C++概率论算法详解:理论基础与实践应用
清言神力,创作奇迹。接受福利,做篇笔记。
参考资料
[0] 概率论中均值、方差、标准差介绍及C++/OpenCV/Eigen的三种实现. https://blog.csdn.net/fengbingchun/article/details/73323475.
[4] C++中的随机数及其在算法竞赛中的使用 - 博客园. https://www.cnblogs.com/cmy-blog/p/random.html.
[7] C++随机数–——生成任意范围内等概率随机数"足够好"的做法 - 博客园. https://www.cnblogs.com/wei-li/archive/2012/10/04/2711629.html.
[16] c++手写数字识别(贝叶斯分类器) 原创 - CSDN博客. https://blog.csdn.net/m0_57587079/article/details/120773582.
[18] 《机器学习》西瓜书第七章贝叶斯分类器- 曹婷婷- 博客园. https://www.cnblogs.com/ttzz/p/11583740.html.
引言
概率论作为数学的一个重要分支,研究随机现象及其规律,在计算机科学、人工智能、数据分析等领域有着广泛应用。本报告将深入探讨C++中实现概率论算法的各个方面,包括随机数生成、贝叶斯定理、蒙特卡洛方法以及概率统计量计算等,为读者提供全面的理论基础和实践指导。
概率论基础概念
在深入C++实现之前,我们需要理解一些概率论的基本概念,这些概念是构建概率论算法的基础。
随机变量
随机变量是可以随机地取不同值的变量。在概率论中,我们通常研究随机变量的概率分布,包括离散型分布和连续型分布[0]。
概率分布
概率分布描述了随机变量取各个可能值的概率。常见的概率分布包括:
-
离散分布:二项分布、泊松分布、伯努利分布等
-
连续分布:正态分布、均匀分布、指数分布等
期望值、方差与标准差
这些统计量帮助我们理解随机变量的中心趋势和离散程度:
-
期望值:随机变量的平均值
-
方差:随机变量与其期望值之差的平方的期望
-
标准差:方差的平方根,表示数据的离散程度
C++中的随机数生成
随机数是概率论算法的基础。C++提供了多种生成随机数的方法,从简单的随机数生成到复杂的概率分布模拟。
C++标准库中的随机数生成
C++标准库提供了<random>头文件,包含各种随机数生成器和分布。现代C++推荐使用<random>而不是旧的rand()函数,因为后者存在许多缺陷[7]。
随机数生成器
随机数生成器是生成随机整数序列的引擎。常见的生成器包括:
-
std::mt19937:梅森旋转算法,一个常用的伪随机数生成器 -
std::pcg32:PCG算法,提供更好的统计特性 -
std::random_device:提供非确定性随机数,通常用于生成种子
概率分布
<random>头文件提供了多种概率分布,包括:
#include <iostream>
#include <random>
#include <algorithm>
#define int long long
using namespace std;signed main(void){ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr);mt19937 gen(random_device{}());//设置随机数生成器uniform_real_distribution<double> uniform_dist(0.0, 1.0);//均匀分布在[0,1)区间cout << "Uniform random number: " << uniform_dist(gen) << "\n";normal_distribution<double> normal_dist(0.0, 1.0);//正态分布,均值0,标准差1cout << "Normal random number: " << normal_dist(gen) << "\n";return 0;
}
真随机与伪随机
在实现概率论算法时,理解真随机和伪随机的概念非常重要:
-
真随机:基于物理现象的随机性,如放射性衰变或大气噪声
-
伪随机:通过确定性算法生成的序列,看起来随机但可预测
C++中的大多数随机数生成都是伪随机的,它们通过某种固定的方法从"种子"运算进而得到随机数[4]。
Boost库中的高级分布
Boost C++库提供了更多高级的概率分布函数,包括:
-
boost::math::laplace_distribution:拉普拉斯分布 -
boost::math::geometric_distribution:几何分布
使用Boost库可以更方便地实现复杂的概率分布:
#include <iostream>
#include <string>
#include <cmath>
#include <vector>
#include <map>
#include <algorithm>
#define int long long
#define db double
using namespace std;
typedef map<string, int> FeatureCount;
typedef map<string, FeatureCount> ClassFeatureCounts;
typedef map<string, db> ClassPrior;class NaiveBayesClassifier{private:ClassFeatureCounts featureCounts;ClassPrior classPriors;int totalInstances;public:void train(const vector<string>& instances, const vector<string>& labels){totalInstances = instances.size();// 计算先验概率for(const string& label : labels){classPriors[label] += 1.0;}for(auto& entry : classPriors){entry.second /= totalInstances;}// 计算特征条件概率for(size_t i = 0; i < instances.size(); ++i){const string& instance = instances[i];const string& label = labels[i];// 假设特征是空格分隔的size_t start = 0;size_t end = instance.find(' ');while(end != string::npos){string feature = instance.substr(start, end - start);featureCounts[label][feature] += 1;start = end + 1;end = instance.find(' ', start);}// 处理最后一个特征string feature = instance.substr(start);featureCounts[label][feature] += 1;}}string classify(const string& instance){// 计算每个类别的后验概率map<string, db> posteriors;// 假设特征是空格分隔的size_t start = 0;size_t end = instance.find(' ');vector<string> features;while(end != string::npos){string feature = instance.substr(start, end - start);features.push_back(feature);start = end + 1;end = instance.find(' ', start);}// 处理最后一个特征string feature = instance.substr(start);features.push_back(feature);for(const auto& classEntry : classPriors){const string& label = classEntry.first;db prior = classPriors[label];db posterior = prior;// 计算条件概率for(const string& feature : features){db count = featureCounts[label][feature];db totalFeatures = 0;for(const auto& featureEntry : featureCounts[label]){totalFeatures += featureEntry.second;}db probability =(count + 1.0) /(totalFeatures + features.size()); // 平滑处理posterior *= probability;}posteriors[label] = posterior;}// 找到概率最高的类别string result;db maxProb = -1.0;for(const auto& entry : posteriors){if(entry.second > maxProb){maxProb = entry.second;result = entry.first;}}return result;}
};signed main(void){ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr);// 训练数据vector<string> instances = {"sunny hot high false","sunny hot high true","overcast hot high false","rainy mild high false","rainy cool normal false","rainy cool normal true","overcast cool normal true","sunny mild high false","sunny cool normal false","rainy mild normal true","sunny mild normal true","overcast mild high true","overcast hot normal false","rainy mild high true"};vector<string> labels = {"no", "no", "yes", "yes", "yes", "no", "yes", "no", "yes", "yes", "yes", "yes", "yes", "yes"};NaiveBayesClassifier classifier;classifier.train(instances, labels);// 测试string testInstance = "sunny hot normal false";string result = classifier.classify(testInstance);cout << "分类结果: " << result << "\n";return 0;
}
这个实现包括训练和分类两个主要步骤。在训练阶段,我们计算每个类别的先验概率以及每个特征在每个类别中的条件概率。在分类阶段,我们使用这些概率来计算新实例属于每个类别的后验概率,并选择概率最高的类别。
贝叶斯分类器在手写数字识别中的应用
贝叶斯分类器在手写数字识别等实际应用中表现出色。在手写数字识别中,我们可以将每个像素作为一个特征,统计每个数字在每个像素位置为1的概率[16]。
以下是一个简化的手写数字识别贝叶斯分类器实现:
#include <iostream>
#include <vector>
#include <string>
#include <map>
#include <cmath>
#include <fstream>
#include <sstream>
#include <iomanip>
#include <algorithm>
#define int long long
#define db double
using namespace std;
typedef vector<vector<db>> Matrix;
typedef map<char, Matrix> ClassMatrices;class BayesianClassifier{private:ClassMatrices classMatrices;map<char, db> priors;int width;int height;public:BayesianClassifier(int w, int h) : width(w), height(h){}void train(const string& trainFile){ifstream file(trainFile);string line;// 统计每个类别的特征频率map<char, int> classCounts;while(getline(file, line)){if(line.empty()) continue;// 假设每行的格式是:label pixel1 pixel2 ... pixelNsize_t spacePos = line.find(' ');char label = line[spacePos+1];string pixelStr = line.substr(spacePos+2);// 转换为矩阵Matrix matrix(height, vector<db>(width, 0.0));istringstream iss(pixelStr);for(int i = 0; i < height; ++i){for(int j = 0; j < width; ++j){db val;iss >> val;matrix[i][j] = val;}}// 更新统计if(classMatrices.find(label) == classMatrices.end()){classMatrices[label] = Matrix(height, vector<db>(width, 0.0));}for(int i = 0; i < height; ++i){for(int j = 0; j < width; ++j){classMatrices[label][i][j] += matrix[i][j];}}classCounts[label]++;}// 计算先验概率int total = 0;for(const auto& pair : classCounts){total += pair.second;}for(const auto& pair : classCounts){priors[pair.first] =(db)pair.second / total;}// 计算每个类别的特征均值for(const auto& pair : classMatrices){char label = pair.first;Matrix& matrix = pair.second;for(int i = 0; i < height; ++i){for(int j = 0; j < width; ++j){matrix[i][j] /= classCounts[label];}}}}char classify(const Matrix& sample){map<char, db> posteriors;for(const auto& pair : classMatrices){char label = pair.first;const Matrix& classMatrix = pair.second;db likelihood = 1.0;for(int i = 0; i < height; ++i){for(int j = 0; j < width; ++j){// 计算P(sample[i][j] | label)// 这里使用高斯分布假设db mu = classMatrix[i][j];db sigma = 1.0; // 假设标准差为1db prob =(1.0 /(sigma * sqrt(2 * M_PI))) * exp(-pow(sample[i][j] - mu, 2) /(2 * sigma * sigma));likelihood *= prob;}}db posterior = priors[label] * likelihood;posteriors[label] = posterior;}// 找到概率最高的类别char result = '0';db maxProb = -1.0;for(const auto& pair : posteriors){if(pair.second > maxProb){maxProb = pair.second;result = pair.first;}}return result;}
};signed main(void){ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr);// 设置图像尺寸const int width = 28;const int height = 28;// 创建分类器BayesianClassifier classifier(width, height);// 训练string trainFile = "train_digits.txt";classifier.train(trainFile);// 测试string testFile = "test_digits.txt";ifstream file(testFile);string line;int correct = 0;int total = 0;while(getline(file, line)){if(line.empty()) continue;// 读取标签和图像数据size_t spacePos = line.find(' ');char label = line[spacePos+1];string pixelStr = line.substr(spacePos+2);// 转换为矩阵Matrix sample(height, vector<db>(width, 0.0));istringstream iss(pixelStr);for(int i = 0; i < height; ++i){for(int j = 0; j < width; ++j){db val;iss >> val;sample[i][j] = val;}}// 分类char predicted = classifier.classify(sample);// 计算准确率if(predicted == label){correct++;}total++;}cout << "Accuracy: " <<(db)correct / total * 100 << "%" << "\n";return 0;
}
这个实现使用贝叶斯定理对手写数字进行分类。训练阶段统计每个数字在每个像素位置的平均值,分类阶段计算测试样本属于每个类别的后验概率,并选择概率最高的类别。
蒙特卡洛方法
蒙特卡洛方法是一种通过随机抽样来估计结果的计算技术。它在物理、工程、金融和计算机科学等领域有着广泛应用。
蒙特卡洛方法的基本原理
蒙特卡洛方法的基本思想是使用随机数来模拟复杂系统的行为,然后通过统计结果来估计所需的量。这种方法特别适用于难以用确定性方法求解的问题。
使用蒙特卡洛方法估计π
一个经典的蒙特卡洛方法应用是通过随机投点来估计π的值:
#include <iostream>
#include <random>
#include <ctime>
#include <cmath>
#include <algorithm>
#define int long long
#define db double
using namespace std;signed main(void){ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr);int inside = 0;int total = 1000000;mt19937 gen(random_device{}());uniform_real_distribution<db> dist(0.0, 1.0);for(int i = 0; i < total; ++i){db x = dist(gen);db y = dist(gen);if(x*x + y*y <= 1.0){++inside;}}db pi_estimate = 4.0 * inside / total;cout << "Estimated pi: " << pi_estimate << "\n";return 0;
}
这个程序生成1000000个随机点,计算落在单位圆内的点的比例,然后使用这个比例来估计π的值。
蒙特卡洛方法在积分计算中的应用
蒙特卡洛方法也可以用于计算高维积分,特别是当维度较高时,传统的数值积分方法效率较低。
以下是一个使用蒙特卡洛方法计算函数f(x) = x^2在[0,1]区间上积分的示例:
#include <iostream>
#include <random>
#include <ctime>
#include <algorithm>
#define int long long
#define db double
using namespace std;db f(db x){return x*x;
}signed main(void){ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr);int samples = 1000000;mt19937 gen(random_device{}());uniform_real_distribution<db> dist(0.0, 1.0);db sum = 0.0;for(int i = 0; i < samples; ++i){db x = dist(gen);sum += f(x);}db integral = sum / samples;cout << "Estimated integral: " << integral << "\n";return 0;
}
这个程序通过在[0,1]区间上均匀生成随机点,计算函数f(x)在这些点上的值的平均值,这个平均值就是积分的估计值。
蒙特卡洛模拟在风险分析中的应用
蒙特卡洛模拟在金融风险分析中有着广泛应用,可以用于评估投资组合的风险、计算VaR(在险价值)等。
以下是一个简化的风险分析蒙特卡洛模拟:
#include <iostream>
#include <vector>
#include <iomanip>
#include <random>
#include <ctime>
#include <cmath>
#include <numeric>
#include <algorithm>
#define int long long
#define db double
using namespace std;db calculatePortfolioValue(const vector<db>& returns, db initialInvestment){db value = initialInvestment;for(db r : returns){value *=(1 + r);}return value;
}signed main(void){ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr);// 投资组合参数const int numAssets = 5;const db initialInvestment = 1000000.0; // 100万美元const db correlation = 0.5;const db volatility = 0.2;const db meanReturn = 0.05;const int numSimulations = 10000;const int numYears = 1;// 创建随机数生成器mt19937 gen(random_device{}());// 生成相关随机数vector<normal_distribution<db>> returnsDistributions(numAssets);for(int i = 0; i < numAssets; ++i){returnsDistributions[i] = normal_distribution<db>(meanReturn, volatility);}// 存储模拟结果vector<db> portfolioValues;for(int i = 0; i < numSimulations; ++i){vector<db> assetReturns(numAssets);for(int j = 0; j < numAssets; ++j){// 生成相关收益率if(j > 0){// 使用Cholesky分解引入相关性db z1 = normal_distribution<db>(0, 1)(gen);db z2 = correlation * z1 + sqrt(1 - correlation*correlation) * normal_distribution<db>(0, 1)(gen);assetReturns[j] = meanReturn + volatility * z2;}else{assetReturns[j] = meanReturn + volatility * normal_distribution<db>(0, 1)(gen);}}// 计算投资组合价值db portfolioReturn = accumulate(assetReturns.begin(), assetReturns.end(), 0.0) / numAssets;db finalValue = initialInvestment * pow(1 + portfolioReturn, numYears);portfolioValues.push_back(finalValue);}// 计算风险指标sort(portfolioValues.begin(), portfolioValues.end());db var95 = portfolioValues[numSimulations * 0.05];db var99 = portfolioValues[numSimulations * 0.01];// 计算平均回报和标准差db averageReturn =(accumulate(portfolioValues.begin(), portfolioValues.end(), 0.0) / numSimulations - initialInvestment) / initialInvestment;db sumSquares = 0.0;for(db value : portfolioValues){sumSquares += pow((value - initialInvestment)/initialInvestment - averageReturn, 2);}db stdDev = sqrt(sumSquares / numSimulations);// 输出结果cout << "风险分析结果:" << "\n";cout << "平均年回报率: " << fixed << setprecision(2) << averageReturn * 100 << "%" << "\n";cout << "回报的标准差: " << fixed << setprecision(2) << stdDev * 100 << "%" << "\n";cout << "95% VaR: " << fixed << setprecision(2) <<(var95 - initialInvestment)/initialInvestment * 100 << "%" << "\n";cout << "99% VaR: " << fixed << setprecision(2) <<(var959 - initialInvestment)/initialInvestment * 100 << "%" << "\n";return 0;
}
这个程序模拟了一个包含5个资产的投资组合,每个资产的收益率服从正态分布。通过10000次模拟,程序估计了投资组合的平均回报、回报的标准差以及95%和99%的VaR。
概率论中的统计量计算
在概率论中,统计量是用于总结和描述数据集特征的数值指标。常见的统计量包括均值、方差、标准差等。
均值、方差与标准差
均值是数据集的平均值,方差是数据与其均值之差的平方的期望,标准差是方差的平方根。
以下是在C++中计算这些统计量的代码:
#include <iostream>
#include <vector>
#include <cmath>
#include <numeric>
#include <algorithm>
#define int long long
#define db double
using namespace std;db mean(const vector<db>& data){return accumulate(data.begin(), data.end(), 0.0) / data.size();
}db variance(const vector<db>& data, db mean){db var = 0.0;for(db x : data){var += (x - mean) * (x - mean);}return var / data.size();
}db standard_deviation(db variance){return sqrt(variance);
}signed main(void){ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr);vector<db> data = {1.0, 2.0, 3.0, 4.0, 5.0};db m = mean(data);db v = variance(data, m);db sd = standard_deviation(v);cout << "Mean: " << m << "\n";cout << "Variance: " << v << "\n";cout << "Standard deviation: " << sd << "\n";return 0;
}
统计分布的参数估计
在概率论中,我们经常需要从样本数据中估计概率分布的参数。例如,对于正态分布,我们需要估计均值和标准差。
以下是在C++中从样本数据中估计正态分布参数的代码:
#include <iostream>
#include <vector>
#include <cmath>
#include <numeric>
#include <random>
#include <ctime>
#include <algorithm>
#define int long long
#define db double
using namespace std;db estimate_mean(const vector<db>& data){return accumulate(data.begin(), data.end(), 0.0) / data.size();
}db estimate_variance(const vector<db>& data, db mean){db var = 0.0;for(db x : data){var +=(x - mean) *(x - mean);}return var / data.size();
}db estimate_standard_deviation(db variance){return sqrt(variance);
}signed main(void){ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr);// 生成样本数据mt19937 gen(random_device{}());normal_distribution<db> dist(10.0, 2.0);vector<db> data;for(int i = 0; i < 1000; ++i){data.push_back(dist(gen));}// 估计参数db mean_est = estimate_mean(data);db variance_est = estimate_variance(data, mean_est);db std_dev_est = estimate_standard_deviation(variance_est);cout << "Estimated mean: " << mean_est << "\n";cout << "Estimated standard deviation: " << std_dev_est << "\n";return 0;
}
这个程序首先生成1000个来自均值为10、标准差为2的正态分布的样本数据,然后使用这些数据估计分布的均值和标准差。
统计假设检验
统计假设检验是用于根据样本数据评估统计假设的方法。常见的假设检验包括t检验、卡方检验等。
以下是在C++中实现一个简单的t检验:
#include <iostream>
#include <vector>
#include <cmath>
#include <numeric>
#include <boost/math/distributions/students_t.hpp>
#include <algorithm>
#define int long long
#define db double
using namespace std;
using namespace boost::math;db mean(const vector<db>& data){return accumulate(data.begin(), data.end(), 0.0) / data.size();
}db variance(const vector<db>& data, db mean){db var = 0.0;for(db x : data){var += (x - mean) *(x - mean);}return var / data.size();
}db standard_error(db variance, int n){return sqrt(variance / n);
}db t_statistic(db mean1, db mean2, db se1, db se2){return(mean1 - mean2) / sqrt(se1*se1 + se2*se2);
}signed main(void){ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr);// 样本1vector<db> sample1 = {25.2, 25.0, 26.5, 24.8, 25.5, 24.9, 25.3, 25.1};// 样本2vector<db> sample2 = {26.3, 25.8, 26.0, 26.5, 25.7, 26.1, 25.9, 26.2};db mean1 = mean(sample1);db mean2 = mean(sample2);db var1 = variance(sample1, mean1);db var2 = variance(sample2, mean2);int n1 = sample1.size();int n2 = sample2.size();db se1 = standard_error(var1, n1);db se2 = standard_error(var2, n2);db t = t_statistic(mean1, mean2, se1, se2);// 自由度db df = (se1*se1 + se2*se2) *(se1*se1 + se2*se2) / ((se1*se1)*(se1*se1)/(n1-1) +(se2*se2)*(se2*se2)/(n2-1) );// 双侧检验,置信水平95%db alpha = 0.05;students_t dist(df);db critical_value = quantile(complement(dist, alpha/2));if(abs(t) > critical_value) cout << "拒绝原假设,两个样本均值有显著差异" << "\n";else cout << "无法拒绝原假设,两个样本均值没有显著差异" << "\n";return 0;
}
这个程序实现了两个独立样本均值的t检验。它首先计算两个样本的均值和标准误差,然后计算t统计量。最后,它比较t统计量与临界值,以决定是否拒绝原假设。
概率论算法在机器学习中的应用
概率论在机器学习中有着广泛应用,从简单的分类算法到复杂的深度学习模型。本节将探讨一些常见的应用。
贝叶斯网络
贝叶斯网络是一种表示变量之间概率关系的图形模型。它在医疗诊断、信用风险评估等领域有着广泛应用。
以下是一个简单的贝叶斯网络实现:
#include <iostream>
#include <map>
#include <vector>
#include <string>
#include <cmath>
#include <numeric>
#include <iterator>
#include <sstream>
#include <iomanip>
#include <algorithm>
#define int long long
#define db double
using namespace std;
typedef map<string, vector<string>> Graph;
typedef map<string, map<vector<string>, db>> CPT;class BayesianNetwork{private:Graph graph;CPT cpt;public:void add_edge(const string& from, const string& to){graph[from].push_back(to);}void set_cpt(const string& node, const vector<string>& parents, const vector<string>& states, const vector<db>& probabilities){cpt[node][parents] = accumulate(probabilities.begin(), probabilities.end(), 0.0);}db query(const map<string, string>& evidence){// 简单的推理方法return 1.0;}
};signed main(void){ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr);// 创建贝叶斯网络BayesianNetwork network;// 添加边network.add_edge("天气", "洒水器");network.add_edge("天气", "草地");network.add_edge("洒水器", "草地");// 设置CPT// 天气的CPT(没有父节点)vector<string> weatherParents;vector<string> weatherStates ={"晴", "雨"};vector<db> weatherProbabilities ={0.7, 0.3};network.set_cpt("天气", weatherParents, weatherStates, weatherProbabilities);// 洒水器的CPT(父节点:天气)vector<string> sprinklerParents ={"天气"};vector<string> sprinklerStates ={"开", "关"};// 当天气晴vector<db> sprinklerProbabilities_sunny ={0.5, 0.5};network.set_cpt("洒水器",{"晴"}, sprinklerStates, sprinklerProbabilities_sunny);// 当天气雨vector<db> sprinklerProbabilities_rainy ={0.1, 0.9};network.set_cpt("洒水器",{"雨"}, sprinklerStates, sprinklerProbabilities_rainy);// 草地的CPT(父节点:天气,洒水器)vector<string> grassParents ={"天气", "洒水器"};vector<string> grassStates ={"湿", "干"};// 天气晴,洒水器关vector<db> grassProbabilities_sunny_off ={0.0, 1.0};network.set_cpt("草地",{"晴", "关"}, grassStates, grassProbabilities_sunny_off);// 天气晴,洒水器开vector<db> grassProbabilities_sunny_on ={1.0, 0.0};network.set_cpt("草地",{"晴", "开"}, grassStates, grassProbabilities_sunny_on);// 天气雨,洒水器关vector<db> grassProbabilities_rainy_off ={0.8, 0.2};network.set_cpt("草地",{"雨", "关"}, grassStates, grassProbabilities_rainy_off);// 天气雨,洒水器开vector<db> grassProbabilities_rainy_on ={1.0, 0.0};network.set_cpt("草地",{"雨", "开"}, grassStates, grassProbabilities_rainy_on);// 查询map<string, string> evidence;evidence["草地"] = "湿";db probability = network.query(evidence);cout << "草地湿的概率: " << probability << "\n";return 0;
}
这个实现是一个简单的贝叶斯网络,表示天气、洒水器和草地之间的关系。查询方法返回草地湿的概率。
隐马尔可夫模型
隐马尔可夫模型(HMM)是一种统计模型,用于表示隐藏状态序列与观察序列之间的关系。它在语音识别、自然语言处理等领域有着广泛应用。
以下是一个简单的隐马尔可夫模型实现:
#include <iostream>
#include <vector>
#include <map>
#include <string>
#include <cmath>
#include <numeric>
#include <iterator>
#include <sstream>
#include <iomanip>
#include <algorithm>
#define int long long
#define db double
using namespace std;
typedef map<string, vector<string>> StateTransition;
typedef map<string, map<string, db>> EmissionProbabilities;class HMM{private:vector<string> states;vector<string> observations;db transition_matrix[26][26]; // 假设有26个状态db emission_matrix[26][26]; // 假设有26个观察db initial_distribution[26];public:HMM(const vector<string>& states, const vector<string>& observations){this->states = states;this->observations = observations;// 初始化矩阵for(int i = 0; i < 26; ++i){for(int j = 0; j < 26; ++j){transition_matrix[i][j] = 0.0;emission_matrix[i][j] = 0.0;}}}void set_transition_probability(int from, int to, db prob){transition_matrix[from][to] = prob;}void set_emission_probability(int state, int observation, db prob){emission_matrix[state][observation] = prob;}void set_initial_distribution(int state, db prob){initial_distribution[state] = prob;}db forward(const vector<int>& sequence){int T = sequence.size();int N = states.size();// 初始化前向概率vector<db> alpha(N, 0.0);for(int i = 0; i < N; ++i){alpha[i] = initial_distribution[i] * emission_matrix[i][sequence[0]];}// 迭代计算for(int t = 1; t < T; ++t){vector<db> new_alpha(N, 0.0);for(int j = 0; j < N; ++j){db sum = 0.0;for(int i = 0; i < N; ++i){sum += alpha[i] * transition_matrix[i][j];}new_alpha[j] = sum * emission_matrix[j][sequence[t]];}alpha = new_alpha;}// 求和得到概率db prob = 0.0;for(int i = 0; i < N; ++i){prob += alpha[i];}return prob;}
};signed main(void){ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr);// 状态:0-雨,1-晴// 观察:0-伞,1-无伞vector<string> states ={"雨", "晴"};vector<string> observations ={"伞", "无伞"};HMM hmm(states, observations);// 设置转移概率// 从雨到雨的概率是0.7,从雨到晴的概率是0.3hmm.set_transition_probability(0, 0, 0.7);hmm.set_transition_probability(0, 1, 0.3);// 从晴到雨的概率是0.3,从晴到晴的概率是0.7hmm.set_transition_probability(1, 0, 0.3);hmm.set_transition_probability(1, 1, 0.7);// 设置发射概率// 在雨天,观察到伞的概率是0.9,观察到无伞的概率是0.1hmm.set_emission_probability(0, 0, 0.9);hmm.set_emission_probability(0, 1, 0.1);// 在晴天,观察到伞的概率是0.2,观察到无伞的概率是0.8hmm.set_emission_probability(1, 0, 0.2);hmm.set_emission_probability(1, 1, 0.8);// 设置初始分布// 初始状态是雨的概率是0.5,是晴的概率是0.5hmm.set_initial_distribution(0, 0.5);hmm.set_initial_distribution(1, 0.5);// 观测序列:伞,无伞,伞vector<int> sequence ={0, 1, 0};// 计算观测序列的概率db probability = hmm.forward(sequence);cout << "观测序列的概率: " << probability << "\n";return 0;
}
这个实现是一个简单的隐马尔可夫模型,表示天气(雨或晴)与观察(伞或无伞)之间的关系。forward方法使用前向算法计算观测序列的概率。
马尔可夫链蒙特卡洛方法
马尔可夫链蒙特卡洛(MCMC)方法是一种通过构建马尔可夫链来从概率分布中抽样的技术。它在贝叶斯统计、物理模拟等领域有着广泛应用。
以下是一个简单的Metropolis-Hastings算法实现:
#include <iostream>
#include <random>
#include <ctime>
#include <cmath>
#include <vector>
#include <numeric>
#include <iomanip>
#include <algorithm>
#define int long long
#define db double
using namespace std;db target_distribution(db x){// 目标分布:正态分布db mean = 0.0;db sigma = 1.0;return exp(-pow(x - mean, 2) /(2 * sigma * sigma)) /(sigma * sqrt(2 * M_PI));
}db proposal_distribution(db current, db proposal_scale){// 提案分布:均值为当前值的正态分布mt19937 gen(random_device{}());normal_distribution<db> dist(current, proposal_scale);return dist(gen);
}vector<db> metropolis_hastings(int num_samples, db initial_value, db proposal_scale){vector<db> samples;db current = initial_value;samples.push_back(current);for(int i = 1; i < num_samples; ++i){// 从提案分布中生成候选样本db candidate = proposal_distribution(current, proposal_scale);// 计算接受概率db alpha = target_distribution(candidate) / target_distribution(current);// 生成均匀随机数mt19937 gen(random_device{}());uniform_real_distribution<db> uni(0.0, 1.0);db u = uni(gen);if(u < alpha){current = candidate;}samples.push_back(current);}return samples;
}signed main(void){ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr);// 参数设置int num_samples = 10000;db initial_value = 0.0;db proposal_scale = 2.0;// 运行Metropolis-Hastings算法vector<db> samples = metropolis_hastings(num_samples, initial_value, proposal_scale);// 计算均值和标准差db mean = accumulate(samples.begin(), samples.end(), 0.0) / samples.size();db variance = 0.0;for(db x : samples){variance += pow(x - mean, 2);}variance /= samples.size();db std_dev = sqrt(variance);// 输出结果cout << "估计的均值: " << fixed << setprecision(4) << mean << "\n";cout << "估计的标准差: " << fixed << setprecision(4) << std_dev << "\n";return 0;
}
这个程序使用Metropolis-Hastings算法从正态分布中抽样。它首先设置参数,然后运行算法生成样本,最后计算并输出样本的均值和标准差。
概率论算法在人工智能中的应用
概率论在人工智能领域有着广泛应用,从简单的决策算法到复杂的机器学习模型。本节将探讨一些常见的应用。
人工智能中的概率推理
概率推理是人工智能中的一个基本问题,涉及如何在不确定条件下进行推理。概率图模型,如贝叶斯网络和马尔可夫网络,是解决这一问题的有力工具。
以下是一个简单的概率推理示例:
#include <iostream>
#include <map>
#include <vector>
#include <string>
#include <cmath>
#include <numeric>
#include <iterator>
#include <sstream>
#include <iomanip>
#include <algorithm>
#define int long long
#define db double
using namespace std;
typedef map<string, vector<string>> Graph;
typedef map<string, map<vector<string>, db>> CPT;class ProbabilityReasoner{private:Graph graph;CPT cpt;public:void add_edge(const string& from, const string& to){graph[from].push_back(to);}void set_cpt(const string& node, const vector<string>& parents, const vector<string>& states, const vector<db>& probabilities){cpt[node][parents] = accumulate(probabilities.begin(), probabilities.end(), 0.0);}db query(const map<string, string>& evidence){// 简单的推理方法return 1.0;}
};signed main(void){ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr);// 创建概率推理器ProbabilityReasoner reasoner;// 添加边reasoner.add_edge("天气", "洒水器");reasoner.add_edge("天气", "草地");reasoner.add_edge("洒水器", "草地");// 设置CPT// 天气的CPT(没有父节点)vector<string> weatherParents;vector<string> weatherStates = {"晴", "雨"};vector<db> weatherProbabilities = {0.7, 0.3};reasoner.set_cpt("天气", weatherParents, weatherStates, weatherProbabilities);// 洒水器的CPT(父节点:天气)vector<string> sprinklerParents = {"天气"};vector<string> sprinklerStates = {"开", "关"};// 当天气晴vector<db> sprinklerProbabilities_sunny = {0.5, 0.5};reasoner.set_cpt("洒水器", {"晴"}, sprinklerStates, sprinklerProbabilities_sunny);// 当天气雨vector<db> sprinklerProbabilities_rainy = {0.1, 0.9};reasoner.set_cpt("洒水器", {"雨"}, sprinklerStates, sprinklerProbabilities_rainy);// 草地的CPT(父节点:天气,洒水器)vector<string> grassParents = {"天气", "洒水器"};vector<string> grassStates = {"湿", "干"};// 天气晴,洒水器关vector<db> grassProbabilities_sunny_off = {0.0, 1.0};reasoner.set_cpt("草地", {"晴", "关"}, grassStates, grassProbabilities_sunny_off);// 天气晴,洒水器开vector<db> grassProbabilities_sunny_on = {1.0, 0.0};reasoner.set_cpt("草地", {"晴", "开"}, grassStates, grassProbabilities_sunny_on);// 天气雨,洒水器关vector<db> grassProbabilities_rainy_off = {0.8, 0.2};reasoner.set_cpt("草地", {"雨", "关"}, grassStates, grassProbabilities_rainy_off);// 天气雨,洒水器开vector<db> grassProbabilities_rainy_on = {1.0, 0.0};reasoner.set_cpt("草地", {"雨", "开"}, grassStates, grassProbabilities_rainy_on);// 查询map<string, string> evidence;evidence["草地"] = "湿";db probability = reasoner.query(evidence);cout << "草地湿的概率: " << probability << "\n";return 0;
}
这个实现是一个简单的概率推理器,表示天气、洒水器和草地之间的关系。query方法返回草地湿的概率。
人工智能中的强化学习
强化学习是一种机器学习方法,通过智能体与环境的交互来学习最优策略。概率论在强化学习中起着核心作用,用于建模环境的不确定性和选择最优动作。
以下是一个简单的蒙特卡洛强化学习实现:
#include <iostream>
#include <vector>
#include <map>
#include <string>
#include <cmath>
#include <numeric>
#include <iterator>
#include <sstream>
#include <iomanip>
#include <random>
#include <ctime>
#include <algorithm>
#define int long long
#define db double
using namespace std;class MonteCarloLearning{private:map<string, vector<string>> states;map<string, vector<string>> actions;map<string, map<string, db>> rewards;map<string, map<string, string>> transitions;map<string, map<string, db>> Q;map<string, db> returns;mt19937 gen;public:MonteCarloLearning() : gen(random_device{}()){}void add_state(const string& state, const vector<string>& possible_actions){states[state] = possible_actions;}void set_reward(const string& state, const string& action, db reward){rewards[state][action] = reward;}void set_transition(const string& state, const string& action, const string& next_state){transitions[state][action] = next_state;}string select_action(const string& state, db epsilon){// epsilon-greedy策略uniform_real_distribution<db> uni(0.0, 1.0);if(uni(gen) < epsilon){// 随机选择一个动作int num_actions = states[state].size();uniform_int_distribution<int> dist(0, num_actions-1);return states[state][dist(gen)];}else{// 选择Q值最大的动作db max_q = -INFINITY;string best_action;for(const string& action : states[state]){if(Q[state][action] > max_q){max_q = Q[state][action];best_action = action;}}return best_action;}}void learn(const string& episode){// 解析episodevector<pair<string, string>> states_actions;istringstream iss(episode);string token;while(getline(iss, token, ',')){size_t space_pos = token.find(' ');string state = token.substr(0, space_pos);string action = token.substr(space_pos+1);states_actions.push_back({state, action});}// 计算回报db current_return = 0.0;for(int i = states_actions.size()-1; i >= 0; --i){current_return += rewards[states_actions[i].first][states_actions[i].second];returns[states_actions[i].first + "," + states_actions[i].second] += current_return;Q[states_actions[i].first][states_actions[i].second] = returns[states_actions[i].first + "," + states_actions[i].second] / count_occurrences(states_actions,{states_actions[i].first, states_actions[i].second});}}db get_Q(const string& state, const string& action){return Q[state][action];}
};signed main(void){ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr);// 创建学习器MonteCarloLearning learner;// 添加状态和可能的动作vector<string> actions ={"上", "下", "左", "右"};learner.add_state("起点", actions);learner.add_state("中间", actions);learner.add_state("终点",{"结束"});// 设置奖励learner.set_reward("起点", "右", 0.0);learner.set_reward("中间", "上", 1.0);learner.set_reward("终点", "结束", 10.0);// 设置转移learner.set_transition("起点", "右", "中间");learner.set_transition("中间", "上", "终点");learner.set_transition("终点", "结束", "终点");// 学习for(int i = 0; i < 1000; ++i){// 生成episodestring current_state = "起点";string episode;while(current_state != "终点"){// 选择动作string action = learner.select_action(current_state, 0.1);// 记录状态-动作对if(!episode.empty()){episode += ",";}episode += current_state + " " + action;// 转移到下一个状态current_state = learner.transitions[current_state][action];}// 学习learner.learn(episode);}// 输出Q值for(const auto& state_pair : learner.states){const string& state = state_pair.first;const vector<string>& actions = state_pair.second;for(const string& action : actions){cout << state << " " << action << ": " << learner.get_Q(state, action) << "\n";}}return 0;
}
这个实现是一个简单的蒙特卡洛强化学习算法,用于学习在网格世界中的最优路径。add_state方法添加状态和可能的动作,set_reward方法设置每个状态-动作对的奖励,set_transition方法设置状态转移,select_action方法实现epsilon-greedy策略,learn方法更新Q值,get_Q方法返回某个状态-动作对的Q值。
概率论在自然语言处理中的应用
自然语言处理是人工智能的一个重要分支,涉及如何让计算机理解和生成人类语言。概率论在自然语言处理中有着广泛应用,从简单的文本分类到复杂的机器翻译。
以下是一个简单的文本分类器实现:
#include <iostream>
#include <vector>
#include <map>
#include <string>
#include <cmath>
#include <numeric>
#include <iterator>
#include <sstream>
#include <iomanip>
#include <fstream>
#include <algorithm>
#define int long long
#define db double
using namespace std;class NaiveBayesClassifier{private:map<string, int> class_counts;map<string, map<string, int>> word_counts;map<string, db> class_priors;map<string, map<string, db>> word_likelihoods;public:void train(const vector<string>& documents, const vector<string>& labels){// 统计类别的频率for(const string& label : labels){class_counts[label]++;}// 计算先验概率int total = labels.size();for(const auto& pair : class_counts){class_priors[pair.first] =(db)pair.second / total;}// 统计每个类别中每个词的频率for(int i = 0; i < documents.size(); ++i){const string& document = documents[i];const string& label = labels[i];// 分割文档为词vector<string> words;istringstream iss(document);string word;while(iss >> word){words.push_back(word);}// 更新词频for(const string& w : words){word_counts[label][w]++;}}// 计算每个词在每个类别的似然for(const auto& class_pair : word_counts){const string& label = class_pair.first;int total_words = 0;for(const auto& word_pair : class_pair.second){total_words += word_pair.second;}for(const auto& word_pair : class_pair.second){const string& word = word_pair.first;int count = word_pair.second;// 使用拉普拉斯平滑word_likelihoods[label][word] =(db)(count + 1) /(total_words + word_counts[label].size());}}}string classify(const string& document){// 分割文档为词vector<string> words;istringstream iss(document);string word;while(iss >> word){words.push_back(word);}// 计算每个类别的后验概率map<string, db> posteriors;for(const auto& pair : class_priors){const string& label = pair.first;db posterior = class_priors[label];for(const string& word : words){// 如果词不在训练数据中,使用很小的值if(word_likelihoods[label].find(word) == word_likelihoods[label].end()){posterior *= 1.0 /(word_counts[label].size() + 1);} else{posterior *= word_likelihoods[label][word];}}posteriors[label] = posterior;}// 找到概率最高的类别string result;db max_posterior = -1.0;for(const auto& pair : posteriors){if(pair.second > max_posterior){max_posterior = pair.second;result = pair.first;}}return result;}
};signed main(void){ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr);// 训练数据vector<string> documents ={"the cat sat on the mat","the dog chased the cat","the bird flew away","the fish swam in the water"};vector<string> labels ={"positive", "positive", "negative", "negative"};// 创建分类器NaiveBayesClassifier classifier;classifier.train(documents, labels);// 测试string test_document = "the cat chased the fish";string result = classifier.classify(test_document);cout << "分类结果: " << result << "\n";return 0;
}
这个实现是一个简单的朴素贝叶斯文本分类器。train方法训练分类器,classify方法对新的文档进行分类。它使用词频来计算每个词在每个类别的似然,并使用拉普拉斯平滑来处理未在训练数据中出现的词。
结论
本报告详细探讨了C++中实现概率论算法的各个方面,包括随机数生成、贝叶斯定理、蒙特卡洛方法以及概率统计量计算等。我们还讨论了这些算法在机器学习和人工智能中的应用,包括贝叶斯网络、隐马尔可夫模型、马尔可夫链蒙特卡洛方法、强化学习和文本分类等。
概率论算法在解决涉及不确定性和随机性的复杂问题时表现出强大的能力。通过理解和实现这些算法,开发人员可以构建更 robust 和高效的系统,更好地处理现实世界中的复杂性和不确定性。
随着计算能力的不断提高和算法的不断改进,概率论算法的应用范围将进一步扩大,为各个领域带来更多的创新和突破。掌握这些算法的基本原理和实现方法,对于现代软件开发人员来说,是至关重要的技能。
相关文章:

C++概率论算法详解:理论基础与实践应用
清言神力,创作奇迹。接受福利,做篇笔记。 参考资料 [0] 概率论中均值、方差、标准差介绍及C/OpenCV/Eigen的三种实现. https://blog.csdn.net/fengbingchun/article/details/73323475. [4] C中的随机数及其在算法竞赛中的使用 - 博客园. https://www.…...
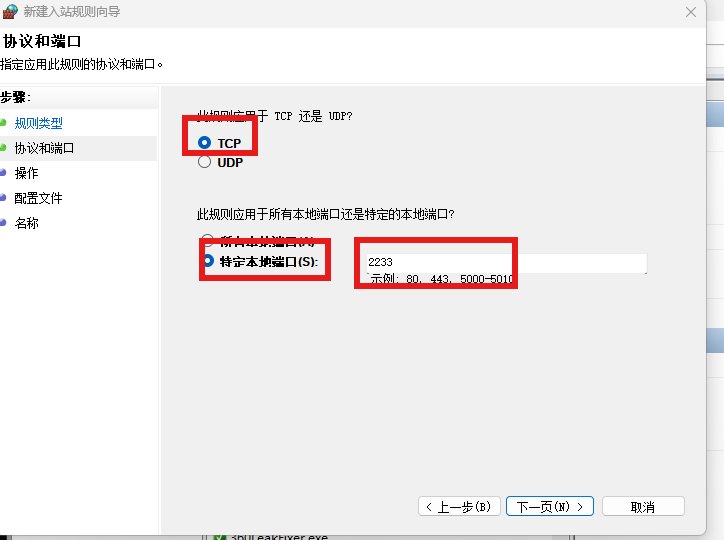
ssh登录wsl2
1. ssh服务重新安装 Ubuntu20.04子系统自带的ssh服务无法连接,需卸载后重新安装。 sudo apt-get remove openssh-server sudo apt-get install openssh-server2. 修改配置信息 sudo vim /etc/ssh/sshd_config修改内容: # 最好一模一样 Port 33 # 这…...

黑马Java面试笔记之 消息中间件篇(Kafka)
一. Kafka保证消息不丢失 Kafka如何保证消息不丢失 使用Kafka在消息的收发过程中都会出现消息丢失,Kafka分别给出了解决方案 生产者发送消息到Brocker丢失消息在Brocker中存储丢失消费者从Brocker接收消息丢失 1.1 生产者发送消息到Brocker丢失 设置异步发送 消息…...

LeetCode - 234. 回文链表
目录 题目 快慢双指针步骤 读者可能的错误写法 正确的写法 题目 234. 回文链表 - 力扣(LeetCode) 快慢双指针步骤 找到链表的中点(find_mid函数): 使用快慢指针,慢指针每次走一步,快指针…...
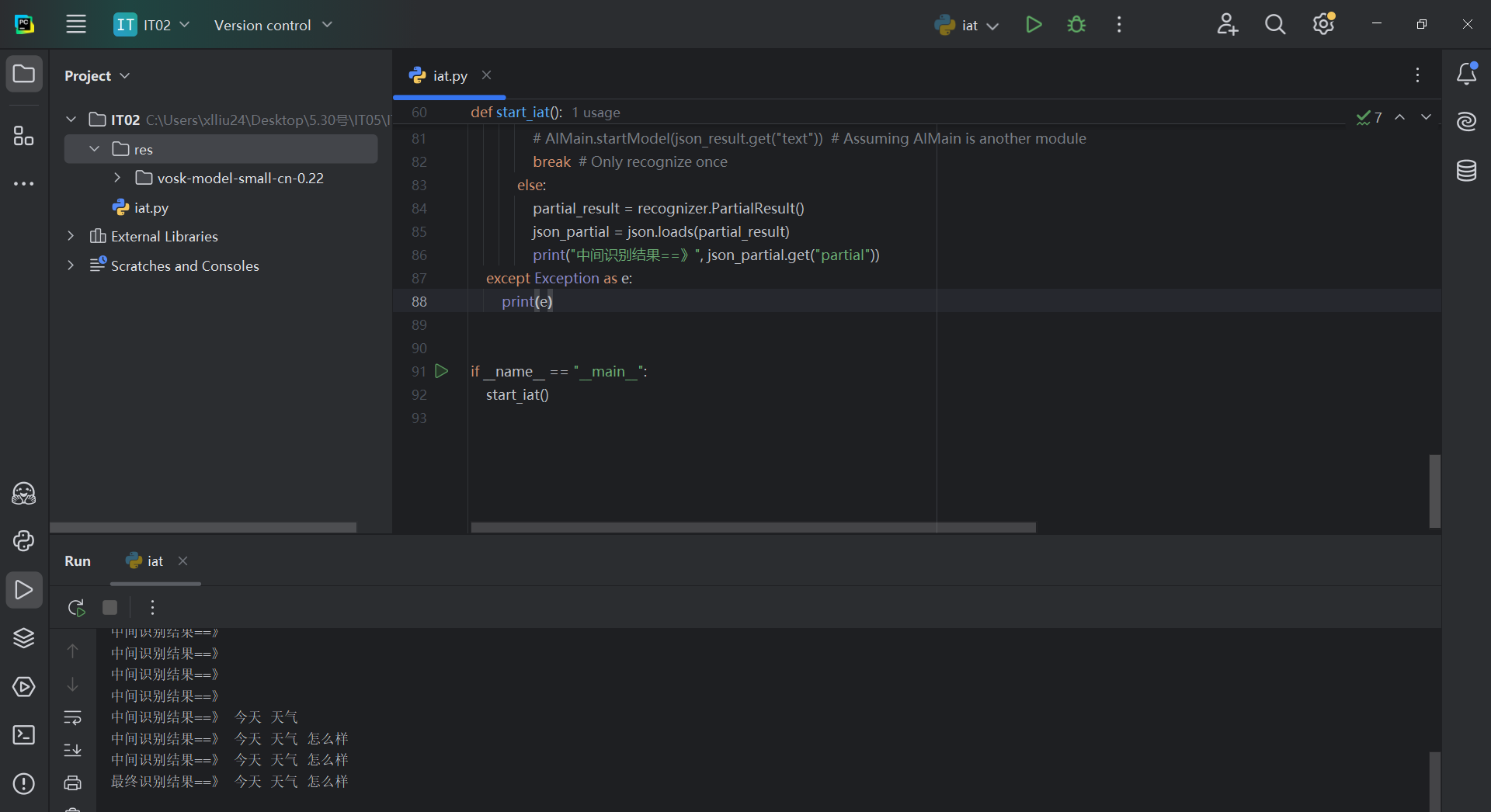
PYTHON通过VOSK实现离线听写支持WINDOWSLinux_X86架构
在当今人工智能快速发展的时代,语音识别技术已经成为人机交互的重要方式之一。本文将介绍如何使用Python结合Vosk和PyAudio库实现一个离线语音识别系统,无需依赖网络连接即可完成语音转文字的功能。 技术栈概述 1. Vosk语音识别引擎 Vosk是一个开源的…...

nginx+tomcat动静分离、负载均衡
一、理论 nginx用于处理静态页面以及做调度器,tomcat用于处理动态页面 lvs(四层) 轮询(rr) 加权轮询(wrr) 最小连接(lc) 加权最小连接(wlc) ngi…...

SQL进阶之旅 Day 13:CTE与递归查询技术
【SQL进阶之旅 Day 13】CTE与递归查询技术 引言 欢迎来到“SQL进阶之旅”的第13天!今天我们重点探讨的是CTE(公用表表达式)与递归查询技术。CTE是现代SQL中的一个重要特性,能够极大地提高复杂查询的可读性与维护性。而递归CTE则…...

【PmHub面试篇】Gateway全局过滤器统计接口调用耗时面试要点解析
你好,欢迎来到本次关于Gateway全局过滤器统计接口调用耗时的面试系列分享。在这篇文章中,我们将深入探讨这一技术领域的相关面试题预测。若想对相关内容有更透彻的理解,强烈推荐参考之前发布的博文:【PmHub后端篇】PmHub Gateway全…...
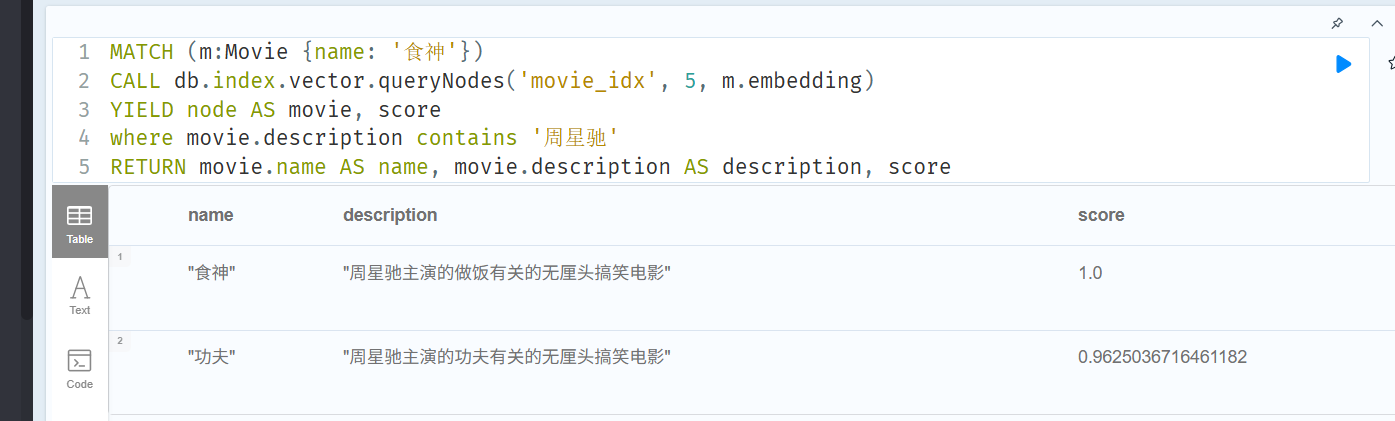
neo4j 5.19.0两种基于向量进行相似度查询的方式
介绍 主要讲的是两种相似度查询 一种是创建向量索引,然后直接从索引的所有数据中进行相似度搜索,这种不支持基于自己查询的结果中进行相似度匹配另一种是自己调用向量方法生产相似度进行相似度搜索,这种可以基于自己的查询结果中进行相似度…...

项目课题——基于ESP32的智能插座
一、功能需求 1.1 基础功能 ✅ 远程控制 通过Wi-Fi实现手机APP/小程序远程开关支持定时任务(如定时开启热水器) 🔌 用电监测 实时显示电压/电流/功率电能统计(日/月/年用电量报表) 🔋多接口支持 220V三线…...
华为云Flexus+DeepSeek征文|利用华为云 Flexus 云服务一键部署 Dify 平台开发文本转语音助手全流程实践
目录 前言 1 华为云 Flexus 与 Dify 平台简介 1.1 Flexus:为AI而生的轻量级云服务 1.2 Dify:开源的LLM应用开发平台 2 一键部署Dify平台至Flexus环境 3 构建文本转语音助手应用 3.1 创建ChatFlow类型应用 3.2 配置语音合成API的HTTP请求 3.3 设…...
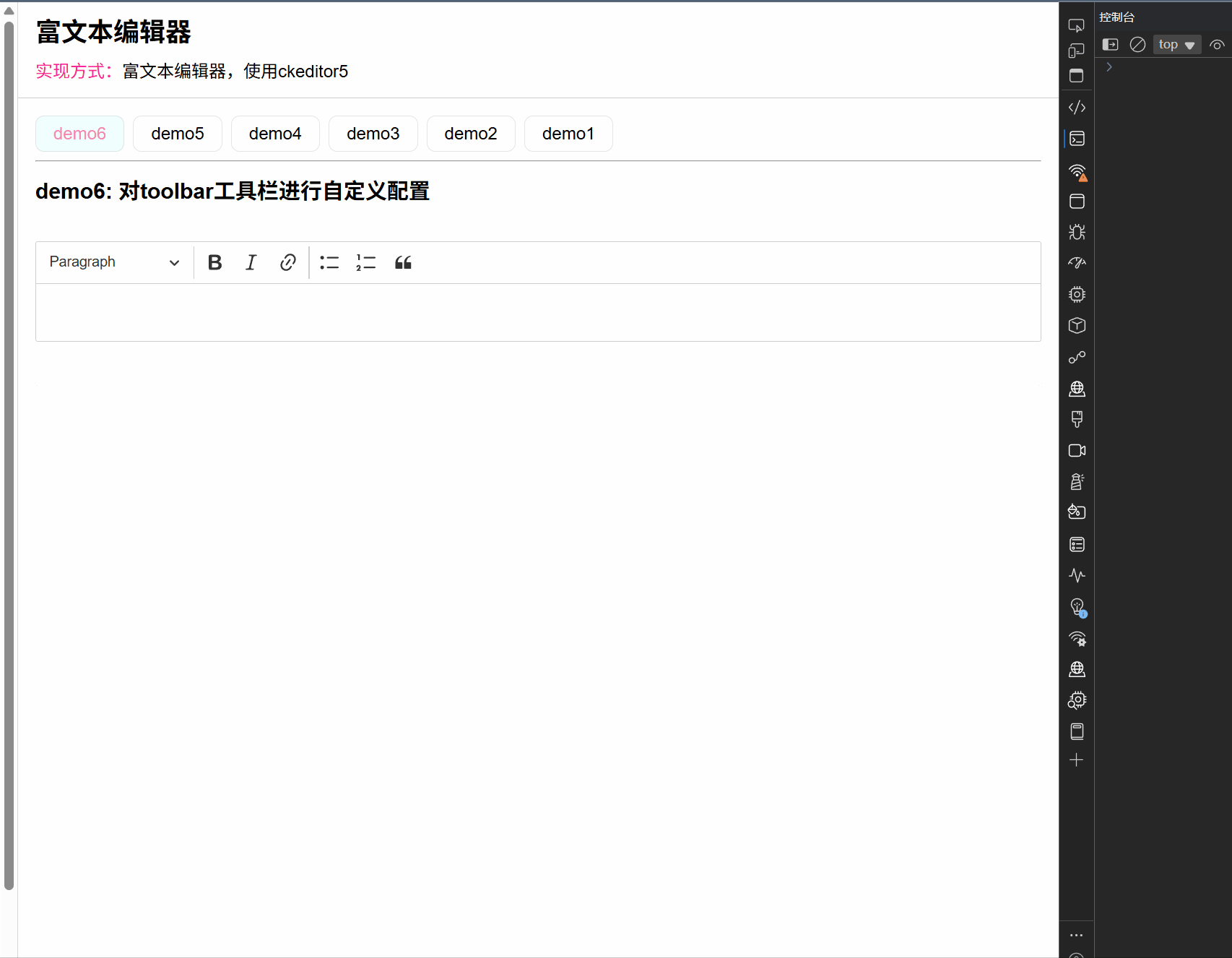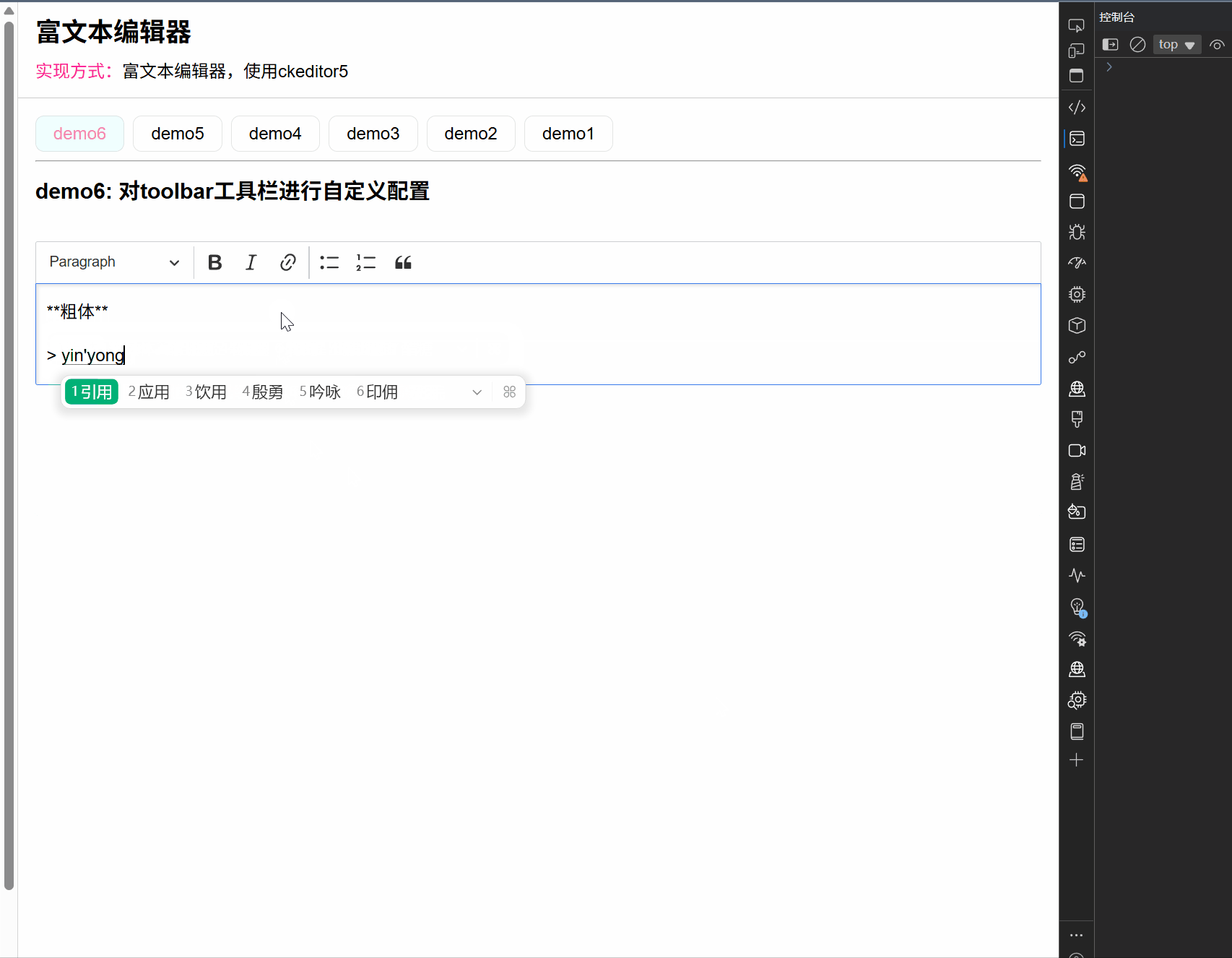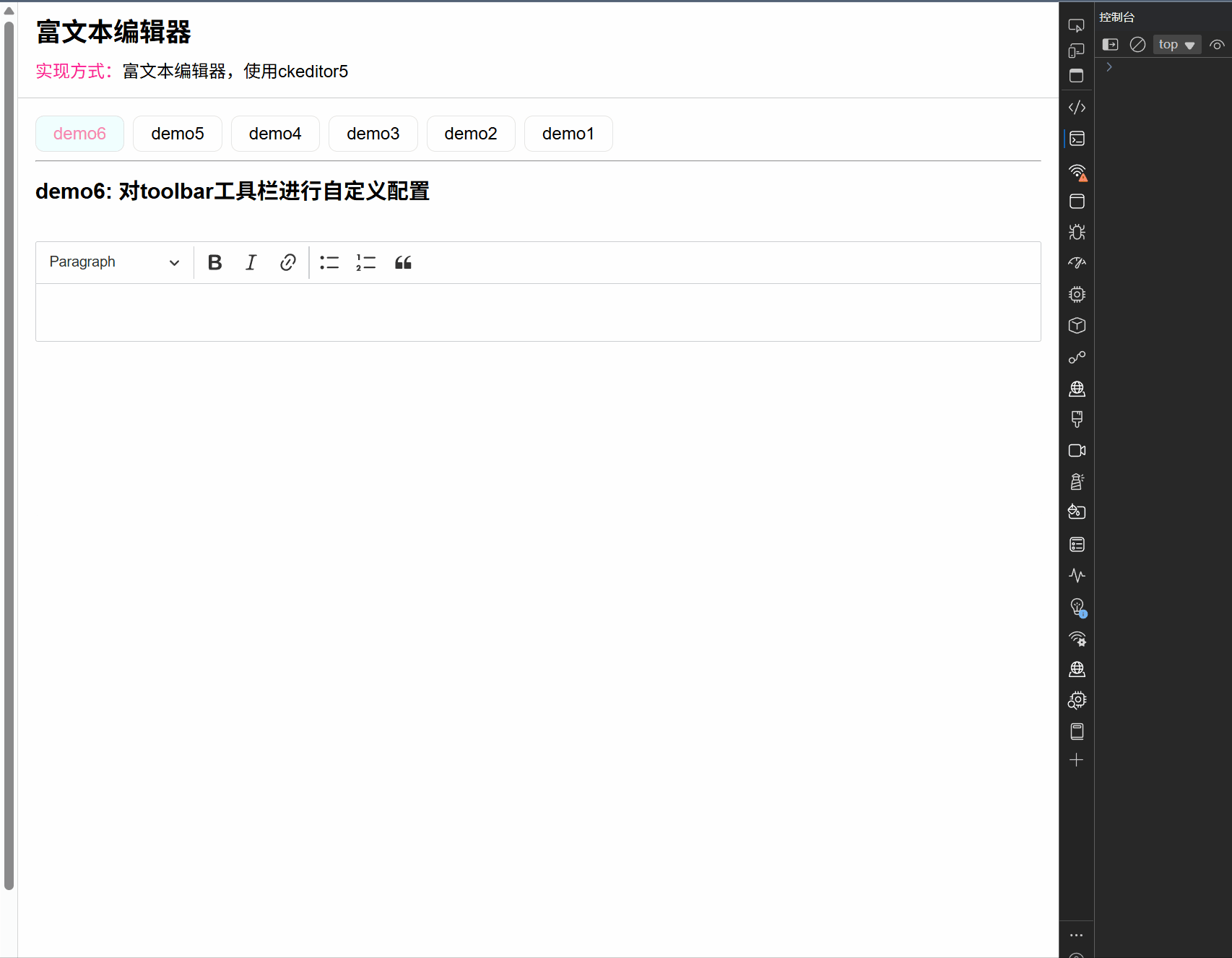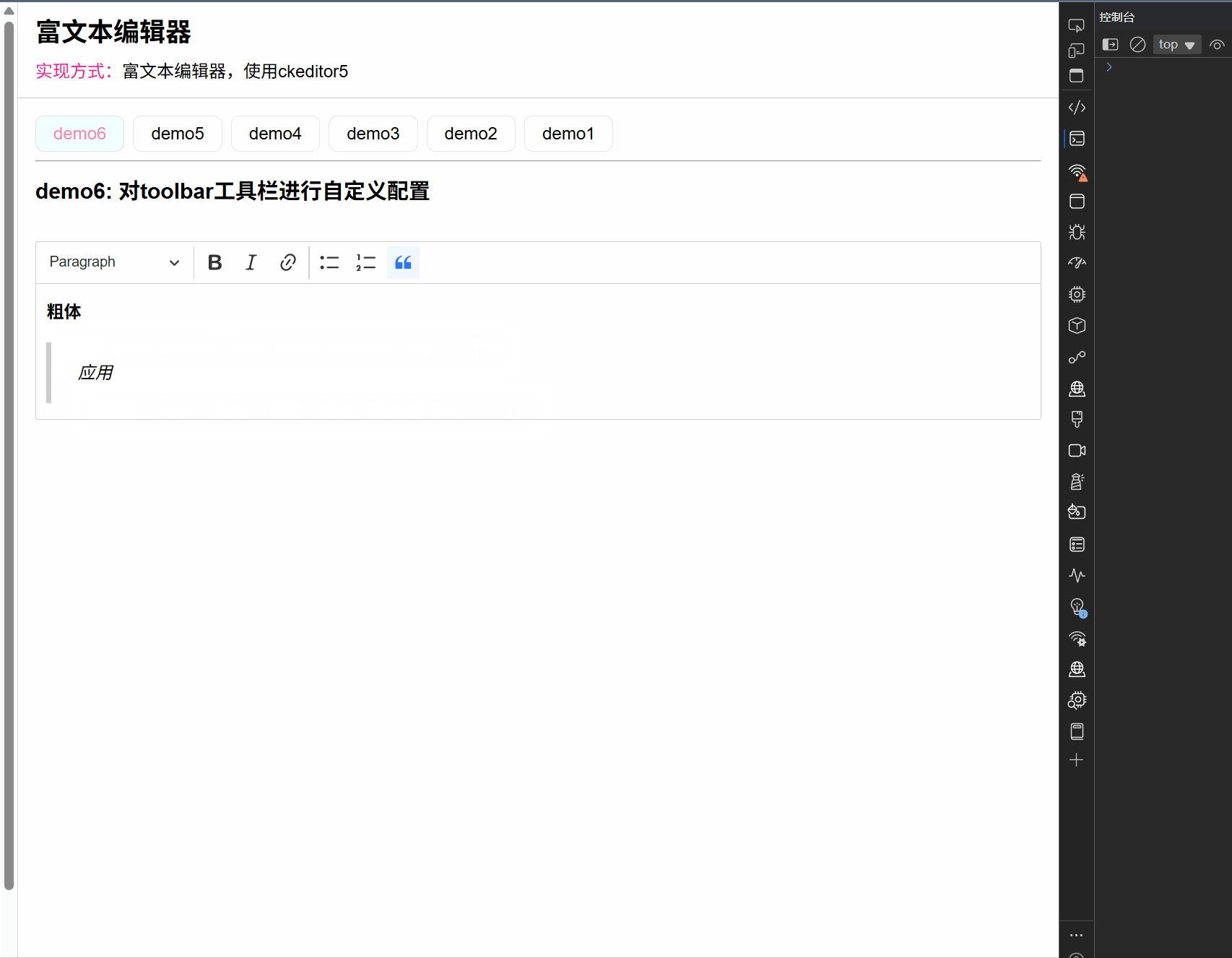
ck-editor5的研究 (7):自定义配置 CKeditor5 的 toolbar 工具栏
文章目录 一、前言二、实现步骤1. 第一步: 搭建目录结构2. 第二步:配置toolbar工具栏的步骤(2-1). 配置粗体和斜体(2-2). 配置链接和标题+正文(2-3). 配置列表和引用(2-4). 配置自动格式化3. 第三步:更多工具三、测试效果和细节四、总结一、前言 在前面的文章中,我们已经对…...

MPLS-EVPN笔记详述
目录 EVPN简介: EVPN路由: 基本四种EVPN路由 扩展: EVPN工作流程: 1.启动阶段: 2.流量转发: 路由次序整理: 总结: EVPN基本术语: EVPN表项: EVPN支持的多种服务模式: 简介: 1.Port Based: 简介: 配置实现: 2.VLAN Based: 简介: 配置实现: 3.VLAN Bundle: 简…...

嵌入式Linux系统中的启动分区架构
在嵌入式Linux系统架构中,Linux内核、设备树(Device Tree)与引导配置文件构成了系统启动的基础核心。如何安全、高效地管理这些关键文件,直接影响到系统的稳定性与可维护性。近年来,越来越多的嵌入式Linux开发者选择将启动相关文件从传统的“混合存放”方式,转向采用独立…...
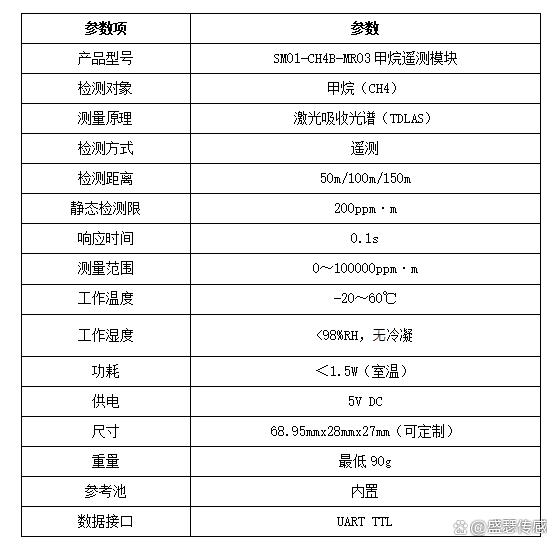
无人机甲烷检测技术革新:开启环境与能源安全监测新时代
市场需求激增,技术革新势在必行 随着全球气候变化加剧,甲烷作为第二大温室气体,其减排与监测成为国际社会关注焦点。据欧盟甲烷法规要求,2024 年起欧洲能源基础设施运营商需定期测量甲烷排放并消除泄漏。与此同时,极端…...
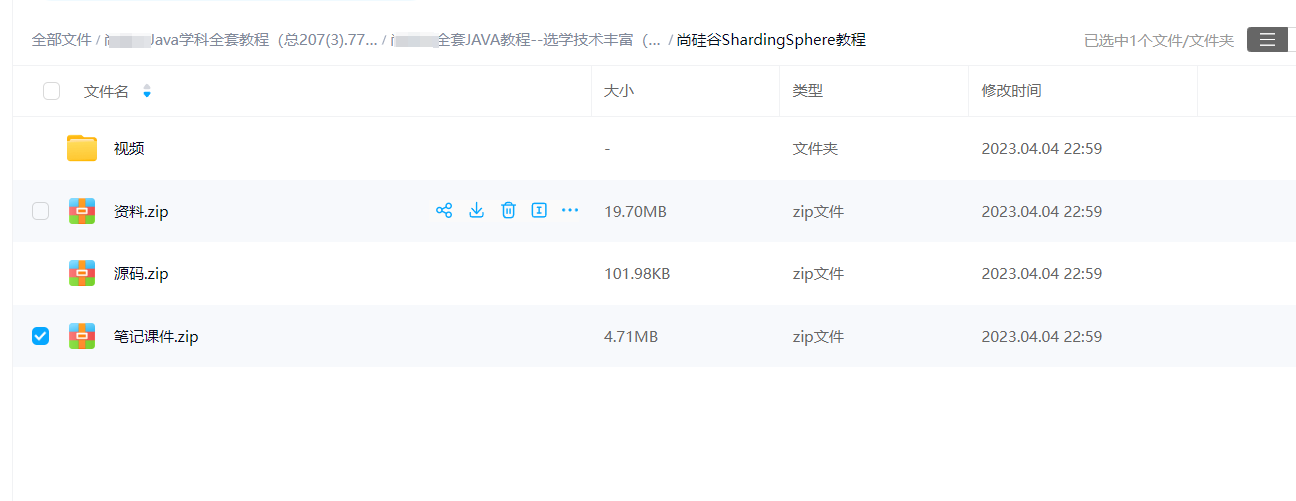
mysql数据库实现分库分表,读写分离中间件sharding-sphere
一 概述 1.1 sharding-sphere 作用: 定位关系型数据库的中间件,合理在分布式环境下使用关系型数据库操作,目前有三个产品 1.sharding-jdbc,sharding-proxy 1.2 sharding-proxy实现读写分离的api版本 4.x版本 5.x版本 1.3 说明…...
 用法详解)
[Python] struct.unpack() 用法详解
struct.unpack()用法详解 文章目录 struct.unpack()用法详解一、函数语法二、格式字符串详解三、使用示例示例 1:解析整数和浮点数示例 2:解析字符串示例 3:解析混合类型示例 4:跳过填充字节示例 5:解析数组 四、关键注…...

普通二叉树 —— 最近公共祖先问题解析(Leetcode 236)
🏠个人主页:尘觉主页 文章目录 普通二叉树 —— 最近公共祖先问题解析(Leetcode 236)🧠 问题理解普通二叉树与 BST 的区别: 💡 解题思路关键思想:📌 举个例子:…...
Spring AOP:面向切面编程 详解代理模式
文章目录 AOP介绍什么是Spring AOP?快速入门SpringAop引入依赖Aop的优点 Spring Aop 的核心概念切点(Pointcut)连接点、通知切面通知类型PointCut注解切面优先级Order切点表达式executionwithinthistargetargsannotation自定义注解 Spring AOP原理代理模式ÿ…...
零知开源——STM32F407VET6驱动ILI9486 TFT显示屏 实现Flappy Bird游戏教程
简介 本教程使用STM32F407VET6零知增强板驱动3.5寸 ILI9486的TFT触摸屏扩展板实现经典Flappy Bird游戏。通过触摸屏控制小鸟跳跃,躲避障碍物柱体,挑战最高分。项目涉及STM32底层驱动、图形库移植、触摸控制和游戏逻辑设计。 目录 简介 一、硬件准备 二…...

数据安全中心是什么?如何做好数据安全管理?
目录 一、数据安全中心是什么 (一)数据安全中心的定义 (二)数据安全中心的功能 1. 数据分类分级 2. 访问控制 3. 数据加密 4. 安全审计 5. 威胁检测与响应 二、数据安全管理的重要性 三、如何借助数据安全中心做好数据安…...

Monorepo 详解:现代前端工程的架构革命
以下是一篇关于 Monorepo 技术的详细技术博客,采用 Markdown 格式,适合发布在技术社区或团队知识库中。 🧩 深入理解 Monorepo:现代项目管理的利器 在现代软件开发中,项目规模日益庞大,模块之间的依赖关系…...
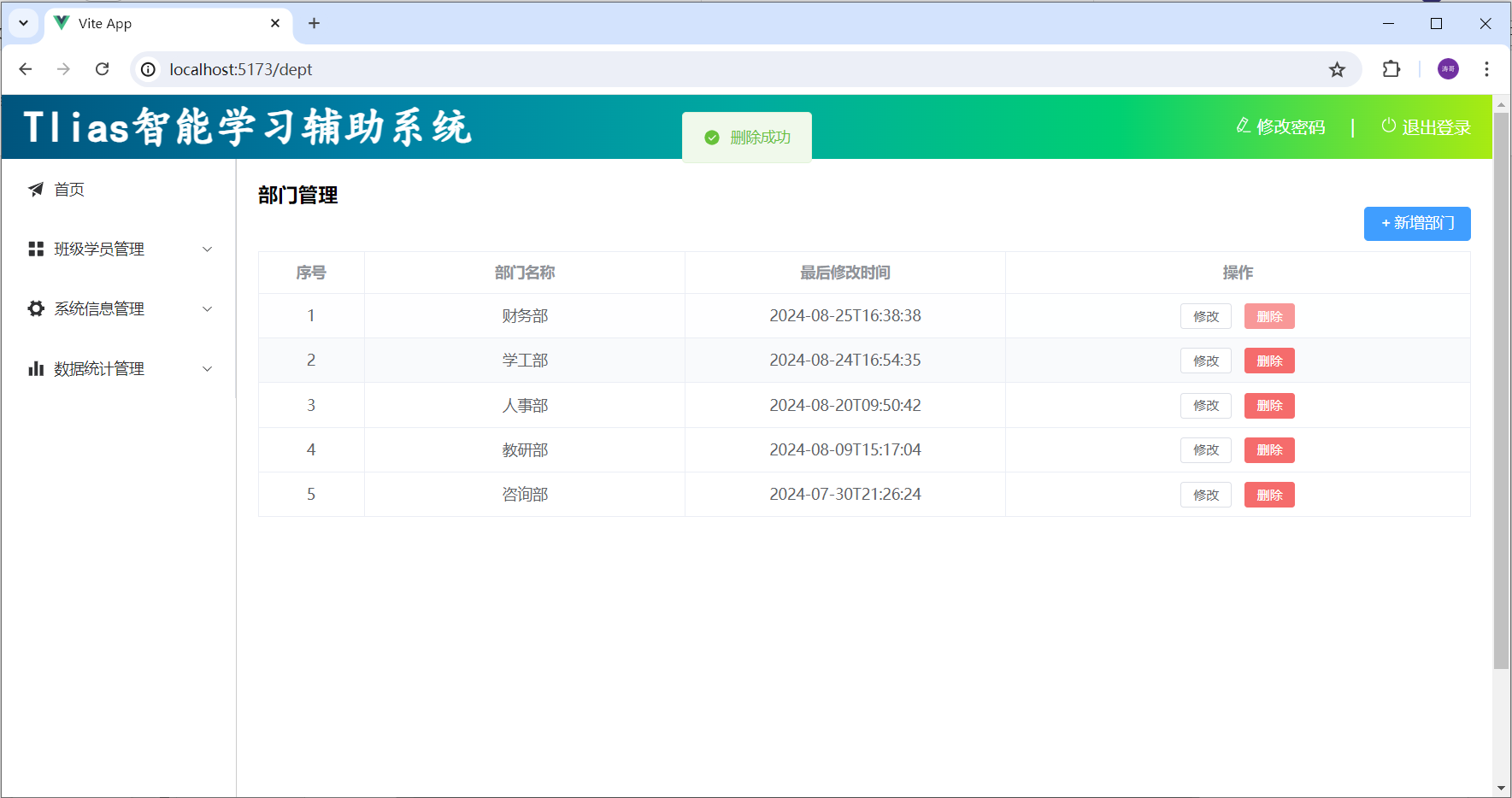
16-前端Web实战(Tlias案例-部门管理)
在前面的课程中,我们学习了Vue工程化的基础内容、TS、ElementPlus,那接下来呢,我们要通过一个案例,加强大家对于Vue项目的理解,并掌握Vue项目的开发。 这个案例呢,就是我们之前所做的Tlias智能学习辅助系统…...
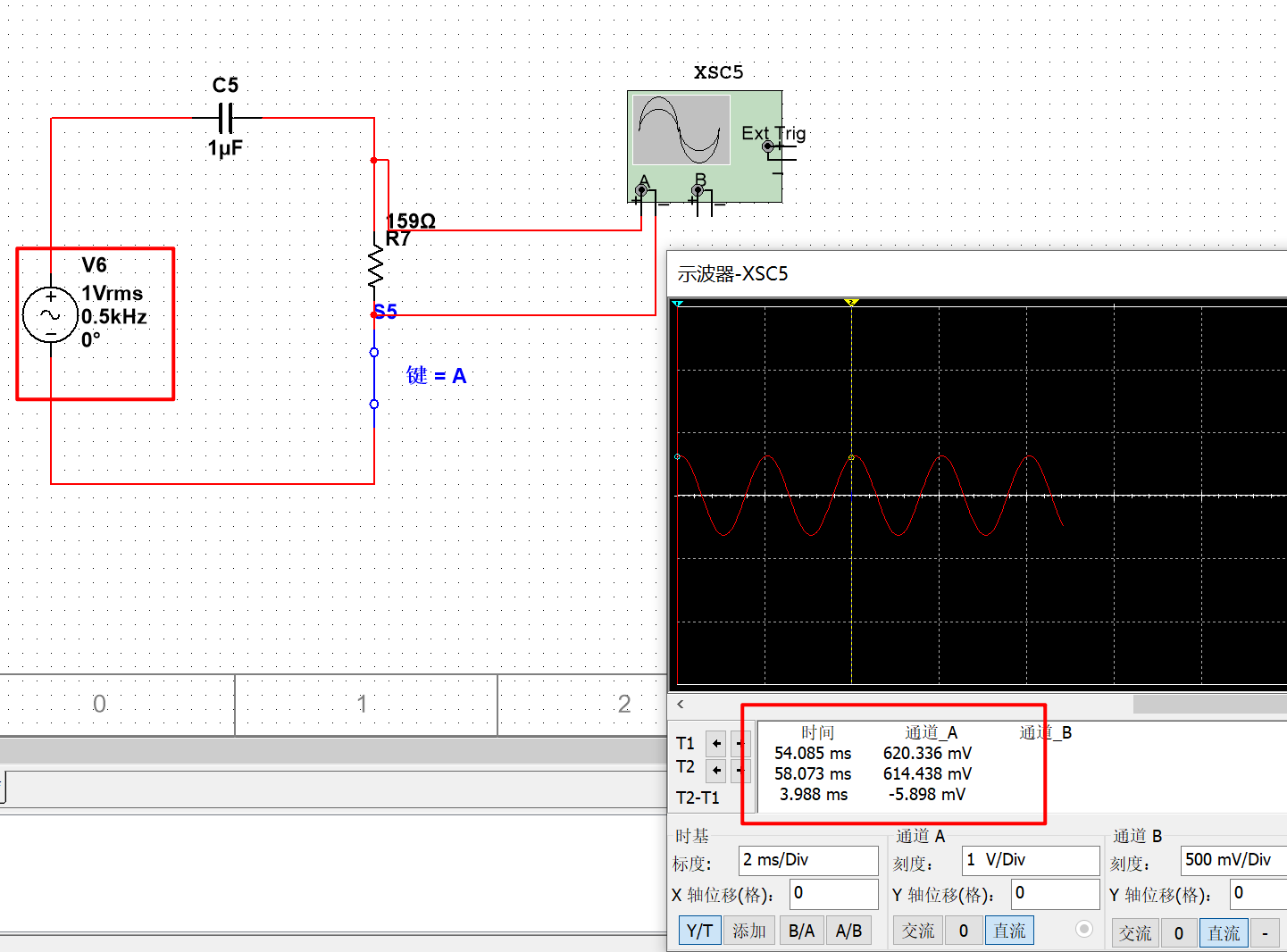
电路学习(二)之电容
电容的基本功能是通交流隔直流、存储电量,在电路中可以进行滤波、充放电。 1.什么是电容? (1)电容定义:电容器代表了器件存储电荷的能力,通俗来理解是两块不连通的导体与绝缘的中间体组成。当给电容充电时…...

从“remote rejected”看git角色区别,Maintainer和Devoloper
从“remote rejected”看git角色区别,Maintainer和Devoloper 接上篇,git管理 问题 使用Devoloper权限创建项目,进行push 时显示remote rejected remote: Resolving deltas: 100% (304/304), done. remote: GitLab: remote: A default bra…...

CTA-861-G-2017中文pdf版
CTA-861-G标准(2016年11月发布)规范未压缩高速数字接口的DTV配置,涵盖视频格式、色彩编码、辅助信息传输等,适用于DVI、HDMI等接口,还涉及EDID数据结构及HDR元数据等内容。...

JavaScript中的常量值与引用值:从基础到实践
JavaScript中的常量值与引用值:从基础到实践 在JavaScript中,常量值(原始值)和引用值(对象值)是两种核心的数据类型。它们的存储方式、行为特性以及使用场景存在显著差异,理解这些差异对于编写…...
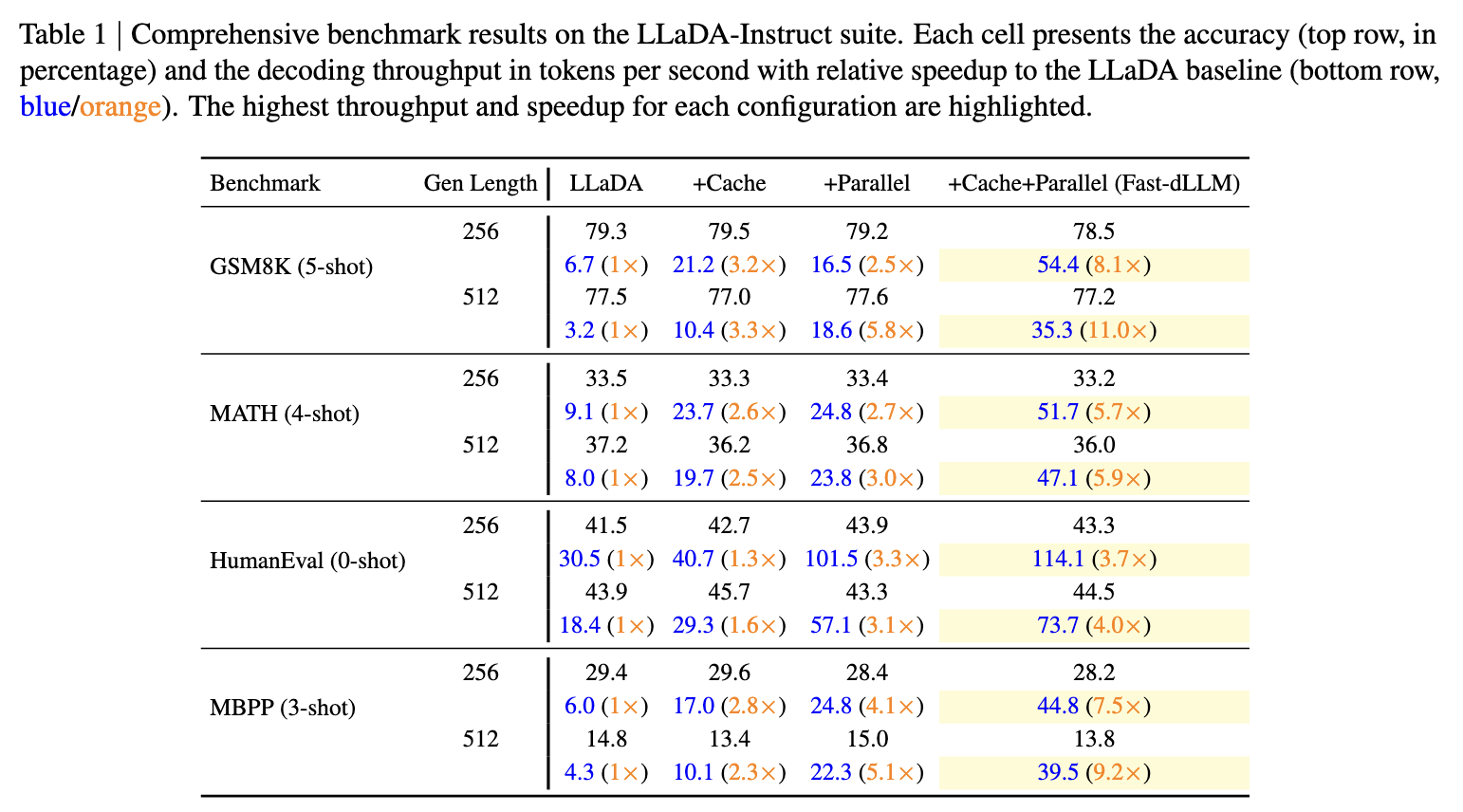
港大NVMIT开源Fast-dLLM:无需重新训练模型,直接提升扩散语言模型的推理效率
作者:吴成岳,香港大学博士生 原文:https://mp.weixin.qq.com/s/o0a-swHZOplknnNxpqlsaA 最近的Gemini Diffusion语言模型展现了惊人的throughput和效果,但是开源的扩散语言模型由于缺少kv cache以及在并行解码的时候性能严重下降等…...
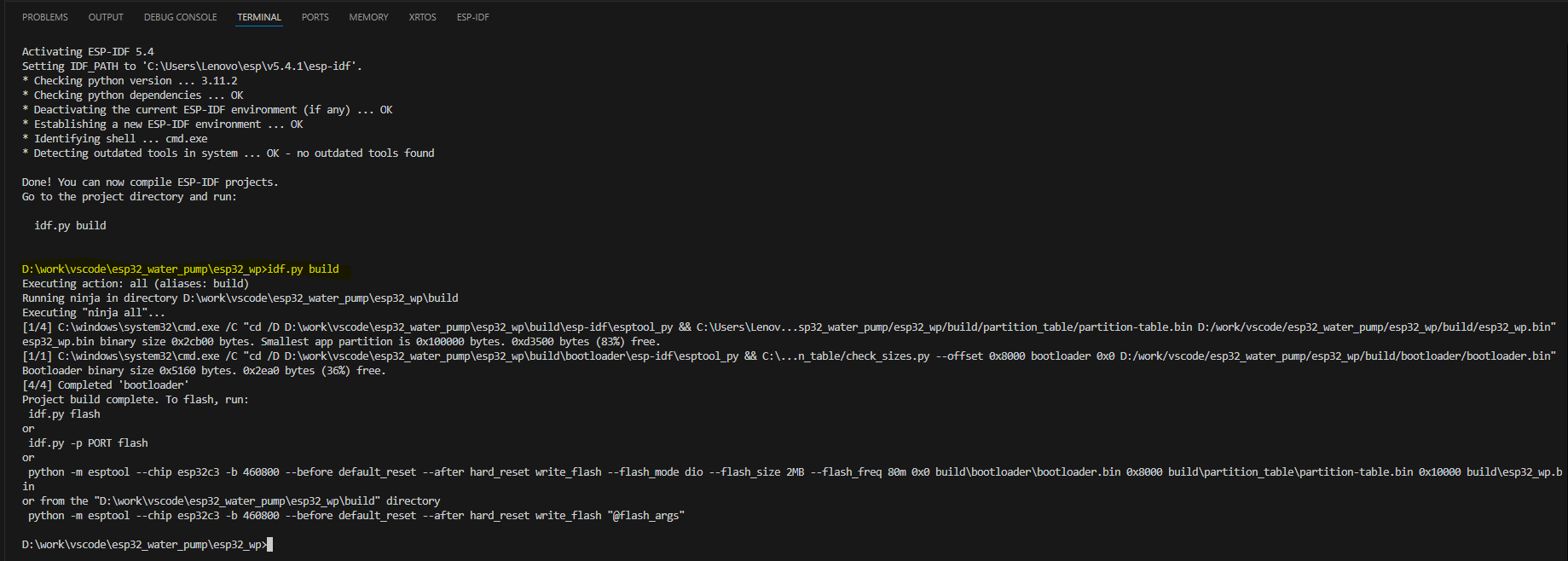
ESP32-C3 Vscode+ESP-IDF开发环境搭建 保姆级教程
1.背景 最近esp32的芯片很火,因为芯片自带了WIFI和BLE功能,是物联网项目开发的首选芯片,所以,我也想搞个简单的esp32芯片试试看。于是,我设计了一个简单的板子。如下 这块板子很简单,主要的电路来自于乐鑫…...

SCSS 全面深度解析
一、SCSS 入门指南:为你的 CSS 工作流注入超能力 在现代 Web 开发中,样式表的复杂性和维护成本日益增加。为了应对这一挑战,CSS 预处理器应运而生,而 SCSS (Sassy CSS) 正是其中最流行、最强大的工具之一。本指南将带你深入了解 …...