MySQL 全量、增量备份与恢复
一.MySQL 数据库备份概述
备份的主要目的是灾难恢复,备份还可以测试应用、回滚数据修改、查询历史数据、审计等。之前已经学习过如何安装 MySQL,本小节将从生产运维的角度了解备份恢复的分类与方法。
1 数据备份的重要性
在企业中数据的价值至关重要,数据保障了企业业务的正常运行。因此,数据的安全性及数据的可靠性是运维的重中之重,任何数据的丢失都可能对企业产生严重的后果。通常情况下造成数据丢失的原因有如下几种:
- 程序错误。
- 人为操作错误。
- 运算错误。
- 磁盘故障。
- 灾难(如火灾、地震)和盗窃
2 数据库备份类型
2.1 从物理与逻辑的角度分类
数据库备份可以分为物理备份和逻辑备份。
物理备份是对数据库操作系统物理文件(如数据文件、日志文件等)的备份
这种类型的备份适用于在出现问题时需要快速恢复的大型重要数据库。
物理备份又可以分为冷备份(脱机备份)、热备份(联机备份)和温备份
- 冷备份:在数据库关闭状态下进行备份操作。
- 热备份:在数据库处于运行状态时进行备份操作,该备份方法依赖数据库的日志文件。
- 温备份:数据库锁定表格(不可写入但可读)的状态下进行备份操作
逻辑备份是对数据库逻辑组件(如表等数据库对象)的备份,表示为逻辑数据库结构(CREATE DATABASE,CREATE TABLE 语句)和内容(INSERT 语句或分隔文本文件)的信息。这种类型的备份适用于可以编辑数据值或表结构较小的数据量,或者在不同的机器体系结构上重新创建数据。
2.2.从数据库的备份策略角度分类
从数据库的备份策略角度,数据库的备份可分为完全备份、差异备份和增量备份。
完全备份:每次对数据进行完整的备份,即对整个数据库、数据库结构和文件结构的备份,保存的是备份完成时刻的数据库,是差异备份与增量备份的基础。完全备份的备份与恢复操作都非常简单方便,但是数据存在大量的重复,并且会占用大量的磁盘空间,备份的时间也很长。
差异备份:备份那些自从上次完全备份之后被修改过的所有文件,备份的时间节点是从上次完整备份起,备份数据量会越来越大。恢复数据时,只需恢复上次的完全备份与最近的一次差异备份。
增量备份:只有那些在上次完全备份或者增量备份后被修改的文件才会被备份。以上次完整备份或上次增量备份的时间为时间点,仅备份这之间的数据变化,因而备份的数据量小,占用空间小,备份速度快。但恢复时,需要从上一次的完整备份开始到最后一次增量备份之间的所有增量依次恢复,如中间某次的备份数据损坏,将导致数据的丢失。
3常见的备份方法
MySQL 数据库的备份可以采用很多种方式,如直接打包数据库文件(物理冷备份)、专用备份工具(mysqldump)、二进制日志增量备份、第三方工具备份等。
3.1 物理冷备份
物理冷备份时需要在数据库处于关闭状态下,能够较好地保证数据库的完整性。物理冷备份一般用于非核心业务,这类业务一般都允许中断,物理冷备份的特点就是速度快,恢复时也是最为简单的。通常通过直接打包数据库文件夹(本章中的数据库文件夹位于/usr/1ocal/mysql/data)来实现备份。
3.2 专用备份工具 mysqldump 或 mysqlhotcopy
mysqldump 程序和 mysqlhotcopy 都可以做备份。mysqldump 是客户端常用逻辑备份程序,能够产生一组被执行以后再现原始数据库对象定义和表数据的SQL 语句。它可以转储一个到多个 MySQL 数据库,对其进行备份或传输到远程SQL 服务器。mysqldump 更为通用,因为它可以备份各种表。mysqlhotcopy 仅适用于某些存储引擎。
mysqlhotcopy是由TimBunce 最初编写和贡献的Perl 脚本。mysqlhotcopy 仅用于备份 MyISAM 和 ARCHIVE 表。它只能运行在 UNIX 或 Linux上。因为使用范围小,因此本文中不做详细介绍,如果同学们有兴趣可以在课下研究。
3.3 通过启用二进制日志进行增量备份
MySQL 支持增量备份,进行增量备份时必须启用二进制日志。二进制日志文件为用户 提供复制,对执行备份点后进行的数据库更改所需的信息进行恢复。如果进行增量备份(包含自上次完全备份或增量备份以来发生的数据修改),需要刷新二进制日志
3.4 通过第三方工具备份
Percona XtraBackup 是一个免费的 MySQL 热备份软件,支持在线热备份Innodb 和 XtraDB,也可以支持 MySQL 表备份,不过 MyISAM 表的备份要在表锁的情况下进行。本节对于 Percona XtraBackupr 的叙述是基于 2.4 版本的。
Percona XtrBackup 有三个主要的工具:xtrabackup、innobackupex、xbstream.
- xtrabackup:是一个编译了的二进制文件,只能备份Innodb/Xtradb 数据文件。
- innodbackupex :是一个封装了 xtrabackup 的Perl 脚本,除了可以备份Innodb/Xtradb 之外,还可以备份 MySIAM。
- xbstream:是一个新组件,能够允许将文件格式转成xbstream 格式或从xbstream 格式转到文件格式。
xtrabackup 工具可以单独使用,但推荐使用 innobackupex 来进行备份,这是因为 innobackupex本身就已经包含了 xtrabackup 的所有功能。
xtrabackup 是基于 Innodb 的灾难恢复功能进行设计的,备份工具复制Innodb 的数据文件。但是,由于不锁表,这样复制出来的数据将不一致。Innodb维护了一个重做日志,包含 Innodb 数据的所有改动情况。在 xtrabackup 备份Innodb 数据的同时,xtrabackup 还有另外一个线程用来监控重做日志,一但日志发生变化,就把发生变化的日志数据复制走。这样就可以利用重做日志做灾难恢复了。
以上是备份过程,如果需要恢复数据,则在准备阶段,xtrabackup 就需要使用之前复制的重做日志对备份出来的 Innodb 数据文件进行灾难恢复,此阶段完成之后,数据库就可以进行重建还原了。
Percona XtraBackup 对 MySIAM 的复制,是按这样的一个顺序进行的:首先锁定表,然后复制,再解锁表。第三方工具备份操作本章中不做详细介绍,如果同学们有兴趣可以在课下研究
二.数据库完全备份操作
上面提到根据数据库备份策略分类,备份可分为完全备份、差异备份和增量备份。在本章中我们只介绍完全备份与增量备份,感兴趣的同学可以课下自学差异备份的方法。
1 物理冷备份与恢复
物理冷备份一般用 tar 命令直接打包数据库文件夹,而在进行备份之前需要使用“systemctl stop mysqld”命令关闭 mysqld 服务。
1.1备份数据库
创建一个/backup 目录作为备份数据存储路径,使用 tar 创建备份文件。
整个数据库文件夹备份属于完全备份。


1.2 恢复数据库
执行下面操作将数据库文件/usr/local/mysql/data/转移至 bak 目录下模拟故障。
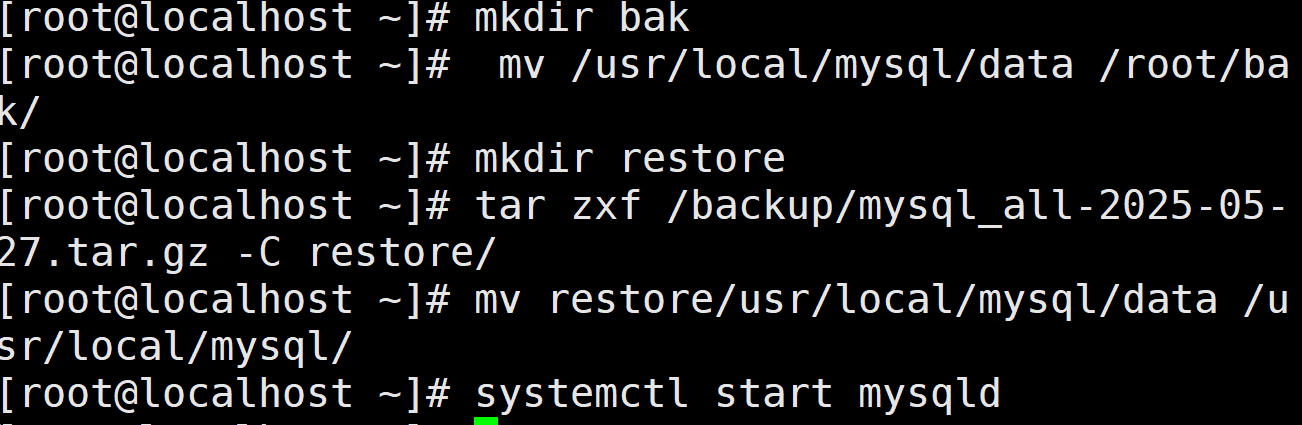
2 mysqldump 备份与恢复
通过 mysqldump 命令可以将指定的库、表或全部的库导出为 SQL 脚本,便于该命令在不同版本的 MySQL 服务器上使用。例如,当需要升级 MySQL 服务器时,可以先使用 mysqldump 命令将原有库信息导出,然后直接在升级后的 MySQI服务器中导入即可。
2.1备份数据库
使用 mysqldump 命令导出数据时,默认会直接在终端显示,若要保存到文件,还需要结合 Shel1 的“>”重定向输出操作,命令格式如下所示。
格式1:备份指定库中的部分表。
![]()
格式2:备份一个或多个完整的库(包括其中所有的表)
![]()
格式3:备份MySQL服务器中所有的库。
![]()
其中,常用的选项包括“-u”、“-p”,分别用于指定数据库用户名、密码。例如,以下操作分别使用格式1、格式 2,将 mysql 库中的 user 表导出为mysq1-user.sql,将整个 test 库导出为 test.sql 文件,所有操作均以 root用户身份验证。
若需要备份整个 MySQL 服务器中的所有库,应使用格式 3。当导出的数据量较大的时候,可以添加“--opt”选项以优化执行速度。例如,执行以下操作将创建备份文件 all-data.sql,其中包括 MySQL 服务器中的所有库。



2.2 查看备份文件
通过 mysqldump 工具导出的 SQL 脚本是文本文件,其中“/*…*/”部分或以“--”开头的行表示注释信息。使用 grep、less、cat 等文本工具可以查看脚本内容。例如,执行以下操作可以过滤出 test.sql 脚本中的数据库操作语句。

2.3 恢复数据库
使用 mysqldump 命令导出的 SQL 备份脚本,在需要恢复时可以通过 mysq1命令对其进行导入操作,命令格式如下所示。

当备份文件中只包含表的备份,而不包含创建的库的语句时,执行导入操作时必须指定库名,且目标库必须存在。
例如,执行以下操作可以从备份文件 mysql-user.sql 中将表导入test 库。其中“-e”选项是用于指定连接 MySQL 后执行的命令,命令执行完后自动退出。

若备份文件中已经包括完整的库信息,则执行导入操作时无须指定库名
例如,执行以下操作可以从备份文件 test.sql 恢复 test 库:

//删除 test 数据库,模拟故障
//查看 test 数据库是否存在

除了使用 mysq1 命令结合“<”恢复数据外,还可以使用 source 命令恢复数据,具体用法如下
3 MySQL 增量备份与恢复
使用 mysqldump 进行完全备份,备份的数据中有重复数据,备份时间与恢复时间过长。而增量备份就是自上一次备份之后增加或改变的内容。
3.1 MySQL 增量备份概述
(1)增量备份的特点
与完全备份不同,增量备份没有重复数据,备份量不大,时间短;但其恢复麻烦,需要上次完全备份及完全备份之后所有的增量备份才能恢复,而且要对所有增量备份进行逐个反推恢复。MySQL 没有提供直接的增量备份办法,可以通过MySQL 提供的二进制日志 (binary logs)间接实现增量备份。
(2) MySQL 二进制日志对备份的意义
二进制日志保存了所有更新数据库的操作。二进制日志在启动 MySQL 服务器后开始记录,并在文件达到二进制日志所设置的最大值或者接收到flushlogs 命令后重新创建新的日志文件,生成二进制文件序列,并及时把这些日志保存到安全的存储位置,即可完成一个时间段的增量备份。使maxbinlog_size配置项可以设置二进制日志文件的最大值,如果二进制文件的大小超过了max binlog size,它就会自动创建新的二进制文件。
要进行 MySQL 的增量备份,首先要开启二进制日志功能。开启 MySQL的进制日志功能的实现方法有很多种,最常用的是在 MySQL配置文件的 mysqld项下加入“log-bin=/文件路径/文件名”前缀,如1og-bin=/usr/local/mysql/mysq1-bin,然后重启 MySQL 服务就可 以在指定路径下查看二进制日志文件了。默认情况下,二进制日志文件的扩展名是一个六位的数字,如 mysql-bin.000001。
Mysq18.0 默认已经开启 binlog,无需显示配置 binlog(默认 binlog 文件为:binlog.000001),如需自定义binlog 配置,请添加如下配置项
vim /etc/my.cnf


3.2 MySQL 增量恢复
在维护数据库时,因为各种各样的原因可能会导致数据丢失,如:人为的 SQI语句破坏数据库、在进行下一次全备份之前发生系统故障导致数据库数据丢失、在数据库主从架构中主库的数据发生故障等。当出现以上场景时可以使用增量恢复来恢复数据。
常用的增量恢复的方法有三种:一般恢复、基于位置的恢复、基于时间点的恢复。
一般恢复:将所有备份的二进制日志内容全部恢复,命令格式如下所示
![]()
基于位置的恢复:数据库管理员在操作数据库时可能在同一时间点既有错误的操作也有正确的操作,通过基于位置进行恢复可以更加精准,命令格式如下所小。
- 格式 1:恢复数据到指定位置
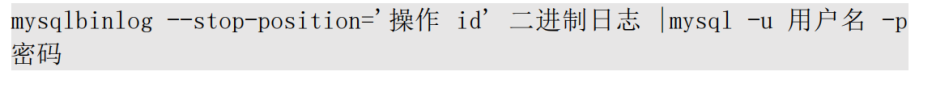
- 格式 2:从指定的位置开始恢复数据。

基于时间点的恢复:跳过某个发生错误的时间点实现数据恢复,而基于时间点的恢复可以分成三种情况。
- 格式 1:从日志开头截止到某个时间点的恢复。

- ·格式 2:从某个时间点到日志结尾的恢复。

- 格式 3:从某个时间点到某个时间点的恢复。

3.3 MySQL 企业备份案例
需求描述:北京移电通信公司的用户信息数据库为client,用户资费数据表为 user info,该公司每周需要进行完全备份,每天需要进行增量备份。新增加的用户信息如表 4-1 所示。
| 身份证 | 姓名 | 性别 | 用户ID号 | 资费 |
| 000006 | 张三 | 男 | 016 | 10 |
| 000007 | 李四 | 女 | 017 | 91 |
| 000008 | 王五 | 女 | 018 | 23 |
| 000009 | 赵六 | 男 | 019 | 37 |
| 000010 | 孙七 | 男 | 020 | 36 |
1.一般恢复
(1)添加数据库、表,录入信息
在进行备份之前,先根据给出的需求创建用户信息数据库 client、用户资费数据表 user info,并且根据需求描述中的表格插入前三条用户的数据。
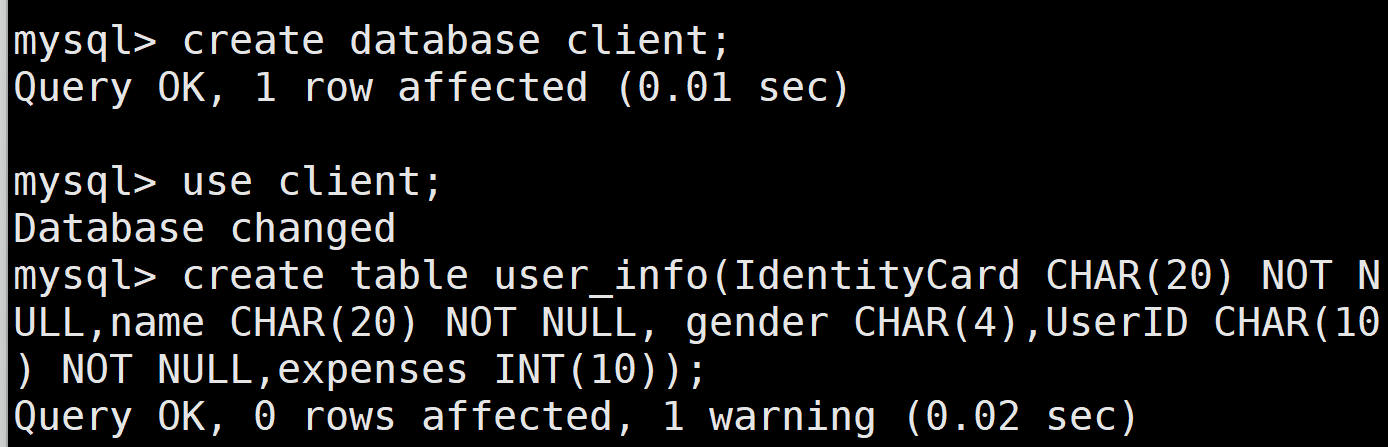
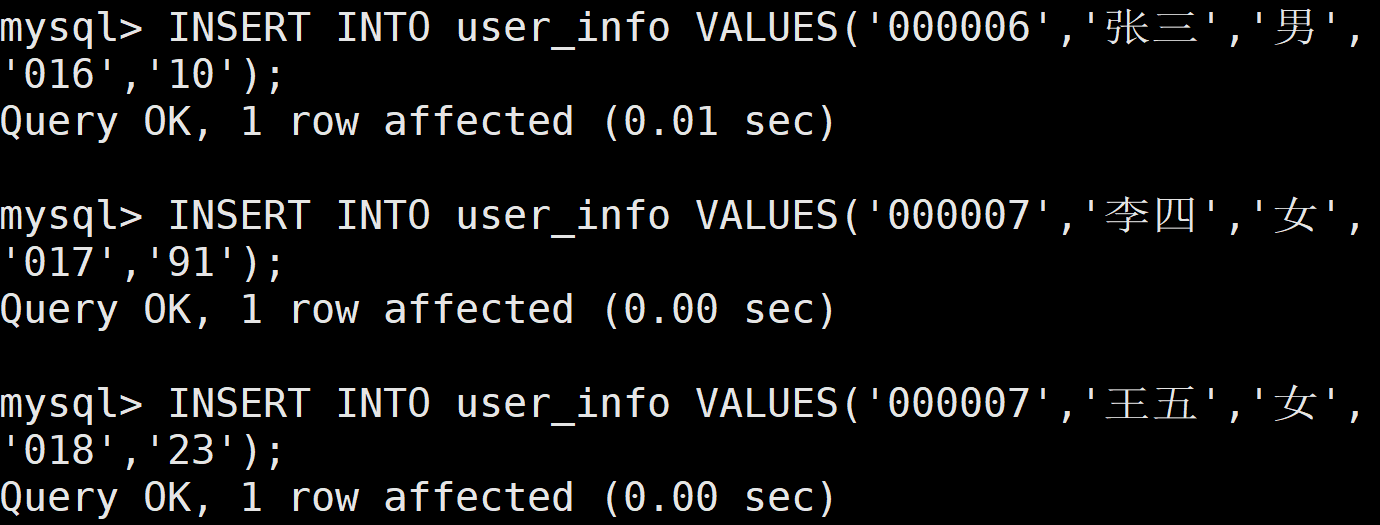
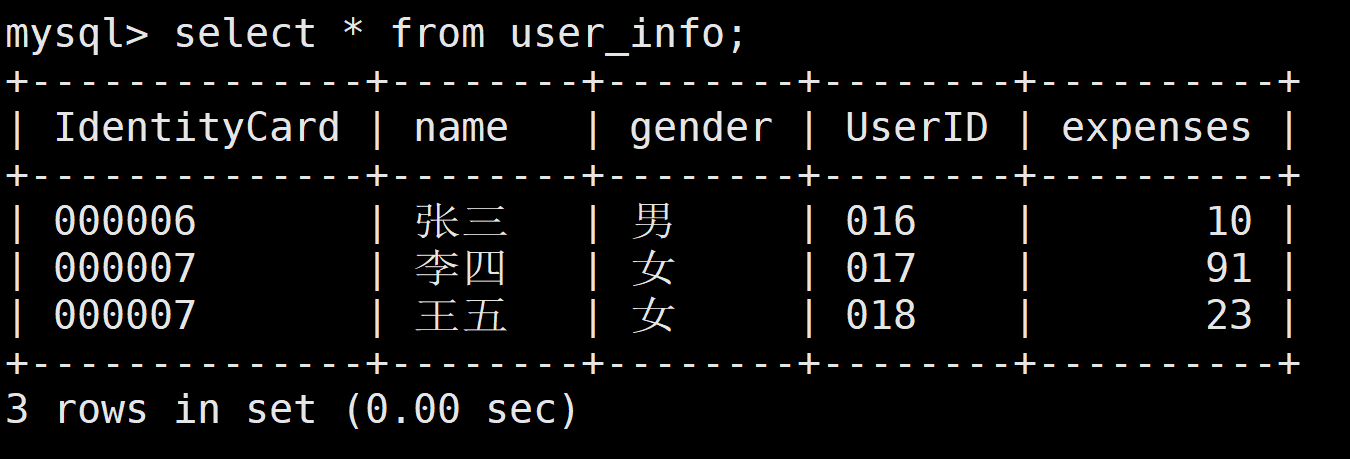
(2)先进行一次完全备份
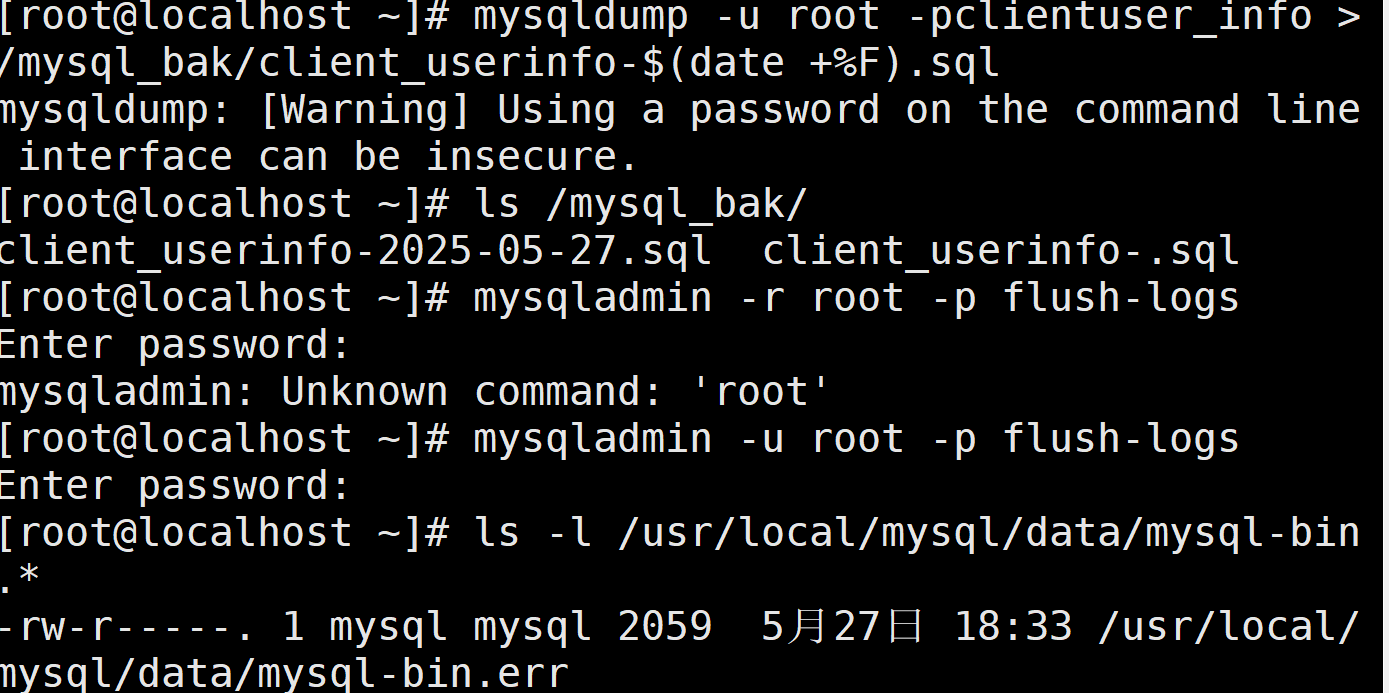
为方便验证二进制日志的增量恢复功能,在插入三条用户数据后先对client 数据库的 user info 表进行一次完全备份。然后在 Linux 系统命令行下执行“mysqladmin -uroot -p flush-logs”命令或在“mysql>”命令提示符下执行“flush logs;”生成新的二进制日志。
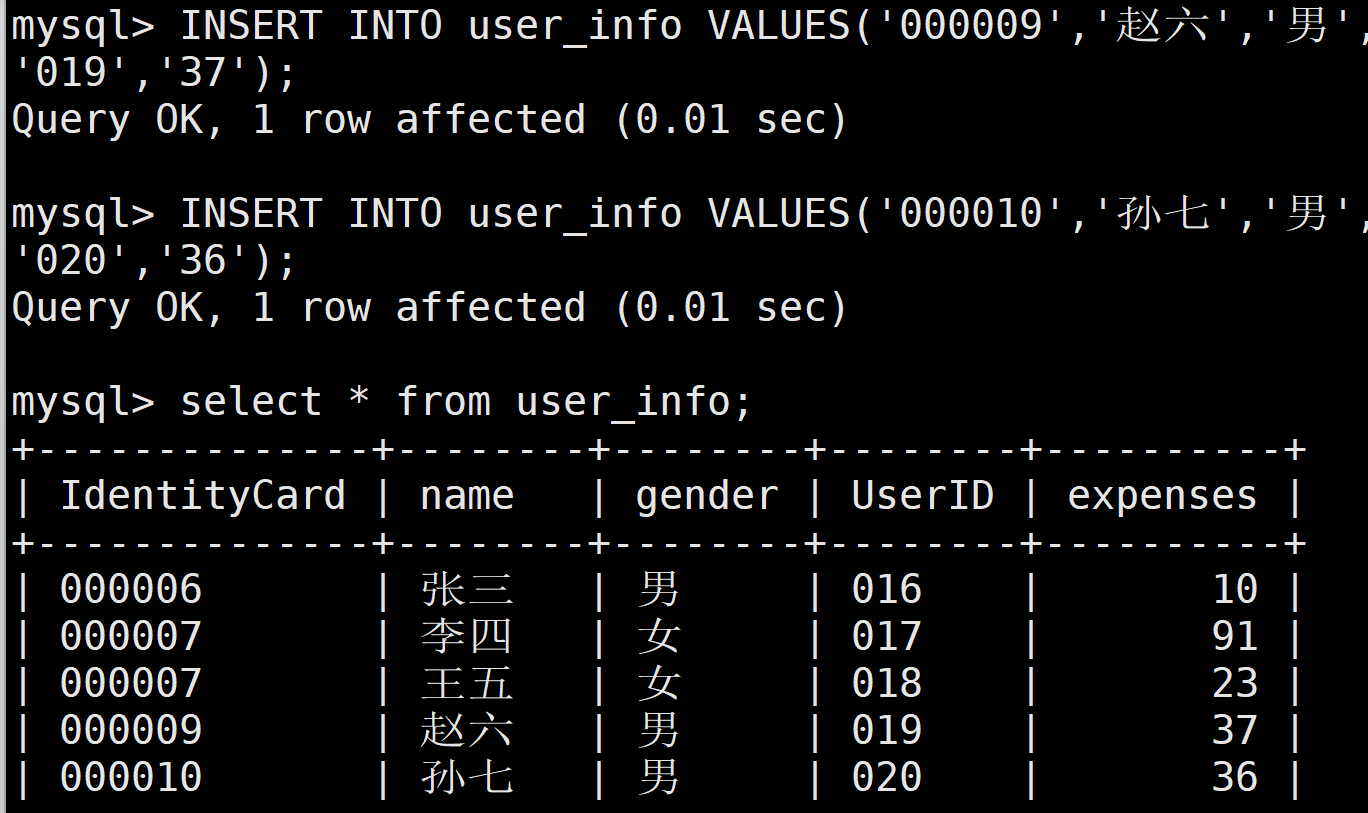
(3)继续录入新的数据并进行增量备份
继续录入两个用户的数据,并执行“mysqladmin-uroot-p flush-logs命令刷新二进制日志,进行增量备份。如此,二进制日志文件 mysql-bin.000002
中仅保留插入两个用户数据的操作。

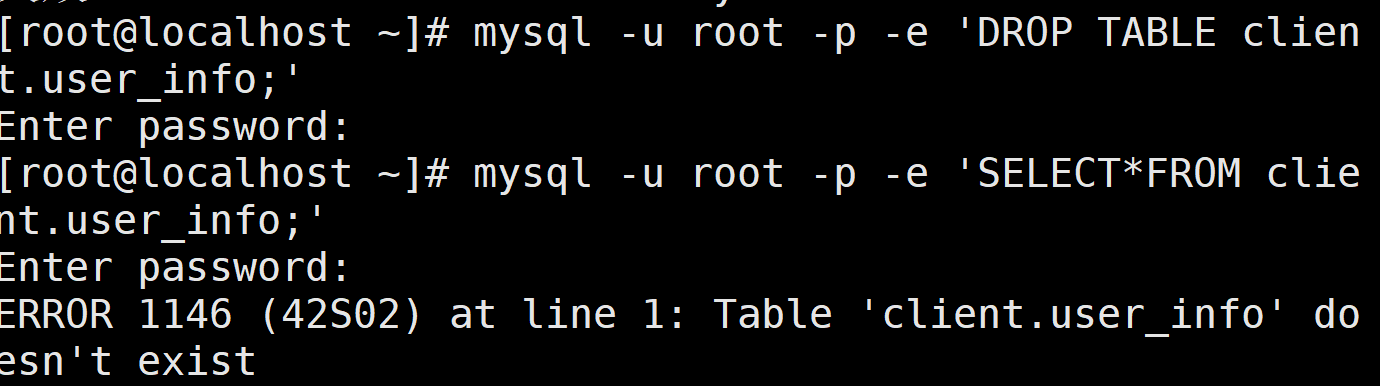
(4)模拟误操作删除user info 表
(5)恢复操作
再执行恢复操作时,需要先恢复完全备份,然后恢复增量备份。

//恢复完全备份

//恢复增量备份

2.基于位置恢复
由于前面已经做过备份操作,接下来直接进行模拟故障与数据恢复的操作。
[root@localhost ~]# mysql -u root -p -e 'DROP *TABLE client.user_info;'
//模拟误操作删除 user info 表
[root@localhost ~]#mysql -u root -p-e 'SELECT * FROM client.user_info;
//查看 user_info 表是否存在
[root@localhost ~]#mysql -u root -p client</mysql bak/client userinfo-2025-05-27.sql
//恢复完全备份
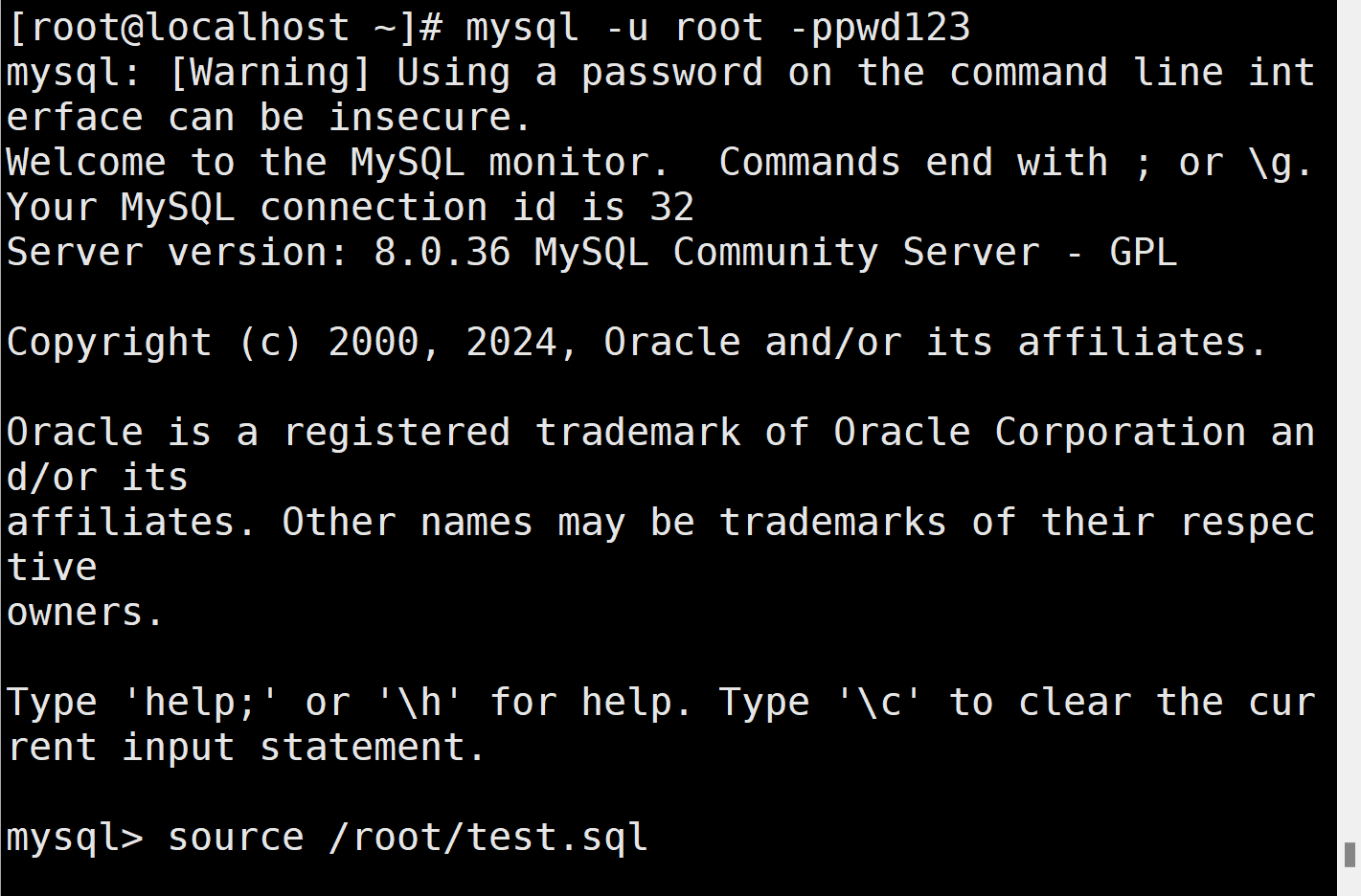
想要实现基于位置或时间点恢复数据,必须先通过查看二进制日志文件确定恢复的位置或时间点。使用“mysqlbinlog--no-defaults 二进制日志文件”可以查看二进制日志文件的具体内容。
[root@localhost ~]#mysqlbinlog --no-defaults /mysql bak/mysql-bin.00002
通过查看日志文件的具体内容可以发现,在每进行一个操作之前都会有一个独特的编号,如“# at 663”。此编号随着操作数增多而变大,我们称之为操作ID。在操作 ID 下面紧跟着的是时间标记。要实现基于位置或时间点恢复数据,需要分别依赖二进制日志文件中的操作 ID或者时间标记。例如,通过二进制日志文件得知,在操作 ID 为“663”的时候,user info 表中插入了“孙七”的用户数据。因此执行以下命令可以实现仅恢复到操作ID为“663”之前的数据即不恢复“孙七”的信息。这时所恢复的数据是从二进制日志文件的开始位置直到指定位置。
[root@localhost ~]#mysqlbinlog --no-defaults --stop-position='623’/mysql bak/mysql-bin.00002 mysql -uroot -p
[root@localhost ~]#mysql -uroot -p -e 'SELECT * FROM client.user_info;'
上述操作命令中,“--stop-position”指定的是停止的位置。如果仅恢复“孙七”的信息,跳过“赵六”的信息恢复,可以使用“--start-position”选项指定开始恢复数据的位置。这时所恢复的数据是从指定位置开始直到二进制日志文件的最后。
[root@localhost ~]#mysql -uroot -p -e 'DROP TABLE client.user_info;'
[root@localhost ~]#mysql -uroot -p client</mysql bak/client userinfo-2025-05-27.sql
[root@localhost ~]#mysqlbinlog --no-defaults --start-position='663/mysql bak/mysql-bin.000002 mysql -uroot -p
[root@localhost ~]#mysql -uroot -pe'SELECT * FROM client.user_info;'
3.基于时间点恢复
基于时间点的数据恢复所使用的选项是“--stop-datetime”’,指定的时间同样也是查询二进制日志所得。执行以下操作可以实现仅恢复到 16:41∶24 之前的数据,即不恢复“孙七”的信息。
[root@localhost ~]#mysql -uroot -p -e 'DROP TABLE client.user_info;'
[root@localhost ~]#mysql -uroot -p client</mysql bak/client userinfo-2025-05-27.sql
[root@localhost ~]#mysql -uroot -pe'SELECT * FROM client.user_info;'
执行以下操作可以实现仅恢复“孙七”的信息,跳过“赵六”的信息恢复。
[root@localhost ~]#mysql -uroot -p -e 'DROP TABLE client.user_info;'
[root@localhost ~]#mysql -uroot -p client</mysql bak/client userinfo-2025-05-27.sql
[root@localhost ~]#mysql -uroot -pe'SELECT * FROM client.user_info;'
三.制定企业备份策略的思路
在企业中备份策略并不是千篇一律的,而是根据每个企业的实际生产环境与业务需求制定合适的备份策略。无论是选择完全备份,还是选择增量备份,都需考虑它们的优缺点,是否适合当前的生产环境。同时,为了保证恢复的完整性,建议开启二进制日志功能,二进制日志文件给恢复工作也带来了很大的灵活性,可以基于时间点或位置进行恢复。考虑到数据库性能,可以将二进制日志文件保存到其他安全的硬盘中。
在进行热备份时,备份操作和应用服务在同时运行,这样就十分消耗系统资源了,导致数据库服务性能下降,这就需要选择一个合适的时间(如在应用负担很小的时候)再来进行备份操作。
需要注意的是,不是备份完就万事大吉,最好确认备份是否可用,所以备份之后的恢复测试是非常有必要的。同时备份时间也要灵活调整,如:
- 数据更新频繁,则应该频繁地备份,
- 数据的重要性,在有适当更新时进行备份。在数据库压力小的时间段进行备份,如一周一次完全备份,每天进行增量备
- 中小公司,完全备份一般一天一次即可。
- 大公司可每周进行一次完全备份,每天进行一次增量备份。
- 尽量为企业实现主从复制架构,以增加数据的可用性。
四.扩展:Mysql的GTID 和 XtraBackup
1.Mysql 的 GTID
GTID 即全局事务 ID(global transaction identifier),其保证为每一个在主上提交的事务在复制集群中可以生成一个唯一的 ID。GTID 最初由 google实现,官方 MySQL在5.6才加入该功能
GTID 实际上是由 UUID+TID(即 transactionId)组成的。其中 UUID(即server uuid)产生于 auto. conf 文件(cat /data/mysql/data/auto.cnf),是个 MySQL,实例的唯一标识。TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增,所以GTID能够保证每个MySQL实例事务的执行(不会重复执行同一个事务,并且会补全没有执行的事务)。GTID在一组复制中,全局唯
通过下面的实验,了解基于 gtid 的增量备份和恢复(Gtid 的备份也是基于binlog 的)
(1)配置my.cnf 开启 gtid

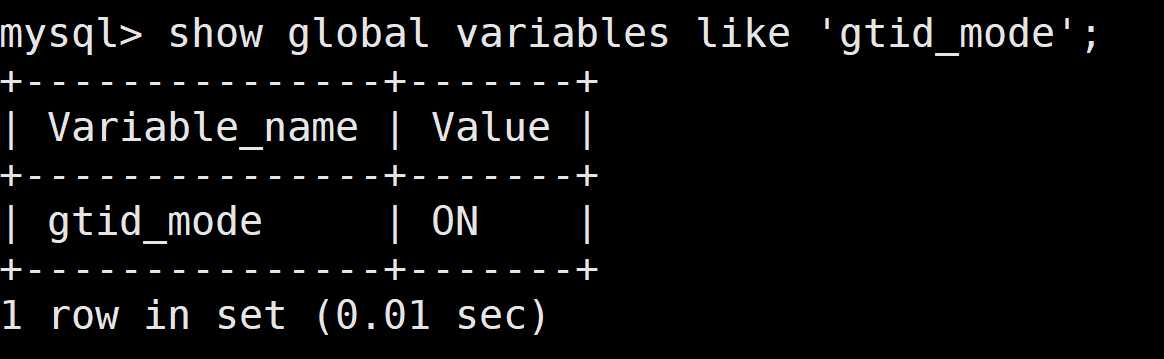 (2)创建基本测试库、表、数据
(2)创建基本测试库、表、数据
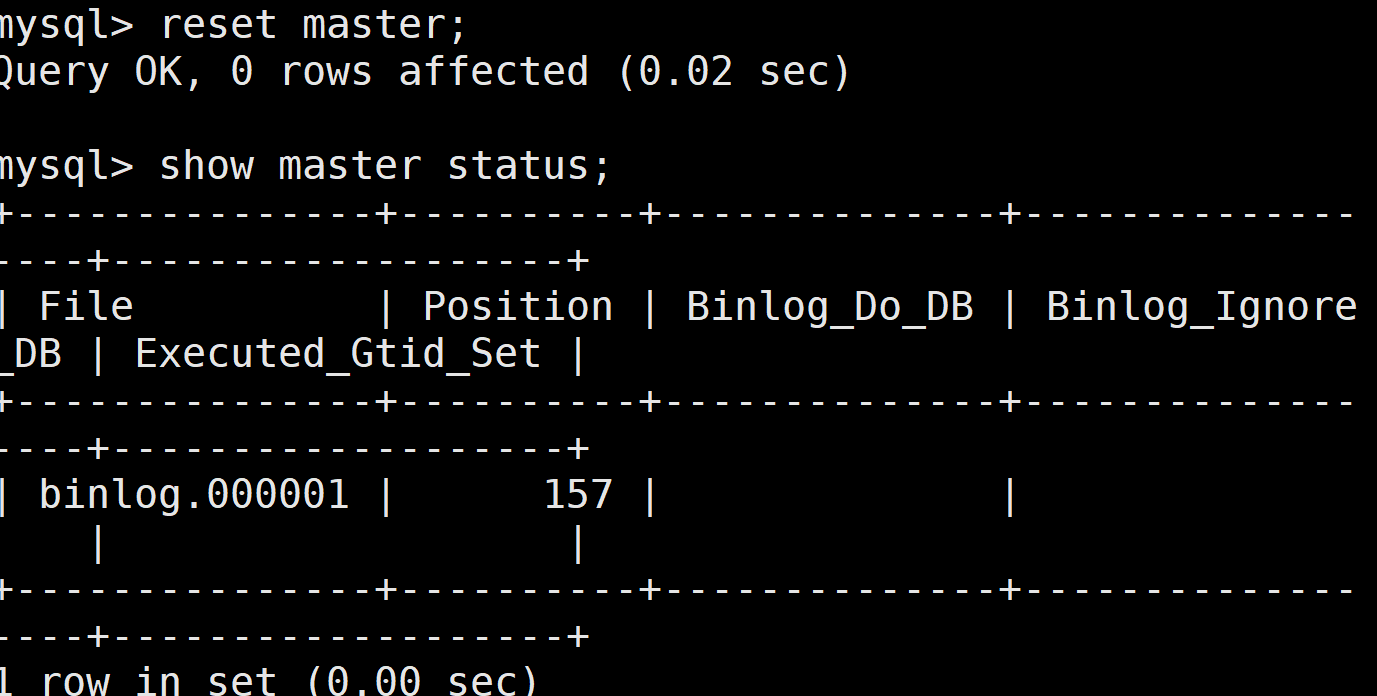
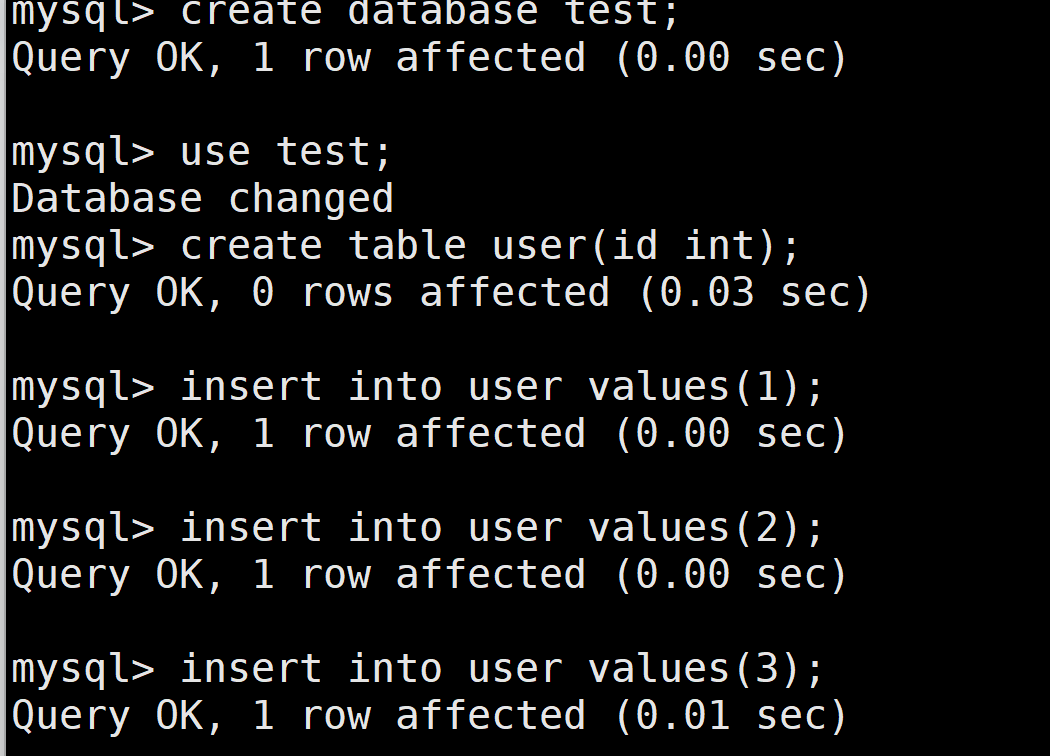
创建测试库 test,测试表user,并导入3条数据
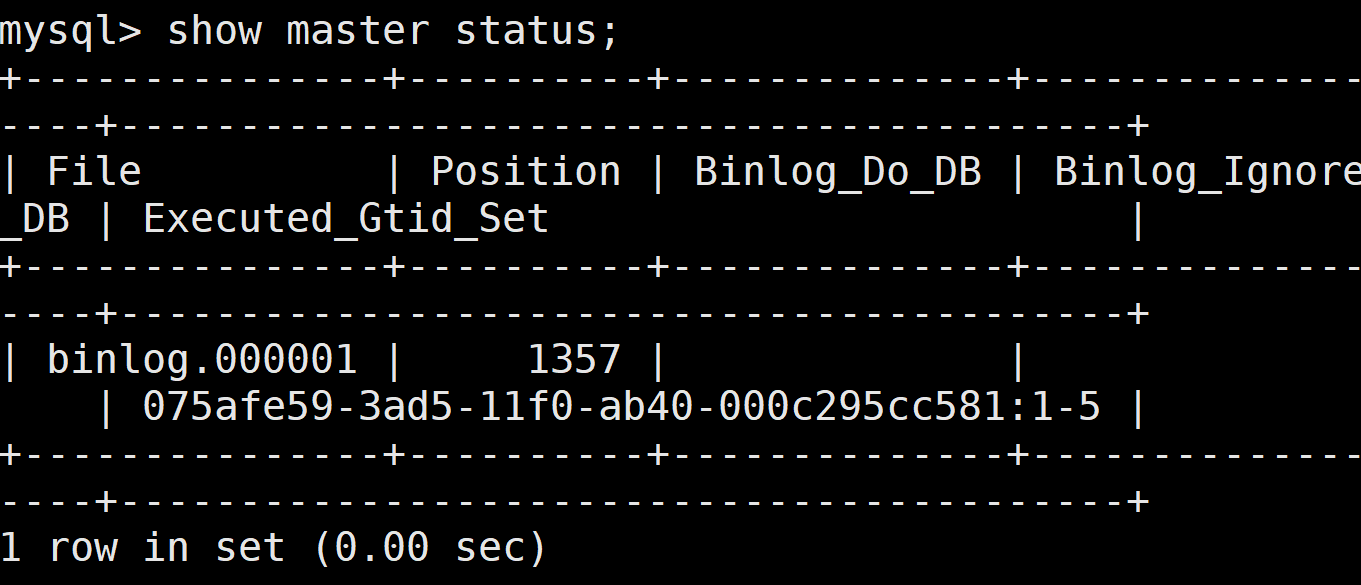
(3)全量备份
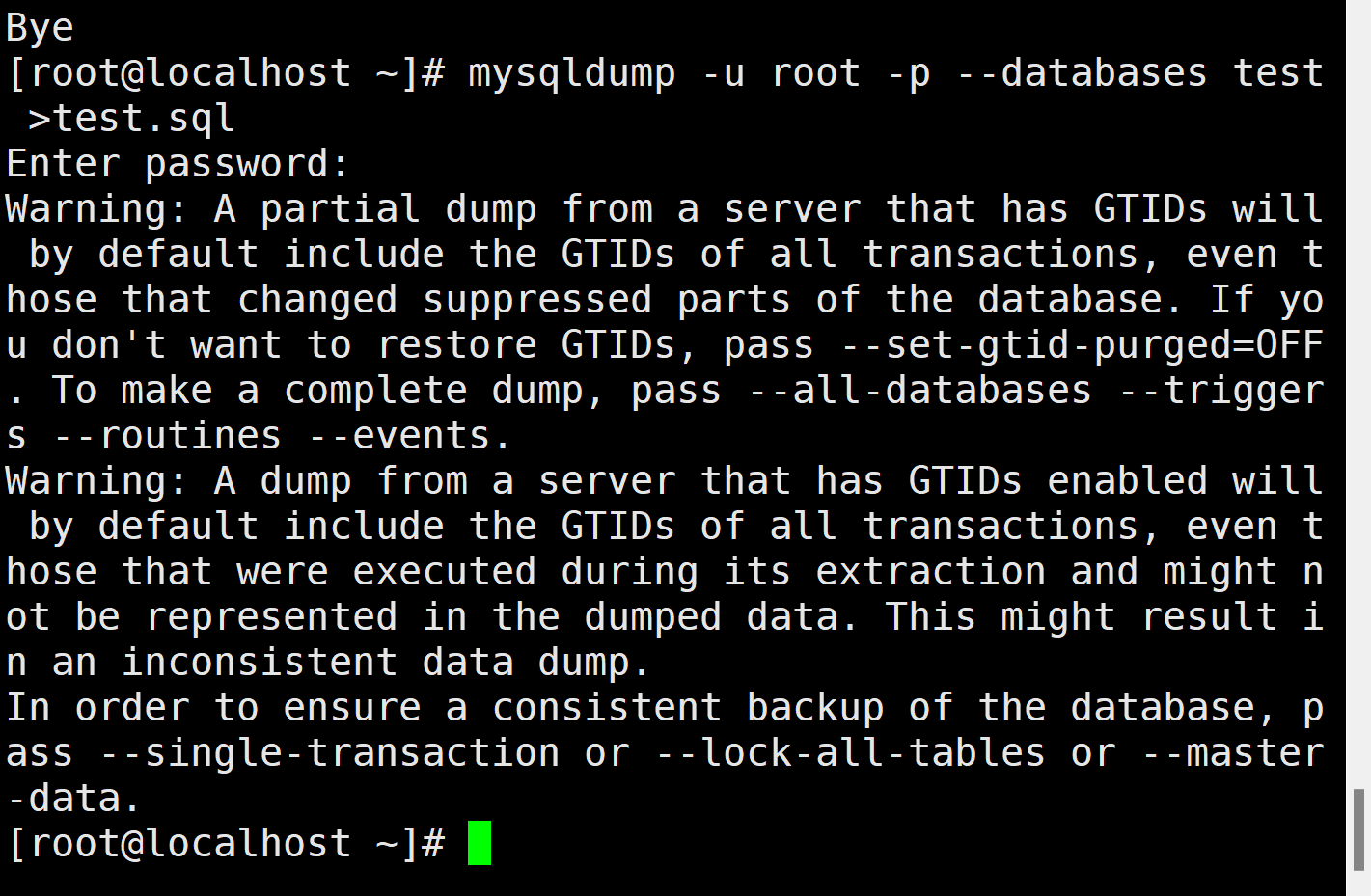
关于数据一致性的提醒的警告信息,可忽略

(4)插入新数据
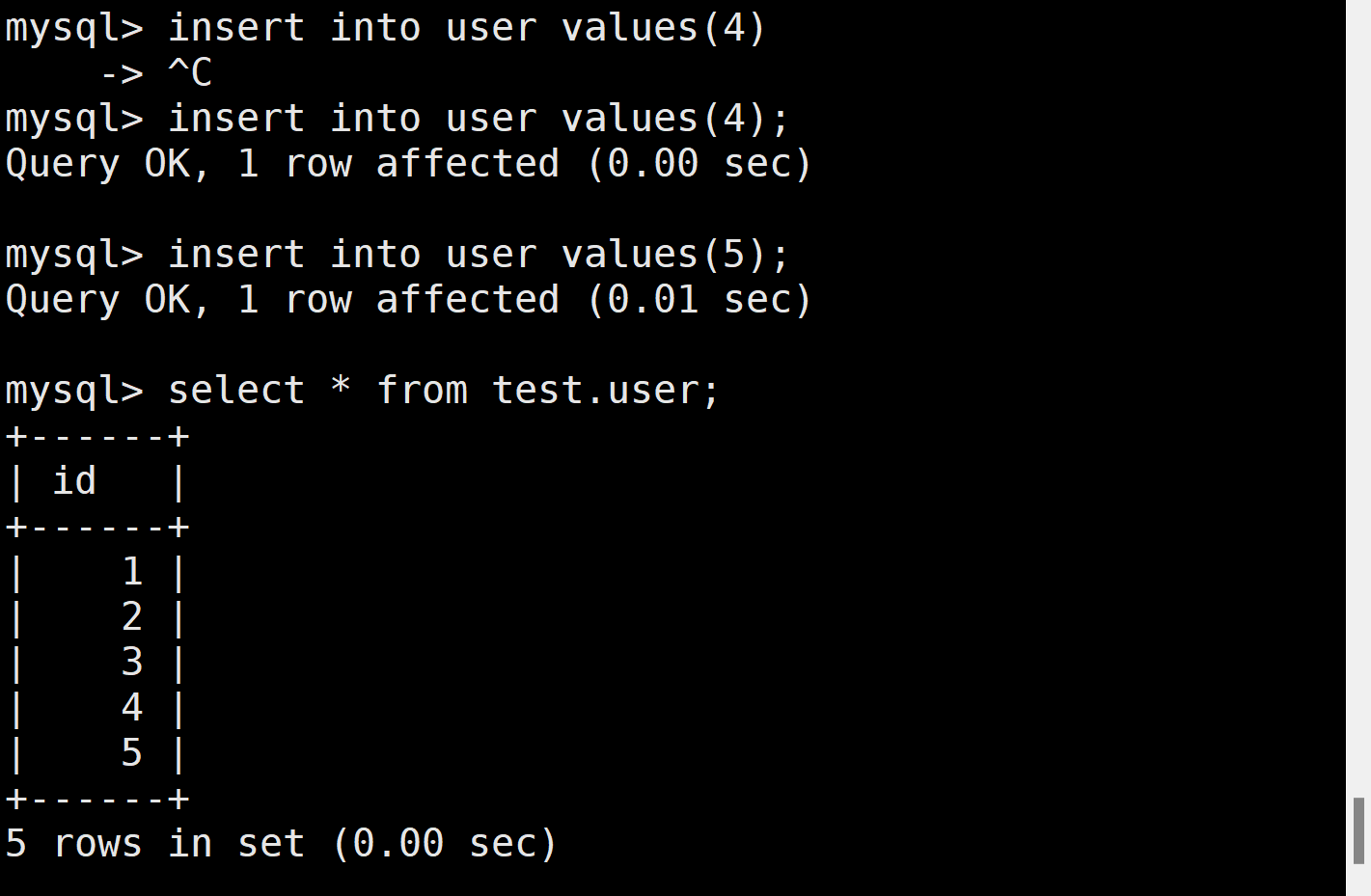
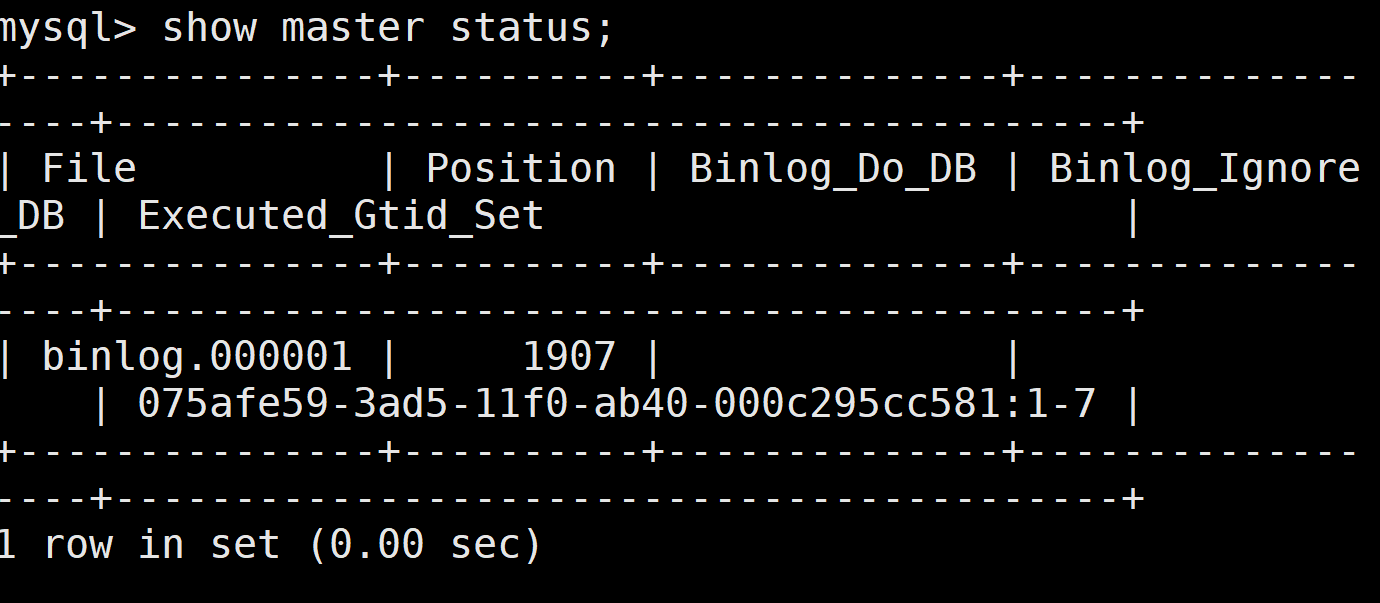
(5)模拟数据误删除
(6)导出增量数据
[root@localhost ~]#mysqlbinlog--include-gtids= d780a5a6-055f-11f0-b6e6-000c29078b04:3-7/usr/local/mysql/data/mysql-bin.000001 >/mysqlbak. sql
(7)恢复全量
[root@localhost ~]#mysql -u root p e "RESET MASTER;'
[root@localhost ~]#mysql -uroot p<test.sql
[root@localhost ~]#mysql -uroot -p -e 'select *from test.user,'
(8)恢复增量
mysqluroot -p<mysqlbak.sql
mysql -uroot -p -e"select * from test.user;
2.XtraBackup
MySQL 冷备、mysqldump、MySQL 热拷贝都无法实现对数据库进行增量备份。在实际生产环境中增量备份是非常实用的,如果数据大于50G或100G,存储空间足够的情况下,可以每天进行完整备份,如果每天产生的数据量较大,需要定制数据备份策略。例如每周实用完整备份,周一到周六实用增量备份。而Percona-Xtrabackup 就是为了实现增量备份而出现的一款主流备份工具,xtrabakackup有2个工具,分别是xtrabakup、innobakupe。
Percona-xtrabackup 是 Percona 公司开发的一个用于 MySQL, 数据库物理热备的备份工具,支持 MySQL、Percona server 和 MariaDB,开源免费,是目前较为受欢迎的主流备份工具。xtrabackup 只能备份 innoDB 和 xtraDB 两种数据引擎的表,而不能备份 MyISAM 数据表。
(1)安装xtrabackup
(2)安装 qpress
qpress 是解压缩需要用到的工具
(3)完整备份与恢复
恢复(恢复数据的时候要先关闭 MySQL,清理数据存储目录)
(5)增量备份与恢复
备份
增量恢复
恢复数据的时候要先关闭 MySQL,清理数据存储目录
# 解压备份数据
#解压备份数据
# 准备数据
#把增量备份的数据合并到完整备份里面
#完整重放日志
#恢复数据
#修改权限,替换成自己的数据存储目录
# 然后启动 MySQL 即可
总结
通过本课程的学习,我们不仅系统掌握了数据库备份的核心方法论,包括物理备份与逻辑备份的本质差异、冷温热备的场景适配原则,更通过实战深入理解了 MySQL, 完全备份与恢复的标准化流程,以及基于 XtraBackup 的增量备份链构建与恢复策略。课程特别强调,完全备份是数据安全的基石,而增量备份则通过日志链机制实现了存储效率与恢复能力的平衡;在恢复环节,从备份目录准备到日志重放的完整流程,尤其是 prepare 阶段对--apply-log-only 参数的精准把控,确保了数据恢复的可靠性。扩展部分深入解析的 GTID 全局事务标识技术,
相关文章:
MySQL 全量、增量备份与恢复
一.MySQL 数据库备份概述 备份的主要目的是灾难恢复,备份还可以测试应用、回滚数据修改、查询历史数据、审计等。之前已经学习过如何安装 MySQL,本小节将从生产运维的角度了解备份恢复的分类与方法。 1 数据备份的重要性 在企业中数据的价值至关…...

【25.06】FISCOBCOS使用caliper自定义测试 通过webase 单机四节点 helloworld等进行测试
前置条件 安装一个Ubuntu20+的镜像 基础环境安装 Git cURL vim jq sudo apt install -y git curl vim jq Docker和Docker-compose 这个命令会自动安装docker sudo apt install docker-compose sudo chmod +x /usr/bin/docker-compose docker versiondocker-compose vers…...
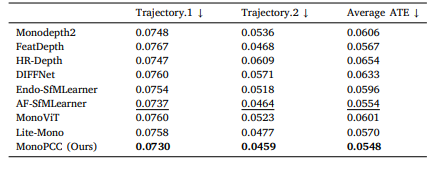
MonoPCC:用于内窥镜图像单目深度估计的光度不变循环约束|文献速递-深度学习医疗AI最新文献
Title 题目 MonoPCC: Photometric-invariant cycle constraint for monocular depth estimation of endoscopic images MonoPCC:用于内窥镜图像单目深度估计的光度不变循环约束 01 文献速递介绍 单目内窥镜是胃肠诊断和手术的关键医学成像工具,但其…...

如何计算H5页面加载时的白屏时间
计算 H5 页面加载时的 白屏时间(First Paint Time)是前端性能优化的重要指标,通常指从用户发起页面请求到浏览器首次渲染像素(如背景色、文字等)的时间。以下是几种常用的计算方法: 1. 使用 Performance AP…...
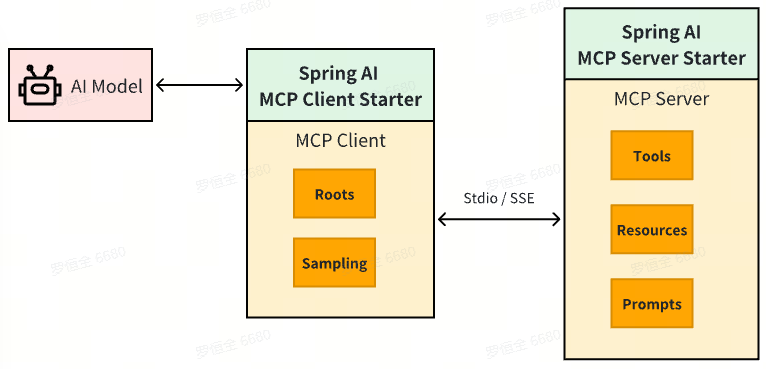
SpringAI系列 - MCP篇(三) - MCP Client Boot Starter
目录 一、Spring AI Mcp集成二、Spring AI MCP Client Stater三、spring-ai-starter-mcp-client-webflux集成示例3.1 maven依赖3.2 配置说明3.3 集成Tools四、通过SSE连接MCP Server五、通过STDIO连接MCP Server六、通过JSON文件配置STDIO连接一、Spring AI Mcp集成 Spring AI…...

【深度学习新浪潮】以Dify为例的大模型平台的对比分析
我们从核心功能、适用群体、易用性、可扩展性和安全性五个维度展开对比分析: 一、核心功能对比 平台核心功能多模型支持插件与工具链Dify低代码开发、RAG增强、Agent自律执行、企业级安全支持GPT-4/5、Claude、Llama3、Gemini及开源模型(如Qwen-VL-72B),支持混合模型组合可…...
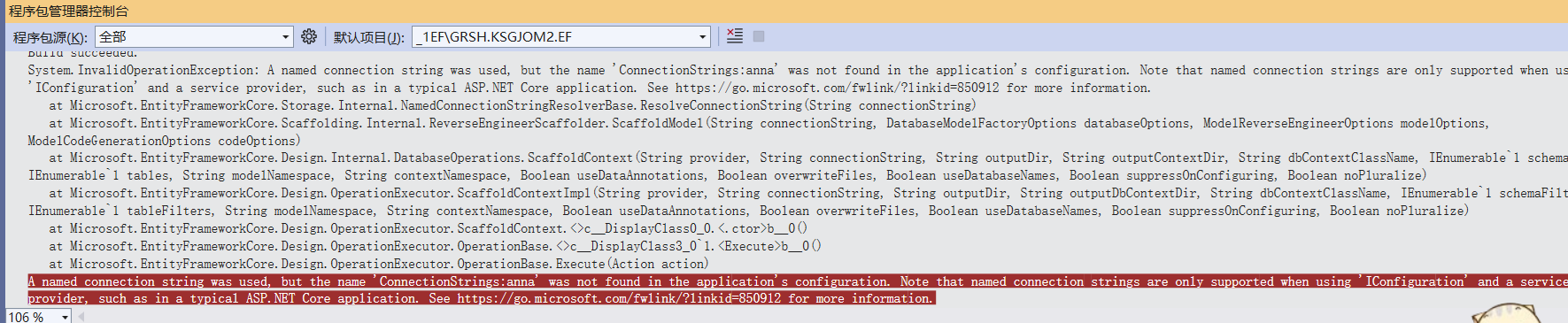
Asp.net core 使用EntityFrame Work
安装以下Nuget 包 Microsoft.EntityFrameworkCore.Tools Microsoft.EntityFrameworkCore.Design Microsoft.AspNetCore.Diagnostics.EntityFrameworkCore Microsoft.EntityFrameworkCore.SqlServer或者Npgsql.EntityFrameworkCore.PostgreSQL 安装完上述Nuget包之后,在appset…...

isp中的 ISO代表什么意思
isp中的 ISO代表什么意思 在摄影和图像信号处理(ISP,Image Signal Processor)领域,ISO是一个用于衡量相机图像传感器对光线敏感度的标准参数。它最初源于胶片摄影时代的 “国际标准化组织(International Organization …...

AI Coding 资讯 2025-06-03
Prompt工程 RAG-MCP:突破大模型工具调用瓶颈,告别Prompt膨胀 大语言模型(LLM)在工具调用时面临Prompt膨胀和决策过载两大核心挑战。RAG-MCP创新性地引入检索增强生成技术,通过外部工具向量索引和动态检索机制,仅将最相关的工具信…...

2024年12月 C/C++(三级)真题解析#中国电子学会#全国青少年软件编程等级考试
C/C++编程(1~8级)全部真题・点这里 第1题:最近的斐波那契数 斐波那契数列 Fn 的定义为:对 n ≥ 0 有 Fn+2 = Fn+1 + Fn,初始值为 F0 = 0 和 F1 = 1。所谓与给定的整数 N 最近的斐波那契数是指与 N 的差之绝对值最小的斐波那契数。 本题就请你为任意给定的整数 N 找出与之最…...

3d GIS数据来源与编辑工具
1、卫星遥感 2、航空摄影测量 3、地面实测技术 全站仪 3维扫描 3D GIS数据制作全流程详解 一、数据采集:多源数据获取 3D GIS数据的制作需从多维度采集地理空间信息,以下是主要采集方式及适用场景: (一)遥感与航测…...

NeRF PyTorch 源码解读 - 体渲染
文章目录 1. 体渲染公式推导1.1. T ( t ) T(t) T(t) 的推导1.2. C ( r ) C(r) C(r) 的推导 2. 体渲染公式离散化3. 代码解读 1. 体渲染公式推导 如下图所示,渲染图像上点 P P P 的颜色值 c c c 是累加射线 O P → \overrightarrow{OP} OP 在近平面和远平面范围…...
SpringBoot 数据库批量导入导出 Xlsx文件的导入与导出 全量导出 数据库导出表格 数据处理 外部数据
介绍 poi-ooxml 是 Apache POI 项目中的一个库,专门用于处理 Microsoft Office 2007 及以后版本的文件,特别是 Excel 文件(.xlsx 格式)和 Word 文件(.docx 格式)。 在管理系统中需要对数据库的数据进行导…...
解决:install via Git URL失败的问题
为解决install via Git URL失败的问题,修改安全等级security_level的config.ini文件,路径如下: 还要重启: 1.reset 2.F5刷新页面 3.关机服务器,再开机(你也可以省略,试试) 4.Wind…...
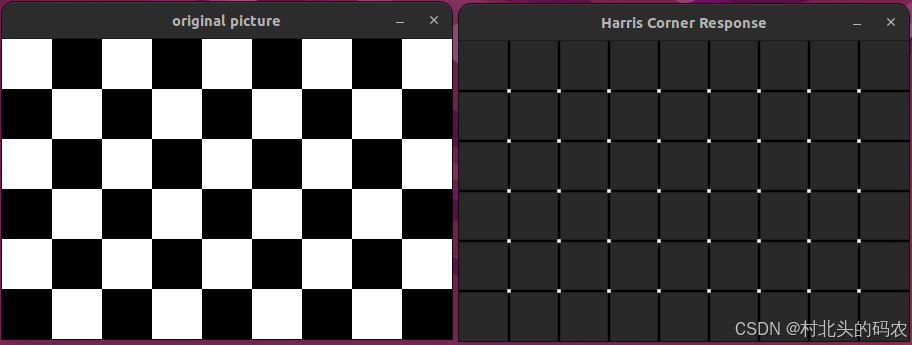
OpenCV CUDA模块特征检测------创建Harris角点检测器的GPU实现接口cv::cuda::createHarrisCorner
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 该函数创建一个 基于 Harris 算法的角点响应计算对象,专门用于在 GPU 上进行高效计算。 它返回的是一个 cv::Ptrcv::cuda::Cornernes…...

【氮化镓】钝化层对p-GaN HEMT阈值电压的影响
2021年5月13日,中国台湾阳明交通大学的Shun-Wei Tang等人在《Microelectronics Reliability》期刊发表了题为《Investigation of the passivation-induced VTH shift in p-GaN HEMTs with Au-free gate-first process》的文章。该研究基于二次离子质谱(SIMS)、光致发光(PL)…...

C++:优先级队列
目录 1. 概念 2. 特征 3. 优先级队列的使用 1. 概念 优先级队列虽然名字有队列二字,但根据队列特性来说优先级队列不满足先进先出这个特征,优先级队列的底层是用堆来实现的。 优先级队列是一种容器适配器,就是将特定容器类封装作为其底层…...
睡眠分期 html
截图 代码 <!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>睡眠图表</title><script src…...

Java求职者面试:Spring、Spring Boot、Spring MVC与MyBatis技术深度解析
Java求职者面试:Spring、Spring Boot、Spring MVC与MyBatis技术深度解析 一、第一轮提问(基础概念问题) 1. 请解释什么是Spring框架?它的核心功能是什么? JY:Spring是一个开源的Java/Java EE企业级应用开…...

Github 2025-05-29 Go开源项目日报Top9
根据Github Trendings的统计,今日(2025-05-29统计)共有9个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Go项目9Assembly项目1Ollama: 本地大型语言模型设置与运行 创建周期:248 天开发语言:Go协议类型:MIT LicenseStar数量:42421 个Fork数量:27…...

前端项目种对某个文件夹进行大小写更改,git识别不到差异导致无变化
问题背景 开发过程中可能遇到一个文件名要更改大小写,但是更改后之后本地会有变化,但是git识别不到差异化,正常去更改一个文件名称git差异化会出现删除了原有文件,新增了一个新文件,但是更改大小写则不会 如何解决 在终端中输入git config…...
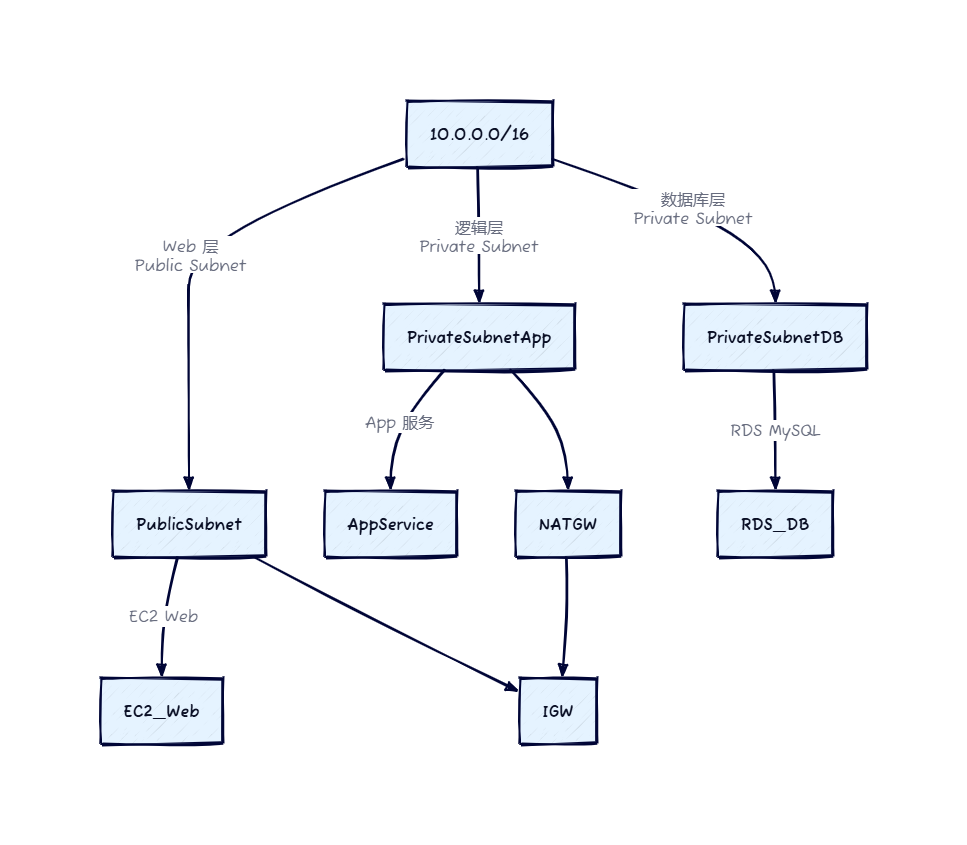
AWS VPC 网络详解:理解云上专属内网的关键要素
全面解读 AWS VPC、子网、安全组、路由与 NAT 网关的实际应用 在使用 AWS 云服务的过程中,许多用户最先接触的是 EC2(云服务器)。但你是否曾遇到过这样的情况:实例启动正常,却无法访问公网?或者数据库无法…...
Ubuntu24.04.2 + kubectl1.33.1 + containerdv1.7.27 + calicov3.30.0
Ubuntu24.04.2 kubectl1.33.1 containerdv1.7.27 calicov3.30.0 安装Ubuntu24.04.2 kubectl1.33.1 containerdv1.7.27 calicov3.30.0 1.安装Ubuntu24.04.2,设置阿里云镜像地址 $ sudo vim /etc/apt/sources.list.d/ubuntu.sources URIs: https://mirrors.aliy…...

循环神经网络(RNN)全面教程:从原理到实践
循环神经网络(RNN)全面教程:从原理到实践 引言 循环神经网络(Recurrent Neural Network, RNN)是处理序列数据的经典神经网络架构,在自然语言处理、语音识别、时间序列预测等领域有着广泛应用。本文将系统介绍RNN的核心概念、常见变体、实现方法以及实际…...
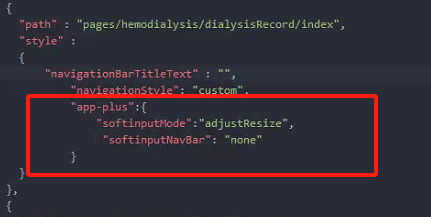
uniapp 键盘顶起页面问题
关于uniapp中键盘顶起页面的问题。这是一个在移动应用开发中常见的问题,特别是当输入框位于页面底部时,键盘弹出会顶起整个页面,导致页面布局错乱。 pages.json 文件内,在需要处理软键盘的页面添加 softinputMode 配置࿱…...

利用TOA与最小二乘法直接求解
为了利用到达时间(TOA)和最小二乘法直接求解,我们首先需要理解TOA定位的基本原理和最小二乘法的应用。 步骤1: 理解TOA定位原理 到达时间(TOA)定位是通过测量信号从发射源到达接收器的时间来确定位置的一种方法。假设…...

SpringBoot系列之RabbitMQ 实现订单超时未支付自动关闭功能
系列博客专栏: JVM系列博客专栏SpringBoot系列博客 RabbitMQ 实现订单超时自动关闭功能:从原理到实践的全流程解析 一、业务场景与技术选型 在电商系统中,订单超时未支付自动关闭功能是保障库存准确性、提升用户体验的核心机制。传统定时任…...
【C++高级主题】命令空间(五):类、命名空间和作用域
目录 一、实参相关的查找(ADL):函数调用的 “智能搜索” 1.1 ADL 的核心规则 1.2 ADL 的触发条件 1.3 ADL 的典型应用场景 1.4 ADL 的潜在风险与规避 二、隐式友元声明:类与命名空间的 “私密通道” 2.1 友元声明的基本规则…...

ArcGIS Pro 3.4 二次开发 - 地图创作 1
环境:ArcGIS Pro SDK 3.4 + .NET 8 文章目录 ArcGIS Pro 3.4 二次开发 - 地图创作 11 样式管理1.1 如何通过名称获取项目中的样式1.2 如何创建新样式1.3 如何向项目添加样式1.4 如何从项目中移除样式1.5 如何向样式添加样式项1.6 如何从样式中移除样式项1.7 如何判断样式是否可…...

2.1HarmonyOS NEXT开发工具链进阶:DevEco Studio深度实践
HarmonyOS NEXT开发工具链进阶:DevEco Studio深度实践 在HarmonyOS NEXT全栈自研的技术体系下,DevEco Studio作为一站式开发平台,通过深度整合分布式开发能力,为开发者提供了从代码编写到多端部署的全流程支持。本章节将围绕多设…...