的传送数据。有了前面基础知识的铺垫。对于本章的理解将会变得简单。将会从基础的 Serve 的初始化,进阶到 Client 的初始化,以及 run。最后实现一个简陋的小型的网络聊天室。 目录 1.UdpSever.h 1.1 构造…...
谷歌地图2022高清卫星地图手机版v10.38.2 安卓版 - 前端工具导航
谷歌地图2022高清卫星地图手机版是由谷歌公司推出的一款非常好用的手机地图服务软件,用户能够通过精准的导航和定位来查看地图,周边的商店等生活服务都会在地图上显示,用起来超级方便。 谷歌卫星高清地图 下载链接:夸克网盘分享 …...
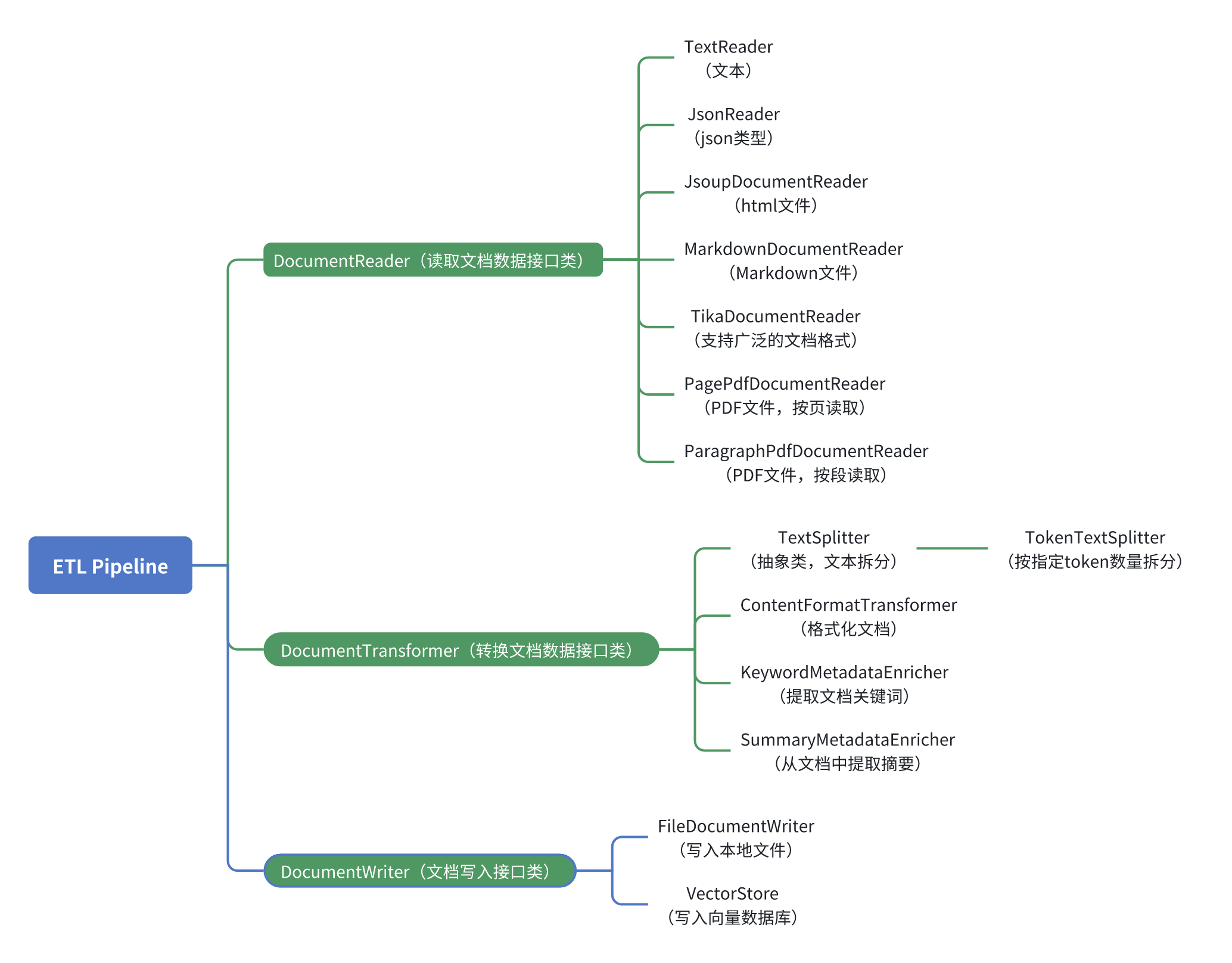
RAG的ETL Pipeline源码解读
原文链接:SpringAI(GA):RAG下的ETL源码解读 教程说明 说明:本教程将采用2025年5月20日正式的GA版,给出如下内容 核心功能模块的快速上手教程核心功能模块的源码级解读Spring ai alibaba增强的快速上手教程 源码级解读 版本&a…...

杭州白塔岭画室怎么样?和燕壹画室哪个好?
杭州作为全国美术艺考集训的核心区域,汇聚了众多实力强劲的画室,其中白塔岭画室和燕壹画室备受美术生关注。对于怀揣艺术梦想的考生而言,选择一所契合自身需求的画室,对未来的艺术之路影响深远。接下来,我们将从多个维…...

Linux文件系统:从VFS到Ext4的奇幻之旅
Linux文件系统:从VFS到Ext4的奇幻之旅 从虚拟文件到物理磁盘的魔法桥梁 引言:数据宇宙的"时空管理者" 当你在Linux终端输入ls -l时,一场跨越多个抽象层的精密协作悄然展开。文件系统作为操作系统中最复杂且最精妙的子系统之一&…...

5月底 端午节
感觉五月写的很少啊,尤其是这一周,真的事情特别多可能。但是实际上我晚上回宿舍之后大概九点十点这块,最后睡觉一般在十一点半到十二点。这一段时间我基本上都是浪费了。要么在打游戏要么在刷视频。但是最基本的生活保障和学习都没有做好。。…...

为何选择Spring框架学习设计模式与编码技巧?
📌 结论先行 推荐项目:Spring Framework 推荐理由:设计模式覆盖全面 编码技巧教科书级实现 Java 生态基石地位 🏆 三维度对比分析 维度SpringMyBatisXXL-JOB设计模式⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐代码抽象⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐生态价…...

软件评测师 综合测试 真题笔记
计算机组成原理 用作科学计算为主的计算机,其对主机的运算速度要求很高,应该重点考虑 CPU的主频和字长,以及内存容量; 用作大型数据库处理为主的计算机,其对主机的内存容量、存取速度和外存储器的读写速度要求较高; 对…...
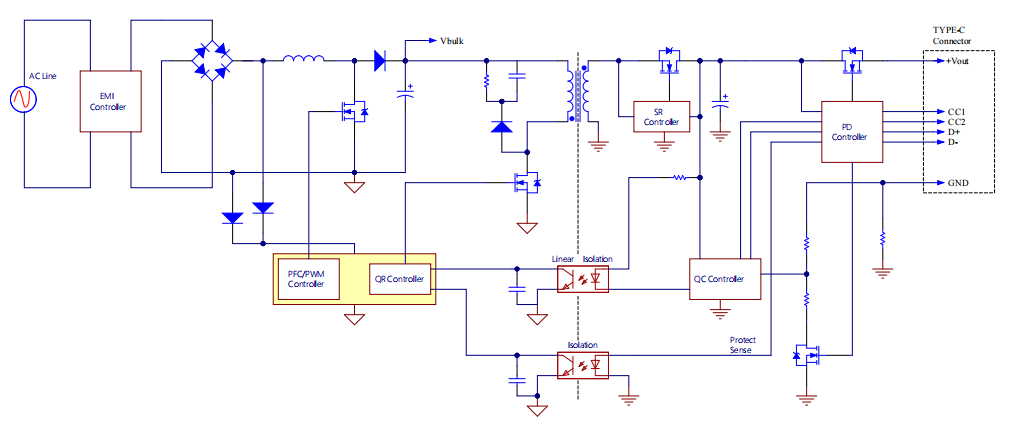
晶台光耦在手机PD快充上的应用
光耦(光电隔离器)作为关键电子元件,在手机PD快充中扮演信号隔离与传输的“安全卫士”。其通过光信号实现电气隔离,保护手机电路免受高电压损害,同时支持实时信号反馈,优化充电效率。 晶台品牌推出KL817、KL…...

JS对数据类型的检测
typeof对基本数据类型有用,但是对引用数据类型不行 console.log(typeof 2)//number console.log(typeof [])//object 失效 instanceof只对引用数据类型有用 console.log([] instanceof Array) //true console.log(2 instanceof String) //false constructor基本…...

llama.cpp:纯 C/C++ 实现的大语言模型推理引擎详解一
🚀 llama.cpp:纯 C/C 实现的大语言模型推理引擎详解 一、什么是 llama.cpp? llama.cpp 是一个由 Georgi Gerganov 开源的项目,旨在使用纯 C/C 在 CPU 上运行 Meta 的 LLaMA 系列大语言模型。 它通过量化、优化注意力机制和内存…...
【亲测有效 | Cursor Pro每月500次快速请求扩5倍】(Windows版)Cursor中集成interactive-feedback-mcp
前言:使用这个interactive-feedback-mcp组件可以根据用户反馈来决定是否结束这一次的请求。如果本次请求并没有解决我们的问题,那我们便可以选择继续这次请求流程,直到问题解决。这样的话,就可以避免为了修复bug而白白多出的请求。…...

BaseTypeHandler用法-笔记
1.BaseTypeHandler简介 org.apache.ibatis.type.BaseTypeHandler 是 MyBatis 提供的一个抽象类,通过继承该类并实现关键方法,可用于实现 Java 类型 与 JDBC 类型 之间的双向转换。当数据库字段类型与 Java 对象属性类型不一致时(如ÿ…...

鸿蒙OSUniApp集成WebGL:打造跨平台3D视觉盛宴#三方框架 #Uniapp
UniApp集成WebGL:打造跨平台3D视觉盛宴 在移动应用开发日新月异的今天,3D视觉效果已经成为提升用户体验的重要手段。本文将深入探讨如何在UniApp中集成WebGL技术,实现炫酷的3D特效,并特别关注鸿蒙系统(HarmonyOS)的适配与优化。 …...

华为盘古 Ultra MoE 模型:国产 AI 的技术突破与行业影响
2025 年 5 月 30日,华为正式发布参数规模达 7180 亿的盘古 Ultra MoE 模型,全程基于昇腾 AI 计算平台完成训练。这一进展标志着中国在超大规模人工智能模型领域的自主研发能力达到新高度,同时也为全球 AI 技术发展提供了新的技术路径。 盘古 …...

Payload CMS:开发者优先的Next.js原生开源解决方案,重新定义无头内容管理
在无头内容管理系统(CMS)竞争激烈的今天,Payload CMS凭借其独特的开发理念和技术架构迅速崛起,成为Microsoft、ASICS、Blue Origin等创新企业的选择。这款基于Node.js与TypeScript构建的开源解决方案,正在彻底改变开发…...

CRM管理软件的数据可视化功能使用技巧:让数据驱动决策
在当今数据驱动的商业环境中,CRM管理系统的数据可视化功能已成为企业优化客户管理、提升销售效率的核心工具。据企销客研究显示,具备优秀可视化能力的CRM系统,用户决策效率可提升47%。本文将深入解析如何通过数据可视化功能最大化CRM管理软件…...

linux批量创建文件
文章目录 批量创建空文件touch命令批量创建空文件循环结构创建 创建含内容文件echo重定向多行内容写入 按日期创建日志文件根据文件中的列内容,创建文件一行只有一列内容一行有多列内容 批量创建空文件 touch命令批量创建空文件 # 创建文件file1.txt到file10.txt …...
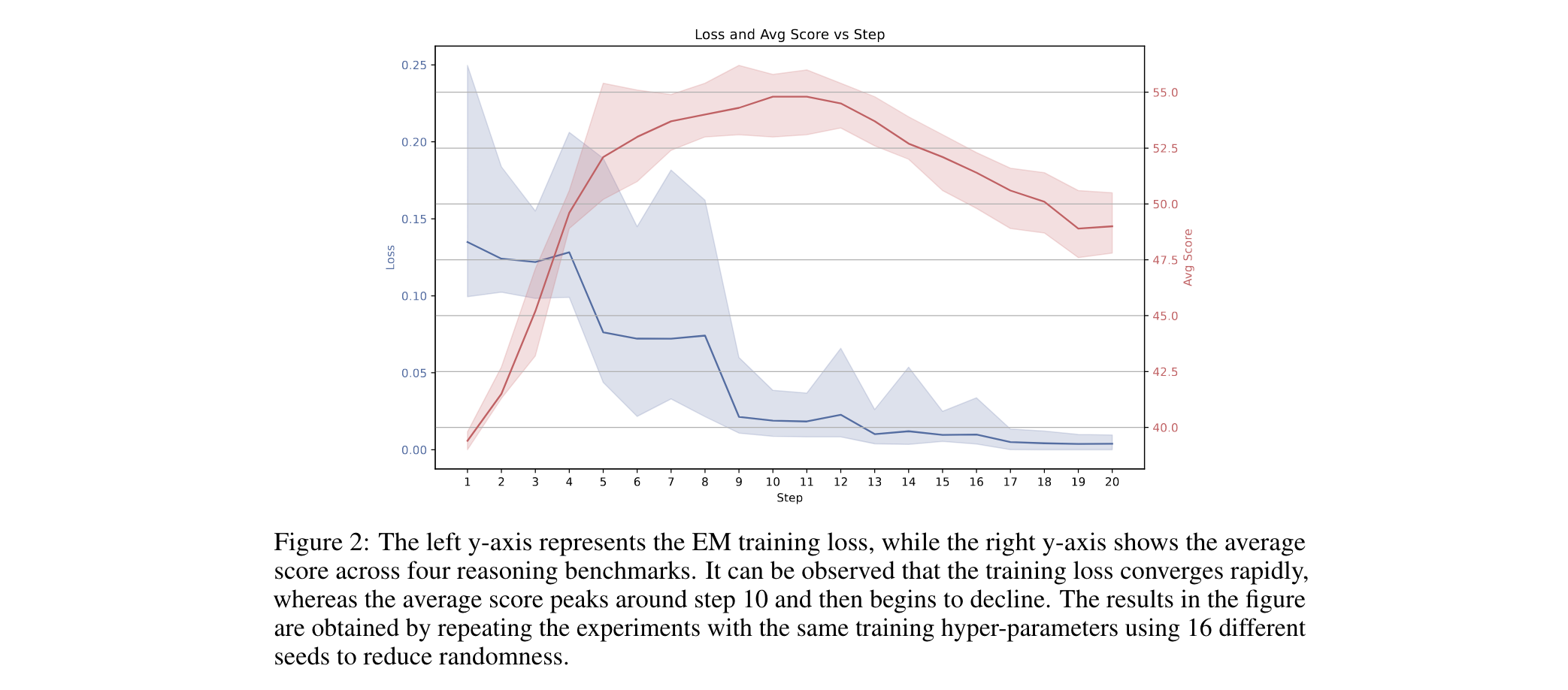
颠覆传统!单样本熵最小化如何重塑大语言模型训练范式?
颠覆传统!单样本熵最小化如何重塑大语言模型训练范式? 大语言模型(LLM)的训练往往依赖大量标注数据与复杂奖励设计,但最新研究发现,仅用1条无标注数据和10步优化的熵最小化(EM)方法…...

华为数据之道 精读——【173页】读书笔记【附全文阅读】
在数字化浪潮中,企业数据管理的优劣直接关乎竞争力。华为凭借丰富实践经验总结的《华为数据之道》,为企业提供了全面且深入的数据治理方案。 笔记聚焦数字化转型与数据治理的紧密联系。华为作为非数字原生企业,在转型过程中克服了产业链条长、数据复杂等诸多难题,其…...

数据库OCP专业认证培训
认证简介 OCP 即 Oracle 数据库认证专家(Oracle Certified Professional),是 Oracle 公司的 Oracle 数据库 DBA(Database Administrator 数据库管理员)认证课程。通过该认证,表明持证人能够管理大型数据库…...
ssm学习笔记day04
RequestMapping 首先添加依赖 Maven的配置 测试 在controller创建HelloController,如果只加RequestMapping,默认跳转到新页面 如果要是加上ResponseBody就把数据封装在包(JSON),标签RestController是前后分离的注解(因为默认用…...
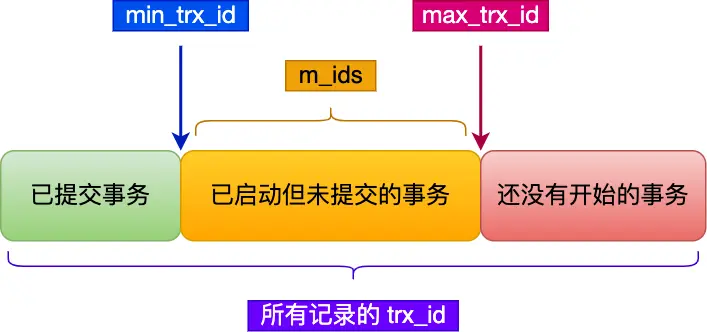
Read View在MVCC里如何工作
Read View的结构 Read View中有四个重要的字段: m_ids:创建 Read View 时,数据库中启动但未提交的「活跃事务」的事务 id 列表 。min_trx_id:创建 Read View 时,「活跃事务」中事务 id 最小的值,即 m_ids …...

HDFS 写入和读取流程
HDFS 写入流程细化 1. 主线流程速记口诀 “先找主脑定文件,分配块副找节点;流水传块多副本,写完通知主脑存。” 2. 详细流程拆解 1. 客户端请求上传(Create 文件) 关键方法: org.apache.hadoop.fs.File…...