neo4j 5.19.0两种基于向量进行相似度查询的方式
介绍
主要讲的是两种相似度查询
- 一种是创建向量索引,然后直接从索引的所有数据中进行相似度搜索,这种不支持基于自己查询的结果中进行相似度匹配
- 另一种是自己调用向量方法生产相似度进行相似度搜索,这种可以基于自己的查询结果中进行相似度搜索
相关地址
向量索引的创建、查询、删除等
在线向量字段生成(也有包含离线生成的相关模型的链接)
相似度算法 Function
测试数据集
基于向量索引进行相似度查询
创建向量字段
创建字段代码
此处主要讲离线的创建方式,在线的需要大模型的key ,需要联网,我没试过,但是开头有提供官网链接,需要的可以自己看。
本质都是查出需要建向量字段的所有数据,然后看需要用哪些字段生成向量字段,将这些字段拼接起来后调用模型生成向量后给对应的节点插入一个 embedding 字段
下面是用 bert 的模型生成的 768 维的 embedding
from neo4j import GraphDatabase
from transformers import BertTokenizer, BertModel
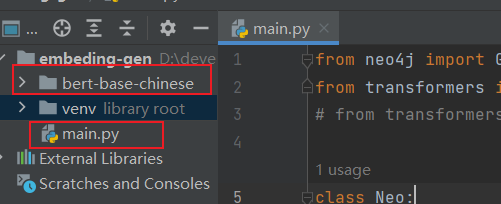
# from transformers import AutoTokenizer, AutoModelForMaskedLMclass Neo:def __init__(self, uri, user, password):self.driver = GraphDatabase.driver(uri, auth=(user, password))def close(self):self.driver.close()def listMovies(self):result = self.driver.execute_query('match (n:Movie) return elementId(n) as id,n.description as description,n.name as name')return result.recordsdef writeMovieEmbedding(self,id,embedding):#插入embedding 字段result = self.driver.execute_query('match (n:Movie) where elementId(n) = $id set n.embedding=$embedding',id=id,embedding=embedding)return result.recordsclass Embedding:def __init__(self):self.tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')self.model = BertModel.from_pretrained('bert-base-chinese')# self.tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese')# self.model = AutoModelForMaskedLM.from_pretrained('bert-base-chinese')def gen(self,text):#根据文本生成embeddinginputs = self.tokenizer(text, return_tensors='pt')outputs = self.model(**inputs)pooler_output = outputs.pooler_output# pooler_output = outputs.logitsreturn pooler_output.detach().numpy()if __name__ == "__main__":em = Embedding()neo = Neo("bolt://192.168.91.128:7687", "neo4j", "12345678")movies = neo.listMovies()for record in movies:data = record.data()# 需要进行相似度查询的文本,可以从neo4j查出的结果字段拼接,也可以拼接其他自己想拼接的东西embeddingText = data.get('name')+","+data.get('description')embedding = em.gen(embeddingText)neo.writeMovieEmbedding(data.get("id"),embedding.tolist()[0])neo.close()模型我是放在和代码同目录的地方,如下图所示
效果如下图所示,多了个 embedding 字段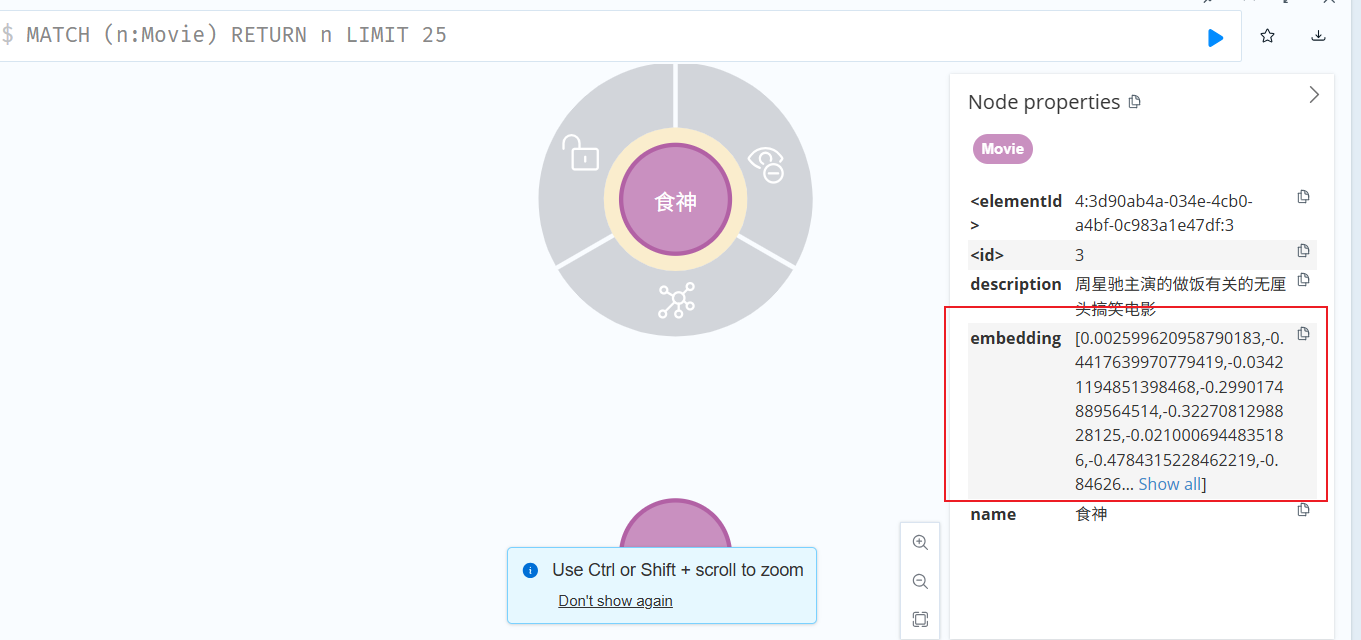
相关依赖
下面是我使用的依赖和版本
python:3.8
torch:2.4.0
neo4j:5.28.1
transformers:4.46.3
向量模型下载
下面是我使用模型的下载地址,可以从网址中找到其他模型。你们也可以选择其他模型
官网,需要翻墙的地址
镜像地址,不需要翻墙,但不知道啥时候失效
创建向量索引
执行如下语句创建索引
CREATE VECTOR INDEX $indexName IF NOT EXISTS
FOR (m:Movie)
ON m.embedding
OPTIONS { indexConfig: {`vector.dimensions`: 768,`vector.similarity_function`: 'cosine'
}}$indexName 是自己指定的索引名称,不要创建重复的名称。
FOR 后面的 (m:Movie) 用于配置查询条件指定给哪些数据创建索引
ON 后面的 m.embedding 用于指定用哪个字段创建索引,我创建的向量字段是 embedding
vector.dimensions 配置向量的维度,主要我们生成向量的模型用的什维度,此处就是什么维度,我上面用的模型生成的维度是768,所以没得就是768
vector.similarity_function:配置相似度的计算算法,consine 余弦相似度,euclidean 欧氏距离
向量相似度查询
这种查询方式我目前知道的只能基于索引内的全量数据进行相似度查询,而无法基于自己MATCH 之后的数据集进行相似度查询
基本语法
CALL db.index.vector.queryNodes($indexName, $topK, $embedding)
YIELD node AS movie, score$indexName 要查询的索引名称
$topK 设置要返回最相似的前面多少条
$embedding 查询和这个向量字段相似的数据,double 数组
score 相似度分数,值越大表示越相似
直接从索引查询
这种查询会查询索引下所有数据匹配相似度,然后返回前5条
CALL db.index.vector.queryNodes('movie_idx', 5, $embedding)
YIELD node AS movie, score
RETURN movie.name AS name, movie.description AS description , score$embedding 需要自己将自己要查询的字符串生成向量数组后放进去查询,比如如果需要查询和“食物”相关的电影,将 “食物” 通过上面的模型生产向量,如生成向量的为 [1.8,2.7,3.5] ,则查询写法为
CALL db.index.vector.queryNodes('movie_idx', 5, [1.8,2.7,3.5] )
YIELD node AS movie, score
RETURN movie.name AS name, movie.description AS description, score注意,此处生成的向量 $embedding 维度需要和索引的维度一致,假设量纲不匹配,如上面的[1.8,2.7,3.5] 才三个量纲,于是出现如下错误
Failed to invoke procedure `db.index.vector.queryNodes`: Caused by: java.lang.IllegalArgumentException: Index query vector has 3 dimensions, but indexed vectors have 768.
基于查询的结果进行相似度查询
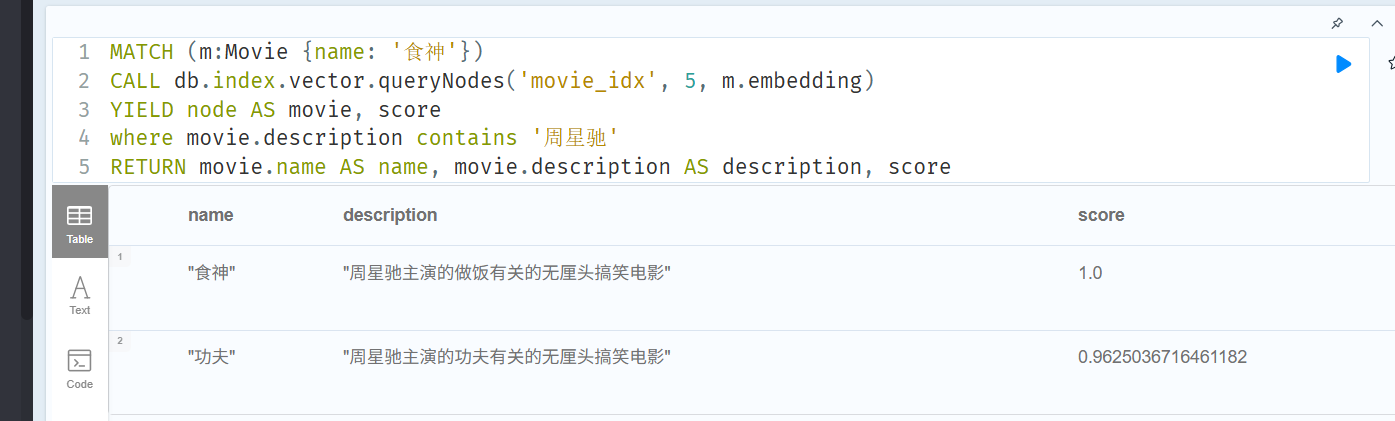
MATCH (m:Movie {name: '食神'})
CALL db.index.vector.queryNodes('movie_idx', 5, m.embedding)
YIELD node AS movie, score
where movie.description contains '周星驰'
RETURN movie.name AS name, movie.description AS description, score1. MATCH 查出一条名称为 "食神" 的节点
2.CALL 里的 m.embedding 表示用这条"食神" 的节点的 embedding 向量字段进行相似度匹配,找出和食神这部电影相似度最高的前五部电影。
注意:
1.前面的 MATCH 是可以返回多条数据的,假设前面的 MATCH 返回两个节点 "食神" ,"功夫",则循环每个节点调用一次后面的 CALL ,结果为和"食神" 相似度最高的五部电影加上和 功夫" 相似度最高的五部电影,总共十部电影。同理,如果返回的是十条数据,那就是得到五十部电影
2. CALL 里的 m.embedding 必须是MATCH的向量属性,不能自己输入向量数组,我一开始是自己输入向量数组,以为 CALL 是基于前面 MATCH 之后的结果集里进行相似度查询。结果返回的数据变成 5 的倍数,然后数据每 5 条重复一次。
3.where 是可以基于匹配结果进行过滤的
查询效果如下图所示
基于Function进行相似度查询
这种方式是自己调用相似度算法生成相似度 Score 后排序获取最相似的数据,所以支持基于 Match 后的数据集进行相似度查询。这种方式不需要建索引。
MATCH (m:Movie)
WITH m, vector.similarity.cosine($embedding, m.vector) AS score
RETURN node, score
ORDER BY score DESCENDING
LIMIT 2;1.MATCH 就是查询出自己需要的数据集
2.WITH 里调用 vector.similarity.cosine 生成余弦相似度作为 score,socre越高表示越相似
3.odder by + limit 就可以查出最相似的前几条数据了
4. $embedding 是向量数组,也是基于要查询的文本生产向量数组后放上去,同 直接从索引查询 的 $embedding 是一样的
相关文章:
neo4j 5.19.0两种基于向量进行相似度查询的方式
介绍 主要讲的是两种相似度查询 一种是创建向量索引,然后直接从索引的所有数据中进行相似度搜索,这种不支持基于自己查询的结果中进行相似度匹配另一种是自己调用向量方法生产相似度进行相似度搜索,这种可以基于自己的查询结果中进行相似度…...

项目课题——基于ESP32的智能插座
一、功能需求 1.1 基础功能 ✅ 远程控制 通过Wi-Fi实现手机APP/小程序远程开关支持定时任务(如定时开启热水器) 🔌 用电监测 实时显示电压/电流/功率电能统计(日/月/年用电量报表) 🔋多接口支持 220V三线…...
华为云Flexus+DeepSeek征文|利用华为云 Flexus 云服务一键部署 Dify 平台开发文本转语音助手全流程实践
目录 前言 1 华为云 Flexus 与 Dify 平台简介 1.1 Flexus:为AI而生的轻量级云服务 1.2 Dify:开源的LLM应用开发平台 2 一键部署Dify平台至Flexus环境 3 构建文本转语音助手应用 3.1 创建ChatFlow类型应用 3.2 配置语音合成API的HTTP请求 3.3 设…...
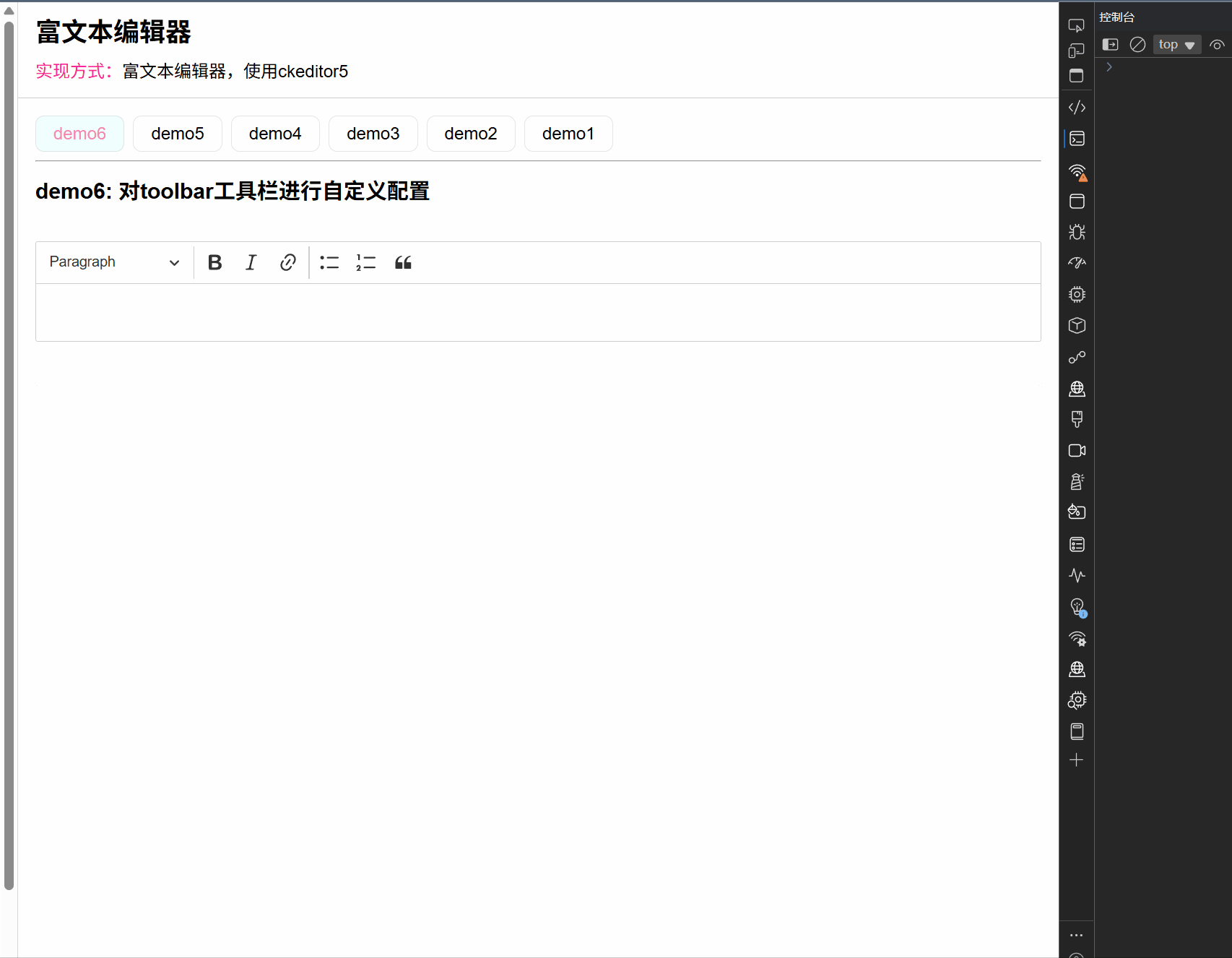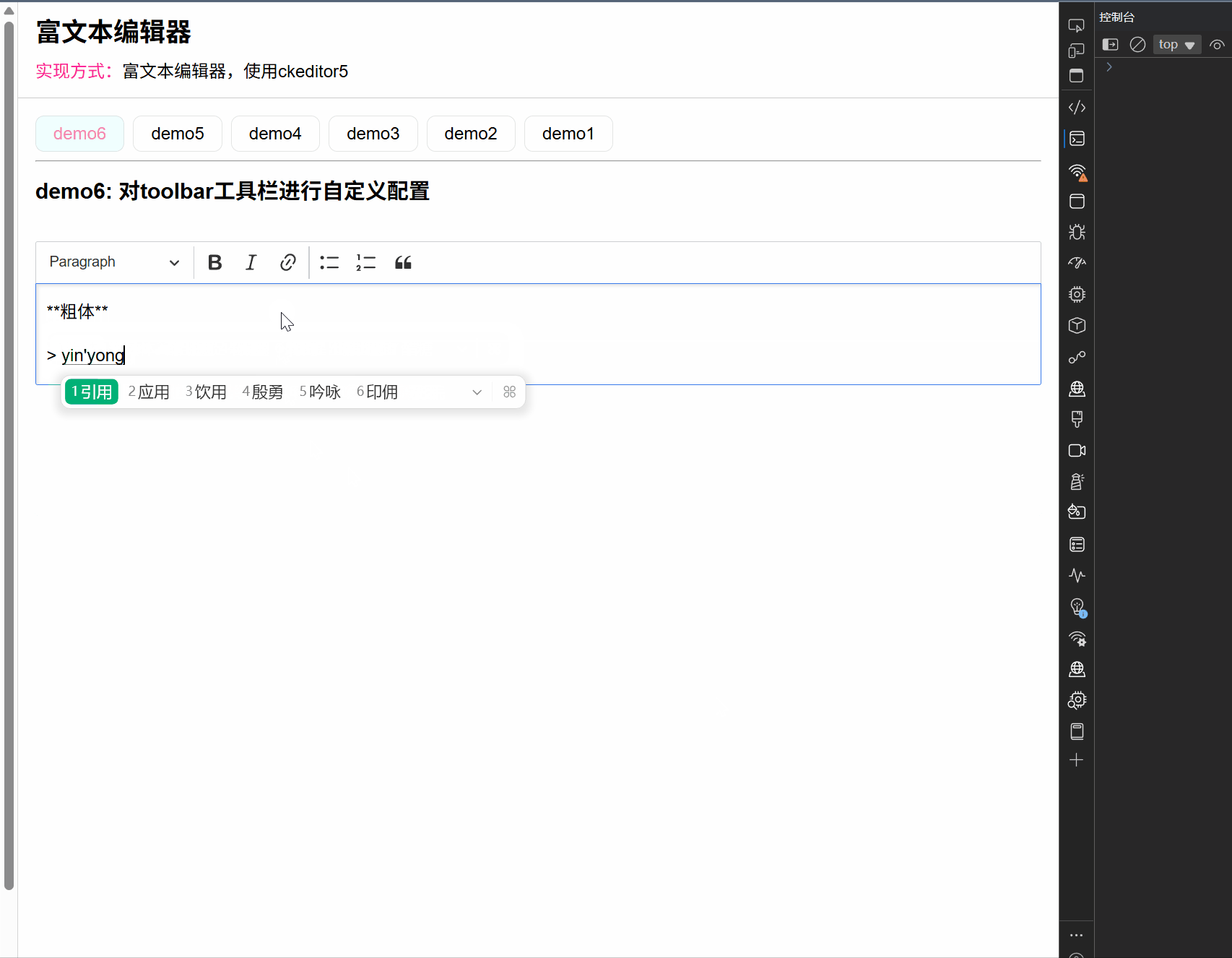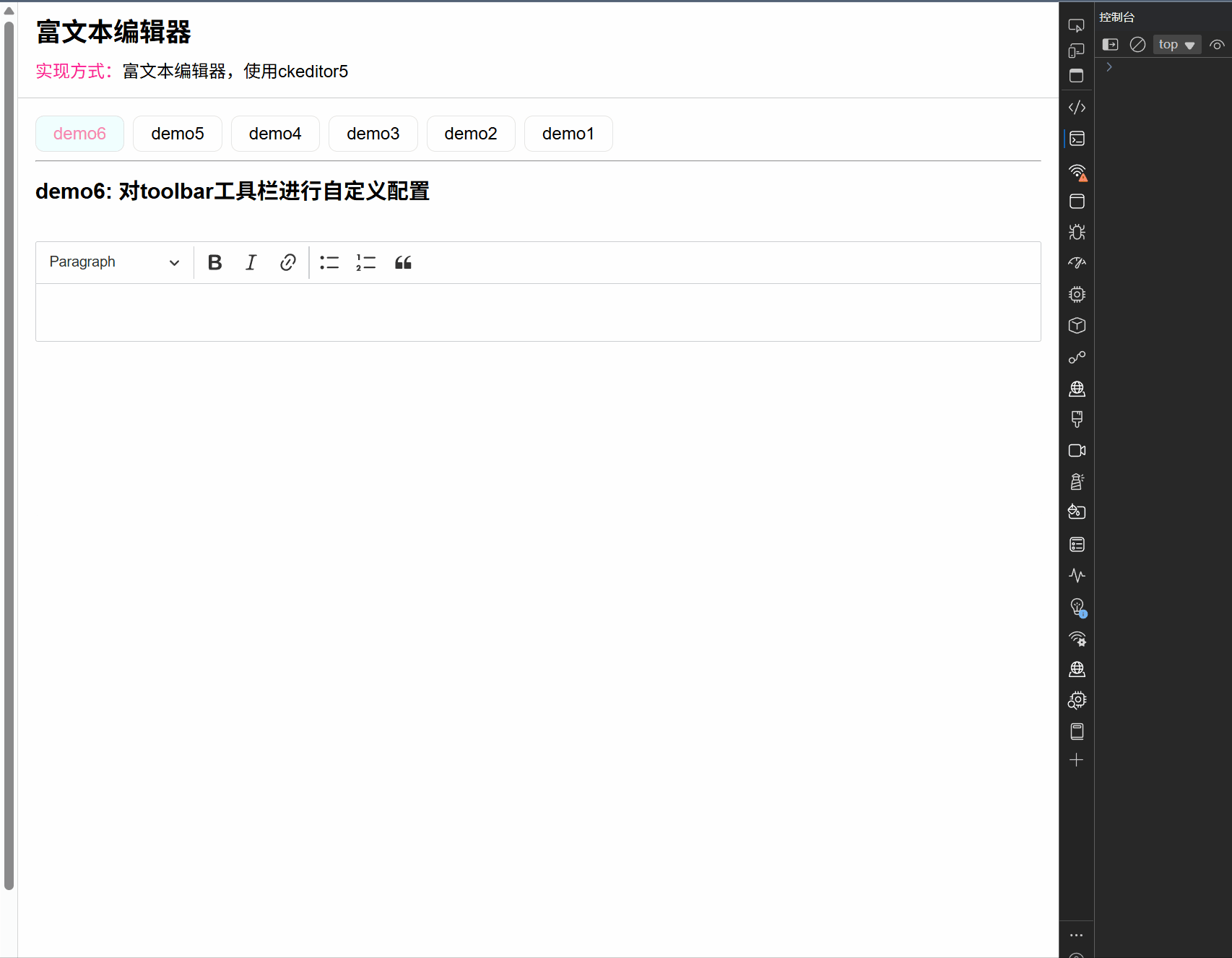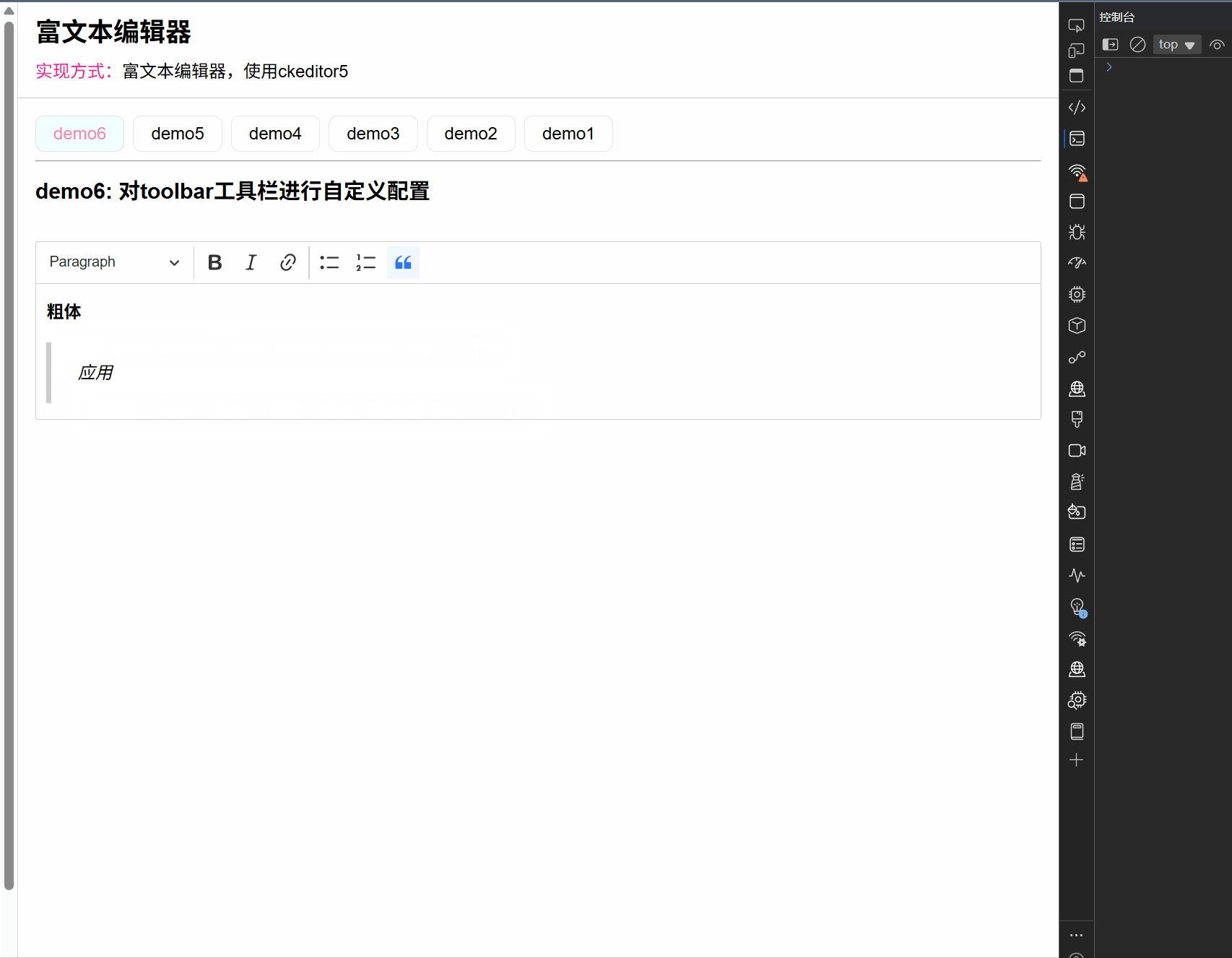
ck-editor5的研究 (7):自定义配置 CKeditor5 的 toolbar 工具栏
文章目录 一、前言二、实现步骤1. 第一步: 搭建目录结构2. 第二步:配置toolbar工具栏的步骤(2-1). 配置粗体和斜体(2-2). 配置链接和标题+正文(2-3). 配置列表和引用(2-4). 配置自动格式化3. 第三步:更多工具三、测试效果和细节四、总结一、前言 在前面的文章中,我们已经对…...

MPLS-EVPN笔记详述
目录 EVPN简介: EVPN路由: 基本四种EVPN路由 扩展: EVPN工作流程: 1.启动阶段: 2.流量转发: 路由次序整理: 总结: EVPN基本术语: EVPN表项: EVPN支持的多种服务模式: 简介: 1.Port Based: 简介: 配置实现: 2.VLAN Based: 简介: 配置实现: 3.VLAN Bundle: 简…...

嵌入式Linux系统中的启动分区架构
在嵌入式Linux系统架构中,Linux内核、设备树(Device Tree)与引导配置文件构成了系统启动的基础核心。如何安全、高效地管理这些关键文件,直接影响到系统的稳定性与可维护性。近年来,越来越多的嵌入式Linux开发者选择将启动相关文件从传统的“混合存放”方式,转向采用独立…...
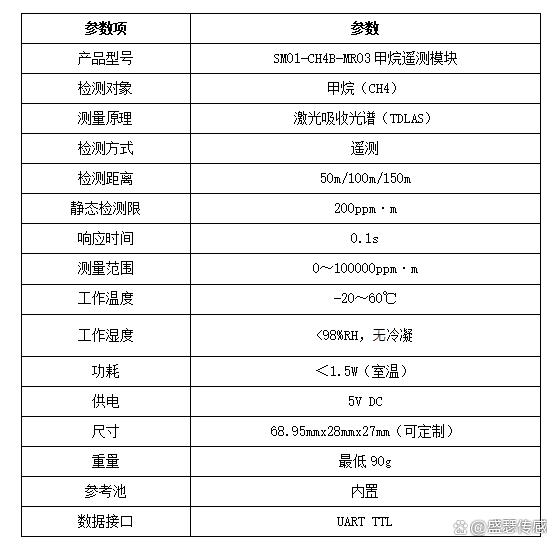
无人机甲烷检测技术革新:开启环境与能源安全监测新时代
市场需求激增,技术革新势在必行 随着全球气候变化加剧,甲烷作为第二大温室气体,其减排与监测成为国际社会关注焦点。据欧盟甲烷法规要求,2024 年起欧洲能源基础设施运营商需定期测量甲烷排放并消除泄漏。与此同时,极端…...
mysql数据库实现分库分表,读写分离中间件sharding-sphere
一 概述 1.1 sharding-sphere 作用: 定位关系型数据库的中间件,合理在分布式环境下使用关系型数据库操作,目前有三个产品 1.sharding-jdbc,sharding-proxy 1.2 sharding-proxy实现读写分离的api版本 4.x版本 5.x版本 1.3 说明…...
 用法详解)
[Python] struct.unpack() 用法详解
struct.unpack()用法详解 文章目录 struct.unpack()用法详解一、函数语法二、格式字符串详解三、使用示例示例 1:解析整数和浮点数示例 2:解析字符串示例 3:解析混合类型示例 4:跳过填充字节示例 5:解析数组 四、关键注…...

普通二叉树 —— 最近公共祖先问题解析(Leetcode 236)
🏠个人主页:尘觉主页 文章目录 普通二叉树 —— 最近公共祖先问题解析(Leetcode 236)🧠 问题理解普通二叉树与 BST 的区别: 💡 解题思路关键思想:📌 举个例子:…...
Spring AOP:面向切面编程 详解代理模式
文章目录 AOP介绍什么是Spring AOP?快速入门SpringAop引入依赖Aop的优点 Spring Aop 的核心概念切点(Pointcut)连接点、通知切面通知类型PointCut注解切面优先级Order切点表达式executionwithinthistargetargsannotation自定义注解 Spring AOP原理代理模式ÿ…...
零知开源——STM32F407VET6驱动ILI9486 TFT显示屏 实现Flappy Bird游戏教程
简介 本教程使用STM32F407VET6零知增强板驱动3.5寸 ILI9486的TFT触摸屏扩展板实现经典Flappy Bird游戏。通过触摸屏控制小鸟跳跃,躲避障碍物柱体,挑战最高分。项目涉及STM32底层驱动、图形库移植、触摸控制和游戏逻辑设计。 目录 简介 一、硬件准备 二…...

数据安全中心是什么?如何做好数据安全管理?
目录 一、数据安全中心是什么 (一)数据安全中心的定义 (二)数据安全中心的功能 1. 数据分类分级 2. 访问控制 3. 数据加密 4. 安全审计 5. 威胁检测与响应 二、数据安全管理的重要性 三、如何借助数据安全中心做好数据安…...

Monorepo 详解:现代前端工程的架构革命
以下是一篇关于 Monorepo 技术的详细技术博客,采用 Markdown 格式,适合发布在技术社区或团队知识库中。 🧩 深入理解 Monorepo:现代项目管理的利器 在现代软件开发中,项目规模日益庞大,模块之间的依赖关系…...
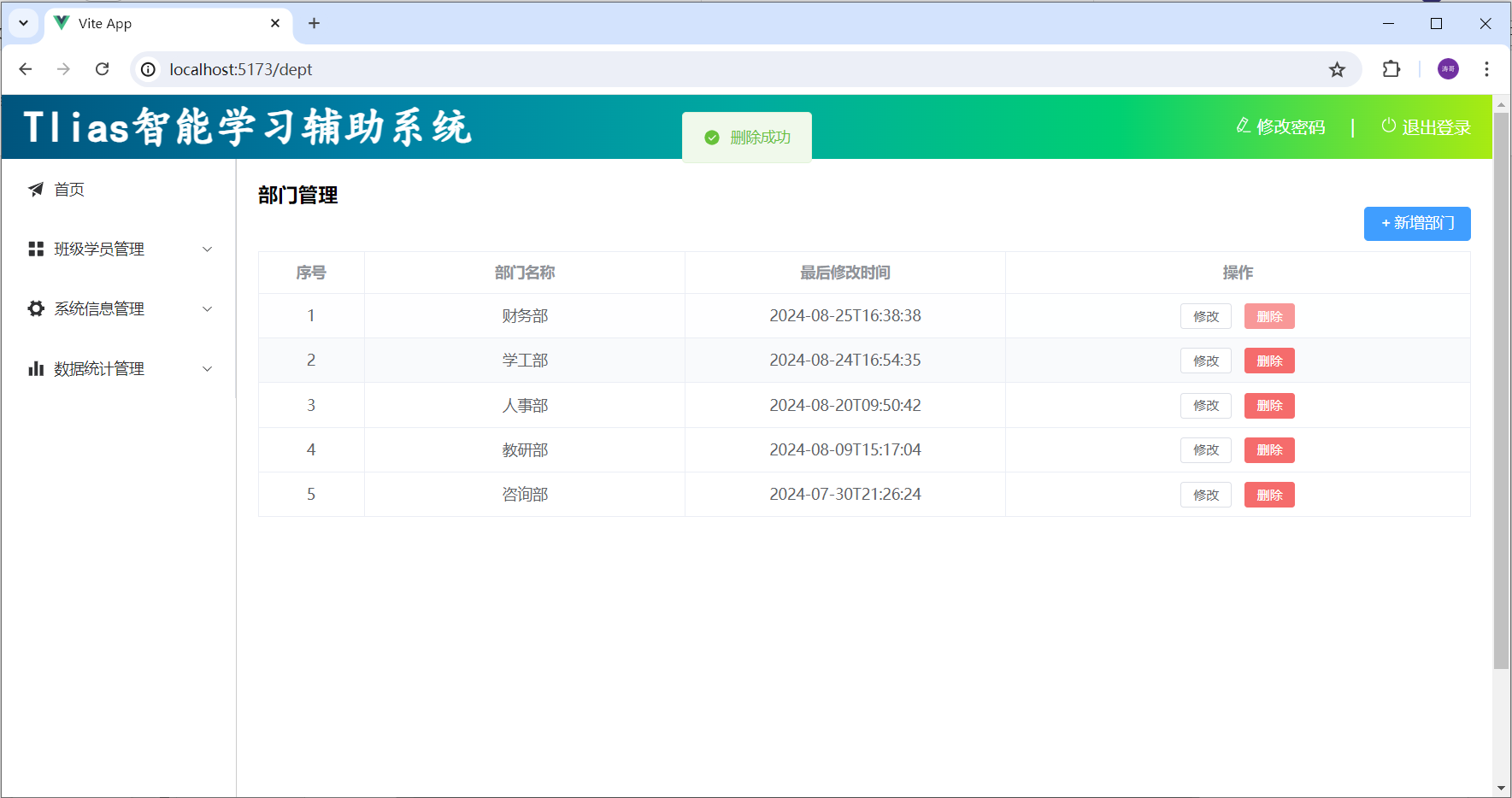
16-前端Web实战(Tlias案例-部门管理)
在前面的课程中,我们学习了Vue工程化的基础内容、TS、ElementPlus,那接下来呢,我们要通过一个案例,加强大家对于Vue项目的理解,并掌握Vue项目的开发。 这个案例呢,就是我们之前所做的Tlias智能学习辅助系统…...
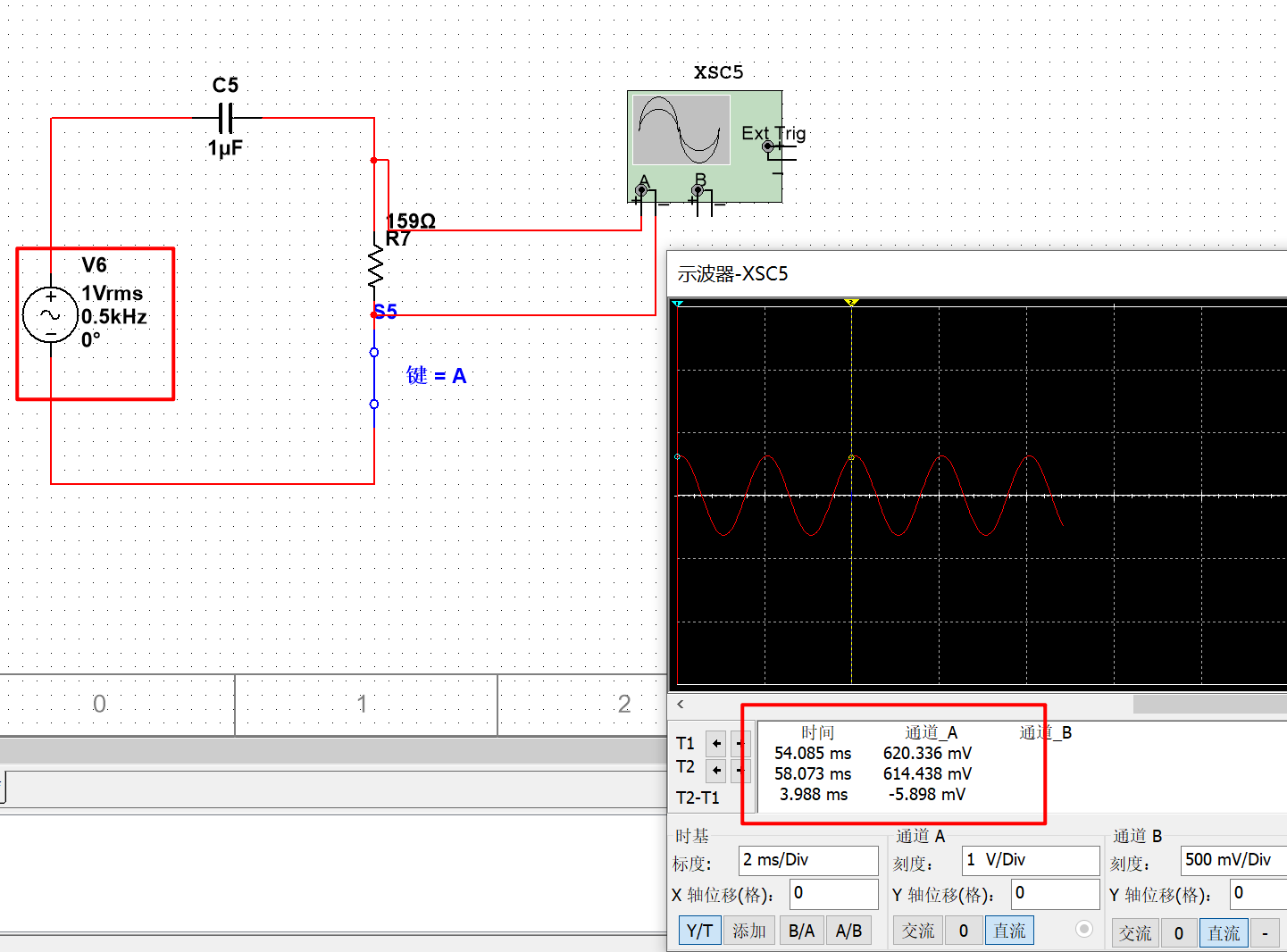
电路学习(二)之电容
电容的基本功能是通交流隔直流、存储电量,在电路中可以进行滤波、充放电。 1.什么是电容? (1)电容定义:电容器代表了器件存储电荷的能力,通俗来理解是两块不连通的导体与绝缘的中间体组成。当给电容充电时…...

从“remote rejected”看git角色区别,Maintainer和Devoloper
从“remote rejected”看git角色区别,Maintainer和Devoloper 接上篇,git管理 问题 使用Devoloper权限创建项目,进行push 时显示remote rejected remote: Resolving deltas: 100% (304/304), done. remote: GitLab: remote: A default bra…...

CTA-861-G-2017中文pdf版
CTA-861-G标准(2016年11月发布)规范未压缩高速数字接口的DTV配置,涵盖视频格式、色彩编码、辅助信息传输等,适用于DVI、HDMI等接口,还涉及EDID数据结构及HDR元数据等内容。...

JavaScript中的常量值与引用值:从基础到实践
JavaScript中的常量值与引用值:从基础到实践 在JavaScript中,常量值(原始值)和引用值(对象值)是两种核心的数据类型。它们的存储方式、行为特性以及使用场景存在显著差异,理解这些差异对于编写…...
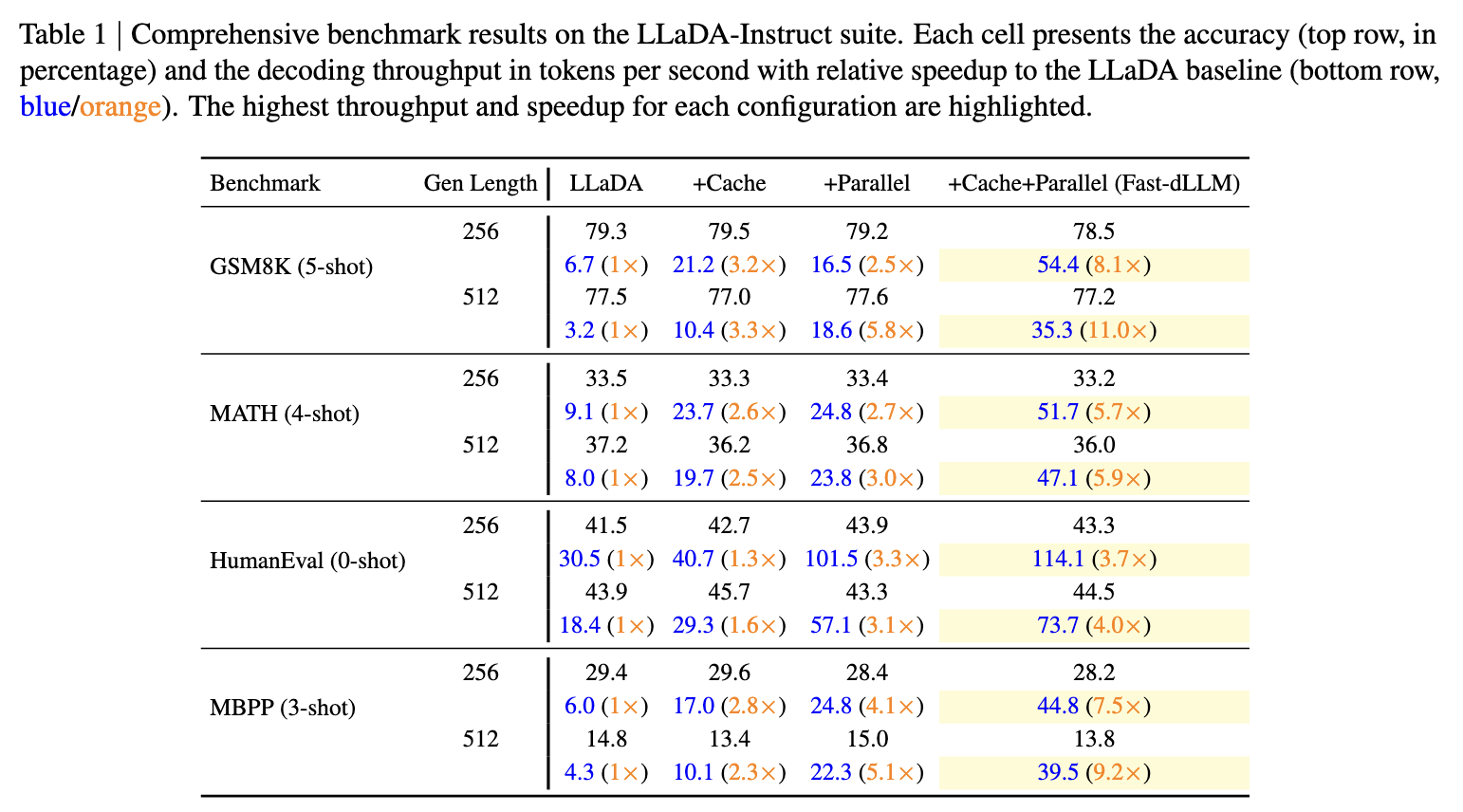
港大NVMIT开源Fast-dLLM:无需重新训练模型,直接提升扩散语言模型的推理效率
作者:吴成岳,香港大学博士生 原文:https://mp.weixin.qq.com/s/o0a-swHZOplknnNxpqlsaA 最近的Gemini Diffusion语言模型展现了惊人的throughput和效果,但是开源的扩散语言模型由于缺少kv cache以及在并行解码的时候性能严重下降等…...
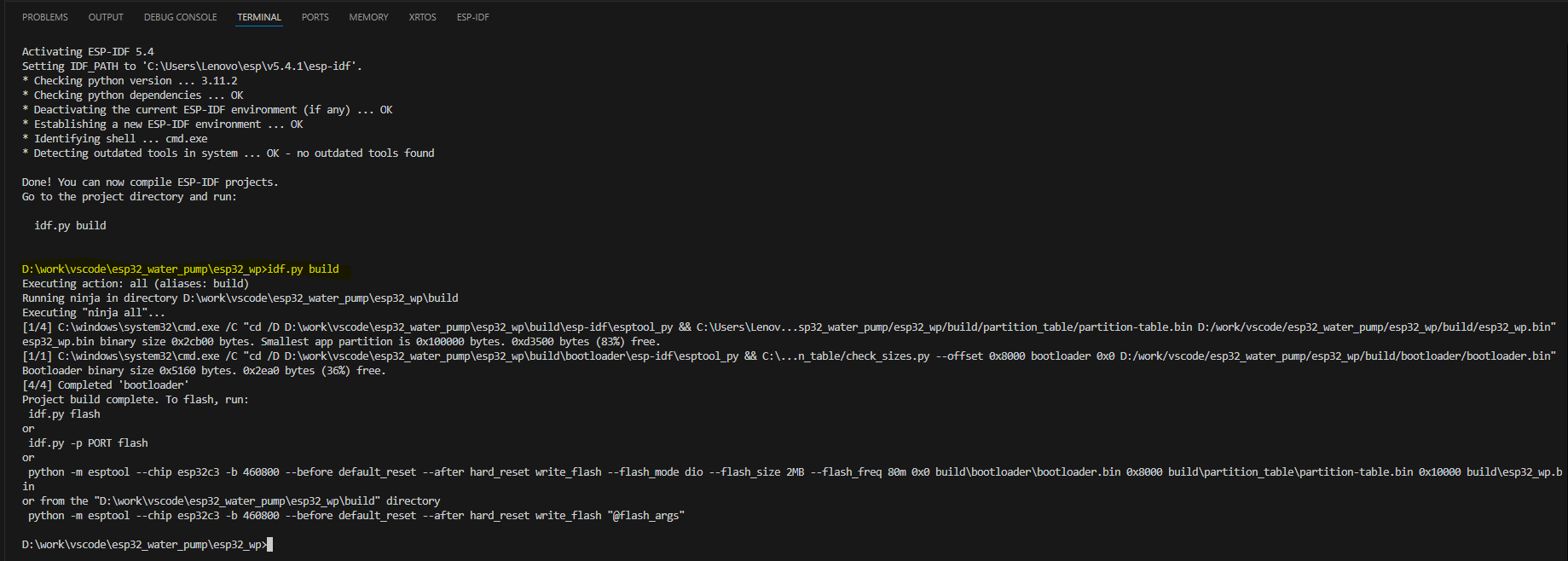
ESP32-C3 Vscode+ESP-IDF开发环境搭建 保姆级教程
1.背景 最近esp32的芯片很火,因为芯片自带了WIFI和BLE功能,是物联网项目开发的首选芯片,所以,我也想搞个简单的esp32芯片试试看。于是,我设计了一个简单的板子。如下 这块板子很简单,主要的电路来自于乐鑫…...

SCSS 全面深度解析
一、SCSS 入门指南:为你的 CSS 工作流注入超能力 在现代 Web 开发中,样式表的复杂性和维护成本日益增加。为了应对这一挑战,CSS 预处理器应运而生,而 SCSS (Sassy CSS) 正是其中最流行、最强大的工具之一。本指南将带你深入了解 …...
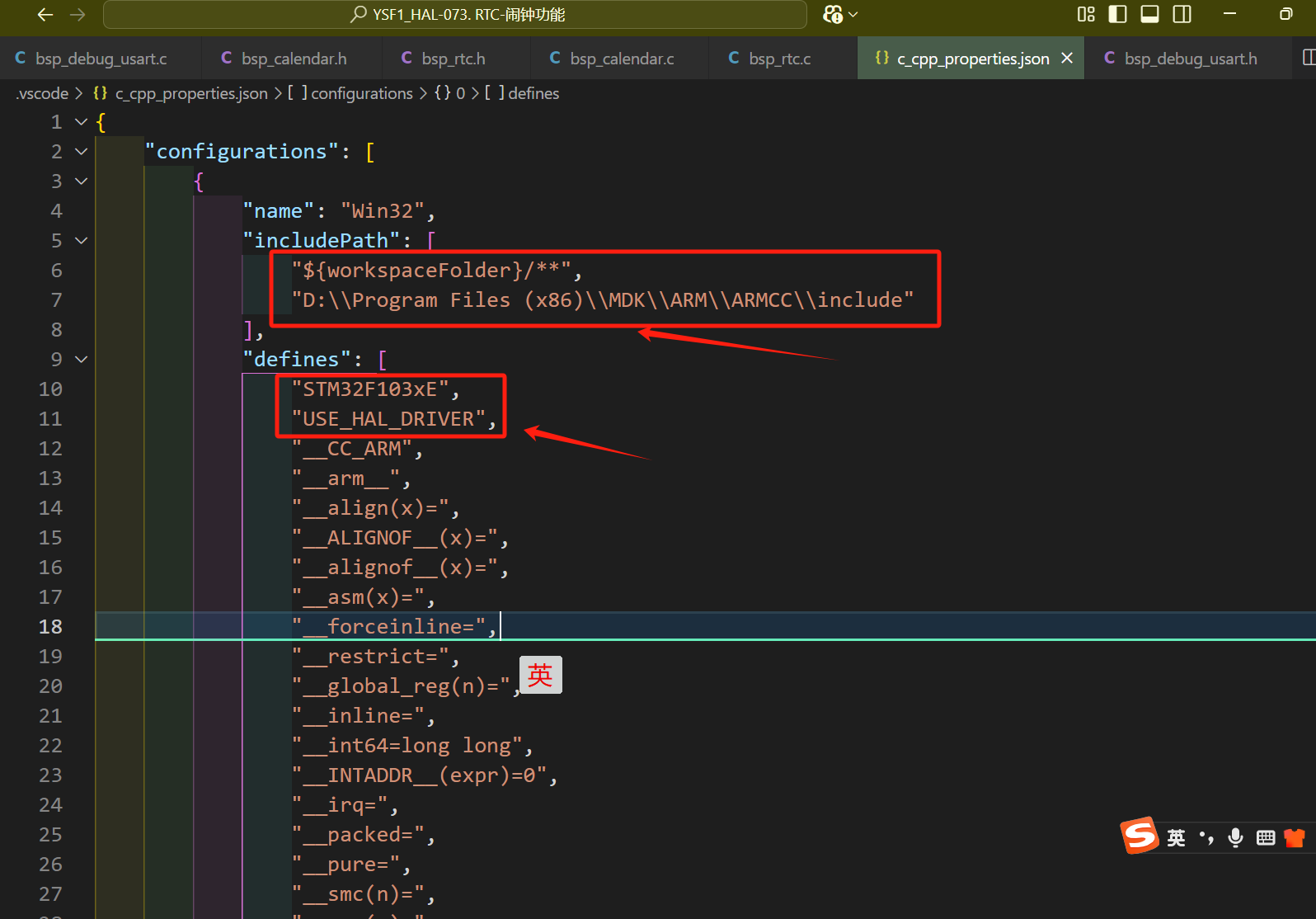
解决vscode打开一个单片机工程文件(IAR/keil MDK)因无法找到头文件导致的结构体成员不自动补全问题。
最近一直在用vscode安装c/c插件后编辑STM32标准库(keil MDK)项目源文件,因为我感觉vscode在代码编辑方面比keil MDK本身优秀太多。发现打开工程后,结构体变量的成员在输入“.”后不自己弹出的问题,后来查找各方资料&am…...

Python 在金融中的应用- Part 1
早在2018年,我开始对资本市场产生兴趣。理解资本市场的基本理论对财富积累至关重要。我开始阅读所有经典著作,如《聪明的投资者》和《证券分析》。在这一系列文章中,我想与读者分享在Python编程语言背景下理解金融理论的旅程。在文章的第一大部分,我们将专注于金融模型的线…...

【Node.js 深度解析】npm install 遭遇:npm ERR! code CERT_HAS_EXPIRED 错误的终极解决方案
目录 📚 目录:洞悉症结,精准施治 🔍 一、精准剖析:CERT_HAS_EXPIRED 的本质 🕵️ 二、深度溯源:证书失效的 N 重诱因 💡 三、高效解决策略:六脉神剑,招招…...
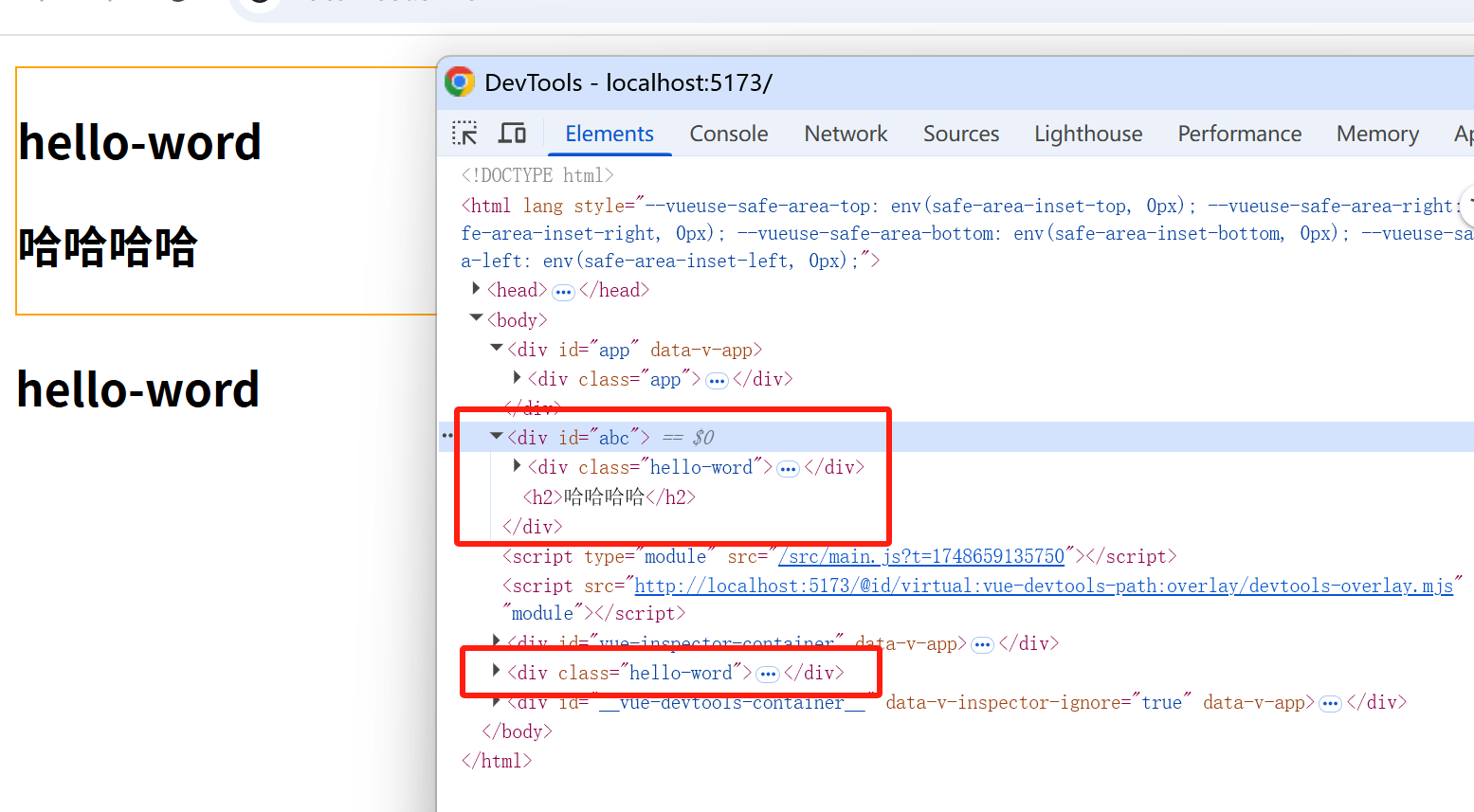
Vue内置组件Teleport和Suspense
一. Vue内置组件Teleport 认识Teleport( teleport:允许我们把组件的模板渲染到特定的元素上) 1.1. 在组件化开发中,我们封装一个组件A,在另外一个组件B中使用 组件A中template的元素,会被挂载到组件B中template的某个位置…...

Java网络编程实战:TCP/UDP Socket通信详解与高并发服务器设计
🔍 开发者资源导航 🔍🏷️ 博客主页: 个人主页📚 专栏订阅: JavaEE全栈专栏 内容: socket(套接字)TCP和UDP差别UDP编程方法使用简单服务器实现 TCP编程方法Socket和ServerSocket之间的关系使用简…...

vue+threeJs 绘制3D圆形
嗨,我是小路。今天主要和大家分享的主题是“vuethreeJs 绘制圆形”。 今天找到一个用three.js绘制图形的项目,主要是用来绘制各种形状。 项目案例示意图 1.THREE.ShapeGeometry 定义:是 Three.js 中用于从 2D 路径形状(…...
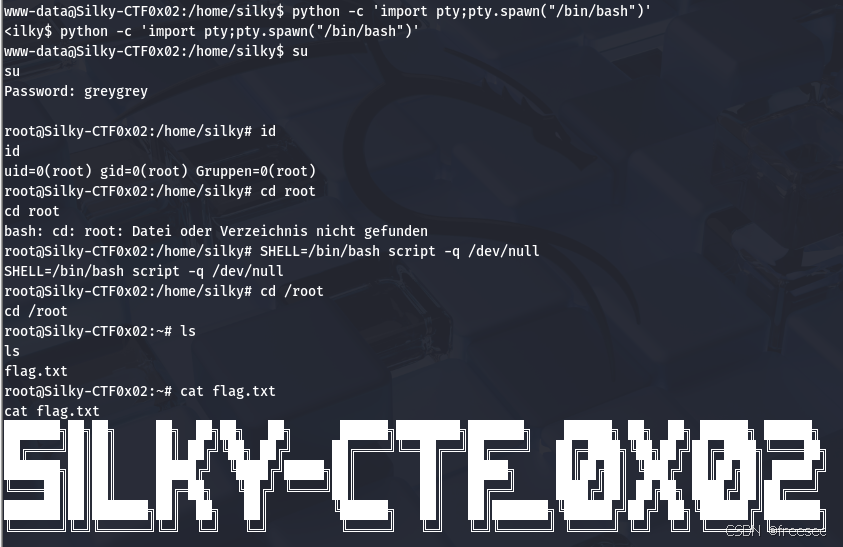
Silky-CTF: 0x02靶场
Silky-CTF: 0x02 来自 <Silky-CTF: 0x02 ~ VulnHub> 1,将两台虚拟机网络连接都改为NAT模式 2,攻击机上做namp局域网扫描发现靶机 nmap -sn 192.168.23.0/24 那么攻击机IP为192.168.23.128,靶场IP192.168.23.131 3,对靶机进…...

Kafka 的优势是什么?
Kafka 作为分布式流处理平台的核心组件,其设计哲学围绕高吞吐、低延迟、高可扩展性展开,在实时数据管道和大数据生态中具有不可替代的地位。 一、超高吞吐量与低延迟 1. 磁盘顺序 I/O 优化 突破磁盘瓶颈:Kafka 将消息持久化到磁盘ÿ…...